АЛГОРИТМЫ И СТРУКТУРЫ ДАННЫХ
Электронный учебный материал для студентов всех специальностей факультета Прикладная информатика Кубанского государственного аграрного университета
- Главная
- Лекции
- курс лекций для ИСиТ
- Курс лекций для БИ
- Курс лекций для ПИ
- Презентации
- Темы лабораторных работ
- Темы курсовых работ
- Пример выполнения курсовой работы
- Вопросы к экзамену ПИ
- Вопросы к экзамену ИСиТ
- Вопросы к экзамену БИ
Поиск
Об авторах
Курс разработан на кафедре Компьютерных технологий и систем Кубанского государственного аграрного унивеситета. Авторами являются заведующий кафедрой, доктор технических наук, профессор Лойко Валерий Иванович и доцент кафедры, кандидат физико-математических наук Лаптев Сергей Владимирович.
Основные цели сайта
-
Сайт предназанчен для максимально эффективного и быстрого доступа ко всем материалам курса «Алгоритмы и структуры данных», имеющимся на кафедре компьютерных технологий и систем КубГАУ. Основной задачей его создания является повышения эффективности освоения дисциплины студентами и всеми желающими.
Динамические структуры данных
Использование при программировании только статических объектов может вызвать определенные трудности, особенно с точки зрения получения эффективной машинной программы. Дело в том, что иногда мы заранее не знаем не только размера значения того или иного программного объекта, но также и того, будет ли существовать этот объект или нет. Такого рода программные объекты, которые возникают уже в процессе выполнения программы или размер значений которых определяется при выполнении программы, называются динамическими объектами.
Динамические структуры данных имеют две особенности:
1. Заранее не определено количество элементов в структуре.
2. Элементы динамических структур физически не имеют жесткой линейной упорядоченности. Они могут быть разбросаны по памяти.

P1 и P2 это указатели, содержащие адреса элементов, с которыми связаны соответствующие элементы структуры. Указатели содержат номер ячейки памяти, с которой начинается соответствующий элемент структуры.
Связные списки
С точки зрения логического представления различают линейные и нелинейные списки.
К линейным спискам относятся односвязные и двусвязные списки. К нелинейным — многосвязные.
Элемент списка в общем случае представляет собой информационное поле и одно или несколько полей указателей.
Данные динамические структуры наиболее распростанены.
Односвязные списки
Элемент односвязного списка содержит, как минимум, два поля: информационное поле (info) и поле указателя (ptr).

Особенностью указателя является то, что он дает только адрес последующего элемента списка. Поле указателя последнего элемента в списке является пустым (NIL). LST — указатель на начало списка. Список может быть пустым, тогда LST будет равен NIL. Доступ к элементу списка осуществляется только от его начала, то есть обратной связи в этом списке нет.
При дальнейшем изучении односвязных списков мы будем использовать следующую терминологию:
p — указательnode(p) – узел, на который ссылается указатель p (при этом неважно в какое место изображения элемента (узла) списка он направлен на рисунке)
ptr(p) – ссылка на последующий элемент узла node(p)
ptr(ptr(p)) – ссылка последующего для node(p) узла на последующий для него элемент.Кольцевой односвязный список
Кольцевой односвязный список получается из обычного односвязного списка путем присваивания указателю последнего элемента списка значения указателя начала списка.

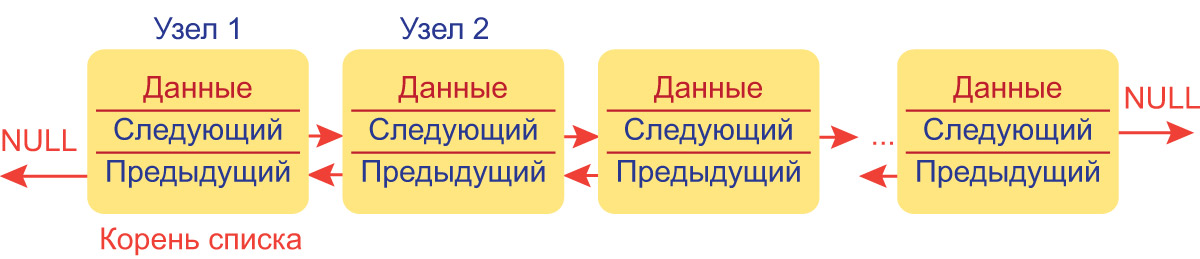
Двусвязный список
Использование однонаправленных списков при решении ряда задач может вызвать определенные трудности. Дело в том, что по однонаправленному списку можно двигаться только в одном направлении, от заглавного звена к последнему звену списка. Между тем нередко возникает необходимость произвести какую-либо обработку элементов, предшествующих элементу с заданным свойством. Однако после нахождения элемента с этим свойством в односвязном списке у нас нет возможности получить достаточно удобный и быстрый доступ к предыдущим элементам. Для достижения этой цели придется усложнить алгоритм, что неудобно и нерационально.
Для устранения этого неудобства добавим в каждое звено списка еще одно поле, значением которого будет ссылка на предыдущее звено списка. Динамическая структура, состоящая из элементов такого типа, называется двунаправленным или двусвязным списком.
Двусвязный список характеризуется тем, что у любого элемента есть два указателя.
Один указывает на предыдущий (левый) элемент (L), другой указывает на последующий (правый) элемент (R).
Фактически двусвязный список это два односвязных списка с одинаковыми элементами, записанные в противоположной последовательности.

Кольцевой двусвязный список
Кольцевые двусвязные списки получают следующим образом: в качестве значения поля R последнего элемента принимают ссылку на первый элемент, а в качестве значения поля L первого элемента — ссылку на последний элемент.

Простейшие операции над односвязными списками
Вставка элемента в начало односвязного списка
Удаление элемента из начала односвязного списка
Вставка в начало списка
Надо вставить в начало односвязного списка элемент с информационным полем D. Для этого необходимо сгенерировать пустой элемент (P=GetNode). Информационному полю этого элемента присвоить значение D (INFO(P)=D), значению указателя на этот элемент присвоить значение указателя на начало списка (Ptr(P) = Lst), значению указателя начала списка присвоить значение указателя P (Lst = P).

Удаление из начала списка
Надо удалить первый элемент списка, но запомнить информацию, содержащуюся в поле Info этого элемента. Для этого введем указатель P, который будет указывать на удаляемый элемент (P = Lst). В переменную X занесем значение информационного поля Info удаляемого элемента (X=Info(P)). Значению указателя на начало списка присвоим значение указателя следующего за удаляемым элемента (Lst = Ptr(P)). Удалим элемент (FreeNode(P)).

- Лекция 1. Понятие структуры данных. Статические и полустатические стурктуры данных
- Лекция 2. Полустатические структуры данных (продолжение)
- Лекция 3. Понятие динамических структур данных. Связные списки
- Лекция 4. Односвязный список как самостоятельная структура данных.
- Лекция 5. Нелинейные связанные структуры. Деревья. Бинарные деревья
- Лекция 6. Основные операции с деревьми
- Лекция 7. Поиск. Классификация основных видов поиска
- Лекция 8. Дерево оптимального поиска
- Лекция 9. Понятие сортировки. Прямые методы сортировки
- Лекция 10. Улучшенные методы сортировки
Список (информатика)

В информатике, спи́сок (англ. list ) — это абстрактный тип данных, представляющий собой упорядоченный набор значений, в котором некоторое значение может встречаться более одного раза. Экземпляр списка является компьютерной реализацией математического понятия конечной последовательности. Экземпляры значений, находящихся в списке, называются элементами списка (англ. item, entry либо element ); если значение встречается несколько раз, каждое вхождение считается отдельным элементом.
Термином список также называется несколько конкретных структур данных, применяющихся при реализации абстрактных списков, особенно связных списков.
Определение
При помощи нотации метода синтаксически-ориентированного конструирования Ч. Хоара определение списка можно записать следующим образом:
Первая строка данного определения обозначает, что список элементов типа (говорят: «список над ») представляет собой размеченное объединение пустого списка и декартова произведения атома типа со списком над . Для создания списков используются два конструктора (вторая строка определения), первый из которых создаёт пустой список, а второй — непустой соответственно. Вполне понятно, что второй конструктор получает на вход в качестве параметров некоторый атом и список, а возвращает список, первым элементом которого является исходный атом, а остальными — элементы исходного списка. То есть получается префиксация атома к списку, с чем и связано такое наименование конструктора. Здесь необходимо отметить, что пустой список не является атомом, а потому не может префиксироваться. С другой стороны, пустой список является как бы нулевым элементом для конструирования списков, поэтому любой список содержит в самом своём конце именно пустой список — с него начинается конструирование.
Третья строка определяет селекторы для списка, то есть операции для доступа к элементам внутри списка. Селектор получает на вход список и возвращает первый элемент этого списка, то есть типом результата является тип . Этот селектор не может получить на вход пустой список — в этом случае результат операции неопределён. Селектор возвращает список, полученный из входного в результате отсечения его головы (первого элемента). Этот селектор также не может принимать на вход пустой список, так как в этом случае результат операции неопределён. При помощи этих двух операций можно достать из списка любой элемент. Например, чтобы получить третий элемент списка (если он имеется), необходимо последовательно два раза применить селектор , после чего применить селектор . Другими словами, для получения элемента списка, который находится на позиции (начиная с для первого элемента, как это принято в программировании), необходимо раз применить селектор , после чего применить селектор .
Четвёртая строка определения описывает предикаты для списка, то есть функции, возвращающие булевское значение в зависимости от некоторых условий. Первый предикат возвращает значение в случае, если заданный список пуст. Второй предикат действует наоборот. Наконец, пятая строка описывает части списка, которые, как уже сказано, представляют собой пустой и непустой списки.
Свойства
У определённой таким образом структуры данных имеются некоторые свойства:
- Размер списка — количество элементов в нём, исключая последний «нулевой» элемент, являющийся по определению пустым списком.
- Тип элементов — тот самый тип , над которым строится список; все элементы в списке должны быть этого типа.
- Отсортированность — список может быть отсортирован в соответствии с некоторыми критериями сортировки (например, по возрастанию целочисленных значений, если список состоит из целых чисел).
- Возможности доступа — некоторые списки в зависимости от реализации могут обеспечивать программиста селекторами для доступа непосредственно к заданному по номеру элементу.
- Сравниваемость — списки можно сравнивать друг с другом на соответствие, причём в зависимости от реализации операция сравнения списков может использовать разные технологии.
Как должно быть понятно из названия рассматриваемой структуры данных, списки используются для хранения наборов однотипных элементов. Такие элементы могут быть отсортированы для использования в функциях поиска или функциях для быстрой вставки новых элементов в список.
Списки в языках программирования
Функциональные языки
Списки в функциональных языках являются фундаментальной структурой. Большинство функциональных языков имеет встроенные средства для работы со списками вроде получения длины списка, головы (первый элемент списка), хвоста (часть списка, идущая за первым элементом), применения функции к каждому элементу списка (Map), свертки списка и пр.
Язык Haskell
Язык Lisp
Императивные языки
См. также
Напишите отзыв о статье «Список (информатика)»
Отрывок, характеризующий Список (информатика)
– Графинюшка, – послышался голос графа из за двери. – Ты не спишь? – Наташа вскочила босиком, захватила в руки туфли и убежала в свою комнату.
Она долго не могла заснуть. Она всё думала о том, что никто никак не может понять всего, что она понимает, и что в ней есть.
«Соня?» подумала она, глядя на спящую, свернувшуюся кошечку с ее огромной косой. «Нет, куда ей! Она добродетельная. Она влюбилась в Николеньку и больше ничего знать не хочет. Мама, и та не понимает. Это удивительно, как я умна и как… она мила», – продолжала она, говоря про себя в третьем лице и воображая, что это говорит про нее какой то очень умный, самый умный и самый хороший мужчина… «Всё, всё в ней есть, – продолжал этот мужчина, – умна необыкновенно, мила и потом хороша, необыкновенно хороша, ловка, – плавает, верхом ездит отлично, а голос! Можно сказать, удивительный голос!» Она пропела свою любимую музыкальную фразу из Херубиниевской оперы, бросилась на постель, засмеялась от радостной мысли, что она сейчас заснет, крикнула Дуняшу потушить свечку, и еще Дуняша не успела выйти из комнаты, как она уже перешла в другой, еще более счастливый мир сновидений, где всё было так же легко и прекрасно, как и в действительности, но только было еще лучше, потому что было по другому.На другой день графиня, пригласив к себе Бориса, переговорила с ним, и с того дня он перестал бывать у Ростовых.
31 го декабря, накануне нового 1810 года, le reveillon [ночной ужин], был бал у Екатерининского вельможи. На бале должен был быть дипломатический корпус и государь.
На Английской набережной светился бесчисленными огнями иллюминации известный дом вельможи. У освещенного подъезда с красным сукном стояла полиция, и не одни жандармы, но полицеймейстер на подъезде и десятки офицеров полиции. Экипажи отъезжали, и всё подъезжали новые с красными лакеями и с лакеями в перьях на шляпах. Из карет выходили мужчины в мундирах, звездах и лентах; дамы в атласе и горностаях осторожно сходили по шумно откладываемым подножкам, и торопливо и беззвучно проходили по сукну подъезда.
Почти всякий раз, как подъезжал новый экипаж, в толпе пробегал шопот и снимались шапки.
– Государь?… Нет, министр… принц… посланник… Разве не видишь перья?… – говорилось из толпы. Один из толпы, одетый лучше других, казалось, знал всех, и называл по имени знатнейших вельмож того времени.
Уже одна треть гостей приехала на этот бал, а у Ростовых, долженствующих быть на этом бале, еще шли торопливые приготовления одевания.
Много было толков и приготовлений для этого бала в семействе Ростовых, много страхов, что приглашение не будет получено, платье не будет готово, и не устроится всё так, как было нужно.
Вместе с Ростовыми ехала на бал Марья Игнатьевна Перонская, приятельница и родственница графини, худая и желтая фрейлина старого двора, руководящая провинциальных Ростовых в высшем петербургском свете.
В 10 часов вечера Ростовы должны были заехать за фрейлиной к Таврическому саду; а между тем было уже без пяти минут десять, а еще барышни не были одеты.
Наташа ехала на первый большой бал в своей жизни. Она в этот день встала в 8 часов утра и целый день находилась в лихорадочной тревоге и деятельности. Все силы ее, с самого утра, были устремлены на то, чтобы они все: она, мама, Соня были одеты как нельзя лучше. Соня и графиня поручились вполне ей. На графине должно было быть масака бархатное платье, на них двух белые дымковые платья на розовых, шелковых чехлах с розанами в корсаже. Волоса должны были быть причесаны a la grecque [по гречески].
Все существенное уже было сделано: ноги, руки, шея, уши были уже особенно тщательно, по бальному, вымыты, надушены и напудрены; обуты уже были шелковые, ажурные чулки и белые атласные башмаки с бантиками; прически были почти окончены. Соня кончала одеваться, графиня тоже; но Наташа, хлопотавшая за всех, отстала. Она еще сидела перед зеркалом в накинутом на худенькие плечи пеньюаре. Соня, уже одетая, стояла посреди комнаты и, нажимая до боли маленьким пальцем, прикалывала последнюю визжавшую под булавкой ленту.
– Не так, не так, Соня, – сказала Наташа, поворачивая голову от прически и хватаясь руками за волоса, которые не поспела отпустить державшая их горничная. – Не так бант, поди сюда. – Соня присела. Наташа переколола ленту иначе.
– Позвольте, барышня, нельзя так, – говорила горничная, державшая волоса Наташи.
– Ах, Боже мой, ну после! Вот так, Соня.
– Скоро ли вы? – послышался голос графини, – уж десять сейчас.
– Сейчас, сейчас. – А вы готовы, мама?
– Только току приколоть.
– Не делайте без меня, – крикнула Наташа: – вы не сумеете!
– Да уж десять.
На бале решено было быть в половине одиннадцатого, a надо было еще Наташе одеться и заехать к Таврическому саду.
Окончив прическу, Наташа в коротенькой юбке, из под которой виднелись бальные башмачки, и в материнской кофточке, подбежала к Соне, осмотрела ее и потом побежала к матери. Поворачивая ей голову, она приколола току, и, едва успев поцеловать ее седые волосы, опять побежала к девушкам, подшивавшим ей юбку.
Дело стояло за Наташиной юбкой, которая была слишком длинна; ее подшивали две девушки, обкусывая торопливо нитки. Третья, с булавками в губах и зубах, бегала от графини к Соне; четвертая держала на высоко поднятой руке всё дымковое платье.
– Мавруша, скорее, голубушка!- Информатика
- Структуры данных
- Статьи со ссылками на отсутствующие файлы
- Статьи о списках
Информатика. 10 класс (Повышенный уровень)
Список — динамическая линейная структура данных, хранящая конечную последовательность элементов, порядок которых определяется с помощью ссылок.
Список является динамической линейной структурой данных, в которой каждый элемент ссылается либо только на следующий — однонаправленный линейный список (пример 21.3), либо на предыдущий и следующий за ним — двунаправленный линейный список (пример 21.4).
Список представляет собой последовательность связанных структур. Каждая структура содержит ссылку, связывающую ее с другой структурой, входящей в список. Обычно структура состоит из двух смысловых частей — информационной и дополнительной. Информационная часть содержит данные, в дополнительной находятся указатели на последующую или предыдущую структуру списка. Порядок элементов определяется ссылкой на первый элемент. Такая организация структуры данных позволяет последовательно перемещаться по ссылкам от одного элемента списка к другому.
Основные операции, производимые над списком, перечислены в примере 21.5.
Добавление в список элемента, следующего за заданным, включает в себя следующие этапы:
- создание добавляемого элемента и заполнение его поля данных;
- переустановка указателя элемента, предшествующего добавляемому, на добавляемый элемент;
- установка указателя добавляемого элемента на следующий элемент (тот, на который раньше указывал предшествующий элемент).
Удаление из списка элемента, следующего за заданным, включает в себя следующие этапы:
- установка указателя предыдущего элемента на элемент, следующий за удаляемым;
- освобождение памяти удаляемого элемента.
Поиск элемента x в линейном списке осуществляется последовательным просмотром элементов. Он заканчивается либо при обнаружении искомого элемента, либо при достижении конца списка. Поиск в списке аналогичен поиску в линейном массиве, только обращение к элементам осуществляется не по индексу, а по указателю.
Если воспользоваться структурой данных list , входящей в STL, то все моменты, связанные с хранением элементов списка, а также с выделением и освобождением памяти, будут решаться самой структурой данных. Для пользователя операции доступны в виде функций, присущих данному классу.
Для работы со списком необходимо подключить библиотеку . Описание списка:
list имя переменной;
В библиотеке list реализован двунаправленный список, который является более общим, чем однонаправленный, и поддерживает большее количество операций. Если необходима работа с однонаправленным списком, можно использовать тип данных forward_list с подключением одноименной библиотеки.
В примере 21.8 перечислены некоторые операции, доступные для работы со списком. С другими можно ознакомиться в Приложение к главе 1.1. Многие функции аналогичны функциям, определенным для типа данных vector.
Пример 21.9. В файле хранится список фамилий. Написать программу, которая отсортирует фамилии в списке, найдет номер человека по фамилии Королев, вставит перед ним фамилию Иванов и удалит фамилию после Королева (Королев не последний в списке). Преобразованный список вывести в файл.
Этапы выполнения задания
I. Исходные данные: переменные n — количество фамилий в списке, spis — список.
II. Результат: номер Королева и преобразованный список.
III. Алгоритм решения задачи.
1. Ввод исходных данных. Будем считывать строку из файла и добавлять ее в конец списка, используя функцию push_back .
2. Для решения задачи будем использовать структуру данных list .2.1. Для сортировки списка используем функцию sort . Поскольку список нужно сортировать по возрастанию, компаратор не потребуется.
2.2. Для поиска n1 — номера Королева воспользуемся линейным поиском. Просмотр элементов списка осуществляется с помощью итератора.
2.3. Для вставки фамилии будем использовать функцию insert .
2.4. Для удаления фамилии будем использовать функцию erase .3. Вывод результата.
Списки отличаются от массивов тем, что доступ к их элементам осуществляется последовательно, в то время как массивы – структура данных произвольного доступа (предоставляет возможность в любой момент времени обратиться к любому элементу по его индексу).
Пример 21.3. Однонаправленный линейный список:

Пример 21.4. Двунаправленный линейный список:
Элементы связанного списка (в отличие от элементов массива) не обязаны располагаться в памяти друг за другом.

Связные списки иногда называют самоссылочными (self-referent) структурами. Хотя ссылка элемента обычно указывает на другой элемент, возможны и ссылки на себя (прямо или косвенно, через другие элементы), поэтому связные списки могут представлять собой циклические (cyclic) структуры.
Пример 21.5. Основные операции над списком:
1. Инициализация списка.
2. Добавление элемента в список.
3. Удаление элемента из списка.
4. Поиск заданного элемента x.
5. Просмотр элементов списка.Пример 21.6. Добавление элемента в однонаправленный список:

Пример 21.7 . Удаление элемента из однонаправленного списка:

Пример 21.8. Некоторые операции для типа данных list.
Доступ к первому элементу
Доступ к последнему элементу
Вставляет элемент в начало
Удаляет первый элемент
Вставляет элемент в конец
Удаляет последний элемент
Проверяет отсутствие элементов
Возвращает количество элементов
Изменяет порядок элементов на обратный
Списки оптимизированы для выполнения операций по добавлению и удалению элементов. Если мы знаем месторасположение элемента, то для вставки или удаления элемента достаточно изменить значения указателей. Сами элементы при этом не перемещаются (в отличие от вставки и удаления элементов в массиве). Для поиска элемента x в списке понадобится (в худшем случае) порядка n операций сравнения.
using namespace std ;
ifstream fin ( «input.txt» );
ofstream fout ( «output.txt» );
for ( int i = 0 ; i < n ; i ++)
spis . push_back ( t );
list < string >:: iterator fm = spis . end ();
for ( list < string >:: iterator
i != spis . end (); i ++)
if (* i == » Королев » )
if ( fm != spis . end ())
spis . insert ( fm , » Иванов » );
spis . erase ( fm );
for ( list < string >:: iterator
i != spis . end (); i ++)



VII. Анализ результатов. В итоговом списке Королев имеет номер 40, поскольку перед ним вставили Иванова. До вставки номер был 39.
§ 21. Структуры данных
В информатике структура данных — программная единица, позволяющая хранить и обрабатывать данные, а также обеспечивающая их эффективное использование. Данные при этом должны быть однотипными или логически связанными.
Различные виды структур данных подходят для различных задач; некоторые из них имеют узкую специализацию, другие являются универсальными (пример 21.1).
При разработке программного обеспечения сложность реализации и качество работы программ существенно зависят не только от выбора алгоритма, но и от правильного выбора структур данных. Одни и те же данные можно сохранить в структурах, требующих различного объема памяти, а алгоритмы работы с разными структурами данных могут иметь различную эффективность. Структура данных, наиболее подходящая для решения конкретной задачи, позволяет выполнять большое количество различных операций, используя как можно меньший объем ресурсов.
Ни одна профессиональная программа сегодня не пишется без использования структур данных, поэтому многие из них содержатся в стандартных библиотеках современных языков программирования (например, STL для С++).
Структура данных представляет собой набор значений данных, отношения между ними, а также функции и (или) операции, которые могут быть применены к данным.
Структуры данных классифицируют по разным признакам. В примере 21.2 приведена классификация структур данных по организации взаимосвязей между элементами.
Пример 21.1. Примеры некоторых структур данных:
1. Массив (вектор в C++) — самая простая и широко используемая структура данных.
2. Запись (структура в С++) — совокупность элементов данных разного типа. Содержит постоянное количество элементов, которые называют полями.
3. Связный список (Linked List) представляет набор связанных узлов, каждый из которых хранит собственно данные и ссылку на следующий узел. В реальной жизни связный список можно представить в виде поезда, каждый вагон которого может содержать некоторый груз или пассажиров и при этом может быть связан с другим вагоном.
4. Граф — совокупность вершин (узлов) и связей между ними (ребер). В реальной жизни по такому принципу устроены социальные сети: узлы — это люди, а ребра — их отношения.
5. Множество — совокупность данных, значения которых не повторяются, реализация математического объекта множество, за исключением того, что множество в программировании конечно.
Пример 21.2. Классификация структур данных.
-
- массив;
- список;
- связанный список;
- стек;
- очередь;
- хэш-таблица.
Иерархические:
-
- двоичные деревья;
- n-арные деревья;
- иерархический список.
-
- неориентированный граф;
- ориентированный граф.
-
- таблица реляционной базы данных;
- двумерный массив.
21.2. Список
Список — динамическая линейная структура данных, хранящая конечную последовательность элементов, порядок которых определяется с помощью ссылок.
Список является динамической линейной структурой данных, в которой каждый элемент ссылается либо только на следующий — однонаправленный линейный список (пример 21.3), либо на предыдущий и следующий за ним — двунаправленный линейный список (пример 21.4).
Список представляет собой последовательность связанных структур. Каждая структура содержит ссылку, связывающую ее с другой структурой, входящей в список. Обычно структура состоит из двух смысловых частей — информационной и дополнительной. Информационная часть содержит данные, в дополнительной находятся указатели на последующую или предыдущую структуру списка. Порядок элементов определяется ссылкой на первый элемент. Такая организация структуры данных позволяет последовательно перемещаться по ссылкам от одного элемента списка к другому.
Основные операции, производимые над списком, перечислены в примере 21.5.
Добавление в список элемента, следующего за заданным, включает в себя следующие этапы:
- создание добавляемого элемента и заполнение его поля данных;
- переустановка указателя элемента, предшествующего добавляемому, на добавляемый элемент;
- установка указателя добавляемого элемента на следующий элемент (тот, на который раньше указывал предшествующий элемент).
Удаление из списка элемента, следующего за заданным, включает в себя следующие этапы:
- установка указателя предыдущего элемента на элемент, следующий за удаляемым;
- освобождение памяти удаляемого элемента.
Поиск элемента x в линейном списке осуществляется последовательным просмотром элементов. Он заканчивается либо при обнаружении искомого элемента, либо при достижении конца списка. Поиск в списке аналогичен поиску в линейном массиве, только обращение к элементам осуществляется не по индексу, а по указателю.
Если воспользоваться структурой данных list , входящей в STL, то все моменты, связанные с хранением элементов списка, а также с выделением и освобождением памяти, будут решаться самой структурой данных. Для пользователя операции доступны в виде функций, присущих данному классу.
Для работы со списком необходимо подключить библиотеку . Описание списка:
list имя переменной;
В библиотеке list реализован двунаправленный список, который является более общим, чем однонаправленный, и поддерживает большее количество операций. Если необходима работа с однонаправленным списком, можно использовать тип данных forward_list с подключением одноименной библиотеки.
В примере 21.8 перечислены некоторые операции, доступные для работы со списком. С другими можно ознакомиться в Приложение к главе 1.1. Многие функции аналогичны функциям, определенным для типа данных vector.
Пример 21.9. В файле хранится список фамилий. Написать программу, которая отсортирует фамилии в списке, найдет номер человека по фамилии Королев, вставит перед ним фамилию Иванов и удалит фамилию после Королева (Королев не последний в списке). Преобразованный список вывести в файл.
Этапы выполнения задания
I. Исходные данные: переменные n — количество фамилий в списке, spis — список.
II. Результат: номер Королева и преобразованный список.
III. Алгоритм решения задачи.
1. Ввод исходных данных. Будем считывать строку из файла и добавлять ее в конец списка, используя функцию push_back .
2. Для решения задачи будем использовать структуру данных list .2.1. Для сортировки списка используем функцию sort . Поскольку список нужно сортировать по возрастанию, компаратор не потребуется.
2.2. Для поиска n1 — номера Королева воспользуемся линейным поиском. Просмотр элементов списка осуществляется с помощью итератора.
2.3. Для вставки фамилии будем использовать функцию insert .
2.4. Для удаления фамилии будем использовать функцию erase .3. Вывод результата.
Списки отличаются от массивов тем, что доступ к их элементам осуществляется последовательно, в то время как массивы – структура данных произвольного доступа (предоставляет возможность в любой момент времени обратиться к любому элементу по его индексу).
Пример 21.3. Однонаправленный линейный список:
Пример 21.4. Двунаправленный линейный список:
Элементы связанного списка (в отличие от элементов массива) не обязаны располагаться в памяти друг за другом.
Связные списки иногда называют самоссылочными (self-referent) структурами. Хотя ссылка элемента обычно указывает на другой элемент, возможны и ссылки на себя (прямо или косвенно, через другие элементы), поэтому связные списки могут представлять собой циклические (cyclic) структуры.
Пример 21.5. Основные операции над списком:
1. Инициализация списка.
2. Добавление элемента в список.
3. Удаление элемента из списка.
4. Поиск заданного элемента x.
5. Просмотр элементов списка.Пример 21.6. Добавление элемента в однонаправленный список:
Пример 21.7 . Удаление элемента из однонаправленного списка:
Пример 21.8. Некоторые операции для типа данных list.
Доступ к первому элементу
Доступ к последнему элементу
Вставляет элемент в начало
Удаляет первый элемент
Вставляет элемент в конец
Удаляет последний элемент
Проверяет отсутствие элементов
Возвращает количество элементов
Изменяет порядок элементов на обратный
Списки оптимизированы для выполнения операций по добавлению и удалению элементов. Если мы знаем месторасположение элемента, то для вставки или удаления элемента достаточно изменить значения указателей. Сами элементы при этом не перемещаются (в отличие от вставки и удаления элементов в массиве). Для поиска элемента x в списке понадобится (в худшем случае) порядка n операций сравнения.
using namespace std ;
ifstream fin ( «input.txt» );
ofstream fout ( «output.txt» );
for ( int i = 0 ; i < n ; i ++)
spis . push_back ( t );
list < string >:: iterator fm = spis . end ();
for ( list < string >:: iterator
i != spis . end (); i ++)
if (* i == » Королев » )
if ( fm != spis . end ())
spis . insert ( fm , » Иванов » );
spis . erase ( fm );
for ( list < string >:: iterator
i != spis . end (); i ++)
VII. Анализ результатов. В итоговом списке Королев имеет номер 40, поскольку перед ним вставили Иванова. До вставки номер был 39.
21.3. Стек
Стек — динамическая линейная структура данных, хранящая последовательность элементов, в которой размещение новых и удаление существующих происходит с одного конца, называемого вершиной стека (top).
Стек организован по принципу LIFO (англ. last in — first out, «последним пришел — первым ушел»).
Для стека определены операции добавления элемента и удаления элемента (пример 21.10). По своей организации стек является линейным списком, добавление и удаление элементов в который допускается только в начало списка.
В STL для работы со стеком определен тип данных stack, для чего подключается одноименная библиотека. Описание стека:
stack имя переменной;
В примере 21.11 перечислены операции, доступные для работы со стеком. Большинство функций для работы со стеком имеют аналоги для типа данных list .
Пример 21.12. Правильная скобочная последовательность — последовательность, состоящая из символов — «скобок», в которой каждой открывающейся скобке соответствует закрывающаяся скобка такого же типа, что и открывающаяся скобка. Проверить, является ли заданная скобочная последовательность правильной.
Этапы выполнения задания
I. Исходные данные: переменная s — строка, содержащая скобочную последовательность.
II. Результат: ответ «да» или «нет».
III. Алгоритм решения задачи.
1. Ввод исходных данных.
2. Проверку скобочной последовательности, состоящей из скобок различного типа, удобно выполнить при помощи структуры стек. Будем просматривать строку слева направо.2.1. Если текущий символ — открывающаяся скобка, то этот символ заносится в стек.
2.2. Если текущий символ — закрывающаяся скобка, то проверяем, что находится в вершине стека.
2.2.1. Если в вершине стека лежит соответствующая открывающаяся скобка, то очередная скобка не добавляется, а имеющаяся в вершине удаляется.
2.2.2. Если в вершине скобка другого типа, то работа программы прерывается и выдается ответ «нет».
2.2.3. Если стек пуст, то работа программы прерывается и выдается ответ «нет».
2.3. Если в конце работы программы стек оказывается пустым, то скобочная последовательность правильная, иначе — нет.3. Вывод результата.
Принцип работы стека часто сравнивают со стопкой тарелок: чтобы взять тарелку из середины стопки, нужно снять верхние. Стек также можно сравнить с железнодорожным путём: вагон, который попал туда последним, заберут первым.
Пример 21.10. Добавление и удаление элемента в вершине стека:

Пример 21.11. Операции для типа данных stack .
Доступ к вершине стека
Проверяет отсутствие элементов
Возвращает количество элементов
Удаляет верхний элемент
Правильные скобочные последовательности: [([])((([[[]]])))], ()((()))[[]]. Неправильные скобочные последовательности: [[)) (несоответствие типа закрывающихся скобок типу открывающихся), >< (закрывающая скобка стоит раньше открывающейся), [[>] (не каждой открывающейся скобке соответствует закрывающаяся).
using namespace std ;
using namespace std :: __cxx11 ;
int n = s . length ();
bool f = true ;
for ( int i = 0 ; i < n ; i ++)
if ( otkr . find ( s [ i ]) != — 1 )
if ( zakr . find ( s [ i ]) != — 1 )
if ( st . empty ())
if ( zakr . find ( s [ i ]) ==
otkr . find ( st . top ()))
if ( st . empty () && f )


VII. Анализ результатов. Рассмотрим пример для правильной скобочной последовательности [([])(([]))]. В первой строке — текущий символ, во второй — состояние стека.
21.4. Очередь
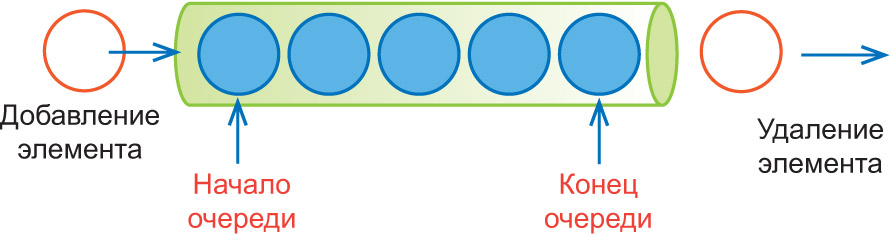
Очередь — динамическая линейная структура данных, хранящая последовательность элементов, в которой добавление новых элементов происходит в конец очереди ( хвост , tail ), а удаление — из начала очереди ( головы, head ).
Очередь организована по принципу FIFO (англ. first in — first out, «первым пришел — первым ушел»).
Для очереди определены операции добавления элемента и удаления элемента (пример 21.13). По своей организации очередь является линейным списком, добавление в который допускается только в конец списка, а удаление только из начала.
В STL для работы со стеком определен тип данных queue , для работы с которым подключается одноименная библиотека. Описание стека:
queue имя переменной ;
В примере 21.14 перечислены операции, доступные для работы с очередью. Большинство функций для работы с очередью имеют аналоги для типа данных list .
Пример 21.15. Задана строка, состоящая из прописных и строчных латинских букв. Вывести буквы парами. В каждой паре первая буква прописная, а вторая строчная. Пары образуются в том порядке, в котором следуют буквы в строке. (В реальности это могут быть, например, фамилии пациентов, ожидающих определенное лекарство, и аптеки, в которые это лекарство поступило.)
Этапы выполнения задания
I. Исходные данные: переменная s — строка, содержащая прописные и строчные буквы.
II. Результат: пары букв и набор букв, оставшийся без пары.
III. Алгоритм решения задачи.
1. Ввод исходных данных.
2. Будем просматривать строку слева направо.2.1. В очередь будем заносить буквы одного регистра.
2.2. Если появляется символ в другом регистре, то достаем букву из очереди и выводим пару.
2.2.1. Для проверки того, что две буквы относятся к одному регистру, создадим логическую функцию check. Буква x является прописной, если для нее выполняется условие x >= ‘A’ && x = ‘a’ && x 2.2.2. Для вывода букв в нужном порядке создадим функцию vyvod .3. Если в конце очередь не пуста, то в ней остались символы, которым не хватило пары. Для того чтобы вывести все символы из очереди, будем после вывода удалять символ, пока очередь не станет пустой.
IV. Описание переменных: s – string, q – queue.
Структуру данных очередь можно представить себе как очередь к врачу, где новые пациенты встают в конец очереди, а прием пациентов осуществляется с начала очереди. На основе очереди организована обработка событий в Windows. Когда пользователь оказывает какое-либо действие на приложение, то сообщение об этом ставится в очередь, и только когда будут обработаны сообщения, пришедшие ранее, приложение выполнит необходимое действие.
Пример 21.13. Добавление и удаление элемента в очереди:
Пример 21.14. Операции для типа данных queue.
Доступ к первому элементу
Доступ к последнему элементу
Проверяет отсутствие элементов
Возвращает количество элементов
Если на вход подана строка ZHJKqwertASDyuiopQWERTYUIOPasdf, то должны получиться следующие пары: Zq Hw Je Kr At Sy Du Qi Wo Ep Ra Ts Yd Uf. Буквы I O P останутся без пары.
using namespace std ;
bool check ( char x , char y )
bool u1 = x >= ‘A’ && x
bool u2 = y >= ‘A’ && y
bool u3 = x >= ‘a’ && x
bool u4 = y >= ‘a’ && y
void vyvod ( char x , char y )
int n = s . length ();
for ( int i = 0 ; i < n ; i ++)
if ( q . empty ())
if ( check ( s [ i ], q . front ()))
vyvod ( s [ i ], q . front ());
if ( q . empty ())
while (! q . empty ())

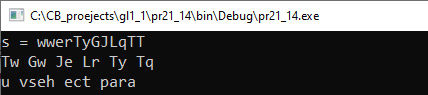
VII. Анализ результатов. Рассмотрим пример для строки wwerTyGJLqTT. В первой строке — текущий символ, во второй — состояние очереди.
Пример 21.16. Добавление и удаление элемента в деке:
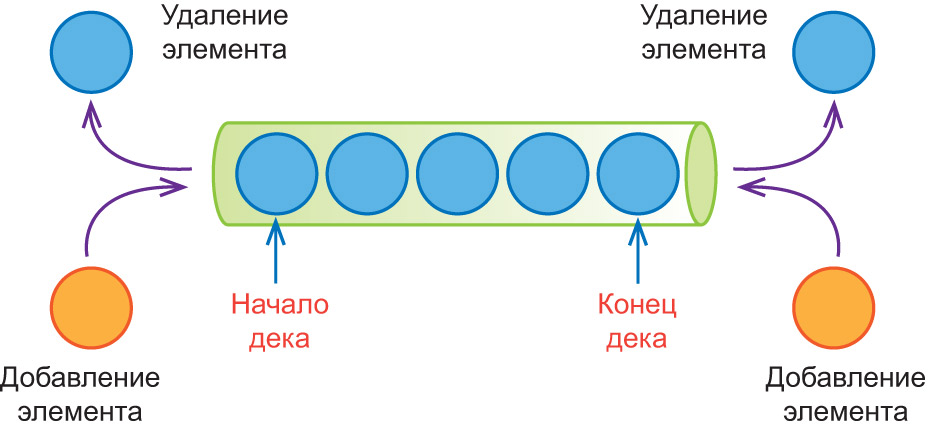
В STL для работы с деком определен тип данных deque, для работы с которым подключается одноименная библиотека. Функции для работы с деком можно посмотреть в см. Приложение к главе 1.1.
Вопросы к параграфу
1. Что понимают под структурой данных?
2. Как добавить элемент в список?
3. Как удалить элемент из списка?
4. Как устроен стек?
5. Какие операции определены для очереди?
Упражнения



1. В файле хранится список фамилий. Написать программу, которая определит, есть ли в списке одинаковые фамилии, и, если есть, удалит их. Преобразованный список вывести в файл.
2. Дано целое число x и список, состоящий из целых чисел. Удалить из списка все элементы со значением x .
3. Осуществить циклический сдвиг элементов двусвязного списка на k позиций вправо.
4. По заданному текстовому файлу получите новый текстовый файл, в котором слова из первого файла расположены в обратном порядке. Используйте структуру данных стек.
5. В файле хранятся целые числа. Разместить числа в два стека. В первый стек — положительные числа, а во второй — отрицательные. Если количество чисел в стеках одинаково, то в итоговый файл вывести попарные произведения чисел: один множитель из первого стека, другой — из второго, иначе в итоговый файл записать значения вершины каждого стека.
6. В стеке хранятся целые числа. Найдите минимальное число в стеке.
7. В очереди хранятся целые числа. Найдите максимальное число в очереди.
8. Дана величина a строкового типа из четного количества символов. Получить и вывести величину b , состоящую из символов первой половины величины a , записанных в обратном порядке, после которых идут символы второй половины величины a , также записанные в обратном порядке. Например, при а = «привет» b должно быть равно «ирптев».
9. Имеется n черных и белых карточек, сложенных в стопку. Карточки раскладываются на стол в одну линию следующим образом: первая кладется на стол, вторая — под низ стопки, третья — на стол, четвертая — под низ стопки и т. д., пока все карточки не будут выложены на стол. Каким должно быть исходное расположение карточек в стопке, чтобы разложенные на столе карточки чередовались по цвету: белая, черная, белая, черная и т. д.? Подсказка: используйте очередь.