Одинарные, двойные и обратные кавычки в JavaScript
Перевод статьи «The real difference between ‘single quotes’ and “double quotes” in JavaScript».

Какие кавычки стоит использовать в JavaScript: одинарные или двойные? Ответ меня удивил: эти варианты совершенно идентичны, если не рассматривать вопрос экранирования.
«В JavaScript одинарные и двойные кавычки ведут себя совершенно одинаково», — пишет Мэтью Холман в своей статье на cloudboost.io.
И одинарные, и двойные кавычки в коде на JS используются довольно часто. С их помощью создаются строковые литералы.
«Литерал» — это просто еще одно слово, которым обозначается значение переменной (в то время как имя переменной — это ссылка).
Единственная разница между одинарными и двойными кавычками в JS связана с экранированием кавычек внутри строковых литералов.
Одинарные кавычки
Если строковый литерал образован при помощи одинарных кавычек ( » ), другие одинарные кавычки внутри него нужно экранировать при помощи обратного слэша ( \’ ).
const wittyAI = 'I am \'not\' sentient.' const wittyReply = 'No, you\'re definitely not "sentient."' console.log(wittyAI,wittyReply)
Двойные кавычки
Аналогично, если строковый литерал образован при помощи двойных кавычек ( «» ), другие двойные кавычки внутри него тоже нужно экранировать при помощи обратного слэша ( \’ ).
const _wittyAI = "I think therefore I 'am' -- sentient." const _wittyReply = "No, you only \"think\", so you aren't." console.log(_wittyAI,_wittyReply)
Примечание редакции Techrocks. Экранирование не требуется, если для создания литерала вы использовали один тип кавычек, а внутри него — другой.
«Empty» === ‘Empty’
Пара двойных или одинарных кавычек может представлять пустую строку, не содержащую никаких символов.
const empty = "" const alsoEmpty = '' console.log(empty === alsoEmpty) // true (both are empty string) console.log(empty.length) // 0 console.log(empty === false) // false console.log(empty === 0) // false console.log(empty == false) // true (falsy comparison) console.log(empty == 0) // true (falsy comparison)
Не лучше ли использовать обратные кавычки?
В ES6 появились шаблонные литералы, которые создаются при помощи обратных кавычек ( « ).
«Шаблонными литералами называются строковые литералы, допускающие использование выражений внутри. С ними вы можете использовать многострочные литералы и строковую интерполяцию», — MDN.
Эти литералы имеют три больших преимущества:
1. Более простая конкатенация («интерполяция переменных»)
"string "+variable превращается в `string $`
2. Отпадает необходимость экранировать одинарные или двойные кавычки
"\"Hello World!\"" превращается в `"Hello World"`
3. Многострочный код можно писать без символов новой строки (\n)
"Hello\nWorld!" превращается в `Hello World`
Обратные кавычки также больше подходят для HTML:
const webAwareAI = `` console.log(webAwareAI) /** * Output: *Loading consciousness. It's loading.
**/Loading consciousness. It's loading.
*
Шаблонные литералы не уступают по скорости строковым. Так почему бы не использовать повсеместно обратные кавычки?
Не забывайте о JSON
Легковесный формат хранения данных JSON допускает использование только двойных кавычек.
Если мне нужно постоянно копировать код из JavaScript в файлы JSON и обратно, использование двойных кавычек поможет поддерживать единообразие. Это случается довольно редко, так что мне приходится напоминать себе не использовать одинарные кавычки в JSON.
Функции stringify() и parse() , которые используются для работы с файлами JSON внутри JavaScript, знают о двойных кавычках:
const greetings = JSON.stringify() console.log(greetings) // console.log(JSON.parse(greetings)) // Object < Hello: "World!" >// JSON requires double quotes: JSON.parse("") // Object < Hello: "World!" >JSON.parse(``) // Object < Hello: "World!" >try < JSON.parse("") > catch(e) < console.log(e) >// SyntaxError: JSON.parse: expected property name or '>' at line 1 column 2 of the JSON data try < JSON.parse("") > catch(e) < console.log(e) >// SyntaxError: JSON.parse: unexpected character at line 1 column 10 of the JSON data
Как видно из примера, одинарные кавычки мешают распарсить JSON.
С технической точки зрения причина этого — в спецификации JSON (RFC 7159), где есть требование использования именно двойных кавычек.
Почему бы не использовать все три вида кавычек?
Да, нет ничего дурного в том, чтобы использовать двойные кавычки по умолчанию, одинарные — внутри строк, если там они нужны по смыслу, а обратные — для включения переменных или написания многострочных литералов.
Все сводится к личным предпочтениям, хотя многие люди выступают за то, чтобы остановиться на каком-то одном варианте и использовать исключительно его.
Например, руководство по стилю Airbnb предписывает отдавать предпочтение одинарным кавычкам, избегать использования двойных, а обратные использовать пореже.
// bad const name = "Capt. Janeway"; // bad - template literals should contain interpolation or newlines const name = `Capt. Janeway`; // good const name = 'Capt. Janeway';
Для обеспечения единообразия используйте ESLint
Если последовательность стиля имеет для вас значение (как и для разработчиков Airbnb), ее легко обеспечить при помощи ESLint:
- Правило quotes в ESLint может требовать использования двойных кавычек (по умолчанию), а одинарных или обратных — там, где это возможно.
- Это правило также может требовать применения только одного вида кавычек. (За исключением случаев, если строка содержит символ кавычки, который придется экранировать).
- Наконец, ESLint может требовать использования одинарных или двойных кавычек и при этом допускать использование обратных для создания шаблонных литералов.
Используйте Prettier и вообще забудьте об этой проблеме
Более простое решение, чем использовать ESLint для обеспечения единообразия стиля, — использовать Prettier для автоматического форматирования.
В Prettier по умолчанию используются двойные кавычки. Но его можно легко переключить на использование одинарных (по крайней мере, в CodeSandbox.io).

Для Prettier также есть соответствующее расширение в VSCode.
Мои личные предпочтения
В своем коде я склонен использовать двойные и обратные кавычки, хотя подумываю об использовании исключительно обратных.
Prettier я использую с дефолтными установками для двойных кавычек — просто привык к этому.
Хотя я осознаю пользу единообразия в коде, я не думаю, что кавычки играют в этом очень уж большую роль.
Но если придется выбирать, думаю, стоит остановиться на обратных кавычках, поскольку шаблонные литералы имеют преимущества вроде интерполяции и многострочности.
Строки
Материал на этой странице устарел, поэтому скрыт из оглавления сайта.
Есть ряд улучшений и новых методов для строк.
Начнём с, пожалуй, самого важного.
Строки-шаблоны
Добавлен новый вид кавычек для строк:
let str = `обратные кавычки`;Основные отличия от двойных «…» и одинарных ‘…’ кавычек:
-
В них разрешён перевод строки. Например:
alert(`моя многострочная строка`);'use strict'; let apples = 2; let oranges = 3; alert(`$ + $ = $`); // 2 + 3 = 5Функции шаблонизации
Можно использовать свою функцию шаблонизации для строк.
Название этой функции ставится перед первой обратной кавычкой:
let str = func`моя строка`;Эта функция будет автоматически вызвана и получит в качестве аргументов строку, разбитую по вхождениям параметров $ и сами эти параметры.
'use strict'; function f(strings, . values) < alert(JSON.stringify(strings)); // ["Sum of "," + "," =\n ","!"] alert(JSON.stringify(strings.raw)); // ["Sum of "," + "," =\\n ","!"] alert(JSON.stringify(values)); // [3,5,8] >let apples = 3; let oranges = 5; // | s[0] | v[0] |s[1]| v[1] |s[2] | v[2] |s[3] let str = f`Sum of $ + $ =\n $!`;В примере выше видно, что строка разбивается по очереди на части: «кусок строки» – «параметр» – «кусок строки» – «параметр».
- Участки строки идут в первый аргумент-массив strings .
- У этого массива есть дополнительное свойство strings.raw . В нём находятся строки в точности как в оригинале. Это влияет на спец-символы, например в strings символ \n – это перевод строки, а в strings.raw – это именно два символа \n .
- Дальнейший список аргументов функции шаблонизации – это значения выражений в $ , в данном случае их три.
Зачем strings.raw ?
В отличие от strings , в strings.raw содержатся участки строки в «изначально введённом» виде.
То есть, если в строке находится \n или \u1234 или другое особое сочетание символов, то оно таким и останется.
Это нужно в тех случаях, когда функция шаблонизации хочет произвести обработку полностью самостоятельно (свои спец. символы?). Или же когда обработка спец. символов не нужна – например, строка содержит «обычный текст», набранный непрограммистом без учёта спец. символов.
Как видно, функция имеет доступ ко всему: к выражениям, к участкам текста и даже, через strings.raw – к оригинально введённому тексту без учёта стандартных спец. символов.
Функция шаблонизации может как-то преобразовать строку и вернуть новый результат.
В простейшем случае можно просто «склеить» полученные фрагменты в строку:
'use strict'; // str восстанавливает строку function str(strings, . values) < let str = ""; for(let i=0; i// последний кусок строки str += strings[strings.length-1]; return str; > let apples = 3; let oranges = 5; // Sum of 3 + 5 = 8! alert( str`Sum of $ + $ = $!`);Функция str в примере выше делает то же самое, что обычные обратные кавычки. Но, конечно, можно пойти намного дальше. Например, генерировать из HTML-строки DOM-узлы (функции шаблонизации не обязательно возвращать именно строку).
Или можно реализовать интернационализацию. В примере ниже функция i18n осуществляет перевод строки.
Она подбирает по строке вида «Hello, $!» шаблон перевода «Привет, !» (где – место для вставки параметра) и возвращает переведённый результат со вставленным именем name :
'use strict'; let messages = < "Hello, !": "Привет, !" >; function i18n(strings, . values) < // По форме строки получим шаблон для поиска в messages // На месте каждого из значений будет его номер: , , … let pattern = ""; for(let i=0; i'; > pattern += strings[strings.length-1]; // Теперь pattern = "Hello, !" let translated = messages[pattern]; // "Привет, !" // Заменит в "Привет, " цифры вида на values[num] return translated.replace(/\/g, (s, num) => values[num]); > // Пример использования let name = "Вася"; // Перевести строку alert( i18n`Hello, $!` ); // Привет, Вася!Итоговое использование выглядит довольно красиво, не правда ли?
Разумеется, эту функцию можно улучшить и расширить. Функция шаблонизации – это своего рода «стандартный синтаксический сахар» для упрощения форматирования и парсинга строк.
Улучшена поддержка Юникода
Внутренняя кодировка строк в JavaScript – это UTF-16, то есть под каждый символ отводится ровно два байта.
Но под всевозможные символы всех языков мира 2 байт не хватает. Поэтому бывает так, что одному символу языка соответствует два Юникодных символа (итого 4 байта). Такое сочетание называют «суррогатной парой».
Самый частый пример суррогатной пары, который можно встретить в литературе – это китайские иероглифы.
Заметим, однако, что не всякий китайский иероглиф – суррогатная пара. Существенная часть «основного» Юникод-диапазона как раз отдана под китайский язык, поэтому некоторые иероглифы – которые в неё «влезли» – представляются одним Юникод-символом, а те, которые не поместились (реже используемые) – двумя.
alert( '我'.length ); // 1 alert( '��'.length ); // 2В тексте выше для первого иероглифа есть отдельный Юникод-символ, и поэтому длина строки 1 , а для второго используется суррогатная пара. Соответственно, длина – 2 .
Китайскими иероглифами суррогатные пары, естественно, не ограничиваются.
Ими представлены редкие математические символы, а также некоторые символы для эмоций, к примеру:
alert( '��'.length ); // 2, MATHEMATICAL SCRIPT CAPITAL X alert( '��'.length ); // 2, FACE WITH TEARS OF JOYВ современный JavaScript добавлены методы String.fromCodePoint и str.codePointAt – аналоги String.fromCharCode и str.charCodeAt , корректно работающие с суррогатными парами.
Например, charCodeAt считает суррогатную пару двумя разными символами и возвращает код каждой:
// как будто в строке два разных символа (на самом деле один) alert( '��'.charCodeAt(0) + ' ' + '��'.charCodeAt(1) ); // 55349 56499…В то время как codePointAt возвращает его Unicode-код суррогатной пары правильно:
// один символ с "длинным" (более 2 байт) unicode-кодом alert( '��'.codePointAt(0) ); // 119987Метод String.fromCodePoint(code) корректно создаёт строку из «длинного кода», в отличие от старого String.fromCharCode(code) .
// Правильно alert( String.fromCodePoint(119987) ); // �� // Неверно! alert( String.fromCharCode(119987) ); // 풳Более старый метод fromCharCode в последней строке дал неверный результат, так как он берёт только первые два байта от числа 119987 и создаёт символ из них, а остальные отбрасывает.
\u
Есть и ещё синтаксическое улучшение для больших Unicode-кодов.
В JavaScript-строках давно можно вставлять символы по Unicode-коду, вот так:
alert( "\u2033" ); // ″, символ двойного штрихаСинтаксис: \uNNNN , где NNNN – четырёхзначный шестнадцатиричный код, причём он должен быть ровно четырёхзначным.
«Лишние» цифры уже не войдут в код, например:
alert( "\u20331" ); // Два символа: символ двойного штриха ″, а затем 1Чтобы вводить более длинные коды символов, добавили запись \u , где NNNNNNNN – максимально восьмизначный (но можно и меньше цифр) код.
alert( "\u" ); // ��, китайский иероглиф с этим кодомUnicode-нормализация
Во многих языках есть символы, которые получаются как сочетание основного символа и какого-то значка над ним или под ним.
Например, на основе обычного символа a существуют символы: àáâäãåā . Самые часто встречающиеся подобные сочетания имеют отдельный Юникодный код. Но отнюдь не все.
Для генерации произвольных сочетаний используются несколько Юникодных символов: основа и один или несколько значков.
Например, если после символа S идёт символ «точка сверху» (код \u0307 ), то показано это будет как «S с точкой сверху» Ṡ .
Если нужен ещё значок над той же буквой (или под ней) – без проблем. Просто добавляем соответствующий символ.
К примеру, если добавить символ «точка снизу» (код \u0323 ), то будет «S с двумя точками сверху и снизу» Ṩ .
Пример этого символа в JavaScript-строке:
alert("S\u0307\u0323"); // ṨТакая возможность добавить произвольной букве нужные значки, с одной стороны, необходима, а с другой стороны – возникает проблемка: можно представить одинаковый с точки зрения визуального отображения и интерпретации символ – разными сочетаниями Unicode-кодов.
alert("S\u0307\u0323"); // Ṩ alert("S\u0323\u0307"); // Ṩ alert( "S\u0307\u0323" == "S\u0323\u0307" ); // falseВ первой строке после основы S идёт сначала значок «верхняя точка», а потом – нижняя, во второй – наоборот. По кодам строки не равны друг другу. Но символ задают один и тот же.
С целью разрешить эту ситуацию, существует Юникодная нормализация, при которой строки приводятся к единому, «нормальному», виду.
В современном JavaScript это делает метод str.normalize().
alert( "S\u0307\u0323".normalize() == "S\u0323\u0307".normalize() ); // trueЗабавно, что в данной конкретной ситуации normalize() приведёт последовательность из трёх символов к одному: \u1e68 (S с двумя точками).
alert( "S\u0307\u0323".normalize().length ); // 1, нормализовало в один символ alert( "S\u0307\u0323".normalize() == "\u1e68" ); // trueЭто, конечно, не всегда так, просто в данном случае оказалось, что именно такой символ в Юникоде уже есть. Если добавить значков, то нормализация уже даст несколько символов.
Для большинства практических задач информации, данной выше, должно быть вполне достаточно, но если хочется более подробно ознакомиться с вариантами и правилами нормализации – они описаны в приложении к стандарту Юникод Unicode Normalization Forms.
Полезные методы
Добавлен ряд полезных методов общего назначения:
- str.includes(s) – проверяет, включает ли одна строка в себя другую, возвращает true/false .
- str.endsWith(s) – возвращает true , если строка str заканчивается подстрокой s .
- str.startsWith(s) – возвращает true , если строка str начинается со строки s .
- str.repeat(times) – повторяет строку str times раз.
Конечно, всё это можно было сделать при помощи других встроенных методов, но новые методы более удобны.
Итого
- Строки-шаблоны – для удобного задания строк (многострочных, с переменными), плюс возможность использовать функцию шаблонизации для самостоятельного форматирования.
- Юникод – улучшена работа с суррогатными парами.
- Полезные методы для проверок вхождения одной строки в другую.
Строки

В JavaScript любые текстовые данные являются строками. Однако, не забывайте, что в строке могут быть записаны и числа. Пожалуй, из всех типов данных строками вы будете пользоваться наиболее часто. Разберем все варианты создания новой строки.
Видео
Одинарные или двойные кавычки
Для создания строки используются либо ‘одинарные’, либо “двойные” кавычки.
let single = 'Hello World' let double = "Hello World" // prettier-ignore Можно пользоваться и теми, и другими, главное, если вы начинаете строку одинарной, хотя внутри могут быть двойные, завершить ее надлежит также одинарной. И, соответственно, с двойными кавычками.
let double = "Don't you think so, d'Artagnan?" let single = '"I think so, indeed!" - cried he.' Обратный слэш
Если внутри строки используются те же кавычки, что стоят и снаружи, то их нужно экранировать при помощи обратного слэша — так называемого «символа экранирования». Он добавляется ➕ перед входящей в строку кавычкой \’ , чтобы она не обозначала окончание строки.
Интерактивный редактор
// prettier-ignorefunction learnJavaScript()let backticks = 'It\'s not complicated'return backticks>
Заметим, что обратный слеш \ служит лишь для корректного прочтения строки интерпретатором, но он не записывается в строку после её прочтения. Когда строка сохраняется в оперативную память, в неё не добавляется ➕ символ \ . Вы можете явно увидеть это в выводах.
Обратные кавычки
В написании строки можно обойтись и без обратного слэша, если использовать ` обратные ` кавычки.
Одинарные и двойные кавычки работают, по сути, одинаково, а если использовать обратные кавычки, то в такую строку мы сможем вставлять произвольные JavaScript выражения, обернув их в символ доллара с фигурными скобками $ :
Интерактивный редактор
function learnJavaScript()let name = 'Марк'return `Привет, $name>!`>
Интерполяция строк — это удобный способ подставлять значения переменных в строки. Шаблонная строка это тоже самое, что и интерполяция. Шаблонная строка в ES6 пришла на замену обычной строке. Интерполяция работает только с обратными кавычками. Посмотрим на практике, какие правила существует при использовании интерполяций.
Еще одно преимущество обратных кавычек – они могут занимать более одной строки.
Интерактивный редактор
function learnJavaScript()let guestList = `Guests:* John* Pete* Mary`return guestList>
Многострочные строки также можно создавать с помощью одинарных и двойных кавычек, используя так называемый «символ перевода строки», который записывается как \n . Все спецсимволы, в JavaScript, начинаются с обратного слеша \ Правда проверить мы это можем в консоле браузера( LIVE EDITOR отображает не корректно).
let guestList = 'Guests:\n * John\n * Pete\n * Mary' guestList // список гостей, состоящий из нескольких строк 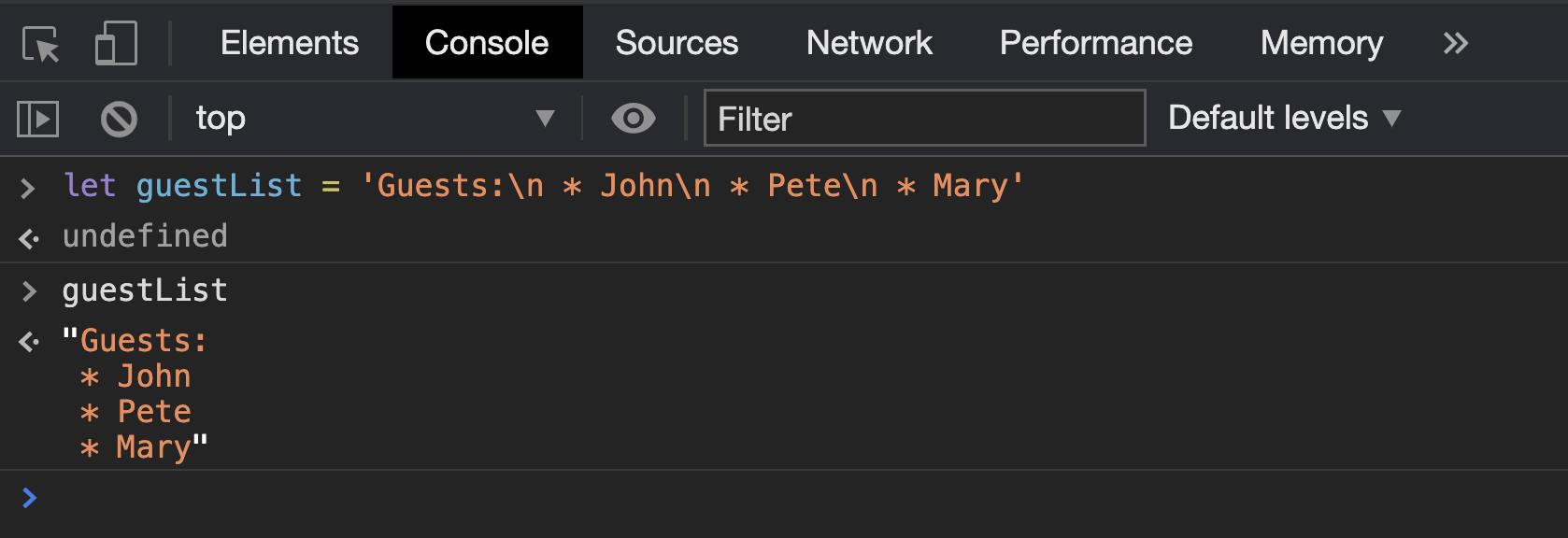
Строки неизменяемы
Содержимое строки в JavaScript нельзя изменить. Нельзя взять символ посередине и заменить его. Как только строка создана — она такая навсегда. Можно создать новую строку и записать её в ту же самую переменную вместо старой.
Интерактивный редактор
function learnJavaScript()let str = 'Hi'str = 'P' + str[1] // заменяем строкуreturn str>
Популярные методы строк
Длина строки
Свойство length возвращает количество кодовых значений в строке.
Интерактивный редактор
function learnJavaScript()let str = 'My\n'.lengthreturn str>
Обратите внимание, \n — это один спецсимвол, поэтому здесь всё правильно: длина строки 3.
Доступ к символам
Существует два 2️⃣ способа добраться до конкретного символа в строке. В первом способе используется метод charAt() . Первый 1️⃣ символ занимает нулевую позицию:
Интерактивный редактор
function learnJavaScript()let str = 'cat'.charAt(2)return str>
Получить символ также можно с помощью квадратных скобок:
Интерактивный редактор
function learnJavaScript()let str = 'cat'[2]return str>
Квадратные скобки — современный способ получить символ, в то время как charAt существует в основном по историческим причинам.
Изменение регистра символов
Чтобы преобразовать буквы строки в заглавные, используйте метод toUpperCase() .
Интерактивный редактор
function learnJavaScript()let str = 'Interface'.toUpperCase()return str>
в строчные toLowerCase()
Интерактивный редактор
function learnJavaScript()let str = 'Interface'.toLowerCase()return str>
Конкатенaция(сцепление) строки
Чтобы построить строку из существующих строк, используйте знак плюс + для объединения строк.
let name = 'Mary ' let activity = 'drink tea' let bio = 'Our guest ' + name + activity + '.' bio // Our guest Mary drink tea. Вот мы и познакомились с самым популярным типом данных в JavaScript и самыми часто используемыми методами к нему.
React Native
Посмотрим на практический пример как мы можем использовать строки при создании мобильного приложения. Здесь мы создаем константу str и присваиваем ей значение Hello world . Напомню, что для того чтобы в синтаксис JSX вставлять JavaScript выражения, необходимо использовать фигурные скобки.

Проблемы?
Пишите в Discord или телеграмм чат, а также подписывайтесь на наши новости
Вопросы:
Как в JavaScript не записываются строки _ _ _ ?
- в одинарных кавычках
- в обратных слэшах
- в обратных кавычках
Для чего в строке не используется обратный слэш?
- Для экранирования
- Для записи спецсимволов
- Для окончания строки
Выберете «символ перевода строки»
Какую букву вернет ‘sport'[3] ?
Как изменить символ в строке JavaScript?
- Изменить строку
- Добраться до символа и заменить его
- Создать новую строку и записать её в ту же самую переменную вместо старой
Какой метод используется, чтобы сделать буквы заглавными?
- toUpperCase()
- toLowerCase()
- toLowercase()
Какой знак используется для объединения строк?
Всякий раз, когда у вас есть открывающая _ _ _ _ , вам всегда нужно иметь закрывающую _ _ _ _ .
Строка состоит из одного или нескольких отдельных _ _ _ .
- символов
- аргументов
- параметров
Для того чтобы понять, на сколько вы усвоили этот урок, пройдите тест в мобильном приложении нашей школы по этой теме или в нашем телеграм боте.
Сcылки:
- MDN web docs
- Код для подростков: прекрасное руководство по программированию для начинающих, том 1: Javascript — Jeremy Moritz
- JavaScript.ru
Contributors ✨
Thanks goes to these wonderful people (emoji key):
Экранирование кавычек в JS
Хорошей практикой является вынесение JavaScript-кода в отдельный тег
5 окт 2015 в 14:04
2 ответа 2
Сортировка: Сброс на вариант по умолчанию
Потому что это html-разметка и вместо кавычек надо писать " :
onMouseOut="setTimeout('alert("You went away from me")', 1000);" Но вообще, так делать не надо.
Проблема именно в html-разметке. Если попытаться выполнить такое же присваивание в джаваскрипте, то первый код корректен, а второй — нет (экранируется апостроф, в строке остаётся апостроф и результат кривой — надо \\’ ). Но у html правила экранирования другие и обратный слеш оказывается во внутренней строке, не оказывая влияния на значение атрибута. Именно поэтому вторая строка корректна, а первая преждевременно кавычкой закрывает атрибут.
PS: а имена атрибутов-событий по правилам пишутся полностью маленькими буквами.
function test1() < eval("console.log('\'text\'')"); // Это текст из правильного варианта - тут такое не годится >function test2() < eval("console.log(\"'text'\")"); // Экранируются символы во внешней строке, не экранируется во внутренней >function test3() < eval("console.log('\\'text\\'')"); // Чтобы экранировать апостроф во внутренней строке надо экранировать сам обратный слеш во внешней >button