Чем отличаются ссылки от указателей в С++
В чем принципиальное отличие ссылки от указателя в С++? Когда лучше использовать ссылку, а когда указатель? Какие ограничения есть у первых, а какие у вторых?
Отслеживать
878 2 2 золотых знака 10 10 серебряных знаков 23 23 бронзовых знака
задан 22 ноя 2010 в 10:55
Nicolas Chabanovsky Nicolas Chabanovsky
51.2k 86 86 золотых знаков 266 266 серебряных знаков 505 505 бронзовых знаков
Уже и забыл,что,существуют ссылки в с++.Никогда не пользовался.Всегда казалось,что,ссылки в с++ введены для «косметики»,чтобы не смущать честной народ,воспитанный на современных синтаксисах древними и ужасными сишными письменами.Ссылки для тех,кому не нужны все прелести и возможности указателей,но,необходимо изменять сами переменные а не их копии.Я,вот,лично,не пойму как при работе с железом без указателя через ссылку получить,например,контекст устройства,поскольку там все через пойнтеры и только через них.
14 мая 2017 в 12:45
@Roman Пожалуйста, используйте ответы исключительно для ответов. Если у вас возник новый вопрос, пожалуйста, задайте его отдельным вопросом.
14 мая 2017 в 12:48
не понятно откуда такой интерес к этому вопросу, если такой вопрос уже давно был в SO, но добавлю, что далеко не все было сказано в ответах о ссыльках и указательях.
28 ноя 2018 в 14:22
3 ответа 3
Сортировка: Сброс на вариант по умолчанию
Еще отличия:
- Нельзя объявить массив ссылок.
- У ссылки нет адреса.
- Существует арифметика указателей, но нет арифметики ссылок.
- Указатель может иметь «невалидное» значение с которым его можно сравнить перед использованием. Если вызывающая сторона не может не передать ссылку, то указатель может иметь специальное значение nullptr :
void f(int* num, int& num2) < if(num != nullptr) // if nullptr ignored algorithm < >// can't check num2 on need to use or not > (Standart) A null pointer constant is an integer literal (2.13.2) with value zero or a prvalue of type std::nullptr_t. A null pointer constant can be converted to a pointer type; the result is the null pointer value of that type and is distinguishable from every other value of object pointer or function pointer type.
#include int main() < std::cout ::value >; if(!is_const) std::cout
О весёлом
Некоторые ссылаются на отрывок с интервью с Страуструпом:
Очевидной реализацией ссылки является (константный) указатель, при каждом использовании которого происходит разыменование. В некоторых случаях компилятор может оптимизировать ссылку таким образом, что во время исполнения вообще не будет существовать объекта, представляющего ссылку.
Другие задают в ответ лишь в один вопрос:
Чем является реультат разыменовывания указателя?
На тему, нужно ли знать отличия указателя от ссылки, писал Джоэл Спольски в своей статье «Закон Дырявых Абстракций».
Отслеживать
11.5k 8 8 золотых знаков 42 42 серебряных знака 69 69 бронзовых знаков
ответ дан 12 янв 2016 в 13:58
rikimaru2013 rikimaru2013
2,643 1 1 золотой знак 19 19 серебряных знаков 23 23 бронзовых знака
Первый пункт — точно?
12 янв 2016 в 14:20
@Qwertiy: По идее, следует из первого пункта принятого ответа.
12 янв 2016 в 14:28
@VladD, но ведь массив можно инициализировать сразу?
12 янв 2016 в 14:30
@Qwertiy: Это да, но ведь по идее любой массив не обязательно инициализировать, а можно присвоить значение позже? Так пришлось бы подправлять правила для массива, добавлять исключение.
12 янв 2016 в 14:33
@VladD, да, верно: stackoverflow.com/a/1164306/4928642
12 янв 2016 в 14:33
Принципиальных отличий два:
- ссылка, в отличии от указателя, не может быть неинициализированной;
- ссылка не может быть изменена после инициализации.
Отсюда и получаем плюсы и минусы использования того и другого:
- ссылки лучше использовать когда нежелательно или не планируется изменение связи ссылка → объект;
- указатель лучше использовать, когда возможны следующие моменты в течении жизни ссылки:
- ссылка не указывает ни на какой объект;
- ссылка указаывает на разные объекты в течении своего времени жизни.
Отслеживать
11.5k 8 8 золотых знаков 42 42 серебряных знака 69 69 бронзовых знаков
ответ дан 18 дек 2010 в 18:18
2,309 14 14 серебряных знаков 14 14 бронзовых знаковСсылки проще понять в сравнении с указателями. По сути, это те же указатели, но немного измененные.
Напишу только про обычные ссылки («lvalue-ссылки» & ). Про «rvalue-ссылки» && — читать отдельно.
-
Ссылки всегда разыменовываются автоматически (после того, как были созданы):
int x = 0; int x = 0; int *y = &x; int &y = x; *y = 42; y = 42; // Не нужно разыменование.- Следствие: Ссылку нельзя «перенацелить» на другой объект, после того, как она создана. Если для указателя можно написать y = &z; , то для ссылки присваивание меняет объект, на который она ссылается, а не ее саму.
- Следствие: Ссылку обязательно инициализировать сразу при создании.
int *z; /* ок */ int &z; // Ошибка компиляции.- Следствие: Ссылки не бывают нулевыми. Указатель можно инициализировать nullptr — нулевым адресом. А поскольку ссылка инициализируется не адресом, туда указатель не подойдет. Попытка создать нулевую ссылку (пример: int *x = nullptr; int &y = *x; ) вызывает неопределенное поведение. Но компиляторы обычно никак не защищают от этого (вероятнее всего, крашнет при использовании ссылки, а не при создании). Но поскольку это UB (т.е. «undefined behavior», т.е. «неопределенное поведение»), проверки а-ля &ссылка == nullptr не имеют никакого смысла, поскольку могут быть выброшены компилятором как всегда ложные.
И указатели, и ссылки часто используют как параметры функций — когда передавать по значению не хочется (либо потому, что нужно изменить параметр и видеть изменения снаружи функции, либо потому, что тип параметра дорого копировать). Соответственно, чаще всего указатели — для опциональных параметров (вместо которых можно передать ноль), а ссылки — для обязательных.
Чтобы передать в функцию массив, традиционно используют указатель на первый элемент, хотя чисто с точки зрения языка, ссылка на первый элемент ничем не хуже.
Некоторые не любят использовать неконстантные ссылки в параметрах. Дескать, нагляднее писать & при вызове, чтобы сразу видеть, что объект меняется.
-
И указатели и ссылки нельзя инициализировать rvalue (грубо говоря, временными объектами, у которых компилятор не дает взять адрес):
int *x = &42; // ошибка компиляции, сразу на `&`. int &y = 42; // ошибка компиляции- Исключение: Ссылки на константные типы — можно.
const int &z = 42; // окДальше идут тонкости.
-
Ссылки продляют время жизни временных объектов.
const int &x = 42; int y = x;- Следствие: Формально, у ссылок нет адресов. &ссылка выдает адрес не самой ссылки, а того, на что она указывает (это следует из того, что ссылки разыменовываются автоматически). Можно положить ссылку в структуру, и взять адрес структуры. Технически, по этому адресу как раз будет лежать ссылка (в виде указателя), но формально — по этому адресу непонятно что.
- Следствие: Менять какие-то байтики по «адресу» ссылки — UB.
Ссылки и указатели в c чем отличаются
На языке C++ есть ссылки (reference), и есть указатели (pointer). В сущности ссылки являются синтаксическим «бантиком» над указателями, упрощающим чтение и написание кода. Однако чем реально различаются ссылки и указатели?
int x = 5;
int y = 6;
int x = 5;
int y = 6;
int *mypointer;
mypointer = &x; mypointer = &y;
*mypointer = 10;
assert(x == 5); assert(y == 10);
Если кратко, то вот отличия ссылок от указателей:
1. Указатель может быть переназначен любое количество раз, в то время как ссылка после привязки не может быть перемещена на другую ячейку памяти.
2. Указатели могут указывать «в никуда» (быть равными NULL), в то время как ссылка всегда указывает на определенный объект. GCC может без выдачи предупреждений обработать код наподобие int &x = *( int *)0; , однако поведение подобного кода может быть непредсказуемым.
3. Вы не можете получить адрес ссылки, как можете это делать с указателями.
4. Не существует арифметики ссылок, в то время как существует арифметика указателей. Однако есть возможность получить адрес объекта, указанного по ссылке, и применить к этому адресу арифметику указателей (например &obj + 5 ).
Стандарт C++ старательно избегает диктовать правила, каким образом компилятор должен реализовать поведение ссылок, однако любой компилятор C++ реализует ссылки как указатели. Так что декларация ссылки, наподобие следующей:
если не будет полностью оптимизирована, то выделит такое же количество памяти, как и для указателя, и поместит адрес переменной i в это хранилище. Таким образом, и указатель, и ссылка занимают одинаковый объем памяти.
Основные правила использования ссылок и указателей:
• Используйте ссылки в параметрах функции и возвращаемых типах, чтобы определить удобный и самодокументируемый интерфейс программирования.
• Используйте указатели для реализации алгоритмов и структур данных.На языке C++ ссылки и указатели имеют перекрывающий друг друга функционал. Здесь приведена информация, которая поможет Вам принять решение, что лучше использовать для определенной задачи.
И язык C, и язык C++ предоставляют указатели (pointer) как способ косвенно обратиться к объекту. C++ также предоставляет ссылки как альтернативный механизм, который в сущности выполняет ту же самую работу. В некоторых ситуациях, где требуется косвенное обращение, C++ настаивает на использовании указателей. В немногих других случаях C++ требует использовать ссылки. Но как правило C++ позволяет и то, и другое. Принятие решения, использовать ли указатели вместо ссылок, или наоборот, часто является вопросом выбранного стиля программирования.
Многие программисты C++ не имеют четкого представления, в каких случаях что использовать — указатели или ссылки. В этой статье автор предлагает некоторые идеи по поводу причин, по каким C++ предлагает ссылки, и почему Вы можете предпочесть использовать ссылки вместо указателей (перевод [3], Saks, Dan. «Introduction to References,» Embedded Systems Programming, January 2001, page 81).
[Основы]
Декларация ссылки почти идентична декларации указателя, отличие только в том, что декларация ссылки использует оператор & вместо оператора *. Например, если:
int i = 3;
int *pi = &i;
декларирует pi как объект типа «указатель на int», у которого начальное значение будет адресом объекта i. В то время как:
декларирует ri как объект типа «ссылка на int», который ссылается на i. Инициализация ссылки для обращения к объекту часто описывают как «привязку ссылки к объекту».
Ключевое отличие между указателями и ссылками состоит в том, что нужно явно использовать оператор * для разыменования указателя (т. е. чтобы обратиться к объекту, на который он указывает), однако для такого же разыменования ссылки не нужно применять специальный оператор. Как только предыдущие определения были выполнены, выражение косвенной адресации *pi разыменовывает указатель pi, чтобы обратиться к переменной i. В отличие от этого выражение ri без каких-либо операторов сразу делает разыменование ссылки ri для обращения к переменной i. Таким образом, присвоение с указателем:
*pi = 4;
поменяет значение i на 4, и то же самое сделает присвоение с помощью ссылки:
ri = 4;
Стандарт C++ не заморачивается с требованиями к компиляторам по поводу того, как генерировать код под обработку ссылок, так что все компиляторы работают со ссылками так же, как и с указателями. Таким образом, выделение памяти под хранение указателя будет таким же, как и для хранения ссылки. Также присвоение
ri = 4;
сгенерирует одинаковый код ассемблера, который сгенерируется для присвоения с помощью указателя:
*pi = 4;
Ни одно из этих вариантов присвоений не работают лучше другого, поведение одинаковое.
[Ссылки как параметры]
На языке C++ Вы можете декларировать параметры функции, у которых будет тип ссылок. Рассмотрим реализацию функции перестановки значений переменных (с именем swap), которая принимает два аргумента int и меняет значение своего первого аргумента на значение во втором аргументе. Например:
int i, j; . swap(i, j);оставит значение, которое было в i, в переменной j, и значение, которое было в переменной j, оставит в переменной i.
Вот одна из возможных реализаций для этой функции:
void swap(int v1, int v2) < int temp = v1;
v1 = v2; v2 = temp; >
Эта реализация проста и код понятен, но он работать не будет. Проблема языка C++, как и языка C, что он передает аргументы функции как значения. Таким образом, вызов:
swap(i, j);
сделает копию аргумента i в параметр v1, и копию аргумента j в параметр v2. Тело функции поменяет значение v1 на значение в переменной v2, но при возврате v1 и v2 будут уничтожены (обычно параметры функции передаются в стеке). Оригинальные значения переменных i и j останутся неизменными после вызова функции.
Чтобы перестановка работала, на языке C вы обязаны реализовать функцию с использованием в параметрах указателей, вот так:
void swap(int *v1, int *v2) < int temp = *v1;
*v1 = *v2; *v2 = temp; >
Тогда она будет вызываться следующим образом:
swap(&i, &j);
Этот вызов будет передавать адрес переменной i вместо её копии. То же самое и для j. В коде тела функции *v1 обращается к i, и *v2 обращается к j, так что вызов сделает реальную перестановку значений переменных i и j.
На языке C++ Вы также можете использовать ссылки вместо указателей в параметрах функции, вот так:
void swap(int &v1, int &v2) < int temp = v1;
v1 = v2; v2 = temp; >
В этом случае вызов будет выглядеть так:
swap(i, j);
В момент вызова параметр ссылки v1 будет привязан к аргументу i, и параметр ссылки v2 будет привязан к j. В теле функции swap, v1 обращается к i и v2 обращается к j, так что этот вызов также правильно сделает изменение значений i и j.
Независимо от того, как Вы реализовали функцию swap — с помощью указателей в параметрах или с помощью ссылок в параметрах — компилятор сгенерирует одинаковый машинный код. Так что выбор конкретной нотации — ссылки или указатели? — будет всего лишь вопросом выбранного стиля программирования.
Некоторые программисты утверждают, что присутствие & в вызове функции делает факт вызова с передачей адреса переменной более явным. В конце концов в вызове:
swap(i, j);
непонятно, что будет передано в вызов функции — значения переменной или же ссылка (если не заглядывать в определение функции swap). При этом вызов:
swap(&i, &j);
однозначно говорит нам о том, что в функцию передаются адреса переменных.
Хотя это утверждение для данного случая выглядит справедливым, C++ позволяет Вам написать функции, для которых Вы не захотите видеть & в вызовах. Это чаще случается, когда происходит работа с перегруженными операторами (overloaded operator), как показано в следующем примере, где вовлечены типы перечисления.
[Оператор перезагрузки и перечисления]
На языке C++, как и на языке C, типы перечислений (enum) предоставляют простой механизм для определения новых скалярных типов. К примеру предположим, что у Вас есть приложение, которое работает с днями недели и месяцами года. Вы можете определить тип day, представляющий дни недели, следующим образом:
enum day < Sunday, Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, not_a_day >;После этого определения константа Sunday получит значение 0, Monday значение 1, и так далее. Позже в программе Вы можете написать код с циклом наподобие такого:
day d;
d = Sunday;while (Saturday > d) < // здесь выполняются какие-либо действия с переменной d ++d; >
Этот код нормально скомпилируется в языке C, но не в C++. Компиляторы C++ пожалуются на выражение ++d в последнем операторе тела цикла.
На языке C каждый тип перечисления это просто целочисленный тип (int). Вы можете применять ++ или любой другой арифметический оператор, так что day это все равно что любое целое число. Но язык C++ рассматривает каждое перечисление как новый тип, отличающийся от целых чисел. Встроенные арифметические операторы C++ не применяются к перечислениям. Чтобы сохранить некоторую обратную совместимость с C, значения перечислений в C++ неявно преобразуются в целочисленные значения. Таким образом, на языке C++ Вы можете получить цикл, как в предыдущем примере путем изменения типа day объекта d на int:
int d;d = Sunday;while (Saturday > d) < // здесь выполняются какие-либо действия с переменной d ++d; >
Теперь присвоение d = Sunday конвертирует Sunday в 0, и присваивает его переменной d. Неравенство Saturday > d эффективно сравнивает d с 6.
Использование объектов int вместо объектов перечисления ослабляет возможности компилятора для обнаружения случайных (ошибочных) преобразований между разными типами перечисления. C++ предоставляет подход лучше этого. Вы можете сделать перезагрузку оператора ++ для типа day. Для такого решения Вы определяете функцию с именем operator++, которая принимает аргумент типа day. После этого, когда компилятор видит выражение ++d, он транслирует это выражение в вызов функции operator++(d).
Вот первая попытка определить такую функцию:
day operator++(day d) < d = (day)(d + 1); return d; >
Для любого x арифметического типа или типа указателя, справедливо, что:
x = x + 1;
Для day d, выражение d + 1 преобразует d в int перед прибавлением 1 (которая тоже типа int). В результате получится int. Хотя C++ преобразует day в int, он не может преобразовать int в day без явного приведения типа (cast). Поэтому присвоение:
d = (day)(d + 1);
использует явное приведение типа, чтобы преобразовать результат сложения из int обратно в day перед тем, как присвоить его переменной d.
Как и в первой версии swap, эта первая версия operator++ не выполнит свою работу. Вызов operator++(d) передаст d по значению, поэтому в теле оператора будет модифицирована копия переменной d, а не сама переменная d.
Вы можете определить operator++ так, чтобы в аргументе передавался адрес переменной, вот так:
day *operator++(day *d) < *d = (day)(*d + 1); return d; >
Но с таким определением оператора нужно использовать выражения наподобие ++&d, что не выглядит по-настоящему правильным. Весь смысл перезагрузки оператора в том, чтобы код для обработки пользовательских типов выглядел точно так же, как и для встроенных. Но выражение ++&d выглядит несколько иначе, как если бы оператор ++ применялся для встроенного типа. В этом случае & в вызове оператора снижает ясность кода.
Чтобы по-настоящему правильно путь определить operator++, нужно использовать ссылки на тип как в параметре, так и в возвращаемом значении:
day &operator++(day &d) < d = (day)(d + 1); return d; >
При использовании этой функции все выражения наподобие ++d будут не только выглядеть ожидаемо, но и будут правильно работать.
[Что внутри?]
Скорее всего, причина появления ссылок в C++ в том, чтобы позволить перезагрузку операторов для пользовательских типов. Чтобы перезагрузка выглядела и работала так же, как и операторы.
Указатели могут делать почти все, что и ссылки, но указатели могут привести в появлению к выражениям, которые не выглядят красиво. С другой стороны, для ссылок есть некоторые ограничения, что делает их менее удобными, чем указатели, для реализации алгоритмов и структур данных. Ссылки уменьшают, но не устраняют полностью необходимость в использовании указателей.
На языке C++ ссылки предоставляют доступ к многим возможностям, для которых на языке C всегда применяют указатели. Хотя большинству программистов C++ кажется, что они уже выработали интуицию в том, чтобы сделать понятным выбор между ссылкой и указателем (когда что лучше использовать — ссылку вместо указателя или наоборот), но все еще они сталкиваются с ситуациями, где выбор не является таким очевидным. Если Вы хотите разработать для себя действительно непротиворечивую философию по использованию ссылок, то реальную помощь окажет точное понимание, чем ссылки отличаются от указателей (перевод статьи [4]).
[Давайте копнем глубже]
Ссылка, как и указатель, это объект, который может использоваться для косвенного доступа (по адресу) к другому объекту (подробнее что такое ссылки и указатели см. врезку «Что такое ссылка (reference). Для чего нужны ссылки»). Отличие семантики определения ссылок и указателей имеет место (& вместо *), однако это не дает основание для принятия решения, что именно использовать — ссылку или указатель. Реальное основание для выбора — различие между ссылками и указателями, когда Вы используете их в выражениях.
Большое отличие между указателями и ссылками состоит в том, что для разыменования указателя нужно использовать оператор *, но для разыменования ссылки не нужен никакой специальный оператор. Эта разница становится важной, когда Вы делаете выбор между указателями и ссылками для параметра функции и для возвращаемого типа функции. Особенно это верно для декларирования перезагруженных операторов (см. предыдущую врезку «Что такое ссылка . «). Пример декаларации перезагрузки оператора из предыдущей врезки с использованием ссылок:
Передача ссылки не просто лучший путь для написания operator++, это единственный путь. C++ реально не дает Вам другого выбора. Декларация наподобие:
day *operator++(day *d);
не будет скомпилирована. Каждая перегруженная функция оператора должна быть либо членом класса, либо иметь параметр типа T, T & или T const &, где T это класс или перечисляемый тип. Другими словами, каждый перезагруженный оператор должен принимать в аргументе тип класса или перечисляемый тип. Указатель, даже если он указывает на объект класса или перечисляемого типа, не в счет. C++ не позволит Вам перегрузить операторы, которые меняют смысл операторов для встроенных типов, включая типы указателя. Таким образом, Вы не можете декларировать:
int operator++(int i); // ошибка
что делает попытку изменить смысл ++ для int, и также не получится декларировать:
int *operator++(int *i); // ошибка
что делает попытку переопределить ++ для int *.
[Отличие ссылок от указателей const]
В [5] объясняется, что C++ не позволяет декларировать «const reference», потому что ссылка по своей сути константа. Другими словами, как только Вы привязали ссылку к объекту, то больше не сможете перепривязать её к другому объекту. Нет синтаксиса изменения привязки, после того как Вы декларировали ссылку. Пример:
привяжет ri к переменной i. Тогда присвоение наподобие следующего:
ri = j;не привяжет ri к j. Вместо этого значение в j попадет в объект, на который ссылается ri, т. е. в переменную i.
Короче говоря, тогда как указатель может указывать на разные объекты в течение своей жизни, ссылка может обращаться только к одному объекту в течение своей жизни. Некоторые утверждают, что это значимое различие между ссылками и указателями. Автор не разделяет эту идею. Может быть, что это различие между ссылками и указателями, но это не различие между ссылками и постоянными указателями. И снова, как только Вы сделали привязку ссылки к объекту, то уже не сможете поменять это, чтобы ссылаться на что-то другое. Поскольку Вы не можете поменять ссылку после её привязки, то должны выполнить эту привязку в начале жизни этой ссылки. Иначе ссылка никогда не будет привязана к чему-либо и будет бесполезной, если не реально опасной.
Все операторы в предыдущем параграфе применимы к const-указателям так же, как применимы к ссылкам (здесь идет речь о const-указателях, но не об указателях на const). Например декларация ссылки в области действия блока должен иметь инициализатор:
void f() < int &r = i; . >
Пропуск инициализатора приведет ошибке компиляции:
void f() < int &r; // ошибка . >
Декларация постоянного указателя в блоке области действия также должен иметь инициализатор:
void f() < int *const p = &i; . >
Пропуск такого инициализатора также приведет к ошибке:
void f() < int *const p; // ошибка . >
То, что Вы не можете поменять привязку ссылки, не делает больше отличие между ссылками и указателями, чем отличие, которое существует между постоянными указателями и переменными указателями.
[NULL-ссылки]
Несмотря на все сказанное, постоянные указатели отличаются от ссылок одним тонким, но значительным моментом. Допустимая ссылка должна указывать на объект; указатель этого делать не обязан. Указатель, даже если он постоянный, может иметь нулевое значение (null). Просто нулевой указатель ни на что не указывает.
Это отличие предполагает, что Вы используете ссылку в качестве типа параметра, когда настоятельно хотите, чтобы параметр относился к объекту. Давайте снова рассмотрим функцию swap (см. предыдущую врезку), которая принимает два аргумента int и меняет местами их значения. Например:
int i, j; . swap(i, j);оставит в переменной j значение, которое было в i, и оставит в переменной i значение, которое было в j. Вы могли бы написать эту функцию так:
void swap(int *v1, int *v2) < int temp = *v1; *v1 = *v2; *v2 = temp; >
так что вызов этой функции будет выглядеть следующим образом:
swap(&i, &j);
Такой интерфейс подразумевает, что один из аргументов, или даже оба могут быть нулевыми указателями. Что конечно не имеет смысла. Например, скорее всего Вы не хотели бы сделать вызов:
swap(&i, NULL);
Определение функции с параметрами в виде ссылок, не указателей:
void swap(int &v1, int &v2) < int temp = v1;
v1 = v2; v2 = temp; >
ясно подразумевает, что вызов swap должен предоставить два объекта, у которых будут переставляться значения. В данном случае это несомненно полезно. Как дополнительный бонус, вызов этой функции красивее, чем вызов с загромождающими амперсандами:
swap(i, j);
[Больше безопасности?]
Некоторые люди принимают факт, что ссылка не может быть null, как значащий фактор повышения безопасности в сравнении с использованием указателей. Небольшое улучшение безопасности здесь есть, но это не может считаться значимым. Хотя допустимая ссылка не может быть null, но неправильная может. Гораздо важнее, что есть куча способов, которыми программы могут произвести недопустимые ссылки, не просто null-ссылки. Например, Вы можете определить ссылку, чтобы она ссылалась на объект, адресуемый по указателю, вот так:
int *p; .
Если вдруг получится так, что указатель равен null в момент определения ссылки, то эта ссылка получится нулевой. Технически в привязке такой ссылки нет ошибки, но ошибка появится при разыменовании указателя null. Разыменование указателя (или ссылки), который равен null приведет к непредсказуемому поведению. Это означает что множество вещей может произойти, но большинство из этого не будет хорошим (спасутся не все). Вероятно, что когда программа привязывает ссылку r к *p (к объекту, на который указывает p), то она не может реально сделать разыменование p, чтобы понять, что тут дело нечисто. Вместо этого программа просто выполнит копию значения p в указатель, который реализует r. Программа продолжит работать до тех пор, пока ошибка не вылезет где-то совершенно неожиданным образом. И найти такую ошибку бывает очень непросто.
Следующая функция показывает еще один способ сделать недопустимую ссылку:
int &f() < int i; . return i; >
Эта функция вернет ссылку на локальную переменную i. Однако хранилище для i исчезнет после возврата из функции. Таким образом эта функция вернет ссылку на хранилище, которое было уничтожено (обычно это место в стеке, которое было выделено при вызове функции). Поведение будет такое же, как если вернуть указатель на локальную переменную. Некоторые компиляторы определяют эту частную ошибку во время компиляции. Однако Вы можете при желании так замаскировать этот баг, что он останется необнаруженным.
Мне нравятся ссылки. Есть веские причины использовать их вместо указателей. Но если Вы ожидаете, что применение ссылок сделает Вашу программу устойчивее, то скорее всего будете разочарованы.
Как уже упоминалось в предыдущих врезках, ссылка это объект, который косвенно обращается к другому объекту. Ссылки предоставляют многие те же самые возможности, которые предоставляют указатели. Ключевое отличие между ссылками и указателями в том, как они появляются в коде, когда Вы их используете. В то время как Вы должны обязательно использовать специальный оператор, такой как * или [], чтобы разыменовать указатель, ничего подобного не нужно для разыменования ссылки. Ссылка разыменовывает сама себя, когда Вы её используете.
Точно так же, как Вы используете квалификатор const в декларациях указателей, можете также использовать const для деклараций ссылок — с одним важным исключением. При декларации указателя Вы можете декларировать его либо как «указатель на const» (указатель на постоянную величину), либо как «const-указатель» (постоянный, не изменяемый указатель). По при декларации ссылки Вы можете декларировать её только как «ссылка на const». Вы не можете сделать декларацию ссылки как «const-ссылка», как минимум не напрямую. Здесь будет подробно объяснено, почему так происходит.
[Вернемся снова к деклараторам]
В предыдущих врезках был рассмотрен синтаксис декларации ссылок. Было показано, что синтаксис похож, но не идентичен, синтаксису деклараций указателей (см. «Что такое ссылка . «). Здесь будет повторено описание синтаксиса, относящееся только к ссылкам.
Каждая декларация языка C и C++ содержит две принципиальные части: последовательность из нулевого или большего количества спецификаторов декларации, и последовательности их одной или большего количества деклараторов, отделяемых друг от друга запятыми. Например:
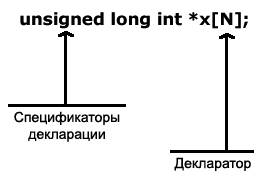
Декларатор это имя, которое декларируется, которое возможно появляется совместно с такими операторами, как *, &, [] и (). Оператор * в деклараторе означает «указатель на . «, & означает «ссылка на . » и [] означает «массив из . «.
Операторы в группе декларатора обрабатываются с таким же приоритетом, с каким обрабатываются в выражении. Например, у оператора [] выше приоритет, чем у *. Таким образом, декларатор *x[N] означает, что x это «массив из N элементов, каждый из которых имеет тип указатель», а не «указатель на массив из N элементов».
Круглые скобки выполняют 2 роли в деклараторах: как оператор вызова функции и как группирующий элемент. Как оператор вызова функции, оператор () имеет тот же самый приоритет, что и оператор []. Как группирующий элемент, () превосходит все другие операторы. Например, в выражении:
char *f(int);
круглые скобки вокруг списка параметров имеют более высокий приоритет, чем оператор *. Таким образом, здесь f декларируется просто как «функция, возвращающая указатель на char» вместо «указатель на функцию, возвращающую char». Если последнее то, что Вам нужно, то нужно написать так:
char (*f)(int);
Оператор & имеет тот же приоритет, что и *. Таким образом:
char &g(int);
декларирует g как «функция, возвращающая ссылку на char» вместо «ссылка на функцию, которая возвращает char». Если последнее именно то, что нужно, то следует переписать эту декларацию так:
char (&g)(int);
[Немного о стиле написания кода]
Вероятно, что большинство программистов C++ пишут декларации ссылок таким образом, что оператор & прилегает к последнему спецификатору декларации, вместо того чтобы сделать оператор & частью декларатора. Например, они пишут декларации так:
char& g(int);
Автор предпочитает приклеивать & к декларатору, вот так:
char &g(int);
Оба определения эквивалентны, но последняя форма аккуратнее отражает синтаксическую структуру декларации. Декларации это одна из самых запутанных частей языка C++. Отделение & от декларатора будет чаще добавлять путаницы.
[Ссылка на const]
Спецификаторы декларации которые появляются перед декларатором, могут указывать тип, как например int, unsigned, или здесь может быть указан идентификатор имени типа. Они могут быть со спецификаторами класса памяти (storage class specifiers), такими как extern или static. Они также могут быть спецификаторами функции, такими как inline или virtual.
Когда ключевое слово const появляется как спецификатор декларации, оно является спецификатором типа. Например, const в декларации:
int const &ri = n;
модифицирует int, тип объекта, на который ссылается ri. Здесь декларируется, что ri является «ссылкой на константу int», и ri ссылается на n.
Когда Вы используете ссылку ri в выражении, она ведет себя как объект типа «const int». Это означает, что Вы можете использовать ri для чтения, но не для модификации числа типа int, на которое ri ссылается. Например, следующие выражения приведут к ошибке компиляции:
ri = 0; // ошибка
++ri; // ошибка
Они не скомпилируются, потому что сделана попытка модифицировать объект, на который ссылается ri.
В этом частном примере ri ссылается на n. Хотя Вы не можете использовать ri для модификации n, но все еще можно модифицировать n в каком-нибудь другом выражении. Все зависит от того, как Вы декларируете n. Если n декларирована так:
int const n = 255;
то n конечно не модифицируемый объект, и Вы не можете изменить n каким-либо образом (кроме как путем использования выражения приведения типа, cast expression). С другой стороны, если переменная n декларирована так:
int n = 255;
то n является модифицируемым объектом. Вы можете модифицировать n, используя выражение наподобие следующих:
n = 2 * n;
Вы не можете выполнить эти операции, используя ri, потому что ri декларирована со спецификатором const.
В общем, для любого типа T объект типа «ссылка на const T» может обращаться к объекту, который либо просто обычный объект типа T, либо объект типа «const T». В обоих случаях компилятор обрабатывает ссылку так, как если бы она обращалась к const-объекту. C++ обрабатывает «указатель на const T» точно таким же способом. Объект типа «указатель на const T» может указывать на объект, который как обычный объект типа T, так и как объект типа «const T». В любом случае, компилятор обрабатывает этот указатель, как если бы он указывал на const-объект [7].
[Снова поговорим о стиле]
Порядок, в котором спецификаторы декларации появляются в декларации, не имеет никакого значения для компилятора. Это еще одна вещь, которая запутывает синтаксис декларации C/C++ [8]. Поэтому, к примеру:
const int &ri = i; //(1)
int const &ri = i; //(2)
Многие программисты C++ предпочитают писать const в левой части, перед другими спецификаторами типа, как в (1). В статье [6] объясняется, почему автор считает, что правильнее будет писать const справа, как в (2). Второй способ предпочтительнее, потому что это помогает лучше понимать эффект от применения квалификатора const. Автор пишет декларации ссылки в том же стиле, что и декларации указателя, чтобы поддержать целостность стиля.
[Постоянные ссылки]
Как упоминалось выше, декларации указателя позволяют декларировать его либо как «указатель на const», либо как «const-указатель». Например:
int const *p = &i;
декларирует p как объект типа «указатель на const int», в то время как:
int *const q = &j;
декларирует q как объект типа «const-указатель на int». В последней декларации ключевое слово const появляется в деклараторе. В частности это часть модуля синтаксиса, который называется оператор указателя (ptr-operator). Этот ptr-operator может быть либо просто *, либо *, за которым сразу идет ключевое слово const.
Конечно, ptr-operator может быть также и оператором &, как в декларации:
Однако он не может быть оператором &, за которым идет const. Поэтому следующая декларация приведет к ошибке синтаксиса:
int &const rj = j; // ошибка
Если коротко, когда декларируете ссылку, то она может быть «ссылкой на const», но Вы не можете декларировать её как «const-ссылку». Грамматика языка C++ просто не позволяет этого. Причина этого в том, что ссылка и так уже сама по себе константа. Как только Вы сделали привязку ссылки, чтобы она ссылалась на объект, то Вы уже не можете привязать её к другому объекту. Нет никакой нотации для перепривязки ссылки, после того, как она была декларирована. Например:
делает привязку ri, чтобы она ссылалась на i. Тогда присваивание, такое как:
ri = j;не делает привязку ri к j. Это присваивает значение в j объекту, на который ссылается ri, т. е. значение будет присвоено переменной i.
Как только Вы определили ссылку, то больше не можете поменять это, чтобы обращаться к какому-то другому объекту. Из-за того, что Вы не можете поменять ссылку после того, как определили её, то Вы обязаны сделать привязку ссылки к объекту в момент начала жизни ссылки в коде. Например, декларация ссылки в блоке кода обязательно должна иметь свой инициализатор:
void f() < int &ri = i; . >
Пропуск инициализатора приведет к ошибке:
void f() < int &ri; // ошибка . >
Хотя Вы не можете определить напрямую «const-ссылку», Вы можете сделать это косвенно через typedef. Например,
typedef int &ref_to_int; . ref_to_int const r = i;
определяет r как «const int_ref». Поскольку int_ref это просто алиас (псевдоним) для «ссылки на int», тип r появляется как «const-ссылка на int». Но ссылка сама по себе уже изначально константа, так что ключевое слово const здесь избыточно, и не дает эффекта. Компилятор C++ просто игнорирует const в этой декларации, так что r получит тип «ссылка на int».
[Немного о терминологии]
В то время как автор пишет декларации так:
int const &ri = i;
многие программисты C++ написали бы так:
const int& ri = i;
Автор не может примириться с этим. Еще больше беспокоит то, что многие программисты также назвали бы ri «const-ссылкой». Хотя на самом деле это «ссылка на const». Важно то, что в то время как нет никакой причины разделять «ссылку на const» и «const-ссылку» (поскольку последнего не существует в природе), все еще важно понимать разницу «указателя на const» и «const-указателя». «Указатель на const» совсем не то же самое, что «const-указатель», разница существенная.
Проблема в том, что многие программисты, которые говорят «const-ссылка», не имеют в виду ничего плохого и подразумевают просто «ссылку на const», но они допускают при этом неаккуратность. Скорее всего они сделают ошибку и скажут подобным образом «const-указатель», имея в виду «указатель на const». На самом деле, многие используют термин «const-указатель» для обозначения либо «const-указателя», либо «указателя на const». Поди разберись.
Так что лучше избегать термина «const-ссылка», когда имеете в виду «ссылка на const».
[Ссылки]
1. Differences between a pointer variable and a reference variable in C++ site:stackoverflow.com.
2. What is a reference? site:yosefk.com.
3. An Introduction to References site:embedded.com.
4. References vs. Pointers site:embedded.com.
5. References and const site:embedded.com.
6. Saks, Dan, «const T vs. T const,» Embedded Systems Programming, February 1999, page 13.
7. Saks, Dan , «What const Really Means,» Embedded Systems Programming, August 1998, page 11.
8. Определения «char const *» и «const char *» — в чем разница?отличие указателей от ссылок
Вообще говоря указатель и ссылка это одно и то же, это значение адреса в памяти.
Два варианта обозначения одного и того же придумали с целью объяснения компилятору надо ли создавать копию этого значения в памяти или нет (при входе в функцию например).
Объявление переменной i, создание ссылки на нее и указателя на нее :
int i=0x12; int &ri=i; int *pi=&i;i=12 pi=28ff20 0028FF20 *pi=12 00000012 ri=12 00000012 &ri=28ff20 0028FF20 &pi=28ff1c 0028FF1C // адрес самого указателя1. Сразу отметим важный момент — синтаксическое отличие указателя от ссылки:
для указателя : int *pi=&i; *pi - это само значение , pi - это адрес значения у ссылки наоборот : int &ri=i; ri - это само значение , &ri - это адрес значения Далее надо тупо это понимать! *xxx - значение, xxx - адрес &xxx - адрес , xxx - значение2. Создание указателя — это новая ячейка в памяти, а ссылка ничего не создает нового в памяти
int *pi=&i; // итак pi - - это адрес указателя printf("&pi=%x %p \n",&pi,&pi); так можно делать и вы увидите адрес самой ссылки&ri - адрес "ссылки", но ri по сути это просто псевдоним i, просто нам хочется i обозвать еще также ri. Но это все равно останется только одна ячейка памяти с одним и тем же адресом. а как вывести адрес ссылки &ri & - правильно никак - так нельзя делать ( &&ri )Другими словами можно создать указатель на указатель и т.д. Но нельзя создавать ссылку на ссылку!
на картинке создаются указатель , потом опять указатель на указатель и т.д.

volatile
Применяйте директиву volatile , если не хотите , чтобы компилятор оптимизировал размещение в памяти ваших переменных(данных), а вы потом ломали голову почему оттуда такие странные значения читаются.
«Это как его волюнтаризм. «
Маленький , но принципиальный пример на с
Разрабатывая микроконтроллер STM32 пришлось юникодить , делать таблицы точек для каждого символа , чтобы выводить на термопринтер текст.
В очередной раз завис с указателями на элементы этих таблиц, как их использовать . Допустим есть двухмерный массив :
volatile uint8_t lat00[256][5]=< < 0 , 0 , 0 , 0 , 0 >, < 0 , 0 , 0 , 0 , 0 >, . < 0x3E, 0x51, 0x49, 0x45, 0x3E >, // 0x30 '0' < 0x00, 0x42, 0x7F, 0x40, 0x00 >, // 0x31 '1' < 0x42, 0x61, 0x51, 0x49, 0x46 >, // 0x32 >;В [5] байтах лежит растровое представление символа 5*8. Но не об этом.
Хотим получить указатель на какой-то байт массива, пожалуйста :
volatile uint8_t *b8 = &lat00[b1][0];А как дальше добраться до остальных 1,2,3,4 байт — вот тут меня подзаклинило, но не надолго. Вот так надо:
uint8_t b1 = (uint8_t)*(b8 k); // k=1,2.Еще задачка и непонятого
Поимел проблемы вот с такими вариантами одного и того же массива:
volatile uint8_t lat00[][5]=< uint8_t lat00[][5]=< const uint8_t lat00[][5]=Только третий вариант размещает байты в памяти последовательно подряд.
const кстати размещает массив в .rodata это flash контроллера. А 1,2 варианты в куче или стеке.
Ссылки
Ссылка reference — механизм языка программирования (C++), позволяющий привязать имя к значению. В частности, ссылка позволяет дать дополнительное имя переменной и передавать в функции сами переменные, а не значения переменных.
Синтаксически ссылка оформляется добавлением знака & (амперсанд) после имени типа. Ссылка на ссылку невозможна.
Ссылка требует инициализации. В момент инициализации происходит привязка ссылки к тому, что указано справа от = . После инициализации ссылку нельзя “отвязать” или “перепривязать”.
Любые действия со ссылкой трактуются компилятором как действия, которые будут выполняться над объектом, к которому эта ссылка привязана. Следующий пример демонстрирует ссылку в качестве дополнительного имени переменной.
int n = 0; int &r = n; /* теперь r -- ссылка на n или второе имя переменной n */ n = 10; cout '\n'; // выведет 10 r = 20; cout '\n'; // выведет 20 cout '\n'; // выведет 1, т.е. истинаКазалось бы, зачем нам второе имя переменной? Ответа может быть, по крайней мере, два.
- Что-то имеет слишком длинное, неудобное название. Привязав к нему ссылку, мы получим более удобное, короткое локальное название. При этом мы можем не указывать тип этого “чего-то”, можно использовать вместо типа ключевое слово auto :
auto &short_name = some_namespace::some_long_long_name;- Выбор объекта привязки ссылки может происходить во время исполнения программы и зависеть от некоего условия. Пример:
int a = 0, b = 0; cin >> a >> b; int &max = a < b? b: a; // привязать к b, если a < b, иначе -- к amax = 42; cout "a = " << a "; b = " << b '\n';Впрочем, основным применением ссылок является передача параметров в функции “по ссылке” и возвращение функциями ссылок на некие внешние объекты.
Передача по ссылке by reference напоминает передачу “по имени”. Таким образом, можно сказать, что, используя ссылки, мы передаём не значения, а сами переменные, содержащие эти значения. В реальности “за ширмой” происходит передача адресов этих переменных. Передача ссылки на переменную, время жизни которой заканчивается, например, возврат из функции ссылки на локальную переменную, приводит к неопределённому поведению.
Ранний пример использования ссылок для возврата из функции более одного значения представлен в самостоятельной работе 3.
Приведём здесь ещё один пример: функцию, которая возвращает одну из двух переменных, содержащую максимальное значение. Для этого модифицируем предыдущий пример:
int& max_byref(int &a, int &b) < return a < b? b: a; >int main() < int x = 0, y = 0; // собственно имена переменных не обязаны совпадать cin >> x >> y; max_byref(x, y) = 42; cout "x = " << x "; y = " << y '\n'; return 0; >Так как при передаче ссылки реально копируется лишь адрес значения, а не само значение, то передав ссылку можно избежать копирования значения. Поэтому ссылки широко используются для передачи в функцию аргументов, которые или запрещено копировать или вычислительно дорого копировать. Типичный пример — объекты string. При копировании строки происходит выделение динамической памяти, копирование всех символов, затем — при удалении этой копии — освобождение памяти. Часто нет никакой необходимости в копировании. Например, следующей функции, считающей количество повторений заданного символа в строке нет нужды копировать строку — можно обойтись ссылкой:
size_t char_freq(const string &s, char c) < size_t freq = 0; for (size_t i = 0, sz = s.size(); i != sz; ++i) freq += s[i] == c; return freq; >Обратите внимание на ключевое слово const . Данное ключевое слово позволяет нам указать, что мы хотим ссылку на константу, т.е. функция char_freq использует s как константу и не пытается её изменять, а ссылка нужна для того, чтобы избежать копирования. Рекомендуется использовать const везде, где достаточно константы. Компилятор проверит, действительно ли мы соблюдаем константность.
Ставить слово const можно перед именем типа и после имени типа, это эквивалентные записи.
int x; const int &r1 = x; // ссылка на x "только для чтения" int const &r2 = x; // тоже ссылка на x "только для чтения" int & const r3 = x; // ошибка компиляции, нельзя ставить const после &Указатели
Общие сведения
Что такое указатель pointer уже рассказывалось во введении.
В C и C++ указатель определяется с помощью символа * после типа данных, на которые этот указатель будет указывать.
Указатель — старший родственник ссылки. Указатели активно использовались ещё в машинных языках и оттуда были перенесены в C. Ссылки же доступны только в C++.
Указатели — простые переменные. Указатели не “делают вид”, что они — те значения в памяти, к которым они привязаны. Чтобы получить указатель на переменную, нужно явно взять её адрес с помощью оператора & . Чтобы обратиться к переменной, на которую указывает указатель, требуется явно разыменовать его с помощью оператора * .
int n = 0; int *r = &n; // теперь r -- указатель на n n = 10; cout '\n'; // выведет 10 *r = 20; cout '\n'; // выведет 20 cout '\n'; // выведет 1Так же, как и в случае ссылок, можно использовать ключевое слово const , чтобы создать указатель на константу.
int x = 0, y = 1; const int *p1 = &x; // указатель на x "только для чтения" y = *p1; // можно *p1 = 10; // ошибка компиляции: нельзя изменить константу *p1 p1 = &y; // можно: сам указатель p1 не является константой int const *p2 = &x; // тоже указатель на x "только для чтения", всё аналогично p1 int * const p3 = &x; // теперь константа -- сам указатель y = *p3; // можно *p3 = 10; // тоже можно! p3 = &y; // ошибка компиляции: нельзя изменить константу p3 const int * const p4 = &x; /* комбо: теперь у нас константный указатель на x "только для чтения" */ y = *p4; // можно *p4 = 10; // ошибка компиляции: нельзя изменить константу *p4 p4 = &y; // ошибка компиляции: нельзя изменить константу p4Указатели можно сравнивать друг с другом. Указатели равны, если указывают на один и тот же объект, и не равны в противном случае.
Указатели можно передавать в функции и возвращать из функций как и любые “элементарные” значения. Ещё пример с указателями:
int* max_byptr(int *a, int *b) < return *a < *b? b: a; >int main() < int x = 0, y = 0; // собственно имена переменных не обязаны совпадать cin >> x >> y; *max_byref(&x, &y) = 42; cout "x = " << x "; y = " << y '\n'; return 0; >Для обращения к полю структуры по указателю на объект структуры предусмотрен специальный оператор -> (“стрелка”).
struct Point < float x, y; >; Point a = < 20, 30 >; cout ' ' '\n'; // > 20 30 Point *p = &a; p->x = 42; (*p).y = 23; // то же самое, что p->y = 23; cout ' ' '\n'; // > 42 23В отличие от ссылок, указатели не обязательно инициализировать. Указатели можно инициализировать специальным значением нулевой указатель nullptr , которое сигнализирует об отсутствии привязки указателя к чему-либо. Присваивание указателю другого адреса меняет его привязку. Это позволяет использовать указатели там, где семантика ссылок слишком сильно ограничивает наши возможности.
Соответственно, ограничения, накладываемые на ссылки по сравнению с указателями, позволяют, с одной стороны, защитить программиста от ряда ошибок, и, с другой стороны, открывают ряд возможностей оптимизации кода для компилятора. Ссылки используются там, где нет нужды в “полноценных” указателях или есть желание не перегружать код взятиями адреса и разыменованиями.
Наличие нулевого указателя позволяет, например, возвращать указатель на искомый объект и в том случае, когда ничего не было найдено. Просто в этой ситуации возвращаем нулевой указатель, а принимающая сторона должна быть готова к такому развитию событий. Указатель автоматически преобразуется к булевскому значению: нулевой указатель даёт false , прочие указатели дают true , поэтому, если p — указатель, то
if (p) .есть то же самое, что
if (p != nullptr) .if (!p) .есть то же самое, что
if (p == nullptr) .Например, поиск самого левого нуля в массиве чисел с плавающей точкой может быть записан так:
// Ищет нулевой элемент в диапазоне [from, to). // Возвращает нулевой указатель, если нуль не был найден. float* find_next_zero(float *from, float *to) < for (; from != to; ++from) if (*from == 0.f) return from; // нашли return nullptr; // ничего не нашли > int main() < float num[] < 1, 2, 3, 0, 3, 4 >; if (auto zero_pos = find_next_zero(num, num + sizeof(num)/sizeof(num[0]))) cout '\n'; else cout "zero not found\n"; // невозможно! return 0; >Данный пример использует арифметику указателей и массивы. Данная тема освещена в разделе массивы и ссылки.
Бестиповый указатель
Вместо типа данных при объявлении указателя можно поставить ключевое слово void . Данное ключевое слово означает, что мы описываем указатель “на что угодно”, т. е. просто адрес в памяти. Любой указатель автоматически приводится к типу void* — бестиповому указателю typeless pointer . Прочие указатели, соответственно, называются типизированными или типизованными typed . Приведение от void* к типизованному указателю возможно с помощью оператора явного приведения типа.
В C бестиповые указатели широко применяются для оперирования кусками памяти или реализации обобщённых функций, которые могут работать со значениями разных типов. В последнем случае конкретный тип маскируется с помощью void (“пустышка”). При использовании таких функций обычно приходится где-то явно приводить тип указателей. C++ позволяет отказаться от подобной практики благодаря поддержке полиморфизма и обобщённого программирования (материал 2-го семестра).
#include #include // setw -- ширина поля вывода, hex -- вывод в 16-ричной системе #include using namespace std; // Ещё один способ получить битовое представление числа с плавающей точкой. int main() < unsigned char buffer[sizeof(float)]; // Настройка потока вывода. cout.fill('0'); // Заполнять нулями. cout.setf(ios::right); // Выравнивать по правому краю. for (float x; cin >> x; ) < // Скопировать побайтово память x в память buffer. memcpy(buffer, &x, sizeof(float)); // Вывести каждый байт buffer в 16-ричной форме. for (int byte: buffer) cout 2) ' '; cout '\n'; > >О цикле for (int byte: buffer) см. здесь.
Указатель на указатель
Так как указатель — обычная переменная, возможен указатель на указатель. И указатель на указатель на указатель. И указатель (на указатель) n раз для натурального n. Максимальный уровень вложенности задаётся компилятором, но на практике уровни больше 2 практически не используются.
int n = 4; int *p = &n; // уровень косвенности 1 *p = 5; cout // выведет 5 int **pp = &p; // уровень косвенности 2 **p = 6; cout // выведет 6 int ***ppp = &pp; // уровень косвенности 3 ***p = 7; cout // выведет 7“Система ранжирования C-программистов.
Чем выше уровень косвенности ваших указателей (т. е. чем больше “*” перед вашими переменными), тем выше ваша репутация. Беззвёздочных C-программистов практически не бывает, так как практически все нетривиальные программы требуют использования указателей. Большинство являются однозвёздочными программистами. В старые времена (ну хорошо, я молод, поэтому это старые времена на мой взгляд) тот, кто случайно сталкивался с кодом, созданный трёхзвёздочным программистом, приходил в благоговейный трепет.
Некоторые даже утверждали, что видели трёхзвёздочный код, в котором указатели на функции применялись более чем на одном уровне косвенности. Как по мне, так эти рассказы столь же правдивы, сколь рассказы об НЛО.
Просто чтобы было ясно: если вас назвали Трёхзвёздочным Программистом, то обычно это не комплимент."
Условия для проверки себя на “трёхзвёздность” перечислены на другой странице того же сайта.
В случае C указатели на указатели (уровень косвенности 2) используются довольно часто, например, для возвращения указателя из функции, которая возвращает ещё что-то, или для организации двумерных массивов. Пример такой функции из Windows API:
DWORD WINAPI GetFullPathName( _In_ LPCTSTR lpFileName, _In_ DWORD nBufferLength, _Out_ LPTSTR lpBuffer, _Out_ LPTSTR *lpFilePart );Функция принимает имя файла как указатель на си-строку lpFileName, а также размер буфера nBufferLength в символах и адрес буфера lpBuffer, куда записывается в виде си-строки полное имя файла. Функция возвращает длину строки, записанной в буфер, или 0, если произошла ошибка. Кроме того, последний параметр функции — указатель на указатель на си-строку lpFilePart, который используется, чтобы вернуть из функции указатель на последнюю часть имени файла, записанного в буфер.
В случае C++ с помощью ссылок и Стандартной библиотеки можно вообще избежать использования “классических” указателей. Так что “беззвёздочный” C++-программист возможен.
Неограниченный уровень косвенности
Несмотря на ограниченность применения уровня косвенности выше двух, довольно часто встречается то, что можно назвать неограниченным уровнем косвенности или рекурсивным типом данных. Типичный (и простейший) пример — структура данных, называемая “связанный список” linked list .
Следующий пример демонстрирует использование связанного списка для чтения последовательности строк и вывода этой последовательности в обратном порядке:
struct Line < Line *prev; string line; >; int main() < Line *last = nullptr; // Чтение строк. for (string line; getline(cin, line);) < Line *new_line = new Line; new_line->prev = last; new_line->line = line; last = new_line; > // Вывод строк в обратном порядке. while (last) < cout line '\n'; Line *old_line = last; last = last->prev; delete old_line; > return EXIT_SUCCESS; >Упражнение. Попробуйте изменить этот пример так, чтобы введённые строки выводились в том же порядке, в котором были введены.
Указатели на функции
Язык C позволяет определять указатели на функции (в указателе хранится адрес точки входа в функцию) и вызывать функции по указателю. Таким образом, можно во время исполнения программы выбирать какая именно функция будет вызвана в конкретной точке, выбирая значение указателя. Язык C++ позволяет создавать также и ссылки на функции, но ввиду того, что ссылка после инициализации не может быть изменена, область применения ссылок на функции весьма узка.
Функцией высшего порядка higher order function называют функцию, принимающую в качестве параметров другие функции. Функции высшего порядка — одно из базовых понятий функционального программирования. Единственная форма функций высшего порядка в C — функции, принимающие указатели на функции. Язык C++ расширяет круг доступных форм функций высшего порядка, но в примерах ниже мы ограничимся возможностями C.
Простой пример использования указателя на функцию — функция, решающая уравнение вида f(x) = 0, где f(x) — произвольная функция. Конкретные функции f можно передавать по указателю. Приведение функций к указателю на функцию и наоборот производится неявно автоматически, поэтому при присваивании указателю адреса конкретной функции можно не использовать оператор взятия адреса & , а при вызове функции по указателю — не использовать оператор разыменования * (поведение, аналогичное поведению с массивами).
/// Тип "правая часть уравнения" -- функция одного действительного параметра. typedef double (*Unary_real_function)(double); /// Точность приближённого решения, используемая по умолчанию. const double Tolerance = 1e-8; /// Алгоритм численного решения уравнения f(x) = 0 на отрезке [a, b] делением отрезка пополам. /// Данный алгоритм является вариантом двоичного поиска. double nsolve(Unary_real_function f, double a, double b, double tol = Tolerance) < using namespace std; assert(f != nullptr); assert(a < b); assert(0. for (auto fa = f(a), fb = f(b);;) < // Проверим значения функции на концах отрезка. if (fa == 0.) return a; if (fb == 0.) return b; // Делим отрезок пополам. const auto mid = 0.5 * (a + b); // середина отрезка if (mid return abs(fa) < abs(fb)? a: b; if (b - a return mid; // Выберем одну из половин в качестве уточнённого отрезка. const auto fmid = f(mid); if (signbit(fa) != signbit(fmid)) < // Корень на левой половине. b = mid; fb = fmid; > else < assert(signbit(fb) != signbit(fmid)); // Корень на правой половине. a = mid; fa = fmid; > > >Довольно типичной областью применения указателей на функции является связывание источников (регистраторов) некоторых событий, обычно определяемых в составе некоторой библиотеки, и обработчиков событий, предоставляемых пользователем этой библиотеки. Обработчики событий (функции) вызываются автоматически по переданным указателям. Такие функции также называются функциями обратного вызова callback functions или колбеками callbacks . Например, при щелчке мышью по элементу графического интерфейса вызывается функция-обработчик этого события, “зарегистрированная”, путём передачи её адреса библиотеке графического интерфейса.
В качестве простого примера применения функции обратного вызова рассмотрим функцию, занимающуюся поиском набора корней уравнения f(x) = 0 на заданном отрезке. Сама функция будет работать по достаточно простому алгоритму (который, естественно, не гарантирует, что будут найдены все или даже какие-то из существующих на отрезке корней): предполагаем, что есть некая функция, способная найти один корень на отрезке, если он там есть (например, функция nsolve из примера выше). Теперь берём исходный отрезок поиска [a, b] и некоторое значение “шага” step и проходим по этому отрезку с этим шагом, проверяя участки [a + i step, min(b, a + (i + 1)step], i = 0, … пока не пересечём правую границу отрезка. На каждом участке проверяем, являются ли его границы корнями, и есть ли на нём корень (принимает ли функция f разнознаковые значения на границах). В последнем случае используем “решатель” вроде nsolve (переданный по указателю), чтобы найти корень. Каждый найденный корень — это событие, вызываем для него “обработчик” — функцию обратного вызова по указателю report.
/// Тип "решатель уравнения на отрезке" -- функция вроде nsolve, определённой выше. typedef double (*Equation_solver)(Unary_real_function, double a, double b, double tol); /// Тип функции, вызываемой для каждого корня. /// Процесс поиска останавливается, если эта функция возвращает ложь. typedef bool (*Root_reporter)(double); /// Применяет заданный алгоритм поиска корня на отрезке, /// разбивая заданный отрезок [a, b] на отрезки одинаковой длины step (кроме, возможно, последнего). /// Для каждого найденного корня вызывает функцию report (callback-функция). /// Возвращает правую границу пройденного участка (идёт слева направо по заданному отрезку). double repeated_nsolve ( Unary_real_function f, double a, double b, double step, // шаг на отрезке Root_reporter report, double x_tol = TOLERANCE, // чувствительность по аргументу double f_tol = TOLERANCE, // чувствительность по значению функции Equation_solver solver = nsolve ) < assert(x_tol >= 0. && f_tol >= 0.); assert(a 0.); assert(f && report && solver); using namespace std; double left = a, f_left = f(left); bool f_left_zero = abs(f_left) // Корень на левой границе исходного отрезка? if (f_left_zero && !report(left)) return left; while (left != b) < // Правая граница очередного участка. const double right = fmin(b, left + step), f_right = f(right); const bool f_right_zero = abs(f_right) // Корень на правой границе участка? if (f_right_zero && !report(right)) return right; // Есть корень внутри участка? if (!(f_left_zero || f_right_zero) && signbit(f_left) != signbit(f_right)) < const double root = solver(f, left, right, x_tol); if (!report(root)) return root; > // Передвинуть левую границу. left = right; f_left = f_right; f_left_zero = f_right_zero; > return b; >Следующий пример демонстрирует “двухзвёздное программирование” и использование указателя на функцию для определения порядка сортировки массива строк с помощью стандартной функции qsort .
#include // qsort #include // strcmp #include using namespace std; // Функция сравнения строк. int line_compare(const void *left, const void *right) < // Обращаем словарный порядок, поменяв местами left и right. return strcmp(*(const char**)right, *(const char**)left); > int main() < const char *lines[] < "may the force be with you", "this is it", "so be it", "it is a good day to die", "through the time and space", "the light shines in the darkness" >; // Сортировать: массив, количество элементов qsort(lines, sizeof(lines) / sizeof(lines[0]), // размер элемента, функция сравнения. sizeof(lines[0]), line_compare); // Распечатаем результат сортировки. for (auto line : lines) cout '\n'; return EXIT_SUCCESS; >Функция qsort является частью Стандартной библиотеки C. Стандартная библиотека C++ предлагает более удобную и эффективную функцию sort (определённую в заголовочном файле ), однако её рассмотрение выходит за пределы темы данного раздела.
Следующий пример является развитием примера со списком из предыдущего подраздела и использует бестиповые указатели, указатели на указатели и указатели на функции для управления “обобщённым” связанным списком в стиле C. Звенья такого списка могут содержать произвольные данные. Основное требование к звеньям списка — наличие в начале звена указателя на следующее звено, фактически каждый предыдущий указатель указывает на следующий.
/// Возвращает ссылку на указатель на следующее звено звена link. void*& next(void *link) < return *(void**)link; > /// Вставляет link перед head и возвращает link (теперь это -- новая голова списка). void* insert_head(void *head, void *link) < next(link) = head; return link; > /// Вычисляет длину списка. size_t size(void *head) < size_t sz = 0; for (; head; head = next(head)) ++sz; return sz; > /// Указатель на функцию, выполняющую удаление звена. using Link_delete = void(*)(void*); /// Удаляет список, используя пользовательскую функцию удаления. void delete_list(void *head, Link_delete link_delete) < while (head) < auto next_head = next(head); link_delete(head); head = next_head; > >Теперь сама программа, выводящая строки в обратном порядке, упрощается:
/// Звено списка -- одна строка. struct Line < void *prev; string line; >; /// Вывести строку и удалить объект Line. void print_and_delete(void *ptr) < auto line = (Line*)ptr; cout line '\n'; delete line; > int main() < Line *head = nullptr; // Чтение строк. for (string line; getline(cin, line);) < Line *new_line = new Line; new_line->line = line; head = (Line*)insert_head(head, new_line); > // Вывод количества строк -- элементов списка. cout "\nLines: " << size(head) "\n\n"; // Вывод строк в обратном порядке. delete_list(head, print_and_delete); cin.clear(); cin.ignore(); return EXIT_SUCCESS; >Впрочем, необходимо отметить, что сочетая такие приёмы со средствами C++, выходящими за пределы “чистого” C, вы рискуете нарваться на неопределённое поведение. Низкоуровневые средства требуют особой внимательности, так как компилятор в таких случаях не страхует программиста. В частности, в общем случае нельзя интерпретировать произвольный указатель как void* и наоборот без выполнения приведения типа. А это может произойти неявно, например, в примере выше мы полагаем, что указатель prev, указывающий на объект структуры Line совпадает с указателем на поле prev этого объекта.
Синтаксическая справка
Правило чтения сложных описаний типов
Конструкции, определяющие переменные или вводящие новые типы в языках C и C++, могут порой иметь довольно запутанный вид. Ниже дано правило, помогающее разобраться в смысле сложных конструкций.
- Начиная с имени (в случае typedef , в случае using имя находится вне — см. ниже), читать вправо, пока это возможно (до закрывающей круглой скобки или точки с запятой).
- Пока невозможно читать вправо, читать влево (убирая скобки).
Некоторые примеры “расшифровки” типов переменных:
// c (влево) константа char (const и char можно поменять местами) const char c; // str (влево) указатель на (влево) константу char (или константный массив из char) const char* str; // str (влево) константный (влево) указатель на константу char const char* const str; // n (вправо) массив (вправо) из 10 (влево) int int n[10]; // n (вправо) массив (вправо) из 10 (влево) указателей на (влево) int int* n[10]; // n (влево) указатель на (вправо) массив из 10 (влево) указателей на int int* (*n)[10]; // n указатель на массив из 10 (влево) указателей на (вправо) функции, не принимающие аргументов, // (влево) возвращающие указатели (влево) на константы типа int const int* (*(*n)[10])();Разница между typedef и using
Директива typedef объявляет синоним типа. Используется синтаксис определения переменной, к которой добавили ключевое слово typedef , только вместо собственно переменной вводится синоним типа этой как-бы переменной с её именем.
int * p; // переменная: указатель на int typedef int * pt; // имя pt -- синоним типа "указатель на int" pt px; // тоже переменная типа "указатель на int"В С++11 появилась возможность объявлять синонимы типов с помощью using-директивы в стиле инициализации переменных:
using pointer = type*;Объявление typedef можно превратить в using-директиву, заменив typedef на using , вставив после using имя типа и знак равно и убрав это имя типа из объявления справа.
// то же, что typedef double (*Binary_op)(double, double); using Binary_op = double (*)(double, double);Типы, ассоциируемые с массивами
Пусть N — константа времени компиляции и дано определение
float a[N];- float — тип элемента;
- float& — ссылка на элемент, тип результата операции обращения по индексу, например a[0] ;
- float* — указатель на элемент, например &a[0] ; a и &a автоматически неявно приводятся к float* ;
- float[N] — формальный тип переменной a ;
- float(*)[N] — формальный тип указателя на массив a , результат операции взятия адреса &a ;
- float(&)[N] — тип ссылки на массив a ; a автоматически неявно приводятся к этому типу; так же как сам массив, ссылка на него автоматически приводится к указателю на массив и на его первый элемент.
Типы, ассоциируемые с функциями
Пусть дано объявление
float foo(int, int);- float — тип результата, получаемый при вызове функции, например foo(1, 2) ;
- float(int, int) — формальный тип символа foo — foo не является переменной, так как переменные функционального типа невозможны, и тем не менее, имеет тип;
- float(*)(int, int) — указатель на функцию, результат &foo ; foo автоматически неявно приводится к этому указателю;
- float(&)(int, int) — ссылка на функцию; foo автоматически неявно приводится к этому типу; так же как сама функция, ссылка на неё автоматически приводится к указателю на неё же.