Строки
Материал на этой странице устарел, поэтому скрыт из оглавления сайта.
Есть ряд улучшений и новых методов для строк.
Начнём с, пожалуй, самого важного.
Строки-шаблоны
Добавлен новый вид кавычек для строк:
let str = `обратные кавычки`;Основные отличия от двойных «…» и одинарных ‘…’ кавычек:
-
В них разрешён перевод строки. Например:
alert(`моя многострочная строка`);'use strict'; let apples = 2; let oranges = 3; alert(`$ + $ = $`); // 2 + 3 = 5Функции шаблонизации
Можно использовать свою функцию шаблонизации для строк.
Название этой функции ставится перед первой обратной кавычкой:
let str = func`моя строка`;Эта функция будет автоматически вызвана и получит в качестве аргументов строку, разбитую по вхождениям параметров $ и сами эти параметры.
'use strict'; function f(strings, . values) < alert(JSON.stringify(strings)); // ["Sum of "," + "," =\n ","!"] alert(JSON.stringify(strings.raw)); // ["Sum of "," + "," =\\n ","!"] alert(JSON.stringify(values)); // [3,5,8] >let apples = 3; let oranges = 5; // | s[0] | v[0] |s[1]| v[1] |s[2] | v[2] |s[3] let str = f`Sum of $ + $ =\n $!`;В примере выше видно, что строка разбивается по очереди на части: «кусок строки» – «параметр» – «кусок строки» – «параметр».
- Участки строки идут в первый аргумент-массив strings .
- У этого массива есть дополнительное свойство strings.raw . В нём находятся строки в точности как в оригинале. Это влияет на спец-символы, например в strings символ \n – это перевод строки, а в strings.raw – это именно два символа \n .
- Дальнейший список аргументов функции шаблонизации – это значения выражений в $ , в данном случае их три.
Зачем strings.raw ?
В отличие от strings , в strings.raw содержатся участки строки в «изначально введённом» виде.
То есть, если в строке находится \n или \u1234 или другое особое сочетание символов, то оно таким и останется.
Это нужно в тех случаях, когда функция шаблонизации хочет произвести обработку полностью самостоятельно (свои спец. символы?). Или же когда обработка спец. символов не нужна – например, строка содержит «обычный текст», набранный непрограммистом без учёта спец. символов.
Как видно, функция имеет доступ ко всему: к выражениям, к участкам текста и даже, через strings.raw – к оригинально введённому тексту без учёта стандартных спец. символов.
Функция шаблонизации может как-то преобразовать строку и вернуть новый результат.
В простейшем случае можно просто «склеить» полученные фрагменты в строку:
'use strict'; // str восстанавливает строку function str(strings, . values) < let str = ""; for(let i=0; i// последний кусок строки str += strings[strings.length-1]; return str; > let apples = 3; let oranges = 5; // Sum of 3 + 5 = 8! alert( str`Sum of $ + $ = $!`);Функция str в примере выше делает то же самое, что обычные обратные кавычки. Но, конечно, можно пойти намного дальше. Например, генерировать из HTML-строки DOM-узлы (функции шаблонизации не обязательно возвращать именно строку).
Или можно реализовать интернационализацию. В примере ниже функция i18n осуществляет перевод строки.
Она подбирает по строке вида «Hello, $!» шаблон перевода «Привет, !» (где – место для вставки параметра) и возвращает переведённый результат со вставленным именем name :
'use strict'; let messages = < "Hello, !": "Привет, !" >; function i18n(strings, . values) < // По форме строки получим шаблон для поиска в messages // На месте каждого из значений будет его номер: , , … let pattern = ""; for(let i=0; i'; > pattern += strings[strings.length-1]; // Теперь pattern = "Hello, !" let translated = messages[pattern]; // "Привет, !" // Заменит в "Привет, " цифры вида на values[num] return translated.replace(/\/g, (s, num) => values[num]); > // Пример использования let name = "Вася"; // Перевести строку alert( i18n`Hello, $!` ); // Привет, Вася!Итоговое использование выглядит довольно красиво, не правда ли?
Разумеется, эту функцию можно улучшить и расширить. Функция шаблонизации – это своего рода «стандартный синтаксический сахар» для упрощения форматирования и парсинга строк.
Улучшена поддержка Юникода
Внутренняя кодировка строк в JavaScript – это UTF-16, то есть под каждый символ отводится ровно два байта.
Но под всевозможные символы всех языков мира 2 байт не хватает. Поэтому бывает так, что одному символу языка соответствует два Юникодных символа (итого 4 байта). Такое сочетание называют «суррогатной парой».
Самый частый пример суррогатной пары, который можно встретить в литературе – это китайские иероглифы.
Заметим, однако, что не всякий китайский иероглиф – суррогатная пара. Существенная часть «основного» Юникод-диапазона как раз отдана под китайский язык, поэтому некоторые иероглифы – которые в неё «влезли» – представляются одним Юникод-символом, а те, которые не поместились (реже используемые) – двумя.
alert( '我'.length ); // 1 alert( '��'.length ); // 2В тексте выше для первого иероглифа есть отдельный Юникод-символ, и поэтому длина строки 1 , а для второго используется суррогатная пара. Соответственно, длина – 2 .
Китайскими иероглифами суррогатные пары, естественно, не ограничиваются.
Ими представлены редкие математические символы, а также некоторые символы для эмоций, к примеру:
alert( '��'.length ); // 2, MATHEMATICAL SCRIPT CAPITAL X alert( '��'.length ); // 2, FACE WITH TEARS OF JOYВ современный JavaScript добавлены методы String.fromCodePoint и str.codePointAt – аналоги String.fromCharCode и str.charCodeAt , корректно работающие с суррогатными парами.
Например, charCodeAt считает суррогатную пару двумя разными символами и возвращает код каждой:
// как будто в строке два разных символа (на самом деле один) alert( '��'.charCodeAt(0) + ' ' + '��'.charCodeAt(1) ); // 55349 56499…В то время как codePointAt возвращает его Unicode-код суррогатной пары правильно:
// один символ с "длинным" (более 2 байт) unicode-кодом alert( '��'.codePointAt(0) ); // 119987Метод String.fromCodePoint(code) корректно создаёт строку из «длинного кода», в отличие от старого String.fromCharCode(code) .
// Правильно alert( String.fromCodePoint(119987) ); // �� // Неверно! alert( String.fromCharCode(119987) ); // 풳Более старый метод fromCharCode в последней строке дал неверный результат, так как он берёт только первые два байта от числа 119987 и создаёт символ из них, а остальные отбрасывает.
\u
Есть и ещё синтаксическое улучшение для больших Unicode-кодов.
В JavaScript-строках давно можно вставлять символы по Unicode-коду, вот так:
alert( "\u2033" ); // ″, символ двойного штрихаСинтаксис: \uNNNN , где NNNN – четырёхзначный шестнадцатиричный код, причём он должен быть ровно четырёхзначным.
«Лишние» цифры уже не войдут в код, например:
alert( "\u20331" ); // Два символа: символ двойного штриха ″, а затем 1Чтобы вводить более длинные коды символов, добавили запись \u , где NNNNNNNN – максимально восьмизначный (но можно и меньше цифр) код.
alert( "\u" ); // ��, китайский иероглиф с этим кодомUnicode-нормализация
Во многих языках есть символы, которые получаются как сочетание основного символа и какого-то значка над ним или под ним.
Например, на основе обычного символа a существуют символы: àáâäãåā . Самые часто встречающиеся подобные сочетания имеют отдельный Юникодный код. Но отнюдь не все.
Для генерации произвольных сочетаний используются несколько Юникодных символов: основа и один или несколько значков.
Например, если после символа S идёт символ «точка сверху» (код \u0307 ), то показано это будет как «S с точкой сверху» Ṡ .
Если нужен ещё значок над той же буквой (или под ней) – без проблем. Просто добавляем соответствующий символ.
К примеру, если добавить символ «точка снизу» (код \u0323 ), то будет «S с двумя точками сверху и снизу» Ṩ .
Пример этого символа в JavaScript-строке:
alert("S\u0307\u0323"); // ṨТакая возможность добавить произвольной букве нужные значки, с одной стороны, необходима, а с другой стороны – возникает проблемка: можно представить одинаковый с точки зрения визуального отображения и интерпретации символ – разными сочетаниями Unicode-кодов.
alert("S\u0307\u0323"); // Ṩ alert("S\u0323\u0307"); // Ṩ alert( "S\u0307\u0323" == "S\u0323\u0307" ); // falseВ первой строке после основы S идёт сначала значок «верхняя точка», а потом – нижняя, во второй – наоборот. По кодам строки не равны друг другу. Но символ задают один и тот же.
С целью разрешить эту ситуацию, существует Юникодная нормализация, при которой строки приводятся к единому, «нормальному», виду.
В современном JavaScript это делает метод str.normalize().
alert( "S\u0307\u0323".normalize() == "S\u0323\u0307".normalize() ); // trueЗабавно, что в данной конкретной ситуации normalize() приведёт последовательность из трёх символов к одному: \u1e68 (S с двумя точками).
alert( "S\u0307\u0323".normalize().length ); // 1, нормализовало в один символ alert( "S\u0307\u0323".normalize() == "\u1e68" ); // trueЭто, конечно, не всегда так, просто в данном случае оказалось, что именно такой символ в Юникоде уже есть. Если добавить значков, то нормализация уже даст несколько символов.
Для большинства практических задач информации, данной выше, должно быть вполне достаточно, но если хочется более подробно ознакомиться с вариантами и правилами нормализации – они описаны в приложении к стандарту Юникод Unicode Normalization Forms.
Полезные методы
Добавлен ряд полезных методов общего назначения:
- str.includes(s) – проверяет, включает ли одна строка в себя другую, возвращает true/false .
- str.endsWith(s) – возвращает true , если строка str заканчивается подстрокой s .
- str.startsWith(s) – возвращает true , если строка str начинается со строки s .
- str.repeat(times) – повторяет строку str times раз.
Конечно, всё это можно было сделать при помощи других встроенных методов, но новые методы более удобны.
Итого
- Строки-шаблоны – для удобного задания строк (многострочных, с переменными), плюс возможность использовать функцию шаблонизации для самостоятельного форматирования.
- Юникод – улучшена работа с суррогатными парами.
- Полезные методы для проверок вхождения одной строки в другую.
Руководство по JavaScript, часть 6: исключения, точка с запятой, шаблонные литералы
Темами сегодняшней части перевода руководства по JavaScript станут обработка исключений, особенности автоматической расстановки точек с запятой и шаблонные литералы.

Обработка исключений
Когда при выполнении кода возникает какая-нибудь проблема, в JavaScript она выражается в виде исключения. Если не предпринять меры по обработке исключений, то, при их возникновении, выполнение программы останавливается, а в консоль выводится сообщение об ошибке.
Рассмотрим следующий фрагмент кода.
let obj = let notObj let fn = (a) => a.value console.log(fn(obj)) //message text console.log('Before') //Before console.log(fn(notObj)) //ошибка, выполнение программы останавливается console.log('After')Здесь у нас имеется функция, которую планируется использовать для обработки объектов, имеющих свойство value . Она возвращает это свойство. Если использовать эту функцию по назначению, то есть — передать ей такой объект, на работу с которым она рассчитана, при её выполнении ошибок выдано не будет. А вот если передать ей нечто неподходящее, в нашем случае — объявленную, но неинициализированную переменную, то при попытке обратиться к свойству value значения undefined произойдёт ошибка. В консоль попадёт сообщение об ошибке, выполнение программы остановится.
Вот как это выглядит при запуске данного кода в среде Node.js.
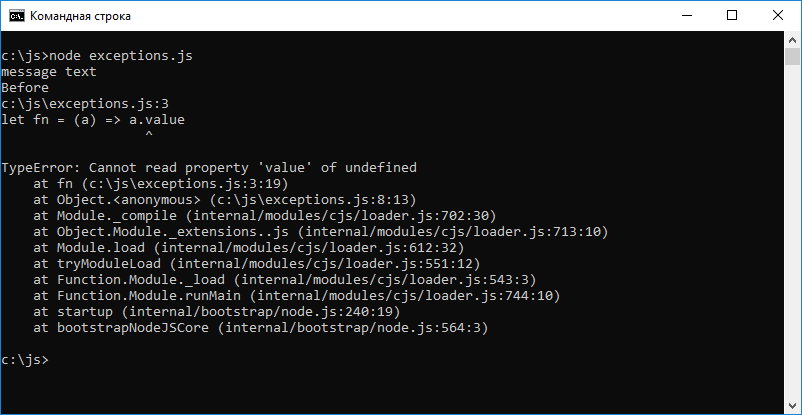
Исключение TypeError в Node.js
Если нечто подобное встретится в JS-коде веб-страницы, в консоль браузера попадёт похожее сообщение. Если такое произойдёт в реальной программе, скажем — в коде веб-сервера, подобное поведение крайне нежелательно. Хорошо было бы иметь механизм, который позволяет, не останавливая программу, перехватить ошибку, после чего принять меры по её исправлению. Такой механизм в JavaScript существует, он представлен конструкцией try. catch .
▍Конструкция try. catch
Конструкция try. catch позволяет перехватывать и обрабатывать исключения. А именно, в неё входит блок try , в который включают код, способный вызвать ошибку, и блок catch , в который передаётся управление при возникновении ошибки. В блоки try не включают абсолютно весь код программы. Туда помещают те его участки, которые могут вызвать ошибки времени выполнения. Например — вызовы функций, которым приходится работать с некими данными, полученными из внешних источников. Если структура таких данных отличается от той, которую ожидает функция, возможно возникновение ошибки. Вот как выглядит схема конструкции try. catch .
try < //строки кода, которые могут вызвать ошибку >catch (e) < //обработка ошибки >Если код выполняется без ошибок — блок catch (обработчик исключения) не выполняется. Если же возникает ошибка — туда передаётся объект ошибки и там выполняются некие действия по борьбе с этой ошибкой.
Применим эту конструкцию в нашем примере, защитив с её помощью опасные участки программы — те, в которых вызывается функция fn() .
let obj = let notObj let fn = (a) => a.value try < console.log(fn(obj)) >catch (e) < console.log(e.message) >console.log('Before') //Before try < console.log(fn(notObj)) >catch (e) < console.log(e.message) //Cannot read property 'value' of undefined >console.log('After') //AfterПосмотрим на результаты выполнения этого кода в среде Node.js.
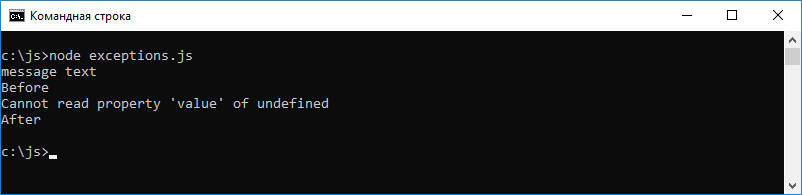
Обработка ошибки в Node.js
Как видите, если сравнить этот пример с предыдущим, теперь выполняется весь код, и тот, что расположен до проблемной строки, и тот, что расположен после неё. Мы «обрабатываем» ошибку, просто выводя в консоль значения свойства message объекта типа Error. В чём будет заключаться обработка ошибки, возникшей в реально используемом коде, зависит от ошибки.
Выше мы обсудили блок try. catch , но, на самом деле, эта конструкция включает в себя ещё один блок — finally .
▍Блок finally
Блок finally содержит код, который выполняется независимо от того, возникла или нет ошибка в коде, выполняющемся в блоке try . Вот как это выглядит.
try < //строки кода >catch (e) < //обработка ошибки >finally < //освобождение ресурсов >Блок finally можно использовать и в том случае, если в блоке try. catch. finally отсутствует блок catch . При таком подходе он используется так же, как и в конструкции с блоком catch , например — для освобождения ресурсов, занятых в блоке try .
▍Вложенные блоки try
Блоки try могут быть вложены друг в друга. При этом исключение обрабатывается в ближайшем блоке catch .
try < //строки кода try < //другие строки кода >finally < //ещё какой-то код >> catch (e)
В данном случае, если исключение возникнет во внутреннем блоке try , обработано оно будет во внешнем блоке catch .
▍Самостоятельное генерирование исключений
Исключения можно генерировать самостоятельно, пользуясь инструкцией throw . Вот как это выглядит.
throw valueПосле того, как выполняется эта инструкция, управление передаётся в ближайший блок catch , или, если такого блока найти не удаётся, выполнение программы прекращается. Значением исключения может быть всё что угодно. Например — определённый пользователем объект ошибки.
О точках с запятой
Использовать точки с запятой в JavaScript-коде необязательно. Некоторые программисты обходятся без них, полагаясь на автоматическую систему их расстановки, и ставя их только там, где это совершенно необходимо. Некоторые предпочитают ставить их везде, где это возможно. Автор этого материала относит себя к той категории программистов, которые стремятся обходиться без точек с запятой. Он говорит, что решил обходиться без них осенью 2017 года, настроив Prettier так, чтобы он удалял их везде, где без их явной вставки можно обойтись. По его мнению код без точек с запятой выглядит естественнее и его легче читать.
Пожалуй, можно сказать, что сообщество JS-разработчиков разделено, по отношению к точкам с запятой, на два лагеря. При этом существуют и руководства по стилю JavaScript, которые предписывают явную расстановки точек с запятой, и руководства, которые рекомендуют обходиться без них.
Всё это возможно из-за того, что в JavaScript существует система автоподстановки точек с запятой (Automatic Semicolon Insertion, ASI). Однако, то, что в JS коде, во многих ситуациях, можно обойтись без этих символов, и то, что точки с запятой расставляются автоматически, при подготовке кода к выполнению, не означает, что программисту не нужно знать правила, по которым это происходит. Незнание этих правил приводит к появлению ошибок.
▍Правила автоподстановки точек с запятой
Парсер JavaScript-кода автоматически добавляет точки с запятой при разборе текста программы в следующих ситуациях:
- Когда следующая строка начинается с кода, который прерывает текущий код (код некоей команды может располагаться на нескольких строках).
- Когда следующая строка начинается с символа > , который закрывает текущий блок.
- Когда обнаружен конец файла с кодом программы.
- В строке с командой return .
- В строке с командой break .
- В строке с командой throw .
- В строке с командой continue .
▍Примеры кода, который работает не так, как ожидается
Вот некоторые примеры, иллюстрирующие вышеприведённые правила. Например, как вы думаете, что будет выведено в результате выполнения следующего фрагмента кода?
const hey = 'hey' const you = 'hey' const heyYou = hey + ' ' + you ['h', 'e', 'y'].forEach((letter) => console.log(letter))При попытке выполнения этого кода будет выдана ошибка Uncaught TypeError: Cannot read property ‘forEach’ of undefined система, основываясь на правиле №1, пытается интерпретировать код следующим образом.
const hey = 'hey'; const you = 'hey'; const heyYou = hey + ' ' + you['h', 'e', 'y'].forEach((letter) => console.log(letter))Проблему можно решить, самостоятельно поставив точку с запятой после предпоследней строки первого примера.
Вот ещё один фрагмент кода.
(1 + 2).toString()Результатом его выполнения станет вывод строки «3» . А что произойдёт, если нечто подобное появится в следующем фрагменте кода?
const a = 1 const b = 2 const c = a + b (a + b).toString()В данной ситуации появится ошибка TypeError: b is not a function так как вышеприведённый код будет интерпретирован следующим образом.
const a = 1 const b = 2 const c = a + b(a + b).toString()Взглянем теперь на пример, основанный на правиле №4.
Можно подумать, что это IIFE вернёт объект, содержащий свойство color , но на самом деле это не так. Вместо этого функция вернёт значение undefined так как система добавляет точку с запятой после команды return .
Для того чтобы решить подобную проблему, открывающую фигурную скобку объектного литерала нужно поместить в той же строке, где находится команда return .
Если взглянуть на следующий фрагмент кода, то можно подумать, что он выведет в окне сообщения 0 .
1 + 1 -1 + 1 === 0 ? alert(0) : alert(2)Но он выводит 2, так как, в соответствии с правилом №1, этот код представляется следующим образом.
1 + 1 -1 + 1 === 0 ? alert(0) : alert(2)В вопросе использования точек с запятой в JavaScript стоит проявлять осторожность. Вы можете встретить как горячих сторонников точек с запятой, так и их противников. На самом деле, решая, нужны ли в вашем коде точки с запятой, можно положиться на тот факт, что JS поддерживает их автоматическую подстановку, но при этом каждый должен сам для себя решить — нужны ли они в его коде или нет. Главное — последовательно и разумно применять выбранный подход. В том, что касается расстановки точек с запятой и структуры кода, можно порекомендовать придерживаться следующих правил:
- Пользуясь командой return , располагайте то, что она должна вернуть из функции, в той же строке, в которой находится эта команда. То же самое касается команд break , throw , continue .
- Уделяйте особое внимание ситуациям, когда новая строка кода начинается со скобки, так как эта строка может быть автоматически объединена с предыдущей и представлена системой как попытка вызова функции или попытка доступа к элементу массива.
Кавычки и шаблонные литералы
Поговорим об особенностях использования кавычек в JavaScript. А именно, речь идёт о следующих допустимых в JS-программах типах кавычек:
- Одинарные кавычки.
- Двойные кавычки.
- Обратные кавычки.
const test = 'test' const bike = "bike"Разницы между ними практически нет. Пожалуй, единственное заметное различие заключается в том, что в строках, заключённых в одинарные кавычки, нужно экранировать символ одинарной кавычки, а в строках, заключённых в двойные — символ двойной.
const test = 'test' const test = 'te\'st' const test = 'te"st' const test = "te\"st" const test = "te'st"В разных руководствах по стилю можно найти как рекомендацию по использованию одинарных кавычек, так и рекомендацию по использованию двойных кавычек. Автор этого материала говорит, что в JS-коде стремится использовать исключительно одинарные кавычки, используя двойные только в HTML-коде.
Обратные кавычки появились в JavaScript с выходом стандарта ES6 в 2015 году. Они, помимо других новых возможностей, позволяют удобно описывать многострочные строки. Такие строки можно задавать и используя обычные кавычки — с применением escape-последовательности \n . Выглядит это так.
const multilineString = 'A string\non multiple lines'Обратные кавычки (обычно кнопка для их ввода находится левее цифровой клавиши 1 на клавиатуре) позволяют обойтись без \n .
const multilineString = `A string on multiple lines`Но этим возможности обратных кавычек не ограничены. Так, если строка описана с использованием обратных кавычек, в неё, используя конструкцию $<> , можно подставлять значения, являющиеся результатом вычисления JS-выражений.
const multilineString = `A string on $ lines`Такие строки называют шаблонными литералами.
Шаблонные литералы отличаются следующими особенностями:
- Они поддерживают многострочный текст.
- Они дают возможность интерполировать строки, в них можно использовать встроенные выражения.
- Они позволяют работать с тегированными шаблонами, давая возможность создавать собственные предметно-ориентированные языки (DSL, Domain-Specific Language).
▍Многострочный текст
Задавая, с помощью обратных кавычек, многострочные тексты, нужно помнить о том, что пробелы в таких текстах так же важны, как и другие символы. Например, рассмотрим следующий многострочный текст.
const string = `First Second`Его вывод даст примерно следующее.
First SecondТо есть оказывается, что когда этот текст вводился в редакторе, то, возможно, программист ожидал, что слова First и Second , при выводе, окажутся строго друг под другом, но на самом деле это не так. Для того чтобы обойти эту проблему, можно начинать многострочный текст с перевода строки, и, сразу после закрывающей обратной кавычки, вызывать метод trim() , который удалит пробельные символы, находящиеся в начале или в конце строки. К таким символам, в частности, относятся пробелы и знаки табуляции. Удалены будут и символы конца строки.
Выглядит это так.
const string = ` First Second`.trim()▍Интерполяция
Под интерполяцией здесь понимается преобразование переменных и выражений в строки. Делается это с использованием конструкции $<> .
const variable = 'test' const string = `something $< variable >` //something testВ блок $<> можно добавлять всё что угодно — даже выражения.
const string = `something $` const string2 = `something $`В константу string попадёт текст something 6 , в константу string2 будет записан либо текст something x , либо текст something y . Это зависит от того, истинное или ложное значение вернёт функция foo() (здесь применяется тернарный оператор, который, если то, что находится до знака вопроса, является истинным, возвращает то, что идёт после знака вопроса, в противном случае возвращая то, что идёт после двоеточия).
▍Тегированные шаблоны
Тегированные шаблоны применяются во множестве популярных библиотек. Среди них — Styled Components, Apollo, GraphQL.
То, что выводят такие шаблоны, подчиняется некоей логике, задаваемой с помощью функции. Вот немного переработанный пример, приведённый в одной из наших публикаций, иллюстрирующий работу с тегированными шаблонными строками.
const esth = 8 function helper(strs, . keys) < const str1 = strs[0] //ES const str2 = strs[1] //is let additionalPart = '' if (keys[0] == 8) < //8 additionalPart = 'awesome' >else < additionalPart = 'good' >return `$$$$.` > const es = helper`ES $ is ` console.log(es) //ES 8 is awesome.Здесь, если в константе esth записано число 8 , в es попадёт строка ES 8 is awesome . В противном случае там окажется другая строка. Например, если в esth будет число 6 , то она будет выглядеть как ES 6 is good .
В Styled Components тегированные шаблоны используются для определения CSS-строк.
const Button = styled.button` font-size: 1.5em; background-color: black; color: white; `;В Apollo они применяются для определения GraphQL-запросов.
const query = gql` query < . >`Зная то, как устроены тегированные шаблоны, несложно понять, что styled.button и gql из предыдущих примеров — это просто функции.
function gql(literals, . expressions)
Например, функция gql() возвращает строку, которая может быть результатом любых вычислений. Параметр literals этой функции представляет собой массив, содержащий разбитое на части содержимое шаблонного литерала, expresions содержит результаты вычисления выражений.
Разберём следующую строку.
const string = helper`something $ `В функцию helper попадёт массив literals , содержащий два элемента. В первом будет текст something с пробелом после него, во втором — пустая строка — то есть то, что находится между выражением $ и концом строки. В массиве espressions будет один элемент — 6 .
Вот более сложный пример.
const string = helper`something another $ new line $ test`Здесь в функцию helper , в качестве первого параметра попадёт следующий массив.
[ 'something\nanother ', '\nnew line ', '\ntest' ]Второй массив будет выглядеть так.
Итоги
Сегодня мы поговорили об обработке исключений, об автоподстановке точки с запятой и о шаблонных литералах в JavaScript. В следующий раз мы рассмотрим ещё некоторые важные концепции языка. В частности — работу в строгом режиме, таймеры, математические вычисления.
Уважаемые читатели! Пользуетесь ли вы возможностями тегированных шаблонов в JavaScript?

- Блог компании RUVDS.com
- Веб-разработка
- JavaScript
Обратные одинарные кавычки — что это за символы

Обратные одинарные кавычки — это одинарные кавычки с «наклонов вправо», в то время как обычные одинарные кавычки «смотрят прямо вниз».
Пара обычных одинарных:
Пара одинарных обратных:
Обратная одинарная кавычка на клавиатуре
Находятся на клавиатуре компьютера там же, где буква Ё (в русской раскладке) — слева вверху под клавишей «Esc».
Key Words for FKN + antitotal forum (CS VSU):
Шаблонные строки
Шаблонными литералами называются строковые литералы, допускающие использование выражений внутри. С ними вы можете использовать многострочные литералы и строковую интерполяцию. В спецификациях до ES2015 они назывались «шаблонными строками».
Синтаксис
`строка текста` `строка текста 1 строка текста 2` `строка текста $ строка текста` tag `строка текста $ строка текста`
Описание
Шаблонные литералы заключены в обратные кавычки (` `) вместо двойных или одинарных. Они могут содержать подстановки, обозначаемые знаком доллара и фигурными скобками ( $ ). Выражения в подстановках и текст между ними передаются в функцию. По умолчанию функция просто объединяет все части в строку. Если перед строкой есть выражение (здесь это tag ), то шаблонная строка называется «теговым шаблоном». В этом случае, теговое выражение (обычно функция) вызывается с обработанным шаблонным литералом, который вы можете изменить перед выводом. Для экранирования обратной кавычки в шаблонных литералах указывается обратный слеш \.
`\`` === "`"; // --> true
Многострочные литералы
Символы новой строки являются частью шаблонных литералов. Используя обычные строки, вставка переноса потребовала бы следующего синтаксиса:
.log("string text line 1\n" + "string text line 2"); // "string text line 1 // string text line 2"
То же с использованием шаблонных литералов:
.log(`string text line 1 string text line 2`); // "string text line 1 // string text line 2"
Интерполяция выражений
Для вставки выражений в обычные строки вам пришлось бы использовать следующий синтаксис:
var a = 5; var b = 10; console.log("Fifteen is " + (a + b) + " and not " + (2 * a + b) + "."); // "Fifteen is 15 and not 20."
Теперь, при помощи шаблонных литералов, вам доступен «синтаксический сахар», делающий подстановки вроде той более читабельными:
var a = 5; var b = 10; console.log(`Fifteen is $a + b> and not $2 * a + b>.`); // "Fifteen is 15 and not 20."
Вложенные шаблоны
Временами, вложить шаблон — это кратчайший и, возможно, более читабельный способ составить строку. Просто поместите внутрь шаблона с обратными кавычками ещё одни, обернув их в подстановку $ < >. Например, если выражение истинно, можно вернуть шаблонный литерал.
var classes = "header"; classes += isLargeScreen() ? "" : item.isCollapsed ? " icon-expander" : " icon-collapser";
В ES2015 с шаблонными литералами без вложения:
const classes = `header $ isLargeScreen() ? "" : item.isCollapsed ? "icon-expander" : "icon-collapser" >`;
В ES2015 с вложенными шаблонными литералами:
const classes = `header $ isLargeScreen() ? "" : `icon-$item.isCollapsed ? "expander" : "collapser">` >`;
Теговые шаблоны
Расширенной формой шаблонных литералов являются теговые шаблоны. Они позволяют разбирать шаблонные литералы с помощью функции. Первый аргумент такой функции содержит массив строковых значений, а остальные содержат выражения из подстановок. В итоге, функция должна вернуть собранную строку (или что-либо совсем иное, как будет показано далее). Имя функции может быть любым.
var person = "Mike"; var age = 28; function myTag(strings, personExp, ageExp) var str0 = strings[0]; // "That " var str1 = strings[1]; // " is a " // Технически, в конце итогового выражения // (в нашем примере) есть ещё одна строка, // но она пустая (""), так что пропустим её. // var str2 = strings[2]; var ageStr; if (ageExp > 99) ageStr = "centenarian"; > else ageStr = "youngster"; > // Мы даже можем вернуть строку, построенную другим шаблонным литералом return `$str0>$personExp>$str1>$ageStr>`; > var output = myTag`That $person> is a $age>`; console.log(output); // That Mike is a youngster
Функция тега не обязана возвращать строку, как показано в примере ниже:
function template(strings, . keys) return function (. values) var dict = values[values.length - 1] || >; var result = [strings[0]]; keys.forEach(function (key, i) var value = Number.isInteger(key) ? values[key] : dict[key]; result.push(value, strings[i + 1]); >); return result.join(""); >; > var t1Closure = template`$0>$1>$0>!`; t1Closure("Y", "A"); // "YAY!" var t2Closure = template`$0> $"foo">!`; t2Closure("Hello", foo: "World" >); // "Hello World!"
Сырые строки
Специальное свойство raw , доступное для первого аргумента тегового шаблона, позволяет получить строку в том виде, в каком она была введена, без экранирования.
function tag(strings) return strings.raw[0]; > tag`string text line 1 \\n string text line 2`; // выводит "string text line 1 \\n string text line 2", // включая 'n' и два символа '\'
Вдобавок, существует метод String.raw() , возвращающий точно такую же исходную строку, какую вернула бы функция шаблона по умолчанию и строковая конкатенация вместе.
var str = String.raw`Hi\n$2 + 3>!`; // "Hi\n5!" str.length; // 6 str.split("").join(","); // "H,i,\,n,5,!"
Теговые шаблоны и экранирование символов
Поведение в ES2016
В ECMAScript 2016 теговые шаблоны следуют правилам экранирования следующих символов:
- символы Unicode, начинающиеся с «\u», например, \u00A9
- точки кода Unicode, начинающиеся с «\u<>«, например, \u
- шестнадцатеричные представления символов, начинающиеся с «\x», например, \xA9
- восьмеричные представления символов, начинающиеся с «\», например, \251
Отсюда вытекает проблема теговых шаблонов: следуя грамматике ECMAScript, анализатор кода, найдя символ \ , будет искать корректное представление символа Unicode, но может не найти его вовсе. Пример ниже показывает это:
`\unicode`; // В старых версиях ECMAScript (ES2016 и раньше) выкинет исключение: // SyntaxError: malformed Unicode character escape sequence
Поведение в ES2018
Теговые шаблоны должны позволять встраивать языки (например, DSLs или LaTeX), в которых широко используются многие другие экранирования. Предложение Редакция шаблонных литералов (уровень 4, одобренный к добавлению в стандарт ECMAScript 2018) устраняет синтаксические ограничения экранирования теговых шаблонов в ECMAScript.
Однако, некорректное экранирование символов по-прежнему нужно отображать в «приготовленном» отображении. Оно показывается в виде undefined в «приготовленном» массиве:
function latex(str) return cooked: str[0], raw: str.raw[0] >; > latex`\unicode`; //
Заметьте, что ограничение на экранирование символов проявляется лишь в теговых шаблонах, и не проявляется в нетеговых шаблонных литералах:
let bad = `bad escape sequence: \unicode`;
Спецификации
| Specification |
|---|
| ECMAScript Language Specification # sec-template-literals |
Совместимость с браузерами
BCD tables only load in the browser
Смотрите также
- String
- String.raw()
- Лексическая грамматика
- Подобные шаблонам строки в ES3-совместимом синтаксисе
- ES6 в деталях: шаблонные строки
Found a content problem with this page?
- Edit the page on GitHub.
- Report the content issue.
- View the source on GitHub.
This page was last modified on 7 авг. 2023 г. by MDN contributors.
Your blueprint for a better internet.
MDN
Support
- Product help
- Report an issue
Our communities
Developers
- Web Technologies
- Learn Web Development
- MDN Plus
- Hacks Blog
- Website Privacy Notice
- Cookies
- Legal
- Community Participation Guidelines
Visit Mozilla Corporation’s not-for-profit parent, the Mozilla Foundation.
Portions of this content are ©1998– 2023 by individual mozilla.org contributors. Content available under a Creative Commons license.