Доступ по индексу в DataFrame
Мы уже рассказывали о структуре DataFrame в Pandas — высокоуровневой Python-библиотеке для анализа данных. Но как осуществляется доступ по индексу в DataFrame?
На самом деле, индекс по строкам мы можем задавать различными способами, к примеру, в процессе формирования самого объекта DataFrame либо, как говорится «на лету»:
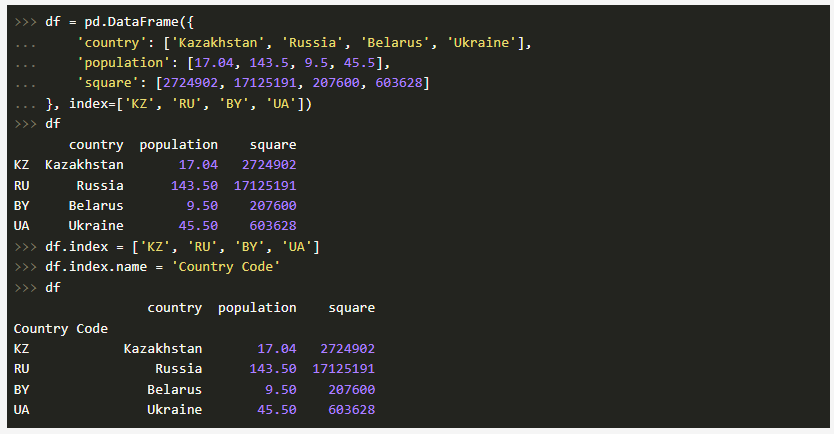
Таким образом, мы видим, что индексу задается имя Country Code. Также стоит отметить, что объекты Series из DataFrame приобретут те же самые индексы, что и объект DataFrame:

При этом доступ к строкам по индексу можно осуществить 2-мя способами:
- .loc — для доступа по строковой метке;
- .iloc — для доступа по числовому значению (от 0 и выше).

Идем дальше. У нас есть возможность выполнять выборку по индексу и интересующим колонкам:

Обратите внимание, что .loc в квадратных скобках принимает два аргумента. Кроме интересующего индекса, поддерживаются колонки и слайсинг.

Следующий момент — у нас есть возможность фильтровать DataFrame, используя для этого булевы массивы:

Кроме того, существует возможность обращения к столбцам — для этого применяется атрибут либо нотация словарей Python, то есть df.population и df[‘population’] — это, по сути, одно и то же.
Если надо сбросить индексы, сделать это можно следующим образом:

Также Pandas при операциях над DataFrame осуществляет возвращение нового объекта DataFrame.
Давайте выполним добавление нового столбца, где население, исчисляемое в миллионах человек, мы поделим на площадь государства, тем самым получив плотность:
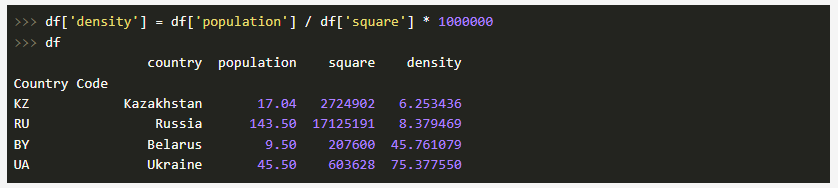
Теперь представим, что новый столбец нас чем-то не устраивает. Не беда — его можно без проблем удалить:

Ну а если вы очень ленивы, то достаточно написать del df[‘density’].
Для переименования столбцов воспользуемся методом rename:
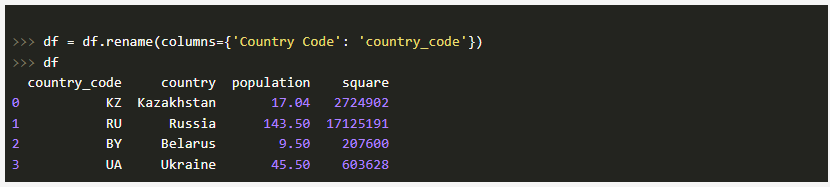
В вышеприведенном примере перед переименованием столбца Country Code следует сначала удостовериться, что с него сброшен индекс. В обратном случае никакого эффекта не будет.
DataFrame: как обратиться к элементу массива
Выводит следующее:[list([‘Martha’, ‘A1’]) 87]
А мне нужно [‘A1’, 87]
Подскажите пожалуйста, как это можно осуществить? Буду очень сильно благодарен за помощь!
Добавлено через 50 минут
Всем спасибо большое, кто хотел помочь. Я разобрался:
print(df["Name"].str[1])
94731 / 64177 / 26122
Регистрация: 12.04.2006
Сообщений: 116,782
Ответы с готовыми решениями:
Как обратиться к элементу массива?
Заранее извиняюсь за нубство, но ассемблер начал изучать вчера(буквально) и много чего пока не.

Как обратиться к элементу массива
Всем привет. Есть массив такого вида Array ( => 12 .
Как обратиться к предыдущему элементу массива
Доброго времени суток. В общем задача такова: нужно создать двумерный массив 20 на 20 в котором.
Как обратиться к элементу строкового массива
Добрый вечер ;). Подскажите что значит ошибка "SelectedItem не является членом String" в строке. .
Как обратиться к конкретному элементу массива?
не понимаю, как используя дженерики, вывести конкретный элемент массива. в виде: номер.
Как выбрать строки по индексу в Pandas DataFrame
Часто вам может понадобиться выбрать строки кадра данных pandas на основе их значения индекса.
Если вы хотите выбрать строки на основе целочисленного индексирования, вы можете использовать функцию .iloc .
Если вы хотите выбрать строки на основе индексации меток, вы можете использовать функцию .loc .
В этом руководстве представлен пример использования каждой из этих функций на практике.
Пример 1: выбор строк на основе целочисленного индексирования
В следующем коде показано, как создать кадр данных pandas и использовать .iloc для выбора строки с целочисленным значением индекса 4 :
import pandas as pd import numpy as np #make this example reproducible np.random.seed (0) #create DataFrame df = pd.DataFrame(np.random.rand (6,2), index=range(0,18,3), columns=['A', 'B']) #view DataFrame df A B 0 0.548814 0.715189 3 0.602763 0.544883 6 0.423655 0.645894 9 0.437587 0.891773 12 0.963663 0.383442 15 0.791725 0.528895 #select the 5th row of the DataFrame df.iloc [[4]] A B 12 0.963663 0.383442 Мы можем использовать аналогичный синтаксис для выбора нескольких строк:
#select the 3rd, 4th, and 5th rows of the DataFrame df.iloc [[2, 3, 4]] A B 6 0.423655 0.645894 9 0.437587 0.891773 12 0.963663 0.383442 Или мы могли бы выбрать все строки в диапазоне:
#select the 3rd, 4th, and 5th rows of the DataFrame df.iloc [2:5] A B 6 0.423655 0.645894 9 0.437587 0.891773 12 0.963663 0.383442 Пример 2. Выбор строк на основе индексации меток
В следующем коде показано, как создать кадр данных pandas и использовать .loc для выбора строки с меткой индекса 3 :
import pandas as pd import numpy as np #make this example reproducible np.random.seed (0) #create DataFrame df = pd.DataFrame(np.random.rand (6,2), index=range(0,18,3), columns=['A', 'B']) #view DataFrame df A B 0 0.548814 0.715189 3 0.602763 0.544883 6 0.423655 0.645894 9 0.437587 0.891773 12 0.963663 0.383442 15 0.791725 0.528895 #select the row with index label '3' df.loc[[3]] A B 3 0.602763 0.544883 Мы можем использовать аналогичный синтаксис для выбора нескольких строк с разными метками индекса:
#select the rows with index labels '3', '6', and '9' df.loc[[3, 6, 9]] A B 3 0.602763 0.544883 6 0.423655 0.645894 9 0.437587 0.891773 Разница между .iloc и .loc
Приведенные выше примеры иллюстрируют тонкую разницу между .iloc и .loc :
- .iloc выбирает строки на основе целочисленного индекса.Итак, если вы хотите выбрать 5-ю строку в DataFrame, вы должны использовать df.iloc[[4]], так как первая строка имеет индекс 0, вторая строка имеет индекс 1 и так далее.
- .loc выбирает строки на основе помеченного индекса.Итак, если вы хотите выбрать строку с меткой индекса 5, вы должны напрямую использовать df.loc[[5]].
DataFrame: как обратиться к элементу списка в ячейке
Подскажите пожалуйста, как я могу обратиться к элементу списка внутри dataframe? У меня есть следующий код:
import pandas as pd dict = df = pd.DataFrame(dict) print(df.values[0]) # Я пробовал сделать df.values[0][1] - но так не работает Выводит следующее: [list([‘Martha’, ‘A1’]) 87] А мне нужно [‘A1’, 87] Подскажите пожалуйста, как это можно осуществить? Буду очень сильно благодарен за помощь
Отслеживать
24.8k 4 4 золотых знака 20 20 серебряных знаков 36 36 бронзовых знаков