Собираем кластер PostgreSQL для разработки и тестирования
Сегодня СУБД PostgreSQL является одной из самых известных и популярных систем управления баз данными в мире. Открытый исходный код, отсутствие платы за использование, контроль целостности, репликация – это далеко не все преимущества данной СУБД. В современных реалиях, когда тема импортозамещения особенно актуальна, PostgreSQL может оказаться подходящим вариантом.
Обычно PostgreSQL разворачивают в качестве кластера – системы, которая состоит из нескольких связанных между собой компьютеров (серверов) с целью обеспечения отказоустойчивости.
Как правило, при развертывании кластеров PostgreSQL используют сторонние инструменты такие как Patroni, stolon, repmgr.
В статье будет описана установка кластера PostgreSQL с помощью Ansible – инструмента, предназначенного для автоматизации настройки и развертывания программного обеспечения, а также инструмента repmgr, предназначенного для управления репликами и отказоустойчивостью в кластерах PostgreSQL.
В компаниях не всегда имеется возможность быстро выделить ресурсы для разворачивания ВМ, чтобы организовать рабочую среду для разработки или тестирования. Чтобы избежать излишней бюрократии, если такая имеет место быть, можно локально поднять систему и сразу приступить к работе с ней. Поэтому в статье в качестве примера приведен также алгоритм по установке и работе с утилитой Vagrant, которая позволяет быстро решить эту задачу.
Подготовка к установке
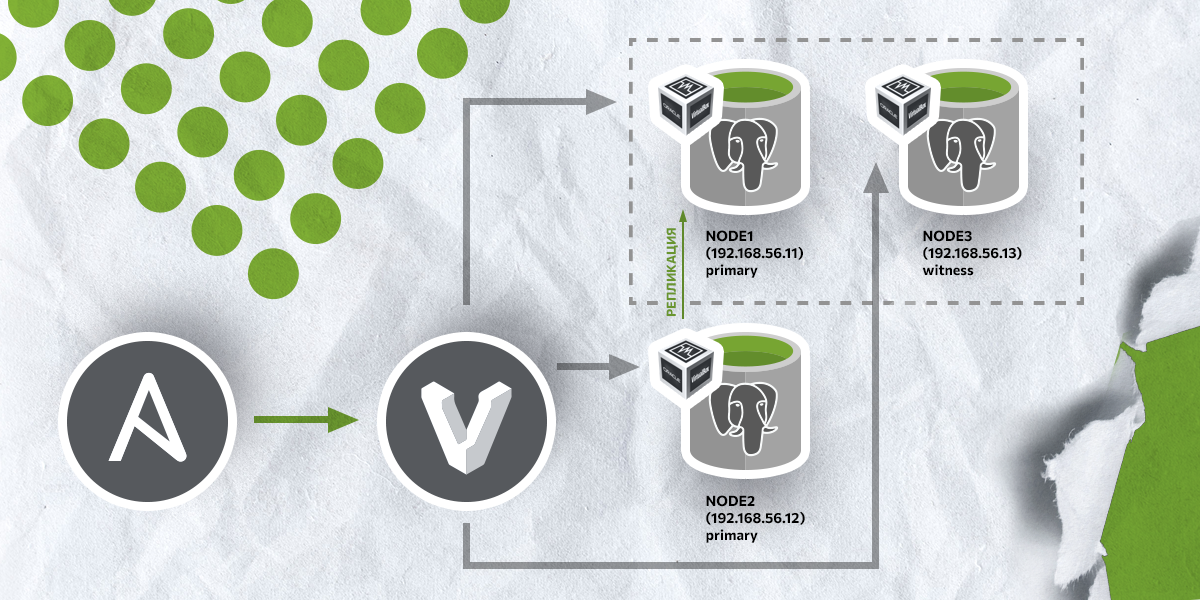
В качестве примера будет использоваться виртуальная машина с установленной операционной системой Ubuntu 20.04.3 LTS. Узлы кластера будут представлены в виде 3 виртуальных машин под управлением ОС Ubuntu 18.04 Bionic Beaver, которые будут запущены на гипервизоре VirtualBox. Сами ВМ будут развернуты при помощи Vagrant – утилиты, предназначенной для создания и конфигурирования виртуальных окружений (под виртуальным окружением понимается более стандартное понятие – виртуальная машина). Ниже описаны хосты, которые будут использоваться в качестве кластера PostgreSQL:
node1 192.168.56.11 Роль primary, она же мастер-нода;
node2 192.168.56.12 Роль standby. Обычная рабочая нода;
node3 192.168.56.13 Роль witness. В терминологии repmgr witness это нода, которая не является частью кластера и предназначена для выбора новой мастер-ноды в случае возникновения проблем с кластером.
Ниже перечислено ПО, которое будет использоваться в статье:
Ansible;
Vagrant;
VirtualBox;
PostgreSQL;
repmgr.
Сначала на управляющий хост (основной хост, с которого будет вестись управление Vagrant и Ansible) необходимо установить Ansible, Vagrant и VirtualBox.
Произвести установку Ansible можно разными способами. В данном примере установка будет произведена при помощи официального репозитория ansible. Для этого необходимо выполнить следующие шаги:
1) Обновить списки пакетов:
sudo apt update2) Установить пакет software-properties-common:
sudo apt -y install software-properties-common3) Добавить официальный репозиторий Ansible:
sudo add-apt-repository --yes --update ppa:ansible/ansible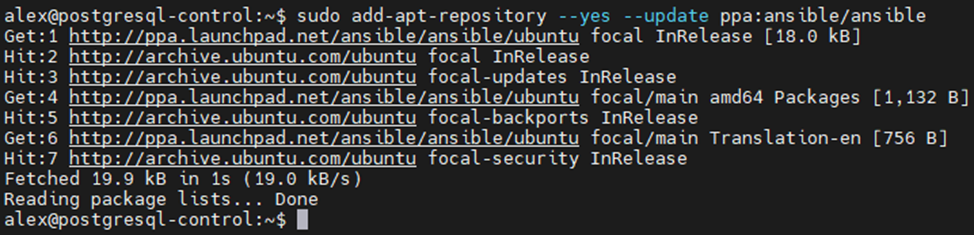
4) Установить Ansible:
sudo apt -y install ansible
После того как установка будет завершена, можно проверить, что Ansible установился корректно, путем вывода его версии. Для этого достаточно выполнить команду:
ansible --version
Если команда отобразила версию (первая строка с названием ansible [core ]), значит, пакет успешно и без ошибок установлен в системе.
Далее необходимо установить Vagrant. Установка производится из официального репозитория. Шаги по установке Vagrant:
1) Добавить gpg ключ от официального репозитория Vagrant:
wget -O- https://apt.releases.hashicorp.com/gpg | gpg --dearmor | sudo tee /usr/share/keyrings/hashicorp-archive-keyring.gpg2) Добавить официальный репозиторий hashicorp:
echo "deb [signed-by=/usr/share/keyrings/hashicorp-archive-keyring.gpg] https://apt.releases.hashicorp.com $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/hashicorp.list
3) Обновить список репозиториев и установить пакет vagrant:
sudo apt update && sudo apt -y install vagrant
После установки необходимо убедиться, что установка прошла успешно. Для этого в терминале необходимо ввести команду:
vagrant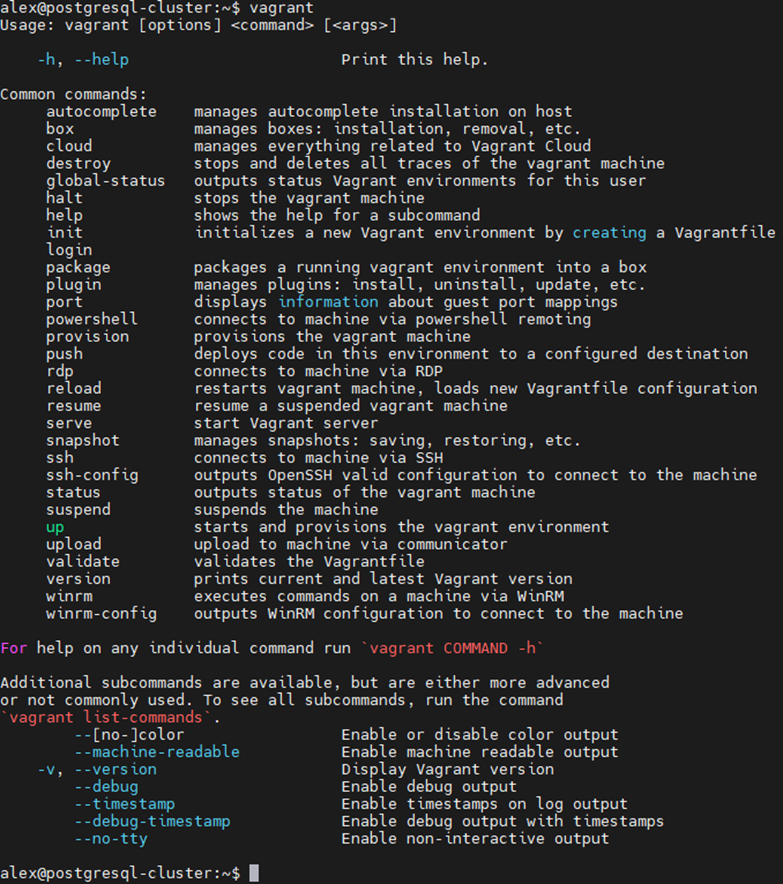
Если команда вернула список команд и их описание, значит установка vagrant прошла успешно.
Последний шаг – установка VirtualBox. Необходимые пакеты уже присутствуют в официальных репозиториях. Для установки достаточно выполнить одну команду:
sudo apt -y install virtualbox virtualbox-dkms
Создание и подготовка Vagrantfile
Для создания виртуальных машин в vagrant используется специальный файл – vagranfile. Для его создания необходимо выполнить команду:
vagrant init
Команда сгенерирует специальный шаблон, где указываются ВМ, которые будут созданы. Также в этом файле прописываются имена хостов, IP адреса хостов и способ подключения к ним.
Содержимое файла будет следующим
Vagrant.configure("2") do |config| (1..3).each do |n| config.vm.define "node#" do |define| define.ssh.insert_key = false define.vm.box = "ubuntu/bionic64" define.vm.hostname = "node#" define.vm.network :private_network, ip: "192.168.56.1#" # if you would like to use port forwarding, uncomment the line below # define.vm.network :forwarded_port, guest: 5432, host: "543#" define.vm.provider :virtualbox do |v| v.cpus = 1 v.memory = 1024 v.name = "node#" end if n == 3 define.vm.provision :ansible do |ansible| ansible.limit = "all" ansible.playbook = "playbook.yaml" ansible.host_vars = < "node1" => "192.168.56.11", :node_id => 1, :role => "primary" >, "node2" => "192.168.56.12", :node_id => 2, :role => "standby" >, "node3" => "192.168.56.13", :node_id => 3, :role => "witness" > > # to enable ansible playbook verbose mode, uncomment the line below # ansible.verbose = "v" end end end end enddefine.ssh.insert_key – если выставлен в false, то vagrant не будет автоматически создавать и использовать собственные SSH ключи;
define.vm.box – задает имя образа для ВМ. Образы хранятся на сайте Vagrant Cloud;
define.vm.hostname – задает hostname виртуальным машинам;
define.vm.network – задает тип сети и диапазон IP адресов;
v.cpus – задает количество ядер, которое будет выделено для ВМ;
v.memory – задает количество оперативной памяти, которое будет выделено для ВМ;
ansible.playbook – прописывается полный путь до playbook Ansible. Vagrant имеет полную поддержку и интеграцию с Ansible;
ansible.host_vars – в данном блоке прописываются хосты, на которых будет запущен playbook Ansible. Эквивалентен файлу инвентаризации в Ansible.
Создание ролей в Ansible
Так как для установки и настройки кластера необходимо выполнить много действий, они будут разбиты на роли.
Роли в Ansible – это способ логического разбиения файлов или, проще говоря, независимая сущность, решающая какой-то набор задач. С технической точки зрения роль – это директория с поддиректориями и файлами, где расположены задачи.
Для удобства создадим директорию с именем postgres-cluster:
mkdir postgres-clusterДалее необходимо перейти в созданный каталог и создать следующие директории:
mkdir group_vars mkdir rolesВ директории roles будут храниться все необходимые роли. В ней необходимо создать:
mkdir roles/postgres_12/tasks mkdir roles/postgres_12/templates mkdir roles/registration/tasks mkdir roles/registration/templates mkdir roles/repmgr/tasks mkdir roles/repmgr/templates mkdir roles/ssh/files/keys mkdir roles/ssh/tasksНачнем заполнять директории файлами с описанием необходимых действий (в терминологии Ansible каждая задача называется task). Но сначала необходимо заполнить файл с переменными. Они будут храниться в директории group_vars в файле с именем all.yaml.
Содержимое файла представлено ниже:
group_vars/all.yaml node1_ip: "192.168.56.11" node2_ip: "192.168.56.12" node3_ip: "192.168.56.13" pg_version: "12"В переменных с именем node прописаны IP-адреса, которые будут присвоены виртуальным машинам. Переменная pg_version содержит версию PostgreSQL, которая будет установлена на хосты. В данном примере будет использоваться 12 версия.
Далее описываются роли. Для каждой роли в своей директории будет создана еще одна директория с именем roles, в которой будет находиться файл с именем main.yaml.
Первая роль предназначена для установки PostgreSQL
roles/postgres_12/tasks/main.yaml - name: Add PostgreSQL apt key apt_key: url: https://www.postgresql.org/media/keys/ACCC4CF8.asc - name: Add PostgreSQL repository apt_repository: # ansible_distribution_release = xenial, bionic, focal repo: deb http://apt.postgresql.org/pub/repos/apt/ >-pgdg main - name: Install PostgreSQL 12 apt: name: postgresql-12 update_cache: yes - name: Copy database configuration template: src: full_postgresql.conf.j2 dest: /etc/postgresql/12/main/postgresql.conf group: postgres mode: '0644' owner: postgres - name: Copy user access configuration template: src: pg_hba.conf.j2 dest: /etc/postgresql/12/main/pg_hba.conf group: postgres mode: '0640' owner: postgres Порядок действий, описанный в роли, следующий:
1) Добавление ключа от официального репозитория postgres;
2) Добавление официального репозитория postgres;
3) Установка PostgreSQL 12;
4) Копирование и использование конфигурационного файла full_postgresql.conf.j2, который заменит стандартный конфигурационный файл postgresql.conf;
5) Копирование и использование конфигурационного файла pg_hba.conf.j2, который заменит стандартный конфигурационный файл pg_hba.conf.
Конфигурационные файлы full_postgresql.conf.j2и pg_hba.conf.j2будут находиться по следующему пути: roles/postgres_12/templates.
Содержимое файлов описано ниже
roles/postgres_12/templates/full_postgresql.conf.j2 data_directory = '/var/lib/postgresql/12/main' hba_file = '/etc/postgresql/12/main/pg_hba.conf' ident_file = '/etc/postgresql/12/main/pg_ident.conf' external_pid_file = '/var/run/postgresql/12-main.pid' port = 5432 max_connections = 100 unix_socket_directories = '/var/run/postgresql' shared_buffers = 128MB dynamic_shared_memory_type = posix # repmgr listen_addresses = '*' shared_preload_libraries = 'repmgr' wal_level = replica max_wal_senders = 5 wal_keep_segments = 64 max_replication_slots = 5 hot_standby = on wal_log_hints = onСтроки под комментарием # repmgr относятся к настройкам утилиты repmgr и предназначены для настройки репликации.
В конфигурационном файле pg_hba.conf.j2 прописаны сетевые доступы до всех нод кластера.

Следующая задача – создание SSH ключей для подключения к виртуальным машинам. Сначала на хостовой ОС необходимо сгенерировать SSH ключи. Команда ниже эквивалента команде ssh-keygen с той лишь разницей, что команда ниже сгенерирует ключи без интерактивного режима:
ssh-keygen -q -t rsa -f ~/.ssh/id_rsa /dev/null 2>&1Закрытый (id_rsa) и открытый (id_rsa.pub) ключи будут сохранены по умолчанию — в домашней директории пользователя в скрытой директории .ssh
Далее необходимо скопировать файл с открытым и закрытым ключом в директорию /roles/ssh/files/keys Итого в поддиректории keys будет два файла — id_rsa и id_rsa.pub.
Роль по использованию SSH ключей описана ниже
roles/ssh/tasks/main.yaml - name: Install OpenSSH apt: name: openssh-server update_cache: yes state: present - name: Create postgres SSH directory file: mode: '0755' owner: postgres group: postgres path: /var/lib/postgresql/.ssh/ state: directory - name: Copy SSH private key copy: src: "keys/id_rsa" dest: /var/lib/postgresql/.ssh/id_rsa owner: postgres group: postgres mode: '0600' - name: Copy SSH public key copy: src: "keys/id_rsa.pub" dest: /var/lib/postgresql/.ssh/id_rsa.pub owner: postgres group: postgres mode: '0644' - name: Add key to authorized keys file authorized_key: user: postgres state: present key: ">" - name: Restart SSH service service: name: sshd enabled: yes state: restartedПорядок действий, описанный в роли, следующий:
1) Установка пакета OpenSSH.
2) Создание директории, где будут храниться SSH ключи — /var/lib/postgresql/.ssh/;
3) Копирование закрытого ключа в директорию /var/lib/postgresql/.ssh/;
4) Копирование открытого ключа в директорию /var/lib/postgresql/.ssh/;
5) Добавление открытого ключа в файл authorized_key;
6) Перезапуск демона sshd.
Следующая задача – установка и настройка repmgr.
roles/repmgr/tasks/main.yaml - name: Download repmgr repository installer get_url: dest: /tmp/repmgr-installer.sh mode: 0700 url: https://dl.2ndquadrant.com/default/release/get/deb - name: Execute repmgr repository installer shell: /tmp/repmgr-installer.sh - name: Install repmgr for PostgreSQL > apt: name: postgresql->-repmgr update_cache: yes - name: Setup repmgr user and database become_user: postgres ignore_errors: yes shell: | createuser --replication --createdb --createrole --superuser repmgr && psql -c 'ALTER USER repmgr SET search_path TO repmgr_test, "$user", public;' && createdb repmgr --owner=repmgr - name: Copy repmgr configuration template: src: repmgr.conf.j2 dest: /etc/repmgr.conf - name: Restart PostgreSQL systemd: name: postgresql enabled: yes state: restartedПорядок действий, описанный в роли, следующий:
1) Скачивание установщика, содержащего официальный репозиторий repmgr;
2) Запуск скачанного установщика;
3) Установка пакета repmgr для 12 версии PostgreSQL;
4) Инициализация и создание репликационного кластера;
5) Копирование и использование конфигурационного файла repmgr.conf.j2, который заменит стандартный конфигурационный файл repmgr.conf;
6) Перезапуск демона PostgreSQL.
Конфигурационный файл repmgr.conf.j2 будет находиться по следующему пути roles/repmgr/templates
Содержимое файла описано ниже
roles/repmgr/templates/repmgr.conf.j2 node_id = > node_name = 'node>' conninfo = 'host=> user=repmgr dbname=repmgr' data_directory = '/var/lib/postgresql/>/main' use_replication_slots = yes reconnect_attempts = 5 reconnect_interval = 1 failover = automatic pg_bindir = '/usr/lib/postgresql/>/bin' promote_command = 'repmgr standby promote -f /etc/repmgr.conf' follow_command = 'repmgr standby follow -f /etc/repmgr.conf' log_level = INFO log_file = '/var/log/postgresql/repmgr.log' #monitoring_history=yes #monitor_interval_secs=5 #log_status_interval=5 #promote_check_timeout=5 #promote_check_interval=1 #master_response_timeout=5Последняя роль – это присвоение ролей нодам кластера.
roles/repmgr/registration/main.yaml - name: Register primary node become_user: postgres shell: repmgr primary register ignore_errors: yes when: role == "primary" - name: Stop PostgreSQL systemd: name: postgresql state: stopped when: role == "standby" - name: Clean up PostgreSQL data directory become_user: postgres file: path: /var/lib/postgresql/>/main force: yes state: absent when: role == "standby" - name: Clone primary node data become_user: postgres shell: repmgr -h > -U repmgr -d repmgr standby clone ignore_errors: yes when: role == "standby" - name: Start PostgreSQL systemd: name: postgresql state: started when: role == "standby" - name: Register > node become_user: postgres shell: repmgr -h > > register -F ignore_errors: yes when: role != "primary" - name: Start repmgrd become_user: postgres shell: repmgrd ignore_errors: yesПорядок действий, описанный в роли, следующий:
1) Регистрация primary ноды (она же мастер-нода).
2) Остановка демона PostgreSQL.
3) Удаление всех данных из директории /var/lib/postgresql/12/main.
4) Регистрация stan-by ноды.
5) Запуск демона PostgreSQL.
6) Запуск демона repmrg.
Создание и запуск playbook
Чтобы собрать все задачи воедино, необходимо создать один общий playbook, в который будут включены все задачи и файлы, что были созданы ранее. Для этого в корневой директории (в данном примере это директория с именем postgres-cluster) необходимо создать файл с именем playbook.yaml со следующим содержанием:
postgres-cluster/playbook.yaml --- - hosts: all gather_facts: yes become: yes roles: - postgres_12 - ssh - repmgr - registrationВ параметре roles перечислены все роли, которые будут запущены на хостах. Обратите внимание на порядок ролей.
В итоге получится следующая структура файлов:

Также в корневой директории присутствует ранее созданный Vagrantfile.
Когда все файлы будут созданы, можно запускать установку виртуальных машин и playbook Ansible. Для этого достаточно выполнить одну команду:
vagrant upНачнется процесс установки (см. скриншот ниже). Сначала будут созданы 3 виртуальные машины, далее будет запущен playbook, который установит СУБД PostgreSQL, утилиту repmgr и настроит репликацию.
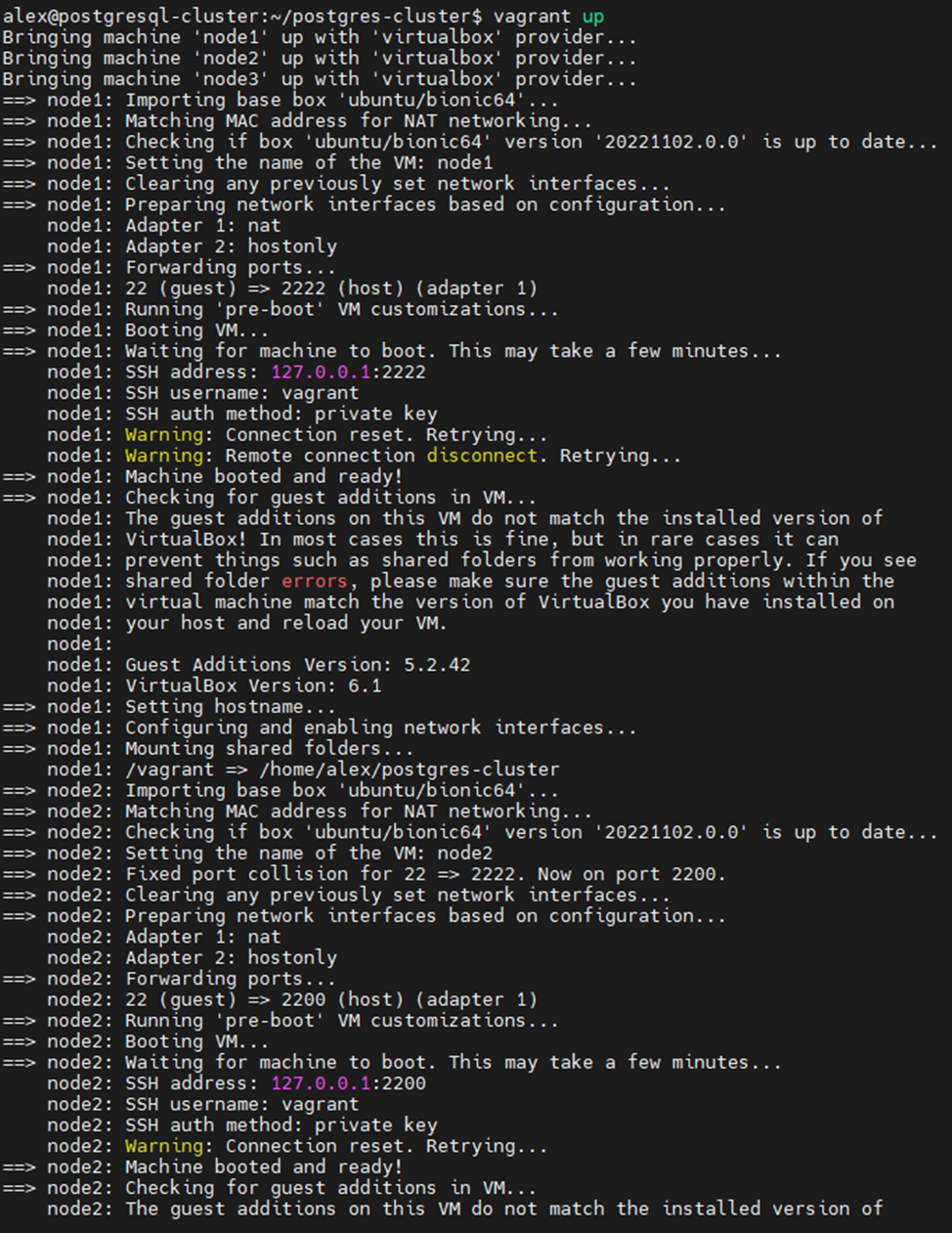
Ниже показан процесс запуска ролей Ansible:

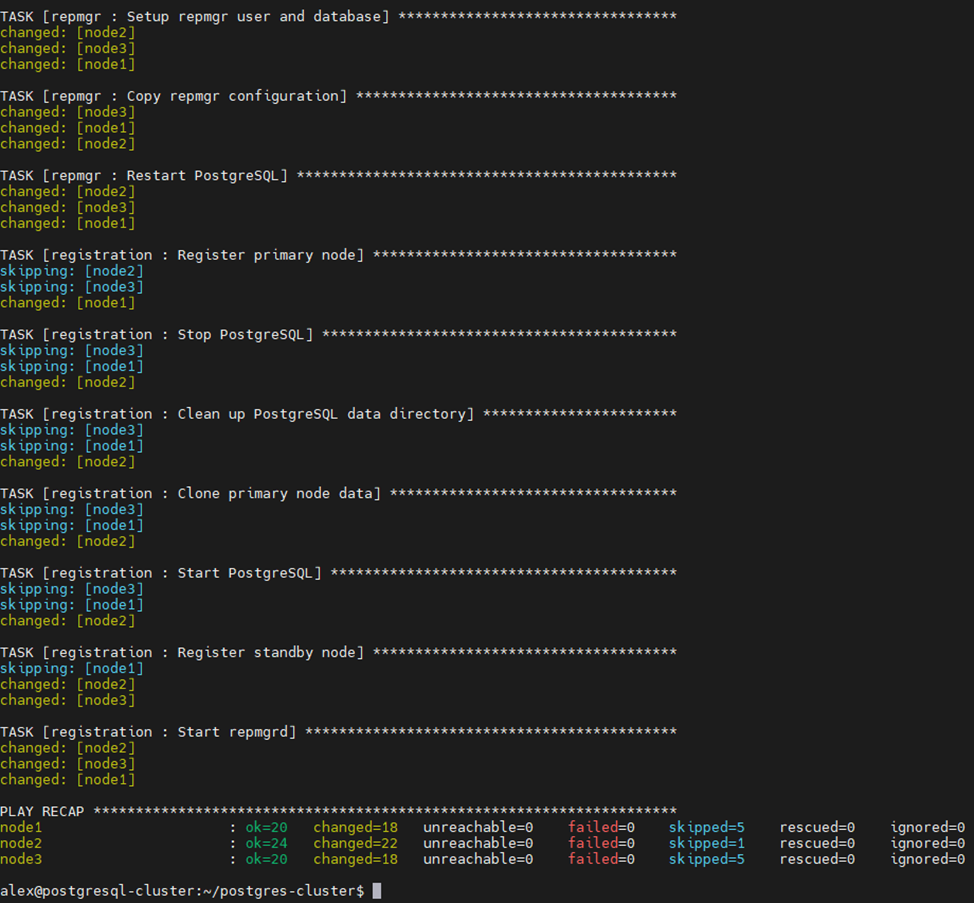
После того как установка будет завершена, можно подключиться к любой из 3 созданных ВМ для проверки статуса репликации. Для этого необходимо ввести команду vagrant ssh node1, где node1 — это имя хоста одной из ВМ:
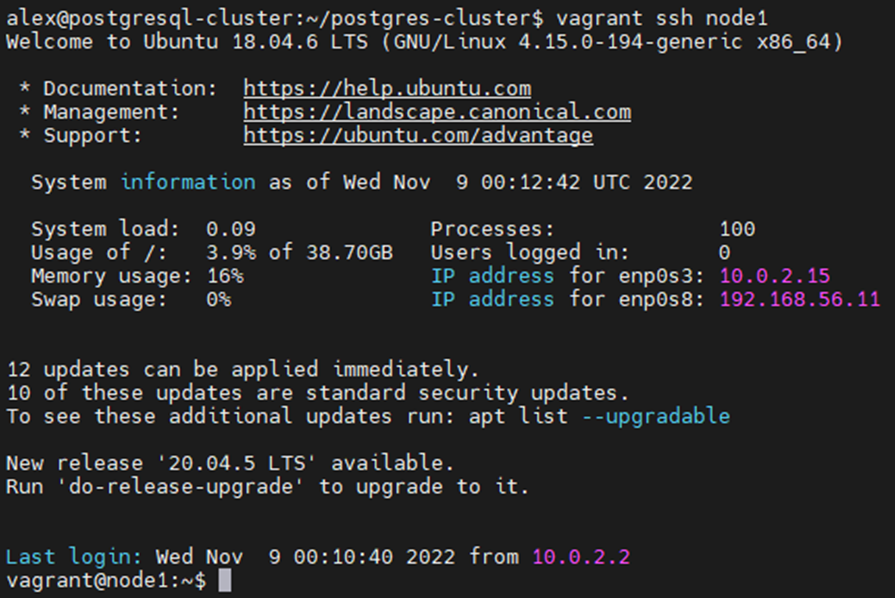
При подключении по SSH пароль вводить не нужно, так как был настроен вход по SSH ключам.
Для проверки статуса кластера и репликации необходимо выполнить команду:
repmgr service status
Как видно из вывода команды, у нас создался кластер PostgreSQL с 3 нодами. У каждой ноды своя роль (столбец Role).
Итог
Созданный кластер можно использовать в качестве тестовой инсталляции, а также для знакомства с утилитой репликации repmgr. Роли нод кластера при желании можно поменять. Также можно легко производить горизонтальное масштабирование – добавлять новые ноды кластера.
НЛО прилетело и оставило здесь промокод для читателей нашего блога:
— 15% на все тарифы VDS (кроме тарифа Прогрев) — HABRFIRSTVDS.
Построение отказоустойчивого кластера PostgreSQL. Настройка внешней синхронизации на PostgreSQL для механизма копий баз данных.
Целью данной статьи является описание способов построения отказоустойчивого кластера PostgreSQL, для систем на базе 1С:Предприятие, подобного решению «MS SQL Server Always On Availability Groups» от Microsoft. Построение такого отказоустойчивого кластера затруднено тем, что в PostgreSQL не предоставляет механизмов автоматического переключения на резервный сервер. Ниже будет описано, каким образом можно реализовать автоматическое переключение на резервный сервер в случае сбоя ведущего сервера PostgreSQL.
Используемые программные продукты
Patroni — шаблон для построения отказоустойчивых кластеров на базе PostgreSQL. Обеспечивает автоматическое переключение на резервный сервер при сбое ведущего сервера. Patroni управляет экземпляром базы данных PostgreSQL и использует внешние системы (ZooKeeper, etcd, Consul или Kubernetes) для хранения общей для всех узлов кластера информации, такой как список узлов кластера и положение ведущего сервера.
etcd — согласованное распределенное хранилище пар ключ-значение, обеспечивающее надежный способ хранения данных, к которым могут обращаться распределенная система или кластер машин.
HAProxy — прокси сервер TCP и HTTP трафика. Позволяет создать единую точку подключения к PostgreSQL, не зависящую от распределения ролей в кластерах PostgreSQL.
Развёртывание стенда
Описание стенда
Для демонстрации работы кластера будет использоваться четыре машины под управлением CentOS 7:
| Имя | IP-адрес | Описание |
|---|---|---|
| Core.example | 10.0.0.11 | симуляция инфраструктуры |
| DBOne.example | 10.0.0.21 | первый сервер PostgreSQL |
| DBTwo.example | 10.0.0.22 | второй сервер PostgreSQL |
| DBThree.example | 10.0.0.23 | третий сервер PostgreSQL |
- Машины уже созданы и на них установлена операционная система
- Операционная система обновлена
- Машины находятся в одной сети
- Машины могут обнаруживать друг друга по DNS именам (core.example, dbone.example, dbtwo.example, dbthree.example).
Дополнительные настройки
Приведём имя машины к её имени в DNS и проверим результат. Для этого выполняем следующие команды:
> sudo hostnamectl set-hostname core.example --static > hostname core.example
> sudo hostnamectl set-hostname dbone.example --static > hostname dbone.example
> sudo hostnamectl set-hostname dbtwo.example --static > hostname dbtwo.example
> sudo hostnamectl set-hostname dbthree.example --static > hostname dbthree.example
Подготовка дистрибутивов
Следует скачать следующие дистрибутивы:
Сервер 1С:Предприятия для RPM-based Linux-систем (https://releases.1c.ru/project/Platform83), использовалась версия 8.3.16.1224
СУБД PostgreSQL для Linux x86 (64-bit) одним архивом (RPM) (https://releases.1c.ru/project/AddCompPostgre), использовалась версия 11.5_12.1C
Установка дистрибутивов
Core.example
На этот сервер следует установить и запустить сервер 1С:Предприятие. Подробную инструкцию по установке можно найти по ссылке: https://its.1c.ru/db/metod8dev#content:5953:hdoc
DBOne.example, DBTwo.example, DBThree.example
На этом этапе настройки этих машин не отличаются. На обоих необходимо установить PostgreSQL с модификациями фирмы 1С.
Установим PostgreSQL версии 11.5_12.1С. Для этого в каталоге с распакованным дистрибутивом PostgreSQL 11.5_12.1C выполняем: Копировать в буфер обмена
> sudo yum install -y postgresql11-1c-*.rpm
> sudo systemctl disable postgresql-11 Removed symlink /etc/systemd/system/multi-user.target.wants/postgresql-11.service.
Развёртывание отказоустойчивого кластера PostgreSQL + Patroni + etcd + HAProxy
Ниже описано создание кластера etcd и добавление нового узла в кластер. Затем будет построен кластер Patroni, использующий etcd для хранения своей конфигурации. После будет настроен HAProxy, который будет отслеживать смену ведущего сервера и скрывать это событие от 1С:Предприятие.
etcd
Кластер etcd будет развёрнут на всех машинах стенда.
Создание кластера etcd
Создадим первый узел кластера. На core.example выполняем следующие действия:
> sudo yum install -y etcd
> sudo mv /etc/etcd/etcd.conf /etc/etcd/etcd.conf.def
#[Member] ETCD_DATA_DIR="/var/lib/etcd" ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380" ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379" ETCD_NAME="core" ETCD_HEARTBEAT_INTERVAL="1000" ETCD_ELECTION_TIMEOUT="5000" #[Clustering] ETCD_INITIAL_ADVERTISE_PEER_URLS="http://core.example:2380" ETCD_ADVERTISE_CLIENT_URLS="http://core.example:2379" ETCD_INITIAL_CLUSTER="core=http://core.example:2380" ETCD_INITIAL_CLUSTER_TOKEN="etcd-example" ETCD_INITIAL_CLUSTER_STATE="new"
> sudo systemctl start etcd.service
Демон должен быть запущен и находиться в состоянии «active» Копировать в буфер обмена
> sudo systemctl status etcd.service ? etcd.service - Etcd Server Loaded: loaded (/usr/lib/systemd/system/etcd.service; disabled; vendor preset: disabled) Active: active (running) since Wed 2020-03-04 07:39:43 UTC; 18s ago Main PID: 16423 (etcd) CGroup: /system.slice/etcd.service ??16423 /usr/bin/etcd --name=core --data-dir=/var/lib/etcd --listen-client-urls=http://0.0.0.0:2379 Mar 04 07:39:43 core.example etcd[16423]: 18cd9dc4a590c73e became leader at term 6 Mar 04 07:39:43 core.example etcd[16423]: raft.node: 18cd9dc4a590c73e elected leader 18cd9dc4a590c73e at term 6 Mar 04 07:39:43 core.example etcd[16423]: setting up the initial cluster version to 3.3 Mar 04 07:39:43 core.example etcd[16423]: publishedЕсли запуск завершился с ошибкой, следует проверить сообщения в системном журнале Копировать в буфер обмена
> journalctl -xel> etcdctl cluster-health member 6390c5e1e694effa is healthy: got healthy result from http://core.example:2379 cluster is healthy> sudo systemctl enable etcd.service Created symlink from /etc/systemd/system/multi-user.target.wants/etcd.service to /usr/lib/systemd/system/etcd.service.При запуске etcd пытается найти все узлы, перечисленные в параметре "ETCD_INITIAL_CLUSTER". Если какой-то из узлов не будет найден - запуск завершится сбоем. Если что-то пошло не так, удалите содержимое каталога из параметра "ETCD_DATA_DIR".
Добавление нового узла etcd
Добавление нового узла в кластер etcd происходит в два этапа. На первом этапе кластер предупреждается о появлении нового узла. На втором запускается сам новый узел.
Следующие действия необходимо последовательно выполнить на всех оставшихся серверах стенда. Для примера будет использоваться dbtwo.example
На core.example выполняем оповещение кластера о появлении нового узла Копировать в буфер обмена> etcdctl member add dbtwo http://dbtwo.example:2380 Added member named dbtwo with ID 871ff309aeb9cd1 to cluster ETCD_NAME="dbtwo" ETCD_INITIAL_CLUSTER="dbtwo=http://dbtwo.example:2380,core=http://core.example:2380" ETCD_INITIAL_CLUSTER_STATE="existing"> sudo yum install -y etcd > sudo mv /etc/etcd/etcd.conf /etc/etcd/etcd.conf.def#[Member] ETCD_DATA_DIR="/var/lib/etcd" ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380" ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379" ETCD_NAME="dbtwo" ETCD_HEARTBEAT_INTERVAL="1000" ETCD_ELECTION_TIMEOUT="5000" #[Clustering] ETCD_INITIAL_ADVERTISE_PEER_URLS="http://dbtwo.example:2380" ETCD_ADVERTISE_CLIENT_URLS="http://dbtwo.example:2379" ETCD_INITIAL_CLUSTER="core=http://core.example:2380,dbtwo=http://dbtwo.example:2380" ETCD_INITIAL_CLUSTER_TOKEN="etcd-example" ETCD_INITIAL_CLUSTER_STATE="existing"> sudo systemctl start etcd.service
демон должен быть запущен и находится в состоянии "active" Копировать в буфер обмена
> sudo systemctl status etcd.service
> etcdctl cluster-health member 871ff309aeb9cd1 is healthy: got healthy result from http://core.example:2379 member 99789c1c8817dff1 is healthy: got healthy result from http://dbtwo.example:2379 cluster is healthy > etcdctl member list 871ff309aeb9cd1: name=dbtwo peerURLs=http://dbtwo.example:2380 clientURLs=http:dbtwo.example:2379 isLeader=true 99789c1c8817dff1: name=core peerURLs=http://core.example:2380 clientURLs=http://core.example:2379 isLeader=false
> sudo systemctl enable etcd.service Created symlink from /etc/systemd/system/multi-user.target.wants/etcd.service to /usr/lib/systemd/system/etcd.service.
Завершение установки etcd
После установки и успешного запуска etcd на всех серверах, следует привести содержание файла /etc/etcd/etcd.conf в окончательное состояние. Для этого необходимо изменить следующие параметры в этом файле на всех серверах.
параметр "ETCD_INITIAL_CLUSTER" должен быть одинаковым на всех узлах Копировать в буфер обмена
ETCD_INITIAL_CLUSTER="core=http://core.example:2380,dbone=http://dbonew.example:2380,dbtwo=http://dbtwo.example:2380,dbthree=http://dbthree.example:2380"
ETCD_INITIAL_CLUSTER_STATE="existing"
Создание пользователя в etcd
Добавим авторизацию по логину и паролю при обращениях на клиентский интерфейс etcd.
> etcdctl user add root New password: User root created
Это первый пользователь и поэтому ему автоматически назначается роль "root". Копировать в буфер обмена
> etcdctl user get root User: root Roles: root
> etcdctl auth enable Authentication Enabled
> etcdctl user get root Insufficient credentials > etcdctl --username root user get root Password: User: root Roles: root
Patroni
Установка Patroni
Следующие действия выполняются на всех серверах PostgreSQL (dbone.example, dbtwo.example и dbthree.exemple).
> sudo yum install -y python3 > sudo python3 -m pip install --upgrade pip
проверяем результат: Копировать в буфер обмена
> python3 --version Python 3.6.8
> sudo yum install -y gcc python3-devel > sudo python3 -m pip install psycopg2-binary
> sudo python3 -m pip install patroni[etcd]
> patroni --version patroni 1.6.4
Первый узел Patroni
Следующие действия выполняются на dbone.example
> sudo mkdir /etc/patroni > sudo chown postgres:postgres /etc/patroni > sudo chmod 700 /etc/patroni
name: dbone namespace: /db/ scope: postgres restapi: listen: 0.0.0.0:8008 connect_address: dbone.example:8008 authentication: username: patroni password: patroni etcd: hosts: localhost:2379 username: root password: rootpassword bootstrap: dcs: ttl: 30 loop_wait: 10 retry_timeout: 10 maximum_lag_on_failover: 1048576 master_start_timeout: 300 postgresql: use_pg_rewind: true use_slots: true parameters: wal_level: replica hot_standby: "on" wal_keep_segments: 8 max_wal_senders: 5 max_replication_slots: 5 checkpoint_timeout: 30 initdb: - auth-host: md5 - auth-local: peer - encoding: UTF8 - data-checksums - locale: ru_RU.UTF-8 pg_hba: - host replication replicator samenet md5 - host replication all 127.0.0.1/32 md5 - host replication all ::1/128 md5 users: usr1cv8: password: usr1cv8 options: - superuser postgresql: listen: 0.0.0.0:5432 connect_address: dbone.example:5432 config_dir: /var/lib/pgsql/11/data bin_dir: /usr/pgsql-11/bin/ data_dir: /var/lib/pgsql/11/data pgpass: /tmp/pgpass authentication: superuser: username: postgres password: V6OxPStvMPh0V7Q982DG replication: username: replicator password: PdR2lIAdwNdcSP4erAXc rewind: username: rewind_user password: WfcuDtEzEbLCHBaYQXX3 parameters: unix_socket_directories: '/var/run/postgresql/' tags: nofailover: false noloadbalance: false clonefrom: false nosync: false
- maximum_lag_on_failover - максимальное количество байт, на которые может отставать резервный сервер от ведущего, участвующий в выборах нового лидера.
- master_start_timeout - задержка в секундах, между обнаружением аварийной ситуации и началом отработки переключения на резервный сервер. По умолчанию 300 секунд. Если задано 0, то переключение начнётся немедленно. При использовании асинхронной репликации (как в приведённом примере) это может привести к потере последних транзакций. Максимальное время переключения на реплику равно "loop_wait" + "master_start_timeout" + "loop_wait". Если "master_start_timeout" установленно в 0, то это время становится равно значению параметра "loop_wait".
Подробнее о возможных вариантах репликации можно прочитать в документации
[Unit] Description=Runners to orchestrate a high-availability PostgreSQL After=syslog.target network.target [Service] Type=simple User=postgres Group=postgres ExecStart=/usr/local/bin/patroni /etc/patroni/patroni.yml ExecReload=/bin/kill -s HUP $MAINPID KillMode=process TimeoutSec=30 Restart=no [Install] WantedBy=multi-user.target
- TimeoutSec - время в секундах, которое система будет ожидать при запуске и остановке сервиса, перед тем как произвести попытку его внештатного завершения.
- Restart - может принимать значения: no, on-success, on-failure, on-abnormal, on-watchdog, on-abort, или always. Определяет политику перезапуска сервиса в случае, если он завершает работу не по команде от systemd.
> sudo systemctl daemon-reload
> sudo systemctl start patroni.service
Статус службы должен быть "active" Копировать в буфер обмена
> sudo systemctl status patroni.service ? patroni.service - Runners to orchestrate a high-availability PostgreSQL Loaded: loaded (/etc/systemd/system/patroni.service; disabled; vendor preset: disabled) Active: active (running) since Wed 2020-03-04 09:22:32 UTC; 7s ago Main PID: 19572 (patroni) CGroup: /system.slice/patroni.service ??19572 /usr/bin/python3 /usr/local/bin/patroni /etc/patroni/patroni.yml ??19581 /usr/pgsql-11/bin/pg_ctl initdb -D /var/lib/pgsql/11/data -o --encoding=UTF8 --data-checksums --locale=ru_RU.UTF-8 --use. ??19583 /usr/pgsql-11/bin/initdb -D /var/lib/pgsql/11/data --encoding=UTF8 --data-checksums --locale=ru_RU.UTF-8 --username=post. Mar 04 09:22:33 dbone.example patroni[19572]: Data page checksums are enabled. Mar 04 09:22:33 dbone.example patroni[19572]: fixing permissions on existing directory /var/lib/pgsql/11/data . ok Mar 04 09:22:33 dbone.example patroni[19572]: creating subdirectories . ok Mar 04 09:22:33 dbone.example patroni[19572]: selecting default max_connections . 100 Mar 04 09:22:33 dbone.example patroni[19572]: selecting default shared_buffers . 128MB Mar 04 09:22:33 dbone.example patroni[19572]: selecting default timezone . UTC Mar 04 09:22:33 dbone.example patroni[19572]: selecting dynamic shared memory implementation . posix Mar 04 09:22:33 dbone.example patroni[19572]: creating configuration files . ok Mar 04 09:22:33 dbone.example patroni[19572]: running bootstrap script . ok Mar 04 09:22:34 dbone.example patroni[19572]: performing post-bootstrap initialization . ok
> sudo ls -l /var/lib/pgsql/11/data drwx------. 5 postgres postgres 38 Mar 4 09:28 base drwx------. 2 postgres postgres 4096 Mar 4 09:28 global drwx------. 2 postgres postgres 6 Mar 4 09:28 pg_commit_ts drwx------. 2 postgres postgres 6 Mar 4 09:28 pg_dynshmem -rw-------. 1 postgres postgres 4581 Mar 4 09:28 pg_hba.conf -rw-------. 1 postgres postgres 1636 Mar 4 09:28 pg_ident.conf drwx------. 4 postgres postgres 65 Mar 4 09:28 pg_logical drwx------. 4 postgres postgres 34 Mar 4 09:28 pg_multixact drwx------. 2 postgres postgres 17 Mar 4 09:28 pg_notify drwx------. 2 postgres postgres 6 Mar 4 09:28 pg_replslot drwx------. 2 postgres postgres 6 Mar 4 09:28 pg_serial drwx------. 2 postgres postgres 6 Mar 4 09:28 pg_snapshots drwx------. 2 postgres postgres 6 Mar 4 09:28 pg_stat drwx------. 2 postgres postgres 6 Mar 4 09:28 pg_stat_tmp drwx------. 2 postgres postgres 17 Mar 4 09:28 pg_subtrans drwx------. 2 postgres postgres 6 Mar 4 09:28 pg_tblspc drwx------. 2 postgres postgres 6 Mar 4 09:28 pg_twophase -rw-------. 1 postgres postgres 3 Mar 4 09:28 PG_VERSION drwx------. 3 postgres postgres 58 Mar 4 09:28 pg_wal drwx------. 2 postgres postgres 17 Mar 4 09:28 pg_xact -rw-------. 1 postgres postgres 88 Mar 4 09:28 postgresql.auto.conf -rw-------. 1 postgres postgres 24084 Mar 4 09:28 postgresql.conf
> ss -ltn | grep 5432 LISTEN 0 128 0.0.0.0:5432 0.0.0.0:*
> psql -U usr1cv8 -d postgres
> sudo systemctl enable patroni.service Created symlink from /etc/systemd/system/multi-user.target.wants/patroni.service to /etc/systemd/system/patroni.service.
Настройка patronictl
Создание файла с настройками по умолчанию позволит не указывать настройки подключения для patronictl.
Создаём файл ~/.config/patroni/patronictl.yaml со следующим содержимым: Копировать в буфер обмена
dcs_api: etcd://localhost:2379 namespace: /db/ scope: postgres authentication: username: patroni password: patroni
> patronictl list +----------+------------+---------------+--------+---------+----+-----------+-----------------+ | Cluster | Member | Host | Role | State | TL | Lag in MB | Pending restart | +----------+------------+---------------+--------+---------+----+-----------+-----------------+ | postgres | dbone | dbone.example | Leader | running | 1 | 0.0 | | +----------+------------+---------------+--------+---------+----+-----------+-----------------+
Добавление нового узла Patroni
Для добавления нового узла в кластер Patroni, выполняются действия из раздела "Первый узел Patroni". Различия будут заключаться только в файле /etc/patroni/patroni.yml - все изменения заключаются в замене "dbone" на имя текущего сервера. Поэтому для dbtwo.example содержимое будет следующим:
name: dbtwo namespace: /db/ scope: postgres restapi: listen: 0.0.0.0:8008 connect_address: dbtwo.example:8008 authentication: username: patroni password: patroni etcd: hosts: localhost:2379 username: root password: rootpassword bootstrap: dcs: ttl: 30 loop_wait: 10 retry_timeout: 10 maximum_lag_on_failover: 1048576 master_start_timeout: 300 postgresql: use_pg_rewind: true use_slots: true parameters: wal_level: replica hot_standby: "on" wal_keep_segments: 8 max_wal_senders: 5 max_replication_slots: 5 checkpoint_timeout: 30 initdb: - auth-host: md5 - auth-local: peer - encoding: UTF8 - data-checksums - locale: ru_RU.UTF-8 pg_hba: - host replication replicator samenet md5 - host replication all 127.0.0.1/32 md5 - host replication all ::1/128 md5 users: usr1cv8: password: usr1cv8 options: - superuser postgresql: listen: 0.0.0.0:5432 connect_address: dbtwo.example:5432 config_dir: /var/lib/pgsql/11/data bin_dir: /usr/pgsql-11/bin/ data_dir: /var/lib/pgsql/11/data pgpass: /tmp/pgpass authentication: superuser: username: postgres password: V6OxPStvMPh0V7Q982DG replication: username: replicator password: PdR2lIAdwNdcSP4erAXc rewind: username: rewind_user password: WfcuDtEzEbLCHBaYQXX3 parameters: unix_socket_directories: '/var/run/postgresql/' tags: nofailover: false noloadbalance: false clonefrom: false nosync: false
После запуска Patroni на резервном сервере происходит следующее:
- Patroni подключается к кластеру на dbone.example
- Создаётся новый кластер PostgreSQL и заполняется данными с dbone.example
- Новый кластер PostgreSQL переводится в "slave mode"
В результате в кластере Patroni должно быть три узла:
> patronictl list +----------+------------+---------------+--------+---------+----+-----------+-----------------+ | Cluster | Member | Host | Role | State | TL | Lag in MB | Pending restart | +----------+------------+---------------+--------+---------+----+-----------+-----------------+ | postgres | dbone | 10.0.0.21 | Leader | running | 1 | | | | postgres | dbtwo | 10.0.0.22 | | running | 1 | 0.0 | | | postgres | dbthree | 10.0.0.23 | | running | 1 | 0.0 | | +----------+------------+---------------+--------+---------+----+-----------+-----------------+
HAProxy
Установка HAProxy
В настройках информационной базы, в кластере 1С:Предприятие, необходимо указывать имя сервера СУБД. В нашем случае им может быть один из серверов PostgreSQL. Так как указать все имена сразу мы не можем, а роли серверов (ведущий сервер и резервный сервер) могут поменяться в любой момент, следует создать точку подключения к PostgreSQL. В качестве точки подключения будет выступать HAProxy установленный на core.example. В задачe HAProxy будет входить слежение за ролями серверов PostgreSQL и, в случае их изменения, оперативное перенаправление запросов от 1С:Предприятие к СУБД на новый ведущий сервер.
Следующие действия выполняются на core.example
Устанавливаем HPAroxy из пакета и откладываем в сторону настройки по умолчанию Копировать в буфер обмена
> sudo yum install -y haproxy > sudo mv /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.conf.def
global maxconn 100 defaults log global mode tcp retries 2 timeout client 30m timeout connect 4s timeout server 30m timeout check 5s listen stats mode http bind *:7000 stats enable stats uri / listen postgres bind *:5432 option httpchk http-check expect status 200 default-server inter 3s fastinter 1s fall 2 rise 2 on-marked-down shutdown-sessions server dbone dbone.example:5432 maxconn 100 check port 8008 server dbtwo dbtwo.example:5432 maxconn 100 check port 8008 server dbthree dbthree.example:5432 maxconn 100 check port 8008
> sudo setsebool -P haproxy_connect_any=1 > sudo systemctl start haproxy.service
> sudo systemctl status haproxy.service ? haproxy.service - HAProxy Load Balancer Loaded: loaded (/usr/lib/systemd/system/haproxy.service; disabled; vendor preset: disabled) Active: active (running) since Wed 2020-03-04 10:59:47 UTC; 2s ago Main PID: 17617 (haproxy-systemd) CGroup: /system.slice/haproxy.service ??17617 /usr/sbin/haproxy-systemd-wrapper -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid ??17618 /usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -Ds ??17619 /usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -Ds Mar 04 10:59:47 core.example systemd[1]: Started HAProxy Load Balancer. Mar 04 10:59:47 core.example systemd[1]: Starting HAProxy Load Balancer. Mar 04 10:59:47 core.example haproxy-systemd-wrapper[17617]: haproxy-systemd-wrapper: executing /usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -Ds
> sudo systemctl enable haproxy.service Created symlink from /etc/systemd/system/multi-user.target.wants/haproxy.service to /usr/lib/systemd/system/haproxy.service.
Изменение настроек PostgreSQL через Patroni
Так как PostgreSQL теперь управляется Patroni, то и настройки PostgreSQL задаются через конфигурационный файл Paroni. Рекомендуется поддерживать данные настройки одинаковыми на всех узлах. Для задания настроек PostgreSQL используется параметр "parameters" в секции "postgresql" файла /etc/patroni/patroni.yml Сейчас он выглядит следующим образом:
parameters: unix_socket_directories: '/var/run/postgresql/'
Следующие действия выполняются на серверах PostgreSQL.
Приводим "parameters" к следующему виду Копировать в буфер обмена
parameters: unix_socket_directories: '/var/run/postgresql/' shared_buffers: '1024MB' temp_buffers: '256MB' work_mem: '64MB' standard_conforming_strings: off escape_string_warning: off shared_preload_libraries: 'online_analyze, plantuner' plantuner.fix_empty_table: on online_analize.enable: on online_analize.table_type: 'temporary' online_analize.local_tracking: on online_analize.verbose: off maintenance_work_mem: '256MB' max_locks_per_transaction: 256 lc_messages: 'en_US.UTF-8' log_line_prefix: '%m [%p] %q%u@%d '
> patronictl reload postgres dbone > patronictl restart postgres dbone > patronictl reload postgres dbtwo > patronictl restart postgres dbtwo > patronictl reload postgres dbthree > patronictl restart postgres dbthree
> psql -U usr1cv8 -d postgres postgres> SHOW ALL;
Проверка переключения на резервный сервер PostgreSQL
Проведём несколько проверок отказоустойчивости кластера.
Подготовка
Создаём информационную базу в кластере 1С:Предприятие. Параметры создания информационной базы:
Имя: test Сервер баз данных: localhost Тип СУБД: PostgreSQL База данных: test Пользователь сервера БД: usr1cv8 Пароль пользователя сервера БД: usr1cv8
Загружаем в базу произвольную конфигурацию.
После окончания загрузки проверяем, что данные переданы на резервный сервер
> patronictl list +----------+------------+---------------+--------+---------+----+-----------+-----------------+ | Cluster | Member | Host | Role | State | TL | Lag in MB | Pending restart | +----------+------------+---------------+--------+---------+----+-----------+-----------------+ | postgres | dbone | 10.0.0.21 | Leader | running | 10 | | | | postgres | dbtwo | 10.0.0.22 | | running | 1 | 0.0 | | | postgres | dbthree | 10.0.0.23 | | running | 1 | 0.0 | | +----------+------------+---------------+--------+---------+----+-----------+-----------------+
в колонке "Lag in MB" должно быть 0.0
Тесты
Для выполнения тестов, откроем информационную базу "Test" в режиме 1С:Предприятие.
Плановое переключение ведущего сервера
- На dbone.example выполняем команду смены ведущего сервера Копировать в буфер обмена
> patronictl failover
> patronictl list +----------+------------+---------------+--------+---------+----+-----------+-----------------+ | Cluster | Member | Host | Role | State | TL | Lag in MB | Pending restart | +----------+------------+---------------+--------+---------+----+-----------+-----------------+ | postgres | dbone | 10.0.0.21 | | running | 10 | 0.0 | | | postgres | dbtwo | 10.0.0.22 | Leader | running | 1 | | | | postgres | dbthree | 10.0.0.23 | | running | 10 | 0.0 | | +----------+------------+---------------+--------+---------+----+-----------+-----------------+
Сбой ведущего сервера
- На dbtwo.example выполняем команду для перезагрузки Копировать в буфер обмена
> shutdown -r
> patronictl list +----------+------------+---------------+--------+---------+----+-----------+-----------------+ | Cluster | Member | Host | Role | State | TL | Lag in MB | Pending restart | +----------+------------+---------------+--------+---------+----+-----------+-----------------+ | postgres | dbone | 10.0.0.21 | Leader | running | 10 | | | | postgres | dbtwo | 10.0.0.22 | | running | 1 | 0.0 | | | postgres | dbthree | 10.0.0.23 | | running | 1 | 0.0 | | +----------+------------+---------------+--------+---------+----+-----------+-----------------+
Проверяем работу в информационной базе - 1С:Предприятие изменений в инфраструктуре заменить не должно
Резервное копирование
Ниже приведён пример создания резервной копии кластера PostgreSQL, теми средствами, что идут в его поставке. Резервная копия может быть снята не только на ведущем сервере, но и на резервном сервере.
> pg_basebackup -D ~/postgres.bak -Ft -z -P -U usr1cv8
> ls ~/postgres.bak base.tar.gz pg_wal.tar.gz
Восстановление после сбоев
Ниже приведена последовательность действий для проверки восстановления резервной копии на демонстрационном стенде. Поэтому, в реальной ситуации, раздел "Удаление данных" должен быть пересмотрен с учётом реальных обстоятельств сбоя. Раздел "Восстановление" предполагает, что описанное решение по созданию отказоустойчивого кластера Patroni полностью выполнено и его лишь надо наполнить данными.
Удаление данных
- Проверяем текущие роли узлов кластера Patroni Копировать в буфер обмена
> patronictl list
> sudo systemctl stop patroni > sudo systemctl stop postgresql-11
> sudo systemctl stop patroni > sudo systemctl stop postgresql-11
> patronictl remove postgres
> sudo rm -rf /var/lib/pgsql/11/data
Восстановление
- Восстанавливаем каталог кластера PostgreSQL на новом ведущем сервере
Следующие действия выполняются на dbone.example Копировать в буфер обмена
> sudo mkdir /var/lib/pgsql/11/data > sudo chown postgres:postgres /var/lib/pgsql/11/data > sudo chmod 700 /var/lib/pgsql/11/data > sudo tar xzf base.tar.gz -C /var/lib/pgsql/11/data > sudo tar xzf pg_wal.tar.gz -C /var/lib/pgsql/11/data/pg_wal > sudo rm /var/lib/pgsql/11/data/recovery.conf > sudo rm /var/lib/pgsql/11/data/recovery.done > sudo systemctl start patroni
> scp -r ~/postgres.bak dbtwo.example:postgres.bak > scp -r ~/postgres.bak dbthree.example:postgres.bak
> patronictl list +----------+------------+---------------+--------+---------+----+-----------+-----------------+ | Cluster | Member | Host | Role | State | TL | Lag in MB | Pending restart | +----------+------------+---------------+--------+---------+----+-----------+-----------------+ | postgres | dbone | 10.0.0.21 | Leader | running | 1 | | | | postgres | dbtwo | 10.0.0.22 | | running | 1 | 0.0 | | | postgres | dbthree | 10.0.0.23 | | running | 1 | 0.0 | | +----------+------------+---------------+--------+---------+----+-----------+-----------------+
Использование резервного сервера PostgreSQL для механизма копий базы данных
Механизм копий баз данных имеет особенность в использовании внешнего типа репликации данных при размещении данных в PostgreSQL. Особенность связана с тем, что резервный сервер PostgreSQL доступен только на чтение, включая временные таблицы. Такое ограничение приводит к тому, что запросы к СУБД, с созданием временных таблиц, выполняемые 1С:Предприятие, будут завершаться с ошибкой.
Для снятия этого ограничения требуется развёртывание дополнительного кластера PostgreSQL, доступного для записи данных. Ниже будет описан пример развёртывания такого сервера.
Создание дополнительного кластера PostgreSQL
Для создания дополнительного кластера PostgreSQL можно добавить новый сервер и установить на него PostgreSQL. В этом случае порядок действий не отличается от обычной установки PostgreSQL.
В случае, если добавление нового сервера нежелательно, дополнительный кластер PostgreSQL можно разместить на одном из существующих серверов PostgreSQL. Ниже показан пример развёртывания дополнительного кластера на уже существующем сервере.
Следующие действия выполняются на dbthree.example
Данные кластера будут расположены в каталоге /var/lib/pgsql/11/proxy
> export LANG="ru_RU.UTF-8" > sudo -u postgres /usr/pgsql-11/bin/initdb -D /var/lib/pgsql/11/proxy --auth-local=peer --auth-host=md5 The files belonging to this database system will be owned by user "postgres". This user must also own the server process. The database cluster will be initialized with locales COLLATE: ru_RU.UTF-8 CTYPE: ru_RU.UTF-8 MESSAGES: ru_RU.UTF-8 MONETARY: en_GB.UTF-8 NUMERIC: en_GB.UTF-8 TIME: en_GB.UTF-8 The default database encoding has accordingly been set to "UTF8". The default text search configuration will be set to "russian". Data page checksums are disabled. creating directory /var/lib/pgsql/11/proxy . ok creating subdirectories . ok selecting default max_connections . 100 selecting default shared_buffers . 128MB selecting default timezone . Europe/Moscow selecting dynamic shared memory implementation . posix creating configuration files . ok running bootstrap script . ok performing post-bootstrap initialization . ok syncing data to disk . ok Success. You can now start the database server using: /usr/pgsql-11/bin/pg_ctl -D /var/lib/pgsql/11/proxy -l logfile start
[Unit] Description=PostgreSQL 11 database proxy server After=syslog.target After=network.target [Service] Type=notify User=postgres Group=postgres Environment=PGDATA=/var/lib/pgsql/11/proxy/ OOMScoreAdjust=-1000 ExecStartPre=/usr/pgsql-11/bin/postgresql-11-check-db-dir $ ExecStart=/usr/pgsql-11/bin/postmaster -D $ ExecReload=/bin/kill -HUP $MAINPID KillMode=mixed KillSignal=SIGINT TimeoutSec=300 [Install] WantedBy=multi-user.target
#------------------------------------------------------------------------------ # CONNECTIONS AND AUTHENTICATION #------------------------------------------------------------------------------ # - Connection Settings - listen_addresses = '*' # what IP address(es) to listen on; # comma-separated list of addresses; # defaults to 'localhost'; use '*' for all # (change requires restart) port = 5433
> sudo systemctl daemon-reload > sudo systemctl start postgresql-11-proxy.service
> ss -ltn | grep 5433 LISTEN 0 128 0.0.0.0:5433 0.0.0.0:*
> sudo systemctl enable postgresql-11-proxy.service
Настройка кластера
- Создаём пользователя для 1С:Предприятие
- входим пользователем postgres
Копировать в буфер обмена
> sudo -u postgres psql -p 5433
- создаём нового пользователя
posgres> CREATE USER usr1cv8 WITH SUPERUSER LOGIN ENCRYPTED PASSWORD 'usr1cv8';
Имя: test Сервер баз данных: dbthree.example port=5433 Тип СУБД: PostgreSQL База данных: test Пользователь сервера БД: usr1cv8 Пароль пользователя сервера БД: usr1cv8
Настройка промежуточной базы данных
- Входим пользователем postgres в созданную базу данных Копировать в буфер обмена
> sudo -u postgres psql -p 5433 -d test
select 'DROP TABLE ' || string_agg(tablename, ', ') || ';' from pg_tables where schemaname = 'public' \gexec
CREATE EXTENSION postgres_fdw;
CREATE SERVER standby_server FOREIGN DATA WRAPPER postgres_fdw OPTIONS (host '', dbname 'test', port '5432');
CREATE USER MAPPING FOR postgres SERVER standby_server OPTIONS (user 'usr1cv8', password 'usr1cv8'); CREATE USER MAPPING FOR usr1cv8 SERVER standby_server OPTIONS (user 'usr1cv8', password 'usr1cv8');
IMPORT FOREIGN SCHEMA public FROM SERVER standby_server INTO public;
В настройках подключения к копии базы данных следует указывать промежуточную базу:
Сервер: dbthree.example port=5433 База данных: test
В варианте использования резервного сервера для копии базы данных, имеет смысл запретить Patroni выбирать этот сервер в качестве ведущего. Для этого следует изменить секцию "tags" patroni.yml По умолчанию, секция "tags" содержит следующие параметры:
tags: nofailover: false noloadbalance: false clonefrom: false nosync: false
- nofailover - значение "true" запрещает выбирать этот узел в качестве ведущего
- clonefrom - значение "true" рекомендует выбирать этот узел для создания резервной копии при развёртывании нового узла Patroni. Если значение "true" установлено у нескольких узлов, будет случайным образом выбран один из них
- noloadbalance - устанавливает HTTP код возврата 503 для запроса GET /replica REST API
- nosync - значение true запрещает выбирать этот узел для синхронной репликации
В результате выполнения указанных настроек внешняя синхронизация для механизма копий баз данных при использовании СУБД MS SQL Server, а также выполнение запросов на копии, должны работать корректно.
Реструктуризация информационной базы
В случае изменения структуры метаданных информационной базы в структуру базы данных вносятся соответствующие изменения. Эти изменения необходимо перенести в промежуточную базу данных. Для этого следует удалить импортированные таблицы и импортировать схему заново.
Следующие действия выполнятся на dbthree.example.
Входим пользователем postgres в промежуточную базу данных Копировать в буфер обмена
> sudo -u postgres psql -p 5433 -d test
select 'DROP FOREIGN TABLE ' || string_agg(table_name, ', ') || ';' from information_schema.tables where table_type = 'FOREIGN' \gexec
IMPORT FOREIGN SCHEMA public FROM SERVER standby_server INTO public;
Как создать новый кластер postgresql
Прежде чем вы сможете работать с базами данных, вы должны проинициализировать область хранения баз данных на диске. Мы называем это хранилище кластером баз данных. (В SQL применяется термин «кластер каталога».) Кластер баз данных представляет собой набор баз, управляемых одним экземпляром работающего сервера. После инициализации кластер будет содержать базу данных с именем postgres , предназначенную для использования по умолчанию утилитами, пользователями и сторонними приложениями. Сам сервер баз данных не требует наличия базы postgres , но многие внешние вспомогательные программы рассчитывают на её существование. При инициализации в каждом кластере создаётся ещё одна база, с именем template1 . Как можно понять из имени, она применяется впоследствии в качестве шаблона создаваемых баз данных; использовать её в качестве рабочей не следует. (За информацией о создании новых баз данных в кластере обратитесь к Главе 22.)
С точки зрения файловой системы, кластер баз данных представляет собой один каталог, в котором будут храниться все данные. Мы называем его каталогом данных или областью данных. Где именно хранить данные, вы абсолютно свободно можете выбирать сами. Какого-либо стандартного пути не существует, но часто данные размещаются в /usr/local/pgsql/data или в /var/lib/pgsql/data . Для инициализации кластера баз данных применяется команда initdb , которая устанавливается в составе PostgreSQL . Расположение кластера базы данных в файловой системе задаётся параметром -D , например:
$initdb -D /usr/local/pgsql/data
Заметьте, что эту команду нужно выполнять от имени учётной записи PostgreSQL , о которой говорится в предыдущем разделе.
Подсказка
В качестве альтернативы параметра -D можно установить переменную окружения PGDATA .
Также можно запустить команду initdb , воспользовавшись программой pg_ctl , примерно так:
$pg_ctl -D /usr/local/pgsql/data initdb
Этот вариант может быть удобнее, если вы используете pg_ctl для запуска и остановки сервера (см. Раздел 18.3), так как pg_ctl будет единственной командой, с помощью которой вы будете управлять экземпляром сервера баз данных.
Команда initdb попытается создать указанный вами каталог, если он не существует. Конечно, она не сможет это сделать, если initdb не будет разрешено записывать в родительский каталог. Вообще рекомендуется, чтобы пользователь PostgreSQL был владельцем не только каталога данных, но и родительского каталога, так что такой проблемы быть не должно. Если же и нужный родительский каталог не существует, вам нужно будет сначала создать его, используя права root, если вышестоящий каталог защищён от записи. Таким образом, процедура может быть такой:
root#mkdir /usr/local/pgsqlroot#chown postgres /usr/local/pgsqlroot#su postgrespostgres$initdb -D /usr/local/pgsql/data
Команда initdb не будет работать, если указанный каталог данных уже существует и содержит файлы; это мера предохранения от случайной перезаписи существующей инсталляции.
Так как каталог данных содержит все данные базы, очень важно защитить его от неавторизованного доступа. Для этого initdb лишает прав доступа к нему всех пользователей, кроме пользователя PostgreSQL и, возможно, его группы. Если группе разрешается доступ, то только для чтения. Это позволяет непривилегированному пользователю, входящему в одну группу с владельцем кластера, делать резервные копии данных кластера или выполнять другие операции, для которых достаточно доступа только для чтения.
Заметьте, чтобы корректно разрешить или запретить доступ группы к данным существующего кластера, необходимо выключить кластер и установить соответствующий режим для всех каталогов и файлов до запуска PostgreSQL . В противном случае в каталоге данных возможно смешение режимов. Для кластеров, к которым имеет доступ только владелец, требуется установить режим 0700 для каталогов и 0600 для файлов, а для кластеров, в которых также разрешается чтение группой, режим 0750 для каталогов и 0640 для файлов.
Однако даже когда содержимое каталога защищено, если проверка подлинности клиентов настроена по умолчанию, любой локальный пользователь может подключиться к базе данных и даже стать суперпользователем. Если вы не доверяете другим локальным пользователям, мы рекомендуем использовать один из параметров команды initdb : -W , --pwprompt или --pwfile и назначить пароль суперпользователя баз данных. Кроме того, воспользуйтесь параметром -A md5 или -A password и отключите разрешённый по умолчанию режим аутентификации trust ; либо измените сгенерированный файл pg_hba.conf после выполнения initdb , но перед тем, как запустить сервер в первый раз. (Возможны и другие разумные подходы — применить режим проверки подлинности peer или ограничить подключения на уровне файловой системы. За дополнительными сведениями обратитесь к Главе 20.)
Команда initdb также устанавливает для кластера баз данных локаль по умолчанию. Обычно она просто берёт параметры локали из текущего окружения и применяет их к инициализируемой базе данных. Однако можно выбрать и другую локаль для базы данных; за дополнительной информацией обратитесь к Разделу 23.1. Команда initdb задаёт порядок сортировки по умолчанию для применения в определённом кластере баз данных, и хотя новые базы данных могут создаваться с иным порядком сортировки, порядок в базах-шаблонах, создаваемых initdb, можно изменить, только если удалить и пересоздать их. Также учтите, что при использовании локалей, отличных от C и POSIX , возможно снижение производительности. Поэтому важно правильно выбрать локаль с самого начала.
Команда initdb также задаёт кодировку символов по умолчанию для кластера баз данных. Обычно она должна соответствовать кодировке локали. За подробностями обратитесь к Разделу 23.3.
Для локалей, отличных от C и POSIX , порядок сортировки символов зависит от системной библиотеки локализации, а он, в свою очередь, влияет на порядок ключей в индексах. Поэтому кластер нельзя перевести на несовместимую версию библиотеки ни путём восстановления снимка, ни через двоичную репликацию, ни перейдя на другую операционную систему или обновив её версию.
18.2.1. Использование дополнительных файловых систем
Во многих инсталляциях кластеры баз данных создаются не в « корневом » томе, а в отдельных файловых системах (томах). Если вы решите сделать так же, то не следует выбирать в качестве каталога данных самый верхний каталог дополнительного тома (точку монтирования). Лучше всего создать внутри каталога точки монтирования каталог, принадлежащий пользователю PostgreSQL , а затем создать внутри него каталог данных. Это исключит проблемы с разрешениями, особенно для таких операций, как pg_upgrade , и при этом гарантирует чистое поведение в случае, если дополнительный том окажется отключён.
18.2.2. Файловые системы
Вообще говоря, для PostgreSQL может использоваться любая файловая система с семантикой POSIX. Пользователи предпочитают различные файловые системы по самым разным причинам, в частности, по соображениям производительности, изученности или поддержки поставщиком. Как показывает практика, в результате лишь смены файловой системы или корректировки её параметров при прочих равных не следует ожидать значительного изменения производительности или поведения.
18.2.2.1. NFS
Каталог данных PostgreSQL может размещаться и в файловой системе NFS . PostgreSQL не подстраивается специально под NFS , что означает, что с NFS он работает точно так же, как и с локально подключёнными устройствами. PostgreSQL не использует такую функциональность файловых систем, которая имеет свои особенности в NFS , например блокировки файлов.
Единственное убедительное требование — используя NFS c PostgreSQL , монтируйте эту файловую систему в режиме hard . При использовании режима hard процессы могут « зависать » на неопределённое время в случае сетевых проблем, поэтому могут потребоваться особые меры контроля. В режиме soft системные вызовы будут прерываться в случаях перебоев в сети, но PostgreSQL не повторяет вызовы, прерванные таким образом, и это будет проявляться в ошибках ввода/вывода.
Использовать параметр монтирования sync не обязательно. Поведения режима async достаточно, так как PostgreSQL вызывает fsync в нужные моменты для сброса кеша записи (так же, как и с локальной файловой системой). Однако параметр sync настоятельно рекомендуется использовать при экспортировании файловой системы на сервере NFS в тех ОС, где он поддерживается (в основном это касается Linux). В противном случае не гарантируется, что в результате выполнения fsync или аналогичного вызова NFS-клиентом данные действительно окажутся в надёжном хранилище на сервере, вследствие чего возможно повреждение данных, как и при выключенном параметре fsync. Значения по умолчанию параметров монтирования и экспортирования меняются от производителя к производителю и от версии к версии, поэтому рекомендуется перепроверить их или, возможно, явно задать нужные значения во избежание неоднозначности.
В некоторых случаях внешнее устройство хранение может быть подключено по NFS или посредством низкоуровневого протокола, например iSCSI. В последнем случае такое хранилище представляется в виде блочного устройства, и на нём можно создать любую файловую систему. При этом администратору не придётся иметь дело со странностями NFS, но надо понимать, что сложности управления удалённым хранилищем в таком случае просто перемещаются на другие уровни.
| Пред. | Наверх | След. |
| 18.1. Учётная запись пользователя PostgreSQL | Начало | 18.3. Запуск сервера баз данных |
�� Создание кластера баз данных PostgreSQL
Первое, что надо сделать после установки PostgreSQL на компьютер — это создать новый кластер баз данных. В терминах Postgresql — кластер баз данных это набор баз , которые управляются одним экземпляром сервера. Один экземпляр PostgreSQL может запускать и контролировать набор баз данных, которые изолированы друг от друга, но обслуживаются через один и тот же сокет TCP/IP или UNIX.
Ограничений по количеству запущенных экземпляров PostgreSQL, кроме ограничений накладываемых доступными ресурсами системы и количеством свободных сокетов.
Процесс создания кластера баз данных состоит из создания директории, где будут храниться данные, создания общих таблиц (shared catalog tables) (таблицы, которые относятся ко всему кластеру, а не к какой-либо конкретной базе), создания базы-шаблона template1 (вообще-то создаются две шаблонные базы: template1 и template0. template0 выступает в качестве дублирующей копии для template1, в случае, если последняя будет разрушена) и служебной базы postgres.
Таким образом кластер использует файловую систему для хранения всех баз и их данных: есть главная директория (индивидуальная на кластер), состоящая из нескольких поддиректорий, по одной на каждую базу, которые, в свою очередь, хранят все объекты в базе (таблицы, генераторы последовательностей и т.п.).
initdb — создание нового PostgreSQL кластера баз данных
initdb [ option …] [ —pgdata | -D ] directory
Команда initdb должна выполняться от имени пользователя, под которым будет запускаться сервер, т.к. ему необходим полный доступ к файлам и директориям, создаваемым initdb. Сервер не может запускаться от имени суперпользователя, поэтому выполнение команды initdb от его лица будет отклонено.
initdb инициализирует локали и кодировки баз данных кластера, которые будут использоваться по умолчанию. Кодировка, порядок сортировки (LC_COLLATE), классы наборов символов (LC_CTYPE, например, верхний, нижний, цифра) могут устанавливаться раздельно при создании новой базы данных. initdb определяет настройки для шаблона template1, которые будут применяться по умолчанию для новых баз.
Чтобы изменить порядок сортировки по умолчанию или классы наборов символов, используются опции —lc-collate и —lc-ctype. Порядок сортировки, отличающийся от C или POSIX, оказывает влияние на производительность. Поэтому необходимо тщательно выбирать необходимую и достаточную локаль при выполнении initdb.
Другие категории локали можно изменить и после старта сервера. Также можно использовать опцию —locale, чтобы задать локаль для всех категорий одновременно, включая порядок сортировки и классы наборов символов. Значения локалей сервера (lc_*) можно вывести командой SHOW ALL. Подробнее см. в Раздел 22.1.
Для изменения кодировки по умолчанию используется опция —encoding.
-A authmethod
—auth=authmethod
Опция указывает на метод аутентификации локальных пользователей, используемый в файле pg_hba.conf (строки host и local). trust используется по умолчанию для облегчения процесса установки.
-D directory
—pgdata=directory
Опция указывает директорию хранения кластера. Это единственная опция, обязательная для команды initdb. Но и ее можно не использовать, а указать в переменной окружения PGDATA, что будет удобным при дальнейшем использовании (postgres обращается к этой же переменной).
-E encoding
—encoding=encoding
Устанавливает кодировку шаблона баз данных по умолчанию, если не указать иное при их создании. По умолчанию устанавливается исходя из указанной локали.
Указывает на необходимость проверки системой ввода/вывода контрольных сумм страниц для обнаружения поврежденных данных, т.к. по умолчанию проверка не производится. Включение проверки может в значительной мере оказать влияние на производительность. Устанавливается на этапе развертывания кластера, и далее не может быть изменена. Когда проверка включена, производится вычисление контрольных сумм для всех объектов всех баз данных кластера.
Устанавливает локаль кластера по умолчанию. Если флаг не указан, локаль устанавливается согласно окружению, в котором исполняется команда initdb.
—lc-collate=locale
—lc-ctype=locale
—lc-messages=locale
—lc-monetary=locale
—lc-numeric=locale
—lc-time=locale
Аналогично —locale устанавливает необходимую локаль, но в заданной категории.
Указывает initdb прочитать пароль суперпользователя БД из файла. В качестве пароля используется первая строка файла
-U username
—username=username
Устанавливает имя суперпользователя кластера. По умолчанию используется имя пользователя, от которого был запущен initdb.
Указывает initdb на необходимость запросить пароль для суперпользователя. Если не хотите использовать аутентификацию по паролю — эта опция Вам не нужна. В противном же случае не сможете использовать аутентификацию по паролю до тех пор пока не зададите пароль.
-X directory
—xlogdir=directory
Эта опция определяет каталог где будет храниться лог транзакции
Другие реже используемые опции описаны здесь:
Распечатывает отладочный вывод и некоторую дополнительную информацию при начальной работе загрузчика. Загрузчик это приложение initdb, используемое для создания каталога таблиц.
Указывает initdb, где необходимо искать входные файлы для развертывания кластера. Обычно это не требуется. Приложение само запросит эти данные, если будет необходимо.
По умолчанию, при выявлении ошибки на этапе развертывания кластера, initdb удаляет все файлы, которые к тому моменту были созданы. Опция предотвращает очистку файлов для целей отладки.
Выводит версию initdb и останавливается.
Показывает помощь по аргументам команды initdb и останавливается.
Указывает директорию хранения данных кластера, можно изменить опцией -D.
Указывает временную зону кластера по умолчанию. Значение это полное имя временной зоны.
И в завершении — initdb можно выполнить и командой pg_ctl initdb.
�� Похожие статьи на сайте
- Резервное копирование и восстановление баз данных PostgreSQL
- Создание кластера баз данных PostgreSQL
- Настройка аутентификации клиентов в PostgreSQL — файл pg_hba.conf
- Системные колонки таблиц PostgreSQL
- Оптимизация PostgreSQL. Autovacuum — сборка мусора
- Оптимизация PostgreSQL. Журнал транзакций и контрольные точки
- Оптимизация PostgreSQL. Настройка ресурсов
- Шпаргалка по основным командам PostgreSQL
- Установка 1C 8.3 под PostgreSQL 9.3 на Ubuntu Server 14.04 X64