Процессы в Linux
Данной теме посвящено много статей, но в Сети мало сугубо практических статей. О какой именно практике идет речь, вы узнаете прочитав эту статью. Правда, одной только практикой нам не обойтись — вдруг вы не читали всю эту серую массу теории, которую можно найти в Сети.
Немного теории
- программа на стадии выполнения
- «объект», которому выделено процессорное время
- асинхронная работа
- состояния выполнения
- состояния ожидания
- состояния готовности
Выполнение — это активное состояние, во время которого процесс обладает всеми необходимыми ему ресурсами. В этом состоянии процесс непосредственно выполняется процессором.
Ожидание — это пассивное состояние, во время которого процесс заблокирован, он не может быть выполнен, потому что ожидает какое-то событие, например, ввода данных или освобождения нужного ему устройства.
Готовность — это тоже пассивное состояние, процесс тоже заблокирован, но в отличие от состояния ожидания, он заблокирован не по внутренним причинам (ведь ожидание ввода данных — это внутренняя, «личная» проблема процесса — он может ведь и не ожидать ввода данных и свободно выполняться — никто ему не мешает), а по внешним, независящим от процесса, причинам. Когда процесс может перейти в состояние готовности? Предположим, что наш процесс выполнялся до ввода данных. До этого момента он был в состоянии выполнения, потом перешел в состояние ожидания — ему нужно подождать, пока мы введем нужную для работы процесса информацию. Затем процесс хотел уже перейти в состояние выполнения, так как все необходимые ему данные уже введены, но не тут-то было: так как он не единственный процесс в системе, пока он был в состоянии ожидания, его «место под солнцем» занято — процессор выполняет другой процесс. Тогда нашему процессу ничего не остается как перейти в состояние готовности: ждать ему нечего, а выполняться он тоже не может.
Из состояния готовности процесс может перейти только в состояние выполнения. В состоянии выполнения может находится только один процесс на один процессор. Если у вас n-процессорная машина, у вас одновременно в состоянии выполнения могут быть n процессов.
Из состояния выполнения процесс может перейти либо в состояние ожидания или состояние готовности. Почему процесс может оказаться в состоянии ожидания, мы уже знаем — ему просто нужны дополнительные данные или он ожидает освобождения какого-нибудь ресурса, например, устройства или файла. В состояние готовности процесс может перейти, если во время его выполнения, квант времени выполнения «вышел». Другими словами, в операционной системе есть специальная программа — планировщик, которая следит за тем, чтобы все процессы выполнялись отведенное им время. Например, у нас есть три процесса. Один из них находится в состоянии выполнения. Два других — в состоянии готовности. Планировщик следит за временем выполнения первого процесса, если «время вышло», планировщик переводит процесс 1 в состояние готовности, а процесс 2 — в состояние выполнения. Затем, когда, время отведенное, на выполнение процесса 2, закончится, процесс 2 перейдет в состояние готовности, а процесс 3 — в состояние выполнения.
Диаграмма модели трех состояний представлена на рисунке 1.
Рисунок 1. Модель трех состояний
Более сложная модель — это модель, состоящая из пяти состояний. В этой модели появилось два дополнительных состояния: рождение процесса и смерть процесса. Рождение процесса — это пассивное состояние, когда самого процесса еще нет, но уже готова структура для появления процесса. Как говорится в афоризме: «Мало найти хорошее место, надо его еще застолбить», так вот во время рождения как раз и происходит «застолбление» этого места. Смерть процесса — самого процесса уже нет, но может случиться, что его «место», то есть структура, осталась в списке процессов. Такие процессы называются зобми и о них мы еще поговорим в этой статье.
Диаграмма модели пяти состояний представлена на рисунке 2.
Рисунок 2. Модель пяти состояний
- Создание процесса — это переход из состояния рождения в состояние готовности
- Уничтожение процесса — это переход из состояния выполнения в состояние смерти
- Восстановление процесса — переход из состояния готовности в состояние выполнения
- Изменение приоритета процесса — переход из выполнения в готовность
- Блокирование процесса — переход в состояние ожидания из состояния выполнения
- Пробуждение процесса — переход из состояния ожидания в состояние готовности
- Запуск процесса (или его выбор) — переход из состояния готовности в состояние выполнения
- Присвоить процессу имя
- Добавить информацию о процессе в список процессов
- Определить приоритет процесса
- Сформировать блок управления процессом
- Предоставить процессу нужные ему ресурсы
Подробнее о списке процессов, приоритете и обо всем остальном мы еще поговорим, а сейчас нужно сказать пару слов об иерархии процессов. Процесс не может взяться из ниоткуда: его обязательно должен запустить какой-то процесс. Процесс, запущенный другим процессом, называется дочерним (child) процессом или потомком. Процесс, который запустил процесс называется родительским (parent), родителем или просто — предком. У каждого процесса есть два атрибута — PID (Process ID) — идентификатор процесса и PPID (Parent Process ID) — идентификатор родительского процесса.
Процессы создают иерархию в виде дерева. Самым «главным» предком, то есть процессом, стоящим на вершине этого дерева, является процесс init (PID=1).
На мой взгляд, приведенной теории вполне достаточно, чтобы перейти к практике, а именно — «пощупать» все состояния процессов. Конечно, мы не рассмотрели системные вызовы fork(), exec(), exit(), kill() и многие другие, но в Сети предостаточно информации об этом. Тем более, что про эти вызовы вы можете прочитать в справочной системе Linux, введя команду man fork. Правда, там написано на всеми любимом English, так что за переводом (если он вам нужен) все-таки придется обратиться за помощью к WWW.
Практика
Для наблюдения за процессами мы будем использовать программу top.
15:03:11 up 58 min, 4 users, load average: 0,02, 0,01, 0,00 52 processes: 51 sleeping, 1 running, 0 zombie, 0 stopped CPU states: 0,8% user, 0,6% system, 0,0% nice, 0,0% iowait, 98,3% idle Mem: 127560k av, 124696k used, 2864k free, 0k shrd, 660k buff 13460k active, 17580k inactive Swap: 152576k av, 8952k used, 143624k free 28892k cached PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME COMMAND 3097 den 15 0 1128 1128 832 R 2,8 0,8 0:00 top 1 root 8 0 120 84 60 S 0,0 0,0 0:04 init 2 root 12 0 0 0 0 SW 0,0 0,0 0:00 keventd 3 root 19 19 0 0 0 SWN 0,0 0,0 0:00 ksoftirqd_CPU0 .
Полный вывод программы я по понятным причинам урезал. Рассмотрим по порядку весь вывод программы. В первой строке программа сообщает текущее время, время работы системы ( 58 min), количество зарегистрированных (login) пользователей (4 users), общая средняя загрузка системы (load average).
Примечание. Общей средней загрузкой системы называется среднее число процессов, находящихся в состоянии выполнения (R) или в состоянии ожидания (D). Общая средняя загрузка измеряется каждые 1, 5 и 15 минут.
Во второй строке вывода программы top сообщается, что в списке процессов находятся 52 процесса, из них 51 спит (состояние готовности или ожидания), 1 выполняется (у меня только 1 процессор), 0 процессов зомби и 0 остановленных процессов.
В третьей-пятой строках приводится информация о загрузке процессора, использования памяти и файла подкачки. Нас данная информация не очень интересует, поэтому переходим сразу к таблице процессов.
В таблице отображается различная информация о процессе. Нас сейчас интересуют колонки PID (идентификатор процесса), USER (пользователь, запустивший процесс), STAT (состояние процесса) и COMMAND (команда, которая была введена для запуска процесса).
-
R — процесс выполняется или готов к выполнению (состояние готовности)
- D — процесс в «беспробудном сне» — ожидает дискового ввода/вывода
- T — процесс остановлен (stopped) или трассируется отладчиком
- S — процесс в состоянии ожидания (sleeping)
- Z — процесс-зобми
- < — процесс с отрицательным значением nice
- N — процесс с положительным значением nice (о команде nice мы поговорим позже)
Давайте просмотрим, когда же процесс находится в каждом состоянии. Создайте файл process — это обыкновенный bash-сценарий
#!/bin/bash x=1 while [ $x -lt 10 ] do x=2 done
Сделайте этот файл исполнимым chmod +x ./process и запустите его ./process. Теперь перейдите на другую консоль (ALT + Fn) и введите команду ps -a | grep process. Вы увидите следующий вывод команды ps:
4035 pts/1 00:00:15 process
Данный вывод означает, что нашему процессу присвоен идентификатор процесса 4035. Теперь введите команду top -p 4035
15:30:15 up 1:25, 6 users, load average: 0,44, 0,19, 0,07 1 processes: 0 sleeping, 1 running, 0 zombie, 0 stopped CPU states: 2,3% user, 0,6% system, 0,0% nice, 0,0% iowait, 96,8% idle Mem: 127560k av, 124496k used, 3064k free, 0k shrd, 1208k buff 15200k active, 16400k inactive Swap: 152576k av, 15676k used, 136900k free 27548k cached PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME COMMAND 4035 den 15 0 1320 1320 988 R 99,9 1,0 0:31 process
Обратите внимание на колонку состояния нашего процесса. Она содержит значение R, которое означает, что в данный момент выполняется процесс с номером 4035.
Теперь приостановим наш процесс — состояние T. Перейдите на консоль, на которой запущен ./process и нажмите Ctrl + Z. Вы увидите сообщение Stopped.
PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME COMMAND 4035 den 9 0 1320 1320 988 T 0,0 1,0 0:51 process
Теперь попробуем «усыпить» наш процесс. Для этого нужно сначала «убить» его: kill 4035. Затем добавить перед циклом while в сценарии ./process строку sleep 10m, которая означает, что процесс будет спать 10 минут. После этого опять запустите команду ps -a | grep process, чтобы узнать PID процесса, а затем — команду top -p PID. Вы увидите в колонке состояния букву S, что означает, что процесс находится в состоянии ожидания или готовности — попросту говоря «спит».
Мы вплотную подошли к самому интересному — созданию процесса-зомби. Во многих статьях, посвященных процессам, пишется «зомби = не жив, не мертв». А что это означает на самом деле? При завершении процесса должна удаляться его структура из списка процессов. Иногда процесс уже завершился, но его имя еще не удалено из списка процессов. В этом случае процесс становится зомби — его уже нет, но мы его видим в таблице команды top. Такое может произойти, если процесс-потомок (дочерний процесс) завершился раньше, чем этого ожидал процесс-родитель. Сейчас мы напишем программу, порождающую зомби, который будет существовать 8 секунд. Процесс-родитель будет ожидать завершения процесса-потомка через 10 секунд, а процесс-потомок завершить через 2 секунды.
#include <unistd.h> #include <signal.h> #include <stdlib.h> #include <sys/wait.h> #include <stdio.h> int main() < int pid; int status, died; pid=fork(); switch(pid) < case -1: printf("can't fork\n"); exit(-1); case 0 : printf(" I'm the child of PID %d\n", getppid()); printf(" My PID is %d\n", getpid()); // Ждем 2 секунды и завершаемся, следующую строку я закомментировал // чтобы зомби "прожил" на 2 секунды больше // sleep(2); exit(0); default: printf("I'm the parent.\n"); printf(" My PID is %d\n", getpid()); // Ждем завершения дочернего процесса через 10 секунд, а потом убиваем его sleep(10); if (pid & 1) kill(pid,SIGKILL); died= wait(&status); >>
Для компиляции данной программы нам нужен компилятор gcc:
gcc -o zombie zombie.c
Для тех, у кого не установлен компилятор, скомпилированная программа доступна отсюда.
После того, как программа будет откомпилирована, запустите ее: ./zombie. Программа выведет следующую информацию:
I'm the parent My PID is 1147 I'm the child of PID 1147 My PID is 1148
Запомните последний номер и быстро переключайтесь на другую консоль. Затем введите команду top -p 1148
16:04:22 up 2 min, 3 users, load average: 0,10, 0,10, 0,04 1 processes: 0 sleeping, 0 running, 1 zombie, 0 stopped CPU states: 4,5% user, 7,6% system, 0,0% nice, 0,0% iowait, 87,8% idle Mem: 127560k av, 76992k used, 50568k free, 0k shrd, 3872k buff 24280k active, 19328k inactive Swap: 152576k av, 0k used, 152576k free 39704k cached PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME COMMAND 1148 den 17 0 0 0 0 Z 0,0 0,0 0:00 zombie <defunct>
Мы видим, что в списке процессов появился 1 зомби (STAT=Z), который проживет аж 10 секунд.
Мы уже рассмотрели все возможные состояния процессов. Осталось только рассмотреть команду для повышения приоритета процесса — это команда nice. Повысить приоритет команды может только пользователь root, указав соответствующий коэффициент понижения. Для увеличения приоритета нужно указать отрицательный коэффициент, например, nice -5 process
Управление процессами в Linux
Денис Колисниченко Процессы. Системные вызовы fork() и exec(). Нити.
Перенаправление ввода/вывода
Команды для управление процессами
Материал этой статьи ни в коем случае не претендует на свою избыточность. Более подробно о процессах вы можете прочитать в книгах, посвященных программированию под UNIX.
Процессы. Системные вызовы fork() и exec(). Нити.
- Выделяется память для описателя нового процесса в таблице процессов
- Назначается идентификатор процесса PID
- Создается логическая копия процесса, который выполняет fork() — полное копирование содержимого виртуальной памяти родительского процесса, копирование составляющих ядерного статического и динамического контекстов процесса-предка
- Увеличиваются счетчики открытия файлов (порожденный процесс наследует все открытые файлы родительского процесса).
- Возвращается PID в точку возврата из системного вызова в родительском процессе и 0 — в процессе-потомке.
Сигнал — способ информирования процесса ядром о происшествии какого-то события. Если возникает несколько однотипных событий, процессу будет подан только один сигнал. Сигнал означает, что произошло событие, но ядро не сообщает сколько таких событий произошло.
- окончание порожденного процесса (например, из-за системного вызова exit (см. ниже))
- возникновение исключительной ситуации
- сигналы, поступающие от пользователя при нажатии определенных клавиш.
Установить реакцию на поступление сигнала можно с помощью системного вызова signal
func = signal(snum, function);
snum — номер сигнала, а function — адрес функции, которая должна быть выполнена при поступлении указанного сигнала. Возвращаемое значение — адрес функции, которая будет реагировать на поступление сигнала. Вместо function можно указать ноль или единицу. Если был указан ноль, то при поступлении сигнала snum выполнение процесса будет прервано аналогично вызову exit. Если указать единицу, данный сигнал будет проигнорирован, но это возможно не для всех процессов.
С помощью системного вызова kill можно сгенерировать сигналы и передать их другим процессам.
kill(pid, snum);
где pid — идентификатор процесса, а snum — номер сигнала, который будет передан процессу. Обычно kill используется для того, чтобы принудительно завершить («убить») процесс.
Pid состоит из идентификатора группы процессов и идентификатора процесса в группе. Если вместо pid указать нуль, то сигнал snum будет направлен всем процессам, относящимся к данной группе (понятие группы процессов аналогично группе пользователей). В одну группу включаются процессы, имеющие общего предка, идентификатор группы процесса можно изменить с помощью системного вызова setpgrp. Если вместо pid указать -1, ядро передаст сигнал всем процессам, идентификатор пользователя которых равен идентификатору текущего выполнения процесса, который посылает сигнал.
Таблица 1. Номера сигналов
| Номер | Название | Описание |
| 01 | SIGHUP | Освобождение линии (hangup). |
| 02 | SIGINT | Прерывание (interrupt). |
| 03 | SIGQUIT | Выход (quit). |
| 04 | SIGILL | Некорректная команда (illegal instruction). Не переустанавливается при перехвате. |
| 05 | SIGTRAP | Трассировочное прерывание (trace trap). Не переустанавливается при перехвате. |
| 06 | SIGIOT или SIGABRT | Машинная команда IOT. |
| 07 | SIGEMT | Машинная команда EMT. |
| 08 | SIGFPE | Исключительная ситуация при выполнении операции с вещественными числами (floating-point exception) |
| 09 | SIGKILL | Уничтожение процесса (kill). Не перехватывается и не игнорируется. |
| 10 | SIGBUS | Ошибка шины (bus error). |
| 11 | SIGSEGV | Некорректное обращение к сегменту памяти (segmentation violation). |
| 12 | SIGSYS | Некорректный параметр системного вызова (bad argument to system call). |
| 13 | SIGPIPE | Запись в канал, из которого некому читать (write on a pipe with no one to read it). |
| 14 | SIGALRM | Будильник |
| 15 | SIGTERM | Программный сигнал завершения |
| 16 | SIGUSR1 | Определяемый пользователем сигнал 1 |
| 17 | SIGUSR2 | Определяемый пользователем сигнал 2 |
| 18 | SIGCLD | Завершение порожденного процесса (death of a child). |
| 19 | SIGPWR | Ошибка питания |
| 22 | Регистрация выборочного события |
Сигналы (точнее их номера) описаны в файле singnal.h
Для нормального завершение процесса используется вызов
exit(status);
где status — это целое число, возвращаемое процессу-предку для его информирования о причинах завершения процесса-потомка.
Вызов exit может задаваться в любой точке программы, но может быть и неявным, например при выходе из функции main (при программировании на C) оператор return 0 будет воспринят как системный вызов exit(0);
Перенаправление ввода/вывода
Практически все операционные системы обладают механизмом перенаправления ввода/вывода. Linux не является исключением из этого правила. Обычно программы вводят текстовые данные с консоли (терминала) и выводят данные на консоль. При вводе под консолью подразумевается клавиатура, а при выводе — дисплей терминала. Клавиатура и дисплей — это, соответственно, стандартный ввод и вывод (stdin и stdout). Любой ввод/вывод можно интерпретировать как ввод из некоторого файла и вывод в файл. Работа с файлами производится через их дескрипторы. Для организации ввода/вывода в UNIX используются три файла: stdin (дескриптор 1), stdout (2) и stderr(3).
Символ > используется для перенаправления стандартного вывода в файл.
Пример:
$ cat > newfile.txt Стандартный ввод команды cat будет перенаправлен в файл newfile.txt, который будет создан после выполнения этой команды. Если файл с этим именем уже существует, то он будет перезаписан. Нажатие Ctrl + D остановит перенаправление и прерывает выполнение команды cat.
Символ < используется для переназначения стандартного ввода команды. Например, при выполнении команды cat > используется для присоединения данных в конец файла (append) стандартного вывода команды. Например, в отличие от случая с символом >, выполнение команды cat >> newfile.txt не перезапишет файл в случае его существования, а добавит данные в его конец.
Символ | используется для перенаправления стандартного вывода одной программы на стандартный ввод другой. Напрмер, ps -ax | grep httpd.
Команды для управления процессами
Предназначена для вывода информации о выполняемых процессах. Данная команда имеет много параметров, о которых вы можете прочитать в руководстве (man ps). Здесь я опишу лишь наиболее часто используемые мной:
| Параметр | Описание |
| -a | отобразить все процессы, связанных с терминалом (отображаются процессы всех пользователей) |
| -e | отобразить все процессы |
| -t список терминалов | отобразить процессы, связанные с терминалами |
| -u идентификаторы пользователей | отобразить процессы, связанные с данными идентификаторыми |
| -g идентификаторы групп | отобразить процессы, связанные с данными идентификаторыми групп |
| -x | отобразить все процессы, не связанные с терминалом |
Например, после ввода команды ps -a вы увидите примерно следующее:
PID TTY TIME CMD 1007 tty1 00:00:00 bash 1036 tty2 00:00:00 bash 1424 tty1 00:00:02 mc 1447 pts/0 00:00:02 mpg123 2309 tty2 00:00:00 ps
Для вывода информации о конкретном процессе мы можем воспользоваться командой:
# ps -ax | grep httpd 698 ? S 0:01 httpd -DHAVE_PHP4 -DHAVE_PROXY -DHAVE_ACCESS -DHAVE_A 1261 ? S 0:00 httpd -DHAVE_PHP4 -DHAVE_PROXY -DHAVE_ACCESS -DHAVE_A 1262 ? S 0:00 httpd -DHAVE_PHP4 -DHAVE_PROXY -DHAVE_ACCESS -DHAVE_A 1263 ? S 0:00 httpd -DHAVE_PHP4 -DHAVE_PROXY -DHAVE_ACCESS -DHAVE_A 1264 ? S 0:00 httpd -DHAVE_PHP4 -DHAVE_PROXY -DHAVE_ACCESS -DHAVE_A 1268 ? S 0:00 httpd -DHAVE_PHP4 -DHAVE_PROXY -DHAVE_ACCESS -DHAVE_A 1269 ? S 0:00 httpd -DHAVE_PHP4 -DHAVE_PROXY -DHAVE_ACCESS -DHAVE_A 1270 ? S 0:00 httpd -DHAVE_PHP4 -DHAVE_PROXY -DHAVE_ACCESS -DHAVE_A 1271 ? S 0:00 httpd -DHAVE_PHP4 -DHAVE_PROXY -DHAVE_ACCESS -DHAVE_A 1272 ? S 0:00 httpd -DHAVE_PHP4 -DHAVE_PROXY -DHAVE_ACCESS -DHAVE_A 1273 ? S 0:00 httpd -DHAVE_PHP4 -DHAVE_PROXY -DHAVE_ACCESS -DHAVE_A 1280 ? S 0:00 httpd -DHAVE_PHP4 -DHAVE_PROXY -DHAVE_ACCESS -DHAVE_A
В приведенном выше примере используется перенаправление ввода вывода между программами ps и grep, и как результат получаем информацию обо всех процессах содержащих в строке запуска «httpd». Данную команду (ps -ax | grep httpd) я написал только лишь в демонстрационных целях — гораздо проще использовать параметр -С программы ps вместо перенаправления ввода вывода и параметр -e вместо -ax.
Программа top
Предназначена для вывода информации о процессах в реальном времени. Процессы сортируются по максимальному занимаемому процессорному времени, но вы можете изменить порядок сортировки (см. man top). Программа также сообщает о свободных системных ресурсах.
# top 7:49pm up 5 min, 2 users, load average: 0.03, 0.20, 0.11 56 processes: 55 sleeping, 1 running, 0 zombie, 0 stopped CPU states: 7.6% user, 9.8% system, 0.0% nice, 82.5% idle Mem: 130660K av, 94652K used, 36008K free, 0K shrd, 5220K buff Swap: 72256K av, 0K used, 72256K free 60704K cached PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME COMMAND 1067 root 14 0 892 892 680 R 2.8 0.6 0:00 top 1 root 0 0 468 468 404 S 0.0 0.3 0:06 init 2 root 0 0 0 0 0 SW 0.0 0.0 0:00 kflushd 3 root 0 0 0 0 0 SW 0.0 0.0 0:00 kupdate 4 root 0 0 0 0 0 SW 0.0 0.0 0:00 kswapd 5 root -20 -20 0 0 0 SW< 0.0 0.0 0:00 mdrecoveryd
Просмотреть информацию об оперативной памяти вы можете с помощью команды free, а о дисковой - df. Информация о зарегистрированных в системе пользователей доступна по команде w.
Изменение приоритета процесса - команда nice
nice [-коэффициент понижения] команда [аргумент]
Команда nice выполняет указанную команду с пониженным приоритетом, коэффициент понижения указывается в диапазоне 1..19 (по умолчанию он равен 10). Суперпользователь может повышать приоритет команды, для этого нужно указать отрицательный коэффициент, например --10. Если указать коэффициент больше 19, то он будет рассматриваться как 19.
nohup - игнорирование сигналов прерывания
nohup команда [аргумент]
nohup выполняет запуск команды в режиме игнорирования сигналов. Не игнорируются только сигналы SIGHUP и SIGQUIT.
kill - принудительное завершение процесса
kill [-номер сигнала] PID
где PID - идентификатор процесса, который можно узнать с помощью команды ps.
Команды выполнения процессов в фоновом режиме - jobs, fg, bg
Команда jobs выводит список процессов, которые выполняются в фоновом режиме, fg - переводит процесс в нормальные режим ("на передний план" - foreground), а bg - в фоновый. Запустить программу в фоновом режиме можно с помощью конструкции &
Все, что вам нужно знать о процессах в Linux
Оригинал: All You Need To Know About Processes in Linux [Comprehensive Guide]
Автор: Aaron Kili
Дата публикации: 31 марта 2017 года
Перевод: А. Кривошей
Дата перевода: август 2017 г.
В этой статье мы дадим базовое понимание процессов и кратко рассмотрим управление процессами в Linux с помощью специальных команд.
Процесс относится к выполнению программы - он представляет собой запущенный экземпляр программы, составленный из инструкций, данных, считанных из файлов, других программ, или полученных от пользователя.
Типы процессов
В Linux есть два основных типа процессов:
Процессы переднего плана (также известны как интерактивные процессы) - они инициализируются и контролируются в терминальной сессии. Другими словами, для запуска таких процессов в системе должен находиться пользователь, они не запускаются автоматически как часть системных служб.
Фоновые процессы (также известны как неинтерактивные/автоматические процессы) - не подключены к терминалу. Они не ждут ввода от пользователя.
Что такое демоны
Это специальные типы фоновых процессов, которые запускаются при загрузке системы и остаются запущенными в виде служб, они не завершаются. Демоны запускаются как системные задачи, спонтанно. Тем не менее, пользователь может контролировать их через процесс init.
Создание процессов в Linux
Обычно новый процесс создается уже существующим процессом, который делает в памяти свою точную копию. Дочерний процесс получает то же окружение, что и его родительский процесс, отличается только номер ID.
Есть два распространенных способа создания нового процесса в Linux:
1. С помощью функции System(). Этот способ сравнительно прост, однако неэффективен и создает определенные риски с точки зрения безопасности.
2. С помощью функций fork() и exec() - более продвинутая техника с точки зрения гибкости, скорости и безопасности.
Как Linux идентифицирует процессы?
Поскольку Linux - многопользовательская система, и различные пользователи могут одновременно запускать разные программы, каждый запущенный экземпляр программы должен получать уникальный идентификатор от ядра системы.
Программы идентифицируются по ID процесса (PID), а также по ID родительского процесса (PPID), поэтому процессы можно разделить на следующие категории:
Родительские процессы - это процессы, которые в процессе работы создают другие процессы.
Дочерние процессы - это процессы, созданные другими процессами.
Процесс Init
Процесс Init - это родительский процесс для всех процессов в системе, это первая программа, которая исполняется при загрузке системы Linux; он управляет всеми другими процессами в системе. Init запускается непосредственно ядром системы, поэтому он в принципе не имеет родительского процесса.
Процесс Init всегда получает ID 1. Он функционирует как приемный родитель для всех осиротевших процессов.
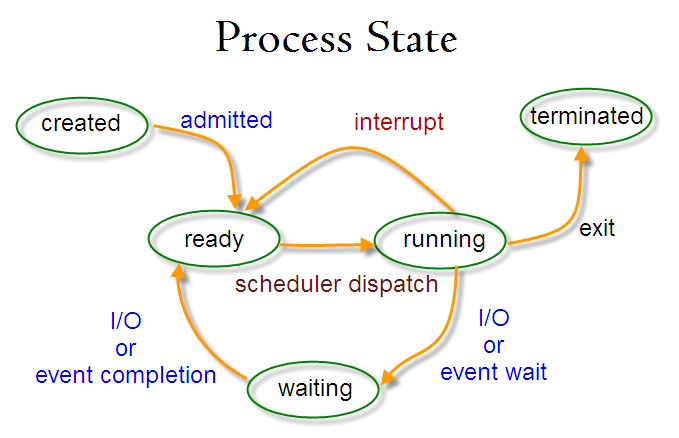
Для определения ID процесса можно использовать команду pidof:
# pidof systemd # pidof top # pidof httpd
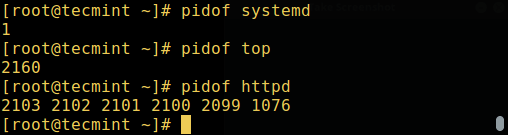
Найти ID процесса и ID родительского процесса для системной оболочки можно с помощью команд:
$ echo $$ $ echo $PPID
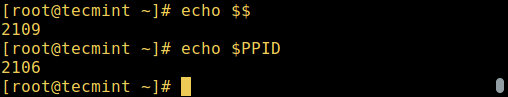
Запуск процессов в Linux
При старте команды или программы (например cloudcmd – CloudCommander), она запускает процесс в системе. Вы можете запустить процесс переднего плана (интерактивный), как показано ниже, он подключится к терминалу и пользователь сможет взаимодействовать с ним:
# cloudcmds

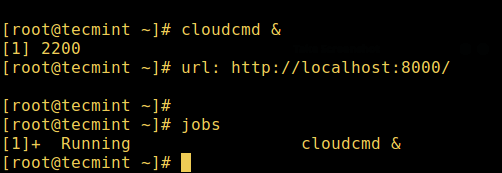
Фоновые процессы в Linux
Для запуска фонового процесса (неинтерактивного) используется символ &, при этом процесс не сможет читать ввод от пользователя, пока не будет перемещен на передний план.
# cloudcmd & # jobs
Вы также можете отправить процесс на задний план, приостановив его с помощью [Ctrl + Z], это отправит сигнал SIGSTOP процессу, тем самым прекратив его работу; он простаивает:
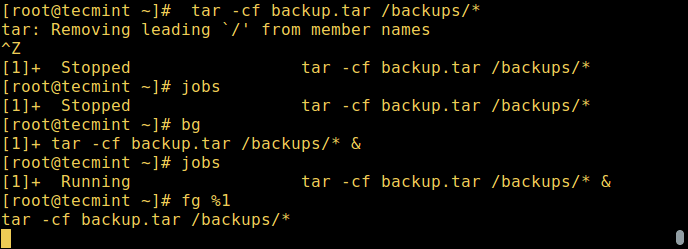
# tar -cf backup.tar /backups/* #press Ctrl+Z # jobs
Для продолжения выполнения приостановленного в фоне процесса, используется команда bg:
Для перевода процесса из фонового режима на передний план используется команда fg вместе с ID:
# jobs # fg %1
Состояние процесса в Linux
В зависимости от различных обстоятельств состояние процесса во время работы может меняться. В Linux процесс может находиться в следующих состояниях:
Running (работа) - процесс работает (он является текущим процессом в системе) или готов к работе (ждет выделения ресурсов процессора).
Waiting (ожидание) - в этом состоянии процесс ждет события, которое должно запустить его, или выделения системных ресурсов.
Кроме того, ядро системы делит процессы в состоянии ожидания на два типа: перываемые процессы, состояние ожидания которых может быть прервано сигналом, и непрерываемые, состояние ожидания которых может быть прервано только аппаратным способом.
Stopped (остановка) - в этом состоянии процесс останавливает работу, обычно после получения соответствующего сигнала. Например, процесс может быть остановлен для отладки.
Zombie (зомби) - процесс мертв, то есть он был остановлен, но в системе осталась выполняемая им задача.
Как просмотреть активные процессы в Linux
В Linux есть несколько утилит для просмотра запущенных в системе процессов, наиболее широко известны команды ps и top:
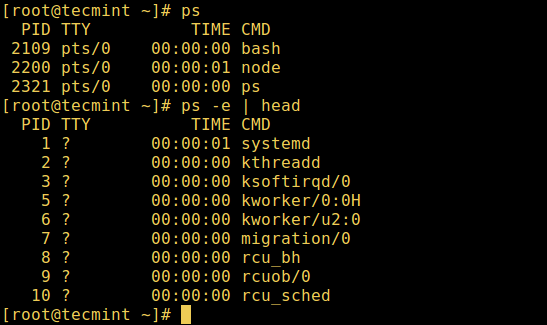
1. Команда ps
Она выводит информацию о выбранных активных процессах, как показано ниже.
# ps # ps -e | head
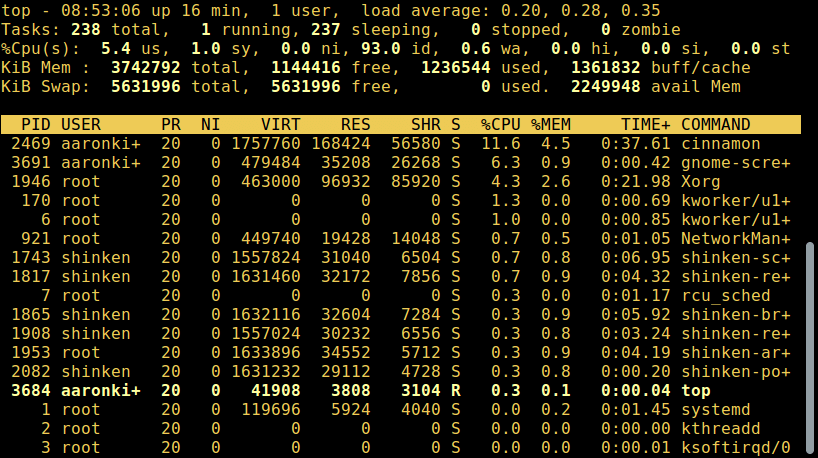
2. top – утилита системного мониторинга
top - это мощная утилита, которая позволяет в режиме реального времени просматривать список запущенных процессов, как показано ниже:
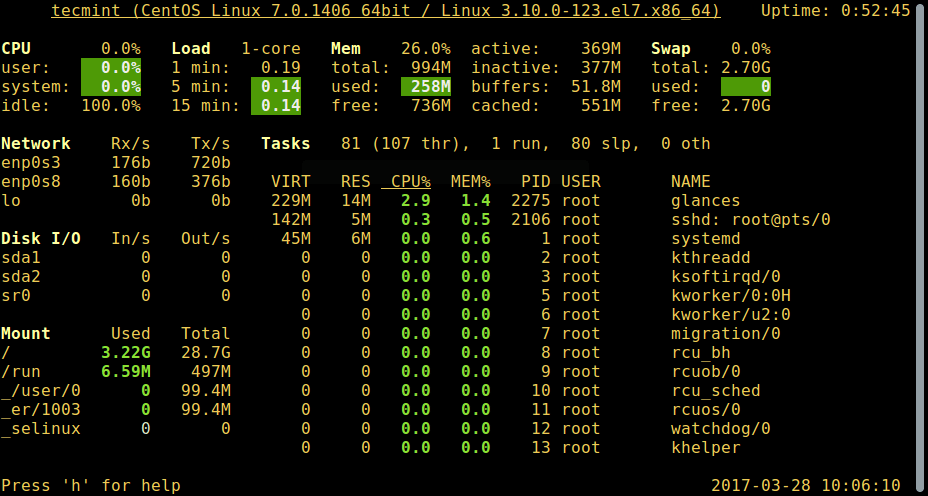
3. glances – утилита системного мониторинга
glances - это сравнительно новая утилита для мониторинга активности системы с продвинутыми возможностями:
# glances
Есть также еще несколько полезных программ, которые вы можете использовать для просмотра списка активных процессов, почитать о них можно по ссылкам ниже.
Управление процессами в Linux
В Linux также имеются команды для управления процессами, например kill, pkill, pgrep и killall. Ниже приведено несколько примеров их использования:
$ pgrep -u tecmint top $ kill 2308 $ pgrep -u tecmint top $ pgrep -u tecmint glances $ pkill glancesми $ pgrep -u tecmint glances
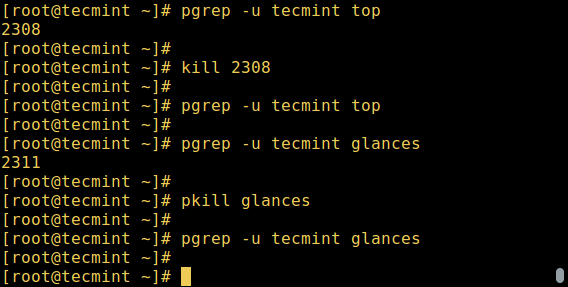
Если вы хотите подробно изучить использование этих команд, информация по ссылкам ниже.
Обратите внимание, что с их помощью вы можете завршать зависшие приложения, которые тормозят вашу систему.
Отправка сигналов процессу
Фундаментальный способ управления процессами в Linux - это отправка им сигналов, которых имеется достаточно много. Посмотреть список всех сигналов можно с помощью команды:
$ kill -l
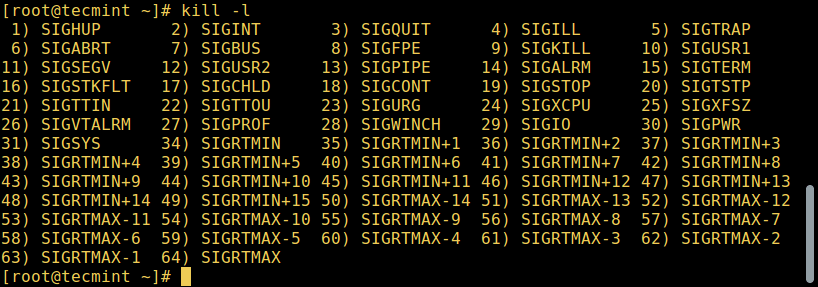
Для отправки сигналов процессу используются описанные выше команды kill, pkill или pgrep. Однако программа ответит на сигнал, только если она запрограммирована распознавать такой сигнал.
Большинство сигналов предназначены для использования системой или программистами при написании кода. Следующие сигналы могут быть полезны пользователю:
SIGHUP 1 – отправляется процессу при закрытии контролирующего его терминала.
SIGINT 2 – отправляется процессу контролирующим его терминалом, если пользователь прерывает работу процесса клавишами [Ctrl+C].
SIGQUIT 3 – отправляется процессу, если пользователь посылает сигнал выхода из программы [Ctrl+D].
SIGKILL 9 – этот сигнал немедленно завершает (убивает) процесс без выполнения любых операций очистки файлов, логов и т.д.
SIGTERM 15 – это сигнал завершения работы программы (он по умоланию отправляется командой kill).
SIGTSTP 20 – отправляется процессу контролирующим его терминалом с запросом на остановку (terminal stop); инициируется при нажатии [Ctrl+Z].
Ниже приведены примеры использования команд kill для завершения работы Firefox при его зависании с использованием PID:
$ pidof firefox $ kill 9 2687 OR $ kill -KILL 2687 OR $ kill -SIGKILL 2687
Для завершения программы с использованием ее названия используются команды pkill или killall:
$ pkill firefox $ killall firefox
Изменение приоритета процесса
В Linux все активные процессы имеют определенное значение приоритета (nice). Процессы с более высоким приоритетом обычно получают больше процессорного времени, чем процессы с более низким приоритетом.
Однако пользователь с привилегиями root может менять приоритет с помощью команд nice и renice.
В выводе команды top столбец NI отображает значения nice для процессов.
Вы можете использовать команду nice, чтобы задать значение nice процесса. Не забывайте, что обычный пользователь может присвоить процессу значение nice от 0 до 20, только если это процесс ему принадлежит.
Отрицательные значения nice может использовать только пользователь root.
Для понижения приоритета процесса используется команда renice:
$ renice +8 2687 $ renice +8 2103
Другие статьи об управлении процессами в Linux вы найдете на странице "Процессы в Linux-системе".
Изучаем процессы в Linux

В этой статье я хотел бы рассказать о том, какой жизненный путь проходят процессы в семействе ОС Linux. В теории и на примерах я рассмотрю как процессы рождаются и умирают, немного расскажу о механике системных вызовов и сигналов.
Данная статья в большей мере рассчитана на новичков в системном программировании и тех, кто просто хочет узнать немного больше о том, как работают процессы в Linux.
Всё написанное ниже справедливо к Debian Linux с ядром 4.15.0.
Введение
Системное программное обеспечение взаимодействует с ядром системы посредством специальных функций — системных вызовов. В редких случаях существует альтернативный API, например, procfs или sysfs, выполненные в виде виртуальных файловых систем.
Атрибуты процесса
Процесс в ядре представляется просто как структура с множеством полей (определение структуры можно прочитать здесь).
Но так как статья посвящена системному программированию, а не разработке ядра, то несколько абстрагируемся и просто акцентируем внимание на важных для нас полях процесса:
- Идентификатор процесса (pid)
- Открытые файловые дескрипторы (fd)
- Обработчики сигналов (signal handler)
- Текущий рабочий каталог (cwd)
- Переменные окружения (environ)
- Код возврата
Жизненный цикл процесса
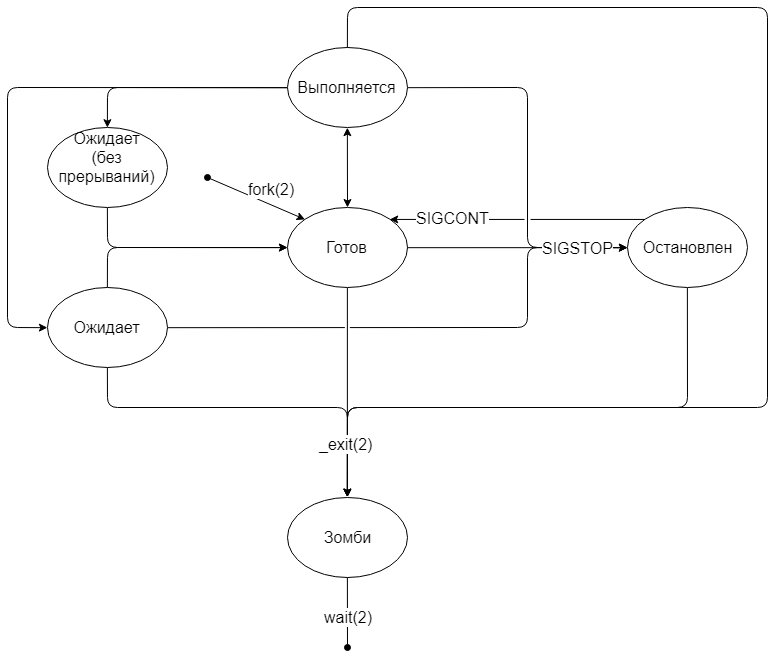
Рождение процесса
Только один процесс в системе рождается особенным способом — init — он порождается непосредственно ядром. Все остальные процессы появляются путём дублирования текущего процесса с помощью системного вызова fork(2) . После выполнения fork(2) получаем два практически идентичных процесса за исключением следующих пунктов:
- fork(2) возвращает родителю PID ребёнка, ребёнку возвращается 0;
- У ребёнка меняется PPID (Parent Process Id) на PID родителя.
Пример простой бесполезной программы с fork(2)
#include #include #include #include #include int main() < int pid = fork(); switch(pid) < case -1: perror("fork"); return -1; case 0: // Child printf("my pid = %i, returned pid = %i\n", getpid(), pid); break; default: // Parent printf("my pid = %i, returned pid = %i\n", getpid(), pid); break; >return 0; > $ gcc test.c && ./a.out my pid = 15594, returned pid = 15595 my pid = 15595, returned pid = 0 Состояние «готов»
Сразу после выполнения fork(2) переходит в состояние «готов».
Фактически, процесс стоит в очереди и ждёт, когда планировщик (scheduler) в ядре даст процессу выполняться на процессоре.
Состояние «выполняется»
Как только планировщик поставил процесс на выполнение, началось состояние «выполняется». Процесс может выполняться весь предложенный промежуток (квант) времени, а может уступить место другим процессам, воспользовавшись системным вывозом sched_yield .
Перерождение в другую программу
В некоторых программах реализована логика, в которой родительский процесс создает дочерний для решения какой-либо задачи. Ребёнок в данном случае решает какую-то конкретную проблему, а родитель лишь делегирует своим детям задачи. Например, веб-сервер при входящем подключении создаёт ребёнка и передаёт обработку подключения ему.
Однако, если нужно запустить другую программу, то необходимо прибегнуть к системному вызову execve(2) :
int execve(const char *filename, char *const argv[], char *const envp[]); или библиотечным вызовам execl(3), execlp(3), execle(3), execv(3), execvp(3), execvpe(3) :
int execl(const char *path, const char *arg, . /* (char *) NULL */); int execlp(const char *file, const char *arg, . /* (char *) NULL */); int execle(const char *path, const char *arg, . /*, (char *) NULL, char * const envp[] */); int execv(const char *path, char *const argv[]); int execvp(const char *file, char *const argv[]); int execvpe(const char *file, char *const argv[], char *const envp[]); Все из перечисленных вызовов выполняют программу, путь до которой указан в первом аргументе. В случае успеха управление передаётся загруженной программе и в исходную уже не возвращается. При этом у загруженной программы остаются все поля структуры процесса, кроме файловых дескрипторов, помеченных как O_CLOEXEC , они закроются.
Как не путаться во всех этих вызовах и выбирать нужный? Достаточно постичь логику именования:
- Все вызовы начинаются с exec
- Пятая буква определяет вид передачи аргументов:
- l обозначает list, все параметры передаются как arg1, arg2, . NULL
- v обозначает vector, все параметры передаются в нуль-терминированном массиве;
Пример вызова /bin/cat --help через execve
#define _GNU_SOURCE #include int main() < char* args[] = < "/bin/cat", "--help", NULL >; execve("/bin/cat", args, environ); // Unreachable return 1; >$ gcc test.c && ./a.out Usage: /bin/cat [OPTION]. [FILE]. Concatenate FILE(s) to standard output. *Вывод обрезан*Семейство вызовов exec* позволяет запускать скрипты с правами на исполнение и начинающиеся с последовательности шебанг (#!).
Пример запуска скрипта с подмененным PATH c помощью execle
#define _GNU_SOURCE #include int main() < char* e[] = ; execle("/tmp/test.sh", "test.sh", NULL, e); // Unreachable return 1; >$ cat test.sh #!/bin/bash echo $0 echo $PATH $ gcc test.c && ./a.out /tmp/test.sh /habr:/rulezЕсть соглашение, которое подразумевает, что argv[0] совпадает с нулевым аргументов для функций семейства exec*. Однако, это можно нарушить.
Пример, когда cat становится dog с помощью execlp
#define _GNU_SOURCE #include int main() < execlp("cat", "dog", "--help", NULL); // Unreachable return 1; >$ gcc test.c && ./a.out Usage: dog [OPTION]. [FILE]. *Вывод обрезан*Любопытный читатель может заметить, что в сигнатуре функции int main(int argc, char* argv[]) есть число — количество аргументов, но в семействе функций exec* ничего такого не передаётся. Почему? Потому что при запуске программы управление передаётся не сразу в main. Перед этим выполняются некоторые действия, определённые glibc, в том числе подсчёт argc.
Состояние «ожидает»
Некоторые системные вызовы могут выполняться долго, например, ввод-вывод. В таких случаях процесс переходит в состояние «ожидает». Как только системный вызов будет выполнен, ядро переведёт процесс в состояние «готов».
В Linux так же существует состояние «ожидает», в котором процесс не реагирует на сигналы прерывания. В этом состоянии процесс становится «неубиваемым», а все пришедшие сигналы встают в очередь до тех пор, пока процесс не выйдет из этого состояния.
Ядро само выбирает, в какое из состояний перевести процесс. Чаще всего в состояние «ожидает (без прерываний)» попадают процессы, которые запрашивают ввод-вывод. Особенно заметно это при использовании удалённого диска (NFS) с не очень быстрым интернетом.Состояние «остановлен»
В любой момент можно приостановить выполнение процесса, отправив ему сигнал SIGSTOP. Процесс перейдёт в состояние «остановлен» и будет находиться там до тех пор, пока ему не придёт сигнал продолжать работу (SIGCONT) или умереть (SIGKILL). Остальные сигналы будут поставлены в очередь.
Завершение процесса
Ни одна программа не умеет завершаться сама. Они могут лишь попросить систему об этом с помощью системного вызова _exit или быть завершенными системой из-за ошибки. Даже когда возвращаешь число из main() , всё равно неявно вызывается _exit .
Хотя аргумент системного вызова принимает значение типа int, в качестве кода возврата берется лишь младший байт числа.Состояние «зомби»
Сразу после того, как процесс завершился (неважно, корректно или нет), ядро записывает информацию о том, как завершился процесс и переводит его в состояние «зомби». Иными словами, зомби — это завершившийся процесс, но память о нём всё ещё хранится в ядре.
Более того, это второе состояние, в котором процесс может смело игнорировать сигнал SIGKILL, ведь что мертво не может умереть ещё раз.Забытье
Код возврата и причина завершения процесса всё ещё хранится в ядре и её нужно оттуда забрать. Для этого можно воспользоваться соответствующими системными вызовами:
pid_t wait(int *wstatus); /* Аналогично waitpid(-1, wstatus, 0) */ pid_t waitpid(pid_t pid, int *wstatus, int options);Вся информация о завершении процесса влезает в тип данных int. Для получения кода возврата и причины завершения программы используются макросы, описанные в man-странице waitpid(2) .
Пример корректного завершения и получения кода возврата
#include #include #include #include #include int main() < int pid = fork(); switch(pid) < case -1: perror("fork"); return -1; case 0: // Child return 13; default: < // Parent int status; waitpid(pid, &status, 0); printf("exit normally? %s\n", (WIFEXITED(status) ? "true" : "false")); printf("child exitcode = %i\n", WEXITSTATUS(status)); break; >> return 0; >$ gcc test.c && ./a.out exit normally? true child exitcode = 13Пример некорректного завершения
Передача argv[0] как NULL приводит к падению.
#include #include #include #include #include int main() < int pid = fork(); switch(pid) < case -1: perror("fork"); return -1; case 0: // Child execl("/bin/cat", NULL); return 13; default: < // Parent int status; waitpid(pid, &status, 0); if(WIFEXITED(status)) < printf("Exit normally with code %i\n", WEXITSTATUS(status)); >if(WIFSIGNALED(status)) < printf("killed with signal %i\n", WTERMSIG(status)); >break; > > return 0; >$ gcc test.c && ./a.out killed with signal 6Бывают случаи, при которых родитель завершается раньше, чем ребёнок. В таких случаях родителем ребёнка станет init и он применит вызов wait(2) , когда придёт время.
После того, как родитель забрал информацию о смерти ребёнка, ядро стирает всю информацию о ребёнке, чтобы на его место вскоре пришёл другой процесс.
Благодарности
Спасибо Саше «Al» за редактуру и помощь в оформлении;
Спасибо Саше «Reisse» за понятные ответы на сложные вопросы.
Они стойко перенесли напавшее на меня вдохновение и напавший на них шквал моих вопросов.
- linux
- системное программирование
- Системное программирование
- C
- Разработка под Linux