Пишем асинхронного Телеграм-бота

Привет! Меня зовут Александр, я руководитель бэкенд-разработки в KTS.
Сегодня я покажу, как написать своего Телеграм-бота на основе asyncio и aiohttp. Мы не будем использовать ни aiogram, ни любые другие библиотеки, а напишем бота с нуля, чтобы немного познакомиться с асинхронным программированием, корутинами и некоторыми примитивами синхронизации.
Что будет в статье:
Основы ботоведения
Бот — сущность в мессенджере.
Они есть практически везде: в Телеграме, ВК. Это программа, которая на основе определенных алгоритмов отвечает на сообщения пользователей. Задачи и направления самые разные: бот может просто присылать сообщения «С добрым утром!» А может, например, управлять участниками внутри чата.
Перед началом работы с ботом его нужно создать и познакомиться с Telegram API.
Шаг 1. Сначала создаем бота с помощью BotFather внутри Телеграма:
https://core.telegram.org/bots#6-botfather
После создания вы получите сообщение:
Done! Congratulations on your new bot.
Use this token to access the HTTP API:
.
В сообщении будет токен, который нужно использовать для запросов в Телеграм.
Шаг 2. Выполните первый запрос к Telegram API по инструкции: https://core.telegram.org/bots/api#authorizing-your-bot
В ответ вы должны получить что-то подобное:
Шаг 3. Далее нужно научиться получать уведомления из Телеграма. Существует 2 способа:
- webhook — инициатором запроса выступает Телеграм.
Когда пользователь пишет боту, Телеграм делает запрос на URL, который вы установите с помощью метода setwebhook. У этого метода есть недостатки: его трудно отлаживать, так как должен быть публичный адрес бота. Также на каждое сообщение выполняется HTTP-запрос, и при 1000+ сообщений в секунду серверы не справятся. - long polling — инициатором является ваше приложение.
Оно обращается к Telegram API и получает уведомления или ожидает, если уведомлений нет — отсюда название long.
Мы для получения уведомлений будем использовать long polling. Описание метода.
- Выполните в браузере такой запрос:
https://api.telegram.org/bot/getUpdates
Он завершится моментально и вернет: - Теперь выполните другой запрос:
https://api.telegram.org/bot/getUpdates?timeout=30- Он будет висеть 30 секунд и, если ничего не написать боту, вернет:
- Если написать боту хоть что-то, он моментально вернет Update.
Шаг 4. Теперь давайте научимся отправлять сообщение пользователю в ответ. Сначала отправим сообщение боту, для чего используем метод sendMessage. Метод принимает два обязательных параметра:
- chat_id — поле, которое пришло в объекте Update. Может быть как id персонального чата, так и id группового чата.
- text
Выполните в браузере запрос. chat_id нужно получить из предыдущего запроса: https://api.telegram.org/bot/sendMessage?chat_id=85364161&text=hello.
В результате бот напишет вам сообщение hello.
Для работы с методами Telegram API будем использовать класс TgClient.
Echo-бот
Для начала давайте получим сообщения из Telegram. Для этого нужно вызвать метод get_updates класса TgClient :
import asyncio import os from clients.tg import TgClient async def run_echo(): c = TgClient(os.getenv("BOT_TOKEN")) print(await c.get_updates(offset=0, timeout=5)) if __name__ == "__main__": asyncio.run(run_echo())Обратите внимание, что код получает токен бота из переменной окружения, поэтому перед запуском нужно установить значение переменной BOT_TOKEN .
При запуске кода может быть два исхода:

- Если боту отправляли сообщение не более 24 часов назад, метод get_updates вернет все последние сообщения. Чтобы было проще, далее по тексту я буду использовать термин «новые сообщения», а не «новые объекты update».
- Если боту не писали вообще, или писали давно, он зависнет на 5 секунд (timeout=5) и вернет пустой список: при этом, если боту написать во время ожидания, он моментально вернет результат, как и в первом случае.
Чтобы получать сообщения из Телеграма постоянно, в цикле нужно вызывать get_updates , так как он завершается сразу после написания боту нового сообщения.
async def run_echo(): c = TgClient(os.getenv("BOT_TOKEN")) while True: print(await c.get_updates(offset=0, timeout=60))Но если запустить такой код, мы будем получать последние сообщения из Телеграма в бесконечном цикле. А чтобы получать только новые, нужно использовать параметр offset .
async def run_echo(): c = TgClient(os.getenv("BOT_TOKEN")) offset = 0 while True: res = await c.get_updates(offset=offset, timeout=60) for item in res["result"]: offset = item["update_id"] + 1 print(item)Правило Телеграма: после получения новой пачки сообщений нужно взять из ответа параметр update_id и следующий запрос выполнять с offset на единицу больше, чем последнее сообщение, пришедшее из get_updates .
Теперь можно завершить написание полноценного echo-бота:
async def run_echo(): c = TgClient(os.getenv("BOT_TOKEN")) offset = 0 while True: res = await c.get_updates_in_objects(offset=offset, timeout=60) for item in res.result: offset = item.update_id + 1 await c.send_message(item.message.chat.id, item.message.text)В функции заменили get_updates на get_updates_in_objects , потому что гораздо удобнее оперировать объектами, чем словарями.
Текущая реализация имеет большой недостаток — бот не работает параллельно: после получения обновления он сразу начинает выполнять бизнес-логику бота. В нашем случае он отправляет echo-сообщение, и в это время новые сообщения от бота получаться не будут. Получается, другие пользователи простаивают. Нужно как-то организовать параллельную обработку пользователей и обеспечить возможность масштабирования.
Поэтому мы пойдем другим путем.
Архитектура бота
Введем сущность poller. Он будет получать сообщения из Телеграма и ставить их в очередь, никакую бизнес-логику он не реализует. Он должен быть в единственном экземпляре.
Введем сущность worker. Он будет выполнять все рабочие задачи. worker берет задачу из очереди и каким-то образом выполняет ее.
Сущностей worker может быть много:

Такая схема лучше изначальной по двум причинам:
- при возрастании нагрузки мы можем соответственно увеличить количество worker;
- сообщения от пользователей обрабатываются параллельно.
Реализация схемы
poller.py
import asyncio from clients.tg import TgClient class Poller: def __init__(self, token: str, queue: asyncio.Queue): self.tg_client = TgClient(token) self.queue = queue async def _worker(self): offset = 0 while True: res = await self.tg_client.get_updates_in_objects(offset=offset, timeout=60) for u in res.result: offset = u.update_id + 1 print(u) self.queue.put_nowait(u) async def start(self): asyncio.create_task(self._worker())poller в точности повторяет логику echo-бота, за исключением отправки echo-сообщения:
- работает бесконечно;
- получает уведомления из Телеграма;
- кладет сообщения в очередь.
Логика получения уведомлений описана в методе _worker , для запуска получения уведомлений нужно запустить именно его. Но просто вызвать await self._worker() не получится, потому что мы заблокируем основной поток выполнения, а нам еще нужно запустить worker, который будет вычитывать сообщения из очереди. Поэтому нужно запустить фоновую задачу с помощью asyncio.create_task.
Теперь рассмотрим, как запустить poller.
import asyncio import os from bot.poller import Poller async def start(): q = asyncio.Queue() poller = Poller(os.getenv("BOT_TOKEN"), q) await poller.start() def run(): loop = asyncio.get_event_loop() try: print('bot has been started') loop.create_task(start()) loop.run_forever() except KeyboardInterrupt: pass if __name__ == '__main__': run()Так как бот должен работать бесконечно, то необходимо организовать бесконечный цикл. В echo-боте мы просто оставили while True , но в текущей реализации так сделать будет неудобно, поэтому лучше использовать метод запуска run_forever , предварительно положив все необходимые задачи в event loop с помощью метода create_task.
Документация по методу run_forever
Документация по методу create_taskОбратите внимание:
1. В коде poller используется asyncio.create_task , а при его запуске используется loop.create_task .
Отличие заключается в том, что мы явно указали, какой event loop нужно использовать в синхронной функции def run . В асинхронных функциях async def loop явно можно не указывать, потому что Python сам знает текущий цикл событий и прикрепляет задачу к нему. Функция, из которой запускается create_task, тоже запущена в этом loop2. Если в запущенной в фоне корутине create_task происходит исключение, мы можем не увидеть его сразу, только после остановки event loop . Из-за этого могут возникнуть сложности в нахождении ошибок. Почитать подробнее в этой статье.
worker.py
import asyncio from clients.tg import TgClient from clients.tg.dcs import UpdateObj class Worker: def __init__(self, token: str, queue: asyncio.Queue, concurrent_workers: int): self.tg_client = TgClient(token) self.queue = queue self.concurrent_workers = concurrent_workers async def handle_update(self, upd: UpdateObj): print("before", upd) await asyncio.sleep(1) print("after", upd) async def _worker(self): while True: upd = await self.queue.get() await self.handle_update(upd) async def start(self): for _ in range(self.concurrent_workers): asyncio.create_task(self._worker())У worker есть несколько кардинальных отличий от poller:
- для обеспечения параллельной обработки входящих сообщений запускается несколько _worker , а количество параллельных воркеров регулируется параметром concurrent_workers ;
- новые сообщения приходят не из Telegram, а из очереди, которую предварительно заполнил poller;
- внутри handle_update — который запускается при появлении нового сообщения в очереди — реализуется бизнес-логика обработки сообщения, т.е. бизнес-логика бота.
Теперь добавим запуск worker в корутину async def start. Обратите внимание, что очередь должна быть общая между poller и worker:
async def start(): q = asyncio.Queue() poller = Poller(os.getenv("BOT_TOKEN"), q) await poller.start() worker = Worker(os.getenv("BOT_TOKEN"), q, 2) await worker.start()На этом минимальная реализация бота готова, но есть нюансы, которые стоит улучшить:
- в корутине start мы оперируем внутренними компонентами бота: очередью, poller, worker. Было бы хорошо иметь сущность Bot с одним методом “start”;
- при остановке бота он завершается моментально, не дожидаясь выполнения запущенной логики бота. Поэтому может быть такое, что мы прервем пользовательский сценарий на середине.
Class Bot
Всю работу с компонентами бота вынесем в отдельный класс Bot:
import asyncio from bot.poller import Poller from bot.worker import Worker class Bot: def __init__(self, token: str, n: int): self.queue = asyncio.Queue() self.poller = Poller(token, self.queue) self.worker = Worker(token, self.queue, n) async def start(self): await self.poller.start() await self.worker.start()И перепишем функцию run :
import asyncio import os from bot.base import Bot def run(): loop = asyncio.get_event_loop() bot = Bot(os.getenv("BOT_TOKEN"), 2) try: print('bot has been started') loop.create_task(bot.start()) loop.run_forever() except KeyboardInterrupt: pass if __name__ == '__main__': run()Код запуска стал чище, теперь не нужно думать про внутренние компоненты бота. Достаточно запустить bot.start(), и бот начнет функционировать
Остановка бота
Сейчас остановка происходит при нажатии Ctrl + C. Возникает исключение KeyboardInterrupt , которое мы ловим и молча завершаем работу бота:
try: print('bot has been started') loop.create_task(bot.start()) loop.run_forever() except KeyboardInterrupt: passПочему нужно делать красивое завершение (graceful shutdown):
1. Бизнес-логика бота может прерваться посередине, и для пользователя это будет выглядеть багом.
Пример: пользователь отправил файл боту, бот отправил сообщение, что файл загружается, и в этот момент его остановили. Бот будет загружать файл вечно, а пользователь останется в недоумении.2. Если в боте есть подключения к другим компонентам, например, к базе данных или очереди, их нужно корректно завершать.
Поэтому введем функцию stop в Bot и каждый внутренний компонент. Она будет отвечать за корректное завершение. Начнем с poller.
class Poller: def __init__(self, token: str, queue: asyncio.Queue): self.tg_client = TgClient(token) self.queue = queue self._task: Optional[Task] = None async def _worker(self): . async def start(self): self._task = asyncio.create_task(self._worker()) async def stop(self): self._task.cancel()Для этого введем переменную _task, в которую сохраним объект созданной задачи, а в момент остановки poller вызовем cancel .
В случае с worker нельзя просто взять и вызвать cancel у всех запущенных задач:
- нужно обработать все задачи, которые poller положил в очередь, иначе обновления из Телеграма просто потеряются;
- нельзя прерывать обработку конкретной задачи, т.е. у запущенной задачи cancel вызвать нельзя.
Получается, нужно дождаться выполнения всех задач, которые находятся в очереди. Для такой задачи есть метод join .
https://docs.python.org/3/library/asyncio-queue.html#asyncio.Queue.joinclass Worker: def __init__(self, token: str, queue: asyncio.Queue, concurrent_workers: int): . self._tasks: List[asyncio.Task] = [] async def handle_update(self, upd: UpdateObj): . async def _worker(self): while True: try: upd = await self.queue.get() await self.handle_update(upd) finally: self.queue.task_done() async def start(self): self._tasks = [asyncio.create_task(self._worker()) for _ in range(self.concurrent_workers)] async def stop(self): await self.queue.join() for t in self._tasks: t.cancel()Давайте разберемся, что мы сделали:
- в методе start сохранили все запущенные задачи в self._tasks ;
- внутри метода stop перед вызовом метода cancel у всех задач дождались, когда все задачи из очереди будут выполнены с помощью await self.queue.join() ;
- с помощью self.queue.task_done() помечаем «выполненными» задачи внутри метода _worker .
В итоге получается:
- остановили poller, новые задачи не добавляются в очередь.
- внутри worker ждем, пока выполнятся все задачи (self.queue.join()) , и только после этого вызываем отмену воркеров.
- так как все задачи завершились, а новые не поступают — poller остановлен — то можно вызывать cancel у задач и не бояться прервать бизнес-логику бота.
Теперь добавим в Bot метод stop :
async def stop(self): await self.poller.stop() await self.worker.stop()И после возникновения исключения KeyboardInterrupt запустим остановку бота с помощью loop.run_until_complete.
https://docs.python.org/3/library/asyncio-eventloop.html#asyncio.loop.run_until_completetry: print('bot has been started') loop.create_task(bot.start()) loop.run_forever() except KeyboardInterrupt: print("\nstopping", datetime.datetime.now()) loop.run_until_complete(bot.stop()) print('bot has been stopped', datetime.datetime.now())Чтобы проверить, что мы все сделали правильно, можно добавить asyncio.sleep(10) в метод handle_update , отправить боту сообщение и попробовать завершить бота раньше, чем через 10 секунд. В итоге должна получиться подобная картина:

Заключение
Цель этой статьи — показать на примере, как работать с базовым асинхронным программированием и примитивами синхронизации asyncio, а задача написания бота хорошо подходит для этих целей. Исходный код.
Другие наши статьи по бэкенду и асинхронному программированию для начинающих:
- Цикл статей «Первые шаги в aiohttp»: пишем первое hello-world-приложение, подключаем базу данных, выкладываем проект в Интернет
- Визуализация 5 алгоритмов сортировки на Python
- Разбираемся в асинхронности: где полезно, а где — нет?
Другие наши статьи по бэкенду и асинхронному программированию для продвинутого уровня:
- Пишем свой Google, или асинхронный краулер с rate limits на Python
- Пишем Websocket-сервер для геолокации на asyncio
На чём писать чатботов?
Фрймворков для написания чатботов очень много. Из популярных – есть aiogram , telethon , python-telegram-bot . Есть и no code решения по созданию чатботов.
Здесь мы разберём какие библиотеки/решения существуют, их плюсы и минусы и границы применимости.
aiogram
Самый популярный вариант, который фигурирует в каждом первом видео на ютубе. Самое распространённое заблуждение насчёт него – что “асинхронность ускорит вашего чатбота”.
На самом деле не совсем. Она сделает это, но для этого недостаточно просто писать async и await в начале объявления/вызова функций. Для асинхронной работы бота все операции внутри него не должны быть блокирующими (или хотя бы какая-то ощутимая их часть). Это значит, что больше нельзя пользоваться бибилотекой requests , ведь она синхронная, а вам нужен её асинхронный аналог, например, httpx или asks . Нельзя пользоватья redis , нужен aioredis . И так далее.
Библиотека хороша для написания асинхронного кода, но если вы не умеете его писать, то трогать не стоит, получите кучу проблем асинхронного кода, не получив его преимуществ.
python-telegram-bot
Библиотека поддерживает сразу 2 версии: синхронную и асинхронную. Синхронная – это версии 13.X, вот их документация. Асинхронная – в том же репозитории, просто для неё нужно установить версию библиотеки 20.X и старше, документация.
За счёт этого библиотека дружелюбнее для начинающих, пусть это и создаёт некоторую путаницу для новичков, но если вы разобрались один раз “где синхронная, а где нет” – дальше в целом всё понятно. Зато асинхронщину можно совсем не трогать, пока вы к ней не готовы.
Библиотека обладает куда более подробной документацей в сравнении с aiogram, есть статьи о архитектуре, персистентности или обходе спам-лимита Telegram. Функционал, кажется, тоже богаче.
Из минусов – библиотека не обладает таким же активным коммьюнити, как aiogram , в репозитории которого есть ссылки на сообщества по странам.
Мы пользуемся ей в своих пет-проектах и используем как основную в курсе Чат-боты на Python.
telethon
Эта библиотека нужна уже если вы хотите сделать не обычного бота в Telegram, а хотите подключить Python уже к аккаунту в Telegram и “роботизировать” его. Получится, что Python-скрипт как бы управляет вашим аккаунтом, в то время как библиотеки выше управляют ботами, которые в рамках Telegram являются отдельными сущностями, так же, как и каналы или группы.
Это подходит далеко не под все проекты и нужно не во всех ситуациях. Пригодится, например, если вы хотите писать пользователям первым, т.к. боты так делать не умеют. Но и попасть под бан из-за спама так тоже куда легче, чем если работать с ботом.
Документация библиотеки тоже весьма подробная и иногда даже раскрывает “дополнительные” темы, вроде философии библиотеки или чёрной магией, не предусмотренной библиотекой.
No code
Программисты обычно не любят обсуждать этот вариант, некоторые даже начинают шипеть и кусаться. Но это тоже вполне себе валидный вариант написать чатбота в Telegram.
No code – это когда вы создаёте чатбота/сайт/etc без написания кода, просто накликивая их в веб-интерфейсах. Например, Tilda позволяет собрать сайт вообще без знаний программирования, по тому же принципу, как делаются слайды в PowerPoint.
Если бот делает какие-то очень типовые действия, вроде “если пользователь сказал X, ответь Y”, то питон может и не пригодиться, куда проще нарисовать небольшую схему прямо в веб-интерфейсе любого nocode решения. Более того, для этого не обязательно быть программистом, с таким чатботом может справиться и менеджер/маркетолог. Выглядит примерно так:

Минусов у такого подхода, конечно, тоже хватает. Иначе зачем бы разработчикам платили такие зарплаты?
Первый минус – это ограниченность функциональности. В no code-решениях можно пользоваться только тем, что предлагает платформа. Если хочется чего-то своего – извините, придётся писать код.
Второй минус – с ростом проекта он очень быстро превращается в нечитаемый треш. Вот до чего разогнался небольшой чатбот-викторина, буквально на 2-3 окна экрана в одном из наших проектов (см. ниже). Очевидно, ни о каком “быстром росте функционала” тут не может быть и речи, в то время как в коде на Python этот же чатбот уместился бы в сотню строк чистого, читаемого кода.
Попробуйте бесплатные уроки по Python
Получите крутое код-ревью от практикующих программистов с разбором ошибок и рекомендациями, на что обратить внимание — бесплатно.
Переходите на страницу учебных модулей «Девмана» и выбирайте тему.
Глава 7 Добавляем боту асинхронность
По умолчанию созданные вами боты работают в параллельном, однопоточном режиме. Т.е. они выполняют заданные команды последовательно. Это не доставит никаких дополнительных трудностей если:
- ваш бот выполняет простейшие команды длительность работы которых не превышает 1 секунды;
- вашего бота использует всего несколько пользователей, и редко используют его одновременно.
Асинхронность в программировании — выполнение процесса в неблокирующем режиме системного вызова, что позволяет потоку программы продолжить обработку.
– tproger.ru
7.2 Пример последовательного бота с поддержкой длительных команд
В этом разделе мы разберёмся с тем, как сделать нашего бота асинхронным, т.е. способным обрабатывать одновременно несколько команд, таким образом, что бы одна длительная команда, не блокировала работу боту на время её выполнения. Для демонстрации примера мы создадим бота с двумя простейшими командами:
- fast — быстрая команда, время выполнение которой менее 1 секунды.
- slow — команда, на выполнение которой боту требуется некоторое время, в нашем случае более 10 секунд.
Для создания бота выполните приведённый ниже код:
library(telegram.bot) library(stringr) updater Updater("Токен вашего бота") # Функция с длительным временем вычислений slow_fun function(bot, update) # Сообщение о том, что начата работа длительного вычисления bot$sendMessage( update$message$chat_id, text = str_glue("Медленная функция, начало работы!\nID процесса: "), parse_mode = "Markdown" ) # Добавляем паузу, для того, что бы исскусственно сделать функцию длительной Sys.sleep(10) # Сообщаем о том, что все вычисления выполнены bot$sendMessage(update$message$chat_id, text = str_glue("Медленная функция выполнена!\nID процесса: "), parse_mode = "Markdown") > # Функция с коротким временем вычислений fast_fun function(bot, update) # Просто отправляем сообщение bot$sendMessage(update$message$chat_id, text = str_glue("Быстрая функция, выполняется последовательный режим!\nID процесса: "), parse_mode = "Markdown") > # создаём обработчики slow_hendler CommandHandler('slow', slow_fun) fast_hendler CommandHandler('fast', fast_fun) # добавляем обработчик в диспетчер updater updater + slow_hendler + fast_hendler # запускаем бота updater$start_polling()В многофункциональных ботах также можно разделить все команды на быстрые и медленные. Команды, которые бот выполняет мгновенно не требуют асинхронности, а вот команды реализующие длительные, дорогие вычисления, например запросы к API, лучше выполнять в параллельном, фоновом процессе не блокируя на период вычислений работу бота.
Для демонстрации проблемы давайте попробуем запустить бота, по приведённому выше примеру кода.

Изначально мы запустили медленную команду /slow , и не дожидаясь её выполнения отправили быструю команду /fast . Но, к выполнению команды /fast бот приступил только после того, как выполнил длительную команду /slow . Это видно из диалога, т.к. после того, как боту была отправлена команда /fast , он завершил работу команды /slow , сообщил нам “Медленная функция выполнена! ID процесса: 868”. Только после этого приступил к выполнению быстрой функции, сообщив “Быстрая функция, выполняется последовательный режим!ID процесса: 868”.
Представьте ситуацию, если у вас одновременно 5 пользователей отправят вперемешку быстрые и длительные команды. В качестве эксперимента давайте отправим боту очередь команд:

В данном случае не важно, эти команды запустил один пользователь или 5, выполняться они будут последовательно. Несмотря на то, что 5ая команда является быстрой, пользователю, который её отправил придётся ждать выполнения всех 4ёх, предыдущих команд. Если изобразить этот процесс схематически, и допустить, что быстрая команда выполняется за 1 секунду, а медленная за 10, то получится следующее:

В последовательном режиме выполнения, несмотря на то, что 5ая по счёту команда требует всего 1 секунду на вычисления, она 31 секунду находится в ожидании, пока будут выполнены 4 предыдущие операции.
7.3 Многопоточность в R
В языке R есть множество реализаций многопоточности:
Это далеко не полный перечень пакетов, которые позволяют вам производить вычисления в многопоточном режиме используя язык R. Для реализации многопоточности при разработке telegram ботов наиболее удобным является пакет future , о котором я подробно рассказывал в уроке “Пакет future” курса “Циклы и функционалы в языке R”. Крайне рекомендую пройти весь курс “Циклы и функционалы в языке R” для большего погружения в тему многопоточности. Т.к. в данном курсе мы не будет подробно рассматривать параллельное программирование.
Пакет future позволяет вам, выполнять вычисления как в последовательном (обычном) режиме, так и в многопоточном. При этом данный пакет поддерживает несколько различных многопоточных режима:

Изменять план выполнения вычислений можно с помощью future::plan() . Наиболее простым, и удобным для использования при построении telegram ботов многопоточный план вычислений — multisession. Данный план позволяет запускать на вашем локальном ПК параллельные R сеансы в фоновом режиме, после выполнения вычислений их результат импортируется в основной R сеанс.

Далее, после переопределения плана вычислений, запустить вычисление в многопоточном режиме можно с помощью одноимённой функции future() .
7.4 Используем future для построения асинхронного бота
Хочу обратить ваше внимание, когда мы в начале этого урока запустили бота в последовательном режиме, он с помощью функции Sys.getpid() получал, и выводил в сообщении идентификатор R сеанса, в ходе которого выполнялись все вычисления бота. Во всех представленных выше сообщение идентификатор процесса был одинаковым — 868. Это связано с тем, что все вычисления производились последовательно в рамках одного R сеанса.
Ниже я приведу пример, доработанного бота, таким образом, что бы функция /slow запускалась в фоновом, параллельном R сеансе, и не блокировала работу бота. При этом функцию /fast мы оставим без изменений, т.к. она выполняется ботом достаточно быстро, и скорее всего накладные расходы на создание фонового сеанса будут больше, чем вычисление самой функции.
library(telegram.bot) library(stringr) # Включаем параллельный план вычислений future::plan('multisession') updater Updater("Токен вашего бота") # Функция с длительным временем вычислений slow_fun function(bot, update) # Запускаем выполнение кода в параллельной сессии future::future( # Сообщение о том, что начата работа длительного вычисления bot$sendMessage(update$message$chat_id, text = str_glue("Медленная функция, начало работы!\nID процесса: "), parse_mode = "Markdown") # Добавляем паузу, для того, что бы исскусственно сделать функцию длительной Sys.sleep(10) # Сообщаем о том, что все вычисления выполнены bot$sendMessage(update$message$chat_id, text = str_glue("Медленная функция выполнена!\nID процесса: "), parse_mode = "Markdown") > ) > # Функция с коротким временем вычислений fast_fun function(bot, update) # Просто отправляем сообщение bot$sendMessage(update$message$chat_id, text = str_glue("Быстрая функция, выполняется последовательный режим!\nID процесса: "), parse_mode = "Markdown") > # создаём обработчик slow_hendler CommandHandler('slow', slow_fun) fast_hendler CommandHandler('fast', fast_fun) # добавляем обработчик в диспетчер updater updater + slow_hendler + fast_hendler # запускаем бота updater$start_polling()Что мы изменили в коде бота: 1. В начале скрипта, командой future::plan(‘multisession’) мы переопределили план вычислений с последовательного на многопоточный. На самом деле весь код будет выполняться последовательно, кроме кода используемого внутри функции future() . 2. Весь код внутри функции бота slow_fun() мы завернули в future::future() , таким образом, при запуске медленной функции будет запускаться параллельный фоновый R процесс, и все вычисления данной функции будут выполняться там, не блокируя основной сеанс.
Теперь давайте попробуем в параллельном режиме запустить такую же очередь команд, как и в предыдущем последовательном примере:

Обратите внимание на то, что вычисление всех долгих команд /slow выполняются в разных процессах, бот выводит в каждом сообщение информацию “ID процесса: XX”. При этом вычисление быстрой команды /fast оба раза выполнялись в корневом процессе с id 868.
Схематически весь процесс обработки команд, даже при одновременном их запуске, теперь выглядит так:

В последовательном режиме выполнение всех команд заняло 32 секунды (10 + 10 + 1 + 10 + 1), в многопоточном всего 10 секунд. При этом даже в течении этих 10 секунд основной сеанс практически не был заблокирован, только на первые две секунды, когда в нём происходили вычисления быстрых команд /fast в последовательном режиме.
7.5 Управление количеством потоков
По умолчанию функция future::plan() при изменении плана с последовательного на многопоточный автоматически определяет оптимальное количество потоков, т.е. фоновых процессов, которые будут доступны в фоновом режиме. По умолчанию будет создано столько процессов, сколько ядер доступно в процессоре вашего ПК. Программно можно посмотреть количество доступных ядер следующим образом:
## system ## 8В моём случае одновременно будет доступно 8 фоновых R сеансов. Для большинства задач этого будет достаточно, но в функции future::plan() доступен аргумент workers , который позволяет самостоятельно задать необходимое количество фоновых процессов.
future::plan('multisession', workers = 4)Приведённый выше код демонстрирует сокращение количества доступных процессов до 4ёх.
7.6 Функция promises::future_promise()
Пакет promises часто используется в связке с future органично дополняя его.
В приведённых выше практических примерах нам было достаточно количества созданных фоновых потоков. Но всегда есть вероятность того, что все потоки будут заняты. Например, мы включили мультисессионый режим вычислений с двумя потоками (workers = 4) и бот получил практически одновременно 3 команды /slow . В таком случае первые две команды уйдут выполняться в фоновые процессы, а третья, и последующие встанут в очередь ожидания свободного процесса, заняв при этом основной процесс. В такой ситуации до тех пор, пока не появится свободный процесс, основной процесс будет заблокирован, и даже при попытке отправить быструю функцию /fast , она будет также поставлена в очередь.
Решить эту проблему можно с помощью функции promises::future_promise() . Преимущество promises::future_promise() перед future::future() , заключается в том, что даже если нет свободных потоков, созданная очередь не будет блокировать основной поток, она будет создана так же в фоновом потоке. Для доработки приведенного ранее примера достаточно просто заменить в коде функции slow() функцию future::future() на promises::future_promise() .
library(telegram.bot) library(stringr) # Включаем параллельный план вычислений future::plan('multisession') updater Updater("Токен вашего бота") # Функция с длительным временем вычислений slow_fun function(bot, update) # Запускаем выполнение кода в параллельной сессии promises::future_promise( # Сообщение о том, что начата работа длительного вычисления bot$sendMessage(update$message$chat_id, text = str_glue("Медленная функция, начало работы!\nID процесса: "), parse_mode = "Markdown") # Добавляем паузу, для того, что бы исскусственно сделать функцию длительной Sys.sleep(10) # Сообщаем о том, что все вычисления выполнены bot$sendMessage(update$message$chat_id, text = str_glue("Медленная функция выполнена!\nID процесса: "), parse_mode = "Markdown") > ) > # Функция с коротким временем вычислений fast_fun function(bot, update) # Просто отправляем сообщение bot$sendMessage(update$message$chat_id, text = str_glue("Быстрая функция, выполняется последовательный режим!\nID процесса: "), parse_mode = "Markdown") > # создаём обработчик slow_hendler CommandHandler('slow', slow_fun) fast_hendler CommandHandler('fast', fast_fun) # добаляем добавляем в диспетчер updater updater + slow_hendler + fast_hendler # запускаем бота updater$start_polling()7.7 Заключение
Итак, для того, что бы ваш бот умел одновременно обрабатывать входящие команды необходимо:
- Выявить список команд, требующих длительных вычислений.
- В начале скрипта добавить команду future::plan(‘multisession’) , для того, что бы у вас была возможность запускать вычисление длительных операций в фоновых, параллельных R сеансах.
- Код методов бота, которые требуют длительных вычислений заворачиваем в future::future() .
- Улучшить многопоточность бота можно заменив функцию future::future() на promises::future_promise() , которая оставляет свободным основной поток R, даже если все фоновые потоки заняты.
Асинхронный телеграм-бот с вебхуками на Heroku
Посредством этой статьи я поделюсь своим опытом разработки телеграм-бота для большого количества пользователей: разберу свои ошибки и шаги для их решения.
Одной из моих рабочих задач как программиста была автоматизация проведения викторины. Конечно, уже существуют специализированные бесплатные приложения, заточенные под эти задачи, но нужно было такое, в котором не было бы ничего лишнего, оно было всегда под рукой и такое привычное, чтобы не нужно было с ним разбираться. Выбор пал на телеграм бота и для того, чтобы он справлялся с большей нагрузкой было принято решение использовать асинхронную библиотеку aiogram.
Начнём с создания эхо бота на aiogram, тут нет ничего сложного, возьмём пример из документации:
import logging from aiogram import Bot, Dispatcher, executor, types # Токен, выданный BotFather в телеграмме API_TOKEN = 'BOT TOKEN HERE' # Configure logging logging.basicConfig(level=logging.INFO) # Initialize bot and dispatcher bot = Bot(token=API_TOKEN) dp = Dispatcher(bot) @dp.message_handler() async def echo(message: types.Message): await message.answer(message.text) if __name__ == '__main__': executor.start_polling(dp, skip_updates=True)Однако преимущество aiogram над python-telegram-bot и pyTelegramBotAPI в том, что он асинхронный, а значит может обрабатывать несколько запросов почти единовременно. Стандартная база данных sqlite отлично подходит для несложных проектов и уже входит в стандартную библиотеку питона, поэтому для начала я решил использовать её.
Через несколько часов работы приложение было написано, и мы с коллегами решили протестировать на себе его работоспособность. Бот запускался с использование технологии long polling, и запускался он на локальном компьютере. Для небольшого количества человек этого вполне достаточно: 3-4 человека в секунду бот выдерживает без особых проблем.
Но, к сожалению или к счастью, во время проведения викторины боту посыпалось бОльшее количество запросов, на которое мы не рассчитывали, в связи с чем посыпались ошибки не обрабатываемые ошибки, связанные с одновременным постоянным запросом новых сообщений у сервера и обработкой уже полученных.
Решением этой проблемы стал переход на вебхуки. И, для обеспечения бесперебойной работы, разместим его на удалённом сервере. Отличным решением для этого является heroku: здесь можно управлять запуском приложения как с компьютера, так и с мобильного приложения, отслеживать логи и, что является наиболее важным для нас, настраивать вебхуки.
Алгоритм, для реализации эхо бота в данном случае занимает больше времени, но он достаточно прост:
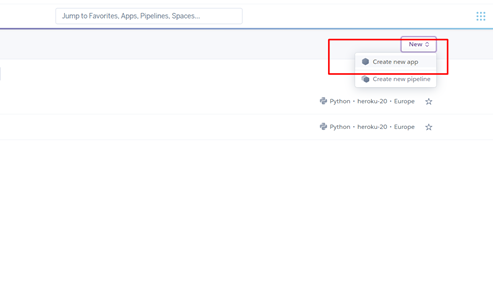
2) На странице Personal создаём новое приложение
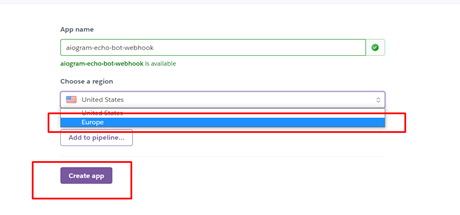
Выбираем имя нашего приложения (у меня это «aiogram-echo-bot-webhook» — запомним его, оно нам ещё понадобится!), меняем сервер на Europe и нажимаем кнопку «create app»
Отлично, мы подготовили контейнер для нашего приложения! Передать туда код самого приложения можно несколькими способами, например через Heroku CLI или через GitHub. Разберём деплой через гитхаб, так как при любой возможности лучше использовать контроль версий 🙂
Перед деплоем на Heroku хорошо бы переписать наше приложение на вебхуки:
import logging import os from aiogram import Bot from aiogram.dispatcher import Dispatcher from aiogram.utils.executor import start_webhook from aiogram import Bot, types TOKEN = os.getenv('BOT_TOKEN') bot = Bot(token=TOKEN) dp = Dispatcher(bot) HEROKU_APP_NAME = os.getenv('HEROKU_APP_NAME') # webhook settings WEBHOOK_HOST = f'https://.herokuapp.com' WEBHOOK_PATH = f'/webhook/' WEBHOOK_URL = f'' # webserver settings WEBAPP_HOST = '0.0.0.0' WEBAPP_PORT = os.getenv('PORT', default=8000) async def on_startup(dispatcher): await bot.set_webhook(WEBHOOK_URL, drop_pending_updates=True) async def on_shutdown(dispatcher): await bot.delete_webhook() @dp.message_handler() async def echo(message: types.Message): await message.answer(message.text) if __name__ == '__main__': logging.basicConfig(level=logging.INFO) start_webhook( dispatcher=dp, webhook_path=WEBHOOK_PATH, skip_updates=True, on_startup=on_startup, on_shutdown=on_shutdown, host=WEBAPP_HOST, port=WEBAPP_PORT, )Что здесь происходит?
TOKEN, HEROKU_APP_NAME – мы считываем из переменных окружения, которые скоро добавим в наш проект.
WEBHOOK_HOST – доменное имя нашего приложения
WEBHOOK_PATH – часть пути, на который мы будем принимать запросы. Его следует придумать таким, чтобы не было возможности его угадать, во избежание фальсификации запросов. В нашем случае используется токен бота, так как его, также, следует держать в секрете.
WEBHOOK_URL – полный url адрес, на который будут принимать запросы.
WEBAPP_HOST – хост нашего приложения, оставляем локальный.
WEBAPP_PORT – порт, на котором работает наше приложение, так же считывается с переменных окружения, которое предоставляет Heroku, его мы не заполняем.
Асинхронная функция on_startup устанавливает вебхук для нашего телеграм бота, на который будут отсылаться уведомления о получении новых сообщений. И on_shutdown, наоборот, удаляет этот вебхук при выключении.
Далее мы переключаем вывод логов только на вывод только чисто информативной информации. И, собственно, запускаем наш диспетчер, при этом при запуске опускаются все сообщения, которые были получены в то время, когда бот не работал, что указано в параметре «skip_updates».
Почти всё готово, но чтобы дать инструкции Heroku, как именно развернуть наше приложение, нужно создать файл «Procfile» и вставляем туда следующий код:
web: python main.pyЗдесь: web – значит, что наше приложение будет web приложением, а то, что идёт после «:» это строка, которую необходимо выполнить в первую очередь. Запустить наш файл main.py с помощью питона.
И ещё один файл, который необходим для запуска, это requirements.txt, в котором мы указываем все зависимости нашего проекта. Его создаём, выполнив команду pip freeze > requirements.txt .
Также можно указать, какую конкретную версию питона использовать: для этого создадим файл «runtime.txt» и впишем туда версию питона по шаблону «python-3.9.7»
Теперь подготовим переменные среды на Heroku: для этого переходим на вкладку «Settings» и жмём кнопку «Reveal Config Vars»
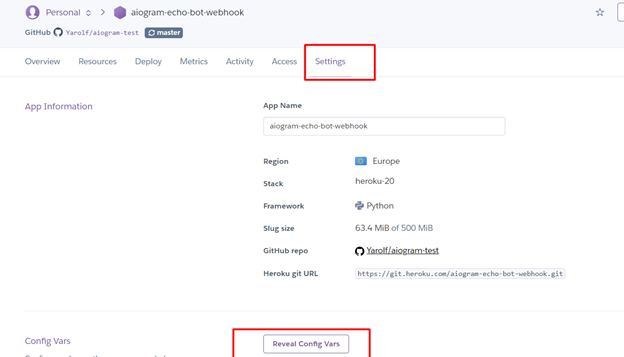
Здесь добавляем два поля:
BOT_TOKEN – токен, полученный у BotFather
HEROKU_APP_NAME – имя приложения созданного на heroku, которое мы с вами запоминали.

Кликаем на кнопку «connect».

Для того, чтобы наше приложение обновлялось каждый раз, как мы заливаем новые изменения в ветку «master», можем нажать кнопку «Enable Automatic Deploys»
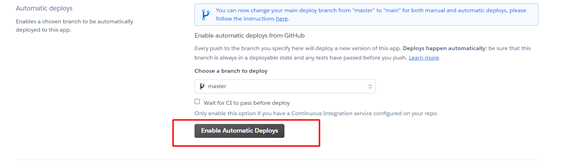
В первый раз, всё-таки придётся деплоить самим, для этого нажимаем кнопку ниже:

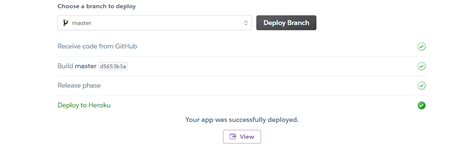
И дожидаемся окончания деплоя. При положительном результате, вывод будет, примерно таким:
Также можно посмотреть логи в верху окна кнопка «More»->«View logs»:


Переходим в наш бот и отправляем ему пару сообщений, если бот отвечает, значит всё в порядке, если нет, то переходим в логи и смотрим, в чём может быть ошибка.
На этом можно было бы остановиться, эхо-бот готов, но в реальном проекте нам понадобится сохранять различные данные из приложения. Для этого нужна база данных, как и в прошлый раз мы можем воспользоваться стандартной sqlite, но так как мы используем асинхронную библиотеку, то и запросы в бд должны быть асинхронными. Поэтому устанавливаем библиотеку databases для sqlite: pip install databases[sqlite] .
Разобьём код по модулям и подключимся к базе данных: создаём файл config.py и выносим туда все переменные (WEBHOOK_HOST, WEBHOOK_PATH и т.д.).
И ещё один модуль «db.py», в котором пишем следующий код:
from databases import Database database = Database('sqlite:///bot.db') # где bot.db – путь к файлу базы данныхCREATE TABLE messages ( id INTEGER PRIMARY KEY AUTOINCREMENT, telegram_id INTEGER NOT NULL, text text NOT NULL );И дополняем модуль main.py:
async def save(user_id, text): await database.execute(f"INSERT INTO messages(telegram_id, text) " f"VALUES (:telegram_id, :text)", values=) async def read(user_id): messages = await database.fetch_all('SELECT text ' 'FROM messages ' 'WHERE telegram_id = :telegram_id ', values=) return messages @dp.message_handler() async def echo(message: types.Message): await save(message.from_user.id, message.text) messages = await read(message.from_user.id) await message.answer(messages)Здесь мы после получения сообщения сохраняем его в базу данных, и затем просто возвращаем все сообщения, полученные от этого пользователя.
Не забываем обновить requirements.txt
Пушим всё на гитхаб, процесс сборки можно посмотреть на вкладке «Activity»
Проверяем в боте: отправляем пару сообщений, бот возвращает нам список сохранённых в базу.

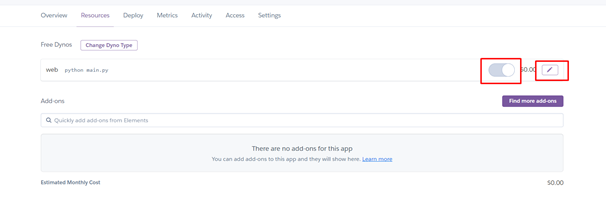
Казалось бы, всё хорошо, но вдруг произошла непредвиденная ошибка и приложение необходимо перезапустить: зайдём на вкладку «Resources»
Нажимаем на карандаш, жмём переключатель, для выключения приложения и подтверждаем «confirm».
Вновь включаем таким же способом и пробуем отправить боту сообщения:

Ужас, мы потеряли все данные! Но почему, ведь они хранятся в базе данных? Это происходит потому, что деплой происходит в изолированных контейнерах и при каждом новом запуске создаётся новый контейнер, а как мы помним исходный файл с бд у нас был пустым.
В нашем случае данные нужны будут и после выключения, поэтому нам нужна изолированная от приложения база данных. К счастью на Heroku, помимо множества приложений, можно бесплатно развернуть и базу данных, например postgres.
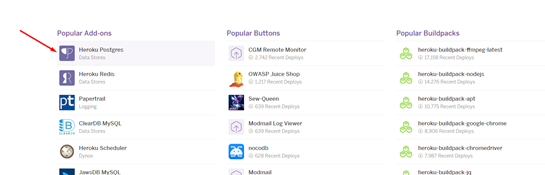
Переходим в «elements»

Выбираем «Heroku Postgres»

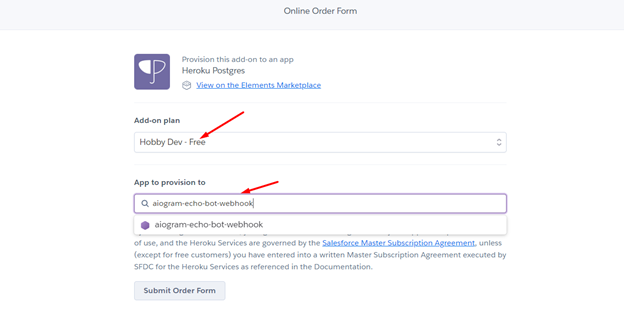
Выбираем бесплатный план и вводим имя приложения, для которого подключаем бд, для того чтобы потом мы могли считывать строку подключения с переменных среды:
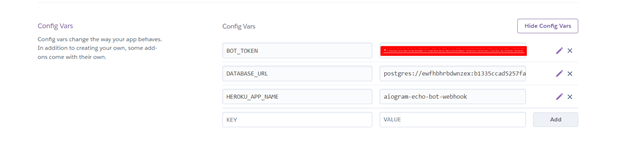
Переходим в переменные среды нашего приложения и видим, что там появился ключ «DATABASE_URL», который мы и будем использовать для подключения.
Для подключения к бд postgresql, установим пакет databases[postgresql]: pip install databases[postgresql] . Создаём исходные таблицы, но синтаксис создания таблицы немного поменяется:
CREATE TABLE messages ( id SERIAL PRIMARY KEY, telegram_id INTEGER NOT NULL, text text NOT NULL );async def read(user_id): results = await database.fetch_all('SELECT text ' 'FROM messages ' 'WHERE telegram_id = :telegram_id ', values=) return [next(result.values()) for result in results]Вновь обновляем requirements.txt и пушим на гит.
Дожидаемся окончания деплоя, если приложение не запущено, то запускаем его и отправляем проверочные сообщения боту:
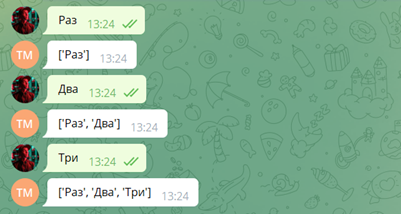
Получаем сообщения, всё отлично! Как и в прошлый раз возникает непредвиденная ситуация, из-за которой приходится перезапускать приложение. Перезапускаем, отправляем ещё одно сообщение и …
Видим, что все данные сохранились в бд!
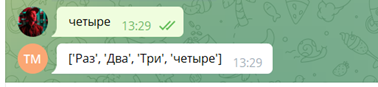
Вот всё и готово! А дальше всё зависит только от ваших предпочтений: для чего и под какие задачи разработать функционал бота, но вы можете быть уверенны, что его производительность будет на высоте, а данные надёжно сохранены.
Исходный код приложения размещён в репозитории: ссылка.