Группа разработчиков предлагает перейти на UTF-8
Недавно на Hacker News опубликовали манифест программистов из Тель-Авива. Они предложили сделать UTF-8 решением по умолчанию для хранения текстовых строк в памяти и коммуникации.
Материал породил активную дискуссию, и мы решили разобраться в ситуации, рассмотреть аргументы ИТ-экспертов — в том числе инженеров IBM и специалистов консорциума W3C.

Фото — Raphael Schaller — Unsplash
Ситуация с кодировками
В 1988 году Джо Беккер (Joseph Becker) представил первый драфт стандарта Unicode. В основу документа легло предположение, что для хранения любого символа хватит 16 бит. Однако довольно быстро стало понятно, что этого недостаточно. Поэтому появились новые варианты кодировок — в том числе UTF-8 и UTF-16. Но разнообразие форматов и отсутствие строгих рекомендаций по их использованию привело к сумятице в ИТ-индустрии (в том числе в терминологии).
Внутренний формат ОС Windows — это UTF-16. При этом авторы манифеста, обсуждение которого велось на Hacker News, говорят, что одно время в Microsoft упоминали термины Unicode и widechar в качестве синонимов для UTF-16 и UCS-2 (которая считается своеобразным предшественником UTF-16). Что касается экосистемы Linux, то в ней принято использовать UTF-8. Многообразие кодировок порой приводит к тому, что файлы повреждаются при передаче между компьютерами с различными ОС.
Решением проблемы может стать стандартизация отрасли — переход на UTF-8 для хранения текстовых строк в памяти или на диске и обмена пакетами по сети.
Почему UTF-8 считают лучше UTF-16
Один из главных аргументов связан с тем, что UTF-8 сокращает объем памяти, занимаемый символами на латинице (их использует множество языков программирования). Латинские буквы, цифры и распространенные знаки препинания кодируются в UTF-8 лишь одним байтом. При этом их коды соответствует кодам в ASCII, что дает обратную совместимость.
Также специалисты из IBM говорят, что UTF-8 лучше подходит для взаимодействия с системами, не ожидающими прихода многобайтных данных. Другие кодировки юникода содержат многочисленные нулевые байты. Утилиты могут посчитать их концом файла. Например, в UTF-16 символ A выглядит так: 00000000 01000001. В строке Си эта последовательность может быть обрезана. В случае с UTF-8 нулем является только NUL. В этой кодировке первая буква латинского алфавита представлена как 01000001 — здесь проблем с непредвиденным обрывом не возникает.
По этой же причине инженеры из консорциума W3C рекомендуют использовать UTF-8 при разработке внешних интерфейсов. Так можно избежать сложностей с работой сетевых устройств.

Фото — Kristian Strand — Unsplash
Резидент Hacker News отметил, что UTF-8 позволяет отлавливать ошибки кодирования на ранних этапах. В ней байты читаются последовательно, а служебные биты определяют их количество. Таким образом, значение кодовой точки (code point) вычисляется однозначно и разработчикам приложений не нужно задумываться о проблеме Little-Endian или Big-Endian.
Где у UTF-16 преимущество
Буквы латинского алфавита и символы пунктуации могут занимать меньше памяти в UTF-8 (по сравнению с UTF-16). Некоторым кодовым точкам требуется одинаковое количество байтов в обеих кодировках — например, этот факт справедлив для греческого языка и иврита.
Иначе обстоят дела с азиатскими иероглифами — в случае с UTF-8 им нужно больше места. Например, китайский символ 語 будет представлен тремя байтами: 11101000 10101010 10011110. Этот же символ в UTF-16 будет выглядеть как 10001010 10011110.
Что в итоге
Дебаты, касающиеся проблемы внедрения единой кодировки, идут уже давно. Этот вопрос поднимался почти одиннадцать лет назад в треде на Stack Overflow. В нем принимал участие Павел Радзивиловский (Pavel Radzivilovsky) — один из авторов манифеста. С тех пор UTF-8 уже успела стать одной из самых популярных кодировок в интернете. И её признали обязательной для «всех ситуаций» в WHATWG — сообществе специалистов по HTML и API, развивающем соответствующие стандарты.
С недавних пор в Microsoft тоже начали рекомендовать использовать UTF-8 при разработке веб-приложений. Возможно, в будущем эта практика распространится на другие утилиты.
Что еще мы публикуем:
 «Прячь www»: почему разработчики мейнстрим-браузера снова отказались от отображения поддомена
«Прячь www»: почему разработчики мейнстрим-браузера снова отказались от отображения поддомена
«Как мы строим IaaS»: материалы о работе 1cloud
Ситуация: нарушают ли AdTech-компании GDPR?
Эра 10-нм чипов — что ждет индустрию в будущем
 Компьютер, который отказывается умирать
Компьютер, который отказывается умирать
- 1cloud
- UTF-8
- UTF-16
- кодировки
- разработка веб-приложений
- стандарты кодирования
- it-стандарты
- Блог компании 1cloud.ru
- Веб-разработка
- Анализ и проектирование систем
- Разработка мобильных приложений
- IT-стандарты
В чем причина популярности и широкого распространения кодировки utf 8
Reg.ru: домены и хостинг
Крупнейший регистратор и хостинг-провайдер в России.
Более 2 миллионов доменных имен на обслуживании.
Продвижение, почта для домена, решения для бизнеса.
Более 700 тыс. клиентов по всему миру уже сделали свой выбор.
Бесплатный Курс «Практика HTML5 и CSS3»
Освойте бесплатно пошаговый видеокурс
по основам адаптивной верстки
на HTML5 и CSS3 с полного нуля.
Фреймворк Bootstrap: быстрая адаптивная вёрстка
Пошаговый видеокурс по основам адаптивной верстки в фреймворке Bootstrap.
Научитесь верстать просто, быстро и качественно, используя мощный и практичный инструмент.
Верстайте на заказ и получайте деньги.
Бесплатный тренинг «PHP для Создания Сайтов: Введение»
Что нужно знать для создания PHP-сайтов?
Ответ здесь. Только самое важное и полезное для начинающего веб-разработчика.
Узнайте, как создавать качественные сайты на PHP всего за 2 часа и 27 минут!
—> Бесплатный курс «Сайт-Визитка За 15 уроков»
Создайте свой сайт за 3 часа и 30 минут.
После просмотра данного видеокурса у Вас на компьютере будет готовый к использованию сайт, который Вы сделали сами.
Вам останется лишь наполнить его нужной информацией и изменить дизайн (по желанию).
—> Бесплатный курс «Основы HTML и CSS»
Изучите основы HTML и CSS менее чем за 4 часа.
После просмотра данного видеокурса Вы перестанете с ужасом смотреть на HTML-код и будете понимать, как он работает.
Вы сможете создать свои первые HTML-страницы и придать им нужный вид с помощью CSS.
Бесплатный курс «Сайт на WordPress»
Хотите освоить CMS WordPress?
Получите уроки по дизайну и верстке сайта на WordPress.
Научитесь работать с темами и нарезать макет.
Бесплатный видеокурс по рисованию дизайна сайта, его верстке и установке на CMS WordPress!
Бесплатный курс «Основы работы с JavaScript»
Хотите изучить JavaScript, но не знаете, как подступиться?
После прохождения видеокурса Вы освоите базовые моменты работы с JavaScript.
Развеются мифы о сложности работы с этим языком, и Вы будете готовы изучать JavaScript на более серьезном уровне.
*Наведите курсор мыши для приостановки прокрутки.
Кодировки: полезная информация и краткая ретроспектива
Данную статью я решил написать как небольшой обзор, касающийся вопроса кодировок.
Мы разберемся, что такое вообще кодировка и немного коснемся истории того, как они появились в принципе.
Мы поговорим о некоторых их особенностях а также рассмотрим моменты, позволяющие нам работать с кодировками более осознанно и избегать появления на сайте так называемых кракозябров, т.е. нечитаемых символов.
Что такое кодировка?
Упрощенно говоря, кодировка — это таблица сопоставлений символов, которые мы можем видеть на экране, определенным числовым кодам.
Т.е. каждый символ, который мы вводим с клавиатуры, либо видим на экране монитора, закодирован определенной последовательностью битов (нулей и единиц). 8 бит, как вы, наверное, знаете, равны 1 байту информации, но об этом чуть позже.
Внешний вид самих символов определяется файлами шрифтов, которые установлены на вашем компьютере. Поэтому процесс вывода на экран текста можно описать как постоянное сопоставление последовательностей нулей и единиц каким-то конкретным символам, входящим в состав шрифта.
Прародителем всех современных кодировок можно считать ASCII.

Эта аббревиатура расшифровывается как American Standard Code for Information Interchange (американская стандартная кодировочная таблица для печатных символов и некоторых специальных кодов).
Это однобайтовая кодировка, в которую изначально заложено всего 128 символов: буквы латинского алфавита, арабские цифры и т.д.
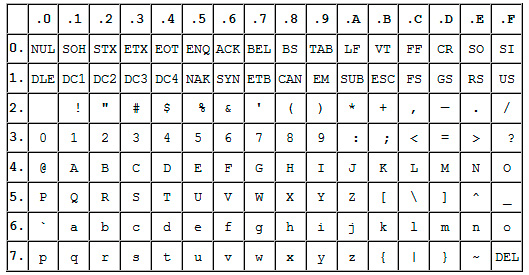
Позже она была расширена (изначально она не использовала все 8 бит), поэтому появилась возможность использовать уже не 128, а 256 (2 в 8 степени) различных символов, которые можно закодировать в одном байте информации.
Такое усовершенствование позволило добавлять в ASCII символы национальных языков, помимо уже существующей латиницы.
Вариантов расширенной кодировки ASCII существует очень много по причине того, что языков в мире тоже немало. Думаю, что многие из вас слышали о такой кодировке, как KOI8-R — это тоже расширенная кодировка ASCII, предназначенная для работы с символами русского языка.
Следующим шагом в развитии кодировок можно считать появление так называемых ANSI-кодировок.
По сути это были те же расширенные версии ASCII, однако из них были удалены различные псевдографические элементы и добавлены символы типографики, для которых ранее не хватало «свободных мест».
Примером такой ANSI-кодировки является всем известная Windows-1251. Помимо типографических символов, в эту кодировку также были включены буквы алфавитов языков, близких к русскому (украинский, белорусский, сербский, македонский и болгарский).
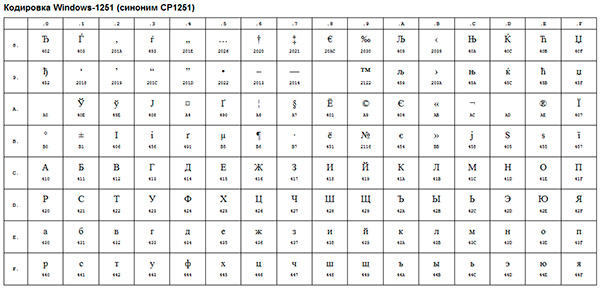
ANSI-кодировка — это собирательное название. В действительности, реальная кодировка при использовании ANSI будет определяться тем, что указано в реестре вашей операционной системы Windows. В случае с русским языком это будет Windows-1251, однако, для других языков это будет другая разновидность ANSI.
Как вы понимаете, куча кодировок и отсутствие единого стандарта до добра не довели, что и стало причиной частых встреч с так называемыми кракозябрами — нечитаемым бессмысленным набором символов.
Причина их появления проста — это попытка отобразить символы, закодированные с помощью одной кодировочной таблицы, используя другую кодировочную таблицу.
В контексте веб-разработки, мы можем столкнуться с кракозябрами, когда, к примеру, русский текст по ошибке сохраняется не в той кодировке, которая используется на сервере.
Разумеется, это не единственный случай, когда мы можем получить нечитаемый текст — вариантов тут масса, особенно, если учесть, что есть еще база данных, в которой информация также хранится в определенной кодировке, есть сопоставление соединения с базой данных и т.д.
Возникновение всех этих проблем послужило стимулом для создания чего-то нового. Это должна была быть кодировка, которая могла бы кодировать любой язык в мире (ведь с помощью однобайтовых кодировок при всем желании нельзя описать все символы, скажем, китайского языка, где их явно больше, чем 256), любые дополнительные спецсимволы и типографику.
Одним словом, нужно было создать универсальную кодировку, которая решила бы проблему кракозябров раз и навсегда.
Юникод — универсальная кодировка текста (UTF-32, UTF-16 и UTF-8)
Сам стандарт был предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (Unicode Consortium, Unicode Inc.), и первым результатом его работы стало создание кодировки UTF-32.
Кстати, сама аббревиатура UTF расшифровывается как Unicode Transformation Format (Формат Преобразования Юникод).
В этой кодировке для кодирования одного символа предполагалось использовать аж 32 бита, т.е. 4 байта информации. Если сравнивать это число с однобайтовыми кодировками, то мы придем к простому выводу: для кодирования 1 символа в этой универсальной кодировке нужно в 4 раза больше битов, что «утяжеляет» файл в 4 раза.
Очевидно также, что количество символов, которое потенциально могло быть описано с помощью данной кодировки, превышает все разумные пределы и технически ограничено числом, равным 2 в 32 степени. Понятно, что это был явный перебор и расточительство с точки зрения веса файлов, поэтому данная кодировка не получила распространения.
На смену ей пришла новая разработка — UTF-16.
Как очевидно из названия, в этой кодировке один символ кодируют уже не 32 бита, а только 16 (т.е. 2 байта). Очевидно, это делает любой символ вдвое «легче», чем в UTF-32, однако и вдвое «тяжелее» любого символа, закодированного с помощью однобайтовой кодировки.
Количество символов, доступное для кодирования в UTF-16 равно, как минимум, 2 в 16 степени, т.е. 65536 символов. Вроде бы все неплохо, к тому же окончательная величина кодового пространства в UTF-16 была расширена до более, чем 1 миллиона символов.
Однако и данная кодировка до конца не удовлетворяла потребности разработчиков. Скажем, если вы пишете, используя исключительно латинские символы, то после перехода с расширенной версии кодировки ASCII к UTF-16 вес каждого файла увеличивался вдвое.
В результате, была предпринята еще одна попытка создания чего-то универсального, и этим чем-то стала всем нам известная кодировка UTF-8.
UTF-8 — это многобайтовая кодировка с переменной длинной символа. Глядя на название, можно по аналогии с UTF-32 и UTF-16 подумать, что здесь для кодирования одного символа используется 8 бит, однако это не так. Точнее, не совсем так.
Дело в том, что UTF-8 обеспечивает наилучшую совместимость со старыми системами, использовавшими 8-битные символы. Для кодирования одного символа в UTF-8 реально используется от 1 до 4 байт (гипотетически можно и до 6 байт).
В UTF-8 все латинские символы кодируются 8 битами, как и в кодировке ASCII. Иными словами, базовая часть кодировки ASCII (128 символов) перешла в UTF-8, что позволяет «тратить» на их представление всего 1 байт, сохраняя при этом универсальность кодировки, ради которой все и затевалось.
Итак, если первые 128 символов кодируются 1 байтом, то все остальные символы кодируются уже 2 байтами и более. В частности, каждый символ кириллицы кодируется именно 2 байтами.
Таким образом, мы получили универсальную кодировку, позволяющую охватить все возможные символы, которые требуется отобразить, не «утяжеляя» без необходимости файлы.
C BOM или без BOM?
Если вы работали с текстовыми редакторами (редакторами кода), например Notepad++, phpDesigner, rapid PHP и т.д., то, вероятно, обращали внимание на то, что при задании кодировки, в которой будет создана страница, можно выбрать, как правило, 3 варианта:
— ANSI
— UTF-8
— UTF-8 без BOM
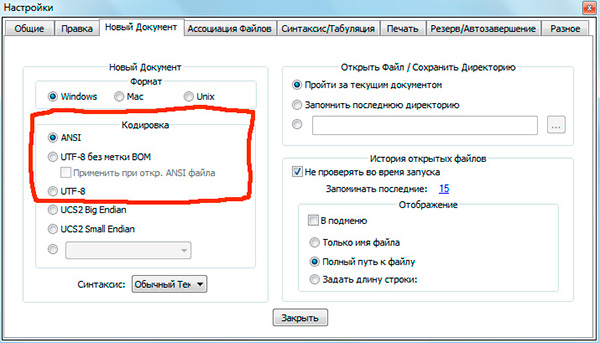
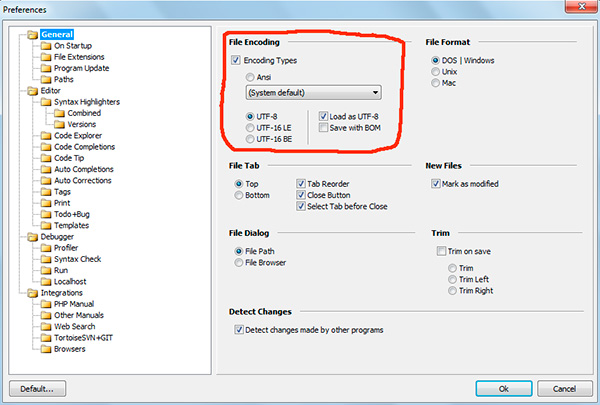
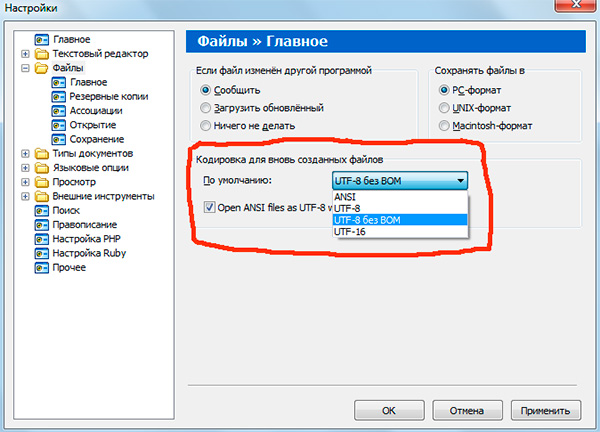
Сразу скажу, что выбирать всегда стоит именно последний вариант — UTF-8 без BOM.
Итак, что же такое BOM и почему нам это не нужно?
BOM расшифровывается как Byte Order Mark. Это специальный Unicode-символ, используемый для индикации порядка байтов текстового файла. По спецификации его использование не является обязательным, однако если BOM используется, то он должен быть установлен в начале текстового файла.
Не будем вдаваться в детали работы BOM. Для нас главный вывод следующий: использование этого служебного символа вместе с UTF-8 мешает программам считывать кодировку нормальным образом, в результате чего возникают ошибки в работе скриптов.
Поэтому, при работе с UTF-8 используйте именно вариант «UTF-8 без BOM». Также лучше не используйте редакторы, в которых в принципе нельзя указать кодировку (скажем, Блокнот из стандартных программ в Windows).
Кодировка текущего файла, открытого в редакторе кода, как правило, указывается в нижней части окна.

Обратите внимание, что запись «ANSI as UTF-8» в редакторе Notepad++ означает то же самое, что и «UTF-8 без BOM». Это одно и то же.

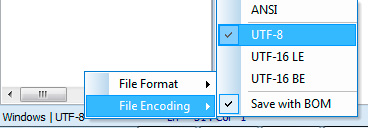
В программе phpDesigner нельзя сразу точно сказать, используется BOM, или нет. Для этого нужно кликнуть правой кнопкой мыши по надписи «UTF-8», после чего во всплывающем окне можно увидеть, используется ли BOM (опция Save with BOM).

В редакторе rapid PHP кодировка UTF-8 без BOM обозначается как «UTF-8*».
Как вы понимаете, в разных редакторах все выглядит немного по-разному, однако главную идею вы поняли.
После того, как документ сохранен в UTF-8 без BOM, нужно также убедиться, что верная кодировка указана в специальном метатэге в секции head вашего html-документа:
Соблюдение этих простых правил уже позволит вам избежать многих пробелем с кодировками.
На этом все, надеюсь, что данный небольшой экскурс и пояснения помогли вам лучше понять, что такое кодировки, какие они бывают и как работают.
Если вам интересна эта тема с более прикладной точки зрения, то рекомендую вам изучить мой видеоурок Полный UTF-8: чеклист для начинающих.
Дмитрий Науменко.
P.S. Присмотритесь к премиум-урокам по различным аспектам сайтостроения, а также к бесплатному курсу по созданию своей CMS-системы на PHP с нуля. Все это поможет вам быстрее и проще освоить различные технологии веб-разработки.
Понравился материал и хотите отблагодарить?
Просто поделитесь с друзьями и коллегами!
Смотрите также:











Поиск по сайту
Фреймворк Yii2: первая практика

Овладейте начальными знаниями и навыками по работе в фреймворке Yii2, которые необходимы любому веб-разработчику!
Дизайн лендинга

Создавайте дизайн любых сайтов — для себя и на заказ!
В Гармонии с Кодом
Если вы хотите создать сайт своими руками, то вы оказались в нужном месте. Здесь вы найдете обучающие видеокурсы, а также множество видеоуроков и статей по веб-разработке и созданию сайтов.
Уважаемый веб-мастер! В создание данного ресурса вложено много сил и времени. Буду рад, если при копировании материалов вы будете ставить активную ссылку на Codeharmony.ru.
Как придумали кодировку UTF-8: выдержки из переписки создателей

Всем известна кодировка UTF-8, что давно доминирует в интернет пространстве, и которой пользуются много лет. Казалось бы, о ней все известно, и ничего интересного на эту тему не рассказать. Если почитать популярные ресурсы типа Википедии, то действительно там нет ничего необычного, разве что в английской версии кратко упоминается странная история о том, как ее «набросали на салфетке в закусочной».
На самом деле изобретение этой кодировки не может быть настолько банальным хотя бы потому, что к ее созданию приложил руку Кен Томпсон — легендарная личность. Он работал вместе с Деннисом Ритчи, был одним из создателей UNIX, внес вклад в разработку C (изобрел его предшественника — B), а позднее, во время работы в Google, принял участие в создании языка Go.
Перед вами — перевод нескольких писем, в которых разработчики вспоминают историю создания кодировки.
Действующие лица:
ken (at) entrisphere.com — Кен Томпсон

Кен Томпсон (слева) с Деннисом Ритчи
«Rob ‘Commander’ Pike» — Роберт Пайк, канадский программист, работавший над UTF-8 вместе c Кеном Томпсоном

mkuhn (at) acm.org — Маркус Кун, немецкий ученый в области информатики

henry (at) spsystems.net — Генри Сперсер, автор одной из реализаций RegExp

Russ Cox — Русс Кокс, сотрудник Bell Labs, работавший над системой Plan 9

Greger Leijonhufvud — Один из сотрудников X/Open

Plan 9 — Операционная система, в которой впервые была использована кодировка UTF-8 для обеспечения ее мультиязычности.

UTF-8 — Кодировка символов Юникода

Переписка 2003 года
Ниже переписка создателей кодировки, Роберта и Кена, которую Роберт Пайк начал, сетуя на то, что их вклад в создание UTF-8 незаслуженно забыли. Роберт просит одного из старых знакомых порыться в архивах почтового сервера и найти там доказательства их участия. (прим. пер.)
Subject: UTF-8 history From: "Rob 'Commander' Pike" Date: Wed, 30 Apr 2003 22:32:32 -0700 (Thu 06:32 BST) To: mkuhn (at) acm.org, henry (at) spsystems.net Cc: ken (at) entrisphere.comГлядя на разговоры о происхождении UTF-8, я вижу, как постоянно повторяют одну и ту же историю.
- UTF-8 разработала IBM.
- Она была реализована в Plan 9 (операционная система, разработанная Bell Laboratories)
Произошло это таким образом. Мы пользовались оригинальным UTF из стандарта ISO 10646 для поддержки 16-битных символов в Plan 9, который ненавидели, и уже были готовы к выпуску Plan 9, когда однажды поздно вечером мне позвонили одни парни, кажется они были из IBM. Я припоминаю, что встречался с ними на заседании комитета X/Open в Остине. Они хотели, чтобы мы с Кеном посмотрели их проект FSS/UTF.
В то время подавляющее большинство компьютерных программ и систем (документация, сообщения об ошибках и т.п.) было только на английском и только слева направо. Инженерам из Bell Labs показалось, что релиз Plan 9 — хороший повод для того, чтобы изменить это, поскольку проще всего вводить новшества в систему на этапе ее разработки, а не исправлять уже выпущенный продукт. Потому они стали искать специалистов, которые помогут им интернационализировать их проект.
В существующей реализации Unicode было много недостатков, например, чтобы понять, где именно начинается произвольный символ, надо было разобрать всю строку с самого начала, без этого нельзя было определить границы символов.
Мы поняли, почему они хотят изменить дизайн и решили, что это хорошая возможность использовать наш опыт, чтобы разработать новый стандарт и заставить ребят из X/Open продвинуть его. Нам пришлось рассказать им об этом, и они согласились при условии, что мы быстро с этим справимся.
Потом мы пошли перекусить, и во время ужина Кен разобрался с упаковкой битов, а когда вернулись, то позвонили ребятам из X/Open и объяснили им нашу идею. Мы отправили по почте наш набросок, и они ответили, что это лучше, чем у них (но я точно помню, что они нам свой вариант не показывали), и спросили, когда мы сможем это реализовать.
Одним из вариантов разграничения символов был слэш, но это могло запутать файловую систему, она бы могла интерпретировать его как эскейп-последовательность.
Мне кажется, что это происходило в среду вечером. Мы пообещали, что запустим систему к понедельнику, когда у них, как мне кажется, намечалось какое-то важное совещание. В тот же вечер Кен написал код кодировщика/раскодировщика, а я начал разбираться с С и с графическими библиотеками. На следующий день код был готов, и мы начали конвертировать текстовые файлы системы. К пятнице Plan 9 уже запускался и работал на так называемом UTF-8.
А в дальнейшем история была немного переписана.
Почему мы просто не воспользовались их FSS/UTF?
Насколько я помню, в том первом телефонном звонке я напел им Дезидерату своих требований для кодировки, и в FSS/UTF не было как минимум одного — возможности синхронизировать поток байтов взятых из середины потока, используя для синхронизации как можно меньше символов (см выше, про определение границ символов. прим. пер).
напел им Дезидерату
Имеется в виду крылатая фраза, берущая начало из альбома Леса Крейна 1971 года, чье название и заглавная композиция: «Desiderata» взяты из одноименной поэмы, что переводится с латыни, как: «Желаемое». То есть, «напел им Дезидерату» следует понимать как «высказал пожелания». (прим пер.)
Поскольку нигде решения не было, мы были вольны делать это как хотели.
Я думаю, что «историю придумали IBM, а реализовали в Plan 9» берет свое начало в документации по RFC 2279. Мы были так счастливы, когда UTF-8 прижился, что никому не рассказали эту историю.
Никто из нас больше не работает в Bell Labs, но я уверен, что сохранился архив электронной почты, которая может подтвердить нашу историю, и я могу попросить кого-нибудь покопаться в ней.
Итак, вся слава достается парням из X/Open и IBM за то, что они сделали это возможным и продвинули кодировку, но разработал ее Кен, и я ему помогал в этом, что бы там ни говорилось в книгах по истории.
Date: Sat, 07 Jun 2003 18:44:05 -0700 From: "Rob `Commander' Pike" To: Markus Kuhn cc: henry@spsystems.net, ken@entrisphere.com, Greger Leijonhufvud Subject: Re: UTF-8 historyЯ попросил Расса Кокса покопаться в архивах. Прикладываю его сообщение. Я думаю, вы согласитесь, что это подтверждает историю, которую я отправил раньше. Письмо, которое мы выслали в X/Open (думаю, что Кен редактировал и рассылал этот документ) включает новый «desideratum номер 6» про обнаружение границ символов.
Мы уже не узнаем, какое влияние оказало на нас оригинальное решение от X/Open. Они хоть и отличаются, но имеют общие характерные черты. Я не помню, чтобы подробно его рассматривал, это было слишком давно (в прошлом письме он говорит, что X/Open им свой вариант реализации не показывали. прим. пер). Но я очень хорошо помню, как Кен писал наброски на салфетке и потом жалел, что мы ее не сохранили.
From: Russ Cox To: r@google.com Subject: utf digging Date-Sent: Saturday, June 07, 2003 7:46 PM -0400Файл пользователя bootes /sys/src/libc/port/rune.c был изменен пользователем division-heavy 4 сентября 1992 года. Версия, попавшая в дамп имеет время 19:51:55. На другой день в него был добавлен комментарий, но в остальном он не изменялся до 14 ноября 1996 года, когда runelen была ускорена путем явной проверки значения rune вместо использования значения, возвращаемого runetochar . Последнее изменение было 26 мая 2001 года, когда была добавлена runenlen . (Rune — структура, содержащая значение Юникод. Runelen и runetochar — функции, работающие с этим типом данных. прим.пер)
Нашлось несколько писем из ваших ящиков, которые выдал грепинг по строке utf.
В первом идет речь про файл utf.c , который является копией wctomb и mbtowc (функции преобразования символов. прим. пер.), что обрабатывают полную 6-байтовую кодировку UTF-8, 32-битных runes. С логикой управления потоком это выглядит довольно уродливо. Я предполагаю, что этот код появился в результате того первого письма.
В /usr/ken/utf/xutf я нашел копию того, что, по видимому, является исходником того не самосинхронизирующегося способа кодирования.со схемой UTF-8, добавленной в конце письма (начинается со слов «Мы определяем 7 типов byte »).
Приведенная ниже версия письма, датированная 2 сентября 23:44:10, является первой. После нескольких правок, утром 8 сентября, получилась вторая версия. Логи почтового сервера показывают, как отправляется вторая версия письма и, через некоторое время, возвращается к Кену:
helix: Sep 8 03:22:13: ken: upas/sendmail: remote inet!xopen.co.uk!xojig >From ken Tue Sep 8 03:22:07 EDT 1992 (xojig@xopen.co.uk) 6833 helix: Sep 8 03:22:13: ken: upas/sendmail: delivered rob From ken Tue Sep 8 03:22:07 EDT 1992 6833 helix: Sep 8 03:22:16: ken: upas/sendmail: remote pyxis!andrew From ken Tue Sep 8 03:22:07 EDT 1992 (andrew) 6833 helix: Sep 8 03:22:19: ken: upas/sendmail: remote coma!dmr From ken Tue Sep 8 03:22:07 EDT 1992 (dmr) 6833 helix: Sep 8 03:25:52: ken: upas/sendmail: delivered rob From ken Tue Sep 8 03:24:58 EDT 1992 141 helix: Sep 8 03:36:13: ken: upas/sendmail: delivered ken From ken Tue Sep 8 03:36:12 EDT 1992 6833Файлы из почтового архива
Далее файл с перепиской из дапма почтового сервера, который Расс Кокс приаттачил к своему, в ответ на просьбу Роберта покопаться в истории. Это «первая версия». (прим пер.)
>From ken Fri Sep 4 03:37:39 EDT 1992 Вот наше предложение по модификации FSS-UTF. Речь идет о том же, о чем и в предыдущем. Приношу свои извинения автору.
Код был в какой-то степени протестирован и должен быть в довольно неплохой форме. Мы переделали код Plan 9 для использования с этой кодировкой, собрались выпустить дистрибутив и отобрать пользователей университета для начального тестирования.
File System Safe Universal Character Set Transformation Format (FSS-UTF)
В связи с утверждением ISO/IEC 10646 (Unicode) в качестве международного стандарта и ожиданием широкого распространения этого Универсального Набора Кодированных символов (UCS), для операционных систем, исторически основанных на формате ASCII, необходимо разработать способы представления и обработки большого количества символов, которые можно закодировать с помощью нового стандарта. У UCS есть несколько проблем, которые нужно решить в исторически сложившихся операционных системах и среде для программирования на языке C.
(Далее в тексте несколько раз упоминаются «historical operating systems». Видимо в контексте «исторически работающие с кодировкой ASCII». Я или опускал этот эпитет, или заменял его на «существующие» и т.п. прим. пер)
Самой серьезной проблемой является схема кодирования, используемая в UCS. А именно объединение стандарта UCS с существующими языками программирования, операционными системами и утилитами. Проблемы в языках программирования и операционных системах решаются в разных отраслях, тем не менее мы все еще сталкиваемся с обработкой UCS операционными системами и утилитами.
Среди проблем, связанных с обработкой UCS в операционных системах, главной является представление данных внутри файловой системы. Основополагающей концепцией является то, что надо поддерживать существующие операционные системы, в которые были вложены инвестиции, и в тоже время пользоваться преимуществами большого количества символов, предоставляемых UCS.
UCS дает возможность закодировать многоязычный текст с помощью одного набора символов. Но UCS и UTF не защищают нулевые байты (конец строки в некоторых языках. прим. пер.) и/или слеш в ASCII /, что делает эти кодировки несовместимыми с Unix. Следующее предложение обеспечивает формат преобразования UCS, совместимый с Unix, и, таким образом, Unix-системы могут поддерживать многоязычный текст в рамках одной кодировки.
Данная кодировка формата преобразования предназначена для кодирования файлов, как промежуточный шаг к полной поддержке UCS. Однако, поскольку почти все реализации Unis сталкиваются с одинаковыми проблемами поддержки UCS, это предложение предназначено для обеспечения общей совместимости кодировки на данном этапе.
Цель/Задача
Исходя из предположения получаем, что если известны практически все проблемы обработки и хранения UCS в файловых системах ОС, то надо пользоваться таким форматом преобразования UCS, который будет работать не нарушая структуры операционной системы. Цель состоит в том, чтобы процесс преобразования формата можно было использовать для кодирования файла.
Критерии для формата преобразования
Ниже приведены рекомендации, которые должны соблюдаться, при определении формата преобразования UCS:
- Совместимость с существующими файловыми системами.
Запрещено использовать нулевой байт и символ слэша как часть имени файла. - Совместимость с существующими программами.
В существующей модели многобайтовой обработки не должны использоваться коды ASCII. В формате преобразования представления символа UCS, которого нет в наборе символов ASCII, не должны использоваться коды ASCII. - Простота конвертации из UCS и обратно.
- Первый байт содержит указание на длину многобайтовой последовательности.
- Формат преобразования не должен быть затратным, в смысле количества байт, используемых для кодирования.
- Должна быть возможность легко определять начало символа, находясь в любом месте байтового потока (строки. прим.пер.).
Предписания FSS-UTF
Предлагаемый формат преобразования UCS кодирует значения UCS в диапазоне [0,0x7fffffff] с использованием нескольких байт на один символ и длиной 1, 2, 3, 4, 5, и 6 байт. Во всех случаях кодирования более чем одним байтом начальный байт определяет количество используемых байтов, при этом в каждом байте устанавливается старший бит. Каждый байт, который не начинается с 10XXXXXX, является началом последовательности символов UCS.
Простой способ запомнить формат: количество старших единиц в первом байте означает количество байт в многобайтовом символе.
Bits Hex Min Hex Max Byte Sequence in Binary 1 7 00000000 0000007f 0vvvvvvv 2 11 00000080 000007FF 110vvvvv 10vvvvvv 3 16 00000800 0000FFFF 1110vvvv 10vvvvvv 10vvvvvv 4 21 00010000 001FFFFF 11110vvv 10vvvvvv 10vvvvvv 10vvvvvv 5 26 00200000 03FFFFFF 111110vv 10vvvvvv 10vvvvvv 10vvvvvv 10vvvvvv 6 31 04000000 7FFFFFFF 1111110v 10vvvvvv 10vvvvvv 10vvvvvv 10vvvvvv 10vvvvvv Значение символа UCD в многобайтовой кодировке — это конкатенация v-битов. Если возможно несколько способов кодирования, например UCS 0, то допустимым считается самый короткий.
Ниже приведены примеры реализаций стандартных функций C wcstombs() и mbstowcs() , которые демонстрируют алгоритмы конвертирования из UCS в формат преобразования и конвертирования из формата преобразования в UCS. Примеры реализаций включают проверку ошибок, некоторые из которых могут быть не нужны для согласования:
typedef struct < int cmask; int cval; int shift; long lmask; long lval; >Tab; static Tab tab[] = < 0x80, 0x00, 0*6, 0x7F, 0, /* 1 byte sequence */ 0xE0, 0xC0, 1*6, 0x7FF, 0x80, /* 2 byte sequence */ 0xF0, 0xE0, 2*6, 0xFFFF, 0x800, /* 3 byte sequence */ 0xF8, 0xF0, 3*6, 0x1FFFFF, 0x10000, /* 4 byte sequence */ 0xFC, 0xF8, 4*6, 0x3FFFFFF, 0x200000, /* 5 byte sequence */ 0xFE, 0xFC, 5*6, 0x7FFFFFFF, 0x4000000, /* 6 byte sequence */ 0, /* end of table */ >; int mbtowc(wchar_t *p, char *s, size_t n) < long l; int c0, c, nc; Tab *t; if(s == 0) return 0; nc = 0; if(n cmask; t++) < nc++; if((c0 & t->cmask) == t->cval) < l &= t->lmask; if(l < t->lval) return -1; *p = l; return nc; > if(n return -1; > int wctomb(char *s, wchar_t wc) < long l; int c, nc; Tab *t; if(s == 0) return 0; l = wc; nc = 0; for(t=tab; t->cmask; t++) < nc++; if(l lmask) < c = t->shift; *s = t->cval | (l>>c); while(c > 0) < c -= 6; s++; *s = 0x80 | ((l>>c) & 0x3F); > return nc; > > return -1; >>From ken Tue Sep 8 03:24:58 EDT 1992Я послал его по почте, но письмо ушло в черную дыру, потому я не получил свою копию. Наверное, это интернет-адрес был в коме.
Вторая версия письма, с правками
Далее прикладывается копия письма, которая выше описывается как: «После нескольких правок, утром 8 сентября, получилась вторая версия». Повторяющаяся часть скрыта под спойлером. (прим.пер.)
>From ken Tue Sep 8 03:42:43 EDT 1992Наконец-то я получил свою копию.
--- /usr/ken/utf/xutf from dump of Sep 2 1992 ---Скрытый текст
File System Safe Universal Character Set Transformation Format (FSS-UTF)
В связи с утверждением ISO/IEC 10646 (Unicode) в качестве международного стандарта и ожиданием широкого распространения этого Универсального Набора Кодированных символов (UCS), для операционных систем, исторически основанных на формате ASCII, необходимо разработать способы представления и обработки большого количества символов, которые можно закодировать с помощью нового стандарта. У UCS есть несколько проблем, которые нужно решить в исторически сложившихся операционных системах и среде для программирования на языке C.
Самой серьезной проблемой является схема кодирования, используемая в UCS. А именно объединение стандарта UCS с существующими языками программирования, операционными системами и утилитами. Проблемы в языках программирования и операционных системах решаются в разных отраслях, тем не менее мы все еще сталкиваемся с обработкой UCS операционными системами и утилитами.
Среди проблем, связанных с обработкой UCS в операционных системах, главной является представление данных внутри файловой системы. Основополагающей концепцией является то, что надо поддерживать существующие операционные системы, в которые были вложены инвестиции, и в тоже время пользоваться преимуществами большого количества символов, предоставляемых UCS.
UCS дает возможность закодировать многоязычный текст с помощью одного набора символов. Но UCS и UTF не защищают нулевые байты (конец строки в некоторых языках. прим. пер.) и/или слеш в ASCII /, что делает эти кодировки несовместимыми с Unix. Следующее предложение обеспечивает формат преобразования UCS, совместимый с Unix, и, таким образом, Unix-системы могут поддерживать многоязычный текст в рамках одной кодировки.
Данная кодировка формата преобразования предназначена для кодирования файлов, как промежуточный шаг к полной поддержке UCS. Однако, поскольку почти все реализации Unis сталкиваются с одинаковыми проблемами поддержки UCS, это предложение предназначено для обеспечения общей совместимости кодировки на данном этапе.
Цель/Задача
Исходя из предположения получаем, что если известны практически все проблемы обработки и хранения UCS в файловых системах ОС, то надо пользоваться таким форматом преобразования UCS, который будет работать не нарушая структуры операционной системы. Цель состоит в том, чтобы процесс преобразования формата можно было использовать для кодирования файла.
Критерии для формата преобразования
Ниже приведены рекомендации, которые должны соблюдаться, при определении формата преобразования UCS:
- Совместимость с существующими файловыми системами.
Запрещено использовать нулевой байт и символ слэша как часть имени файла. - Совместимость с существующими программами.
В существующей модели многобайтовой обработки не должны использоваться коды ASCII. В формате преобразования представления символа UCS, которого нет в наборе символов ASCII, не должны использоваться коды ASCII. - Простота конвертации из UCS и обратно.
- Первый байт содержит указание на длину многобайтовой последовательности.
- Формат преобразования не должен быть затратным, в смысле количества байт, используемых для кодирования.
- Должна быть возможность легко определять начало символа, находясь в любом месте байтового потока (строки. прим.пер.).
Предписания FSS-UTF
Предлагаемый формат преобразования UCS кодирует значения UCS в диапазоне [0,0x7fffffff] с использованием нескольких байт на один символ и длиной 1, 2, 3, 4, 5, и 6 байт. Во всех случаях кодирования более чем одним байтом начальный байт определяет количество используемых байтов, при этом в каждом байте устанавливается старший бит. Каждый байт, который не начинается с 10XXXXXX, является началом последовательности символов UCS.
Простой способ запомнить формат: количество старших единиц в первом байте означает количество байт в многобайтовом символе.
Bits Hex Min Hex Max Byte Sequence in Binary 1 7 00000000 0000007f 0vvvvvvv 2 11 00000080 000007FF 110vvvvv 10vvvvvv 3 16 00000800 0000FFFF 1110vvvv 10vvvvvv 10vvvvvv 4 21 00010000 001FFFFF 11110vvv 10vvvvvv 10vvvvvv 10vvvvvv 5 26 00200000 03FFFFFF 111110vv 10vvvvvv 10vvvvvv 10vvvvvv 10vvvvvv 6 31 04000000 7FFFFFFF 1111110v 10vvvvvv 10vvvvvv 10vvvvvv 10vvvvvv 10vvvvvv Значение символа UCD в многобайтовой кодировке — это конкатенация v-битов. Если возможно несколько способов кодирования, например UCS 0, то допустимым считается самый короткий.
Ниже приведены примеры реализаций стандартных функций C wcstombs() и mbstowcs() , которые демонстрируют алгоритмы конвертирования из UCS в формат преобразования и конвертирования из формата преобразования в UCS. Примеры реализаций включают проверку ошибок, некоторые из которых могут быть не нужны для согласования:
typedef struct < int cmask; int cval; int shift; long lmask; long lval; >Tab; static Tab tab[] = < 0x80, 0x00, 0*6, 0x7F, 0, /* 1 byte sequence */ 0xE0, 0xC0, 1*6, 0x7FF, 0x80, /* 2 byte sequence */ 0xF0, 0xE0, 2*6, 0xFFFF, 0x800, /* 3 byte sequence */ 0xF8, 0xF0, 3*6, 0x1FFFFF, 0x10000, /* 4 byte sequence */ 0xFC, 0xF8, 4*6, 0x3FFFFFF, 0x200000, /* 5 byte sequence */ 0xFE, 0xFC, 5*6, 0x7FFFFFFF, 0x4000000, /* 6 byte sequence */ 0, /* end of table */ >; int mbtowc(wchar_t *p, char *s, size_t n) < long l; int c0, c, nc; Tab *t; if(s == 0) return 0; nc = 0; if(n cmask; t++) < nc++; if((c0 & t->cmask) == t->cval) < l &= t->lmask; if(l < t->lval) return -1; *p = l; return nc; > if(n return -1; > int wctomb(char *s, wchar_t wc) < long l; int c, nc; Tab *t; if(s == 0) return 0; l = wc; nc = 0; for(t=tab; t->cmask; t++) < nc++; if(l lmask) < c = t->shift; *s = t->cval | (l>>c); while(c > 0) < c -= 6; s++; *s = 0x80 | ((l>>c) & 0x3F); > return nc; > > return -1; >int mbtowc(wchar_t *p, const char *s, size_t n) < unsigned char *uc; /* so that all bytes are nonnegative */ if ((uc = (unsigned char *)s) == 0) return 0; /* no shift states */ if (n == 0) return -1; if ((*p = uc[0]) < 0x80) return uc[0] != '\0'; /* return 0 for '\0', else 1 */ if (uc[0] < 0xc0) < if (n < 2) return -1; if (uc[1] < 0x80) goto bad; *p &= 0x3f; *p if (uc[0] < 0xe0) < if (n < 3) return -1; if (uc[1] < 0x80 || uc[2] < 0x80) goto bad; *p &= 0x1f; *p if (uc[0] < 0xf0) < if (n < 4) return -1; if (uc[1] < 0x80 || uc[2] < 0x80 || uc[3] < 0x80) goto bad; *p &= 0x0f; *p if (uc[0] < 0xf8) < if (n < 5) return -1; if (uc[1] < 0x80 || uc[2] < 0x80 || uc[3] < 0x80 || uc[4] < 0x80) goto bad; *p &= 0x07; *p bad:; errno = EILSEQ; return -1; > Мы определяем 7 байтовых типов:
T0 0xxxxxxx 7 free bits Tx 10xxxxxx 6 free bits T1 110xxxxx 5 free bits T2 1110xxxx 4 free bits T3 11110xxx 3 free bits T4 111110xx 2 free bits T5 111111xx 2 free bits Кодирование выглядит следующим образом:
>From hex Thru hex Sequence Bits 00000000 0000007f T0 7 00000080 000007FF T1 Tx 11 00000800 0000FFFF T2 Tx Tx 16 00010000 001FFFFF T3 Tx Tx Tx 21 00200000 03FFFFFF T4 Tx Tx Tx Tx 26 04000000 FFFFFFFF T5 Tx Tx Tx Tx Tx 32 - Двумя байтами можно закодировать 2^11 степени символов, но использоваться будут только 2^11—2^7. Коды в диапазоне 0-7F будут считаться недопустимыми. Я думаю, что это лучше, чем добавление кучи «магических» констант без реальной пользы. Это замечание применимо ко всем более длинным последовательностям.
- Последовательности из 4, 5 и 6 байт существуют только по политическим причинам. Я бы предпочел их удалить.
- 6-байтовая последовательность охватывает 32 бита, предложение FSS-UTF охватывает только 31.
- Все последовательности синхронизируются по любому байту, не являющемуся Tx.
Эта короткая переписка расставила все по своим местам. Хоть и не сохранилась та «легендарная салфетка», но выдержек из архива почтового сервера хватило, чтобы сообщество признало их заслуги. В Википедию добавили имена Кена и Роберта и забавный факт про салфетку в закусочной, а в сети эта история гуляет и обсуждается «как есть», в виде простого текста, содержащего несколько писем и часть дампа из почтового сервера.
Давно забыта операционная система Plan 9, никто не помнит для чего ее писали и почему она «номер девять», а UTF-8, спустя почти тридцать лет, все еще актуальна и не собирается уходить на покой.
Казалось бы, это всего лишь кодировка, но даже такая простая история может оказаться занимательной, если немного в нее углубиться. На заре развития технологий нельзя было предугадать, что выстрелит и войдет в историю, а что забудется.
Что такое кодировка UTF-8? Руководство для непрограммистов

Текст: его важность в Интернете само собой разумеется. Это первая буква «Т» в «HTTP», единственная буква «Т» в «HTML», и практически каждый веб-сайт каким-то образом использует ее, будь то URL-адрес, рекламный текст, обзор продукта, вирусный твит или Сообщение блога. (Всем привет!)
Но веб-текст на самом деле может быть не таким простым, как вы думаете. Рассмотрим тысячи языков, на которых сегодня говорят, или все знаки препинания и символы, которые мы можем добавить, чтобы улучшить их, или тот факт, что создаются новые смайлики, чтобы уловить каждую человеческую эмоцию. Как веб-сайты все это хранят и обрабатывают?
По правде говоря, даже такая простая вещь, как текст, требует хорошо скоординированной, четко определенной системы для отображения в веб-браузерах. В этом посте я объясню основы одной технологии, которая имеет ключевое значение для текста в Интернете, UTF-8. Мы изучим основы хранения и кодирования текста и обсудим, как это помогает размещать привлекательные слова на вашем сайте.
Прежде чем мы начнем, вы должны быть знакомы с основами HTML и готовы погрузиться в легкую информатику.
Что такое UTF-8?
UTF-8 означает «Формат преобразования Unicode – 8 бит». Это пока не помогает нам, поэтому давайте вернемся к основам.
Двоичный: как компьютеры хранят информацию
Для хранения информации компьютеры используют двоичную систему. В двоичном формате все данные представлены в виде последовательностей единиц и нулей. Самая основная единица двоичного кода – это бит, который представляет собой всего лишь 1 или 0. Следующая по величине единица двоичного кода, байт, состоит из 8 бит. Пример байта – «01101011».
Каждый цифровой актив, с которым вы когда-либо сталкивались – от программного обеспечения до мобильных приложений, от веб-сайтов до историй в Instagram – построен на этой системе байтов, которые связаны друг с другом таким образом, что это имеет смысл для компьютеров. Когда мы говорим о размерах файлов, мы имеем в виду количество байтов. Например, килобайт – это примерно тысяча байт, а гигабайт – примерно миллиард байтов.
Текст – это один из многих ресурсов, которые компьютеры хранят и обрабатывают. Текст состоит из отдельных символов, каждый из которых представлен в компьютерах строкой битов. Эти строки собираются в цифровые слова, предложения, абзацы, любовные романы и т.д.
ASCII: преобразование символов в двоичные
Американский стандартный код обмена информацией (ASCII) был ранней стандартизированной системой кодирования текста. Кодирование – это процесс преобразования символов человеческих языков в двоичные последовательности, которые могут обрабатывать компьютеры.
Библиотека ASCII включает все буквы в верхнем и нижнем регистре латинского алфавита (A, B, C…), каждую цифру от 0 до 9 и некоторые общие символы (например, /,! И?). Он присваивает каждому из этих символов уникальный трехзначный код и уникальный байт.
В таблице ниже показаны примеры символов ASCII с соответствующими кодами и байтами.
| символ | Код ASCII | БАЙТ |
| А | 065 | 01000001 |
| а | 097 | 01100001 |
| B | 066 | 01000010 |
| б | 098 | 01100010 |
| С УЧАСТИЕМ | 090 | 01011010 |
| с участием | 122 | 01111010 |
| 0 | 048 | 00110000 |
| 9 | 057 | 00111001 |
| ! | 033 | 00100001 |
| ? | 063 | 00111111 |
Подобно тому, как символы объединяются в слова и предложения в языке, двоичный код делает это в текстовых файлах. Итак, фраза «Быстрая коричневая лисица перепрыгивает через ленивого пса». в двоичном формате ASCII будет:
01010100 01101000 01100101 00100000 01110001 01110101 01101001 01100011 01101011 00100000 01100010 01110010 01101111 01110111 01101110 00100000 01100110 01101111 01111000 00100000 01101010 01110101 01101101 01110000 01110011 00100000 01101111 01110110 01100101 01110010 00100000 01110100 01101000 01100101 00100000 01101100 01100001 01111010 01111001 00100000 01100100 01101111 01100111 00101110 Это мало что значит для нас, людей, но это хлеб с маслом для компьютера.
Количество символов, которые может представлять ASCII, ограничено количеством доступных уникальных байтов, поскольку каждый символ получает один байт. Если вы посчитаете, то обнаружите, что существует 256 различных способов группировки восьми единиц и нулей вместе. Это дает нам 256 различных байтов или 256 способов представления символа в ASCII. Когда в 1960 году был представлен ASCII, это было нормально, поскольку разработчикам требовалось всего 128 байт для представления всех необходимых им английских символов и символов.
Но по мере глобального распространения компьютерных технологий компьютерные системы начали хранить текст не только на английском, но и на других языках, многие из которых использовали символы, отличные от ASCII. Были созданы новые системы для сопоставления других языков с тем же набором из 256 уникальных байтов, но использование нескольких систем кодирования было неэффективным и запутанным. Разработчикам требовался лучший способ кодирования всех возможных символов с помощью одной системы.
Юникод: способ хранить каждый символ, когда-либо
Используйте Unicode, систему кодирования, которая решает проблему пространства ASCII. Как и ASCII, Unicode присваивает каждому символу уникальный код, называемый кодовой точкой. Однако более сложная система Unicode может генерировать более миллиона кодовых точек, чего более чем достаточно для учета каждого символа на любом языке.
Юникод теперь является универсальным стандартом для кодирования всех человеческих языков. И да, он даже включает смайлы.
Ниже приведены несколько примеров текстовых символов и соответствующих им кодовых точек. Каждая кодовая точка начинается с буквы «U» для «Unicode», за которой следует уникальная строка символов для представления символа.
| символ | Кодовая точка |
| А | U+0041 |
| а | U+0061 |
| 0 | U+0030 |
| 9 | U+0039 |
| ! | U+0021 |
| ОСТРОВ | U + 00D8 |
| ڃ | U+0683 |
| Ch | U + 0C9A |
| �� | U+2070E |
| �� | U+1F601 |
Если вы хотите узнать, как генерируются кодовые точки и что они означают в Unicode, ознакомьтесь с этим подробным объяснением.
Итак, теперь у нас есть стандартизированный способ представления каждого символа, используемого каждым человеческим языком, в единой библиотеке. Это решает проблему нескольких систем маркировки для разных языков – любой компьютер на Земле может использовать Unicode.
Но один только Unicode не хранит слова в двоичном формате. Компьютерам нужен способ перевода Unicode в двоичный код, чтобы его символы можно было хранить в текстовых файлах. Вот где пригодится UTF-8.
UTF-8: последний кусок головоломки
UTF-8 – это система кодирования Unicode. Он может преобразовывать любой символ Юникода в соответствующую уникальную двоичную строку, а также может преобразовывать двоичную строку обратно в символ Юникода. Это значение «UTF» или «Формат преобразования Unicode».
Помимо UTF-8, существуют и другие системы кодирования Unicode, но UTF-8 уникален, поскольку представляет символы в однобайтовых единицах. Помните, что один байт состоит из восьми бит, отсюда и «-8» в его названии.
Более конкретно, UTF-8 преобразует кодовую точку (которая представляет один символ в Unicode) в набор от одного до четырех байтов. Первые 256 символов в библиотеке Unicode, включая символы, которые мы видели в ASCII, представлены как один байт. Символы, которые появляются позже в библиотеке Unicode, кодируются как двухбайтовые, трехбайтовые и, возможно, четырехбайтовые двоичные единицы.
Ниже приведена та же таблица символов, что и выше, с выводом UTF-8 для каждого добавленного символа. Обратите внимание, что некоторые символы представлены одним байтом, а другие используют больше.
| символ | Кодовая точка | Двоичная кодировка UTF-8 |
| А | U+0041 | 01000001 |
| а | U+0061 | 01100001 |
| 0 | U+0030 | 00110000 |
| 9 | U+0039 | 00111001 |
| ! | U+0021 | 00100001 |
| ОСТРОВ | U + 00D8 | 11000011 10011000 |
| ڃ | U+0683 | 11011010 10000011 |
| Ch | U + 0C9A | 11100000 10110010 10011010 |
| �� | U+2070E | 11110000 10100000 10011100 10001110 |
| �� | U+1F601 | 11110000 10011111 10011000 10000001 |
Почему UTF-8 преобразовывает одни символы в один байт, а другие – в четыре байта? Короче для экономии памяти. Используя меньше места для представления более общих символов (например, символов ASCII), UTF-8 уменьшает размер файла, позволяя использовать гораздо большее количество менее распространенных символов. Эти менее распространенные символы кодируются в два или более байта, но это нормально, если они хранятся экономно.
Пространственная эффективность – ключевое преимущество кодировки UTF-8. Если бы вместо этого каждый символ Unicode был представлен четырьмя байтами, текстовый файл, написанный на английском языке, был бы в четыре раза больше, чем тот же файл, закодированный с помощью UTF-8.
Еще одно преимущество кодировки UTF-8 – обратная совместимость с ASCII. Первые 128 символов в библиотеке Unicode соответствуют символам в библиотеке ASCII, и UTF-8 переводит эти 128 символов Unicode в те же двоичные строки, что и ASCII. В результате UTF-8 может без проблем преобразовывать текстовый файл, отформатированный в ASCII, в читаемый человеком текст.
Символы UTF-8 в веб-разработке
UTF-8 – наиболее распространенный метод кодирования символов, используемый сегодня в Интернете, и набор символов по умолчанию для HTML5. Таким образом хранятся персонажи более 95% всех веб-сайтов, в том числе и ваш собственный. Кроме того, распространенные методы передачи данных через Интернет, такие как XML и JSON, кодируются стандартами UTF-8.
Поскольку теперь это стандартный метод кодирования текста в Интернете, все страницы вашего сайта и базы данных должны использовать UTF-8. Система управления контентом или конструктор веб-сайтов по умолчанию сохранят ваши файлы в формате UTF-8, но все же рекомендуется убедиться, что вы придерживаетесь этой передовой практики.
Текстовые файлы, закодированные с помощью UTF-8, должны указывать на это программному обеспечению, обрабатывающему их. В противном случае программа не сможет должным образом преобразовать двоичный код обратно в символы. В файлах HTML вы можете увидеть строку кода, подобную следующей, вверху:
Это сообщает браузеру, что файл HTML закодирован в UTF-8, чтобы браузер мог преобразовать его обратно в разборчивый текст.
UTF-8 против UTF-16
Как я уже упоминал, UTF-8 – не единственный метод кодирования символов Unicode – существует также UTF-16. Эти методы различаются количеством байтов, необходимых для хранения символа. UTF-8 кодирует символ в двоичную строку из одного, двух, трех или четырех байтов. UTF-16 кодирует символ Unicode в строку из двух или четырех байтов.
Это различие видно из их названий. В UTF-8 наименьшее двоичное представление символа составляет один байт или восемь битов. В UTF-16 наименьшее двоичное представление символа составляет два байта или шестнадцать бит.
И UTF-8, и UTF-16 могут переводить символы Unicode в двоичные файлы, удобные для компьютера, и обратно. Однако они несовместимы друг с другом. Эти системы используют разные алгоритмы для сопоставления кодовых точек с двоичными строками, поэтому двоичный вывод для любого заданного символа будет отличаться от обоих методов:
| символ | Двоичная кодировка UTF-8 | Двоичная кодировка UTF-16 |
| А | 01000001 | 01000001 11011000 00001110 11011111 |
| �� | 11110000 10100000 10011100 10001110 | 01000001 11011000 00001110 11011111 |
Кодировка UTF-8 предпочтительнее UTF-16 на большинстве веб-сайтов, потому что она использует меньше памяти. Напомним, что UTF-8 кодирует каждый символ ASCII всего одним байтом. UTF-16 должен кодировать эти же символы в двух или четырех байтах. Это означает, что текстовый файл на английском языке с кодировкой UTF-16 будет как минимум вдвое больше размера того же файла с кодировкой UTF-8.
UTF-16 более эффективен, чем UTF-8, только на некоторых неанглоязычных сайтах. Если веб-сайт использует язык с символами, находящимися дальше в библиотеке Unicode, UTF-8 будет кодировать все символы как четыре байта, тогда как UTF-16 может кодировать многие из тех же символов только как два байта. Тем не менее, если ваши страницы заполнены буквами ABC и 123, придерживайтесь UTF-8.
Расшифровка мира кодировки UTF-8
Это было много слов о словах, поэтому давайте резюмируем то, что мы рассмотрели:
- Компьютеры хранят данные, включая текстовые символы, как двоичные (единицы и нули).
- ASCII был ранним способом кодирования или отображения символов в двоичный код, чтобы компьютеры могли их хранить. Однако в ASCII не было достаточно места для представления нелатинских символов и чисел в двоичном формате.
- Юникод был решением этой проблемы. Юникод присваивает уникальный «код» каждому символу на каждом человеческом языке.
- UTF-8 – это метод кодировки символов Unicode. Это означает, что UTF-8 берет кодовую точку для данного символа Юникода и переводит ее в строку двоичного кода. Он также делает обратное, считывая двоичные цифры и преобразуя их обратно в символы.
- UTF-8 в настоящее время является самым популярным методом кодирования в Интернете, поскольку он может эффективно хранить текст, содержащий любой символ.
- UTF-16 – еще один метод кодирования, но он менее эффективен для хранения текстовых файлов (за исключением тех, которые написаны на некоторых неанглийских языках).
Перевод Unicode – это не то, о чем большинству из нас нужно думать при просмотре или разработке веб-сайтов, и именно в этом суть – создать бесшовную систему обработки текста, которая работает для всех языков и веб-браузеров. Если он работает хорошо, вы этого не заметите.
Но если вы обнаружите, что страницы вашего веб-сайта занимают чрезмерно много места или если ваш текст завален буквами and и, пора применить ваши новые знания о UTF-8.