Полное руководство: как читать файлы CSV с помощью Pandas
Файлы CSV (значения, разделенные запятыми) являются одним из наиболее распространенных способов хранения данных. К счастью, функция pandas read_csv() позволяет легко читать CSV-файлы в Python практически в любом формате, который вам нужен.
В этом руководстве объясняется несколько способов чтения CSV-файлов в Python с использованием следующего CSV-файла с именем «data.csv» :
playerID,team,points 1,Lakers,26 2,Mavs,19 3,Bucks,24 4,Spurs,22 Пример 1: Чтение CSV-файла в pandas DataFrame
В следующем коде показано, как прочитать файл CSV в DataFrame pandas:
#import CSV file as DataFrame df = pd.read_csv('data.csv') #view DataFrame df playerID team points 0 1 Lakers 26 1 2 Mavs 19 2 3 Bucks 24 3 4 Spurs 22 Пример 2. Чтение определенных столбцов из CSV-файла
Следующий код показывает, как прочитать только столбцы с названиями playerID и points в CSV-файле в pandas DataFrame:
#import only specific columns from CSV file df = pd.read_csv('data.csv', usecols=['playerID', 'points']) #view DataFrame df playerID points 0 1 26 1 2 19 2 3 24 3 4 22 В качестве альтернативы вы можете указать индексы столбцов для чтения в pandas DataFrame:
#import only specific columns from CSV file df = pd.read_csv('data.csv', usecols=[ 0 , 1 ]) #view DataFrame df playerID team 0 1 Lakers 1 2 Mavs 2 3 Bucks 3 4 Spurs Пример 3. Укажите строку заголовка при импорте файла CSV
В некоторых случаях строка заголовка может быть не первой строкой в CSV-файле. Например, рассмотрим следующий файл CSV, в котором строка заголовка фактически появляется во второй строке:
random,data,values playerID,team,points 1,Lakers,26 2,Mavs,19 3,Bucks,24 4,Spurs,22 Чтобы прочитать этот файл CSV в DataFrame pandas, мы можем указать заголовок = 1 следующим образом:
#import from CSV file and specify that header starts on second row df = pd.read_csv('data.csv', header= 1 ) #view DataFrame df playerID team points 0 1 Lakers 26 1 2 Mavs 19 2 3 Bucks 24 3 4 Spurs 22 Пример 4: Пропустить строки при импорте CSV-файла
Вы также можете легко пропустить строки при импорте CSV-файла, используя аргумент skiprows.Например, следующий код показывает, как пропустить вторую строку при импорте файла CSV:
#import from CSV file and skip second row df = pd.read_csv('data.csv', skiprows=[ 1 ] ) #view DataFrame df playerID team points 0 2 Mavs 19 1 3 Bucks 24 2 4 Spurs 22 А следующий код показывает, как пропустить вторую и третью строку при импорте CSV-файла:
#import from CSV file and skip second and third rows df = pd.read_csv('data.csv', skiprows=[ 1, 2 ] ) #view DataFrame df playerID team points 1 3 Bucks 24 2 4 Spurs 22 Пример 5. Чтение CSV-файлов с настраиваемым разделителем
Иногда у вас может быть файл CSV с разделителем, отличным от запятой. Например, предположим, что в нашем CSV-файле в качестве разделителя используется символ подчеркивания:
playerID_team_points 1_Lakers_26 2_Mavs_19 3_Bucks_24 4_Spurs_22 Чтобы прочитать этот CSV-файл в pandas, мы можем использовать аргумент sep , чтобы указать разделитель, который будет использоваться при чтении файла:
#import from CSV file and specify delimiter to use df = pd.read_csv('data.csv', sep='_') #view DataFrame df playerID team points 0 1 Lakers 26 1 2 Mavs 19 2 3 Bucks 24 3 4 Spurs 22 Вы можете найти полную документацию для функции pandas read_csv() здесь .
Основы Pandas №1 // Чтение файлов, DataFrame, отбор данных
Pandas — одна из самых популярных библиотек Python для аналитики и работы с Data Science. Это как SQL для Python. Все потому, что pandas позволяет работать с двухмерными таблицами данных в Python. У нее есть и масса других особенностей. В этой серии руководств по pandas вы узнаете самое важное (и часто используемое), что необходимо знать аналитику или специалисту по Data Science. Это первая часть, в которой речь пойдет об основах.
Примечание: это практическое руководство, поэтому рекомендуется самостоятельно писать код, повторяя инструкции!
Чтобы разобраться со всем, необходимо…
- Установить Python3.7+, numpy и Pandas.
- Следующий шаг: подключиться к серверу (или локально) и запустить Jupyter. Затем открыть Jupyter Notebook в любимом браузере. Создайте новый ноутбук с именем «pandas_tutorial_1».
- Импортировать numpy и pandas в Jupyter Notebook с помощью двух строк кода:
import numpy as np import pandas as pd 
Примечание: к «pandas» можно обращаться с помощью аббревиатуры «pd». Если в конце инструкции с import есть as pd , Jupyter Notebook понимает, что в будущем, при вводе pd подразумевается именно библиотека pandas.
Теперь все настроено! Переходим к руководству по pandas! Первый вопрос:
Как открывать файлы с данными в pandas
Информация может храниться в файлах .csv или таблицах SQL. Возможно, в файлах Excel. Или даже файлах .tsv. Или еще в каком-то другом формате. Но цель всегда одна и та же. Если необходимо анализировать данные с помощью pandas, нужна структура данных, совместимая с pandas.
Структуры данных Python
В pandas есть два вида структур данных: Series и DataFrame.
Series в pandas — это одномерная структура данных («одномерная ndarray»), которая хранит данные. Для каждого значения в ней есть уникальный индекс.
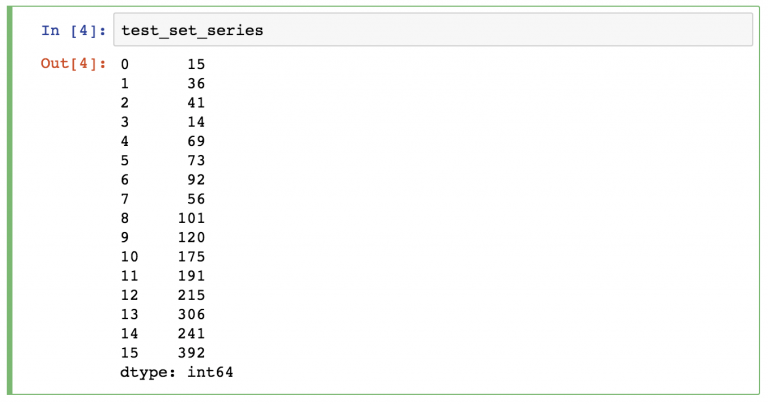
DataFrame — двухмерная структура, состоящая из колонок и строк. У колонок есть имена, а у строк — индексы.
В руководстве по pandas основной акцент будет сделан на DataFrames. Причина проста: с большей частью аналитических методов логичнее работать в двухмерной структуре.
Загрузка файла .csv в pandas DataFrame
Для загрузки .csv файла с данными в pandas используется функция read_csv() .
Начнем с простого образца под названием zoo. В этот раз для практики вам предстоит создать файл .csv самостоятельно. Вот сырые данные:
animal,uniq_id,water_need elephant,1001,500 elephant,1002,600 elephant,1003,550 tiger,1004,300 tiger,1005,320 tiger,1006,330 tiger,1007,290 tiger,1008,310 zebra,1009,200 zebra,1010,220 zebra,1011,240 zebra,1012,230 zebra,1013,220 zebra,1014,100 zebra,1015,80 lion,1016,420 lion,1017,600 lion,1018,500 lion,1019,390 kangaroo,1020,410 kangaroo,1021,430 kangaroo,1022,410 Вернемся во вкладку “Home” https://you_ip:you_port/tree Jupyter для создания нового текстового файла…
затем скопируем данные выше, чтобы вставить информацию в этот текстовый файл…
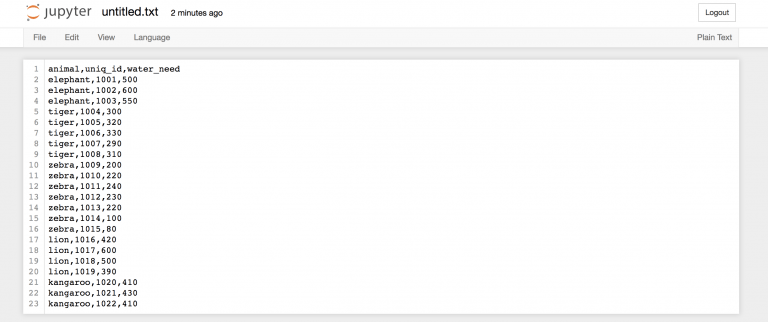
…и назовем его zoo.csv!
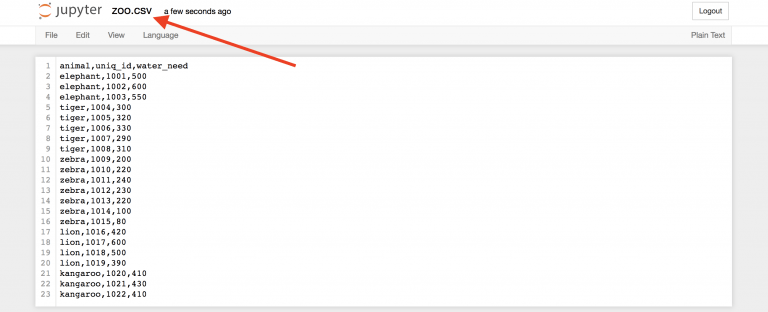
Это ваш первый .csv файл.
Вернемся в Jupyter Notebook (который называется «pandas_tutorial_1») и откроем в нем этот .csv файл!
Для этого нужна функция read_csv()
Введем следующее в новую строку:
pd.read_csv('zoo.csv', delimiter=',') 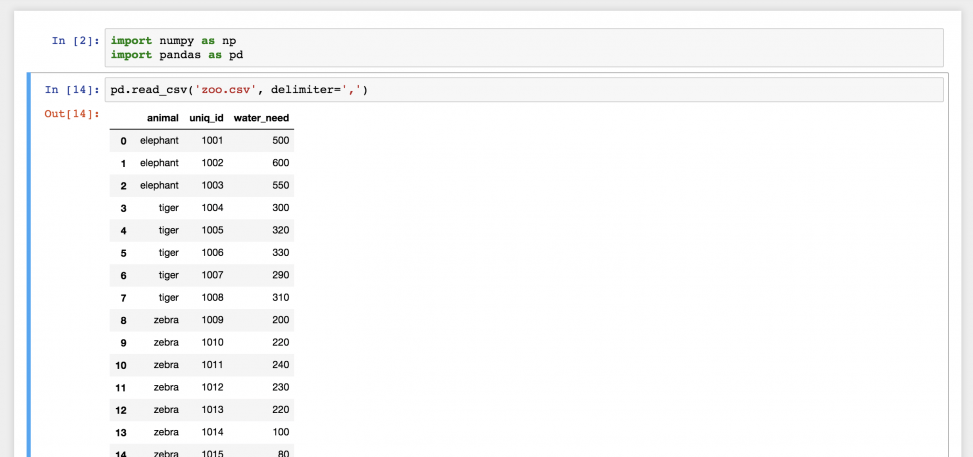
Готово! Это файл zoo.csv , перенесенный в pandas. Это двухмерная таблица — DataFrame. Числа слева — это индексы. А названия колонок вверху взяты из первой строки файла zoo.csv.
На самом деле, вам вряд ли придется когда-нибудь создавать .csv файл для себя, как это было сделано в примере. Вы будете использовать готовые файлы с данными. Поэтому нужно знать, как загружать их на сервер!
Вот небольшой набор данных: ДАННЫЕ
Если кликнуть на ссылку, файл с данными загрузится на компьютер. Но он ведь не нужен вам на ПК. Его нужно загрузить на сервер и потом в Jupyter Notebook. Для этого нужно всего два шага.
Шаг 1) Вернуться в Jupyter Notebook и ввести эту команду:
!wget https://pythonru.com/downloads/pandas_tutorial_read.csv Это загрузит файл pandas_tutorial_read.csv на сервер. Проверьте:
Если кликнуть на него…
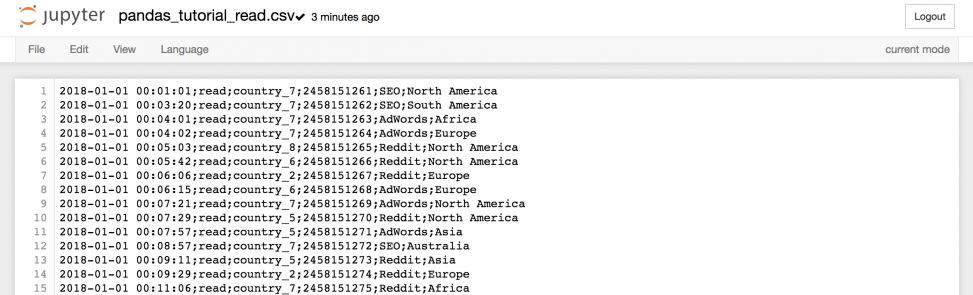
…можно получить всю информацию из файла.
Шаг 2) Вернуться в Jupyter Notebook и использовать ту же функцию read_csv (не забыв поменять имя файла и значение разделителя):
pd.read_csv('pandas_tutorial_read.csv', delimete=';') Данные загружены в pandas!
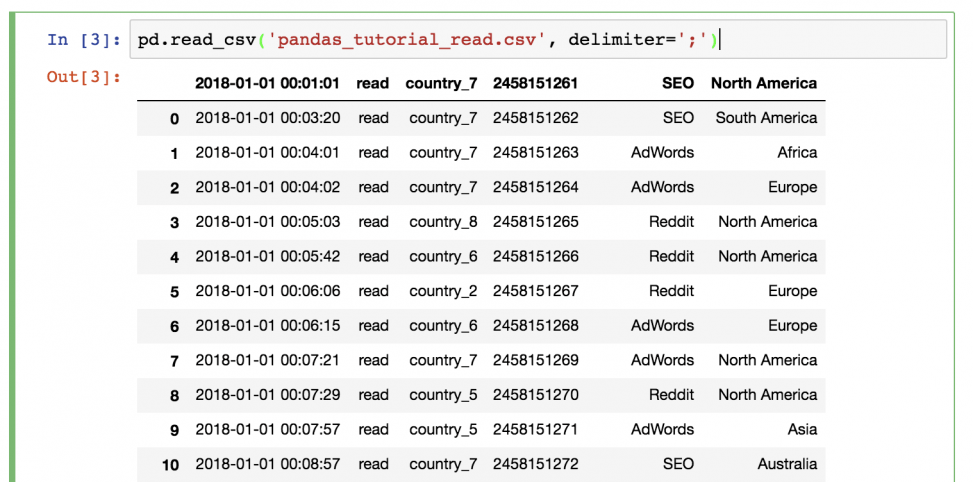
Что-то не так? В этот раз не было заголовка, поэтому его нужно настроить самостоятельно. Для этого необходимо добавить параметры имен в функцию!
pd.read_csv('pandas_tutorial_read.csv', delimiter=';', names=['my_datetime', 'event', 'country', 'user_id', 'source', 'topic']) 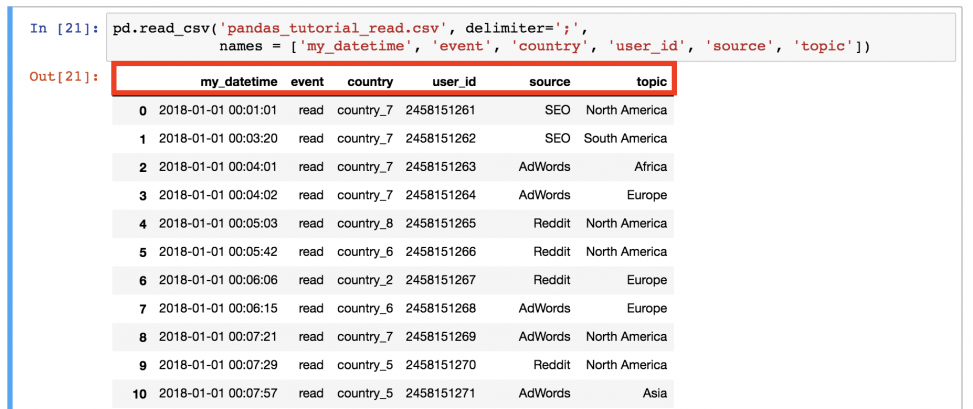
Так лучше!
Теперь файл .csv окончательно загружен в pandas DataFrame .
Примечание: есть альтернативный способ. Вы можете загрузить файл .csv через URL напрямую. В этом случае данные не загрузятся на сервер данных.
pd.read_csv( 'https://pythonru.com/downloads/pandas_tutorial_read.csv', delimiter=';', names=['my_datetime', 'event', 'country', 'user_id', 'source', 'topic'] ) Примечание: если вам интересно, что в этом наборе, то это лог данных из блога о путешествиях. Ну а названия колонок говорят сами за себя.
Отбор данных из dataframe в pandas
Это первая часть руководства, поэтому начнем с самых простых методов отбора данных, а уже в следующих углубимся и разберем более сложные.
Вывод всего dataframe
Базовый метод — вывести все данные из dataframe на экран. Для этого не придется запускать функцию pd.read_csv() снова и снова. Просто сохраните денные в переменную при чтении!
article_read = pd.read_csv( 'pandas_tutorial_read.csv', delimiter=';', names = ['my_datetime', 'event', 'country', 'user_id', 'source', 'topic'] ) После этого можно будет вызывать значение article_read каждый раз для вывода DataFrame!
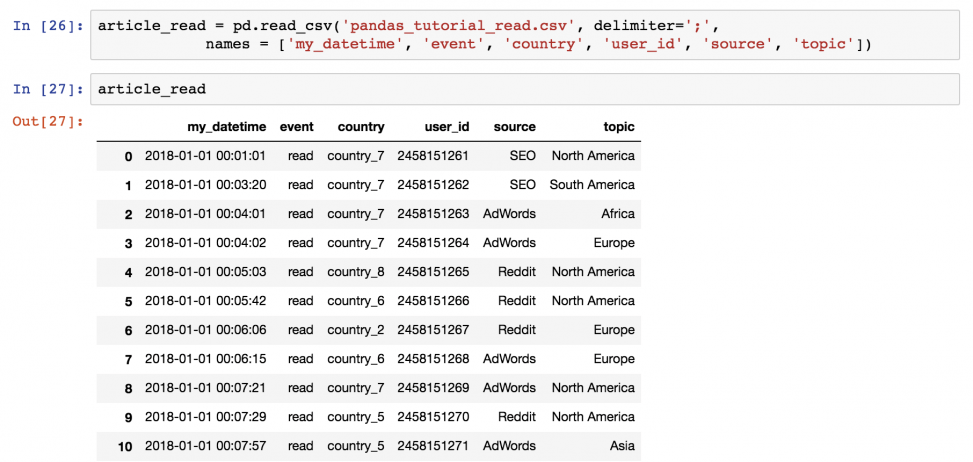
Вывод части dataframe
Иногда удобно вывести не целый dataframe, заполнив экран данными, а выбрать несколько строк. Например, первые 5 строк можно вывести, набрав:
article_read.head() 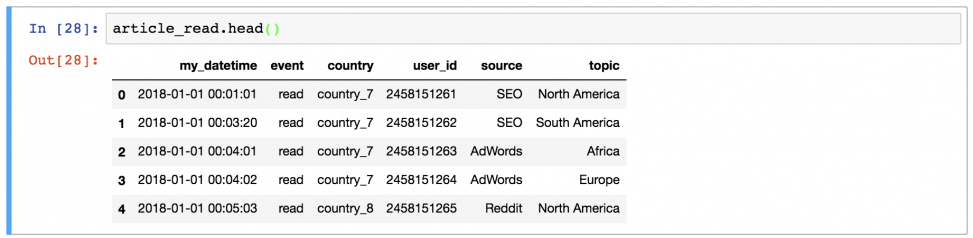
Или последние 5 строк:
article_read.tail() 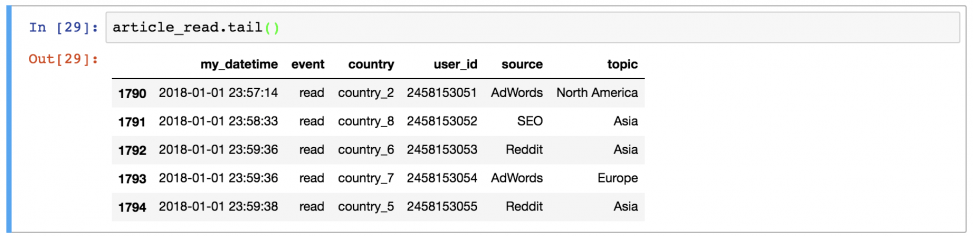
Или 5 случайных строк:
article_read.sample(5) 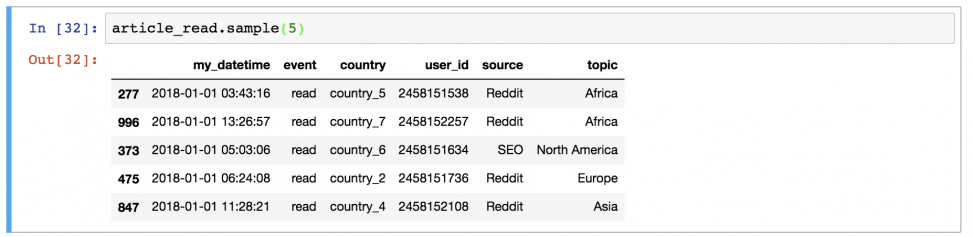
Вывод определенных колонок из dataframe
А это уже посложнее! Предположим, что вы хотите вывести только колонки «country» и «user_id».
Для этого нужно использовать команду в следующем формате:
article_read[['country', 'user_id']] 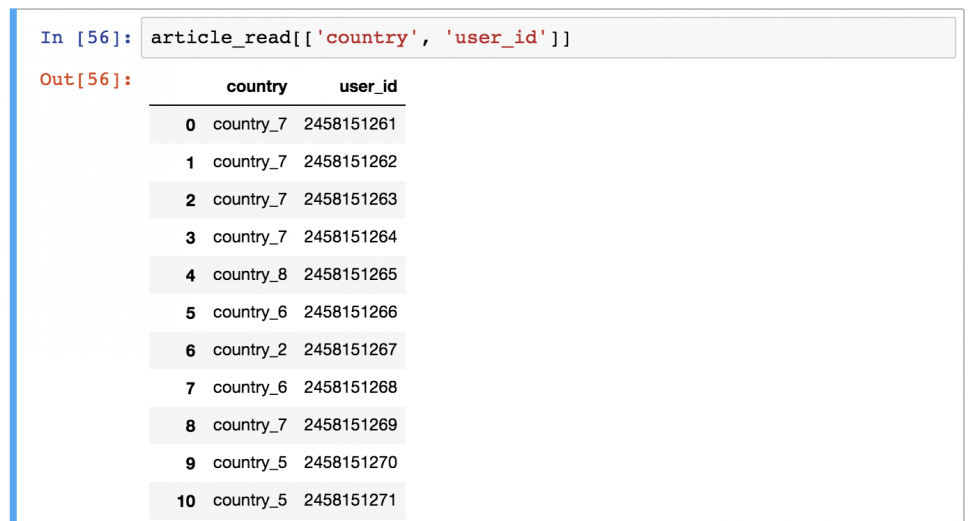
Есть предположения, почему здесь понадобились двойные квадратные скобки? Это может показаться сложным, но, возможно, так удастся запомнить: внешние скобки сообщают pandas, что вы хотите выбрать колонки, а внутренние — список (помните? Списки в Python указываются в квадратных скобках) имен колонок.
Поменяв порядок имен колонов, изменится и результат вывода.
Это DataFrame выбранных колонок.
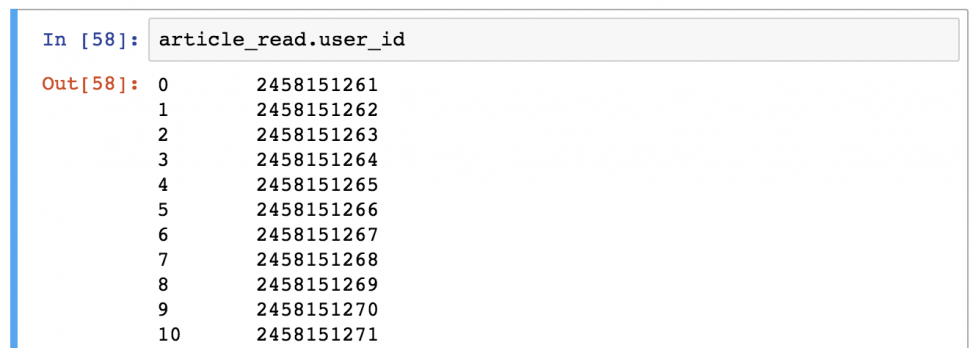
Примечание: иногда (особенно в проектах аналитического прогнозирования) нужно получить объекты Series вместе DataFrames. Это можно сделать с помощью одного из способов:
- article_read.user_id
- article_read[‘user_id’]
Фильтрация определенных значений в dataframe
Если прошлый шаг показался сложным, то этот будет еще сложнее!
Предположим, что вы хотите сохранить только тех пользователей, которые представлены в источнике «SEO». Для этого нужно отфильтровать по значению «SEO» в колонке «source»:
article_read[article_read.source == 'SEO'] Важно понимать, как pandas работает с фильтрацией данных:
Шаг 1) В первую очередь он оценивает каждую строчку в квадратных скобках: является ли ‘SEO’ значением колонки article_read.source ? Результат всегда будет булевым значением ( True или False ).
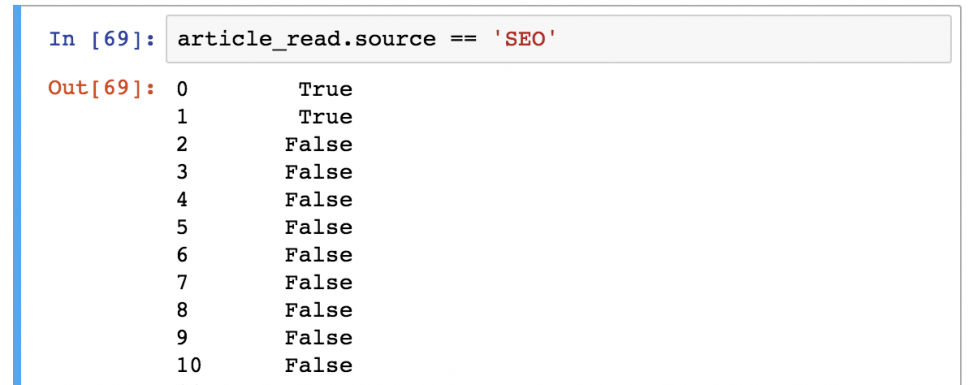
Шаг 2) Затем он выводит каждую строку со значением True из таблицы article_read .
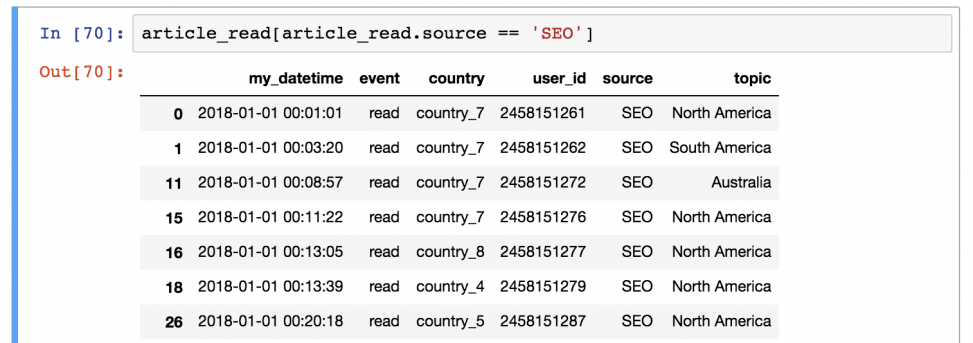
Выглядит сложно? Возможно. Но именно так это и работает, поэтому просто выучите, потому что пользоваться этим придется часто!
Функции могут использоваться одна за другой
Важно понимать, что логика pandas очень линейна (как в SQL, например). Поэтому если вы применяете функцию, то можете применить другую к ней же. В таком случае входящие данные последней функции будут выводом предыдущей.
Например, объединим эти два метода перебора:
article_read.head()[['country', 'user_id']] Первая строчка выбирает первые 5 строк из набора данных. Потом она выбирает колонки «country» и «user_id».
Можно ли получить тот же результат с иной цепочкой функций? Конечно:
article_read[['country', 'user_id']].head() В этом случае сначала выбираются колонки, а потом берутся первые 5 строк. Результат такой же — порядок функций (и их исполнение) отличается.
А что будет, если заменить значение «article_read» на оригинальную функцию read_csv():
pd.read_csv( 'pandas_tutorial_read.csv', delimiter=';', names = ['my_datetime', 'event', 'country', 'user_id', 'source', 'topic'] )[['country', 'user_id']].head() Так тоже можно, но это некрасиво и неэффективно. Важно понять, что работа с pandas — это применение функций и методов один за одним, и ничего больше.
Проверьте себя!
Как обычно, небольшой тест для проверки! Выполните его, чтобы лучше запомнить материал!
Выберите used_id , country и topic для пользователей из country_2 . Выведите первые 5 строк!
А вот и решение!
Его можно преподнести одной строкой:
article_read[article_read.country == 'country_2'][['user_id','topic', 'country']].head() Или, чтобы было понятнее, можно разбить на несколько строк:
ar_filtered = article_read[article_read.country == 'country_2'] ar_filtered_cols = ar_filtered[['user_id','topic', 'country']] ar_filtered_cols.head() В любом случае, логика не отличается. Сначала берется оригинальный dataframe ( article_read ), затем отфильтровываются строки со значением для колонки country — country_2 ( [article_read.country == ‘country_2’] ). Потому берутся три нужные колонки ( [[‘user_id’, ‘topic’, ‘country’]] ) и в конечном итоге выбираются только первые пять строк ( .head() ).
Итого
Вот и все. В следующей статье вы узнаете больше о разных методах агрегации (например, sum, mean, max, min) и группировки.
Read_csv в pandas записывает все значения в первый столбец
Есть проблема, при открытии csv файла через библиотеку pandas, все данные записываются только в первый столбец. Вот код:
1 2 3 4
import pandas as pd data = pd.read_csv('titanic.csv', index_col='PassengerId') print(data)
Когда программа печатает ‘data’, то первая строка (с названиями столбцов) разделяется, а все последующие строки остаются неразделёнными и записаны в первый столбец. У остальных колонн значения NaN. Я пробовала писать имя файла полностью, а также sep=’,’, но это не помогло. Что надо написать в коде, чтобы произошло это разделение и в каждом столбце были значения?
94731 / 64177 / 26122
Регистрация: 12.04.2006
Сообщений: 116,782
Ответы с готовыми решениями:

Python pandas read_csv
При помощи Python pandas read_csv нужно прочитать файл csv прочитать нужно определенные колонки.
Перенести в первый столбец максимальные значения элементов строк
Доброго времени суток. Я понимаю, что просить что-то сделать за тебя не очень приветствуется тут.
Автоматизируй это!
![]()
7540 / 4556 / 1206
Регистрация: 30.03.2015
Сообщений: 13,118
Записей в блоге: 29
а у меня все нормально, давай пример цсвшки
Регистрация: 29.07.2019
Сообщений: 9
Я не знаю, как прикрепить файл, поэтому вот ссылка, надеюсь, сработает
![]()
5415 / 3839 / 1214
Регистрация: 28.10.2013
Сообщений: 9,554
Записей в блоге: 1
![]()
5415 / 3839 / 1214
Регистрация: 28.10.2013
Сообщений: 9,554
Записей в блоге: 1
P.S. Не надо выводить dataframe в консоль. Для этого существует Jupyter Notebook.
Регистрация: 29.07.2019
Сообщений: 9
Jupyter Notebook скачала, но при его открытии открывается вкладка в браузере, где предлагается написать код. Так должно быть?
Ещё, если я пишу там код, то он не работает: OSError: File b’titanic.csv’ does not exist.
![]()
5415 / 3839 / 1214
Регистрация: 28.10.2013
Сообщений: 9,554
Записей в блоге: 1
![]() Сообщение от lazy_fox
Сообщение от lazy_fox 
File b’titanic.csv’ does not exist
Тут написано что файла не существует. Это не значит что Jupyter Notebook не работает, это значит что вы не понимаете элементарных вещей. Если путь к файлу не указан полностью — как интерпретатор узнает, где он находится?
Он будет искать его в текущем рабочем каталоге, но если текущий рабочий каталог не совпадает с локацией файла — файл не будет найден.
![]() Сообщение от lazy_fox
Сообщение от lazy_fox
но при его открытии открывается вкладка в браузере, где предлагается написать код. Так должно быть?
Это web-среда выполнения кода для научных библиотек — с огромным числом плюшек. Вы документацию хотя бы попробуйте прочитать.
Регистрация: 29.07.2019
Сообщений: 9
Допустим, код стал рабочим, но он по-прежнему выводит все данные строк в первом столбце
![]()
5415 / 3839 / 1214
Регистрация: 28.10.2013
Сообщений: 9,554
Записей в блоге: 1
У меня нет.
Версия pandas последняя — ‘0.25.0’.
![]()
5415 / 3839 / 1214
Регистрация: 28.10.2013
Сообщений: 9,554
Записей в блоге: 1
P.S. В Jupyter не нужно использовать print.
Добавлено через 37 минут
И попробуйте явно указать сепаратор и прочие настройки в read_csv: sep=’,’,quotechar='»‘
На версии Python 3.7 все работает адекватно настройкам по умолчанию.
Регистрация: 29.07.2019
Сообщений: 9
Решение нашлось! Было внесено небольшое изменение, а именно — заменить файл, на ссылку на него же.
1 2 3
import pandas as pd data = pd.read_csv(r'https://d3c33hcgiwev3.cloudfront.net/_ea07570741a3ec966e284208f588e50e_titanic.csv?Expires=1564531200&Signature=M4epRwTTp4dI7UVyfrknLlFK3pkcArrTSUcbsH9UlifN7unlI~VNbd6eXEbH00CPSR8gIDab0U9k7DDVCRQgo2vqL-O1bUJMFWiwEJGV4PHJsuePclNaYUasQSZbynojhbG8CCojS-vUs0Sqhf1lGGiyvPrEW~v~Z6BW~rj0ETk_&Key-Pair-Id=APKAJLTNE6QMUY6HBC5A', index_col='PassengerId') print(data)
Такое решение сработало и все строки разделились по нужным столбцам.
![]()
5415 / 3839 / 1214
Регистрация: 28.10.2013
Сообщений: 9,554
Записей в блоге: 1
![]() Сообщение от lazy_fox
Сообщение от lazy_fox
Решение нашлось!
Это не решение. Это какой-то очень странный костыль.
Регистрация: 29.07.2019
Сообщений: 9
Ещё 1 вариант, который как мне кажется более простой для исправления. Дело в кодировке. По крайней мере у меня требовалось при чтении файла encoding=’cp1251′
То есть сама программа должна выглядеть так:
1 2 3 4
import pandas as pd data = pd.read_csv('titanic.csv', index_col='PassengerId', encoding='cp1251') print(data)
Ну или какая-то другая кодировка
87844 / 49110 / 22898
Регистрация: 17.06.2006
Сообщений: 92,604
Помогаю со студенческими работами здесь
перенести в первый столбец максимальные значения элементов строк
собственно задание: перенести в первый столбец максимальные значения элементов строк. Подсобите.
Поменять местами первый столбец и столбец и столбец, где находится максимальный элемент массива
Дан двумерный массив вещественных чисел из 4 столбцов и 3 строк. Поменять местами первый столбец и.
Программа, определяющая, есть ли в массиве хотя бы один столбец, содержащий все одинаковые значения, содержащий все разные значения
Написать программу, определяющую есть ли в массиве хотя бы один столбец, содержащий все одинаковые.
перенести в первый столбец максимальные значения элементов строк матрицы
Помогитие реализовать: перенести в первый столбец максимальные значения элементов строк.
Найти в матрице первый столбец, все элементы которого положительны
Здравствуйте . Помогите пожалуйста написать код. Уже 3 день бьюсь. не получается. Найти в.
Найти в матрице первый столбец, все элементы которого отрицательны
Есть затруднения с заданием 1. Необходимо создать программу, которая выполняет действия из.
Найти в матрице первый столбец, все элементы которого отрицательны
Найти в матрице первый столбец, все элементы которого отрицательны, и среднее арифметическое этих.
Редактируем CSV-файлы, чтобы не сломать данные

Продукты HFLabs в промышленных объемах обрабатывают данные: адреса, ФИО, реквизиты компаний и еще вагон всего. Естественно, тестировщики ежедневно с этими данными имеют дело: обновляют тест-кейсы, изучают результаты очистки. Часто заказчики дают «живую» базу, чтобы тестировщик настроил сервис под нее.
Первое, чему мы учим новых QA — сохранять данные в первозданном виде. Все по заветам: «Не навреди». В статье я расскажу, как аккуратно работать с CSV-файлами в Excel и Open Office. Советы помогут ничего не испортить, сохранить информацию после редактирования и в целом чувствовать себя увереннее.
Материал базовый, профессионалы совершенно точно заскучают.
Что такое CSV-файлы
Формат CSV используют, чтобы хранить таблицы в текстовых файлах. Данные очень часто упаковывают именно в таблицы, поэтому CSV-файлы очень популярны.

CSV-файл состоит из строк с данными и разделителей, которые обозначают границы столбцов
CSV расшифровывается как comma-separated values — «значения, разделенные запятыми». Но пусть название вас не обманет: разделителями столбцов в CSV-файле могут служить и точки с запятой, и знаки табуляции. Это все равно будет CSV-файл.
У CSV куча плюсов перед тем же форматом Excel: текстовые файлы просты как пуговица, открываются быстро, читаются на любом устройстве и в любой среде без дополнительных инструментов.
Из-за своих преимуществ CSV — сверхпопулярный формат обмена данными, хотя ему уже лет 40. CSV используют прикладные промышленные программы, в него выгружают данные из баз.
Одна беда — текстового редактора для работы с CSV мало. Еще ничего, если таблица простая: в первом поле ID одной длины, во втором дата одного формата, а в третьем какой-нибудь адрес. Но когда поля разной длины и их больше трех, начинаются мучения.

Следить за разделителями и столбцами — глаза сломаешь
Еще хуже с анализом данных — попробуй «Блокнотом» хотя бы сложить все числа в столбце. Я уж не говорю о красивых графиках.
Поэтому CSV-файлы анализируют и редактируют в Excel и аналогах: Open Office, LibreOffice и прочих.
Ветеранам, которые все же дочитали: ребята, мы знаем об анализе непосредственно в БД c помощью SQL, знаем о Tableau и Talend Open Studio. Это статья для начинающих, а на базовом уровне и небольшом объеме данных Excel с аналогами хватает.
Как Excel портит данные: из классики
Все бы ничего, но Excel, едва открыв CSV-файл, начинает свои лукавые выкрутасы. Он без спроса меняет данные так, что те приходят в негодность. Причем делает это совершенно незаметно. Из-за этого в свое время мы схватили ворох проблем.
Большинство казусов связано с тем, что программа без спроса преобразует строки с набором цифр в числа.
Округляет. Например, в исходной ячейке два телефона хранятся через запятую без пробелов: «5235834,5235835». Что сделает Excel? Лихо превратит номера́ в одно число и округлит до двух цифр после запятой: «5235834,52». Так мы потеряем второй телефон.
Приводит к экспоненциальной форме. Excel заботливо преобразует «123456789012345» в число «1,2E+15». Исходное значение потеряем напрочь.
Проблема актуальна для длинных, символов по пятнадцать, цифровых строк. Например, КЛАДР-кодов (это такой государственный идентификатор адресного объекта: го́рода, у́лицы, до́ма).
Удаляет лидирующие плюсы. Excel считает, что плюс в начале строки с цифрами — совершенно лишний символ. Мол, и так ясно, что число положительное, коль перед ним не стоит минус. Поэтому лидирующий плюс в номере «+74955235834» будет отброшен за ненадобностью — получится «74955235834». (В реальности номер пострадает еще сильнее, но для наглядности обойдусь плюсом).
Потеря плюса критична, например, если данные пойдут в стороннюю систему, а та при импорте жестко проверяет формат.
Разбивает по три цифры. Цифровую строку длиннее трех символов Excel, добрая душа, аккуратно разберет. Например, «8 495 5235834» превратит в «84 955 235 834».
Форматирование важно как минимум для телефонных номеров: пробелы отделяют коды страны и города от остального номера и друг от друга. Excel запросто нарушает правильное членение телефона.
Удаляет лидирующие нули. Строку «00523446» Excel превратит в «523446».
А в ИНН, например, первые две цифры — это код региона. Для Республики Алтай он начинается с нуля — «04». Без нуля смысл номера исказится, а проверку формата ИНН вообще не пройдет.
Меняет даты под локальные настройки. Excel с удовольствием исправит номер дома «1/2» на «01.фев». Потому что Windows подсказал, что в таком виде вам удобнее считывать даты.
Побеждаем порчу данных правильным импортом
Если серьезно, в бедах виноват не Excel целиком, а неочевидный способ импорта данных в программу.
По умолчанию Excel применяет к данным в загруженном CSV-файле тип «General» — общий. Из-за него программа распознает цифровые строки как числа. Такой порядок можно победить, используя встроенный инструмент импорта.
Запускаю встроенный в Excel механизм импорта. В меню это «Data → Get External Data → From Text».
Выбираю CSV-файл с данными, открывается диалог. В диалоге кликаю на тип файла Delimited (с разделителями). Кодировка — та, что в файле, обычно определяется автоматом. Если первая строка файла — шапка, отмечаю «My Data Has Headers».
Перехожу ко второму шагу диалога. Выбираю разделитель полей (обычно это точка с запятой — semicolon). Отключаю «Treat consecutive delimiters as one», а «Text qualifier» выставляю в «». (Text qualifier — это символ начала и конца текста. Если разделитель в CSV — запятая, то text qualifier нужен, чтобы отличать запятые внутри текста от запятых-разделителей.)
На третьем шаге выбираю формат полей, ради него все и затевалось. Для всех столбцов выставляю тип «Text». Кстати, если кликнуть на первую колонку, зажать шифт и кликнуть на последнюю, выделятся сразу все столбцы. Удобно.
Дальше Excel спросит, куда вставлять данные из CSV — можно просто нажать «OK», и данные появятся в открытом листе.
Перед импортом придется создать в Excel новый workbook
Но! Если я планирую добавлять данные в CSV через Excel, придется сделать еще кое-что.
После импорта нужно принудительно привести все-все ячейки на листе к формату «Text». Иначе новые поля приобретут все тот же тип «General».
- Нажимаю два раза Ctrl+A, Excel выбирает все ячейки на листе;
- кликаю правой кнопкой мыши;
- выбираю в контекстном меню «Format Cells»;
- в открывшемся диалоге выбираю слева тип данных «Text».
Чтобы выделить все ячейки, нужно нажать Ctrl+A два раза. Именно два, это не шутка, попробуйте
После этого, если повезет, Excel оставит исходные данные в покое. Но это не самая твердая гарантия, поэтому мы после сохранения обязательно проверяем файл через текстовый просмотрщик.
Альтернатива: Open Office Calc
Для работы с CSV-файлами я использую именно Calc. Он не то чтобы совсем не считает цифровые данные строками, но хотя бы не применяет к ним переформатирование в соответствии с региональными настройками Windows. Да и импорт попроще.
Конечно, понадобится пакет Open Office (OO). При установке он предложит переназначить на себя файлы MS Office. Не рекомендую: хоть OO достаточно функционален, он не до конца понимает хитрое микрософтовское форматирование документов.
А вот назначить OO программой по умолчанию для CSV-файлов — вполне разумно. Сделать это можно после установки пакета.
Итак, запускаем импорт данных из CSV. После двойного клика на файле Open Office показывает диалог.
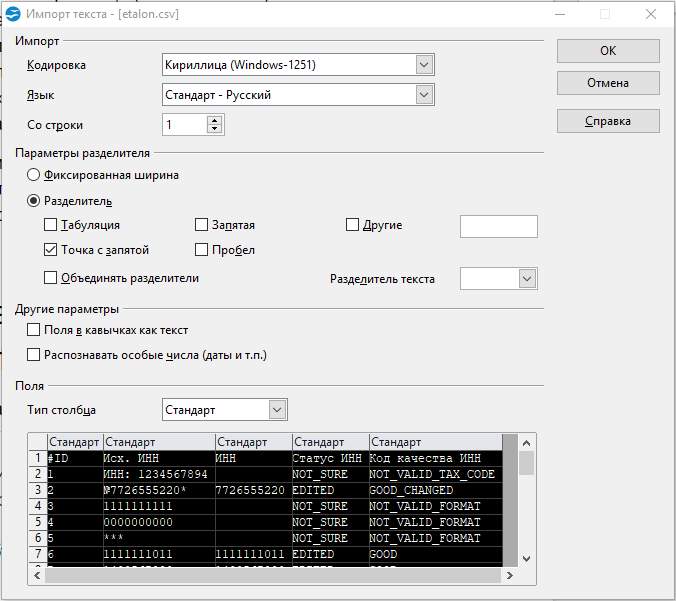
Заметьте, в OO не нужно создавать новый воркбук и принудительно запускать импорт, все само
- Кодировка — как в файле.
- «Разделитель» — точка с запятой. Естественно, если в файле разделителем выступает именно она.
- «Разделитель текста» — пустой (все то же, что в Excel).
- В разделе «Поля» кликаю в левый-верхний квадрат таблицы, подсвечиваются все колонки. Указываю тип «Текст».
Помимо Calc у нас в HFLabs популярен libreOffice, особенно под «Линуксом». И то, и другое для CSV применяют активнее, чем Excel.
Бонус-трек: проблемы при сохранении из Calc в .xlsx
Если сохраняете данные из Calc в экселевский формат .xlsx, имейте в виду — OO порой необъяснимо и масштабно теряет данные.
Белая пустошь, раскинувшаяся посередине, в оригинальном CSV-файле богато заполнена данными
Поэтому после сохранения я еще раз открываю файл и убеждаюсь, что данные на месте.
Если что-то потерялись, лечение — пересохранить из CSV в .xlsx. Или, если установлен Windows, импортнуть из CSV в Excel и сохранить оттуда.
После пересохранения обязательно еще раз проверяю, что все данные на месте и нет лишних пустых строк.
Если интересно работать с данными, посмотрите на наши вакансии. HFLabs почти всегда нужны аналитики, тестировщики, инженеры по внедрению, разработчики. Данными обеспечим так, что мало не покажется 🙂
- Блог компании HFLabs
- Информационная безопасность
- IT-стандарты
- Хранение данных
- Софт