MongoDB: Запросы
Хоть и некоторые писали относительно моего предыдущего топика MongoDB: Создание, обновление и удаление документов, что это пересказ офф. документации, я с этим не полностью согласен. Мне показалось, что информация в нём оказалось кому-то полезной, поэтому выкладываю продолжение.
Find — аналог SELECT в MySQL. Используется для выборки документов из MongoDB. Возвращает массив документов в виде коллекции, если документов нет — пустую коллекцию. Пример:
Вернёт всех пользователей из коллекции.
Вернёт всех пользователей, у которых возраст равен 27.
Можно указывать несколько параметров, например, вот так:
Иногда бывает необходимо получить какие то конкретные поля из документов. В этом случае запрос выглядит так:
В итоге получим всех пользователей только с полями «username» и «email» + поле «_id», которое возращается всегда по умолчанию. Если поле «_id» или какое-либо другое не нужно, мы можем это указать вот так:
Запросы с условием
Операторы: $lt — меньше, $lte — меньше или равно, $gt — больше, $gte — больше или равно, $ne — не равно.
Примеры использования:
Получаем всех пользователей, возраст которых больше 18 и меньше 30
Получаем всех пользователей, «username» которых не равен “joe”
Допустим, у нас коллекция хранит лотерейные билеты с номерами и нам нужно найти только те, в которых есть победившие номера 390, 754, 454. В таком случае мы используем оператор $in:
т.е. билет должен содержать один из этих номеров.
Противоположным оператору $in является $nin. Он, по аналогии, получает только те билеты, где нет, указанных выше, номеров.
Оператор $or используется при запросах, когда нужно выбрать документы по совпадению одному из значений. Например, нам нужно выбрать все билеты с номером 547 или где поле «winner» равно true:
Оператор $mod используется для выборки ключей, значения которых делятся на первый аргумент и остаток от деления получается равным второму аргументу. Звучит непонятно, вот более наглядно:
Такой запрос вернёт всех пользователей, «user_id» которых равен 1, 6, 11, 16 и так далее.
Чтоб получить всех пользователей, кроме вышеуказанных можно использовать оператор $not:
Получим пользователей с «user_id» 2, 3, 4, 5, 7, 8, 9, 10, 12 и так далее.
Существует также оператор для проверки существует ли какой то ключ или нет — $exist
Так можно выбрать все документы коллекции, где существует ключ “z” и он равен null.
Регулярные выражения
Все мы знаем, что регулярные выражения очень мощная штука. MongoDB использует Perl-совместимые регулярные выражения.
Вот так можно найти всех пользователей с именем joe или Joe:
Вообщем есть где разгуляться. Есть куча сервисов для того же javascript’a, где можно писать и проверять свои регулярки.
Запросы в массивах
Допустим есть у нас коллекция food и мы туда вставляем документ с массивом фруктов
То вот такой запрос
успешно его найдёт.
Если нужно выбрать документы больше, чем по одному элементу массива, то мы можем использовать оператор $all
Такой запрос вернёт все документы, в массиве фруктов которых, есть и яблоки, и бананы.
Получить документы по полному совпадению элементов в массиве можем так:
Есть у нас блог, в нём хранятся комментарии. Мы хотим получить первые 10 комментариев. На помощь нам приходит оператор $slice:
findOne — работает аналогично find, но возвращает первый совпавший документ.
Если нужно получить последние 10 комментариев пишем вот так:
Также $slice умеет получать документы из середины:
в этом случае будет пропущено 23 начальных элемента и вернутся элементы с 24 по 34, если это возможно
Команды limit, skip и sort
Для того, чтоб получить ограниченное количество документов по запросу используется команда limit:
Вернёт первых 3-х пользователей.
Для того, чтоб пропустить несколько документов и получить все остальные используется команда skip:
Получаем всех пользователей, кроме первых трёх.
Для сортировки используется команда sort. Сортировка может быть по возрастанию (1) и по убыванию (- 1). Сортировка может производится по нескольким ключам в порядке их приоритета:
Все эти три команды можно использовать вместе:
Использование команды skip с большими значениями работает не особо быстро. Рассмотрим это на примере пагинации:
Самый простой способ сделать пагинацию это в первый раз вернуть фиксированное количество документов, а потом каждый раз смещать диапазон на это значение
> var page1 = db.foo.find(criteria).limit(100)
> var page2 = db.foo.find(criteria).skip(100).limit(100)
> var page3 = db.foo.find(criteria).skip(200).limit(100)
но это будет работать довольно медленно. Допустим мы будет делать выборку относительно даты создания документа:
> var page1 = db.foo.find().sort( ).limit(100);
Сортируем по убыванию и берём первые 100. Чтоб не делать skip мы можем получить дату последнего документа и сделать запрос уже относительно этой даты:
Так можно избежать использования команды skip для больших значений.
По сути это основные вещи относительно запросов в MongoDB. Надеюсь это кому-нибудь пригодится.
Какая команда в mongodb заменяет select из mysql
Наиболее простой способом выборки документов из коллекции представляет использование функции find() . Действие этой функции во многом аналогично обычному запросу SELECT * FROM Table , который применяется в SQL и который извлекает все строки. Например, чтобы извлечь все документы из коллекции users, созданной в прошлой теме, мы можем использовать команду:
db.users.find()
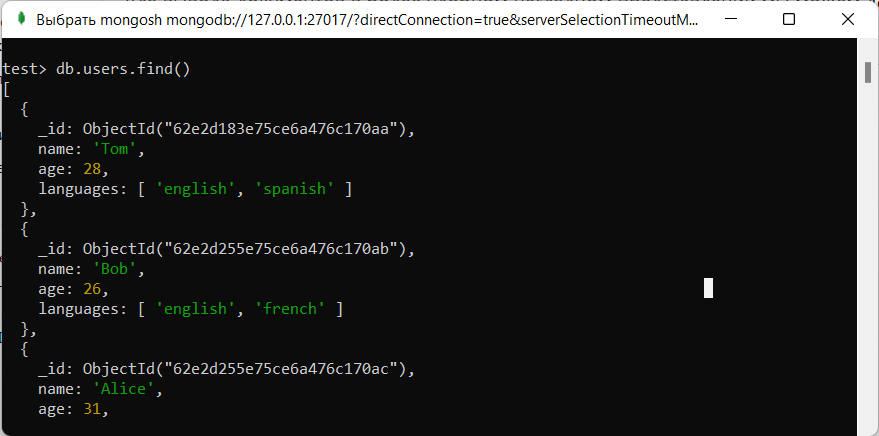
Фильтрация данных
Однако что, если нам надо получить не все документы, а только те, которые удовлетворяют определенному требованию. Например, мы ранее в базу добавили следующие документы:
db.users.insertOne() db.users.insertOne() db.users.insertOne()
Выведем все документы, в которых name=Tom:
db.users.find()
Такой запрос выведет нам два документа, в которых name=Tom.
test> db.users.find() [ < _id: ObjectId("62e2d6a5e75ce6a476c170b3"), name: 'Tom', age: 28, languages: [ 'english', 'spanish' ] >, < _id: ObjectId("62e2d348e75ce6a476c170ae"), _id: ObjectId("62e2d6a5e75ce6a476c170b5"), name: 'Tom', age: 32,s: [ 'english', 'spanish' ] languages: [ 'english', 'german' ] >] _id: ObjectId("62e2d3d5e75ce6a476c170af"), test>
Теперь более сложный запрос: нам надо вывести те объекты, у которых name=Tom и одновременно age=32. То есть на языке SQL это могло бы выглядеть так: SELECT * FROM Table WHERE Name=’Tom’ AND Age=32 . Данному критерию у нас соответствует последний добавленный объект. Тогда мы можем написать следующий запрос:
db.users.find()
Фильтрация по отсутствующим свойствам
Какие-то документы могут иметь определенное свойство, другие могут его не иметь. Что если мы хотим получить документы, в которых отсутствует определенное свойство? В этом случае для свойства передается значение null . Например, найдем все документы, где отсутствует свойство languages :
db.users.find()
Или найдем все документы, где name=»Tom» , но свойство languages не определено.
db.users.find()
Фильтрация по элементам массива
Также несложно отыскать по элементу в массиве. Например, следующий запрос выводит все документы, у которых в массиве languages есть english:
db.users.find()
Усложним запрос и получим те документы, у которых в массиве languages одновременно два языка: «english» и «german»:
db.users.find()
Причем именно в этом порядке, где «english» определен первым, а «german» — вторым.
Теперь выведем все документы, в которых «english» в массиве languages находится на первом месте:
db.users.find()
Обратите внимание, что «languages.0» предоставляет сложное свойство и поэтому берется в кавычки. Соответственно если нам надо вывести документы, где english на втором месте (например, [«german», «english»] ), то вместо нуля ставим единицу: «languages.1» .
Рассмотрим более сложный пример, где элемент массива представляет сложный объект. Допустим, у нас в базе данных следующие документы:
db.users.insertOne(, ]>) db.users.insertOne(, ]>) db.users.insertOne(<"name": "Sam", "age": 31, friends: []>) db.users.insertOne(, , ]>)
Выберем все документы, где в массиве friends свойство name первого элемента равно «Bob»:
test> db.users.find()
test> db.users.find() [ < _id: ObjectId("62e39da1c881653067e87901"), name: 'Tim', age: 29, friends: [ < name: 'Bob' >, < name: 'Tom' >] >, < _id: ObjectId("62e39da1c881653067e87903"), name: 'Tom', age: 32, friends: [ < name: 'Bob' >, < name: 'Tim' >, < name: 'Sam' >] > ] test>
Проекция
Документ может иметь множество полей, но не все эти поля нам могут быть нужны и важны при запросе. И в этом случае мы можем включить в выборку только нужные поля, использовав проекцию. Например, выведем только порцию информации, например, значения полей «age» у все документов, в которых name=Tom:
db.users.find(, )
Использование единицы в качестве параметра указывает, что запрос должен вернуть только содержание свойства age.
test> db.users.find(, ) [ < _id: ObjectId("62e2d6a5e75ce6a476c170b3"), age: 28 >, < _id: ObjectId("62e2d6a5e75ce6a476c170b5"), age: 32 >, < _id: ObjectId("62e2d799e75ce6a476c170b7"), age: 28 >, < _id: ObjectId("62e39da1c881653067e87903"), age: 32 >] test>
И обратная ситуация: мы хотим найти все поля документа кроме свойства age. В этом случае в качестве параметра указываем 0:
db.persons.find(, )
При этом надо учитывать, что даже если мы отметим, что мы хотим получить только поле name, поле _id также будет включено в результирующую выборку. Поэтому, если мы не хотим видеть данное поле в выборке, то надо явным образом указать:
Альтернативно вместо 1 и 0 можно использовать true и false:
db.users.find(, )
Если мы не хотим при этом конкретизировать выборку, а хотим вывести все документы, то можно оставить первые фигурные скобки пустыми:
db.users.find(<>, )
Запрос к вложенным объектам
Предыдущие запросы применялись к простым объектам. Но документы могут быть очень сложными по структуре. Например, добавим в коллекцию users следующий документ:
db.users.insertOne(>)
Здесь определяется вложенный объект с ключом company. И чтобы найти все документы, у которых в ключе company вложенное свойство name=microsoft, нам надо использовать оператор точку:
db.users.find()
Использование JavaScript
Кроме выполнения запросов к базе данных мы можем выполнять выражения JavaScript. Например, мы можем создать какую-нибудь функцию и применять ее:
function sqrt(n) < return n*n; >sqrt(5)
test> function sqrt(n) < return n*n; >[Function: sqrt] test> sqrt(5) 25 test>
И подобные функции и выражения JavaScript мы можем применять в запросах к БД. Например, найдем все документы, где поле age равно sqrt(5)+3:
test> db.users.find() [ < _id: ObjectId("62e2d6a5e75ce6a476c170b3"), name: 'Tom', age: 28, languages: [ 'english', 'spanish' ] >, < _id: ObjectId("62e2d76ae75ce6a476c170b6"), name: 'Tomas', age: 28 >, < _id: ObjectId("62e2d799e75ce6a476c170b7"), name: 'Tom', age: 28 >, < _id: ObjectId("62e39da1c881653067e87900"), name: 'Bob', age: 28 >] test>
Использование регулярных выражений
Еще одной замечательной возможностью при построении запросов является использование регулярных выражений. Например, найдем все документы, в которых значение ключа name начинается с буквы B:
db.users.find()
Примерный консольный вывод:
test> db.users.find() [ < _id: ObjectId("62e2d6a5e75ce6a476c170b4"), name: 'Bill', age: 32, languages: [ 'english', 'french' ] >, < _id: ObjectId("62e39da1c881653067e87900"), name: 'Bob', age: 28 >] test>
Поиск одиночного документа
Если все документы извлекаются функцией find , то одиночный документ извлекается функцией findOne
Например, выберем один элемент с name=»Tom» :
test> db.users.findOne() < _id: ObjectId("62e2d6a5e75ce6a476c170b3"), name: 'Tom', age: 28, languages: [ 'english', 'spanish' ] >test>
Курсоры
Результат выборки, получаемой с помощью функции find , называется курсором . При необходимости мы можем передать курсор в отдельную переменную:
var cursor = db.users.find()
Курсоры инкапсулируют в себе наборы получаемых из бд объектов. Используя синтаксис языка javascript и методы курсоров, мы можем вывести полученные документы на экран и как-то их обработать. Например:
var cursor = db.users.find() while(cursor.hasNext())
Курсор обладает методом hasNext , который показывает при переборе, имеется ли еще в наборе документ. А метод next извлекает текущий документ и перемещает курсор к следующему документу в наборе. В итоге в переменной obj оказывается документ, к полям которого мы можем получить доступ.
test> var cursor = db.users.find() test> while(cursor.hasNext()) < . obj = cursor.next(); . print(obj["name"]); . >Tom Bob Sam test>
Также для перебора документов в курсоре в качестве альтернативы мы можем использовать конструкцию итератора javascript — forEach :
var cursor = db.users.find() cursor.forEach(function(obj)< print(obj.name); >)
Учебник Express часть 3: Использование базы данных (с помощью Mongoose)
В этой статье даётся краткое введение в базы данных, и методика их использования в приложениях Node/Express. Затем мы покажем, как можно использовать Mongoose для доступа к базе данных веб-сайта LocalLibrary. Мы объясним, как объявляются схемы и модели объектов, укажем основные типы полей, и методику базовой валидации. В статье также кратко показаны основные методы доступа к данным модели.
| Предварительные сведения: | Express Tutorial Part 2: Creating a skeleton website |
|---|---|
| Цель: | Уметь спроектировать и создать свои модели, используя Mongoose. |
Обзор
Сотрудники библиотеки будут использовать сайт Local Library для хранения информации о книгах и абонентах, а абоненты библиотеки будут использовать его для просмотра и поиска книг, для получения информации о доступных копиях, для резервирования или одалживания книг. Чтобы эффективно хранить и извлекать информацию, мы будем хранить её в базе данных.
Express-приложения могут использовать различные базы данных, и есть несколько подходов, которые можно использовать для выполнения операций Create, Read, Update and Delete (CRUD) (создать, прочесть, обновить, удалить). В руководстве дан краткий обзор некоторых доступных опций, и детально рассмотрены некоторые механизмы работы.
Какие базы данных можно использовать?
*Express-*приложение может использовать любые базы данных, поддерживаемые Node (сам по себе Express не определяет каких-либо конкретных дополнительных свойств и требований для управления базами данных). Есть много популярных вариантов — PostgreSQL, MySQL, Redis, SQLite, и MongoDB.
При выборе базы данных следует учитывать такие факторы как время разработки, время обучения, простота репликации и копирования, расходы, поддержка сообщества и т. д. Хотя нет единственной «лучшей» базы данных, почти любое из популярных решений будет приемлемым для сайта малого и среднего размера, такого как наша Local Library.
Более подробно о вариантах смотрите в: Database integration (Express docs).
Каков наилучший способ взаимодействия с базой данных?
Существует два подхода при работе с базой данных:
- Использование родного языка запросов баз данных (т.е. SQL)
- Использование объектной модели данных (ODM) или объектно-реляционной модели (ORM). ODM / ORM представляют данные веб-сайта как объекты JavaScript, которые затем отображаются на поддерживающую базу данных. Некоторые ORM привязаны к определённой базе данных, тогда как другие не зависят от конкретной базы данных.
Наилучшую производительность можно получить с помощью SQL или другого языка запросов, поддерживаемого базой данных. Объектные модели (ODM) часто медленнее, потому что требуют перевода объектов в формат базы данных, при этом не обязательно будут использованы наиболее эффективные запросы к базе данных (особенно, если ODM предназначена для различных баз данных и должна идти на большие компромиссы в смысле поддержки тех или иных функций базы данных).
Преимущество применения ORM состоит в том, что программисты могут сосредоточиться на объектах JavaScript, а не на семантике базы данных — особенно, если требуется работать с разными базами данных (на одном или разных веб-сайтах). Они также дают очевидное место для валидации и проверки данных.
Примечание: Совет: Применение ODM / ORMs часто приводит к снижению затрат на разработку и обслуживание! Если вы не очень хорошо знакомы с языком запросов базы данных или если производительность не имеет первостепенного значения, следует серьёзно рассмотреть возможность применения ODM.
Какую модель ORM/ODM следует использовать?
Есть много ODM/ORM доступных решений на сайте менеджера пакетов NPM (проверьте теги по подгруппе odm и orm).
Популярные решения на момент написания статьи:
- Mongoose: — это средство моделирование объектов базы данных MongoDB, предназначенное для асинхронной работы.
- Waterline: ORM фреймворка Sails (основан на Express) . Она предоставляет единый API для доступа к множеству баз данных, в том числе Redis, mySQL, LDAP, MongoDB, и Postgres.
- Bookshelf: поддерживает как promise- так и традиционные callback- интерфейсы, поддержка транзакций, eager/nested-eager relation loading, полиморфные ассоциации, и поддержка, один к одному, один ко многим, и многие ко многим. Работает с PostgreSQL, MySQL, и SQLite3.
- Objection: Делает настолько лёгким, насколько возможно, использование всей мощи SQL и движка базы данных ( поддерживает SQLite3, Postgres, и MySQL).
- Sequelize: Основанная на промисах ORM для Node.js и io.js. Поддерживает диалекты PostgreSQL, MySQL, MariaDB, SQLite и MSSQL, обладает надёжной поддержкой транзакций, отношений, чтения копий и т.д.
- Node ORM2 — это OR менеджер для NodeJS. Поддерживает MySQL, SQLite и Progress, помогает работать с БД, используя объектный подход.
- JugglingDB — это кросс-ДБ ORM для NodeJS, обеспечивающая общий интерфейс для доступа к наиболее популярным форматам БД. Поддерживает MySQL, SQLite3, Postgres, MongoDB, Redis и хранение данных в памяти js (собственный движок, только для тестирования).
Как правило, при выборе решения следует учитывать как предоставляемые функции, так и «деятельность сообщества» ( загрузки, вклад, отчёты об ошибках, качество документации, и т.д. ) . На момент написания статьи Mongoose являлась очень популярной ORM, и разумно, если вы выбрали MongoDB.
Применение Mongoose и MongoDb для LocalLibrary
В примере LocalLibrary (и до конца раздела) мы будем использовать Mongoose ODM для доступа к данным нашей библиотеки. Mongoose является интерфейсом для MongoDB, NoSQL-базы данных с открытым исходным кодом, в которой использована документов-ориентированная модель данных. В MongoDB «коллекции» и «документы» — это аналоги «таблиц» и «строк» в реляционных БД.
Это сочетание ODM и БД весьма популярно в сообществе Node, частично потому, что система хранения документов и запросов очень похожа на JSON и поэтому знакома разработчикам JavaScript.
Примечание: Не обязательно знать MongoDB, чтобы использовать Mongoose, хотя документацию Mongoose легче использовать и понимать, если вы уже знакомы с MongoDB.
Далее показано, как определить и получить доступ к схеме и моделям Mongoose для примера веб-сайта LocalLibrary.
Проектирование моделей LocalLibrary
Прежде чем начинать писать код моделей, стоит обдумать, какие данные нам нужно хранить, и каковы отношения между разными объектами.
Мы знаем, что нужно хранить информацию о книгах (название, резюме (краткое описание), автор, жанр, ISBN (Международный стандартный книжный номер) ) и что может быть несколько доступных экземпляров (с уникальными идентификаторами, статусом наличия и т. д.). Может потребоваться хранить больше информации об авторе (не только имя, т.к. могут быть авторы с одинаковыми или похожими именами). Мы хотим иметь возможность сортировать данные по названиям книг, по авторам, по жанрам и категориям.
При проектировании моделей имеет смысл иметь отдельные модели для каждого «объекта» (группы связанных данных). В этом случае очевидными объектами являются книги, экземпляры книг и авторы.
Можно также использовать модели для представления параметров списка выбора (например, как выпадающий список вариантов), вместо жёсткого кодирования выбора на самом веб-сайте — рекомендуется, когда не все параметры известны или могут быть изменены. Явный кандидат для модели такого типа — это жанр книги (например, «Научная фантастика», «Французская поэзия» и т.д.),
Как только мы определились с моделями и полями, следует подумать об отношениях между ними.
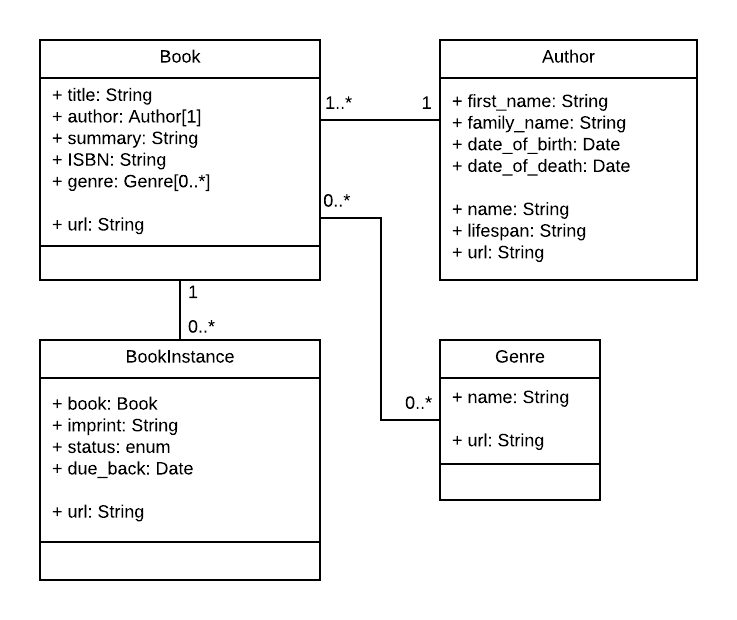
С учётом сказанного, UML-диаграмма связей (см. ниже) показывает модели, которые представлены как прямоугольники. Мы решили, что создадим модели для книги (общие сведения о книге), для экземпляра книги (состояние отдельных физических копий книги, доступных в системе) и для автора. Кроме того, у нас будет модель для жанра, чтобы эти значения можно было создавать динамически. Решено не создавать модель для BookInstance:status — мы пропишем в коде необходимые значения, потому что не ожидаем их изменения. На элементах диаграммы показаны имя модели, имена и типы полей, имена методов и типы их результатов .
Также показаны отношения между моделями, включая множественные отношения. Числа на линиях связи показывают максимум и минимум моделей, участвующих отношении. Например, линия между Book и Genre показывает, что Book и Genre связаны. Числа на этой линии рядом с моделью Book показывают, что жанр может быть связан с любым количеством книг, а числа на другом конце линии рядом с Genre отмечают, что книга может быть связана с любым количеством жанров.
Примечание: Как показано в Учебнике по Mongoose ниже, часто лучше иметь поле, определяющее отношение между документами (моделями), только в одной модели (обратное отношение можно найти по присвоенному идентификатору _id в другой модели). Ниже мы предпочли задать отношения между Book/Genre и между Book/Author в схеме Book, а отношение между Book/BookInstance — в схеме BookInstance. Этот выбор в некотором смысле был произвольным — таким же хорошим мог бы быть выбор другого поля в другой схеме.
Примечание: В следующем разделе дан базовый учебник, в котором объясняется, как задавать и как использовать модели. При чтении обратите внимание, как будут создаваться модели, приведённые на диаграмме.
Учебник по Mongoose
В этом разделе кратко описано как подключиться к базе MongoDB с помощью Mongoose, как определить схемы и модели, как сформировать основные запросы.
Установка Mongoose и MongoDB
Mongoose устанавливается в ваш проект (package.json) как и другие зависимости — при помощи NPM. Команда установки (выполняется из каталога проекта):
npm install mongoose
Установка Mongoose добавит все зависимости, включая драйвер MongoDB, но не установит саму базу данных. При желании установить сервер MongoDB локально, можно скачать установочный файл здесь для своей операционной системы и установить его. Также можно использовать облако MongoDB.
Примечание: В примере для хранения базы данных мы используем облачный сервис sandbox tier («песочницу»). Это удобно для разработки и имеет смысл для руководства, потому что такой подход делает «установку» базы данных независимой от операционной системы (база данных как веб-сервис — это также подход, который вы можете использовать для своей базы данных, находящейся в реальной эксплуатации).
Подключение к MongoDB
Mongoose требует подключение к MongoDB. Вы можете использовать require() и подключится к локальной БД при помощи mongoose.connect(), как показано ниже.
// Импортировать модуль mongoose var mongoose = require("mongoose"); // Установим подключение по умолчанию var mongoDB = "mongodb://127.0.0.1/my_database"; mongoose.connect(mongoDB); // Позволим Mongoose использовать глобальную библиотеку промисов mongoose.Promise = global.Promise; // Получение подключения по умолчанию var db = mongoose.connection; // Привязать подключение к событию ошибки (получать сообщения об ошибках подключения) db.on("error", console.error.bind(console, "MongoDB connection error:"));
При помощи mongoose.connection можно получить стандартный объект Connection . После подключения в экземпляре Connection возникает событие open (открыт).
Примечание: Если необходимо создать дополнительные подключения, можно использовать mongoose.createConnection() . При этом будут применены те же БД URI (хост, БД, порт, опции и т.д.), что и в connect() и будет возвращён объект Connection .
Определение и создание моделей
Модели можно создать при помощи интерфейса Schema . Schema позволяет указать поля, которые будут в каждом документе, значения полей по умолчанию и требования по валидации. Кроме того, можно задать статические методы и методы-хелперы (от help), облегчающие работу с вашими типами данных, а также задать виртуальные свойства, которые можно использовать как и обычные поля, но без влияния на данные в самой базе данных.
Схемы «компилируются » в окончательную модель методом mongoose.model() . После создания модели её можно использовать для поиска, создания, обновления и удаления объектов данного типа.
Примечание: Каждой модели соответствует коллекция документов в ДБ MongoDB. Документы будут содержать поля тех типов, которые заданы в модели Schema .
Определение схем данных
Код ниже показывает, как можно задать простую схему. Сначала при помощи require() создаётся объект mongoose, затем конструктор Schema создаёт новый экземпляр схемы, при этом различные поля задаются как параметры конструктора.
//Требуется Mongoose var mongoose = require("mongoose"); //Определяем схему var Schema = mongoose.Schema; var SomeModelSchema = new Schema( a_string: String, a_date: Date, >);
В примере созданы два поля, типа String и типа Date. В следующем разделе будут примеры полей других типов, их валидации и примеры других методов.
Создание модели
Модели создаются из схем методом mongoose.model() :
// Определяем схему var Schema = mongoose.Schema; var SomeModelSchema = new Schema( a_string: String, a_date: Date, >); // Компилируем модель из схемы var SomeModel = mongoose.model("SomeModel", SomeModelSchema);
Первый аргумент — уникальное имя создаваемой для модели коллекции(Mongoose создаст коллекцию для модели SomeModel), второй аргумент — схема, которая используется для создания модели.
Примечание: После создания классов модели они могут применяться для создания, обновления или удаления записей в базе, для выполнения запросов по всем записям или по их подмножествам. Как это делать, будет показано в разделе Использование моделей, и когда будут создаваться представления.
Типы схемы (поля)
Схема может содержать любое количество полей, причём каждое поле будет полем документа, хранимого в БД MongoDB. Схема-пример содержит определения многих широко используемых типов полей.
var schema = new Schema( name: String, binary: Buffer, living: Boolean, updated: type: Date, default: Date.now >, age: type: Number, min: 18, max: 65, required: true >, mixed: Schema.Types.Mixed, _someId: Schema.Types.ObjectId, array: [], ofString: [String], // You can also have an array of each of the other types too. nested: stuff: type: String, lowercase: true, trim: true > >, >);
Большинство типов в SchemaTypes (указаны после «type:» или после имён полей) достаточно очевидны. Исключения:
- ObjectId : Представляет отдельный экземпляр модели в БД. Например, book может ссылаться на объект- автора. Поле будет содержать уникальный идентификатор ( _id ) отдельного объекта. При необходимости использования этой информации применяют метод populate() .
- Mixed: Произвольный тип в схеме.
- []: Массив элементов. В таких моделях можно выполнять JavaScript-операции для массивов (push, pop, unshift, etc.). Выше показан пример массива объектов неопределённого типа и массив строк, но можно использовать массив объектов любого типа.
Код содержит также два способа объявления полей:
- Имя и тип поля как пара «ключ-значение» (поля name , binary и living ).
- Имя поля, после которого указывается объект, определяющий тип и другие возможности поля, такие как:
- значения по умолчанию.
- встроенные валидаторы (например, значения max и min) и функции-валидаторы пользователя.
- Является ли поле обязательным
- Должны ли строковые поля автоматически преобразовываться в нижний или верхний регистр, удалять ли ведущие и хвостовые пробелы ( пример: < type: String, lowercase: true, trim: true >)
Дополнительная информация — в SchemaTypes (документация Mongoose).
Валидация (проверка допустимости)
Mongoose предусматривает встроенные валидаторы, валидаторы пользователя, синхронные и асинхронные валидаторы. Во всех случаях можно задать допустимые диапазоны или значения, а также сообщения об ошибках при нарушении условий валидации.
Встроенные валидаторы включают:
- Все SchemaTypes имеют встроенный валидатор required, который определяет, должно ли поле быть заданным перед сохранением документа.
- Числа имеют валидаторы min и max.
- Строки имеют:
- enum (перечисления): задают множество допустимых для поля значений.
- match (соответствия)): задают регулярное выражение, которому должна соответствовать строка.
- maxlength, minlength -максимальная и минимальная длина строки.
Пример ниже (с небольшими изменениями из документации Mongoose) показывает, как задать некоторые валидаторы и сообщения об ошибках:
var breakfastSchema = new Schema( eggs: type: Number, min: [6, 'Too few eggs'], max: 12 required: [true, 'Why no eggs?'] >, drink: type: String, enum: ['Coffee', 'Tea', 'Water',] > >);
Подробная информация по валидации полей — в разделе Validation (документация Mongoose).
Виртуальные свойства
Виртуальные свойства — это свойства документа, которые можно читать (get) и задавать (set), но которые не хранятся в MongoDB. Методы «геттеры» полезны для форматирования и соединения полей, а «сеттеры» применяют для декомпозиции отдельных значений на несколько частей перед сохранением в БД. Пример из документации собирает (и разбирает) виртуальное свойство «полное имя» из полей «имя» и «фамилия», что удобнее, чем конструировать полное имя каждый раз, когда оно используется в шаблоне.
Примечание: В библиотеке виртуальное свойство будет применено для определения уникального URL каждой записи в модели по пути и по значению _id записи.
Подробная информация — в разделе Virtuals (документация Mongoose).
Методы и помощники запросов
В схеме можно также задать методы экземпляра (instance methods), статические (static) методы и помощники запросов. Статические методы и методы экземпляра аналогичны, но различаются тем, что методы экземпляра связаны с конкретной записью и имеют доступ к текущему объекту. Помощники запросов позволяют расширить API построителя цепочек запросов (например, можно добавить запрос «byName» («по имени») в дополнение к методам find() , findOne() и findById() ).
Применение моделей
Подготовленную схему можно использовать для создания моделей. Модель представляет коллекцию документов в базе данных, в которой можно выполнять поиск, тогда как экземпляры модели представляют отдельные документы, которые можно сохранять и извлекать.
Ниже предлагается краткий обзор. Более подробно смотрите в Models (документация Mongoose).
Создание и изменение документов
Чтобы создать запись, следует определить экземпляр модели и вызвать метод save() . В примере ниже SomeModel — это модель с единственным полем «name», которую мы создадим из нашей схемы.
// Создать экземпляр модели SomeModel var awesome_instance = new SomeModel( name: "awesome" >); // Сохранить новый экземпляр, передав callback awesome_instance.save(function (err) if (err) return handleError(err); // сохранили! >);
Создание записей (а также обновления, удаления и запросы) — это асинхронные операции, поэтому следует предусмотреть колбэк-функцию, которая будет вызвана при завершении операции. В API используется соглашение о первом аргументе, согласно которому первый аргумент колбэк-функции должен быть значением ошибки (или null). Если API возвращает некоторый результат, он должен быть вторым аргументом.
Можно использовать метод create() для создании экземпляра модели при его сохранении. Тогда колбэк-функция вернёт ошибку (или null) как первый аргумент и только что созданный экземпляр как второй аргумент.
.create( name: "also_awesome" >, function (err, awesome_instance) if (err) return handleError(err); // сохранили! >);
Каждая модель ассоциирована с соединением (с соединением по умолчанию, если используется mongoose.model() ). Следует создать новое соединение и вызвать для него .model() , чтобы создать документ в другой базе данных.
Поля в новой записи могут быть получены и изменены с применением dot (точка)-синтаксиса. Для сохранения изменений служат методы save() и update() .
// Доступ к полям модели в dot-нотации console.log(awesome_instance.name); //вывод в консоль 'also_awesome' // Изменить запись, модифицируя поля, потом вызвать save(). awesome_instance.name = "New cool name"; awesome_instance.save(function (err) if (err) return handleError(err); // сохранили! >);
Поиск записей
При поиске записей методами запросов, условия поиска следует задавать как документ JSON. Приведённый фрагмент кода (ниже) показывает, как в БД найти имена (name) и возраст (age) всех спортсменов-теннисистов. Соответствие будет определяться по одному полю (sport), но можно добавить критерии поиска, задав, например, регулярное выражение, или удалить все критерии, чтобы получить список всех спортсменов.
var Athlete = mongoose.model("Athlete", yourSchema); // найти всех теннисистов, выбирать поля 'name' и 'age' Athlete.find( sport: "Tennis" >, "name age", function (err, athletes) if (err) return handleError(err); // 'athletes' содержит список спортсменов, соответствующих критерию. >);
Если задать колбэк-функцию так, как показано выше, запрос будет выполнен немедленно. Однако колбэк-функция будет вызвана только после завершения поиска.
Примечание: Все колбэк-функции в Mongoose используют образец callback(error, result) . Если при выполнении запроса возникает ошибка, параметр error будет содержать объект error, а result будет null. При успешном запросе параметр error будет null, а result будет содержать результат запроса.
Если не задать колбэк-функцию, API вернёт переменную типа Query. Можно использовать объект запроса, чтобы создать и выполнить свой запрос (с колбэк-функцией) позже, при помощи метода exec() .
// найти всех теннисистов var query = Athlete.find( sport: "Tennis" >); // выбрать поля 'name' и 'age' query.select("name age"); // ограничить результат 5 элементами query.limit(5); // сортировать по возрасту query.sort( age: -1 >); // выполнить запрос позже query.exec(function (err, athletes) if (err) return handleError(err); // athletes содержит упорядоченный список из 5 теннисистов >);
Выше условия поиска были заданы в методе find() . Можно также использовать функцию where() , кроме того, можно соединить все части в одном запросе применением оператора dot (.) вместо того, чтобы выполнять их раздельно. Фрагмент кода (см. ниже) выполняет тот же запрос, что и предыдущий фрагмент, но с дополнительным условием для возраста.
Athlete. find(). where('sport').equals('Tennis'). where('age').gt(17).lt(50). //Дополнительное условие limit(5). sort(< age: -1 >). select('name age'). exec(callback); // callback - имя нашей колбэк-функции.Метод find() находит все записи, удовлетворяющие условию, но часто требуется найти только одну из таких записей. Вот методы для поиска одной записи:
- findById() : Находит документ по заданному идентификатору id (каждый документ имеет уникальный идентификатор id ).
- findOne() : Находит один документ, удовлетворяющий заданному критерию.
- findByIdAndRemove() , findByIdAndUpdate() , findOneAndRemove() , findOneAndUpdate() : Находит один документ по id или по критерию, а затем или обновляет, или удаляет его. Эти методы весьма полезны для обновления или удаления записей.
Примечание: Есть также метод count() , который определяет количество записей, соответствующих условию. Он полезен при выполнении подсчётов без фактического извлечения записей.
Запросы полезны и во многих других случаях. Дополнительная информация — в Queries (документация Mongoose).
Работа со связанными документами — загрузка
Один документ (экземпляр модели) может ссылаться на другой документ при помощи поля ObjectId схемы, или на много других документов, используя массив идентификаторов ObjectIds . Идентификатор соответствующей модели хранится в поле. При необходимости получить действительное содержимое связанного документа, следует использовать в запросе метод populate() , который заменит идентификатор в запросе действительными данными.
Например, в следующей схеме определены авторы и рассказы. У каждого автора может быть несколько рассказов, которые представим массивом ссылок of ObjectId . У каждого рассказа может быть только один автор. Ссылка «ref» (выделена жирным) указывает в схеме, какая модель должна быть связана с этим полем.
var mongoose = require("mongoose"), Schema = mongoose.Schema; var authorSchema = Schema( name: String, stories: [ type: Schema.Types.ObjectId, ref: "Story" >], >); var storySchema = Schema( author: type: Schema.Types.ObjectId, ref: "Author" >, title: String, >); var Story = mongoose.model("Story", storySchema); var Author = mongoose.model("Author", authorSchema);
Можно сохранить ссылки в связанном документе, используя значение идентификатора _id . Ниже создаётся автор, затем рассказ, и значение идентификатора id автора сохраняется в поле «author» рассказа.
var bob = new Author( name: "Bob Smith" >); bob.save(function (err) if (err) return handleError(err); //автор Bob создан, создаём рассказ var story = new Story( title: "Bob goes sledding", author: bob._id, // присваиваем полю значение идентификатора Боба. Идентификатор создаётся по умолчанию! >); story.save(function (err) if (err) return handleError(err); // У Боба теперь есть рассказ! >); >);
Теперь документ «story» ссылается на автора по идентификатору документа «author». Для получения информации об авторе применяется метод populate() (показано ниже).
.findOne( title: "Bob goes sledding" >) .populate("author") //подменяет идентификатор автора информацией об авторе! .exec(function (err, story) if (err) return handleError(err); console.log("The author is %s", story.author.name); // выводит "The author is Bob Smith" >);
Примечание: Внимательные читатели заметили, что автор добавлен к рассказу, но ничего не сделано, чтобы добавить рассказ к массиву рассказов stories автора. Как же тогда получить список всех рассказов конкретного автора? Один из возможных вариантов — добавить автора в массив рассказов, но при этом пришлось бы хранить данные об авторах и рассказах в двух местах и поддерживать их актуальность.
Лучше получить _id нашего автора author, и применить find() для поиска этого идентификатора в поле «author» всех рассказов.
.find( author: bob._id >).exec(function (err, stories) if (err) return handleError(err); // возвращает все рассказы, у которых идентификатор Боба. >);
Это почти все, что следует знать для работы со связанными данными в нашем руководстве. Более полную информацию можно найти в Population (документация Mongoose).
Одна схема (модель) — один файл
Можно использовать любую структуру файлов при создании схем и моделей, однако мы настоятельно рекомендуем определять каждую схему модели в отдельном модуле (файле), экспортируя метод для создания модели. Пример приведён ниже:
// Файл: ./models/somemodel.js //Требуется Mongoose var mongoose = require("mongoose"); //Определяем схему var Schema = mongoose.Schema; var SomeModelSchema = new Schema( a_string: String, a_date: Date, >); //экспортируется функция для содания класса модели "SomeModel" module.exports = mongoose.model("SomeModel", SomeModelSchema);
You can then require and use the model immediately in other files. Below we show how you might use it to get all instances of the model.
//Создаём модель SomeModel просто вызовом модуля из файла var SomeModel = require("../models/somemodel"); // Используем объект SomeModel (модель) для поиска всех записей в SomeModel SomeModel.find(callback_function);
Установка базы данных MongoDB
Мы уже немного понимаем, что может делать Mongoose и как следует проектировать модели. Теперь самое время начать работу над сайтом LocalLibrary. Самое первое, что мы должны сделать — установить базу данных MongoDb, в которой будут храниться данные нашей библиотеки.
В этом руководстве мы будем использовать базу данных в «песочнице» («sandbox») — бесплатный облачный сервис, предоставляемый mLab. Такая база не очень подходит для промышленных веб-сайтов, поскольку не имеет избыточности, но она очень удобна для разработки и прототипирования. Мы используем её, так как она бесплатна, её легко установить, и потому что mLab — популярный поставщик базы данных как сервиса, и это может быть разумным выбором для промышленной базы данных (на данный момент другие известные возможности включают Compose, ScaleGrid и MongoDB Atlas).
Примечание: При желании можно установить БД MongoDb локально, загрузив и установив подходящие для вашей системы двоичные файлы. В этом случае приводимые ниже инструкции не изменятся, за исключением URL базы данных, который нужно будет задать для установки соединения.
Первым делом надо создать аккаунт на mLab (это бесплатно, требует только основных контактных данных и ознакомления с условиями обслуживания).
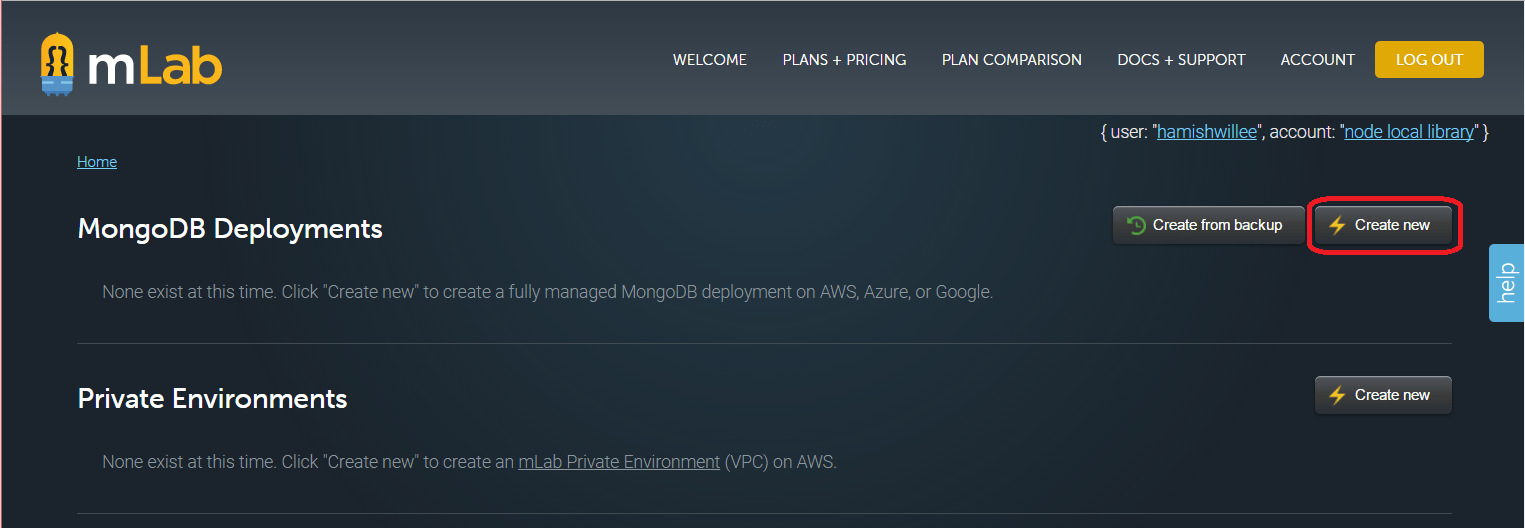
После входа в систему вы увидите главную страницу home:
- Щёлкните Create New в разделе MongoDB Deployments для создания новой БД.
- Откроется экран Cloud Provider Selection — раздела провайдера облака.
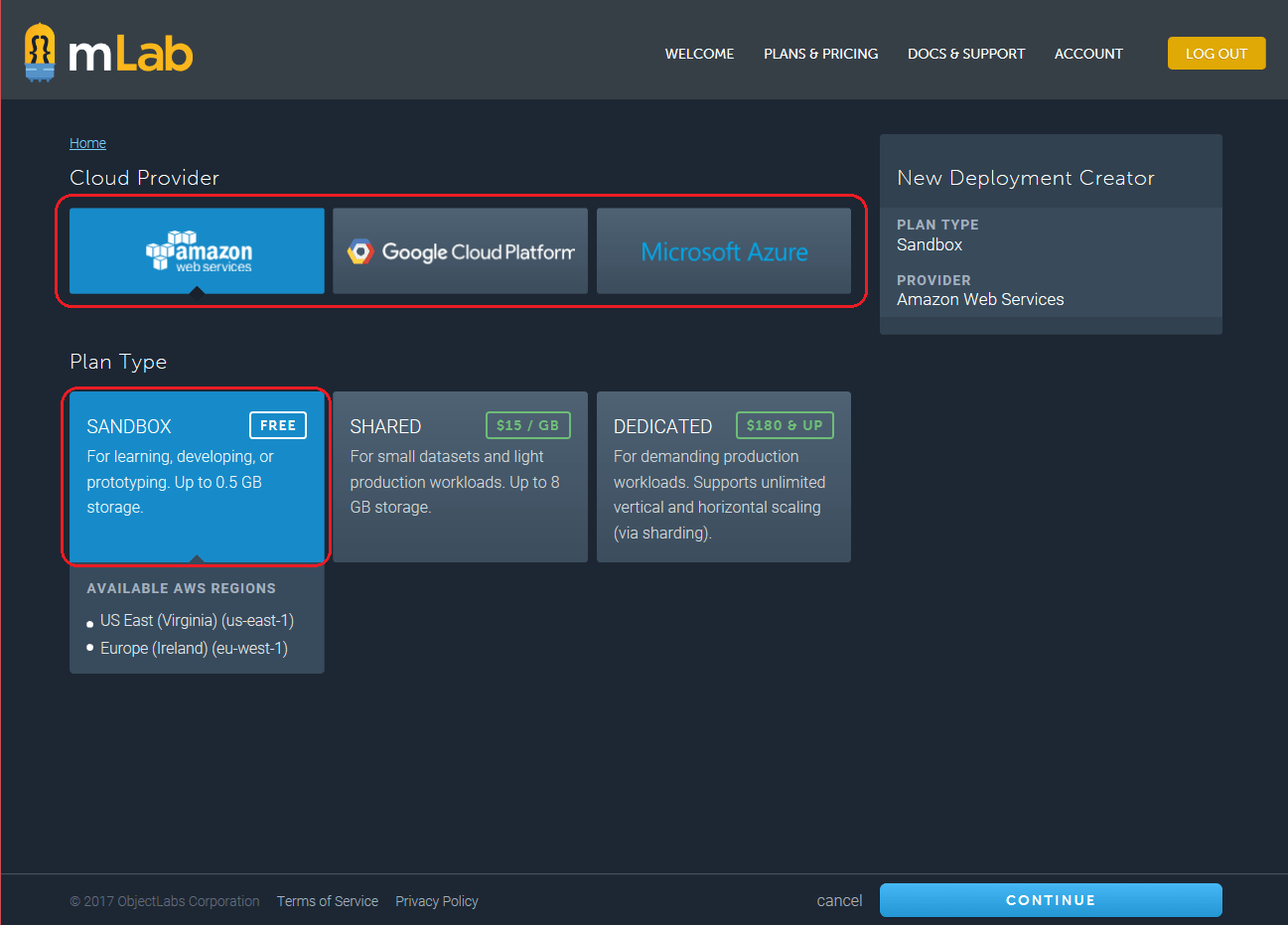
- Выберите план SANDBOX (Free) из раздела Plan Type (тип плана).
- Выберите любого провайдера в разделе Cloud Provider (провайдер облака). Разные провайдеры обслуживают разные регионы (показаны под выбранным типом плана).
- Щёлкните кнопку Continue.
- Откроется экран выбора региона Select Region.
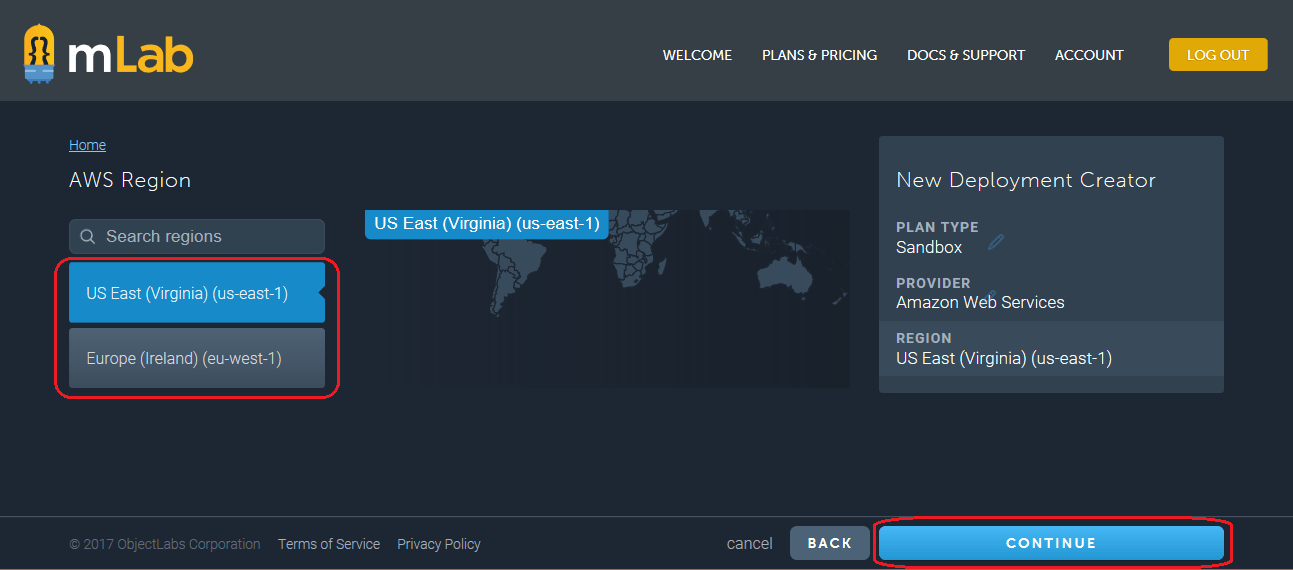
- Выберите ближайший к вам регион и щёлкните кнопку Continue.
- Откроется экран Final Details для ввода названия БД.
- Введите имя новой базы — local_library и нажмите Continue.
- Откроется экран подтверждения заказа Order Confirmation.
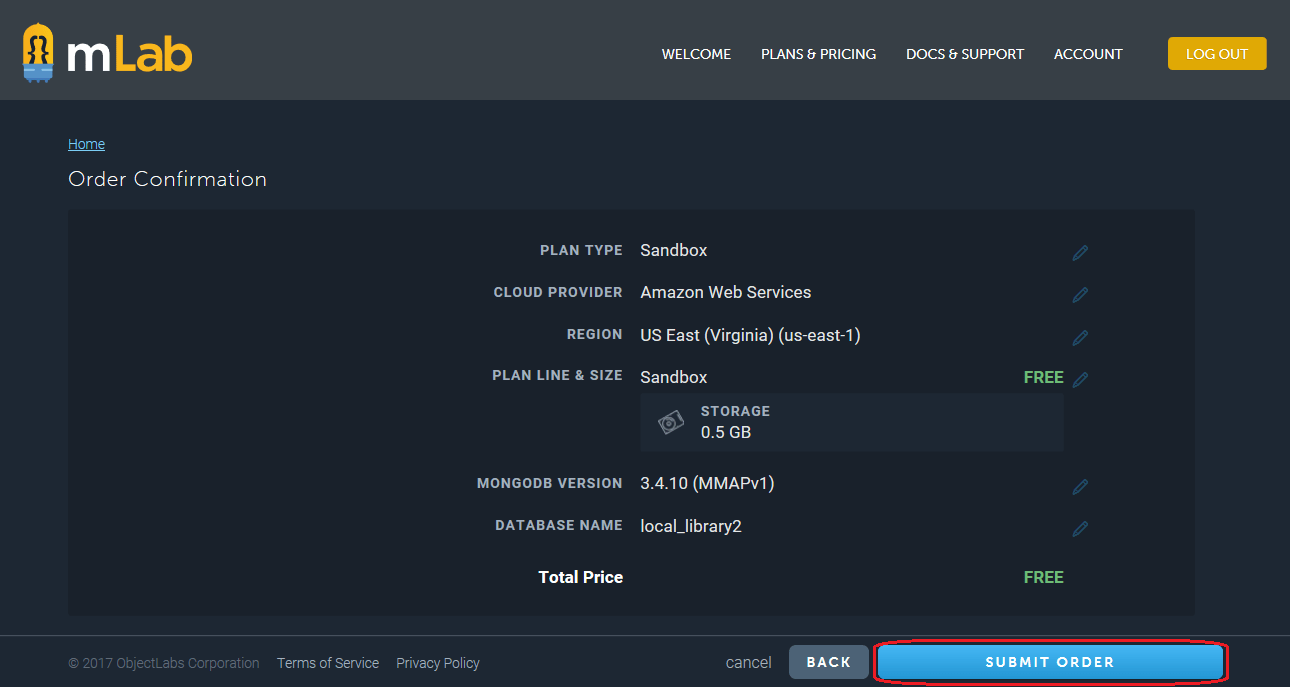
- Щёлкните Submit Order (подтвердить заказ), чтобы создать БД.
- Вы вернётесь на главный (home) экран. Щёлкните по вновь созданной базе, чтобы открыть экран с детальной информацией. Как видно, в БД нет коллекций (данных).
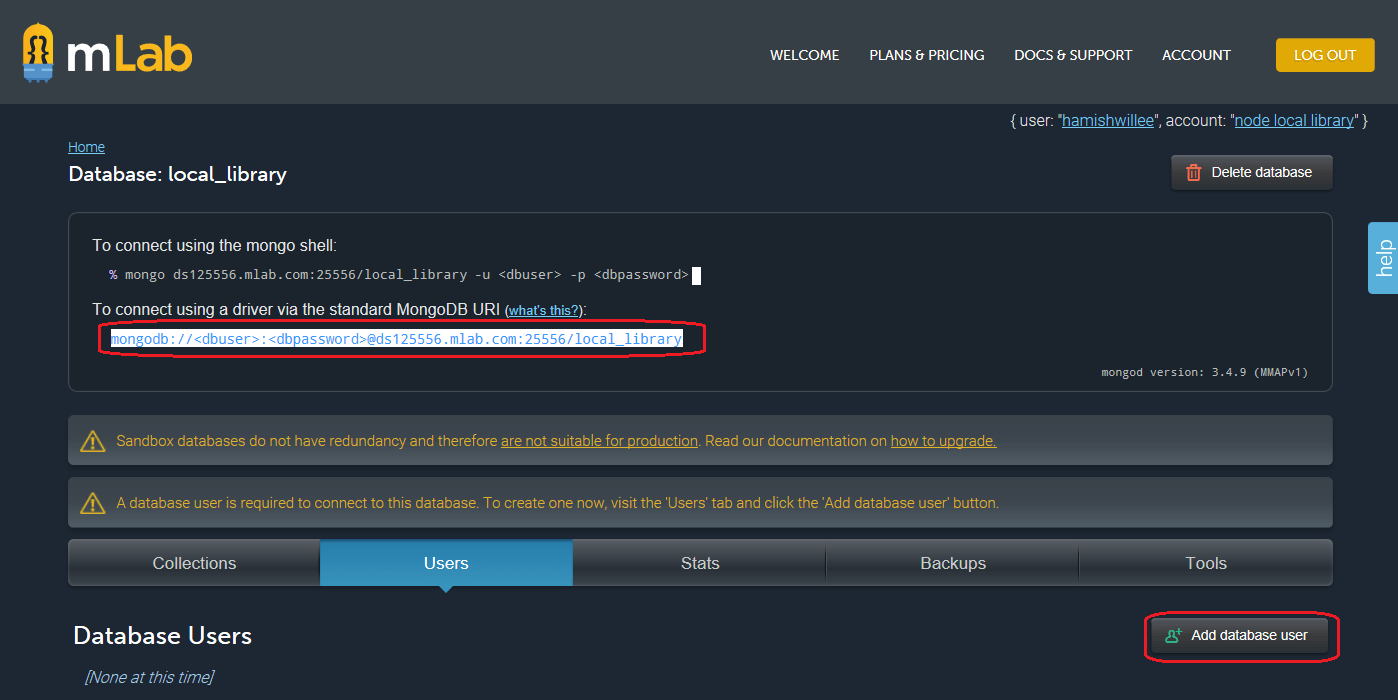 На форме выше обведён URL для соединения с вашей БДthat you need to use to access your database is displayed on the form above (shown for this database circled above). Чтобы его использовать, необходимо создать пользователя БД, который позже введёт этот URL.
На форме выше обведён URL для соединения с вашей БДthat you need to use to access your database is displayed on the form above (shown for this database circled above). Чтобы его использовать, необходимо создать пользователя БД, который позже введёт этот URL. - Щёлкните по вкладке Users и выберите кнопку Add database user (добавить пользователя БД).
- Введите имя пользователя и пароль (дважды), затем нажмите Create (создать). Не отмечайте Make read only (только для чтения)!
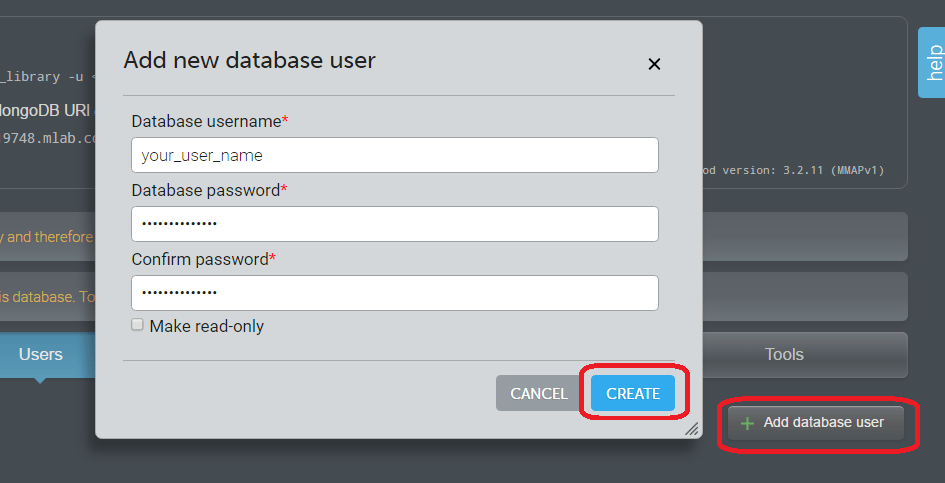
Теперь БД создана, и для доступа к ней есть URL, имя пользователя и пароль. Это должно выглядеть примерно так: mongodb://your_user_namer:your_password@ds119748.mlab.com:19748/local_library .
Установка Mongoose
Откройте окно команд и перейдите в каталог, в котором создан каркас веб-сайта Local Library. Введите команду install, чтобы установить Mongoose (и её зависимости), а также добавьте её в файл package.json, если вы ещё не сделали этого ранее, при чтении Учебника по Mongoose.
npm install mongooseПодключение к MongoDB
Откройте /app.js (в корне проекта) и скопируйте приведённый ниже текст, в котором объявляется объект приложения Express (после строки var app = express(); ). Замените строку url БД (‘insert_your_database_url_here‘) тем URL, который представляет вашу БД (т.е. используйте информацию, полученную от mLab).
//Устанавливаем соединение с mongoose var mongoose = require("mongoose"); var mongoDB = "insert_your_database_url_here"; //замените url. mongoose.connect(mongoDB); mongoose.Promise = global.Promise; var db = mongoose.connection; db.on("error", console.error.bind(console, "MongoDB connection error:"));
Как указано ранее в Учебнике по Mongoose, этот код задаёт соединение по умолчанию с привязкой события ошибки error (так что ошибки будут выведены в консоль).
Определение схемы LocalLibrary
Мы определим отдельный модуль для каждой модели как уже обсуждалось выше. Начнём с создания каталога для моделей в корне проекта (/models), после чего создадим отдельные файлы для каждой модели:
/express-locallibrary-tutorial //the project root /models author.js book.js bookinstance.js genre.js
Модель автора Author
Скопируйте код схемы автора Author (приведён ниже) в файл ./models/author.js . В схеме определено, что у автора есть обязательные поля имени и фамилии типа String длиной не более 100 символов, и поля типа Date дата рождения и дата смерти.
var mongoose = require("mongoose"); var Schema = mongoose.Schema; var AuthorSchema = new Schema( first_name: type: String, required: true, max: 100 >, family_name: type: String, required: true, max: 100 >, date_of_birth: type: Date >, date_of_death: type: Date >, >); // Виртуальное свойство для полного имени автора AuthorSchema.virtual("name").get(function () return this.family_name + ", " + this.first_name; >); // Виртуальное свойство - URL автора AuthorSchema.virtual("url").get(function () return "/catalog/author/" + this._id; >); //Export model module.exports = mongoose.model("Author", AuthorSchema);
Мы объявим также в схеме AuthorSchema виртуальное свойство «url» , которое позволит получить абсолютный URL конкретного экземпляра модели — используем это свойство в шаблонах, если потребуется получить связь с конкретным автором.
Примечание: Объявить в схеме URL как виртуальные свойства — хорошая идея, т.к. URL отдельного элемента при необходимости изменения требует коррекции только в одном месте. Сейчас связь при помощи этого URL ещё не работает, так как у нас ещё нет кода, поддерживающего маршруты для экземпляров модели. Мы построим его в следующей статье!
В конце модуля экспортируется модель.
Модель книги Book
Скопируйте код схемы Book (приведён ниже) в файл ./models/book.js. Большая часть кода подобна коду для модели автора — объявляется схема с рядом строковых полей, с виртуальным свойством URL для получения URL конкретных книг, затем модель экспортируется.
var mongoose = require("mongoose"); var Schema = mongoose.Schema; var BookSchema = new Schema( title: type: String, required: true >, author: type: Schema.ObjectId, ref: "Author", required: true >, summary: type: String, required: true >, isbn: type: String, required: true >, genre: [ type: Schema.ObjectId, ref: "Genre" >], >); // Virtual for book's URL BookSchema.virtual("url").get(function () return "/catalog/book/" + this._id; >); //Export model module.exports = mongoose.model("Book", BookSchema);
Основное отличие в том, что созданы две ссылки на другие модели:
- author — это ссылка на единственный объект модели Author , обязательный элемент.
- genre (жанр) — ссылка на массив объектов модели Genre . Эта модель ещё не объявлена!
Модель экземпляра книги BookInstance
Наконец, скопируйте код схемы BookInstance (приведён ниже) в файл ./models/bookinstance.js. Схема BookInstance представляет конкретный экземпляр книги, которую можно одолжить на время, и содержит информацию о доступности экземпляров книги, о дате возврата одолженной книги, о деталях версии или печатного экземпляра.
var mongoose = require("mongoose"); var Schema = mongoose.Schema; var BookInstanceSchema = new Schema( book: type: Schema.ObjectId, ref: "Book", required: true >, //ссылка на книгу imprint: type: String, required: true >, status: type: String, required: true, enum: ["Available", "Maintenance", "Loaned", "Reserved"], default: "Maintenance", >, due_back: type: Date, default: Date.now >, >); // Virtual for bookinstance's URL BookInstanceSchema.virtual("url").get(function () return "/catalog/bookinstance/" + this._id; >); //Export model module.exports = mongoose.model("BookInstance", BookInstanceSchema);
В этой схеме новыми являются опции поля:
- enum : Позволяет указать допустимые значения строки. В нашем случае используются, чтобы задать статус доступности книги (применение enum (перечисления) означает, что мы ходим предотвратить ошибочное написание и произвольные значения статуса)
- default : определяет значение статуса по умолчанию (maintenance) при создании экземпляра книги, и дату due_back возврата книги ( now, сейчас). Отметьте, как используется функция Date при установке даты!
Все остальное знакомо по предыдущим схемам.
Модель жанра Genre — проверьте себя!
Откройте файл ./models/genre.js и создайте схему для хранения жанра (категории книги, т.е. художественная или научная, романтика или военная история и т.д.).
Определение будет подобно другим моделям:
- В модели должно быть поле name типа String для указания жанра.
- Это поле должно быть обязательным, допустимый размер — от 3 до 100 символов.
- Объявите виртуальное (virtual) свойство с именем url для URL жанра.
- Экспортируйте модель.
Тестирование — создаём элементы БД
Вот так. У нас теперь есть все модели для создания сайта!
Для тестирования моделей (и для создания примеров книг и других элементов, которые потребуются в следующих статьях) выполним независимый скрипт, который создаст элементы каждого типа:
-
Загрузите (или создайте) файл populatedb.js в каталоге express-locallibrary-tutorial (на том же уровне, что и package.json ).
Примечание: Не обязательно понимать, как работает populatedb.js; он просто помещает некоторые данные в базу данных.
npm install asyncnode populatedb your mongodb url>Примечание: Откройте свою базу на Lab. Вы сможете увидеть коллекции Book, Author, Genre, BookInstance (книги, авторы, жанры, экземпляры книг) и просмотреть содержащиеся в них документы.
Итог
В этой статье мы познакомились с БД и ОРМ (объектно-реляционными моделями) в системе Node/Express, узнали, как определяются схемы и модели Mongoose. Мы применили эти знания при проектировании и реализации моделей Book , BookInstance , Author и Genre для веб-сайта LocalLibrary.
В конце мы испытали свои модели путём создания ряда элементов (при помощи автономного скрипта). В следующей статье мы рассмотрим создание страниц, на которых будут показаны эти элементы.
Смотрите также
- Database integration Интеграция БД (документация Express)
- Mongoose website Веб-сайт Mongoose (документация Mongoose)
- Mongoose Guide Справочник Mongoose (документация Mongoose)
- Validation Валидация (документация Mongoose)
- Schema Types Типы в схемах (документация Mongoose)
- Models Модели (документация Mongoose)
- Queries Запросы (документация Mongoose)
- Population Пополнение БД (документация Mongoose)
- Назад
- Обзор: Express Nodejs
- Далее
In this module
- Express/Node introduction
- Setting up a Node (Express) development environment
- Express Tutorial: The Local Library website
- Express Tutorial Part 2: Creating a skeleton website
- Express Tutorial Part 3: Using a Database (with Mongoose)
- Express Tutorial Part 4: Routes and controllers
- Express Tutorial Part 5: Displaying library data
- Express Tutorial Part 6: Working with forms
- Express Tutorial Part 7: Deploying to production (en-US)
Found a content problem with this page?
- Edit the page on GitHub.
- Report the content issue.
- View the source on GitHub.
This page was last modified on 3 авг. 2023 г. by MDN contributors.
Your blueprint for a better internet.
MongoDB vs. MySQL Differences
What are the main differences between MongoDB and MySQL?
MySQL
MySQL is a popular, free-to-use, and open-source relational database management system (RDBMS) developed by Oracle. As with other relational systems, MySQL stores data using tables and rows, enforces referential integrity, and uses structured query language (SQL) for data access. When users need to retrieve data from a MySQL database, they must construct an SQL query that joins multiple tables together to create the view on the data they require.
Database schemas and data models need to be defined ahead of time, and data must match this schema to be stored in the database. This rigid approach to storing data offers some degree of safety, but trades this for flexibility. If a new type or format of data needs to be stored in the database, schema migration must occur, which can become complex and expensive as the size of the database grows.
MongoDB
MongoDB is also free to use and open source; however, its design principles differ from traditional relational systems. Often styled as a non-relational (or NoSQL) system, MongoDB adopts a significantly different approach to storing data, representing information as a series of JSON-like documents (actually stored as binary JSON, or BSON), as opposed to the table and row format of relational systems.
MongoDB documents consist of a series of key/value pairs of varying types, including arrays and nested documents; however, the primary difference is that the structure of the key/value pairs in a given collection can vary from document to document. This more flexible approach is possible because documents are self-describing.
When to use MongoDB vs. MySQL
The core differences between these two database systems are significant. Choosing which one to use is really a question of approach rather than purely a technical decision.
MySQL is a mature relational database system, offering a familiar database environment for experienced IT professionals.
MongoDB is a well-established, non-relational database system offering improved flexibility and horizontal scalability, but at the cost of some safety features of relational databases, such as referential integrity.
Which one should you choose?
In the following sections, we’re going to look at some of the different considerations when deciding between MongoDB and MySQL.
MongoDB vs. MySQL user-friendliness
MongoDB is an attractive option to developers. Its data storage philosophy is simple and immediately understandable to anybody with programming experience.
MongoDB stores data in collections with no enforced schema. This flexible approach to storing data makes it particularly suitable for developers who may not be database experts, yet want to use a database to support the development of their applications.
Compared to MySQL, this flexibility is a significant advantage: to get the best out of a relational database, you must first understand the principles of normalization, referential integrity, and relational database design.
With the ability to store documents of varying schemas, including unstructured data sets, MongoDB provides a flexible developer interface for teams that are building applications that don’t need all of the safety features offered by relational systems. A common example of such an application is a web application that doesn’t depend on structured schemas; it can easily serve unstructured, semi-structured, or structured data, all from the same MongoDB collection.
MySQL is a common choice for users who have extensive experience using traditional SQL scripting, designing solutions for relational databases, or who are modifying or updating existing applications that already work with a relational system. Relational databases may also be a better choice for applications that require very complex but rigid data structures and database schemas across a large number of tables.
A common example of such a system could be a banking application that requires very strong referential integrity and transactional guarantees to be enforced to maintain exact point-in-time integrity of data.
However, it is important to clarify that MongoDB also supports ACID properties of transactions (atomicity, consistency, isolation, and durability). This enables greater flexibility in building a transactional data model that can horizontally scale in a distributed environment and has no impact on performance for multi-document transactions.
MongoDB vs. MySQL scalability
A key benefit of the MongoDB design is that the database is extremely easy to scale. Configuring a sharded cluster allows a portion of the database, called a shard, to also be configured as a replica set. In a sharded cluster, data is distributed across many servers. This highly flexible approach allows MongoDB to horizontally scale both read and write performance to cater to applications of any scale.
A replica set is the replication of a group of MongoDB servers that hold the same data, ensuring high availability and disaster recovery.
With a MySQL database system, options for scalability are much more limited. Typically, you have two choices: vertical scalability, or adding read replicas. Scaling vertically involves adding more resources to the existing database server, but this has an inherent upper limit.
Read replication involves adding read-only copies of the database to other servers. However, this is typically limited to five replicas in total, which can only be used for read operations. This can cause issues with applications that are either write-heavy, or write and read regularly for the database, since it’s common for replicas to lag behind the write master. Multi-master replication support has been added to MySQL, but its implementation is more limited than the functionality available in MongoDB.
MongoDB vs. MySQL performance
Assessing the performance of two completely different database systems is very difficult, since both management systems approach the task for data storage and retrieval in completely different ways. While it’s possible to directly compare two SQL databases with a set of standard SQL benchmarks, achieving the same across non-relational and relational databases is much more difficult and subjective.
For example: MySQL is optimized for high performance joins across multiple tables that have been appropriately indexed. In MongoDB, joins are supported with the $lookup operation, but they are less needed due to the way MongoDB documents tend to be used; they follow a hierarchical data model and keep most of the data in one document, therefore eliminating the need for joins across multiple documents.
MongoDB is also optimized for write performance, and features a specific insertMany() API for rapidly inserting data, prioritizing speed over transaction safety wherein MySQL data needs to be inserted row by row.
Observing some of the high-level query behaviors of the two systems, we can see that MySQL is faster at selecting a large number of records, while MongoDB is significantly faster at inserting or updating a large number of records.
MongoDB vs. MySQL flexibility
This is an easy one, and a hands-down win for MongoDB. The schemaless design of MongoDB documents makes it extremely easy to build and enhance applications over time, without needing to run complex and expensive schema migration processes as you would with a relational database.
With MongoDB, there are more dynamic options for updating the schema of a collection, such as creating new fields based on an aggregation pipeline or updating nested array fields. This benefit is particularly important as databases grow in size. In contrast, larger MySQL databases are slower to migrate schemas and stored procedures that can be dependent on the updated schemas. MongoDB’s flexible design makes this much less of a concern.
It’s worth pointing out that both databases have a lot in common. Both are free to get started with, both are easy to install on Linux and Windows, and both have wide programming language support for popular languages like Java, node.js, and Python.
In addition, MongoDB offers MongoDB Atlas, a managed cloud solution which is also forever free to use for exploratory purposes, while for a MySQL managed cloud version, you would need to have an account with one of the major public cloud providers and fall within their free tier terms in order to not pay.
MongoDB vs. MySQL security
MongoDB leverages the popular role-based access control model with a flexible set of permissions. Users are assigned to a role, and that role grants them specific permissions over datasets and database operations. All communication is encrypted with TLS, and it’s possible to write encrypted documents to MongoDB data collections using a master key which is never available to MongoDB, achieving encryption of data at rest.
MySQL supports the same encryption features as MongoDB; its authentication model is also similar. Users can be granted roles but also privileges, giving them permissions over particular database operations and against particular datasets.
Conclusion
In this article, we have talked about the main differences between MongoDB and MySQL, a schemaless non-relational database system and a relational database system, respectively. We have explained when it is better to use one over the other. We have discussed the scalability, performance, and user-friendliness for each system. Finally, we have also explained the flexibility and security features for both database systems from a comparison point of view.
If MongoDB is the right solution for you and you’re currently using MySQL, check out our migration guide. To get started for free, try MongoDB Atlas.
Another option to consider is a hybrid deployment approach — giving you the benefit of both worlds, and the flexibility to choose the tool that works for you. Check out this hybrid deployment guide for more details.