PARALLEL.RU — Информационно-аналитический центр по параллельным вычислениям
Для начинающих пользователей вычислительных кластеров
Данная страница написана с таким расчетом, чтобы она могла быть полезной не только пользователям вычислительных кластеров НИВЦ, но и всем, желающим получить представление о работе вычислительного кластера. Решение типичных проблем пользователей кластера НИВЦ изложено на отдельной странице.
Что такое вычислительный кластер?
В общем случае, вычислительный кластер — это набор компьютеров (вычислительных узлов), объединенных некоторой коммуникационной сетью. Каждый вычислительный узел имеет свою оперативную память и работает под управлением своей операционной системы. Наиболее распространенным является использование однородных кластеров, то есть таких, где все узлы абсолютно одинаковы по своей архитектуре и производительности.
Подробнее о том, как устроен и работает вычислительный кластер можно почитать в книге А.Лациса «Как построить и использовать суперкомпьютер».
Как запускаются программы на кластере?
Для каждого кластера имеется выделенный компьютер — головная машина (front-end). На этой машине установлено программное обеспечение, которое управляет запуском программ на кластере. Собственно вычислительные процессы пользователей запускаются на вычислительных узлах, причем они распределяются так, что на каждый процессор приходится не более одного вычислительного процесса. Запускать вычислительные процессы на головной машине кластера нельзя.
Пользователи имеют терминальный доступ на головную машину кластера, а входить на узлы кластера для них нет необходимости. Запуск программ на кластере осуществляется в т.н. «пакетном» режиме — это значит, что пользователь не имеет непосредственного, «интерактивного» взаимодействия с программой, программа не может ожидать ввода данных с клавиатуры и выводить непосредственно на экран. Более того, программа пользователя может работать тогда, когда пользователь не подключен к кластеру.
Какая установлена операционная система?
Вычислительный кластер, как правило, работает под управлением одной из разновидностей ОС Unix — многопользовательской многозадачной сетевой операционной системы. В частности, в НИВЦ МГУ кластеры работают под управлением ОС Linux — свободно распространяемого варианта Unix. Unix имеет ряд отличий от Windows, которая обычно работает на персональных компьютерах, в частности эти отличие касаются интерфейса с пользователем, работы с процессами и файловой системы.
Более подробно об особенностях и командах ОС UNIX можно почитать здесь:
- Инсталляция Linux и первые шаги (книга Matt Welsh, перевод на русский язык А.Соловьева).
- Учебник по Unix для начинающих.
- Энциклопедия Linux.
- Операционная система UNIX (информационно-аналитические материалы на сервере CIT-Forum).
Как хранятся данные пользователей?
Все узлы кластера имеют доступ к общей файловой системе, находящейся на файл-сервере. То есть файл может быть создан, напрмер, на головной машине или на каком-то узле, а затем прочитан под тем же именем на другом узле. Запись в один файл одновременно с разных узлов невозможна, но запись в разные файлы возможна. Кроме общей файловой системы, могут быть локальные диски на узлах кластера. Они могут использоваться программами для хранения временных файлов. После окончания (точнее, непосредственно перед завершением) работы программы эти файлы должны удаляться.
Какие используются компиляторы?
Никаких специализированных параллельных компиляторов для кластеров не существует. Используются обычные оптимизирующие компиляторы с языков Си и Фортран — GNU, Intel или другие, умеющие создавать исполняемые программы ОС Linux. Как правило, для компиляции параллельных MPI-программ используются специальные скрипты (mpicc, mpif77, mpif90 и др.), которые являются надстройками над имеющимися компиляторами и позволяют подключать необходимые библиотеки.
Как использовать возможности кластера?
Существует несколько способов задействовать вычислительные мощности кластера.
1. Запускать множество однопроцессорных задач. Это может быть разумным вариантом, если нужно провести множество независимых вычислительных экспериментов с разными входными данными, причем срок проведения каждого отдельного расчета не имеет значения, а все данные размещаются в объеме памяти, доступном одному процессу.
2. Запускать готовые параллельные программы. Для некоторых задач доступны бесплатные или коммерческие параллельные программы, которые при необходимости Вы можете использовать на кластере. Как правило, для этого достаточно, чтобы программа была доступна в исходных текстах, реализована с использованием интерфейса MPI на языках С/C++ или Фортран. Примеры свободно распространяемых параллельных программ, реализованных с помощью MPI: GAMESS-US (квантовая химия), POVRay-MPI (трассировка лучей).
3. Вызывать в своих программах параллельные библиотеки. Также для некоторых областей, таких как линейная алгебра, доступны библиотеки, которые позволяют решать широкий круг стандартных подзадач с использованием возможностей параллельной обработки. Если обращение к таким подзадачам составляет большую часть вычислительных операций программы, то использование такой параллельной библиотеки позволит получить параллельную программу практически без написания собственного параллельного кода. Примером такой библиотеки является SCALAPACK. Русскоязычное руководство по использованию этой библиотеки и примеры можно найти на сервере по численному анализу НИВЦ МГУ. Также доступна параллельная библиотека FFTW для вычисления быстрых преобразований Фурье (БПФ). Информацию о других параллельных библиотеках и программах, реализованных с помощью MPI, можно найти по адресу http://www-unix.mcs.anl.gov/mpi/libraries.html.
4. Создавать собственные параллельные программы. Это наиболее трудоемкий, но и наиболее универсальный способ. Существует два основных варианта. 1) Вставлять параллельные конструкции в имеющиеся параллельные программы. 2) Создавать «с нуля» параллельную программу.
Как работают параллельные программы на кластере?
Параллельные программы на вычислительном кластере работают в модели передачи сообщений (message passing). Это значит, что программа состоит из множества процессов, каждый из которых работает на своем процессоре и имеет свое адресное пространство. Причем непосредственный доступ к памяти другого процесса невозможен, а обмен данными между процессами происходит с помощью операций приема и посылки сообщений. То есть процесс, который должен получить данные, вызывает операцию Receive (принять сообщение), и указывает, от какого именно процесса он должен получить данные, а процесс, который должен передать данные другому, вызывает операцию Send (послать сообщение) и указывает, какому именно процессу нужно передать эти данные. Эта модель реализована с помощью стандартного интерфейса MPI. Существует несколько реализаций MPI, в том числе бесплатные и коммерческие, переносимые и ориентированные на конкретную коммуникационную сеть.
Как правило, MPI-программы построены по модели SPMD (одна программа — много данных), то есть для всех процессов имеется только один код программы, а различные процессы хранят различные данные и выполняют свои действия в зависимости от порядкового номера процесса.
Более подробно об MPI можно почитать здесь:
- Курс Вл.В.Воеводина «Параллельная обработка данных». Лекция 5. Технологии параллельного программирования. Message Passing Interface.
- Вычислительный практикум по технологии MPI (А.С.Антонов).
- А.С.Антонов «Параллельное программирование с использованием технологии MPI».
- MPI: The Complete Reference (на англ.яз.).
- Глава 8: Message Passing Interface в книге Яна Фостера «Designing and Building Parallel Programs» (на англ.яз.).
Где можно посмотреть примеры параллельных программ?
Схематичные примеры MPI-программ можно посмотреть здесь:
- Курс Вл.В.Воеводина «Параллельная обработка данных». Приложение к лекции 5.
- Примеры из пособия А.С.Антонова «Параллельное программирование с использованием технологии MPI».
Примеры простейших работающих MPI-программ доступны в составе пакета MPICH, свободно распространяемой реализации MPI. Для пользователей НИВЦ МГУ простейшие примеры MPI-программ на Си и Фортране доступны в директории /home/examples/mpi. Примеры использования конструкций MPI в программах на языке Си можно посмотреть в тестах производительности для параллельных компьютеров. Примеры программ на Фортране с комментариями можно посмотреть в англоязычном документе «MPI User’s Guide in Fortran» (формат Word).
Можно ли отлаживать параллельные программы на персональном компьютере?
Разработка MPI-программ и проверка функциональности возможна на обычном ПК. Можно запускать несколько MPI-процессов на однопроцессорном компьютере и таким образом проверять работоспособность программы. Желательно, чтобы это был ПК с ОС Linux, где можно установить пакет MPICH. Это возможно и на компьютере с Windows, но более затруднительно.
Насколько трудоемко программировать вычислительные алгоритмы c помощью MPI и есть ли альтернативы?
Набор функций интерфейса MPI иногда называют «параллельным ассемблером», т.к. это система программирования относительно низкого уровня. Для начинающего пользователя-вычислителя может быть достаточно трудоемкой работой запрограммировать сложный параллельный алгоритм с помощью MPI и отладить MPI-программу. Существуют и более высокоуровневые системы программирования, в частности российские разработки — DVM и НОРМА, которые позволяют пользователю записать задачу в понятных для него терминах, а на выходе создают код с использованием MPI, и поэтому могут быть использованы практически на любом вычислительном кластере.
Как ускорить проведение вычислений на кластере?
Во-первых, нужно максимально ускорить вычисления на одном процессоре, для чего можно принять следующие меры.
1. Подбор опций оптимизации компилятора. Подробнее об опциях компиляторов можно почитать здесь:
- Компиляторы Intel C++ и Fortran (русскоязычная страница на нашем сайте).
- GCC online documentation.
2. Использование оптимизированных библиотек. Если некоторые стандартные действия, такие как умножение матриц, занимают значительную долю времени работы программы, то имеет смысл использовать готовые оптимизированные процедуры, выполняющие эти действия, а не программировать их самостоятельно. Для выполнения операций линейной алгебры над матричными и векторными величинами была разработана библиотека BLAS («базовые процедуры линейной алгебры»). Интерфейс вызова этих процедур стал уже фактически стандартом и сейчас существуют несколько хорошо оптимизированных и адаптированных к процессорным архитектурам реализаций этой библиотеки. Одной из таких реализаций является свободно распространяемая библиотека ATLAS, которая при установке настраивается с учетом особенностей процессора. Компания Интел предлагает библиотеку MKL — оптимизированную реализацию BLAS для процессоров Intel и SMP-компьютеров на их основе. Тут статья про подбор опций MKL.
Подробнее о библиотеках линейной алгебры (BLAS) можно почитать здесь:
3. Исключение своппинга (автоматического сброса данных из памяти на диск). Каждый процесс должен хранить не больше данных, чем для него доступно оперативной памяти (в случае двухпроцессорного узла это примерно половина от физической памяти узла). В случае необходимости работать с большим объемом данных может быть целесообразным организовать работу со временными файлами или использовать несколько вычислительных узлов, которые в совокупности предоставляют необходимый объем оперативной памяти.
4. Более оптимальное использование кэш-памяти. В случае возможности изменять последовательность действий программы, нужно модифицировать программу так, чтобы действия над одними и те же или подряд расположенными данными данными выполнялись также подряд, а не «в разнобой». В некоторых случаях может быть целесообразно изменить порядок циклов во вложенных циклических конструкциях. В некоторых случаях возможно на «базовом» уровне организовать вычисления над такими блоками, которые полностью попадают в кэш-память.
5. Более оптимальная работа с временными файлами. Например, если программа создает временные файлы в текущем каталоге, то более разумно будет перейти на использование локальных дисков на узлах. Если на узле работают два процесса и каждый из них создает временные файлы, и при этом на узле доступны два локальных диска, то нужно, чтобы эти два процесса создавали файлы на разных дисках.
6. Использование наиболее подходящих типов данных. Например, в некоторых случаях вместо 64-разрядных чисел с плавающей точкой двойной точности (double) может быть целесообразным использовать 32-разрядные числа одинарной точности (float) или даже целые числа (int).
Более подробно о тонкой оптимизации программ можно почитать в руководстве по оптимизации для процессоров Intel и в других материалах по этой теме на веб-сайте Intel.
Как оценить и улучшить качество распараллеливания?
Для ускорения работы параллельных программ стоит принять меры для снижения накладных расходов на синхронизацию и обмены данными. Возможно, приемлемым подходом окажется совмещение асинхронных пересылок и вычислений. Для исключения простоя отдельных процессоров нужно наиболее равномерно распределить вычисления между процессами, причем в некоторых случаях может понадобиться динамическая балансировка.
Важным показателем, который говорит о том, эффективно ли в программе реализован параллелизм, является загрузка вычислительных узлов, на которых работает программа. Если загрузка на всех или на части узлов далека от 100% — значит, программа неэффективно использует вычислительные ресурсы, т.е. создает большие накладные расходы на обмены данными или неравномерно распределяет вычисления между процессами. Пользователи НИВЦ МГУ могут посмотреть загрузку через веб-интерфейс для просмотра состояния узлов.
В некоторых случаях для того, чтобы понять, в чем причина низкой производительности программы и какие именно места в программе необходимо модифицировать, чтобы добиться увеличения производительности, имеет смысл использовать специальные средства анализа производительности — профилировщики и трассировщики. На кластере Ant установлена система для отладки MPI-программ deb-MPI. Краткую информацию по системе можно найти по адресу http://parallel.ru/cluster/deb-MPI-UG.html .—>
Подробнее об улучшении производительности параллельных программ можно почитать в книге В.В.Воеводина и Вл.В.Воеводина «Параллельные вычисления».
Как создать кластер из двух ноутбуков?

У меня родилась «гениальная» идея: создать соединить мощности двух компов.
Погуглил, такая технология есть, существует и активно используется людьми со всего мира.
Погуглил ещё, оказывается, что это можно сделать на Windows Server и Linux
Ну и соответственно, вопросы:
1.1 Можно ли комфортно работать на Сервере — играть в игры, отвечать на Тостере, смотреть кино? В том числе на кластеризированном?
1.2 Будет ли на кластеризированном линуксе нормально работать Wine и\или подобные средства запуска windows — программ?
Погуглил еще — оказывается, что скорости моего инета для нормального функционирования кластера не хватит, а надо для таких вещей кабельного сообщения компьютеров.
Ну и вопросы:
2.1 Можно ли просто напрямую соединить два компа каким-нибудь таким lan кабелем?
2.2 Если я захочу к этой бандуре подключить еще нетбук, то можно ли просто всё присоединить к подобному свитчу и радоваться жизни?
Хар-ки компьютеров:
2.40 Ghz | 2.27 Ghz — оба двухядерные, от intel
4 Gb RAM- одинаково
512 Mb GPU — одинаково, от nvidia
Dell|Asus
- Вопрос задан более трёх лет назад
- 12990 просмотров
Комментировать
Решения вопроса 2
Для того, для чего вы хотите — никак не создать.
Кластер — это даже согласно статье из Википедии, которую вы приводите — это слабо связанная вычислительная система.
Попробую объяснить, используя аналогию.
Вы считаете, что компьютеры можно объединять также, как можно объединять усилия людей, наполняющих бочку водой, таская ее ведрами. Один человек наполнит за час, два — за полчаса, и так далее. Но это процесс, который распараллеливается элементарно.
А на самом деле, кластер работает подобно команде сценаристов, которые пишут сценарий сериала из двадцати серий, работая удаленно по бумажной почте: сначала главный сценарист придумывает персонажей и общий сюжет, записывает это, потом ему нужно разбить его на серии и отослать каждому из сценаристов, указав, какую серию тому нужно прописать в подробностях. Если бы он писал все сам, ему бы понадобилось по неделе на серию, итого — двадцать недель. А съемки можно начинать, когда готова первая серия (через неделю). Поскольку съемки одной серии занимают три дня, съемочная группа будет простаивать четыре дня из каждой недели, пока не будет готова следующая серия (деньги во время простоя тоже расходуются, хотя ничего не производится). Съемки будут, таким образом, завершены через 20*7+3=143 дня.
Наемным сценаристам тоже нужно по неделе на написании серий, но начальная работа главного сценариста тоже занимает неделю, плюс — три дня на доставку «каркаса сценария» наемным сценаристам, три дня на доставку сценария серий обратно, еще пять дней на проверку и исправление нестыковок. Итог — начинать съемки можно только через 25 дней, а не через семь, но продолжать их можно уже непрерывно. Съемки будут завершены через 25+3*20=85 дней.
Ровно как здесь нельзя ускорить процесс еще больше, заставив больше сценаристов писать по половине серии (потому что при этом растет сложность стыковки кусков сюжета, которые написаны разными людьми, потому им придется переписываться, теряя время), так и пытаясь запустить на кластере условную игру, придется просадить кучу времени на медленное общение узлов между собой по сети.
Чтобы всё «летало» в реальном времени в игре, вам нужен один мощный компьютер с многоядерным процессором, мощной видеокартой и быстрой шиной, которая всех их объединяет. А собрать кластер из сотни древних ноутов на медленном Ethernet и получить производительность в сто раз больше в играх — это фантастика из дурацких фильмов про хакеров.
Создание кластера для расчета в OpenFOAM
В статье я расскажу, как можно (при необходимости) быстро и дешево собрать кластер Beowulf на основе домашних компьютеров. Выполню я это с помощью компьютеров находящихся в аудитории университета, используя существующую локальную сеть. Используемые программные инструменты: средства численного моделирования механики сплошных сред OpenFOAM, сетевого протокола прикладного уровня SSH и распределенного протокола файловой системы NFS. Все выполнялось под управлением операционной системы ubuntu 20.04.
Предисловие
Я студент, и мне в прошлом полугодии необходимо было произвести расчет аэродинамики крайне сложного аэродинамического изделия. Мой стационарный компьютер справился с этой задачей весьма долго, в связи с чем потребовалось объединение вычислительных мощностей нескольких компьютеров. Так что в этой статье будет рассмотрены только создание и тестовый запуск расчетов без визуализации массива данных с помощью программы ParaView.
Тут будет написана инструкция туториал для тех кто хочет повторить. По учебной деятельности я являюсь конструктором, в результате чего при описании команд могут возникать неточности.
Введение
Определение кластера
Кластер – группа компьютеров, объединенных в локальную вычислительную сеть (ЛВС) и способных работать в качестве единого вычислительного ресурса.
Предполагается, что для кластера обеспечивается более высокая надежность и эффективность, нежели для ЛВС, и существенно более низкая стоимость в сравнении с другими типами параллельных вычислительных систем (за счет использования типовых аппаратных и программных решений).
Кластер Beowulf

В настоящее время под кластером типа Beowulf понимается система, которая состоит из одного серверного узла и одного или более клиентских узлов, соединенных при помощи Ethernet или некоторой другой сети. Это система, построенная из готовых серийно выпускающихся промышленных компонентов, на которых может работать ОС Linux, стандартных адаптеров Ethernet и коммутаторов. Она не содержит специфических аппаратных компонентов и легко воспроизводима. Серверный узел управляет всем кластером и является файл-сервером для клиентских узлов. Он также является консолью кластера и шлюзом во внешнюю сеть. Большие системы Beowulf могут иметь более одного серверного узла, а также, возможно, специализированные узлы, например консоли или станции мониторинга. Они конфигурируются и управляются серверными узлами и выполняют только то, что предписано серверным узлом.
Вычислительная среда OpenFOAM
OpenFOAM — это бесплатное программное обеспечение CFD с открытым исходным кодом, разработанное, в основном, компанией OpenCFD Ltd с 2004 года. Оно имеет большую базу пользователей в большинстве областей техники и науки, как коммерческих, так и академических организаций. OpenFOAM имеет широкий набор функций для решения любых задач — от сложных потоков жидкости, включающих химические реакции, турбулентность и теплопередачу, до акустики, механики твердого тела и электромагнитных систем.
Настройка рабочей среды
Физическое соединение устройств
Два и более компьютера нужно соединить друг с другом. Самый простой способ это сделать — задействовать коммутатор и соединить их с помощью витой пары.
Выбор операционной системы
Решено использовать систему Linux, конкретный дистрибутив — Ubuntu 20.04, десктопной и серверной версии соответственно.
Это связано с тем, что по состоянию на 2022 год среда вычисления OpenFOAM, выбранная для расчётов, стабильно работает именно на этом дистрибутиве именно этой версии. Также система Linux, будучи системой с распространяемыми исходными кодами, является основой для кластера Beowulf.
Десктоп-версия
Десктоп-версия — это версия системы, имеющая графический интерфейс. Он нужен будет для удобного взаимодействия с файлами, а также для просмотра результатов расчёта. Десктоп-версия будет стоять на главном компьютере.
После того, как вы с загрузочного диска запустите установщик, следуйте серии шагов:
- Выберите язык (предпочтителен English);
- Нажимаем install ubuntu;
- Выберите язык (предпочтителен English);
- Не изменяем предустановленные программы;
- Не изменяем типы инсталляторов;
- Выбираем время системы;
- Введите имя пользователя (в данном случае используется pisi), а также пароль. Пароли и имена серверов должны быть абсолютно одинаковы для всех компьютеров, связанных с кластером.
- После перезагрузите систему (вам предложит это сделать система)
Серверная версия
Серверная же версия будет стоять на всех остальных компьютерах. На них не потребуется работать с файлами, или просматривать результаты. Все остальные компьютеры нужны исключительно, как дополнительные ресурсы для вычислений, и поэтому для них достаточно самой компактной системы с самым малым набором функций.
После того, как вы с загрузочного диска запустите установщик, следуйте серии шагов:
- Выберите язык (предпочтителен English);
- Не обновляйте установщик;
- Не изменяйте настройки клавиатуры;
- Не изменяйте настройки сети;
- Используйте весь диск для установки и подтвердите его перезапись, если потребуется;
- Не изменяйте настройки зеркала;
- Не изменяйте настройки файловой системы;
- Введите имя пользователя, сервера, а также пароль. Пароли и имена серверов должны быть абсолютно одинаковы для всех компьютеров, связанных с кластером.
- Установите OpenSSH-сервер;
- Server Snaps оставьте без изменений;
После окончания установки извлеките загрузочный диск и перезагрузите компьютер.
Завершения установки
В обоих случаях, вам надо завершить установку, зайдя в директорию Home /home//, и создать папку OpenFOAM mkdir/OpenFOAM. Должен получиться путь: /home//OpenFOAM. — это заданное вами имя пользователя (на изображениях в данном документе можно заметить имя «pisi»).
Наличие подкаталогов в текущем каталоге можно проверить с помощью команды ls.
Установка OpenFOAM
Установка OpenFOAM состоит так же из двух этапах и должна производиться всех компьютерах участвующих в объединении, это связано с тем, что OpenFOAM это не программа, а набор библиотек необходимых для произведения расчетов системы.
Для того чтобы установить OpenFOAM необходимо в терминале прописать следующую команду что представлена ниже.
curl -s https://dl.openfoam.com/add-debian-repo.sh | sudo bashКратко опишем функционал команды.
- curl — команда взаимодействия с интернетом.
- -s –- сохранение скачанных фалов в систему.
- url — ссылка на скачиваемый файл.
- bash — дает возможность создания скриптов.
Примечание: если по каким то причинам не оказалось команды curl, то введите следующую команду в терминал: sudo apt install curl и убедиться что установлена правильная версия системы.
Далее необходимо распаковать и скомпилировать выше установленный набор библиотек. Для этого необходимо выполнить команду, приведенную ниже.
sudo apt-get install openfoam2006-defaultПримечания: так как это набор библиотек, то нет практического способа проверить правильность действий, то необходимо проверить их наличие в файловой системе операционной системы.
Для этого необходимо выполнить следующую команду в терминале.
cd /usr/lid/openfoam2006/Кратко опишем функционал команды.
- cd — это переход в папку по пути.
- далее идет путь.
Если в результате выполнения команды не появилось ошибок, то все действия выполнены правильно, в противном случае выполните последовательность действий начиная с скачивания OpenFOAM.
Если проверка прошла успешно, то выполняем команду cd.
Установка и настройка SSH
SSH — это защищенный протокол для удаленного управления операционной системой. Он пригодится для безопасного соединения компьютеров друг с другом.
Десктоп-версия
Десктоп-версия по-умолчанию не имеет встроенного SSH, поэтому его нужно установить, это продемонстрировано на примере ниже.
sudo apt install openssh-serverДругих отличий нет. Выполняйте все те шаги, что описаны ниже, для серверной версии.
Серверная версия
В отличие от версии с графическим интерфейсом, серверная версия по-умолчанию имеет в себе предустановленный пакет OpenSSH (точнее, эту опцию можно выбрать при установке), и здесь этап установки не требуется. В противном же случае повторите действия, предназначенные для десктоп-версии.
Следом выполните следующие шаги.
Создаёт директорию SSH. Может выдать ошибку, если директория уже есть.
Назначает права полного доступа для этой директории. Может потребоваться ввести вместе с sudo.
Создаёт новый ключ. Оставьте все поля по-умолчанию.
ssh-copy-id -i /home//.ssh/id_rsa.pub @
Копирует ваш ключ на другой компьютер по IP-адресу. Это позволит вам позже входить на этот компьютер без пароля.
— это имя вашего пользователя.
— это IP-адрес компьютера, куда вы передаёте ключ.
Проверка подключения (должна быть без пароля).
Настройте так все компьютеры. Ключи должны быть переданы каждому сателлиту от сервера, и наоборот.
Примечание: для проверки работоспособности SSH соединение необходимо проверить несколько условий:
- Соединение должно работать от каждого устройства к каждому.
- Все устройства должны производить соединения без пароля за исключением первого раза.
- Главное, чтобы главный компьютер мог подключиться к серверу и наоборот без пароля.
Установка и настройка NFS
Установка NFS для Десктоп-версии
В командной строке необходимо прописать команду установки утилиты для создания общей сетевой папки среди всех компьютерах кластера.
Примечание: предварительно необходимо иметь папку в домашнем каталоге, если этого нет, то просмотрите пункт «Завершения установки».
Чтобы установить NFS, необходимо скачать его. Для этого пропишем в терминале следующую команду.
sudo apt install nfs-kernell-serverПосле установки системной утилиты необходимо указать права доступа к папке, которую необходимо синхронизировать. Для этого в терминале нужно прописать следующий набор команд.
sudo chown nobody:nogroup /home//OpenFOAM/Кратко опишем функционал команды.
- chown — это изменение владельца файла или папки
- nobody:nogroup — сообщает системе что папка не принадлежит не одному владельцу и группе
Предоставим права доступа для папки.
sudo chown 777 /home//OpenFOAM/Кратко опишем функционал команды:
- 777 — это теговое значение прав доступа к последующей папке.
После необходимо внести изменения в файл exports, указав узлы связи, которые вы хотите подключить к ранее приписываемой папке.
sudo nano /etc/exportsКратко опишем функционал команды:
- nano — это встроенный редактор текста, основные команды которого являются: Ctrl+S (сохранение файла) и Ctrl+X (выход из редактора).
В самом редакторе необходимо в конце прописать следующую строку.
/home//OpenFOAM (rw, sync,no_subtree_check)После вписывания в файл следующей команды, повторяем её со всеми компьютерами серверной версии операционной системы.
Примечание: для того чтобы узнать IP-адрес компьютера, в командной строке введите команду ip address, там вы сможете узнать узнать адрес конкретной системы.
После всех вышеописанных действий необходимо произвести монтирование сервера. Для этого пропишем в терминале команду.
sudo exportfs -aКратко опишем функционал команды:
- exportfs — это изменяемый файл.
- -a — то применения изменений к нему.
Следующим шагом необходимо произвести перезагрузку сервера с настроенными параметрами сетевой папки. Для этого пропишем команду в терминале, представленную ниже.
sudo systemctl restart nfs-kernel-server.serviceКратко опишем функционал команды:
- systemctl — системный диспетчер.
- restart — рестарт сервера.
- nfs-kernel-server.service — файл сервера .
Настройка утилиты NFS для серверной версии
Для этого необходимо произвести закачку программного пакета на устройства. Воспользуемся командной, вводимой в терминале.
sudo apt install nfs-commonПосле, по аналогии с десктоп-версией, необходимо изменить файлы настройки сетевой папки. Для этого воспользуемся командой.
sudo nano /efc/fstabПосле введем в редакторе кода одну строчку, относящуюся к десктоп-версии системы.
:/home//OpenFOAM nfs defoults 0 1Примечание: Ctrl+S (сохранение файла) и Ctrl+X (выход из редактора).
Далее смонтируем точку для того, чтобы сообщить десктоп-версии, что сервер готов к общению.
sudo mount —allПримечание: Тут могут возникнуть проблемы, это нормально, значит вы что то сделали не так, как было указано в инструкции, это связано с тем что в Ubuntu нет фиксации ошибок. Для этого необходимо произвести ряд проверок, чтобы определить где произошла ошибка.
- Проверьте настройку SSH, произведя подключения со всех устройств ко всем командой: ssh @.
- Проверьте отсутствие запрашиваемого пароля при SSH-соединение..
- Проверьте правильность файлов, где прописываются IP-адреса.
- Проверьте, чтобы не изменились IP-адреса во время настройки (такой случай возможен).
- Проверьте опечатки местоположения синхронизируемой папки.
- Проверьте одинаковость названий синхронизируемой папки.
- Если все вышеперечисленные проверки прошли верно, однако система все равно не заработала, то сделайте все шаги заново, так как старые файлы не удаляются, есть шанс что вы случайно исправите ошибку (на практике это часто срабатывало).
Начало вычислений
Тест проверки ядер
Перед началом работы непосредственно с OpenFOAM стоит разработать программу, которая смогла бы проверить, отзываются ли ядра у всех компьютеров, которые надо будет использовать для последующих вычислений.
Программа написана на языке С. Исходный код этой программы компилируется в исполняемый файл, именуемый «mpi_hello» (тестовое наименование, наподобие «Hello World!»). Команда компиляции в терминале следующая.
mpicc mpi_hello.c -o mpi_hello ./mpi_helloКратко опишем функционал команды:
- mpicc — команда запуска компиляции.
- mpi_hello.c — файл с исходным кодом.
- -o mpi_hello — выходной файл.
Полный исходный код этой программы приведен в приложении 1, здесь описаны основные моменты её работы.
int comm_sz; MPI_Comm_size(MPI_COMM_WORLD, &comm_sz); int rank; MPI_Comm_rank(MPI_COMM_WORLD, &rank); char hostname[MPI_MAX_PROCESSOR_NAME]; int name_sz; MPI_Get_processor_name(hostname, &name_sz);
Данный фрагмент кода последовательно получает три параметра: количество ядер, ранг текущего процесса, и имя хоста. Затем эти данные выводятся в терминал.
printf("Hello from %s, rank %d (of %d).\n", hostname, rank, comm_sz);Программу можно запустить с помощью команды, представленной ниже.
mpirun ./mpi_helloКратко опишем функционал команды:
- mpirun — запуск исполняемого файла.
- ./mpi_hello — исполняемый файл.
Результат выводится в консоль.
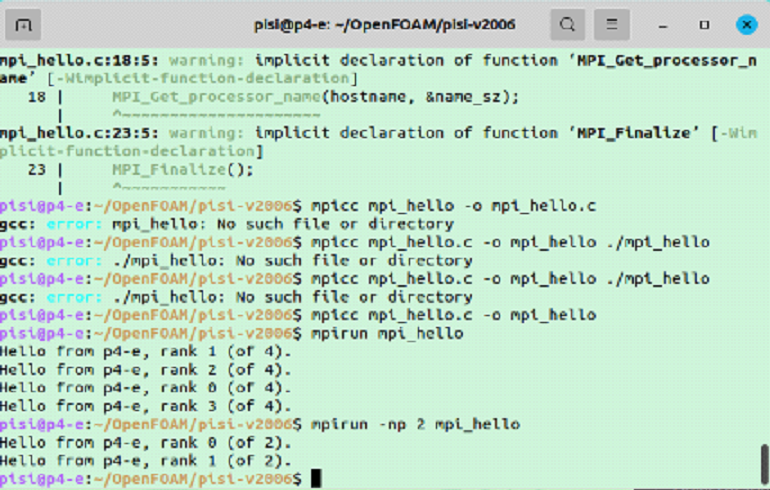
Проверка работы программы на нескольких ядрах
Следующий этап — указание количества ядер. Для mpirun это возможно сделать с помощью аргумента «np».
mpirun -np 2 ./mpi_helloКратко опишем функционал команды:
- -np — указания количества ядер.
Результат работы представлен ниже.
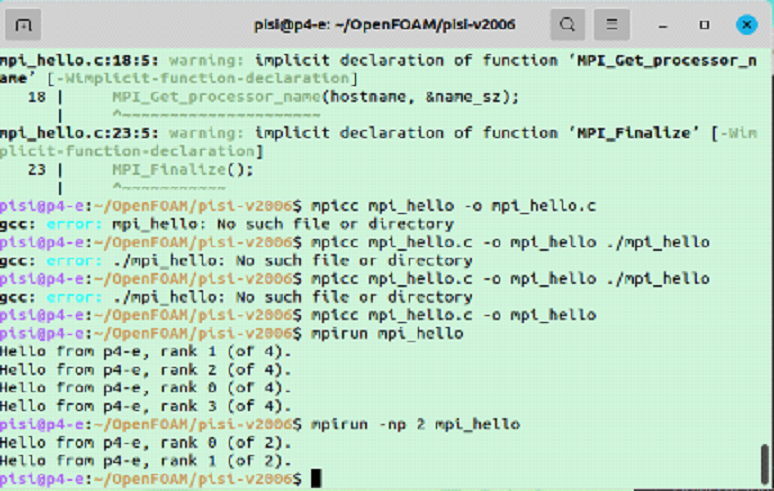
Проверка работы на нескольких компьютерах
С помощью команды “mpirun” в терминале можно также послать скомпилированную программу на несколько компьютеров.
mpirun -np --hostfile ./mpi_helloКоличество процессоров –- общее для всех компьютеров, а имя файла — это имя файла, где перечислены IP-адреса и количество ядер, которое будет у него использоваться.
127.0.0.1 slots=4 192.168.0.1 slots=4 192.168.0.105 slots=4- Параметр slots отвечает за количество ядер.
- Первый адрес, 127.0.0.1, — это локальный адрес компьютера (localhost), с него всегда начинается основная работа. Другие IP-адреса — это IP-адреса других компьютеров.
Примечание. Данную команду не надо выполнять на компьютере-сателлите, так как локальный адрес будет совпадать с одним из ниже перечисленных, что приведёт к путанице с распределением и последующей ошибке.
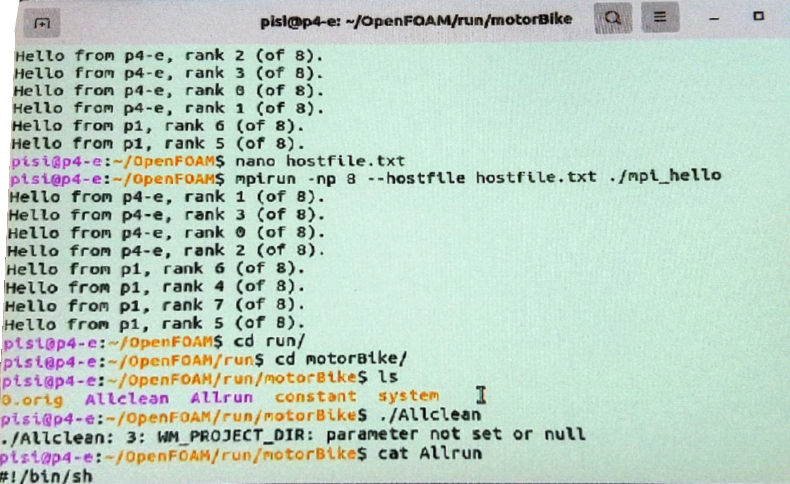
Проверка концепции ускорения (уменьшение времени) скорости вычислений общей задачи. Для этого воспользуемся стандартной задачей предложенной openfoam на головной странице. Так что первоначально копируем пример из домашней директории OpenFOAM в папку, синхронизируемую ранее (сетевую папку).
cp /usr/lid/openfoam2006/tutorials/incompressible/simplefoam/motorBike /home//OpenFOAM/-v2006/Примечание: предварительно необходимо создать папку -v2006 в папке синхронизируемой системы. Это можно сделать в ручном режиме, если вы создаёте его в десктоп-версии.
Далее, после того, как в соответствующий каталог скопируются файлы, необходимо будет запустить утилиту создания служебных файлов, находясь в импортированной папке.
./AllrunПосле необходимо распаковать файл геометрии мотоцикла, для этого воспользуемся командой, описанной ниже, при использовании встроенного разархиватора.
cp $FOAM_TUTORIALS/resources/geometry/motorBike.obj.gz constant/triSurface/Далее необходимо создать сетку на компьютере, так как необходимые файлы были экспортированы и распакованы выше. Для того, чтобы выполнить расчет сетки, необходимо прописать в консоли команду.
blockMeshПримечание: этот процесс занимает крайне много времени и требует большой объем оперативной памяти. В нашем случае — около 80 ГБ на 3 компьютера. Чтобы не устанавливать дорогостоящую память в компьютер, необходимо увеличить файл подкачки на SSD-диске. Для этого необходимо выполнить команду.
sudo swapoff /swapfile sudo fallocate -l G /swapfileПримечание: все промежуточные значения прописываются в файле log ,и если что то пошло не так, то подробности можно узнать там.
Далее, после просчета сетки, можно приступить к запуску самого расчета задачи. Для этого вставим в командную строку текст.
foamJob -p snappyHexMeshЗАКЛЮЧЕНИЕ
В результате проведения стресс тестов кластера на расчет были выявлены закономерности, приведенные в таблицах ниже с выводами. Так же приводятся казусы, которые не решились, или частично были решены в ходе выполнения работы.
Примечание: точность выводов основана на субъективной оценке в связи с невозможностью составления прогноза работы и скорости вычислений.
Мы провели два теста, на машине из 4-х ядер и одном компьютере и машине из 12 ядер и трех компьютеров. Расчет времени выполнения производился автоматически с записью в файл log, это нужно было для отладки работоспособности кластера, но этот процесс занимает определенное время, которое посчитать не удалось. Однако, так как геометрия была одинаковой и файлы log аналогичные, следовательно приобретенное время в двух тестах было одинаковым и в сравнении друг с другом не будут вносить ошибку. Далее приведена таблица с характеристиками двух тестов, которые мы посчитали уместным.
Свойство
1 тест
2 тест
Вычислительный кластер
Вычислительный кластер – это набор соединенных между собой компьютеров (серверов), которые работают вместе и могут рассматриваться как единая система. В отличие от грид-вычислений, все узлы компьютерного кластера выполняют одну и ту же задачу и управляются одной системой управления.
Серверы кластера обычно соединяются между собой по быстродействующей локальной сети, причем на каждом из серверов работает собственный экземпляр операционной системы. В большинстве случаев все вычислительные узлы кластера используют одинаковое оборудование и одну и ту же операционную систему. Однако в некоторых инсталляциях, например, с использованием платформы приложений для организации кластеров OSCAR (Open Source Cluster Application Resources), могут использоваться различные операционные системы или разное серверное оборудование.
Кластеры обычно развертываются для большей производительности и доступности, чем то, что можно получить от одного компьютера, пусть даже очень мощного. Часто такое решение более экономично, чем отдельные компьютеры.
Компоненты кластера
Вычислительные кластеры обычно состоят из следующих компонентов:
- узел доступа;
- вычислительные узлы;
- файловый сервер;
- файловая или объектная СХД с общим доступом;
- локальная сеть LAN.

Виды кластеров
Различают следующие основные виды кластеров:
- кластеры высокой доступности (High-availability clusters, HA);
- кластеры с балансировкой нагрузки (Load balancing clusters);
- высокопроизводительные кластеры (High performance computing clusters, HPC).
Кластеры высокой доступности
Кластеры высокой доступности НА (high-availability cluster) известны также как отказоустойчивые (failover) кластеры, построенные по схеме сети с большой избыточностью (redundancy). Они применяются для критических серверных приложений, например сервера баз данных. Компьютерный кластер может называться НА-кластером, если он обеспечивает доступность приложений не менее, чем «пять девяток», т. е. приложение должно быть доступно (uptime) в течение 99,999 % времени за год.
Чрезвычайно высокая доступность в НА-кластерах достигается за счет использования специального программного обеспечения и аппаратных решений со схемами обнаружения отказов, а также благодаря работе по подготовке к отказам.
ПО для НА-кластеров обычно заблаговременно конфигурирует узел на резервном сервере и запускает на нем приложение в фоновом режиме так, чтобы основной экземпляр приложения мог немедленно переключиться на свою реплику на резервном компьютере при отказе основного.
НА-кластеры обычно используются для терминальных серверов, серверов баз данных, почтовых серверов, а также для серверов общего доступа к файлам. Они могут быть развернуты как на одном местоположении («серверной ферме»), так и в географически разнесенных местоположениях.
Но не следует думать, что технология кластера высокой доступности, или вообще кластеризация, могут служить заменой резервному копированию (backup), а также решениям катастрофоустойчивости (disaster recovery).
Кластеры с балансировкой нагрузки
Балансировка нагрузки – это эффективное распределение входящего сетевого трафика в группе (кластере) серверов.
Современные веб-сайты должны одновременно обслуживать сотни тысяч и даже миллионы запросов от пользователей или клиентов и не слишком задерживать их в получении контента: текста, видео или данных приложений. Чем больше серверов будут обслуживать эти запросы, тем лучше будет качество воспринимаемого сервиса для клиентов. Однако может возникнуть ситуация, когда одни серверы сайта будут работать с перегрузкой, а другие будут почти простаивать.
Балансировщик нагрузки направляет запросы клиентов равномерно на все серверы кластера, которые способны ответить на те или иные запросы. Таким образом, балансировщик максимизирует процент использования вычислительной емкости, а также обеспечивает то, что ни один сервер не оказывается перегруженным, вызывая общую деградацию производительности кластера.
Если какой-то сервер отказывает, то балансировщик перенаправляет трафик на оставшиеся серверы. Когда новый сервер добавляется к группе (кластеру), то балансировщик автоматически перераспределяет нагрузку на всех серверах с учетом вновь вступившего в работу.
Таким образом, балансировщик нагрузки выполняет следующие функции:
- Распределяет запросы клиентов и нагрузку сети эффективным образом в во всем кластере серверов.
- Обеспечивает высокую доступность и надежность посылкой запросов только на те серверы, которые находятся в режиме онлайн.
- Обеспечивает гибкость, добавляя или удаляя серверы по мере надобности.

Работа балансировщика нагрузки
Алгоритмы балансировки нагрузки
Различные алгоритмы балансировки предназначены для разных целей и достижения разных выгод. Можно назвать следующие алгоритмы балансировки:
- Round Robin – запросы распределяются по кластеру серверов последовательно.
- Least Connections – новый запрос посылается на сервер с наименьшим числом подключений клиентов, однако при этом учитывается и вычислительная мощность каждого сервера.
- Least Time – запросы посылаются на сервер, выбираемый по формуле, которая комбинирует быстроту ответа и наименьшее число активных запросов.
- Hash – распределяет запросы на основании определяемого пользователем ключа, например, IP-адреса клиента или URL запрашиваемого сайта.
- Random with Two Choices – выбираются два сервера по методу произвольного выбора и затем запрос посылается на один из них, который выбирается по критерию наименьшего числа подключений.
Программная и аппаратная балансировка нагрузки
Балансировщики нагрузки бывают двух типов: программные и аппаратные. Программные балансировщики можно установить на любой сервер достаточной для задачи емкости. Поставщики аппаратных балансировщиков просто загружают соответствующее программное обеспечение балансировки нагрузки на серверы со специализированными процессорами. Программные балансировщики менее дорогие и более гибкие. Можно также использовать облачные решения сервисов балансировки нагрузки, такие как AWS EC2.
Высокопроизводительные кластеры (HPC)
Высокопроизводительные вычисления HPC (High-performance computing) – это способность обрабатывать данные и выполнять сложные расчеты с высокой скоростью. Это понятие весьма относительное. Например, обычный лэптоп с тактовой частотой процессора в 3 ГГц может производить 3 миллиарда вычислений в секунду. Для обычного человека это очень большая скорость вычислений, однако она меркнет перед решениями HPC, которые могут выполнять квадриллионы вычислений в секунду.
Одно из наиболее известных решений HPC – это суперкомпьютер. Он содержит тысячи вычислительных узлов, которые работают вместе над одной или несколькими задачами, что называется параллельными вычислениями.
HPC очень важны для прогресса в научных, промышленных и общественных областях.
Такие технологии, как интернет вещей IoT (Internet of Things), искусственный интеллект AI (artificial intelligence), и аддитивное производство (3D imaging), требуют значительных объемов обработки данных, которые экспоненциально растут со временем. Для таких приложений, как живой стриминг спортивных событий в высоком разрешении, отслеживание зарождающихся тайфунов, тестирование новых продуктов, анализ финансовых рынков, – способность быстро обрабатывать большие объемы данных является критической.
Чтобы создать HPC-кластер, необходимо объединить много мощных компьютеров при помощи высокоскоростной сети с широкой полосой пропускания. В этом кластере на многих узлах одновременно работают приложения и алгоритмы, быстро выполняющие различные задачи.
Чтобы поддерживать высокую скорость вычислений, каждый компонент сети должен работать синхронно с другими. Например, компонент системы хранения должен быть способен записывать и извлекать данные так, чтобы не задерживать вычислительный узел. Точно так же и сеть должна быстро передавать данные между компонентами НРС-кластера. Если один компонент будет подтормаживать, он снизит производительность работы всего кластера.
Существует много технических решений построения НРС-кластера для тех или иных приложений. Однако типовая архитектура НРС-кластера выглядит примерно так, как показано на рисунке ниже.

Примеры реализации вычислительного кластера
В лаборатории вычислительного интеллекта создан вычислительный кластер для решения сложных задач анализа данных, моделирования и оптимизации процессов и систем.
Кластер представляет собой сеть из 11 машин с распределенной файловой системой NFS. Общее число ядер CPU в кластере – 61, из них высокопроизводительных – 48. Максимальное число параллельных высокоуровневых задач (потоков) – 109. Общее число ядер графического процессора CUDA GPU – 1920 (NVidia GTX 1070 DDR5 8Gb).
На оборудовании кластера успешно решены задачи анализа больших данных (Big Data): задача распознавания сигнала от процессов рождения суперсимметричных частиц, задача классификации кристаллических структур по данным порошковой дифракции, задача распределения нагрузки электросетей путем определения выработки электроэнергии тепловыми и гидроэлектростанциями с целью минимизации расходов, задача поиска оптимального расположения массива кольцевых антенн и другие задачи.

Архитектура вычислительного кластера
Другой вычислительный НРС-кластер дает возможность выполнять расчеты в любой области физики и проводить многодисциплинарные исследования.

Графические результаты расчета реактивного двигателя, полученные на НРС-клатере (источник: БГТУ «ВОЕНМЕХ»)
На рисунке показана визуализация результатов расчета реактивного двигателя, зависимость скорости расчетов и эффективности вычислений от количества ядер процессора.
Вам может быть интересно: