Как скачать сайт?
Пожалуйста, уточните вашу конкретную проблему или приведите более подробную информацию о том, что именно вам нужно. В текущем виде сложно понять, что именно вы спрашиваете.
10 апр 2022 в 17:46
Если «просто посмотреть», то зачем скачивать? Просто открываете в браузере исходный код страницы да и всё
10 апр 2022 в 17:46
это не удобно, хотелось бы на vscode его смотреть
10 апр 2022 в 17:47
Ну тогда в любом браузере есть пункт меню «Сохранить как»
10 апр 2022 в 17:48
спасибо все получилось 🙂
10 апр 2022 в 18:10
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
В гугл хроме или яндекс браузере нажимаете ctrl + s или правой кнопкой мыши «и сохранить страницу как», выбираете путь и вам скачается html файл и папка с js b css, а вообще не понимаю зачем скачивать, если вам нужно просто посмотреть.
Отслеживать
ответ дан 10 апр 2022 в 19:18
Тв0р0бушек Тв0р0бушек
63 8 8 бронзовых знаков
- html
- css
- вёрстка
-
Важное на Мете
Похожие
Подписаться на ленту
Лента вопроса
Для подписки на ленту скопируйте и вставьте эту ссылку в вашу программу для чтения RSS.
Дизайн сайта / логотип © 2023 Stack Exchange Inc; пользовательские материалы лицензированы в соответствии с CC BY-SA . rev 2023.10.27.43697
Нажимая «Принять все файлы cookie» вы соглашаетесь, что Stack Exchange может хранить файлы cookie на вашем устройстве и раскрывать информацию в соответствии с нашей Политикой в отношении файлов cookie.
Два способа скачать сайт целиком на компьютер

Иногда возникает необходимость посмотреть не только фронт-энд сайта, но и его код. Бывает так, что встречается хороший веб-ресурс с необычным дизайном и хочется понять, как в нём сделаны те или иные элементы, какие используются теги и стили.
Предупреждаю сразу – воровать, таким образом, чужие проекты нельзя! Но для того чтобы сделать резервную копию своего сайта или посмотреть на то как свёрстан тот или другой элемент понравившегося вам ресурса, такой подход может быть использован.
Особенно удобно иметь файлы нужного сайта на жёстком диске своего ПК или в хранилище dropbox. Просмотреть его код можно в любое время, вне зависимости от того есть интернет или нет.
Скачиваем сайт своими руками
Итак, первый способ как скачать сайт целиком на компьютер состоит в том, что делаем всё своими руками, без сторонних он-лайн сервисов или особых программ. Для этого нам понадобится браузер и простой редактора кода, например Noutepad++.
- Создаём на рабочем столе корневую папку с названием сайта
- Создаём в ней ещё три папки и называем одну images (сюда будем складывать картинки); вторую — css (для файлов со стилями); и третью — js (для скриптов).
Загружаем html код страницы
Далее всё очень просто: находим интересующий нас проект, открываем главную страницу и нажимаем на клавиши ctrl + U. Браузер сразу же показывает нам её код.
Копируем его, создаём новый файл в редакторе кода, вставляем код главной страницы, в новый файл, сохраняя его под названием index, с расширением html (index.html). Всё, главная страница сайта готова. Размещаем её в корне документа, то есть кладём файл индекс.html рядом с папками images, css и js
Далее чтобы скачать сайт целиком на компьютер проделываем тоже со всеми страницами сайта. (Данный метод подходит, только если ресурс имеет не слишком много страниц). Таким же образом, копируем все html-страницы понравившегося нам сайта в корневую папку, сохраняем их с расширением html и называем каждую из них соответствующим образом (не русскими буквами – contact.html, about.html).
Создаём css и js файлы
После того как мы сделали все страницы сайта, находим и копируем все его css стили и java скрипты. Для этого кликаем по ссылкам, ведущим на css и js файлы в коде.

Таким же образом как мы копировали файлы html, копируем все стили и скрипты создавая в редакторе Notepad++ соответствующие файлы. Делать их можно с такими же названиями, сохраняя их в папках сss и js. Файлы стилей кладём в папку css, а код java script в папку js.
Копируем картинки сайта
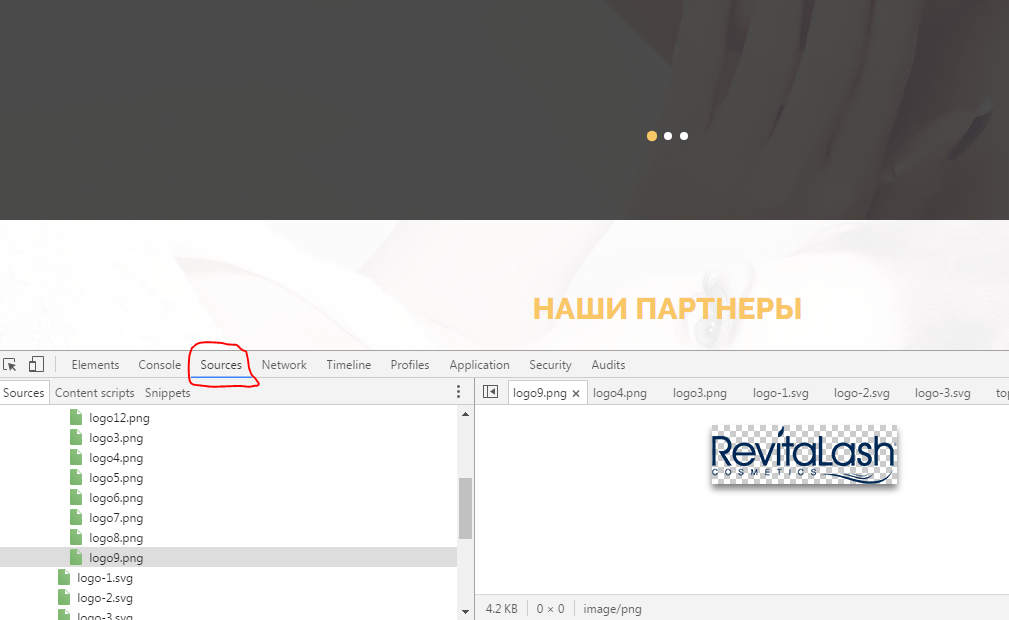
Чтобы скачать сайт целиком на компьютер также нам нужны все его картинки. Их можно загрузить, находя в коде сайта и открывая по порядку одну за другой. Ещё можно увидеть все картинки сайта, открыв инструменты разработчика в браузере с помощью клавиши F12. Находим там директорию Sources и ищем в ней папку img или images В них мы увидим все картинки и фотографии сайта. Скачиваем их все, ложа в папку images.
Убираем всё лишнее в html коде
После того как мы скачали все файлы сайта нужно почистить его код от всего лишнего. Например, можно удалить:
- код google analytics и yandex метрики;
- код верификации сайта в панелях для веб мастеров яндекса и гугла:
- можно удалить любой код, который нам не нужен и оставить тот, что нужен.
Настраиваем пути к картинкам, скриптам и стилям
Теперь если открыть файл index.html с помощью браузера то мы увидим только его хтмл код, который выглядит так же как сайты на заре появления интернета. Чтобы сайт стал таким же, как он есть он-лайн нужно подключить к нему css стили, скрипты и фотографии. Для этого подключаем в html коде файлы со стилями css и скрипты, а так же прописываем правильный путь к фотографиям. Чтобы не ошибиться при прописывании пути к файлам, я не рекомендую делать большую вложенность папок в папки. Все фотографии пусть будут в папке images а стили в css . Ссылки на файлы css и js могут быть приблизительно такими:
А вот ссылка к файлу с логотипом лежащим в папке images:
![]()
Если мы всё правильно подключили то, открыв индексный файл с помощью браузера, мы увидим сайт точно таким же, как он есть в интернете.
Скачиваем сайт целиком на компьютер с помощью wget
Этот способ намного быстрее предыдущего. Скачиваем последнюю версию консольной программы wget здесь.
Подробно об этой программе написано в Википедии и сейчас нет необходимости расписывать все нюансы её работы.
Далее распаковываем архив и создаём на диске С в папке Program Files папку с названием wget. Затем вставляем файлы из корневой папки распакованного архива в только что созданную папку.
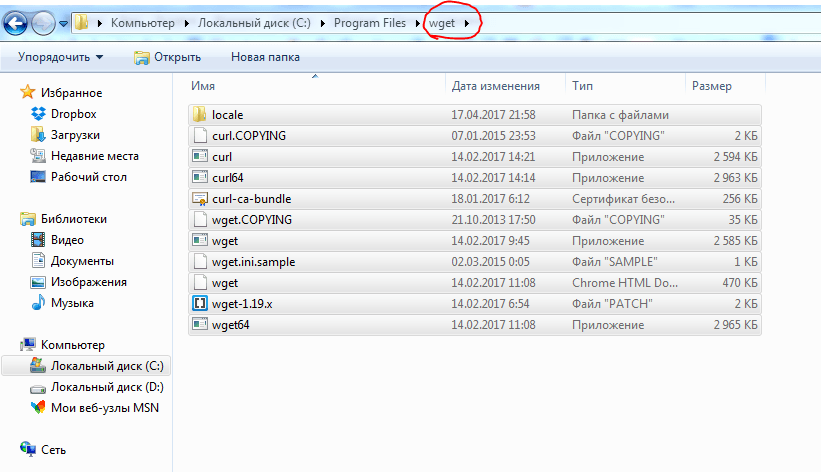
После этого находим на рабочем столе системный значок «Компьютер», кликаем правой кнопкой мыши по нему, открываем «Свойства», заходим в «Дополнительные свойства системы», «Перемены среды» и находим здесь строку «Path» в директории «Системные переменные» и жмём на кнопку «Изменить».
Перед нами появится строка, в конце которой нужно поставить точку с запятой и затем вставить скопированный путь к папке wget на диске С (C:\Program Files\wget). Вставляем его после точки с запятой в строке и сохраняем всё.
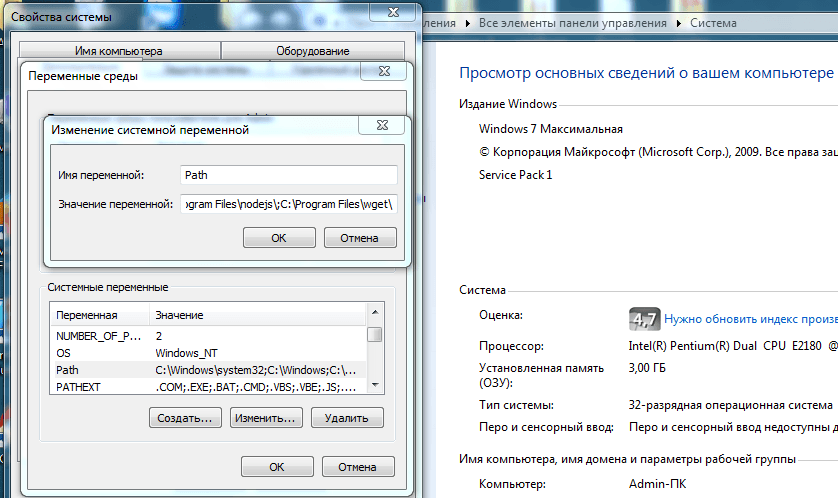
После этого чтобы скачать сайт целиком на компьютер, открываем консоль windows в директории «Пуск» и вводим в командную строку cmd. После этого мы увидим консоль, куда вводим wget –h чтобы убедится, что данное приложение работает.
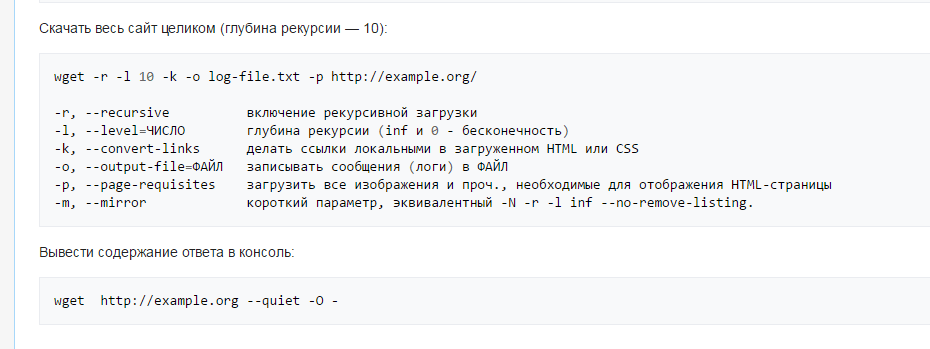
После копируем url нужного сайта и вводим wget —page-requisites -r -l 10 http://adress-sayta.com и запускаем консоль. (Параметр —page-requisites отвечает за то чтобы все картинки, шрифты и стили сайта скачались. Если оставить этот параметр и вставить в конце только url сайта, то загрузится только его главная страница. Поэтому нужно добавить ключи -l и -r и 10-ый уровень вложенности глубины загрузки.
Всё, скачивание сайта началось. Скопированные файлы теперь находятся на диске С в папке «Пользователи», «Admin» (на windows 7). В папке «Админ» находим папку сайта со всеми его файлами. Запускаем файл index.html и убеждаемся, что веб-ресурс скачан на компьютер полностью и он такой же, как он-лайн.
Как вытащить видео с сайта?
У данного сайта на бэкграунде играет видео.
Как его вытащить и сохранить себе на компьютер?
- Вопрос задан более трёх лет назад
- 422265 просмотров
1 комментарий
Сложный 1 комментарий
Daria13131 @Daria13131
Добрый вечер! Раньше скачивала по вашему способу видео с Геткурс, сейчас снова пыталась, но никак не получается. Уже перепробовала миллион способов и все никак(
И код в видео немного другой стал, мб как то поменяли все и теперь данным способом нельзя так пользоваться? Кто сталкивался с таким, помогите пожалуйста, оч нужно скачать курсы, пока доступ к ним еще есть(
Решения вопроса 2

Travel Expert @TravelExpert
LifeHacker
Если видео с youtube — очень просто!
1.Если оно встроено в сайт — запускаем его, затем щелкаем на значок youtube и нас перебросит на youtube.
2.Затем переходим в адресную строку youtube.com/. и дописываем перед этим «ss», таким образом получиться адрес вида ssyoutube.com/. — вот туда и переходим и скачиваем.
Так же есть программы, которые скачивают, если указать им ссылку на видео на youtube или другом популярном сервисе. Например, Download Master(westbyte).
Если видео не с ютуба, то в большинстве случаев его тоже просто скачать.
Для этого в браузерах, например, таких как Firefox, Opera(старая) есть плагины обнаруживающие видео и качающие их.
В Chrome же, всё еще проще:
1.На странице видео нажмите правую клавишу в любом месте страницы и выберите в конце списка «Просмотреть код» или Ctrl+Shift+i. Видео не запускаем!
2. Переходим во вкладку Network, запускаем видео на странице и прописываем фильтр — обычно это mp4, flv, webm или же вместо фильтра тыкаем на Media. prntscr.com/cz9fba
3. В списке находим нужный файл, правой кнопкой мышки — Copy — Copy link.
4. Вставляем ссылку в любой менеджер закачки, тот же Download Master например.
Либо: открываем в браузере — откроется плеер, также правой кнопкой — Сохранить видео как.
Менеджер закачек предпочтительнее, т.к. позволяет качать в несколько потоков, поддерживает докачку, можно поставить на паузу и т.д.
Например, некоторые сайты, выдают ссылку на видео на определенный IP и на ограниченное время. Тогда, если вдруг сменится IP(интернет ребутнется) или если большой объем и не успеете скачать или еще что, то нужно будет так же получить новую ссылку и в свойствах закачки указать новую ссылку-источник.
Ответ написан более трёх лет назад
Нравится 7 5 комментариев
SixthHouseCult @SixthHouseCult
все эти советы бесполезны! в 99% случаев видео резаное потоковое, когда заходишь в network, media ничего не отображается в media, и m3u тоже нет там
timursarsembayev @timursarsembayev
SixthHouseCult, три года назад это работало, а сейчас видео в ВК потоковое. Тут принцип действия остается прежним, просто детали различаются.
Vitalii Bryl @shuffler_agr0s
А если видео делится на сегменты, как в таком случае вытащить видео?
Сайт защищен, только по доступу возможен просмотр.

Vitalii Bryl, Посмотрите тут
только расширение возьмите это. Другие которые я попробовал требовали оплаты либо не грузили сегментированное видео.
Отличный мануал. Спасибо, работает, если смекалку подключить. А то до этого не понимал, как работают сегменты, как их забирать и склеивать. На базе этого уже пишу себе скрипт на пайтоне. Там кто то ниже предлагал расширения для браузеров. Вы что, собираетесь руками каждый видосик выкачивать? Крэйзи )))
Nahlebnik1983 @Nahlebnik1983
вытащить из кода страницы.
https://youtu.be/3y6TkKaQXss
https://youtu.be/D7QmfCrtBmY
Ответ написан более трёх лет назад
Нравится 2 1 комментарий
nickname01 @nickname01 Автор вопроса
Эти слова стоит искать во всех случаях, когда нужно вытащить видео с сайта или такое сработает не всегда?
Ответы на вопрос 4
timursarsembayev @timursarsembayev
ОТВЕТ 2020 ГОДА
Решение для Linux (у меня Linux Mint):
1. Откройте страницу с видео роликом, видео не включайте
2. Открываете инспектор, вкладку Network
3. Включаете воспроизведение видео
4. В инспекторе в строке поиска вбиваете m3u8 и находите данный файл плейлиста (он обычно только один)
5. Скачиваете плейлист файл с расширением m3u8
6. Отдельно сохраните ссылку на m3u8, она будет примерно такой:
https://cs9-4v4.vkuservideo.net/video/hls/p2/3ebb0cd8afd8/index-f3-v1-a1.m3u8?extra=hkhc5u2Cz0VxVRI1gf8Zw_p-K1zG5eCCK_-AKvw8v0tBNO4CmLZSO8j5PKdHBSebK_Ph_sY7PqEDwFNzHJt-eXnOKPj1QRZD0ahfqy24z6ZIdGKqvRnHuE-PhoocuvBqMpKPAI46LFv4juflt6hO6mO4ElcОтсюда нужно вычленить название самого файла и параметры после него, останется только это:
https://cs9-4v4.vkuservideo.net/video/hls/p2/3ebb0cd8afd8/(у вас ссылка будет отличаться, это просто пример)
7. Откройте скачанный файл m3u8 в редакторе, например, Sublime Text
8. Откройте поиск по содержимому файла, включите режим регулярных выражений (regular expression), от строки поиска слева это кнопка .* или кликните по строке поиска и нажмите Alt+R
9. Введите в строку поиска #EXT.* и нажмите на кнопку Найти всё (Find All) и нажмите Backspace
10. Скопируйте полученный урл из 6 шага
11. Введите в строку поиска символ ^ (на англ.раскладке клавиатуры нажмите Shift+6) и нажмите Найти всё (Find All)
12. Вставьте скопированный урл (нажмите Ctrl+V) и сохраните изменения в файле
13. Откройте uGet (если не установлено, то установите его), перейдите в File -> Batch Downloads -> Text file import и выберите файл плейлиста m3u8, начнется скачивание отдельных файлов формата .ts в вашу домашнюю папку /home/username где username это имя вашей учетной записи
14. По окончании скачивания снова откройте файл плейлист в редакторе Sublime Text
15. В строку поиска вставьте скопированный урл из 6 шага и нажмите Найти всё (Find All), нажмите Backspace и сразу же напишите file ‘ ( слово file, пробел и одинарная кавычка ‘ )
16. В строку поиска введите ?extra.* ( если у вас включен режим регулярок, то введите \?extra.* ), нажмите клавишу Backspace, а затем клавишу ‘ (одинарная кавычка)
17. В итоге вы получите файл со списком что-то вроде этого:
file ‘seg-1-f3-v1-a1.ts’
file ‘seg-2-f3-v1-a1.ts’
file ‘seg-3-f3-v1-a1.ts’
и так далее.
18. Переименуйте файл плейлиста и измените его расширение, например так:
dwl_local.txt
19. Переместите файл dwl_local.txt в домашнюю папку /home/username куда были скачаны все файлы .ts
20. Откройте терминал в домашней папке и введите в нём следующее:
ffmpeg -f concat -i dwn_local.txt -c copy output.ts
или скопируйте эту строку и вставьте в терминал путем Shift+Ctrl+V
где dwn_local.txt это название файла со списком файлов
output.ts это название конечного файла
Если по каким-то причинам у вас не установлен ffmpeg, то установите его через терминал:
sudo apt install ffmpeg
Решение для Windows:
Всё то же самое, что и для Linux с 1 по 12 шаги
13. Нужен Download Master, также импортируйте файл плейлиста со ссылками, возможно нужно будет его переименовать сразу и поменять расширение, например, на dwn_local.txt
Дальше шаги с 14 по 18 повторите как в инструкции для Linux
19. Переместите файл dwn_local.txt в папку с загруженными файлами, возможно это папка Downloads (Загрузки)
20. Откройте командную строку Windows (найдите её в меню Start или Пуск) или нажмите клавиши Win+R и введите cmd, затем клавишу Enter
В командной строке введите следующее:
ffmpeg -f concat -i dwn_local.txt -c copy output.ts
где dwn_local.txt это список файлов
output.ts это конечный объединенный файл
Таким образом вы получаете объединенный файл .ts из нескольких фрагментов .ts
Сконвертировать в другие форматы можно при помощи VLC плеера или других программ
Файл .ts можно загружать себе на YouTube канал без конвертаций
Как скачать документ, книгу с защищенного сайта(только чтение) (Для примера взял книгу с открытым доступом)?
(заранее извиняюсь, что цитирую того человека, просто ту тему я найти не могу, она не высвечивается в браузере, как ранее. Некоторые важные моменты сохранились. Если вдруг автор скажет что-то удались — сразу удалю)
Буду раскрывать все карты — поэтапно, поскольку пока что вообще не разбираюсь коде, но один добрый человек вдохновил меня на поиски решения. Но пришлось на некоторое время забыть. Как видите — по итогу безуспешно, раз пишу сюда (потому что слишком туп). Теперь по существу: «предмет исследования» — книга-пример с открытым доступом из сайта юрайт: https://urait.ru/viewer/grazhdanskoe-pravo-i-proce. . «объект исследования» — возможность скачать ее любым способом (пожалуйста, только не надо предлагать нажать «сохранить как» правой кнопкой мыши несколько сотен раз.)
Так вот, внезапно тот добрый человек кидает результат через день: https://disk.yandex.ru/d/wOHMnfNx-rsxaQ (не в том порядке страницы, но меня удивил сам факт того, что это получилось). Я его стал расспрашивать что да как. Он отвечает, что в отладке (F12) увидел, что каждая страница качается в .svg по ссылке вида */page_N.svg.gz выкачал все страницы конвертировал в pdf и объединил. Далее он пишет что есть куча способов выкачать ссылку, от curl и wget, до python скрипта. Он использовал Download Master «добавить группу закачек» На сайтах, где требуется авторизация, он из консоли разработчика скрипт писал, чтобы ссылки выкачать.
Это все что тогда я успел взять с развития темы. После пост удален скорее всего. Сейчас появился CHAT GPT. Я в шоке с его возможностей, но из-за своего непонимания ситуации даже он мне не помог. Я ему предложил написать код для скачивания всех картинок на примере данных с этого URL: https://urait.ru/library/svobodnyy-dostup/pravo-yu. (уже другая книга, но тоже с открытым доступом) . Он мне скинул этот код:
for (let i = 1; i .svg.gz`; fetch(url) .then(res => res.arrayBuffer()) .then(data => < const blob = new Blob([data], < type: 'image/png' >); const link = document.createElement('a'); link.href = URL.createObjectURL(blob); link.download = `page$.png`; link.click(); >); >В этом коде, вы создаете цикл от 1 до 302, который загружает каждую страницу в формате .svg.gz. Затем, используя fetch API, вы загружаете этот файл в бинарный формат. Наконец, вы создаете ссылку на этот файл и скачиваете его с помощью метода click.
Я: Вставил эту команду, все 302 файла скачались, но формат файлов не поддерживается и они имеют одинаковый размер. Вылезала ошибка в консоли 302 раза: Failed to load resource: the server responded with a status of 404 ()
ЧатЖПТ: Судя по всему, сервер не поддерживает скачивание этих файлов или они просто не существуют. Возможно, эти файлы генерируются динамически при запросе или требуется определенный доступ для их загрузки. Попробуйте найти информацию об этом на сайте или у администратора сайта.
Я: забыл добавить еще ошибку: Не удалось загрузить карту исходного кода с помощью инструментов разработчика: Не удалось загрузить контент для https://static.isu.pub/fe/product-header-frontend/. : Ошибка HTTP. Код статуса 403, net::ERR_HTTP_RESPONSE_CODE_FAILURE.
ЧатЖПТ: Эти ошибки говорят о том, что ваш браузер не может загрузить какие-либо файлы, потому что сервер вернул статус ошибки 404 или 403. Ошибка 404 означает, что сервер не нашел файл, который вы запрашиваете. Ошибка 403 означает, что ваш доступ к файлу запрещен. В этом случае, вам нужно обратиться к владельцу сайта или администратору, чтобы убедиться, что у вас есть необходимые права доступа.
Если у кого-то есть опыт, сообщите, пожалуйста!
- Вопрос задан 06 февр.
- 4660 просмотров
3 комментария
Простой 3 комментария