Big Data: что это и где применяется?
Почему все вокруг говорят про большие данные? Какие именно данные считаются большими? Где их искать, зачем они нужны, как на них заработать? Объясняем простыми словами, что такое «Биг Дата», вместе с экспертом SkillFactory — ведущим автором курса по машинному обучению, старшим аналитиком в «КиноПоиске» Александром Кондрашкиным.

Освойте профессию «Data Scientist» на курсе с МГУ
Data Scientist с нуля до PRO
Освойте профессию Data Scientist с нуля до уровня PRO на углубленном курсе совместно с академиком РАН из МГУ. Изучите продвинутую математику с азов, получите реальный опыт на практических проектах и начните работать удаленно из любой точки мира.

25 месяцев
Data Scientist с нуля до PRO
Создавайте ML-модели и работайте с нейронными сетями
11 317 ₽/мес 6 790 ₽/мес

Что такое большие данные?
Big Data («Биг Дата», большие данные) — огромные наборы разнообразных данных. Огромные, потому что их объемы такие, что простой компьютер не справится с их обработкой, а разнообразные — потому что эти данные разного формата, неструктурированные и содержат ошибки. Большие данные быстро накапливаются и используются для разных целей. Big Data — это не обычная база данных, даже если она очень большая. Вот отличия:
Не большие данные
Большие данные
База записей о тысячах работников корпорации. Информация в такой базе имеет заранее известные характеристики и свойства, ее можно представить в виде таблицы, как в Excel.
Журнал действий сотрудников. Например, все данные, которые создает во время работы колл-центр, где работает 500 человек.
Информация об именах, возрасте и семейном положении всех 2,5 миллиардов пользователей Фейсбук* — это всего лишь очень большая база данных.
Переходы по ссылкам, отправленные и полученные сообщения, лайки и репосты, движения мыши или касания экранов смартфонов всех пользователей Фейсбук*.
Архив записей городских камер видеонаблюдения.
Данные системы видеофиксации нарушений правил дорожного движения с информацией о дорожной ситуации и номерах автомобилей нарушителей; информация о пассажирах метро, полученная с помощью системы распознавания лиц, и о том, кто из них числится в розыске.

Объем информации в мире увеличивается ежесекундно, и то, что считали большими данными десятилетие назад, теперь умещается на жесткий диск домашнего компьютера. 60 лет назад жесткий диск на 5 мегабайт был в два раза больше холодильника и весил около тонны. Современный жесткий диск в любом компьютере вмещает до полутора десятков терабайт (1 терабайт равен 1 млн мегабайт) и по размерам меньше обычной книги. В 2021 году большие данные измеряют в петабайтах. Один петабайт равен миллиону гигабайт. Трехчасовой фильм в формате 4K «весит» 60‒90 гигабайт, а весь YouTube — 5 петабайт или 67 тысяч таких фильмов. 1 млн петабайт — это 1 зеттабайт. Пройдите наш тест и узнайте, какой вы Data Scientist. Ссылка в конце статьи.
Как работает технология Big Data?
- социальные;
- машинные;
- транзакционные.
Все, что человек делает в сети, — источник социальных больших данных. Каждую секунду пользователи загружают в Инстаграм* 1 тыс. фото и отправляют более 3 млн электронных писем. Ежесекундный личный вклад каждого человека — в среднем 1,7 мегабайта.
Другие примеры социальных источников Big Data — статистики стран и городов, данные о перемещениях людей, регистрации смертей и рождений и медицинские записи.
Большие данные также генерируются машинами, датчиками и «интернетом вещей». Информацию получают от смартфонов, умных колонок, лампочек и систем умного дома, видеокамер на улицах, метеоспутников.
Транзакционные данные возникают при покупках, переводах денег, поставках товаров и операциях с банкоматами.

Станьте дата-сайентистом на курсе с МГУ и решайте амбициозные задачи с помощью нейросетей
Как обрабатывают большие данные?
Массивы Big Data настолько большие, что простой Excel с ними не справится. Поэтому для работы с ними используют специальное ПО.
Его называют «горизонтально масштабируемым», потому что оно распределяет задачи между несколькими компьютерами, одновременно обрабатывающими информацию. Чем больше машин задействовано в работе, тем выше производительность процесса.
Такое ПО основано на MapReduce, модели параллельных вычислений. Модель работает так:
- сначала данные фильтруются по условиям, которые задает исследователь, сортируются и распределяются между отдельными компьютерами (узлами);
- затем узлы параллельно рассчитывают свои блоки данных и передают результат вычислений на следующую итерацию.
MapReduce — не конкретная программа, а скорее алгоритм, с помощью которого можно решить большинство задач обработки больших данных.
Примеры ПО, которое основывается на MapReduce:
- Hadoop — набор программ с открытым исходным кодом для хранения файлов, планирования и совместной работы с данными. Система разработана так, чтобы при сбое на одном узле нагрузка сразу перераспределялась на другие, не прерывая вычисления.
- Apache Spark — набор библиотек, которые позволяют выполнять вычисления в оперативной памяти и многократно обращаться к результатам расчетов. Его применяют для решения широкого круга задач, от простой обработки и фильтрации данных до машинного обучения.
Специалисты по большим данным используют оба инструмента: Hadoop для создания инфраструктуры данных и Spark для обработки потоковой информации в реальном времени.
Где применяется аналитика больших данных?
Большие данные нужны в маркетинге, перевозках, автомобилестроении, здравоохранении, науке, сельском хозяйстве и других сферах, в которых можно собрать и обработать нужные массивы информации.
Бизнесу большие данные нужны, чтобы:
- Оптимизировать процессы — например, крупные банки используют большие данные, чтобы обучать чат-бота — программу, которая заменит живого сотрудника по простым вопросам и при необходимости переключит на специалиста.
- Делать прогнозы — анализируя большие данные о продажах, компании могут предсказать поведение клиентов и покупательский спрос на товары в зависимости от времени года или ситуации в мире.
- Строить модели — с помощью анализа данных о прибыли и издержках компания может построить модель для прогнозирования выручки.
Анализ больших данных позволяет бизнесу не только систематизировать информацию, но и находить неочевидные причинно-следственные связи.
Продажи товаров
Онлайн-маркетплейс Amazon запустил решение для рекомендаций товаров, работающую на машинном обучении. Она учитывает не только поведение и предыдущие покупки пользователя, но и время года, ближайшие праздники и остальные факторы, важные для бизнеса. После того как эта система заработала, рекомендации начали генерировать 35% всех продаж сервиса.
В супермаркетах «Лента» с помощью больших данных анализируют информацию о покупках и предлагают персонализированные скидки на товары. К примеру, говорят в компании, система по данным о покупках может понять, что клиент изменил подход к питанию, и начнет предлагать ему подходящие продукты.
Американская сеть Kroger использует большие данные для персонализации скидочных купонов, которые получают покупатели по электронной почте. После того как их сделали индивидуальными, подходящими конкретным покупателям, доля покупок только по ним выросла с 3,7 до 70%.
Найм сотрудников
Крупные компании, в том числе российские, стали прибегать к помощи роботов-рекрутеров, чтобы на начальном этапе поиска сотрудника отсеять тех, кто не заинтересован в вакансии или не подходит под нее. Так, компания Stafory разработала робота Веру, которая сортирует резюме, делает первичный обзвон и выделяет заинтересованных кандидатов. PepsiCo заполнила 10% нужных вакансий только с помощью робота.
Банки
Обработка больших данных помогает защищать клиентов от мошенников. Именно с помощью этих технологий обнаруживают аномалии в поведении пользователя, нетипичные для него покупки или переводы. Уже в 2017 году Visa с помощью анализа данных ежегодно предотвращала мошенничества на $2 млрд.
Автомобилестроение
В 2020 году у автоконцерна Toyota возникла проблема: нужно было понять причину большого числа аварий по вине водителей, перепутавших педали газа и тормоза. Компания собрала данные со своих автомобилей, подключенных к интернету, и на их основе определила, как именно люди нажимают на педали.
Оказалось, что сила и скорость давления различаются в зависимости от того, хочет человек затормозить или ускориться. Теперь компания разрабатывает новый сервис, который будет определять манеру давления на педали во время движения и сбросит скорость автомобиля, если водитель давит на педаль газа, но делает это так, будто хочет затормозить.
Медицина
Американские ученые научились с помощью больших данных определять, как распространяется депрессия. Исследователь Мунмун Де Чаудхури и ее коллеги загрузили в прогностическую модель сообщения из Twitter, Фейсбук* с геометками. Сообщения отбирали по словам, которые могут указывать на депрессивное и подавленное состояние. Расчеты совпали с официальными данными.
Госструктуры
Большие данные просто необходимы госструктурам. С их помощью ведется не только статистика, но и слежка за гражданами. Подобные технологии используют во многих странах: известен новый сервис PRISM, которыми пользуются ФБР и ЦРУ для сбора персональных данных из соцсетей и продуктов Microsoft, Google и Apple. В России информацию о пользователях и телефонных звонках собирает решение СОРМ.
Маркетинг
Работа с большими данными нужна и в этой сфере. Социальные большие данные помогают группировать пользователей по интересам и персонализировать для них рекламу. Людей ранжируют по возрасту, полу, интересам и месту проживания. Те, кто живут в одном регионе, бывают в одних и тех же местах, смотрят видео и читают статьи на похожие темы, скорее всего, заинтересуются одними и теми же товарами.
При этом регулярно происходят скандалы, связанные с использованием больших данных в маркетинге. Так, в 2018 году стриминговую платформу Netflix обвинили в расизме из-за того, что она показывает пользователям разные постеры фильмов и сериалов в зависимости от их пола и национальности.
Медиа
С помощью анализа больших данных в медиа измеряют аудиторию. В этом случае Big Data может даже повлиять на политику редакции. Так, издание Huffington Post использует решение, которое в режиме реального времени показывает статистику посещений, комментариев и других действий пользователей, а также готовит аналитические отчеты.
Новый сервис в Huffington Post оценивает, насколько эффективно заголовки привлекают внимание читателя, разрабатывает методы доставки контента определенным категориям пользователей. Например, выяснилось, что родители чаще читают статьи со смартфона и поздно вечером в будни, после того как уложили детей спать, а по выходным они обычно заняты, — в итоге контент для родителей публикуется на сайте в удобное для них время.
Логистика
Анализ больших данных помогает оптимизировать перевозки, сделать доставку быстрее и дешевле. В компании DHL работа с большими данными коснулась так называемой проблемы последней мили, когда необходимость проехать через дворы и найти парковку перед тем, как отдать заказ, съедает в общей сложности 28% от стоимости доставки. В компании стали анализировать «последние мили» с помощью информации с GPS и данных о дорожной обстановке. В результате удалось сократить затраты на топливо и время доставки груза.
Внутри компании большие объемы данных помогают отслеживать качество работы сотрудников, соблюдение контрольных сроков, правильность их действий. Для анализа используют машинные данные, например со сканеров посылок в отделениях, и социальные — отзывы посетителей отделения в приложении, на сайтах и в соцсетях.
Обработка фото
До 2016 года не было технологии нейросетей на мобильных устройствах, это даже считали невозможным. Прорыв в этой области (в том числе благодаря российскому стартапу Prisma) позволяет нам сегодня пользоваться огромным количеством фильтров, стилей и разных эффектов на фотографиях и видео.
Аренда недвижимости
Сервис Airbnb с помощью технологий Big Data изменил поведение пользователей. Однажды выяснилось, что посетители сайта по аренде недвижимости из Азии слишком быстро его покидают и не возвращаются. Оказалось, что они переходят с главной страницы на «Места поблизости» и уходят смотреть фотографии без дальнейшего бронирования.
Компания детально проанализировала поведение пользователей и заменила ссылки в разделе «Места поблизости» на самые популярные направления для путешествий в азиатских странах. В итоге конверсия в бронирования из этой части планеты выросла на 10%.
*деятельность компании Meta Platforms Inc., которой принадлежит Инстаграм / Фейсбук, запрещена на территории РФ в части реализации данной (-ых) социальной (-ых) сети (-ей) на основании осуществления ею экстремистской деятельности
Кто работает с большими данными?
Дата-сайентисты специализируются на анализе Big Data. Они ищут закономерности, строят модели и на их основе прогнозируют будущие события.
Например, исследователь больших объемов данных может использовать статистику по снятиям денег в банкоматах, чтобы разработать математическую модель для предсказания спроса на наличные. Эта система подскажет инкассаторам, сколько денег и когда привезти в конкретный банкомат.
Чтобы освоить эту профессию, необходимо понимание основ математического анализа и знание языков программирования, например Python или R, а также умение работать с SQL-базами данных.
Аналитик данных использует тот же набор инструментов, что и дата-сайентист, но для других целей. Его задачи — делать описательный анализ, интерпретировать и представлять данные в удобной для восприятия форме. Он обрабатывает данные и выдает результат, составляя аналитические отчеты, статистику и прогнозы.
С Big Data также работают и другие специалисты, для которых это не основная сфера работы:
- дизайнеры интерфейсов, анализирующие данные поведенческих исследований для создания пользовательских интерфейсов;
- NLP-инженеры, которые разрабатывают программы для чат-ботов и автоматизации колл-центров, анализируя естественный язык;
- маркетологи-аналитики, которые исследуют массив данных для выстраивания маркетинговой политики и персонализации рекламы;
- инженеры и программисты на предприятиях, занимающиеся обработкой объема данных.
Дата-инженер занимается технической стороной вопроса и первый работает с информацией: организует ее сбор, хранение и первоначальную обработку.
Дата-инженеры помогают исследователям, создавая ПО и алгоритмы для автоматизации задач. Без таких инструментов большие данные были бы бесполезны, так как их объемы невозможно обработать. Для этой профессии важно знание Python и SQL, уметь работать с фреймворками, например со Spark.
Александр Кондрашкин о других профессиях, в которых может понадобиться Big Data: «Где-то может и product-менеджер сам сходить в Hadoop-кластер и посчитать что-то несложное, если обладает такими навыками. Наверняка есть множество backend-разработчиков и DevOps-инженеров, которые настраивают хранение и сбор данных от пользователей».
Востребованность больших данных и специалистов по ним
Востребованность больших данных растет: по исследованиям 2020 года, даже при пессимистичном сценарии объем рынка Big Data в России к 2024 году вырастет с 45 млрд до 65 млрд рублей, а при хорошем развитии событий — до 230 млрд.
Компании все чаще прибегают к анализу больших данных, так как те, кто этого не делает, замечают упущенную выгоду: The Bell приводит пример корпорации Caterpillar. В 2014 году ее дистрибьюторы ежегодно упускали от $9 до $18 млрд прибыли только из-за того, что не внедряли технологии обработки Биг Дата. Теперь 3,5 млн единиц техники компании оборудованы датчиками, которые собирают информацию о ее состоянии и степени износа ключевых деталей, что позволяет лучше управлять затратами на техобслуживание.
Вместе с популярностью больших данных растет запрос и на тех, кто может эффективно с ними работать. В середине 2020 года Академия больших данных MADE от Mail.ru Group и HeadHunter провели исследование и выяснили, что специалисты по анализу данных уже являются одними из самых востребованных на рынке труда в России. За четыре года число вакансий в этой области увеличилось почти в 10 раз
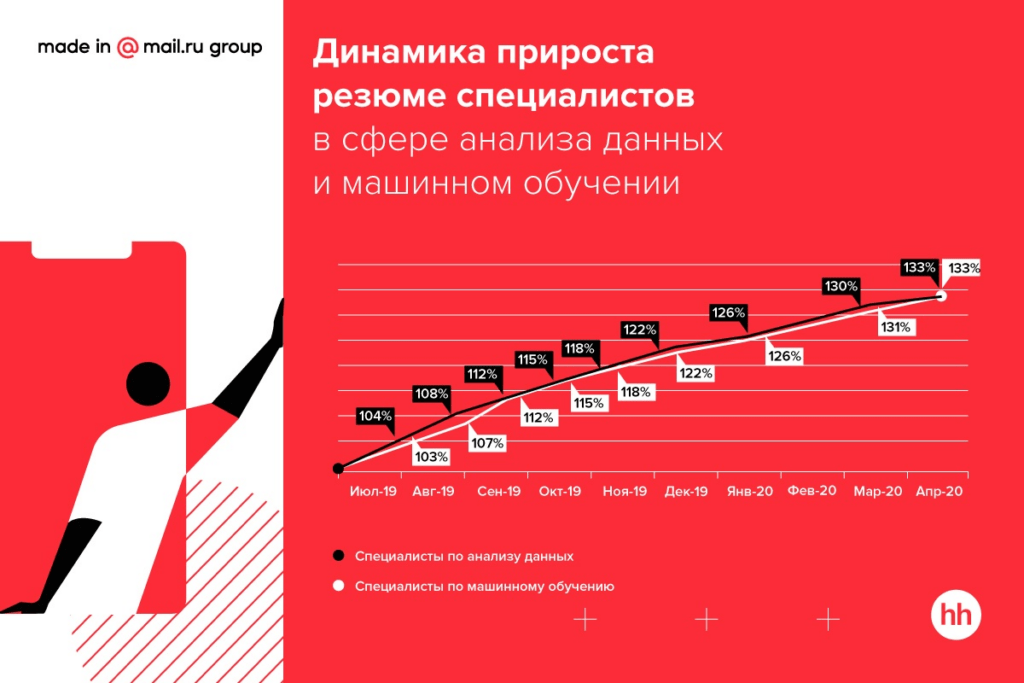
Более трети вакансий для специалистов по анализу данных (38%) приходится на IT-компании, финансовый сектор (29%) и сферу услуг для бизнеса (9%). В сфере машинного обучения IT-компании публикуют 55% вакансий на рынке, 10% приходит из финансового сектора и 9% — из сферы услуг.
Как начать работать с большими данными?
Проще будет начать, если у вас уже есть понимание алгоритмов и хорошее знание математики, но это не обязательно. Например, Оксана Дереза была филологом и для нее главной трудностью в Data Science оказалось вспомнить математику и разобраться в алгоритмах, но она много занималась и теперь анализирует данные в исследовательском институте.
Еще несколько историй людей, которые успешно освоили data-профессию.
Если у вас нет математических знаний, на курсе SkillFactory «Data Science с нуля» вы получите достаточную подготовку, чтобы работать с большими данными. За год вы научитесь получать данные из веб-источников или по API, визуализировать данные с помощью Pandas и Matplotlib, применять методы математического анализа, линейной алгебры, статистики и теории вероятности для обработки данных и многое другое.
Чтобы стать аналитиком данных, вам пригодится знание Python и SQL — эти навыки очень популярны в вакансиях компаний по поиску соответствующей позиции. На курсе «Аналитик данных» вы получите базу знаний основных инструментов аналитики (от Google-таблиц до Python и Power BI) и закрепите их на тренажерах.
Важно определиться со сферой, в которой вы хотите работать. Студентка SkillFactory Екатерина Карпова, рассказывает, что после обучения ей была важна не должность, а сфера (финтех), поэтому она сначала устроилась консультантом в банк «Тинькофф», а теперь работает там аналитиком.
FAQ
Что понимается под Big Data?
Big Data — это большие объемы данных, которые невозможно обработать и анализировать с помощью стандартных средств.
Что такое Big Data и где это используется?
Технологии Big Data применяются во многих сферах, таких как банковское дело, здравоохранение, розничная торговля, производство, научные исследования и др.
Для чего нужны Big Data?
Технологии Big Data используются для анализа больших объемов данных, выявления скрытых закономерностей, определения потребностей клиентов и оптимизации бизнес-процессов.
Что такое работа с Big Data?
Работа с Big Data — это анализ больших объемов данных с помощью специальных технологий, которые позволяют обрабатывать и анализировать данные быстро и эффективно.
Что нужно знать для работы с Big Data?
Для работы с Big Data необходимо знание базовых технологий, таких как Hadoop, Spark, NoSQL и др.
Кто работает с Big Data?
С Big Data работают аналитики данных, разработчики, инженеры данных, специалисты по машинному обучению и др.
Что является примером больших данных?
Примеры больших данных включают в себя данные о клиентах, данные о продажах для бизнеса, данные о посетителях веб-сайтов, данные о здоровье и др.
Где хранятся Big Data?
Big Data хранятся на серверах в облаке или на серверах компаний, которые занимаются обработкой данных.
Где учат работе с Big Data?
Учиться Big Data можно на онлайн-курсах, в университетах, технических колледжах и других учебных заведениях.
Какой язык программирования используется в Big Data?
В Big Data используется язык программирования Java, Python, R, Scala и др.
Можно ли стать аналитиком данных без образования?
Да, можно. Для этого нужно изучить базовые принципы и технологии работы с данными, учиться на курсах и в онлайн-школах, получать опыт работы в сфере аналитики данных.
Big Data Analyst (аналитик больших данных)

Big Data Analyst (аналитик больших данных) обрабатывает и интерпретирует массивы данных, ищет логические связи, помогает клиенту выявить факторы, представляющие интерес для бизнеса. Профессия подойдет тем, кто интересуются большими данными, информационными технологиями и анализом. Кстати, недавно центр профориентации ПрофГид разработал точный тест на профориентацию, который сам расскажет, какие профессии вам подходят, даст заключение о вашем типе личности и интеллекте.
Краткое описание
Big Data Analyst работает с большими данными, его клиенты в основном представители бизнеса, но не только – технологии «биг дата» во многих странах на государственном уровне используются в здравоохранении, медицине, фармации. Обработка, анализ и интерпретация данных позволяют взглянуть на привычные вещи по-другому, выявить новые процессы, феномены и т. д. В идеале аналитики больших данных должны разбираться в той сфере, в которой ведут деятельность, но на практике это далеко не всегда так.
Аналитик данных не ограничен одной областью, в которой работает. Технически его обязанности не меняются, меняется бизнес-контекст, и найти узкопрофильных специалистов, например, для медицины, в реальности практически невозможно. Также сложно искать вакансии внутри одной индустрии. Аналитики спокойно лавируют между компаниями, вливаясь в специфику по ходу работы.

Вероника Голубева
Главный инженер «Сбера» по разработке в Data Analytics
Однозначного определения больших данных пока еще нет, но чаще всего под Big Data подразумевают наборы неструктурированных и разнородных данных, существенно превосходящие традиционные реляционные (структурированные) базы данных по объему. Сведения совершенно разного формата в общий массив поступают из разнообразных источников (датчики, приложения, камеры видеонаблюдения, социальные сети и т. д.) и постоянно пополняются в режиме реального времени. Сбором и обработкой нужной для определенных целей информации занимается аналитик больший данных.
Что такое Big Data и почему их называют «новой нефтью»

Смартфоны предлагают нам загрузить все данные в облако, а большие компании вроде Google и «Яндекса» — воспользоваться своими экосистемами. Проще говоря, мы живем в эпоху Big Data. Но что это значит на самом деле?
Что такое Big Data?
Big Data или большие данные — это структурированные или неструктурированные массивы данных большого объема. Их обрабатывают при помощи специальных автоматизированных инструментов, чтобы использовать для статистики, анализа, прогнозов и принятия решений. Сам термин «большие данные» предложил редактор журнала Nature Клиффорд Линч в спецвыпуске 2008 года [1]. Он говорил о взрывном росте объемов информации в мире. К большим данным Линч отнес любые массивы неоднородных данных более 150 Гб в сутки, однако единого критерия до сих пор не существует.
«Лиза Алерт» использует Big Data, чтобы находить пропавших людей
До 2011 года анализом больших данных занимались только в рамках научных и статистических исследований. Но к началу 2012-го объемы данных выросли до огромных масштабов, и возникла потребность в их систематизации и практическом применении.
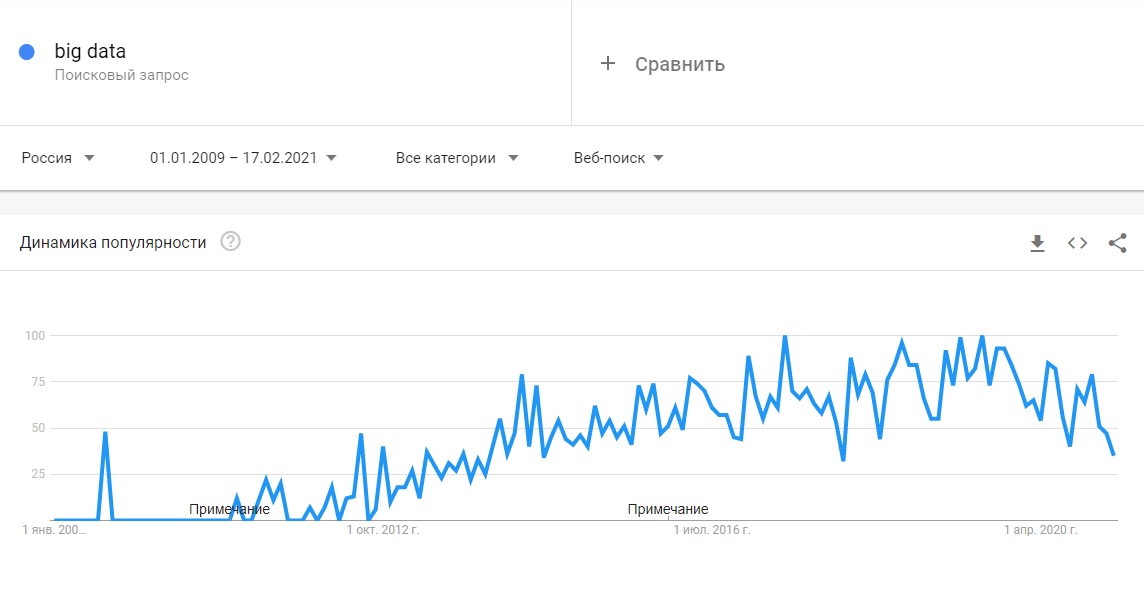
Всплеск интереса к большим данным в Google Trends
С 2014 на Big Data обратили внимание ведущие мировые вузы, где обучают прикладным инженерным и IT-специальностям. Затем к сбору и анализу подключились IT-корпорации — такие, как Microsoft, IBM, Oracle, EMC, а затем и Google, Apple, Facebook (с 21 марта 2022 года соцсеть запрещена в России решением суда) и Amazon. Сегодня большие данные используют крупные компании во всех отраслях, а также — госорганы. Подробнее об этом — в материале «Кто и зачем собирает большие данные?»
Какие есть характеристики Big Data?
- Volume — объем данных: от 150 Гб в сутки;
- Velocity — скорость накопления и обработки массивов данных. Большие данные обновляются регулярно, поэтому необходимы интеллектуальные технологии для их обработки в режиме онлайн;
- Variety — разнообразие типов данных. Данные могут быть структурированными, неструктурированными или структурированными частично. Например, в соцсетях поток данных не структурирован: это могут быть текстовые посты, фото или видео.
Сегодня к этим трем добавляют еще три признака [3]:
- Veracity — достоверность как самого набора данных, так и результатов его анализа;
- Variability — изменчивость. У потоков данных бывают свои пики и спады под влиянием сезонов или социальных явлений. Чем нестабильнее и изменчивее поток данных, тем сложнее его анализировать;
- Value — ценность или значимость. Как и любая информация, большие данные могут быть простыми или сложными для восприятия и анализа. Пример простых данных — это посты в соцсетях, сложных — банковские транзакции.
Как работает Big Data: как собирают и хранят большие данные?
Большие данные необходимы, чтобы проанализировать все значимые факторы и принять правильное решение. С помощью Big Data строят модели-симуляции, чтобы протестировать то или иное решение, идею, продукт.
Главные источники больших данных:
- интернет вещей (IoT) и подключенные к нему устройства;
- соцсети, блоги и СМИ;
- данные компаний: транзакции, заказы товаров и услуг, поездки на такси и каршеринге, профили клиентов;
- показания приборов: метеорологические станции, измерители состава воздуха и водоемов, данные со спутников;
- статистика городов и государств: данные о перемещениях, рождаемости и смертности;
- медицинские данные: анализы, заболевания, диагностические снимки.
С 2007 года в распоряжении ФБР и ЦРУ появилась PRISM — один из самых продвинутых сервисов, который собирает персональные данные обо всех пользователях соцсетей, а также сервисов Microsoft, Google, Apple, Yahoo и даже записи телефонных разговоров.
Современные вычислительные системы обеспечивают мгновенный доступ к массивам больших данных. Для их хранения используют специальные дата-центры с самыми мощными серверами.
Как выглядит современный дата-центр
Помимо традиционных, физических серверов используют облачные хранилища, «озера данных» (data lake — хранилища большого объема неструктурированных данных из одного источника) и Hadoop — фреймворк, состоящий из набора утилит для разработки и выполнения программ распределенных вычислений. Для работы с Big Data применяют передовые методы интеграции и управления, а также подготовки данных для аналитики.
Big Data Analytics — как анализируют большие данные?
Благодаря высокопроизводительным технологиям — таким, как грид-вычисления или аналитика в оперативной памяти, компании могут использовать любые объемы больших данных для анализа. Иногда Big Data сначала структурируют, отбирая только те, что нужны для анализа. Все чаще большие данные применяют для задач в рамках расширенной аналитики, включая искусственный интеллект.
Выделяют четыре основных метода анализа Big Data [4]:
1. Описательная аналитика (descriptive analytics) — самая распространенная. Она отвечает на вопрос «Что произошло?», анализирует данные, поступающие в реальном времени, и исторические данные. Главная цель — выяснить причины и закономерности успехов или неудач в той или иной сфере, чтобы использовать эти данные для наиболее эффективных моделей. Для описательной аналитики используют базовые математические функции. Типичный пример — социологические исследования или данные веб-статистики, которые компания получает через Google Analytics.
«Есть два больших класса моделей для принятия решений по ценообразованию. Первый отталкивается от рыночных цен на тот или иной товар. Данные о ценниках в других магазинах собираются, анализируются и на их основе по определенным правилам устанавливаются собственные цены.
Второй класс моделей связан с выстраиванием кривой спроса, которая отражает объемы продаж в зависимости от цены. Это более аналитическая история. В онлайне такой механизм применяется очень широко, и мы переносим эту технологию из онлайна в офлайн».
2. Прогнозная или предикативная аналитика (predictive analytics) — помогает спрогнозировать наиболее вероятное развитие событий на основе имеющихся данных. Для этого используют готовые шаблоны на основе каких-либо объектов или явлений с аналогичным набором характеристик. С помощью предикативной (или предиктивной, прогнозной) аналитики можно, например, просчитать обвал или изменение цен на фондовом рынке. Или оценить возможности потенциального заемщика по выплате кредита.
3. Предписательная аналитика (prescriptive analytics) — следующий уровень по сравнению с прогнозной. С помощью Big Data и современных технологий можно выявить проблемные точки в бизнесе или любой другой деятельности и рассчитать, при каком сценарии их можно избежать их в будущем.
Сеть медицинских центров Aurora Health Care ежегодно экономит $6 млн за счет предписывающей аналитики: ей удалось снизить число повторных госпитализаций на 10% [5].
4. Диагностическая аналитика (diagnostic analytics) — использует данные, чтобы проанализировать причины произошедшего. Это помогает выявлять аномалии и случайные связи между событиями и действиями.
Например, Amazon анализирует данные о продажах и валовой прибыли для различных продуктов, чтобы выяснить, почему они принесли меньше дохода, чем ожидалось.
Данные обрабатывают и анализируют с помощью различных инструментов и технологий [6] [7]:
- Cпециальное ПО: NoSQL, MapReduce, Hadoop, R;
- Data mining — извлечение из массивов ранее неизвестных данных с помощью большого набора техник;
- ИИ и нейросети — для построения моделей на основе Big Data, включая распознавание текста и изображений. Например, оператор лотерей «Столото» сделал большие данные основой своей стратегии в рамках Data-driven Organization. С помощью Big Data и искусственного интеллекта компания анализирует клиентский опыт и предлагает персонифицированные продукты и сервисы;
- Визуализация аналитических данных — анимированные модели или графики, созданные на основе больших данных.
Примеры визуализации данных (data-driven animation)
Как отметил в подкасте РБК Трендов менеджер по развитию IoT «Яндекс.Облака» Александр Сурков, разработчики придерживаются двух критериев сбора информации:
- Обезличивание данных делает персональную информацию пользователей в какой-то степени недоступной;
- Агрегированность данных позволяет оперировать лишь со средними показателями.
Чтобы обрабатывать большие массивы данных в режиме онлайн используют суперкомпьютеры: их мощность и вычислительные возможности многократно превосходят обычные. Подробнее — в материале «Как устроены суперкомпьютеры и что они умеют».
Big Data и Data Science — в чем разница?
Data Science или наука о данных — это сфера деятельности, которая подразумевает сбор, обработку и анализ данных, — структурированных и неструктурированных, не только больших. В ней используют методы математического и статистического анализа, а также программные решения. Data Science работает, в том числе, и с Big Data, но ее главная цель — найти в данных что-то ценное, чтобы использовать это для конкретных задач.
В каких отраслях уже используют Big Data?
- Государственное управление. Изучение и анализ больших данных помогает правительствам принимать решения в таких областях, как здравоохранение, занятость населения, экономическое регулирование, борьба с преступностью и обеспечение безопасности, реагирование на чрезвычайные ситуации;
- Промышленность. Внедрение инструментов Big Data помогает повысить прозрачность промышленных процессов и внедрять «предиктивное производство», позволяющее более точно прогнозировать спрос на продукцию и, соответственно, планировать расходование ресурсов;
- Медицина. Огромное количество данных, собираемых медицинскими учреждениями и различными электронными приспособлениями (фитнес-браслетами и т.п.) открывает принципиально новые возможности перед индустрией здравоохранения. Большие данные помогают находить новые лекарства, точнее ставить диагнозы, подбирать эффективное лечение, бороться с пандемий;
- Ретейл. Развитие сетевой и электронной торговли невозможно представить без основанных на Big Data решениях — так магазины персонализируют ассортимент и доставку;
- Интернет вещей. Big Data и интернет вещей неразрывно связаны между собой. Промышленные и бытовые приборы, подключенные к интернету вещей, собирают огромное количество данных, на основе анализа которых впоследствии регулируется работа этих приборов;
- Рынок недвижимости. Девелоперы используют технологии Big Data, чтобы собрать и проанализировать весь массив информации, а затем выдать пользователю наиболее интересные для него варианты. Уже сейчас будущий покупатель может посмотреть понравившийся дом без продавца;
- Спорт. С помощью больших данных футбольные клубы отбирают самых перспективных игроков и разрабатывают эффективную стратегию для каждого противника.
Выпуск «Индустрии 4.0» о том, как используют Big Data в футболе
«IoT-решение из области так называемого точного земледелия — это когда специальные метеостанции, которые стоят в полях, с помощью сенсоров собирают данные (температура, влажность) и с помощью передающих радио-GSM-модулей отправляют их на IoT-платформу. На ней посредством алгоритмов big data происходит обработка собранной с сенсоров информации и строится высокоточный почасовой прогноз погоды. Клиент видит его в интерфейсе на компьютере, планшете или смартфоне и может оперативно принимать решения», — прокомментировали в «МегаФоне».
Big Data в России и мире
По данным компании IBS [8], в 2012 году объем хранящихся в мире цифровых данных вырос на 50%: с 1,8 до 2,7 Збайт (2,7 трлн Гбайт). В 2015-м в мире каждые десять минут генерировалось столько же данных, сколько за весь 2003 год.
По данным компании NetApp, к 2003 году в мире накопилось 5 Эбайтов данных (1 Эбайт = 1 млрд Гбайт). В 2015-м — более 6,5 Збайта, причем тогда большие данные использовали лишь 17% компаний по всему миру [9]. Большую часть данных будут генерировать сами компании, а не их клиенты. При этом обычный пользователь будет коммуницировать с различными устройствами, которые генерируют данные, около 4 800 раз в день.
Первыми Big Data еще пять лет назад начали использовать в ИТ, телекоме и банках. Именно в этих сферах скапливается большой объем данных о транзакциях, геолокации, поисковых запросах и профилях в Сети. В 2019 году прибыль от использования больших данных оценивались в $189 млрд [10] — на 12% больше, чем в 2018-м, при этом к 2022 году она ежегодно будет удваиваться.
Сейчас в США с большими данными работает более 55% компаний [11], в Европе и Азии — около 53%. Только за последние пять лет распространение Big Data в бизнесе выросло в три раза.
Как большие данные помогают онлайн-кинотеатрам подбирать персональные рекомендации
Мировыми лидерами по сбору и анализу больших данных являются США и Китай. Так, в США еще при Бараке Обаме правительство запустило шесть федеральных программ по развитию больших данных на общую сумму $200 млн. Главными потребителями Big Data считаются крупные корпорации, однако их деятельность по сбору данных ограничена в некоторых штатах — например, в Калифорнии.
В Китае действует более 200 законов и правил, касающихся защиты личной информации. С 2019 года все популярные приложения для смартфонов начали проверять и блокировать, если они собирают данные о пользователях вопреки законам. В итоге данные через местные сервисы собирает государство, и многие из них недоступны извне.
С 2018 года в Евросоюзе действует GDPR — Всеобщий регламент по защите данных. Он регулирует все, что касается сбора, хранения и использования данных онлайн-пользователей. Когда закон вступил в силу год назад, он считался самой жесткой в мире системой защиты конфиденциальности людей в Интернете.
В России рынок больших данных только зарождается. К примеру, сотовые операторы делятся с банками информацией о потенциальных заемщиках [12]. Среди корпораций, которые собирают и анализируют данные — «Яндекс», «Сбер», Mail.ru. Появились специальные инструменты, которые помогают бизнесу собирать и анализировать Big Data — такие, как российский сервис Ctrl2GO.
Big Data в бизнесе
Большие данные полезны для бизнеса в трех главных направлениях:
- Запуск продуктов и сервисов, которые точнее всего «выстрелят» по потребностям целевой аудитории;
- Анализ клиентского опыта в отношении продукта или услуги, чтобы улучшить их;
- Привлечение и удержание клиентов с помощью аналитики.
Большие данные помогают MasterCard предотвращать мошеннические операции со счетами клиентов на сумму более $3 млрд в год [13]. Они позволяют рекламодателям эффективнее распределять бюджеты и размещать рекламу, которая нацелена на самых разных потребителей.
Крупные компании — такие, как Netflix, Procter & Gamble или Coca-Cola — с помощью больших данных прогнозируют потребительский спрос. 70% решений в бизнесе и госуправлении принимается на основе геоданных. Подробнее — в материале о том, как бизнес извлекает прибыль из Big Data.
Каковы проблемы и перспективы Big Data?
Главные проблемы:
- Большие данные неоднородны, поэтому их сложно обрабатывать для статистических выводов. Чем больше требуется параметров для прогнозирования, тем больше ошибок накапливается при анализе;
- Для работы с большими массивами данных онлайн нужны огромные вычислительные мощности. Такие ресурсы обходятся очень дорого, и пока что доступны только большим корпорациям;
- Хранение и обработка Big Data связаны с повышенной уязвимостью для кибератак и всевозможных утечек. Яркий пример — скандалы с профилями Facebook;
- Сбор больших данных часто связан с проблемой приватности: не все хотят, чтобы каждое их действие отслеживали и передавали третьим лицам. Герои подкаста «Что изменилось» объясняют, почему конфиденциальности в Сети больше нет, и технологическим гигантам известно о нас все;
- Большие данные используют в своих целях не только корпорации, но и политики: например, чтобы повлиять на выборы.
Плюсы и перспективы:
- Большие данные помогают решать глобальные проблемы — например, бороться с пандемией, находить лекарства от рака и предотвращать экологический кризис;
- Big Data — хороший инструмент для создания умных городов и решения проблемы транспорта;
- Большие данные помогают экономить средства даже на государственном уровне: например, в Германии вернули в бюджет около €15 млрд [14], обнаружив, что часть граждан получают пособие по безработице без всяких оснований. Их вычислили с помощью транзакций.
Как Big Data и ИИ меняют наше представление о справедливости
В ближайшем будущем большие данные станут главным инструментом для принятия решений — начиная с сетевых бизнесов и заканчивая целыми государствами и международными организациями [15].
Что такое Big Data?
Большие данные: что именно обозначает этот термин?
Большие данные — это разнообразные данные, поступающие с более высокой скоростью, объем которых постоянно растет. Таким образом, три основных свойства больших данных — это разнообразие, высокая скорость поступления и большой объем.
Если говорить простыми словами, большие данные — более крупные и сложные наборы данных, особенно из новых источников данных. Размер этих наборов данных настолько велик, что традиционные программы для обработки не могут с ними справиться. Однако эти большие данные можно использовать для решения бизнес-задач, которые раньше не могли быть решены.
Основные свойства больших данных
| Объем | Количество данных — важный фактор. Располагая ими в больших количествах, Вам потребуется обрабатывать большие объемы неструктурированных данных низкой плотности. Ценность таких данных не всегда известна. Это могут быть данные каналов Twitter, данные посещаемости веб-страниц, а также данные мобильных приложений, сетевой трафик, данные датчиков. В некоторые организации могут поступать десятки терабайт данных, в другие — сотни петабайт. |
| Скорость | Скорость в данном контексте — это скорость приема данных и, возможно, действий на их основе. Обычно высокоскоростные потоки данных поступают прямо в оперативную память, а не записываются на диск. Некоторые «умные» продукты, функционирующие на основе Интернета, работают в режиме реального или практически реального времени. Соответственно, такие данные требуют оценки и действий в реальном времени. |
| Разнообразие | Разнообразие означает, что доступные данные принадлежат к разным типам. Традиционные типы данных структурированы и могут быть сразу сохранены в реляционной базе данных. С появлением Big Data данные стали поступать в неструктурированном виде. Такие неструктурированные и полуструктурированные типы данных как текст, аудио и видео, требуют дополнительной обработки для определения их значения и поддержки метаданных. |
Ценность больших данных и их достоверность
Еще два свойства сформировались за последние несколько лет: ценность и достоверность. Данные имеют внутренне присущую им ценность. Однако чтобы они приносили пользу, эту ценность необходимо раскрыть. Не менее важно и то, насколько достоверны Ваши большие данные и насколько Вы можете на них полагаться?
Сегодня большие данные стали разновидностью капитала. Подумайте о крупнейших технологических компаниях. Ценность их предложений в значительной степени зависит от их данных, которые они постоянно анализируют, чтобы повышать эффективность и разрабатывать новые продукты.
Новейшие достижения в сфере технологий позволили значительно снизить стоимость хранилищ и вычислений, что дает возможность хранить и обрабатывать постоянно растущие объемы данных. Современные технологии позволяют хранить и обрабатывать больше данных за меньшую стоимость, что позволяет Вам принимать более точные и взвешенные бизнес-решения.
Извлечение ценности из больших данных не сводится только к их анализу (это их отдельное преимущество). Речь о комплексном исследовательском процессе с участием специалистов по глубокому анализу, корпоративных пользователей и руководителей, которые будут задавать правильные вопросы, выявлять шаблоны, делать обоснованные предположения и предсказывать поведение.
Но как мы к этому пришли?
История больших данных
Хотя сама по себе концепция больших данных не нова, первые большие наборы данных начали использовать в 1960-70 гг., когда появились первые в мире ЦОД и реляционные базы данных.
К 2005 году бизнес начал осознавать, насколько велик объем данных, которые пользователи создают при использовании Facebook, YouTube и других интернет-сервисов. В том же году появилась платформа Hadoop на основе открытого кода, которая была создана специально для хранения и анализа наборов больших данных. В то же время начала набирать популярность методология NoSQL.
Появление платформ на основе открытого кода, таких как Hadoop и позднее Spark, сыграло значительную роль в распространении больших данных, так как эти инструменты упрощают обработку больших данных и снижают стоимость хранения. За прошедшие годы объемы больших данных возросли на порядки. Огромные объемы данных появляются в результате деятельности пользователей — но теперь не только их.
С появлением Интернета вещей (IoT) все большее число устройств получает подключение к Интернету, что позволяет собирать данные о моделях действий пользователей и работе продуктов. А когда появились технологии машинного обучения, объем данных вырос еще больше.
Большие данные имеют долгую историю развития, однако их потенциал еще далеко не раскрыт. Облачные вычисления раздвинули границы применения больших данных еще шире. Облачные технологии обеспечивают по-настоящему гибкие возможности масштабирования, что позволяет разработчикам развертывать кластеры для тестирования выборочных данных по требованию. Кроме того, также все более значимыми становятся графовые базы данных, позволяющие отображать громадные объемы данных так, чтобы анализировать их можно было быстро и всеобъемлюще.
- Большие данные дают возможность получать более полные ответы, потому они предоставляют больше информации.
- Более подробные ответы означают, что Вы можете быть более уверены в достоверности данных — что обеспечивает абсолютно новый подход к решению задач.
Примеры использования больших данных
Большие данные можно применять в самых различных сферах деятельности — от взаимодействия с заказчиками до аналитики. Вот лишь несколько сценариев практического использования.
| Разработка продуктов | Такие компании, как Netflix и Procter & Gamble, используют большие данные для прогнозирования потребительского спроса. Они классифицируют ключевые атрибуты существующих и снятых с использования продуктов и услуг и моделируют связи между этими атрибутами и коммерческим успехом предложений, чтобы создавать предиктивные модели для новых продуктов и услуг. Кроме того, P&G использует данные и статистику, получаемые от фокусных групп, а также из социальных сетей, по результатам рыночных тестов и пробных продаж, после чего выпускает новые продукты. |
| предиктивное управление обслуживанием; | Факторы, которые позволяют прогнозировать сбои механики, могут скрываться в недрах структурированных данных, таких как год, марка и модель оборудования, или в неструктурированных данных, таких как записи журналов, данные датчиков, сообщения об ошибках и сведения о температуре двигателя. Проанализировав индикаторы вероятных проблем до их возникновения, организации могут повысить экономическую эффективность техобслуживания и максимально продлить срок службы запчастей и оборудования. |
| Взаимодействие с заказчиками | Борьба за заказчиков в самом разгаре. Сегодня получить точные данные о качестве обслуживания клиентов проще, чем когда-либо. Большие данные позволят Вам извлечь полезные сведения из соцсетей, информации о посещении веб-сайтов и других источников, таким образом повысив качество взаимодействия с клиентами и сделав свои предложения максимально полезными. Обеспечьте индивидуальный подход, сократите отток клиентской базы и предотвращайте возникновение проблем. |
| Обнаружение несанкционированного доступа и выполнение нормативных требований | Когда дело касается безопасности, речь идет не просто о паре хакеров: против Вас выступают целые команды опытных специалистов. Нормативные требования и стандарты безопасности постоянно меняются. Большие данные позволяют определять шаблоны, характерные для мошенников, и собирать значительные объемы данных, чтобы ускорить предоставление нормативной отчетности. |
| Машинное обучение | Сегодня машинное обучение — одна из самых популярных тем для обсуждения. И данные — в особенности большие данные — являются одной из причин этой популярности. Сегодня мы можем обучать машины вместо того, чтобы программировать их. Именно доступность больших данных сделала это возможным. |
| Операционная эффективность | Операционная эффективность редко становится обсуждаемой темой, однако именно в этой области большие данные играют самую значительную роль. Большие данные позволяют получать доступ к сведениям о производстве, мнении заказчиков и доходах, а также анализировать эти и другие факторы, чтобы сократить число простоев и прогнозировать будущий спрос. Большие данные также позволяют принимать более взвешенные решения в соответствии с рыночным спросом. |
| Внедрение инноваций | Большие данные позволяют выявлять взаимозависимости между пользователями, учреждениями и компаниями, внедрять их и определять новые способы применения полученных сведений. Используйте результаты исследований данных, чтобы повысить эффективность финансовых решений и планирования. Изучайте тенденции и желания покупателей, чтобы выпускать новые продукты и услуги. Внедрите динамическое ценообразование. Возможности поистине безграничны. |
Сложности при использовании больших данных
Большие данные — это большие возможности, но и немалые трудности.
Прежде всего большие данные предсказуемо занимают много места. Хотя новые технологии хранения постоянно развиваются, объемы данных возрастают вдвое почти каждые два года. Организации до сих пор сталкиваются с проблемами роста объемов данных и их эффективного хранения.
Но недостаточно просто найти большое хранилище. Данные необходимо использовать, чтобы они приносили выгоду, и размер этой выгоды зависит от обработки данных. Чистые данные, то есть данные, актуальные для клиента и организованные для эффективного анализа, требуют тщательной обработки. Специалисты по изучению данных тратят от 50 до 80% рабочего времени на обработку и подготовку данных для использования.
И, наконец, технологии больших данных развиваются семимильными шагами. Несколько лет назад Apache Hadoop была самой популярной технологией для работы с большими данными. Платформа Apache Spark появилась в 2014 году. Сегодня оптимальным подходом является совместное использование этих двух платформ. Чтобы успевать за развитием больших данных, требуется прилагать большие усилия.
Ознакомьтесь с дополнительными ресурсами о больших данных:
Как работают большие данные
Большие данные позволяют извлекать новые ценные сведения, которые открывают новые возможности и бизнес-модели. Чтобы начать работу с большими данными, необходимо выполнить три действия.
1. Интеграция
Технология больших данных позволяет объединять данные из разрозненных источников и приложений. Традиционные механизмы интеграции, такие как средства для извлечения, преобразования и загрузки данных (ETL), не справляются с подобными задачами. Для анализа наборов данных размером в терабайт, а то и петабайт, нужны новые стратегии и технологии.
Во время этапа интеграции происходит добавление, обработка и форматирование данных, чтобы корпоративным аналитикам было удобно с ними работать.
2. Управление
Большим данным требуется объемное хранилище. Решение для хранения может быть размещено в локальной или облачной среде или и там и там. Вы можете хранить данные в предпочтительном формате и применять желаемые требования к обработке (и необходимые механизмы обработки) к наборам данным по мере необходимости. Большинство организаций выбирают решение для хранения данных в зависимости от того, где они хранятся в настоящее время. Облачные хранилища пользуются растущей популярностью, так как поддерживают актуальные требования к вычислениям и позволяют задействовать ресурсы по мере надобности.
3. Анализ
Вложения в большие данные окупятся сполна, когда Вы приступите к анализу данных и начнете предпринимать действия, исходя из полученных сведений. Обеспечьте новый уровень прозрачности благодаря визуальному анализу разнообразных наборов данных. Используйте глубокий анализ данных, чтобы совершать новые открытия. Делитесь своими открытиями с другими. Создавайте модели данных с помощью машинного обучения и искусственного интеллекта. Примените свои данные на деле.
Лучшие практики при работе с большими данными
Чтобы помочь Вам в освоении новой технологии, мы подготовили список лучших практик, которых рекомендуем придерживаться. Ниже приведены наши рекомендации по созданию надежного фундамента для работы с большими данными.
Анализ больших данных сам по себе ценен. Однако Вы сможете извлечь еще большее количество полезных сведений за счет сопоставления и интеграции больших данных низкой плотности с уже используемыми структурированными данными.
Неважно, какие данные Вы собираете — данные о заказчиках, продукции, оборудовании или окружающей среде — цель состоит в том, чтобы добавить больше релевантных единиц информации в эталонные и аналитические сводки и обеспечить более точные выводы. Например, важно различать отношение всех заказчиков от отношения наиболее ценных заказчиков. Именно поэтому многие организации рассматривают большие данные как неотъемлемую часть существующего набора средств бизнес-анализа, платформ хранения данных и информационной архитектуры.
Не забывайте, что процессы и модели больших данных могут выполняться и разрабатываться как человеком, так и машинами. Аналитические возможности больших данных включают статистику, пространственный анализ, семантику, интерактивное изучение и визуализацию. Использование аналитических моделей позволяет соотносить различные типы и источники данных, чтобы устанавливать связи и извлекать полезные сведения.
Обнаружение полезных сведений в данных не всегда обходится без сложностей. Иногда мы даже не знаем, что именно ищем. Это нормально. Руководство и специалисты по ИТ должны с пониманием относиться к отсутствию четкой цели или требований.
В то же время специалисты по анализу и изучению данных должны тесно сотрудничать с коммерческими подразделениями, чтобы ясно представлять, в каких областях имеются пробелы и каковы требования бизнеса. Чтобы обеспечить интерактивное исследование данных и возможность экспериментов со статистическими алгоритмами, необходимы высокопроизводительные рабочие среды. Убедитесь, что в тестовых средах есть доступ ко всем необходимым ресурсам и что они надлежащим образом контролируются.
Подробнее о больших данных в Oracle
- Попробуйте бесплатный семинар по большим данным
- Инфографика: как создавать эффективные озера данных