Страница неизвестна роботу при проверке в я.вебмастер. Как исправить?
При проверке в статуса url в ЯВМ показывает статус: Страница неизвестна роботу.
Отправил на переобход страницы, после подтверждения еще раз запустил проверку статуса url — результат тот же.
Никто с подобным не сталкивался? Как это можно исправить?
п.с. здесь уже смотрел http://pr-cy.ru/qa/question/33071
- яндекс.вебмастер
- страница неизвестна роботу
Ответы на пост (8) Написать ответ
12.07.2017 14:13
Так какай урл то
12.07.2017 17:09
Отправил на переобход страницы, после подтверждения еще раз запустил проверку статуса url. Ты что думаешь, что бот по первому требованию уже помчался обходить эту страницу? Жди, когда проиндексирует — напишет. Читай на форуме как ускорить индексацию.
12.07.2017 17:11
Да вообще то как раз бот мчится
12.07.2017 18:54
Вебмастер тормоз, он не отображает индексацию в реальном времени. Жди пока url появится в разделе «Статистика обхода». Если переобход пишет, что «Робот обошел», где-то к утру страница появится в «Статистике обхода».
12.07.2017 19:02
Да через часа три уже она в индексе это по ггл или миралинкс если страницы выпали
12.07.2017 19:42
Видна, не видна. проблема, бином ньютона.
Сегодня нет, завтра есть. С Яндекс — лучше не «вязаться», он. не совсем вменяем.
Непонятно, в чём, собстно — «горечь» ситуации? Какая срочность? — то. Проверить пару сотен тысяч страниц, например, на предмет: «В Яндекс ли она, страница с описаловом какой-то фигни?» — да. опупеешь.
Попадет, куда она денется (если не агс).
А если эксклюзивные новости — твиттер вам в руки, завтра страница в индексе «безумного шляпника» — Яши — будет.
Не будет? — хреновая страница.
12.07.2017 19:52
Да как бы Твиттер уже как пару лет не фига не загоняет в Яндекс или опять стал работать
12.07.2017 20:01
Ну. мои страницы «загоняет» все и сразу. Впрочем, возможно, от площадки (возраста и репутации) зависит.
Честно. вопрос надуманный. Страница. Если сайт исчез (большой) — проблема, а страница. 🙂
А уж тем паче — Яндекс.
Может и доживу до момента, что веб-мастера перестанут его (Яндекс) вообще учитывать. Популизм, тщеславие, продажность — «ключи» популярного «поисковика». В принципе, Яндекс — уже не поисковик с Яндекс. Директ, а поисковик — по Яндекс. Директ.
Похожие посты
- Ошибка при проверке css на валидность. Что значит и как исправить?
3 - Падает посещаемость сайта\Проблемы с Яндексом
27 - Вопрос по webmaster.yandex
11 - Нарушения и угрозы безопасности на сайте (яндекс). Что делать?
10 - Умер сайт, почему? Не проходите мимо. подскажите.
37
Анализ сайта
Поможем улучшить ваш сайт.
Исправляем ошибки и правильно настраиваем файл robots.txt
Robots.txt — это текстовый файл, в котором прописаны указания (директивы) по индексации страниц сайта. С помощью данного файла можно указывать поисковым роботам, какие страницы на веб-ресурсе нужно сканировать и заносить в индекс (базу данных поисковой системы), а какие — нет.
Файл располагается в корневом каталоге сайта и доступен по адресу: domain.com/robots.txt.
Почему robots.txt важен для SEO-продвижения?
Этот файл дает поисковым системам важные указания, которые напрямую будут влиять на результативность продвижения сайта. Использование Роботс может помочь:
- предотвращению сканирования дублированного контента и бесполезных для пользователей страниц (результаты внутреннего поиска, технические страницы и др.);
- сохранению конфиденциальности разделов веб-сайта (например, можно закрыть системную информацию CMS);
- избежать перегрузки сервера;
- эффективно расходовать краулинговый бюджет на обход полезных страниц.
С другой стороны, если robots.txt содержит неверные данные, то поисковые системы будут неправильно индексировать сайт, и в результатах поиска окажется не та информация, которая нужна.
Можно случайно запретить индексирование важных для продвижения страниц, и они не попадут в результаты поиска.
User-Agent: * Disallow: /
Эта запись говорят о том, что поисковые системы не смогут увидеть и проиндексировать ваш сайт.
Пустой или недоступный файл Роботс поисковые роботы воспринимают как разрешение на сканирование всего сайта.
Ниже приведены ссылки на инструкции по использованию файла:
Какие директивы используются в robots.txt
User-agent
User-agent — основная директива, которая указывает, для какого поискового робота прописаны нижеследующие указания по индексации, например:
Для всех роботов:
User-agent: *
Для поискового робота Яндекс:
User-agent: Yandex
Для поискового робота Google:
User-agent: Googlebot
Disallow и Allow
Директива Disallow закрывает раздел или страницу от индексации. Allow — принудительно открывает страницы сайта для индексации (например, разрешает сканирование подкаталога или страницы в закрытом для обработки каталоге).
Операторы, которые используются с этими директивами: «*» и «$». Они применяются для указания шаблонов адресов при объявлении директив, чтобы не прописывать большой перечень конечных URL для блокировки.
* — спецсимвол звездочка обозначает любую последовательность символов. Например, все URL сайта, которые содержат значения, следующие после этого оператора, будут закрыты от индексации:
User-agent: * Disallow: /cgi-bin* # блокирует доступ к страницам # начинающимся с '/cgi-bin' Disallow: /cgi-bin # то же самое
$ — знак доллара означает конец адреса и ограничивает действие знака «*», например:
User-agent: * Disallow: /example$ # запрещает '/example', # но не запрещает '/example.html'
Crawl-delay
Crawl-delay — директива, которая позволяет указать минимальный промежуток времени между окончанием загрузки одной страницы и началом загрузки следующей. Использовать ее следует в случаях, если сервер сильно загружен и не успевает обрабатывать запросы поискового робота.
User-agent: * Crawl-delay: 3.0 # задает тайм-аут в 3 секунды
С 22 февраля 2018 года Яндекс перестал учитывать директиву Crawl-delay. Чтобы задать скорость, с которой роботы будут загружать страницы сайта, используйте раздел «Скорость обхода сайта» в Яндекс.Вебмастере. Google также не поддерживает эту директиву. Для Google-бота установить частоту обращений можно в панели вебмастера Search Console. Однако роботы Bing и Yahoo соблюдает директиву Crawl-delay.
Clean-param
Директива используется только для робота Яндекса. Google и другие роботы не поддерживают Clean-param .
Директива указывает, что URL страниц содержат GET-параметры, которые не влияют на содержимое, и поэтому их не нужно учитывать при индексировании. Робот Яндекса, следуя инструкциям Clean-param , не будет обходить страницы с динамическими параметрами, которые полностью дублируют контент основных страниц.
Пример директивы Clean-param :
Clean-param: s /forum/showthread.php
Данная директива означает, что параметр «s» будет считаться незначащим для всех URL, которые начинаются с /forum/showthread.php.
Подробнее прочитать о директиве Clean-param можно в указаниях от Яндекс, ссылка на которые расположена выше.
Sitemap
Sitemap — это карта сайта для поисковых роботов, которая содержит рекомендации того, какие страницы необходимо проверить в первую очередь и с какой частотой. Наличие карты сайта помогает роботам быстрее индексировать нужные страницы.
Следует указать полный путь к странице, в которой содержится файл sitemap.
Sitemap: https://www.site.ru/sitemap.xml
Пример правильно составленного файла robots.txt :
User-agent: * # нижеследующие правила задаются для всех поисковых роботов Allow: / # сайт открыт для индексации Sitemap: https://www.site.ru/sitemap.xml # карта сайта для поисковых систем
Как найти ошибки в robots.txt с помощью Labrika?
Для проверки файла robots используйте Labrika. Она позволяет увидеть 26 видов ошибок в структуре файла – это больше, чем определяет сервис Яндекса. Отчет «Ошибки robots.txt » находится в разделе «Технический аудит» левого бокового меню. В отчете приводится содержимое строк файла. При наличии в какой-либо директиве проблемы Labrika дает её описание.
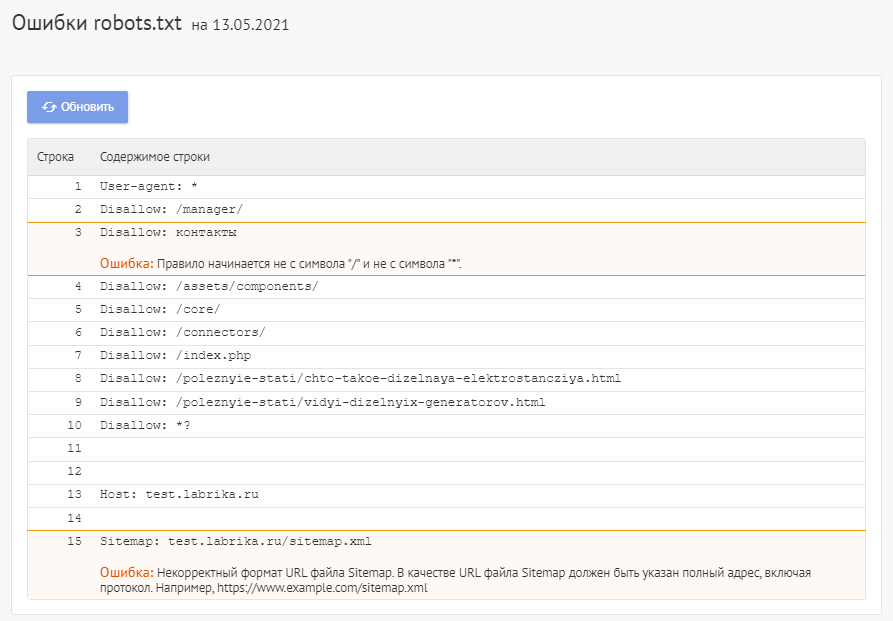
Ошибки robots.txt, которые определяет Labrika:
Сервис находит следующие:
Директива должна отделятся от правила символом «:».
Каждая действительная строка в файле Роботс должна состоять из имени поля, двоеточия и значения. Использовать пробелы не обязательно, но рекомендуется для удобства чтения. Для добавления комментария применяется символ решётки «#», который ставится перед его началом. Весь текст после символа «#» и до конца строки робот поисковой системы будет игнорировать.
User-agent Googlebot
User-agent: Googlebot
Пустая директива и пустое правило.
Недопустимо делать пустую строку в директиве User-agent , поскольку она указывает, для какого поискового робота предназначены инструкции.
User-agent:
Не указан пользовательский агент.
User-agent: название бота
User-agent: Googlebot
Директивы Allow или Disallow задаются в формате: directive: [path], где значение [path] (путь к странице или разделу) указывать не обязательно. Однако роботы игнорируют директивы Allow и Disallow без указания пути. В этом случае они могут сканировать весь контент. Пустая директива Disallow: равнозначна директиве Allow: / , то есть «не запрещать ничего».
Пример ошибки в директиве Sitemap:
Sitemap:
Не указан путь к карте сайта.
Sitemap: https://www.site.ru/sitemap.xml
Перед правилом нет директивы User-agent
Правило должно всегда стоять после директивы User-agent . Размещение правила перед первым именем пользовательского агента означает, что никакие сканеры не будут ему следовать.
Disallow: /category User-agent: Googlebot
User-agent: Googlebot Disallow: /category
Найдено несколько правил вида «User-agent: *»
Должна быть только одна директива User-agent для одного робота и только одна директива вида User-agent: * для всех роботов. Если в файле несколько раз указан один и тот же пользовательский агент с разными списками правил, то поисковым роботам будет сложно определить, какие из этих правил нужно учитывать. В результате возникает большая неопределенность в действиях роботов.
User-agent: * Disallow: /category User-agent: * Disallow: /*.pdf.
User-agent: * Disallow: /category Disallow: /*.pdf.
Неизвестная директива
Обнаружена директива, которая не поддерживается поисковой системой (например, не описана в правилах использования Роботс от Яндекса).
Причины этого могут быть следующие:
- была прописана несуществующая директива;
- допущен ошибочный синтаксис, использованы запрещенные символы и теги;
- эта директива может использоваться роботами других поисковых систем.
Disalow: /catalog
Директивы «Disalow» не существует, допущена опечатка в написании слова.
Disallow: /catalog
Количество правил в файле robots.txt превышает максимально допустимое
Поисковые роботы будут корректно обрабатывать файл robots.txt , если его размер не превышает 500 КБ. Допустимое количество правил в файле — 2048. Контент сверх этого лимита игнорируется. Чтобы не превышать его, вместо исключения каждой отдельной страницы применяйте более общие директивы.
Например, если вам нужно заблокировать сканирование файлов PDF, не запрещайте каждый отдельный файл. Вместо этого запретите все URL-адреса, содержащие .pdf, с помощью директивы:
Disallow: /*.pdf
Правило превышает допустимую длину
Правило не должно содержать более 1024 символов.
Некорректный формат правила
В файле robots.txt должен быть обычный текст в кодировке UTF-8. Поисковые системы могут проигнорировать символы, не относящиеся к коду UTF-8. В таком случае правила из файла robots.txt не будут работать.
Чтобы поисковые роботы корректно обрабатывали инструкции в файле robots.txt , все правила должны быть написаны согласно стандарту исключений для роботов (REP).
Использование кириллицы и других национальных языков
Использование кириллицы запрещено в файле robots.txt . Согласно утверждённой стандартом системе доменных имен название домена может состоять только из ограниченного набора ASCII-символов (буквы латинского алфавита, цифры от 0 до 9 и дефис). Если домен содержит символы, не относящиеся к ASCII (в том числе буквы национальных алфавитов), его нужно преобразовать с помощью Punycode в допустимый набор символов.
User-agent: Yandex Sitemap: сайт.рф/sitemap.xml
User-agent: Yandex Sitemap: https://xn--80aswg.xn--p1ai/sitemap.xml
Возможно, был использован недопустимый символ
Допускается использование спецсимволов «*» и «$». Например:
Disallow: /*.php$
Директива запрещает индексировать любые php файлы.
Если /*.php соответствует всем путям, которые содержат .php., то /*.php$ соответствует только тем путям, которые заканчиваются на .php.
Символ «$» прописан в середине значения
Знак «$» можно использовать только один раз и только в конце правила. Он показывает, что стоящий перед ним символ должен быть последним.
Allow: /file$html
Allow: /file.html$
Правило начинается не с символа «/» и не с символа «*».
Правило может начинаться только с символов «/» и «*».
Если значение пути указывается относительно корневого каталога сайта, оно должно начинаться с символа слэш «/», обозначающего корневой каталог.
Disallow: products
Правильным вариантом будет:
Disallow: /products
Disallow: *products
в зависимости от того, что вы хотите исключить из индексации.
Некорректный формат URL файла Sitemap
В качестве URL файла Sitemap должен быть указан полный адрес, который содержит обозначение протокола (http:// или https://), название домена (главная страница сайта), путь к файлу карты сайта, а также имя файла.
Sitemap: /sitemap.xml
Sitemap: https://www.site.ru/sitemap.xml
Некорректное имя главного зеркала сайта
Директива Host указывала роботу Яндекса главное зеркало сайта, если к веб-ресурсу был доступ по нескольким доменам. Остальные поисковые роботы её не воспринимали.
Директива Host могла содержать только протокол (необязательный) и домен сайта. Прописывался протокол https, если он использовался. Указывалась только одна директива Host . Если их было несколько, робот учитывал первую.
User-agent: Yandex Host: http://www.example.com/catalog Host: https://example.com
User-agent: Yandex Host: https://example.com
С марта 2018 года Яндекс отказался от директивы Host. Вместо неё используется раздел «Переезд сайта» в Вебмастере и 301 редирект.
Некорректный формат директивы Crawl-delay
При указании в директиве Crawl-delay интервала между загрузками страниц можно использовать как целые значения, так и дробные. В качестве разделителя применяется точка. Единица измерения – секунды.
К ошибкам относят:
- несколько директив Crawl-delay ;
- некорректный формат директивы Crawl-delay .
Crawl-delay: 0,5 second
Crawl-delay: 0.5
Некорректный формат директивы Clean-param
Labrika определяет некорректный формат директивы Clean-param , например:
В именах GET-параметров встречается два или более знака амперсанд «&» подряд:
Clean-param: sort&&session /category
Clean-param: sort&session /category
Правило должно соответствовать виду «p0[&p1&p2&..&pn] [path]». В первом поле через символ «&» перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых применяется правило. Параметры отделяются от префикса пути пробелом.
Имена GET-параметров должны содержать только буквы латинского алфавита, цифры, нижнее подчеркивание и дефис.
Префикс PATH URL для директивы Clean-param может включать только буквы латинского алфавита, цифры и некоторые символы: «.», «-«, «/», «*», «_».
Ошибкой считается и превышение допустимой длины правила — 500 символов.
Строка содержит BOM (Byte Order Mark) — символ U+FEFF
BOM (Byte Order Mark — маркер последовательности байтов) — символ вида U+FEFF, который находится в самом начале текста. Этот Юникод-символ используется для определения последовательности байтов при считывании информации.
Стандартные редакторы, создавая файл, могут автоматически присвоить ему кодировку UTF-8 с BOM меткой.
BOM – это невидимый символ. У него нет графического выражения, поэтому большинство редакторов его не показывает. Но при копировании этот символ может переноситься в новый документ.
Использование маркера последовательности байтов в файлах .html приводит к сбою настроек дизайна, смещению блоков, появлению нечитаемых наборов символов, поэтому рекомендуется удалять маркер из веб-скриптов и CSS-файлов.
Избавиться от ВОМ довольно сложно. Один из простых способов это сделать — открыть файл в редакторе, который может изменять кодировку документа, и пересохранить его с кодировкой UTF-8 без BOM.
Например, вы можете бесплатно скачать редактор Notepad++, открыть в нём файл с ВОМ меткой и выбрать во вкладке меню «Кодировки» пункт «Кодировать в UTF-8 (без BOM)».
Название
В наименовании должен быть использован нижний регистр букв.
Как исправить ошибки в robots.txt?
Исправьте ошибки в директивах robots.txt , следуя рекомендациям Labrika. Наш сервис проверяет файл robots.txt согласно стандарту исключений для роботов (REP), который поддерживают Google, Яндекс и большинство известных поисковых машин.
После исправления указанных в отчете Labrika ошибок нажмите кнопку «Обновить», чтобы получить свежие данные о наличии ошибок в файле robots.txt и убедиться в правильном написании директив.
Не забудьте добавить новую версию Роботс в Вебмастера.
О том, как написать правильный файл robots.txt и ответы на другие вопросы вы можете найти в отдельной статье на нашем сайте.
Читать дальше подобные статьи
- Файл robots.txt для WordPress, Modx. Как не закрыть сайт от индексации?
- Закрыть от индексации в robots.txt страницу на сайте, текст, фильтр или поддомен
- Тег noindex: запрещенные к индексированию страницы
- Ошибки в файле карты сайта sitemap.xml
Яндекс выкинул весь сайт по Clean-param:
Народ, сказать что я в шоке — ничего не сказать. Сайту 17 лет. Примерно столько же и robots.txt , в котором есть строка Clean-param: PHPSESSID&lang&yclid&_openstat&page&nextPageSearch&numPage Вдруг, ни с того ни с сего, 21.09.2023 из индекса вылетают ВСЕ СТРАНИЦЫ по причине: Исключена по Clean-param При этом инструмент проверки robots.txt говорит что страница разрешена (любая). Что это было, кто знает? И главное что теперь делать? Вернуть назад-то похоже, не получится просто удалением Clean-param: (что я и сделал уже). Такое впечатление, что робот яндекса в строке Clean-param: посчитал разделители & как одно из того, что надо запртить, и запретил все страницы! В итоге было в поиске 10 000 стало 83 (восемьдесят три!) Это просто полная задница.
Могу порекомендовать только хостинг: https://traf.at/vps — за 3 года все на 4++ и цены не подняли. Ну и банк для белых ИП: https://traf.at/bankm
- Яндекс.Вебмастер поможет найти дубли страниц с незначащими GET-параметрами
- Как правильно искать и удалять дубли страниц на сайте
- В Яндексе рассказали, как обнаружить дубли страниц на сайте
На сайте с 21.12.2009
24 сентября 2023, 10:48
Есть ощущение, что какой то сбой. Сегодня вылетело более 5000 страниц, страницы в большинстве были в топе. Статус стоит «Статус неизвестен». Написал Платонам, жду ответ.
Яндекс.Вебмастер: как зарегистрировать новый сайт и добавить его на индексацию
Яндекс.Вебмастер – один из первых сервисов, в которые нужно добавить новосозданный сайт. Он обеспечивает процесс и оценку результатов индексации, осуществляет диагностику ошибок и проблем, а также отслеживает статистику. После добавления сайта в Яндекс.Вебмастер владелец получит полную картину по индексации, позициям в выдаче и техническому состоянию. Процедура занимает не более 30 минут: рассказываем, как пройти регистрацию и зачем она нужна.
Что такое Яндекс.Вебмастер, какие функции он имеет
Сервис помогает разработчикам, вебмастерам и владельцам эффективно управлять сайтами, что важно для сокращения ошибок и гибкого реагирования на форс-мажоры. Наделен следующими возможностями:
- анализ индексирования. Роботы Яндекса осуществляют регулярный обход сайтов: они улавливают любые изменения и проводят ранжирование. После подключения можно получить доступ к статистике обходов, а также вручную отправлять обновленные страницы на переобход;
- мониторинг поисковых запросов. Речь идет о словах и фразах, по которым пользователи находят сайт: предоставляются данные о самых эффективных запросах;
- диагностика. Проводятся проверки и выявляются ошибки, способные негативно влиять на работоспособность сайта, есть рекомендации общего характера по устранению.
Сервис проводит мониторинг внутренних и внешних ссылок на предмет наличия нерабочих, диагностирует проблемы безопасности, корректирует сниппеты, проверяет индексный файл и региональность. Помогает узнать, насколько сайт адаптирован для мобильных устройств, а также:
- определяет качество;
- дает сведения о представлении в поиске;
- позволяет подключить Турбо-страницы;
- проверяет ответ сервера, Sitemap и robots.txt;
- обеспечивает подключение к Яндекс.Метрике.
Все функции собраны в одной панели – это единая система для эффективного управления из одного окна.
Как добавить сайт в Яндекс.Вебмастер
Для добавления сайта предварительно необходимо создать аккаунт на базе Яндекс (если его еще нет): потребуются активный номер телефона (на него придет SMS-сообщение с кодом для подтверждения), резервная электронная почта и кодовое слово. После этого придется перейти на официальный сайт Яндекс.Вебмастер: здесь будут отображаться уже подключенные ресурсы если их нет – нажмите на кнопку «Добавить сайт».
Добавление в Яндекс.Вебмастер
Произойдет перенаправление на страницу для ввода URL-адреса, технические требования следующие:
- с префиксом или без префикса www;
- протоколы HTTP или HTTPS;
- домен и поддомен добавляются в сервис отдельно (подтверждение прав возможно одним кодом);
- в ходе добавления сайт отвечает HTTP-кодом 200 ОК.
Адрес можно скопировать прямо из поисковой строки, следующий этап – подтверждение прав доступа, что легко выполнить с привлечением одного из трех доступных методов – рассмотрим каждый.
Подтверждение прав на сайт в Яндекс.Вебмастере
Через HTML-файл
Подтверждение через HTML-файл – самый простой и быстрый способ, с которым легко справится даже человек без опыта. Достаточно выбрать HTML в панели и скачать файл: его нельзя переименовывать или видоизменять.

Файл для скачивания находится здесь
Следующий этап – загрузка файла на сайт. Если он создан на базе платформы inSales, то достаточно следовать инструкции:
- перейдите в раздел «Файлы». Он находится слева: кликните на «Сайт» и выберите нужный пункт из выпадающего списка;
- нажмите на кнопку «Добавить файлы» и загрузите необходимое.

Так выполняется подключение сайта на базе inSales
После загрузки нужно вернуться в Яндекс.Вебмастер и нажать на кнопку «Проверить»: все, права успешно подтверждены. В качестве альтернативного способа можно привлечь файловый менеджер.
Метатег
Если первый способ по какой-то причине не сработал, то можно попробовать подтвердить права через метатег. Нужно сохранить код и вставить его в код главной страницы подключаемого сайта (поместить в раздел head), после обновления – провести проверку. Если самостоятельно выполнить процедуру сложно, то лучше обратиться в техническую поддержку платформы, на которой функционирует сайт, или к разработчику (при заказе в агентстве или у частного специалиста).
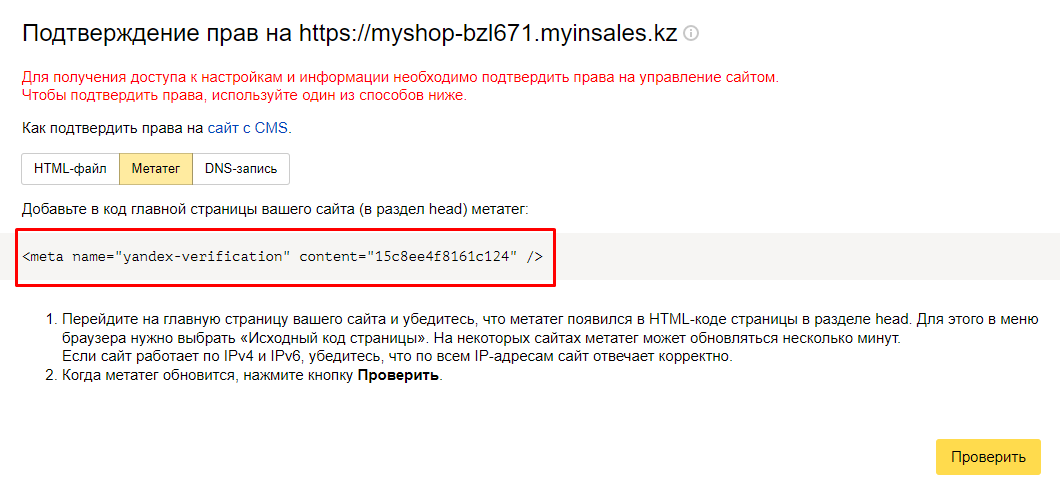
Инструкция от вебмастера по работе с метатегами
DNS-запись
По версии вебмастеров подтверждение прав через DNS-запись – один из самых неудобных способов. Принцип в том, что в DNS домена добавляется TXT-запись (для сайтов на inSales через раздел «Домены»), процесс может затянуться на 2-3 дня: метод рекомендован для тех, кто не смог подключиться по HTML и метатегу.

TXT-запись в Яндекс.Вебмастер
Настройки после добавления сайта в Яндекс.Вебмастер
В рамках предварительной настройки необходимо отсортировать страницы, которые не должны попасть в поиск, например, с личными данными, решить вопрос с региональностью и индексацией. Географическая привязка выполняется в разделе «Информация о сайте – региональность»: после завершения процесса ресурс будет отнесен к определенному региону. Однако данные придется подтвердить, предоставив ссылку на страницу с контактами или адресом компании.
Дальше – регистрация в Яндекс.Справочнике, компании, имеющие филиалы в разных регионах, могут указать эту информацию, чтобы расширить географию. На этом этапе можно добавить счетчик Яндекс.Метрики (доступно из панели Вебмастера) – бесплатный инструмент для веб-аналитики, предоставляющий отчеты, мониторящий источники трафика, оценивающий разные рекламные каналы.

Пример отчетов из демо-счетчика Метрики
Как работать с Яндекс.Вебмастер дальше
Сервис отличается интуитивно понятным меню и интерфейсом, данные предоставляются в форме удобных графиков и диаграмм: с функционалом разобраться не сложно.
Сводка
Раздел «Сводка» – информационный, в нем отражаются выявленные проблемы, сведения о страницах, которые были добавлены в поиск или удалены, история обхода роботами. Доступны данные о последних внешних ссылках, поисковых запросах, трубо-страницах и ИКС – изучив раздел, вебмастер сможет быстро оценить текущую ситуацию.
Качество сайта
Сервис отслеживает, удобно ли пользователям взаимодействовать с ресурсом, а также учитывает другие критерии. На финише присваивается индекс качества, владелец постоянно получает рекомендации о том, как нарастить объем трафика и какие меры лучше предпринять. Учитывается не только сухие статистические данные, но и мнения пользователей, например, отзывы.

Как рассчитывается ИКС
Поисковые запросы
В этом разделе представлены все запросы, которые пользователи используют для поиска с последующим переходом на сайт. Информация полезна при работе с ключевыми словами или сниппетами. Дополнительно – статистика запросов (популярные, избранные, тренды, иные), сведения о кликах и показах, отдельно – «Рекомендованные», обеспечивающие привлечение трафика. Перечень рекомендованных запросов формируется с учетом конкурентов, тематики и других индивидуальных характеристик.
Информация о сайте, ссылки
Здесь находится региональность, особо важная для компаний по предоставлению услуг или владельцев наземных точек продаж: если пользователь будет искать продавца в своем городе, то в первую очередь увидит локальные предложения. В этом разделе можно выполнить следующие настройки:
- загрузка текстов: до публикации на сайте они закрепляются в Вебмастере, что позволяет сохранить и доказать авторство в случае необходимости;
- загрузка фида для отображения товаров и цен;
- быстрые ссылки, которые были размещены автоматически.
Отдельно – данные о внутренних и внешних ссылках: можно проверить работоспособность, источники, индекс качества по каждому ресурсу. Полезный инструмент – график для отслеживания появления ссылок.
Индексирование
В разделе аккумулируются сведения обо всех процессах, связанных с индексацией. Доступны следующие данные:
- статистика обхода поисковым роботом с датами;
- сведения о страницах с обновленными статусами и датами последнего сканирования роботами;
- мониторинг важных страниц. Отображаются метатеги, даты последних изменений и обхода, код ответа и другая информация;
- запрос внеочередного обхода: используется после внесения изменений, которые должны быть быстро проверены и отображены.
Создан раздел для загрузки Sitemap с последующим отслеживанием, обход по счетчикам Метрики, решения для переезда сайта.

Отчеты об индексировании страниц: источник – Яндекс
Диагностика
В этом разделе сосредоточены данные, касающиеся проблем и ошибок. Если сайт недоступен, то проблема является фатальной, критичная – длительный ответ сервера или масса внутренних ссылок, которые не работают. Третья разновидность – возможные проблемы, возникающие при дублях страниц, некорректных Sitemap или robots.txt. «Диагностика» имеет подразделы, где аккумулируется информация об опасных ошибках: вредоносный код, нехватка оригинального контента, проблемы с дизайном. Этот раздел нужно изучать с особой тщательностью: все выявленные проблемы оказывают прямое влияние на индексацию – чем скорее они будут устранены, тем лучше. После внесения правок сайт нужно отправить на проверку.
В заключение
Регистрация в Яндекс.Вебмастере не занимает много времени и не требует специфических знаний: достаточно следовать инструкциям, через 20-30 минут сайт будет подключен к сервису. Вебмастер предоставляет владельцам ресурсов большое количество полезной информации, которая предупреждает запущенные ошибки, санкции и фильтры, низкую безопасность. Рекомендуется проходить регистрацию в дополнительных сервисах Яндекса – это Метрика, Справочник и другие: чем больше данных поисковая система соберет о бизнесе, тем лучше будет ранжировать сайт, а владелец получит удобные бесплатные инструменты для мониторинга.