Семь практических советов по массовой загрузке данных в PostgreSQL
Иногда возникает необходимость в несколько простых шагов загрузить в БД PostgreSQL большой объём данных. Данная практика обычно называется массовым импортом, когда в качестве источника данных служит один или несколько больших файлов. Данный процесс иногда может проходить неприемлемо медленно. Существует несколько причин такой низкой производительности. Вызывать задержки могут индексы, триггеры, внешние и первичные ключи или даже запись WAL – файлов.
В этой статье мы дадим несколько практических советов по массовому импорту данных в БД PostgreSQL. Однако, могут возникнуть ситуации, когда ни один из них не станет эффективным решением проблемы. Мы рекомендуем читателям рассмотреть достоинства и недостатки любого метода, прежде чем применить его.
Совет 1. Перевод целевой таблицы в нежурналируемый режим
В PostgreSQL9.5 и выше целевую таблицу можно перевести в нежурналируемый режим, а после загрузки данных вернуть в журналируемый.
ALTER TABLE SET UNLOGGED; ALTER TABLE LOGGED;Нежурналируемый режим гарантирует, что PostgreSQL не будет отправлять операции загрузки в таблицу в журнал предзаписи (WAL). Это может значительно ускорить процесс загрузки. Однако, раз эти операции не логируются, данные не смогут быть восстановлены в случае сбоя или незапланированного падения сервиса PostgreSQL вовремя заливки. PostgreSQL автоматически странкейтит любую нежурналируемую таблицу после рестарта.
Кроме того, нежурналируемые таблицы не реплицируются на слэйв – серверы. В таких случаях целесообразно остановить накат изменений на реплике до загрузки и восстановить его после. В зависимости от объёма данных на мастере и количества реплик, восстановление репликации может выполняться довольно долго, что может не соответствовать требованиям, предъявляемым к системам высокой доступности.
Мы рекомендуем следующие подходы для заливки данных в нежурналируемые таблицы:
- cоздание резервной копии таблицы перед переключением в нежурналируемый режим;
- восстановление наката изменений на реплики после загрузки данных;
- использование массовых нелогируемых вставок для таблиц, которые можно легко перезалить, например большие таблицы поиска или таблицы измерений.
Совет 2. Удаление и пересоздание индексов
Существующие индексы могут стать причиной значительных задержек при массовом импорте данных. Это потому, что при добавлении каждой новой строки, соответствующая строка индекса также должна обновляться.
Мы рекомендуем, по-возможности, удалять индексы на целевой таблице перед запуском массового импорта и восстанавливать их после того, как загрузка будет завершена. Несмотря на то, что создание индексов на больших таблицах может занять много времени, в целом, это будет быстрее, чем обновлять индексы во время загрузки.
DROP INDEX , … CREATE INDEX ON (column1, …,column n)Непосредственно перед созданием индексов может оказаться целесообразным временно увеличить конфигурационный параметр maintenance_work_mem. Выделение дополнительной рабочей памяти может помочь создать индексы быстрее.
Другой способ обезопасить себя, сделать копию целевой таблицы в той же БД с существующими данными и индексами. Затем эту вновь скопированную таблицу можно протестировать с массовым импортом с использованием обоих сценариев: удалением и восстановлением индексов или их динамическим обновлением. Метод, показавший лучшую производительность, потом можно использовать на основной таблице.
Совет 3. Удаление и пересоздание внешних ключей
Так же, как и индексы, ограничения внешнего ключа могут оказать влияние на производительность массового импорта из – за того, что каждый внешний ключ в каждой вставленной строке должен быть проверен на наличие соответствующего первичного ключа. Неявно PostgreSQL использует специальный триггер для проведения этой проверки.
Когда загружается большое количество строк, данный триггер должен срабатывать для каждой строки, увеличивая накладные расходы. Если это не запрещено требованиями бизнеса, мы рекомендуем удалить все внешние ключи на целевой таблице, загрузить все данные в одиночной транзакции, а после фиксации транзакции пересоздать внешние ключи.
ALTER TABLE DROP CONSTRAINT ; BEGIN TRANSACTION; COMMIT; ALTER TABLE ADD CONSTRAINT FOREIGN KEY () REFERENCES (). ;Опять же, увеличение параметра maintenance_work_mem поможет улучшить производительность при пересоздании внешних ключей.
Совет 4. Деактивация триггеров
Триггеры на INSERT или DELETE (если процесс загрузки также содержит удаление записей из целевой таблицы) могут стать причиной замедления в процессе массового импорта данных. Это связано с тем, что каждый триггер содержит программную логику, которую нужно проверить и операции, которые нужно выполнить сразу после каждой вставки или удаления строки.
Мы рекомендуем деактивировать все триггеры в целевой таблице перед началом массового импорта данных и активировать их после того, как загрузка будет завершена. Отключение всех триггеров также включает деактивацию системных триггеров, которые принудительно проверяют ограничения внешнего ключа.
ALTER TABLE DISABLE TRIGGER ALL; ALTER TABLE ENABLE TRIGGER ALL;Совет 5. Используйте команду COPY
Мы рекомендуем использовать штатную команду PostgreSQL – COPY для загрузки данных из одного или нескольких файлов. COPY оптимизирована для массовой загрузки данных. Это более эффективно, нежели запуск большого количества операторов INSERT и даже одного INSERT-а с множественным включением выражения VALUE
COPY [( column1>, … , )] FROM '' WITH (, , … , )Среди других преимуществ использования команды COPY:
- поддержка импорта, как из текстовых, так и из двоичных файлов;
- работа в транзакционном режиме;
- возможность указать структуру исходных файлов;
- возможность ограничить выборку загружаемых данных использованием выражения WHERE.
Совет 6. Используйте оператор INSERT с множественным выражением VALUE
Запуск нескольких тысяч или даже нескольких сотен тысяч операторов INSERT – плохое решение для массового импорта данных. Это потому, что каждая отдельная команда INSERT разбирается и подготавливается оптимизатором запросов, проходит все проверки ограничений целостности, оборачивается в отдельную транзакцию и записывается в WAL.
Использование оператора INSERT с множественным включением выражения VALUE поможет избежать этих накладных расходов.
INSERT INTO (, , …, ) VALUES (, , …, ), (, , …, ), (, , …, ), (, , …, ), . ;На производительность INSERTа с множественным VALUES влияют существующие индексы. Мы рекомендуем удалить индексы до запуска команды и пересоздать потом.
Ещё один аспект, который следует учесть, это общий объём оперативный памяти, доступный PostgreSQL для запуска INSERTа с множественным VALUES. Когда запускается такой INSERT, большое количество входных значений должно уместиться в RAM и если доступной памяти недостаточно, процесс может упасть с ошибкой.
Мы рекомендуем выставить параметр effective_cache_size в значение 50%, а параметр shared_buffer в значение 25% от общего объёма оперативной памяти компьютера. Также, в целях безопасности, при запуске серии INSERTов с множественным VALUES, каждый оператор будет запущен с ограничением в 1000 строк.
Совет 7. Запуск ANALYZE
Это не связано с повышением производительности массового импорта, но мы настоятельно рекомендуем запустить команду ANALYZE на целевой таблице сразу же после завершения вставки. Большое количество новых строк вызовет значительное смещение распределения данных в столбцах, и станет причиной того, что существующая статистика по таблице станет устаревшей. Когда оптимизатор запросов использует устаревшую статистику, скорость выполнения запросов может быть неприемлемо низкой. Запуск команды ANALYZE обеспечит обновление существующей статистики.
Заключение
Массовый импорт данных для приложений БД происходит не каждый день, но его работа влияет на производительность запросов. Вот почему необходимо, насколько это возможно, сократить время загрузки. Есть одна вещь, которые администраторы БД могут сделать, чтобы минимизировать возможность появления любых неожиданностей – провести оптимизацию загрузки в тестовой среде с аналогичным сервером и подобным образом сконфигурированным PostgreSQL. Есть различные сценарии загрузки данных и будет лучше испробовать каждый метод и выбрать один, который хорошо работает.
Ускорение вставки значений в базу данных
Первое, это комит после каждой записи. На HDD диске с 7200 оборотами, даже теоретический максимум — 120 транзакций в секунду, поэтому комит после каждой вставки очень плохо для производительности.
Дальше, нельзя использовать конструирование параметров в виде строки, т.е. речь о переменной values и ее подстановке . Это во-первых, уязвимо к SQL-injection, а, во-вторых, плохо для производительности, так как не используются prepared statements.
Самый быстрый способ вставки это использовать команду postgres COPY . psycopg2 выставляет ее через функции copy_from и copy_expert . Там код посложнее чем наивная вставка или даже execute_batch , но того стоит. Я наблюдал ускорение и до того правильного кода в 100 раз после перехода на COPY .
Смысл в том, что используется низкоуровневый протокол постгрес для вставки, который хорошо оптимизирован как раз для чтения/записи большого количества данных.
Как быстро вставить записи в postgresql python
Переезжаем с сервера mssql на postgresql. Я делаю это все с помощью этого кода, все работает, но жутко медленно. За 24! часа скопировало около половины, да и вроде не много там строк, да таблица большая, есть блоб поле, всего полей 40, размер таблицы около 300к строк (~2.5гб) Может есть способ ускорить процесс? или это нормально? может изза индексов? как то можно их временно отключать? комп уже сутки пашет вставляя записи, сам скрипт завис, но вставка идет, я вижу что растет размер базы.
conn_mssql = pymssql.connect(server='127.0.0.1', database='. ') cursor_mssql = conn_mssql.cursor() conn_pg = psycopg2.connect(database="..", user=". ", password="..", host="127.0.0.1", port="5432") cursor_pg = conn_pg.cursor() print "Opened database successfully" l = ["тут список полей"] cursor_mssql.execute('SELECT TOP 333333 * FROM ". "."documents";') row = cursor_mssql.fetchone() while row: # . тут обработка записей, формирование списка vals sql = """ INSERT INTO "documents" (%s) VALUES (%s); """ print sql # вот сама вставка cursor_pg.execute(sql, vals) # берем следующую сроку из MSSQL row = cursor_mssql.fetchone() conn_mssql.close() # подтверждаем записи conn_pg.commit() conn_pg.close() Отслеживать
задан 24 фев 2018 в 13:30
Алекс Лизенберг Алекс Лизенберг
908 1 1 золотой знак 7 7 серебряных знаков 19 19 бронзовых знаков
Судя по описанию, драйвер в питоне производит компиляцию каждого запроса отдельно. так что быстро с помощью этого драйвера не выйдет. хотя в документации есть initd.org/psycopg/docs/extras.html#fast-execution-helpers Надо смотреть как оно работает. В большизстве других языков можно явно отдельно делать prepare перед циклом и внутри только execute, что значительно ускоряет работу. Еще можно попробовать формировать запросы вставляющие группы строк: insert . values(%s),(%s),(%s).
24 фев 2018 в 13:44
так что возможно сымым быстрым способом окажется формирование файла с текстом inser и его выполнение утилитой командной строки psql (или передача команд ему на лету)
Как ускорить insert postgresql
Рассмотрим добавление в базу данных PostgreSQL на примере следующей таблицы:
CREATE TABLE people ( id SERIAL PRIMARY KEY, name VARCHAR(50), age INTEGER)
Добавление данных
Для добавления данных применяется SQL-инструкция INSERT . Для добавления одной строки используем метод execute() :
import psycopg2 conn = psycopg2.connect(dbname="metanit", user="postgres", password="123456", host="127.0.0.1") cursor = conn.cursor() # добавляем строку в таблицу people cursor.execute("INSERT INTO people (name, age) VALUES ('Tom', 38)") # выполняем транзакцию conn.commit() print("Данные добавлены") cursor.close() conn.close()
Здесь добавляется одна строка, где name = «Tom», а age = 38. Перед выполнением команды INSERT открывается транзакция, для завершения которой необходимо вызвать метод commit() текущего объекта Connection.
Установка параметров
С помощью второго параметра в метод execute() можно передать значения для параметров SQL-запроса:
import psycopg2 conn = psycopg2.connect(dbname="metanit", user="postgres", password="123456", host="127.0.0.1") cursor = conn.cursor() # данные для добавления bob = ("Bob", 42) cursor.execute("INSERT INTO people (name, age) VALUES (%s, %s)", bob) conn.commit() print("Данные добавлены") cursor.close() conn.close()
В данном случае добавляемые в БД значения представляют кортеж bob. В SQL-запросе вместо конкретных значений используются знаки подстановки %s . Вместо этих символов при выполнении запроса будут вставляться данные из кортежа data. Так, первый элемент кортежа — строка «Bob» передается на место первого плейсхолдера %s, второй элемент — число 42 передается на место второго плейсхолдера %s. То есть в итоге команды SQL будет выглядеть следующим образом:
INSERT INTO people (name, age) VALUES ('Bob', 42)
Также обратите внимание, что НЕ надо помещать плейсхолдер %s в кавычки — psycopg2 делает это автоматически.
И если мы посмотрим на содержимое базы данных, то найдем там все добавленные объекты:
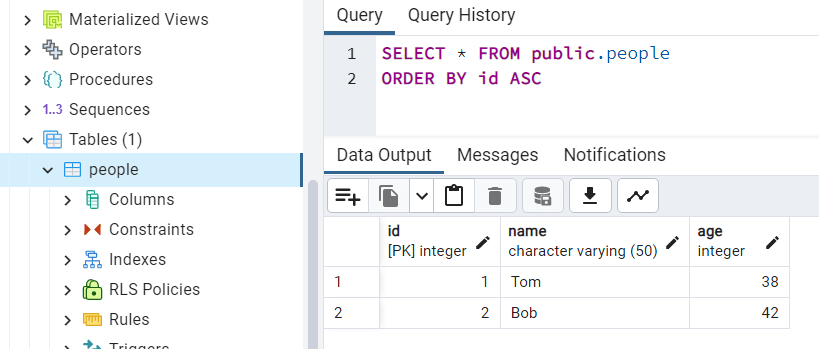
Множественная вставка
Метод executemany() позволяет вставить набор строк:
import psycopg2 conn = psycopg2.connect(dbname="metanit", user="postgres", password="123456", host="127.0.0.1") cursor = conn.cursor() # данные для добавления people = [("Sam", 28), ("Alice", 33), ("Kate", 25)] cursor.executemany("INSERT INTO people (name, age) VALUES (%s, %s)", people) conn.commit() print("Данные добавлены") cursor.close() conn.close()
В метод cursor.executemany() по сути передается то же самое выражение SQL, только теперь данные определены в виде списка кортежей people. Фактически каждый кортеж в этом списке представляет отдельную строку — данные отдельного пользователя, и при выполнении метода для каждого кортежа будет создаваться свое выражение INSERT INTO