Понимаем JIT в PHP 8

Одной из наиболее комментируемых фич PHP 8 является компилятор Just In Time (JIT). Он на слуху во множестве блогов и сообществ — вокруг него много шума, но пока я нашел не очень много подробностей о работе JIT в деталях.
После многократных попыток и разочарований найти полезную информацию, я решил изучить исходный код PHP. Совмещая свои небольшие познания языка С и всю разбросанную информацию, которую я смог собрать до сих пор, я сумел подготовить эту статью и надеюсь, что она поможет вам лучше понять JIT PHP.
Упрощая вещи: когда JIT работает должным образом, ваш код не будет выполняться через Zend VM, вместо этого он будет выполняться непосредственно как набор инструкций уровня процессора.
В этом вся идея.
Но чтобы лучше это понять, нам нужно подумать о том, как php работает внутри. Это не очень сложно, но требует некоторого введения.
Я уже писал статью с кратким обзором того, как работает php. Если вам покажется, что эта статья становится чересчур сложной, просто прочитайте ее предшественницу и возвращайтесь. Это должно немного облегчить ситуацию.
Как выполняется PHP-код?
Мы все знаем, что php — интерпретируемый язык. Но что это на самом деле означает?
Всякий раз, когда вы хотите выполнить код PHP, будь то фрагмент или целое веб-приложение, вам придется пройти через интерпретатор php. Наиболее часто используемые из них — PHP FPM и интерпретатор CLI. Их работа очень проста: получить код php, интерпретировать его и выдать обратно результат.
Это обычная картина для каждого интерпретируемого языка. Некоторые шаги могут варьироваться, но общая идея та же самая. В PHP это происходит так:
- Код PHP читается и преобразуется в набор ключевых слов, известных как токены (Tokens). Этот процесс позволяет интерпретатору понять, в какой части программы написан каждый фрагмент кода. Этот первый шаг называется лексирование (Lexing) или токенизация (Tokenizing).
- Имея на руках токены, интерпретатор PHP проанализирует эту коллекцию токенов и постарается найти в них смысл. В результате абстрактное синтаксическое дерево (Abstract Syntax Tree — AST) генерируется с помощью процесса, называемого синтаксическим анализом (parsing). AST представляет собой набор узлов, указывающих, какие операции должны быть выполнены. Например, «echo 1 + 1» должно фактически означать «вывести результат 1 + 1» или, более реалистично, «вывести операцию, операция — 1 + 1».
- Имея AST, например, гораздо проще понять операции и их приоритет. Преобразование этого дерева во что-то, что может быть выполнено, требует промежуточного представления (Intermediate Representation IR), которое в PHP мы называем операционный код (Opcode). Процесс преобразования AST в операционный код называется компиляцией.
- Теперь, когда у нас есть опкоды, происходит самое интересное: выполнение кода! PHP имеет движок под названием Zend VM, который способен получать список опкодов и выполнять их. После выполнения всех опкодов программа завершается.
Чтобы сделать это немного нагляднее, я составил диаграмму:
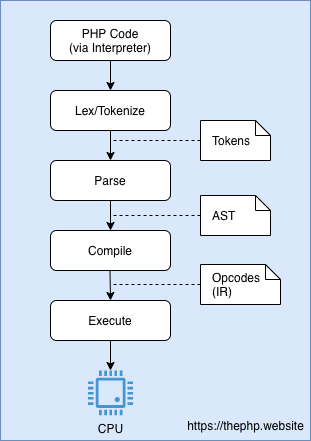
Упрощенная схема процесса интерпретации PHP.
Достаточно прямолинейно, как вы можете заметить. Но здесь есть и узкое место: какой смысл лексировать и парсить код каждый раз, когда вы его выполняете, если ваш php-код может даже не меняется так часто?
В конце концов, нас интересуют только опкоды, верно? Правильно! Вот зачем существует расширение Opcache.
Расширение Opcache
Расширение Opcache поставляется с PHP, и, как правило, нет особых причин его деактивировать. Если вы используете PHP, вам, вероятно, следует включить Opcache.
Что он делает, так это добавляет слой оперативного общего кэша для опкодов. Его задача состоит в том, чтобы извлекать опкоды, недавно сгенерированные из нашего AST, и кэшировать их, чтобы при дальнейших выполнениях можно было легко пропустить фазы лексирования и синтаксического анализа.
Вот схема того же процесса с учетом расширения Opcache:
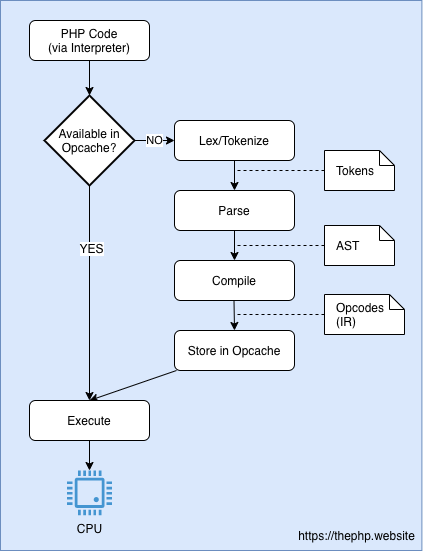
Поток интерпретации PHP с Opcache. Если файл уже был проанализирован, php извлекает для него кэшированный операционный код, а не анализирует его заново.
Это просто завораживает, как красиво пропускаются шаги лексирования, синтаксического анализа и компиляции.
Примечание: именно здесь лучше всего себя проявляет функция предварительной загрузки PHP 7.4! Это позволяет вам сказать PHP FPM анализировать вашу кодовую базу, преобразовывать ее в опкоды и кэшировать их даже до того, как вы что-либо выполните.
Вы можете начать задумываться, а куда сюда можно прилепить JIT, верно?! По крайней мере я на это надеюсь, именно поэтому я и пишу эту статью…
Что делает компилятор Just In Time?
Прослушав объяснение Зива в эпизоде подкастов PHP и JIT от PHP Internals News, мне удалось получить некоторое представление о том, что на самом деле должен делать JIT…
Если Opcache позволяет быстрее получать операционный код, чтобы он мог переходить непосредственно к Zend VM, JIT предназначить заставить его работать вообще без Zend VM.
Zend VM — это программа, написанная на C, которая действует как слой между операционным кодом и самим процессором. JIT генерирует скомпилированный код во время выполнения, поэтому php может пропустить Zend VM и перейти непосредственно к процессору. Теоретически мы должны выиграть в производительности от этого.
Поначалу это звучало странно, потому что для компиляции машинного кода вам нужно написать очень специфическую реализацию для каждого типа архитектуры. Но на самом деле это вполне реально.
Реализация JIT в PHP использует библиотеку DynASM (Dynamic Assembler), которая отображает набор команд ЦП в конкретном формате в код сборки для многих различных типов ЦП. Таким образом, компилятор Just In Time преобразует операционный код в машинный код для конкретной архитектуры, используя DynASM.
Хотя одна мысль все-таки не давала мне покоя…
Если предварительная загрузка способна парсить php-код в операционный перед выполнением, а DynASM может компилировать операционный код в машинный (компиляция Just In Time), почему мы, черт возьми, не компилируем PHP сразу же на месте, используя Ahead of Time компиляцию?!
Одна из мыслей, на которые меня натолкнул эпизода подкаста, заключалась в том, что PHP слабо типизирован, то есть часто PHP не знает, какой тип имеет переменная, пока Zend VM не попытается выполнить определенный опкод.
Это можно понять, посмотрев на тип объединения zend_value, который имеет много указателей на различные представления типов для переменной. Всякий раз, когда виртуальная машина Zend пытается извлечь значение из zend_value, она использует макросы, подобные ZSTR_VAL, которые пытаются получить доступ к указателю строки из объединения значений.
Дублирование такой логики вывода типов с помощью машинного кода неосуществимо и потенциально может сделать работу еще медленнее.
Финальная компиляция после того, как типы были оценены, также не является хорошим вариантом, потому что компиляция в машинный код является трудоемкой задачей ЦП. Так что компиляция ВСЕГО во время выполнения — плохая идея.
Как ведет себя компилятор Just In Time?
Теперь мы знаем, что не можем вывести типы, чтобы генерировать достаточно хорошую опережающую компиляцию. Мы также знаем, что компиляция во время выполнения стоит дорого. Чем же может быть полезен JIT для PHP?
Чтобы сбалансировать это уравнение, JIT PHP пытается скомпилировать только несколько опкодов, которые, по его мнению, того стоят. Для этого он профилирует коды операций, выполняемые виртуальной машиной Zend, и проверяет, какие из них имеет смысл компилировать. (в зависимости от вашей конфигурации).
Когда определенный опкод компилируется, он затем делегирует выполнение этому скомпилированному коду вместо делегирования на Zend VM. Это выглядит как на диаграмме ниже:
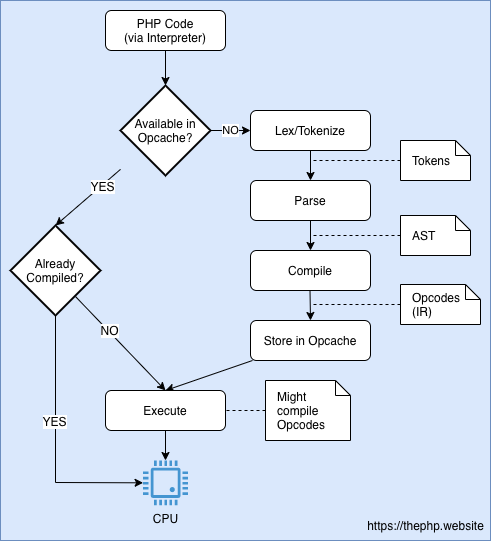
Поток интерпретации PHP с JIT. Если они уже скомпилированы, опкоды не выполняются через Zend VM.
Таким образом, в расширении Opcache есть пара инструкций, определяющих, должен ли определенный операционный код быть скомпилирован или нет. Если да, то компилятор преобразует его в машинный код с помощью DynASM и выполняет этот новый сгенерированный машинный код.
Интересно, что, поскольку в текущей реализации есть ограничение в мегабайтах для скомпилированного кода (также настраиваемое), выполнение кода должно иметь возможность беспрепятственного переключения между JIT и интерпретируемым кодом.
Кстати, эта беседа Бенуа Жакемона о JIT от php ОЧЕНЬ помогла мне разобраться во всем этом.
Я до сих пор не уверен в том, в каких конкретных случаях происходит компиляция, но я думаю, что пока не очень хочу это знать.
Так что, вероятно, ваш прирост производительности не будет колоссальным
Я надеюсь, что сейчас гораздо понятнее, ПОЧЕМУ все говорят, что большинство приложений php не получат больших преимуществ в производительности от использования компилятора Just In Time. И почему рекомендация Зива для профилирования и эксперимента с различными конфигурациями JIT для вашего приложения — лучший путь.
Скомпилированные опкоды обычно будут распределены между несколькими запросами, если вы используете PHP FPM, но это все равно не изменит правила игры.
Это потому, что JIT оптимизирует операции с процессором, а в настоящее время большинство php-приложений в большей степени завязаны на вводе/выводе, нежели на чем-либо еще. Не имеет значения, скомпилированы ли операции обработки, если вам все равно придется обращаться к диску или сети. Тайминги будут очень похожи.
Если только.
Вы делаете что-то не завязанное на ввод/вывод, например, обработку изображений или машинное обучение. Все, что не касается ввода/вывода, получит пользу от компилятора Just In Time. Это также причина, по которой люди сейчас говорят, что они склоняются больше к написанию нативных функций PHP, написанных на PHP, а не на C. Накладные расходы не будут разительно отличаться, если такие функции будут скомпилированы в любом случае.
Интересное время быть программистом PHP…
Я надеюсь, что эта статья была полезна для вас, и вам удалось лучше разобраться, что такое JIT в PHP 8. Не стесняйтесь связываться со мной в твиттере, если вы хотите добавить что-то, что я мог забыть здесь, и не забудьте поделиться этим со своими коллегами-разработчиками, это, несомненно, добавит немного пользы вашим беседам! — @nawarian
PHP 8.0: новые функции, классы и JIT (4/4)
Вышла версия PHP 8.0. Она полна новых функций, как ни одна другая версия до этого. Их введение заслуживает четырех отдельных статей. В последней части мы рассмотрим новые функции и классы, а также представим компилятор Just in Time.

Новые функции
str_contains() str_starts_with() str_ends_with()
Функции для определения начала, конца или наличия подстроки в строке.
if (str_contains('Nette', 'te'))
С появлением этой троицы PHP определяет, как обрабатывать пустую строку при поиске, чего придерживаются все остальные связанные функции, а именно пустая строка встречается везде:.
str_contains('Nette', '') // true str_starts_with('Nette', '') // true strpos('Nette', '') // 0 (previously false) Благодаря этому поведение троицы полностью идентично аналогам Nette:
str_contains() # Nette\Utils\String::contains() str_starts_with() # Nette\Utils\String::startsWith() str_ends_with() # Nette\Utils\String::endsWith() Почему эти функции так важны? Стандартные библиотеки всех языков всегда отягощены историческим развитием; несоответствий и ошибок не избежать. Но в то же время это свидетельство соответствующего языка. Удивительно, но в 25-летнем PHP отсутствуют функции для таких базовых операций, как возврат первого или последнего элемента массива, экранирование HTML без неприятных сюрпризов ( htmlspecialchars не экранирует апостроф) или просто поиск строки в строке. Это не значит, что его можно как-то обойти, потому что в результате не получится разборчивого и понятного кода. Это урок для всех авторов API. Когда вы видите, что большая часть документации функции занята объяснениями подводных камней (таких как возвращаемые значения strpos ), это явный знак, что нужно модифицировать библиотеку и добавить str_contains .
get_debug_type()
Заменяет устаревший get_type() . Вместо длинных типов, таких как integer , возвращает используемый сегодня int , в случае объектов возвращает непосредственно тип:
| Value | gettype() | get_debug_type() |
|---|---|---|
| ‘abc’ | string | string |
| [1, 2] | array | array |
| 231 | integer | int |
| 3.14 | double | float |
| true | boolean | bool |
| null | NULL | null |
| new stdClass | object | stdClass |
| new Foo\Bar | object | Foo\Bar |
| function() <> | object | Closure |
| new class <> | object | class@anonymous |
| new class extends Foo <> | object | Foo@anonymous |
| curl_init() | resource | resource (curl) |
| curl_close($ch) | resource (closed) | resource (closed) |
Миграция ресурсов в объекты
Значения типа ресурсов пришли из тех времен, когда в PHP еще не было объектов, но они были очень нужны. Так родились ресурсы. Сегодня у нас есть объекты, и, по сравнению с ресурсами, они гораздо лучше работают со сборщиком мусора, поэтому планируется постепенно заменить их все на объекты.
$res = imagecreatefromjpeg('image.jpg'); $res instanceof GdImage // true is_resource($res) // false - BC break Эти объекты пока не имеют методов, и вы не можете инстанцировать их напрямую. Пока что это просто вопрос избавления PHP от устаревших ресурсов без изменения API. И это хорошо, потому что создание хорошего API – это отдельная и сложная задача. Никто не желает создания новых классов PHP, таких как SplFileObject, с методами под названиями fgetc() или fgets() .
PhpToken
Токенизатор и функции вокруг token_get_all также переносятся на объекты. На этот раз речь не идет об избавлении от ресурсов, но мы получаем полноценный объект, представляющий один PHP-токен.
id; // T_OPEN_TAG echo $token->text; // 'line; // 1 echo $token->getTokenName(); // 'T_OPEN_TAG' echo $token->is(T_STRING); // false echo $token->isIgnorable(); // true Метод isIgnorable() возвращает true для токенов T_WHITESPACE , T_COMMENT , T_DOC_COMMENT и T_OPEN_TAG .
Слабые карты
Слабые карты связаны со сборщиком мусора, который освобождает из памяти все объекты и значения, которые больше не используются (т.е. нет переменной или свойства, содержащего их). Поскольку потоки PHP недолговечны и на наших серверах достаточно памяти, мы обычно вообще не обращаемся к вопросам эффективного освобождения памяти. Но для более длительно работающих скриптов они крайне важны.
Объект WeakMap похож на SplObjectStorage Оба используют объекты в качестве ключей и позволяют хранить под ними произвольные значения. Разница в том, что WeakMap не предотвращает освобождение объекта сборщиком мусора. Т.е. если единственное место, где объект существует в данный момент, это ключ в слабой карте, он будет удален из карты и памяти.
$map = new WeakMap; $obj = new stdClass; $map[$obj] = 'data for $obj'; dump(count($map)); // 1 unset($obj); dump(count($map)); // 0 Для чего это полезно? Например, для кэширования. Пусть у нас есть метод loadComments() , которому мы передаем статью блога, а он возвращает все ее комментарии. Поскольку метод вызывается многократно для одной и той же статьи, мы создадим еще один getComments() , который будет кэшировать результат первого метода:
class Comments < private WeakMap $cache; public function __construct() < $this->cache = new WeakMap; > public function getComments(Article $article): ?array < $this->cache[$article] ??= $this->loadComments($article); return $this->cache[$article] > . > Дело в том, что когда объект $article освобождается (например, приложение начинает работать с другой статьей), его запись также освобождается из кэша.
PHP JIT (Just in Time Compiler)
Возможно, вы знаете, что PHP компилируется в так называемые опкоды – низкоуровневые инструкции, которые вы можете увидеть, например, здесь и которые выполняются виртуальной машиной PHP. А что такое JIT? JIT может прозрачно компилировать PHP непосредственно в машинный код, который исполняется непосредственно процессором, так что более медленное исполнение виртуальной машиной обходится стороной.
Поэтому JIT предназначен для ускорения работы PHP.
Усилия по внедрению JIT в PHP начались еще в 2011 году и поддерживаются Дмитрием Стоговым. С тех пор он попробовал 3 различных реализации, но ни одна из них не попала в финальный релиз PHP по трем причинам: результатом никогда не было значительное увеличение производительности для типичных веб-приложений; усложняется сопровождение PHP (т.е. никто, кроме Дмитрия, не понимает этого �� ); существовали другие способы повысить производительность без необходимости использования JIT.
Скачкообразное увеличение производительности, наблюдаемое в PHP версии 7, было побочным продуктом работы над JIT, хотя, как ни парадоксально, он не был развернут. Это происходит только сейчас в PHP 8. Но я буду сдерживать завышенные ожидания: скорее всего, вы не увидите никакого увеличения скорости.
Так почему же JIT входит в PHP? Во-первых, другие способы повышения производительности постепенно исчерпываются, и JIT – это просто следующий шаг. В обычных веб-приложениях он не дает никакого прироста скорости, но значительно ускоряет, например, математические вычисления. Это открывает возможность начать писать такие вещи на PHP. Фактически, можно будет реализовать некоторые функции непосредственно в PHP, которые раньше требовали прямой реализации на C из-за скорости.
zend_extension=php_opcache.dll opcache.jit=1205 ; configuration using four digits OTRC opcache.enable_cli=1 ; in order to work in the CLI as well opcache.jit_buffer_size=128M ; dedicated memory for compiled code Проверить, что JIT запущен, можно, например, в информационной панели Tracy Bar.
JIT работает очень хорошо, если все переменные имеют четко определенные типы и не могут меняться даже при многократном вызове одного и того же кода. Поэтому мне интересно, будем ли мы когда-нибудь объявлять типы в PHP для переменных: string $s = ‘Bye, this is the end of the series’;
Дальнейшее чтение
- PHP 8.0: полный обзор новостей (1/4)
- PHP 8.0: Новости в типах данных (2/4)
- PHP 8.0: Атрибуты (3/4)
- PHP 8.0: новые функции, классы и JIT (4/4)
Розуміння JIT в PHP 8

Однією з найбільш обговорюваних фіч PHP 8 є компілятор Just In Time (JIT). Він на слуху у багатьох блогів і спільнот — навколо нього багато шуму, але поки я знайшов не дуже багато подробиць про роботу JIT в деталях.
Після багаторазових спроб і розчарувань знайти корисну інформацію, я вирішив вивчити вихідний код PHP. Поєднуючи свої невеликі пізнання мови та всю розкидану інформацію, яку я зміг зібрати досі, я зумів підготувати цю статтю і сподіваюся, що вона допоможе вам краще зрозуміти JIT PHP.
Спрощуючи речі: коли JIT працює належним чином, ваш код не буде виконуватися через Zend VM, замість цього він буде виконуватися безпосередньо як набір інструкцій рівня процесора.
У цьому вся ідея.
Але щоб краще це зрозуміти, нам потрібно подумати про те, як php працює всередині. Це не дуже складно, але вимагає деякого роз’яснення.
Я вже писав статтю з коротким оглядом того, як працює php. Якщо вам здасться, що ця стаття стає надто складною, просто прочитайте її попередницю і повертайтеся. Це повинно трохи полегшити ситуацію.
Як виконується PHP-код?
Ми всі знаємо, що php — мова що інтерпретується. Але що це насправді означає?
Всякий раз, коли ви хочете виконати код PHP, будь то фрагмент або цілий веб застосунок, вам доведеться пройти через інтерпретатор php. Найчастіше використовуються — PHP-FPM і інтерпретатор CLI. Їх робота дуже проста: отримати код php, інтерпретувати його і видати назад результат.
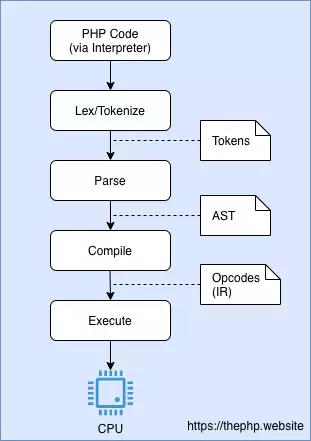
Це звичайна картина для кожної мови що інтерпретується. Деякі кроки можуть змінюватись, але загальна ідея та ж сама. В PHP це відбувається так:
- PHP Код читається і перетворюється на набір ключових слів, відомих як токени (Tokens). Цей процес дозволяє інтерпретатору зрозуміти, в якій частині програми написаний кожен фрагмент коду. Цей перший крок називається лексування (Lexing) або токенізація (Tokenizing).
- Маючи на руках токени, інтерпретатор PHP проаналізує цю колекцію токенів і постарається знайти в них сенс. В результаті абстрактне синтаксичне дерево (Abstract Syntax Tree — AST) генерується з допомогою процесу, званого синтаксичним аналізом (parsing). AST являє собою набір вузлів, що вказують, які дії повинні бути виконані. Наприклад, «echo 1 + 1» має фактично означати «вивести результат 1 + 1» або, більш реалістично, «вивести операцію, операція — 1 + 1».
- Маючи AST, наприклад, набагато простіше зрозуміти операції і їх пріоритет. Перетворення цього дерева в щось, що може бути виконано, вимагає проміжного представлення (Intermediate Representation IR), яке в PHP ми називаємо операційний код (Opcode). Процес перетворення AST в операційний код називається компіляцією.
- Тепер, коли у нас є опкоди, відбувається найцікавіше: виконання коду! В PHP є рушій під назвою Zend VM, який здатний отримувати список опкодов і виконувати їх. Після виконання всіх опкодів програма завершується.
Щоб зробити це трохи наочніше, я склав діаграму:
Спрощена схема процесу інтерпретації PHP. Досить прямолінійно, як ви можете помітити. Але тут є і вузьке місце: який сенс лексуваті та парсити код кожного разу, коли ви його виконуєте, якщо ваш php-код може навіть не змінюється так часто?
Зрештою, нас цікавлять тільки опкоди, вірно? Правильно! Ось навіщо існує розширення Opcache.
Розширення Opcache
Розширення Opcache поставляється з PHP, і, як правило, немає особливих причин його вимкнути. Якщо ви використовуєте PHP, вам, ймовірно, слід включити Opcache.
Що він робить, так це додає шар оперативного загального кеша для опкодів. Його завдання полягає в тому, щоб отримувати опкоди, нещодавно згенеровані з нашого AST, і кешувати їх, щоб при подальших виконаннях можна було легко пропустити фази лексування та синтаксичного аналізу.
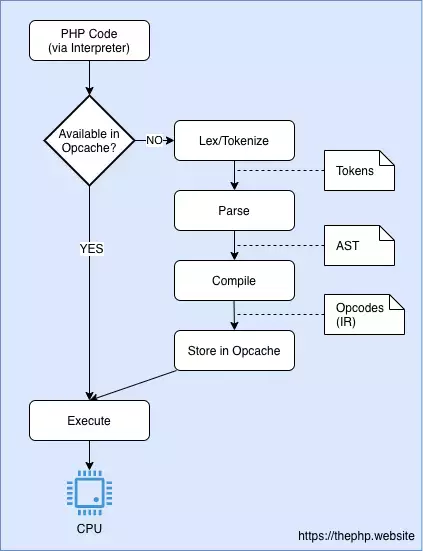
Ось схема того ж процесу з урахуванням розширення Opcache:Потік інтерпретації PHP з Opcache. Якщо файл вже був проаналізований, php отримує для нього параметр операційний код, а не аналізує його заново.
Це просто заворожує, як красиво пропускаються кроки лексування, синтаксичного аналізу та компіляції.
Примітка: саме тут краще всього себе проявляє функція попереднього завантаження PHP 7.4! Це дозволяє вам сказати PHP-FPM аналізувати вашу кодову базу, перетворювати її в опкоди та кешувати їх навіть до того, як ви виконаєте.
Ви можете почати замислюватися, а куди сюди можна приліпити JIT, вірно?! Принаймні я на це сподіваюся, саме тому я і пишу цю статтю.
Що робить компілятор Just In Time?
Прослухавши пояснення Зіва в епізоді подкастів PHP і JIT від PHP Internals News, мені вдалося отримати деяке уявлення про те, що насправді повинен робити JIT.
Якщо Opcache дозволяє швидше отримувати операційний код, щоб він міг переходити безпосередньо до Zend VM, JIT призначити змусити його працювати взагалі без Zend VM.
Zend VM — це програма, написана на C, яка діє як шар між операційним кодом і самим процесором. JIT генерує скомпільований код під час виконання, тому php може пропустити Zend VM і перейти безпосередньо до процесора. Теоретично ми повинні виграти в продуктивності від цього.
Спочатку це звучало дивно, тому що для компіляції машинного коду вам потрібно написати дуже специфічну реалізацію для кожного типу архітектури. Але насправді це цілком реально.
Реалізація JIT в PHP використовує бібліотеку DynASM (Dynamic Assembler), яка створює набір інструкцій для ЦП в одному конкретному форматі і код збірки для різних ЦП. Таким чином, компілятор Just In Time перетворює операційний код в машинний код для конкретної архітектури, використовуючи DynASM.
Хоча одна думка все-таки не давала мені спокою.
Якщо попереднє завантаження здатне парсити php-код в операційний перед виконанням, а DynASM може компілювати операційний код в машинний (компіляція Just In Time), чому ми, чорт візьми, не компілюємо PHP відразу ж на місці, використовуючи Ahead of Time компіляцію?!
Одна з думок, на які мене наштовхнув один з епізодів подкасту з Зівом Сураскі, полягала в тому, що PHP слабо типізований, тобто часто PHP не знає, який тип має змінна, поки Zend VM не спробує виконати певний опкод.
Це можна зрозуміти, подивившись на тип об’єднання zend_value, який має багато покажчиків на різні представлення типів для змінної. Всякий раз, коли віртуальна машина Zend намагається отримати значення з zend_value, вона використовує макроси, подібні ZSTR_VAL, які намагаються отримати доступ до покажчика рядку з об’єднання значень.
Дублювання такої логіки виведення типів з допомогою машинного коду нездійсненно і потенційно може зробити роботу ще повільніше.
Фінальна компіляція після того, як типи були оцінені, також не є хорошим варіантом, тому що компіляція в машинний код є трудомістким завданням ЦП. Так що компіляція ВСЬОГО під час виконання — погана ідея.
Як поводитися компілятор Just In Time?
Тепер ми знаємо, що не можемо вивести типи, щоб генерувати достатньо хорошу компіляцію на випередження. Ми також знаємо, що компіляція під час виконання коштує дорого. Чим може бути корисний JIT для PHP?
Щоб збалансувати це рівняння, JIT PHP намагається зібрати лише кілька опкодів, які, на його думку, того варті. Для цього він профілює коди операцій, що виконуються віртуальною машиною Zend, і перевіряє, які з них має сенс компілювати. (залежно від конфігурації).
Коли певний опкод компілюється, він потім делегує виконання цього скомпільованого коду замість делегування на Zend VM. Це виглядає як на діаграмі нижче:
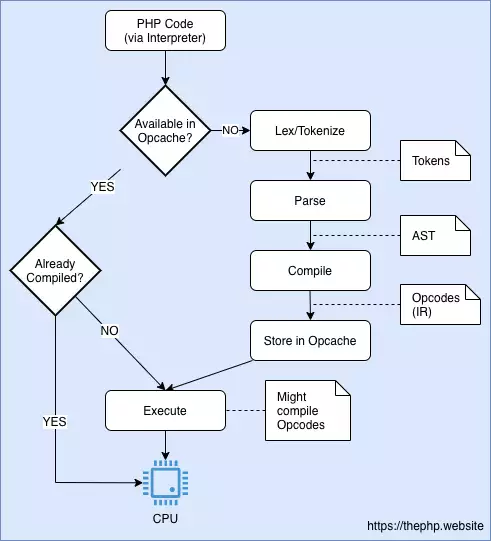
Потік інтерпретації PHP з JIT. Якщо вони вже скомпільовані, опкоди не виконуються через Zend VM.
Таким чином, у розширенні Opcache є пара інструкцій, які визначають, чи має певний операційний код бути скомпільований чи ні. Якщо так, то компілятор перетворює його в машинний код з допомогою DynASM і виконує цей новий згенерований машинний код.
Цікаво, що, оскільки в поточній реалізації є обмеження в мегабайтах для скомпільованого коду (також настроюється), виконання коду повинна мати можливість безперешкодного перемикання між JIT і кодом що інтерпретується.
До речі, ця бесіда Бенуа Жакемона про JIT від php ДУЖЕ допомогла мені розібратися у всьому цьому.
Я досі не впевнений в тому, в яких конкретних випадках відбувається компіляція, але я думаю, що поки не дуже хочу це знати.
Так що, ймовірно, ваш приріст продуктивності не буде колосальним
Я сподіваюся, що зараз набагато зрозуміліше, ЧОМУ всі кажуть, що більшість застосунків php не отримають великих переваг в продуктивності від використання компілятора Just In Time. І чому рекомендація Зіва для профілювання та експерименту з різними конфігураціями JIT для вашого застосунку — найкращий шлях.
Скомпільовані опкоди зазвичай будуть розподілені між декількома запитами, якщо ви використовуєте PHP-FPM, але це все одно не змінить правила гри.
Це тому, що JIT оптимізує операції з процесором, а нині більшість php-застосунків більшою мірою зав’язані на вводі/виводі, ніж на чому-небудь ще. Не має значення, скомпільовані операції обробки, якщо вам все одно доведеться звертатися до диска або мережі. Таймінги будуть дуже схожі.
Якщо тільки.
Ви робите щось не зав’язане на введення/виведення, наприклад, обробку зображень або машинне навчання. Все, що не стосується введення/виводу, отримає користь від компілятора Just In Time. Це також причина, по якій люди зараз кажуть, що вони схиляються більше до написання нативних функцій PHP, написаних на PHP, а не на C. Накладні витрати не будуть разюче відрізнятися, якщо такі функції будуть скомпільовані в будь-якому випадку.
PHP JIT

Несмотря на то, что JIT может не предлагать каких-либо существенных краткосрочных улучшений, нужно понимать, что он откроет множество возможностей для роста PHP как в качестве веб-языка, так и в качестве языка общего назначения
Что такое JIT? JIT — это Just In Time, или просто компиляция «на лету», вы вероятно знаете, что PHP является интерпретируемым языком, он не компилирует программы в прямом смысле этого значения, как, например это делают C, Haskell, Go или Rust.
PHP реализован на базе виртуальной машины (Zend VM). Язык компилирует исходный PHP-код в инструкции, которые понимает виртуальная машина (это называется стадией компиляции). Полученные на стадии компиляции инструкции виртуальной машины называются опкоды (opcodes). На стадии исполнения (runtime) Zend VM исполняет опкоды, выполняя тем самым требуемую работу. Операционные коды довольно низкоуровневые, поэтому их гораздо быстрее преобразовать в машинный код, чем в исходный код PHP. В ядре PHP есть расширение OPcache для кэширования этих кодов операций.
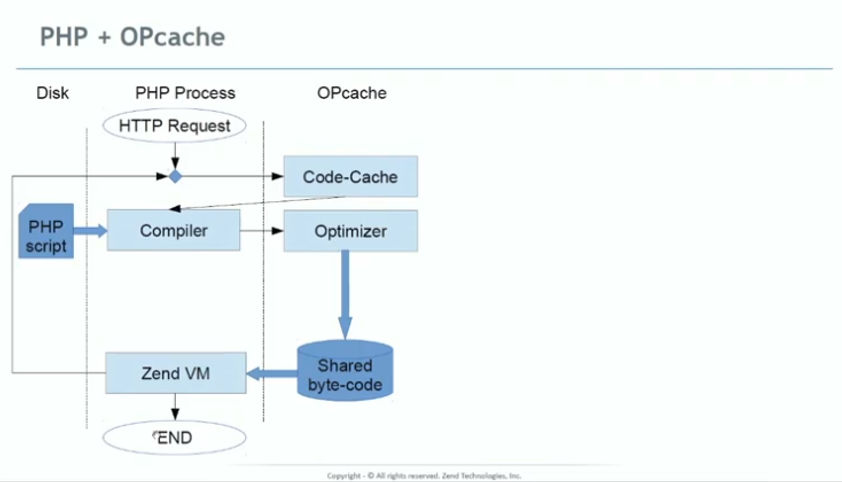
«Just In Time» — это стратегия компилятора, при которой, во время выполнения приложения, компилируются части кода, так что вместо интерпретирования каждый раз, можно всегда использовать скомпилированную версию.
Это можно представить себе как «кэшированную версию» интерпретируемого кода, сгенерированного во время выполнения.
В PHP это означает, что JIT будет рассматривать полученные на стадии компиляции инструкции для виртуальной машины как промежуточное представление и выдавать машинный код, который будет выполняться уже не Zend VM, а непосредственно процессором.
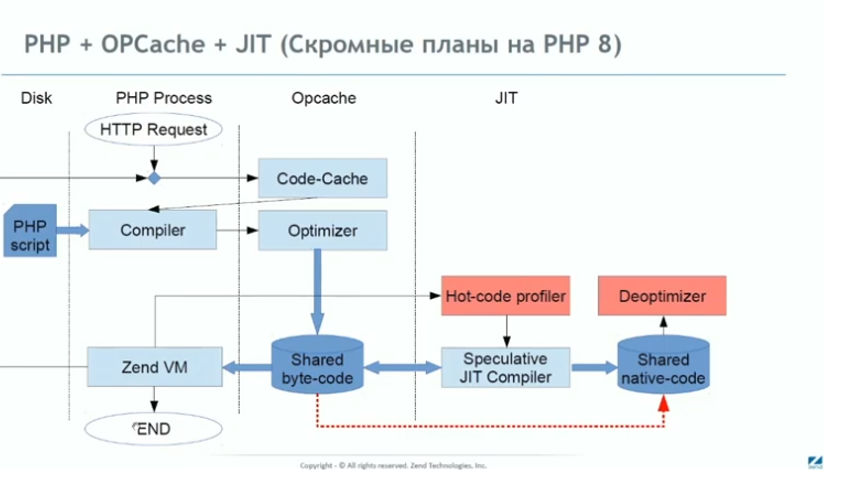
Как это работает?
Есть так называемый «монитор», который будет смотреть на код во время его работы. Когда этот монитор обнаруживает повторяющиеся части вашего кода, он помечает эти части как «теплые» или «горячие», в зависимости от частоты использования.
Эти горячие части могут быть скомпилированы как оптимизированный машинный код и использоваться на лету, в нужный момент, вместо реального кода. Конечно на самом деле все гораздо сложнее, если вы хотите узнать больше, вы можете чекнуть ускоренный курс Mozilla в JIT-компиляторах.
Для этого поста в блоге достаточно понять, что JIT-компилятор может значительно улучшить производительность вашей программы. ну или нет :))
Зеев Сураски, один из разработчиков ядра PHP, недавно продемонстрировал демо с генерацией фракталов:
Необычно для PHP, не правда ли? «Слон в комнате»: Часто ли вы видели, чтобы PHP использу для создания фрактальных анимаций :)))
Зная, что JIT-компилятор пытается идентифицировать «горячие» части вашего кода, вы можете догадаться, почему он оказывает такое влияние на фрактальный пример: множество одних и тех же вычислений происходит снова и снова.
Однако, поскольку PHP чаще всего используется при создании веб-приложений, мы также должны измерить влияние JIT именно на эту область.
А оказывается, что во время обработки веб-запроса кода гораздо меньше. Это не означает, что JIT вообще не может улучшить производительность сети, но мы уже не увидим подобных улучшений, как в случае с фрактальным примером. Дело в том, что в большинстве случаев PHP-приложения ограничены по вводу-выводу (I/O bound, обработка сетевых соединений, чтение и запись файлов, обращение к СУБД, кэширование и т.п.), а JIT лучше всего работает с кодом, который ограничен по процессору (CPU bound).
Это причина, чтобы отказаться от JIT? Точно нет! Есть веские аргументы, чтобы добавить его, хотя это может и не оказать должного влияния на производительность, на которую мы все же надеемся.
JIT открывает возможности для использования PHP как очень производительного языка вне области веб.
Это достаточно веские аргументы в пользу JIT. К сожалению, есть аргументы и против JIT:
— Сложность в обслуживании
Поскольку JIT генерирует машинный код, вы можете представить его как достаточно сложный материал для понимания «программистом языка более высокого уровня».
Имея машинный код в качестве вывода, будет сложнее отлаживать возможные ошибки в JIT-компиляторе PHP. К счастью, есть инструменты, помогающие отладке. Но все же, это машинный код.
Скажем, в JIT-компиляторе есть ошибка, вам нужен разработчик, который знает, как ее исправить. Дмитрий Стогов — тот, кто до сих пор делал большую часть кода, и да, надо помнить, что разработка ядра PHP осуществляется на добровольной основе сообществом контрибьюторов.
Так вот, на сегодняшний день, лишь несколько человек могут поддерживать такую кодовую базу, поэтому вопрос о том, можно ли поддерживать компилятор JIT должным образом, кажется оправданным.
Конечно, люди могут узнать, как работает компилятор. Но это все же сложный материал. Прямо сейчас он насчитывает около 50+ тысяч строк кода. И обратите внимание: это не обычная база кодов клиент-веб-приложение. Это почти-так-же-близко-как-программирования-CPU .
Опять же, это не должно быть причиной отказа от JIT, но стоимость обслуживания должна быть тщательно продумана.
Стоит упомянуть еще одну деталь:
Кроссплатформенность. Начиная с последних версий, JIT также работает в Windows и Mac! Большой шаг вперед.
Так и зачем нам это?
Если после всего выше написанного вы думаете, что JIT предлагает небольшие краткосрочные преимущества для ваших веб-приложений, вы совершенно правы. Трудно сказать, какое влияние это окажет на производительность приложения, прежде чем выйдет окончательный релиз и разработчики не опробуют его в боевых реалиях.
Конечно не будучи экспертом в этой области, все это кажется очень сложным, но очень интересно видеть как такие вещи движутся в мире PHP. Мне очень любопытно, куда этот путь приведет. Это может сделать PHP более жизнеспособным выбором для таких ресурсоемких процессов, как, например, машинное обучение, 3D-рендеринг, 2D (графический интерфейс) и анализ данных, и это лишь некоторые из них.
JIT безопасность
JIT скомпилирует коды операций в машинный код и выполнит их. Все это находится в памяти. Проблема заключается в том, что по соображениям безопасности память должна быть доступна либо для записи, либо для исполнения (W ^ X). Но никогда не одновременно.
Текущая реализация PHP отключает запись в буфер JIT во время выполнения, используя системный вызов mprotect(). Это означает, что он скомпилирует код, запишет его в память и защитит его, чтобы сделать его недоступным для записи во время выполнения, предотвращая всевозможные эксплойты.
В настоящее время есть 2 основных расширения PHP, которые нарушают принцип W ^ X. Phar и PCRE JIT. Но новый PHP JIT в opcache с самого начала учитывает W ^ X, что очень радует.
Проверка текущей версии JIT на OpenBSD 6.0, в которой по умолчанию включен W ^ X, показывает, что все работает нормально. Нарушений нет. Обратите внимание, что SELinux (Security-Enhanced Linux) также включает такие виды защиты.
Ну и последнее, в JIT RFC было предложено включить JIT в PHP 8, а также добавить экспериментальную версию в PHP 7.4. К сожалению или счастью, RFC прошел только для PHP 8, но не для версии 7.4. Это означает, что нам придется подождать до PHP 8, прежде чем мы сможем опробовать его на реальных проектах. Конечно, вы можете скомпилировать PHP 8 из исходного кода, если хочется «пощупать» его уже сейчас.