Работаем с Pandas: основные понятия и реальные данные
Разбираемся в том, как работает библиотека Pandas и проводим первый анализ данных.

Иллюстрация: Катя Павловская для Skillbox Media

Антон Яценко
Изучает Python, его библиотеки и занимается анализом данных. Любит путешествовать в горах.
Python используют для анализа данных и машинного обучения, подключая к нему различные библиотеки: Pandas, Matplotlib, NumPy, TensorFlow и другие. Каждая из них используется для решения конкретных задач.
Сегодня мы поговорим про Pandas: узнаем, для чего нужна эта библиотека, как импортировать её в Python, а также проанализируем свой первый датасет и выясним, в какой стране самый быстрый и самый медленный интернет.
Для чего нужна библиотека Pandas в Python
Pandas — главная библиотека в Python для работы с данными. Её активно используют аналитики данных и дата-сайентисты. Библиотека была создана в 2008 году компанией AQR Capital, а в 2009 году она стала проектом с открытым исходным кодом с поддержкой большого комьюнити.
Вот для каких задач используют библиотеку:
Аналитика данных: продуктовая, маркетинговая и другая. Работа с любыми данными требует анализа и подготовки: необходимо удалить или заполнить пропуски, отфильтровать, отсортировать или каким-то образом изменить данные. Pandas в Python позволяет быстро выполнить все эти действия, а в большинстве случаев ещё и автоматизировать их.
Data science и работа с большими данными. Pandas помогает подготовить и провести первичный анализ данных, чтобы потом использовать их в машинном или глубоком обучении.
Статистика. Библиотека поддерживает основные статистические методы, которые необходимы для работы с данными. Например, расчёт средних значений, их распределения по квантилям и другие.
Работа с Pandas
Для анализа данных и машинного обучения обычно используются особые инструменты: Google Colab или Jupyter Notebook. Это специализированные IDE, позволяющие работать с данными пошагово и итеративно, без необходимости создавать полноценное приложение.
В этой статье мы посмотрим на Google Colab, облачное решение для работы с данными, которое можно запустить в браузере на любом устройстве: десктопе, ноутбуке, планшете или даже смартфоне.
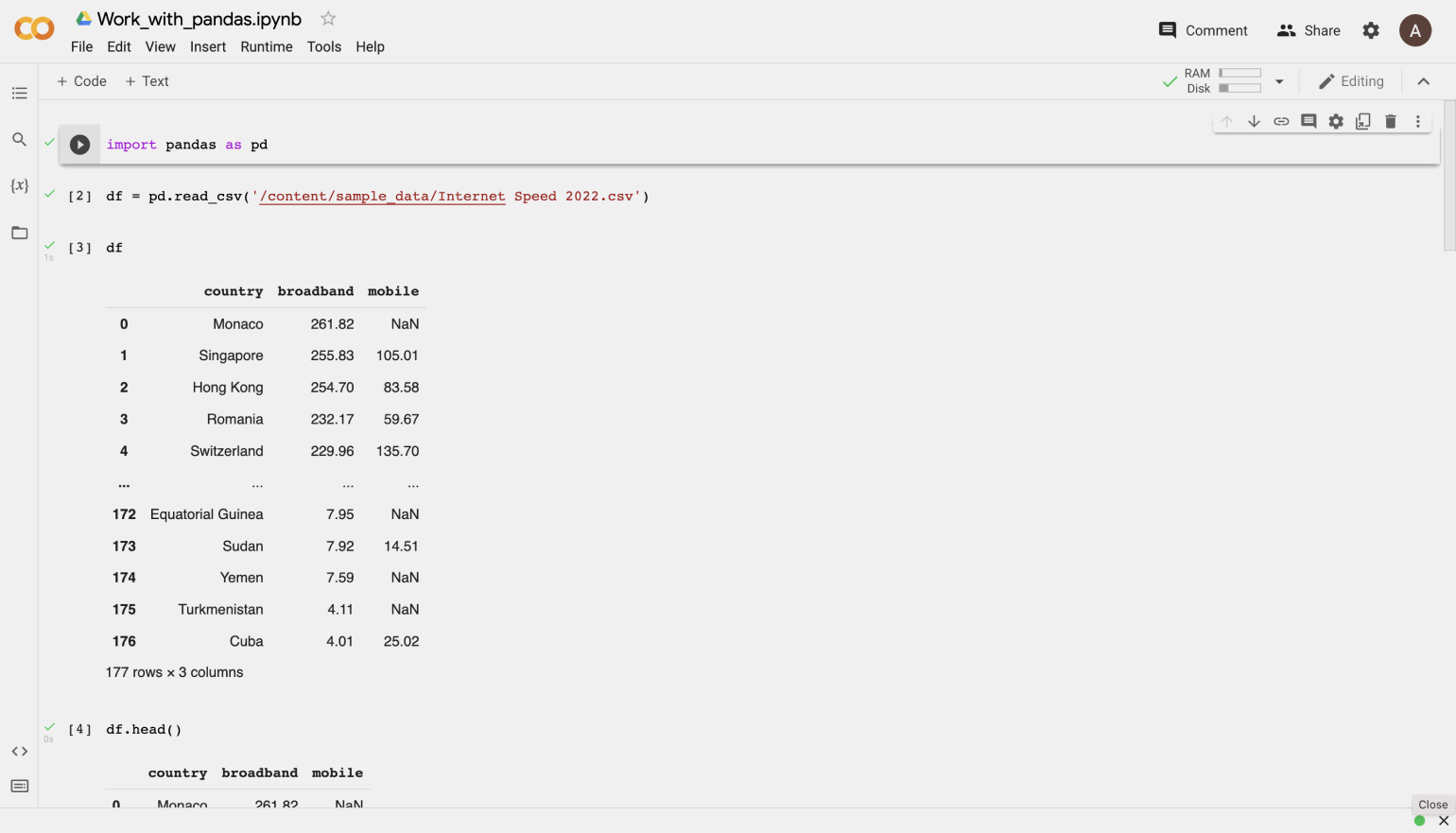
Каждая строчка кода на скриншоте — это одно действие, результат которого Google Colab и Jupyter Notebook сразу демонстрируют пользователю. Это удобно в задачах, связанных с аналитикой и data science.
Устанавливать Pandas при работе с Jupyter Notebook или Colab не требуется. Это стандартная библиотека, которая уже будет доступна сразу после их запуска. Останется только импортировать её в ваш код.

Series отображается в виде таблицы с индексами элементов в первом столбце и значениями во втором.
DataFrame — основной тип данных в Pandas, вокруг которого строится вся работа. Его можно представить в виде обычной таблицы с любым количеством столбцов и строк. Внутри ячеек такой «таблицы» могут быть данные самого разного типа: числовые, булевы, строковые и так далее.
У DataFrame есть и индексы строк, и индексы столбцов. Это позволяет удобно сортировать и фильтровать данные, а также быстро находить нужные ячейки.
Создадим простой DataFrame с помощью словаря и посмотрим на его отображение:
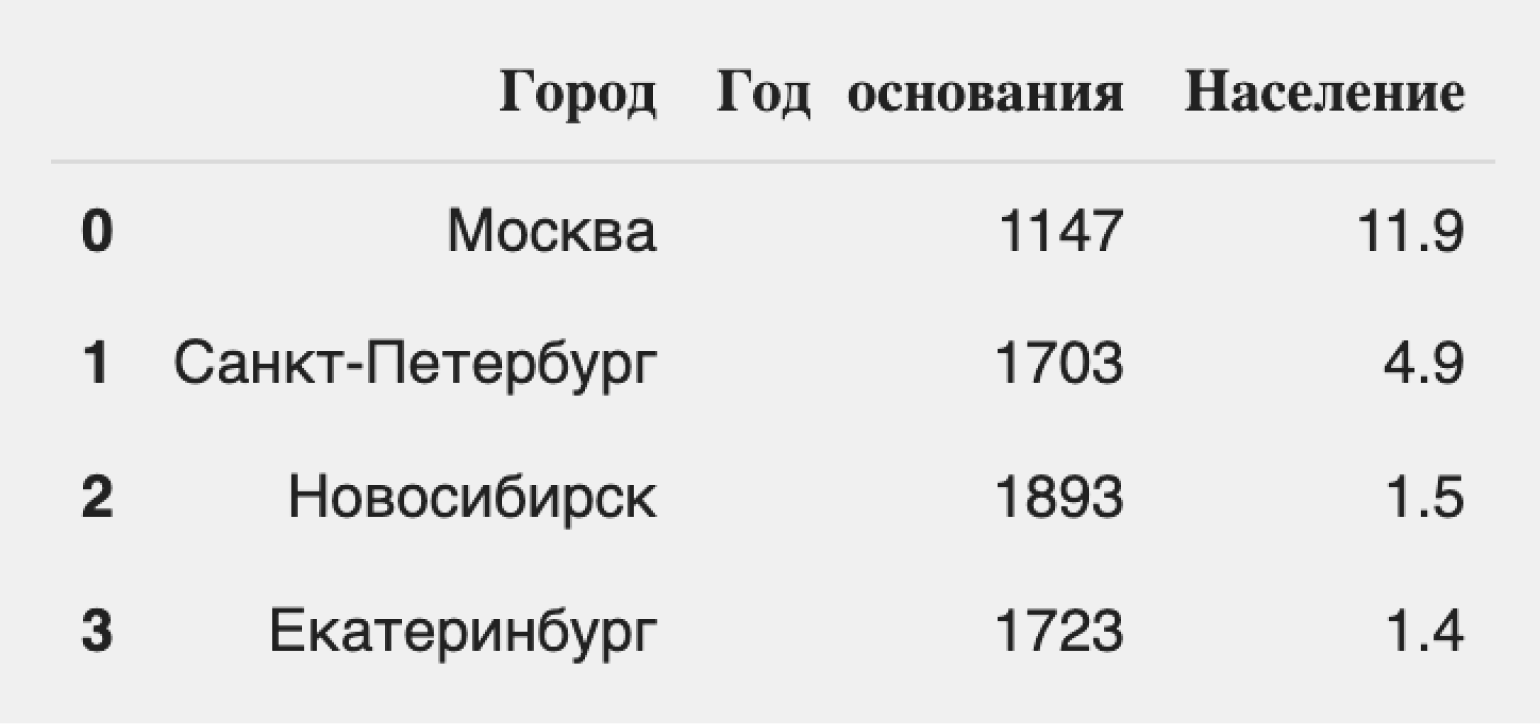
Мы видим таблицу, строки которой имеют индексы от 0 до 3, а «индексы» столбцов соответствуют их названиям. Легко заметить, что DataFrame состоит из трёх Series: «Город», «Год основания» и «Население». Оба типа индексов можно использовать для навигации по данным.

Импорт данных
Pandas позволяет импортировать данные разными способами. Например, прочесть их из словаря, списка или кортежа. Самый популярный способ — это работа с файлами .csv, которые часто применяются в анализе данных. Для импорта используют команду pd.read_csv().
read_csv имеет несколько параметров для управления импортом:
- sep — позволяет явно указать разделитель, который используется в импортируемом файле. По умолчанию значение равно ,, что соответствует разделителю данных в файлах формата .csv. Этот параметр полезен при нестандартных разделителях в исходном файле, например табуляции или точки с запятой;
- dtype — позволяет явно указать на тип данных в столбцах. Полезно в тех случаях, когда формат данных автоматически определился неверно. Например, даты часто импортируются в виде строковых переменных, хотя для них существует отдельный тип.
Подробно параметры, позволяющие настроить импорт, описаны в документации.
Давайте импортируем датасет с информацией о скорости мобильного и стационарного интернета в отдельных странах. Готовый датасет скачиваем с Kaggle. Параметры для read_csv не указываем, так как наши данные уже подготовлены для анализа.
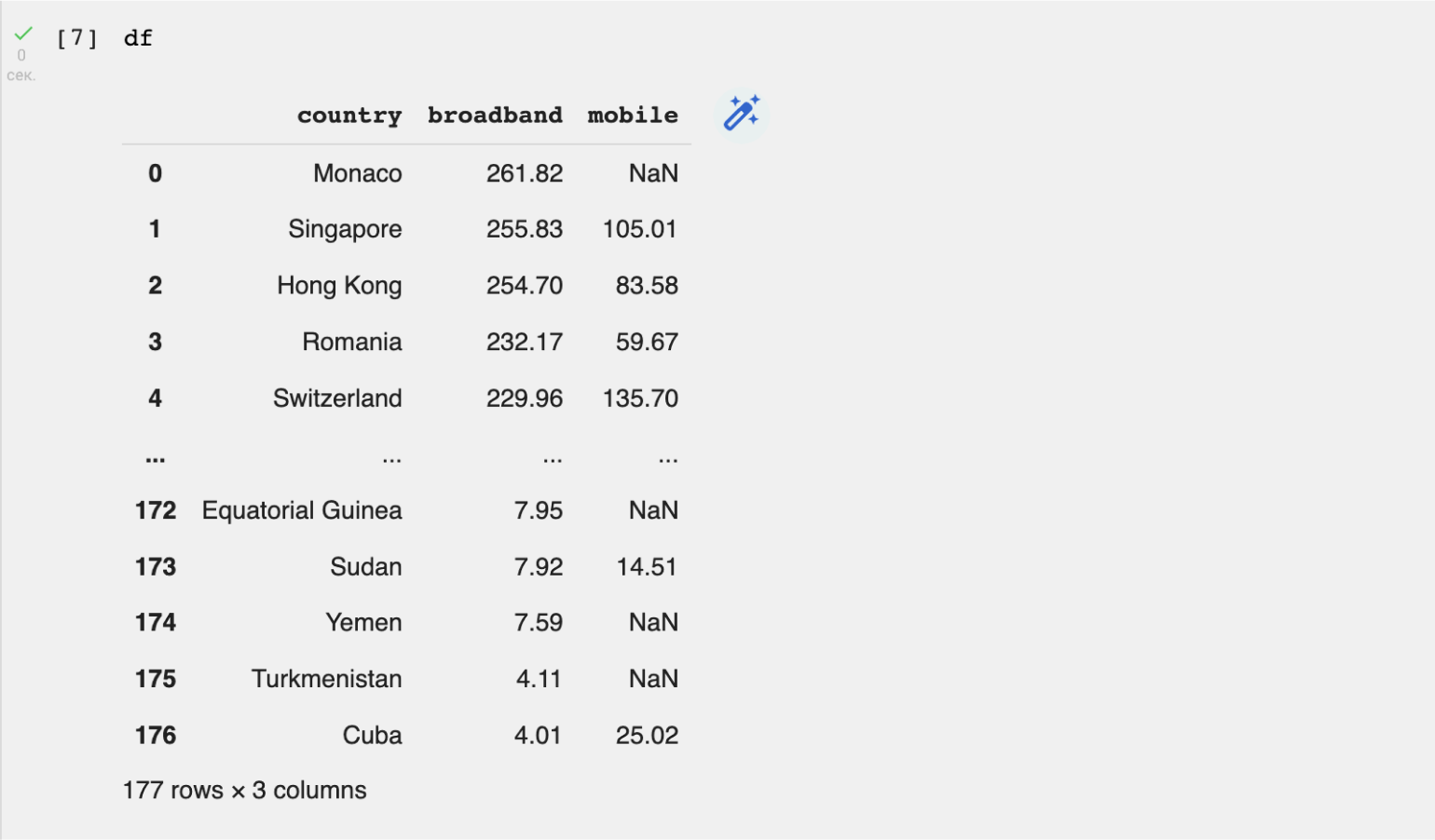
В верхней части таблицы мы видим названия столбцов: country (страна), broadband (средняя скорость интернета) и mobile (средняя скорость мобильного интернета). Слева указаны индексы — от 0 до 176. То есть всего у нас 177 строк. В нижней части таблицы Pandas отображает и эту информацию.
Выводить таблицу полностью необязательно. Для первого знакомства с данными достаточно показать пять первых или пять последних строк. Сделать это можно с помощью df.head() или df.tail() соответственно. В скобках можно указать число строк, которое требуется указать. По умолчанию параметр равен 5.

Так намного удобнее. Мы можем сразу увидеть названия столбцов и тип данных в столбцах. Также в некоторых ячейках мы видим значение NaN — к нему мы вернёмся позже.
Изучаем данные и описываем их
Теперь нам надо изучить импортированные данные. Действовать будем пошагово.
Шаг 1. Проверяем тип данных в таблице. Это поможет понять, в каком виде представлена информация в датасете — а иногда и найти аномалии. Например, даты могут быть сохранены в виде строк, что неудобно для последующего анализа. Проверить это можно с помощью стандартного метода:

- столбец country представляет собой тип object. Это тип данных для строковых и смешанных значений;
- столбцы broadband и mobile имеют тип данных float, то есть относятся к числам с плавающей точкой.
Шаг 2. Быстро оцениваем данные и делаем предварительные выводы. Сделать это можно очень просто: для этого в Pandas существует специальный метод describe(). Он показывает среднее со стандартным отклонением, максимальные, минимальные значения переменных и их разделение по квантилям.
Посмотрим на этот метод в деле:

Пройдёмся по каждой строчке:
- count — это количество заполненных строк в каждом столбце. Мы видим, что в столбце с данными о скорости мобильного интернета есть пропуски.
- mean — среднее значение скорости обычного и мобильного интернета. Уже можно сделать вывод, что мобильный интернет в большинстве стран медленнее, чем кабельный.
- std — стандартное отклонение. Важный статистический показатель, показывающий разброс значений.
- min и max — минимальное и максимальное значение.
- 25%, 50% и 75% — значения скорости интернета по процентилям. Если не углубляться в статистику, то процентиль — это число, которое показывает распределение значений в выборке. Например, в выборке с мобильным интернетом процентиль 25% показывает, что 25% от всех значений скорости интернета меньше, чем 24,4.
Обратите внимание, что этот метод работает только для чисел. Информация для столбца с названиями стран отсутствует.
Какой вывод делаем? Проводной интернет в большинстве стран работает быстрее, чем мобильный. При этом скорость проводного интернета в 75% случаев не превышает 110 Мбит/сек, а мобильного — 69 Мбит/сек.
Шаг 3. Сортируем и фильтруем записи. В нашем датафрейме данные уже отсортированы от большего к меньшему по скорости проводного интернета. Попробуем найти страну с наилучшим мобильным интернетом. Для этого используем стандартный метод sort_values, который принимает два параметра:
- название столбца, по которому происходит сортировка, — обязательно должно быть заключено в одинарные или двойные кавычки;
- параметр ascending= — указывает на тип сортировки. Если мы хотим отсортировать значения от большего к меньшему, то параметру присваиваем False. Для сортировки от меньшего к большему используем True.
Перейдём к коду:
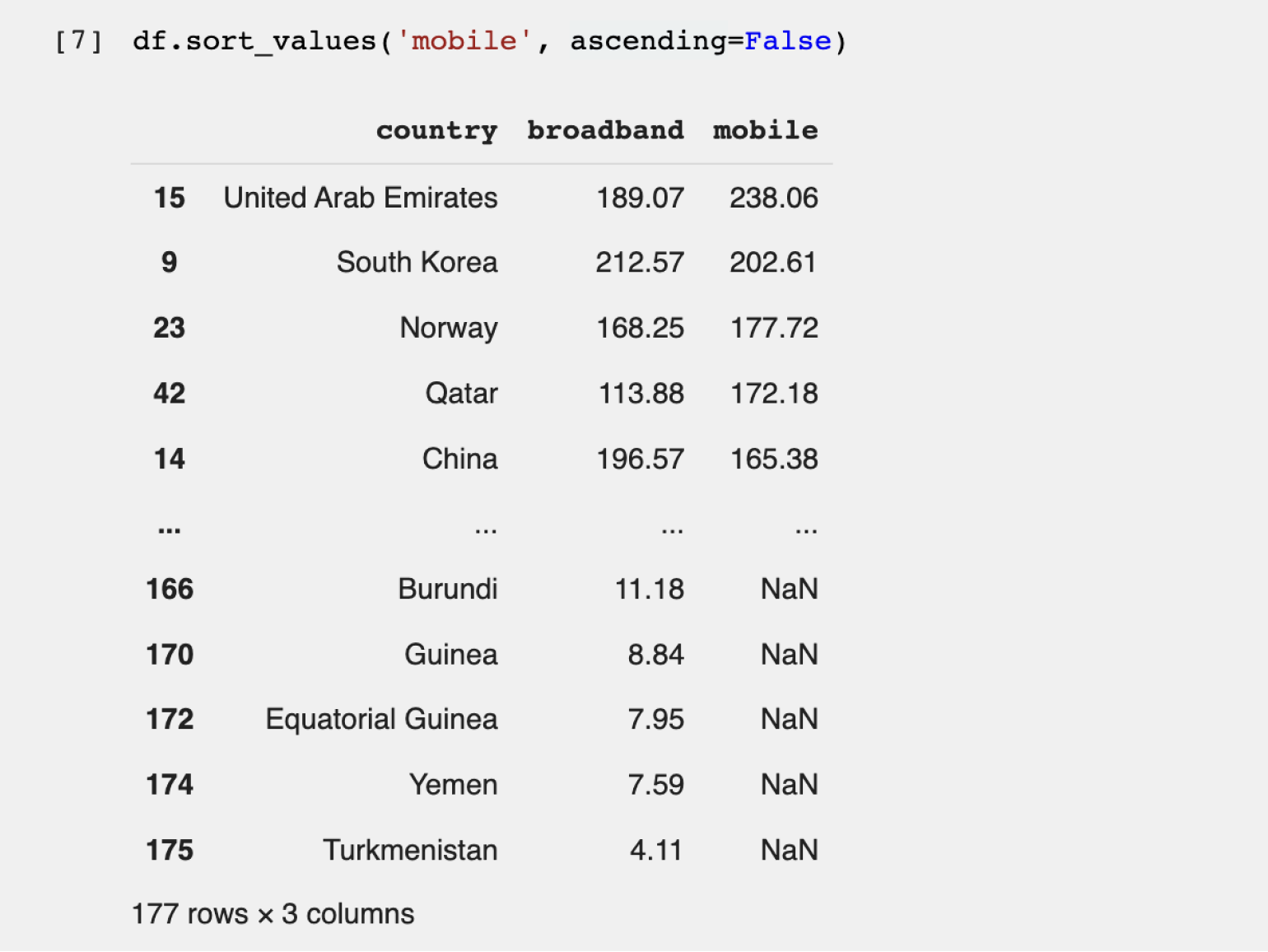
Теперь рейтинг стран другой — пятёрка лидеров поменялась (потому что мы отсортировали данные по другому значению). Мы выяснили, что самый быстрый мобильный интернет в ОАЭ.
Но есть нюанс. Если вернуться к первоначальной таблице, отсортированной по скорости проводного интернета, можно заметить, что у лидера — Монако — во втором столбце написано NaN. NaN в Python указывает на отсутствие данных. Поэтому мы не знаем скорость мобильного интернета в Монако из этого датасета и не можем сделать однозначный вывод о лидерах в мире мобильной связи.
Попробуем отфильтровать значения, убрав страны с неизвестной скоростью мобильного интернета, и посмотрим на худшие по показателю страны (если оставить NaN, он будет засорять «дно» таблицы и увидеть реальные значения по самому медленному мобильному интернету будет сложновато).
В Pandas существуют различные способы фильтрации для удаления NaN. Мы воспользуемся методом dropna(), который удаляет все строки с пропусками. Важно, что удаляется полностью строка, содержащая NaN, а не только ячейки с пропущенными значениями в столбце с пропусками.
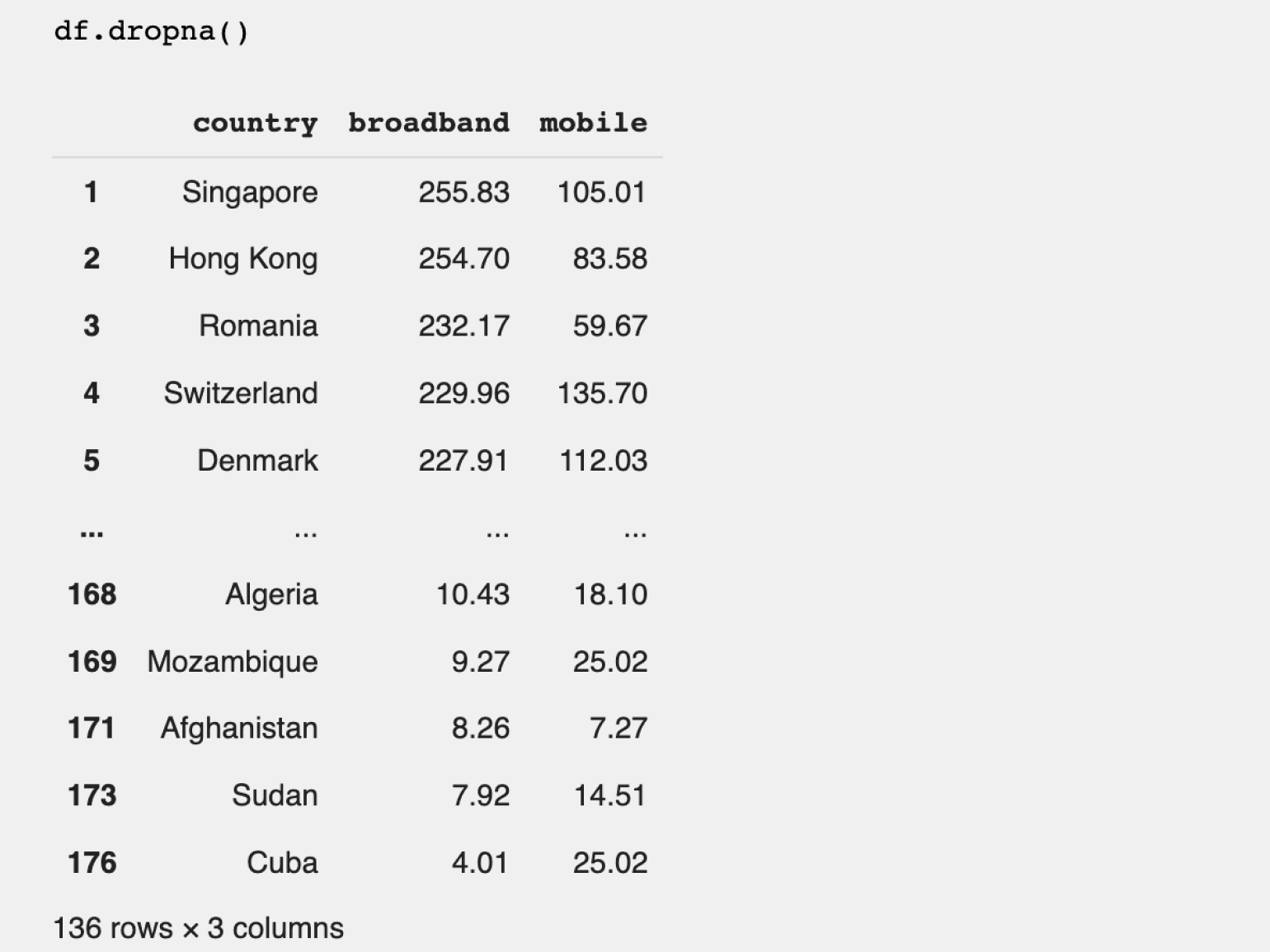
Количество строк в датафрейме при удалении пустых данных уменьшилось до 136. Если вернуться ко второму шагу, то можно увидеть, что это соответствует количеству заполненных строк в столбце mobile в начальном датафрейме.
Сохраним результат в новый датафрейм и назовём его df_without_nan. Изначальный DataFrame стараемся не менять, так как он ещё может нам понадобиться.
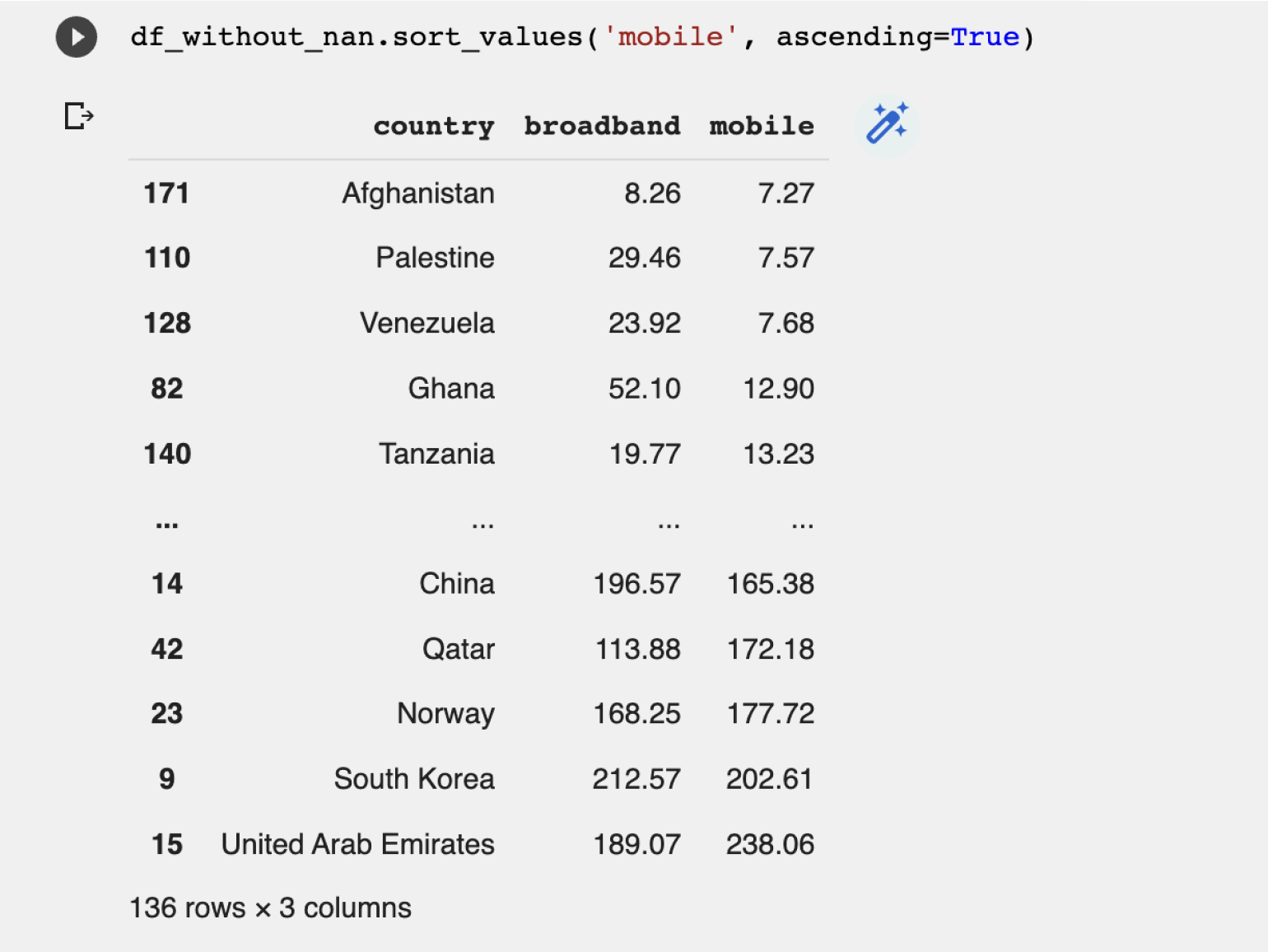
Худший мобильный интернет в Афганистане с небольшим отставанием от Палестины и Венесуэлы.
Что дальше?
Pandas в Python — мощная библиотека для анализа данных. В этой статье мы прошли по базовым операциям. Подробнее про работу библиотеки можно узнать в документации. Углубиться в работу с библиотекой можно благодаря специализированным книгам:
- «Изучаем pandas. Высокопроизводительная обработка и анализ данных в Python» Майкла Хейдта и Артёма Груздева;
- «Thinking in Pandas: How to Use the Python Data Analysis Library the Right Way», Hannah Stepanek;
- «Hands-On Data Analysis with Pandas: Efficiently perform data collection, wrangling, analysis, and visualization using Python», Stefanie Molin.
Читайте также:
- Библиотеки в программировании: для чего нужны и какими бывают
- Тест: угадайте, где эзотерические языки программирования, а где — нет
- Как начать программировать на Python: экспресс-гайд
Как анализировать данные на Python с Pandas: первые шаги


Мария Жарова Эксперт по Python и математике для Data Science, ментор одного из проектов на курсе по Data Science.
Pandas — главная Python-библиотека для анализа данных. Она быстрая и мощная: в ней можно работать с таблицами, в которых миллионы строк. Вместе с Марией Жаровой, ментором проекта на курсе по Data Science, рассказываем про команды, которые позволят начать работать с реальными данными.
Среда разработки
Pandas работает как в IDE (средах разработки), так и в облачных блокнотах для программирования. Как установить библиотеку в конкретную IDE, читайте тут. Мы для примера будем работать в облачной среде Google Colab. Она удобна тем, что не нужно ничего устанавливать на компьютер: файлы можно загружать и работать с ними онлайн, к тому же есть совместный режим для работы с коллегами. Про Colab мы писали в этом обзоре. Пройдите тест и узнайте, какой вы аналитик данных и какие перспективы вас ждут. Ссылка в конце статьи.

Освойте профессию «Data Scientist» на курсе с МГУ
Data Scientist с нуля до PRO
Освойте профессию Data Scientist с нуля до уровня PRO на углубленном курсе совместно с академиком РАН из МГУ. Изучите продвинутую математику с азов, получите реальный опыт на практических проектах и начните работать удаленно из любой точки мира.

25 месяцев
Data Scientist с нуля до PRO
Создавайте ML-модели и работайте с нейронными сетями
11 317 ₽/мес 6 790 ₽/мес

Анализ данных в Pandas
-
Создание блокнота в Google Colab На сайте Google Colab сразу появляется экран с доступными блокнотами. Создадим новый блокнот:
Импортирование библиотеки Pandas недоступна в Python по умолчанию. Чтобы начать с ней работать, нужно ее импортировать с помощью этого кода:
import pandas as pd
pd — это распространенное сокращенное название библиотеки. Далее будем обращаться к ней именно так.
И прочитать с помощью такой команды:
Это можно сделать через словарь и через преобразование вложенных списков (фактически таблиц).

Если нужно посмотреть на другое количество строк, оно указывается в скобках, например df.head(12) . Последние строки фрейма выводятся методом .tail() .
Также чтобы просто полностью красиво отобразить датасет, используется функция display() . По умолчанию в Jupyter Notebook, если написать имя переменной на последней строке какой-либо ячейки (даже без ключевого слова display), ее содержимое будет отображено.

Характеристики датасета Чтобы получить первичное представление о статистических характеристиках нашего датасета, достаточно этой команды: df.describe()
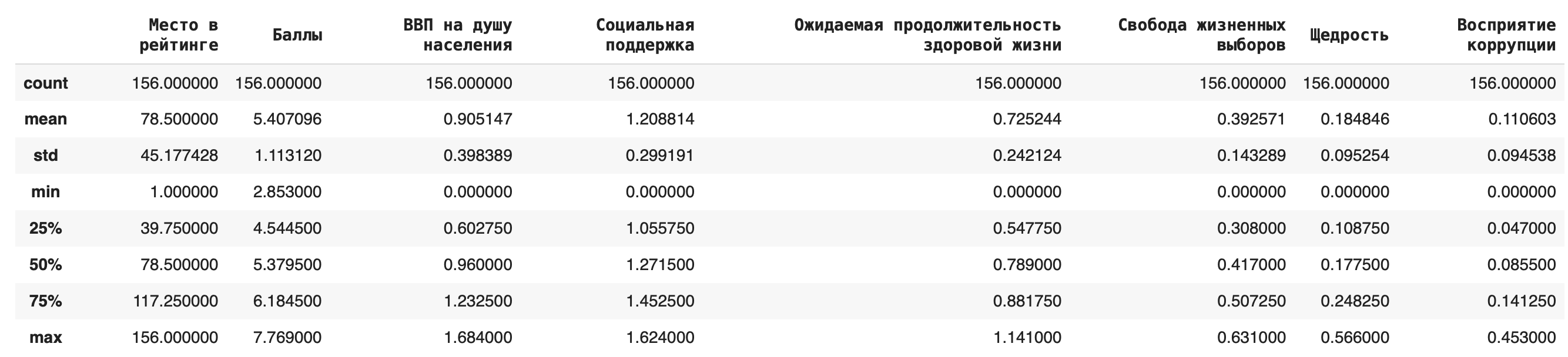

Обзор содержит среднее значение, стандартное отклонение, минимум и максимум, верхние значения первого и третьего квартиля и медиану по каждому столбцу.
Работа с отдельными столбцами или строками
Выделить несколько столбцов можно разными способами.
1. Сделать срез фрейма df[[‘Место в рейтинге’, ‘Ожидаемая продолжительность здоровой жизни’]]

Срез можно сохранить в новой переменной: data_new = df[[‘Место в рейтинге’, ‘Ожидаемая продолжительность здоровой жизни’]]
Теперь можно выполнить любое действие с этим сокращенным фреймом.
2. Использовать метод loc
Если столбцов очень много, можно использовать метод loc, который ищет значения по их названию: df.loc [:, ‘Место в рейтинге’:’Социальная поддержка’]
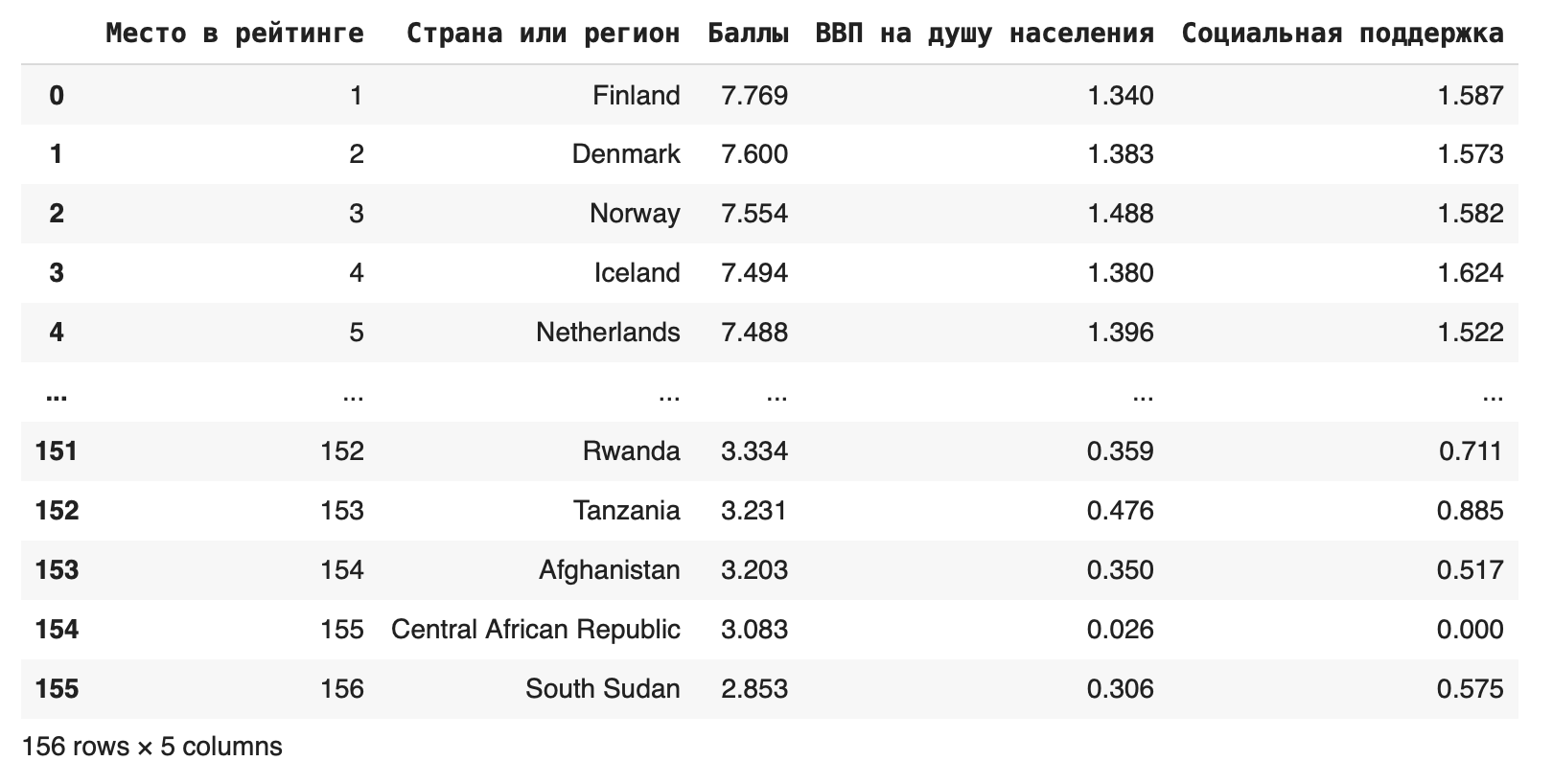
В этом случае мы оставили все столбцы от Места в рейтинге до Социальной поддержки.

Станьте дата-сайентистом на курсе с МГУ и решайте амбициозные задачи с помощью нейросетей
3. Использовать метод iloc
Если нужно вырезать одновременно строки и столбцы, можно сделать это с помощью метода iloc: df.iloc[0:100, 0:5]
Первый параметр показывает индексы строк, которые останутся, второй — индексы столбцов. Получаем такой фрейм:
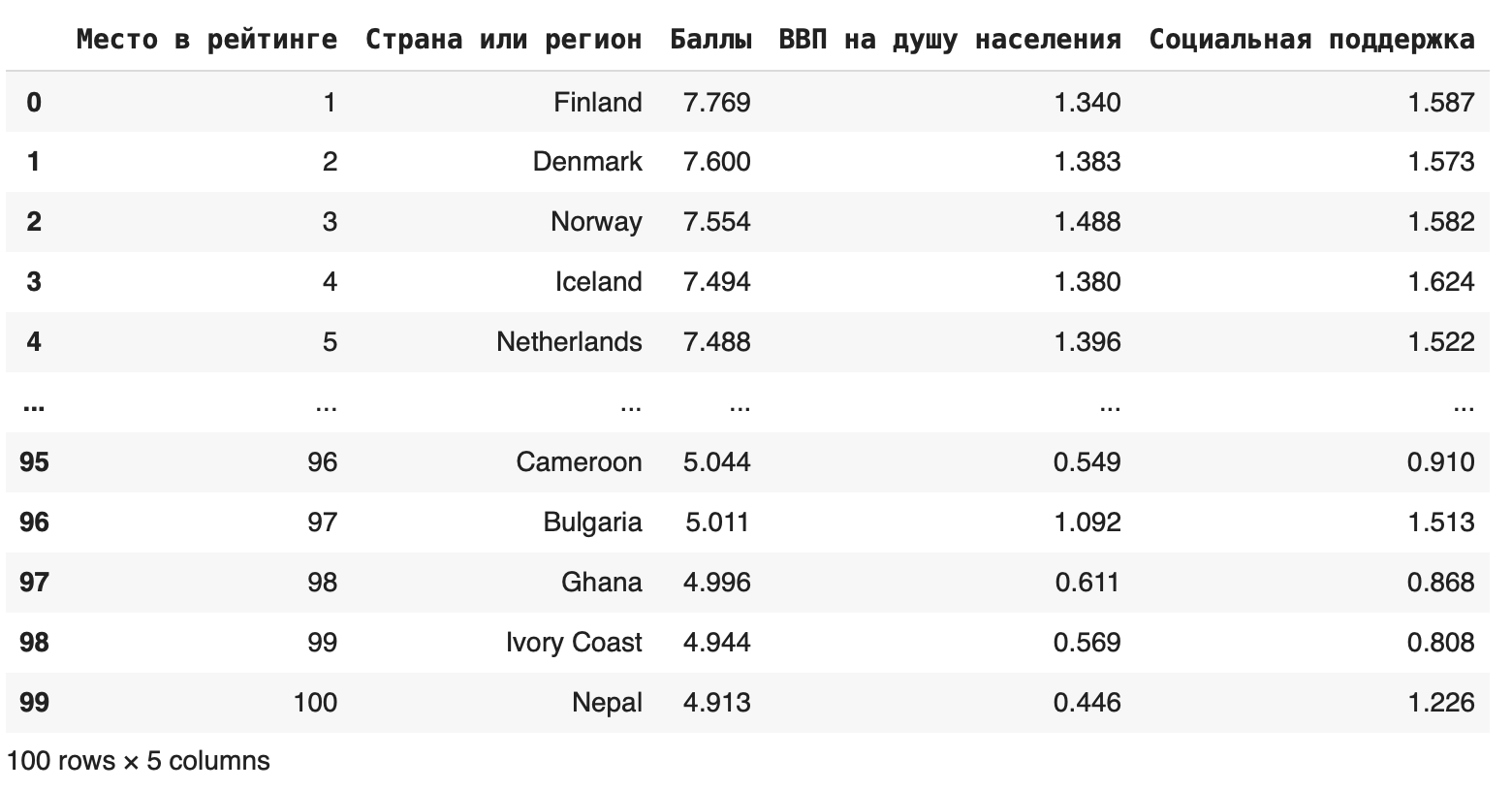
В методе iloc значения в правом конце исключаются, поэтому последняя строка, которую мы видим, — 99.
4. Использовать метод tolist()
Можно выделить какой-либо столбец в отдельный список при помощи метода tolist(). Это упростит задачу, если необходимо извлекать данные из столбцов: df[‘Баллы’].tolist()
Часто бывает нужно получить в виде списка названия столбцов датафрейма. Это тоже можно сделать с помощью метода tolist(): df.columns.tolist()

Добавление новых строк и столбцов
В исходный датасет можно добавлять новые столбцы, создавая новые «признаки», как говорят в машинном обучении. Например, создадим столбец «Сумма», в который просуммируем значения колонок «ВВП на душу населения» и «Социальная поддержка» (сделаем это в учебных целях, практически суммирование этих показателей не имеет смысла): df[‘Сумма’] = df[‘ВВП на душу населения’] + df[‘Социальная поддержка’]

Можно добавлять и новые строки: для этого нужно составить словарь с ключами — названиями столбцов. Если вы не укажете значения в каких-то столбцах, они по умолчанию заполнятся пустыми значениями NaN. Добавим еще одну страну под названием Country: new_row = df = df.append(new_row, ignore_index=True)
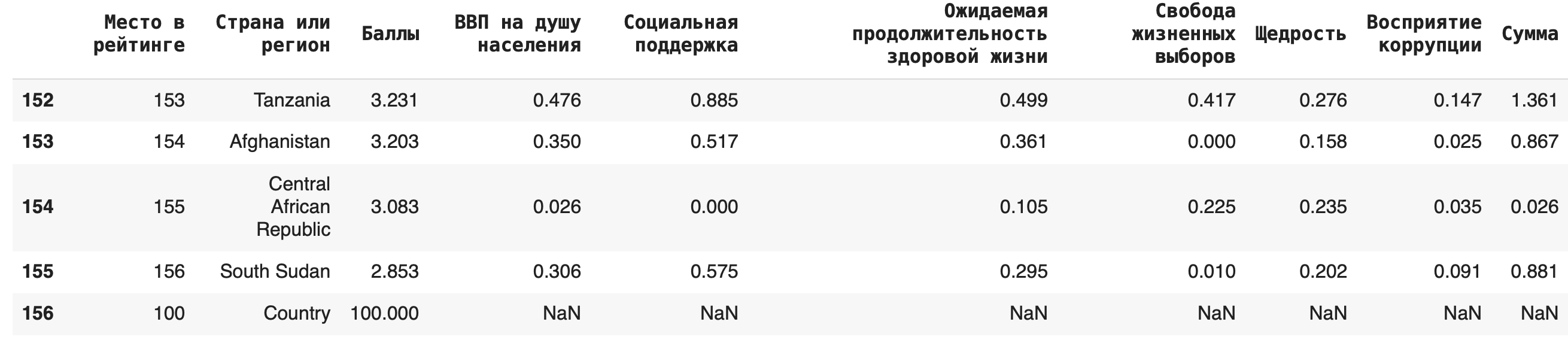
Важно: при добавлении новой строки методом .append() не забывайте указывать параметр ignore_index=True, иначе возникнет ошибка.
Иногда бывает полезно добавить строку с суммой, медианой или средним арифметическим) по столбцу. Сделать это можно с помощью агрегирующих (aggregate (англ.) — группировать, объединять) функций: sum(), mean(), median(). Для примера добавим в конце строку с суммами значений по каждому столбцу: df = df.append(df.sum(axis=0), ignore_index = True)
Удаление строк и столбцов
Удалить отдельные столбцы можно при помощи метода drop() — это целесообразно делать, если убрать нужно небольшое количество столбцов. df = df.drop([‘Сумма’], axis = 1)
В других случаях лучше воспользоваться описанными выше срезами.
Обратите внимание, что этот метод требует дополнительного сохранения через присваивание датафрейма с примененным методом исходному. Также в параметрах обязательно нужно указать axis = 1, который показывает, что мы удаляем именно столбец, а не строку.
Соответственно, задав параметр axis = 0, можно удалить любую строку из датафрейма: для этого нужно написать ее номер в качестве первого аргумента в методе drop(). Удалим последнюю строчку (указываем ее индекс — это будет количество строк): df = df.drop(df.shape[0]-1, axis = 0)
Копирование датафрейма
Можно полностью скопировать исходный датафрейм в новую переменную. Это пригодится, если нужно преобразовать много данных и при этом работать не с отдельными столбцами, а со всеми данными: df_copied = df.copy()
Уникальные значения
Уникальные значения в какой-либо колонке датафрейма можно вывести при помощи метода .unique(): df[‘Страна или регион’].unique()
Чтобы дополнительно узнать их количество, можно воспользоваться функцией len(): len(df[‘Страна или регион’].unique())
Подсчет количества значений
Отличается от предыдущего метода тем, что дополнительно подсчитывает количество раз, которое то или иное уникальное значение встречается в колонке, пишется как .value_counts(): df[‘Страна или регион’].value_counts()

Группировка данных
Некоторым обобщением .value_counts() является метод .groupby() — он тоже группирует данные какого-либо столбца по одинаковым значениям. Отличие в том, что при помощи него можно не просто вывести количество уникальных элементов в одном столбце, но и найти для каждой группы сумму / среднее значение / медиану по любым другим столбцам.
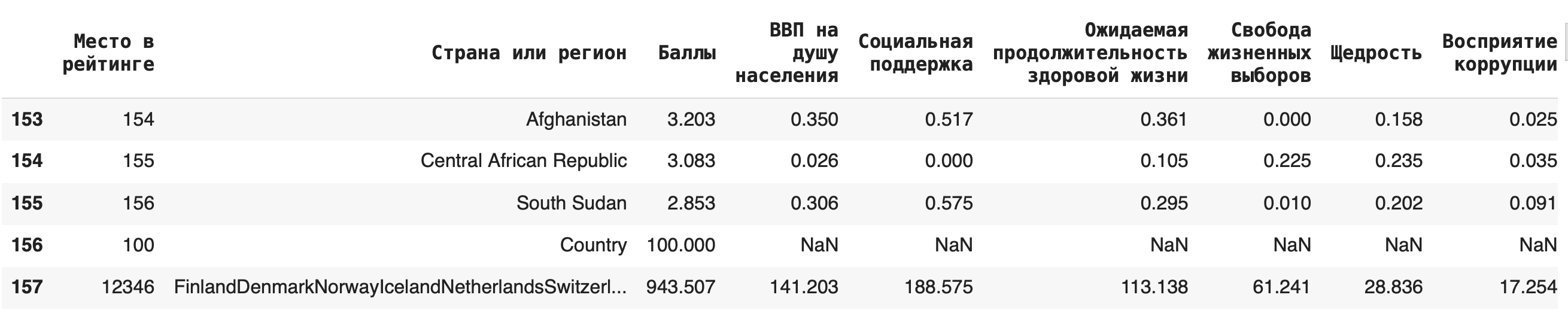
Рассмотрим несколько примеров. Чтобы они были более наглядными, округлим все значения в столбце «Баллы» (тогда в нем появятся значения, по которым мы сможем сгруппировать данные): df[‘Баллы_new’] = round(df[‘Баллы’])
1) Сгруппируем данные по новому столбцу баллов и посчитаем, сколько уникальных значений для каждой группы содержится в остальных столбцах. Для этого в качестве агрегирующей функции используем .count(): df.groupby(‘Баллы_new’).count()
Получается, что чаще всего страны получали 6 баллов (таких было 49):
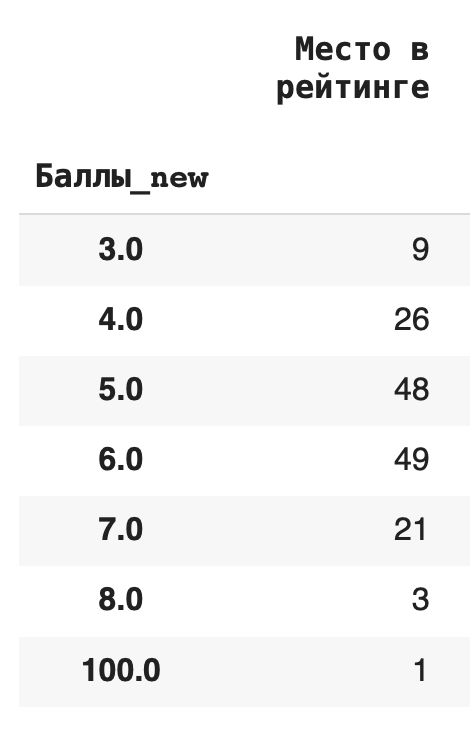
2) Получим более содержательный для анализа данных результат — посчитаем сумму значений в каждой группе. Для этого вместо .count() используем sum(): df.groupby(‘Баллы_new’).sum()
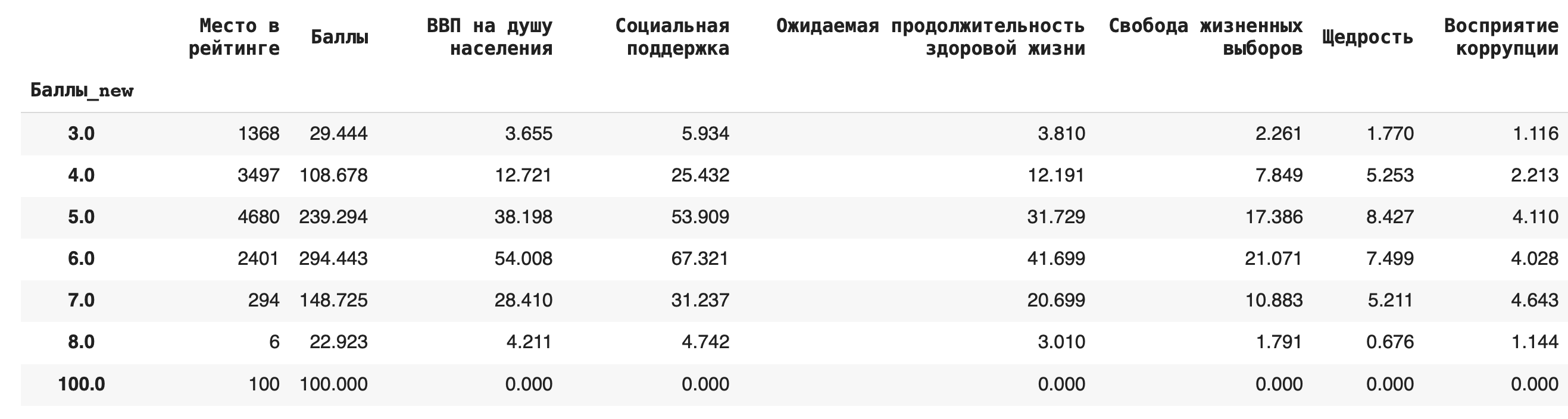
3) Теперь рассчитаем среднее значение по каждой группе, в качестве агрегирующей функции в этом случае возьмем mean(): df.groupby(‘Баллы_new’).mean()
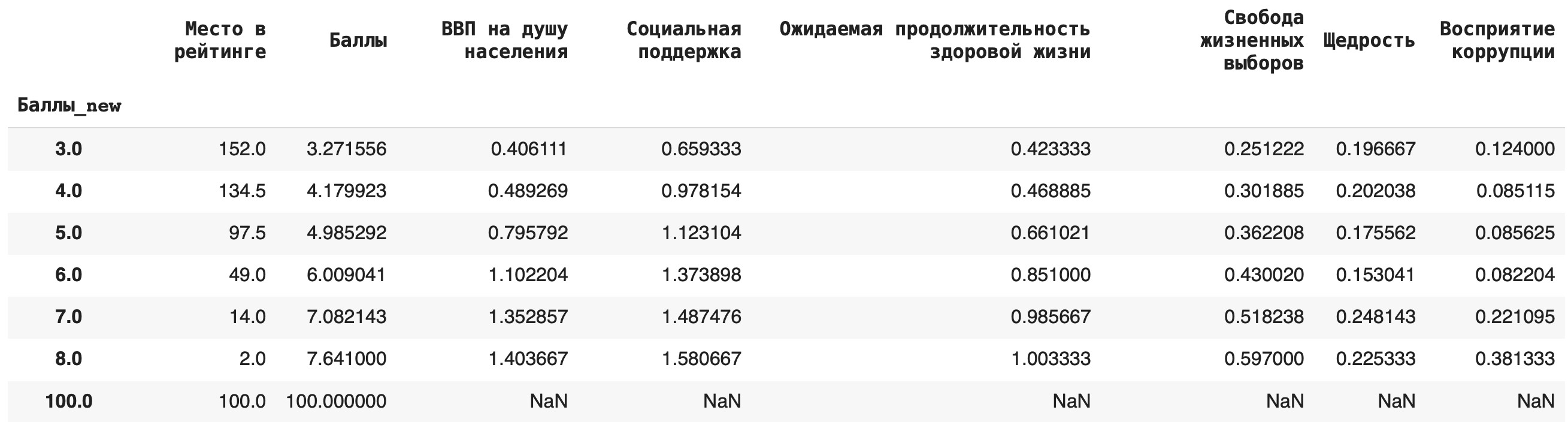
4) Рассчитаем медиану. Для этого пишем команду median(): df.groupby(‘Баллы_new’).median()
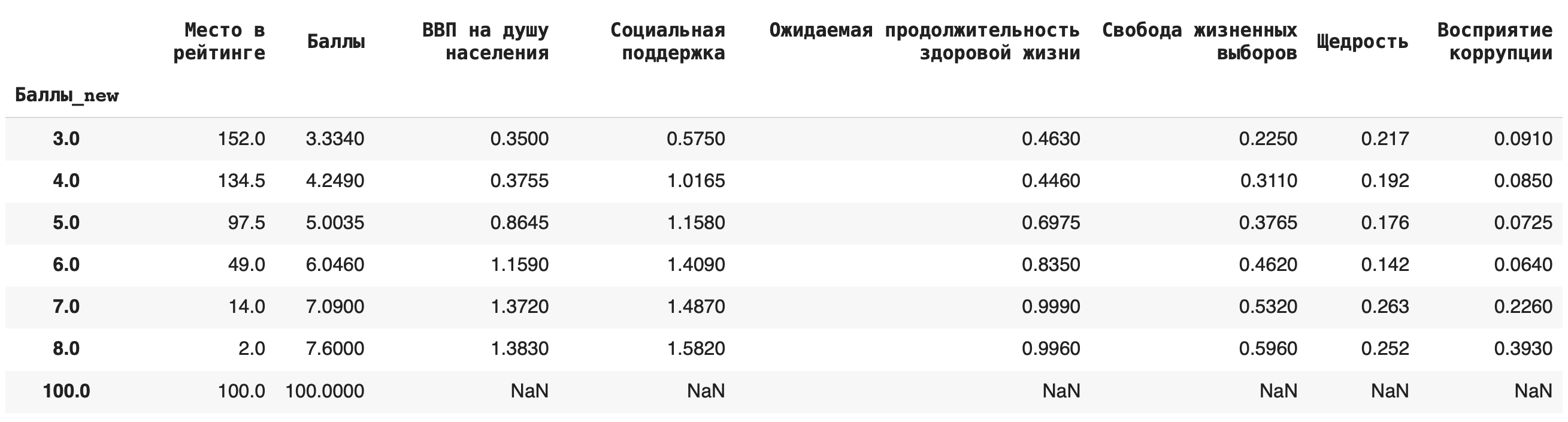
Это самые основные агрегирующие функции, которые пригодятся на начальном этапе работы с данными.
Вот пример синтаксиса, как можно сагрегировать значения по группам при помощи сразу нескольких функций:
df_agg = df.groupby(‘Баллы_new’).agg(< 'Баллы_new': 'count', 'Баллы_new': 'sum', 'Баллы_new': 'mean', 'Баллы_new': 'median' >)
Сводные таблицы
Бывает, что нужно сделать группировку сразу по двум параметрам. Для этого в Pandas используются сводные таблицы или pivot_table(). Они составляются на основе датафреймов, но, в отличие от них, группировать данные можно не только по значениям столбцов, но и по строкам.
В ячейки такой таблицы помещаются сгруппированные как по «координате» столбца, так и по «координате» строки значения. Соответствующую агрегирующую функцию указываем отдельным параметром.
Разберемся на примере. Сгруппируем средние значения из столбца «Социальная поддержка» по баллам в рейтинге и значению ВВП на душу населения. В прошлом действии мы уже округлили значения баллов, теперь округлим и значения ВВП: df[‘ВВП_new’] = round(df[‘ВВП на душу населения’])
Теперь составим сводную таблицу: по горизонтали расположим сгруппированные значения из округленного столбца «ВВП» (ВВП_new), а по вертикали — округленные значения из столбца «Баллы» (Баллы_new). В ячейках таблицы будут средние значения из столбца «Социальная поддержка», сгруппированные сразу по этим двум столбцам: pd.pivot_table(df, index = [‘Баллы_new’], columns = [‘ВВП_new’], values = ‘Социальная поддержка’, aggfunc = ‘mean’)
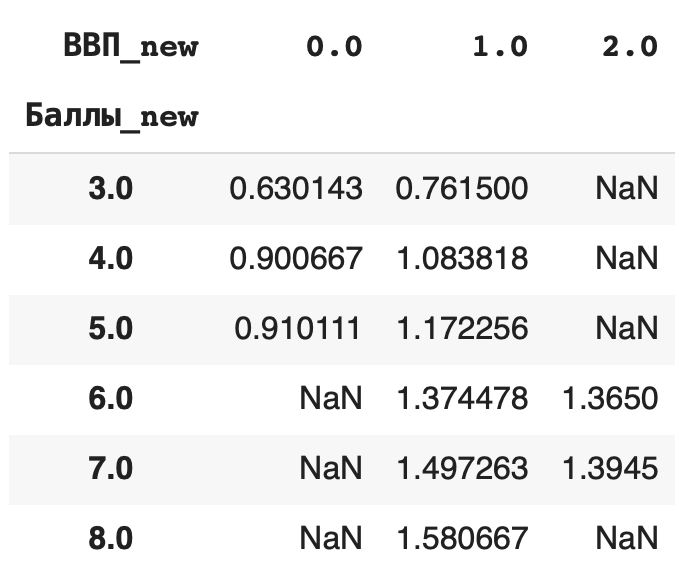
Сортировка данных
Строки датасета можно сортировать по значениям любого столбца при помощи функции sort_values(). По умолчанию метод делает сортировку по убыванию. Например, отсортируем по столбцу значений ВВП на душу населения: df.sort_values(by = ‘ВВП на душу населения’).head()
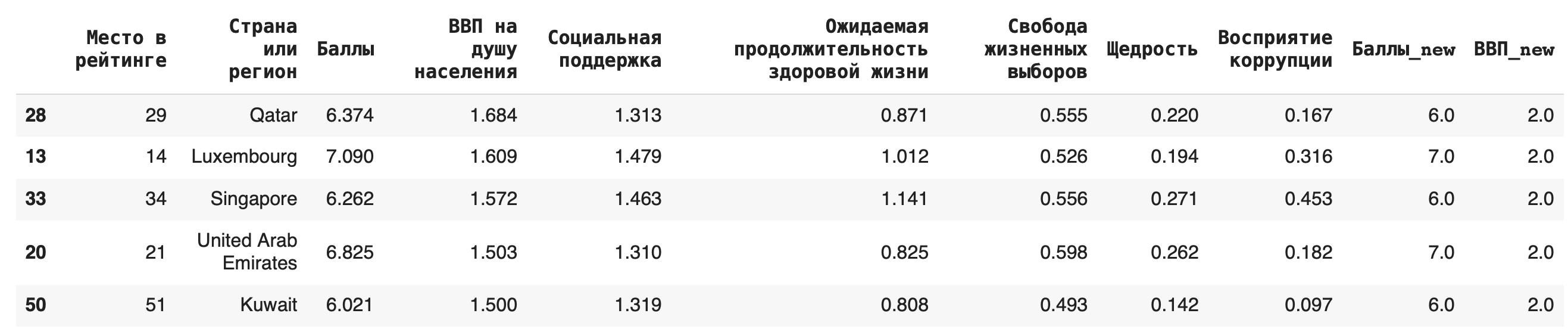
Видно, что самые высокие ВВП совсем не гарантируют высокое место в рейтинге.
Чтобы сделать сортировку по убыванию, можно воспользоваться параметром ascending (от англ. «по возрастанию») = False: df.sort_values(by = ‘ВВП на душу населения’, ascending=False)
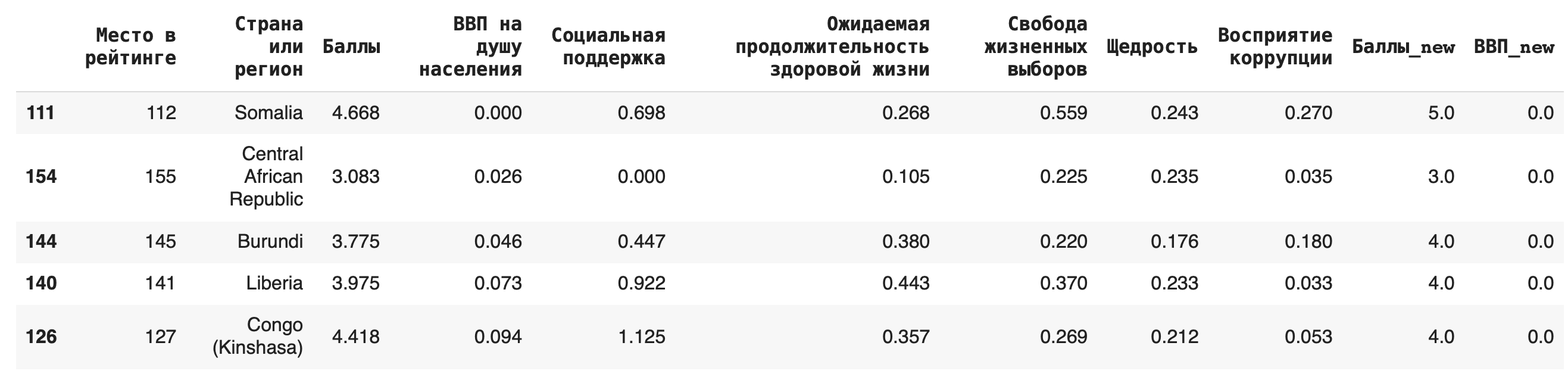
Фильтрация
Иногда бывает нужно получить строки, удовлетворяющие определенному условию; для этого используется «фильтрация» датафрейма. Условия могут быть самые разные, рассмотрим несколько примеров и их синтаксис:
1) Получение строки с конкретным значением какого-либо столбца (выведем строку из датасета для Норвегии): df[df[‘Страна или регион’] == ‘Norway’]

2) Получение строк, для которых значения в некотором столбце удовлетворяют неравенству. Выведем строки для стран, у которых «Ожидаемая продолжительность здоровой жизни» больше единицы:
df[df[‘Ожидаемая продолжительность здоровой жизни’] > 1]
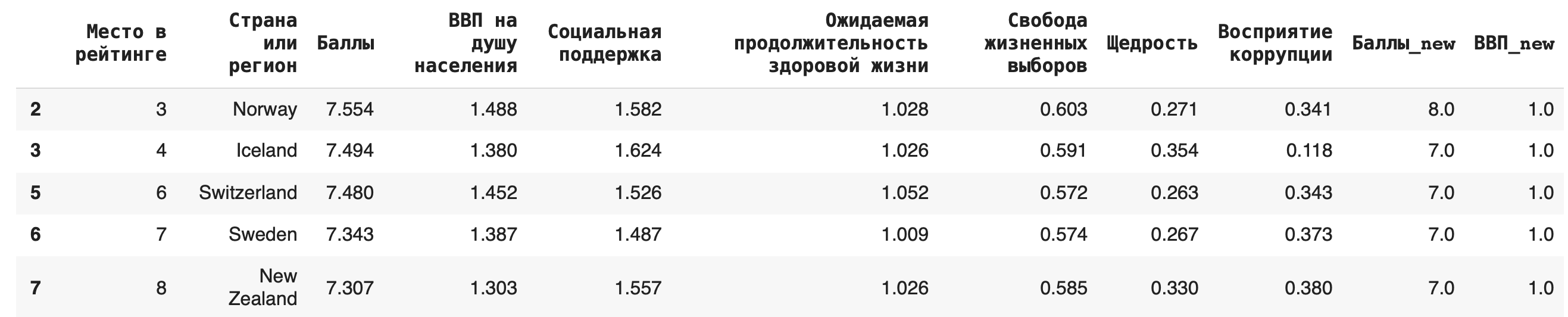
3) В условиях фильтрации можно использовать не только математические операции сравнения, но и методы работы со строками. Выведем строки датасета, названия стран которых начинаются с буквы F, — для этого воспользуемся методом .startswith():
df[df[‘Страна или регион’].str.startswith(‘F’)]

4) Можно комбинировать несколько условий одновременно, используя логические операторы. Выведем строки, в которых значение ВВП больше 1 и уровень социальной поддержки больше 1,5: df[(df[‘ВВП на душу населения’] > 1) & (df[‘Социальная поддержка’] > 1.5)]

Таким образом, если внутри внешних квадратных скобок стоит истинное выражение, то строка датасета будет удовлетворять условию фильтрации. Поэтому в других ситуациях можно использовать в условии фильтрации любые функции/конструкции, возвращающие значения True или False.
Применение функций к столбцам
Зачастую встроенных функций и методов для датафреймов из библиотеки бывает недостаточно для выполнения той или иной задачи. Тогда мы можем написать свою собственную функцию, которая преобразовывала бы строку датасета как нам нужно, и затем использовать метод .apply() для применения этой функции ко всем строкам нужного столбца.
Рассмотрим пример: напишем функцию, которая преобразует все буквы в строке к нижнему регистру, и применим к столбцу стран и регионов: def my_lower(row): return row.lower() df[‘Страна или регион’].apply(lower)

Очистка данных
Это целый этап работы с данными при подготовке их к построению моделей и нейронных сетей. Рассмотрим основные приемы и функции.
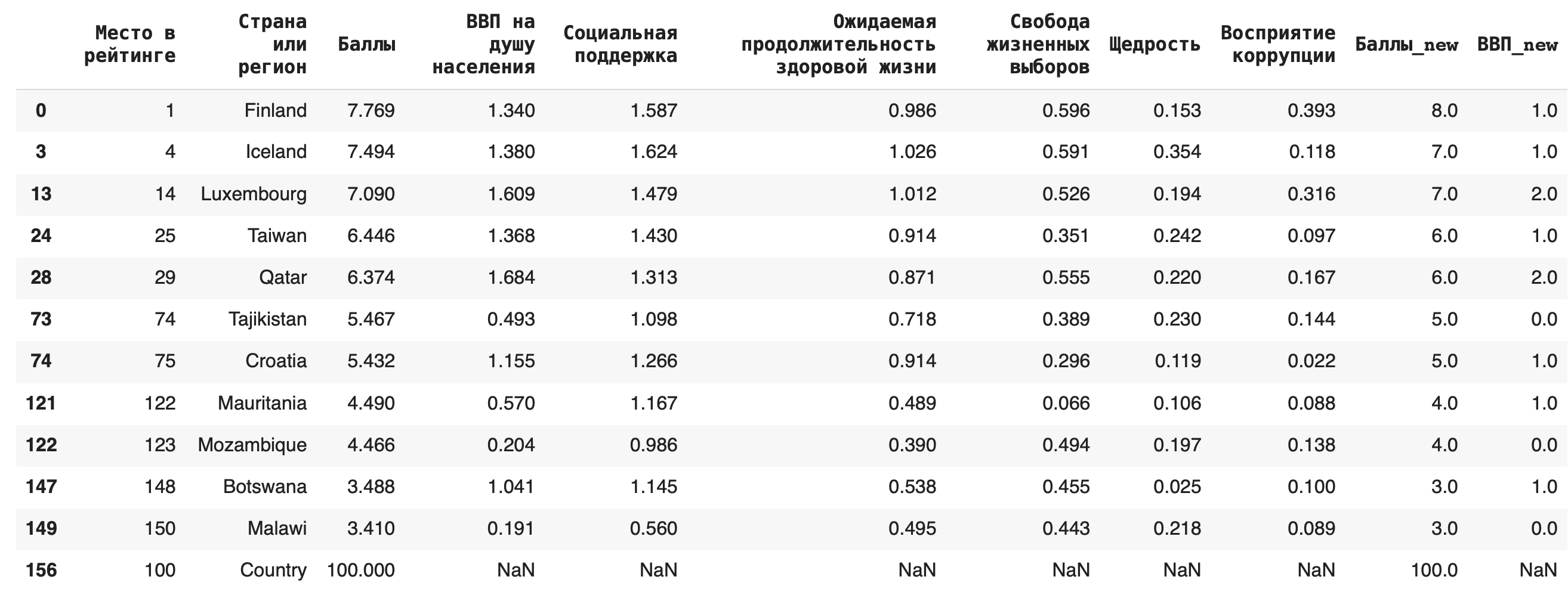
1) Удаление дубликатов из датасета делается при помощи функции drop_duplucates(). По умолчанию удаляются только полностью идентичные строки во всем датасете, но можно указать в параметрах и отдельные столбцы. Например, после округления у нас появились дубликаты в столбцах «ВВП_new» и «Баллы_new», удалим их: df_copied = df.copy() df_copied.drop_duplicates(subset = [‘ВВП_new’, ‘Баллы_new’])
Этот метод не требует дополнительного присваивания в исходную переменную, чтобы результат сохранился, — поэтому предварительно создадим копию нашего датасета, чтобы не форматировать исходный.
Строки-дубликаты удаляются полностью, таким образом, их количество уменьшается. Чтобы заменить их на пустые, можно использовать параметр inplace = True. df_copied.drop_duplicates(subset = [‘ВВП_new’, ‘Баллы_new’], inplace = True)
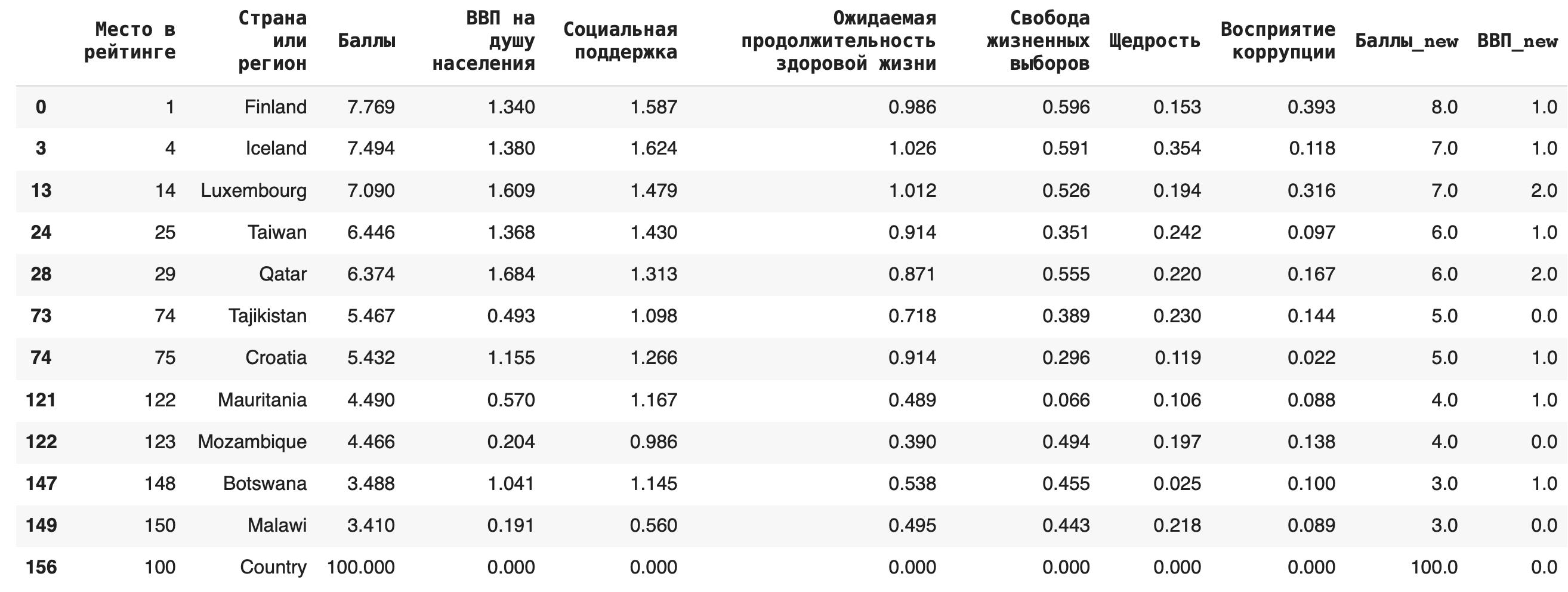
2) Для замены пропусков NaN на какое-либо значение используется функция fillna(). Например, заполним появившиеся после предыдущего пункта пропуски в последней строке нулями: df_copied.fillna(0)
3) Пустые строки с NaN можно и вовсе удалить из датасета, для этого используется функция dropna() (можно также дополнительно указать параметр inplace = True): df_copied.dropna()
Построение графиков
В Pandas есть также инструменты для простой визуализации данных.
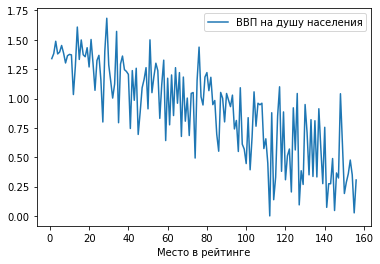
1) Обычный график по точкам.
Построим зависимость ВВП на душу населения от места в рейтинге: df.plot(x = ‘Место в рейтинге’, y = ‘ВВП на душу населения’)
2) Гистограмма.
Отобразим ту же зависимость в виде столбчатой гистограммы: df.plot.hist(x = ‘Место в рейтинге’, y = ‘ВВП на душу населения’)
3) Точечный график.
df.plot.scatter(x = ‘Место в рейтинге’, y = ‘ВВП на душу населения’)
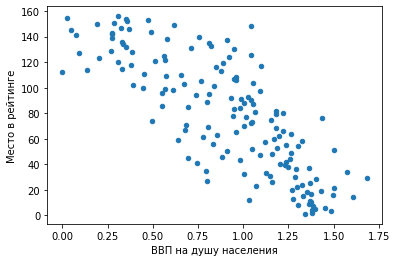
Мы видим предсказуемую тенденцию: чем выше ВВП на душу населения, тем ближе страна к первой строчке рейтинга.
Сохранение датафрейма на компьютер
Сохраним наш датафрейм на компьютер: df.to_csv(‘WHR_2019.csv’)
Теперь с ним можно работать и в других программах.
Блокнот с кодом можно скачать здесь (формат .ipynb).
Получение первых N строк в DataFrame Pandas
Чтобы получить первые N строк DataFrame Pandas, используйте функцию head(). Вы можете передать необязательное целое число, представляющее первые N строк. Если вы не передадите никакого числа, он вернет первые 5 строк, это означает, что по умолчанию N равно 5.
Пример 1
В этом примере мы получим первые 3 строки.
import pandas as pd #initialize a dataframe df = pd.DataFrame( [[21, 72, 67], [23, 78, 62], [32, 74, 56], [73, 88, 67], [32, 74, 56], [43, 78, 69], [32, 74, 54], [52, 54, 76]], columns=['a', 'b', 'c']) #get first 3 rows df1 = df.head(3) #print the dataframe print(df1)

Пример 2
В этом примере мы не будем передавать какое-либо число в функцию head(), которая по умолчанию возвращает первые 5 строк.
import pandas as pd #initialize a dataframe df = pd.DataFrame( [[21, 72, 67], [23, 78, 62], [32, 74, 56], [73, 88, 67], [32, 74, 56], [43, 78, 69], [32, 74, 54], [52, 54, 76]], columns=['a', 'b', 'c']) #get first default number of rows df1 = df.head() #print the dataframe print(df1)

В этом руководстве по Pandas мы извлекли первые N строк, используя метод head() с помощью примеров программ Python.
Изучаем pandas. Урок 3. Доступ к данным в структурах pandas


В рамках этого урока будет подробно раскрыт вопрос доступа к данным в структурах Series и DataFrame . Также рассмотрены вопросы использования атрибутов, добавления элементов данных в структуры, выборка с использованием условных выражений и многое другое.
- Два подхода получения доступа к данным в pandas
- Использование различных способов доступа к данным
- Доступ к данным структуры Series
- Доступ с использованием меток
- Доступ с использованием целочисленных индексов
- Обращение через callable функцию
- Обращение через логическое выражение
- Доступ с использованием меток
- Обращение через callable функцию
- Обращение через логическое выражение
Два подхода получения доступа к данным в pandas
При работе со структурами Series и DataFrame из библиотеки pandas , как правило, используют два основных способа получения значений элементов.
Первый способ основан на использовании меток, в этом случае работа ведется через метод .loc . Если вы обращаетесь к отсутствующей метке, то будет сгенерировано исключение KeyError .
Такой подход позволяет использовать:
- метки в виде отдельных символов [‘ a ’] или чисел [5], числа используются в качестве меток, если при создании структуры не был указан список с метками;
- список меток [‘ a ’, ‘ b ’, ‘ c ’];
- слайс меток [‘ a ’:’ c ’];
- массив логических переменных;
- callable функция с одним аргументом.
Второй способ основан на использовании целых чисел для доступа к данных, он предоставляется через метод .iloc . При использовании .iloc , если вы обращаетесь к несуществующему элементу, то будет сгенерировано исключение IndexError . Логика использования .iloc очень похожа на работу с .loc . При таком подходе можно использовать:
- отдельные целые числа для доступа к элементам структуры;
- массивы целых чисел [0, 1, 2];
- слайсы целых чисел [1:4];
- массивы логических переменных;
- callable функцию с одним аргументом.
В зависимости от типа используемой структуры, будет меняться форма .loc :
- для Series , она выглядит так: s.loc[indexer] ;
- для DataFrame так: df.loc[row_indexer, column_indexer].
Использование различных способов доступа к данным
Создадим объекты типов Series и DataFrame , которые в дальнейшем будут использованы для экспериментов. Для этого сначала импортируем необходимые библиотеки.
In [1]: import pandas as pd
Создадим структуру Series.
In [3]: s = pd.Series([10, 20, 30, 40, 50], ['a', 'b', 'c', 'd', 'e']) In [4]: s['a'] Out[4]: 10 In [5]: s Out[5]: a 10 b 20 c 30 d 40 e 50 dtype: int64
Создадим структуру DataFrame .
In [6]: d = "price":[1, 2, 3], "count": [10, 20, 30], "percent": [24, 51, 71]> In [7]: df = pd.DataFrame(d, index=['a', 'b', 'c']) In [8]: df Out[8]: count percent price a 10 24 1 b 20 51 2 c 30 71 3
Доступ к данным структуры Series
Доступ с использованием меток
При использовании меток для доступа к данным можно применять один из следующих подходов:
- первый, когда вы записываете имя переменной типа Series и в квадратных скобках указываете метку, по которой хотите обратиться (пример: s[‘a’] );
- второй, когда после имени переменной пишите .loc и далее указываете метку в квадратных скобках (пример: s.loc[‘a’] ).
Обращение по отдельной метке.
Получение элементов с меткой ‘a’ :
In [9]: s['a'] Out[9]: 10
Обращение по массиву меток.
Получение элементов с метками ‘a’, ‘c’ и ‘e’:
In [10]: s[['a', 'c', 'e']] Out[10]: a 10 c 30 e 50 dtype: int64
Обращение по слайсу меток.
Получение элементов структуры с метками от ‘a’ до ‘e’ :
In [11]: s['a':'e'] Out[11]: a 10 b 20 c 30 d 40 e 50 dtype: int64
Доступ с использованием целочисленных индексов
При работе с целочисленными индексами, индекс можно ставить сразу после имени переменной в квадратных скобках (пример: s[1] ), или можно воспользоваться .iloc (пример: s.iloc[1] ).
Обращение по отдельному индексу.
Получение элемента с индексом 1:
In [12]: s[1] Out[12]: 20
Обращение с использованием списка индексов.
Получение элементов с индексами 1, 2 и 3.
In [13]: s[[1, 2 ,3]] Out[13]: b 20 c 30 d 40 dtype: int64
Обращение по слайсу индексов.
Получение первых трех элементов структуры:
In [14]: s[:3] Out[14]: a 10 b 20 c 30 dtype: int64
Обращение через callable функцию
При таком подходе в квадратных скобках указывается не индекс или метка, а функция (как правило, это лямбда функция), которая используется для выборки элементов структуры.
Получение всех элементов, значение которых больше либо равно 30:
In [15]: s[lambda x: x>= 30] Out[15]: c 30 d 40 e 50 dtype: int64
Обращение через логическое выражение
Данный подход похож на использование callable функции: в квадратных скобках записывается логическое выражение, согласно которому будет произведен отбор.
Получение всех элементов, значение которых больше 30:
In [16]: s[s > 30] Out[16]: d 40 e 50 dtype: int64
Доступ к данным структуры DataFrame
Доступ с использованием меток
Рассмотрим различные варианты использования меток, которые могут являться как именами столбцов таблицы, так и именами строк.
Обращение к конкретному столбцу.
Получение всех элементов столбца ‘count’ :
In [17]: df['count'] Out[17]: a 10 b 20 c 30 Name: count, dtype: int64
Обращение с использованием массива столбцов.
Получение элементов столбцов ‘count’ и ‘price’ :
In [18]: df[['count','price']] Out[18]: count price a 10 1 b 20 2 c 30 3
Обращение по слайсу меток.
Получение элементов с метками от ‘a’ до ‘b’ .
In [19]: df['a':'b'] Out[19]: count percent price a 10 24 1 b 20 51 2
Обращение через callable функцию
Подход в работе с callable функцией для DataFrame аналогичен тому, что используется для Series , только при формировании условий необходимо дополнительно указывать имя столбца.
Получение всех элементов, у которых значение в столбце ‘count’ больше 15:
In [20]: df[lambda x: x['count'] > 15] Out[20]: count percent price b 20 51 2 c 30 71 3
Обращение через логическое выражение
При формировании логического выражения необходимо указывать имена столбцов, также как и при работе с callable функциями, по которым будет производиться выборка.
Получить все элементы, у которых ‘price’ больше либо равен 2.
In [21]: df[df['price'] >= 2] Out[21]: count percent price b 20 51 2 c 30 71 3
Использование атрибутов для доступа к данным
Для доступа к данным можно использовать атрибуты структур, в качестве которых выступают метки.
Начнем со структуры Series .
Воспользуемся уже знакомой нам структурой.
In [3]: s = pd.Series([10, 20, 30, 40, 50], ['a', 'b', 'c', 'd', 'e'])
Для доступа к элементу через атрибут необходимо указать его через точку после имени переменной.
In [4]: s.a Out[4]: 10 In [5]: s.c Out[5]: 30
Т.к. структура s имеет метки ‘a’, ‘b’, ‘c’, ‘d’, ‘e’ , то для доступа к элементу с меткой ‘a’ мы может использовать синтаксис s.a .
Этот же подход можно применить для переменной типа DataFrame .
In [6]: d = "price":[1, 2, 3], "count": [10, 20, 30], "percent": [24, 51, 71]> In [6]: df = pd.DataFrame(d, index=['a', 'b', 'c'])
Получим доступ к столбцу ‘price’ .
In [7]: df.price Out[7]: a 1 b 2 c 3 Name: price, dtype: int64
Получение случайного набора из структур pandas
Библиотека pandas предоставляет возможность получить случайный набор данных из уже существующей структуры. Такой функционал предоставляет как Series так и DataFrame . У данных структур есть метод sample() , предоставляющий случайную подвыборку.
Начнем наше знакомство с этим методом на примере структуры Series .
In [3]: s = pd.Series([10, 20, 30, 40, 50], ['a', 'b', 'c', 'd', 'e'])
Для того, чтобы выбрать случайным образом элемент из Series воспользуйтесь следующим синтаксисом.
In [4]: s.sample() Out[4]: c 30 dtype: int64
Можно сделать выборку из нескольких элементов, для этого нужно передать нужное количество через параметр n .
In [5]: s.sample(n=3) Out[5]: e 50 a 10 b 20 dtype: int64
Также есть возможность указать долю от общего числа объектов в структуре, используя параметр frac .
In [6]: s.sample(frac=0.3) Out[6]: a 10 c 30 dtype: int64
Очень интересной особенностью является то, что мы можем передать вектор весов, длина которого должна быть равна количеству элементов в структуре. Сумма весов должна быть равна единице, вес, в данном случае, это вероятность появления элемента в выборке.
В нашей тестовой структуре пять элементов, сформируем вектор весов для нее и сделаем выборку из трех элементов.
In [7]: w = [0.1, 0.2, 0.5, 0.1, 0.1] In [8]: s.sample(n = 3, weights=w) Out[8]: c 30 e 50 a 10 dtype: int64
Данный функционал также доступен и для структуры DataFrame .
In [9]: d = "price":[1, 2, 3, 5, 6], "count": [10, 20, 30, 40, 50], "percent": [24, 51, 71, 25, 42]> In [10]: df = pd.DataFrame(d) In [11]: df.sample() Out[11]: count percent price 0 10 24 1
При работе с DataFrame можно указать ось.
df.sample(axis=1) Out[12]: count 0 10 1 20 2 30 3 40 4 50
In [13]: df.sample(n=2, axis=1) Out[13]: count price 0 10 1 1 20 2 2 30 3 3 40 5 4 50 6
In [14]: df.sample(n=2) Out[14]: count percent price 4 50 42 6 3 40 25 5
Добавление элементов в структуры
Увеличение размера структуры – т.е. добавление новых, дополнительных, элементов – это довольно распространенная задача. В pandas она решается очень просто. И самый быстрый способ понять, как это делать – попробовать реализовать эту задачу на практике.
Добавление нового элемента в структуру Series .
In [3]: s = pd.Series([10, 20, 30, 40, 50], ['a', 'b', 'c', 'd', 'e']) In [4]: s Out[4]: a 10 b 20 c 30 d 40 e 50 dtype: int64 In [5]: s['f'] = 60 In [6]: s Out[6]: a 10 b 20 c 30 d 40 e 50 f 60 dtype: int64
Добавление нового элемента в структуру DataFrame .
In [3]: d = "price":[1, 2, 3, 5, 6], "count": [10, 20, 30, 40, 50], "percent": [24, 51, 71, 25, 42]> In [4]: df Out[4]: count percent price 0 10 24 1 1 20 51 2 2 30 71 3 3 40 25 5 4 50 42 6 In [5]: df['value'] = [3, 14, 7, 91, 5] In [6]: df Out[6]: count percent price value 0 10 24 1 3 1 20 51 2 14 2 30 71 3 7 3 40 25 5 91 4 50 42 6 5
Индексация с использованием логических выражений
На практике очень часто приходится получать определенную подвыборку из существующего набора данных. Например, получить все товары, скидка на которые больше пяти процентов, или выбрать из базы информацию о сотрудниках мужского пола старше 30 лет. Это очень похоже на процесс фильтрации при работе с таблицами или получение выборки из базы данных. Похожий функционал реализован в pandas и мы уже касались этого вопроса, когда рассматривали различные подходы к индексации.
Условное выражение записывается вместо индекса в квадратных скобках при обращении к элементам структуры.
При работе с Series возможны следующие варианты использования.
In [3]: s = pd.Series([10, 20, 30, 40, 50, 10, 10], ['a', 'b', 'c', 'd', 'e', 'f', 'g']) In [4]: s[s>30] Out[4]: d 40 e 50 dtype: int64 In [5]: s[s==10] Out[5]: a 10 f 10 g 10 dtype: int64 In [6]: s[(s>=30) & (s50)] Out[6]: c 30 d 40 dtype: int64
При работе с DataFrame необходимо указывать столбец по которому будет производиться фильтрация (выборка).
In [3]: d = "price":[1, 2, 3, 5, 6], "count": [10, 20, 30, 40, 50], "percent": [24, 51, 71, 25, 42], . : "cat":["A", "B", "A", "A", "C"]> In [4]: df = pd.DataFrame(d) In [5]: df Out[5]: cat count percent price 0 A 10 24 1 1 B 20 51 2 2 A 30 71 3 3 A 40 25 5 4 C 50 42 6 In [6]: df[df["price"] > 3] Out[6]: cat count percent price 3 A 40 25 5 4 C 50 42 6
В качестве логического выражения можно использовать довольно сложные конструкции с использованием map , filter , лямбда-выражений и т.п.
In [7]: fn = df["cat"].map(lambda x: x == "A") In [8]: df[fn] Out[8]: cat count percent price 0 A 10 24 1 2 A 30 71 3 3 A 40 25 5
Использование isin для работы с данными в pandas
По структурам данных pandas можно строить массивы с данными типа boolean , по которому можно проверить наличие или отсутствие того или иного элемента. Проще всего это показать на примере.
In [3]: s = pd.Series([10, 20, 30, 40, 50, 10, 10], ['a', 'b', 'c', 'd', 'e', 'f', 'g']) In [4]: s.isin([10, 20]) Out[4]: a True b True c False d False e False f True g True dtype: bool
Работа с DataFrame аналогична работе со структурой Series .
In [3]: df = pd.DataFrame("price":[1, 2, 3, 5, 6], "count": [10, 20, 30, 40, 50], "percent": [24, 51, 71, 25, 42]>) In [4]: df.isin([1, 3, 25, 30, 10]) Out[4]: count percent price 0 True False True 1 False False False 2 True False True 3 False True False 4 False False False
P.S.
Раздел: Pandas Python Машинное обучение и анализ данных Метки: Pandas, Python
Изучаем pandas. Урок 3. Доступ к данным в структурах pandas : 4 комментария
- Владимир Хлуденьков 08.02.2021 Большое спасибо за уроки!
Но не нашёл на странице кнопки навигации “Следующий урок” (может она спряталась?).
Было бы намного удобнее.
- Доступ к данным структуры Series