Размер буфера журнала на Android: что это такое?
Наверняка вы уже успели заметить, что раздел Для разработчиков содержит в себе уйму информации и различных пунктов меню. Название некоторых из них совершенно непонятно. К примеру, что значит Размер буфера журнала?
Все просто: с помощью этого пункта пользователь может установить предельный объем памяти, используемый для системного журнала. Используется, как правило, разработчиками, обычному пользователю менять размер буфера журнала не рекомендуем.
Чтобы добраться до этого пункта, нужно открыть настройки.

Выбрать раздел Для разработчиков (как он включается, читайте тут).

Найти указанный пункт меню.

При необходимости выбрать размер буфера журнала.

Как и было сказано выше, если нет необходимости, не меняйте настройки, установленные по умолчанию.
Как вам статья?
Размер буфера журнала на андроид для чего он?
Скорее всего эту функцию вы нашли в меню «Для разработчиков».
На самом деле, этот не тот буфер, как может показаться на первый взгляд, куда отправляется скопированный текст, когда вы например ссылку копируете, чтобы вставить её в адресную строку, чтобы не переписывать вручную. Этот буфер отвечает за количество задач, которые могут одновременно хранится в оперативной, или процессоре, не знаю точно, и собственно чем больше их может обрабатываться, тем лучше производительность, но выше расход батареи
из-за повышенной нагрузки на систему.
Так что лучше поставить 64 кб для более экономной работы, или оставить 256, для более оптимальной и быстрой работы телефона. Другие значения трогать не советую.
Какой оптимальный размер буфера?
Доброе время суток. Имеются ли какие-нибудь статьи по выбору оптимального размера буфера для считывания файла и запись в файл?
В интернете только натыкался на вот эту статью 2004 года, где рекомендуется применять 4 кб или 64 кб, но т.к. прошло уже 13 лет и мощности компов стали больше то уже доверия таким статьям мало. На стеке люди тоже пишут что мол 4 кб лучше использовать.
Просто у меня работа будет чаще всего с файлами более 10 гб и 4кб для них брать это как-то несерьезно (долгая работа с файлом)
P.S. необходимо это для диплома.
- Вопрос задан более трёх лет назад
- 7913 просмотров
2 комментария
Оценить 2 комментария
Никита, а какова тема диплома? И что за данные хранятся у вас в 10ГБ файлах?
Никита @Smiz001 Автор вопроса
4ainik, Исследование способов резервирования зашифрованных данных в облачных хранилищах, делается это для хранение бэкапов sql баз и не только. Также будет применяться компрессия файлов.
Решения вопроса 1
начинал с бейсика на 286 в 1994
ну раз это нужно для диплома, то будет вполне уместно провести анализ: ряд тестов на чтений/запись больших файлов скажем размером в 10ГБ.
Читать/писать разными блоками начиная от 512 байт, далее степень двойки (1024,2048,4096,8192. ) замеряя при этом скорость. программа простецкая, за вечер думаю управитесь. построите график зависимости производительности от размера буфера. будет шикарный раздел диплома.
Ответ написан более трёх лет назад
Нравится 4 1 комментарий
Никита @Smiz001 Автор вопроса
Наверно так и поступлю, спасибо.
Ответы на вопрос 3

Пишу веб-проекты не до конца
На самом деле идеальный буфер от много зависит: от размера блоков вашей файловой системы, от кэша и т.д. Если обобщить, то главное не превышать область кэшей процессора, вот про регистры в таких крупных размерах речи и не идет, конечно. Так что можете смело брать ровно столько, сколько на L1 кэш влезет. Пока выше не залезете, то и не попадете в область оперативной памяти, а следовательно не уйдете вниз по кривой перформанса.
Я бы советовал батчить файл на 64кб и не проводить раннюю оптимизацию, написать сначала как есть, а потом уже заниматься такой микро-оптимизацией. Не думаю, что будет большой разлет по перфомансу.
Ответ написан более трёх лет назад
Нравится 1 27 комментариев
Никита @Smiz001 Автор вопроса
Интересно, про L1 кэш надо будет почитать
А че, прогресс уже дошел до того, что с диска данные летят в L1? =))))
d-stream, верное замечание, так то да, данные от HDD обычно пересылаются напрямую с ДИСКА в ОЗУ минуя процессор, занимается этим контроллер DMA это точно так для IDE интерфейса, насчет SATA точно не скажу, но тоже наверняка за это отвечает контроллер. По крайней мере это справедливо для больших блоков данных, но при малых объемах например 1 сектор процессор может и сам считать этот блок без DMA.
4ainik, скажем в стиле деда Щукаря: кэш — внутри процессора, диск снаружи -))
d-stream, не понял что вы хотели сказать, немного перефразирую:
в современных компьютерах, операции чтения/записи с диска/на диск, происходят без активного участия процессора, т.е. практически не расходуется процессорное время на данные операции и производительность процессора также практически не влияет на скорость этих операций, но тем не менее существует второй способ операций чтения/записи с активным участием процессорного времени, производительность его очень низкая и применяется он лишь в очень редких случаях.
4ainik, поясню попроще: нет прямого пути с диска в кэш процессора.
4ainik, эм, что значит минует кэш процессора? Да, контроллер считает данные и без процессора, но обработкой этих данных будет заниматься наш процессор, разве нет? Данные как ни крути попадут на кэш процессора, а потом в его регистры, это обычный процесс для работы с информацией. Как вы с данными работать иначе будете?
4ainik, вот, например, ответ на стак-оверфлоу, полностью солидарен с моим ответом.
Дмитрий Threy, так это уже другой вопрос. ТС спросил
Какой оптимальный размер буфера? . оптимального размера буфера для считывания файла и запись в файл?
т.е. конкретно для операций чтения/записи в данном случае процессор не важен и почти не нужен.
Как тут уже писали, факторов, влияющих на производильность дисковых операций довольно много, но размер буфера это как раз один из основных после производительности самого диска.
4ainik, перед записью в файл и считывания с него с этими данными работают, иначе какой смысл считывать/записывать, если мы не получили никакой информации и не изменили ее? Так что не согласен с вами, это все тот же вопрос и ответ был дан на наценку перфоманса.
Дмитрий Threy, оптимальный размер буфера это сферический конь в вакууме, но в большинстве случаев лучше придерживаться диапазона 512 — 64к, кратного степени двойки. Не забывайте, что вы работаете с диском не напрямую, а через API ОС, а там куча посредников и своя логика работы.
В любом случае чем больше буфер тем меньше оверхед, ну чисто математически:
1) вызвать 1 раз fwrite(buf, 512, 1);
2) вызвать 512 раз fwrite(buf, 1, 1);
Очевидно второй вариант будет хуже в плане производительности, хотя и вполне уместен для например терминала 🙂
А конкретно для условий описанных ТС, я бы выбрал максимальный размер буфера равный 64к.
4ainik, Кто же с этим спорит? Вопрос в другом, что в погоне за идеальным буфером есть ориентиры, о чем я и сказал. То есть если вы будете укладываться в машинное слово и попадете в cash line, то перфоманс будет гораздо и гораздо лучше.
Перформанс чего? Дисковых операций или всей программы в целом?
Давайте дождемся результатов тестов ТС и посмотрим на результирующий график?! ОК? Я думаю, что при размере буфера в 16к — 64к производительность будет примерно одинаковая.
4ainik, мой ответ выше и говорит использовать 64кб, тем самым не выходить за рамки кэша, какой смысл смотреть на результирующий график при таких буферах, если мы говорим использовать одно и тоже?
Я бы предложил ему выйти за размер кэша при батчинге файла на 10гб и вот тогда он почует разницу.
4ainik, что значит дисковых операций? Я вам уже говорил, что данные просто так не считывают, а с ними работают и именно поэтому важно знать про cashline процессора и попытаться туда влезть. Дисковые операции мы будем мерить вместе с использованием полученной информации и никак иначе.
Дмитрий Threy, мы можем читать данные с диска в одном потоке, писать в другом, обрабатывать в третьем, а еще параллельно работает ОС и куча других программ, что будет в кеше процессора? — Никому не известно.
4ainik, какая разница, какой поток? Каждый поток делит время на определенном ядре процессора и часть одного потока в одном регистре и часть другого на том же самом регистре — просто невозможно, такого просто не бывает, вру, на самом деле бывает, если вы не делаете safe-threaded приложений с блоками, но мы же говорим о грамотном написании программ. Так, о чем я, одновременно там будет одно исполнение потока, т.е. если вы написали буфер в 64кб и работаете с ним, то он и попробует вместить туда ровно 64кб.
Или вы мне сейчас хотите сказать, что большинство практик для перформанса, типа inline методов/unroll циклов и выравнивания структур по полям полный бред, потому что мы не знаем, что там внутри? А зря, потому что они как раз нацелены на то, что мы догадываемся, что там внутри и пытаемся сделать лучше.
Дмитрий Threy, разница очень даже большая, сколько будут эти данные там храниться и будут ли вообще они там храниться.
Копирование файла это «работа» с данными? — да.
А требуется ли в данном случае участие процессора? — не особо.
Требуется кеш L1, L2? — да тоже вроде не особо.
Вот у меня сейчас процессов 40+, потоков 700+, а ядро одно, что сейчас в кеше L1?
Я верю что процессор работает быстрее с L1 чем с ОЗУ.
Я так же верю, что данные обработаются быстрее если они попали в L1.
Но вопрос в другом. Ключевые слова «дисковые операции», «оптимальный размер буфера» и «размер файлов 10Гб».
4ainik, при чем тут, что у вас сейчас в кэше, если идет речь о том, когда будет конкретное приложение? Если в коде приложения написано выделить 64кб и работать с ними, то, повторяю, будет попытка вставить туда именно столько данных. Советую вам прочитать про cache misses.
Копирование файла это «работа» с данными? — да.
А требуется ли в данном случае участие процессора? — не особо.
при копировании файла путем перебора его через внутренний буфер? У вас буфер, это что такое? Правильно, переменная. А где она хранится? Правильно, в кэше процессора, а далее в регистрах.
разница очень даже большая, сколько будут эти данные там храниться и будут ли вообще они там храниться.
Будут ли они вообще там храниться? А как вы себе это представляете? Данные, если мы с ними работаем, процессор вообще никак не обойдут, хоть ты лопни, но такого не будет.
Дмитрий Threy, беспредметный разговор. буфер это переменная, но очень большая, такая ни в какой «регистр» процессора НЕ влезет, разрядность регистра всего 32-64бита к слову 🙂
char buf[512];
while(!feof(in)) fread(in, buf, 512, 1);
fwrite(out, buf, 512, 1);
>
Зачем мне здесь кэш L1 процессора? buf это переменная, которая находится либо стеке (а это ОЗУ), либо выделена из «кучи», что так же является ОЗУ.
И в данном конкретном случае процессор даже не обращается к этой переменной, ну вообще ни как. Он лишь знает ее адрес (начальный адрес ОЗУ по которому расположен этот буфер) и только.
4ainik, в регистр лезут переменные из кэша, поделенные на размерность этого регистра, то есть по 64бита и 32бита.
Зачем мне здесь кэш L1 процессора? buf это переменная, которая находится либо стеке (а это ОЗУ), либо выделена из «кучи», что так же является ОЗУ
Да не знает процессор о вашей ОЗУ, у него есть память на регистрах. Все взаимодействие с данными происходит именно там, я это уже пытаюсь объяснить час.
но очень большая, такая ни в какой «регистр» процессора НЕ влезет
А куда она влезет тогда? Где процессор с ней будет общаться? Из оперативной памяти напрямую? Вы в своем уме? Она чанками раскидывается на регистры из кэша.
Еще раз, ТС спросил о размере БУФЕРА при ДИСКОВЫХ операциях и судя по тегам писать программу он будет на C#, что он дальше будет делать с этими данными он не уточнил и его это видимо не волнует.
Переменные никуда не лезут 🙂 И вообще не нужно путать понятия:
буфер != переменная != память != регистр != ОЗУ, это все очень узкие понятия, сильно зависящие от контекста.
есть случаи когда буфер != переменная, а есть буфер == переменная.
есть случаи когда переменная != память, переменная == память или переменная == регистр.
есть случаи когда регистр != ОЗУ и регистр == ОЗУ (процессора)
Никита @Smiz001 Автор вопроса
- Размер блока 1кб, среднее время = 0:00:0.0226849
- Размер блока 2кб, среднее время = 0:00:0.021518
- Размер блока 4кб, среднее время = 0:00:0.0208970
- Размер блока 8кб, среднее время = 0:00:0.0200017
- Размер блока 16кб, среднее время = 0:00:0.0200935
- Размер блока 32кб, среднее время = 0:00:0.0196690
- Размер блока 64кб, среднее время = 0:00:0.0196175
- Размер блока 128кб, среднее время = 0:00:0.0202932
- Размер блока 256кб, среднее время = 0:00:0.0205030
- Размер блока 512кб, среднее время = 0:00:0.0200344
- Размер блока 1мб, среднее время = 0:00:0.0250169
- Размер блока 1кб, среднее время = 00:00:00.6086737
- Размер блока 2кб, среднее время = 00:00:00.5704494
- Размер блока 4кб, среднее время = 00:00:00.5701250
- Размер блока 8кб, среднее время = 00:00:00.5489293
- Размер блока 16кб, среднее время = 00:00:00.5387132
- Размер блока 32кб, среднее время = 00:00:00.5380544
- Размер блока 64кб, среднее время = 00:00:00.5314811
- Размер блока 128кб, среднее время = 00:00:00.5325442
- Размер блока 256кб, среднее время = 00:00:00.5379496
- Размер блока 512кб, среднее время = 00:00:00.5288921
- Размер блока 1мб, среднее время = 00:00:00.5284209
- Размер блока 1кб, среднее время = 00:00:04,0827317
- Размер блока 2кб, среднее время = 00:00:04,0602448
- Размер блока 4кб, среднее время = 00:00:03,9731101
- Размер блока 8кб, среднее время = 00:00:03,881938
- Размер блока 16кб, среднее время = 00:00:03,7614141
- Размер блока 32кб, среднее время = 00:00:03,8049724
- Размер блока 64кб, среднее время = 00:00:03,7621202
- Размер блока 128кб, среднее время = 00:00:03,7688710
- Размер блока 256кб, среднее время = 00:00:03,7608635
- Размер блока 512кб, среднее время = 00:00:03,8076113
- Размер блока 1мб, среднее время = 00:00:03,765408
- Размер блока 1кб, среднее время = 00:00:48,9506655
- Размер блока 2кб, среднее время = 00:00:49,0770333
- Размер блока 4кб, среднее время = 00:00:48,6813174
- Размер блока 8кб, среднее время = 00:00:47,6786507
- Размер блока 16кб, среднее время = 00:00:45,6271946
- Размер блока 32кб, среднее время = 00:00:46,1870477
- Размер блока 64кб, среднее время = 00:00:45,9454532
- Размер блока 128кб, среднее время = 00:00:45,157257
- Размер блока 256кб, среднее время = 00:00:45,0101140
- Размер блока 512кб, среднее время = 00:00:44,722839
- Размер блока 1мб, среднее время = 00:00:44,4402667
Никита, ээээ, тут есть несколько моментов.
1) современные жесткие диски обладают большой скоростью чтения/записи в зависимости от модели диска и интерфейса он может выдавать данные со скоростью 100МБайт/сек и более
2) современные ОС умеют очень хорошо кешировать данные в оперативной памяти, вполне себе могут закешировать весь файл целиком. Обычно это легко заметить при чтении файла, в первый раз он читается существенно дольше, последующих.
Не знаю как вы проводили тесты, но тесты на файлах размером меньше 1Гб практически не представляют полезной информации.
ЗЫ: График в данном случае показательнее цифр.
ЗЫ2: Какой у вас жесткий диск? уж не SSD?
ЗЫ3: Исходный код программы в студию 🙂
Никита @Smiz001 Автор вопроса
4ainik, Жесткий HDD
Вот 2 основных метода.
private static void Test(int bufSize) < var intput = @"D:\Для тестов\1гб\SW_DVD5_Office_2010w_SP1_W32_Russian_CORE_MLF_X17-82148.ISO"; var output = @"D:\temp\1.gz"; var watch = new Stopwatch(); for (int i = 0; i < 100; i++) < watch.Start(); WorkWithFile(intput, output, bufSize); watch.Stop(); measurements.Add(watch.Elapsed); File.Delete(@"D:\temp\1.gz"); watch.Reset(); >> public static void WorkWithFile(string sourceFile, string outputFile, int bufferSize) < using (var readStream = new FileStream(sourceFile, FileMode.Open, FileAccess.ReadWrite)) < using (var writeStream = new FileStream(outputFile, FileMode.OpenOrCreate, FileAccess.Write, FileShare.ReadWrite)) < int bytesRead = -1; byte[] bytes = new byte[bufferSize]; while ((bytesRead = readStream.Read(bytes, 0, bufferSize)) >0) < writeStream.Write(bytes, 0, bytesRead); >> > >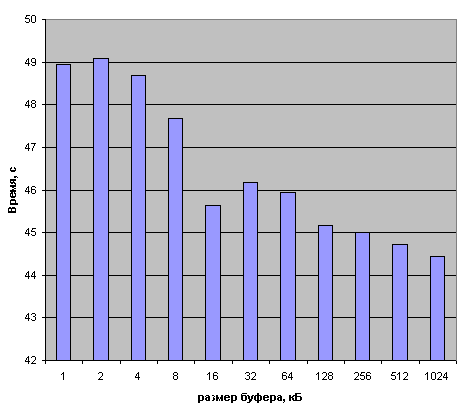
Никита, Понятно 🙂
Т.е. у вас получается измерение среднего времени выполнения операций чтения+записи.
Вот здесь как-то странно выглядит первый столбец (1кБ), по какой-то непонятной причине он показал лучше результат чем следующий (2кБ).
16кБ вполне себе ожидаемо показал результаты гораздо лучше чем все предыдущие, а вот почему 16кБ опередил 32кБ и даже 64кБ — не совсем понятно. Вполне возможно, что здесь работают какие-то особые механизмы кеширования, возможно упреждающего чтения, но могут влиять другие факторы, например фрагментация диска, тип файловой системы, размер кластера и размер сектора (обычно он 512байт, но в некоторых больших дисках бывает 4кБ). Вполне ожидаемо снижение оверхеда программы по мере увеличения размера буфера, вообще интересно посмотреть на картину происходящего по мере дальнейшего увеличения размера буфера до 10МБ 🙂
Размер буфера журнала на Андроид: что такое?
Люди часто могут задаваться различными вопросами, которые касаются мобильных устройств и для того, чтобы знать определенную информацию нужно обладать знаниями в этой сфере, поэтому достаточно часто обращаются на интернет порталы или сайты в объяснениями или инструкциями. В данной статье можно узнать о причинах появления буфер журнала и его размере.
Буфер журнала помогает и способствует копированию нужной информации, которая пригодится в дальнейшем с одного источника в другой. Мы можем не замечать этого, но такую процедуру выполняем фактически постоянно по необходимости, например, находим в интернете интересную статью или полезный навык и хотим отправить другу в социальные сети для этого копируем с сайта и затем переходим в диалог и вставляем в окно для ввода текста. Это достаточно полезная система, которая помогает уменьшить количество времени, которые мы могли бы тратить на переписывание одних и тех же данных в разные места. С этим можно столкнуться не только на Андроид, но в на других операционных системах или для пользователей ПК тоже достаточно актуальная тема, которая используется не слишком редко.
Читайте также: Где в телефоне найти загрузки?