SQL — Урок 1. Создание базы данных и таблиц
Итак, вы установили MySQL, и мы начинаем осваивать язык SQL. В уроке 3 по основам баз данных, мы создали концептуальную модель маленькой БД для форума. Пришло время реализовать ее в СУБД MySQL.
Для этого прежде всего надо запустить сервер MySQL. Идем в системное меню Пуск — Программы — MySQL — MySQL Server 5.1 — MySQL Command Line Client. Откроется окно, предлагающее ввести пароль.
Нажимаем Enter на клавиатуре, если вы не указывали пароль при настройке сервера или указываем пароль, если вы его задавали. Ждем приглашения mysql>.
Нам надо создать базу данных, которую мы назовем forum. Для этого в SQL существует оператор create database. Создание базы данных имеет следующий синтаксис:
create database имя_базы_данных;
Максимальная длина имени БД составляет 64 знака и может включать буквы, цифры, символ «_» и символ «$». Имя может начинаться с цифры, но не должно полностью состоять из цифр. Любой запрос к БД заканчивается точкой с запятой (этот символ называется разделителем — delimiter). Получив запрос, сервер выполняет его и в случае успеха выдает сообщение «Query OK . «
Итак, создадим БД forum:
Нажимаем Enter и видим ответ «Query OK . «, означающий, что БД была создана:
Вот так все просто. Теперь в этой базе данных нам надо создать 3 таблицы: темы, пользователи и сообщения. Но перед тем, как это делать, нам надо указать серверу в какую именно БД мы создаем таблицы, т.е. надо выбрать БД для работы. Для этого используется оператор use. Синтаксис выбора БД для работы следующий:
use имя_базы_данных;
Итак, выберем для работы нашу БД forum:
Нажимаем Enter и видим ответ «Database changed» — база данных выбрана.
Выбирать БД необходимо в каждом сеансе работы с MySQL.
Для создания таблиц в SQL существует оператор create table. Создание базы данных имеет следующий синтаксис:
create table имя_таблицы (имя_первого_столбца тип, имя_второго_столбца тип, . имя_последнего_столбца тип );
Требования к именам таблиц и столбцов такие же, как и для имен БД. К каждому столбцу привязан определенный тип данных, который ограничивает характер информации, которую можно хранить в столбце (например, предотвращает ввод букв в числовое поле). MySQL поддерживает несколько типов данных: числовые, строковые, календарные и специальный тип NULL, обозначающий отсутствие информации. Подробно о типах данных мы будем говорить в следующем уроке, а пока вернемся к нашим таблицам. В них у нас всего два типа данных — целочисленные значения (int) и строки (text). Итак, создадим первую таблицу — Темы:
Нажимаем Enter — таблица создана:
Итак, мы создали таблицу topics (темы) с тремя столбцами:
id_topic int — id темы (целочисленное значение),
topic_name text — имя темы (строка),
id_author int — id автора (целочисленное значение).
Аналогичным образом создадим оставшиеся две таблицы — users (пользователи) и posts (сообщения):
Итак, мы создали БД forum и в ней три таблицы. Сейчас мы об этом помним, но если наша БД будет очень большой, то удержать в голове названия всех таблиц и столбцов просто невозможно. Поэтому надо иметь возможность посмотреть, какие БД у нас существуют, какие таблицы в них присутствуют, и какие столбцы эти таблицы содержат. Для этого в SQL существует несколько операторов:
show databases — показать все имеющиеся БД,
show tables — показать список таблиц текущей БД (предварительно ее надо выбрать с помощью оператора use),
describe имя_таблицы — показать описание столбцов указанной таблицы.
Давайте попробуем. Смотрим все имеющиеся базы данных (у вас она пока одна — forum, у меня 30, и все они перечислены в столбик):
Теперь посмотрим список таблиц БД forum (для этого ее предварительно надо выбрать), не забываем после каждого запроса нажимать Enter:
В ответе видим названия наших трех таблиц. Теперь посмотрим описание столбцов, например, таблицы topics:
Первые два столбца нам знакомы — это имя и тип данных, значения остальных нам еще предстоит узнать. Но прежде мы все-таки узнаем какие типы данных бывают, какие и когда следует использовать.
А сегодня мы рассмотрим последний оператор — drop, он позволяет удалять таблицы и БД. Например, давайте удалим таблицу topics. Так как мы два шага назад выбирали БД forum для работы, то сейчас ее выбирать не надо, можно просто написать:
drop table имя_таблицы;
Теперь снова посмотрим список таблиц нашей БД:
Наша таблица действительно удалена. Теперь давайте удалим и саму БД forum (удаляйте, не жалейте, ее все равно придется переделывать). Для этого напишем:
drop database имя_базы данных;
И убедитесь в этом, сделав запрос на все имеющиеся БД:
У вас, наверно, нет ни одной БД, у меня их стало 29 вместо 30.
На сегодня все. Мы научились создавать базы данных и таблицы, удалять их и извлекать информацию об имеющихся базах данных, таблицах и их описаниях.

Онлайн-курс. Освойте востребованную профессию с зарплатой от 70 000 руб в месяц!
Теперь нажмите кнопку, что бы не забыть адрес и вернуться к нам снова.
admin@site-do.ru
site-do.ru © 2009-2019 Копировать материалы сайта запрещено!
За нарушение авторских прав предусмотрена уголовная ответственность!
Телефон редакции +7(499)346-89-56
127051, г.Москва, Цветной бульвар, д. 11, стр. 6, офис 405.
Основы T-SQL
Для создания базы данных используется команда CREATE DATABASE .
Чтобы создать новую базу данных откроем SQL Server Management Studio. Нажмем на назначение сервера в окне Object Explorer и в появившемся меню выберем пункт New Query .
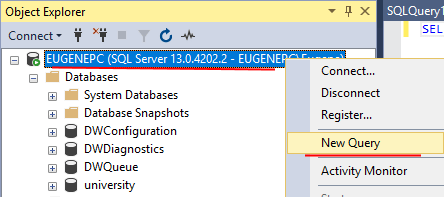
В центральное поле для ввода выражений sql введем следующий код:
CREATE DATABASE usersdb
Тем самым мы создаем базу данных, которая будет называться «usersdb»:
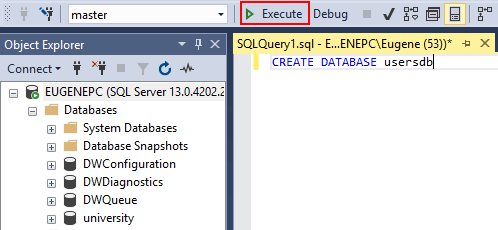
Для выполнения команды нажмем на панели инструментов на кнопку Execute или на клавишу F5. И на сервере появится новая база данных.
После создания базы даных, мы можем установить ее в качестве текущей с помощью команды USE :
USE usersdb;
Прикрепление базы данных
Возможна ситуация, что у нас уже есть файл базы данных, который, к примеру, создан на другом компьютере. Файл базы данных представляет файл с расширением mdf, и этот файл в принципе мы можем переносить. Однако даже если мы скопируем его компьютер с установленным MS SQL Server, просто так скопированная база данных на сервере не появится. Для этого необходимо выполнить прикрепление базы данных к серверу. В этом случае применяется выражение:
CREATE DATABASE название_базы_данных ON PRIMARY(FILENAME='путь_к_файлу_mdf_на_локальном_компьютере') FOR ATTACH;
В качестве каталога для базы данных лучше использовать каталог, где хранятся остальные базы данных сервера. На Windows 10 по умолчанию это каталог C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA . Например, пусть в моем случае файл с данными называется userstoredb.mdf. И я хочу этот файл добавить на сервер как базу данных. Вначале его надо скопировать в выше указанный каталог. Затем для прикрепления базы к серверу надо использовать следующую команду:
CREATE DATABASE contactsdb ON PRIMARY(FILENAME='C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\userstoredb.mdf') FOR ATTACH;
После выполнения команды на сервере появится база данных contactsdb.
Удаление базы данных
Для удаления базы данных применяется команда DROP DATABASE , которая имеет следующий синтаксис:
DROP DATABASE database_name1 [, database_name2].
После команды через запятую мы можем перечислить все удаляемые базы данных. Например, удаление базы данных contactsdb:
DROP DATABASE contactsdb
Стоит учитывать, что даже если удаляемая база данных была прикреплена, то все равно будут удалены все файлы базы данных.
Основы правил проектирования базы данных
Как это часто бывает, архитектору БД нужно разработать базу данных под конкретное решение.
Однажды в пятницу вечером, возвращаясь на электричке домой с работы, я подумал о том, как бы я создал сервис по найму сотрудников в разные компании. Ведь ни один из существующих сервисов не позволяет быстро понять насколько подходит тебе кандидат. Нет возможности создать сложные фильтры, включающие или исключающие совокупность определенных навыков, проектов или позиций. Максимум, что обычно предлагают сервисы — фильтры по компаниям и частично по навыкам.
В данной статье я позволю себе немного разбавить строгое изложение материала, смешав техническую информацию с не техническими примерами из жизни.
Для начала, разберем создание базы данных в MS SQL Server для сервиса поиска соискателей на работу.
Этот материал можно перенести и на другую СУБД такую как MySQL или PostgreSQL.
Основы правил проектирования
Для проектирования схемы базы данных, нужно вспомнить 7 формальных правил и саму концепцию нормализации и денормализации. Они и лежат в основе всех правил проектирования.
Опишем более детально 7 формальных правил:
-
отношение один к одному:
1.1) с обязательной связью:
примером может выступать гражданин и его паспорт: у любого гражданина должен быть паспорт; паспорт один для каждого гражданина
Реализовать данную связь можно двумя способами:
1.1.1) в одной сущности (таблице):

Рис.1. Сущность Citizen
Здесь таблица Citizen представляет собой сущность гражданина, а атрибут (поле) PassportData содержит все паспортные данные гражданина и не может быть пустым (NOT NULL).
1.1.2) в двух разных сущностях (таблицах):

Рис.2. Отношение сущностей Citizen и PassportData
Здесь таблица Citizen представляет собой сущность гражданина, а таблица PassportData — сущность паспортных данных гражданина (самого паспорта). Сущность гражданина содержит атрибут (поле) PassportID, который ссылается на первичный ключ таблицы PassportData. В свою очередь сущность паспортных данных содержит атрибут (поле) CitizenID, которое ссылается на первичный ключ CitizenID таблицы Citizen. Поле PassportID таблицы Citizen не может быть пустым (NOT NULL). Также здесь важно поддерживать целостность поля CitizenID таблицы PassportData, чтобы обеспечить связь один к одному. Иными словами, поле PassportID таблицы Citizen и поле CitizenID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), представленная в пункте 1.1.1.
1.2) с необязательной связью:
примером может выступать человек, имеющий или не имеющий паспорт конкретной страны. В первом случае он будет являться гражданином рассматриваемой страны, а во втором — нет.
Реализовать данную связь можно двумя способами:
1.2.1) в одной сущности (таблице):

Рис.3. Сущность Person
Таблица Person представляет собой сущность человека, а атрибут (поле) PassportData содержит все его паспортные данные и может быть пустым (NULL).
1.2.2) в двух сущностях (таблицах):
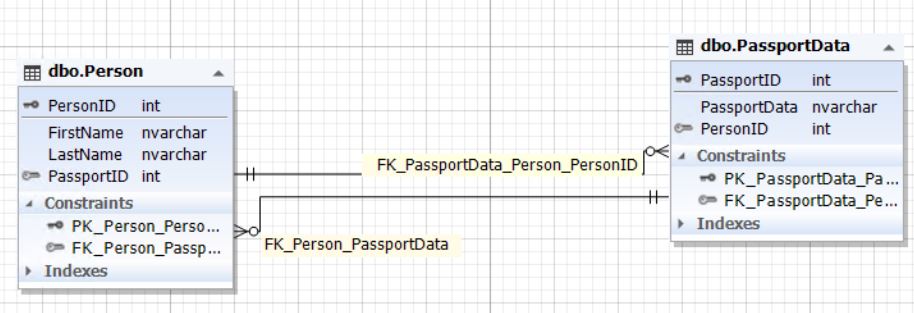
Рис.4. Отношение сущностей Person и PassportData
Таблица Person представляет собой сущность человека, а таблица PassportData — сущность паспортных данных человека (самого паспорта). Сущность человека содержит атрибут (поле) PassportID, который ссылается на первичный ключ таблицы PassportData. В свою очередь сущность паспортных данных содержит атрибут (поле) PersonID, которое ссылается на первичный ключ PersonID таблицы Person. Поле PassportID таблицы Person может быть пустым (NULL). Здесь также важно поддерживать целостность поля PersonID таблицы PassportData. Это нужно, чтобы обеспечить связь один к одному. Поле PassportID таблицы Person и поле PersonID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), показанная в пункте 1.2.1. Или же данные поля должны быть неопределенными, то есть, содержать NULL.
отношение один ко многим:
2.1) с обязательной связью:
примером могут выступать родитель и его дети. У каждого родителя есть как минимум один ребенок.
Реализовать данную связь можно двумя способами:
2.1.1) в одной сущности (таблице):
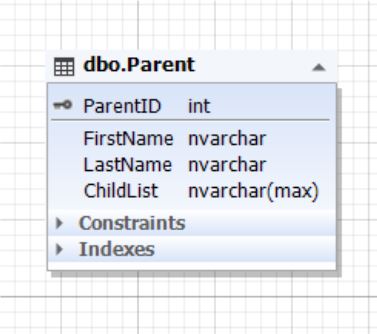
Рис.5. Сущность Parent
Таблица Parent представляет сущность родителя, а атрибут (поле) ChildList содержит информацию о детях. Данное поле не может быть пустым (NOT NULL). Обычно типом поля ChildList выступают неполно структурированные данные (NoSQL) такие как XML, JSON и т д.
2.1.2) в двух сущностях (таблицах):
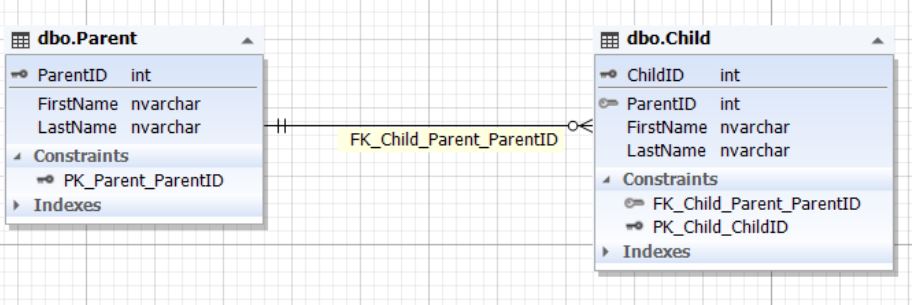
Рис.6. Отношение сущностей Parent и Child
Таблица Parent представляет сущность родителя, а таблица Child — сущность ребенка. У таблицы Child есть поле ParentID, ссылающееся на первичный ключ ParentID таблицы Parent. Поле ParentID таблицы Child не может быть пустым (NOT NULL).
2.2) с необязательной связью:
примером может выступать человек, у которого могут быть дети или их может не быть.
Реализовать данную связь можно двумя способами:
2.2.1) в одной сущности (таблице):
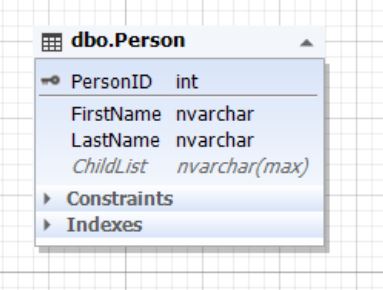
Рис.7. Сущность Person
Таблица Parent представляет сущность родителя, а атрибут (поле) ChildList содержит информацию о детях. Данное поле может быть пустым (NULL). Обычно типом поля ChildList выступают неполно структурированные данные (NoSQL) такие как XML, JSON и т д.
2.2.2) в двух сущностях (таблицах):
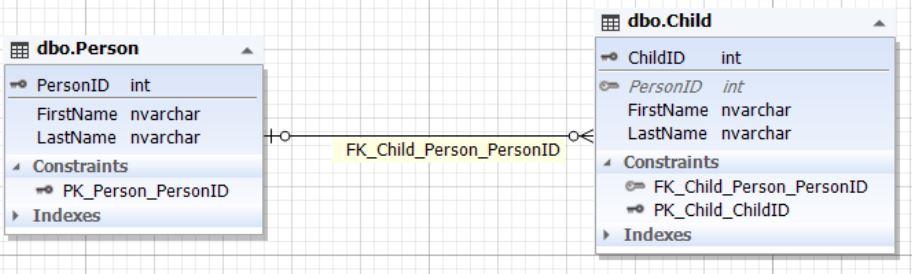
Рис.8. Отношение сущностей Person и Child
Таблица Parent представляет сущность родителя, а таблица Child — сущность ребенка. У таблицы Child есть поле ParentID, ссылающееся на первичный ключ ParentID таблицы Parent. Поле ParentID таблицы Child может быть пустым (NULL).
2.2.3) в одной сущности со ссылкой на саму себя при условии, что у сущностей (таблиц) родителя и ребенка будут одинаковые наборы атрибутов (полей) без учета ссылки на родителя:

Рис.9. Сущность Person со связью на саму себя
Сущность (таблица) Person содержит атрибут (поле) ParentID, который ссылается на первичный ключ PersonID этой же таблицы Person и может содержать пустое значение (NULL).
Примером может выступить недвижимость: она может быть в собственности как одного человека, так и нескольких. С другой стороны, один человек может владеть несколькими домами или долями нескольких домов.
Реализовать данное отношение, с привлечением NoSQL, можно так же, как в описанных выше отношениях. Однако, в рамках реляционной модели обычно такое отношение реализуют через 3 сущности (таблицы):
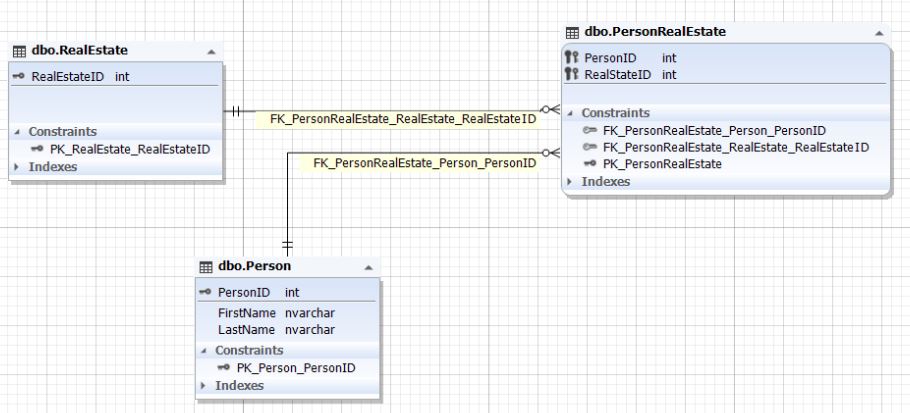
Рис.10. Отношение сущностей Person и RealEstate
Таблицы Person и RealEstate представляют соответственно сущности человека и недвижимости. Связываются данные сущности (таблицы) через сущность (таблицы) PersonRealEstate. Атрибуты (поля) PersonID и RealEstateID ссылаются на первичные ключи PersonID таблицы Person и RealEstateID таблицы RealEstate соответственно. Обратите внимание, что для таблицы PersonRealEstate пара (PersonID; RealEstateID) всегда является уникальной и потому может выступать первичный ключем для самой связующей сущности PersonRealEstate.
А где же семь формальных правил?
- п.1 (п.1.1 и п.1.2) — первое и второе формальные правила
- п.2 (п.2.1 и п.2.2) — третье и четвертое формальные правила
- п.3 (аналогично п.2) — пятое и шестое формальные правила
- п.4 — седьмое формальное правило
Говоря о нормализации, нужно понимать ее суть. Нормализация ведет к уменьшению повторяемости хранения информации, а следовательно и к уменьшению возможности появления аномалий в данных. Однако, нормализация при дроблении сущностей приводит к более сложным построениям запросов для манипуляций с данными (вставки, модификации, выборки и удаления).
Обратным процессом нормализации называется денормализация. Это упрощение построения запросов доступа к данным за счет укрупнения и вложенности сущностей (например, как было показано выше в пунктах 2.1.1 и 2.2.1 с помощью неполно-структурированных данных (NoSQL)).
Вот и вся суть правил проектирования баз данных.
А вы уверены, что поняли отношения в семи формальных правилах? Именно поняли, а не узнали? Ведь знать и понимать — две совершенно разных концепции.
Объясню более детально. Спросите себя, можете ли вы за пару часов набросать пусть и укрупненную по сущностям, но модель базы данных для любой предметной области и для любой информационной системы? (тонкости и детали можно достроить, поспрашивав аналитиков и представителей заказчиков). Если вопрос вас удивил, и вы думаете, что это невозможно, значит вы знаете семь формальных правил, но не понимаете их.
Почему-то многие источники игнорируют тот факт, что эти отношения были не придуманы, а выявлены. Они изначально существуют в реальном мире как между субъектами, так и между субъектами и объектами.
Также, эти отношения могут меняться, переходя из один к одному к одному ко многим, многие к одному или многие ко многим. Обязательность связи может меняться или остаться неизменной.
Позволю себе рассказать об одном случае, когда от знания семи формальных правил я пришел именно к пониманию этих отношений.
В свое время меня смущало то, что в ВУЗе я знал эти семь формальных правил, но на производственной практике (ВУЗ отправляет студентов в различные компании для приобретения профессионального опыта) очень долго строил модели баз для разных предметных областей. Я задумался и понял, что не понимаю этих отношений.
Мне помогло наблюдение за людьми, а суть отношений раскрылась в сновидении. Этот сон я перескажу в упрощенной форме: только то, что позволяет лучше понять именно эти семь формальных правил — без детализации всего остального.
Сон был про семью, в которой есть отец, мать и дети. Отец погибает в автомобильной катастрофе, а мать начинает пить, и детей в итоге забирают в детский дом. Эти дети надолго остаются без родителей. Затем у некоторых детей появляются попечители, их тоже несколько.
Вы проследили, какие отношения были между субъектами, и как менялись эти отношения?
Давайте присмотримся внимательнее.
- Когда семья была полной, с несколькими детьми, отношение между родителями и детьми имело вид многие ко многим.
- Когда остались мать и дети, отношение между родителем и детьми стало один ко многим с обязательной связью. Однако, в любой семье, где может и не быть детей, это отношение будет таким же, но уже с необязательной связью.
- А вот со стороны детей отношение к родителю было как многие к одному с обязательной связью пока родителя не лишили родительских прав.
- Когда дети оказались в детском доме — отношение изменилось на многие к одному с необязательной связью.
- Когда у детей появились попечители, связь между ними стала многие ко многим: у каждого попечителя могут быть другие подопечные дети, а у каждого ребенка могут быть другие попечители (родители).
Надеюсь, теперь вы значительно приблизились к пониманию этих семи формальных правил.
Стоит постоянно практиковаться: наблюдать за людьми и выявлять существующие отношения как между субъектами, так и между субъектами и объектами. Выше описывался гражданин и его паспорт как отношение один к одному с обязательной связью. В тоже время, пример человека и его паспорта — это отношение один к одному с необязательной связью.
Поняв семь формальных правил, вы сможете без труда спроектировать модель базы данных любой сложности для любой информационной системы.
Также вы увидите, что реализовать отношение можно разными способами, а сами отношения могут меняться. Модель (схема) базы данных — это «снимок» отношений между сущностями в определенный момент времени. Именно поэтому важно определить как сами сущности — образы объектов из реального мира или предметной области, так и их отношения между собой с учетом изменений в будущем.
Хорошо спроектированную модель базы данных с учетом изменения отношений в реальности или в предметной области не понадобится менять годами или даже десятилетия. Это особенно важно для хранилищ данных, где изменения влекут пересохранение больших объемов данных (от нескольких гигабайт до многих терабайт).
Важно запомнить, что таблицы в реляционной модели — это отношения сущностей, а строки (кортежи) — это экземпляры этих отношений. Но чтобы было проще, под таблицами часто понимаются сущности, а под строками таблицы — экземпляры сущностей. Их отношения выражаются через связи в форме внешних ключей.
Проектирование схемы базы данных для поиска соискателей на работу
После того, как мы описали основы правил проектирования БД в первой части, давайте создадим схему базы данных для поиска соискателей на работу.
Для начала, определим, что важно для сотрудников из компании, которые ищут кандидатов:
- Сотрудник (Employee)
- Компания (Company)
- Позиция (должность) (Position)
- Проект (Project)
- Навык (Skill)
- Компании и сотрудники относятся как многие ко многим, так как сотрудник мог работать в нескольких компаниях, а в компании работают многие люди.
- Аналогично относятся позиции и сотрудники: несколько сотрудников могут занимать одну позицию как в рамках как одной, так и нескольких компаний.
- С другой стороны, сотрудник мог работать на разных позициях как в рамках одной, так разных компаний. Таким образом, отношение между позициями и компаниями — многие ко многим.
- Аналогично и по проектам: проекты относятся ко всем выше рассмотренным сущностям как многие ко многим.
- Для простоты будем считать, что в проекте сотрудник использует один набор навыков.
- Тогда проекты и навык относятся как многие ко многим.
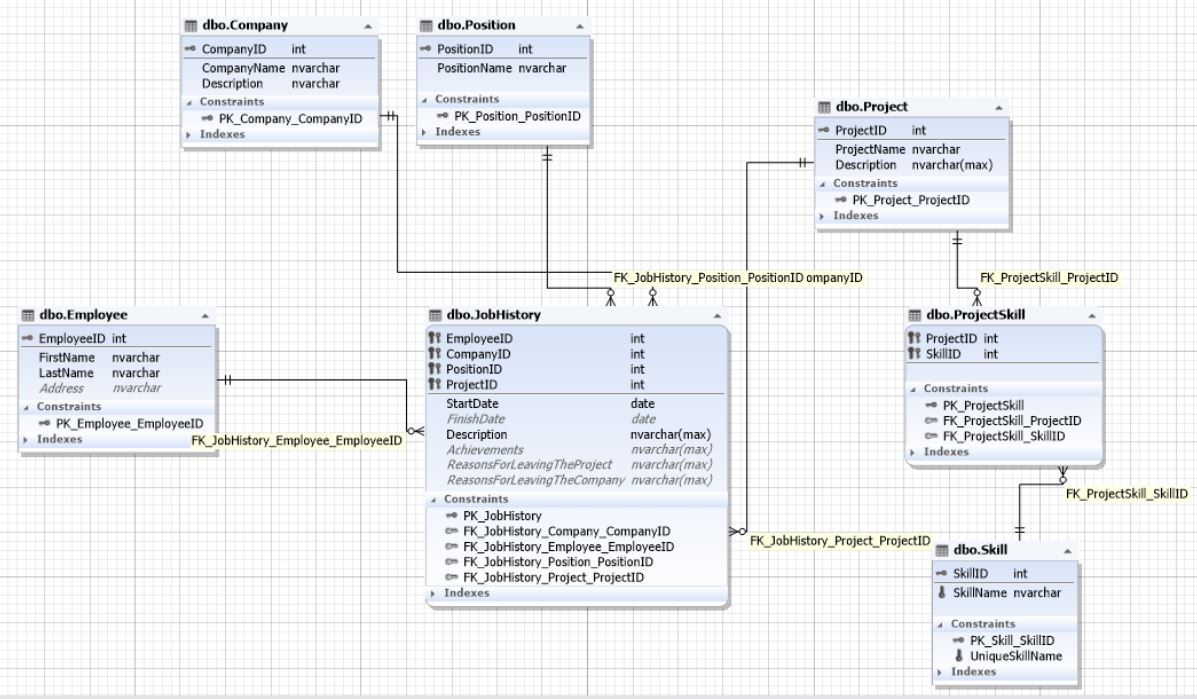
Рис.11. Схема базы данных для поиска соискателей на работу
Здесь таблица JobHistory выступает как сущность истории работы каждого соискателя. То есть, это резюме, которое педставляет отношения многие ко многим между сущностями сотрудник, компания, позиция и проект.
Проекты и навыки относятся друг другу как многие ко многим и потому связываются между собой через сущность (таблицу) ProjectSkill.
Когда вы понимаете отношения между субъектами и между субъектами и объектами — уже упомянутые семь формальных правил — эту или схожую схему можно реализовать «на коленке»: на листке бумаги, мене чем за час. И это еще с учетом усталости после плодотворного рабочего дня.
Здесь можно было упростить схему добавления данных, если «навыки» вложить в сущность «проекты» через неполно структурированные данные (NoSQL) в виде XML, JSON или просто перечислять названия навыков через точку с запятой. Но это бы усложнило выборку с группировкой по навыкам и фильтрацию по отдельным навыкам.
Подобная модель лежит в основе базы данных проекта Geecko.
Как видите, ничего сложного в проектировании информационных систем в части проектирования базы данных нет. Это всего лишь отражение объектов и субъектов из реальности, перенесенное в «сущности» схемы базы данных. Отношения между этими сущностями фиксируются на определенный момент времени, с учетом будущих изменений.
Что именно мы возьмем из реальности и вложим в сущность схемы, и какие отношения построим в модели, будет зависеть от того, что мы хотим от информационной системы в общем, здесь и в будущем. Иными словами — какие данные мы хотим получить в текущий момент времени и через определенное время в будущем.
Немного лирики
После того, как вы внедрите модель в работу, остановитесь на миг и подумайте: только что был создан новый маленький мир. В нем есть свои сущности из реального мира и свои отношения. Да, это цифровой мир, но он теперь будет развиваться своей дорогой. Он будет общаться (интегрироваться) с другими системами (мирами), тоже созданными по своим правилам. Данные будут течь в этих системах, как кровь в живом организме.
А перед сном подумайте о том, что семь формальных правил были всегда, и что они окружают нас всюду. Не больше и не меньше, всегда семь. Все отношения реальной жизни можно разложить на эти семь формальных правил. А когда вы думаете или видите сны, как там сущности относятся друг к другу — не по тем же семи формальным правилам?
Вообще, я уверен, что эти отношения (семь формальных правил) выявил очень хороший психотерапевт, возможно — женщина. Это было очень давно, задолго до появления самого понятия информационных технологий. И самое интересное, что эти отношения живут вне базы данных и ИТ — последние лишь используют их для моделирования информационных систем.
Но мы немного отошли от темы. Я лишь призываю в момент создания новой системы подойти к этому процессу с душой. И тогда поверьте, случится момент творения. Спроектированная таким образом система будет живее всех живых в цифровом мире.
Послесловие
Диаграммы для примеров были реализованы с помощью инструмента Database Diagram Tool for SQL Server. Однако, подобный функционал есть и в DBeaver.
Источники
- SQL Database Design Basics with Example
- Geecko
- Microsoft SQL documentation
- SSMS
- Database Diagram Tool for SQL Server
Урок по структуризации и проектированию баз данных
База данных, профессионально спроектированная с помощью надежного инструмента схематизации, такого как Lucidchart, откроет своим пользователям доступ к важнейшей информации. Принципы, изложенные на этой странице, помогут вам спланировать базу данных, которая не только слаженно работает, но и отлично подстраивается под дальнейшие нужды вашего проекта. В этом уроке мы рассмотрим основные принципы построения баз данных, а также способы внесения ясности в структуру для достижения оптимальных результатов.
Читается за 15 мин.
Хотите создать схему базы данных самостоятельно? Попробуйте Lucidchart! Быстро, удобно и совершенно бесплатно.
Процесс проектирования базы данных
Хорошо структурированная база данных:
- экономит место на диске, так как не содержит лишней информации
- поддерживает целостность и точность данных
- обеспечивает удобный доступ к данным
Проектирование содержательной и эффективной базы данных — вопрос выполнения надлежащей процедуры, в которую входят следующие фазы:
- Анализ требований, или выявление цели базы данных
- Организация данных в таблицы
- Указание первичных ключей и анализ связей
- Нормализация и стандартизация таблиц
Давайте подробнее рассмотрим каждый из этих этапов. Но сначала хотим обратить ваше внимание на то, что данный урок построен на примере модели реляционной базы данных Эдгара Кодда, написанной на SQL (в противопоставление иерархической, сетевой или информационной модели). Подробнее ознакомиться с разными моделями баз данных можно в нашем руководстве по этой ссылке.
Анализ требований: выявление цели создания базы данных
Осмысление цели, с которой создается база данных, поможет вам принимать взвешенные решения на протяжении всего процесса проектирования. Непременно взгляните на свою базу данных под разным углами. К примеру, если вы разрабатываете базу данных публичной библиотеки, вам придется принять во внимание, как получают доступ к данным не только ее сотрудники, но и читатели.
Вот несколько способов сбора информации для подготовки базы данных:
- Опрос людей, которые будут ей пользоваться
- Анализ стандартных деловых документов, например, счетов, табелей учета рабочего времени, заполненных анкет и так далее
- Ознакомление с существующими системами данных (в бумажном и цифровом формате)
Начните работу со сбора уже имеющейся информации, которая подлежит включению в базу данных. Затем составьте список всех видов данных, которые вы планируете хранить, а также сущностей или лиц, объектов, мест и событий, которые описывают эти данные, например:
- Имя
- Адрес
- Город, регион, почтовый индекс
- Адрес электронной почты
- Имя
- Цена
- Количество на складе
- Количество в заказе
- Номер заказа
- Консультант
- Дата
- Товар(ы)
- КоличествоS
- Цена
- Общая стоимость
Впоследствии эта информация войдет в состав словаря данных, где будет представлена сводка таблиц и полей внутри базы данных. Постарайтесь разбить информацию на мельчайшие функциональные фрагменты. Например, страну можно отделить от остальной части адреса, что позволит впоследствии отфильтровать людей по стране проживания. Также старайтесь не помещать одну и ту же точку данных более чем в одну таблицу, так как это излишне усложняет базу.
Когда вы определитесь с тем, какие типы данных включить в базу, откуда они будут поступать и как использоваться, самое время приступить непосредственно к проектированию.
Структура базы данных: строительные кирпичики
На следующем этапе процесса вам предстоит составить наглядную картину своей базы данных. Для этого необходимо разобраться в том, как именно устроена реляционная база данных.
Схожие данные в пределах базы группируются в таблицы, каждая из которых состоит из строк (или кортежей) и столбцов.
Чтобы преобразовать списки данных в таблицы, в первую очередь создайте таблицу по каждому типу сущности, (товар, продажа, клиенты и так далее). Вот пример:
Каждая строка таблицы называется записью. Записи содержат информацию о людях и объектах, например, о конкретном клиенте компании. В отличие от них, столбцы (которые также называют полями или атрибутами) содержат информацию одного типа, которая присутствует в каждой записи, например, адреса всех клиентов, перечисленных в таблице.
| Имя | Фамилия | Возраст | Почтовый индекс |
|---|---|---|---|
| Роджер | Уильямс | 43 | 34760 |
| Джеррика | Йоргенсен | 32 | 97453 |
| Саманта | Хопкинс | 56 | 64829 |
Чтобы поддерживать постоянство формата всех записей, задайте каждому столбцу свой тип данных. Вот примеры р