Необходимо прочитать XML файл и вывести на экран в заданном формате
Так вот. Я могу написать код для двух xml, но они выводятся на экран один за другим (содержимое 1-го файла и следом содержимое 2-го), не так, как в примере.
import java.io.BufferedWriter; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.DocumentBuilder; import org.w3c.dom.Document; import org.w3c.dom.NodeList; import org.w3c.dom.Node; import org.w3c.dom.Element; import java.io.File; import java.io.FileWriter; import java.io.PrintWriter; public class лаба3 < public static void main(String[] args) < try < File fXmlFile = new File("C:/ee.xml"); DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance(); DocumentBuilder dBuilder = dbFactory.newDocumentBuilder(); Document doc = dBuilder.parse(fXmlFile); doc.getDocumentElement().normalize(); NodeList nList = doc.getElementsByTagName("note"); for (int temp = 0; temp < nList.getLength(); temp++) < Node nNode = nList.item(temp); < Element eElement = (Element) nNode; System.out.println("От: " + eElement.getElementsByTagName("to").item(0).getTextContent()); System.out.println("Кому: " + eElement.getElementsByTagName("from").item(0).getTextContent()); System.out.println("Тема: " + eElement.getElementsByTagName("heading").item(0).getTextContent()); System.out.println("Сообщение: " + eElement.getElementsByTagName("body").item(0).getTextContent()); >> File fXmlFile2 = new File("C:/e.xml"); DocumentBuilderFactory dbFactory2 = DocumentBuilderFactory.newInstance(); DocumentBuilder dBuilder2 = dbFactory2.newDocumentBuilder(); Document doc2 = dBuilder2.parse(fXmlFile2); doc2.getDocumentElement().normalize(); NodeList nList2 = doc2.getElementsByTagName("note"); for (int temp = 0; temp < nList2.getLength(); temp++) < Node nNode2 = nList2.item(temp); < Element eElement = (Element) nNode2; System.out.println("От: " + eElement.getElementsByTagName("to").item(0).getTextContent()); System.out.println("Кому: " + eElement.getElementsByTagName("from").item(0).getTextContent()); System.out.println("Тема: " + eElement.getElementsByTagName("heading").item(0).getTextContent()); System.out.println("Сообщение: " + eElement.getElementsByTagName("body").item(0).getTextContent()); >> > catch (Exception e) < e.printStackTrace(); >> > П.С. — можно ли объединить два for и Node в одно?
Java. Работа с XML-документами
Привет, Хабр! Меня зовут Михаил, я SDET-специалист компании SimbirSoft. Я занимаюсь автоматизацией тестирования, в основном это работа с WEB и REST API. Но на последнем проекте использовался SOAP, поэтому при автоматизации тестирования я работал с сообщениями этого протокола, а именно:
- выполнять проверку наличия обязательных атрибутов и тегов SOAP сообщений;
- сравнивать содержание различных сообщений;
- вносить изменения или генерировать новые сообщения для исходящих запросов.
В своей статье я поделюсь несколькими способами работы с XML-документами. Материал будет полезен тем, кто впервые сталкивается в работе из кода с подобными документами на Java.

Для работы я преобразовывал SOAP сообщения в Java-объекты. Этот процесс называется демаршаллинг. Обратный процесс называется маршаллинг, как десериализация и сериализация JSON.
Отличие маршалинга от сериализации заключается в том, что сериализация предполагает упаковку лишь данных программы. Например, при сериализации объекта класса, состоящего из полей и различных методов, сохраняться будет информация только о полях, а о методах — нет.
При маршалинге объекта запишется не только информацию о его данных (полях), но и информация по восстановлению структуры объекта — класс объекта, либо его мета-информацию для реконструирования типа.
В Java существует множество инструментов и способов преобразования документов формата XML в объекты. Я выбирал между использованием JAXB и DOM.
В качестве примера приведу XML-документ со следующим содержанием:
Личный кабинет Выберите действие Атрибут №1 Атрибут №2 Атрибут №3 Это описание экрана некоторого продукта.
Корневым элементом является , содержащий в себе теги заглавия, описания экрана, а также блок кнопок и несколько атрибутов.
Кнопки, в свою очередь, содержат заглавия и различное количество подсказок. В некоторых тегах есть атрибуты, описывающие состояние и цвет элемента. А также команду “Action”, которую необходимо использовать при выполнении запроса на определенное действие.
У данного продукта все формируемые экраны соответствуют единой схеме, отличия могут быть в содержании тегов, их количестве и значениях атрибутов. К примеру, на экране может быть больше или меньше кнопок с различными состояниями, атрибутами и др.
JAXB
JAXB (Java Architecture for XML Binding) — это специальный инструмент для маршалинга и демаршалинга объектов.
JAXB предоставляет аннотации, которыми размечаются поля JAVA-классов.
Для начала необходимо создать требуемые классы.
Принцип получается примерно следующий: если тег имеет дочерние элементы или атрибуты, значит это объект. Если тег в документе не имеет дочерних элементов, значит это поле объекта.
Корневой класс Screen:
public class Screen < private String stage; private String title; private String description; private ListbuttonList = new ArrayList<>(); private List attributeList = new ArrayList<>(); >Он содержит в себе три строковых поля: “stage”, “title”, “description” и коллекции “buttonList” и “attributeList”.
3 класса вложенных элементов:
public class Button < private String action; private String color; private String condition; private String t; private ListdList = new ArrayList<>(); > public class Attribute < private String a; private String v; >public class D
Всего нужно 4 класса.
Теперь нам необходимо разметить наши поля и классы аннотациями, чтобы иметь возможность выполнять операции маршаллинга и демаршаллинга.
В этом случае нам понадобятся следующие аннотации:
— @XmlRootElement(name = «Screen») — определяет корневой элемент. Может быть указана над классом или полем класса;
— @XmlAccessorType(XmlAccessType.FIELD) — определяет сущности, которые используются в процессах преобразования;
— @XmlAttribute(name = «Stage») — определяет, что поле является атрибутом, а не тегом в XML-документе;
— @XmlElement(name = «Title») — определяет, что поле является тегом в XML-документе;
— @XmlElementWrapper(name=»Buttons») — создает некоторую обертку вокруг группы повторяющихся тегов;
— @XMLValue — определяет, что поле содержит в себе значение тега.
Получились следующие классы:
@Data @XmlRootElement(name = "Screen") @XmlAccessorType(XmlAccessType.FIELD) public class Screen < @XmlAttribute(name = "Stage") private String stage; @XmlElement(name = "Title") private String title; @XmlElement(name = "Description") private String description; @XmlElementWrapper(name="Buttons") @XmlElement(name="Button") private ListbuttonList; @XmlElementWrapper(name="Attributes") @XmlElement(name="Attribute") private List attributeList; > @Data @XmlAccessorType(XmlAccessType.FIELD) public class Attribute < @XmlAttribute(name = "A") private String a; @XmlElement(name = "V") private String v; >@Data @XmlAccessorType(XmlAccessType.FIELD) public class Button < @XmlAttribute(name = "Action") private String action; @XmlAttribute(name = "Color") private String color; @XmlAttribute(name = "Condition") private String condition; @XmlElement(name = "T") private String t; @XmlElement(name="D") private ListdList = new ArrayList<>(); > @Data @XmlAccessorType(XmlAccessType.FIELD) public class D
В аннотациях, в параметре “name”, указывается имя тега XML, значение которого мы присваиваем полю объекта при маршаллинге.
А при демаршалинге этот параметр, наоборот, задает имя тега XML для значения поля объекта.
В примере сеттеры и геттеры реализованы через аннотацию Lombok @Data. Но в JAXB они не требуются и не используются. Таким образом, отсутствует возможность редактирования значений полей при преобразованиях. Но они нужны для других стандартных операций с объектами.
Для удобства во всех классах переопределен метод toString(). Вот так этот метод реализован в классе Screen:
@Override public String toString() < StringBuilder sb = new StringBuilder(); sb.append("\n"); sb.append(" "); sb.append((this.title == null) ? "null" : this.title); sb.append(" \n"); sb.append(" "); sb.append((this.description == null) ? "null" : this.description); sb.append(" \n"); sb.append(" \n"); for(Button button : buttonList) < sb.append(button); >sb.append(" \n"); sb.append(" \n"); for(Attribute attribute : attributeList) < sb.append(attribute); >sb.append(" \n"); sb.append("В остальных классах он переопределен аналогичным образом.
Классы готовы к работе.
Демаршаллинг
Реализуем чтение документа XML. Для этого используем BufferedReader c чтением из файла и StringReader, который будет считывать созданную строку в процессе преобразования.
После создаем JAXBContext — сущность, которая лежит в основе работы процессов маршаллинга и демаршаллинга. Это точка входа в API JAXB, она предоставляет абстракцию для управления информацией о привязке XML/Java. В качестве параметра при создании указываем класс получаемого объекта — Screen.class.
С помощью JAXBContext создадим Unmarshaller, необходимый для преобразования XML-документа в объект Screen с приведением типа. Для этого в метод unmarshal() передается ранее созданный StringReader:
public class Main < public static void main(String[] args) < BufferedReader br = new BufferedReader(new FileReader("./body.xml")); String body = br.lines().collect(Collectors.joining()); StringReader reader = new StringReader(body); JAXBContext context = JAXBContext.newInstance(Screen.class); Unmarshaller unmarshaller = context.createUnmarshaller(); Screen screen = (Screen) unmarshaller.unmarshal(reader); >>Результат можно увидеть, развернув объект в окне отладки, или путем выведения в консоль — для чего и переопределялись методы toString().
Это был процесс демаршаллинга. Из документа (сообщения SOAP) получили объект Java с методами для работы, всеми полями и атрибутами.
Маршалинг
Создаем StringWriter, который будет записывать строку.
Также создадим сущность Marshaller с установкой параметров форматирования данных.
Чтобы проверить, что все работает, внесем изменения в полученный ранее объект screen: изменяется заголовок и цвет с описанием для первой кнопки.
После чего в метод marshal() передаем объект и StringWriter:
StringWriter writer = new StringWriter(); Marshaller marshaller = context.createMarshaller(); marshaller.setProperty(Marshaller.JAXB_FORMATTED_OUTPUT, Boolean.TRUE); screen.setTitle("Изменили заглавие"); screen.getButtonList().get(0).getDList().get(0).setColor("black"); screen.getButtonList().get(0).getDList().get(0).setD("Цвет кнопки черный"); marshaller.marshal(screen, writer);
Теперь writer хранит в себе данные объекта screen в виде строки, с помощью которой можно перезаписать или создать новый XML-документ, либо сгенерировать сообщение SOAP.
Для просмотра результата можно воспользоваться окном отладки или вывести в консоль.
Более подробно с JAXB можно ознакомиться тут.
DOM
Второй способ преобразований с использованием DOM (Document Object Model) в сравнении с предыдущим может показаться более трудным и запутанным. Здесь не используются аннотации для поиска и определения тегов и полей классов. При использовании DOM весь XML-документ представлен в виде древовидной структуры. Для перемещения по этой модели, получения узлов, значений имен тегов, их атрибутов и т.д. существуют специальные методы и сущности.
Сначала также создаем классы:
@Data public class ScreenDom < private HashMapattributes = new HashMap<>(); private String title; private String description; private List buttonListt = new ArrayList<>(); private List attributeList = new ArrayList<>(); > @Data public class ButtonDom < private HashMapattributes = new HashMap<>(); private String t; private List dList = new ArrayList<>(); > @Data public class AttributeDom < private HashMapattributes = new HashMap<>(); private String v; > @Data public class DDom < private HashMapattributes = new HashMap<>(); private String d; public DDom withD(String value) < this.d = value; return this; >>Основное отличие заключается в том, что для хранения атрибутов тега используется HashMap<> attributes. Теперь не важно, какие именно могут быть атрибуты у тега — при преобразовании они все будут добавлены в мапу в формате «ключ-значение».
Здесь гетеры и сеттеры используются при преобразованиях. Можно написать свои и при необходимости реализовать в них изменения входных и выходных параметров.
Для начала немного об определениях некоторых сущностей, которые нам понадобятся.
Важно понять, что основной «атомарной» единицей в этой модели является Node — узел.
Узлом может быть:
- Node — класс, который предназначен для любого XML-элемента: текст, тег, или атрибут. Т.е. все в XML есть Node. Далее идет специализация.
- NamedNodeMap — сущность, в которой хранятся данные «ключ-значение», она используется при получении атрибутов тега.
- NodeList — список узлов, используемый при получении дочерних элементов и узлов с одинаковыми тегами.
Пример кода по заполнению объекта данными из XML-документа с использованием DOM:
public class Main < public static void main(String[] args) < //Создаем объект. ScreenDom screen = new ScreenDom(); //Для создания древовидной структуры создается объект класса DocumentBuilder DocumentBuilder builder = DocumentBuilderFactory.newInstance().newDocumentBuilder(); //Создается объект Document — он является представлением всей информации внутри XML Document document = builder.parse("./body.xml"); //Создается узел root путем получения первого дочернего узла. Это будет тег Node root = document.getFirstChild(); //Создается нода, в которую сохраняются все атрибуты корневого тега NamedNodeMap attributes = root.getAttributes(); for (int i = 0; i < attributes.getLength(); i++) < screen.getAttributes().put(attributes.item(i).getNodeName(), attributes.item(i).getNodeValue()); >//Создается список всех дочерних узлов NodeList childNode = root.getChildNodes(); //В цикле выполняется поиск и присвоение значений согласно заданным условиям for (int i = 0; i < childNode.getLength(); i++) < Node element = childNode.item(i); if (element.getNodeName().equals("Title")) < screen.setTitle(element.getTextContent()); >if (element.getNodeName().equals("Description")) < screen.setDescription(element.getTextContent()); >> // Создается список узлов по тегу . Их может быть несколько NodeList rootList = document.getDocumentElement().getElementsByTagName("Button"); //Внешний цикл списка всех узлов for (int j = 0; j < rootList.getLength(); j++) < //Извлекаются все атрибуты для тега текущей итерации attributes = rootList.item(j).getAttributes(); //Создается новый объект ButtonDom для сохранения найденных значений screen.getButtonList().add(new ButtonDom()); for (int i = 0; i < attributes.getLength(); i++) < screen.getButtonList().get(j).getAttributes().put(attributes.item(i).getNodeName(), attributes.item(i).getNodeValue()); >//Создается список всех дочерних узлов childNode = rootList.item(j).getChildNodes(); //В цикле выполняется поиск и присвоение значений дочерних узлов //к объекту ButtonDom текущей итерации for (int i = 0; i < childNode.getLength(); i++) < Node element = childNode.item(i); NamedNodeMap attr = element.getAttributes(); if (element.getNodeName().equals("T")) < screen.getButtonList().get(j).setT(element.getTextContent()); >if (element.getNodeName().equals("D")) < DDom d = new DDom(); d.setD(element.getTextContent()); // В случае наличия атрибутов у тегов они добавляются в мапу if (attr.getLength() != 0) < for (int k = 0; k < attr.getLength(); k++) < d.getAttributes().put(attr.item(k).getNodeName(), attr.item(k).getNodeValue()); >> // Объект DDom добавляется в ButtonsDom текущей итерации первого цикла screen.getButtonList().get(j).getDList().add(d); > > > rootList = document.getDocumentElement().getElementsByTagName("Attribute"); for (int j = 0; j < rootList.getLength(); j++) < AttributeDom attributeDom = new AttributeDom(); attributes = rootList.item(j).getAttributes(); for (int i = 0; i < attributes.getLength(); i++) < attributeDom.getAttributes().put(attributes.item(i).getNodeName(), attributes.item(i).getNodeValue()); >childNode = rootList.item(j).getChildNodes(); for (int i = 0; i < childNode.getLength(); i++) < Node element = childNode.item(i); if (element.getNodeName().equals("V")) < attributeDom.setV(element.getTextContent()); >> screen.getAttributeList().add(attributeDom); //Итоговым объектом является заполненная сущность screen класса Screen > >Для удобства можно написать специальные классы-парсеры. В приведенном выше коде представлены некоторые методы, которые возможно для этого использовать.
Как такового обратного процесса, как в случае с JAXB, этот способ не подразумевает. Но есть переопределенный метод toString() объекта ScreenDom, который возвращает строку формата XML. Привести ее к нужному формату уже не составит труда.
К дополнению метода описанного выше также используется XPath.
XPath — это язык запросов к элементам XML. Он позволит создать выражение запроса и получить интересующие данные из документа.
В своей работе при тестировании API я использую RestAssured и его поисковые выражения.
Чтобы получить значение «Атрибут №1» из Response RestAssured, можно использовать следующий код:
String value = response.xmlPath().getString(“**.find ”);Поисковое выражение прочитаем следующим образом: во всем документе найти значение первого тега, у которого есть атрибут “A”, равный значению “BC”.
Есть и другие способы и выражения XPath, поддерживаемые RestAssured:
- root.parent.child.grandchild;.
- root.parant.child[0];
- (child[0]);
- root.parent[0];
- it.@type == ‘специфическое значение’;
Вышеописанный способ отлично подходит для поиска определенных значений в XML-документе. Он не требует создания сущностей Java, применяется довольно легко и быстро. Но стоит отметить, что данный способ не подходит для полного процесса преобразования из документа в объект и обратно.
Более подробно об использовании Xpath в RestAssured вы можете ознакомиться в документации.
Весь код статьи доступен в удаленном репозитории по этой ссылке.
Это рабочий проект, в котором реализованы оба способа маршаллинга и демаршаллинга. Кроме того, в нем реализован тест, пример возможного использования данных методов при автоматизации тестирования сообщений SOAP- или XML-документов.
Заключение
В этой статье я поделился своим опытом в решении некоторых задач, с которыми столкнулся при автоматизации тестирования сообщений SOAP. Это далеко не все способы и инструменты, доступные для преобразования XML на Java. Но они работают и их довольно легко понять и реализовать.
Каждый способ имеет свои плюсы и минусы. Для удобного восприятия я представил их в таблице ниже:
Инструмент
Плюсы
Минусы
JAXB
Прост в реализации.
Отлично подходит, если используется XML-схема.
Возможно частичное использование.
Нужно точно знать возможные атрибуты тегов.
Нет возможности редактировать значения при преобразовании объектов.
DOM
Нет необходимости заранее знать возможные атрибуты тегов.
Возможность редактирования значений при преобразовании объектов.
Гибкость в использовании.
Иногда трудночитаемый код.
В своем случае я выбрал DOM из-за неизвестности атрибутов тегов в получаемых сообщениях SOAP. Мне понадобилась возможность добавлять новые узлы в древовидную структуру документа при преобразованиях. При помощи методов DOM я реализовал классы — парсеры, которые позволили достаточно легко и просто выполнить маршаллинг и демаршлаллинг по необходимым мне условиям.
Надеюсь, эта статья была вам интересна. Спасибо за внимание!
Рекомендуем другие наши SDET-статьи:
Авторские материалы для разработчиков мы также публикуем в наших соцсетях – ВКонтакте и Telegram.
XML документ — DOM, SAXParser
Существуют две стратегии обработки XML документов: DOM (Document Object Model) и SAX (Simple API for XML). Основное их отличие связано с тем, что использование DOM позволяет читать и вносить изменения в существующий XML-документ, а также создавать новый. Стратегия использования SAX основывается на том, что содержимое XML-документа только анализируется. XML-текст может быть больших размеров: DOM должен весь документ «заглотить» и проанализировать, а SAX-парсер обрабатывает XML-документ последовательно и не требует дополнительной памяти.
Для работы с XML-файлами Java располагает достаточно большим набором инструментов, начиная от встроенных возможностей, которые предоставляет Core Java, и заканчивая большим набором разнообразного стороннего кода, оформленного в виде библиотек. Сначала рассмотрим использование DOM для чтения XML-файла и создания нового файла/документа. А в заключение будет приведено описание и применение SAX-парсера SAXParser.
XML документ представляет собой набор узлов (тегов). Каждый узел может иметь неограниченное количество дочерних узлов, которые, в свою очередь, также могут содержать потомков или не содержать их совсем. Таким образом строится дерево объектов. DOM — это объектная модель документа, которая представляет собой это дерево в виде специальных объектов/узлов org.w3c.dom.Node. Каждый узел Node соответствует своему XML-тегу и содержит полную информацию о том, что это за тег, какие он имеет атрибуты, какие дочерние узлы содержит внутри себя и т.д. На самой вершине этой иерархии находится org.w3c.dom.Document, который является корневым элементов дерева.
Чтение XML-файла
Получить объект Document XML-файла можно следующим образом :
DocumentBuilderFactory dbf; DocumentBuilder db ; Document doc; dbf = DocumentBuilderFactory.newInstance(); db = dbf.newDocumentBuilder(); doc = db.parse(new File("data.xml"));
Чтобы найти какой-либо узел в дереве можно использовать метод getElementsByTagName, который возвращает список всех элементов :
NodeList Document.getElementsByTagName(String name); . . . // Пример использования метода getElementsByTagName NodeList nodeList = doc.getElementsByTagName("tagname");
Метод getElementsByTagName является case-sensitive, т.е. различает прописные и строчные символы.
В цикле можно просмотреть все дочерние узлы. C помощью метода getAttributes можно узнать атрибуты узла. Метод getNodeType позволяет проверить тип узла :
NodeList children = node.getChildNodes(); for (int i = 0; i < children.getLength(); i++) < // дочерний узел Node node = children.item(i); if (node.getNodeType() == Node.ELEMENT_NODE) < // атрибуты узла NamedNodeMap attributes = node.getAttributes(); Node nameAttrib; nameAttrib = attributes.getNamedItem("attrib_name"); System.out.println ("" + i + ". " + nameAttrib.getNodeValue()); >>
Создание XML-файла
Для создания нового объекта Document используйте следующий код :
DocumentBuilderFactory dbf; DocumentBuilder db ; Document doc; dbf = DocumentBuilderFactory.newInstance(); db = dbf.newDocumentBuilder(); doc = db.newDocument();
Элемент Element объекта Document создается с использованием метода createElement. Для определения значения элемента следует использовать метод setTextContent. Для добавления элемента в узловую запись используйте метод appendChild (Node). Элемент может содержать атрибуты. Чтобы добавить к элементу атрибут следует использовать метод setAttribute. Если элемент уже содержит атрибут, то его значение изменится.
Element org.w3c.dom.Document.createElement(String s) throws DOMException; void org.w3c.dom.Node.setTextContent(String text) throws DOMException; Node org.w3c.dom.Node.appendChild(Node newChild) throws DOMException; void org.w3c.dom.Element.setAttribute(String name, String value) throws DOMException; // Пример Element root = doc.createElement("Users"); Element user = doc.createElement("user"); user.setTextContent("Остап Бендер"); user.setAttribute ("book", "12 стульев"); root.appendChild(user); doc.appendChild(root);
В результате работы примера будет создан Document следующей структуры :
Остап Бендер
Пример чтения и создания XML-файла
Для чтения готового XML-файла и формирования нового файла создадим в IDE Eclipse простой проект XMLSample, структура которого представлена на следующем скриншоте.
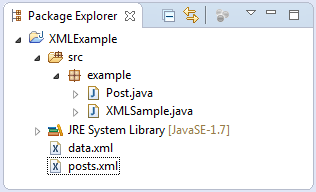
Проект включает XML-файл «posts.xml» с исходными данными, создаваемый XML-файл данных «data.xml», класс Post.java, в который будут упаковываться отдельные записи массива данных и основной класс проекта XMLSample, который будет производить все необходимые действия.
Структура XML-файла
В качестве исходных данных используется XML-файл «posts.xml» из примеров разработчиков Sencha GXT 3.1.1. Структура XML-данных содержит корневой элемент и набор объектов/сущностей, представленных тегами .
Листинг класса Person
import java.util.Date; public class Post < private static int private int id; private String username; private String subject; private String forum; private Date date; public Post() < setId(ID++); >>
Класс Person имеет несколько полей. Идентификатор записи id определяется при создании объекта в конструкторе. Методы set/get не представлены в листинге.
Чтение XML-файла
Для чтения XML-файла в проекте используется метод readDataXML(), который создает список persons типа List, читает XML-файл данных и формирует объект doc типа Document. После этого в цикле создается массив данных. Вспомогательная функция getValue извлекает текст атрибута записи.
import org.w3c.dom.Node; import org.w3c.dom.Element; import org.w3c.dom.Document; import org.w3c.dom.NodeList; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; . . . public class XMLSample < private final String FILE_post = "posts.xml"; private Listposts; private String getValue(NodeList fields, int index) < NodeList list = fields.item(index).getChildNodes(); if (list.getLength() >0) < return list.item(0).getNodeValue(); >else < return ""; >> private void readDataXML() < posts = new ArrayList(); SimpleDateFormat sdf = null; DocumentBuilderFactory dbf = null; DocumentBuilder db = null; Document doc = null; try < sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); dbf = DocumentBuilderFactory.newInstance(); db = dbf.newDocumentBuilder(); doc = null; FileInputStream fis = null; if (fileExists(FILE_post)) < try < fis = new FileInputStream(FILE_post); doc = db.parse(fis); >catch (FileNotFoundException e) < e.printStackTrace(); >> doc.getDocumentElement().normalize(); NodeList fields = null; NodeList nodeList = null; nodeList = doc.getElementsByTagName("row"); for (int s = 0; s < nodeList.getLength(); s++) < Node node = nodeList.item(s); if (node.getNodeType() == Node.ELEMENT_NODE) < Element el = (Element) node; fields = el.getElementsByTagName("field"); Post p = new Post(); p.setForum (getValue(fields, 0)); p.setDate (sdf.parse(getValue(fields,1))); p.setSubject (getValue(fields, 2)); p.setUsername(getValue(fields, 4)); posts.add(p); >> > catch (Exception e) < e.printStackTrace(); >> >
Следует обратить внимание, что для чтения значения атрибута записи (объекта Person) сначала получаем ссылку на массив тегов , и после этого по индексу в функции getValue извлекаем значение.
Создание XML-файла
Для создания нового XML-файла на основе массива posts подготовим два списка данных типа List : пользователей users и форумов forums. Эти два массива запишем в XML-файл.
Создание нового объекта Document и сохранение его в XML-файл в проекте выполняет метод writeDataXML :
Листинг метода создания XML-файла
private final String FILE_data = "data.xml"; private void writeDataXML() < DocumentBuilderFactory dbf = null; DocumentBuilder db = null; Document doc = null; try < dbf = DocumentBuilderFactory.newInstance(); db = dbf.newDocumentBuilder(); doc = db.newDocument(); Element e_root = doc.createElement("Posts"); e_root.setAttribute("lang", "en"); Element e_users = doc.createElement("Users"); Element e_forums = doc.createElement("Forums"); e_root.appendChild(e_users); e_root.appendChild(e_forums); doc.appendChild(e_root); if (posts.size() == 0) return; Listusers = new ArrayList(); List forums = new ArrayList(); for (int i = 0; i < posts.size(); i++)< if (!users.contains(posts.get(i).getUsername())) users.add(posts.get(i).getUsername()); if (!forums.contains(posts.get(i).getForum())) forums.add(posts.get(i).getForum()); >System.out.println(" пользователей : " + users.size()); for (String user : users) < Element e = doc.createElement("user"); e.setTextContent(user); e_users.appendChild (e); >System.out.println(" форумов : " + forums.size()); for (String forum : forums) < Element e = doc.createElement("forum"); e.setTextContent(forum); e_forums.appendChild (e); >> catch (ParserConfigurationException e) < e.printStackTrace(); >finally < // Сохраняем Document в XML-файл if (doc != null) writeDocument(doc, FILE_data); >>
Процедура сохранения объекта Document в XML-файл представлена отдельным методом writeDocument :
Листинг процедуры сохранения XML-файла
/** * Процедура сохранения DOM в файл */ private void writeDocument(Document document, String path) throws TransformerFactoryConfigurationError < Transformer trf = null; DOMSource src = null; FileOutputStream fos = null; try < trf = TransformerFactory.newInstance() .newTransformer(); src = new DOMSource(document); fos = new FileOutputStream(path); StreamResult result = new StreamResult(fos); trf.transform(src, result); >catch (TransformerException e) < e.printStackTrace(System.out); >catch (IOException e) < e.printStackTrace(System.out); >>
Если массив posts окажется пустым, то новый XML-файл должен будет иметь следующий вид :
SAX-парсер, SAXParser
SAX-парсеры используют для анализа XML-строки или извлечения из нее необходимой информации. Обычно SAX-парсеры требуют фиксированный объем памяти и не позволяют изменять содержимое. Для связи SAX-парсера с вызывающим приложением, как правило, используется функция обратного вызова.
Рассмотрим пример SAXExample.java с использованием класса SAXParser для анализа XML-текста, представленного файлом phonebook.xml, содержащего 3 записи и имеющего следующий вид :
Файл phonebook.xml
Остап Бендер ostap@12.com 999-987-6543 Киса Воробьянинов kisa@12.com 999-986-5432 Мадам Грицацуева madam@12.com 999-985-4321
Пакеты «javax.xml.parsers» и «org.xml.sax» включают набор классов для «разбора» XML в строковом представлении. К основным классам этих пакетов, с точки зрения разложения XML объекта на составляющие, относятся SAXParser и DefaultHandler.
В примере SAXExample.java создается класс handler типа DefaultHandler, в котором методы анализа XML-строки переопределяются. Все прозрачно.
Листинг SAXExample.java
import javax.xml.parsers.SAXParser; import javax.xml.parsers.SAXParserFactory; import org.xml.sax.Attributes; import org.xml.sax.SAXException; import org.xml.sax.helpers.DefaultHandler; public class SAXExample < final String fileName = "phonebook.xml"; final String TAG_NAME = "name"; DefaultHandler handler = new DefaultHandler() < boolean tagOn = false; // флаг начала разбора тега /** * Метод вызывается, когда SAXParser начинает * обработку тэга */ @Override public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException < // Устанавливаем флаг для тега TAG_NAME tagOn = (qName.equalsIgnoreCase(TAG_NAME)); System.out.println("\t"); > /** * Метод вызывается, когда SAXParser считывает * текст между тэгами */ @Override public void characters(char ch[], int start, int length) throws SAXException < // Проверка флага if (tagOn) < // Флаг установлен System.out.println("\t\t" + new String(ch,start,length)); tagOn = false; >> @Override public void endElement(String uri, String localName, String qName) throws SAXException < super.endElement(uri, localName, qName); >@Override public void startDocument() throws SAXException < System.out.println("Начало разбора документа!"); >@Override public void endDocument() throws SAXException < System.out.println("Разбор документа завершен!"); >>; public SAXExample() < try < SAXParserFactory factory; factory = SAXParserFactory.newInstance(); SAXParser saxParser = factory.newSAXParser(); // Стартуем разбор XML-документа saxParser.parse(fileName, handler); >catch (Exception e) < e.printStackTrace(); >> public static void main(String args[]) < new SAXExample(); System.exit(0); >>
В результате выполнения примера использования SAXParser в консоль будут выведены следующие сообщения :
Начало разбора документа! Остап Бендер Киса Воробьянинов Мадам Грицацуева Разбор документа завершен!
Скачать примеры
Рассмотренные на странице примеры использования DOM для чтения и создания XML-документа, применения SAXParser’а для анализа XML-текста в виде проекта Eclipse можно скачать здесь (133 Кб).
Основы Java XML – учебник для новичка
Это пособие для программистов знакомит с XML и его использованием с Java, статью подготовил Ларс Фогель, переведено нами на русский язык.

XML – это сокращение от Extensible Markup Language и установленный формат обмена данными. XML был определен в 1998 году Консорциумом World Wide Web (W3C).
Для удобства и экономии времени, вы также можете найти онлайн курс на сайте https://jms.university/. XML-документ состоит из элементов, каждый элемент имеет начальный тег, контент и конечный тег. Должен иметь ровно один корневой элемент (т. е. Один тег, который включает остальные теги). Различает заглавные и не заглавные буквы.
Файл XML должен быть правильно сформирован. Это означает, что он должен применяться к следующим условиям:
- XML-документ всегда начинается с пролога
- Каждый открывающий тег имеет закрывающий тег.
- Все теги полностью вложены.
Правильный XML-файл должен содержать ссылку на XML-схему и быть действительным в соответствии с этой схемой. Ниже приведен правильный, корректный XML-файл.
Сравнение XML с другими форматами
Обрабатывать XML-документ относительно легко по сравнению с двоичным или неструктурированным форматом. Это из-за следующих характеристик:
- простой текст
- представляет данные без определения способа отображения данных
- может быть преобразован в другие форматы через XSL
- может быть легко обработан с помощью стандартных анализаторов
- XML-файлы являются иерархическими
Если данные представлены в виде XML, размер этих данных является относительно большим по сравнению с другими форматами. JSON или двоичные форматы часто используются для замены, если важна пропускная способность данных.
Элементы XML
XML-документ всегда начинается с пролога, который описывает XML-файл. Этот пролог может быть минимальным, например . Он также может содержать другую информацию, например, кодировку .
Тег, который не содержит никакого содержимого, называется «пустым тегом», например, .
Комментарии в XML определяются как: .
Обзор XML Java
Язык программирования Java содержит несколько методов для обработки и написания XML.
Более старые версии Java поддерживали только API DOM (объектная модель документа) и API SAX (простой API для XML).
В DOM вы получаете доступ к документу XML через дерево объектов. DOM может использоваться для чтения и записи файлов.
SAX (простой API для XML) – это Java API для последовательного чтения XML-файлов. SAX обеспечивает управляемую событиями обработку XML по модели Push-Parsing. В этой модели вы регистрируете слушателей в виде Handlers to the Parser. Они уведомляются через методы обратного вызова.
И DOM, и Sax – старые API, и я рекомендую больше их не использовать.
Stax (Streaming API for XML) – это API для чтения и записи XML-документов. Он был представлен в Java 6.0 и считается превосходящим SAX и DOM.
Архитектура Java для привязки XML (JAXB) – это стандарт Java, который позволяет преобразовывать объекты Java в XML и наоборот. JAXB определяет API для чтения и записи объектов Java в документы XML. Он также позволяет выбирать реализацию JAXB. JAXB применяет множество настроек по умолчанию, что делает чтение и запись очень простым.
Ниже объясняется интерфейс Stax.
Потоковый API для XML (StaX)
Потоковый API для XML, называемый StaX, представляет собой API для чтения и записи XML-документов.
StaX – это модель Pull-Parsing, может взять на себя управление анализом XML-документов, извлекая (принимая) события из анализатора.
Ядро StaX API делится на две категории, и они перечислены ниже.
- Курсор API
- Event Iterator API
Приложения могут использовать любой из этих двух API. Далее речь пойдет об API итератора событий, так как я считаю его более удобным в использовании.
API Event Iterator
API итератора событий имеет два основных интерфейса: XMLEventReader для синтаксического анализа XML и XMLEventWriter для генерации XML.
XMLEventReader – читаем пример XML
Этот пример хранится в проекте “de.vogella.xml.stax.reader”.
Приложения зацикливаются на всем документе. API-интерфейс Event Iterator реализован поверх API-интерфейса Cursor.
В этом примере мы прочитаем следующий XML-документ и создадим из него объекты.
1 900 1 1 2 400 2 5 9 5 100 3
Определим следующий класс для хранения отдельных записей.
package de.vogella.xml.stax.model; public class Item < private String date; private String mode; private String unit; private String current; private String interactive; public String getDate() < return date; >public void setDate(String date) < this.date = date; >public String getMode() < return mode; >public void setMode(String mode) < this.mode = mode; >public String getUnit() < return unit; >public void setUnit(String unit) < this.unit = unit; >public String getCurrent() < return current; >public void setCurrent(String current) < this.current = current; >public String getInteractive() < return interactive; >public void setInteractive(String interactive) < this.interactive = interactive; >@Override public String toString() < return "Item [current=" + current + ", date=" + date + ", interactive=" + interactive + ", mode=" + mode + ", unit=" + unit + "]"; >>
Далее читается файл XML и создается список элементов объекта из записей.
package de.vogella.xml.stax.read; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.InputStream; import java.util.ArrayList; import java.util.Iterator; import java.util.List; import javax.xml.stream.XMLEventReader; import javax.xml.stream.XMLInputFactory; import javax.xml.stream.XMLStreamException; import javax.xml.stream.events.Attribute; import javax.xml.stream.events.EndElement; import javax.xml.stream.events.StartElement; import javax.xml.stream.events.XMLEvent; import de.vogella.xml.stax.model.Item; public class StaXParser < static final String DATE = "date"; static final String ITEM = "item"; static final String MODE = "mode"; static final String UNIT = "unit"; static final String CURRENT = "current"; static final String INTERACTIVE = "interactive"; @SuppressWarnings(< "unchecked", "null" >) public List readConfig(String configFile) < List items = new ArrayList(); try < // First, create a new XMLInputFactory XMLInputFactory inputFactory = XMLInputFactory.newInstance(); // Setup a new eventReader InputStream in = new FileInputStream(configFile); XMLEventReader eventReader = inputFactory.createXMLEventReader(in); // read the XML document Item item = null; while (eventReader.hasNext()) < XMLEvent event = eventReader.nextEvent(); if (event.isStartElement()) < StartElement startElement = event.asStartElement(); // If we have an item element, we create a new item if (startElement.getName().getLocalPart().equals(ITEM)) < item = new Item(); // We read the attributes from this tag and add the date // attribute to our object Iterator attributes = startElement .getAttributes(); while (attributes.hasNext()) < Attribute attribute = attributes.next(); if (attribute.getName().toString().equals(DATE)) < item.setDate(attribute.getValue()); >> > if (event.isStartElement()) < if (event.asStartElement().getName().getLocalPart() .equals(MODE)) < event = eventReader.nextEvent(); item.setMode(event.asCharacters().getData()); continue; >> if (event.asStartElement().getName().getLocalPart() .equals(UNIT)) < event = eventReader.nextEvent(); item.setUnit(event.asCharacters().getData()); continue; >if (event.asStartElement().getName().getLocalPart() .equals(CURRENT)) < event = eventReader.nextEvent(); item.setCurrent(event.asCharacters().getData()); continue; >if (event.asStartElement().getName().getLocalPart() .equals(INTERACTIVE)) < event = eventReader.nextEvent(); item.setInteractive(event.asCharacters().getData()); continue; >> // If we reach the end of an item element, we add it to the list if (event.isEndElement()) < EndElement endElement = event.asEndElement(); if (endElement.getName().getLocalPart().equals(ITEM)) < items.add(item); >> > > catch (FileNotFoundException e) < e.printStackTrace(); >catch (XMLStreamException e) < e.printStackTrace(); >return items; > >
Вы можете проверить парсер с помощью следующей тестовой программы. Обратите внимание, что файл config.xml должен существовать в папке проекта Java.
package de.vogella.xml.stax.read; import java.util.List; import de.vogella.xml.stax.model.Item; public class TestRead < public static void main(String args[]) < StaXParser read = new StaXParser(); List readConfig = read.readConfig("config.xml"); for (Item item : readConfig) < System.out.println(item); >> >
Пример записи файла XML
Этот пример хранится в проекте “de.vogella.xml.stax.writer”.
Предположим, вы хотели бы написать следующий простой XML-файл.
1 900 1 1
StaX не предоставляет функциональные возможности для автоматического форматирования, поэтому вам необходимо добавить в конец файла строки и информацию табуляции.
package de.vogella.xml.stax.writer; import java.io.FileOutputStream; import javax.xml.stream.XMLEventFactory; import javax.xml.stream.XMLEventWriter; import javax.xml.stream.XMLOutputFactory; import javax.xml.stream.XMLStreamException; import javax.xml.stream.events.Characters; import javax.xml.stream.events.EndElement; import javax.xml.stream.events.StartDocument; import javax.xml.stream.events.StartElement; import javax.xml.stream.events.XMLEvent; public class StaxWriter < private String configFile; public void setFile(String configFile) < this.configFile = configFile; >public void saveConfig() throws Exception < // create an XMLOutputFactory XMLOutputFactory outputFactory = XMLOutputFactory.newInstance(); // create XMLEventWriter XMLEventWriter eventWriter = outputFactory .createXMLEventWriter(new FileOutputStream(configFile)); // create an EventFactory XMLEventFactory eventFactory = XMLEventFactory.newInstance(); XMLEvent end = eventFactory.createDTD("\n"); // create and write Start Tag StartDocument startDocument = eventFactory.createStartDocument(); eventWriter.add(startDocument); // create config open tag StartElement configStartElement = eventFactory.createStartElement("", "", "config"); eventWriter.add(configStartElement); eventWriter.add(end); // Write the different nodes createNode(eventWriter, "mode", "1"); createNode(eventWriter, "unit", "901"); createNode(eventWriter, "current", "0"); createNode(eventWriter, "interactive", "0"); eventWriter.add(eventFactory.createEndElement("", "", "config")); eventWriter.add(end); eventWriter.add(eventFactory.createEndDocument()); eventWriter.close(); >private void createNode(XMLEventWriter eventWriter, String name, String value) throws XMLStreamException < XMLEventFactory eventFactory = XMLEventFactory.newInstance(); XMLEvent end = eventFactory.createDTD("\n"); XMLEvent tab = eventFactory.createDTD("\t"); // create Start node StartElement sElement = eventFactory.createStartElement("", "", name); eventWriter.add(tab); eventWriter.add(sElement); // create Content Characters characters = eventFactory.createCharacters(value); eventWriter.add(characters); // create End node EndElement eElement = eventFactory.createEndElement("", "", name); eventWriter.add(eElement); eventWriter.add(end); >>
package de.vogella.xml.stax.writer; public class TestWrite < public static void main(String[] args) < StaxWriter configFile = new StaxWriter(); configFile.setFile("config2.xml"); try < configFile.saveConfig(); >catch (Exception e) < e.printStackTrace(); >> >
Средняя оценка 2.8 / 5. Количество голосов: 5
Спасибо, помогите другим — напишите комментарий, добавьте информации к статье.
Или поделись статьей
Видим, что вы не нашли ответ на свой вопрос.
Помогите улучшить статью.
Напишите комментарий, что можно добавить к статье, какой информации не хватает.