Алгебраические структуры: группы, кольца, поля

1. 1.2. Алгебраические структуры: группы, кольца, поля
1.2. АЛГЕБРАИЧЕСКИЕ
СТРУКТУРЫ: ГРУППЫ, КОЛЬЦА,
ПОЛЯ
ПОДГОТОВИЛ: ПРЕПОДАВАТЕЛЬ, К.Т.Н. РОЙ А.В.
МОСКВА, 2019
2. Введение
ВВЕДЕНИЕ
Ранее мы обсуждали некоторые множества
чисел, таких как Z, Zn, Zn*, Zp^ и Zp*.
Криптография требует, чтобы были заданы
множества целых чисел, и операции,
определенные для них. Комбинация множеств
и операций, которые могут быть применены к
элементам множества, называются
алгебраической структурой. В этой лекции мы
определим три общих алгебраических
структуры: группы, кольца и поля
3. Группы
ГРУППЫ
Группа ( G ) — набор элементов с бинарной операцией «•» обладает четырьмя свойствами (или удовлетворяет аксиомам), которые
будут перечислены ниже.
Коммутативная группа, также называемая абелева, — группа, в которой оператор обладает теми же четырьмя свойствами для групп
плюс дополнительным — коммутативностью. Эти пять свойств определены ниже
• Замкнутость. Если a и b — элементы G, то c = a • b — также элемент G. Это означает, что результат применения операции с
любыми двумя элементами множества есть элемент этого множества.
• Ассоциативность. Если a, b и c — элементы G, то верно (a• b) • c = a• (b •c) Другими словами, не имеет значения, в каком порядке
мы применяем операцию более чем с двумя элементами.
• Коммутативность. Для всех a и b в G мы имеем a • b = b • a. Обратите внимание, что это свойство должно быть верно только для
коммутативной группы.
• Существование нейтрального элемента. Для всех элементов в G существует элемент e, который называется нейтральным
элементом, такой, что e • a = a • e = a.
Существование инверсии. Для каждого a в G существует элемент a’, называемый инверсией, такой, что a • a’ = a’ • a = e.
4. Группы
ГРУППЫ
Хотя группа включает единственный
оператор, свойства, присущие каждой
операции, позволяют использование пары
операций, если они — инверсии друг друга.
Например, если определенный выше
оператор — сложение, то группа
поддерживает и сложение, и вычитание,
ибо вычитание и сложение — аддитивно
инверсные операции. Это также верно для
умножения и деления. Однако группа
может поддержать только
сложение/вычитание или
умножение/деление, но не оба сочетания
операторов одновременно
5. Пример группы № 1
ПРИМЕР ГРУППЫ № 1
Множество целых чисел, входящих в вычет с оператором сложения, G = , является
коммутативной группой. Мы можем выполнить сложение и вычитание на элементах этого множества,
не выходя за его пределы.
Проверим эти свойства.
1. Замкнутость удовлетворяется. Результат сложения двух целых чисел в Zn — другое целое число в
Zn.
2.
3.
4.
5.
Ассоциативность удовлетворяется. Результат 4 + (3 + 2) тот же самый, что в случае (4 + 3) + 2.
Коммутативность удовлетворяется. Мы имеем 3 + 5 = 5 + 3.
Нейтральный элемент — 0. Мы имеем 3 + 0 = 0 + 3 = 3.
Каждый элемент имеет аддитивную инверсию. Инверсия элемента — его дополнение. Например,
инверсия 3 — это –3 ( n – 3 в Zn ), и инверсия –3 — это 3. Инверсия позволяет нам выполнять
вычитание на множестве.
6. Пример группы № 2
ПРИМЕР ГРУППЫ № 2
Множество Zn* с оператором умножения G = , является также
абелевой группой. Мы можем выполнить умножение и деление на
элементах этого множества, не выходя за его пределы. Это облегчает
проверку первых трех свойств. Нейтральный элемент равен 1. Каждый
элемент имеет инверсию, которая может быть найдена согласно
расширенному алгоритму Евклида.
7. Пример Группы № 3
ПРИМЕР ГРУППЫ № 3
• Хотя мы обычно представляем группу как
множество чисел с обычными
операторами, такими, как сложение или
вычитание, определения группы
позволяют нам определять любое
множество объектов и операций,
которые удовлетворяют
вышеупомянутым свойствам. Определим
множество G = , •> и
операцию, показанную с помощью
таблицы.
Таблица 5.1. Таблица операции для примера 5.3
a
b
c
d
a
b
c
d
a
b
c
d
b
c
d
a
c
d
a
b
d
a
b
c
8. Пример Группы № 3
ПРИМЕР ГРУППЫ № 3
Это — абелева группа. Все пять свойств удовлетворены.
1. Замкнутость удовлетворена. Применение оператора на любой паре элементов дает
в результате другой элемент этого множества.
2. Ассоциативность также удовлетворена. Чтобы доказать это, мы должны проверить
свойство для любой комбинации из трех элементов. Например, (a+ b) + c = a+ (b
+ c) = d.
3. Операция коммутативна. Мы имеем a + b = b + a.
4. Группа имеет нейтральный элемент, которым является a.
5. Каждый элемент имеет инверсию. Обратные пары могут быть найдены. В таблице
они указаны теневыми элементами в каждой строке. Пары — (a, a), (b, d), (c, c).
9. Пример Группы № 4
ПРИМЕР ГРУППЫ № 4
В группе элементы в множестве не обязательно должны быть числами или объектами; они могут быть
правилами, отображениями, функциями или действиями. Очень интересная группа — группа
подстановок. Множество всех перестановок и оператор является композицией: применения одной
перестановки за другой. Рисунок показывает композиции двух перестановок, которые перемещают три
входных сигнала, чтобы создать три выходных сигнала.
10. Пример Группы № 4
ПРИМЕР ГРУППЫ № 4
[1 2 3]
[1 3 2]
[2 1 3]
[2 3 1]
[3 1 2]
[3 2 1]
[1 2 3]
[1 2 3]
[1 3 2]
[2 1 3]
[2 3 1]
[3 1 2]
[3 2 1]
Таблица 5.2. Таблица операции для группы перестановок
[1 3 2]
[2 1 3]
[2 3 1]
[1 3 2]
[2 1 3]
[2 3 1]
[1 2 3]
[2 3 1]
[2 1 3]
[3 1 2]
[1 2 3]
[3 2 1]
[3 2 1]
[1 3 2]
[3 1 2]
[2 1 3]
[3 2 1]
[1 2 3]
[2 3 1]
[3 1 2]
[1 3 2]
[3 1 2]
[3 1 2]
[3 2 1]
[1 3 2]
[1 2 3]
[2 3 1]
[2 1 3]
[3 2 1]
[3 2 1]
[3 1 2]
[2 3 1]
[2 1 3]
[1 3 2]
[1 2 3]
В этом случае удовлетворены только четыре свойства; поэтому группа — не абелева.
1.
Замкнутость удовлетворена.
2.
Ассоциативность также удовлетворена. Чтобы доказать это, мы должны проверить свойство для любой комбинации из трех элементов.
3.
Свойство коммутативности не удовлетворено. Это может быть легко проверено, но мы оставим это для упражнения.
4.
Множество имеет нейтральный элемент [1 2 3] (перестановка отсутствует). Эти элементы показаны другим цветом.
5.
Каждый элемент имеет инверсию. Обратные пары могут быть найдены, если использовать нейтральные элементы.
11. Подгруппы
ПОДГРУППЫ
Подмножество H группы G — подгруппа G, если само H — группа относительно операции на G.
Другими словами, если G = — группа, то H = — группа для той же самой операции, и T
— непустое подмножество S, то H — подгруппа G. Вышеупомянутое определение подразумевает, что:
1.
2.
3.
4.
5.
если a и b — члены обеих групп, то c = a • b — также элемент обеих групп;
для группы и подгруппы имеется один и тот же нейтральный элемент;
если этот элемент принадлежит обеим группам, инверсия a — также элемент обеих групп;
группа, полученная с помощью нейтрального элемента G, H = , •>, является подгруппой G ;
каждая группа — подгруппа самой себя.
12. Циклические подгруппы
ЦИКЛИЧЕСКИЕ ПОДГРУППЫ
Если подгруппа группы может быть сгенерирована, используя
возведение в степень элемента, то такая подгруппа называется
циклической подгруппой. Термин возведение в степень здесь означает
многократное применение к элементу групповой операции:
an = a • a • a • … • a (n раз)
Множество, полученное в результате этого процесса, обозначается в
тексте как . Обратите внимание также, что a0 = e.
13. Циклические группы
ЦИКЛИЧЕСКИЕ ГРУППЫ
Циклическая группа — группа, которая является собственной
циклической подгруппой. В примере 5.7 группа G имеет циклическую
подгруппу H5 = G. Это означает, что группа G — циклическая группа. В
этом случае элемент, который генерирует циклическую подгруппу, может
также генерировать саму группу. Этот элемент далее именуется
«генератор». Если g — генератор, элементы в конечной циклической
группе могут быть записаны как , где gn = e.
14. КольцО
КОЛЬЦО
Кольцо, обозначенное как R = , •,┴ — является алгебраической структурой с двумя операциями.
Первая операция должна удовлетворять всем пяти свойствам, требуемым для абелевой группы.
Вторая операция должна удовлетворять только первым двум свойствам абелевой группы. Кроме того,
вторая операция должна быть распределена с помощью первой. Дистрибутивность означает, что для
всех a, b и c элементов из R мы имеем a ┴ (c • b) = (a ┴ c) • (a ┴ b) и (a • b) ┴ c = (a ┴ c) • (b ┴ c).
15. Поле
ПОЛЕ
Поле, обозначенное как F = , •,┴ — это коммутативное кольцо, в котором вторая
операция удовлетворяет всем пяти свойствам, определенным для первой операции, за
исключением того, что нейтральный элемент первой операции (иногда называемый
нулевой элемент) не имеет инверсии. Поле — структура, которая поддерживает две
пары операций, используемые в математике: сложение/вычитание и
умножение/деление. Есть одно исключение: не разрешено деление на нуль.
16. Отличия алгебраических структур
ОТЛИЧИЯ АЛГЕБРАИЧЕСКИХ СТРУКТУР
Таблица 5.3. Итоги определения алгебраических структур
Алгебраическая
структура
Используемые
операции
Используемые наборы
целых чисел
Группа
(+ -) или (x /)
Zn или Zn*
Кольцо
(+ -) и (x)
Z
Поле
(+ -) и (x /)
Zp
Изучение трех алгебраических структур
позволяет нам использовать множества, в
которых могут применяться операции,
подобные сложению/вычитанию и
умножению/делению. Мы должны различать
эти три структуры. Первая структура — группа,
поддерживает одну пару связанных операций.
Вторая структура — кольцо, поддерживает одну
пару связанных операций и одну одиночную
операцию. Третья структура — поле,
поддерживает две пары операций
17. Множество целых чисел. Бинарные операции
МНОЖЕСТВО ЦЕЛЫХ ЧИСЕЛ. БИНАРНЫЕ
ОПЕРАЦИИ
Множество целых чисел, обозначенных Z, содержит все числа (без дробей) от
минус бесконечности до плюс бесконечности.
В криптографии нас интересует три бинарных операции в приложении к
множеству целых чисел. Бинарные операции имеют два входа и один выход.
Для целых чисел определены три общих бинарных операции — сложение,
вычитание и умножение. Каждая из этих операций имеет два входа ( a и b ) и
выход ( c ), как это показано на следующем слайде. Два входа принимают
числа из множества целых чисел; выход выводит результат операции —
число из множества целых чисел.
18. Три бинарных операции для множества целых чисел
ТРИ БИНАРНЫХ ОПЕРАЦИИ ДЛЯ МНОЖЕСТВА
ЦЕЛЫХ ЧИСЕЛ
Следующие примеры показывают результаты трех
бинарных операций на множестве двух целых чисел.
Поскольку каждый вход может быть или положителен
или отрицателен, мы имеем четыре случая для каждой
операции.
Сложение
Вычитание
Умножение
5+9=14
5-9=-4
5 x 9=45
(-5)+9=4
5+(-9)=-4
(-5)+(-9)=-14
(-5)-9=-14
5 — (-9)=14 (-5)- (-9)=+4
(-5) x 9=-45 5 x (-9)=-45 (-5) x (-9)=45
19. Деление целых чисел
ДЕЛЕНИЕ ЦЕЛЫХ ЧИСЕЛ
В арифметике целых чисел, если мы a делим на n, мы можем получить q и r.
Отношения между этими четырьмя целыми числами можно показать как
a=q•n+r
В этом равенстве a называется делимое ; q — частное ; n — делитель и r —
остаток. Обратите внимание, что это — не операция, поскольку результат
деления a на n — это два целых числа, q и r. Мы будем называть это
уравнением деления.
20. Деление целых чисел
ДЕЛЕНИЕ ЦЕЛЫХ ЧИСЕЛ
• Когда мы используем вышеупомянутое уравнение деления в
криптографии, мы налагаем два ограничения. Первое требование:
чтобы делитель был положительным целым числом ( n > 0 ). Второе
требование: чтобы остаток был неотрицательным целым числом ( r >=
0 ).
• Как можно сделать, чтобы выполнялось ограничение, что
число r должно быть положительным? Решение простое: мы
уменьшаем значение q на 1 и добавляем значение n к r, чтобы r стало
положительным:
• -255 = (-23 • 11) + (-2) -255 = (-24 • 11) + 9
21. Теория делимости
ТЕОРИЯ ДЕЛИМОСТИ
• Если a не равно нулю, а r = 0, в равенстве деления мы имеем
•a = q x n
• Мы тогда говорим, что a делится на n (или n — делитель a ). Мы
можем также сказать, что a делится без остатка на n. Когда мы не
интересуемся значением q, мы можем записать вышеупомянутые
отношения как n|a. Если остаток не является нулевым, то n не делит, и
мы можем записать отношения как n†a.
22. Свойства делимости
СВОЙСТВА ДЕЛИМОСТИ
• Свойство 1: если a|1, то a=±1.
• Свойство 2: если a|b и b|a, то a=±b
• Свойство 3: если a|b и b|c, то a|c
• Свойство 4: если a|b и a|c, то a|(m x b + n x c),
где m и n — произвольные целые числа.
23. Наибольший общий делитель
НАИБОЛЬШИЙ ОБЩИЙ ДЕЛИТЕЛЬ
• Одно целое число, часто необходимое в криптографии, — наибольший
общий делитель двух положительных целых чисел. Два положительных
целых числа могут иметь много общих делителей, но только один
наибольший общий делитель. Например, общие делители чисел 12 и
140 есть 1, 2 и 4. Однако наибольший общий делитель.
• Наибольший общий делитель двух положительных целых чисел —
наибольшее целое число, которое делит оба целых числа.
24. Простые и составные числа
ПРОСТЫЕ И СОСТАВНЫЕ ЧИСЛА
• Каждое натуральное число, большее единицы, делится по крайней мере на два
числа: на 1 и на само себя. Если число не имеет делителей, кроме самого себя и
единицы, то оно называется простым, а если у числа есть еще делители,
то составным. Единица же не считается ни простым числом, ни составным.
Например, числа 7, 29 — простые; числа 9, 15 — составные ( 9 делится на 3,
15 делится на 3 и на 5 ).
• Интересный факт: если два простых числа отличаются на 2, то их называют числами»близнецами». Чисел-«близнецов» не очень много. Например, «близнецами»
являются 5 и 7, 29 и 31, 149 и 151, а также 242 206 083*238 880±1 (наибольшая
найденная на момент написания учебного пособия пара «близнецов»).
25. Факторизация простых чисел
ФАКТОРИЗАЦИЯ ПРОСТЫХ ЧИСЕЛ
Поиск больших простых чисел имеет важное значение для математики и не
только. Например, в криптографии большие простые числа используются в
алгоритмах шифрования с открытым ключом. Для обеспечения надежности
шифрования там используются простые числа длиной до 1024 бит.
Перемножить два числа сравнительно нетрудно, особенно если у нас есть
калькулятор, а числа не слишком велики. Существует и обратная задача –
задача факторизации – нахождение двух или более чисел, дающих при
перемножении заданное число. Эта задача гораздо труднее, чем
перемножение чисел, и любому, кто пытался ее решить, об этом известно.
Сложность задачи факторизации используется в некоторых
криптографических алгоритмах, например, в системе шифрования RSA.
26. Основная теорема арифметики
ОСНОВНАЯ ТЕОРЕМА АРИФМЕТИКИ
В математике рассматривается так называемая основная теорема
арифметики, которая утверждает, что любое натуральное число ( n>1 ) либо
само является простым, либо может быть разложено на произведение
простых делителей, причем единственным способом (если не обращать
внимания на порядок следования сомножителей). Воспользовавшись
обозначением степени, разложение числа 2009 на простые множители
можно записать так: 2009 = 72 * 41
Разложение на множители называется каноническим, если все множители
являются простыми и записаны в порядке возрастания. Например, запишем
каноническое разложение числа 150 на множители: 150 = 2 * 3 * 52
27. Взаимно простые числа
ВЗАИМНО ПРОСТЫЕ ЧИСЛА
• Два числа называются взаимно простыми, если они не имеют ни одного общего
делителя кроме единицы. Например, числа 11 и 12 взаимно просты (у них нет общих
делителей кроме единицы), числа 30 и 35 — нет (у них есть общий делитель 5 ).
• Исследованием закономерностей, связанных с целыми числами, долго занимался
швейцарский математик Леонард Эйлер. Одним из вопросов, которым он
интересовался, был следующий: сколько существует натуральных чисел, не
превосходящих n и взаимно простых с n? Ответ на этот вопрос был получен Эйлером
в 1763 году и этот ответ связан с каноническим разложением числа n на простые
множители.
28. функция Эйлера
ФУНКЦИЯ ЭЙЛЕРА
• Если n = p1a1•p2a2• p3a3• … •pna n, где p1, p2, p3… — простые
множители, то число ф натуральных чисел , не превосходящих n и
взаимно простых с n можно точно определить по формуле:
ф (n) = n • 1/(1-p1) • 1/(1-p2) • 1/(1-p3) • …• 1/(1-pn), которая
называется функцией Эйлера. Формулу Эйлера удобно использовать
для больших n, если известно разложение числа n на простые
множители. Для криптографии формула Эйлера важна тем, что она
позволяет легко получить число ф (n) для простых и некоторых других
чисел. Это гораздо удобнее, чем рассматривать все числа из довольно
большого диапазона и проверять на взаимную простоту.
10 типов структур данных, которые нужно знать + видео и упражнения
Екатерина Малахова, редактор-фрилансер, специально для блога Нетологии адаптировала статью Beau Carnes об основных типах структур данных.
«Плохие программисты думают о коде. Хорошие программисты думают о структурах данных и их взаимосвязях», — Линус Торвальдс, создатель Linux.
Структуры данных играют важную роль в процессе разработки ПО, а еще по ним часто задают вопросы на собеседованиях для разработчиков. Хорошая новость в том, что по сути они представляют собой всего лишь специальные форматы для организации и хранения данных.
В этой статье я покажу вам 10 самых распространенных структур данных. Для каждой из них приведены видео и примеры их реализации на JavaScript. Чтобы вы смогли попрактиковаться, я также добавил несколько упражнений из бета-версии новой учебной программы freeCodeCamp.
Обратите внимание, что некоторые структуры данных включают временную сложность в нотации «большого О». Это относится не ко всем из них, так как иногда временная сложность зависит от реализации. Если вы хотите узнать больше о нотации «большого О», посмотрите это видео от Briana Marie.
В статье я привожу примеры реализации этих структур данных на JavaScript: они также пригодятся, если вы используете низкоуровневый язык вроде С. В многие высокоуровневые языки, включая JavaScript, уже встроены реализации большинства структур данных, о которых пойдет речь. Тем не менее, такие знания станут серьезным преимуществом при поиске работы и пригодятся при написании высокопроизводительного кода.
Связные списки
Связный список — одна из базовых структур данных. Ее часто сравнивают с массивом, так как многие другие структуры можно реализовать с помощью либо массива, либо связного списка. У этих двух типов есть преимущества и недостатки.
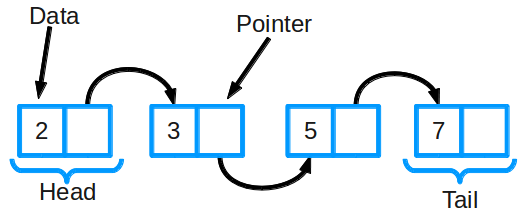
Так устроен связный список
Связный список состоит из группы узлов, которые вместе образуют последовательность. Каждый узел содержит две вещи: фактические данные, которые в нем хранятся (это могут быть данные любого типа) и указатель (или ссылку) на следующий узел в последовательности. Также существуют двусвязные списки: в них у каждого узла есть указатель и на следующий, и на предыдущий элемент в списке.
Основные операции в связном списке включают добавление, удаление и поиск элемента в списке.
Временная сложность связного списка ╔═══════════╦═════════════════╦═══════════════╗ ║ Алгоритм ║Среднее значение ║ Худший случай ║ ╠═══════════╬═════════════════╬═══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(n) ║ O(n) ║ ║ Insert ║ O(1) ║ O(1) ║ ║ Delete ║ O(1) ║ O(1) ║ ╚═══════════╩═════════════════╩═══════════════╝ Упражнения от freeCodeCamp
- Work with Nodes in a Linked List
- Create a Linked List Class
- Remove Elements from a Linked List
- Search within a Linked List
- Remove Elements from a Linked List by Index
- Add Elements at a Specific Index in a Linked List
- Create a Doubly Linked List
- Reverse a Doubly Linked List
Стеки
Стек — это базовая структура данных, которая позволяет добавлять или удалять элементы только в её начале. Она похожа на стопку книг: если вы хотите взглянуть на книгу в середине стека, сперва придется убрать лежащие сверху.
Стек организован по принципу LIFO (Last In First Out, «последним пришёл — первым вышел») . Это значит, что последний элемент, который вы добавили в стек, первым выйдет из него.

Так устроен стек
В стеках можно выполнять три операции: добавление элемента (push), удаление элемента (pop) и отображение содержимого стека (pip).
Временная сложность стека ╔═══════════╦═════════════════╦═══════════════╗ ║ Алгоритм ║Среднее значение ║ Худший случай ║ ╠═══════════╬═════════════════╬═══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(n) ║ O(n) ║ ║ Insert ║ O(1) ║ O(1) ║ ║ Delete ║ O(1) ║ O(1) ║ ╚═══════════╩═════════════════╩═══════════════╝ Упражнения от freeCodeCamp
- Learn how a Stack Works
- Create a Stack Class
Очереди
Эту структуру можно представить как очередь в продуктовом магазине. Первым обслуживают того, кто пришёл в самом начале — всё как в жизни.

Так устроена очередь
Очередь устроена по принципу FIFO (First In First Out, «первый пришёл — первый вышел»). Это значит, что удалить элемент можно только после того, как были убраны все ранее добавленные элементы.
Очередь позволяет выполнять две основных операции: добавлять элементы в конец очереди (enqueue) и удалять первый элемент (dequeue).
Временная сложность очереди ╔═══════════╦═════════════════╦═══════════════╗ ║ Алгоритм ║Среднее значение ║ Худший случай ║ ╠═══════════╬═════════════════╬═══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(n) ║ O(n) ║ ║ Insert ║ O(1) ║ O(1) ║ ║ Delete ║ O(1) ║ O(1) ║ ╚═══════════╩═════════════════╩═══════════════╝ Упражнения от freeCodeCamp
- Create a Queue Class
- Create a Priority Queue Class
- Create a Circular Queue
Множества
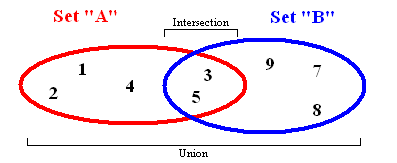
Так выглядит множество
Множество хранит значения данных без определенного порядка, не повторяя их. Оно позволяет не только добавлять и удалять элементы: есть ещё несколько важных функций, которые можно применять к двум множествам сразу.
- Объединение комбинирует все элементы из двух разных множеств, превращая их в одно (без дубликатов).
- Пересечение анализирует два множества и создает еще одно из тех элементов, которые присутствуют в обоих изначальных множествах.
- Разность выводит список элементов, которые есть в одном множестве, но отсутствуют в другом.
- Подмножество выдает булево значение, которое показывает, включает ли одно множество все элементы другого множества.
Упражнения от freeCodeCamp
- Create a Set Class
- Remove from a Set
- Size of the Set
- Perform a Union on Two Sets
- Perform an Intersection on Two Sets of Data
- Perform a Difference on Two Sets of Data
- Perform a Subset Check on Two Sets of Data
- Create and Add to Sets in ES6
- Remove items from a set in ES6
- Use .has and .size on an ES6 Set
- Use Spread and Notes for ES5 Set() Integration
Map
Map — это структура, которая хранит данные в парах ключ/значение, где каждый ключ уникален. Иногда её также называют ассоциативным массивом или словарём. Map часто используют для быстрого поиска данных. Она позволяет делать следующие вещи:
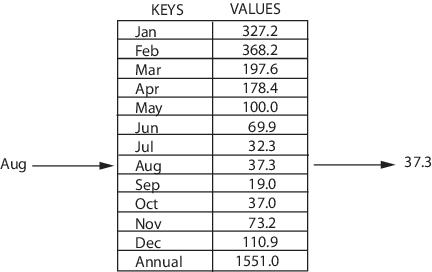
- добавлять пары в коллекцию;
- удалять пары из коллекции;
- изменять существующей пары;
- искать значение, связанное с определенным ключом.
Так устроена структура map
Поисковые структуры данных
Поисковая структура данных — любая структура данных реализующая эффективный поиск конкретных элементов множества, например, конкретной записи в базе данных.
Простейшей, наиболее общей, но менее эффективной поисковой структурой является простая неупорядоченная последовательная всех элементов. Расположив элементы в такой список, неизбежно возникнет ряд операций, которые потребуют линейного времени, в худшем случае, а также в средней случае. Используемые в реальной жизни поисковые структуры данных позволяют совершать операции более быстро, однако они ограничены запросами некоторого конкретного вида. Кроме того, поскольку стоимость построение таких структур пропорциональна [math]n[/math] , их построение окупится, даже если поступает лишь несколько запросов.
Тип
Статические поисковые структуры данных (англ. Offline search structures) предназначены для ответа на запросы на фиксированной базе данных.
Динамические поисковые структуры (англ. Online search structures) также позволяют вставки, удаления или модификации элементов между последовательными запросами. В динамическом случае, необходимо также учитывать стоимость изменения структуры данных. Любую динамическую структуру данных можно сделать статической, если запретить вставку и удаление. Также если множество ключей известно, то можно его заранее упорядочить так, чтобы избежать худших случаев в поисках в структурах данных.
Время работы
Эту классификацию обычно считают самой важной. Оценивают худшее время алгоритма, среднее и лучшее для каждой операции. Лучшее время — минимальное время работы алгоритма на каком-либо наборе. Худшее время — наибольшее время.
Используемая память
Параметр структуры данных, показывающий, сколько памяти ей требуется. Обычно затраты составляют [math]O(n)[/math] .
Сравнение структур данных
Сравним эффективность поисковых структур данных для реализации интерфейса упорядоченного множества. Время работы методов [math]Predecessor[/math] и [math]Successor[/math] совпадает с временем работы [math]Search[/math] .
[math]n[/math] — количество хранимых чисел, каждое из которых представляется с помощью [math]w[/math] битов.
Особенностью этой структуры является то, что все операции выполняются за [math]O(\log w)[/math] , что асимптотически лучше, чем [math]O(\log n)[/math] в большинстве других деревьев поиска, где [math]n[/math] — количество элементов в дереве.
Отсортированный связный список является простейшей структурой с временем поиска [math]\Theta(n)[/math] . Добавление дополнительных уровней, обеспечивающих быстрый доступ через несколько элементов, помогает улучшить асимптотику до [math]\Theta(\log(n))[/math]
См. также
- Сортировка
- Поиск подстроки в строке
- Приоритетные очереди
Источники информации
- Wikidedia — Search data structure
- Habrahabr — Знай сложности алгоритмов
Глава 6. Структуры
Структура — это одна или несколько переменных (возможно, различных типов), которые для удобства работы с ними сгруппированы под одним именем. (В некоторых языках, в частности в Паскале, структуры называются записями.) Структуры помогают в организации сложных данных (особенно в больших программах), поскольку позволяют группу связанных между собой переменных трактовать не как множество отдельных элементов, а как единое целое.
Распространенный пример структуры — строка платежной ведомости. Она содержит такие сведения о служащем, как его полное имя, адрес, номер карточки социального страхования, зарплата и т.д. Некоторые из этих характеристик сами могут быть структурами: например, полное имя состоит из нескольких компонент (фамилии, имени и отчества); аналогично адрес, и даже зарплата. Другой пример (более типичный для Си) — из области графики: точка есть пара координат, прямоугольник есть пара точек и т.д.
Главные изменения, внесенные стандартом ANSI в отношении структур, — это введение для них операции присваивания. Структуры могут копироваться, над ними могут выполняться операции присваивания, их можно передавать функциям в качестве аргументов, а функции могут возвращать их в качестве результатов. В большинстве компиляторов уже давно реализованы эти возможности, но теперь они точно оговорены стандартом. Для автоматических структур и массивов теперь также допускается инициализация.
6.1. Основные сведения о структурах
Сконструируем несколько графических структур. В качестве основного объекта выступает точка с координатами x и y , и пусть они имеют тип int .
Указанные две компоненты можно поместить в структуру, описанную, например, следующим образом:
struct point < int x; int y; >;
Описание структуры начинается с ключевого слова struct и содержит список деклараций, заключенный в фигурные скобки. За словом struct может следовать имя, называемое тегом (от английского слова tag — ярлык, этикетка. — Примеч. пер.) структуры ( point в нашем случае). Тег дает название структуре данного вида и далее может служить кратким обозначением той части декларации, которая заключена в фигурные скобки.
Перечисленные в структуре переменные называются членами. Имена членов и тегов без каких-либо коллизий могут совпадать с именами обычных переменных (т.е. не членов), так как они всегда различимы по контексту. Более того, одни и те же имена членов могут встречаться в разных структурах, хотя, если следовать хорошему стилю программирования, лучше одинаковые имена давать только близким по смыслу объектам.
Декларация структуры — это тип. За правой фигурной скобкой, закрывающей список членов, могут следовать переменные точно так же, как они могут быть указаны после названия любого базового типа. Таким образом, запись
struct < . >x, y, z;
с точки зрения синтаксиса аналогична записи
int x, y, z;
в том смысле, что каждая декларирует x , y и z как переменные указанного типа. Обе записи приведут к тому, что где-то будет выделена память соответствующего размера.
Декларация структуры, не содержащей списка переменных, не резервирует памяти: она просто описывает шаблон, или образец структуры. Однако если структура имеет тег, то этим тегом далее можно пользоваться при определении структурных объектов. Например, с помощью заданной выше декларации структуры point строка
struct point pt;
определяет структурную переменную pt типа struct point . Структурную переменную при ее определении можно инициализировать, формируя список инициализаторов ее членов в виде константных выражений:
struct point maxpt = < 320, 200 >;
Инициализировать автоматические структуры можно также присваиванием или обращением к функции, возвращающей результат в виде структуры соответствующего типа.
Доступ к отдельному члену структуры осуществляется посредством конструкции вида:
имя_структуры . член
Оператор доступа к члену структуры « . » соединяет имя структуры и имя члена. Чтобы напечатать, например, координаты точки pt , годится следующее обращение к printf :
printf("%d, %d", pt.x, pt.y);
Другой пример: чтобы вычислить расстояние от начала координат (0, 0) до pt , можно написать
double dist, sqrt(double); dist = sqrt((double) pt.x * pt.x + (double) pt.y * pt.y);
Структуры могут быть вложены друг в друга. Одно из возможных представлений прямоугольника — это пара точек на углах одной из его диагоналей:
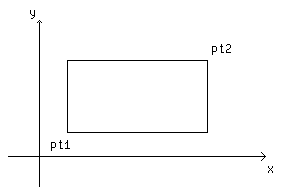
struct rect < struct point pt1; struct point pt2; >;
Структура rect содержит две структуры point . Если мы декларируем screen как
struct rect screen;
screen.pt1.x
ссылается на координату x точки pt1 из screen .
6.2. Структуры и функции
Чтобы лучше познакомиться со структурами, напишем несколько функций, манипулирующих точками и прямоугольниками. Возникает вопрос: а как передавать функциям названные объекты? Существует по крайней мере три подхода: передавать компоненты по отдельности, передавать всю структуру целиком и передавать указатель на структуру. Каждый подход имеет свои плюсы и минусы.
Первая функция, makepoint , получает два целых значения и возвращает структуру point .
/* makepoint: формирует точку по компонентам x и y */ struct point makepoint(int x, int y)
Заметим: никакой путаницы из-за того, что имя аргумента совпадает с именем члена структуры не возникает; более того, одно и то же имя подчеркивает родство обозначаемых им объектов.
Теперь с помощью makepoint можно выполнять динамическую инициализацию любой структуры или формировать структурные аргументы для той или иной функции:
struct rect screen; struct point middle; struct point makepoint(int, int); screen.pt1 = makepoint(0, 0); screen.pt2 = makepoint(XMAX, YMAX); middle = makepoint((screen.pt1.x + screen.pt2.x)/2, (screen.pt1.y + screen.pt2.y)/2);
Нам может понадобиться ряд функций, реализующих различные операции над точками. В качестве примера рассмотрим следующую функцию:
/* addpoint: сложение двух точек */ struct point addpoint(struct point p1, struct point p2)
Здесь оба аргумента и возвращаемое значение — структуры. Мы увеличиваем компоненты прямо в p1 и не используем для этого временной переменной, чтобы подчеркнуть, что структурные параметры передаются по значению так же, как и любые другие.
В качестве другого примера приведем функцию ptinrect , которая проверяет: находится ли точка внутри прямоугольника, относительно которого мы принимаем соглашение, что в него входят его левая и нижняя стороны, но не входят верхняя и правая.
/* ptinrect: возвращает 1, если p в r, и 0 в прот. случае */ int ptinrect(struct point p, struct rect r) < return p.x >= r.pt1.x && p.x < r.pt2.x && p.y >= r.pt1.y && p.y
Здесь предполагается, что прямоугольник представлен в стандартном виде, т.е. координаты точки pt1 меньше соответствующих координат точки pt2 . Следующая функция гарантирует получение прямоугольника в каноническом виде.
#define min(a, b) ((a) < (b) ? (a) : (b)) #define max(a, b) ((a) >(b) ? (a) : (b)) /* canonrect: канонизация координат прямоугольника */ struct rect canonrect ( struct rect r)
Если функции передается большая структура, то, чем копировать ее целиком, эффективнее передать указатель на нее. Указатели на структуры ничем не отличаются от указателей на обычные переменные. Декларация
struct point *pp;
сообщает, что pp есть указатель на структуру типа struct point . Если pp ссылается на структуру point , то *pp есть сама структура, а (*pp).x и (*pp).y — ее члены. Используя указатель pp , мы могли бы написать
struct point origin, *pp; pp = &origin; printf("origin: (%d,%d)\n", (*pp).x, (*pp).y);
Скобки в (*pp).x необходимы, поскольку приоритет оператора выше, чем приоритет * . Выражение *pp.x будет проинтерпретировано как *(pp.x) , что неверно, поскольку pp.x не является указателем.
Указатели на структуры используются весьма часто, поэтому для доступа к ее членам была придумана еще одна, более короткая форма записи. Если p — указатель на структуру, то
p->член_структуры
есть ее отдельный член. (Оператор -> состоит из знака — , за которым сразу следует знак > .) Поэтому printf можно переписать в виде
printf("origin: (%d,%d)\n", pp->x, pp->y);
Оба оператора и -> выполняются слева направо. Таким образом, при наличии декларации
struct rect r, *rp = r;
следующие четыре выражения будут эквивалентны:
r.pt1.x rp->pt1.x (r.pt1).x (rp->pt1).x
Операторы доступа к членам структуры . и -> вместе с операторами вызова функции () и индексации массива [] занимают самое высокое положение в иерархии приоритетов и выполняются раньше любых других операторов. Например, если задана декларация
struct < int len; char *str; >*p;
++p->len
увеличит на 1 значение члена структуры len , а не указатель p , поскольку в этом выражении как бы неявно присутствуют скобки: ++(p->len) . Чтобы изменить порядок выполнения операций, нужны явные скобки. Так, в (++p)->len , прежде чем взять значение len , программа продвинет указатель p . В (p++)->len указатель p увеличится после того, как будет взято значение len (в последнем случае скобки не обязательны).
По тем же правилам *p->str обозначает содержимое объекта, на который ссылается str ; *p->str++ продвинет указатель str после получения значения объекта, на который он указывал (как и в выражении вида *s++ ); ( *p->str)++ увеличит значение объекта, на который ссылается str ; *p++->str продвинет p после того, как будет получено то, на что указывает str .
6.3. Массивы структур
Рассмотрим программу, определяющую число вхождений каждого ключевого слова в текст Си-программы. Нам нужно уметь хранить ключевые слова в виде массива стрингов и счетчики ключевых слов в виде массива целых. Один из возможных вариантов — это иметь два параллельных массива:
char *keyword[NKEYS]; int keycount[NKEYS];
Однако именно тот факт, что они параллельны, подсказывает нам другую организацию хранения — через массив структур. Каждое ключевое слово можно описать парой характеристик
char *word; int count;
Такие пары составляют массив. Декларация
struct key < char *word; int count; >keytab[NKEYS];
описывает структуру типа key и определяет массив keytab , каждый элемент которого есть структура этого типа и которому где-то будет выделена память. Это же можно записать и по-другому:
struct key < char *word; int count; >; struct key keytab[NKEYS];
Так как keytab содержит постоянный набор имен, его легче всего сделать внешним массивом и инициализировать один раз в момент определения. Инициализация структур аналогична ранее демонстрировавшимся инициализациям — за определением следует список инициализаторов, заключенный в фигурные скобки:
struct key < char *word; int count; >keytab[] = < "auto", 0, "break", 0, /* . */ "while", 0 >;
Инициализаторы задаются парами, чтобы соответствовать конфигурации структуры. Строго говоря, пару инициализаторов для каждой отдельной структуры следовало бы заключить в фигурные скобки, как, например, в
Однако, когда инициализаторы — простые константы или цепочки литер, и все они имеются в наличии, во внутренних скобках нет необходимости. Число элементов массива keytab будет вычислено по количеству инициализаторов, поскольку они представлены полностью, а внутри квадратных скобок [] ничего не задано.
Программа подсчета ключевых слов начинается с определения keytab . Программа main читает ввод, многократно обращаясь к функции getword и получая на каждом ее вызове очередное слово. Каждое слово ищется в keytab . Для этого используется функция бинарного поиска, которую мы написали в гл. 3. Список ключевых слов должен быть упорядочен в алфавитном порядке.
#include #include #include #define MAXWORD 100 int getword(char *, int); int binsearch(char *, struct key *, int); /* подсчет ключевых слов Си */ main() < int n; char word[MAXWORD]; while (getword(word, MAXWORD) != EOF) if (isalpha(word[0])) if ((n = binsearch(word, keytab, NKEYS)) >= 0) keytab[n].count++; for (n = 0; n < NKEYS; n++) if (keytab[n].count >0) printf("%d %s\n", keytab[n].count, keytab[n].word); return 0; > /* binsearch: найти слово в tab[0]. tab[n-1] */ int binsearch(char *word, struct key tab[], int n) < int cond; int low, high, mid; low = 0; high = n - 1; while (low 0) low = mid + 1; else return mid; > return -1; >
Чуть позже мы рассмотрим функцию getword , а сейчас нам достаточно знать, что при каждом ее вызове получается очередное слово, которое запоминается в массиве, заданном первым аргументом.
NKEYS — количество ключевых слов в keytab . Хотя мы могли бы подсчитать число таких слов вручную, гораздо легче и безопасней сделать это с помощью машины, особенно если список ключевых слов может быть изменен. Одно из возможных решений — поместить в конец списка инициализаторов пустой указатель ( NULL ) и затем перебирать в цикле элементы keytab , пока не встретится концевой элемент.
Но возможно и более простое решение. Поскольку размер массива полностью определен во время компиляции и равен произведению количества элементов массива на размер его отдельного элемента, число элементов массива можно вычислить по формуле
размер keytab / размер struct key
В Си имеется унарный оператор sizeof , который работает во время компиляции. Его можно применять для вычисления размера любого объекта. Выражения
sizeof объект sizeof (имя типа)
выдают целые значения, равные размеру указанного объекта или типа в байтах. (Строго говоря. sizeof выдает беззнаковое целое, тип которого size_t определен в головном файле .) Что касается объекта, то это может быть переменная, массив или структура. В качестве имени типа может выступать имя базового типа ( int , double . ) или имя производного типа, например, структуры или указателя.
В нашем случае, чтобы вычислить количество ключевых слов, размер массива надо поделить на размер одного элемента. Указанное вычисление используется в инструкции #define для установки значения NKEYS :
#define NKEYS (sizeof keytab / sizeof(struct key))
Этот же результат можно получить другим способом — поделить размер массива на размер какого-то его конкретного элемента:
#define NKEYS (sizeof keytab / sizeof keytab[0])
Преимущество такого рода записей в том, что их не надо корректировать при изменении типа.
Поскольку препроцессор не обращает внимания на имена типов, оператор sizeof нельзя применять в #if . Но в #define выражение препроцессором не вычисляется, так что предложенная нами запись допустима.
Теперь поговорим о функции getword . Мы написали getword в несколько более общем виде, чем требуется для нашей программы, но она от этого не стала заметно сложнее. Функция getword берет из входного потока следующее «слово». Под словом понимается цепочка букв-цифр, начинающаяся с буквы, или отдельная непробельная литера. По концу файла функция выдает EOF , в остальных случаях ее значением является код первой литеры слова или код отдельной литеры, если она не буква.
/* getword: принимает следующее слово или литеру из ввода */ int getword(char *word, int lim) < int c, getch(void); void ungetch(int); char *w = word; while (isspace(c = getch())) ; if (c != EOF) *w++ = c; if (!isalpha(c)) < *w = '\0'; return c; >for ( ; --lim > 0; w++) if (!isalnum(*w = getch())) < ungetch(*w); break; >*w = '\0'; return word[0]; >
Функция getword обращается к getch и ungetch , которые мы написали в гл. 4. При завершении набора букв-цифр оказывается, что getword взяла лишнюю литеру. Обращение к ungetch позволяет вернуть ее назад во входной поток. В getword используются также isspace — для пропуска пробельных литер, isalpha — для идентификации букв и isalnum — для распознавания букв-цифр. Все они описаны в стандартном головном файле .
Упражнение 6.1.
Наша версия getword не обрабатывает должным образом знак подчеркивания, стринговые константы, комментарии и управляющие строки препроцессора. Напишите более совершенный вариант программы.
6.4. Указатели на структуры
Для иллюстрации некоторых моментов, касающихся указателей на структуры и массивов структур, перепишем программу подсчета ключевых слов, пользуясь для получения элементов массива вместо индексов указателями.
Внешняя декларация массива keytab остается без изменения, а main и binsearch нужно модифицировать.
#include #include #include #define MAXWORD 100 int getword(char *, int); struct key *binsearch(char *, struct key *, int); /* подсчет ключевых слов Си; версия с указателями */ main() < char word[MAXWORD]; struct key *p; while (getword(word, MAXWORD) != EOF) if (isalpha(word[0])) if ((p = binsearch(word, keytab, NKEYS)) != NULL) p->count++; for (p = keytab; p < keytab + NKEYS; p++) if (p->count > 0) printf("%4d %s\n", p->count, p->word); return 0; > /* binsearch: найти слово в tab[0]. tab[n-1] */ struct key *binsearch(char *word, struct key *tab, int n) < int cond; struct key *low = &tab[0]; struct key *high = &tab[n]; struct key *mid; while (low < high) < mid = low + (high-low) / 2; if ((cond = strcmp(word, mid->word)) < 0) high = mid; else if (cond >0) low = mid + 1; else return mid; > return NULL; >
Некоторые детали этой программы требуют пояснений. Первое, описание функции binsearch должно отражать тот факт, что она возвращает указатель на struct key , а не целое; соответствующие изменения коснулись как прототипа функции, так и ее заголовка. Если binsearch находит слово, то она выдает указатель на него, в противном случае она возвращает NULL . Второе, к элементам keytab доступ осуществляется в нашей программе через указатели. Это потребовало значительных изменений в binsearch . Инициализаторами для low и high теперь служат указатели на начало и на место сразу после конца массива. Вычисление положения среднего элемента с помощью формулы
mid = (low+high) / 2 /* НЕВЕРНО */
не годится, поскольку указатели нельзя складывать. Однако к ним можно применить операцию вычитания, и так как high-low есть число элементов, присваивание
mid = low + (high-low) / 2
установит в mid указатель на элемент, лежащий посередине между low и high .
Самое важное при переходе на новый вариант программы — сделать так, чтобы не генерировались неправильные указатели и не было попыток обращений за пределы массива. Проблема в том, что и &tab[-1] , и &tab[n] находятся вне границ массива. Первый адрес определенно неверен, нельзя также осуществить доступ и по второму адресу. По правилам языка, однако, гарантируется, что адрес ячейки памяти, следующей сразу за концом массива (т.е. &tab[n] ), в арифметике с указателями воспринимается правильно.
В главной программе мы написали
for (p = keytab; p < keytab + NKEYS; p++)
Если p — указатель на структуру, то при выполнении операций с p учитывается размер структуры. Поэтому p++ увеличит p на такую величину, чтобы выйти на следующий структурный элемент массива, а проверка условия вовремя остановит цикл.
Не следует, однако, полагать, что размер структуры равен сумме размеров ее членов. Вследствие выравнивания объектов разной длины в структуре могут появляться безымянные «дыры». Так, например, если переменная типа char занимает один байт, а int — четыре байта, то для структуры
struct < char c; int i; >;
может потребоваться восемь байт, а не пять. Оператор sizeof возвращает правильное значение.
Наконец, несколько слов относительно формата программы. Если функция возвращает значение сложного типа, как, например, в нашем случае указатель на структуру:
struct key *binsearch(char *word, struct key *tab, int n)
То имя функции «высмотреть» оказывается совсем не просто. В таких случаях иногда пользуются записью вида:
struct key * binsearch(char *word, struct key *tab, int n)
Какой форме отдать предпочтение — дело вкуса. Выберите ту, которая больше всего вам нравится.
6.5. Структуры со ссылками на себя
Предположим, что мы хотим решить более общую задачу — написать программу, подсчитывающую частоту встречаемости для любых слов входного потока. Так как список слов заранее не известен, мы не можем предварительно упорядочить его и применить бинарный поиск. Было бы неразумно пользоваться и линейным поиском каждого полученного слова, чтобы определять, встречалось оно ранее или нет — в этом случае программа работала бы слишком медленно. (Более точная оценка: время работы такой программы пропорционально квадрату количества слов.) Как можно организовать данные, чтобы эффективно справиться со списком произвольных слов?
Один из способов — постоянно поддерживать упорядоченность уже полученных слов, помещая каждое новое слово в такое место, чтобы не нарушалась имеющаяся упорядоченность. Делать это передвижкой слов в линейном массиве не следует, — хотя бы потому, что указанная процедура тоже слишком долгая. Вместо этого мы воспользуемся структурой данных, называемой бинарным деревом.
В дереве на каждое отдельное слово предусмотрен «узел», который содержит:
указатель на текст слова счетчик числа встречаемости указатель на левый сыновний узел указатель на правый сыновний узел
У каждого узла может быть один или два сына, или узел вообще может не иметь сыновей.
Узлы в дереве располагаются так, что по отношению к любому узлу левое поддерево содержит только те слова, которые лексикографически меньше, чем слово данного узла, а правое — слова, которые больше него. Вот как выглядит дерево, построенное для фразы «now is the time for all good men to come to the aid of their party» («настало время всем добрым людям помочь своей партии»), по завершении процесса, в котором для каждого нового слова в него добавлялся новый узел:

Чтобы определить, помещено ли уже в дерево вновь поступившее слово, начинают с корня, сравнивая это слово со словом из корневого узла. Если они совпали, то ответ на вопрос — положительный. Если новое слово меньше слова из дерева, то поиск продолжается в левом поддереве, если больше, то — в правом. Если же в выбранном направлении поддерева не оказалось, то этого слова в дереве нет, а пустующая ссылка, говорящая об отсутствии поддерева, как раз то место, куда нужно «подвесить» узел с новым словом. Описанный процесс по сути рекурсивен, так как поиск в любом узле использует результат поиска в одном из своих сыновних узлов. В соответствии с этим для добавления узла и печати дерева здесь наиболее естественно применить рекурсивные функции.
Вернемся к описанию узла, которое удобно представить в виде структуры с четырьмя компонентами:
struct tnode < /* узел дерева */ char *word; /* указатель на текст */ int count; /* число вхождений */ struct tnode *left; /* левый сын */ struct tnode *right; /* правый сын */ >
Приведенное рекурсивное определение узла может показаться рискованным, но оно правильное. Структура не может включать саму себя, но ведь
struct tnode *left;
определяет left как указатель на tnode , а не сам tnode .
Иногда возникает потребность во взаимоссылающихся структурах: двух структурах, ссылающихся друг на друга. Прием, позволяющий справиться с этой задачей, демонстрирует следующий фрагмент:
struct t < . struct s *p; /* p указывает на s */ >; struct s < . struct t *q; /* q указывает на t */ >;
Вся программа удивительно мала — правда, она использует вспомогательные программы типа getword , уже написанные нами. Главная программа читает слова с помощью getword и вставляет их в дерево посредством addtree .
#include #include #include #define MAXWORD 100 struct tnode *addtree(struct tnode *, char *); void treeprint(struct tnode *); int getword(char *, int); /* подсчет частоты встречаемости слов */ main()
Функция addtree рекурсивна. Первое слово функция main помещает на верхний уровень дерева (корень дерева). Каждое вновь поступившее слово сравнивается со словом узла и «погружается» или в левое, или в правое поддерево с помощью рекурсивного обращения к addtree . Через некоторое время это слово обязательно либо совпадет с каким-нибудь из имеющихся в дереве слов (в этом случае к счетчику будет добавлена 1), либо программа встретит пустую ссылку, что послужит сигналом для заведения нового узла и добавления его к дереву. Создание нового узла сопровождается тем, что addtree возвращает на него указатель, который вставляется в узел родителя.
struct tnode *talloc(void); char *strdup(char *); /* addtree: добавляет узел со словом w в p или ниже него */ struct tnode *addtree(struct tnode *p, char *w) < int cond; if (p == NULL) < /* слово встречается впервые */ p = talloc(); /* создается новый узел */ p->word = strdup(w); p->count = 1; p->left = p->right = NULL; > else if ((cond = strcmp(w, p->word)) == 0) p->count++; /* это слово уже встречалось */ else if (cond < 0) /* < корня левого поддерева */ p->left = addtree(p->left, w); else /* > корня правого поддерева */ p->right = addtree(p->right, w); return p; >
Память для нового узла запрашивается с помощью программы talloc , которая возвращает указатель на свободное пространство, достаточное для хранения одного узла дерева, а копирование нового слова в отдельное место памяти осуществляется с помощью strdup . (Мы рассмотрим эти программы чуть позже.) В тот (и только в тот) момент, когда к дереву подвешивается новый узел, происходит инициализация счетчика и заполнение пустыми ссылками указателей на сыновей. Мы опустили (что неразумно) контроль ошибок, который должен выполняться при получении значений от strdup и talloc .
Функция treeprint печатает дерево в лексикографическом порядке; для каждого узла она печатает его левое поддерево (все слова, которые меньше слова данного узла), затем само слово и, наконец, правое поддерево (слова, которые больше слова данного узла).
/* treeprint: упорядоченная печать дерева p */ void treeprint (struct tnode *p) < if (p != NULL) < treeprint(p->left); printf("%4d %s\n", p->count, p->word); treeprint(p-> ri ght); > >
Если вы не уверены, что досконально разобрались в том, как работает рекурсия, «проиграйте» действия treeprint на дереве, приведенном выше.
Практическое замечание: если дерево «несбалансировано» (что бывает, когда слова поступают не в случайном порядке), то время работы программы может сильно возрасти. Худший вариант, когда слова уже упорядочены; в этом случае затраты на вычисления будут такими же, как при линейном поиске. Существуют обобщения бинарного дерева, которые не страдают этим недостатком, но здесь мы их не описываем.
Прежде чем окончательно оставить этот пример, стоит сделать краткое отступление от темы и поговорить о механизме запроса памяти. Очевидно, хотелось бы иметь всего лишь одну функцию, выделяющую память, даже если эта память предназначается для разного рода объектов. Но если одна и та же функция обеспечивает память, скажем, и для указателей на char , и для указателей на struct tnode , то возникают два вопроса. Первый, как справиться с требованием большинства машин, в которых объекты определенного типа должны быть выровнены (например, целые часто должны размещаться, начиная с четных адресов)? И второе, как описать функцию, которая вынуждена в качестве результата выдавать указатели разных типов?
Вообще говоря, требования, касающиеся выравнивания, можно легко выполнить за счет некоторой потери памяти. Однако для этого возвращаемый указатель должен быть таким, чтобы удовлетворялись любые ограничения, связанные с выравниванием. Функция alloc , описанная в гл. 5, не гарантирует нам любое конкретное выравнивание, поэтому мы будем пользоваться функцией malloc из стандартной библиотеки, которая это делает. В гл. 8 мы покажем один из способов ее реализации.
Вопрос об описании типа таких функций, как malloc , является камнем преткновения в любом языке с жесткой проверкой типов. В Си вопрос решается естественным образом: malloc объявляется как функция, которая возвращает указатель на void . Полученный указатель затем явно приводится к желаемому типу. Описания malloc и связанных с ней функций находятся в стандартном головном файле . Таким образом, функцию talloc можно записать следующим образом:
#include /* talloc: создает tnode */ struct tnode *talloc(void)
Функция strdup просто копирует стринг, указанный в аргументе, в место, полученное с помощью malloc :
/* дублирует s */ char *strdup(char *s) < char *p; p = (char *) malloc(strlen(s) + 1); /* +1 для '\0' */ if (p != NULL) strcpy(p, s); return p; >
Функция malloc возвращает NULL , если свободного пространства нет; strdup передает это значение, оставляя заботу о выходе из ошибочной ситуации той программе, которая к ней обратилась.
Память, полученную с помощью malloc , можно освободить для повторного использования, обратившись к функции free (см. гл. 7 и 8).
Упражнение 6.2.
Напишите программу, которая читает текст Си-программы и печатает в алфавитном порядке все группы имен переменных, в которых совпадают первые 6 литер, но последующие в чем-то различаются. Не обрабатывайте внутренности стрингов и комментариев. Число 6 сделайте параметром, задаваемым в командной строке.
Упражнение 6.3.
Напишите программу печати таблицы «перекрестных ссылок», которая будет печатать все слова документа и указывать для каждого из них номера строк, где оно встретилось. Программа должна игнорировать «шумовые» слова типа «и», «или» и т.д.
Упражнение 6.4.
Напишите программу, которая печатает весь набор различных слов, образующих входной поток, в порядке возрастания частоты их встречаемости. Перед каждым словом должно быть указано число вхождений.
6.6. Просмотр таблиц
В этом разделе, чтобы проиллюстрировать новые аспекты применения структур, мы напишем ядро пакета программ, осуществляющих вставку элементов: в таблицы и их поиск внутри таблиц. Этот пакет — типичный набор программ, с помощью которых работают с таблицами имен в любом макропроцессоре или компиляторе. Рассмотрим, например, инструкцию #define . Когда встречается строка вида
#define IN 1
имя IN и замещающий его текст 1 должны запоминаться в таблице. Если затем это имя IN встретится в инструкции, например, в
state = IN;
оно должно быть заменено на 1.
Существуют две программы, манипулирующие с именами и замещающими их текстами. Это install(s, t) , которая записывает имя s и замещающий его текст t в таблицу, где s и t — стринги, и lookup(s) , осуществляющая поиск s в таблице и возвращающая указатель на место, где имя s было найдено, или NULL , если s в таблице не оказалось.
Алгоритм основан на «хэшировании» (функции расстановки): поступающее имя свертывается в неотрицательное число (хэш-код), которое затем используется в качестве индекса в массиве указателей. Каждый элемент этого массива является указателем на начало связанного ссылками списка блоков, описывающих имена с данным хэш-кодом. Если элемент массива содержит NULL , это значит, что среди имен не встретилось ни одного с соответствующим хэш-кодом.
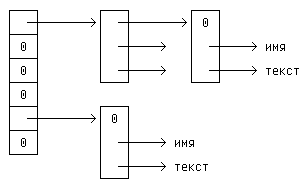
Блок в списке — это структура, содержащая указатели на имя, на замещающий текст и на следующий блок в списке; значение NULL в указателе на следующий блок означает конец списка.
struct nlist < /* элемент таблицы */ struct nlist *next; /* ук-ль на следующий элемент */ char *name; /* определяемое имя */ char *defn; /* замещающий текст */ >;
А вот как записывается определение массива указателей:
#define HASHSIZE 101 static struct nlist *hashtab[HASHSIZE]; /* таблица ук-лей */
Хэш-функция, используемая в lookup и install , суммирует коды литер имени, тем самым «замешивая» их, и в качестве результата выдает остаток от деления полученной суммы на размер массива указателей. Это не самый лучший способ получения хэш-кода, но достаточно лаконичный и эффективный.
/* hash: получает хэш-код по стрингу s */ unsigned hash(char *s)
Беззнаковая арифметика гарантирует, что хэш-код будет неотрицательным.
Хэширование порождает стартовый индекс для массива hashtab ; если соответствующий стринг в таблице есть, он может быть обнаружен только в списке блоков, на начало которого указывает элемент массива hashtab с этим индексом. Поиск осуществляется с помощью lookup . Если lookup находит элемент с заданным стрингом, то он возвращает указатель на него, если не находит, то возвращает NULL .
/* lookup: ищет s */ struct nlist *lookup(char *s) < struct nlist *np; for (np = hashtab[hash(s)]; np != NULL; np = np->next) if (strcmp(s, np->name) == 0) return np; /* нашли */ return NULL; /* не нашли */ >
В for -цикле функции lookup для просмотра списка используется стандартная конструкция
for (ptr = head; ptr != NULL; ptr = ptr->next) .
Функция install обращается к lookup , чтобы определить, имеется ли в наличии вставляемый стринг. Если это так, то старое определение будет заменено новым. В противном случае будет образован новый элемент. Если запрос памяти для нового элемента не может быть удовлетворен, функция install выдает NULL .
struct nlist *lookup(char *); char *strdup(char *); /* install: заносит (name, defn) в таблицу */ struct nlist *install(char *name, char *defn) < struct nlist *np; unsigned hashval; if ((np = (lookup(name)) == NULL) < /* не найден */ np = (struct nlist *) malloc(sizeof(*np)); if (np == NULL || (np->name = strdup(name)) == NULL) return NULL; hashval = hash(name); np->next = hashtab[hashval]; hashtab[hashval] = np; > else /* уже имеется */ free((void *) np->defn); /* освобождаем прежн. defn */ if ((np->defn = strdup(defn)) == NULL) return NULL; return np; >
Упражнение 6.5.
Напишите функцию undef , удаляющую имя и определение из таблицы, организация которой поддерживается функциями lookup и install .
Упражнение 6.6.
Реализуйте простую версию #define -процессора (без аргументов), которая использовала бы программы этого раздела и годилась бы для Си-программ. Вам могут помочь программы getch и ungetch .
6.7. Средство typedef
Язык Си предоставляет средство, называемое typedef , позволяющее давать новые имена типам данных. Например, декларация
typedef int Length;
делает имя Length синонимом int . С этого момента тип Length можно применять в декларациях, в операторе приведения и т.д. точно так же, как тип int :
Length len, maxlen; Length *lengths[];
typedef char *String;
делает String синонимом char * , т.е. указателем на char , и правомерным будет, например, следующее его использование:
String p, lineptr[MAXLINES], alloc(int); int strcmp(String, String); p = (String) malloc(100);
Заметим, что объявляемый в typedef тип стоит на месте имени переменной в обычной декларации, а не сразу за словом typedef . С точки зрения синтаксиса слово typedef занимает место, где обычно располагается спецификатор класса памяти — extern , static и т.д. Имена типов записаны с заглавных букв для того, чтобы они выделялись.
Для демонстрации более сложных примеров применения typedef воспользуемся этим средством при задании узлов деревьев, с которыми мы уже встречались в данной главе.
typedef struct tnode *Treeptr; typedef struct node < /* узел дерева: */ char *word; /* указатель на текст */ int count; /* число вхождений */ Treeptr left; /* левый сын */ Treeptr right; /* правый сын */ >Treenode;
В результате создаются два новых названия типов: Treenode (структура) и Treeptr (указатель на структуру). Теперь программу talloc можно записать в следующем виде:
Treeptr talloc(void)
Следует подчеркнуть, что декларация typedef не создает новый тип, она лишь сообщает новое имя уже существующего типа. Никакого нового смысла эти новые имена не несут, они декларируют переменные в точности с теми же свойствами, как если бы они были объявлены напрямую без переименования типа. Фактически typedef аналогичен #define с тем лишь отличием, что, будучи интерпретируемым компилятором, он может справиться с такой текстовой подстановкой, которая не может быть обработана препроцессором. Например,
typedef int (*PHI)(char *, char *);
определяет тип PHI как «указатель на функцию (двух аргументов типа char * ), возвращающую int », который, например, в программе сортировки, описанной в гл. 5, можно использовать в таком контексте:
PHI strcmp, numcmp;
Помимо просто эстетических соображений, для привлечения typedef существуют две важные причины. Первая — параметризация программы, связанная с проблемой переносимости. Если с помощью typedef объявить типы данных, которые, возможно, являются машинно-зависимыми, то при переносе программы на другую машину потребуется внести изменения только в определения typedef. Одна из распространенных ситуаций — использование typedef -имен для варьирования целыми величинами. Для каждой конкретной машины это предполагает соответствующие установки short , int или long , которые делаются аналогично установкам стандартных типов, например, size_t и ptrdiff_t .
Вторая причина, побуждающая к применению typedef , — желание сделать более ясным текст программы. Тип, названный Treeptr (от английских слов tree — дерево и pointer — указатель) более понятен, чем тот же тип, записанный как указатель на некоторую сложную структуру.
6.8. Объединения
Объединение — это переменная, которая может содержать (в разные моменты времени) объекты различных типов и размеров. Все требования относительно размеров и выравнивания выполняет компилятор. Объединения позволяют хранить разнородные данные в одной и той же области памяти без включения в программу машинно-зависимой информации. Эти средства аналогичны вариантным записям в Паскале.
Примером использования объединений мог бы послужить сам компилятор, заведующий таблицей символов, если предположить, что константы могут иметь тип int , float или являться указателем на стринговый литерал и иметь тип char * . Значение каждой конкретной константы должно храниться в переменной соответствующего этой константе типа. Работать с таблицей символов всегда удобнее, если значения занимают одинаковую по объему память и запоминаются в одном и том же месте независимо от своего типа. Цель введения в программу объединения — иметь переменную, которая бы на законных основаниях хранила в себе значения нескольких типов. Синтаксис объединений аналогичен синтаксису структур. Приведем пример объединения.
union u_tag < int ival; float fval; char *sval; >u;
Переменная u будет достаточно большой, чтобы в ней поместилась любая переменная из указанных трех типов; точный ее размер зависит от реализации. Значение одного из этих трех типов может быть присвоено переменной u и далее использовано в выражениях, если это правомерно, т.е. если тип взятого ею значения совпадает с типом последнего присвоенного ей значения. Выполнение этого требования в каждый текущий момент — целиком на совести программиста. В случае «рассогласованности» типов результат зависит от реализации.
Синтаксис доступа к членам объединения следующий:
имя_объединения . член
указатель_на_объединение -> член
т.е. в точности такой, как в структурах. Если для хранения типа текущего значения u использовать, скажем, переменную utype , то можно написать такой фрагмент программы:
if (utype == INT) printf("%d\n", u.ival); else if (utype == FLOAT) printf("%f\n", u.fval); else if (utype == STRING) printf("%s\n", u.sval); else printf("неверный тип %d в utype\n", utype);
Объединения могут входить в структуры и массивы, и наоборот. Запись доступа к члену объединения, находящегося в структур (как и структуры, находящейся в объединении), такая же, как и для вложенных структур. Например, в массиве структур
struct < char *name; int flags; int utype; union < int ival; float fval; char *sval; >u; > symtab[NSYM];
на ival ссылаются следующим образом:
symtab[i].u.ival
а к первой литере стринга sval можно обратиться любым из следующих двух способов:
*symtab[i].u.sval symtab[i].u.sval[0]
Фактически объединение — это структура, все члены которой имеют нулевое смещение относительно ее базового адреса, размера, который позволяет поместиться в ней самому большому ее члену, и выравнивание которой удовлетворяет всем типам объединения. Операции, применимые к структурам, годятся и для объединений, т.е. законны присваивание объединения и копирование его как единого целого, взятие адреса от объединения и доступ к отдельным его членам.
Инициализировать объединение можно только значением, имеющим тип его первого члена; таким образом, упомянутую выше переменную u можно инициализировать лишь значением типа int .
В гл. 8 (на примере программы, заведующей выделением памяти) мы покажем, как, применяя объединение, можно добиться, чтобы расположение переменной было выровнено по соответствующей границе в памяти.
6.9. Поля битов
При дефиците памяти может возникнуть необходимость запаковать несколько объектов в одно слово машины. Одна из обычных ситуаций, встречающаяся в задачах обработки таблиц символов для компиляторов, — это объединение групп однобитовых флажков. Форматы некоторых данных могут от нас вообще не зависеть и диктоваться, например, интерфейсами с аппаратурой внешних устройств; здесь также возникает потребность адресоваться — к частям слова.
Вообразим себе фрагмент компилятора, который заведует таблицей символов. Каждый идентификатор программы имеет некоторую связанную с ним информацию, которая сообщает, например, представляет ли он собой ключевое слово и к какому классу, если это переменная, она принадлежит: внешняя и/или статическая и т.д. Самый компактный способ кодирования такой информации — расположить однобитовые флажки в одном слове типа char или int .
Один из распространенных приемов работы с битами основан на определении набора «масок», соответствующих позициям этих битов, как, например, в
#define KEYWORD 01 /* ключевое слово */ #define EXTERNAL 02 /* внешний */ #define STATIC 04 /* статический */
enum < KEYWORD = 01, EXTERNAL = 02, STATIC = 04 >;
Числа должны быть степенями двойки. Тогда доступ к битам становится делом «побитовых операций», описанных в гл. 2 (сдвиг, маскирование, взятие дополнения).
Некоторые виды записи выражений встречаются довольно часто. Так,
flags |= EXTERNAL | STATIC;
устанавливает 1 в соответствующих битах переменной flags ,
flags &= ~(EXTERNAL | STATIC);
if ((flags & (EXTERNAL | STATIC)) == 0)
оценивает условие как истинное, если оба бита нулевые.
Хотя научиться писать такого рода выражения не составляет труда, вместо побитовых логических операций можно пользоваться предоставляемым Си другим способом прямого определения и доступа к полям внутри слова. Поле_битов (или для краткости просто поле) — это некоторое множество битов, лежащих рядом внутри одной, зависящей от реализации, единице памяти, которую мы будем называть «словом». Синтаксис определения полей и доступа к ним базируется на синтаксисе структур. Например, строки #define , фигурировавшие выше при задании таблицы символов, можно заменить на определение трех полей:
struct < unsigned int is_keyword : 1; unsigned int is_extern : 1; unsigned int is_static : 1; >flags;
Эта запись определяет переменную flags , которая содержит три однобитовых поля. Число, следующее за двоеточием, задает ширину поля. Поля декларированы как unsigned int , чтобы они воспринимались как беззнаковые величины.
На отдельные поля ссылаются так же, как и на члены обычных структур: flags.is_keyword , flags.is_extern , и т.д. Поля «ведут себя» как малые целые и могут участвовать в арифметических выражениях точно так же, как и другие целые. Таким образом, предыдущие примеры можно написать более естественным образом:
flags.is_extern = flags.is_static = 1;
устанавливает 1 в соответствующие биты;
flags.is_extern = flags.is_static = 0;
if (flags.is_extern == 0 && flags.is_static == 0)
Почти все технические детали, касающиеся полей, в частности, может ли поле перейти границу слова, зависят от реализации. Поля могут не иметь имени; с помощью безымянного поля (задаваемого только двоеточием и шириной) организуется пропуск нужного количества разрядов. Особая ширина, равная нулю, используется, когда требуется выйти на границу следующего слова.
На одних машинах поля размещаются слева направо, на других — справа налево. Это значит, что при всей полезности работы с ними, если формат данных, с которыми мы имеем дело, дан нам свыше, то необходимо самым тщательным образом исследовать порядок расположения полей; программы, зависящие от такого рода вещей, не переносимы. Поля можно определять только с типом int , а для того, чтобы обеспечить переносимость, явно указывая signed или unsigned . Они не могут быть массивами и не имеют адресов, и, следовательно, оператор & к ним не применим.