Как вывести таблицу в питоне
Для отображения данных в виде таблицы параметру show предпочтительно передать значение «headings» (если надо отображать заголовки), либо » » (для таблицы без заголовков). Определим небольшую таблицу с тремя столбцами:
from tkinter import * from tkinter import ttk root = Tk() root.title("METANIT.COM") root.geometry("250x200") # определяем данные для отображения people = [("Tom", 38, "tom@email.com"), ("Bob", 42, "bob@email.com"), ("Sam", 28, "sam@email.com")] # определяем столбцы columns = ("name", "age", "email") tree = ttk.Treeview(columns=columns, show="headings") tree.pack(fill=BOTH, expand=1) # определяем заголовки tree.heading("name", text="Имя") tree.heading("age", text="Возраст") tree.heading("email", text="Email") # добавляем данные for person in people: tree.insert("", END, values=person) root.mainloop()
Здесь данные, которые будут отображаться в таблице, определены в виде списка people, который хранит набор кортежей. Каждый кортеж состоит из трех элементов. Условно будем считать, что первый элемент кортежа представляет имя пользователя, второй — возраст, а третий — электронный адрес. И эти данные нам надо отобразить в таблице:
people = [("Tom", 38, "tom@email.com"), ("Bob", 42, "bob@email.com"), ("Sam", 28, "sam@email.com")]
Для отображения этих данных определяем три столбца: name, age и email в виде кортежа и передаем их параметру columns :
columns = ("name", "age", "email") tree = ttk.Treeview(columns=columns, show="headings")
Далее нам надо настроить заголовки столбца с помощью метода heading() класса Treeview (по умолчанию столбцы не имеют никаких заголовков). Данный метод принимает ряд параметров:
tree.heading("name", text="Имя")
Первый параметр указывает на имя столбца. В примере выше определяем также параметр text , который определяет текст заголовка
И последний момент — добавляем сами данные в таблицу с помощью метода insert() класса Treeview
tree.insert("", END, values=person)
Первый параметр — пустая строка «» указывает, что элемент добавляется как элемент верхнего уровня (то есть у него нет родительского элемента). Значение END указывает, что элемент добавляется в конец набора. И параметр values в качестве добавляемых данных устанавливает кортеж person.
В итоге мы получим следующую таблицу:
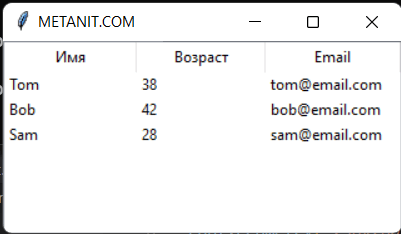
Настройка столбца
Вполне возможно, что изначальные настройки столбцов нас не устроят. Например, текст заголовка располагается по умолчанию по центру, а данные столбца выравниваются по левому краю. Кроме того, каждый столбец имеет некоторую начальную ширину, в следствие чего ширина виджета может оказаться больше ширины окна. Либо мы захотим как-то иначе настроить вид столбца.
Прежде всего мы можем настроить заголовки столбца с помощью метода heading() :
heading(column, text, image, anchor, command)
- column : имя настраиваемого столбца
- text : текст заголовка
- image : картинка для заголовка
- anchor : устанавливает выравнивание заголовка по определенному краю. Может принимать значения n, e, s, w, ne, nw, se, sw, c
- command : функция, выполняемая при нажатии на заголовок
Для настройки столбца в целом применяется метод column() :
column(column, width, minwidth, stretch, anchor)
- column : индекс настраиваемого столбца в формате «# номер_столбца»
- width : ширина столбца
- minwidth : минимальная ширина
- anchor : устанавливает выравнивание заголовка по определенному краю. Может принимать значения n, e, s, w, ne, nw, se, sw, c
- stretch : указывает, будет ли столбец растягиваться при растяжении контейнера. Если будет, то значение True , иначе значение False
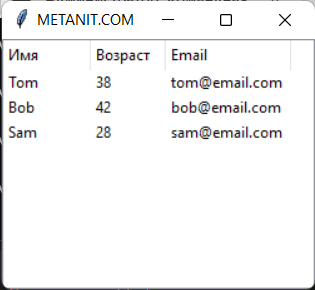
Применим некоторые из этих параметров:
from tkinter import * from tkinter import ttk root = Tk() root.title("METANIT.COM") root.geometry("250x200") # определяем данные для отображения people = [("Tom", 38, "tom@email.com"), ("Bob", 42, "bob@email.com"), ("Sam", 28, "sam@email.com")] # определяем столбцы columns = ("name", "age", "email") tree = ttk.Treeview(columns=columns, show="headings") tree.pack(fill=BOTH, expand=1) # определяем заголовки с выпавниваем по левому краю tree.heading("name", text="Имя", anchor=W) tree.heading("age", text="Возраст", anchor=W) tree.heading("email", text="Email", anchor=W) # настраиваем столбцы tree.column("#1", stretch=NO, width=70) tree.column("#2", stretch=NO, width=60) tree.column("#3", stretch=NO, width=100) # добавляем данные for person in people: tree.insert("", END, values=person) root.mainloop()
В данном случае для заголовков устанавливаем выравнивание по левому краю. Для столбцов запрещаем растяжение и устанавливаем ширину.
При добавлении изображения оно помещается в правой части. Например, установка изображения для третьего столбца:
# предполагается, что в папке приложения располагается файл email_icon_micro.png email_icon = PhotoImage(file="./email_icon_micro.png") tree.heading("email", text="Email", anchor=W, image=email_icon)
Добавление к Treeview прокрутки
from tkinter import * from tkinter import ttk root = Tk() root.title("METANIT.COM") root.geometry("250x200") root.rowconfigure(index=0, weight=1) root.columnconfigure(index=0, weight=1) # определяем данные для отображения people = [ ("Tom", 38, "tom@email.com"), ("Bob", 42, "bob@email.com"), ("Sam", 28, "sam@email.com"), ("Alice", 33, "alice@email.com"), ("Kate", 21, "kate@email.com"), ("Ann", 24, "ann@email.com"), ("Mike", 34, "mike@email.com"), ("Alex", 52, "alex@email.com"), ("Jess", 28, "jess@email.com"), ] # определяем столбцы columns = ("name", "age", "email") tree = ttk.Treeview(columns=columns, show="headings") tree.grid(row=0, column=0, sticky="nsew") # определяем заголовки tree.heading("name", text="Имя", anchor=W) tree.heading("age", text="Возраст", anchor=W) tree.heading("email", text="Email", anchor=W) tree.column("#1", stretch=NO, width=70) tree.column("#2", stretch=NO, width=60) tree.column("#3", stretch=NO, width=100) # добавляем данные for person in people: tree.insert("", END, values=person) # добавляем вертикальную прокрутку scrollbar = ttk.Scrollbar(orient=VERTICAL, command=tree.yview) tree.configure(yscroll=scrollbar.set) scrollbar.grid(row=0, column=1, sticky="ns") root.mainloop()
Управление выводом таблицы, модуль prettytable в Python
Модуль prettytable позволяет управлять выводом таблицы, например можно ограничить вывод только теми полями или строками, которые необходимы к просмотру.
Создадим таблицу с которой будем работать:
from prettytable import PrettyTable mytable = PrettyTable() mytable.field_names = ["City name", "Area", "Population", "Annual Rainfall"] mytable.add_rows( [ ["Adelaide", 1295, 1158259, 600.5], ["Brisbane", 5905, 1857594, 1146.4], ["Darwin", 112, 120900, 1714.7], ["Hobart", 1357, 205556, 619.5], ] )
Управление выводом данных таблицы осуществляется методом PrettyTable.get_string() .
Управление выводом колонок.
Аргумент fields метода PrettyTable.get_string() принимает список имен полей, которые нужно напечатать:
>>> table = mytable.get_string(fields=["City name", "Population"]) >>> print(table) #+-----------+------------+ #| City name | Population | #+-----------+------------+ #| Adelaide | 1158259 | #| Brisbane | 1857594 | #| Darwin | 120900 | #| Hobart | 205556 | #+-----------+------------+
Управление выводом строк.
Аргументы start и end метода PrettyTable.get_string() принимают индекс первой и последней строки для печати соответственно.
Обратите внимание, что индексация работает так же, как срезы списка Python — для печати 3-й и 4-й строк таблицы установите start равным 2 (первая строка — это строка 0, поэтому третья — это строка 2) и установите end на 4 (индекс 4-ой строки, плюс 1):
>>> table = mytable.get_string(start=2, end=4) >>> print(table) #+-----------+------+------------+-----------------+ #| City name | Area | Population | Annual Rainfall | #+-----------+------+------------+-----------------+ #| Darwin | 112 | 120900 | 1714.7 | #| Hobart | 1357 | 205556 | 619.5 | #+-----------+------+------------+-----------------+
Управление сортировкой данных в таблице.
Аргументы sortby метода PrettyTable.get_string() , который принимает строку с именем одного поля, отсортирует данный столбец таблицы по возрастанию (от меньшего к большему).
>>> table = mytable.get_string(sortby='Area') >>> print(table) #+-----------+------+------------+-----------------+ #| City name | Area | Population | Annual Rainfall | #+-----------+------+------------+-----------------+ #| Darwin | 112 | 120900 | 1714.7 | #| Adelaide | 1295 | 1158259 | 600.5 | #| Hobart | 1357 | 205556 | 619.5 | #| Brisbane | 5905 | 1857594 | 1146.4 | #+-----------+------+------------+-----------------+
Если необходимо отсортировать в обратном порядке, то в метод нужно добавить ключевой аргумент reversesort=True .
>>> table = mytable.get_string(sortby='Area', reversesort=True) >>> print(table) #+-----------+------+------------+-----------------+ #| City name | Area | Population | Annual Rainfall | #+-----------+------+------------+-----------------+ #| Brisbane | 5905 | 1857594 | 1146.4 | #| Hobart | 1357 | 205556 | 619.5 | #| Adelaide | 1295 | 1158259 | 600.5 | #| Darwin | 112 | 120900 | 1714.7 | #+-----------+------+------------+-----------------+
Если необходимо, чтобы таблицы сортировались всегда определенным образом, то можно сделать этот параметр долгосрочным при помощи атрибута экземпляра класса PrettyTable.sortby :
# сортировка по колонке `Population` >>> mytable.sortby = "Population" # отсортирует вывод по колонке `Population` >>> print(mytable)
Теперь, команда print(mytable) напечатает таблицу, отсортированную по колонке Population . Также, при помощи атрибута mytable.reversesort = True можно сортировать таблицу по колонке, указанной в mytable.sortby — в обратном порядке. Такое поведение будет сохраняться, пока не отключить сортировку атрибутом x.sortby = None .
# отключение сортировки >>> mytable.sortby = None # выведет таблицу в исходном виде >>> print(mytable)
Если нужно указать пользовательскую функцию сортировки, то можно использовать ключевой аргумент sort_key .
Передайте аргументу sort_key функцию, которая принимает два списка значений и возвращает отрицательное или положительное значение в зависимости от того, должен ли первый список появляться до или после второго. Если в таблице n столбцов, то в каждом списке будет n + 1 элемент. Каждый список соответствует одной строке таблицы. Первым элементом будут данные из соответствующей строки в столбце, заданном аргументом sort_by . Остальные n элементов — это данные в каждом столбце таблицы по порядку, включая повторяющийся экземпляр данных в столбце sort_by .
- КРАТКИЙ ОБЗОР МАТЕРИАЛА.
- Печать табличных данных в файл, модуль prettytable
- Удаление данных из таблицы, модуль prettytable
- Управление выводом таблицы, модуль prettytable
- Управление внешним видом таблицы, модуль prettytable
- Генерация HTML и JSON при помощи prettytable
Многомерные списки
Часто в задачах приходится хранить прямоугольные таблицы с данными. Такие таблицы называются матрицами или двумерными массивами. В языке программирования Питон таблицу можно представить в виде списка строк, каждый элемент которого является в свою очередь списком, например, чисел. Например, создать числовую таблицу из двух строк и трех столбцов можно так:
a = [[1, 2, 3], [4, 5, 6]]
Здесь первая строка списка a[0] является списком из чисел [1, 2, 3] . То есть a[0][0] == 1 , значение a[0][1] == 2 , a[0][2] == 3 , a[1][0] == 4 , a[1][1] == 5 , a[1][2] == 6 .
Для обработки и вывода списка как правило используется два вложенных цикла. Первый цикл по номеру строки, второй цикл по элементам внутри строки. Например, вывести двумерный числовой список на экран построчно, разделяя числа пробелами внутри одной строки, можно так:
for i in range(len(a)): for j in range(len(a[i])): print(a[i][j], end=' ') print()
То же самое, но циклы не по индексу, а по значениям списка:
for row in a: for elem in row: print(elem, end=' ') print()
Естественно для вывода одной строки можно воспользоваться методом join :
for row in a: print(' '.join(map(str, row)))
Используем два вложенных цикла для подсчета суммы всех чисел в списке:
s = 0 for i in range(len(a)): for j in range(len(a[i])): s += a[i][j]
Или то же самое с циклом не по индексу, а по значениям строк:
s = 0 for row in a: for elem in row: s += elem
Создание списка
Пусть даны два числа: количество строк n и количество столбцов m . Необходимо создать список размером n × m , заполненный нулями.
Очевидное решение оказывается неверным:
a = [[0] * m] * n
В этом легко убедиться, если присвоить элементу a[0][0] значение 1 , а потом вывести значение другого элемента a[1][0] — оно тоже будет равно 1! Дело в том, что [0] * m возвращает ccылку на список из m нулей. Но последующее повторение этого элемента создает список из n элементов, которые являются ссылкой на один и тот же список (точно так же, как выполнение операции b = a для списков не создает новый список), поэтому все строки результирующего списка на самом деле являются одной и той же строкой.
Таким образом, двумерный список нельзя создавать при помощи операции повторения одной строки. Что же делать?
Первый способ: сначала создадим список из n элементов (для начала просто из n нулей). Затем сделаем каждый элемент списка ссылкой на другой одномерный список из m элементов:
a = [0] * n for i in range(n): a[i] = [0] * m
Другой (но похожий) способ: создать пустой список, потом n раз добавить в него новый элемент, являющийся списком-строкой:
a = [] for i in range(n): a.append([0] * m)
Но еще проще воспользоваться генератором: создать список из n элементов, каждый из которых будет списком, состоящих из m нулей:
a = [[0] * m for i in range(n)]
В этом случае каждый элемент создается независимо от остальных (заново конструируется список [0] * m для заполнения очередного элемента списка), а не копируются ссылки на один и тот же список.
Ввод списка
Пусть программа получает на вход двумерный массив, в виде n строк, каждая из которых содержит m чисел, разделенных пробелами. Как их считать? Например, так:
a = [] for i in range(n): a.append(list(map(int, input().split())))
Или, без использования сложных вложенных вызовов функций:
a = [] for i in range(n): row = input().split() for i in range(len(row)): row[i] = int(row[i]) a.append(row)
Можно сделать то же самое и при помощи генератора:
a = [list(map(int, input().split())) for i in range(n)]
Сложный пример обработки массива
Пусть дан квадратный массив из n строк и n столбцов. Необходимо элементам, находящимся на главной диагонали, проходящей из левого верхнего угла в правый нижний (то есть тем элементам a[i][j] , для которых i == j ) присвоить значение 1 , элементам, находящимся выше главной диагонали – значение 0, элементам, находящимся ниже главной диагонали – значение 2. То есть получить такой массив (пример для n==4 ):
1 0 0 0 2 1 0 0 2 2 1 0 2 2 2 1
Рассмотрим несколько способов решения этой задачи. Элементы, которые лежат выше главной диагонали – это элементы a[i][j] , для которых i < j , а для элементов ниже главной диагонали i >j . Таким образом, мы можем сравнивать значения i и j и по ним определять значение a[i][j] . Получаем следующий алгоритм:
for i in range(n): for j in range(n): if i < j: a[i][j] = 0 elif i >j: a[i][j] = 2 else: a[i][j] = 1
Данный алгоритм плох, поскольку выполняет одну или две инструкции if для обработки каждого элемента. Если мы усложним алгоритм, то мы сможем обойтись вообще без условных инструкций.
Сначала заполним главную диагональ, для чего нам понадобится один цикл:
for i in range(n): a[i][i] = 1
Затем заполним значением 0 все элементы выше главной диагонали, для чего нам понадобится в каждой из строк с номером i присвоить значение элементам a[i][j] для j = i+1 , . n-1 . Здесь нам понадобятся вложенные циклы:
for i in range(n): for j in range(i + 1, n): a[i][j] = 0
Аналогично присваиваем значение 2 элементам a[i][j] для j = 0 , . i-1 :
for i in range(n): for j in range(0, i): a[i][j] = 2
Можно также внешние циклы объединить в один и получить еще одно, более компактное решение:
for i in range(n): for j in range(0, i): a[i][j] = 2 a[i][i] = 1 for j in range(i + 1, n): a[i][j] = 0
А вот такое решение использует операцию повторения списков для построения очередной строки списка. i -я строка списка состоит из i чисел 2 , затем идет одно число 1 , затем идет n-i-1 число 0 :
for i in range(n): a[i] = [2] * i + [1] + [0] * (n - i - 1)
А можно заменить цикл на генератор:
a = [[2] * i + [1] + [0] * (n - i - 1) for i in range(n)]
Форматирование вывода
В некоторых заданиях этого листка требуется выводить элементы списка аккуратными столбцами, выравнивая числа по правому краю с фиксированной шириной столбца. Это можно сделать разными способами, один из способов: использование метода rjust .
rjust — метод объекта типа str , принимающий два параметра: длину новой строки (ширина поля вывода) и символ-заполнитель: rjust(n, ch) . Например, s.rjust(10, ‘.’) . Метод возвращает новую строку, длина которой равна n символов, исходная строка находится в конце результата (то есть исходная строка “выравнивается” по правому краю), лишние позиции заполняются символом ch. Если опустить ch, то в качестве символа-заполнителя используется пробел. Если длина исходной строки была больше n, то возвращается исходная строка без изменений (строка не обрезается).
Аналогично есть методы ljust , выравнивающий строку по левому краю и center , выравнивающий строку по центру результата.
Как напечатать таблицу с помощью f-string
Разберём, как напечатать красивую таблицу с одинаковой шириной колонок, с разной шириной колонок, с шапкой из двух строк. Создадим функцию с параметром максимальной ширины таблицы и функцию для записи таблицы в текстовый файл.
В этой статье мы разберём как напечатать красивые таблицы:
- с одинаковой шириной колонок;
- с разной шириной колонок;
- с шапкой из двух строк.
А также создадим функции:
- с параметром максимальной ширины таблицы;
- для записи таблицы в текстовый файл.
«F-строки» были введены ещё в версии Python 3.6, и все уже давно, наверно, их используют в своём коде. Для тех, кто хочет освежить память, и ещё раз перечитать документацию — PEP 498 – Literal String Interpolation. Мы же будем использовать «f-строки» для вывода данных в табличном виде. Для примера возьмём данные об автомобилях с одного из онлайн-рынков такой структуры:
data = [ ['Volkswagen', 'Golf V', '2008', '8000', '154000'], ['Mazda', 'CX-5', '2013', '14800', '117000'], ['Honda', 'CR-V AWD', '2017', '22000', '57000'], ['BMW', '320', '2015', '14700', '124000'], ['BMW', 'X1', '2012', '17000', '62000'], ['Mercedes-Benz', 'E 220', '2009', '9300', '240000'], ['Volkswagen', 'Golf VI STYLE', '2011', '9700', '203000'], ['Mazda', '6', '2006', '5600', '218000'], ['Hyundai', 'Tucson LOUNGE 2009', '2008', '8899', '149000'], ['BMW', '520', '2013', '21700', '146000'], ['Toyota', 'Highlander', '2015', '28000', '120000'], ['Mercedes-Benz', 'E 220', '2005', '8200', '276000'], ['BMW', '328', '2012', '12500', '260000'], ['Opel', 'Astra J', '2013', '9500', '224000'], ['Volkswagen', 'Passat B7', '2013', '11750', '138000'], ['Audi', 'A6 Quattro', '2006', '8000', '28000'] ] columns = ['Марка', 'Модель', 'Год', 'Цена', 'Пробег'] Таблица с одинаковой шириной колонок
Для того, чтоб данные в колонках таблицы выровнять по центру, левому или правому краю, нужно рассчитать ширину колонок и определить отступ. Давайте сделаем ширину колонок одинаковой по максимальной строке столбца и отступом в один символ.
# расчёт максимальной длинны колонок max_columns = [] # список максимальной длинны колонок for col in zip(*data): len_el = [] [len_el.append(len(el)) for el in col] max_columns.append(max(len_el)) Функция с параметром максимальной ширины таблицы
Давайте соберём наш код в функцию, но добавим ещё один параметр — максимальную ширину таблицы. И если ширина таблицы будет больше максимальной, заданной по умалчиванию — выведем сообщение. А также сделаем выравнивание текста в строках шапки таблицы по центру, в теле таблицы — по правому краю. Для этого надо всего лишь перед значением ширины строки вставить символ «^» — выравнивание по центру, «>» — выравнивание по правому краю, «
Давайте ещё изменим вывод нашей таблицы. Колонки «Цена $» и «Пробег км» выведем с , , как разделитель тысяч.
def print_table(data, columns, indent, max_width=100): # data — список списков, данные таблицы # columns — список списков, названия колонок таблицы # indent — отступ от края колонки # max_widt — допустимая ширина таблицы # max_columns — список максимальной длинны строки колонок # max_columns_title — список максимальной ширины колонок шапки # width — список ширины каждой колонки таблицы для печати # расчёт макимальной ширины колонок таблицы max_columns = [] for col in zip(*data): len_el = [] [len_el.append(len(el)) for el in col] max_columns.append(max(len_el)) # вычислить максимальную длинну колонки шапки таблицы max_columns_title = [] for col in zip(*columns): max_columns_title.append(max([len(el) for el in col])) # печать таблицы for col in columns: width = [] for n, c in enumerate(col): # сравниваем максимальную колонку шапки с макс колонкой таблицы if max_columns[n] >= max_columns_title[n]: w = max_columns[n] + indent width.append(w) else: w = max_columns_title[n] + indent width.append(w) # пишем название колонок в две строки if sum(width) >', end='') # выравниване по ценру else: print('Ширина таблицы больше допустимого значения') return print() # печать разделителя шапки '=' print(f"") # печать тела таблицы for el in data: for n, col in enumerate(el): if n < 3: print(f'>', end='') # выравнвание по правому краю else: print(f'', end='') # выравнвание по правому краю наследуется, с разделителем тысяч «,» print() Здесь, в 52 строке кода, в f’,> ‘ перед закрывающей фигурной скобкой вставлена запятая, как разделитель тысяч (кроме «,» можно ещё использовать «_»), ну а дальше форматирование сделает всё само:
Но это ещё не все возможности «спецификации формата».
Примечание: в F-string в фигурных скобках <> помещены «заменяющие поля». Двоеточие : указывает на поле format_spec , что означает нестандартный формат замены. Для него существует Мини-язык спецификации формата.
Функция для записи таблицы в текстовый файл
Часто приходится не только печатать таблицу, но и сохранять её в текстовом файле. Имея готовую функцию для печати, нетрудно переделать её для записи.
def write_table(file_name, data, columns, indent, max_width=100): # file_name — название текстового файла # data — список списков, данные таблицы # columns — список списков, названия колонок таблицы # indent — отступ от края колонки # max_widt — допустимая ширина таблицы # max_columns — список максимальной длинны строки колонок # max_columns_title — список максимальной ширины колонок шапки # width — список ширины каждой колонки таблицы для печати # расчёт макимальной ширины колонок таблицы max_columns = [] for col in zip(*data): len_el = [] [len_el.append(len(el)) for el in col] max_columns.append(max(len_el)) # вычислить максимальную длинну колонки шапки таблицы max_columns_title = [] for col in zip(*columns): max_columns_title.append(max([len(el) for el in col])) # запись таблицы with open(file_name, 'w', encoding='utf-8') as f: for col in columns: width = [] for n, c in enumerate(col): # сравниваем максимальную колонку шапки с макс колонкой таблицы if max_columns[n] >= max_columns_title[n]: w = max_columns[n] + indent width.append(w) else: w = max_columns_title[n] + indent width.append(w) # пишем название колонок в две строки if sum(width) >') else: print('Ширина таблицы больше допустимого значения') return f.write('\n')