Визуализация 5 алгоритмов сортировки на Python

Реализация алгоритмов сортировки: выбором, пузырьком, вставками, слиянием и быстрой сортировкой с помощью Python.
Введение
Сортировка массивов часто используется в программировании, чтобы помочь понять данные и выполнить поиск. Поэтому скорость сортировки больших объемов информации крайне важна для функциональных проектов и оптимизации времени работы. Есть много алгоритмов для упорядочения объектов.
В статье вы посмотрите на реализацию и визуализацию пяти популярных алгоритмов сортировки. Код написан на Python, а графический интерфейс построен на Tkinter.
Эти 5 алгоритмов включают:
- Сортировка выбором
- Сортировка пузырьком
- Сортировка вставками
- Сортировка слиянием
- Быстрая сортировка quicksort
Визуализация массива
Как только класс предоставляет перегруженные реализации операторов сравнения, он сортируется. На Python это:
_lt_ : меньше чем
_gt_ : больше чем
Код ниже демонстрирует перегруженный метод меньше чем.
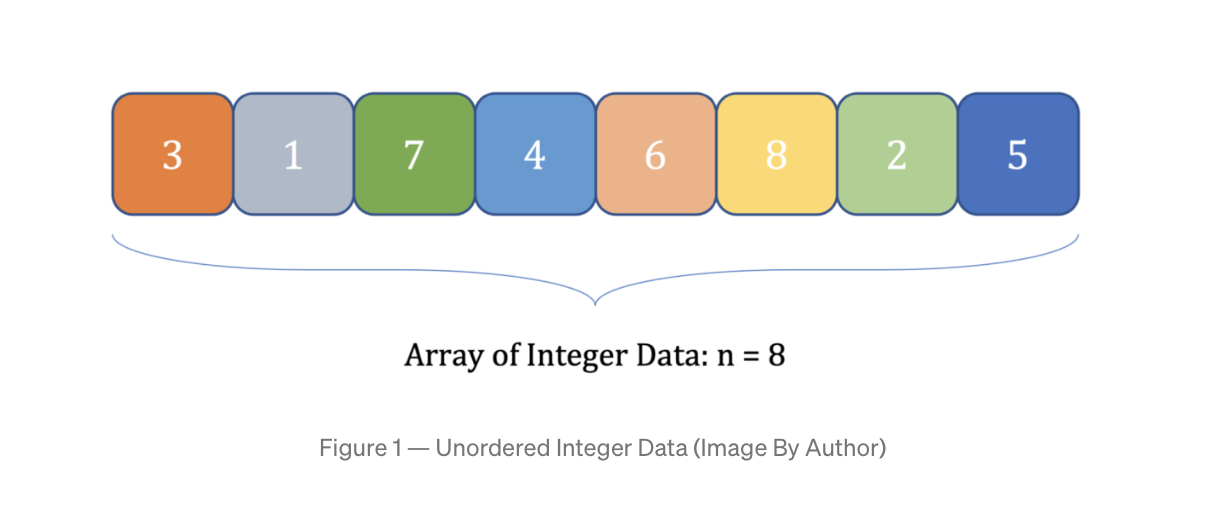
def __lt__(self, other): # compare object with "other" object of same type return self.value < other.valueДавайте представим числовые данные с помощью столбцов. Высота столбца i равна значению элемента массива i. У них всех одинаковая ширина. Такое изображение списка числовых значений с Рис. 1 в виде столбцов приведено на Рис. 2.
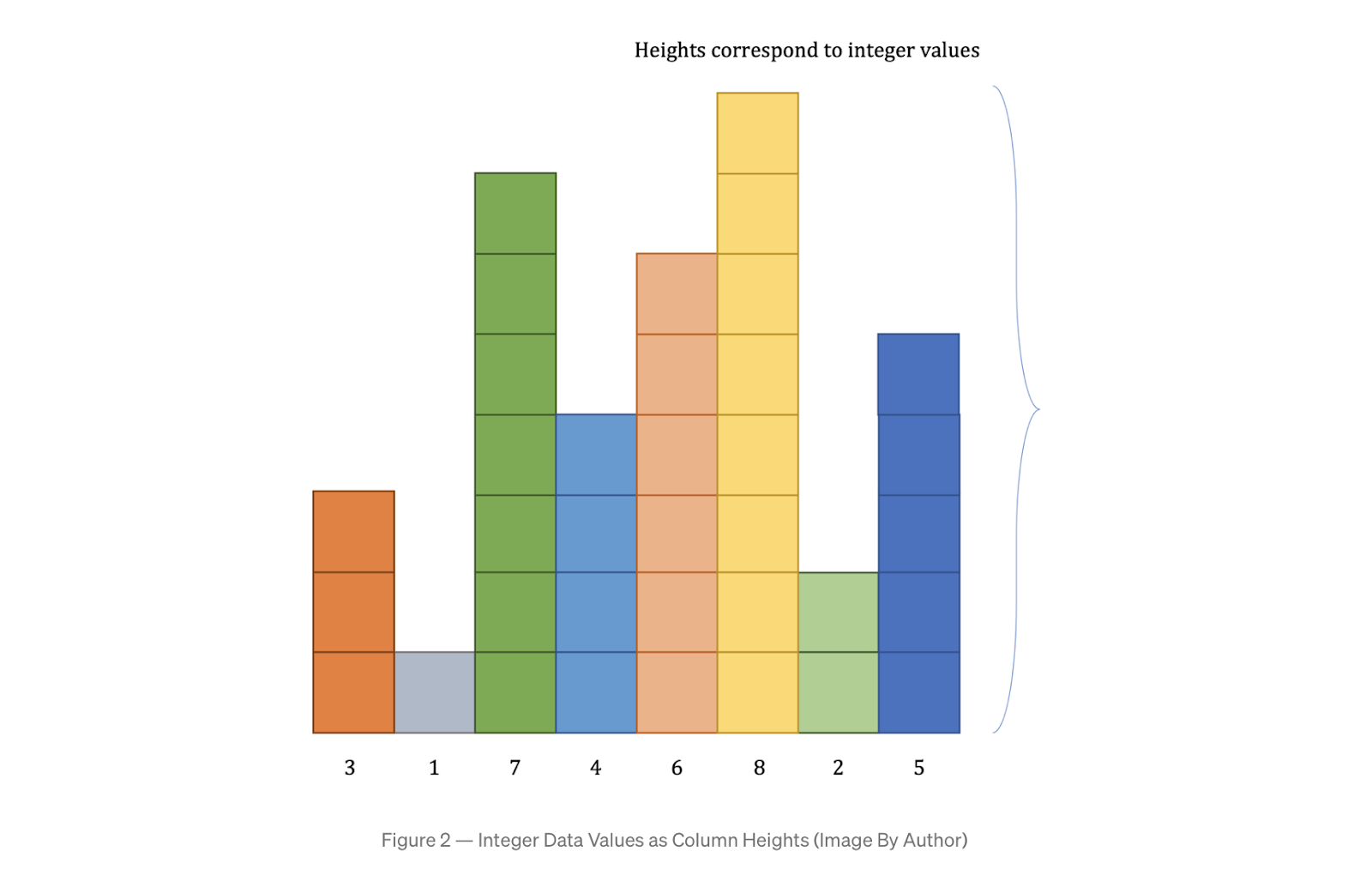
Сортировка числовых данных по убыванию или по возрастанию требует соответствующей перестановки значений. Для анимации каждого алгоритма с данными, требуется обновлять диаграмму после замены отдельных элементов.
Ниже — код Python для замены двух элементов в списке.
def swap(arr, a, b): """ переставляем элементы a и b в массиве """ temp = arr[a] arr[a] = arr[b] arr[b] = temp # возвращаем массивДля рендеринга необходимы два класса: Canvas, и Bar. Код с комментариями для полного пользовательского интерфейса лежит в репозитории GitHub.
Ниже показан необходимый код для отображения обновлений в классе Canvas . Если bar index меняется, как указано выше, setter запускает функцию update_bar на основном холсте. После запуска обновления элементы массива меняются местами.
@index.setter def index(self, i): """ update coordinates when index changes """ self._index = i # update horizontal coordinates self.x1 = self._index * self.width self.x2 = self.x1 + self.width # dispatch updates to subscriber (visualiser) self.subscriber.update_bar(self)Сортировка выбором
Встроенный алгоритм сортировки, то есть отсортированные элементы используют то же хранилище, что и исходные элементы.
Ниже — реализация сортировки выбором на Python с подробными комментариями.
Внешний цикл производит итерации по всей длине несортированного массива. В это время внутренний цикл ищет минимальное значение в оставшейся части набора данных. Затем происходит единая замена, переставляющая элемент под номером i и элемент min_index .
def selection_sort(self, unsorted, n): # итерируемся по массиву for i in range(0, n): # инициализируемся первым значеним current_min = unsorted[i] # инициализируем минимальный индекс min_index = i # итерируемся по оставшимся элементам массива for j in range(i, n): # проверяем, если j-тое значение меньше текушего минимального if unsorted[j] < current_min: # обновляес минимальные значение и индекс current_min = unsorted[j] min_index = j # меняем i-тое и j-тое значения swap(unsorted, i, min_index)Метод сортировки выбором обычно включает параметры:
- Временная сложность = O(n²).
n² итераций очевидны из двух вложенных циклов. - Пространственная сложность = O(1).
Как упоминалось выше, сортировка происходит в том же массиве, поэтому использование памяти не зависит от данных обработки.
Сортировка пузырьком
Несколько раз проходит по списку, сравнивая соседние элементы. Элементы меняются местами в зависимости от условия сортировки.
Ниже показана реализация сортировки выбором на Python с комментариями.
def bubble_sort(self, unsorted, n): """ алгоритм сортировки пузырьком """ # итерируемся по неотсорт. массиву до предпоследнего элемента for i in range(0, n - 1): # проставляем условия флага для финального списка swapped = False # итерируемся по осташвимся неотсортированным объектам for j in range(0, n - 1 - i): # сравниваем соседние элементы if unsorted[j].value > unsorted[j + 1].value: # меняем элементы местами swap(unsorted, j, j + 1) swapped = True # завершаем алгоритм, если смены не произошло if not swapped: breakОбратите внимание, что из всех алгоритмов у сортировки пузырьком наихудший случай и среднее значение:
- Временная сложность = O(n²).
Внутренний цикл работает не менее n раз. Поэтому операция займет не менее n² времени - Пространственная сложность = O(1).
Дополнительная память не используется, потому что происходит обмен элементов в исходном массиве
Большие значения всплывают, как пузырьки, в верхнюю часть списка по мере выполнения программы, как показано на Рис. 4.
Сортировка вставками
Строит конечный массив по одному элементу за раз. Используйте код, указанный ниже для выполнения метода над несортированным массивом объектов.
def insertion_sort(unsorted, n): """ сортировка вставками """ # итерация по неотсортированным массивам for i in range(1, n): # получаем значение элемента val = unsorted[i].value # записываем в hole индекс i hole = i # проходим по массиву в обратную сторону, пока не найдём элемент больше текущего while hole > 0 and unsorted[hole - 1].value > val: # переставляем элементы местами , чтобы получить правильную позицию unsorted[hole].value = unsorted[hole - 1].value # делаем шаг назад hole -= 1 # вставляем значение на верную позицию unsorted[hole].value = val
У сортировки вставками есть наихудший случай:
- Временная сложность = O(n²). Как внешний цикл for, так и внутренний while работают приблизительно n раз
- Пространственная сложность = O(1). Операции проводятся с исходным массивом. Таким образом, дополнительной памяти не требуется.
Сортировка слиянием
Сортировка слиянием — алгоритм сортировки по принципу «разделяй и властвуй». Задача раскладывается на более мелкие аналогичные подзадачи до тех пор, пока не будет решен базовый случай.
Несортированный массив разделяется до тех пор, пока не выделится базовый случай отдельных элементов. Затем происходит сравнение между временными массивами, перемещающимися обратно вверх по стеку рекурсии.
def divide(self, unsorted, lower, upper): """ рекурсивная функция для разделения массива на два подмассива для сортировки """ # с помощью рекурсии достигнут базовый случай if upper У сортировки слиянием есть:
- Временная сложность = O(nlog(n)). У алгоритмов сортировки «разделяй и властвуй» такая временная сложность. Эта сложность – наихудший сценарий для подобных алгоритмов.
- Пространственная сложность = O(n), если выделение памяти увеличивается не быстрее константы kN, т.е. кратной размеру набора данных.
Быстрая сортировка
Быстрая сортировка примерно в два-три раза быстрее основных конкурентов, сортировки слиянием и пирамидальной сортировки. Ее часто реализуют рекурсивно, как на примере ниже.
Значения pivot лежат в основе алгоритма быстрой сортировки. По существу, pivot опорные значения. Постановка pivot означает, что объекты слева всегда меньше, а элементы справа больше, чем pivot .
def quick_sort(self, unsorted, start, end): """ быстрая сортировка """ # останавливаемся, когда индекс слева достиг или превысил индек справа if start >= end: return # определяем позицию следующего пивота i_pivot = partition(unsorted, start, end - 1) # рекурсивный вызов левой части quick_sort(unsorted, start, i_pivot) # рекурсивный вызов правой части quick_sort(unsorted, i_pivot + 1, end) def partition(self, unsorted, start, end): """ arrange (left array < pivot) and (right array >pivot) """ # выбираем значение pivot как последний элемент неотсортированного сегмента pivot = unsorted[end] # назначаем на pivot значение левого индекса i_pivot = start # проходим от начала до конца текущего сегмента for i in range(start, end): # сравниваем текущее значение со значением pivot if unsorted[i].value Рекурсивно разбивая массив, выбирая точки pivot и назначая их в правильном месте, получаем окончательно отсортированный массив.
У быстрой сортировки есть среднее значение:
Временная сложность = O(n*log(n)). Как и сортировка слиянием, данная нотация определяется по принципу разделяй и властвуй или быстрой сортировки. Наихудший сценарий – O(n²). Однако это происходит, только когда элементы массива правильно восходят или нисходят.
Заключение
Оптимизированная сортировка имеет критически важное значение для разработки ПО. Временные сложности конкретных алгоритмов могут варьироваться в зависимости от первоначальногопорядка элементов. Однако наиболее целесообразно предположитьнаихудший сценарий.
В статье мы не рассмотрели некоторые другие методы. Например, пирамидальная , поразрядная сортировка и любимый неэффективный алгоритм случайной сортировки.
Выше представлен код Python и визуализации пяти стандартных алгоритмов сортировки. Понимание данных механизмов ценно для студентов, изучающих компьютерные науки, поскольку некоторые процедуры часто появляются на собеседованиях.
Другие наши статьи по бэкенду и асинхронному программированию для начинающих:
- Цикл статей «Первые шаги в aiohttp»: пишем первое hello-world-приложение, подключаем базу данных, выкладываем проект в Интернет
- Разбираемся в асинхронности: где полезно, а где — нет?
Другие наши статьи по бэкенду и асинхронному программированию для продвинутого уровня:
- Пишем свой Google, или асинхронный краулер с rate limits на Python
- Пишем асинхронного Телеграм-бота
- Пишем Websocket-сервер для геолокации на asyncio
��Асинхронное программирование на Python для джуниор-разработчиков��
Асинхронное программирование используется для высоконагруженных проектов и микросервисов. Его спрашивают на собеседованиях в технологически развитых компаниях, и оно открывает дорогу к работе в интересных проектах. Если вы уже пишете на Python, но пока не изучили модуль Asyncio, приглашаю вас на курс по асинхронному программированию на Python.
- Разберётесь, как работает асинхронное программирование и где его лучше применять.
- Получите опыт работы с микросервисами.
- Освоите стандартную python-библиотеку Asyncio, напишите чат-бота и event loop.
�� Посмотреть программу и записаться на курс: https://vk.cc/cmUy1v
- сортировка
- сортировка слиянием
- сортировка вставками
- сортировка пузырьком
- сортировка выбором
- быстрая сортировка
- python
- backend
Объяснение алгоритмов сортировки с примерами на Python
В этой статье рассмотрены популярные алгоритмы, принципы их работы и реализация на Python. Также сравним, как быстро они сортируют элементы в списке.
В этой статье будут рассмотрены популярные алгоритмы, принципы их работы и реализация на Python. А ещё сравним, как быстро они сортируют элементы в списке.
В качестве общего примера возьмём сортировку чисел в порядке возрастания. Но эти методы можно легко адаптировать под ваши потребности.
Пузырьковая сортировка
Этот простой алгоритм выполняет итерации по списку, сравнивая элементы попарно и меняя их местами, пока более крупные элементы не «всплывут» в начало списка, а более мелкие не останутся на «дне».
Алгоритм
Сначала сравниваются первые два элемента списка. Если первый элемент больше, они меняются местами. Если они уже в нужном порядке, оставляем их как есть. Затем переходим к следующей паре элементов, сравниваем их значения и меняем местами при необходимости. Этот процесс продолжается до последней пары элементов в списке.
При достижении конца списка процесс повторяется заново для каждого элемента. Это крайне неэффективно, если в массиве нужно сделать, например, только один обмен. Алгоритм повторяется n² раз, даже если список уже отсортирован.
Для оптимизации алгоритма нужно знать, когда его остановить, то есть когда список отсортирован.
Чтобы остановить алгоритм по окончании сортировки, нужно ввести переменную-флаг. Когда значения меняются местами, устанавливаем флаг в значение True , чтобы повторить процесс сортировки. Если перестановок не произошло, флаг остаётся False и алгоритм останавливается.
Реализация
def bubble_sort(nums): # Устанавливаем swapped в True, чтобы цикл запустился хотя бы один раз swapped = True while swapped: swapped = False for i in range(len(nums) - 1): if nums[i] > nums[i + 1]: # Меняем элементы nums[i], nums[i + 1] = nums[i + 1], nums[i] # Устанавливаем swapped в True для следующей итерации swapped = True # Проверяем, что оно работает random_list_of_nums = [5, 2, 1, 8, 4] bubble_sort(random_list_of_nums) print(random_list_of_nums) Алгоритм работает в цикле while и прерывается, когда элементы ни разу не меняются местами. Вначале присваиваем swapped значение True , чтобы алгоритм запустился хотя бы один раз.
Время сортировки
Если взять самый худший случай (изначально список отсортирован по убыванию), затраты времени будут равны O(n²), где n — количество элементов списка.
Оценка сложности алгоритмов, или Что такое О(log n)
Сортировка выборкой
Этот алгоритм сегментирует список на две части: отсортированную и неотсортированную. Наименьший элемент удаляется из второго списка и добавляется в первый.
Алгоритм
На практике не нужно создавать новый список для отсортированных элементов. В качестве него используется крайняя левая часть списка. Находится наименьший элемент и меняется с первым местами.
Теперь, когда нам известно, что первый элемент списка отсортирован, находим наименьший элемент из оставшихся и меняем местами со вторым. Повторяем это до тех пор, пока не останется последний элемент в списке.
Реализация
def selection_sort(nums): # Значение i соответствует кол-ву отсортированных значений for i in range(len(nums)): # Исходно считаем наименьшим первый элемент lowest_value_index = i # Этот цикл перебирает несортированные элементы for j in range(i + 1, len(nums)): if nums[j] < nums[lowest_value_index]: lowest_value_index = j # Самый маленький элемент меняем с первым в списке nums[i], nums[lowest_value_index] = nums[lowest_value_index], nums[i] # Проверяем, что оно работает random_list_of_nums = [12, 8, 3, 20, 11] selection_sort(random_list_of_nums) print(random_list_of_nums)По мере увеличения значения i нужно проверять меньше элементов.
Время сортировки
Затраты времени на сортировку выборкой в среднем составляют O(n²), где n — количество элементов списка.
Сортировка вставками
Как и сортировка выборкой, этот алгоритм сегментирует список на две части: отсортированную и неотсортированную. Алгоритм перебирает второй сегмент и вставляет текущий элемент в правильную позицию первого сегмента.
Алгоритм
Предполагается, что первый элемент списка отсортирован. Переходим к следующему элементу, обозначим его х . Если х больше первого, оставляем его на своём месте. Если он меньше, копируем его на вторую позицию, а х устанавливаем как первый элемент.
Переходя к другим элементам несортированного сегмента, перемещаем более крупные элементы в отсортированном сегменте вверх по списку, пока не встретим элемент меньше x или не дойдём до конца списка. В первом случае x помещается на правильную позицию.
Реализация
def insertion_sort(nums): # Сортировку начинаем со второго элемента, т.к. считается, что первый элемент уже отсортирован for i in range(1, len(nums)): item_to_insert = nums[i] # Сохраняем ссылку на индекс предыдущего элемента j = i - 1 # Элементы отсортированного сегмента перемещаем вперёд, если они больше # элемента для вставки while j >= 0 and nums[j] > item_to_insert: nums[j + 1] = nums[j] j -= 1 # Вставляем элемент nums[j + 1] = item_to_insert # Проверяем, что оно работает random_list_of_nums = [9, 1, 15, 28, 6] insertion_sort(random_list_of_nums) print(random_list_of_nums) Время сортировки
Время сортировки вставками в среднем равно O(n²), где n — количество элементов списка.
Пирамидальная сортировка
Также известна как сортировка кучей. Этот популярный алгоритм, как и сортировки вставками или выборкой, сегментирует список на две части: отсортированную и неотсортированную. Алгоритм преобразует второй сегмент списка в структуру данных «куча» (heap), чтобы можно было эффективно определить самый большой элемент.
Алгоритм
Сначала преобразуем список в Max Heap — бинарное дерево, где самый большой элемент является вершиной дерева. Затем помещаем этот элемент в конец списка. После перестраиваем Max Heap и снова помещаем новый наибольший элемент уже перед последним элементом в списке.
Этот процесс построения кучи повторяется, пока все вершины дерева не будут удалены.
Реализация
Создадим вспомогательную функцию heapify() для реализации этого алгоритма:
def heapify(nums, heap_size, root_index): # Индекс наибольшего элемента считаем корневым индексом largest = root_index left_child = (2 * root_index) + 1 right_child = (2 * root_index) + 2 # Если левый потомок корня — допустимый индекс, а элемент больше, # чем текущий наибольший, обновляем наибольший элемент if left_child < heap_size and nums[left_child] >nums[largest]: largest = left_child # То же самое для правого потомка корня if right_child < heap_size and nums[right_child] >nums[largest]: largest = right_child # Если наибольший элемент больше не корневой, они меняются местами if largest != root_index: nums[root_index], nums[largest] = nums[largest], nums[root_index] # Heapify the new root element to ensure it's the largest heapify(nums, heap_size, largest) def heap_sort(nums): n = len(nums) # Создаём Max Heap из списка # Второй аргумент означает остановку алгоритма перед элементом -1, т.е. # перед первым элементом списка # 3-й аргумент означает повторный проход по списку в обратном направлении, # уменьшая счётчик i на 1 for i in range(n, -1, -1): heapify(nums, n, i) # Перемещаем корень Max Heap в конец списка for i in range(n - 1, 0, -1): nums[i], nums[0] = nums[0], nums[i] heapify(nums, i, 0) # Проверяем, что оно работает random_list_of_nums = [35, 12, 43, 8, 51] heap_sort(random_list_of_nums) print(random_list_of_nums) Время сортировки
В среднем время сортировки кучей составляет O(n log n), что уже значительно быстрее предыдущих алгоритмов.
Сортировка слиянием
Этот алгоритм относится к алгоритмам «разделяй и властвуй». Он разбивает список на две части, каждую из них он разбивает ещё на две и т. д. Список разбивается пополам, пока не останутся единичные элементы.
Соседние элементы становятся отсортированными парами. Затем эти пары объединяются и сортируются с другими парами. Этот процесс продолжается до тех пор, пока не отсортируются все элементы.
Алгоритм
Список рекурсивно разделяется пополам, пока в итоге не получатся списки размером в один элемент. Массив из одного элемента считается упорядоченным. Соседние элементы сравниваются и соединяются вместе. Это происходит до тех пор, пока не получится полный отсортированный список.
Сортировка осуществляется путём сравнения наименьших элементов каждого подмассива. Первые элементы каждого подмассива сравниваются первыми. Наименьший элемент перемещается в результирующий массив. Счётчики результирующего массива и подмассива, откуда был взят элемент, увеличиваются на 1.
Реализация
def merge(left_list, right_list): sorted_list = [] left_list_index = right_list_index = 0 # Длина списков часто используется, поэтому создадим переменные для удобства left_list_length, right_list_length = len(left_list), len(right_list) for _ in range(left_list_length + right_list_length): if left_list_index < left_list_length and right_list_index < right_list_length: # Сравниваем первые элементы в начале каждого списка # Если первый элемент левого подсписка меньше, добавляем его # в отсортированный массив if left_list[left_list_index] Обратите внимание, что функция merge_sort() , в отличие от предыдущих алгоритмов, возвращает новый список, а не сортирует существующий. Поэтому такая сортировка требует больше памяти для создания нового списка того же размера, что и входной список.
Время сортировки
В среднем время сортировки слиянием составляет O(n log n).
Быстрая сортировка
Этот алгоритм также относится к алгоритмам «разделяй и властвуй». Его используют чаще других алгоритмов, описанных в этой статье. При правильной конфигурации он чрезвычайно эффективен и не требует дополнительной памяти, в отличие от сортировки слиянием. Массив разделяется на две части по разные стороны от опорного элемента. В процессе сортировки элементы меньше опорного помещаются перед ним, а равные или большие —позади.
Алгоритм
Быстрая сортировка начинается с разбиения списка и выбора одного из элементов в качестве опорного. А всё остальное передвигаем так, чтобы этот элемент встал на своё место. Все элементы меньше него перемещаются влево, а равные и большие элементы перемещаются вправо.
Реализация
Существует много вариаций данного метода. Способ разбиения массива, рассмотренный здесь, соответствует схеме Хоара (создателя данного алгоритма).
def partition(nums, low, high): # Выбираем средний элемент в качестве опорного # Также возможен выбор первого, последнего # или произвольного элементов в качестве опорного pivot = nums[(low + high) // 2] i = low - 1 j = high + 1 while True: i += 1 while nums[i] < pivot: i += 1 j -= 1 while nums[j] >pivot: j -= 1 if i >= j: return j # Если элемент с индексом i (слева от опорного) больше, чем # элемент с индексом j (справа от опорного), меняем их местами nums[i], nums[j] = nums[j], nums[i] def quick_sort(nums): # Создадим вспомогательную функцию, которая вызывается рекурсивно def _quick_sort(items, low, high): if low < high: # This is the index after the pivot, where our lists are split split_index = partition(items, low, high) _quick_sort(items, low, split_index) _quick_sort(items, split_index + 1, high) _quick_sort(nums, 0, len(nums) - 1) # Проверяем, что оно работает random_list_of_nums = [22, 5, 1, 18, 99] quick_sort(random_list_of_nums) print(random_list_of_nums)Время выполнения
В среднем время выполнения быстрой сортировки составляет O(n log n).
Обратите внимание, что алгоритм быстрой сортировки будет работать медленно, если опорный элемент равен наименьшему или наибольшему элементам списка. При таких условиях, в отличие от сортировок кучей и слиянием, обе из которых имеют в худшем случае время сортировки O(n log n), быстрая сортировка в худшем случае будет выполняться O(n²).
Встроенные функции сортировки на Python
Иногда полезно знать перечисленные выше алгоритмы, но в большинстве случаев разработчик, скорее всего, будет использовать функции сортировки, уже предоставленные в языке программирования.
Отсортировать содержимое списка можно с помощью стандартного метода sort() :
>>> apples_eaten_a_day = [2, 1, 1, 3, 1, 2, 2] >>> apples_eaten_a_day.sort() >>> apples_eaten_a_day [1, 1, 1, 2, 2, 2, 3] Или можно использовать функцию sorted() для создания нового отсортированного списка, оставив входной список нетронутым:
>>> apples_eaten_a_day_2 = [2, 1, 1, 3, 1, 2, 2] >>> sorted_apples = sorted(apples_eaten_a_day_2) >>> sorted_apples [1, 1, 1, 2, 2, 2, 3] Оба эти метода сортируют в порядке возрастания, но можно изменить порядок, установив для флага reverse значение True :
# Обратная сортировка списка на месте >>> apples_eaten_a_day.sort(reverse=True) >>> apples_eaten_a_day [3, 2, 2, 2, 1, 1, 1] # Обратная сортировка, чтобы получить новый список >>> sorted_apples_desc = sorted(apples_eaten_a_day_2, reverse=True) >>> sorted_apples_desc [3, 2, 2, 2, 1, 1, 1] В отличие от других алгоритмов, обе функции в Python могут сортировать также списки кортежей и классов. Функция sorted() может сортировать любую последовательность, которая включает списки, строки, кортежи, словари, наборы и пользовательские итераторы, которые вы можете создать.
Функции в Python реализуют алгоритм Tim Sort, основанный на сортировке слиянием и сортировке вставкой.
Сравнение скоростей сортировок
Для сравнения сгенерируем массив из 5000 чисел от 0 до 1000. Затем определим время, необходимое для завершения каждого алгоритма. Повторим каждый метод 10 раз, чтобы можно было более точно установить, насколько каждый из них производителен.
Пузырьковая сортировка — самый медленный из всех алгоритмов. Возможно, он будет полезен как введение в тему алгоритмов сортировки, но не подходит для практического использования.
Быстрая сортировка хорошо оправдывает своё название, почти в два раза быстрее, чем сортировка слиянием, и не требуется дополнительное место для результирующего массива.
Сортировка вставками выполняет меньше сравнений, чем сортировка выборкой и в реальности должна быть производительнее, но в данном эксперименте она выполняется немного медленней. Сортировка вставками делает гораздо больше обменов элементами. Если эти обмены занимают намного больше времени, чем сравнение самих элементов, то такой результат вполне закономерен.
Вы познакомились с шестью различными алгоритмами сортировок и их реализациями на Python. Масштаб сравнения и количество перестановок, которые выполняет алгоритм вместе со средой выполнения кода, будут определяющими факторами в производительности. В реальных приложениях Python рекомендуется использовать встроенные функции сортировки, поскольку они реализованы именно для удобства разработчика.
Виды алгоритмов сортировки в Python

В одной из прошлых статей я рассматривал списки в Python, а также затронул их сортировку. Теперь давайте разберем эту тему более подробно: изучим виды алгоритмов сортировки и сравним их скорость на примере сортировки чисел в порядке возрастания.
Встроенные методы сортировки в Python
Стандартный метод сортировки списка по возрастанию – sort(). Пример использования:
nums = [54, 43, 3, 11, 0] nums.sort() print(nums) # Выведет [0, 3, 11, 43, 54]
Метод sorted() создает новый отсортированный список, не изменяя исходный. Пример использования:
nums = [54, 43, 3, 11, 0] nums2 = sorted(nums) print(nums, nums2) # Выведет [54, 43, 3, 11, 0] [0, 3, 11, 43, 54]
Если нам нужна сортировка от большего числа к меньшему, то установим флаг reverse=True. Примеры:
nums = [54, 43, 3, 11, 0] nums.sort(reverse=True) print(nums) # Выведет [54, 43, 11, 3, 0] nums = [54, 43, 3, 11, 0] nums2 = sorted(nums, reverse=True) print(nums, nums2) # Выведет [54, 43, 3, 11, 0] [54, 43, 11, 3, 0]
Но будет полезно знать и другие виды сортировки, так как не всегда встроенные методы будут подходить под все ваши задачи.
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Пузырьковая сортировка
Алгоритм попарно сравнивает элементы списка, меняя их местами, если это требуется. Он не так эффективен, если нам нужно сделать только один обмен в списке, так как данный алгоритм при достижении конца списка будет повторять процесс заново. Чтобы алгоритм не выполнялся бесконечно, мы вводим переменную, которая поменяет свое значение с True на False, если после запуска алгоритма список не изменился.
Сравниваются первые два элемента. Если первый элемент больше, то они меняются местами. Далее происходит все то же самое, но со следующими элементами до последней пары элементов в списке.
Пример пузырьковой сортировки:
def bubble(list_nums): swap_bool = True while swap_bool: swap_bool = False for i in range(len(list_nums) - 1): if list_nums[i] > list_nums[i + 1]: list_nums[i], list_nums[i + 1] = list_nums[i + 1], list_nums[i] swap_bool = True nums = [54, 43, 3, 11, 0] bubble(nums) print(nums) # Выведет [0, 3, 11, 43, 54]
Сортировка вставками
Алгоритм делит список на две части, вставляя элементы на их правильные места во вторую часть списка, убирая их из первой.
Если второй элемент больше первого, то оставляем его на своем месте. Если он меньше, то вставляем его на второе место, оставив первый элемент на первом месте. Далее перемещаем большие элементы во второй части списка вверх, пока не встретим элемент меньше первого или не дойдем до конца списка.
Пример сортировки вставками:
def insertion(list_nums): for i in range(1, len(list_nums)): item = list_nums[i] i2 = i - 1 while i2 >= 0 and list_nums[i2] > item: list_nums[i2 + 1] = list_nums[i2] i2 -= 1 list_nums[i2 + 1] = item nums = [54, 43, 3, 11, 0] insertion(nums) print(nums) # Выведет [0, 3, 11, 43, 54]
Сортировка выборкой
Как и сортировка вставками, этот алгоритм в Python делит список на две части: основную и отсортированную. Наименьший элемент удаляется из основной части и переходит в отсортированную.
Саму отсортированную часть можно и не создавать, обычно используют крайнюю часть списка. И когда находится наименьший элемент списка, то переносим его на первое место, вставляя первый элемент на прошлое порядковое место наименьшего. Далее делаем все то же самое, но со следующим элементом, пока не достигнем конца списка.
Пример сортировки выборкой:
def selection(sort_nums): for i in range(len(sort_nums)): index = i for j in range(i + 1, len(sort_nums)): if sort_nums[j] < sort_nums[index]: index = j sort_nums[i], sort_nums[index] = sort_nums[index], sort_nums[i] nums = [54, 43, 3, 11, 0] selection(nums) print(nums) # Выведет [0, 3, 11, 43, 54]
Пирамидальная сортировка
Этот алгоритм, как и сортировки вставками или выборкой, делит список на две части. Алгоритм преобразует вторую часть списка в бинарное дерево для эффективного определения самого большого элемента.
Преобразуем список в бинарное дерево, где самый большой элемент является вершиной дерева, и помещаем этот элемент в конец списка. После перестраиваем дерево и помещаем новый наибольший элемент перед последним элементом в списке. Повторяем этот алгоритм, пока все вершины дерева не будут удалены.
Хоть алгоритм и кажется сложным, он значительно быстрее остальных, что особенно заметно при обработке больших списков.
Пример пирамидальной сортировки:
def heapify(sort_nums, heap_size, root): l = root left = (2 * root) + 1 right = (2 * root) + 2 if left < heap_size and sort_nums[left] >sort_nums[l]: l = left if right < heap_size and sort_nums[right] >sort_nums[l]: l = right if l != root: sort_nums[root], sort_nums[l] = sort_nums[l], sort_nums[root] heapify(sort_nums, heap_size, l) def heap(sort_nums): size = len(sort_nums) for i in range(size, -1, -1): heapify(sort_nums, size, i) for i in range(size - 1, 0, -1): sort_nums[i], sort_nums[0] = sort_nums[0], sort_nums[i] heapify(sort_nums, i, 0) nums = [54, 43, 3, 11, 0] heap(nums) print(nums) # Выведет [0, 3, 11, 43, 54]
Сортировка слиянием
Алгоритм разделяет список на две части, каждую из них он разделяет еще на две и так далее, пока не останутся отдельные единичные элементы. Далее соседние элементы сортируются парами. Затем эти пары объединяются и сортируются с другими парами, пока не обработаются все элементы в списке.
Пример сортировки слиянием:
def mergeSort(sort_nums): if len(sort_nums)>1: mid = len(sort_nums)//2 lefthalf = sort_nums[:mid] righthalf = sort_nums[mid:] mergeSort(lefthalf) mergeSort(righthalf) i=0 j=0 k=0 while iБыстрая сортировка в Python
Один из самых популярных алгоритмов при сортировке списков. При правильном использовании он не требует много памяти и выполняется очень быстро.
Алгоритм разделяет список на две равные части, принимая псевдослучайный элемент и используя его в качестве опоры, то есть центра деления. Элементы, меньшие, чем опора, перемещаются влево от опоры, а элементы, размер которых больше опоры – вправо. Этот процесс повторяется для списка слева от опоры, а также для массива элементов справа от опоры, пока весь массив не будет отсортирован. Алгоритм быстрой сортировки будет работать медленно, если опорный элемент равен наименьшему или наибольшему элементу списка.
Пример быстрой сортировки:
def partition(sort_nums, begin, end): part = begin for i in range(begin+1, end+1): if sort_nums[i] = end: return part = partition(sort_nums, begin, end) quick(sort_nums, begin, part-1) quick(sort_nums, part+1, end) return quick(sort_nums, begin, end) nums = [54, 43, 3, 11, 0] quick_sort(nums) print(nums) # Выведет [0, 3, 11, 43, 54]Скорость работы алгоритмов
Сортировка слиянием почти в два раза медленнее, чем быстрая сортировка. Сортировка выборкой выполняет больше сравнений, чем сортировка вставками, но выполняется немного быстрее.
Пузырьковая сортировка не подойдет для практического применения, так как она является самой медленной из всех. Но знать данный алгоритм будет полезно тем, кто хочет полностью изучить тему алгоритмов сортировки списков в Python.
Итог
Мы изучили виды сортировки списков в Python и сравнили их эффективность, а также рассмотрели встроенные методы. Надеюсь, данная статья была полезна для вас!
Методы сортировки и их реализация в Python
Когда имеешь дело с данными, постоянно приходится сортировать их по какому-либо критерию. Иногда это сделать довольно просто, например, когда нужно отсортировать список фамилий по алфавиту, но иногда эта задача не представляется тривиальной. Например, когда имеешь дело с Big Data. В этом случае имеет значение не только сам факт сортировки, но и метод, который был избран для данной цели. Правильно выбранный алгоритм может значительно быстрее справляться с заданием. Давайте посмотрим, какие основные способы сортировки существуют и как они реализуются в программном коде Python.
Динамічний курс від skvot: Візуалізація екстер'єрів у 3DS MAX.
Мистецтво в 3DS MAX.
1. Пузырьковый метод сортировки
Суть этого популярного метода состоит в том, чтобы сравнивать элементы массива попарно. Если один из элементов меньше другого, мы меняем их местами. Далее — сравниваем следующую пару элементов массива и, руководствуясь той же логикой, меняем их местами если это необходимо. И так далее, до конца списка.
После первого прохода самое большое число сдвинется в конец списка и можно выполнять второй проход, чтобы найти предпоследнее число. Количество итераций будет соответствовать числу элементов минус один. Таким образом, самые большие числа оказываются, например, справа, а самые маленькие — слева в ряду значений.
Професійний курс від laba: Управління командою в бізнесі.
Створюйте ефективну робочу атмосферу.На языке Python реализация данного алгоритма будет выглядеть следующим образом:
spisok = [11, 56, 42, 12, 22, -3, 37] # сортируемый массив def buble_sortirovka(massiv): last_element = len(massiv) — 1 for x in range(0, last_element): for y in range(0, last_element): if massiv[y] > massiv[y + 1]: # условие перестановки элементов massiv[y], massiv[y + 1] = massiv[y + 1], massiv[y] # перестановка элементов print(massiv) return massiv print("OLD SPISOK", spisok) noviyspisok = buble_sortirovka(spisok).copy() print("NEW SPISOK", noviyspisok)После выполнения алгоритма можем наблюдать все этапы итерации пузырькового метода:
OLD SPISOK [11, 56, 42, 12, 22, -3, 37] [11, 42, 56, 12, 22, -3, 37] [11, 42, 12, 56, 22, -3, 37] [11, 42, 12, 22, 56, -3, 37] [11, 42, 12, 22, -3, 56, 37] [11, 42, 12, 22, -3, 37, 56] [11, 12, 42, 22, -3, 37, 56] [11, 12, 22, 42, -3, 37, 56] [11, 12, 22, -3, 42, 37, 56] [11, 12, 22, -3, 37, 42, 56] [11, 12, -3, 22, 37, 42, 56] [11, -3, 12, 22, 37, 42, 56] [-3, 11, 12, 22, 37, 42, 56] NEW SPISOK [-3, 11, 12, 22, 37, 42, 56]2. Шейкерная сортировка
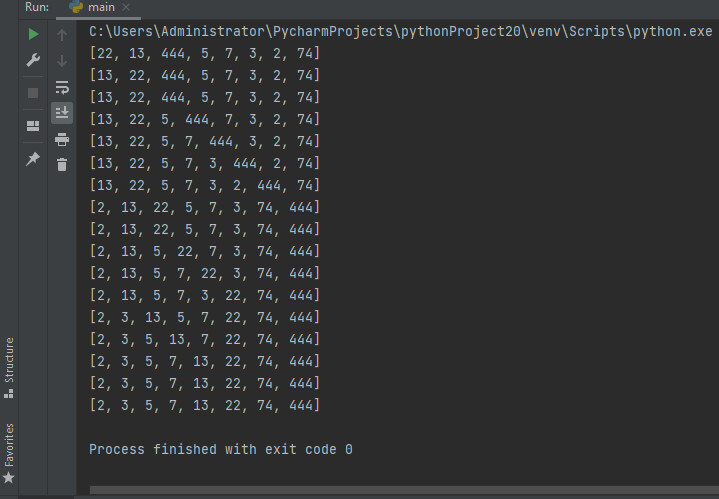
Данный тип сортировки представляет собой улучшенный вариант пузырькового способа упорядочивания данных. Он является двунаправленным и потому еще называется метод сортировки коктейлем. Принцип данного способа состоит в том, что мы делаем проход сначала в одну сторону массива, сравнивая и сортируя по очереди соседние два числа массива. Когда мы дошли до конца массива, наиболее крупное число оказывается в правой его части.
В пузырьковом методе мы возвращались в начало массива и повторяли все заново. В этом методе мы не возвращаемся, а идем влево, попарно сравнивая соседние элементы. Результатом прохода в левую сторону станет минимальное число, которое «вытолкнется» на начало массива. Затем мы снова начинаем движение вправо, сортируя и «выталкивая» предпоследнее число результирующего массива. Дойдя до конца, снова меняем направление сортировки и продолжаем выполнять действия до тех пор, пока массив не будет обработан.
array = [22, 13, 444, 5, 7, 3, 2, 74] left = 0 right = len(array) — 1 while left array[i + 1]: array[i], array[i + 1] = array[i + 1], array[i] right -= 1 for i in range(right, left, -1): if array[i — 1] > array[i]: array[i], array[i — 1] = array[i — 1], array[i] left += 1 print(array)
3. Сортировка «расческой»
Алгоритм сортировки расческой был разработан Влодзимежом Добосевичем в 1980 году. По большому счету, это — еще одна разновидность пузырьковой сортировки.
При пузырьковом алгоритме сравниваются постоянно два элемента. В сортировке расческой эти элементы берутся не соседними, а как бы по краям «расчески» — первый и последний. Расстояние между сравниваемыми элементами наибольшее из возможных, то есть, это максимальный размер расчески. Теперь уменьшаем «расческу» на единицу и начинаем сравнивать элементы находящиеся ближе: первый и предпоследний, второй и последний.
Снова уменьшаем расстояние между сравниваемыми элементами, на этот раз сравниваем первый и перед предпоследним, второй и предпоследний, третий и последний. Дальнейшие итерации мы проводим постепенно уменьшая размер «расчески», то есть уменьшая расстояние между сравниваемыми элементами.
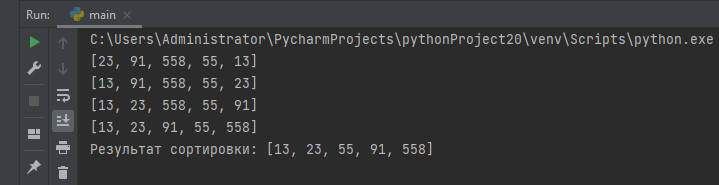
Первую длину «расчески», то есть расстояние между сравниваемыми элементами следует выбирать с учетом специального коэффициента — 1,247. В начале сортировки расстояние между числами равно размеру массива деленного на это число (разумеется, деление целочисленное). Затем, отсортировав массив с этим шагом, мы снова делим шаг на это число и выполняем новую итерацию. Продолжаем выполнять действия до тех пор, пока разность индексов не достигнет единицы. В этом случае массив доупорядочивается обычным пузырьковым методом.
Експертний курс від laba: Стратегічний маркетинг.
Розвивайте бізнес з глибоким пониманням ринку.massiv = [23, 91, 558, 55, 13] def comb(massiv): step = int(len(massiv)/1.247) swap = 1 while step > 1 or swap > 0: swap = 0 i = 0 while i + step < len(massiv): if massiv[i] >massiv[i+step]: massiv[i], massiv[i+step] = massiv[i+step], massiv[i] swap += 1 i = i + 1 if step > 1: step = int(step / 1.247) print(massiv) print(massiv) comb(massiv) print('Результат сортировки:', massiv)
4. Сортировка выбором
Алгоритм сортировки выбором заключается в том, что мы делим список на две части — сортированный и несортированный. После этого мы находим минимальное значение во второй части и передвигаем это значение в начало массива.
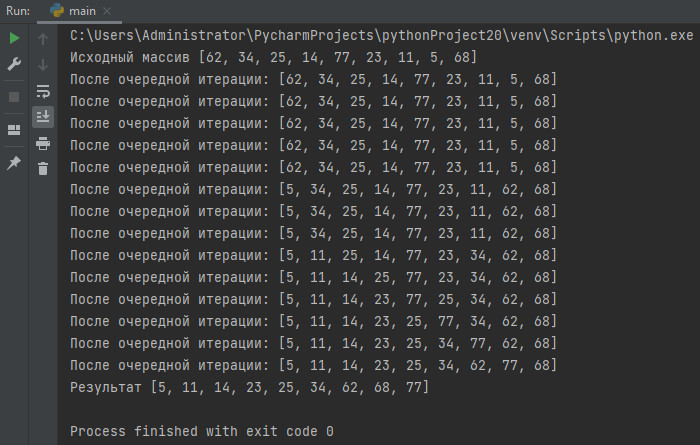
Далее снова делим массив на две части — отсортированную и не сортированную, после чего снова в неотсортированной части ищем минимальное значение и сдвигаем его на место второго элемента первой части. Повторяем итерации до тех пор, пока не отсортируем весь массив. При первой итерации сортировки первая часть считается пустой, а вторая содержит весь список. Реализуем данный алгоритм в Python:
def selection_sort(massiv): for num in range(len(massiv)): min_value = num for item in range(num, len(massiv)): if massiv[min_value] > massiv[item]: min_value = item print("После очередной итерации:", massiv) massiv[num], massiv[min_value] = massiv[min_value], massiv[num] return (massiv) massiv = [62, 34, 25, 14, 77, 23, 11, 5, 68] print("Исходный массив", massiv) resultat = selection_sort(massiv) print("Результат", resultat)
5. Пирамидальная сортировка данных
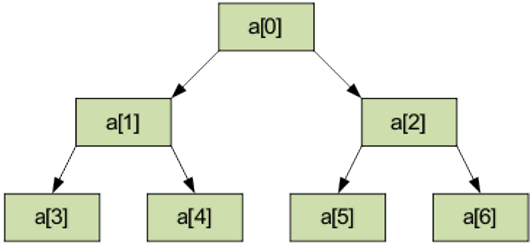
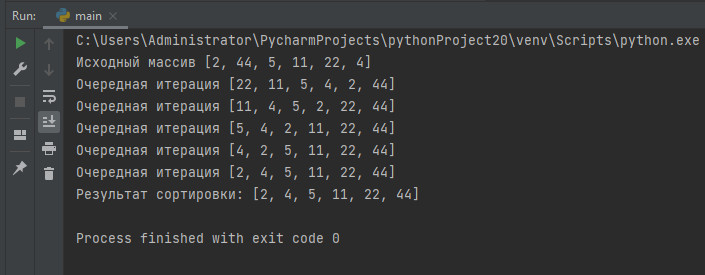
Способ сортировки получил свое название по той причине, что его алгоритм основан на схеме, напоминающей пирамиду. Если быть точным, это даже не пирамида, а так называемое бинарное дерево, узлы которого подчиняются нескольким правилам.
Каждый узел имеет пару узлов-потомков, причем значение числа в узле должно быть выше, чем у потомков. Когда бинарное дерево построено, начинается сортировка. Ее начинают делать с узлов низшего уровня. Берут тройку узлов и перемещают самые большие числа наверх.
После того, как будет выполнена сортировка низших уровней, выполняют аналогичным образом сортировку для узлов на уровень выше. Число, попавшее в вершину пирамиды, записывают в новый массив. Такую сортировку иногда еще называют «сортировка кучей».
array = [2, 44, 5, 11, 22, 4] print("Исходный массив", array) def heapify(array, n, i): largest = i l = 2 * i + 1 r = 2 * i + 2 if l < n and array[i] < array[l]: largest = l if r < n and array[largest] < array[r]: largest = r if largest != i: array[i], array[largest] = array[largest], array[i] heapify(array, n, largest) def heapSort(array): n = len(array) for i in range(n // 2, -1, -1): heapify(array, n, i) for i in range(n — 1, 0, -1): array[i], array[0] = array[0], array[i] heapify(array, i, 0) print("Очередная итерация", array) return array noviyspisok = heapSort(array).copy() print('Результат сортировки:', noviyspisok)
6. Сортировка слиянием
Данный метод является рекурсивным, так как повторяется для частей массива. Сортировка слиянием происходит в несколько этапов. Исходный массив делится на два подмассива, после чего каждый из этих подмассивов сортируется отдельно. Затем оба отсортированных подмассива объединяются в один, сравнивая по одному числу.
Вот как это выглядит на практике. Предположим, у нас есть массив: [4, 8, 6, 2, 1, 7, 5, 3] . Делим его на две части [4, 8, 6, 2] и [1, 7, 5, 3] . Первую часть будем сортировать, разбив снова на две части: [4, 8] и [6, 2] . Сортируем левую часть – числа остались на своих местах — [4, 8] . Сортируем правую часть — [2, 6] . Объединяем их в единую часть.
Ефективний курс від skvot: Основи 3D-моделювання в ZBrush.
Звільніть свою творчість.Смотрим на первые цифры – два меньше четырех, значит, записываем ее в массив [2,…] . Снова сравниваем первые цифры – четыре меньше шести, поэтому дописываем в массив [2, 4..] . И снова сравниваем оставшиеся первые числа — шесть меньше восьми, стало быть дописываем шесть — [2, 4, 6..] . И последний элемента массива: [2, 4, 6, 8] . Переходим ко второй части массива и также делим его на [1, 7] и [5, 3] . Сортируем обе части и соединяем их. Получается [1, 3, 5, 7] . Теперь нужно объединить два отсортированных массива [2, 4, 6, 8] и [1, 3, 5, 7] .
Смотрим по крайним левым цифрам: 1 < 2 , записываем единицу как первый элемент результирующего массива. Теперь сравниваем по первым цифрам оставшихся массивов [., 3, 5, 7] и [2, 4, 6, 8]. 3 >2 , значит второй элемент результирующего массива будет два. Снова смотрим на то, что осталось и нужно отсортировать. Имеем [., 3, 5, 7] и [. 4, 6, 8] .
Реализуем этот рекурсивный алгоритм на языке Python:
A = [1, 3, 444, 55, 66, 45] def merge_sort(A): if len(A) == 1 or len(A) == 0: return A L, R = A[:len(A) // 2], A[len(A) // 2:] merge_sort(L) merge_sort(R) n = m = k = 0 C = [0] * (len(L) + len(R)) while n < len(L) and m < len(R): if L[n]После запуска имеем на выходе отсортированный массив:
Исходный массив: [1, 3, 444, 55, 66, 45] Результат сортировки: [1, 3, 45, 55, 66, 444]7. Быстрая сортировка или сортировка Хоара
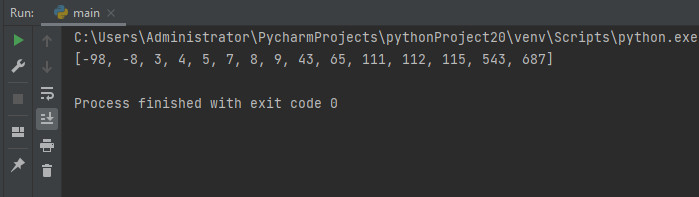
Массив делится на две части относительно опорного элемента. В одну часть помещаются все элементы, величина которых меньше значения опорного элемента, а в правую часть — элементы со значением больше опорного.
Наиболее удачным для сортировки считается разбиение массива на примерно одинаковое количество элементов. Если длина одной из частей превышает один элемент, то ее рекурсивно сортируем, повторно применяя алгоритм на каждом из отрезков.
import random a = [9, 5, 111, 115, 112, 43, 65, -98, 543, 687, 4, 7, 8, 3, -8] def quick_sort(a): if len(a) > 1: x = a[random.randint(0, len(a)-1)] # случайное пороговое значение (для разделения на малые и большие) low = [u for u in a if u < x] eq = [u for u in a if u == x] hi = [u for u in a if u >x] a = quick_sort(low) + eq + quick_sort(hi) return a a = quick_sort(a) print(a)
8. Оценка сложности
Мы рассмотрели наиболее популярные алгоритмы сортировки данных. Чтобы правильно выбрать тот или иной способ, необходимо учитывать сильные и слабые стороны того или иного метода сортировки, а также учитывать сложность.
Для оценки сложности алгоритма в программировании используется заглавная буква О (ее еще называют О-нотация). Если оценочная сложность указана как O(f(n)) , это означает, что время работы алгоритма (либо объём занимаемой памяти) с увеличением параметра n, характеризующего количество входной информации алгоритма, будет возрастать не быстрее, чем f(n) умноженная на некоторую константу.
Сложность сортировки пузырьковым методом составляет O(n2) . На практике данный метод почти не используется, вместо него применяются более эффективные алгоритмы сортировки данных.
Сортировка выбором для массива из n элементов имеет время выполнения в худшем, среднем и лучшем случае O(n2) , предполагая что сравнения делаются за постоянное время.
При использовании метода сортировки расческой сложность алгоритма равняется O(n*log2n) .
Пирамидальная сортировка имеет доказанную оценку худшего случая, она равна O(n) . По причине сложности, алгоритм сортировки эффективен только для больших значений n . Метод пирамидальной сортировки неустойчив, он не поддается распараллеливанию. Пирамидальная сортировка плохо задействует кеширование и подкачку памяти (при одном шаге выборку приходится делать хаотично по всей длине массива).
Сортировка слиянием удобна для работы в параллельном режиме, распределяя задачи между процессорами. Сортировка устойчивая (сохраняет порядок равных элементов), но требует дополнительной памяти под объем входных данных. Скорость работы с «почти упорядоченными» массивами такая же низкая, как и при работе с хаотичными массивами.
Быстрый метод сортировки по Хоару считается одним из самых быстрых алгоритмов упорядочивания данных. Он позволяет реализовывать распараллеливание задач (упорядочивание выделенных подмассивов в параллельно выполняющихся подпроцессах). Данный алгоритм неустойчив.
Заключение
Сегодня мы рассказали про основные алгоритмы сортировки данных. Большинство других алгоритмов, которые можно встретить, обычно являются различными модификациями описанных методов, рассмотренных выше. Соответственно, их достоинства и недостатки вытекают из исходной реализации данного процесса.
И напоследок мы рекомендуем вам посмотреть несколько видео, наглядно демонстрирующие алгоритмы сортировки:
Быстрый метод сортировки:
Пузырьковый метод сортировки:
Сортировка расческой: