Онлайн калькуляторы для расчета статистических критериев
В данном сервисе реализован алгоритм выбора оптимальной методики статистического анализа, который позволит исследователю на основании информации о количестве сравниваемых совокупностей, типе распределения, шкале измерения переменных, отпределить наиболее подходящий статистический метод, статистический критерий.
Калькулятор позволит найти значение любой относительной величины по заданным параметрам: числителю, знаменателю, десятичному коэффициенту. Учитывается вид относительной величины для правильного обозначения вводимых данных и формирования грамотного ответа. Для каждого результата также выводится средняя ошибка m.
Данный статистический метод служит для сравнения двух средних величин (M), рассчитанных для несвязанных между собой вариационных рядов. Для вычислений также понадобятся значения средних ошибок средних арифметических (m). Примеры сравниваемых величин: среднее артериальное давление в основной и контрольной группе, средняя длительность лечения пациентов, принимавших препарат или плацебо.
Парный t-критерий Стьюдента используется для сравнения связанных совокупностей — результатов, полученных для одних и тех же исследуемых (например, артериальное давление до и после приема препарата, средний вес пациентов до и после применения диеты).
Этот калькулятор позволит вам быстро рассчитать все основные показатели динамического ряда, состоящего из любого количества данных. Вводимые данные: количество лет, значение первого года, уровни ряда. Результат: показатели динамического ряда, значения, полученные при его выравнивании, а также графическое изображение динамического ряда.
Здесь вы сможете быстро решить любую задачу по стандартизации, с использованием прямого метода. Вводите данные о сравниваемых совокупностях, выбирайте один из четырех способов расчета стандарта, задавайте значение коэффициента, используемого для расчета относительных величин. Результаты применения метода стандартизации выводятся в виде таблицы.
Относительный риск — позволяет проводить количественную оценку вероятности исхода, связанной с наличием фактора риска. Находит широкое применение в современных научных исследованиях, выборки в которых сформированы когортным методом. Наш онлайн-калькулятор позволит выполнить расчет относительного риска (RR) с 95% доверительным интервалом (CI), а также дополнительных показателей, таких как разность рисков, число пациентов, трующих лечения, специфичность, чувствительность.
Метод отношения шансов (OR), как и относительный риск, используется для количественной оценки взаимосвязи фактора риска и исхода, но применяется в исследованиях, организованных по принципу «случай-контроль».
В данном калькуляторе представлены все основные статистические методы, используемые для анализа четырехпольной таблицы (фактор риска есть-нет, исход есть-нет). Выполняется проверка важнейших статистических гипотез, рассчитываются хи-квадрат, точный критерий Фишера и другие показатели.
Онлайн-калькулятор в автоматизированном режиме поможет рассчитать все основные показатели вариационного ряда: средние величины (средняя арифметическая, мода, медиана), стандартное отклонение, среднюю ошибку средней арифметической. Поддерживается ввод как простых, так и взвешенных рядов.
При помощи данного сервиса вы сможете рассчитать значение U-критерия Манна-Уитни — непараметрического критерия, используемого для сравнения двух выборок, независимо от характера их распределения.
Онлайн-калькулятор для проведения корреляционного анализа используется для выявления и изучения связи между количественными признаками при помощи расчета коэффициента корреляции Пирсона. Также выводится уравнение парной линейной регрессии, используемое при описании статистической модели.
Данный калькулятор используется для расчета рангового критерия корреляции Спирмена, являющегося методом непараметрического анализа зависимости одного количественного признака от другого. Оценка значимости корреляционной связи между переменными выполняется как по коэффициенту Спирмена, так и по t-критерию Стьюдента.
Критерий хи-квадрат является непараметрическим аналогом дисперсионного анализа для сравнения нескольких групп по качественному признаку. Онлайн калькулятор по расчету критерия хи-квадрат позволяет оценить связь между двумя качественными признаками по частоте их значений. Число сравниваемых групп может быть от 2 до 9.
Вычислить статистику (Управление данными)
Вычисляет статистику для набора растровых данных или набора данных мозаики.
Статистика необходима для ваших наборов растровых данных и данных мозаики для выполнения определенных задач, таких как применение растяжки или классификации ваших данных.
Использование
- Коэффициент пропуска контролирует часть растра, которая используются при вычислении статистики. Значение коэффициента определяет горизонтальный и вертикальный коэффициенты пропуска, значение 1 означает, что будет учтен каждый пиксел, а значение 2 – каждый второй пиксел. Коэффициент пропуска может варьироваться от 1 до числа, равного количеству столбцов/строк растра.
- Коэффициенты пропуска для наборов растровых данных, хранящиеся в файловой или многопользовательской базе данных могут сильно варьировать. Во-первых, если коэффициенты пропуска по x и y различаются, для этих двух коэффициентов пропуска по x и y будет использоваться тот, который меньше. Во-вторых, коэффициент пропуска связан с уровнем пирамидного слоя, который наиболее точно соответствует выбранному коэффициенту пропуска. Если значение коэффициента пропуска не соответствует количеству пикселов пирамидного слоя (например, если коэффициент пропуска – 5 и ближайший уровень пирамидного слоя, 4 x 4 пикселов, равен 2), программное обеспечение округлит значение коэффициента в меньшую сторону до ближайшего пирамидного слоя (в приведенном примере – до 2) и это значение будет использовано в качестве коэффициента пропуска.
- Коэффициент пропуска используется не для всех форматов растров. Форматы растров, которые будут вычислять статистику и пользоваться коэффициентом пропуска, включают TIFF, IMG, NITF, DTED, RAW, ADRG, CIB, CADRG/ECRG, DIGEST, GIS, LAN, CIT, COT, ERMapper, ENVI DAT, BIL, BIP, BSQ и базу геоданных.
- Когда вы используете этот инструмент для вычисления статистики для набора данных мозаики, вычисляется статистика для мозаичного изображения верхнего уровня, а не для каждого растра, содержащегося в наборе данных мозаики.
- Настоятельно рекомендуется указывать коэффициент пропуска для набора данных мозаики, поскольку эти наборы данных могут быть очень объемными.
- Опция Игнорировать значения позволяет исключить определенное значение из вычисления статистики. Вам может понадобиться игнорировать значение, если это значение NoData или если оно будет искажать ваши вычисления.
- При вычислении статистики по Esri Grid и форматам RADARSAT2 всегда используется коэффициент пропуска 1.
- При использовании этого инструмента для вычисления статистики многомерного набора данных мозаики или многомерного растра, статистика вычисляется для каждой переменной набора данных.
Параметры
Входной набор растровых данных
Входной набор растровых данных или набор данных мозаики.
Коэффициент пропуска по X
(Дополнительный)
Число пикселов по горизонтали между значениями.
Коэффициент пропуска контролирует часть растра, которая используются при вычислении статистики. Значение коэффициента определяет горизонтальный и вертикальный коэффициенты пропуска, значение 1 означает, что будет учтен каждый пиксел, а значение 2 – каждый второй пиксел. Коэффициент пропуска может варьироваться от 1 до числа, равного количеству столбцов/строк растра.
Значение должно быть больше нуля и меньше или равно числу столбцов растра. По умолчанию используется 1 или последний коэффициент пропуска.
Коэффициенты пропуска для наборов растровых данных, хранящиеся в файловой или многопользовательской базе данных могут сильно варьировать. Во-первых, если коэффициенты пропуска по x и y различаются, для этих двух коэффициентов пропуска по x и y будет использоваться тот, который меньше. Во-вторых, коэффициент пропуска связан с уровнем пирамидного слоя, который наиболее точно соответствует выбранному коэффициенту пропуска. Если значение коэффициента пропуска не равно количеству пикселов в уровне пирамидного слоя, количество округляется в меньшую сторону до следующего уровня пирамидного слоя, и используется его статистика.
Коэффициент пропуска по Y
(Дополнительный)
Число пикселов по вертикали между значениями.
Коэффициент пропуска контролирует часть растра, которая используются при вычислении статистики. Значение коэффициента определяет горизонтальный и вертикальный коэффициенты пропуска, значение 1 означает, что будет учтен каждый пиксел, а значение 2 – каждый второй пиксел. Коэффициент пропуска может варьироваться от 1 до числа, равного количеству столбцов/строк растра.
Значение должно быть больше 0 и меньше или равно общему числу строк в наборе растровых данных. По умолчанию 1 или последний использовавшийся коэффициент пропуска.
Коэффициенты пропуска для наборов растровых данных, хранящиеся в файловой или многопользовательской базе данных могут сильно варьировать. Во-первых, если коэффициенты пропуска по x и y различаются, для этих двух коэффициентов пропуска по x и y будет использоваться тот, который меньше. Во-вторых, коэффициент пропуска связан с уровнем пирамидного слоя, который наиболее точно соответствует выбранному коэффициенту пропуска. Если значение коэффициента пропуска не равно количеству пикселов в уровне пирамидного слоя, количество округляется в меньшую сторону до следующего уровня пирамидного слоя, и используется его статистика.
Игнорировать значения
(Дополнительный)
Значения пикселов, которые не будут включены в вычисление статистики.
По умолчанию нет значения, либо применяется последнее игнорированное значение.
Пропустить существующие
(Дополнительный)
Задает, будет ли статистика вычисляться только там, где она отсутствует, или будет строиться заново, даже если она существует.
- Не отмечено – статистика будет вычислена даже если она уже существует; имеющаяся статистика будет перезаписана. Это значение по умолчанию
- Отмечено – статистика будет вычислена, только если она еще не существует.
Область интереса
(Дополнительный)
Область в наборе данных, на основе которой будет рассчитываться статистика, чтобы не использовать для расчета весь набор данных. Можно выбрать класс пространственных объектов или создать график полигонов на экране.
Производные выходные данные
Выходной набор растровых данных.
arcpy.management.CalculateStatistics(in_raster_dataset, , , , , )
in_raster_dataset
Входной набор растровых данных или набор данных мозаики.
x_skip_factor
(Дополнительный)
Число пикселов по горизонтали между значениями.
Коэффициент пропуска контролирует часть растра, которая используются при вычислении статистики. Значение коэффициента определяет горизонтальный и вертикальный коэффициенты пропуска, значение 1 означает, что будет учтен каждый пиксел, а значение 2 – каждый второй пиксел. Коэффициент пропуска может варьироваться от 1 до числа, равного количеству столбцов/строк растра.
Значение должно быть больше нуля и меньше или равно числу столбцов растра. По умолчанию используется 1 или последний коэффициент пропуска.
Коэффициенты пропуска для наборов растровых данных, хранящиеся в файловой или многопользовательской базе данных могут сильно варьировать. Во-первых, если коэффициенты пропуска по x и y различаются, для этих двух коэффициентов пропуска по x и y будет использоваться тот, который меньше. Во-вторых, коэффициент пропуска связан с уровнем пирамидного слоя, который наиболее точно соответствует выбранному коэффициенту пропуска. Если значение коэффициента пропуска не равно количеству пикселов в уровне пирамидного слоя, количество округляется в меньшую сторону до следующего уровня пирамидного слоя, и используется его статистика.
y_skip_factor
(Дополнительный)
Число пикселов по вертикали между значениями.
Коэффициент пропуска контролирует часть растра, которая используются при вычислении статистики. Значение коэффициента определяет горизонтальный и вертикальный коэффициенты пропуска, значение 1 означает, что будет учтен каждый пиксел, а значение 2 – каждый второй пиксел. Коэффициент пропуска может варьироваться от 1 до числа, равного количеству столбцов/строк растра.
Значение должно быть больше 0 и меньше или равно общему числу строк в наборе растровых данных. По умолчанию 1 или последний использовавшийся коэффициент пропуска.
Коэффициенты пропуска для наборов растровых данных, хранящиеся в файловой или многопользовательской базе данных могут сильно варьировать. Во-первых, если коэффициенты пропуска по x и y различаются, для этих двух коэффициентов пропуска по x и y будет использоваться тот, который меньше. Во-вторых, коэффициент пропуска связан с уровнем пирамидного слоя, который наиболее точно соответствует выбранному коэффициенту пропуска. Если значение коэффициента пропуска не равно количеству пикселов в уровне пирамидного слоя, количество округляется в меньшую сторону до следующего уровня пирамидного слоя, и используется его статистика.
ignore_values
[ignore_value. ]
(Дополнительный)
Значения пикселов, которые не будут включены в вычисление статистики.
По умолчанию нет значения, либо применяется последнее игнорированное значение.
skip_existing
(Дополнительный)
Задает, будет ли статистика вычисляться только там, где она отсутствует, или будет строиться заново, даже если она существует.
- OVERWRITE — Статистика будет вычислена даже если она уже существует; имеющаяся статистика будет перезаписана. Это значение по умолчанию
area_of_interest
(Дополнительный)
Класс пространственных объектов, представляющий область в наборе данных, на основе которой будет рассчитываться статистика, чтобы не использовать для расчета весь набор данных.
Производные выходные данные
Выходной набор растровых данных.
Пример кода
CalculateStatistics, пример 1 (окно Python)
Пример скрипта Python для CalculateStatistics .
import arcpy arcpy.CalculateStatistics_management( "C:/data/image.tif", "5", "5", "0;255", "SKIP_EXISTING", "c:/data/aoi.shp")Инструмент CalculateStatistics, пример 2 (автономный скрипт)
Пример скрипта Python для CalculateStatistics .
# Calculate Statistics for single raster dataset import arcpy arcpy.env.workspace = "C:/Workspace" arcpy.CalculateStatistics_management("image.tif", "4", "6", "0;255;21")Статистика: как рассчитать стандартное отклонение и другие статистические характеристики


Статистические величины, такие как стандартное отклонение и математическое ожидание, полезны при оценке эффективности или характеристик устройства, системы или процесса, смоделированных с помощью COMSOL Multiphysics ® . В этой статье мы рассмотрим функции, графики и другие инструменты COMSOL Multiphysics, предназначенные для расчёта и визуализации статистических величин.
Статистика: вводный обзор
Статистические методы позволяют рассчитать количественные характеристики случайной величины или большого массива данных. Ниже в таблице перечислены некоторые статистические величины, а также названия операторов и операций над массивами данных, которые используются для их вычисления в COMSOL Multiphysics:
| Величина | Параметр | Оператор | Операция над массивом данных |
|---|---|---|---|
| Среднее значение или математическое ожидание | \mu | mean, timeavg | Average |
| Стандартное отклонение | \sigma | stddev | Standard deviation |
| Дисперсия | Var, \sigma^2 | – | Variance |
Теперь расшифруем смысл каждой из перечисленных выше статистических величин:
- Среднее или математическое ожидание (в уравнении ниже обозначается как \mu ) равно сумме всех значений, отнесённой к числу элементов в массиве данных. Этот статистический показатель даёт полезную информацию об уровне любой колеблющейся величины. Среднее значение чувствительно к так называемым выбросам (то есть элементам выборки, значения которых сильно отличаются от значений других элементов). Ещё одним, схожим по смыслу статистическим параметром является медиана — срединное значение, которое находится в середине упорядоченного по возрастанию массива данных (либо полусумма соседних значений, если число элементов в массиве чётное). Например, оператор timeavg в COMSOL Multiphysics позволяет рассчитать среднее значение зависящей от времени величины в заданном интервале времени.
- Стандартное отклонение (обозначается ниже как \sigma ) характеризует степень отклонения данных от среднего значения. Определяется как квадратный корень из дисперсии. В отличие от дисперсии, стандартное отклонение исчисляется в тех же единицах измерения, что и исходные данные.
- Дисперсия (обозначается как Var) является мерой разброса значений относительно ее математического ожидания. Единица измерения дисперсии — это квадрат единицы измерения исходных данных.
Математическое ожидание \mu можно рассчитать по формуле:
\mu(X)=\frac<1>\sum_^nx_i \cdot
Следующее соотношение позволяет определить дисперсию:
Var(X)=\frac<1>\sum_^(x_i-\mu)^2
Здесь X — это величина, дисперсию (и среднее значение) которой нужно рассчитать, x_i — массив значений этой величины, \mu — математическое ожидание. Это определение дисперсии справедливо для массива данных с фиксированным числом элементов.
В COMSOL Multiphysics X и x_i представляют собой фиксированный массив данных.
Стандартное отклонение \sigma равно квадратному корню из дисперсии:
\sigma = \sqrt>Эти формулы можно легко обобщить на случай расчёта статистических величин, определённых на геометрических объектах, если заменить суммирование на интегрирование по пространству. Именно такое обобщение и используется в COMSOL Multiphysics. Интегральная форма соотношения для расчёта средней величины X по области \Omega имеет вид:
\mu(X) = \frac<1><|\Omega|>\int_\Omega x d\Omega
и, аналогично, дисперсия переменной X по области \Omega равна
Var(X) = \frac<1><|\Omega|>\int_\Omega (x-\mu(x))^2 d\Omega
где |\Omega| — размер области (объём, площадь или длина, в зависимости от пространственной размерности модели).
В следующих параграфах мы объясним, как использовать все эти операции и операторы при моделировании в COMSOL Multiphysics.
Статистические величины в COMSOL Multiphysics
Нелокальные операторы
Позже мы рассмотрим, как использовать встроенный оператор stddev для вычисления стандартного отклонения. Но перед этим давайте обсудим, как рассчитать среднее значение величины, например, в объёме или вдоль границ: кликните правой кнопкой мыши по узлу Definitions в текущем компоненте Component, а затем выберите пункт Average в меню Nonlocal Couplings. Так мы добавляем оператор осреднения с именем по умолчанию aveop1 , а затем в настройках этого оператора указываем тип геометрического объекта Geometric entity level (например, Boundary) и выбираем сам объект (например, границы области), в пределах которого нужно выполнить осреднение. Аналогичным образом в дерево модели можно добавить операторы для расчёта интегралов, максимальных и минимальных значений.
Добавленные операторы можно использовать как в процессе расчёта модели, так и на этапе обработки результатов. Например, в задачах вычислительной гидродинамики с помощью оператора осреднения можно рассчитать среднюю скорость среды в выходном сечении расчётной области. Для этого в ветке Results дерева модели к узлу Derived Values нужно добавить подузел Global Evaluation, в окне настройки которого нужно ввести выражение aveop1(spf.U) и нажать кнопку Evaluate. После этого рассчитанные значения средней скорости для каждого сохранённого момента времени нестационарной задачи появятся в окне Table.
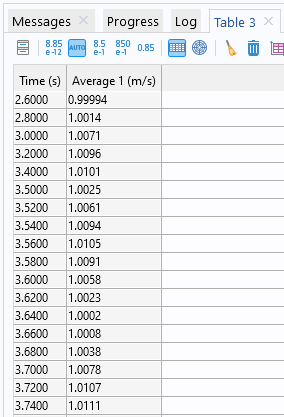
Окно Table, в которое выводятся значения средней скорости для каждого сохранённого момента времени.
Стандартное отклонение или дисперсию можно рассчитать с помощью повторного использования нелокального оператора: сначала с помощью оператора вычисляется среднее значение, а затем тот же оператор используется для расчёта стандартного отклонения или дисперсии. Например, в нашем примере с гидродинамической задачей для определения стандартного отклонения давления на выходной границе можно воспользоваться оператором осреднения aveop1 , заданным на выходной границе. Для этого в окне настройки узла Global Evaluation введём выражение sqrt(aveop1((aveop1(p)-p)^2)) .
Упрощение выражений с помощью оператора Expression Operator
Выражение sqrt(aveop1((aveop1(p)-p)^2)) , которое мы использовали выше, длинновато. Чтобы упростить использование этого выражения для настройки расчётной модели, можно воспользоваться оператором Expression Operator. Для этого сначала включим опцию Variable Utilities в разделе General окна настройки дерева модели Show More Options. Затем добавим узел Expression Operator из контекстного меню Variable Utilities, которое можно вызвать, кликнув правой кнопкой мыши по узлу Definitions текущего компонента модели Component. В окне настройки узла Expression Operator даём новому оператору название, например, stdop1 и вводим его определение, используя то же самое выражение, но уже с произвольным аргументом, который мы обозначим, скажем, pin :
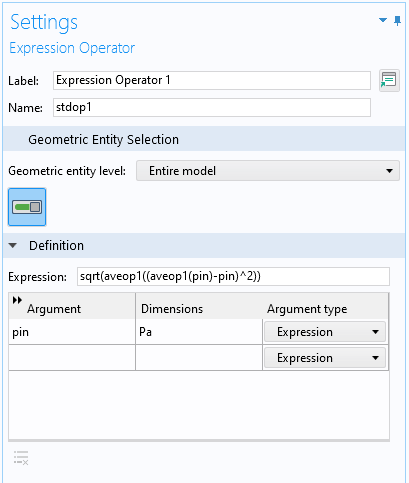
Окно настройки Settings узла Expression Operator, который позволяет дать определение упрощённому оператору stdop1 для расчёта стандартного отклонения.
Теперь этот оператор можно использовать для обработки результатов моделирования, вводя команду stdop1(p) вместо sqrt(aveop1((aveop1(p)-p)^2)) .
Производные величины
На этапе обработки результатов можно добавить узлы для расчёта среднего по объёму Volume Average, по поверхности Surface Average и вдоль контура Line Average, если воспользоваться контекстным меню узла Derived Values и выбрать соответствующую команду из подменю Average. Аналогично можно добавить узлы для вычисления интегральных Integration, максимальных Maximum и минимальных Minimum значений.
Преобразование результатов нестационарных и параметрических исследований
Для обработки массива данных, полученных в результате нестационарного, параметрического исследования или исследования на собственные значения, с помощью узла Point Evaluation можно вычислить следующие значения:
- Среднее
- Интегральное
- Максимальное или минимальное
- Среднеквадратическое (RMS)
- Стандартное отклонение
- Дисперсию
Результатом каждой из этих операций является одно число, которое представляет собой, например, среднее значение всех результатов параметрического исследования или стандартное отклонение переменной нестационарной модели в точке.
Встроенные операторы
В COMSOL Multiphysics доступно большое количество физических переменных, а также встроенных физических и математических констант, функций и операторов, которые можно использовать для обработки и визуализации результатов моделирования. Вы можете ввести имя непосредственно в любое поле Expression или выбрать из списка, нажав кнопку Add Expression или Replace Expression (кнопки расположены на панели инструментов раздела Expression). На скриншоте ниже показаны операторы из группы Integration and statistics COMSOL Multiphysics ® версии 6.0:

Встроенные операторы группы Integration and statistics.
Особый интерес представляет оператор stddev для вычисления стандартного отклонения. С его помощью можно рассчитать стандартное отклонение давления на выходной границе в описанном выше примере, если ввести выражение stddev(‘comp1.aveop1’,p) . Это более простой и эффективный синтаксис, чем последовательное обращение к оператору осреднения, которые мы использовали выше для определения стандартного отклонения. Отметим, что имена компонентов и операторов в выражении приведены для примера, и в ваших моделях они могут быть иными.
Стандартное отклонение и математическое ожидание: пример
Давайте рассчитаем парочку статистических характеристик в нестационарной модели обтекания цилиндра Flow Past a Cylinder model, которую можно найти в разделе Fluid Dynamics библиотеки приложений Application Library в COMSOL Multiphysics. Вычислим следующие величины:
- Среднее значение и стандартное отклонение давления в расчётной области во всём временном интервале моделирования
- Среднее значение и стандартное отклонение скорости в некоторой точке выходной границы во всём временном интервале моделирования
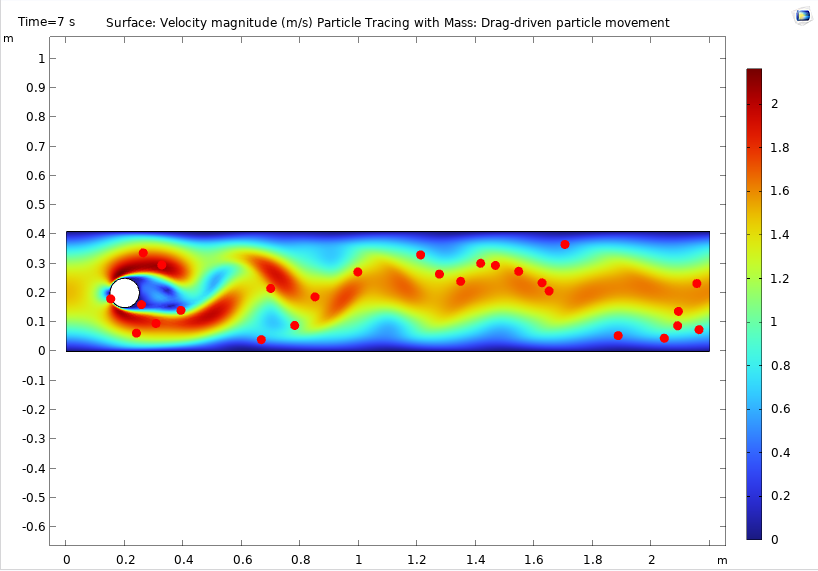
Построенный по умолчанию график в модели обтекания цилиндра Flow Past a Cylinder, показывающий распределение скорости и частиц в момент времени 7 с.
Среднее значение и стандартное отклонение давления в домене и на выходной границе
Чтобы определить среднее значение и стандартное отклонение давления в какой-то области, сначала добавим узел Average с названием оператора, скажем, aveop2 , и выберем область осреднения. (В рассматриваемой геометрической модели существует только один домен). После завершения расчёта добавим подузел Global Evaluation к узлу Derived Values ветки Results дерева модели, и в окне настройки этого подузла введём выражение aveop2(p) . Искомое значение среднего по объёму давления появится в окне Table для всех моментов времени, указанных в списке Time selection (по умолчанию выбраны все сохранённые моменты времени). Если нужно рассчитать среднее по времени значение осреднённого по объёму давления, выберите опцию Average из списка Transformation в разделе Data Series Operation. В результате получится одно скалярное число для среднего по времени значения осреднённого давления. Чтобы вывести стандартное отклонение на каждом шаге по времени, введите также выражение stddev(‘comp1.aveop2’,p) (или воспользуйтесь любым из упомянутых выше вариантов расчёта).
Аргумент оператора stddev не обязательно должен быть средним значением. Например, в качестве аргумента можно ввести оператор интегрирования, но результатом по-прежнему будет правильно рассчитанное значение стандартного отклонения. Кроме того, его можно использовать в комбинации с оператором timeavg , чтобы получить тот же результат, что и в результате использования операций над массивами данных. Это можно сделать с помощью выражения типа stddev(‘timeavg’,t1,t2,expr) , где t1 и t2 — начальный и конечный моменты временного интервала, а expr — это выражение, которое нужно осреднить в заданном временном интервале. Например, чтобы построить график стандартного отклонения давления во временной области для каждой точки выходной границы в интервале времени от 6 до 7 секунд, можно использовать выражение stddev(‘timeavg’,6,7,p) .
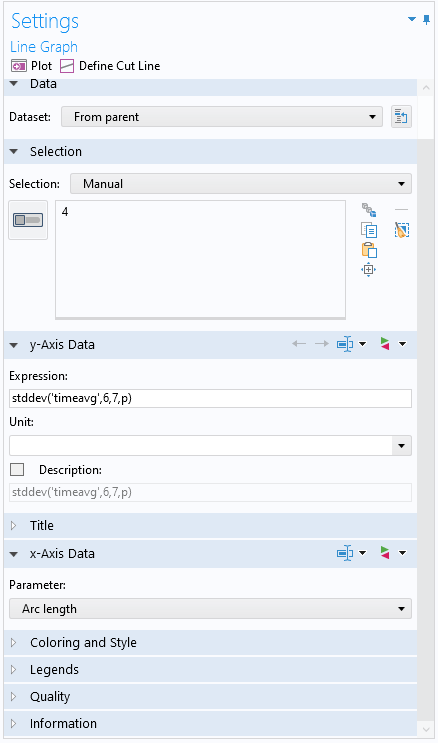
Окно настройки Settings графика Line Graph, в котором используется выражение для расчёта стандартного отклонения во временной области в интервале времени от 6 до 7 секунд.
График показывает, что наименьшее значение стандартного отклонения давления достигается в срединной точке выходной границы.
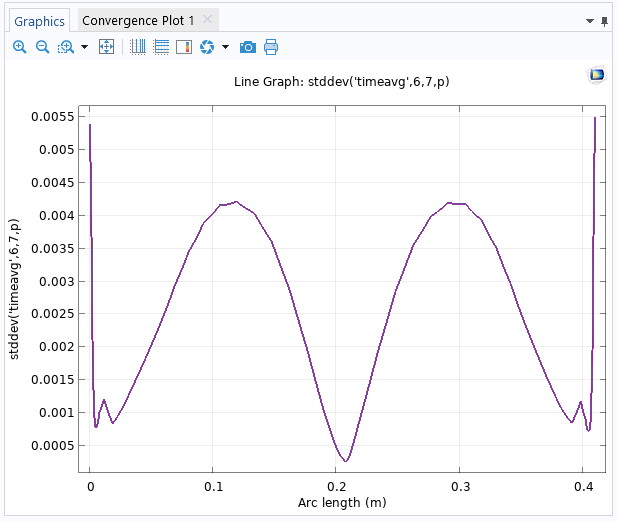
Одномерный график Line Graph стандартного отклонения давления во временной области на выходной границе.
Среднее значение и стандартное отклонение скорости на выходной границе
Если нужно определить среднее значение и стандартное отклонение скорости в срединной точке выходной границы на каждом шаге по времени, то сначала надо найти значение скорости в этой точке. Это можно сделать двумя способами:
- Добавить в геометрическую модель точку посередине выходной границы, даже если эта точка не используется в самой модели
- Добавить набор данных Cut Point (в нашем случае Cut Point 2D), а затем задать координаты точки в окне настройки набора данных
Чтобы найти скорость в средней точке, используйте узел Point Evaluation, в окне настройки которого либо выберите нужную точку в геометрической модели, либо выберите в качестве входных данных для графика набор данных Cut Point 2D. Затем в качестве входной переменной для графика укажите, например, spf.U . В разделе Data Series Operation окна настройки выберите Average или Standard deviation. Кликнув по кнопке Evaluate, расположенной в верхней части окна настройки Settings, вы получите график среднего значения или стандартного отклонения (оба в м/с) для скорости в средней точке выходной границы на каждом сохранённом временном шаге исследования.

Среднее значение и стандартное отклонение скорости выводятся в таблицу в окне Table.
Гистограммы
С помощью гистограмм удобно визуализировать форму и разброс некоторых массивов данных. В COMSOL Multiphysics встроены следующие типы гистограмм:
- Гистограммы Histogram (1D и 2D графики) показывают, как та или иная величина распределена в пространстве в пределах геометрических объектов. В одномерных гистограммах по оси x отложены значения величины (в виде интервалов), а по оси y — общее число элементов в каждом интервале.
- Табличные гистограммы Table Histogram (1D и 2D графики) аналогичны обычным гистограммам Histogram, но строятся на основе данных из таблицы или расчётной группы.
- Матричные гистограммы Matrix Histogram (только 2D графики) позволяют визуализировать матрицы в виде 2D гистограмм.
При построении графиков Histogram и Table Histogram можно выбрать, хотите вы задать количество столбиков на гистограмме или диапазон значений для каждого столбика гистограммы. Для 2D гистограмм можно добавить подузел Height Expression, чтобы придать столбикам трёхмерный вид за счет использования оси z, как показано на рисунке ниже.
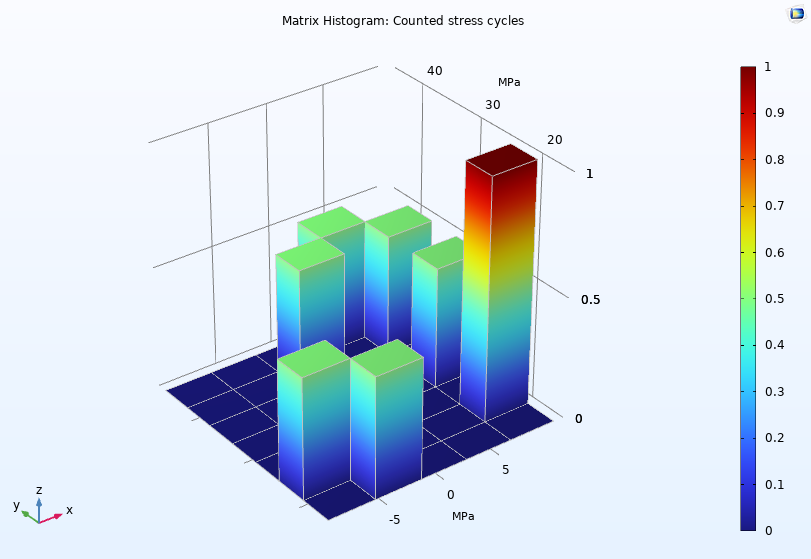
График Matrix Histogram показывает число циклов нагружения, рассчитанное в верификационной модели Cycle Counting in Fatigue Analysis — Benchmark model.
Оценка неопределённости и статистика
С помощью модуля «Оценка неопределённости», дополняющего функционал среды COMSOL Multiphysics, можно получить статистические данные, связанные с количественной оценкой неопределённости, непосредственно в таблицах выходных данных. Например, для анализа распространения неопределенности с использованием неадаптивных суррогатных режимов гауссовского процесса доступны следующие четыре таблицы:
- Таблица доверительных интервалов QoI Confidence interval, в которой для каждой целевой переменной выводятся данные о математическом ожидании, стандартном отклонении, минимальном и максимальном значениях, а также о доверительных интервалах для доверительных вероятностей 90%, 95% и 99%.
- Таблица UP predicted QoI, в которой приведены спрогнозированные суррогатной моделью значения целевых переменных для точек выборки метода Монте-Карло.
- Таблица спрогнозированных значений стандартного отклонения UP predicted standard deviation, в которой указаны спрогнозированные суррогатной моделью стандартные отклонения для точек выборки метода Монте-Карло. Эти данные можно интерпретировать как встроенную оценку погрешности суррогатной модели.
- Таблица максимальных значений энтропии Maximum entropy, в которой указаны максимальные относительные значения стандартного отклонения для каждой целевой переменной.
При использовании адаптивной суррогатной модели гауссовского процесса в группу выходных таблиц также добавляются четыре соответствующие адаптивные таблицы результатов. Они содержат информацию о результатах на всех этапах адаптации.
Дальнейшие шаги
В качестве следующего шага попробуйте использовать некоторые из этих статистических инструментов в своих собственных расчётных моделях; так вы сможете получить статистические характеристики и количественные оценки целевых переменных или параметров. Если у вас возникли вопросы по данной теме, свяжитесь с COMSOL с помощью этой кнопки.
Как решать задачи по статистике
С помощью данных сервисов рассчитываются основные показатели в онлайн режиме. Отчет оформляется в формате Word и Excel .
Статистические распределения. Выборочное наблюдение
- Группировка статистических данных. Получение дискретного вариационного ряда и интервального вариационного ряда. Затем расчет среднего значения производится как по формуле средней взвешенной, так по способу моментов.
- Среднее значение по способу моментов.
- Аналитическая группировка, а также расчет межгрупповой дисперсии.
- Расчет показателей вариации: мода, медиана, коэффициент вариации и другие.
- Проверка гипотезы о виде распределения: нормальное распределение, распределение Пуассона, экспоненциальное распределение, равномерное распределение.
- Расчет доверительного интервала для математического ожидания и дисперсии
Данные для расчета могут быть представлены в виде разных рядов (см. подробнее как выбрать тип ряда). Если необходимо сгруппировать ряд, то можно указать на какое количество групп (если указать 0, то количество групп определяется по формуле Стэрджесса). Если в задании не сказано о доле выборке, то параметр Выборка остается по умолчанию 100%, иначе указывается конкретное значение.
Затем задается количество строк исходных данных либо данные можно скопировать из MS Excel .
Для расчета доверительных интервалов задается уровень значимости или вероятность.
- Пример №1
- Пример №2
- Пример №3
- Рассчитать средние значения признаков по не сгруппированным данным.
- Осуществить группировку по выручке, рассчитав число групп по формуле Стерджесса.
- Подсчитать численность заводов каждой группы и построить графическое изображение структуры совокупности по выручке от реализации.
- Рассчитать в среднем на 1 завод для сгруппированных данных:
- выручку от реализации продукции;
- прибыль предприятия;
- издержки производства;
- себестоимость единицы продукции.
- Изобразить графически ряд распределения по осуществлённой группировке для издержек производства.
- Осуществить группировку по выполнению плана, изобразить графически полученные результаты.
Средние товарные запасы и оборот розничной торговли 20 магазинов райпо за отчетный период (оборот розничной торговли, тыс. руб.;средние товарные запасы, тыс. руб.).
Для выявления зависимости между размером оборота розничной торговли и средними товарными запасами произведите группировку магазинов по размеру оборота розничной торговли, образовав четыре группы с равными интервалами. В каждой группе и по итогу в целом подсчитайте:
1. число магазинов;
2. объём оборота розничной торговли – всего и в среднем на один магазин;
3. товарные запасы — всего и в среднем на один магазин.
Результаты группировки оформите в таблице. Сделайте выводы. Данные задачи удобнее будет решать с помощью сервиса Аналитическая группировка.
- Вид статистического ряда: Дискретный ряд;
- Выборка: 100 ;
- Нажать кнопку Вставить из Excel
- Количество групп: 0 ;
- Выводить в отчет: Показатели формы распределения ;
Оценки различий между выборками
- Ранжирование данных
- Критерий Манна-Уитни предназначен для оценки различий между двумя выборками.
- Методом одномерного дисперсионного анализа проверить нулевую гипотезу о влиянии фактора на качество объекта.
- Двумерный анализ может использоваться для проверки воздействия двух независимых переменных и возможного эффекта взаимодействия на зависимую переменную.
- Проверка гипотезы о равенстве дисперсий и генеральных средних.
- Проверка статистических гипотез.
Ряды динамики
- Аналитическое выравнивание ряда. Онлайн-калькулятор рассчитывает параметры уравнения линейной и не линейной зависимости.
- Расчет параметров уравнения тренда производится в онлайн режиме с возможностью использования метода отсчета времени от условного начала.
- Сглаживание методом простой скользящей средней
- Экспоненциальное сглаживание временного ряда с расчетом ошибки прогноза.
- Показатели рядов динамики. Онлайн-сервис по расчету цепных и базисных показателей временного ряда.
- Другие калькуляторы для временных рядов
Индексный метод
- Общий индекс товарооборота
- Индекс цен переменного состава
- Анализ сезонных колебаний
- Аддитивная модель временного ряда
- Мультипликативная модель временного ряда
Экономическая статистика
- Метод абсолютных разниц
- Метод цепных подстановок
- Способ относительных разниц
- Распределение Стьюдента (t-распределение)
- Распределение Фишера (F-распределение)
- Таблица значений функции Лапласа
- Статистические таблицы Дарбина-Уотсона
- Распределение ХИ квадрат (X 2 ). Используется для определения доверительного интервала дисперсии.