Размах выборки в статистике: определение, форма и как его найти

Размах в статистике, он же размах в выборк е — это разница между самым большим элементом выборки и самым маленьким. Глядя на наш еженедельный бюджет , мы видим, что самым большим элементом у нас является 260, а самым маленьким — 50.
Как найти размах нашей выборки: 260 — 50 = 210. Размах нашей выборки равен 210. Размах в статистике помогает определить амплитуду изменений наших статистических данных.
Как найти размах, используя программировани е
- Вначале нужно сделать выборку данных из их общего массива.
- Отсортировать элементы выборки по возрастанию, то есть от меньшего к большему.
- После сортировки нужно определить наименьшее и наибольшее значени я элементов. После сортировки элемент выборки с самым меньшим индексом будет иметь наименьшее значение, элемент с наибольшим индексом будет иметь наибольшее значение.
- Математически вычислить разниц у между большим и меньшим значени ями выборки.
- Вывести полученный размах на экран.
Заключение
Как найти размах в статистике? Для этого нужно определить наибольшее и наименьшее значени я выборки и найти их разницу. Реализовать подобные действия можно при помощи любого языка программирования, который поддерживает работу с массивами данных.
Мы будем очень благодарны
если под понравившемся материалом Вы нажмёте одну из кнопок социальных сетей и поделитесь с друзьями.
Интерквартильный размах
Для того, чтобы посчитать интерквартильный размах выборки, нужно сначала найти ее медиану. Перед поиском медианы выборку следуют упорядочить. Если выборка содержит нечетное количество элементов, то центральный элемент и будет медианой. Если выборка содержит четное количество — медианой будет среднее арифметическое двух центральных элементов.
Разберемся, как найти интерквартильный размах для выборки с четным количеством элементов. Для начала ее нужно упорядочить от меньшего к большему:
Медианой в этой выборке будет среднее арифметическое двух центральных элементов:
После того, как найдена медиана всей выборки, ее нужно разделить на две части — левее медианы и правее, и найти медиану каждой половины:
Медиана всей выборки — это второй квартиль, медианы левой и правой половин — это, соответственно первый (или нижний) и третий (или верхний) квартили:
Интерквартильный размах — это просто разность между третьим и первым квартилями:
В этом случае интерквартильный размах будет равен 14–3 = 11.
Для выборки с нечетным количеством элементов, размах считается практически так же. Разница состоит в том, что медиана выборки (или второй квартиль) — это центральный элемент, а первый и третий квартили считаются как среднее арифметическое двух центральных элементов подвыборок, лежащих слева и справа от медианы всей выборки (не включая саму медиану):
В этом случае интерквартильный размах будет равен 20–3 = 17.
Кстати, первый, второй и третий квартиль еще называются, соответственно, 25-й, 50-й и 75-й перцентиль. Поэтому, когда вам говорят, что уровень зарплаты для вашего грейда считается как 75-й перцентиль от уровня зарплат по рынку, имеют ввиду именно третий квартиль.
Вариация, размах, межквартильный размах, среднее линейное отклонение
В этой статье мы приступим к изучению показателей вариации: размах вариации, межквартильный размах, среднее линейное отклонение.
В математической статистике вариация занимает одно из центральных мест. Что же такое вариация? Это изменчивость. Вариация показателя – изменчивость показателя.
Показатели вариации дают очень важную характеристику процессам и явлениям. Они отражают устойчивость процессов и однородность явлений. Чем меньше показатель вариации, тем более процесс устойчивый, а значит, и более предсказуемый.
Показатели вариации отражают не отдельно взятые значения, а дают характеристику некоторому явлению или процессу в целом. Имея в наличии показатели среднего значения и вариации, можно получить первичное представление о характере данных. Средняя – это обобщающий уровень, а вариация характеризует, насколько среднее значение (или другой показатель) хорошо обобщает значения некоторой совокупности данных. Если показатель вариации незначительный, то значения совокупности находятся близко к среднему, следовательно, среднее значение хорошо обобщает совокупность. Если вариация большая, то среднее значение плохо обобщает данные (значения разбросаны далеко друг от друга), и получается «средняя температура по больнице».
Размах вариации
Размах вариации – разница между максимальным и минимальным значением:
Ниже приведена графическая интерпретация размаха вариации.
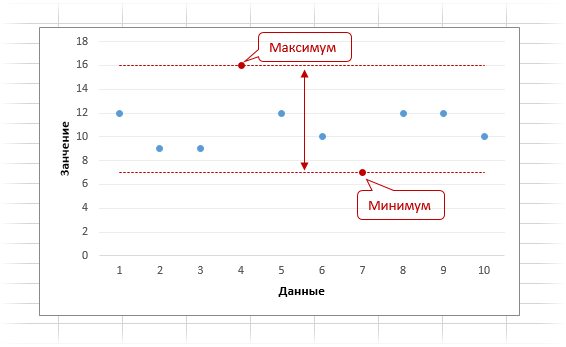
Видно максимальное и минимальное значение, а также расстояние между ними, которое и соответствует размаху вариации.
С одной стороны, показатель размаха может быть вполне информативным и полезным. К примеру, максимальная и минимальная стоимость квартиры в городе N, максимальная и минимальная зарплата по профессии в регионе и проч. С другой стороны, размах может быть очень широким и не иметь практического смысла, т.к. зависит лишь от двух наблюдений. Таким образом, размах вариации очень неустойчивая величина.
Межквартильный размах
В статистике для анализа выборки часто прибегают к другому показателю вариации – межквартильному размаху. Квартиль – это то значение, которые делит ранжированные (отсортированные) данные на части, кратные одной четверти, или 25%. Так, 1-й квартиль – это значение, ниже которого находится 25% совокупности. 2-й квартиль делит совокупность данных пополам (то бишь медиана), ну и 3-й квартиль отделяет 25% наибольших значений. Так вот межквартильный размах – это разница между 3-м и 1-м квартилями. У данного показателя есть одно неоспоримое преимущество: он является робастным, т.е. не зависит от аномальных отклонений.
Наглядное отображение размаха вариации и межкварительного расстояния производят с помощью диаграммы «ящик с усами».
Среднее линейное отклонение
Есть показатели вариации, которые учитывают сразу все значения, а не только отдельные наблюдения (типа максимума или минимума). Одним из таких является среднее линейное отклонение. Этот показатель характеризует меру разброса значений вокруг их среднего. В чем суть? Для того, чтобы показать меру разброса данных, нужно вначале определиться, относительно чего этот самый разброс будет считаться. Обычно это среднее арифметическое. Далее нужно посчитать, насколько каждое значение отклоняется от средней. Нас интересует среднее из таких отклонений. Однако напрямую складывать положительные и отрицательные отклонения нельзя, т.к. они взаимоуничтожатся и их сумма будет равна нулю. Поэтому все отклонения берутся по модулю. Средне линейное отклонение рассчитывается по формуле:
a – среднее линейное отклонение,
X – анализируемый показатель,
X̅ – среднее значение показателя,
n – количество значений в анализируемой совокупности данных.
Рассчитанное по этой формуле значение показывает среднее абсолютное отклонение от средней арифметической. Наглядная картинка в помощь.
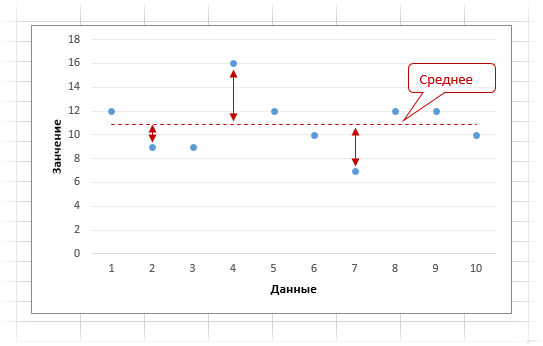
Отклонения каждого наблюдения от среднего указаны маленькими стрелочками. Именно они берутся по модулю и суммируются. Потом все делится на количество значений.
Для полноты картины нужно привести еще и пример. Допустим, имеется фирма по производству черенков для лопат. Каждый черенок должен быть 1,5 метра длиной, но, что еще важней, все должны быть одинаковыми или, по крайней мере, плюс-минус 5 см. Однако нерадивые работники то 1,2 м отпилят, то 1,8 м. Дачники недовольны. Решил директор провести статистический анализ длины черенков. Отобрал 10 штук и замерил их длину, нашел среднюю и рассчитал среднее линейное отклонение. Средняя получилась как раз, что надо – 1,5 м. А вот среднее линейное отклонение вышло 0,16 м. Вот и получается, что каждый черенок длиннее или короче, чем нужно, в среднем на 16 см. Есть, о чем поговорить с работниками.
На этом сегодняшнюю заметку закончим. В следующей статье будут рассмотрены такие показатели вариации, как дисперсия, среднеквадратичное отклонение и коэффициент вариации.
1. Меры разброса
Разность наибольшего и наименьшего значений случайной величины выборки называется её размахом и обозначается \(R\).
задана выборка \(80\), \(80\), \(330\), \(4500\). Размах: \(R=4500-80=4420\).
Отклонение от среднего случайной величины — разность между значением случайной величины и средним значением выборки.
задана выборка \(63\), \(66\), \(62\), \(59\), \(60\).
Пусть значение величины X 1 = 63 , а значение среднего X ¯ = ( 63 + 66 + 62 + 59 + 60 ) 5 = 62 , отклонение от среднего X 1 − X ¯ = 63 − 62 = 1 .
Отклонение от среднего может оказаться как положительным, так и отрицательным числом, их сумма равна нулю. Поэтому обычно находится сумма квадратов отклонений от среднего для оценки стабильности элементов совокупности . Чем меньше эта сумма, тем лучше.
Дисперсия — среднее арифметическое квадратов отклонений.
D = X 1 − X ¯ 2 + X 2 − X ¯ 2 + . + X N − X ¯ 2 N .
На практике используют величину σ = D , имеющую равный порядок с \(X\).
Корень квадратный из дисперсии называют средним квадратичным отклонением и обозначают σ = D .
Корреляция, корреляционная зависимость — статистическая взаимосвязь двух или нескольких случайных величин. При этом изменения значений одной или нескольких из этих величин сопутствуют систематическому изменению значений другой или других величин.
Чтобы определить корреляцию двух признаков, используют графическое изображение — диаграмму корреляции.
На координатной плоскости каждому исследуемому элементу соответствует точка, абсцисса (\(x\)) которой является числовым значением одного признака этого элемента, а ордината (\(y\)) является соответствующим числовым значением другого признака этого элемента.
Если таким образом отложить значения двух признаков, и точки будут расположены приблизительно на прямой , которая соответствует убывающей или возрастающей функции, то между признаками существует корреляция.
Положительная корреляция (точки расположены приблизительно на прямой, соответствующей возрастающей функции) существует, когда при увеличении значения одного признака увеличиваются значения другого признака.
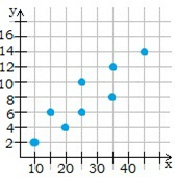
Отрицательная корреляция (точки расположены приблизительно на прямой, соответствующей убывающей функции) существует, когда при увеличении значения одного признака уменьшается значение другого признака.
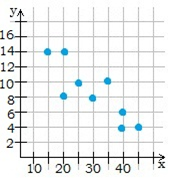
Если между признаками корреляции не существует, то изменение значения одного признака не влияет на изменение другого признака.