Ломаем и чиним etcd-кластер

etcd — это быстрая, надёжная и устойчивая к сбоям key-value база данных. Она лежит в основе Kubernetes и является неотъемлемой частью его control-plane, именно поэтому критически важно уметь бэкапить и восстанавливать работоспособность как отдельных нод, так и всего etcd-кластера.
В предыдущей статье мы подробно рассмотрели перегенерацию SSL-сертификатов и static-манифестов для Kubernetes, а также вопросы связанные c восстановлением работоспособности Kubernetes. Эта статья будет посвящена целиком и полностью восстановлению etcd-кластера.
Для начала я сразу должен сделать оговорку, что рассматривать мы будем лишь определённый кейс, когда etcd задеплоен и используется непосредственно в составе Kubernetes. Приведённые в статье примеры подразумевают что ваш etcd-кластер развёрнут с помощью static-манифестов и запускается внутри контейнеров.
Для наглядности возьмём схему stacked control plane nodes из предыдущей статьи:
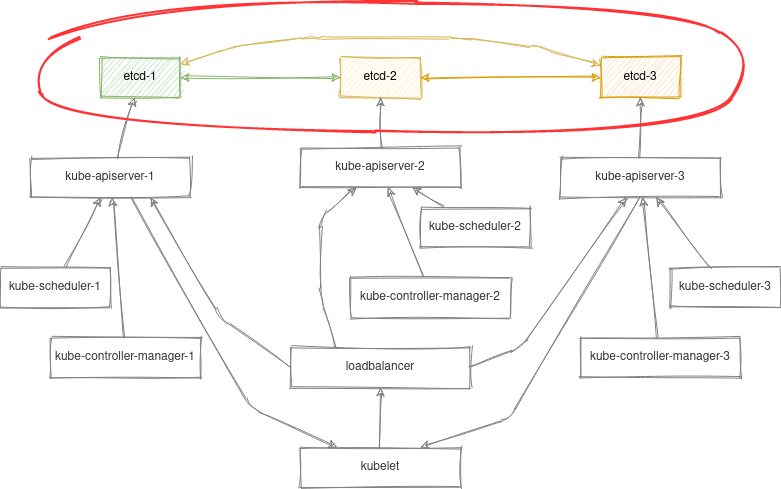
Предложенные ниже команды можно выполнить и с помощью kubectl, но в данном случае мы постараемся абстрагироваться от плоскости управления Kubernetes и рассмотрим локальный вариант управления контейнеризированным etcd-кластером с помощью crictl.
Данное умение также поможет вам починить etcd даже в случае неработающего Kubernetes API.
Подготовка
Поэтому, первое что мы сделаем, это зайдём по ssh на одну из master-нод и найдём наш etcd-контейнер:
CONTAINER_ID=$(crictl ps -a --label io.kubernetes.container.name=etcd --label io.kubernetes.pod.namespace=kube-system | awk 'NR>1 $0~/Running/ END')Так же установим алиас, чтобы каждый раз не перечислять пути к сертификатам в командах:
alias etcdctl='crictl exec "$CONTAINER_ID" etcdctl --cert /etc/kubernetes/pki/etcd/peer.crt --key /etc/kubernetes/pki/etcd/peer.key --cacert /etc/kubernetes/pki/etcd/ca.crt'Приведённые выше команды являются временными, вам потребуется выполнять их каждый раз перед тем как начать работать с etcd. Конечно, для своего удобства вы можете добавить их в .bashrc. Однако это уже выходит за рамки этой статьи.
Если что-то пошло не так и вы не можете сделать exec в запущенный контейнер, посмотрите логи etcd:
crictl logs «$CONTAINER_ID»
А также убедитесь в наличии static-манифеста и всех сертификатов в случае если контейнер даже не создался. Логи kubelet так же бывают весьма полезными.
Проверка состояния кластера
Здесь всё просто:
# etcdctl member list -w table +------------------+---------+-------+---------------------------+---------------------------+------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +------------------+---------+-------+---------------------------+---------------------------+------------+ | 409dce3eb8a3c713 | started | node1 | https://10.20.30.101:2380 | https://10.20.30.101:2379 | false | | 74a6552ccfc541e5 | started | node2 | https://10.20.30.102:2380 | https://10.20.30.102:2379 | false | | d70c1c10cb4db26c | started | node3 | https://10.20.30.103:2380 | https://10.20.30.103:2379 | false | +------------------+---------+-------+---------------------------+---------------------------+------------+Каждый инстанс etcd знает всё о каждом. Информация о members хранится внутри самого etcd и поэтому любое изменение в ней будет также обновленно и на остальных инстансах кластера.
Важное замечание, команда member list отображает только статус конфигурации, но не статус конкретного инстанса. Чтобы проверить статусы инстансов есть команда endpoint status , но она требует явного указания всех эндпоинтов кластера для проверки.
ENDPOINTS=$(etcdctl member list | grep -o '[^ ]\+:2379' | paste -s -d,) etcdctl endpoint status --endpoints=$ENDPOINTS -w tableв случае если какой-то из эндпоинтов окажется недоступным вы увидите такую ошибку:
Failed to get the status of endpoint https://10.20.30.103:2379 (context deadline exceeded)Удаление неисправной ноды
Иногда случается так что какая-то из нод вышла из строя. И вам нужно восстановить работоспособность etcd-кластера, как быть?
Первым делом нам нужно удалить failed member:
etcdctl member remove d70c1c10cb4db26cПрежде чем продолжить, давайте убедимся, что на упавшей ноде под с etcd больше не запущен, а нода больше не содержит никаких данных:
rm -rf /etc/kubernetes/manifests/etcd.yaml /var/lib/etcd/ crictl rm "$CONTAINER_ID"Команды выше удалят static-pod для etcd и дирректорию с данными /var/lib/etcd на ноде.
Разумеется в качестве альтернативы вы также можете воспользоваться командой kubeadm reset , которая удалит все Kubernetes-related ресурсы и сертификаты с вашей ноды.
Добавление новой ноды
Теперь у нас есть два пути:
В первом случае мы можем просто добавить новую control-plane ноду используя стандартный kubeadm join механизм:
kubeadm init phase upload-certs --upload-certs kubeadm token create --print-join-command --certificate-key
Вышеприведённые команды сгенерируют команду для джойна новой control-plane ноды в Kubernetes. Этот кейс довольно подробно описан в официальной документации Kubernetes и не нуждается в разъяснении.
Этот вариант наиболее удобен тогда, когда вы деплоите новую ноду с нуля или после выполнения kubeadm reset
Второй вариант более аккуратный, так как позволяет рассмотреть и выполнить изменения необходимые только для etcd не затрагивая при этом другие контейнеры на ноде.
Для начала убедимся что наша нода имеет валидный CA-сертификат для etcd:
/etc/kubernetes/pki/etcd/ca.
В случае его отсутствия скопируейте его с других нод вашего кластера. Теперь сгенерируем остальные сертификаты для нашей ноды:
kubeadm init phase certs etcd-healthcheck-client kubeadm init phase certs etcd-peer kubeadm init phase certs etcd-serverи выполним присоединение к кластеру:
kubeadm join phase control-plane-join etcd --control-planeДля понимания, вышеописанная команда сделает следующее:
-
Добавит новый member в существующий etcd-кластер:
etcdctl member add node3 --endpoints=https://10.20.30.101:2380,https://10.20.30.102:2379 --peer-urls=https://10.20.30.103:2380--initial-cluster-state=existing --initial-cluster=node1=https://10.20.30.101:2380,node2=https://10.20.30.102:2380,node3=https://10.20.30.103:2380Создание снапшота etcd
Теперь рассмотрим вариант создания и восстановления etcd из резервной копии.
Создать бэкап можно довольно просто, выполнив на любой из нод:
etcdctl snapshot save /var/lib/etcd/snap1.dbОбратите внимание я намеренно использую /var/lib/etcd так как эта директория уже прокинута в etcd контейнер (смотрим в static-манифест /etc/kubernetes/manifests/etcd.yaml )
После выполнения этой команды по указанному пути вы найдёте снапшот с вашими данными, давайте сохраним его в надёжном месте и рассмотрим процедуру восстановления из бэкапа
Восстановление etcd из снапшота
Здесь мы рассмотрим кейс когда всё пошло не так и нам потребовалось восстановить кластер из резервной копии.
У нас есть снапшот snap1.db сделанный на предыдущем этапе. Теперь давайте полностью удалим static-pod для etcd и данные со всех наших нод:
rm -rf /etc/kubernetes/manifests/etcd.yaml /var/lib/etcd/member/ crictl rm "$CONTAINER_ID"Теперь у нас снова есть два пути:
Вариант первый создать etcd-кластер из одной ноды и присоединить к нему остальные ноды, по описанной выше процедуре.
kubeadm init phase etcd localэта команда сгенерирует статик-манифест для etcd c опциями:
--initial-cluster-state=new --initial-cluster=node1=https://10.20.30.101:2380таким образом мы получим девственно чистый etcd на одной ноде.
# etcdctl member list -w table +------------------+---------+-------+---------------------------+---------------------------+------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +------------------+---------+-------+---------------------------+---------------------------+------------+ | 1afbe05ae8b5fbbe | started | node1 | https://10.20.30.101:2380 | https://10.20.30.101:2379 | false | +------------------+---------+-------+---------------------------+---------------------------+------------+Восстановим бэкап на первой ноде:
etcdctl snapshot restore /var/lib/etcd/snap1.db \ --data-dir=/var/lib/etcd/new \ --name=node1 \ --initial-advertise-peer-urls=https://10.20.30.101:2380 \ --initial-cluster=node1=https://10.20.30.101:2380 mv /var/lib/etcd/member /var/lib/etcd/member.old mv /var/lib/etcd/new/member /var/lib/etcd/member crictl rm "$CONTAINER_ID" rm -rf /var/lib/etcd/member.old/ /var/lib/etcd/new/На остальных нодах выполним присоединение к кластеру:
kubeadm join phase control-plane-join etcd --control-planeВариант второй: восстановить бэкап сразу на всех нодах кластера. Для этого копируем файл снапшота на остальные ноды, и выполняем восстановление вышеописанным образом. В данном случае в опциях к etcdctl нам потребуется указать сразу все ноды нашего кластера, к примеру
для node1:
etcdctl snapshot restore /var/lib/etcd/snap1.db \ --data-dir=/var/lib/etcd/new \ --name=node1 \ --initial-advertise-peer-urls=https://10.20.30.101:2380 \ --initial-cluster=node1=https://10.20.30.101:2380,node2=https://10.20.30.102:2380,node3=https://10.20.30.103:2380для node2:
etcdctl snapshot restore /var/lib/etcd/snap1.db \ --data-dir=/var/lib/etcd/new \ --name=node2 \ --initial-advertise-peer-urls=https://10.20.30.102:2380 \ --initial-cluster=node1=https://10.20.30.101:2380,node2=https://10.20.30.102:2380,node3=https://10.20.30.103:2380для node3:
etcdctl snapshot restore /var/lib/etcd/snap1.db \ --data-dir=/var/lib/etcd/new \ --name=node3 \ --initial-advertise-peer-urls=https://10.20.30.103:2380 \ --initial-cluster=node1=https://10.20.30.101:2380,node2=https://10.20.30.102:2380,node3=https://10.20.30.103:2380Потеря кворума
Иногда случается так что мы потеряли большинство нод из кластера и etcd перешёл в неработоспособное состояние. Удалить или добавить новых мемберов у вас не получится, как и создать снапшот.
Выход из этой ситуации есть. Нужно отредактировать файл static-манифеста и добавить ключ —force-new-cluster к etcd:
/etc/kubernetes/manifests/etcd.yamlпосле чего инстанс etcd перезапустится в кластере с единственным экземпляром:
# etcdctl member list -w table +------------------+---------+-------+---------------------------+---------------------------+------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +------------------+---------+-------+---------------------------+---------------------------+------------+ | 1afbe05ae8b5fbbe | started | node1 | https://10.20.30.101:2380 | https://10.20.30.101:2379 | false | +------------------+---------+-------+---------------------------+---------------------------+------------+Теперь вам нужно очистить и добавить остальные ноды в кластер по описанной выше процедуре. Только не забудьте удалить ключ —force-new-cluster после всех этих манипуляций 😉
- Kubernetes
- etcd
- администрирование
- кто читает тэги?
- Системное администрирование
- *nix
- DevOps
- Микросервисы
- Kubernetes
Краткое введение в etcd
Такое чувство, будто в последние месяцы я черезчур уж сильно сосредоточился на дебаггинге и .NET Core, и как-то подзабил на топик, ради которого весь этот блог и затевался — DevOps и распределённые приложения. Ошибку осознал, и сегодня мы посмотрим на что-нибудь более релевантное. Например, etcd.
Во время моего романа с распределёнными приложениями etcd всегда был где-то неподалёку. То он был альтернативой Consul, когда я разбирался с сервис-дискавери и управлением конфигурациями. То etcd всплыл как основное хранилище настроек кластера в Kubernetes. В общем, он везде. Так что я думаю, стоит разобраться, на что же это за зверь такой.
Что такое etcd
etcd — это примитивное но при этом высоконадёжное распределённое хранилище для пар ключ-значение. «Примитивное» не значит, что тупое. Это просто значит что etcd фокусируется только на хранении и связанными с этим задачами. Ну и «высоконадёжный» и «распределённый» подразумевает, что если даже одна из кластера машин с etcd упадёт, то данными и кластером всё будет в порядке. По сравнению с тем же Consul фич тут будет поменьше, но в реальных задачах для того, чтобы забить гвоздь, отбойный молоток и не нужен.
Правда, то, что etcd просто хранит пары ключ-значение, не означает, что там всего три команды (get/set/remove) и на этом всё. Данные можно хранить по-разному, и etcd поддерживает и транзакции для работы с данными, и возможность отслеживать изменения, и настраивать пользователей с ролями, и всякие примитивы для синхронизации использовать, и даже даёт возможность установить время жизни значений (TTL).
В общем, будем смотреть.
Установка
Etcd поддерживает лучший из способов для установки — скачай-и-готово, и это прекрасно. Как всегда, я очень ленивый и параноидальный, поэтому вместо того, чтобы запускать временное и непонятно что на своей машине, я лучше напишу Vagrantfile с инструкциями для закачки и развёртывания, и получу готовую к надругиванию виртуальную с etcd внутри в одну команду.
По итогу, вот какой Vagrantfile у меня получился.
Etcd что это
GolangConf: Go для высоконагруженных систем
Целевая аудитория
Backend разработчики
Тезисы
ETCD — это распределенная key-value база данных, которая набирает все большую популярность. Она написана на Go и работает поверх консенсус-протокола RAFT. Эта та самая база данных, поверх которой работает Kubernetes.
В данный момент я работаю над Kubernetes-like платформой и в какой момент мы начали онбординг части наших данных в ETCD.
В начале этого года я провел много времени вместе с этим решением и теперь готов поделиться опытом и рассказать пару «смешных» историй, за которыми стоит много-много боли.
Что вы узнаете из доклада:
# Что такое ETCD
# Как оно работает
# Как им пользоваться из GO.
# Настолько ли база быстрая, как о ней пишут?
# С какими проблемами можно столкнуться
# Поймете, что watch доверять нельзя 🙂
Что такое etcd

Опубликовано: 08.09.2022
распределенная база типа ключ-значение (kv). Позиционируется как высоконадежное и строго согласованное решение. Название etcd не является аббревиатурой и никак не расшифровывается.
Обладает минимальным набором функций, основной фокус которых направлен только на выполнение основной задачи. Etcd предоставляет следующие возможности:
- Отслеживание изменений.
- Хранение данных (ключ-значение).
- Простой http-интерфейс для манипуляции данными.
Наиболее популярная область применения — хранение конфигураций и реализация обнаружения сервисов (service discovery). В качестве примера использования etcd можно привести:
- Хранение информации о состоянии кластера Kubernetes.
- Реализация кластера PostgreSQL + Patroni.
Программный продукт распространяется бесплатно. Его можно установить путем копирования бинарника. Подробную информацию можно найти на официальном сайте в разделе документации.
Среди аналогов можно выделить Consul, Zookeeper и Redis (KeyDB). Последний не позиционируется как решение service discovery, но является популярным решением kv. В отличие от Consul, etcd не позволяет получить под ключ информацию об активном сервисе. Но он предоставляет удобный инструментарий для выполнения данных операций вручную или с применением специализированного софта, например, confd.
Встречается в статьях
Инструкции:
Мини-инструкции:
- Настройка отказоустойчивого кластера Postgres с помощью Patroni и хранением метеданных в Consul
- Настройка отказоустойчивого кластера Postgres + Patroni на Linux CentOS
- Настройка отказоустойчивого кластера Postgres + Patroni на Linux Ubuntu