Пересечение списков, совпадающие элементы двух списков
В данной задаче речь идет о поиске элементов, которые присутствуют в обоих списках. При этом пересечение списков и поиск совпадающих (перекрывающихся) элементов двух списков будем считать несколько разными задачами.
Если даны два списка, в каждом из которых каждый элемент уникален, то задача решается просто, так как в результирующем списке не может быть повторяющихся значений. Например, даны списки:
[5, 4, 2, ‘r’, ‘ee’] и [4, ‘ww’, ‘ee’, 3]
Областью их пересечения будет список [4, ‘ee’] .
Если же исходные списки выглядят так:
[5, 4, 2, ‘r’, 4, ‘ee’, 4] и [4, ‘we’, ‘ee’, 3, 4] ,
то списком их совпадающих элементов будет [4, ‘ee’, 4] , в котором есть повторения значений, потому что в каждом из исходных списков определенное значение встречается не единожды.
Начнем с простого — поиска области пересечения. Cначала решим задачу «классическим» алгоритмом, не используя продвинутые возможностями языка Python: будем брать каждый элементы первого списка и последовательно сравнивать его со всеми значениями второго.
a = [5, [1, 2], 2, 'r', 4, 'ee'] b = [4, 'we', 'ee', 3, [1, 2]] c = [] for i in a: for j in b: if i == j: c.append(i) break print(c)
Результат выполнения программы:
[[1, 2], 4, 'ee']
Берется каждый элемент первого списка (внешний цикл for ) и последовательно сравнивается с каждым элементом второго списка (вложенный цикл for ). В случае совпадения значений элемент добавляется в третий список c . Команда break служит для выхода из внутреннего цикла, так как в случае совпадения дальнейший поиск при данном значении i бессмыслен.
Алгоритм можно упростить, заменив вложенный цикл на проверку вхождения элемента из списка a в список b с помощью оператора in :
a = [5, [1, 2], 2, 'r', 4, 'ee'] b = [4, 'we', 'ee', 3, [1, 2]] c = [] for i in a: if i in b: c.append(i) print(c)
Здесь выражение i in b при if по смыслу не такое как выражение i in a при for . В случае цикла оно означет извлечение очередного элемента из списка a для работы с ним в новой итерации цикла. Тогда как в случае if мы имеем дело с логическим выражением, в котором утверждается, что элемент i есть в списке b . Если это так, и логическое выражение возвращает истину, то выполняется вложенная в if инструкция, то есть элемент i добавляется в список c .
Принципиально другой способ решения задачи – это использование множеств. Подходит только для списков, которые не содержат вложенных списков и других изменяемых объектов, так как встроенная в Python функция set() в таких случаях выдает ошибку.
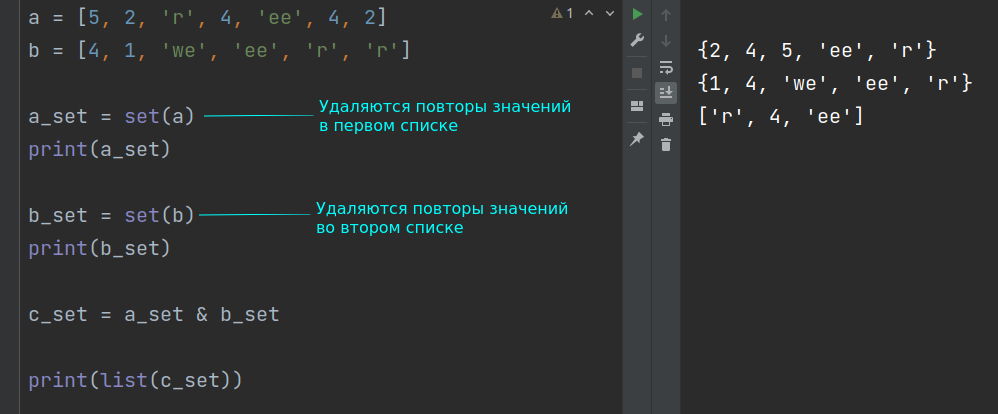
a = [5, 2, 'r', 4, 'ee'] b = [4, 1, 'we', 'ee', 'r'] c = list(set(a) & set(b)) print(c)
['ee', 4, 'r']
Выражение list(set(a) & set(b)) выполняется следующим образом.
- Сначала из списка a получают множество с помощью команды set(a) .
- Аналогично получают множество из b .
- С помощью операции пересечения множеств, которая обозначается знаком амперсанда & , получают третье множество, которое представляет собой область пересечения двух исходных множеств.
- Полученное таким образом третье множество преобразуют обратно в список с помощью встроенной в Python функции list() .
Множества не могут содержать одинаковых элементов. Поэтому, если в исходных списках были повторяющиеся значения, то уже на этапе преобразования этих списков во множества повторения удаляются, а результат пересечения множеств не будет отличаться от того, как если бы в исходных списках повторений не было.
Однако если мы вернемся к решению задачи без использования множеств и добавим в первый список повтор значения, то получим некорректный результат:
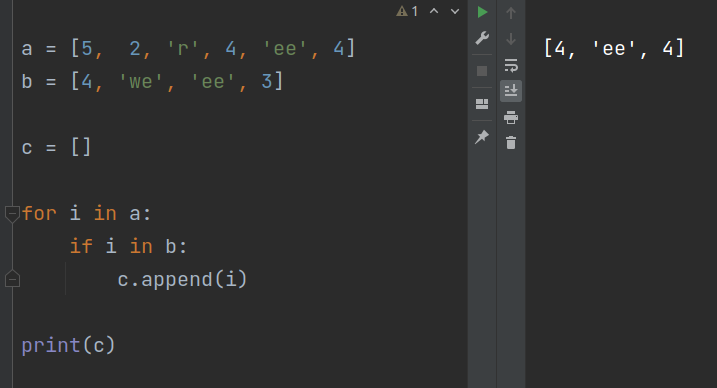
В список пересечения попадают оба равных друг другу значения из первого списка. Это происходит потому, что когда цикл извлекает, в данном случае, вторую 4-ку из первого списка, выражение i in b также возвращает истину, как и при проверке первой 4-ки. Следовательно, выражение c.append(i) выполняется и для второй четверки.
Чтобы решить эту проблему, добавим дополнительное условие в заголовок инструкии if . Очередной значение i из списка a должно не только присутствовать в b , но его еще не должно быть в c . То есть это должно быть первое добавление такого значения в c :
a = [5, 2, 'r', 4, 'ee', 4] b = [4, 'we', 'ee', 3] c = [] for i in a: if i in b and i not in c: c.append(i) print(c)
[4, 'ee']
Теперь усложним задачу. Пусть если в обоих списках есть по несколько одинаковых значений, они должны попадать в список совпадающих элементов в том количестве, в котором встречаются в списке, где их меньше. Или если в исходных списках их равное количетво, то такое же количество должно быть в третьем. Например, если в первом списке у нас три 4-ки, а во втором две, то в третьем списке должно быть две 4-ки. Если в обоих исходных по две 4-ки, то в третьем также будет две.
Алгоритмом решения такой задачи может быть следующий:
- В цикле будем перебирать элементы первого списка.
- Если на текущей итерации цикла взятого из первого списка значения нет в третьем списке, то только в этом случае следует выполнять все нижеследующие действия. В ином случае такое значение уже обрабатывалось ранее, и его повторная обработка приведет к добавлению лишних элементов в результирующий список.
- С помощью спискового метода count() посчитаем количество таких значений в первом и втором списке. Выберем минимальное из них.
- Добавим в третий список количество элементов с текущим значением, равное ранее определенному минимуму.
a = [5, 2, 4, 'r', 4, 'ee', 1, 1, 4] b = [4, 1, 'we', 'ee', 'r', 4, 1, 1] c = [] for item in a: if item not in c: a_item = a.count(item) b_item = b.count(item) min_count = min(a_item, b_item) # c += [item] * min_count for i in range(min_count): c.append(item) print(c)
[4, 4, 'r', 'ee', 1, 1]
Если значение встречается в одном списке, но не в другом, то метод count() другого вернет 0. Соответственно, функция min() вернет 0, а цикл с условием i in range(0) не выполнится ни разу. Поэтому, если значение встречается в одном списке, но его нет в другом, оно не добавляется в третий.
При добавлении значений в третий список вместо цикла for можно использовать объединение списков с помощью операции + и операцию повторения элементов с помощью * . В коде выше данный способ показан в комментарии.
X Скрыть Наверх
Решение задач на Python
Python-сообщество
![]()
- Начало
- » Python для новичков
- » Вычитание списков?
#1 Окт. 24, 2012 11:21:01
tfox Зарегистрирован: 2012-04-13 Сообщения: 55 Репутация: 0 Профиль Отправить e-mail
Вычитание списков?
Как из одного списка удалить все элементы которые есть в другом списке?
l1 = [1, 2, 3] l2 = [2] # сложение списков работает l3 = l1 + l2 print l3 # а это не работает :( l3 = l1 - l2 print l3
#2 Окт. 24, 2012 11:29:09
GaiveR От: Зарегистрирован: 2011-08-13 Сообщения: 122 Репутация: 16 Профиль Отправить e-mail
Вычитание списков?
#3 Окт. 24, 2012 12:17:52
dimy44 От: Евпатория Зарегистрирован: 2012-04-21 Сообщения: 463 Репутация: 42 Профиль
Вычитание списков?
>>> lst1 = range(10) >>> lst2 = [1, 1, 4, 5] >>> col = set(lst2) >>> lst1 = [i for i in lst1 if i not in col] >>> lst1 [0, 2, 3, 6, 7, 8, 9] >>>
это на тот случай, если важно сохранить последовательность элементов уменьшаемого списка.
#4 Окт. 24, 2012 14:14:04
tfox Зарегистрирован: 2012-04-13 Сообщения: 55 Репутация: 0 Профиль Отправить e-mail
Вычитание списков?
dimy44
это на тот случай, если важно сохранить последовательность элементов уменьшаемого списка.
Да. Мне важно сохранить последовательность элементов уменьшаемого списка.
Это выражение тоже сохраняет элементы в том же порядке как они и были:
GaiveR
l3 = list(set(l1).difference(l2))
#5 Окт. 24, 2012 15:01:03
dimy44 От: Евпатория Зарегистрирован: 2012-04-21 Сообщения: 463 Репутация: 42 Профиль
Вычитание списков?
Это уж как карта ляжет.
>>> lst1 = [1, 5, 1, 3, 4, 2, 6]
>>> lst2 = [1, 2]
>>> list(set(lst1).difference(lst2))
[3, 4, 5, 6]
>>>
#6 Окт. 24, 2012 16:33:38
dimy44 От: Евпатория Зарегистрирован: 2012-04-21 Сообщения: 463 Репутация: 42 Профиль
Вычитание списков?
И да, забыл еще указать, что если у Вас в списке будут повторяющиеся элементы, которые не нужно вычитать, то даже если предположить, что очередность не важна, все-равно set испортит Ваш список, т.к. уберет дублирующие элементы.
Как удалить элемент из списка в Python
Рассказываем, как работают методы remove(), pop(), clear() и ключевое слово del.

Иллюстрация: Оля Ежак для Skillbox Media

Иван Стуков
Журналист, изучает Python. Любит разбираться в мелочах, общаться с людьми и понимать их.
В Python есть много удобных механизмов для работы со списками. И удалять элементы из них можно по-разному.
4 главных способа удалить элемент из списка
В этой статье мы рассмотрим четыре основных метода. Их функциональность в некоторых случаях пересекается, поэтому иногда они вполне взаимозаменяемы.
Метод remove(): удаление по значению
remove() можно использовать, когда мы точно знаем значение, от которого хотим избавиться. В качестве аргумента remove() получает объект, находит совпадение и удаляет его, ничего не возвращая:
new_list = ['ноль', 1, [2.1, 'два и два'], 3, 'IV'] new_list.remove(1) print(new_list ) >>> ['ноль', [2.1, 'два и два'], 3, 'IV']
Можно удалять и более сложные объекты: например, внутренние списки. Главное — в точности передать этот объект методу:
new_list = ['ноль', 1, [2.1, 'два и два'], 3, 'IV'] new_list.remove([2.1, 'два и два']) print(new_list) >>> ['ноль', 1, 3, 'IV']
remove() удаляет только первое совпадение с искомым элементом. Например, так он себя поведёт, если в списке будет несколько строк ‘ноль’:
change_list = ['ноль', 1, [2.1, 'два и два'], 'ноль', 3, 'IV'] change_list.remove('ноль') print(change_list) >>> [1, [2.1, 'два и два'], 'ноль', 3, 'IV']
При попытке удалить значение, которого нет в списке, Python выдаст ошибку ValueError.
Метод pop(): удаление по индексу
pop() подойдёт, когда известно точное местоположение удаляемого элемента. В качестве аргумента pop() получает индекс, а возвращает удалённое значение:
new_list = ['ноль', 1, [2.1, 'два и два'], 3, 'IV'] new_list.pop(2) >>> [2.1, 'два и два'] print(new_list) >>> ['ноль', 1, 3, 'IV']
Если передать отрицательное значение, то pop() будет считать индексы не с нуля, а с -1:
new_list = ['ноль', 1, [2.1, 'два и два'], 3, 'IV'] new_list.pop(-2) print(new_list) #Удалили предпоследний элемент. >>> ['ноль', 1, [2.1, 'два и два'], 'IV']
А вот если оставить pop() без аргумента, то удалится последний элемент — потому что -1 является аргументом по умолчанию:
new_list = ['ноль', 1, [2.1, 'два и два'], 3, 'IV'] new_list.pop() print(new_list) >>> ['ноль', 1, [2.1, 'два и два'], 3]
При попытке обратиться в методе pop() к несуществующему индексу, интерпретатор выбросит исключение IndexError.
Метод clear(): очищение списка
clear() удаляет из списка всё, то есть буквально очищает его. Он не принимает аргументов и не возвращает никаких значений:
new_list = ['ноль', 1, [2.1, 'два и два'], 3, 'IV'] new_list.clear() print(new_list) >>> []
Ключевое слово del: удаление срезов
del, как и метод pop(), удаляет элементы списка по индексу. При этом с его помощью можно избавиться как от единичного объекта, так и от целого среза:
new_list = ['ноль', 1, [2.1, 'два и два'], 3, 'IV'] del new_list[2] print(new_list) >>> ['ноль', 1, 3, 'IV']
Если передать срез, то элемент с правым индексом не удалится. В примере ниже это строка ‘IV’:
new_list = ['ноль', 1, [2.1, 'два и два'], 3, 'IV'] del new_list[1:4] print(new_list) >>> ['ноль', 'IV']
Чтобы очистить список, достаточно передать полный срез [:]:
new_list = ['ноль', 1, [2.1, 'два и два'], 3, 'IV'] del new_list[:] print(new_list) >>> []
Также del можно использовать с отрицательными индексами:
new_list = ['ноль', 1, [2.1, 'два и два'], 3, 'IV'] del new_list[-4] print(new_list) >>> ['ноль', [2.1, 'два и два'], 3, 'IV']
Со срезами это тоже работает:
new_list = ['ноль', 1, [2.1, 'два и два'], 3, 'IV'] del new_list[-3:-1] print(new_list) >>> ['ноль', 1, 'IV']
Если при удалении единичного элемента указать несуществующий индекс, то Python выдаст ошибку IndexError.
Как удалить первый элемент списка в Python
Довольно часто, например, при реализации стека, нужно удалить первый элемент списка. Возьмём наш new_list и посмотрим, какими способами это можно сделать.
С помощью метода pop(0)
Передаём в качестве аргумента pop() индекс 0:
new_list = ['ноль', 1, [2.1, 'два и два'], 3, 'IV'] new_list.pop(0) print(new_list) >>> [1, [2.1, 'два и два'], 3, 'IV']
С помощью ключевого слова del
Используем del с элементом с индексом 0.
new_list = ['ноль', 1, [2.1, 'два и два'], 3, 'IV'] del new_list[0] print(new_list) >>> [1, [2.1, 'два и два'], 3, 'IV']
Как удалить несколько элементов
Если элементы, от которых нужно избавиться, находятся по соседству друг с другом, то удобнее всего использовать del.
Допустим, в последовательности чисел от 0 до 9 нужно удалить 4, 5, 6 и 7. Тогда решение будет выглядеть так:
#Сначала создадим лист с числами от 0 до 9. num_list = list(i for i in range(10)) print(num_list) >>> [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] #После чего укажем срез чисел от 4 до 7. #Обратите внимание: элемент с индексом 8 не удаляется. del num_list[4:8] print(num_list) >>> [0, 1, 2, 3, 8, 9]
Как удалить последний элемент списка в Python
Если мы хотим избавиться от последнего элемента, то, как и в случае с первым, удобнее всего это сделать с помощью pop() или del.
С помощью метода pop()
Так как по умолчанию метод принимает аргумент -1, то можно вообще ничего не передавать:
num_list = ['ноль', 1, [2.1, 'два и два'], 3, 'IV'] num_list.pop() print (num_list) >>> ['ноль', 1, [2.1, 'два и два'], 3]
Но если вы истинный приверженец дзена Python («Явное лучше неявного»), то можно указать -1 — ничего не изменится.
С помощью ключевого слова del
А вот если хотите удалить последний элемент с помощью del, то передать -1 нужно обязательно:
num_list = ['ноль', 1, [2.1, 'два и два'], 3, 'IV'] del num_list[-1] print(num_list) >>> ['ноль', 1, [2.1, 'два и два'], 3]
Подведём итоги
Язык Python даёт четыре основных инструмента для удаления элементов из списка:
- remove() — удаляет по названию;
- pop() — удаляет по индексу, положительному или отрицательному;
- clear() — удаляет всё содержимое списка;
- del — позволяет удалить как отдельный элемент, так и целый срез по индексу.
Читайте также:
- Что нужно знать о списках в Python
- Тест: насколько хорошо ты разбираешься во фронтенде?
- Как начать программировать на Python
Списки в Python — 10 примеров работы с функциями и методами

Списки в Python — это составная структура данных, которая позволяет собирать значения в одном месте. В других языках они чаще всего называются динамическими массивами данных. Списки — изменяемый (immutable) тип данных. Это означает, что список можно изменять, например путем добавления или удаления значений.
Какой у списков в Python формальный синтаксис?
[value, value, . ] list([iterable])Для чего вообще нужны списки?
Списки в Python — одна из 4 структур данных, предназначенных для работы с итерируемыми объектами. Представим, что нам нужно написать скрипт, который проверяет, является ли модель машины производства компании Tesla. Код будет выглядеть следующим образом:
Что еще можно делать со списками в Python?
Ниже собраны примеры решений задач на основные вопросы, с которыми сталкиваются Python разработчики и дата-саентисты:
- Как узнать длину списка в Python?
- Как проверить, существует ли элемент в списке?
- Как получить значение из списка по индексу?
- Как перебрать значения списка в Python?
- Какие есть методы списков в Python?
- Как получить значение по индексу из многомерного списка в Python?
- Как проверить, что список пустой?
- All и any в Python — как проверить, что каждое или любое значение списка соответствует критерию?
- Как сравнить списки в Python?
- Как удалить дубликаты в списке?
Как узнать длину списка в Python?
Функция len() , позволяет получить одномерную длину списка.
len(['one', 'two']) # вернет 2 len(['one', [2, 3], 'four']) # вернет 3, а не 4len() также работает со строками, словарями и другими структурами данных, схожими со списками.
Обратите внимание, что len() — это встроенная функция, а не метод списка.
Производительность функции len() равна O(1) (константная), то есть скорость получения длины списка не зависит от его длины.
Как проверить, существует ли элемент в списке?
За проверку вхождения значения в список отвечает оператор in .
lst = ['test', 'twest', 'tweast', 'treast'] 'test' in lst # True 'toast' in lst # FalseПримечание: оператор in в множествах асимптотически быстрее, чем в списках. Если его предстоит использовать много раз в потенциально больших списках, вы можете преобразовать список во множество (set) и проверить наличие значений во множестве.
lst = ['test', 'twest', 'tweast', 'treast'] slst = set(lst) 'test' in slst #TrueКак получить значение списка по индексу?
У каждого элемента списка есть свой уникальный номер. Этот номер называется индексом. Списки в Python имеют нулевую индексацию, как у массивов в других языках. Это означает, что первый элемент списка имеет индекс 0, второй элемент — индекс 1, третий — 2 и т. д.
lst = [1, 2, 3, 4] lst[0] # 1 lst[1] # 2Если запросить элемент по индексу за пределами списка, Python выкинет исключение IndexError .
lst = [1, 2, 3, 4] lst[10] # IndexError: list index out of rangeОтрицательные индексы интерпретируются как подсчёт с конца списка.
lst = [1, 2, 3, 4] lst[-1] # 4 lst[-2] # 3 lst[-5] # IndexError: list index out of rangeТо же действие можно воспроизвести следующим образом:
lst = [1, 2, 3, 4] lst[len(lst)-1] # 4Списки в Python поддерживают слайсинг. Синтаксис слайса: lst[начало:конец:шаг] . Результатом слайса будет новый список, содержащий элементы от начала до конца — 1.
lst = [1, 2, 3, 4] lst[1:] # [2, 3, 4] lst[:3] # [1, 2, 3] lst[::2] # [1, 3] lst[::-1] # [4, 3, 2, 1] lst[-1:0:-1] # [4, 3, 2] lst[5:8] # [] поскольку начальный индекс больше # длины lst, возвращает пустой список lst[1:10] # [2, 3, 4] то же, что опускание конечного индексаСлайсингом можно развернуть список в обратную сторону:
lst = [1, 2, 3, 4] lst[::-1] # [4, 3, 2, 1]Как перебрать значения списка в Python?
Python позволяет использовать цикла for со списками:
my_list = ['foo', 'bar', 'baz'] for item in my_list: print(item) # foo # bar # bazИндекс текущего элемента в цикле можно получить используя функцию enumerate:
for (index, item) in enumerate(my_list): print('The item in position <>: <>'.format(index, item)) # The item in position 0: foo # The item in position 1: bar # The item in position 2: bazТак же, можно проходить по списку используя функцию range. Range генерирует ряд чисел в рамках заданного диапазона, соответственно началом диапазона является число 0 (индекс первого элемента), а концом индекс последнего элемента. Len возвращает длину списка, так как индекс первого элемента является нулем, вычитать из длины списка единицу не нужно, индекс последнего элемента будет соответствовать длине списка:
for i in range(0, len(my_list)): print(my_list[i]) # foo # bar # bazРанее отмечалось, что списки являются изменяемой (или иммютабельной, от англ. immutable) структурой данных. Это означает, что если изменить список во время итерации, мы можем получить неожиданные результаты, например:
for item in my_list: if item == 'foo': del my_list[0] print(item) # Вывод: # foo # bazВ примере мы удалили первый элемент на первой итерации изменив список, что привело к пропуску bar. На второй итерации, baz стал вторым элементом списка.
Какие есть методы списков в Python?
Метод списка append
append(value) — позволяет добавить новый элемент в конец списка.
a = [1, 2, 3, 4, 5] # Добавим значения 6, 7, и 7 в список a a.append(6) a.append(7) a.append(7) # a: [1, 2, 3, 4, 5, 6, 7, 7] # Добавим к значениям списка другой список b = [8, 9] a.append(b) # a: [1, 2, 3, 4, 5, 6, 7, 7, [8, 9]] # Если вы добавляете список к списку, добавляемый # вами будет одним элементом в конце первого # списка. Для расширения списка используйте метод extends # Добавим к списку элемент другого типа my_string = "hello world" a.append(my_string) # a: [1, 2, 3, 4, 5, 6, 7, 7, [8, 9], "hello world"]Метод списка extends
extends (enumerable) — расширяет список, добавляя элементы переданного итерируемого объекта.
a = [1, 2, 3, 4, 5, 6, 7, 7] b = [8, 9, 10] a.extend(b) # Добавляем в список a все элементы из списка b # a: [1, 2, 3, 4, 5, 6, 7, 7, 8, 9, 10] a.extend(range(3)) # Добавляем в список a все элементы # последовательности (0, 1, 2) # a: [1, 2, 3, 4, 5, 6, 7, 7, 8, 9, 10, 0, 1, 2]Списки также можно объединять с помощью оператора +. При этом, оператор + не изменяет список, а создает новый.
a = [1, 2, 3, 4, 5, 6] + [7, 7] + b # a: [1, 2, 3, 4, 5, 6, 7, 7, 8, 9, 10]Метод списка index
index (value, [startIndex]) — возвращает индекс первого вхождения значения. Если вводного значения нет в списке, возникнет исключение ValueError. Если указан второй аргумент, поиск начнется с указанного индекса.
a = [1, 2, 3, 4, 5, 6, 7, 7, 8, 9, 10] a.index(7) # Вернется 6 a.index(49) # Возникнет исключение ValueError, # т. к. значения 49 нет в списке a. a.index(7, 7) # Вернется 7 a.index(7, 8) # Возникнет ValueError, т. к. в списке a нет # значения 7, которое начиналось бы с индекса 8Метод списка insert
insert (index, value) — добавляет значение value непосредственно перед указанным индексом index. После вставки новое значение занимает индекс index.
a = [1, 2, 3, 4, 5, 6, 7, 7, 8, 9, 10] a.insert(0, 0) # вставляет 0 на позицию 0 a.insert(2, 5) # вставляет 5 на позицию 2 a # [0, 1, 5, 2, 3, 4, 5, 6, 7, 7, 8, 9, 10]Метод списка pop
pop([index]) — удаляет и возвращает значение по индексу index. Без аргумента index удаляет и возвращает последний элемент списка.
a = [0, 1, 5, 2, 3, 4, 5, 6, 7, 7, 8, 9, 10] a.pop(2) # Возвращает 5 # a: [0, 1, 2, 3, 4, 5, 6, 7, 7, 8, 9, 10] a.pop(8) # Возвращает 7 # a: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10] # Без аргумента: a.pop() # Возвращает: 10 # a: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]Метод списка remove
remove(value) — удаляет первое вхождение указанного значения. Если указанного значения нет в списке, выдаётся исключение ValueError.
a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] a.remove(0) a.remove(9) # a: [1, 2, 3, 4, 5, 6, 7, 8]Метод списка reverse
reverse() — переворачивает список задом наперёд и возвращает None.
a = [1, 2, 3, 4, 5, 6, 7, 8] a.reverse() # a: [8, 7, 6, 5, 4, 3, 2, 1]Метод списка count
count(value) — подсчитывает количество появлений значения в списке.
a = [1, 2, 3, 4, 5, 6, 7, 7] a.count() # 2Метод списка sort
sort() — сортирует список в числовом и лексическом порядке и возвращает None
a = [1, 2, 3, 4, 5, 6, 7, 8] a.sort() # Отсортирует список в числовом порядке # a = [1, 2, 3, 4, 5, 6, 7, 8]Списки также можно сортировать в обратном порядке используя флаг reverse=True в методе sort().
a = [1, 2, 3, 4, 5, 6, 7, 8] a.sort(reverse=True) # a = [8, 7, 6, 5, 4, 3, 2, 1]Для сортировки списка по атрибутам элементов, можно использовать аргумент key:
class Person(object): def __init__(self, name, height): self.name = name self.height = height def __repr__(self): return self.name lst = [Person("John Cena", 175), Person("Chuck Norris", 180), Person("Jon Skeet", 185)] # Отсортируется по аттрибуту name lst.sort(key=lambda item: item.name) lst # [Chuck Norris, John Cena, Jon Skeet] # Отсортируется по аттрибуту height lst.sort(key=lambda item: item.height) lst # lst: [John Cena, Chuck Norris, Jon Skeet]Метод списка clear
clear() — удаляет все элементы из списка
a = [1, 2, 3, 4, 5, 6, 7, 8] a.clear() a # []Метод списка copy
copy() — возвращает пустую копию списка.
a = [1, 2, 3, 4, 5] aa = a.copy() aa # [1, 2, 3, 4, 5]Как получить значение по индексу из многомерного списка в Python?
Список списков называется многомерным списком, возможная глубина не ограничена. Список списков является двумерным, список списков списков — трехмерным и т. д.
Доступ к значениям многомерного списка:
alist = [[[1,2],[3,4]], [[5,6,7],[8,9,10], [12, 13, 14]]] # Значение второго элемента в первом списке первого списка print(alist[0][0][1]) # Выведет 2 # Значение третьего элемента во втором списке # второго списка втором списк print(alist[1][1][2]) # Выведет 10Использование методов списков на примере добавления значения в мгогомерный список:
alist = [[[1,2],[3,4]], [[5,6,7],[8,9,10], [12, 13, 14]]] alist[0][0].append(11) # Добавим значение 11 в конец первого списка в первом списке print(alist[0][0][2]) # Выведет 11Использование вложенных циклов for для обхода многомерного списка:
alist = [[[1,2,11], [3,4]], [[5,6,7],[8,9,10], [12, 13, 14]]] # Один из способов циклического обхода многомерных списков for row in alist: for col in row: print(col) # Вывод: # [1, 2, 11] # [3, 4] # [5, 6, 7] # [8, 9, 10] # [12, 13, 14]Использование слайсов в многомерном списке:
alist = [[[1,2,11], [3,4]], [[5,6,7],[8,9,10], [12, 13, 14]]] print(alist[1][1:]) #[[8, 9, 10], 15, [12, 13, 14]]Как проверить, что список пустой?
Пустой список эквивалентен значению False, поэтому не нужно проверять len(lst) == 0, а достаточно вызвать lst или not lst:
alst = [] if not lst: print("list is empty") # "List is empty"All и any в Python — как проверить, что каждое или любое значение списка соответствует критерию?
Функция all() помогает определить, все ли значения итерируемого объекта соответствуют значению True
nums = [1, 1, 0, 1] all(nums) # False chars = ['a', 'b', 'c', 'd'] all(chars) # TrueАналогично, any() определяет, соответствует ли одно или несколько значений в итерируемом объекте значению True
nums = [1, 1, 0, 1] any(nums) # True vals = [None, None, None, False] any(vals) # FalseAll и any удобно использовать с генераторами:
vals = [1, 2, 3, 4] any(val > 12 for val in vals) # False any((val * 2) > 6 for val in vals) # TrueКак сравнить списки в Python?
Python поддерживает лексическое сравнение списков с помощью операторов сравнения. Оба операнда должны быть одного типа.
[1, 10, 100] < [2, 10, 100] # True, потому что 1 < 2 [1, 10, 100] < [1, 10, 100] # False, потому что списки равны [1, 10, 100] Если один из списков содержится в начале другого, выигрывает самый короткий список.
[1, 10] < [1, 10, 100] # TrueКак удалить дубликаты в списке?
Удаление повторяющихся значений в списке можно сделать путём преобразования списка во множество (set). Множества представляют собой неупорядоченную коллекцию уникальных значений. Если требуется сохранить структуру данных в виде списка, то множество можно преобразовать обратно в список с помощью функции list():
names = ["aixk", "duke", "edik", "tofp", "duke"] list(set(names)) # ['duke', 'tofp', 'aixk', 'edik']Обратите внимание, что при преобразовании списка во множество теряется исходный порядок. Для сохранения исходного порядка можно использовать OrderedDict.
import collections collections.OrderedDict.fromkeys(names).keys() # ['aixk', 'duke', 'edik', 'tofp']Упражнение
Добавьте числа 1 , 2 и 3 в список numbers , а слова hello и word — в переменную strings .
Затем, заполнить переменную second_name вторым значением из списка names, используя оператор [] . Обратите внимание, что индекс начинается с нуля, поэтому, если вы хотите получить доступ ко второму элементу в списке, его индекс будет равен 1.
Решение упражнения
numbers = [] strings = [] names = ["John", "Eric", "Jessica"] # напишите ниже свой код numbers.append(1) numbers.append(2) numbers.append(3) strings.append("hello") strings.append("world") second_name = names[1] print(numbers) print(strings) print("The second name on the names list is %s" % second_name)