Парсинг
В Unisender есть все для рассылок: можно создавать и отправлять клиентам письма и SMS, настроить чат-бота и делать рассылки в Telegram и даже собрать простой лендинг для пополнения базы контактов.
Парсинг — это автоматический процесс сбора и систематизации данных в интернете. Для него используют специальные программы — парсеры, которые отбирают с сайтов информацию по заданным критериям.
Личный кабинет сервиса для парсинга постов и профилей в Instagram* в программе Apify
Зачем нужен парсинг
Анализ конкурентов . Парсер поможет собрать информацию о том, какие товары и по каким ценам продают другие компании.
SEO-продвижение . При помощи парсинга вы можете собрать семантическое ядро, найти ошибки на своем сайте, проанализировать поисковую выдачу.
Запуск рекламы . Парсинг позволяет собрать базу целевой аудитории или найти потенциальные рекламные площадки.
Наполнение сайтов . Парсинг помогает наполнить сайты, на которые требуется большой объем информации. Например, распространена схема, когда парсят иностранные сайты и переводят информацию о товарах на нужный язык.
Анализ контента . Вы можете проанализировать посты, комментарии, сообщения, хештэги и другой контент, чтобы лучше понять поведение и потребности аудитории.
Сквозная аналитика . Парсер интегрируется с нужной площадкой, автоматически сводит данные о бюджетах и результатах сделок, подсчитывает окупаемость рекламных кампаний.
Как работает парсинг
Процесс парсинга можно схематично разделить на три шага.
- Вы указываете в программе условия, по которым нужно найти данные.
- Парсер сканирует код указанных сайтов — их называют целевыми — и ищет нужные данные.
- Собранные данные выводятся в отчете или собираются в таблицу.
Например, вы выходите на рынок товаров для животных и хотите узнать, какие цены устанавливают конкуренты на аналогичные продукты. Вы указываете в парсере товары, на которые нужно найти цены, выбираете нужный регион, перечисляете сайты конкурентов и запускаете программу.
Парсер анализирует указанные сайты, находит нужные товары и собирает расценки в единую базу. После окончания анализа программа формирует отчет — и вы можете наглядно увидеть ценовую политику в вашей отрасли.
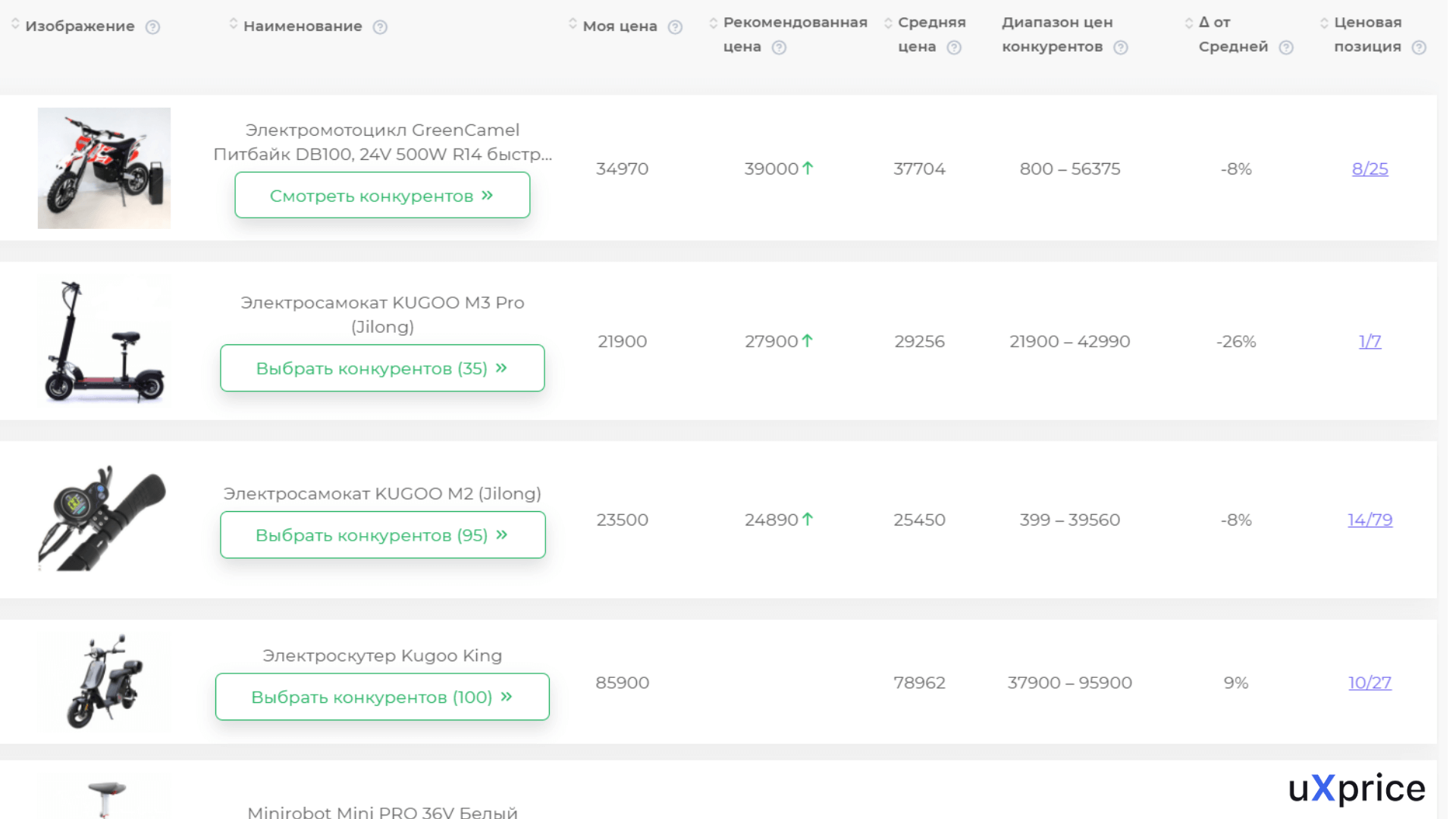
Отчет о ценовой политике конкурентов на рынке электротранспорта в сервисе uXprice. Источник
Законность парсинга
Несмотря на большое количество плюсов, парсинг часто считают «серым» инструментом продвижения из-за последствий, к которым он может привести. Поэтому нужно учитывать некоторые нюансы.
Сам по себе сбор данных из открытых источников законом не запрещен — программы просто автоматизируют то, что маркетолог может сделать вручную. Право искать общедоступную информацию и использовать ее по своему усмотрению гарантируют статья 29 Конституции и статья 7 Закона об информации . При этом и искать, и использовать информацию нужно с соблюдением законодательства — и тут в силу вступают другие правовые нормы:
- Если при помощи парсеров вы полностью копируете информацию с сайтов конкурентов на собственный ресурс, это может привести к нарушению интеллектуального права.
- Чрезмерно агрессивный парсер может создать большую нагрузку на целевой сайт, которая будет выглядеть как DDOS-атака. Если вы парсите такой программой интернет-магазин, то он может стать недоступным на несколько часов, и владельцы сайта потерпят убытки. Даже если сайт не «приляжет», могут возрасти затраты на обслуживание серверов.
- В 272 статье Уголовного кодекса предусмотрена ответственность за «неправомерный доступ к охраняемой законом информации». Эта формулировка включает в себя персональные данные или коммерческую тайну. Например, нельзя парсить чужие списки клиентов, защищенную от несанкционированного доступа информацию, адреса электронной почты для последующей рассылки.
- Согласно поправкам 2021 года к Закону о персональных данных , для сбора и использования даже находящихся в открытом доступе персональных данных нужно получить согласие пользователя. Строго говоря, один из популярных способов использовать парсеры — собирать данные пользователей для запуска таргетированной рекламы — тоже незаконен. Но установить факт парсинга данных при запуске рекламы сейчас технически невозможно, поэтому многие компании продолжают использовать этот инструмент.
Вывод: парсить можно, главное, чтобы этот процесс не приводил к случаям, когда может возникнуть дополнительная ответственность. В частности нельзя продавать полученные данные, использовать персональные данные для рекламы и рассылок, копировать информацию на собственные ресурсы, создавать чрезмерную нагрузку на целевой сайт.
Плюсы парсинга
- Он ускоряет процесс сбора данных. Все эти действия обычно можно совершить вручную, но программа автоматизирует процесс и позволяет получить результат значительно быстрее.
- В программе можно тонко настроить параметры для сбора данных.
Парсер TargetHunter позволяет найти слушателей конкретного музыканта
- Парсинг защищает от ошибок, вызванных человеческим фактором.
- Парсер позволяет сэкономить бюджет как на сборе данных (вместо большого количества сотрудников процесс выполняет одна программа), так и на оптимизации рекламных кампаний. Например, парсеры социальных сетей позволяют более тонко настроить таргетированную рекламу, а значит, сэкономить на продвижении.
Парсинг можно проводить регулярно и автоматически: например, еженедельно отслеживать изменение цен конкурентов.
Виды парсинга
Парсинг товаров . Программа собирает информацию из каталога интернет-магазинов. На основе этих данных можно анализировать ассортимент конкурентов, заполнять страницы собственного сайта.
Парсинг цен . Позволяет проанализировать цены конкурентов и отслеживать изменения в ценовой политике.
Парсинг для SEO . Программа анализирует семантическое ядро целевых сайтов. Данные можно использовать как для наполнения собственного сайта ключевыми словами, так и для контекстной рекламы. Также этот вид парсинга используют, чтобы найти ошибки в мета-тегах, дублирующие элементы, битые ссылки и другие недочеты на собственном сайте.
Парсинг контактов . При этом виде парсинга программа собирает адреса электронной почты, номера телефонов и другую контактную информацию, которая находится в открытом доступе.
Парсинг аудитории . Помогает найти потенциальных клиентов, как правило, среди пользователей социальных сетей. Этот вид парсинга обычно используют для настройки таргетированной рекламы.
15 парсеров для сбора данных с сайтов
Парсинг выдачи . Выявляет лидеров поисковой выдачи по заданным ключевым словам и предоставляет дополнительную информацию — тип сниппета, заголовок, описание, анкоры, связанные ключевые слова. Можно использовать для анализа конкурентов или поиска подходящих рекламных площадок — это позволит размещать рекламу на ресурсах, которые лучше всего индексируются по нужным ключевым словам.
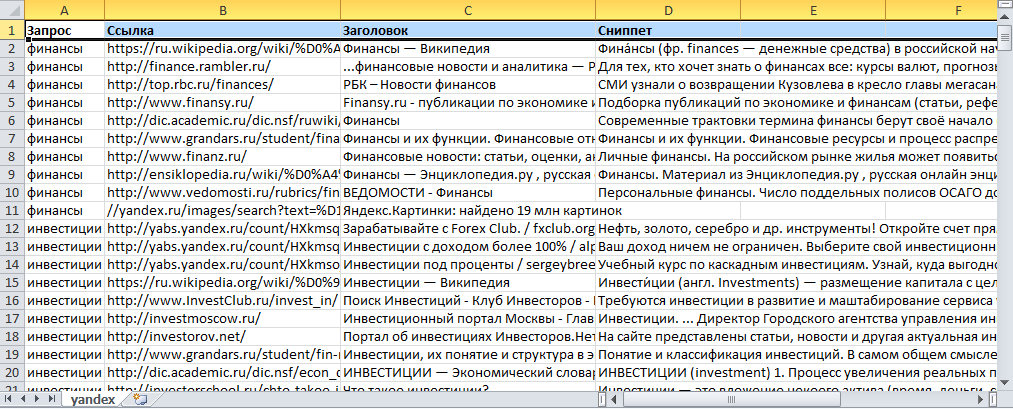
Результатом парсинга выдачи может быть Excel-таблица со всеми интересующими данными: запросом, ссылкой, заголовком, сниппетом. Источник
Возможности парсинга почти безграничны. Например, помимо всем известного парсинга соцсетей или сайтов для анализа конкурентов, мы также парсим ТГ-чаты или сайты для хантинга сотрудников — в них можно отыскать много полезного. Поэтому лучше не фокусироваться на популярных примерах парсинга, а искать свои варианты.
Head of marketing в digital-агентстве i-Media
Программы для парсинга
Программу для парсинга можно разработать самостоятельно, а можно воспользоваться уже готовыми решениями. Вот несколько вариантов:
- Облачные парсеры сайтов: Диггернаут , Import.io , Apify , Mozenda (есть и десктопная версия).
- Десктопные парсеры сайтов: ParserOK , Neatpeak Spider , ComparseR , Parsehub (бесплатный)
- Парсеры социальных сетей: Церебро Таргет , TargetHunter , Pepper.Ninja .
- Парсеры email-адресов: Scrapp.io , Scrapebox Email Scraper .
Как правило, большинство парсеров предоставляют бесплатную версию, но она ограничена либо по времени, либо по возможностям.
10 инструментов, позволяющих парсить информацию с веб-сайтов, включая цены конкурентов + правовая оценка для России

Инструменты web scraping (парсинг) разработаны для извлечения, сбора любой открытой информации с веб-сайтов. Эти ресурсы нужны тогда, когда необходимо быстро получить и сохранить в структурированном виде любые данные из интернета. Парсинг сайтов – это новый метод ввода данных, который не требует повторного ввода или копипастинга.
Такого рода программное обеспечение ищет информацию под контролем пользователя или автоматически, выбирая новые или обновленные данные и сохраняя их в таком виде, чтобы у пользователя был к ним быстрый доступ. Например, используя парсинг можно собрать информацию о продуктах и их стоимости на сайте Amazon. Ниже рассмотрим варианты использования веб-инструментов извлечения данных и десятку лучших сервисов, которые помогут собрать информацию, без необходимости написания специальных программных кодов. Инструменты парсинга могут применяться с разными целями и в различных сценариях, рассмотрим наиболее распространенные случаи использования, которые могут вам пригодиться. И дадим правовую оценку парсинга в России.
1. Сбор данных для исследования рынка
Веб-сервисы извлечения данных помогут следить за ситуацией в том направлении, куда будет стремиться компания или отрасль в следующие шесть месяцев, обеспечивая мощный фундамент для исследования рынка. Программное обеспечение парсинга способно получать данные от множества провайдеров, специализирующихся на аналитике данных и у фирм по исследованию рынка, и затем сводить эту информацию в одно место для референции и анализа.
2. Извлечение контактной информации
Инструменты парсинга можно использовать, чтобы собирать и систематизировать такие данные, как почтовые адреса, контактную информацию с различных сайтов и социальных сетей. Это позволяет составлять удобные списки контактов и всей сопутствующей информации для бизнеса – данные о клиентах, поставщиках или производителях.
3. Решения по загрузке с StackOverflow
С инструментами парсинга сайтов можно создавать решения для оффлайнового использования и хранения, собрав данные с большого количества веб-ресурсов (включая StackOverflow). Таким образом можно избежать зависимости от активных интернет соединений, так как данные будут доступны независимо от того, есть ли возможность подключиться к интернету.
4. Поиск работы или сотрудников
Для работодателя, который активно ищет кандидатов для работы в своей компании, или для соискателя, который ищет определенную должность, инструменты парсинга тоже станут незаменимы: с их помощью можно настроить выборку данных на основе различных прилагаемых фильтров и эффективно получать информацию, без рутинного ручного поиска.
5. Отслеживание цен в разных магазинах
Такие сервисы будут полезны и для тех, кто активно пользуется услугами онлайн-шоппинга, отслеживает цены на продукты, ищет вещи в нескольких магазинах сразу.
В обзор ниже не попал Российский сервис парсинга сайтов и последующего мониторинга цен XMLDATAFEED (xmldatafeed.com), который разработан в Санкт-Петербурге и в основном ориентирован на сбор цен с последующим анализом. Основная задача — создать систему поддержки принятия решений по управлению ценообразованием на основе открытых данных конкурентов. Из любопытного стоит выделить публикация данные по парсингу в реальном времени 🙂

10 лучших веб-инструментов для сбора данных:
Попробуем рассмотреть 10 лучших доступных инструментов парсинга. Некоторые из них бесплатные, некоторые дают возможность бесплатного ознакомления в течение ограниченного времени, некоторые предлагают разные тарифные планы.
Import.io предлагает разработчику легко формировать собственные пакеты данных: нужно только импортировать информацию с определенной веб-страницы и экспортировать ее в CSV. Можно извлекать тысячи веб-страниц за считанные минуты, не написав ни строчки кода, и создавать тысячи API согласно вашим требованиям.
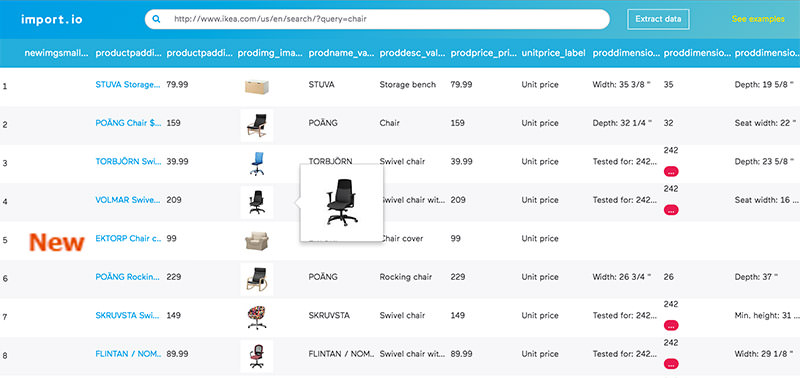
Для сбора огромных количеств нужной пользователю информации, сервис использует самые новые технологии, причем по низкой цене. Вместе с веб-инструментом доступны бесплатные приложения для Windows, Mac OS X и Linux для создания экстракторов данных и поисковых роботов, которые будут обеспечивать загрузку данных и синхронизацию с онлайновой учетной записью.
2. Webhose.io
Webhose.io обеспечивает прямой доступ в реальном времени к структурированным данным, полученным в результате парсинга тысяч онлайн источников. Этот парсер способен собирать веб-данные на более чем 240 языках и сохранять результаты в различных форматах, включая XML, JSON и RSS.

Webhose.io – это веб-приложение для браузера, использующее собственную технологию парсинга данных, которая позволяет обрабатывать огромные объемы информации из многочисленных источников с единственным API. Webhose предлагает бесплатный тарифный план за обработку 1000 запросов в месяц и 50 долларов за премиальный план, покрывающий 5000 запросов в месяц.
3. Dexi.io (ранее CloudScrape)
CloudScrape способен парсить информацию с любого веб-сайта и не требует загрузки дополнительных приложений, как и Webhose. Редактор самостоятельно устанавливает своих поисковых роботов и извлекает данные в режиме реального времени. Пользователь может сохранить собранные данные в облаке, например, Google Drive и Box.net, или экспортировать данные в форматах CSV или JSON.
CloudScrape также обеспечивает анонимный доступ к данным, предлагая ряд прокси-серверов, которые помогают скрыть идентификационные данные пользователя. CloudScrape хранит данные на своих серверах в течение 2 недель, затем их архивирует. Сервис предлагает 20 часов работы бесплатно, после чего он будет стоить 29 долларов в месяц.
4. Scrapinghub
Scrapinghub – это облачный инструмент парсинга данных, который помогает выбирать и собирать необходимые данные для любых целей. Scrapinghub использует Crawlera, умный прокси-ротатор, оснащенный механизмами, способными обходить защиты от ботов. Сервис способен справляться с огромными по объему информации и защищенными от роботов сайтами.

Scrapinghub преобразовывает веб-страницы в организованный контент. Команда специалистов обеспечивает индивидуальный подход к клиентам и обещает разработать решение для любого уникального случая. Базовый бесплатный пакет дает доступ к одному поисковому роботу (обработка до 1 Гб данных, далее — 9$ в месяц), премиальный пакет дает четырех параллельных поисковых ботов.
ParseHub может парсить один или много сайтов с поддержкой JavaScript, AJAX, сеансов, cookie и редиректов. Приложение использует технологию самообучения и способно распознать самые сложные документы в сети, затем генерирует выходной файл в том формате, который нужен пользователю.

ParseHub существует отдельно от веб-приложения в качестве программы рабочего стола для Windows, Mac OS X и Linux. Программа дает бесплатно пять пробных поисковых проектов. Тарифный план Премиум за 89 долларов предполагает 20 проектов и обработку 10 тысяч веб-страниц за проект.
6. VisualScraper
VisualScraper – это еще одно ПО для парсинга больших объемов информации из сети. VisualScraper извлекает данные с нескольких веб-страниц и синтезирует результаты в режиме реального времени. Кроме того, данные можно экспортировать в форматы CSV, XML, JSON и SQL.
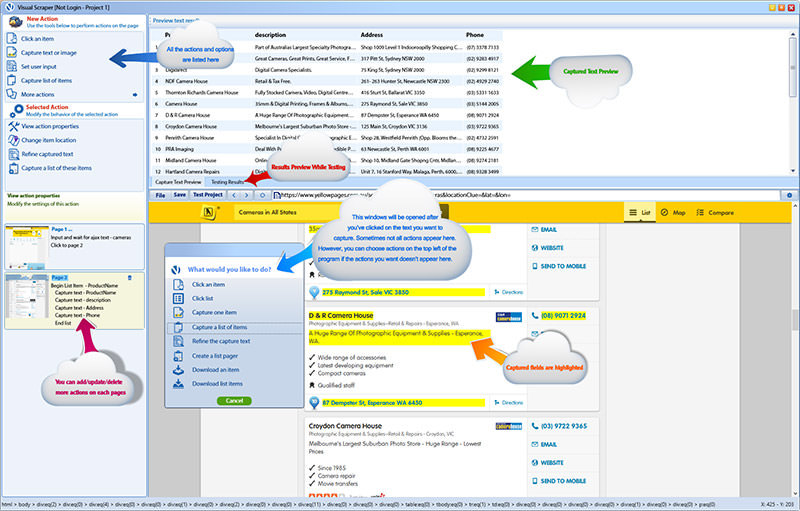
Пользоваться и управлять веб-данными помогает простой интерфейс типа point and click. VisualScraper предлагает пакет с обработкой более 100 тысяч страниц с минимальной стоимостью 49 долларов в месяц. Есть бесплатное приложение, похожее на Parsehub, доступное для Windows с возможностью использования дополнительных платных функций.
Spinn3r позволяет парсить данные из блогов, новостных лент, новостных каналов RSS и Atom, социальных сетей. Spinn3r имеет «обновляемый» API, который делает 95 процентов работы по индексации. Это предполагает усовершенствованную защиту от спама и повышенный уровень безопасности данных.
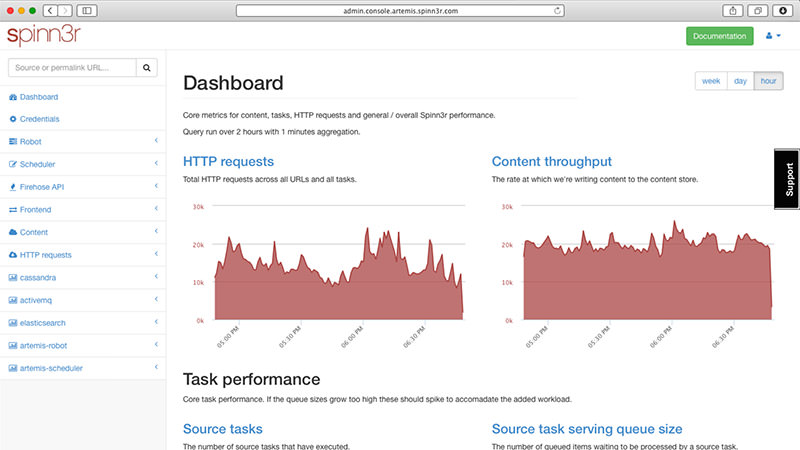
Spinn3r индексирует контент, как Google, и сохраняет извлеченные данные в файлах формата JSON. Инструмент постоянно сканирует сеть и находит обновления нужной информации из множества источников, пользователь всегда имеет обновляемую в реальном времени информацию. Консоль администрирования позволяет управлять процессом исследования; имеется полнотекстовый поиск.
80legs – это мощный и гибкий веб-инструмент парсинга сайтов, который можно очень точно подстроить под потребности пользователя. Сервис справляется с поразительно огромными объемами данных и имеет функцию немедленного извлечения. Клиентами 80legs являются такие гиганты как MailChimp и PayPal.

Опция «Datafiniti» позволяет находить данные сверх-быстро. Благодаря ней, 80legs обеспечивает высокоэффективную поисковую сеть, которая выбирает необходимые данные за считанные секунды. Сервис предлагает бесплатный пакет – 10 тысяч ссылок за сессию, который можно обновить до пакета INTRO за 29 долларов в месяц – 100 тысяч URL за сессию.
Scraper – это расширение для Chrome с ограниченными функциями парсинга данных, но оно полезно для онлайновых исследований и экспортирования данных в Google Spreadsheets. Этот инструмент предназначен и для новичков, и для экспертов, которые могут легко скопировать данные в буфер обмена или хранилище в виде электронных таблиц, используя OAuth.
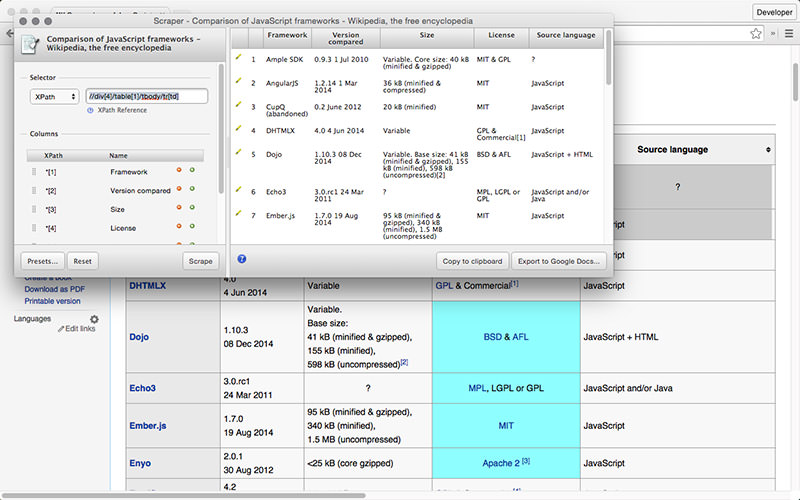
Scraper – бесплатный инструмент, который работает прямо в браузере и автоматически генерирует XPaths для определения URL, которые нужно проверить. Сервис достаточно прост, в нем нет полной автоматизации или поисковых ботов, как у Import или Webhose, но это можно рассматривать как преимущество для новичков, поскольку его не придется долго настраивать, чтобы получить нужный результат.
10. OutWit Hub
OutWit Hub – это дополнение Firefox с десятками функций извлечения данных. Этот инструмент может автоматически просматривать страницы и хранить извлеченную информацию в подходящем для пользователя формате. OutWit Hub предлагает простой интерфейс для извлечения малых или больших объемов данных по необходимости.
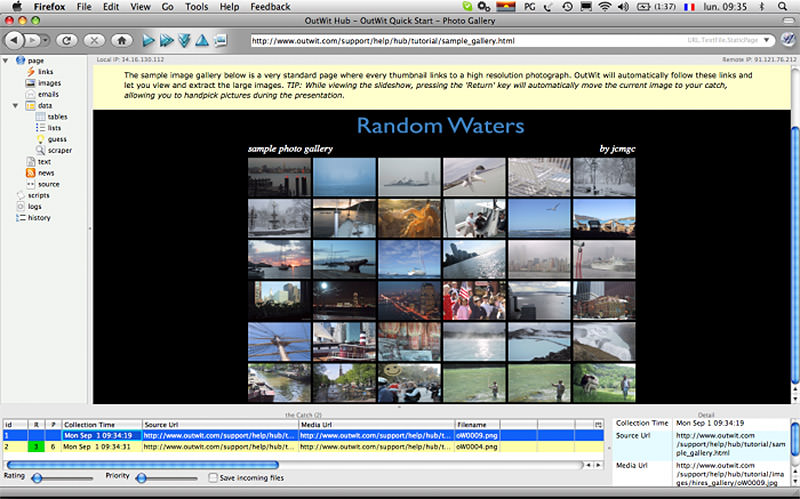
OutWit позволяет «вытягивать» любые веб-страницы прямо из браузера и даже создавать в панели настроек автоматические агенты для извлечения данных и сохранения их в нужном формате. Это один из самых простых бесплатных веб-инструментов по сбору данных, не требующих специальных знаний в написании кодов.
Самое главное — правомерность парсинга?!
Вправе ли организация осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернете (парсинг)?
В соответствии с действующим в Российской Федерации законодательством разрешено всё, что не запрещено законодательством. Парсинг является законным, в том случае, если при его осуществлении не происходит нарушений установленных законодательством запретов. Таким образом, при автоматизированном сборе информации необходимо соблюдать действующее законодательство. Законодательством Российской Федерации установлены следующие ограничения, имеющие отношение к сети интернет:
1. Не допускается нарушение Авторских и смежных прав.
2. Не допускается неправомерный доступ к охраняемой законом компьютерной информации.
3. Не допускается сбор сведений, составляющих коммерческую тайну, незаконным способом.
4. Не допускается заведомо недобросовестное осуществление гражданских прав (злоупотребление правом).
5. Не допускается использование гражданских прав в целях ограничения конкуренции.
Из вышеуказанных запретов следует, что организация вправе осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернет если соблюдаются следующие условия:
1. Информация находится в открытом доступе и не защищается законодательством об авторских и смежных правах.
2. Автоматизированный сбор осуществляется законными способами.
3. Автоматизированный сбор информации не приводит к нарушению в работе сайтов в сети интернет.
4. Автоматизированный сбор информации не приводит к ограничению конкуренции.
При соблюдении установленных ограничений Парсинг является законным.
p.s. по правовому вопросу мы подготовили отдельную статью, где рассматривается Российский и зарубежный опыт.
Какой инструмент для извлечения данных Вам нравится больше всего? Какого рода данные вы хотели бы собрать? Расскажите в комментариях о своем опыте парсинга и свое видение процесса…
- парсинг контента
- парсинг сайтов
- парсинг
- мониторинг цен
Парсинг данных с сайтов: что это и зачем он нужен

Парсинг обычно применяют, когда нужно быстро собрать большой объем данных. Его выполняют с помощью специальных сервисов — парсеров. В этой статье мы разберем, с какой целью можно использовать парсинг, что он позволяет узнать о конкурентах и законен ли он. Также мы рассмотрим, как пошагово спарсить данные с помощью одного из инструментов.
Время чтения 17 минут
- Что такое парсинг
- Способы применения парсинга
- Что могут узнать конкуренты с помощью парсинга
- Законно ли парсить сайты
- Этапы парсинга
- Как парсить данные
- Как защитить свой сайт от парсинга
- Выводы
Что такое парсинг
Парсинг — это процесс автоматического сбора данных и их структурирования.
Специальные программы или сервисы-парсеры «обходят» сайт и собирают данные, которые соответствуют заданному условию.
Простой пример: допустим, нужно собрать контакты потенциальных партнеров из определенной ниши. Вы можете это сделать вручную. Надо будет заходить на каждый сайт, искать раздел «Контакты», копировать в отдельную таблицу телефон и т. д. Так на каждую площадку у вас уйдет по пять-семь минут. Но этот процесс можно автоматизировать. Задаете в программе для парсинга условия выборки и через какое-то время получаете готовую таблицу со списком сайтов и телефонов.
Плюсы парсинга очевидны — если сравнивать его с ручным сбором и сортировкой данных:
- вы получаете данные очень быстро;
- можно задавать десятки параметров для составления выборки;
- в отчете не будет ошибок;
- парсинг можно настроить с определенной периодичностью — например, собирать данные каждый понедельник;
- многие парсеры не только собирают данные, но и советуют, как исправить ошибки на сайте.
В сети достаточно много программ для парсинга. Они могут находиться в «облаке» или «коробке»:
- облачная версия — это SaaS , вам нужно будет зарегистрироваться и работать с сервисом прямо в браузере;
- коробочная версия — решение, которое нужно установить на ваш компьютер, и работать с ним в окне программы.
В обоих случаях вы платите за доступ к парсеру в течение какого-то времени. Например, месяца, года или нескольких лет.
Способы применения парсинга
Область применения парсинга можно свести к двум целям:
- анализ конкурентов, чтобы лучше понимать, как они работают, и заимствовать у них какие-то подходы;
- анализ собственной площадки для устранения ошибок, быстрого внедрения изменений и т. д.

Мы регулярно используем парсер для блога Ringostat. Например, когда нужно найти изображения, к которым по какой-то причине не прописан атрибут Alt. Поисковики считают это ошибкой и могут понизить в выдаче тот сайт, на котором много таких иллюстраций. Даже страшно представить, сколько времени потребовалось бы на ручной поиск таких картинок. А благодаря парсеру мы получаем список со ссылками за несколько минут.
Теперь давайте рассмотрим для каких целей еще можно использовать парсинг.
- Исследование рынка . Парсинг позволяет быстро оценить, какие товары и цены у конкурентов.
- Анализ динамики изменений . Парсинг можно проводить регулярно, чтобы оценивать, как менялись какие-то показатели. Например, росли или падали цены, изменялось количество онлайн-объявлений или сообщений на форуме.
- Устранение недочетов на собственном ресурсе. Выявление ошибок в мета-тегах, битых ссылок, проблем с редиректами, дублирующихся элементов и т. д.
- Сбор ссылок, ведущих на вашу площадку. Это поможет оценить работу подрядчика по линкбилдингу. Как проверять внешние ссылки и какими инструментами это делать, подробно описано в статье . Пример такого отчета:
- Наполнение каталога интернет-магазина. Обычно у таких сайтов огромное количество позиций и уходит много времени, чтобы составить описание для всех товаров. Чтобы упростить этот процесс, часто парсят зарубежные магазины и просто переводят информацию о товарах.
- Составление клиентской базы. В этом случае парсят контактные данные, например, пользователей соцсетей, участников форумов и т. д. Но тут стоит помнить, что сбор информации, которой нет в открытом доступе, незаконен.
- Сбор отзывов и комментариев на форумах, в соцсетях.
- Создание контента, который строится на выборке данных . Например, результаты спортивных состязаний, инфографики по изменению цен, погоды и т. д.
Кстати, недобросовестные люди могут использовать парсеры для DDOS-атак. Если одновременно начать парсить сотни страниц сайта, то площадку можно «положить» на какое-то время. Это, разумеется, незаконно — об этом подробнее ниже От подобных атак можно защититься, если на сервере установлена защита.
Что могут узнать конкуренты с помощью парсинга
В принципе, любую информацию, которая размещена на вашем сайте. Чаще всего ищут:
- цены;
- контакты компании;
- описание товаров, их характеристик и в целом контент;
- фото и видео;
- информацию о скидках;
- отзывы.
Проводить такую «разведку» могут не только конкуренты. Например, журналист может провести исследование, правда ли интернет-магазины предоставляют настоящие скидки на Черную пятницу. Или искусственно завышают цены незадолго до нее и реальную цену выдают за скидку. С этой целью он может заранее спарсить цены десятка интернет-магазинов и сравнить с ценами на Черную пятницу.
Законно ли парсить сайты
Если кратко, то законно — если вы парсите информацию, которая есть в открытом доступе. Это логично, ведь так любой человек и без парсера может собрать интересующие данные. Что преследуется законом:
- парсинг с целью DDOS-атаки;
- сбор личных данных пользователей, которые находятся не на виду — например, в личном кабинете, указывались при регистрации и т. д.;
- парсинг для воровства контента — например, перепост чужих статей под своим именем, использование авторских фото не из бесплатных стоков;
- сбор информации, которая составляет государственную или коммерческую тайну.
Рассмотрим это подробнее с точки зрения законодательства Украины.
Согласно ЗУ «Об информации» , информация по режиму доступа делится на общедоступную и информацию с ограниченным доступом. В свою очередь информация с ограниченным доступом делится на конфиденциальную, гостайну и служебную. Определения каждого вида содержатся в ЗУ «О доступе к публичной информации .
В большей степени любой спор касательно незаконного парсинга и/или распространения информации касается именно конфиденциальных данных.
- Информация о физлице, которая может его идентифицировать, априори является конфиденциальной и может быть использована только по согласию. Поэтому, чтобы парсинг был законным, парсить нужно либо деперсонифицированные данные, либо получать согласие распорядителя информации — владельца сайта, на котором зарегистрирован пользователь.
- Если речь идет об информации, не являющейся персональной, она может считаться конфиденциальной, только если ее владелец определил ее как таковую. Так, чаще всего на сайтах размещается либо политика конфиденциальности, либо правила пользования сайтом. В этом документе/на этой странице указаны права и обязанности посетителей/пользователей, которые нужно соблюдать. Поэтому перед парсингом стоить проверить, не запрещен ли сбор информации и использование данных сайта.
Также важным является возможное нарушение авторских установленных ЗУ «Об авторских и смежных правах» и ГКУ . Перед парсингом нужно понимать, что любой тип контента защищен авторским правом с момента его создания. И только автор определяет как (платно/бесплатно), где (статья/сайт/реклама) и сколько (на протяжении срока действия лицензии/бессрочно) можно использовать его творение.
Даже при условии правомерности парсинга, его осуществление не должно подрывать нормальную работу сайта, который парсят. Если из-за парсинга информации произойдет сбой и утечка или подделка данных, то подобные действия могут расцениваться как несанкционированное вмешательство в работу сайта, что является нарушением согласно УК Украины .
Есть еще один нюанс. Представим, что одна компания долго разрабатывала продукт, вкладывала деньги, чтобы собрать базу пользователей или покупателей, а другая спарсила все и за несколько недель создала практически аналогичный сервис или продукт. Подобные действия при наличии весомой доказательной базы могут расцениваться как нарушение условий конкуренции согласно ЗУ «О защите от недобросовестной конкуренции» .
Этапы парсинга
Если не погружаться в технические подробности, то парсинг строится из таких этапов:
- пользователь задает в парсере условия, которым должна соответствовать выборка — например, все цены на конкретном сайте;
- программа проходится по сайту или нескольким и собирает релевантную информацию;
- данные сортируются;
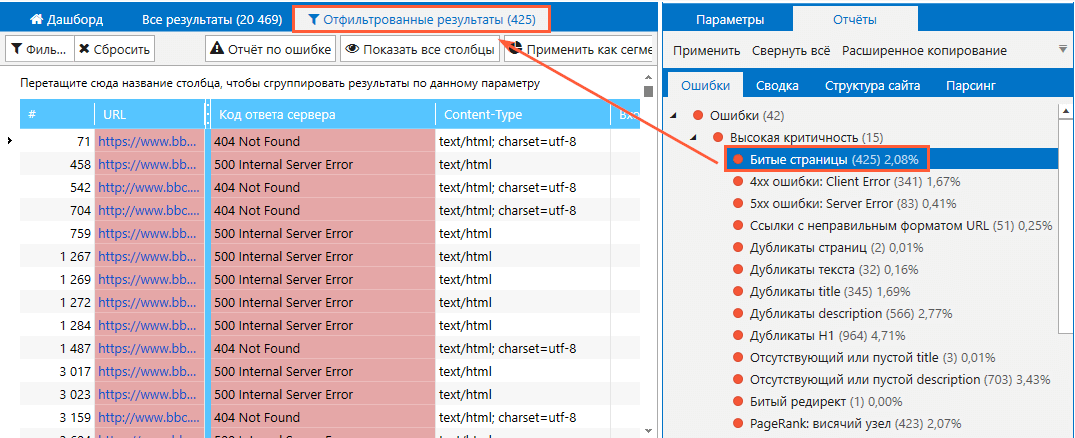
- пользователь получает отчет — если проводилась проверка на ошибки, то критичные выделяются контрастным цветом;
- отчет можно выгрузить в нужном формате — обычно парсеры поддерживают несколько.
Как парсить данные
Теперь давайте более подробно рассмотрим, как парсить данные. Разберем его в разрезе довольно частой задачи для менеджера — собрать базу для «холодного» обзвона. В качестве примера возьмем парсер Netpeak Checker , с которым работаем и сами.
Допустим, наша компания продает оборудование для салонов красоты. И сотруднику нужно собрать базу контактов таких компаний, чтобы позвонить и предложить им наш товар. Обычно на старте готового списка площадок у менеджера нет. Поэтому для поиска можно использовать встроенный в программу инструмент «Парсер поисковых систем».

Вводим в нем нужные запросы — «салон красоты», «парикмахерская», «бьюти-процедуры».
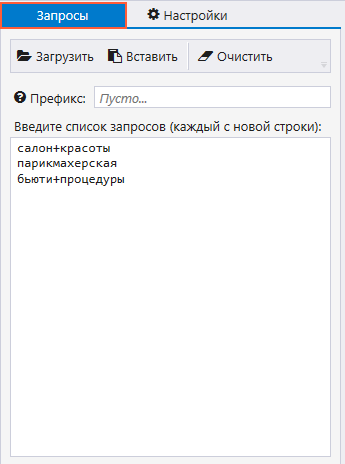
На вкладке «Настройки» выбираем поисковую систему и количество результатов — например, топ-10 или все результаты выдачи. В дополнительных настройках указываем язык выдачи и параметры геолокации, чтобы в результаты попадали салоны красоты только из нужного нам региона. Сохраняем настройки и нажимаем «Старт», чтобы начать парсинг.
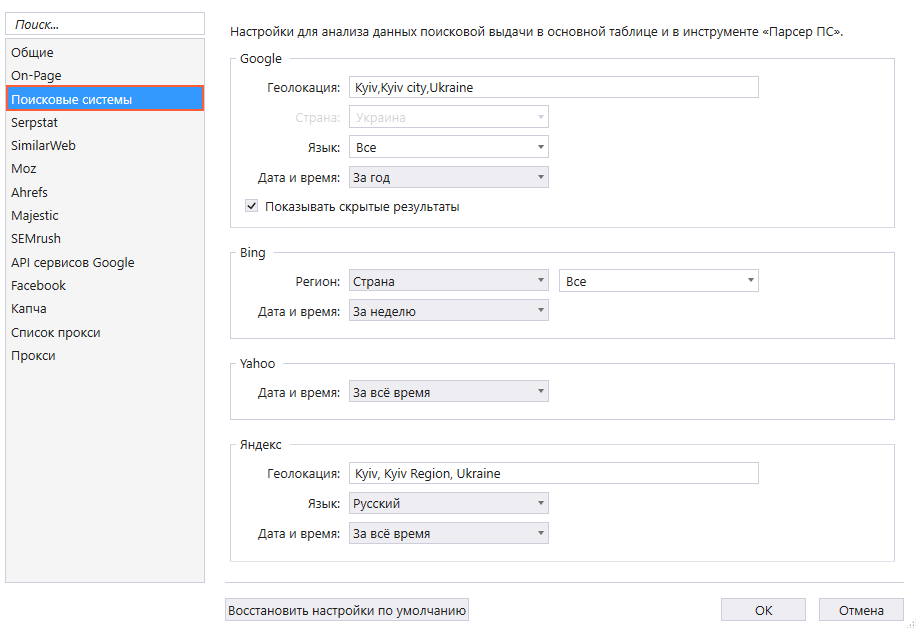
Чтобы провести парсинг номеров телефонов с главных страниц найденных сайтов, нажимаем на кнопку «Перенести хосты». После этого ссылки отобразятся в основной таблице программы.
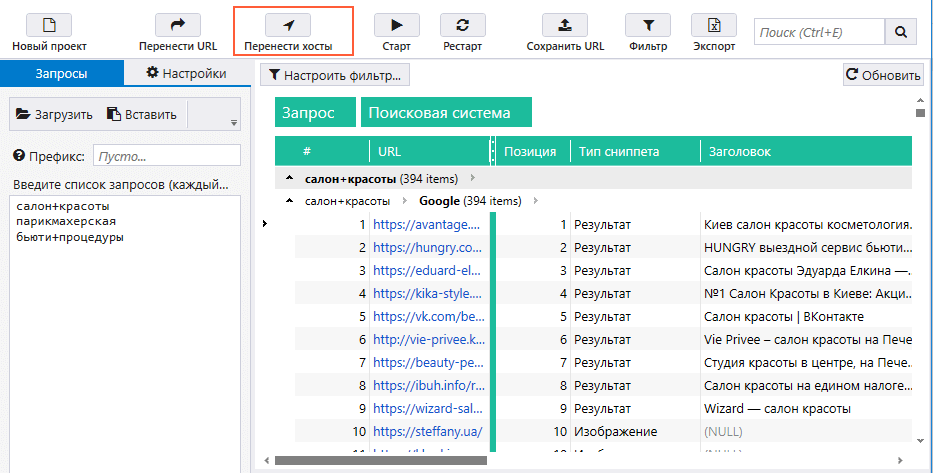
Теперь, когда у нас есть полный список салонов, на боковой панели в разделе параметров «On-Page» отмечаем пункт «Телефонные номера» и нажимаем «Старт». Все найденные телефоны с сайтов и их число будут внесены в соответствующих колонках основной таблицы результатов.
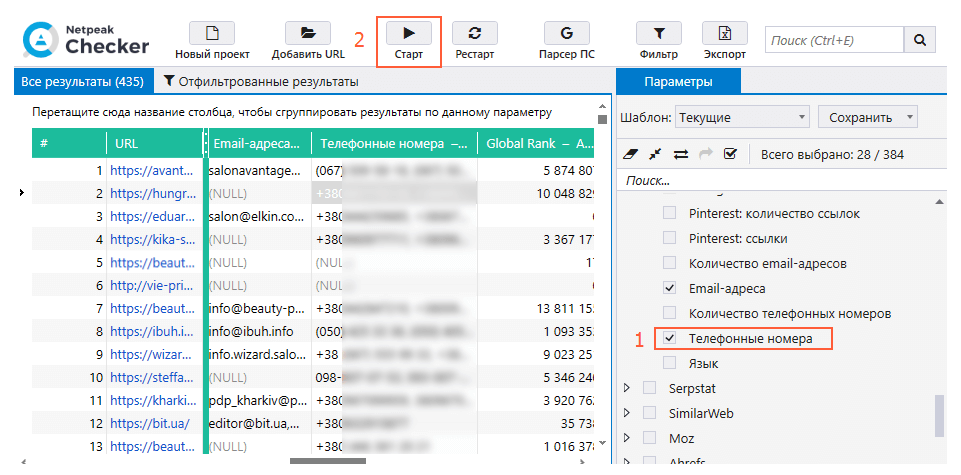
Если бы у нас заранее был собран перечень необходимых адресов, мы могли бы их просто загрузить в программу и точно так же собрать телефоны.
Сохраняем данные в формате CSV, нажав кнопку «Экспорт».
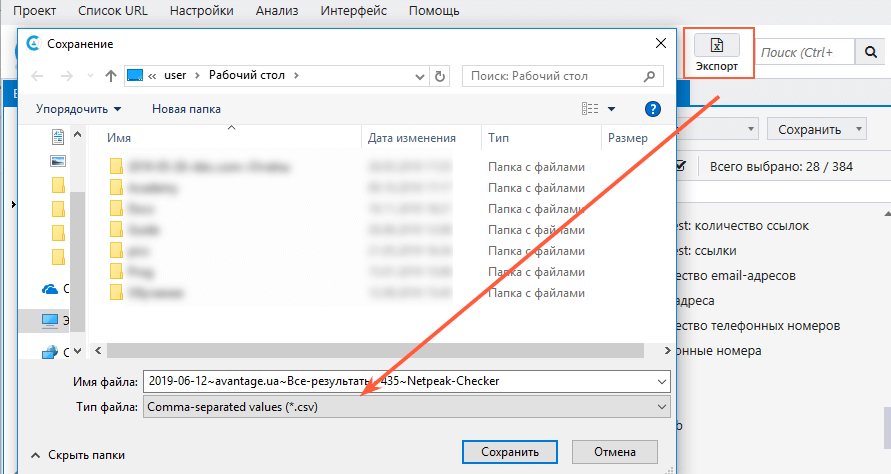
Вот и все — мы получили список салонов и их телефонов.
Кстати, сэкономить время можно не только за счет парсинга. Вы в любом случае тратите где-то минуту, чтобы набрать номер на телефоне. Если в вашем списке хотя бы 50 компаний, на это в сумме уйдет почти час. Но есть способ тратить на набор номера одну секунду. Это Ringostat Smart Phone — умный телефон, встроенный прямо в браузер Chrome. Он позволяет звонить, просто нажав на номер, расположенный на любом сайте, в карточке CRM или просто в таблице. Как в нашем примере.
Подключите Ringostat, установите расширение и сможете обзвонить базу за минимальное время. При желании ее можно сразу перенести в CRM и звонить уже оттуда с помощью Ringostat Smart Phone. Тут видно, что звонок происходит мгновенно:
Как защитить свой сайт от парсинга
Как мы упоминали выше, парсинг не всегда используют в нормальных целях. Если вы боитесь атаки со стороны конкурентов, площадку можно защитить. Существует несколько способов, как это сделать.
- Ограничьте число действий, которые можно совершить на вашей площадке за определенное время. Например, разрешите только три запроса в течение минуты с одного IP-адреса.
- Отслеживайте подозрительную активность. Если заметили сильно много запросов с одного адреса, запретите ему доступ. Или показывайте reCAPTCHA, чтобы пользователь подтвердил, что он человек, а не бот или парсер.
- Создайте учетную запись, чтобы действия на сайте мог совершать зарегистрированный посетитель.
- Идентифицируйте всех, кто заходит на площадку. Например, по скорости заполнения формы или месту нажатия на кнопку. Есть скрипты, которые позволят собирать информацию о местонахождении пользователя, разрешении экрана.
- Скройте информацию о структуре сайта. Пусть доступ к ней будет только у администратора.
- Обращайте внимание на похожие или идентичные запросы, одновременно поступающие с разных IP-адресов. Парсинг может быть распределенным. Например, через прокси-сервера.
В любом случае, помните, что всегда есть риск заблокировать реального пользователя, а не программу. Поэтому тут вам решать, что важнее — безопасность сайта или риск потери потенциального клиента.
Выводы
- Парсинг — это сбор и сортировка данных с определенными параметрами. У этого инструмента масса преимуществ: скорость, отсутствие ошибок в выборке, возможность проводить парсинг регулярно. Плюс, многие парсеры не просто собирают данные, но и советуют, как исправить критические ошибки на вашем сайте.
- Парсинг используется для анализа конкурентов, исследования рынка, поиска и устранения ошибок на собственной площадке, создания контента. Интернет-магазины используют его, чтобы переводить описания товаров с иностранных площадок.
- Парсинг вполне законен, если вы собираете информацию, которая есть в открытом доступе. Нельзя проводить его, чтобы «положить» ресурс конкурента, украсть чужой контент или получить данные, не предназначенные для общего доступа.
- Если боитесь атаки на свой сайт, парсинг можно выявить и запретить. Способов существует несколько, но многие парсеры хвастаются в сети, что умеют их обходить. Плюс, вы всегда рискуете заблокировать «живого» человека
Парсинг сайта вместе с Python и библиотекой Beautiful Soup: простая инструкция в три шага
Рассказываем и показываем, как запросто вытянуть данные из сайта и «разговорить» его без утюга, паяльника и мордобоя.

Иллюстрация: Катя Павловская для Skillbox Media

Антон Яценко
Изучает Python, его библиотеки и занимается анализом данных. Любит путешествовать в горах.
Для парсинга используют разные языки программирования: Python, JavaScript или даже Go. На самом деле инструмент не так важен, но некоторые языки делают парсинг удобнее за счёт наличия специальных библиотек — например, Beautiful Soup в Python.
В этой статье разберёмся в основах парсинга — вспомним про структуру HTML-запроса и спарсим сведения о погоде с сервиса «Яндекса». А ещё поделимся записью мастер-класса, на котором наш эксперт в веб-разработке покажет, как с нуля написать веб-парсер.
Что такое парсинг и зачем он нужен?
Парсинг (от англ. parsing — разбор, анализ), или веб-скрейпинг, — это автоматизированный сбор информации с интернет-сайтов. Например, можно собрать статьи с заголовками с любого сайта, что полезно для журналистов или социологов. Программы, которые собирают и обрабатывают информацию из Сети, называют парсерами (от англ. parser — анализатор).
Сам парсинг используется для решения разных задач: с его помощью телеграм-боты могут получать информацию, которую затем показывают пользователям, маркетологи — подтягивать данные из социальных сетей, а бизнесмены — узнавать подробности о конкурентах.
Существуют различные подходы к парсингу: можно забирать информацию через API, который предусмотрели создатели сервиса, или получать её напрямую из HTML-кода. В любом из этих случаев важно помнить, как вообще мы взаимодействуем с серверами в интернете и как работают HTTP-запросы. Начнём с этого!
HTTP-запросы, XML и JSON
HTTP (HyperText Transfer Protocol, протокол передачи гипертекста) — протокол для передачи произвольных данных между клиентом и сервером. Он называется так, потому что изначально использовался для обмена гипертекстовыми документами в формате HTML.
Для того чтобы понять, как работает HTTP, надо помнить, что это клиент-серверная структура передачи данных․ Клиент, например ваш браузер, формирует запрос (request) и отправляет на сервер; на сервере запрос обрабатывается, формируется ответ (response) и передаётся обратно клиенту. В нашем примере клиент — это браузер.
Запрос состоит из трёх частей:
- Строка запроса (request line): указывается метод передачи, версия HTTP и сам URL, к которому обращается сервер.
- Заголовок (message header): само сообщение, передаваемое серверу, его параметры и дополнительная информация).
- Тело сообщения (entity body): данные, передаваемые в запросе. Это необязательная часть.
Посмотрим на простой HTTP-запрос, которым мы воспользуемся для получения прогноза погоды:
_GET /https://yandex.com.am/weather/ HTTP/1.1_
В этом запросе можно выделить три части:
- _GET — метод запроса. Метод GET позволяет получить данные с ресурса, не изменяя их.
- /https://yandex.com.am/weather/ — URL сайта, к которому мы обращаемся.
- HTTP/1.1_ — указание на версию HTTP.
Ответ на запрос также имеет три части: _HTTP/1.1 200 OK_. В начале указывается версия HTTP, цифровой код ответа и текстовое пояснение. Существующих ответов несколько десятков. Учить их не обязательно — можно воспользоваться документацией с пояснениями.
Сам HTTP-запрос может быть написан в разных форматах. Рассмотрим два самых популярных: XML и JSON.
JSON (англ. JavaScript Object Notation) — простой формат для обмена данными, созданный на основе JavaScript. При этом используется человекочитаемый текст, что делает его лёгким для понимания и написания:
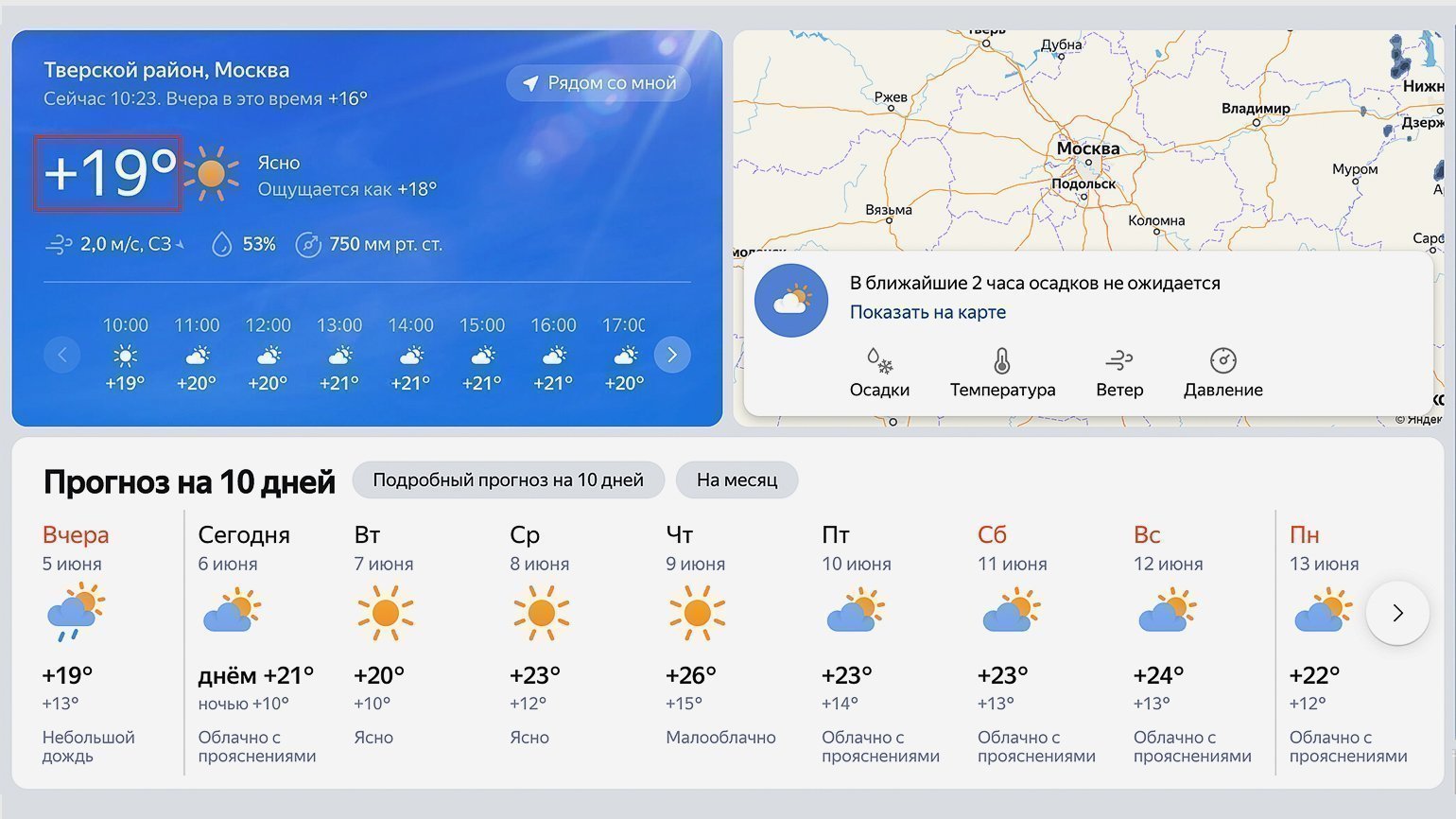
Для просмотра HTML-кода откроем «Инспектор кода». Для этого можно использовать комбинации горячих клавиш: в Google Chrome на macOS — ⌥ + ⌘ + I, на Windows — Сtrl + Shift + I или F12. Инспектор кода выглядит как дополнительное окно в браузере с несколькими вкладками:
Переключаться между вкладками не надо, так как вся необходимая информация уже есть на первой.
Теперь найдём блок в коде, где хранится значение температуры. Для этого следует последовательно разворачивать блоки кода, располагающиеся внутри тега . Сделать это можно, нажимая на символ ▶.
Как понять, что мы на правильном пути? Инспектор кода при наведении на блок кода подсвечивает на сайте ту область, за которую он отвечает. Переходим последовательно вглубь HTML-кода и находим нужный нам элемент.
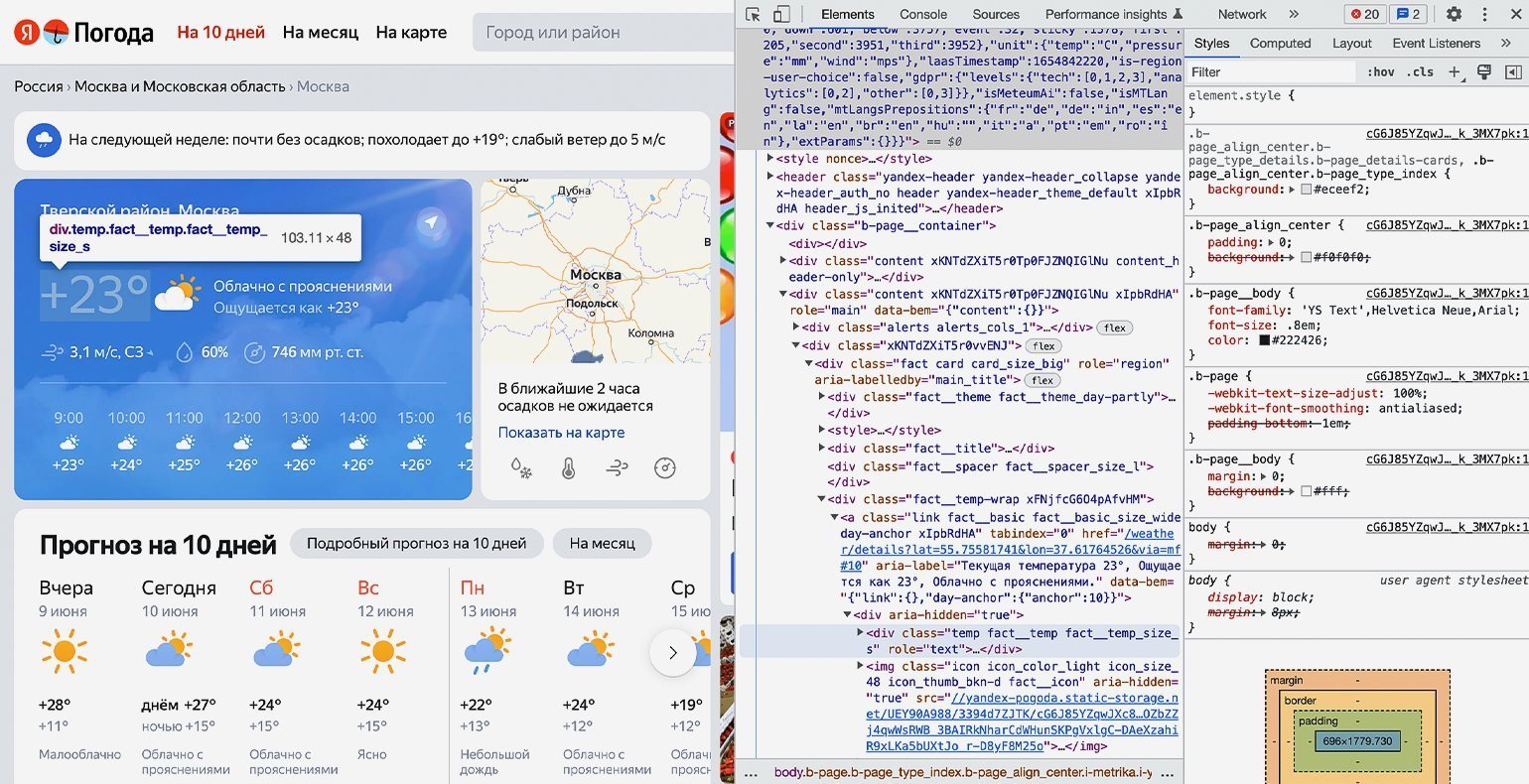
В нашем случае пришлось проделать большой путь: элемент с классом «b‑page__container» → первый элемент с классом «content xKNTdZXiT5r0Tp0FJZNQIGlNu xIpbRdHA» → элемент с классом «xKNTdZXiT5r0vvENJ» → элемент с классом «fact card card_size_big» → элемент с классом «fact__temp-wrap xFNjfcG6O4pAfvHM» → элемент с классом «link fact__basic fact__basic_size_wide day-anchor xIpbRdHA» → элемент с классом «temp fact__temp fact__temp_size_s». Именно последнее название класса нам потребуется на следующем шаге.
Шаг 3
Пишем код и получаем необходимую информацию
Продолжаем писать команды в терминал, командную строку, IDE или онлайн-редактор кода Python. На этом шаге нам остаётся использовать подключённые библиотеки и достать значения температуры из элемента . Но для начала надо проверить работу библиотек.
Сохраняем в переменную URL-адрес страницы, с которой мы планируем парсить информацию:

Но весь код нам не нужен — мы должны выводить только тот блок кода, где хранится значение температуры. Напомним, что это . Найдём его значение с помощью функции find() библиотеки Beautiful Soup.
Функция find() принимает два аргумента:
- указание на тип элемента HTML-кода, в котором происходит поиск;
- наименование этого элемента.
В нашем случае код будет следующим:
temp = bs.find('span', 'temp__value temp__value_with-unit')
И сразу выведем результат на экран с помощью print:
print(temp)
class="temp__value temp__value_with-unit">+17
Получилось! Но кроме нужной нам информации есть ещё HTML-тег с классом — а он тут лишний. Избавимся от него и оставим только значения температуры с помощью свойства text:
print(temp.text)
Всё получилось. Мы смогли узнать текущую температуру в городе с сайта «Яндекс.Погода», используя библиотеку Beautiful Soup для Python. Её можно использовать для своих задач — например, передавая в виджет на своём сайте, — или создать бота для погоды.
Скрапинг веб-сайтов с помощью Python — мастер-класс для новичков
Если вы совсем новичок в веб-скрапинге, но хотите написать свой парсер (например, для автоматической генерации отчётов в Excel), рекомендуем посмотреть вебинар от Михаила Овчинникова — ведущего инженера-программиста из Badoo. Он на понятном примере объясняет основы языка Python и принципы веб-скрапинга. Уже в начале видеоурока вы запустите простой парсер и научитесь читать данные в формате HTML и JSON.
Запись вебинара по скрапингу сайтов с помощью Python и библиотеки Beautiful Soup
Парсинг динамических сайтов c помощью Python и библиотеки Selenium
Бесплатная библиотека Selenium позволяет эмулировать работу веб-браузера — то есть «маскировать» веб-запросы скрипта под действия человека в Google Chrome или Safari. Почему это важно? Сайты умеют распознавать ботов и блокируют IP-адреса, с которых отправляются автоматические запросы.
Избежать «бана» можно двумя способами: изучить HTTP, принципы работы Python с вебом и написать свой эмулятор с нуля или воспользоваться готовым инструментом. Во втором случае Selenium — одно из лучших и самых удобных решений.
О том, как работать с библиотекой, рассказал Михаил Овчинников:
Запись вебинара по сбору данных с помощью библиотек Selenium и Beautiful Soup
Резюме
Парсинг помогает получить нужную информацию с любого сайта. Для него можно использовать разные языки программирования, но некоторые из них содержат стандартные библиотеки для веб-скрейпинга, например Beautiful Soup на Python.
А ещё мы рекомендуем внимательно изучить официальную документацию по библиотекам, которые мы использовали для парсинга. Например, можно углубиться в возможности и нюансы использования библиотеки Beautiful Soup на Python.
Читайте также:
- 3 фреймворка для тестирования на Python: обзор конфигураций
- 5 шаблонов проектирования, которые должен освоить каждый разработчик
- Как происходит модульное тестирование в Python