Уязвимости в коде. Как отличить опасную брешь от незначительной ошибки?
Как обычно выглядит проверка кода приложений на уязвимости? Специалист по безопасности инициирует процедуру, код сканируется, в приложении обнаруживаются тысячи уязвимостей. Все — и безопасник, и разработчики — в шоке. Естественная реакция разработчика: «Да наверняка половина — это ложные срабатывания, а другая — некритичные уязвимости!»
Что касается ложных срабатываний, здесь все просто: можно взять и посмотреть непосредственно те места кода, где обнаружены уязвимости с подозрением на false positive. Действительно, какая-то их часть может оказаться ложными срабатываниями, (хотя явно не половина от общего числа).
А вот о том, что критично, а что нет, хотелось бы поговорить более предметно. Если вы понимаете, почему сейчас уже нельзя использовать SHA-1 и зачем экранировать «;», возможно, эта статья не откроет вам чего-то нового. Но если по итогам сканирования от найденных уязвимостей рябит в глазах, добро пожаловать под кат – расскажем, какие «дыры» чаще всего встречаются в мобильных и веб-приложениях, как они работают, как их исправить, а главное — как понять, что перед вами — опасная брешь или незначительная ошибка в коде.

Внедрение
Ну ооочень распространенный тип уязвимости. Куда только не внедряются: в запросы SQL, LDAP, XML, XPath, XSLT, Xquery… Все эти внедрения отличает использование недоверенных данных, благодаря которому злоумышленник получает доступ к информации или изменяет поведение приложения. Например, с помощью пользовательского ввода, который недостаточно валидируется.
Согласно международной классификации уязвимостей OWASP, атаки с использованием метода «Внедрение» занимают первое место по уровню критичности угроз безопасности веб-приложений. Рассмотрим наиболее типичные виды внедрений.
Внедрение в SQL-запрос. Недоверенные данные попадают в SQL-запрос к базе данных.
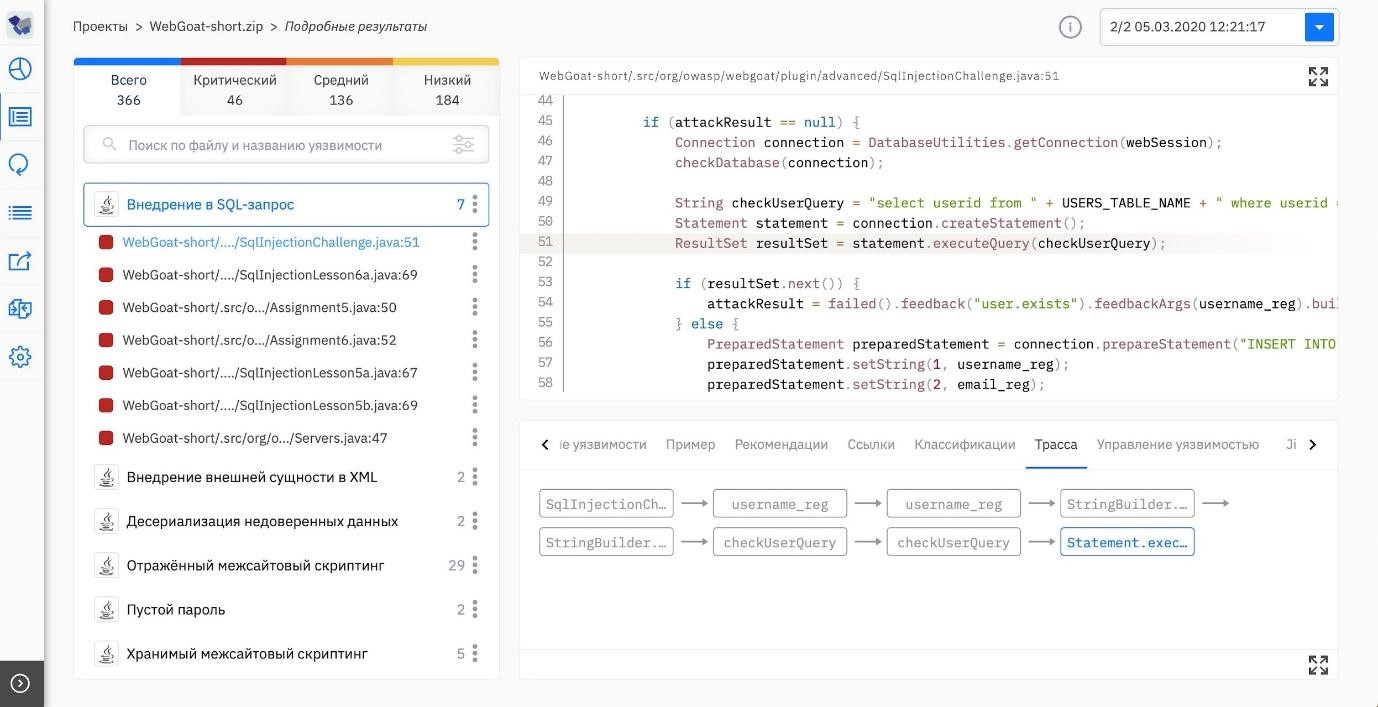
Если в запросе к базе данных не реализована корректная проверка подлинности вводимых данных, злоумышленник может испортить SQL-запрос:
- передать в него вредоносный код;
- добавить символ «—» или «;» и оборвать правильную SQL-команду: всё, что после «—», интерпретируется как комментарий, а символ «;» обозначает конец команды;
- угадать пароль, последовательно выполнив серию SQL-запросов.
- Используйте API, который предоставляет параметризованный интерфейс, или инструменты объектно-реляционного сопоставления (ORM).
- Реализуйте механизм валидации для данных, введённых пользователем. Используйте «белый список» проверки на стороне сервера.
- Экранируйте специальные символы («;», «—», «/*», «*/», «’»; точный список зависит от базы данных).
- Для проверки вводимых пользователем данных используйте хранимые процедуры (stored procedures) вместе с механизмом фильтрации их параметров.
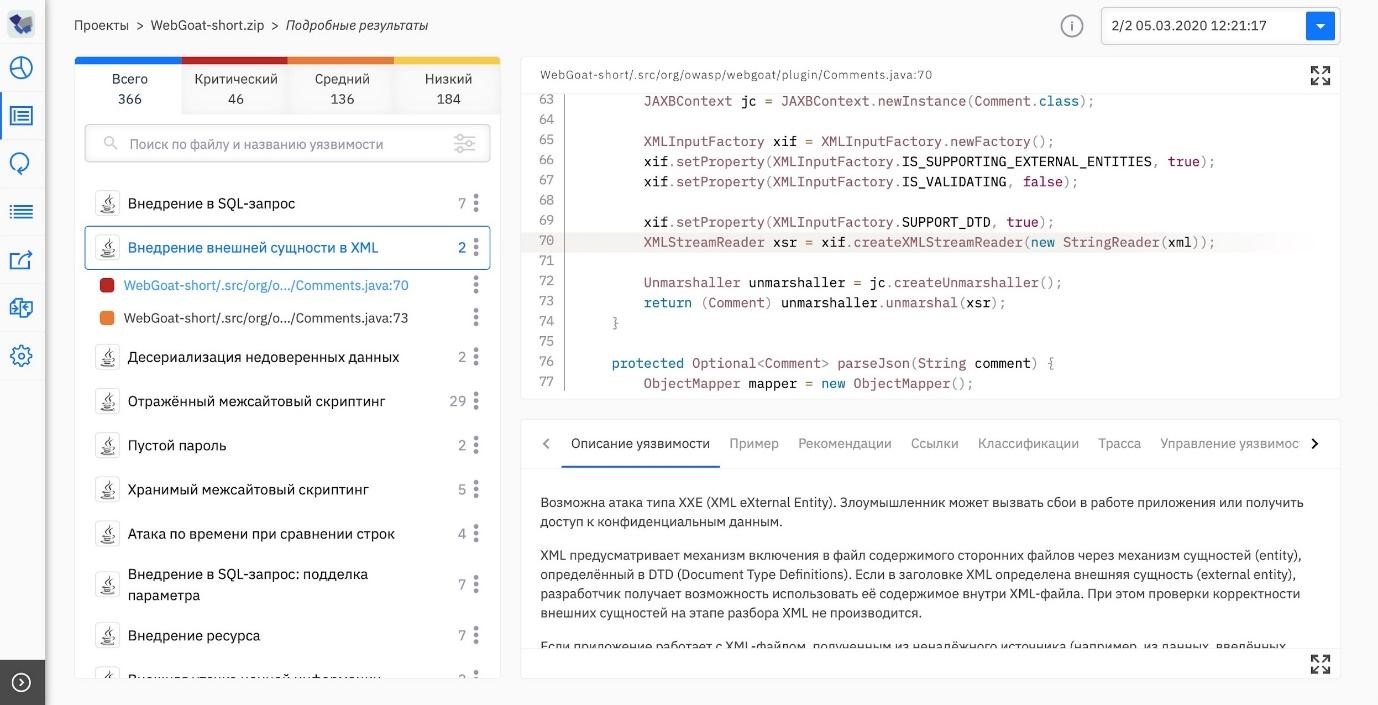
Если злоумышленник может записывать данные в XML-документ, то он может изменять и его семантику. В таком случае самый безобидный сценарий позволит внедрить в документ лишние теги, в результате чего XML-парсер завершит работу с ошибкой. Но можно столкнуться и с инцидентом посерьезнее: например, с подменой аутентификационных данных в базе клиентов или ценой в базе товаров магазина. Внедрение в XML также может привести и к межсайтовому скриптингу (XSS) — внедрению вредоносного кода, который выполнится в браузере пользователя при открытии страницы.
Что можем посоветовать?
- Не создавайте тегов и атрибутов, имена которых получены на основе данных из недоверенного источника (например, введённых пользователем).
- Кодируйте (XML entity encode) данные, введённые пользователем, прежде чем записывать их в XML-документ.
В примере ниже приложение создаёт и выполняет XQuery-выражение на основе параметров username и password из HTTP-запроса (недоверенный источник):
XQDataSource xqs = new XQDataSource(); XQConnection conn = xqs.getConnection(); String query = "for \$user in doc(users.xml)//user[username='" + request.getParameter("username") + "'and pass='" + request.getParameter("password") + "'] return \$user"; XQPreparedExpression xqpe = conn.prepareExpression(query); XQResultSequence rs = xqpe.executeQuery();В случае корректных данных запрос вернёт информацию о пользователе с соответствующими именем и паролем:
for \$user in doc(users.xml)//user[username='test_user' and pass='pass123'] return \$user Если злоумышленник задаст в качестве параметра строку, содержащую специальные символы (например, admin’ or 1=1 or »=’ ), семантика запроса изменится:
//user[username='admin']Полученный запрос вернёт данные обо всех пользователях.
Безопасный вариант (использует prepared statements ):
XQDataSource xqs = new XQDataSource(); XQConnection conn = xqs.getConnection(); String query = "declare variable $username as xs:string external; declare variable $password as xs:string external; for \$user in doc(users.xml)//user[username='$username' and pass='$password'] return \$user"; XQPreparedExpression xqpe = conn.prepareExpression(query); xqpe.bindString(new QName("username"), request.getParameter("username"), null); xqpe.bindString(new QName("password"), request.getParameter("password"), null); XQResultSequence rs = xqpe.executeQuery();Внедрение в XSLT (язык преобразования XML-документов) возможно, если приложение использует данные из недоверенного источника при работе с XSL.
Приложения используют XSL для преобразования XML-документов. Стилевые XSL-файлы содержат функции, которые описывают трансформацию, и при неправильной реализации могут включать в себя уязвимости. В таком случае возрастает риск осуществления сценариев атак, при которых злоумышленник меняет структуру и содержимое стилевого XSL-файла, а значит, и соответствующего XML-файла. Что можем получить на выходе?
Во-первых, XSS-атаку: внедрение в страницу, которую выдает веб-система, вредоносного кода и взаимодействие этого кода с сервером злоумышленника. Во-вторых, получение хакером доступа к системным ресурсам. В-третьих, выполнение произвольного кода. И на десерт – XXE-атаку (XML eXternal Entity — внедрение внешней сущности в XML).
Внедрение в команды LDAP (Lightweight Directory Access Protocol — «легкорасширяемый протокол доступа к каталогам») может привести к утрате конфиденциальности данных или их модификации. В данном случае недоверенные данные попадают в LDAP-запрос.
Внедрение вредоносной команды интерпретатора. Недоверенные данные попадают в команду интерпретатора. Злоумышленник может подобрать такой ввод, чтобы команда выполнилась успешно и ему стали доступны дополнительные полномочия в приложении.
В примере ниже приложение выполняет скрипт, предназначенный для создания резервной копии базы данных. Приложение принимает тип резервной копии в качестве параметра и запускает скрипт с повышенными привилегиями:
String btype = request.getParameter("backuptype"); String cmd = new String("cmd.exe /K \"c:\\util\\rmanDB.bat "+btype+"&&c:\\utl\\cleanup.bat\"") System.Runtime.getRuntime().exec(cmd);Проблема здесь в том, что параметр backuptype не валидируется. Обычно Runtime.exec() не выполняет несколько команд, но в данном случае сначала запускается cmd.exe, чтобы выполнить несколько команд вызовом Runtime.exec() . Как только оболочка командной строки запущена, она может выполнить несколько команд, разделённых символами « && ». Если злоумышленник задаст в качестве параметра строку » && del c:\\dbms\\*.* «, приложение удалит указанную директорию.
- Не позволяйте пользователям непосредственно контролировать выполняемые приложением команды. Если поведение приложения должно зависеть от данных, введённых пользователем, предлагайте пользователю выбор из определённого списка разрешённых команд.
- Если пользовательские данные служат аргументом команды, белый список может оказаться слишком громоздким. Чёрный список также неэффективен, так как его сложно поддерживать в актуальном и полном состоянии. В таком случае рекомендуется опираться на белый список символов, допустимых в параметрах команды.
- Злоумышленник может изменять семантику команды, не только изменяя её, но и влияя на окружение. Окружение не должно восприниматься как доверенный источник. Значения переменных окружения должны также проходить валидацию.
Небезопасное включение внешнего файла в HTML. Уязвимости типа «file inclusion» возникают, когда пользователь вводит путь к подключаемому файлу. Дело в том, что современные скриптовые языки позволяют динамически подключать код из сторонних файлов, чтобы использовать его повторно. Этот механизм применяют для единого внешнего вида страниц или для разделения кода на небольшие модули. Однако таким включением может воспользоваться злоумышленник, подменив путь и подключив свой файл.
Рекомендуем специалистам в области корпоративной информационной безопасности составить «белый список» допустимых путей подключения файлов, чтобы сотрудники могли добавлять файлы только по сценариям из этого списка.
Закладки
Закладками именуют преднамеренно внесённые в код приложения части, с помощью которых при определённых условиях можно выполнить не заложенные в приложении действия. Рассмотрим самые распространенные виды закладок.
Специальные учётные записи. Если приложение сравнивает значение переменной пароля или логина с неизменным значением, стоит насторожиться: эта учётная запись может быть частью закладки. Посмотрим, как это происходит.
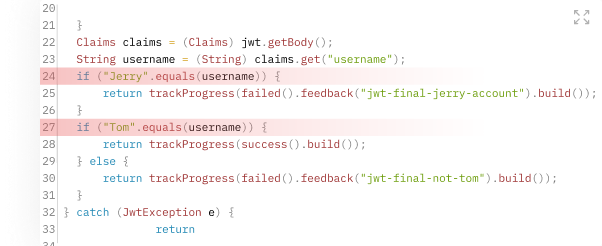
Разработчик приложения использует специальную учётную запись (возможно, с повышенными привилегиями) при отладке и оставляет соответствующие участки кода в финальной версии, сохранив за собой доступ к приложению. Злоумышленник может восстановить исходный код приложения, извлечь константные значения специальной учётной записи и получить доступ к приложению.
Хранить логины, пароли, ключи в исходном коде приложения категорически нельзя.
Скрытая функциональность (НДВ). Код скрытой функциональности запускается, когда срабатывает определенный триггер. В веб-приложениях триггером часто служит «невидимый» параметр запроса. Иногда дополнительно осуществляется проверка, с какого IP пришел запрос с триггером, чтобы активировать закладку мог только её автор. Такие проверки служат сигналом к возможным закладкам.
Недокументированная сетевая активность. К такому виду активности относятся: соединение со сторонними ресурсами в фоновом режиме, прослушивание недокументированных портов, передача информации по протоколами SMTP, HTTP, UDP, ICMP.
Если вы обнаружили в коде подозрительное соединение с адресом, который не входит в список заведомо безопасных, настоятельно рекомендуем вам его удалить.
Изменение параметров безопасности. Приложение содержит код, который изменяет значение переменной, хранящей успешность аутентификации. Распространённая ошибка — использование присваивания (=) вместо сравнения (==). В методах, связанных с аутентификацией, она особенно опасна, поскольку может быть частью бэкдора:
if (isAuthenticated = true)
Временной триггер (timebomb). Закладка, которая срабатывает в определенный момент времени. Приложение сравнивает текущую дату с конкретными годом, месяцем и днём: 1 января 2021 года всех ждёт сюрприз:
Date now = java.util.Date(); // current time if ((now.getYear() == 2021) && (now.getMonth() == 1) && (now.getDate() == 1))
А может быть и нет… На практике при поиске временных триггеров часто происходят ложные срабатывания. Например, если API времени используют и по назначению: запись в лог, вычисление времени выполнения, временные метки для ответов сервера на HTTP-запросы.
Но! Мы все же рекомендуем не закрывать глаза на все подобные срабатывания, так как знаем реальные примеры реализации таких уязвимостей.
Мёртвый код. Куски внедренного кода, которые ничего полезного не делают. Сам по себе мёртвый код не опасен, однако он может быть частью закладки, которую распределили по нескольким файлам. Или же триггер срабатывания закладки планируется внедрить позже. В любом случае, мёртвый код должен вызывать подозрения.
Отсутствие шифрования и использование слабых алгоритмов шифрования
Основные проблемы с шифрованием заключаются в том, что его либо не используют вовсе, либо применяют слабые алгоритмы, а ключи и соль слишком просты или хранятся небезопасно. Последствие у всех этих уязвимостей одно — конфиденциальные данные проще украсть.
В примере показана инициализация шифрования по устаревшему алгоритму DES:
Cipher cipher = Cipher.getInstance("DES");Примеры уязвимых алгоритмов шифрования: RC2, RC4, DES. Безопасный вариант:
Cipher cipher = Cipher.getInstance("AES/CBC/PKCS5Padding"); Согласно международной классификации OWASP, уязвимости типа «утечка конфиденциальных данных» занимают третье место по уровню критичности угроз безопасности веб-приложений.
Наши рекомендации разработчикам: обязательно используйте шифрование с учётом требований безопасности.
Применение незащищённого протокола HTTP вместо HTTPS чревато атакой типа Man in the middle.
Безопасный протокол HTTPS основан на HTTP, но также поддерживает шифрование через криптографические протоколы SSL/TLS. HTTPS шифрует все передаваемые по нему данные, в частности, страницы ввода логина и пароля или данные банковских карт пользователя, защищая их от несанкционированного доступа и изменения. В отличие от HTTP, который не защищает передаваемые данные. В результате злоумышленник может подменить информационный сайт по HTTP и заставить пользователя ввести данные на поддельной странице (фишинговая атака).
Ключ шифрования задан в исходном коде. В результате такие ключи доступны каждому разработчику приложения. Кроме того, после установки приложения удалить ключ из кода можно только с помощью обновления.
В целом, константные строки легко извлекаются из исполняемого файла с помощью программы для восстановления исходного кода (декомпилятора). Поэтому злоумышленнику необязательно иметь доступ к исходному коду, чтобы узнать значение используемого ключа. В нашей практике мы нередко сталкиваемся со случаями, когда в качестве значения ключа разработчики задают null или пустую строку, что просто недопустимо.
Наш совет: генерируйте ключи криптостойкими генераторами псевдослучайных чисел (ГПСЧ) и храните их с помощью специальных модулей.
Небезопасный алгоритм дополнения при шифровании. Если алгоритм шифрования RSA используется без OAEP-дополнения, зашифрованные данные становятся уязвимыми.
Алгоритм OAEP нужен, чтобы обработать сообщения перед использованием RSA. Сначала сообщение дополняется до фиксированной длины с помощью OAEP, затем шифруется с помощью RSA. Такая схема шифрования называется RSA-OAEP и является частью действующего стандарта.
Это пример инициализации RSA-шифрования без дополнения:
rsa = javax.crypto.Cipher.getInstance("RSA/NONE/NoPadding"); rsa = javax.crypto.Cipher.getInstance("RSA/ECB/OAEPWithMD5AndMGF1Padding");Недостаточный размер ключа шифрования. Если вы используете ключ малой длины, такое шифрование уязвимо для атаки методом перебора.
Криптоанализ не стоит на месте, постоянно возникают новые алгоритмы атак, компьютеры обретают бОльшие мощности. Параметры шифрования, которые раньше считались безопасными, устаревают и уже не рекомендуются к использованию. Так, RSA с длиной ключа 1024 бит перестал считаться безопасным в 2010–2015 годах.
Слабый алгоритм хеширования. По описанным в предыдущем пункте причинам хеш-функции MD2, MD5, SHA1 являются небезопасными. Чтобы найти коллизии для функций MD2 и MD5, существенных ресурсов не требуется.
Для SHA1 есть примеры двух разных файлов с одинаковыми хешами. Алгоритм взлома предложили сотрудники Google и Центра математики и информатики в Амстердаме.

Если пароли пользователей хранятся в виде хешей, но с использованием небезопасной хеш-функции, злоумышленник вполне может получить к ним доступ, реализовав следующий сценарий. Зная хеш пароля и используя уязвимость алгоритма хеширования, можно вычислить строку, для которой хеш такой же, как и для пароля. С помощью вычисленной строки злоумышленник проходит аутентификацию.
Хеш-функция для хранения паролей должна быть устойчивой к коллизиям и не слишком быстрой, чтобы нельзя было реализовать атаку методом перебора. Следует использовать безопасные алгоритмы PBKDF2, bcrypt, scrypt.
Несколько интересных цифр: с помощью PBKDF2 скорость перебора ключей сократили до 70 штук в секунду для Intel Core2 и около 1 тысячи на ПЛИС Virtex-4 FX60. Для сравнения, классические функции хеширования пароля LANMAN имеют скорость перебора около сотен миллионов вариантов в секунду.
Слабый алгоритм шифрования. Как и в случае алгоритмов хеширования, безопасность алгоритма шифрования определяется временем и ресурсами, которые придется потратить на его дешифровку. Уязвимыми алгоритмами считаются RC2, RC4, DES. Последний из-за небольшой длины ключа (56 бит) можно взломать методом полного перебора.
Слабый генератор псевдослучайных чисел (ГПСЧ) порождает предсказуемые последовательности. Хакер может обойти аутентификацию и захватить сессию пользователя.
Углубимся немного в природу ГПСЧ. Они порождают цепочки чисел на основе начального значения параметра seed . Есть два типа ГПСЧ – статистические и криптографические.
Статистические ГПСЧ порождают предсказуемые последовательности, которые по статистическим характеристикам похожи на случайные. Их нельзя использовать для обеспечения безопасности.
Результат работы криптографических ГПСЧ, наоборот, невозможно предугадать, если значение параметра seed получено из источника с высокой энтропией. Значение текущего времени обладает небольшой энтропией и также небезопасно в качестве seed . В Java ГПСЧ из классов java.util.Random и java.lang.Math порождают предсказуемые последовательности и не должны использоваться в целях обеспечения информационной безопасности.
Слабое зерно генератора псевдослучайных чисел. Использовать в качестве seed значение из недоверенного источника небезопасно, так как это порождает предсказуемую последовательность.
Работа многих криптографических алгоритмов основана на использовании устойчивого к криптоанализу ГПСЧ. Некоторые алгоритмы могут принимать в качестве дополнительного аргумента значение seed и для каждого значения этого параметра порождать предсказуемую последовательность. В таком случае безопасность системы основана на предположении о том, что значения seed будут непредсказуемы.
Соль задана в исходном коде. Вспомним, для чего нужна соль. Чтобы взломать пароль методом перебора, используют заранее составленные таблицы со значениями хеш-функций от популярных паролей. Соль — произвольная строка, которая подаётся на вход хеш-функции вместе с паролем, чтобы затруднить такую атаку.
Если соль хранится в исходном коде, возникают ровно те же самые проблемы, что и с паролями и ключами. Значение соли доступно разработчикам и легко могут получить злоумышленники, а убрать соль из финальной версии приложения можно только вместе с очередным обновлением приложения.
Манипуляции с логами
Различные ошибки в логах чреваты внедрением в приложения вредоносного кода. Чаще всего встречаются такие связанные с логированием уязвимости, как подделка файла лога и неструктурированное логирование.
Подделка файла лога происходит, когда приложение записывает недоверенные данные в журнал событий (лог). Хакер может подделать записи лога или внедрить в них вредоносный код.
Как правило, приложения записывают в лог историю транзакций для дальнейшей обработки, отладки или сбора статистики. Логи можно разбирать вручную или автоматически.
Если записывать в лог данные «как есть», злоумышленник может внедрить в лог фальшивые записи, нарушить структуру файла, вызвав сбои обработчика логов, или же внедрить вредоносный код, эксплуатирующий известные уязвимости в обработчике.
В этом примере web-приложение пытается считать целочисленное значение из параметра запроса. Если введённое значение не удалось конвертировать в целое число, приложение записывает в лог это значение вместе с сообщением об ошибке:
String val = request.getParameter("val"); try < int value = Integer.parseInt(val); >catch (NumberFormatException nfe) < log.info("Failed to parse val bash">INFO: Failed to parse val=twenty-one INFO: User logged out=badguy Аналогичным образом в лог можно внедрить произвольные записи.
Безопасный вариант (использует NumberFormatException ):
public static final String NFE = "Failed to parse val. The input is required to be an integer value." String val = request.getParameter("val"); try < int value = Integer.parseInt(val); >catch (NumberFormatException nfe)
Неструктурированное логирование, то есть вывод сообщений об ошибках в стандартные потоки out или err является небезопасным методом. Рекомендуется вместо него использовать структурированное логирование. Последнее позволяет генерировать лог с уровнями, метками времени, стандартным форматированием. Если в программе реализован механизм структурированного логирования, но при этом сообщения об ошибках выводятся в стандартные потоки, то в логе может не оказаться критически важной информации.
Выводить сообщения об ошибках в стандартные потоки допустимо только на ранних стадиях разработки.
Небезопасная работа с куки
Уязвимости, связанные со сбором пользовательских куки, весьма разнообразны.
Небезопасная работа с куки. Приложение включает в куки данные из недоверенного источника, что может привести к атакам типа «отравление кэша», XSS (межсайтовый скриптинг) и «расщепление ответа».
Если в приложение внедряется вредоносный код (межсайтовый скриптинг), то злоумышленник сможет изменять куки пользователя.
Поскольку куки задаются в заголовке HTTP-ответа, отсутствие подтверждения данных, включаемых в куки, может привести к атаке «расщепление ответа». «Расщеплением ответа» (HTTP response splitting) называется атака, при которой хакер посылает такой HTTP-запрос, ответ на который примется жертвой сразу за два HTTP-ответа (вместо правильного одного).
Если злоумышленник задаст в качестве параметра author строку вида Hacker \r\nHTTP/1.1 200 OK\r\n. , ответ будет расщеплён на два следующим образом:
HTTP/1.1 200 OK . Set-Cookie: author=Hacker HTTP/1.1 200 OK . Содержимое второго ответа полностью контролируется злоумышленником, что приводит к отравлению кэша, XSS, вредоносным перенаправлениям и другим атакам.
Куки без HttpOnly. Приложение создаёт куки без флага httpOnly . Если httpOnly включается в заголовок ответа http , злоумышленник не сможет заполучить куки с помощью JavaScript-кода. И если пользователь откроет страницу с уязвимостью типа межсайтовый скриптинг (XSS), браузер не раскроет куки третьим лицам. Если же флаг httpOnly не установлен, то куки (обычно, сессионные) можно украсть с помощью скрипта.
Пример создания куки без флага httpOnly :
Cookie cookie = new Cookie("emailCookie", email); response.addCookie(cookie);Устанавливайте флаг httpOnly при создании куки. Однако следует помнить, что существуют способы атак, позволяющие обойти httpOnly , поэтому вам также следует позаботиться о тщательной проверке входных данных.
N.B. Согласно международной классификации OWASP, уязвимости типа «утечка конфиденциальных данных» занимают третье место по уровню критичности угроз безопасности веб-приложений.
Куки для слишком общего домена. Если домен для куки слишком общий (например, .example.com ), уязвимость в одном приложении делает уязвимыми и другие приложения в том же домене.
В следующем примере безопасное web-приложение, установленное по адресу http://secure.example.com , устанавливает куки со значением домена .example.com :
Cookie cookie = new Cookie("sessionID", sessionID); cookie.setDomain(".example.com");Если по адресу http://insecure.example.com установлено приложение, содержащее, например, XSS, то куки авторизованного пользователя безопасного приложения, перешедшего по адресу http://insecure.example.com , могут быть скомпрометированы.
Злоумышленник также может осуществить атаку «отравление куки»: куки с общим доменом, созданные http://insecure.example.com , перезапишут куки http://secure.example.com .
Cookie cookie = new Cookie("sessionID", sessionID); cookie.setDomain("secure.example.com");Куки со слишком общим параметром path . Если путь в куки указан неточно (например, /), возникает такая же проблемы, как и с общим доменом: уязвимость в одном приложении подвергает опасности и другие приложения в том же домене.
В следующем примере приложение, установленное по адресу http://pages.example.com/forum , устанавливает куки с путём /:
Cookie cookie = new Cookie("sessionID", sessionID); cookie.setPath("/"); Тогда вредоносное приложение, установленное по адресу http://pages.example.com/evil , может скомпрометировать куки пользователя. Злоумышленник также может осуществить атаку «отравление куки»: куки с общим путём, созданные /evil , перезапишут куки /forum .
Cookie cookie = new Cookie("sessionID", sessionID); cookie.setPath("/forum"); Куки не по SSL. Приложение создаёт куки, не устанавливая флаг secure равным true . Такие куки можно передавать в незашифрованном виде по HTTP. Сразу же вспоминается уязвимость «Использование незащищённого протокола HTTP».
В следующем примере приложение создаёт куки без флага secure :
Cookie cookie = new Cookie("emailCookie", email); response.addCookie(cookie);Если приложение использует как HTTPS, так и HTTP, то при отсутствии флага secure куки, созданные в рамках HTTPS-запроса, будут передаваться в незашифрованном виде при последующих HTTP-запросах, что может привести к компрометации приложения. Это особенно опасно, если куки содержит ценные данные, в частности, идентификатор сессии.
Cookie cookie = new Cookie("emailCookie", email); cookie.setSecure(true); response.addCookie(cookie);Куки с неограниченным сроком действия. Если хранить ценные куки слишком долго, злоумышленник может успеть получить к ним доступ.
По умолчанию используются непостоянные (сессионные) куки, которые не сохраняются на диск и удаляются после закрытия браузера. Однако разработчик веб-приложения может указать срок хранения куки – в этом случае они будут записаны на диск и сохранены между перезапусками браузера и перезагрузками компьютера. Так мы даем злоумышленнику продолжительное время для разработки плана атаки.
Рекомендации разработчикам: убедитесь, что приложение не создаёт куки с длительным сроком хранения:
Cookie cookie = new Cookie("longCookie", cookie); cookie.setMaxAge(5*365*24*3600); // 5 лет!Указывайте разумный максимальный срок, следуя рекомендациям OWASP.
Утечка информации
Пожалуй, наиболее чувствительный для пользователей приложения вид уязвимостей.
Внешняя утечка информации через страницы ошибок. Приложение использует стандартные страницы ошибок, в которые может попасть информация о конфигурации системы.
Сообщения об ошибках и отладочная информация записываются в лог, выводятся в консоль или передаются пользователю. Из сообщений об ошибках злоумышленник может узнать об уязвимостях системы, что облегчит ему жизнь. Например, ошибка базы данных может говорить о незащищённости от SQL-инъекции. Информация о версии операционной системы, сервера приложений и конфигурации системы упростят хакеру задачу планирования атаки на приложение.
Внешняя утечка ценной информации. В данном случае речь идёт об утечке технической информации о приложении путем ее передачи по сети на другой компьютер. В целом, внешние утечки опаснее внутренних.

Внутренняя утечка ценной информации. Механизм эксплуатации схож с предыдущими двумя видами утечек, но в данном случае информация о системе записывается в лог или выводится на экран пользователя.
Утечка конфиденциальных данных. Ценные персональные данные пользователей попадают в приложение из разных источников: от самого пользователя, из различных баз данных, из сторонних хранилищ. Иногда эти данные не помечены как конфиденциальные либо оказываются ценными не сами по себе, а только в определённом контексте.
Это как раз тот самый случай, когда безопасность приложения и конфиденциальность персональных данных противоречат друг другу. Для обеспечения безопасности целесообразно подробно записывать информацию о действиях в системе, чтобы выявлять вредоносные действия. С точки зрения приватности данных, наоборот, при логировании конфиденциальной информации риск её утечки больше. В целом же обеспечение конфиденциальности персональных данных пользователей приложения является более приоритетной задачей.
Послесловие
Рассмотренные в статье виды уязвимостей охватывают бОльшую часть «универсальных» брешей в приложениях, написанных на разных языках программирования. Однако для некоторых языков встречаются свои, специфические уязвимости. Но это уже тема для отдельной статьи. А напоследок, напомним: при создании приложений не забывайте следовать вышеизложенным рекомендациям, внимательно читайте документацию и проверяйте приложения на уязвимости с помощью специализированного ПО.
Автор: Елизавета Харламова, руководитель отдела аналитики Solar appScreener
- Блог компании Ростелеком-Солар
- Информационная безопасность
- Совершенный код
- Управление продуктом
Поиск уязвимостей в программах с помощью анализаторов кода
В настоящее время разработано большое количество инструментальных средств, предназначенных для автоматизации поиска уязвимостей программ. В данной статье будут рассмотрены некоторые из них.
Введение
Статический анализ кода — это анализ программного обеспечения, который производится над исходным кодом программ и реализуется без реального исполнения исследуемой программы.
Программное обеспечение часто содержит разнообразные уязвимости из-за ошибок в коде программ. Ошибки, допущенные при разработке программ, в некоторых ситуациях приводят к сбою программы, а следовательно, нарушается нормальная работа программы: при этом часто возникает изменение и порча данных, останов программы или даже системы. Большинство уязвимостей связано с неправильной обработкой данных, получаемых извне, или недостаточно строгой их проверкой.
Для выявления уязвимостей используют различные инструментальные средства, например, статические анализаторы исходного кода программы, обзор которых приведён в данной статье.
Классификация уязвимостей защиты
Когда требование корректной работы программы на всех возможных входных данных нарушается, становится возможным появление так называемых уязвимостей защиты (security vulnerability). Уязвимости защиты могут приводить к тому, что одна программа может использоваться для преодоления ограничений защиты всей системы в целом.
Классификация уязвимостей защиты в зависимости от программных ошибок:
- Переполнение буфера (buffer overflow). Эта уязвимость возникает из-за отсутствия контроля за выходом за пределы массива в памяти во время выполнения программы. Когда слишком большой пакет данных переполняет буфер ограниченного размера, содержимое посторонних ячеек памяти перезаписывается, и происходит сбой и аварийный выход из программы. По месту расположения буфера в памяти процесса различают переполнения буфера в стеке (stack buffer overflow), куче (heap buffer overflow) и области статических данных (bss buffer overflow).
- Уязвимости (tainted input vulnerability). Уязвимости могут возникать в случаях, когда вводимые пользователем данные без достаточного контроля передаются интерпретатору некоторого внешнего языка (обычно это язык Unix shell или SQL). В этом случае пользователь может таким образом задать входные данные, что запущенный интерпретатор выполнит совсем не ту команду, которая предполагалась авторами уязвимой программы.
- Ошибки форматных строк (format string vulnerability). Данный тип уязвимостей защиты является подклассом уязвимости . Он возникает из-за недостаточного контроля параметров при использовании функций форматного ввода-вывода printf, fprintf, scanf, и т. д. стандартной библиотеки языка Си. Эти функции принимают в качестве одного из параметров символьную строку, задающую формат ввода или вывода последующих аргументов функции. Если пользователь сам может задать вид форматирования, то эта уязвимость может возникнуть в результате неудачного применения функций форматирования строк.
- Уязвимости как следствие ошибок синхронизации (race conditions). Проблемы, связанные с многозадачностью, приводят к ситуациям, называемым : программа, не рассчитанная на выполнение в многозадачной среде, может считать, что, например, используемые ею при работе файлы не может изменить другая программа. Как следствие, злоумышленник, вовремя подменяющий содержимое этих рабочих файлов, может навязать программе выполнение определенных действий.
Конечно, кроме перечисленных существуют и другие классы уязвимостей защиты.
Обзор существующих анализаторов
Для обнаружения уязвимостей защиты в программах применяют следующие инструментальные средства:
- Динамические отладчики. Инструменты, которые позволяют производить отладку программы в процессе её исполнения.
- Статические анализаторы (статические отладчики). Инструменты, которые используют информацию, накопленную в ходе статического анализа программы.
Статические анализаторы указывают на те места в программе, в которых возможно находится ошибка. Эти подозрительные фрагменты кода могут, как содержать ошибку, так и оказаться совершенно безопасными.
В данной статье предложен обзор нескольких существующих статических анализаторов. Рассмотрим подробнее каждый из них.
1. BOON
Инструмент BOON, который на основе глубокого семантического анализа автоматизирует процесс сканирования исходных текстов на Си в поисках уязвимых мест, способных приводить к переполнению буфера. Он выявляет возможные дефекты, предполагая, что некоторые значения являются частью неявного типа с конкретным размером буфера.
2. CQual
CQual — Инструмент анализа для обнаружения ошибок в Си-программах. Программа расширяет язык Си дополнительными определяемыми пользователем спецификаторами типа. Программист комментирует свою программу с соответствующими спецификаторами, и cqual проверяет ошибки. Неправильные аннотации указывают на потенциальные ошибки. Сqual может использоваться, чтобы обнаружить потенциальную уязвимость форматной строки.
3. MOPS
MOPS (MOdel checking Programs for Security) — инструмент для поиска уязвимостей в защите в программах на Си. Его назначение: динамическая корректировка, обеспечивающая соответствие программы на Си статической модели. MOPS использует модель аудита программного обеспечения, которая призвана помочь выяснить, соответствует ли программа набору правил, определенному для создания безопасных программ.
4. ITS4, RATS, PScan, Flawfinder
Для поиска ошибок переполнения буфера и ошибок форматных строк используют следующие статические анализаторы:
- ITS4. Простой инструмент, который статически просматривает исходный Си/Си++-код для обнаружения потенциальных уязвимостей защиты. Он отмечает вызовы потенциально опасных функций, таких, например, как strcpy/memcpy, и выполняет поверхностный семантический анализ, пытаясь оценить, насколько опасен такой код, а так же дает советы по его улучшению.
- RATS. Утилита RATS (Rough Auditing Tool for Security) обрабатывает код, написанный на Си/Си++, а также может обработать еще и скрипты на Perl, PHP и Python. RATS просматривает исходный текст, находя потенциально опасные обращения к функциям. Цель этого инструмента — не окончательно найти ошибки, а обеспечить обоснованные выводы, опираясь на которые специалист сможет вручную выполнять проверку кода. RATS использует сочетание проверок надежности защиты от семантических проверок в ITS4 до глубокого семантического анализа в поисках дефектов, способных привести к переполнению буфера, полученных из MOPS.
- PScan. Сканирует исходные тексты на Си в поисках потенциально некорректного использования функций, аналогичных printf, и выявляет уязвимые места в строках формата.
- Flawfinder. Как и RATS, это статический сканер исходных текстов программ, написанных на Си/Си++. Выполняет поиск функций, которые чаще всего используются некорректно, присваивает им коэффициенты риска (опираясь на такую информацию, как передаваемые параметры) и составляет список потенциально уязвимых мест, упорядочивая их по степени риска.
Все эти инструменты схожи и используют только лексический и простейший синтаксический анализ. Поэтому результаты, выданные этими программами, могут содержать до 100% ложных сообщений.
5. Bunch
Bunch — средство анализа и визуализации программ на Си, которое строит граф зависимостей, помогающий аудитору разобраться в модульной структуре программы.
6. UNO
UNO — простой анализатор исходного кода. Он был разработан для нахождения таких ошибок, как неинициализированные переменные, нулевые указатели и выход за пределы массива. UNO позволяет выполнять несложный анализ потока управления и потоков данных, осуществлять как внутри- так и межпроцедурный анализ, специфицировать свойства пользователя. Но данный инструмент не доработан для анализа реальных приложений, не поддерживает многие стандартные библиотеки и на данном этапе разработки не позволяет анализировать сколь-нибудь серьёзные программы.
7. FlexeLint (PC-Lint)
FlexeLint (PC-Lint) — этот анализатор предназначен для анализа исходного кода с целью выявления ошибок различного типа. Программа производит семантический анализ исходного кода, анализ потоков данных и управления.
В конце работы выдаются сообщения нескольких основных типов:
- Возможен нулевой указатель;
- Проблемы с выделением памяти (например, нет free() после malloc());
- Проблемный поток управления (например, недостижимый код);
- Возможно переполнение буфера, арифметическое переполнение;
- Предупреждения о плохом и потенциально опасном стиле кода.
8. Viva64
Инструмент Viva64, который помогает специалисту отслеживать в исходном коде Си/Си++-программ потенциально опасные фрагменты, связанные с переходом от 32-битных систем к 64-битным. Viva64 встраивается в среду Microsoft Visual Studio 2005/2008, что способствует удобной работе с этим инструментом. Анализатор помогает писать корректный и оптимизированный код для 64-битных систем.
9. Parasoft C++ Test
Parasoft C++ Test — специализированный инструмент для Windows, позволяющий автоматизировать анализ качества кода Си++. Пакет C++Test анализирует проект и генерирует код, предназначенный для проверки содержащихся в проекте компонентов. Пакет C++Test делает очень важную работу по анализу классов C++. После того как проект загружен, необходимо настроить методы тестирования. Программное обеспечение изучает каждый аргумент метода и возвращает типы соответствующих значений. Для данных простых типов подставляются значения аргументов по умолчанию; можно определить тестовые данные для определенных пользователем типов и классов. Можно переопределить аргументы C++Test, используемые по умолчанию, и выдать значения, полученные в результате тестирования. Особого внимания заслуживает способность C++Test тестировать незавершенный код. Программное обеспечение генерирует код-заглушку для любого метода и функции, которые еще не существуют. Поддерживается имитация внешних устройств и входных данных, задаваемых пользователем. И та и другая функции допускают возможность повторного тестирования. После определения тестовых параметров для всех методов пакет C++Test готов к запуску исполняемого кода. Пакет генерирует тестовый код, вызывая для его подготовки компилятор Visual C++. Возможно формирование тестов на уровне метода, класса, файла и проекта.
10. Coverity
Инструменты Coverity используются для выявления и исправления дефектов безопасности и качества в приложениях критического назначения. Технология компании Coverity устраняет барьеры в написании и внедрении сложного ПО посредством автоматизации поиска и устранения критических программных ошибок и недостатков безопасности во время процесса разработки. Инструмент компании Coverity способен с минимальной положительной погрешностью обрабатывать десятки миллионов строк кода, обеспечивая 100-процентное покрытие трассы.
11. KlocWork K7
Продукты компании Klocwork предназначены для автоматизированного статического анализа кода, выявления и предотвращения дефектов программного обеспечения и проблем безопасности. Инструменты этой компании служат для выявления коренных причин недостатков качества и безопасности программного обеспечения, для отслеживания и предотвращения этих недостатков на протяжении всего процесса разработки.
12. Frama-C
Frama-C — открытый, интегрированный набор инструментов для анализа исходного кода на языке Си. Набор включает ACSL (ANSI/ISO C Specification Language) — специальный язык, позволяющий подробно описывать спецификации функций Си, например, указать диапазон допустимых входных значений функции и диапазон нормальных выходных значений.
Этот инструментарий помогает производить такие действия:
- Осуществлять формальную проверку кода;
- Искать потенциальные ошибки исполнения;
- Произвести аудит или рецензирование кода;
- Проводить реверс-инжиниринг кода для улучшения понимания структуры;
- Генерировать формальную документацию.
13. CodeSurfer
CodeSurfer — инструмент анализа программ, который не предназначается непосредственно для поиска ошибок уязвимости защиты. Его основными достоинствами являются:
- Анализ указателей;
- Различные анализы потока данных (использование и определение переменных, зависимость данных, построение графа вызовов);
- Скриптовый язык.
CodeSurfer может быть использован для поиска ошибок в исходном коде, для улучшения понимания исходного кода, и для реинженерии программ. В рамках среды CodeSurfer велась разработка прототипа инструментального средства для обнаружения уязвимостей защиты, однако разработанное инструментальное средство используется только внутри организации разработчиков.
14. FxCop
FXCop предоставляет средства автоматической проверки .NET-сборок на предмет соответствия правилам Microsoft .NET Framework Design Guidelines. Откомпилированный код проверяется с помощью механизмов рефлексии, парсинга MSIL и анализа графа вызовов. В результате FxCop способен обнаружить более 200 недочетов (или ошибок) в следующих областях:
- Архитектура библиотеки;
- Локализация;
- Правила именования;
- Производительность;
- Безопасность.
FxCop предусматривает возможность создания собственных правил с помощью специального SDK. FxCop может работать как в графическом интерфейсе, так и в командной строке.
15. JavaChecker
JavaChecker — это статический анализатор Java програм, основанный на технологии TermWare.
Это средство позволяет выявлять дефекты кода, такие как:
- небрежная обработка исключений (пустые catch-блоки, генерирование исключений общего вида и.т.п.);
- сокрытие имен (например, когда имя члена класса совпадает с именем формального параметра метода);
- нарушения стиля (вы можете задавать стиль программирования с помощью набора регулярных выражений);
- нарушения стандартных контрактов использования (например, когда переопределен метод equals, но не hashCode);
- нарушения синхронизации (например, когда доступ к синхронизированной переменной находится вне synchronized блока).
Набором проверок можно управлять, используя управляющие комментарии.
Вызов JavaChecker можно осуществлять из ANT скрипта.
16. Simian
Simian — анализатор подобия, который ищет повторяющийся синтаксис в нескольких файлах одновременно. Программа понимает синтаксис различных языков программирования, включая C#, T-SQL, JavaScript и Visual BasicR, а также может искать повторяющиеся фрагменты в текстовых файлах. Множество возможностей настройки позволяет точно настраивать правила поиска дублирующегося кода. Например, параметр порога (threshold) определяет, какое количество повторяющихся строк кода считать дубликатом.
Simian — это небольшой инструмент, разработанный для эффективного поиска повторений кода. У него отсутствует графический интерфейс, но его можно запустить из командной строки или обратиться к нему программно. Результаты выводятся в текстовом виде и могут быть представлены в одном из встроенных форматов (например, XML). Хотя скудный интерфейс и ограниченные возможности вывода результатов Simian требуют некоторого обучения, он помогает сохранить целостность и эффективность продукта. Simian подходит для поиска повторяющегося кода как в больших, так и в маленьких проектах.
Повторяющийся код снижает поддерживаемость и обновляемость проекта. Можно использовать Simian для быстрого поиска дублирующихся фрагментов кода во многих файлах одновременно. Поскольку Simian может быть запущен из командной строки, его можно включить в процесс сборки, чтобы получить предупреждения или остановить процесс в случае повторений кода.
Вывод
Итак, в данной статье были рассмотрены статические анализаторы исходного кода, которые являются вспомогательными инструментами программиста. Все инструментальные средства разные и помогают отслеживать самые различные классы уязвимостей защиты в программах. Можно сделать вывод, что статические анализаторы должны быть точными, восприимчивыми. Но, к сожалению, статические средства отладки не могут дать абсолютно надёжный результат.
Библиографический список
- Alexey Kolosov. Using Static Analysis in Program Development
- Брайан Гетц. Избавьтесь от ошибок.
- Криспин Кован. Безопасность систем с открытым кодом.
- Павел Зуев. О компьютерной безопасности.
- С.С. Гайсарян, А.В. Чернов, А.А. Белеванцев, О.Р. Маликов, Д.М. Мельник, А.В. Меньшикова. О некоторых задачах анализа и трансформации программ.
Анализ кода: проблемы, решения, перспективы

Уязвимости в программном обеспечении были, есть и будут одними из основных ворот, через которые злоумышленники реализуют свои атаки. Поэтому уже не первый год в тренде так называемая безопасная разработка – все больше вендоров уделяют внимание выявлению и устранению уязвимостей на этапе создания программных продуктов. Один из главных инструментов для этого – анализ кода на наличие уязвимостей и закладок. Даниил Чернов, директор Центра Solar appScreener компании «Ростелеком-Солар», рассказал о том, какие технологии анализа кода сейчас наиболее востребованы, в каком направлении они развиваются, какие изменения могут произойти в этой области в ближайшем и далеком будущем.
Динамический, статический и бинарный анализ
Сегодня есть две наиболее зрелые и востребованные технологии анализа кода – динамический анализ (DAST – Dynamic Application Security Testing) и статический анализ (SAST – Static Application Security Testing). Разновидностью SAST является бинарный анализ.
Динамический анализ – его также называют методом «Черного ящика» – представляет собой проверку программы на наличие уязвимостей непосредственно во время ее выполнения. У этого подхода есть свои преимущества. Во-первых, поскольку уязвимости находятся в исполняемой программе и обнаружение ошибки происходит с помощью ее эксплуатации, возникает меньше ложных срабатываний, чем при использовании статического анализа. Плюс для выполнения данного вида анализа не нужен исходный код. Но есть и слабые места, в частности, данным методом нельзя обнаружить все возможные уязвимости, в связи с чем существуют риски пропущенных уязвимостей. Не все уязвимости могут себя проявить при таком методе тестирования. Например, временная бомба или захардкоженные креды. Кроме того, метод требует максимально точного воспроизведения боевой среды при тестировании.

Статический анализ – метод «Белого ящика» – представляет собой тип тестирования, при котором, в отличие от динамического анализа, не происходит выполнения программы, а анализируется весь ее код. В результате мы имеем нахождение большего количества уязвимостей. Также метод выгодно отличает возможность внедрения в начальные стадии разработки: чем раньше обнаруживаем уязвимость, тем дешевле обходится ее устранение.
У метода есть два недостатка. Первый – наличие ложноположительных срабатываний. Как следствие – необходимость оценки, что перед тобой реальная уязвимость или ошибка сканера. Второй недостаток – необходимость наличия исходного кода программы, который не всегда доступен. В последнем случае помогает бинарный анализ – он позволяет с помощью технологий реверс-инжиниринга провести статический анализ кода, даже если у нас нет исходника. Когда в 2015 году мы выводили на рынок анализатор кода приложений Solar appScreener, эта функциональность уже была заложена в системе. Мы видели тогда и видим сейчас, что в реальной жизни это зачастую единственная возможность грамотно и полноценно выявить уязвимости в приложениях.

Например, нам нужно убедиться в том, что исходный код, который мы проверяли, – тот самый, который потом пойдет в продакшн. Помимо ситуаций, когда кто-либо намеренно вносит в код закладки, ряд уязвимостей может добавить и компилятор. И это отнюдь не экзотическая ситуация: компилятор тоже пишут люди, и он не застрахован от ошибок. В общем, нам нужно взять из продакшна исполняемый файл и проверить его на уязвимости.

Альтернативный вариант – прогнать приложение через динамический анализатор: перед нами черный ящик, мы не можем его открыть, но можем на него воздействовать – «пнуть, поднять, потрясти, уронить». И по результатам этого воздействия сделать выводы. При динамическом анализе на вход приложения подаются разные данные, в текстовые поля вводятся различные последовательности, в случае с веб-сайтом посылаются разнообразные команды, протоколы, пакеты. И по ответу от приложения мы делаем вывод, есть ли в нем уязвимости. DAST действительно хорош для веб-приложений, потому что можно повоздействовать на систему, защищенную при этом файрволом. Российский рынок мобильных приложений для бизнеса и госсектора: крупнейшие игроки, тенденции и перспективы. Обзор TAdviser
Однако DAST помогает обнаружить только определенный спектр уязвимостей. А, например, угрозы вроде временной бомбы, которая по триггеру времени запустит в систему вредонос, скрытую «учетку», небезопасный пароль и прочее динамическим анализом не обнаружить. Бинарный анализ же делает из черного ящика белый, позволяя в ходе статического анализа увидеть его содержимое.
Кроме того, бывают ситуации, когда исходный код разработанной системы утерян, при этом она активно эксплуатируется и резко отказаться от нее невозможно. Бинарный анализ поможет проверить эту систему на наличие уязвимостей, чтобы принять оперативные меры по защите.
True or False: как решить главную проблему автоматизированного анализа кода?
Ложные срабатывания – проблема любых систем, которые автоматически что-то анализируют и выдают результат. Очевидно, что она актуальна и для анализаторов кода. Чем больше ложных срабатываний, тем дороже использование инструмента для пользователя. Ведь на верификацию тратятся человеческие ресурсы – время.
Сегодня есть несколько путей развития технологий для минимизации ложных срабатываний. Один из самых хайповых – применение искусственного интеллекта, а точнее его подраздела – машинного обучения (МО). Какими способами можно искать уязвимости в коде с помощью МО?
Во-первых, можно попытаться обучить МО-анализатор вручную: написать множество примеров правильного и неправильного кода и научить анализатор искать такие ошибки. Минус подхода в том, что для обучения анализатора нам придется потратить много времени на подготовку подходящих примеров.
Есть еще вариант — пометить код реальных приложений с указанием фрагментов, в отношении которых анализатор должен выдавать предупреждение о наличии ошибки. В любом случае необходимо будет проделать большой объем работы, так как для обучения необходимы десятки тысяч примеров ошибок кода. Если же учесть, что существуют уязвимости (например, утечка памяти), которые могут содержаться в коде, написанном почти бесконечным числом вариаций, то необходимый для обучения объем примеров делает задачу фактически невыполнимой.
Во-вторых, можно не готовить примеры вручную, а обучать МО-анализатор на основе больших объемов открытого исходного кода. Можно отслеживать историю коммитов на GitHub и выявлять закономерности изменения или исправления программного кода. Однако проблема в том, что правки на GitHub вносятся довольно хаотично: например, пользователь не хочет тратить время на внесение каждой правки в отдельности – и он где-то вносит пару изменения, а где-то просто переписывает кусок кода. Тогда даже человек не сможет разобраться, связаны ли эти исправленные ошибки между собой.
Можно, конечно, нанять маленькую армию специалистов, которые будут проверять исходный код и указывать, где исправлена ошибка – а где код переписан, где добавлена новая функция – а где изменились требования. То есть, по сути, мы опять возвращаемся к ручному обучению. Не говоря уже о росте стоимости и длительности решения задачи. Или же можно попытаться автоматически определять ошибки в открытом исходном коде: можно попробовать запрограммировать такой поиск, что будет непросто, а главное, возникнут вопросы к качеству такого анализа.

Таким образом, в целом использование ИИ для анализа кода – очень трудозатратная и недешевая история при неочевидном результате.
Но есть и другой метод борьбы с ложными срабатываниями – математический.
Нечеткая логика: как это работает
Нечеткая логика – относительно новый раздел математики. Он является обобщением классической логики и теории множеств и базируется на понятии нечеткого множества, впервые введенного в 1965 году. Если в обычной логике у нас есть true или false, 0 или 1, то нечеткая логика оперирует градациями между true и false. Она может сказать, что событие верно на столько-то процентов и на столько-то неверно, – и это ближе к мышлению человека.
Представьте, что у вас есть стакан воды и нужно сказать, что вода холодная, если ее температура ниже 15 градусов, и теплая, если выше 15 градусов. Мы опускаем палец в стакан (допустим, там 16 градусов, но мы об этом не знаем). И мы не скажем: «Да, она точно теплая». На пограничных значениях мы будем внутренне колебаться: вроде теплая, но скорее холодная. Нечеткая логика помогает нам уйти от линейного мышления.
В обычном линейном мышлении, когда систему научили принимать решение, что это true или false, при выставлении математического порога (допустим, мы хотим меньше ложных срабатываний) приходится устанавливать для машины жёсткие фильтры принятия решений. Тогда она начнет выдавать меньше ложных срабатываний, но при этом начнет пропускать реальные уязвимости. Двигаем линейный фильтр в обратную сторону – машина перестает пропускать уязвимости, но при этом ложных срабатываний становится очень много.
Поэтому в своей системе мы реализовали механизм борьбы с уязвимостями на основе математического аппарата нечеткой логики – Fuzzy Logic Engine (FLE), который позволяет тонко настраивать линейные фильтры, балансируя между снижением ложных срабатываний и потерей точности выявления уязвимостей. Фильтры в системе позволяют, например, отображать лишь те уязвимости, в которых FLE полностью уверен. Кроме того, можно практически ювелирно настроить уровень уверенности системы в наличии уязвимости. С помощью шкалы Confidence можно, например, задать для уязвимостей критичного уровня более жесткие критерии, по которым система будет относить потенциальные уязвимости к реальным.

Для уязвимостей средней и низкой критичности можно задать более мягкие критерии оценки.
Чем больше языков, тем лучше
Языков программирования становится все больше, многие из новых быстро набирают популярность. Например, язык Rust, который позиционируется как безопасная замена С++ и сегодня часто используется для написания десктопных приложений и бэкэндов. Или Go (Golang), применяемый для создания высоконагруженных сервисов – площадок онлайн-торговли, ДБО, мессенджеры и т.п. Dart, предназначенный для написания веб и мобильных клиентов.
И нередко бывает так, что какая-то часть системы написана на языке, который можно проверить не всеми инструментами. Поэтому, если мы хотим, чтобы анализ кода был эффективным и удобным, важно, чтобы все языки были на борту. Пользователь не должен задаваться вопросом, на каких языках написано приложение, все ли языки поддерживает анализатор. Код должен загружаться в анализатор, который сам определит, какие языки содержатся в приложении, и все их проверит, ничего не пропуская. Именно по такому принципу мы реализуем Solar appScreener: в апреле прошлого года добавили поддержку Dart и продолжаем лидировать по количеству поддерживаемых языков – сейчас их 36.
Мы довольно гибко подходим к управлению командой и разработке новых фич. Некоторые вендоры не могут просто взять и быстро добавить новый язык в свой анализатор, потому что им нужно просчитать выгоду от реализации той или иной функции на других рынках. Много ли запросов на нее от наиболее приоритетных рынков, или лучше потратить ресурсы команды на создание другой функциональности? Это может отнимать много времени.
Технологии на перспективу
Ну а что же там, за горизонтом? Какие технологии могут быть реализованы в анализаторах кода уже в ближайшем будущем? Сейчас на рынке анализа кода наблюдается растущий спрос на бинарный анализ сложных систем. Допустим, компания покупает софт стороннего вендора, устанавливает его в свою критическую информационную инфраструктуру, и ИБ-специалисты хотят понимать реальный уровень защищенности той или иной системы. В чем здесь отличие от уже существующих технологий? Современный бинарный анализ позволяет загрузить в анализатор и проанализировать лишь каждый исполняемый файл в отдельности. В случае со сложной многокомпонентной системой нужно отправить в анализатор целый зоопарк различных файлов, связанных друг с другом, – инсталляционные файлы, готовые файлы системы, библиотеки, исполняемые файлы и т.п. Это не просто файлы, а единое ПО, которое состоит из разных логических компонентов. Поэтому тут нужен сложнейший анализ, который очень тяжело реализовать. Пока подобная функция является экзотикой.
Весьма реалистичной выглядит перспектива применения интегрированных систем, в которых используются преимущества сразу всех передовых методов анализа – DAST, SAST, IAST, mAST, SCA (Software Composition Analysis). Последний представляет собой инвентаризацию библиотек, кода, предоставленного на анализ, и его сверку с базой данных, включающей перечень библиотек и содержащихся в них уязвимостей. Однако пока нет вендора, который свел бы все эти компоненты воедино, а отчеты, предоставляемые каждой системой, настолько разнятся, что привести их к общему знаменателю нереально. Поэтому создание интегрированной системы, которая объединит возможности разных видов анализа кода, с единой системой отчетности, выглядит многообещающе.
Стоит отметить и еще одну довольно занятную технологию для защиты приложений от уязвимостей – RASP (Runtime application self-protection). О ее перспективности однажды заявлял Gartner, однако пока технология самозащиты приложений кажется малоэффективной. Некоторые вендоры уже пытались ее реализовать, однако работает она только в частных случаях и применима далеко не ко всем языкам программирования. Её суть состоит в том, что в само защищаемое ПО добавляется в код, который позволяет приложению понимать, когда его атакуют, и блокировать атаку. Проблема кроется в том, что архитектура веб-приложений очень разная, поэтому такой подход к защите применим либо при индивидуальной разработке под каждое приложение и каждую новую его версию, либо в случае, если RASP-система допускает очень глубокую кастомизацию. Чтобы говорить о RASP как о полноценной замене анализу кода веб-приложений, нужно сделать определенные шаги в развитии технологий в целом и искусственного интеллекта в частности.
P.S. А если вдруг.

А что, если придет квантовый компьютер и настанет эра квантовых вычислений – как в таком случае защититься, например, от уязвимостей, проэксплуатировать которые можно методом перебора? Вот эти все недостаточные размеры ключа шифрования, слабые алгоритмы хеширования, заданная в исходном коде соль и т.п.? Если такие технологии придут в массовое использование, то все, что сейчас считается безопасным – сложные пароли, алгоритмы шифрования – будет взламываться налету. Очевидно, необходимо будет разрабатывать совершенно другие подходы и к статическому анализу кода, и к динамическому. Как это будет, пока неизвестно, но очень интересно.
Вы узнаете, как Jenkins работает с утилитами SonarQube, Dependency Check и Clair. Поймёте, как он помогает находить уязвимости на ранних стадиях. А ещё на практике разберёте пайплайн, который выполняет проверки и уведомляет о найденных уязвимостях.

Вебинар посвящён всегда актуальной теме безопасности приложений и ориентирован на DevOps-инженеров и тех, кто интересуется DevSecOps.
Если вы хотите:
- разобраться, насколько совместим Jenkins с инструментами статистического анализа кода и поиска уязвимостей;
- научиться решать проблему раннего обнаружения уязвимостей в коде.
Спикер вебинара
Кирилл Борисов
- Infrastructure Engineer технологического центра Deutsche Bank