Суставы, еда и ДНК: какое место занимают полимеры в современной жизни

Жизнь сейчас трудно представить без полимеров. Из них созданы гаджеты, одежда, запчасти и даже контактные линзы. Да и сама молекула ДНК — тоже полимер. РБК Тренды выяснили, какими бывают полимеры и как их получают
Что такое полимеры
- Полиэтилен — термопластичный полимер этилена.
- Полиуретан — сырьем для этого полимера служит полиол. Его получают из сырой нефти.
- Полиамид — получается в результате химической переработки угля, газа и нефти.
- Поливинилхлорид (ПВХ) — синтетический термопластик, который состоит из хлора и этилена.
- Бакелит — продукт реакции фенола и формальдегида под давлением при высоких температурах.
- Полистирол — материал, который получают в результате полимеризации стирола.
- Полиметилметакрилат (оргстекло) — полимер, который пропускает свет, и внешне похож на стекло.
- Полиэфирное волокно — используется в качестве наполнителя в игрушках, одеялах, подушках, мебели.
- Полипропилен — твердое вещество, которое получается в результате полимеризации пропилена (бесцветный газ).
- Полиамиды — в эту группу пластмасс входят найлон, капрон, анид.
- Тефлон — полимер, который содержит углерод и фтор (политетрафторэтилен).
- Полимерные композиты — изготавливаются из двух и более компонентов. В качестве основного (матрицы) выступает полимер.
- Полиакриламид (ПАА) — полимер белого цвета без запаха. Растворяется в воде, в ледяной уксусной и молочной кислотах и глицерине, но не растворяется в этаноле, метаноле и ацетоне.
Применение полимеров
Полимеры в нефтегазовой промышленности
Нефть и газ — это не просто источник топлива для большинства видов транспорта, но и сырье для химического производства. Именно из нефтепродуктов создают большинство видов полимеров.
Также полученные полимеры используются и в самом процессе добычи. Так, для увеличения производительности и очистки трубопроводов используют полиакриламид (ПАА) и его производные. Этот технический водорастворимый полимер помогает увеличивать максимальную пропускную способность нефтепровода и улучшает качество перекачиваемой нефти. Его же используют при ремонтных работах в скважинах.
В медицине
Медицинская сфера уже давно и активно использует изделия из полимеров. Среди них: штифты, одноразовые шприцы, инструменты для хирургии, контейнеры для плазмы и крови, контактные линзы, лабораторная посуда, хирургические нити, бахилы, протезы, искусственные органы и даже полимерные наногели для доставки лекарств.
Изучение возможностей полимеров на этом не останавливается. Так, студенты и профессоры Национального исследовательского технологического университета «МИСиС» в 2017 году решили усовершенствовать полиэтилен, чтобы использовать его в качестве замены костей, суставов и мышц. По мнению ученых, если доработать идею, то срок годности импланта из этого материала составит не менее 15 лет.

В автомобилестроении
Предприятия автомобильной промышленности используют не менее 100 видов полимерных материалов при производстве транспортных средств. Так, колпаки колес, приборные панели и некоторые части двигателя сделаны из полипропилена. Сиденья выполнены из полиуретана, коврики — из полиэтилена. В рычагах включения привода, шестернях, бензобаке, аккумуляторе, корпусах предохранителей есть полиамид. Проводку делают из поливинилхлорида (ПВХ). Этот термопластичный полимер винилхлорида знаком жителям всего мира. Из него обычно изготавливаются линолеум и натяжные потолки.
В строительстве
Не отстает от других и строительная сфера. Из полимеров создают электротехнические конструкции, кабели, провода, трубы, изоляционные эмали, лаки, пленки, сетки, ограждения и защитные покрытия. Более того, полимеры добавляются в состав железобетона и бетона. Это позволяет улучшить качество строительных материалов.
В пищевой промышленности
Полимеры в пищевой промышленности обязаны соответствовать определенным санитарно-гигиеническим требованиям. Они не должны влиять на органолептические свойства продуктов (вкус, цвет, запах), а также содержать токсичные компоненты. Полимеры используются не только в производстве оборудования для пищевой промышленности, но и в упаковочных материалах.
- Оборудование.К примеру, в консервной и молочной промышленности звенья транспортерных лент изготовлены из полиамидов или полиэтилена высокой плотности. А для того, чтобы сырье и полуфабрикаты не прилипали к поверхности оборудования, на металлические конструкции наносят специальные полимерные покрытия.
- Полимерная упаковка. Она позволяет сохранять миллионы тонн сельскохозяйственной продукции и продовольствия в магазинах. Так, одноразовые многослойные пленки сохраняют продукты на 20% дольше без добавления консервантов.
Свойства полимеров
- Ударопрочность. По способности выдерживать механическую нагрузку полимеры ничем не уступают некоторым металлам. Поэтому полимеры используют при создании автомобильных бамперов, защитных чехлов и не только.
- Пластичность и эластичность. Таким свойством обладают, например, природные и синтетические каучуки. Именно поэтому их используют при создании автомобильных шин, шланги, оболочки проводов и кабелей, подошвы для обуви, воздушные шарики и не только.
- Отражательная способность. Благодаря этому свойству из полимеров создают специальные светоотражающие пленки. Обычно их используют для индикации предметов в темное время суток. К примеру, светоотражающие материалы применяют при организации дорожного движения, создании билбордов и баннеров.
- Электроизоляция. Полимеры — диэлектрики (не пропускают через себя электрический ток). Их можно использовать не только в качестве изоляционных материалов в электрооборудовании, но и при изготовлении рукояток инструмента для работы с токопроводящими деталями.
Природные и синтетические полимеры
Природные
Природные полимеры встречаются повсюду. Они представляют собой макромолекулы, созданные самой природой без участия человека. Приведем ряд примеров.
- Полисахариды. В эту большую группу природных полимеров относят крахмал и целлюлозу. Они отличаются друг от друга своими свойствами. Так, крахмал легко растворяется в воде и его можно употреблять в пищу. Целлюлоза не растворяется в воде. Ее обычно используют при производстве бумаги и волокон для ткани.
- Белки (протеины) — природный полимер, который состоит из аминокислот. Именно белок отвечает за рост, строение и развитие живого организма.
- Нуклеиновые кислоты. Нуклеиновые (ДНК) и рибонуклеиновые кислоты (РНК) содержат всю информацию о человека: от болезней до талантов.
- Природный каучук. Это пластичный и вязкий полимер, который содержится в соке каучуконосных растений.

Синтетические
До XIX века промышленности хватало природных полимеров. Но со временем из-за нехватки ресурсов появилась потребность и в других материалах. Так, в 1909 году американский химик Лео Бакеланд пытался найти замену природному шеллаку (смола). Но в итоге опыты помогли ему создать материал под названием бакелит. Он получился в результате реакции фенола и формальдегида под давлением при высоких температурах. Именно с этого открытия началась эра синтетических материалов. В химических лабораториях началась разработка новых видов полимеров.

Обложка TIME за 22 сентября 1924 года с фотографией Бакеланда (Фото: wikipedia.org)
- Перед Второй мировой войной в нескольких странах (Англия, Германия и США) стартовало производство синтетического каучука. В тоже время началась разработка полистирола, поливинилхлорида, полиметилметакрилата.
- В 1950-е годы ученые создали полиэфирное волокно и началось производство тканей на его основе. Тогда же появились полипропилен и полиэтилен низкого давления. Затем в массовое производство запустили полиуретаны.
- В 1960–1970-х годах удалось синтезировать полиамиды.
Как получают полимеры
Полимеры получают двумя способами: полимеризация и поликонденсация. У каждого свои особенности. Полимеризация — это процесс, при котором мономеры объединяются в цепи и удерживаются химическими связями. Полимеризацией получают полистирол, хлоропреновый и бутадиеновый каучуки, тефлон, полипропилен, полиэтилен.
«Полимеры получают реакцией соединения мономеров. Если говорить простым языком, то это бусы, где бусины — это мономеры. При получении полимеров не меняется состав. То есть какие атомы были в веществе, такие и остаются. Меняется только их количество. И в зависимости от количества мономеров меняются их свойства», — объяснила РБК Трендам начальник лаборатории наливной станции «Нагорная» АО «Транснефть — Верхняя Волга» Алина Мусина.
При поликонденсации помимо полимера образуется еще и низкомолекулярное вещество (вода, спирт, хлороводород). В процессе поликонденсации образуются лавсан, полипептиды, фенолформальдегидные смолы. А вот капрон, например, можно получить сразу двумя способами.
Полимеры и пластмассы: в чем разница
Зачастую слово «полимер» используют как синоним понятию «пластмасса». Но это не так. Пластмасса — это лишь один из видов полимеров. Многие виды пластмасс синтезируют из нефти или углеводородного масла. В мире ежегодно производится более 380 млн т пластика. А в Мировой океан каждый год попадает около 8 млн т предметов из этого материала: бутылки, пакеты, рыболовные сети.
По мнению экологов, именно процесс производства пластмасс создал глобальный кризис отходов. Опасения защитников окружающей среды вызывает не только объем выбросов, но и сам процесс создания таких материалов.
По данным Greenpeace, при добыче нефти и газа в воздух и воду попадает масса токсичных веществ. Более 170 химикатов, которые используют при добыче сырья для пластмасс, вызывают множество болезней: от онкологии до ослабления иммунной системы.

Будущее полимеров
В будущем мир не сможет уйти от полимеров, уверены эксперты. С каждым годом они будут приобретать новые формы. На первый план уже сейчас начинают выходить «зеленые» полимеры. Речь идет о композитах, которые объединяют в себе сильные стороны природных и синтетических полимеров.
«Нужно понимать, что полимеры — это не только что-то твердое. Они могут быть жидкими, прозрачными, цветными, более гибкими, менее гибкими, пластичными. Это и объясняет их широкое применение во всех сферах нашей жизни», — добавила Алина Мусина.
Тем временем ученые и производители продолжают искать способы снизить экологический след от некоторых видов полимеров. Одни компании уменьшают количество первичного пластика и делают ставку на вторичную переработку, а другие разрабатывают альтернативные варианты.

Так, английская компания Polythene UK представила несколько видов упаковок на растительной основе. Сейчас предприятие производит компостируемый полиэтилен на основе крахмала. Упаковку из такого материала не нужно перерабатывать — процесс разложения займет не более трех лет. Со временем они распадаются на природные элементы: биомассу, воду, углекислый газ, метан. Еще одна альтернатива — полиэтилен из отходов сахарного тростника. Его можно использовать для крышек поддонов.
Ограничение скорости передачи трафика. Policer или shaper, что использовать в сети?

Когда речь заходит об ограничении пропускной способности на сетевом оборудовании, в первую очередь в голову приходят две технологи: policer и shaper. Policer ограничивает скорость за счёт отбрасывания «лишних» пакетов, которые приводят к превышению заданной скорости. Shaper пытается сгладить скорость до нужного значения путём буферизации пакетов. Данную статью я решил написать после прочтения заметки в блоге Ивана Пепельняка (Ivan Pepelnjak). В ней в очередной раз поднимался вопрос: что лучше – policer или shaper. И как часто бывает с такими вопросами, ответ на него: всё зависит от ситуации, так как у каждой из технологий есть свои плюсы и минусы. Я решил разобраться с этим чуточку подробнее, путём проведения нехитрых экспериментов. Полученные результаты подкатом.
И так, начнём с общей картинки разницы между policer и shaper.
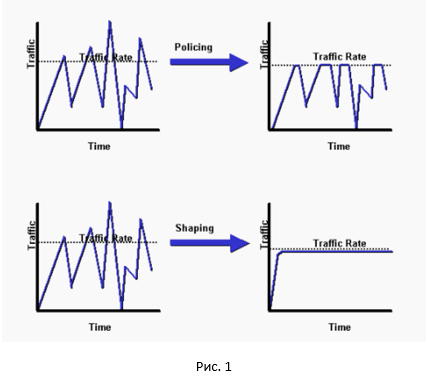
Как видно, policer срезает все пики, shaper же делает сглаживание нашего трафика. Достаточно неплохое сравнение между policer и shaper можно найти здесь.
Обе технологии в своей основе используют механизм токенов (token). В этом механизме присутвует виртуальное ограниченное по размеру ведро (token bucket), в которое с некой регулярностью поступают токены. Токен, как проездной, расходуется для передачи пакетов. Если токенов в ведре нет, то пакет отбрасывается (могут выполняться и другие действия). Таким образом, мы получаем постоянную скорость передачи трафика, так как токены поступают в ведро в соответствии с заданной скоростью.
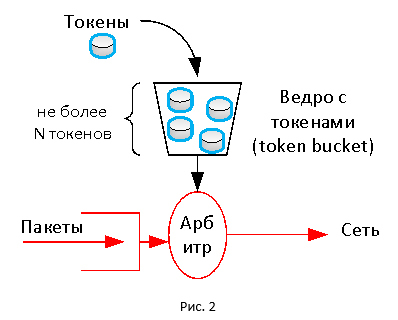
Может стоило сделать проще?
Скорость сессии обычно меряется в отведённый промежуток времени, например, за 5 сек или 5 минут. Брать мгновенное значение бессмысленно, так как данные всегда передаются на скорости канала. При этом если мы будем делать усреднение за разные временные интервалы, мы получим разные графики скорости передачи данных, так как трафик в сети не равномерный. Я думаю, любой с этим сталкивался, строя графики в системе мониторинга.
Механизм токенов позволяет обеспечить гибкость в настройке ограничения скорости. Размер ведра влияет на то, как мы будем усреднять нашу скорость. Если ведро большое (т.е. токенов там может скопиться много), мы позволим трафику сильнее «выпрыгивать» за отведенные ограничения в определённые моменты времени (эквивалент усреднения на большем промежутке времени). Если размер ведра маленький, то трафик будет более равномерный, крайне редко превышая заданный порог (эквивалент усреднения на маленьком промежутке времени).
В случае policer’а наполнение ведра происходит каждый раз, когда приходит новый пакет. Количество токенов, которые загружаются в ведро, зависит от заданной скорости policer’а и времени, прошедшего с момента поступления последнего пакета. Если токенов в ведре нет, policer может отбросить пакеты или, например, перемаркировать их (назначить новые значения DSCP или IPP). В случае shaper’а наполнение ведра происходит через равные промежутки времени независимо от прихода пакетов. Если токенов не хватает, пакеты попадают в специальную очередь, где ждут появления токенов. За счёт этого имеем сглаживание. Но если пакетов приходит слишком много, очередь shaper’а в конечном счёте переполняется и пакеты начинают отбрасываться. Стоит отметить, что приведённое описание является упрощённым, так как и policer и shaper имеют вариации (детальный разбор данных технологий займёт объём отдельной статьи).
Эксперимент
А как это выглядит на практике? Для этого соберём тестовый стенд и проведём следующий эксперимент. Наш стенд будет включать устройство, которое поддерживает технологии policer и shaper (в моём случае – это Cisco ISR 4000; подойдёт устройство любого вендора аппаратное или программное, которое поддерживает данные технологии), генератор трафика iPerf и анализатор трафика Wireshark.
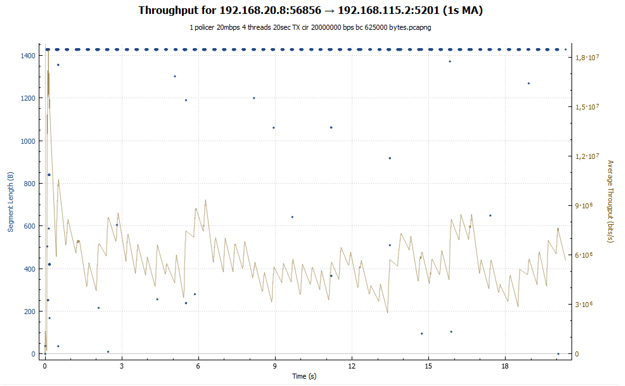
Сначала посмотрим на работу policer. Настроим ограничение скорости равным 20 Мбит/с.
Конфигурация устройства
policy-map Policer_20 class class-default police 20000000 interface GigabitEthernet0/0/1 service-policy output Policer_20Используем автоматически выставляемое значение размера ведра токенов (token bucket). Для нашей скорости – это 625 000 байт.
В iPerf запускаем генерацию трафика в рамках четырёх потоков, используя протокол TCP.
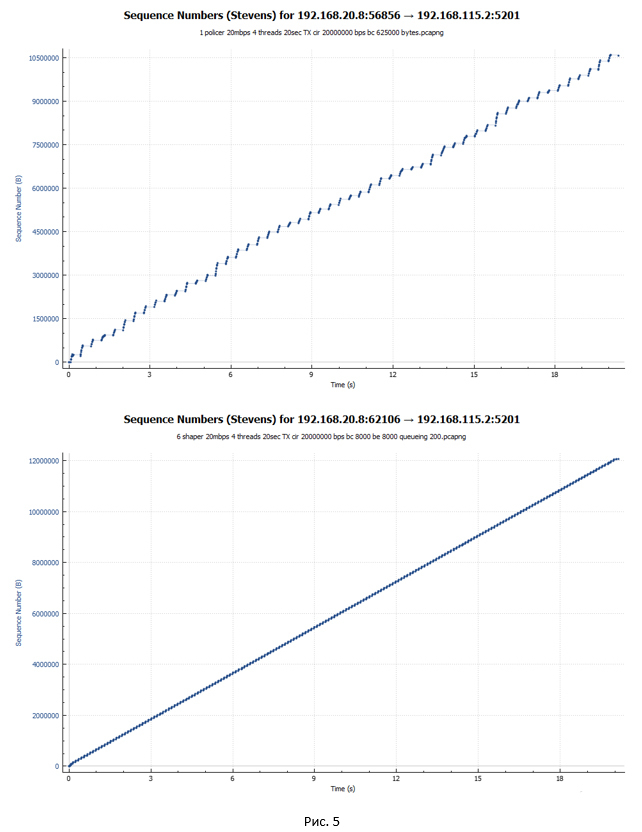
C:\Users\user>iperf3.exe -c 192.168.115.2 -t 20 -i 20 -P 4 Connecting to host 192.168.115.2, port 5201 [ 4] local 192.168.20.8 port 55542 connected to 192.168.115.2 port 5201 [ 6] local 192.168.20.8 port 55543 connected to 192.168.115.2 port 5201 [ 8] local 192.168.20.8 port 55544 connected to 192.168.115.2 port 5201 [ 10] local 192.168.20.8 port 55545 connected to 192.168.115.2 port 5201 [ ID] Interval Transfer Bandwidth [ 4] 0.00-20.01 sec 10.2 MBytes 4.28 Mbits/sec [ 6] 0.00-20.01 sec 10.6 MBytes 4.44 Mbits/sec [ 8] 0.00-20.01 sec 8.98 MBytes 3.77 Mbits/sec [ 10] 0.00-20.01 sec 11.1 MBytes 4.64 Mbits/sec [SUM] 0.00-20.01 sec 40.9 MBytes 17.1 Mbits/sec Средняя скорость составила 17.1 Мбит/с. Каждая сессия получила разную пропускную способность. Обусловлено это тем, что настроенный в нашем случае policer не различает потоки и отбрасывает любые пакеты, которые превышают заданное значение скорости.
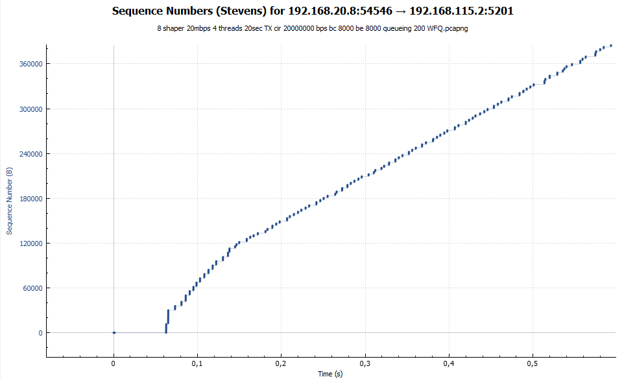
С помощью Wireshark собираем дамп трафика и строим график передачи данных, полученный на стороне отправителя.
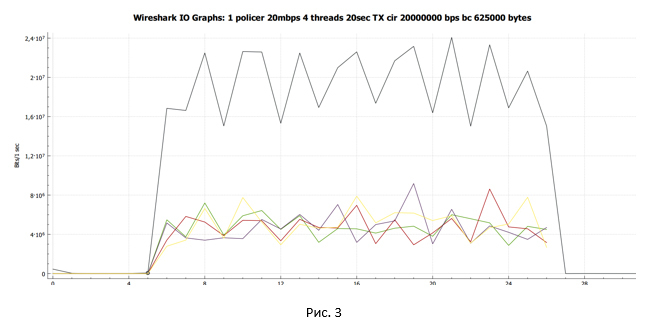
Чёрная линия показывают суммарный трафик. Разноцветные линии – трафик каждого потока TCP. Прежде чем делать какие-то выводы и углубляться в вопрос, давайте посмотрим, что у нас получится, если policer заменить на shaper.
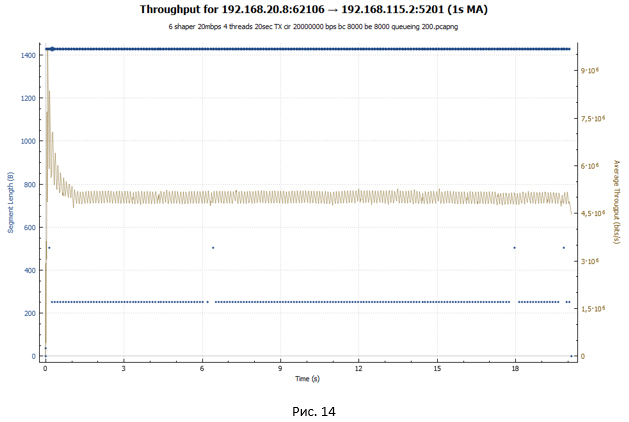
Настроим shaper на ограничение скорости 20 Мбит/с.
Конфигурация устройства
policy-map Shaper_20 class class-default shape average 20000000 queue-limit 200 packets interface GigabitEthernet0/0/1 service-policy output Shaper_20При настройке используем автоматическое выставляемое значение размера ведра токенов BC и BE равное 8000. Но меняем размер очереди с 83 (по умолчанию в версии IOS XE 15.6(1)S2) на 200. Сделано это сознательно, чтобы получить более чёткую картину, характерную для shaper’а. На этом вопросе мы остановимся более подробно в подкате «Влияет ли глубина очереди на нашу сессию?».
cbs-rtr-4000#sh policy-map interface gigabitEthernet 0/0/1 Service-policy output: Shaper_20 Class-map: class-default (match-all) 34525 packets, 50387212 bytes 5 minute offered rate 1103000 bps, drop rate 0000 bps Match: any Queueing queue limit 200 packets (queue depth/total drops/no-buffer drops) 0/0/0 (pkts output/bytes output) 34525/50387212 shape (average) cir 20000000, bc 80000, be 80000 target shape rate 20000000
В iPerf запускаем генерацию трафика в рамках четырёх потоков, используя протокол TCP.
C:\Users\user>iperf3.exe -c 192.168.115.2 -t 20 -i 20 -P 4 Connecting to host 192.168.115.2, port 5201 [ 4] local 192.168.20.8 port 62104 connected to 192.168.115.2 port 5201 [ 6] local 192.168.20.8 port 62105 connected to 192.168.115.2 port 5201 [ 8] local 192.168.20.8 port 62106 connected to 192.168.115.2 port 5201 [ 10] local 192.168.20.8 port 62107 connected to 192.168.115.2 port 5201 [ ID] Interval Transfer Bandwidth [ 4] 0.00-20.00 sec 11.6 MBytes 4.85 Mbits/sec [ 6] 0.00-20.00 sec 11.5 MBytes 4.83 Mbits/sec [ 8] 0.00-20.00 sec 11.5 MBytes 4.83 Mbits/sec [ 10] 0.00-20.00 sec 11.5 MBytes 4.83 Mbits/sec [SUM] 0.00-20.00 sec 46.1 MBytes 19.3 Mbits/sec Средняя скорость составила 19.3 Мбит/с. При этом каждый поток TCP получил примерно одинаковую пропускную способность.
С помощью Wireshark собираем дамп трафика и строим график передачи данных, полученный на стороне отправителя.
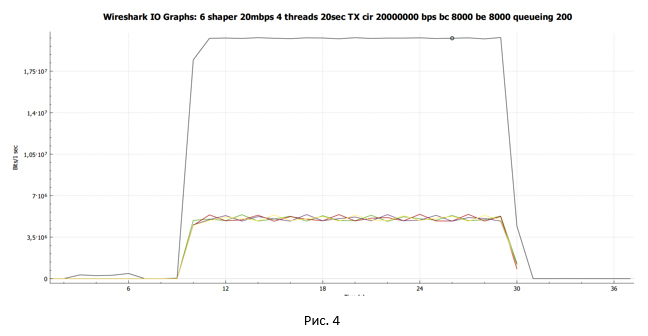
Чёрная линия показывают суммарный трафик. Разноцветные линии – трафик каждого потока TCP.
Сделаем первые промежуточные выводы:
- В случае policer полезная пропускная способность составила 17.1 Мбит/с. Каждый поток в разные моменты времени имел разную пропускную способность.
- В случае shaper полезная пропускная способность составила 19.3 Мбит/с. Все потоки имели примерно одинаковую пропускную способность.
Посмотрим более детально на поведение TCP сессии в случае работы policer и shaper. Благо, в Wireshark достаточно инструментов, чтобы сделать такой анализ.
Начнём c графиков, на которых отображаются пакеты с привязкой ко времени их передачи. Первый график – policer’а, второй – shaper’а.
Из графиков видно, что пакеты в случае shaper передаются более равномерно по времени. При этом в случае policer видны скачкообразные разгоны сессии и периоды пауз.
Анализ TCP сессии при работе policer
Посмотрим поближе на сессию TCP. Будем рассматривать случай policer’а.
Протокол TCP в своей работе опирается на достаточно большой набор алгоритмов. Среди них для нас наиболее интересными являются алгоритмы, отвечающие за управление перегрузками (congestion control). Именно они отвечают за скорость передачи данных в рамках сессии. ПК, на котором запускался iPerf, работает под управлением Windows 10. В Windows 10 в качестве такого алгоритма используется Compound TCP (CTCP). CTCP в своей работе позаимствовал достаточно многое из алгоритма TCP Reno. Поэтому при анализе TCP сессии достаточно удобно посматривать на картинку с состояниями сессии при работе алгоритма TCP Reno.
На следующей картинке представлен начальный сегмент передачи данных.
- На первом этапе у нас устанавливается TCP сессия (происходит тройное рукопожатие).
- Далее начинается разгон TCP сессии. Работает алгоритм TCP slow-start. По умолчанию значение окна перегрузки (congestion window — cwnd) для TCP-сессии в Windows 10 равно объёму десяти максимальных сегментов данных TCP сессии (MSS). Это означает, что данный ПК может отправить сразу 10 пакетов, не дожидаясь получения подтверждения на них в виде ACK. В качестве начального значения порога прекращения работы алгоритма slow-start (ssthresh) и перехода в режим избегания перегрузки (congestion avoidence) берётся значение максимального окна, которое предоставил получатель (advertised window — awnd). В нашем случае ssthresh=awnd=64K. Awnd – максимальное значение данных, которые получатель готов принять себе в буфер.
Где посмотреть начальные данные сессии?
Чтобы посмотреть параметры TCP, можно воспользоваться PowerShell. Смотрим, какой глобальный шаблон TCP используется в нашей системе по умолчанию.  Далее выполняем запрос «Get-NetTCPSetting Internet» и ищем значение величины InitialCongestionWindow(MSS).
Далее выполняем запрос «Get-NetTCPSetting Internet» и ищем значение величины InitialCongestionWindow(MSS). 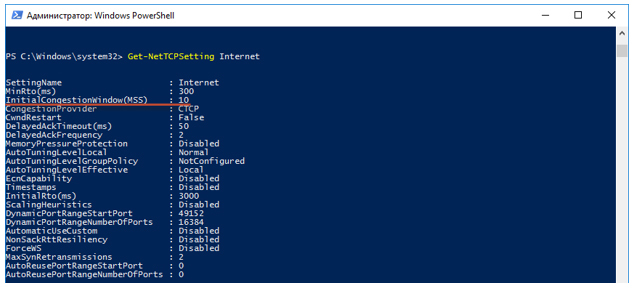 Значение awnd можно найти в пакетах ACK, пришедших от получателя:
Значение awnd можно найти в пакетах ACK, пришедших от получателя: 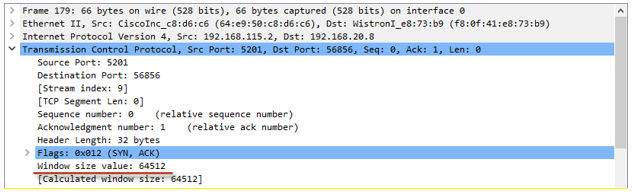
В режиме TCP slow-start размер окна (cwnd) увеличивается каждый раз при получении ACK. При этом оно не может превысить значение awnd. За счёт такого поведения, мы имеем практически экспоненциальный рост количества передаваемых пакетов. Наша TCP сессия разгоняется достаточно агрессивно.
Передача пакетов в режиме TCP slow-start
- ПК устанавливает TCP-соединение (№1-3).
- Отправляет 10 пакетов (№4-13), не дожидаясь подтверждения (ACK), так как cwnd=10*MSS.
- Получает ACK (№14), который подтверждает сразу два пакета (№4-5).
- Увеличивает размер окна Cwnd=(10+2)*MSS=12*MSS.
- Отправляет дополнительно три пакета (№15-17). По идее ПК должен был отправить четыре пакета: два, так как он получил подтверждение на два пакета, которые были переданы ранее; плюс два пакета из-за увеличения окна. Но в реальности на самом первом этапе система шлёт (2N-1) пакетов. Найти ответ на этот вопрос мне не удалось. Если кто-то подскажет, буду благодарен.
- Получает два ACK (№18-19). Первое ACK подтверждает получение удалённой стороной четырёх пакетов (№6-9). Второе — трёх (№10-12).
- Увеличивает размер окна Cwnd=(12+7)*MSS=19*MSS.
- Отправляет 14 пакетов (№20-33): семь новых пакетов, так как получили ACK на семь ранее переданных пакетов, и ещё семь новых пакетов, так как увеличилось окно.
- И так далее.
cwnd = ssthersh
Когда cwnd = ssthersh точного ответа, произойдёт ли смена алгоритма с slow-start на алгоритм congestion avoidance, я найти не смог. RFC точного ответа не даёт. С практической точки зрения это не очень важно, так как размер окна дальше расти не может.
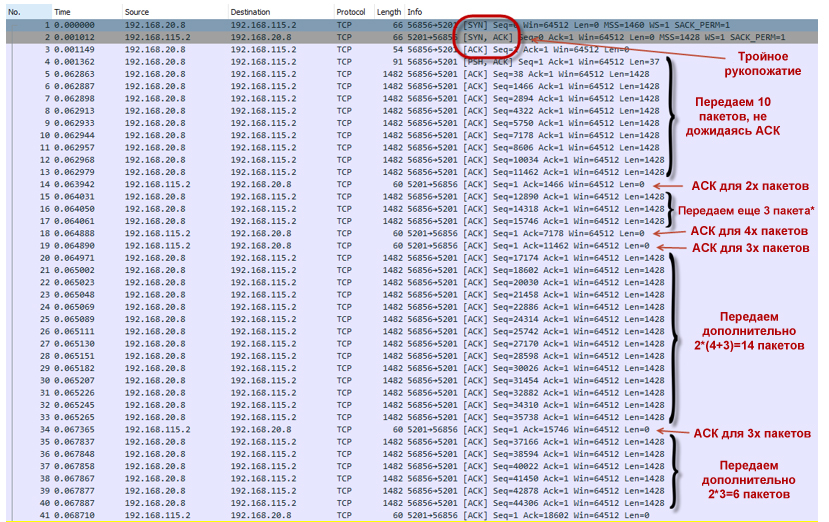
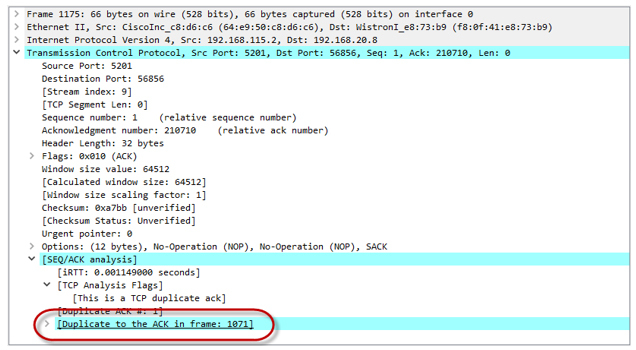 После получения трёх Dup ACK наша TCP сессия переходит в фазу восстановления после потери (loss recovery, включающую алгоритмы Fast Retransmit/Fast Recovery). Отправитель устанавливает новое значение ssthresh = cwnd/2 (32K) и делает окно cwnd = ssthresh+3*MSS.
После получения трёх Dup ACK наша TCP сессия переходит в фазу восстановления после потери (loss recovery, включающую алгоритмы Fast Retransmit/Fast Recovery). Отправитель устанавливает новое значение ssthresh = cwnd/2 (32K) и делает окно cwnd = ssthresh+3*MSS. 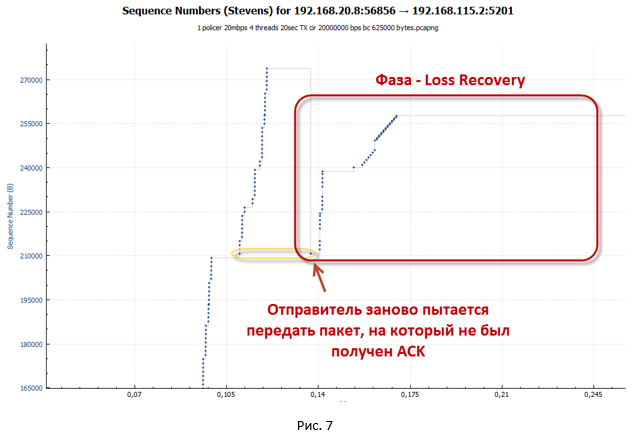
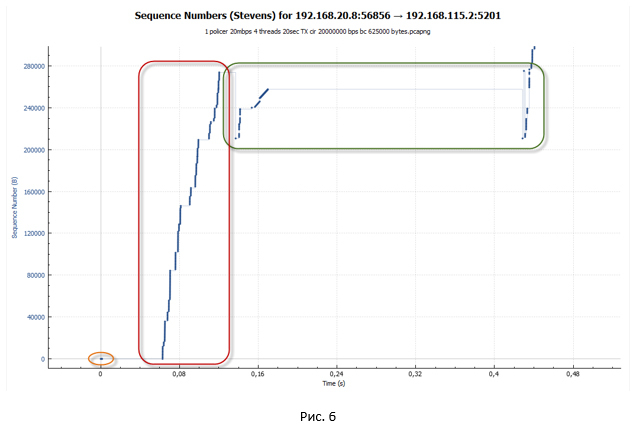
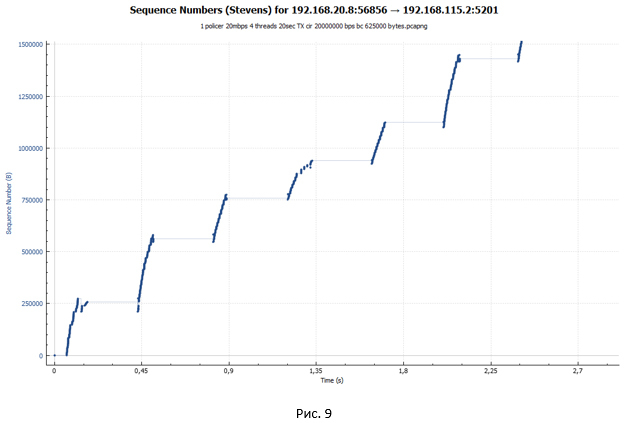 TCP сессия при работе policer выглядит как лестница (идёт фаза передачи, за которой следует пауза).
TCP сессия при работе policer выглядит как лестница (идёт фаза передачи, за которой следует пауза).Анализ TCP сессии при работе shaper
Теперь давайте посмотрим поближе на сегмент передачи данных для случая shaper. Для наглядности возьмём аналогичный масштаб, как и для графика policer на Рис.6.
Из графика мы видим всё ту же лесенку. Но размер ступенек стал существенно меньше. Однако если приглядеться к графику на Рис. 10, мы не увидим небольших «волн» на конце каждой ступеньки, как это было на Рис. 9. Такие «волны» были следствием потери пакетов и попыток их передачи заново.
Рассмотрим начальный сегмент передачи данных для случая shaper.
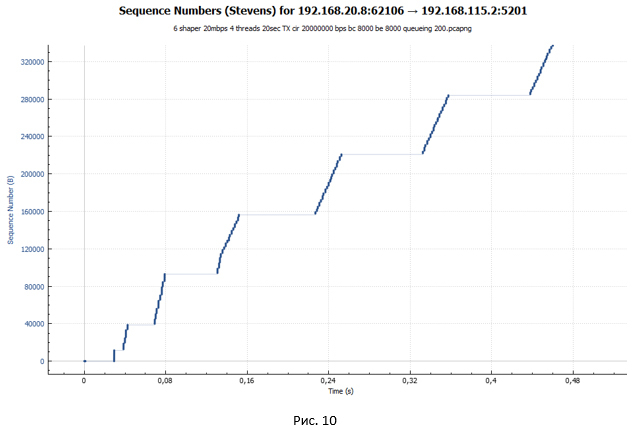
Происходит установление сессии. Далее начинается разгон в режиме TCP slow-start. Но этот разгон более пологий и имеет ярко выраженные паузы, которые увеличиваются в размере. Более пологий разгон обусловлен тем, что размер ведра по умолчанию для shaper всего (BC+BE) = 20 000 байт. В то время как для policer размер ведра — 625 000 байт. Поэтому shaper срабатывает существенно раньше. Пакеты начинают попадать в очередь. Растёт задержка от отправителя к получателю, и ACK приходят позже, чем это было в случае policer. Окно растёт существенно медленнее. Получается, что чем больше система передаёт пакетов, тем больше их накапливается в очереди, а значит, тем больше задержка в получении ACK. Имеем процесс саморегуляции.
Через некоторое время окно cwnd достигает значения awnd. Но к этому моменту у нас накапливается достаточно ощутимая задержка из-за наличия очереди. В конечном итоге при достижении определённого значения RTT наступает равновесное состояние, когда скорость сессии больше не меняется и достигает максимального значения для данного RTT. В моём примере среднее RTT равно 107 мс, awnd=64512 байт, следовательно, максимальная скорость сессии будет соответствовать awnd/RTT= 4.82 Мбит/с. Примерно такое значение нам и выдал iPerf при измерениях.
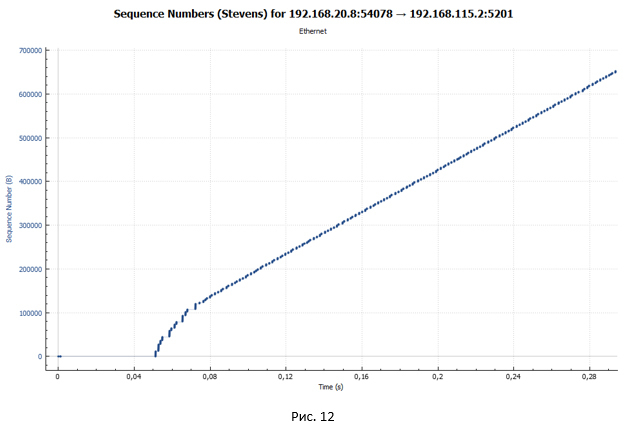
Но откуда берутся ярко выраженные паузы в передаче? Давайте посмотрим на график передачи пакетов через устройство с shaper в случае, если у нас всего одна TCP сессия (Рис.12). Напомню, что в нашем эксперименте передача данных происходит в рамках четырёх TCP сессий.
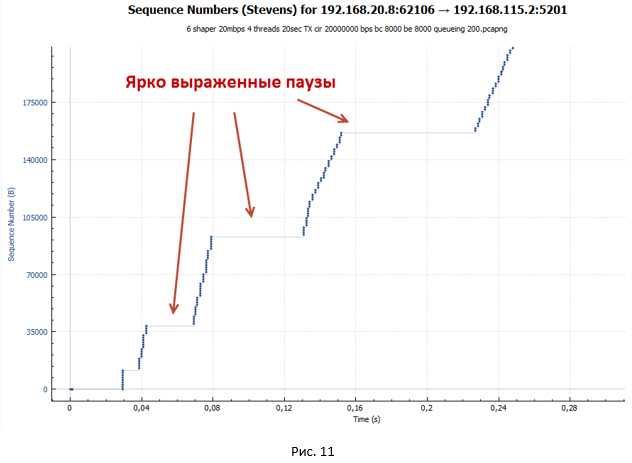
На этом графике очень хорошо видно, что нет никаких пауз. Из этого можно сделать вывод, что паузы на Рис.10 и 11 обусловлены тем, что у нас одновременно передаётся четыре потока, а очередь в shaper одна (тип очереди FIFO).
На Рис.13 представлено расположение пакетов разных сессий в очереди FIFO. Так как пакеты передаются пачками, они будут располагаться в очереди таким же образом. В связи с этим задержка между поступлением пакетов на приёмной стороне будет двух типов: T1 и T2 (где T2 существенно превосходит T1). Общее значение RTT для всех пакетов будет одинаковым, но пакеты будут приходить пачками, разнесёнными по времени на значение T2. Вот и получаются паузы, так как в момент времени T2 никакие ACK к отправителю не приходят, при этом окно сессии остаётся неизменным (имеет максимальное значение равное awnd).
Очередь WFQ
Логично предположить, что, если заменить одну общую очередь FIFO на несколько для каждой сессии, никаких ярко выраженных пауз не будет. Для такой задачи нам подойдёт, например, очередь типа Weighted Fair Queuing (WFQ). В ней для каждой сессии создаётся своя очередь пакетов.
policy-map Shaper class shaper_class shape average 20000000 queue-limit 200 packets fair-queue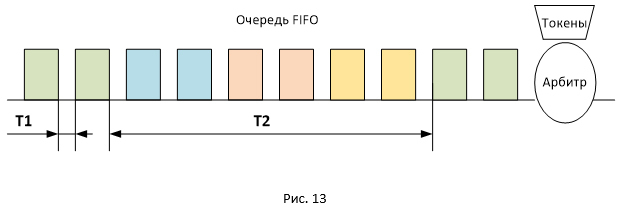
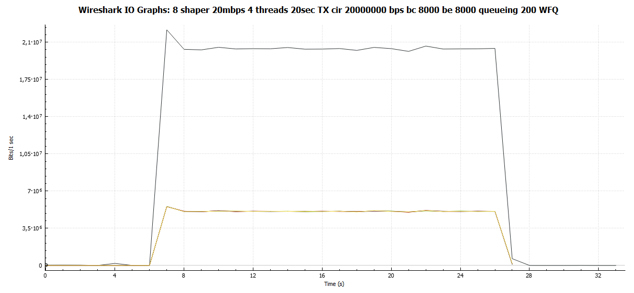
Из общего графика мы сразу видим, что графики всех четырёх TCP сессий идентичны. Т.е. все они получили одинаковую пропускную способность.
А вот и наш график распределения пакетов по времени передачи ровно в том же масштабе, что и на Рис. 11. Никаких пауз нет.
Стоит отметить, что очередь типа WFQ позволит нам получить не только более равномерное распределение пропускной способности, но и предотвратить «забивание» одного типа трафика другим. Мы всё время говорили про TCP, но в сети также присутствует и UDP трафик. UDP не имеет механизмов подстройки скорости передачи (flow control, congestion control). Из-за этого UDP трафик может с лёгкостью забить нашу общую очередь FIFO в shaper’е, что драматически повлияет на передачу TCP. Напомню, что, когда очередь FIFO полностью заполнена пакетами, по умолчанию начинает работать механизм tail-drop, при котором отбрасываются все вновь пришедшие пакеты. Если у нас настроена очередь WFQ, каждая сессия пережидает момент буферизации в своей очереди, а значит, сессии TCP будут отделены от сессий UDP.
Самый главный вывод, который можно сделать после анализов графиков передачи пакетов при работе shaper’а – у нас нет потерянных пакетов. Из-за увеличения RTT скорость сессии адаптируется к скорости shaper’а.
Влияет ли глубина очереди на нашу сессию?
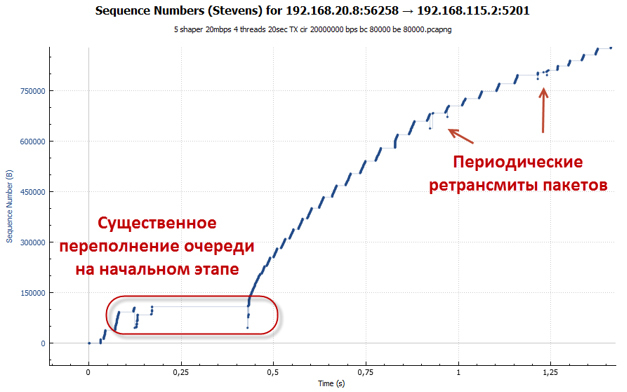
Конечно! Изначально (если кто-то об этом ещё помнит) мы изменили глубину очереди с 83 (значение по умолчанию) на 200 пакетов. Сделали мы это для того, чтобы очереди хватило для получения достаточного значения RTT, при котором суммарная скорость сессий становиться примерно равна 20 Мбит/с. А значит, пакеты «не вываливаются» из очереди shaper’а.
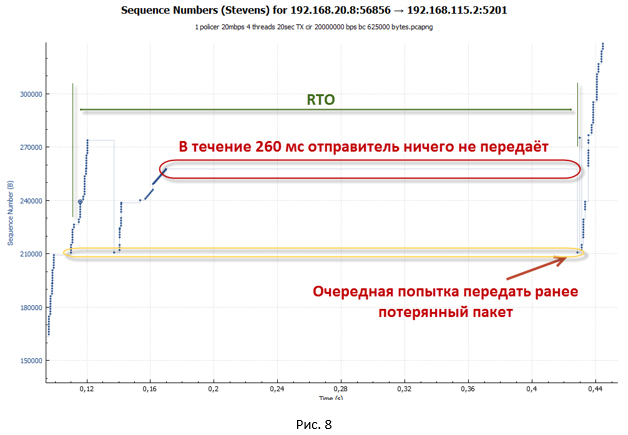
При глубине в 83 пакета очередь переполняется быстрее, нежели достигается нужное значение RTT. Пакеты отбрасываются. Особенно ярко это проявляется на начальном этапе, когда у нас работает механизм TCP slow-start (сессия разгоняется максимально агрессивно). Стоит отметить, что количество отброшенных пакетов несравнимо меньше, чем в случае с policer, так как увеличение RTT приводит к тому, что скорость сессии растёт более плавно. Как мы помним, в алгоритме CTCP размер окна в том числе зависит от значения RTT.
Графики утилизации пропускной способности и задержки при работе policer и shaper
В заключение нашего небольшого исследования построим ещё несколько общих графиков, после чего перейдём к анализу полученных данных.
График утилизации пропускной способности:
В случае policer мы видим скачкообразный график: сессия разгоняется, потом наступают потери, и её скорость падает. После чего всё повторяется снова. В случае shaper наша сессия получает примерно одинаковую пропускную способность на протяжении всей передачи. Скорость сессии регулируется за счёт увеличения значения RTT. На обоих графиках вначале можно наблюдать взрывной рост. Он обусловлен тем, что наши вёдра изначально полностью заполнены токенами и TCP-сессия, ничем не сдерживаемая, разгоняется до относительно больших значений (в случае shaper это значение в 2 раза меньше).
График задержки RTT для policer и shaper (по-хорошему, это первое о чём мы вспоминаем, когда говорим про shaper):
В случае policer (первый график) задержка RTT для большинства пакетов минимальна, порядка 5 мс. На графике также присутствуют существенные скачки (до 340 мс). Это как раз моменты, когда пакеты отбрасывались и передавались заново. Тут стоит отметить, как Wireshark считает RTT для TCP трафика. RTT – это время между отправкой оригинального пакета и получением на него ACK. В связи с этим, если оригинальный пакет был потерян и система передавала пакет повторно, значение RTT растёт, так как точкой отсчёта является в любом случае момент отправки оригинального пакета.
В случае shaper задержка RTT для большинства пакетов составила 107 мс, так как они все задерживаются в очереди. Есть пики до 190 мс.
Выводы
Итак, какие итоговые выводы можно сделать. Кто-то может заметить, что это и так понятно. Но наша цель была копнуть чуточку глубже. Напомню, что в эксперименте анализировалось поведение TCP-сессий.
- Shaper предоставляет нам на 13% больше полезной пропускной способности, чем policer (19.3 против 17.1 Мбит/с) при заданном ограничении в 20 Мбит/с.
- В случае shaper’а пропускная способность распределяется более равномерно между сессиями. Наилучший показатель может быть получен при включении очереди WFQ. При работе policer’а присутствуют существенные пики и падения скорости для каждой сессии.
- При работе shaper’а потерь пакетов практически нет (конечно, это зависит от ситуации и глубины очереди). При работе policer’а мы имеем существенные потери пакетов – 12.7%. Если policer настроен ближе к получателю, наша сеть фактически занимается прокачкой бесполезного трафика, который будет в итоге отброшен policer’ом. Например, в разрезе глобальной сети интернет это может является проблемой, так как трафик режется зачастую ближе к получателю.
- В случае shaper’а у нас появляется задержка (в нашем эксперименте – это дополнительные 102 мс). Если трафик примерно одинаков, без существенных всплесков, очередь shaper’а находится в относительно стабильном состоянии и больших вариаций в задержке (jitter) не будет. Если трафик будет иметь взрывной характер, мы можем получить повышенное значение jitter. Вообще наличие очереди может достаточно негативно сказываться на работе приложений – так называемый эффект излишней сетевой буферизации (Bufferbloat). Поэтому с глубиной очереди надо быть аккуратными.
- Благодаря разным типам очередей shaper позволяет нам учитывать приоритезацию трафика при ограничении скорости. И если встаёт необходимость отбрасывать пакеты, в первую очередь делать это для менее приоритетных. В policer’е добиться этого сложнее, а для некоторых схем невозможно.
- Policer и shaper подвержены ситуации, когда UDP трафик может «забить» TCP. При настройке этих технологий необходимо учитывать данный факт.
- Работа shaper’а создаёт бОльшую нагрузку на сетевое устройство, чем работа policer’а. Как минимум требуется память под очередь.
Можно отметить ещё один факт, хоть и не относящийся непосредственно к задаче ограничения скорости. Shaper позволяет нам настраивать различные типы очередей (FIFO, WFQ и пр.), обеспечивая тем самым разнообразные уровни приоритезации трафика при его отправке через устройство. Это очень удобно в случаях, если фактическая скорость передачи трафика отличается от канальной (например, так часто бывает с выходом в интернет или WAN каналами).
Исследование влияния policer в сети интернет
В этом году при поддержке Google было проведено исследование, в котором анализировался негативный эффект работы policer’а в сети интернет. Было определено, что от 2% до 7% потерь видео трафика по всему Миру вызвано срабатыванием policer’а. Потери пакетов при непосредственной работе policer’а составили порядка 21%, что в 6 раз больше, чем для трафика, который не подвержен срабатыванию данной технологии. Качество видео трафика, который подвергся обработке policer’ом, хуже, чем в случае, если policer не срабатывал.
Для борьбы с негативным эффектом работы policer’а предлагаются следующие меры в зависимости от точки их применения.
- В policer’е уменьшить размер ведра (burst size). Это приведёт к тому, что TCP сессия не сможет слишком сильно разогнаться, пока есть свободные токены, и быстрее начнёт адаптацию под реальную пропускную способность.
- Вместо policer’а использовать shaper (с небольшой глубиной очереди).
- Использовать и shaper, и policer одновременно. В этом случае shaper располагается чуть раньше, чем policer. Shaper задерживает пакеты, сглаживая колебания. Из-за такой задержки policer успевает аккумулировать достаточное количество токенов, чтобы передавать трафик. Потери в таком случае минимизируются.
Однозначных рекомендаций по поводу конфигурации shaper в документе не даётся. Shaper может обеспечивать положительный эффект как при большом, так и при маленьком значении размера ведра (даже если BC = 8 000 байт). Также нет однозначной рекомендации по поводу глубины очереди. Маленькая глубина приводит к лишним потерям, большая может негативно сказаться на задержках в сети. Во всех случаях есть свои плюсы и минусы.
Для контент-провайдеров предлагается ограничивать скорость отправки трафика на сервере, чтобы избегать включения policer’а. Но на практике оценить реальную скорость канала не всегда просто. Второй метод — избегать взрывной передачи трафика за счёт модификации алгоритмов TCP: использовать TCP Pacing (отправлять пакеты с привязкой к RTT, а не к моменту получения ACK) и изменить схему работы фазы loss recovery (на каждый полученный ACK слать только один новый пакет).
Таким образом, нет однозначного ответа на вопрос, что лучше использовать: shaper или policer. Каждая технология имеет свои плюсы и минусы. Для кого-то дополнительная задержка и нагрузка на оборудование не так критична, как для другого. А значит выбор делается в сторону shaper. Кому-то важно минимизировать сетевую буферизацию для борьбы с джиттером – значит наша технология policer. В ряде случаев вообще можно использовать одновременно обе эти технологии. Поэтому выбор технологии зависит от каждой конкретной ситуации в сети.
- End-to-End QoS Network Design
- CCIE Routing and Switching v5.0 Official Cert Guide, Volume 2 (5th Edition)
- Лицензирование Cisco ASA 5500
- AnyСonnect и пересечение адресных пространств
- Дешифрация
- Работа дешифрации NGFW: расшифровка SSL трафика
- Proxy ARP: Нюансы работы оборудования Cisco и интересные случаи. Часть 2
- Вопросы и ответы
- Технические статьи
Базовые принципы полисеров и шейперов
Одними из инструментов обеспечения качества обслуживания в сетях передачи данных являются механизмы полисинга и шейпинга и, может быть, это самые часто используемые инструменты. Ваш Интернет провайдер, наверняка, ограничил вам скорость именно этим.
Тема качества обслуживания не самая простая для понимания, а если вы когда-нибудь интересовались именно полисерами и шейперами, то скорее всего встречали однотипные графики, отображающие зависимость скорости от времени, слышали термины «корзина», «токены» и «burst», может быть даже видели формулы для расчёта каких-то параметров. Хороший и типичный пример есть в СДСМ — глава про QoS и ограничение скорости.
В этой статье попробуем зайти чуть с другой стороны, опираясь на учебник Cisco, RFC 2697 и RFC 2698 — самые базовые понятия.
Первое в чём надо разобраться и на чём строится весь механизм управления скоростью — это понятие самой скорости. Скорость — величина производная, вычисляемая, нигде и ни в каком месте мы не видим её напрямую. Устройства оперируют только данными и их количеством. Про скорость мы говорим в контексте наблюдения и мониторинга, зная объём переданных данных за 5 минут или за 5 секунд и получая разные значения средней скорости.
Второе, количество данных пропускаемое интерфейсом за отрезок времени — константа, абсолют. Его нельзя ни уменьшить ни увеличить. Через 100Мбит/c интерфейс 90Мбит будут пропущены всегда за 0,9 секунды, а оставшуюся 0,1 секунду интерфейс будет простаивать. Но с учётом того что скорость вычисляемое значение, получим что данные были переданы со средней скоростью 90Мбит/c. Это мало похоже на дорожный трафик, у нас всегда либо 100% загруженность, либо полный простой. В контексте сетевого трафика, загруженность интерфейса — это сколько свободных промежутков времени у него остаётся из общего измеряемого интервала. Дальше продолжим употреблять размерность Мбит и секунды, для лучшего понимания, хотя это и не имеет никакого значения.
Отсюда вытекает основная задача и способ ограничения пропуска трафика — передать не больше заданного количества данных за единицу времени. Если у нас есть 100Мбит, а мы хотим ограничить скорость 50Мбит/c, то за эту секунду нам надо передать не больше 50Мбит, а оставшиеся данные передать в следующую секунду. При этом у нас есть только один способ это сделать — включить интерфейс, который всегда работает с постоянной скоростью, или выключить его. Выбор только в том, как часто мы будем включать и выключать.
Burst
Посмотрим на график скорости из учебника 5 класса по физике. Здесь показана зависимость объёма переданных данных по оси Y, от времени по оси X. Чем круче наклон прямой, тем больше скорость. Передать 50Мбит за секунду можно разными способами:
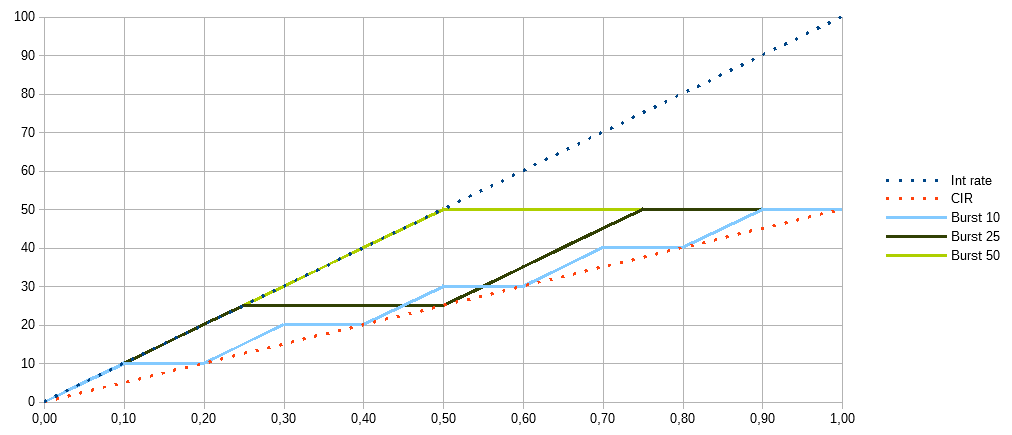
- Передать всё сразу за 0,5 секунды, а потом ждать следующей (зелёная сплошная)
- Передавать чаще, делая меньшие паузы, но увеличив их количество
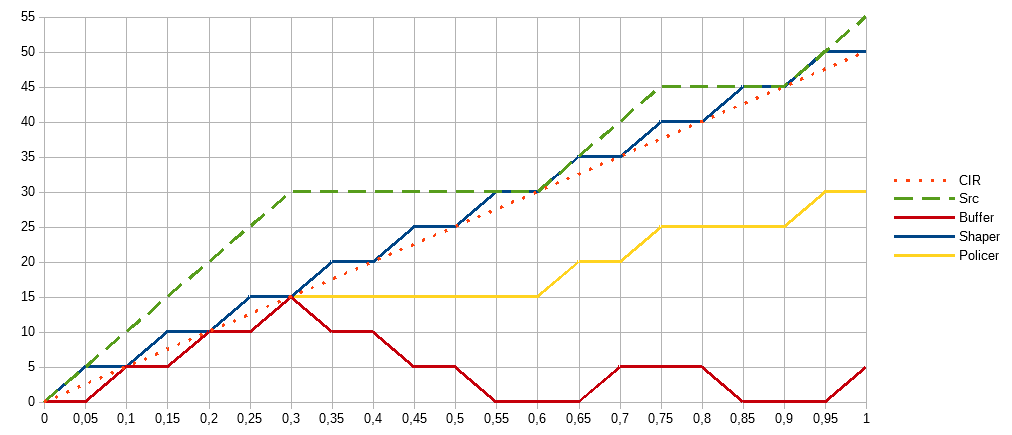
Если burst=50, CIR=50Мбит/c, то время равно 1 секунде: Time Interval = Burst / CIR = 50/50 . Значит каждую секунду, мы можем передать не больше 50Мбит. Так как скорость интерфейса у нас 100Мбит/c, то 50Мбит будут переданы за 0,5 секунды, оставшееся время будет простой. Начиная со следующей секунды у нас опять будет возможность передать 50Мбит.
В случае burst=25, получим 25/50 или 0,5 секунды между передачей каждых 25Мбит. С учётом скорости интерфейса на передачу 25Мбит будет затрачено 25/100=0,25 секунды и следующие 0,25 секунды интерфейс будет простаивать. В каждом случае мы 1/2 = CIR / Interface rate времени тратим на передачу и 1/2 на простой. Если увеличить CIR до 75Мбит/c, то соответственно 75/100=3/4 периода займёт передача и 1/4 пауза.
Обратите внимание что наклон прямых, показывающих объём переданных данных, всегда одинаков. Потому что скорость интерфейса константа (синие точки) и мы физически не можем передавать с другой скоростью.
В большинстве случаев при конфигурации оборудования используются именно burst, хотя могут использоваться и временные интервалы. На графике хорошо видны отличия, меньший burst даёт более строгое следование заданному ограничению — график не убегает далеко от СIR, даже на меньшем измеряемом промежутке и при этом обеспечивает короткие паузы между моментами передачи. А больший burst не ограничивает трафик на коротких отрезках. Если измерять скорость только за первые 0,5 секунды, то получилось бы 50/0,5 = 100Мбит/c. А долгая пауза после такой передачи может негативно сказаться на механизмах управления трафиком за границами нашего устройства, или привести к потере логического соединения.
Если быть ближе к реальности, сетевой трафик, как правило, не передаётся непрерывно, а имеет разную интенсивность в разные моменты времени (зелёный пунктир):
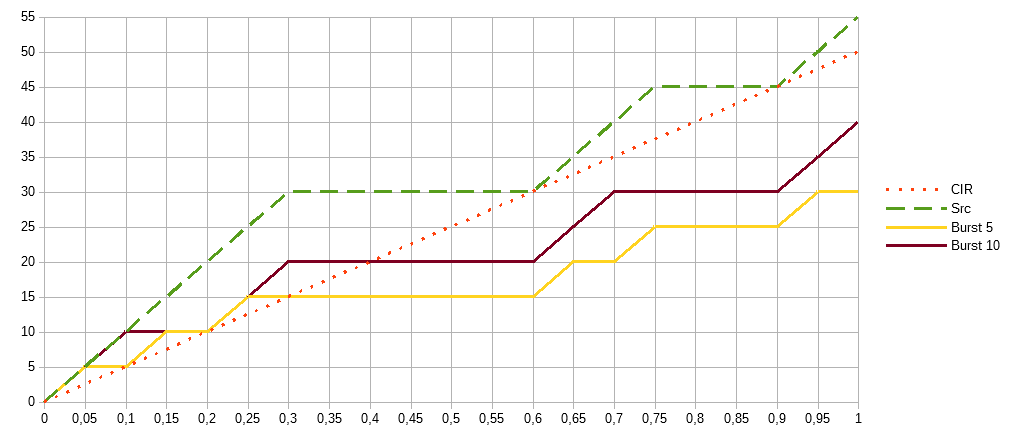
На этом графике видно, что за 1 секунду мы хотим передать 55Мбит при ограничении 50Мбит. То есть, реальный трафик практически не выходит за границы которые мы установили к концу измеряемого интервала. При этом механизмы ограничения приводят к тому, что передаётся меньший объём данных чем мы ожидаем. И здесь больший burst выглядит лучше, так как захватываются интервалы где трафик действительно передаётся, а меньший burst и желание строго ограничивать трафик на всём участке, выливается в большие потери.
Шейпер
Будем ещё ближе к реальности, в которой всегда имеется буфер для передачи данных. С учётом того что интерфейс у нас или занят на 100% или простаивает, а данные могут поступать одновременно из нескольких источников быстрее чем интерфейс может их передавать, то даже простейший буфер формирует очередь, позволяя данным дождаться момента передачи. Он также позволяет компенсировать те потери которые у нас могут возникнуть из-за введённых ограничений:
Policer это график Burst 5 с предыдущего изображения. Shaper тот же график Burst 5, но с учётом буфера, в котором задерживаются не успевшие передаться данные и которые могут быть переданы чуть позже.
В результате, мы полностью обеспечили наши требования по ограничению трафика «сгладив» пики источника и не потеряв данные. Трафик по-прежнему имеет пульсирующую форму: чередующиеся периоды передачи и паузы — потому что мы не можем повлиять на скорость интерфейса и управляем только объёмом передаваемых за раз данных. Это тот самый график сравнения шейпера и полисера из СДСМ QoS, но с другой стороны:
Какой ценой мы этого достигли? Ценой буфера, который не может быть бесконечным и который вносит задержку в передаче данных. Пик на графике буфера приходится на 15Мбит, это те данные которые теряются полисером, но задерживаются шейпером. При заданном ограничении 50Мбит/c — это 15/50=300 миллисекунд, что для многих сетевых приложений уже за гранью дозволенного.
А теперь посмотрим когда эта цена играет роль, достаточно лишь чуть большей интенсивности трафика — 60Мбит/c, при ограничении 50Мбит/c:
Количество переданных данных шейпером и полисером совпали. Полисер, конечно, теряет данные, а шейпер копит в буфере, занятое место в котором непрерывно растёт, то есть растёт задержка. Когда место в буфере кончится, данные шейпером также начнут теряться, но с поправкой на размер буфера, с задержкой.
Поэтому, выбирая шейпер или полисер стоит отталкиваться от того, насколько критична дополнительная задержка, которая выше, чем больше скорость и чем интенсивнее трафик. Или стоит пожертвовать данными и потерять часть из них, учитывая что на следующем логическом уровне почти наверняка сработают механизмы восстанавливающие целостность передачи и реагирующие на заторы и потери.
Корзина
Для учёта объёма трафика переданного через интерфейс используется понятие и термин корзина. Фактически, это счётчик от максимального значения burst до 0, который уменьшается с передачей каждого кванта данных — токена. Соответственно, есть два процесса — один наполняет корзину, второй из неё забирает.
Корзина наполняется до величины burst каждый заданный интервал, при известном CIR. Для burst 5 и CIR 50, каждые 0,1 секунду, как было рассчитано чуть ранее. Но объём трафика за интервал времени может быть меньше чем заданный нами burst, так как условие ограничения — «не больше». Значит этот счётчик может не доходить до 0 и в корзине остаются токены. Тогда в следующий интервал, при заполнении корзины, неиспользуемый объём данных (токенов) будет потерян.
Такая ситуация видна на графике Policer выше, каждые 0,05 секунд мы в состоянии передать 5Мбит на скорости интерфейса, но количества данных которые у нас есть всего 3Мбит, так как скорость поступления данных всего 60Мбит/c. Именно поэтому график почти сливается с CIR, что не совсем корректно. Передача в любом случае осуществляется на скорости интерфейса и 3Мбит будут переданы за 0,03 секунды, а оставшиеся 0,02 будет пауза. Это давало бы нам характерную лесенку, которую мы видим на графике Shaper. Здесь, как раз, пример средней скорости и сглаживания точности измерения, что обычно показывают системы мониторинга оперирующие даже не секундами, а минутами.
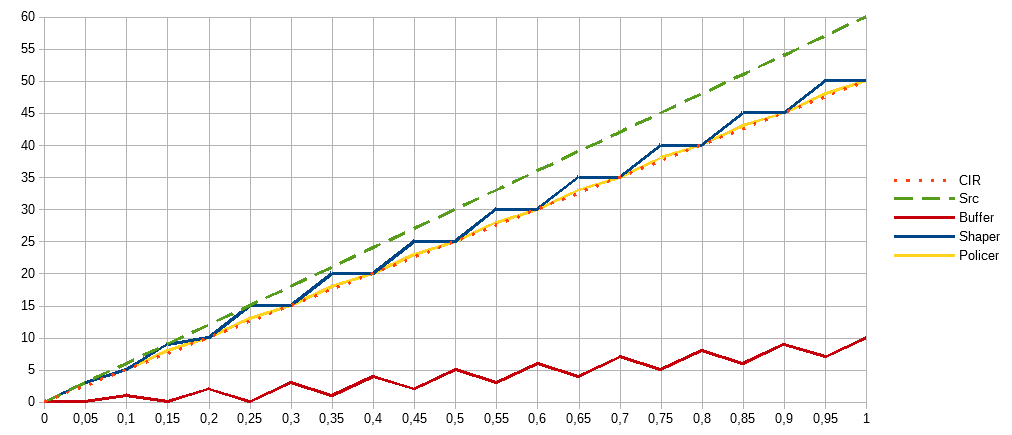
Улучшим подход, зная что трафик спонтанен и больший burst может помочь не потерять данные. Введём ещё одну корзину, куда будем складывать неиспользованные на предыдущем интервале токены. Таким образом, в случае отсутствия трафика от источника, будет частично компенсироваться этот простой, как если бы у нас был больший burst. Для каждой корзины задаётся собственный burst, для основной — Committed Burst, CBS, Bc. А для второй — Excess Burst, EBS, Be. Таким образом максимальный объём данных который может быть непрерывно передан равен CBS+EBS.
Shaper Exs (жёлтый) — график с учётом двух корзин, каждая объёмом burst в 5Мбит. Shaper — график с предыдущего изображения. Теперь максимальный burst=EBS+CBS=10 и первые 0,1 секунду мы используем его. Основную корзину мы пополняем каждые 5/50=0,1 секунду. Соответственно, в момент времени 0,1 опять есть возможность передавать данные и период непрерывной передачи длится 0,15 секунды. В результате длительного простоя, когда трафика с источника не было и все данные из буфера мы передали, в момент времени 0,6 секунд, добавляем неиспользуемый объём данных во вторую корзину. Таким образом, получаем возможность снова вести непрерывный пропуск трафика в течение 0,15 секунд, что позволяет вовсе не использовать буфер. В итоге, получили удачный компромисс точности нарезки полосы, в случае интенсивного трафика, и лояльности в отношении всплесков при использовании большего burst.
Сделаем ещё одно улучшение касающееся времени. Избавимся от периодического процесса пополнения корзины и заменив его на пополнение только в те моменты, в которые к нам поступают данные. В большинстве случаев, меньше чем одним, целым пакетом за раз никто не оперирует. Поэтому можно посчитать период между приходами последовательных пакетов и пополнять корзину тем объёмом данных, которые соответствуют данному периоду. Это, во первых, исключит необходимость держать отдельный таймер для временных интервалов связанных с burst периодами, а во вторых, сократит периоды между возможными пропусками трафика.
Следовательно burst, как максимальный объём непрерывно передаваемых данных, отделился от понятия количество пополняемых за раз данных, хотя формула осталась та же: пополняемый объём в токенах = интервал между последовательными пакетами * CIR . Но пополнить корзину больше чем её максимальный объём burst мы не можем, это то условие с помощью которого и достигается ограничение. Размер пакета задаёт наименьший из возможных burst — размер наименьшего пакета в данной сетевой технологии. Если burst будет меньше, то целый пакет невозможно будет отправить за отведённый интервал, при заданной скорости интерфейса.
Полисер: 1 скорость, 2 корзины, 3 цвета
До этого речь шла, в основном, о шейперах, хотя понятия и термины аналогичны тем что применимы и для полисеров. Полисер, однако, как это определено в RFC 2697 это не механизм ограничения трафика, это механизм его классификации. Каждый проходящий пакет, в соответствии с заданным CIR, CBS и EBS относится к одной из категорий (цвету): conform (green), exceed (yellow), violate (red). На устройствах можно сразу настроить в каком случае трафик стоит блокировать, но в общем случае, это именно назначение метки или покраска.
Для каждого пакета происходит проверка по следующему алгоритму:
- Если размер пакета меньше чем токенов в первой корзине, то этот пакет помечается как green, а из первой корзины вычитается количество токенов соответствующих размеру пакета, иначе
- Если размер пакета меньше чем токенов во второй Excess корзине, то этот пакет помечается как yellow, а из второй корзины вычитается количество токенов соответствующих размеру пакета, иначе
- Пакет помечается как red и ничего и ниоткуда не вычитается.
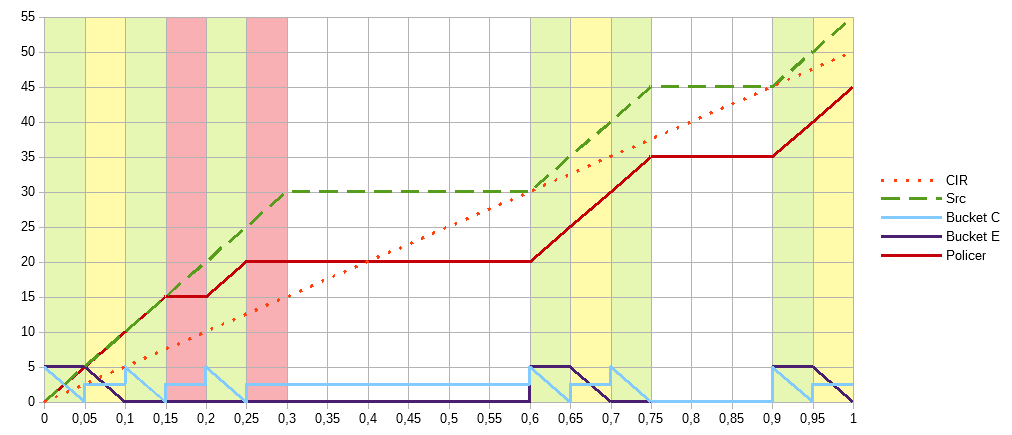
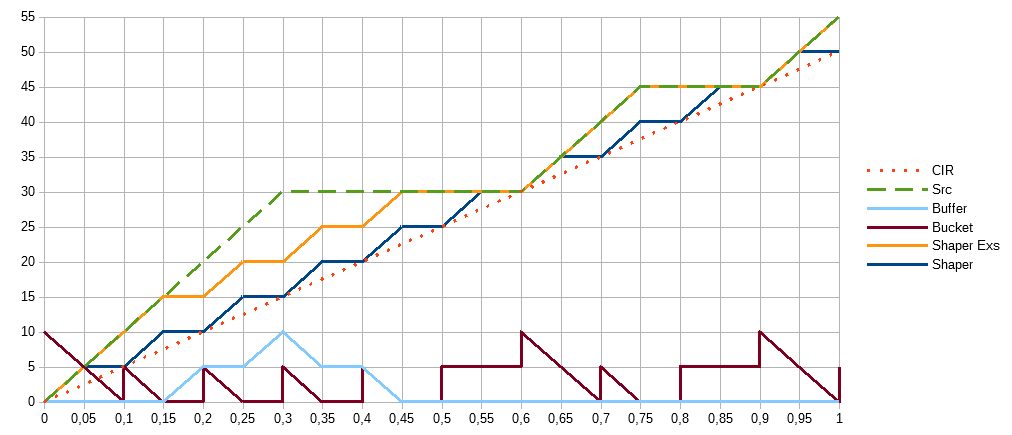
Используем те же параметры что и раньше CIR=50, CBS=5, EBS=5. Количество токенов в корзинах теперь показано отдельно: основная Bucket C (голубой) и дополнительная Bucket E (фиолетовый). Теперь у нас не непрерывный поток битовых данных, а пакеты по 5Мбит. Что не совсем реально, трафик, в общем случае, состоит из разных по размеру пакетов приходящих в разные интервалы времени, и это очень сильно может изменить картину происходящего. Но для демонстрации базовых принципов и удобства подсчёта используем такой вариант. Также, отражён процесс пополнения корзины с приходом каждого пакета.
В первые 0,05 секунд передаём пакет в 5Мбит, опустошая основную корзину. С приходом второго пакета мы пополняем её, но на величину 2,5Мбит, что соответствует заданному CIR 0,05*50. Этих токенов не хватает для передачи следующего пакета в 5Мбит, поэтому мы опустошаем вторую корзину, но пакет помечается по другому. Через 0,05 секунд опять приходит пакет, и мы опять пополняем основную корзину на 2,5Мбит и этого объёма хватает для его передачи в зелёной категории. Следующему пакету, несмотря на то что корзина пополняется, уже не хватает токенов и он попадает в красную категорию. Красный сплошной график отражает ситуацию, если отбрасываются только пакеты помеченные красным.
Во время простоя корзины не пополняются, как это было видно на предыдущем графике, но в момент времени 0,6, при получении следующей порции данных высчитывается интервал между пакетами: 0,6-0,3=0,3 секунды, следовательно у нас есть 0,3*50=15Мбит для того чтобы пополнить основную корзину. Максимальный её объём CBS=5Мбит, остатком пополняется вторая корзина, тоже объёмом EBS=5Мбит. Оставшиеся 5Мбит мы не используем, тем самым трафик с очень длинными паузами всё равно ограничивается, чтобы не допустить ситуации: час бездействия — час без ограничений.
В итоге, на графике 6 зелёных участков или 30Мбит переданных за секунду — средняя скорость 30Мбит/c, что соответствует использованию только одной корзины и двух цветов. 3 жёлтых участка и в сумме с первым графиком 45Мбит/c, с учётом красных участков 55Мбит/c — две корзины, три цвета.
2 скорости, 3 цвета
Существует ещё один подход RFC 2698, в котором задаётся параметр пиковой скорости PIR — Peak Information Rate. И в этом случае используются две корзины, но каждая из которых заполняется независимо от другой — одна в соответствии с CIR, другая с PIR:
- Bucket CIR, пополняемый объём в токенах = интервал между последовательными пакетами * CIR
- Bucket PIR, пополняемый объём в токенах = интервал между последовательными пакетами * PIR
Трафик, как и в предыдущем случае, классифицируется на 3 категории следующим образом:
- Если размер пакета меньше чем токенов в CIR корзине, то этот пакет помечается как green и из обеих корзин вычитается количество токенов соответствующих размеру пакета, иначе
- Если размер пакета меньше чем токенов в PIR корзине, то этот пакет помечается как yellow и только из PIR корзины вычитается количество токенов соответствующих размеру пакета, иначе
- Пакет помечается как red и ничего и ниоткуда не вычитается.
Вспомним для чего нам вторая корзина и больший burst, чтобы компенсировать периоды простоя трафика за счёт менее строго ограничения за больший период. Подход с двумя условиями даёт нам ту же возможность. Сформируем PIR и CIR равными 50Мбит/c, размер первой корзины 5, а второй PBS 10. Почему 10? Потому что это независимое ограничение, что возвращает нас к самому первому графику показывающему разницу burst. То есть, мы хотим добиться среднего результата между burst 5 и burst 10 и задаём эти условия напрямую.
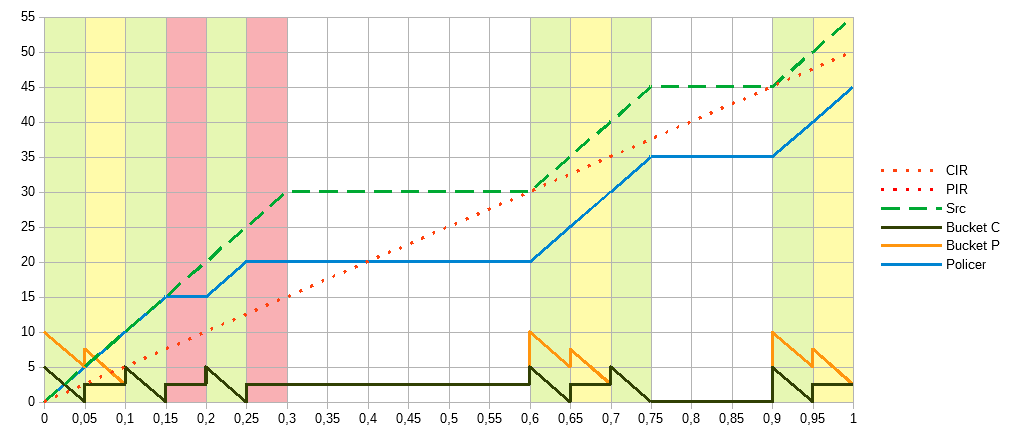
Получили такой же график для полисера, что и при использовании предыдущего метода. При burst=10 получаем больше свободы, а вторым условием burst=5 добавляем точности. Обратите внимание как ведут себя корзины, каждая сама по себе.
Два отдельных условия, каждое из которых выполняется для одних и тех же входящих значений. Более строгое — классифицирует трафик, который гарантированно попадает под него, а менее строгое расширяет эти границы. В случае равных CIR и PIR, получаем взаимозаменяемый с предыдущим метод.
А устанавливая PIR скорость увеличиваем количество степеней свободы. Можно отдельно проверить разные burst при разных профилях трафика с разными CIR, а потом совместить всё вместе с использованием этого метода:
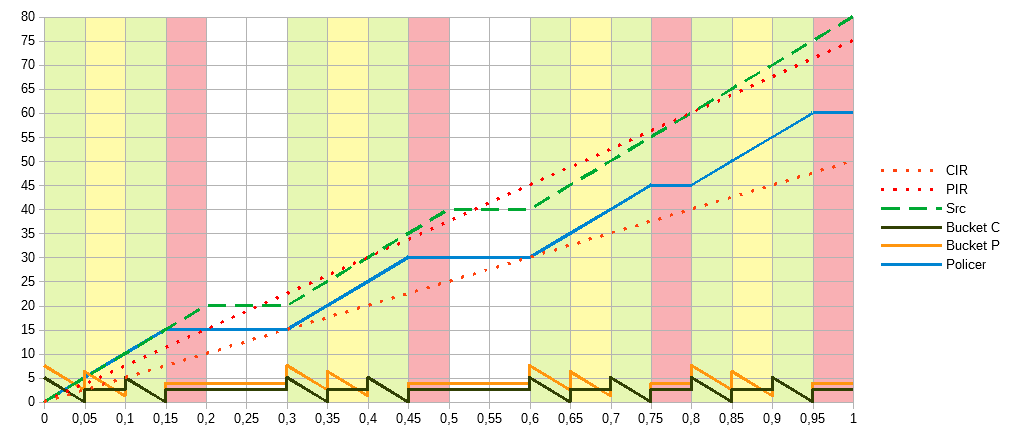
CIR=50, PIR=75, CBS=5, PBS=7,5. CBS и PBS выбраны таким образом, чтобы укладываться в одинаковый интервал. Но, конечно, можно исходить из других условий, например для PIR сделать меньший burst, чтобы увеличить гарантию не выхода за обозначенные границы, а для CIR наоборот, более лояльный.
В принципе, при интенсивном трафике нет причин ставить маленький burst ни в каком случае, ни для какой из корзин. Несколько десятков секунд и несколько лишних мегабайт не сделают погоды на продолжительных временных интервалах, но частые блокировки из-за небольшого burst, могут сломать незаметные для нас механизмы регулировки потока. Для трафика 80Мбит/c, в зелёную зону уложилось 40Мбит/c. Учитывая жёлтую как раз вписались между CIR и PIR — 60МБит/c. Ещё раз, механизмы ограничения пытаются гарантировать не выход за верхние границы, про нижние они ничего не знают. И как видно в примерах, результирующий трафик всегда меньше заданных ограничений, иногда сильно меньше, даже если он сам попадал в них без посторонней помощи.
Описанные выше подходы сформировались в RFC уже больше 20 лет назад, но на свалку истории пока не торопятся, и часто применяются именно как ограничивающий инструмент ухудшающий качество, а не как классификатор, или как компенсирующий механизм. Даже в самых современных реализациях вы обязательно встретите если не эти алгоритмы, но эти термины обязательно и, конечно, сложность применения понятия скорости в сетях передачи данных. Может быть с ещё одной статьёй разобраться во всём этом станет чуть проще.
Жидкий полимер. Полимерное покрытие после мойки кузова

В процессе эксплуатации автомобиля приходится сталкиваться с неприятными неожиданностями: камнями, летящими из-под колёс впереди идущих авто, пылью, грязью, дорожными реагентами. Всё это негативно сказывается на состоянии лакокрасочного покрытия кузова, которое требует защиты. Жидкий полимер – что это? А это и есть тот самый материал, предупреждающий появление микротрещин и царапин и препятствующий попаданию в них влаги.
Преимущества использования полимерных составов
- Жидкий полимер создаёт защитную плёнку, имеющую достаточно высокую плотность. Её наличие позволяет оградить лакокрасочное покрытие от воздействия агрессивных сред.
- Покрытие наделено высокими гидрофобными свойствами, и в процессе обработки жидким полимером кузова им заполняются самые мелкие трещинки, что полностью исключает проникновение в них влаги. Во многом благодаря этому, капли дождя и жидкой грязи не задерживаются на поверхности кузова, а стекают вниз.
- Полимерный слой придаёт авто шикарный внешний вид и улучшает его аэродинамические характеристики. Даже далеко не новый автомобиль, обработанный жидким полимером, выглядит так, будто бы он только что сошёл с конвейера.
- Долговечность. Покрытие настолько прочное, что его невозможно смыть водой, и даже неоднократная мойка кузова с применением автохимии не окажет на него никакого влияния.
Где можно обработать авто жидким полимером?
Материал есть в свободной продаже, а в Интернете можно найти подробный мануал. Вот только для того чтобы правильно использовать по назначению жидкий полимер, нужен опыт и ясное понимание всех своих действий. Провести обработку самостоятельно можно, вот только конечный результат может не порадовать. Поэтому, имеет смысл прибегнуть к услугам профессионалов. Например, все автолюбители Москвы могут обратиться в компанию Мr.Сар, специалисты которой используют для обработки ЛКП особый состав – Formula U.
Данный материал выпускается шведским производителем, что само по себе уже является гарантией качества. Если потребуется обновить слой полимера, то его придётся удалять либо абразивными материалами, либо специальной автохимией, настолько он прочный. Обычные полироли и автомобильные воски не идут ни в какое сравнение с Formula U, потому что это – совершенно другая технология и результат.