Как распарсить xml python?
Здравствуйте!
Ребята, подскажите, каким образом можно корректно распарить xml документ при помощи PYTHON?
Только начинаю, и не могу найти хорошего примера.
Хотелось бы разобраться на практике с комментариями.
Вот мой документ — defaultVar.xml
Host 10.64.13.131:1576 true false String 1559628965605 MaxConnections 10 true false Integer 1559628965605 SID taffy true false String 1559628965605 Может ли кто-то показать, каким образом выбирать тэги SID, HOST (а так же все их атрибуты!).
Совсем не доходит голова. Если можно, то с комментариями.
Спасибо!
- Вопрос задан более трёх лет назад
- 3875 просмотров
1 комментарий
Простой 1 комментарий
Парсинг XML
Долго пробовал, но ничего не получилось.
Предполагаю, что дело в кодировке или содержимом документа. Пробовал принудительно перекодировать в UTF-8, как советуют на stackoverflow, но это не помогло.
Например, нужно получить значение «macStyle» из раздела
1 2 3 4 5
> . value="00000000 00000000"/> . >
Лучшие ответы ( 1 )
94731 / 64177 / 26122
Регистрация: 12.04.2006
Сообщений: 116,782
Ответы с готовыми решениями:

Парсинг XML
Здравствуйте! У меня имеется XML выгрузка в которой необходимо изменить атрибут ns10:capacity в.
Парсинг xml файла
Нужно парсить xml-файл. Вводится начальная и конечная даты, затем вывести отсортированную(по.
Парсинг xml файла
Есть файл подобного содержания. <?xml version="1.0" ?> <default:TED_EXPORT DOC_ID="587390-2020".
Парсинг XML файла на Питоне
Здравствуйте всем, как написать код чтобы Питон выводил всю строку "field name". А не только то что.
Парсинг всех XML в папке на локальном диске
Здравствуйте! Есть задача на Python (IDLE, Anaconda, Windows 10). Как можно провести парсинг.
1303 / 843 / 409
Регистрация: 12.03.2018
Сообщений: 2,305
1 2 3 4 5 6 7 8 9 10
from lxml import etree XML = '''\ ''' xml = etree.XML(XML) # type: etree._Element macStyle = xml.find('macStyle') # type: etree._Element print(macStyle.get('value')) # '00000000 00000000'
Регистрация: 08.11.2019
Сообщений: 66
ioprst
Проблема не самом парсинге а в конкретном XML файле. Его lxml не может обработать.
Мне нужно решение как его правильно открыть, чтобы с ним можно было работать.
1303 / 843 / 409
Регистрация: 12.03.2018
Сообщений: 2,305
TheBogdan, какая кодировка файла, как открываете файл?
Пробовали подавать парсеру текст документа? Что-то типа такого
1 2 3 4 5 6 7
with open(os.path.join(projectPath, 'project.xml'), "r", encoding='UTF-8') as f: src = f.read() # вытащить xml-дерево parser = etree.XMLParser(remove_blank_text=True) projectET = etree.parse(StringIO(src), parser)
Регистрация: 08.11.2019
Сообщений: 66
Пробовал и так как у Вас открывать и с модулем codecs
with codecs.open(file, mode='r', encoding='utf-8') as f:
Всё-равно lxml выдаёт ошибку «ValueError: Unicode strings with encoding declaration are not supported. Please use bytes input or XML fragments without declaration.»
И с simplexml и xml.etree.ElementTree пытался, тоже ошибки.
В файле указано «», но, думаю, там Юникод.
Для того файл и прикрепил, чтобы можно было посмотреть.
Работа с XML из Python

Не все элементы входных данных XML будут в конечном итоге являться элементами анализируемого дерева. В настоящий момент этот модуль пропускает все комментарии XML, инструкции по обработке и объявления типа документа во входных данных. Тем не менее, деревья, построенные с использованием API этого модуля, а не синтаксического анализа из XML-текста, могут иметь комментарии и инструкции по обработке в них.
Создание и сборка XML-документов
Импорт модуля Элемента Дерева
import xml.etree.ElementTree as ET Функция Element () используется для создания элементов XML
p=ET.Element('parent')Функция SubElement (), используемая для создания вложенных элементов в элементе give
c = ET.SubElement(p, 'child1') Функция dump() используется для вывода элементов xml .
ET.dump(p) # Если вы хотите сохранить в файл, создайте дерево XML с функцией ElementTree() и сохраните в файл, используя метод write()
tree = ET.ElementTree(p) tree.write("sample.xml")Функция Comment() используется для вставки комментариев в XML-файл.
comment = ET.Comment('user comment') p.append(comment) #этот комментарий будет добавлен к родительскому элементу ET.dump(p) # Изменение файла XML
Импортируйте модуль ElementTree и откройте файл XML, получите элемент XML
import xml.etree.ElementTree as ET tree = ET.parse('sample.xml') root=tree.getroot() element = root[0] #получите первого ребенка родительского корня element #
Элементом объекта можно управлять, изменяя его поля, добавляя и изменяя атрибуты, добавляя и удаляя дочерние элементы
element.set('attribute_name', 'attribute_value') #установите артрибут xml элементу element.text="string_text"Если вы хотите удалить элемент, используйте метод Element.remove()
root.remove(element) Метод ElementTree.write() , используемый для вывода объекта XML в файлы XML.
tree.write('sample.xml')Открытие и чтение больших файлов XML с помощью iterparse (инкрементальный анализ)
Иногда мы не хотим загружать весь XML-файл, чтобы получить необходимую нам информацию. В этих случаях полезно постепенно загружать соответствующие разделы и затем удалять их, когда мы закончим. С помощью функции iterparse вы можете редактировать дерево элементов, которое хранится при разборе XML.
Импортируйте объект ElementTree:
import xml.etree.ElementTree as ET
Откройте файл .xml и переберите все элементы:
for event, elem in ET.iterparse("yourXMLfile.xml"): # . сделайте что-нибудь . Кроме того, мы можем искать только определенные события, такие как начальный / конечный теги или пространства имен. Если эта опция не указана (как указано выше), возвращаются только события «end»:
events=("start", "end", "start-ns", "end-ns") for event, elem in ET.iterparse("yourXMLfile.xml", events=events): # . сделайте что-нибудь . Вот полный пример, показывающий, как очистить элементы из дерева в памяти, когда мы закончим с ними:
for event, elem in ET.iterparse("yourXMLfile.xml", events=("start","end")): if elem.tag == "record_tag" and event == "end": print elem.text elem.clear() # . сделайтe что-нибудь другое . Открытие и чтение с помощью ElementTree
Импортируйте объект ElementTree, откройте соответствующий XML-файл и получите корневой тег:
import xml.etree.ElementTree as ET tree = ET.parse("yourXMLfile.xml") root = tree.getroot()Есть несколько способов поиска по дереву. Сначала по итерации:
for child in root: print(child.tag, child.attrib)В противном случае вы можете ссылаться на определенные места, такие как список:
print(root[0][1].text)Для поиска конкретных тегов по имени, используйте .find или .findall :
print(root.findall("myTag")) print(root[0].find("myOtherTag")) Поиск в XML с помощью XPath
Начиная с версии 2.7 ElementTree имеет лучшую поддержку XPath запросов. XPath — это синтаксис, позволяющий вам перемещаться по XML, как SQL используется для поиска в базе данных. Как find и findall функции поддержки XPath. Xml ниже будет использоваться для этого примера
Мечтают ли андроиды об электроовцах? Philip K. Dick The Colour of Magic Terry Pratchett The Eye of The World Robert Jordan Поиск всех книг:
import xml.etree.cElementTree as ET tree = ET.parse('sample.xml') tree.findall('Books/Book') Поиск книги с названием «Цвет магии»:
tree.find("Books/Book[Title='The Colour of Magic']") # всегда используйте '' в правой стороне сравненияtree.find("Books/Book[@id='5']") # поиск с xml атрибутами должен иметь '@' перед именем Поиск второй книги:
tree.find("Books/Book[2]") # индексы начинаются с 1, не с 0Поиск последней книги:
tree.find("Books/Book[last()]") # 'last' единственная xpath функция позволенная в ElementTreeПоиск всех авторов:
tree.findall(".//Author") # поиск с // должен использовать родственный путьРуководство по парсингу XML Python: чтение XML-файла
От автора: что такое XML? XML расшифровывается как расширяемый язык разметки. Он был разработан для хранения и передачи небольших и средних объемов данных и широко используется для обмена структурированной информацией.
Python позволяет парсировать и изменять XML-документ. Для парсинга XML-документа вам необходимо иметь в памяти весь XML-документ. В этом руководстве мы рассмотрим, как в Python использовать класс XML minidom для загрузки и парсинга XML-файла.
Как парсить XML с помощью minidom
Как создать XML-узел
Как парсить XML с помощью ElementTree
Как парсить XML с помощью minidom
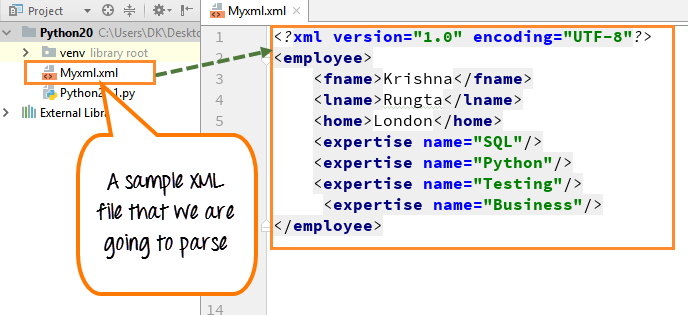
Мы создали образец XML-файла, который мы собираемся парсить.
Шаг 1) Внутри файла мы видим имя, фамилию, дом и навыки (SQL, Python, Testing и Business)
Шаг 2) После того, как мы спарсим документ, мы выведем «имя узла» корня документа и «первый дочерний тэг». Tagname и nodename являются стандартными свойствами файла XML.

Импортируйте модуль xml.dom.minidom и объявите файл для парсинга (myxml.xml)
Этот файл содержит основную информацию о сотруднике, такую как имя, фамилия, адрес, навыки и т. д.
Мы используем функцию parse в minidom XML для загрузки и парсинга файла XML
У нас есть переменная doc, doc получает результат функции parse
Мы хотим вывести имя файла и дочерний тэг, поэтому объявляем это в функции print
Запустите код. Он выведет имя узла (#document) из файла XML и первый дочерний тэг (employee) из файла XML.
Примечание: Nodename и tagname являются стандартными именами или свойствами XML dom. В случае, если вы не знакомы с этим типом именования.
Шаг 3) Мы также можем вызвать список тегов XML из документа XML и вывести его. Здесь мы вывели набор навыков, таких как SQL, Python, Testing и Business.

Объявление переменной expertise, из которой мы будем извлекать всю информацию сотрудника
Используем стандартную функцию dom с именем «getElementsByTagName»
Она получит все элементы с именем skill
Объявляем цикл для каждого из тегов skill
Запустите код — он выдаст список из четырех навыков
Как создать XML-узел
Мы можем создать новый атрибут с помощью функции «createElement», а затем добавить этот новый атрибут или тег к существующим тегам XML. Мы добавили новый тег «BigData» в XML-файл.
Вам нужно написать код, чтобы добавить новый атрибут (BigData) в существующий тег XML
Затем вам нужно вывести тег XML с новыми атрибутами, добавленными к существующему тегу XML.

Чтобы добавить новый XML и вставить его в документ, мы используем код «doc.create elements»
Этот код создаст новый тег skill для нашего нового атрибута «Big-data»
Добавьте этот тег в first child документа (employee)
Запустите код — появится новый тег «big data» с другим списком навыков.
Пример XML-парсера
Пример Python 2