Как получить расширение и размер файла в Python
Мы можем использовать функцию splitext() модуля os в Python, чтобы получить расширение файла. Эта функция разбивает путь к файлу на кортеж, имеющий два значения – корень и расширение.
Вот простая программа для получения расширения файла на Python.
import os # unpacking the tuple file_name, file_extension = os.path.splitext("/Users/pankaj/abc.txt") print(file_name) print(file_extension) print(os.path.splitext("/Users/pankaj/.bashrc")) print(os.path.splitext("/Users/pankaj/a.b/image.png"))

- В первом примере мы напрямую распаковываем значения кортежа в две переменные.
- Обратите внимание, что файл .bashrc не имеет расширения. К имени файла добавляется точка, чтобы сделать его скрытым.
- В третьем примере в имени каталога есть точка.
Получение расширения файла с помощью модуля Pathlib
Мы также можем использовать модуль pathlib, чтобы получить расширение файла. Этот модуль был представлен в версии Python 3.4.
>>> import pathlib >>> pathlib.Path("/Users/pankaj/abc.txt").suffix '.txt' >>> pathlib.Path("/Users/pankaj/.bashrc").suffix '' >>> pathlib.Path("/Users/pankaj/.bashrc") PosixPath('/Users/pankaj/.bashrc') >>> pathlib.Path("/Users/pankaj/a.b/abc.jpg").suffix '.jpg' >>>
Всегда лучше использовать стандартные методы, чтобы получить расширение файла. Если вы уже используете модуль os, используйте метод splitext(). Для объектно-ориентированного подхода используйте модуль pathlib.
Получение размера файла
Мы можем получить размер файла в Python, используя модуль os.
Модуль os имеет функцию stat(), где мы можем передать имя файла в качестве аргумента. Эта функция возвращает структуру кортежа, содержащую информацию о файле. Затем мы можем получить его свойство st_size, чтобы получить размер файла в байтах.
Вот простая программа для печати размера файла в байтах и мегабайтах.
# get file size in python import os file_name = "/Users/pankaj/abcdef.txt" file_stats = os.stat(file_name) print(file_stats) print(f'File Size in Bytes is ') print(f'File Size in MegaBytes is ')

Если вы посмотрите на функцию stat(), мы можем передать еще два аргумента: dir_fd и follow_symlinks. Однако они не реализованы для Mac OS.
Вот обновленная программа, в которой я пытаюсь использовать относительный путь, но выдает NotImplementedError.
# get file size in python import os file_name = "abcdef.txt" relative_path = os.open("/Users/pankaj", os.O_RDONLY) file_stats = os.stat(file_name, dir_fd=relative_path)
Traceback (most recent call last): File "/Users/pankaj/. /get_file_size.py", line 7, in file_stats = os.stat(file_name, dir_fd=relative_path) NotImplementedError: dir_fd unavailable on this platform
Статья Определение типа файла по его сигнатуре с помощью Python
Вполне возможно, что при разработке приложений вам может понадобиться определение типа файла. И не всегда тип файла можно узнать по расширению. Если в ОС Linux это не составляет больших проблем, так как данная операционная система распознает тип файла не по расширению, а по содержимому, то вот в Windows отсутствие расширения иногда вызывает множество вопросов. Давайте попробуем понять, как можно определить тип файла с помощью Python.
К сожалению, в Python встроенного модуля для определения типа файлов нет. Но есть модули сторонних разработчиков. Да, в стандартной поставке есть mimetypes, однако распознавать содержимое файла без расширения он не умеет.
Из сторонних модулей можно выделить magic. С ее помощью довольно точно можно узнать mime-тип файла. Вот только работа данного модуля завязана на библиотеку libmagic1. То есть, по сути это просто оболочка вокруг данной библиотеки. И для работы модуля требуется ее наличие. И если в Linux зачастую она установлена по умолчанию, то вот в Windows понадобиться установить библиотеки DLL. Давайте чуть подробнее рассмотрим, что нужно для того, чтобы работать с данным модулем, его установку и требования.
Что понадобиться?
Для начала необходимо установить сам модуль. Поэтому пишем в терминале команду:
pip install python-magic
В принципе, если вы работаете в Linux, установки библиотеки libmagic1 может и не понадобиться. К примеру, в Linux Mint данная библиотека установлена «из коробки». Однако, если, все же, у вас ее нет, то установка библиотеки в Ubuntu/Debian делается командой:
sudo apt-get install libmagic1
Если вы работаете в операционной системе Windows, то нужно установить DLL с помощью команды:
pip install python-magic-bin
В принципе, на этом все. Для работы модуля больше ничего особо не требуется.
Определение mime-типа файла с помощью magic
Давайте напишем маленький скрипт, для примера, чтобы понять, как работает данная библиотека.
Импортируем в скрипт нужные модули:
from pathlib import Path import magicТеперь напишем небольшую функцию из одной строки, которая будет принимать путь к файлу и просто печатать его mime-тип.
def mime_magic(path): print(magic.Magic(mime=True).from_file(path))И теперь, в функции main, вызовем данную функцию и передадим в нее путь к файлу.
def main(): path = input("Введите путь к файлу: ") if not Path(path).exists(): print("Файла не существует!") mime_magic(path) if __name__ == "__main__": main()Скрипт в сборе
from pathlib import Path import magic def mime_magic(path): print(magic.Magic(mime=True).from_file(path)) def main(): path = input("Введите путь к файлу: ") if not Path(path).exists(): print("Файла не существует!") mime_magic(path) if __name__ == "__main__": main()Я специально удалил расширение у файла и передал в функцию путь к нему. И вот, что я получил на выходе:
Однако, как я уже писал ранее, данный модуль — это только обертка python над библиотекой libmagic1. И здесь, если вы пишите переносимое приложение, придется тащить за собой все остальные зависимости. Проверять, установлена ли библиотека или, в случае с Windows устанавливать библиотеки DLL.
Но, есть еще один, более «хардкорный» путь. Ничего нового в нем нет, но он требует получения сигнатуры файла и сравнения со списком или словарем сигнатур для получения типа файла.
Определение типа файла по его сигнатуре
Понятие сигнатура файла известно так же как «магическое число». Это целочисленная или текстовая константа, с помощью которой можно однозначно идентифицировать ресурс или данные. Само по себе, это число не несет никакого смысла. Примером такого магического числа может служить исполняемый файл Windows с расширением .exe. Он начинается с последовательности байт 0x4D5A, и это само по себе символично, так как соответствует ASCII-символам MZ, которые являются инициалами Марка Збиковски являющегося одним из создателей MS-DOS.
В Linux, как я уже писал выше, тип файла определяется по его содержимому, точнее, по его сигнатуре, вне зависимости от его расширения и названия. Для того, чтобы интерпретировать сигнатуру файла можно использовать стандартную утилиту file.
Как же можно использовать это в скрипте python? Для примера я составил небольшой словарик сигнатур файлов. Конечно же, это только очень маленькая часть от огромного количества самых разнообразных сигнатур. Однако, это уже позволяет определить тип некоторых мультимедийных форматов файлов. Данные сигнатуры были взяты из статьи Википедии по этому
Ссылка скрыта от гостей
. Давайте от теории перейдем к практике.
Для начала импортируем нужные модули в наш скрипт. Здесь нам понадобятся два стандартных модуля: sys и Path из библиотеки pathlib.
import sys from pathlib import PathТеперь инициализируем словарь с сигнатурами. Конечно же, если бы это был более масштабный проект, имело бы смысл вынести данные сигнатуры в отдельный модуль или json-файл. Но, так как, это лишь пример того, как определить сигнатуру, словарь маленький, а потому выносить его в отдельный модуль не имеет смысла.
signature =
Напишем небольшую функцию, в которой и будет происходить основное действие. Я назвал ее read_file(path). На входе она получает путь к файлу, тип которого требуется определить. А на выходе мы получаем тип файла или сообщение о невозможности определить сигнатуру.
Откроем файл на чтение в байтовом режиме. Считаем первые 256 байт. Этого вполне достаточно для того, чтобы определить тип файла. Переведем полученные данные в шестнадцатеричный вид.
with open(path, 'rb') as f: file = f.read(256) hex_bytes = " ".join([''.format(byte) for byte in file])
Запустим цикл для итерации по словарю сигнатур. В данном цикле запустим еще один цикл для итерации по полученной сигнатуре с определенным смещением. Сигнатуры типов файлов, которые представлены в моем словаре имею либо нулевое, либо смещение 4 байта. С учетом пробелов, это будет 12 символов. И дальше сравниваем сигнатуру из словаря с текущим куском байт, со смещением имеющим длину текущей сигнатуры. Если сигнатура найдена, возвращаем сообщение с именем файла и его типом. Если же сигнатура не найдена — возвращаем сообщение о неизвестной сигнатуре.
for hex_ch in signature: for i in [0, 12]: if hex_ch == str(hex_bytes[i:len(hex_ch) + i]): return f'Файл: "" имеет сигнатуру: "" файла' continue return "Неизвестная сигнатура"
Ну и функция main, в которой получаем путь к файлу и вызываем функцию read_file, в которую передаем полученный путь предварительно проверенный на существование.
def main(): path = input("Введите путь к файлу: ") if not Path(path).exists(): print("Файла не существует!") sys.exit(0) print(read_file(path)) if __name__ == "__main__": main()Полный код скрипта
import sys from pathlib import Path signature = < "66 74 79 70 33 67": "3gp, 3gp2", "FF D8 FF E0": "jpg", "49 46 00 01": "jpeg", "89 50 4E 47 0D 0A 1A 0A": "png", "25 50 44 46 2D": "pdf", "4F 67 67 53": "ogg, oga, ogv", "52 49 46 46": "wav", "57 41 56 45": "wav", "41 56 49 20": "avi", "FF FB": "mp3", "FF F3": "mp3", "FF F2": "mp3", "49 44 33": "mp3", "66 4C 61 43": "flac", "1A 45 DF A3": "mkv, mka, mks, mk3d, webm", "47": "ts, tsv, tsa", "00 00 01 BA": "mpg, mpeg", "00 00 01 B3": "mpg, mpeg", "66 74 79 70 4D 53 4E 56": "mp4", "66 74 79 70 69 73 6F 6D": "mp4", "66 74 79 70 6D 70 34 32": "m4v" >def read_file(path: str) -> str: """ Получение сигнатуры файла. Итерация по словарю сигнатур и сравнение их с полученной сигнатурой в соответствии со смещением. :param path: Путь к файлу. :return: Строка, тип файла или сообщение о неизвестной сигнатуре. """ with open(path, 'rb') as f: file = f.read(256) hex_bytes = " ".join([''.format(byte) for byte in file]) for hex_ch in signature: for i in [0, 12]: if hex_ch == str(hex_bytes[i:len(hex_ch) + i]): return f'Файл: "" имеет сигнатуру: "" файла' continue return "Неизвестная сигнатура" def main(): path = input("Введите путь к файлу: ") if not Path(path).exists(): print("Файла не существует!") sys.exit(0) print(read_file(path)) if __name__ == "__main__": main()Для теста я выбрал файл mp3 без расширения и файл mp4 скачанный с YouTube. И вот что у меня получилось:
Как видно из вышеприведенных примеров, определение файла по его сигнатуре работает успешно. Однако, для использования в серьезных проектах, думаю, что словарь со списком сигнатур следует несколько видоизменить и добавить группу сигнатур, которая будет определятся смещением, чтобы при итерации считывать смещение из самого словаря.
А на этом пожалуй все.
Спасибо за внимание. Надеюсь, что данная информация будет вам полезна
Определение типа файла без расширения в Python
Определение типа файла без расширения или по его содержимому (если тип указан неверно) можно при помощи стороннего модуля magic .
Установить модуль magic можно через менеджер пакетов pip . Устанавливайте сторонние модули только в виртуальное окружение.
Модуль python-magic — это интерфейс Python для библиотеки ОС идентификации типов файлов libmagic . Эта библиотека идентифицирует типы файлов, проверяя их заголовки в соответствии с предопределенным списком типов файлов. Функция операционной системы magic() доступна в командной строке с помощью командного файла Unix.
(myVenv) $ pip install python-magic
>>> import magic >>> mime = magic.Magic(mime=True) >>> mime.from_file("testdata/test.pf") # 'application/pdf' >>> magic.from_file('iceland.jpg') # 'JPEG image data, JFIF standard 1.01' >>> magic.from_file('iceland.jpg', mime=True) # 'image/jpeg' >>> magic.from_file('greenland.png') # 'PNG image data, 600 x 1000, 8-bit colormap, non-interlaced' >>> magic.from_file('greenland.png', mime=True) # 'image/png'
Если файл большой, то можно прочитать часть файла в буфер. Рекомендуется использовать по крайней мере первые 2048 байт, так как меньше может привести к неправильной идентификации.
>>> import magic # рекомендуется использовать по крайней мере первые 2048 байт, # так как меньше может привести к неправильной идентификации >>> magic.from_buffer(open("testdata/test.pdf").read(2048)) # 'PDF document, version 1.2'
Можно даже распознать формат файла упакованного в архив!
>>> import magic >>> f = magic.Magic(uncompress=True) >>> f.from_file('testdata/test.gz') # 'ASCII text (gzip compressed data, was "test", last modified: # Mon 04 Jan 2021 01:55:22 PM MSK, from Unix)'
Можно также комбинировать параметры флагов.
>>> f = magic.Magic(mime=True, uncompress=True) >>> f.from_file('testdata/test.gz') # 'text/plain'
- ОБЗОРНАЯ СТРАНИЦА РАЗДЕЛА
- Функция init() модуля mimetypes
- Функция guess_type() модуля mimetypes
- Функции guess_all_extensions() и guess_extensions() модуля mimetypes
- Функция add_type() модуля mimetypes
- Функция read_mime_types() модуля mimetypes
- Класс MimeTypes() модуля mimetypes
- Словари MIME-типов, загружаемые модулем mimetypes из системы
- Как определить тип файла по его содержимому
Шпаргалка по форматам файлов с данными в python
Python понимает все популярные форматы файлов. Кроме того, у каждой библиотеки есть свой, «теплый ламповый», формат. Синтаксис, разумеется, у каждого формата сугубо индивидуален. Я собрал все функции для работы с файлами разных форматов на один лист A4, с приложением в виде примера использования в jupyter notebook.
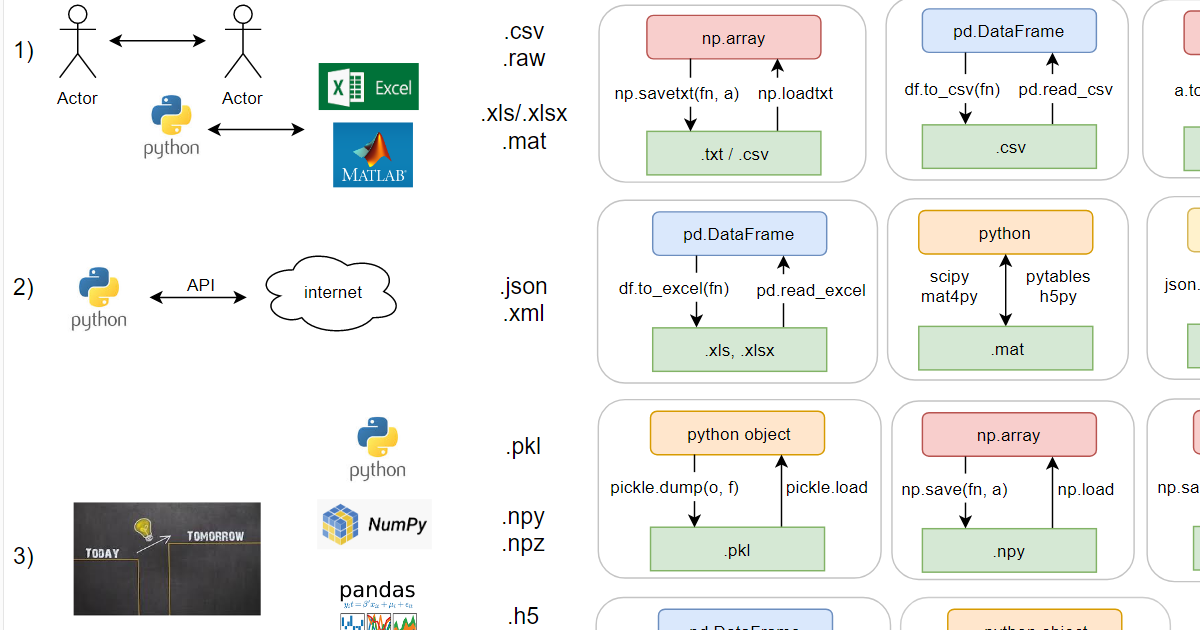
Я условно разделил форматы на три блока по способу использования. Как известно, файлы нужны для обмена информацией: между людьми, между программами (первый блок), между компьютером и сетью (второй) и «save game» – между одной и той же программой в разные моменты времени (третий блок).
Вкратце о каждом блоке:
1) Универсальные форматы:
- .csv – текстовый, значения, разделённые по идее запятыми (comma separated), но например, русский эксель предпочитает разделять точками с запятыми, поскольку в русской локали запятая уже используется – в качестве десятичного разделителя;
- .raw – бинарный формат для тех, кто не любит форматы файлов. Тип данных и, если данные многомерные, соответствующие размеры должны передаваться отдельно, в файле только сами данные;
- .xls/.xlsx – старый бинарный (ограничение в 65k строк) и новый xml’ный форматы экселя;
- .mat – это на самом деле тоже два формата (оба бинарные): старый проприетарный и новый на основе hdf5. Питон умеет работать с обоими (через библиотеки).
- .json – текстовый, выглядит как словарь в питоне, но кавычки можно использовать только двойные;
- .xml – текстовый, похож на html.
- .pkl – бинарный формат, в него умеют сохраняться все встроенные питоновские объекты. Пользовательские классы тоже умеют, а если питон сохраняет как-то не так, можно ему помочь через магические методы. Поддерживает дописывание в конец существующего файла (appending).
- .npy и .npz – в numpy аж целых два своих формата (оба бинарные). Появились как реакция на потерю обратной совместимости у pkl в момент перехода python v2->v3. Накладные расходы минимальные (~ на 100 байт больше, чем соответствующий raw; pkl, впрочем, немногим больше: на ~150 байт больше raw). В .npy можно сохранить только один массив, а в npz – сразу несколько, причём достать их оттуда впоследствии можно по имени.
- .h5 – бинарный формат hdf5. Примечателен тем, что в нем можно хранить целую иерархическую структуру данных, это практически файловая система в одном файле. Кроме того, его можно открыть в matlab без конвертации. Минусы:
a) небольшие файлы занимают неоправданно много места (например, 300 байт pkl vs 3.1 Мb у h5),
b) много багов,
c) есть дописывание в существующий файл, но если при этом случится ошибка (а так бывает), данные из него достать будет проблематично.

– в формате pdf
– в формате png:
Пример использования всех функций с диаграммы: html с оглавлением и ipynb-исходником