. и кое-что о компьютерах.

Вот примерно так часто появляются темы на форумах. Почему это чушь, и почему объём памяти совсем не так уж и важен — я подробнее писал об этом вот здесь. Если коротко –то не в памяти дело, вернее, не только в памяти.
Но объём её всё равно важен. Хотя бы потому, что его указывают в системных требованиях к играм. И пусть эти “системные требования” – часто сильно усреднённая штука, но цифры там вполне конкретные, и они хоть как-то показывают, какими примерно характеристиками должен обладать компьютер для того, чтоб эту игру запускать. Насколько важно количество видеопамяти-можно узнать только в сравнении, по тестам; их много в интернете. Один из примеров- есть здесь, это всего лишь ссылка, найденная за пару секунд в Google. Но даже из неё ясно, что видеокартам среднего уровня (а мобильные в большинстве своём относятся именно к таким, и ниже) практически всё равно, 512мб или 1гб памяти на неё есть- это не даёт сколько-нибудь ощутимых преимуществ, отличающихся от обычной погрешности в таких тестах.
Какие бы не были системные требования игры или программы, может возникнуть необходимость проверить, а сколько же в реальности игра этой самой видеопамяти потребляет. Хотя бы для того, чтоб не ломиться сразу в интернет с вопросом, на что поменять видеокарту в ноутбуке потому,что у неё – “всего” 512мб на борту.
Путаницу вносит и тот факт, что на ноутбках дискретные карты умеют оперировать двумя типами памяти. Первый –это собственная память, собственный чип видеокарты, относительно небольшого (в сравнении с следующим типом) объёма. Второй- это т.н. “разделяемая память” (“shared memory”), память, которая выделяется видеокарте из оперативной по необходимости (повторюсь, я про это писал здесь.) Значит, если у видеокарты 512мб собственной памяти, то при требованиях игры в 1гб она вообще не пойдёт? Или всё-таки будет использована shared memory, а её много, и с запасом больше (пара гигабайт?)
Вот для этого и нужен мониторинг и средство, которое позволило бы определить, сколько ресурсов ваша любимая игра “съедает”.

Стандартные тестовые пакеты вроде Aida и подобных такой возможности не дают- ну или вернее, дают её очень ненаглядным и неудобным способом. Вот так это выглядит в Aida:
Отображение загрузки в процентах тут позволяет увидеть только то, что творится в данную секунду, не давая возможности мониторинга. Т.е. запустив игру и свернув её, вы увидите тут не реальные текущие данные, а результат сворачивания, когда большая часть ресурсов не используется.
Чтоб было хорошо- используем одну из лучших утилит всех времён и народов – Process Explorer (а здесь — страница на русском, но утилита всё равно на английском).
Описывать все её возможности смысла нет, это сделано многократно в интернете. Сейчас нас интересует возможность проверки нагрузки на видео.
После запуска программы в верхней части окна будут видны графики, показывающие различную текущую информацию о процессах в системе, 6-ой слева (или 2-ой справа) нас и интересует. Двойной щелчёк по нему открывает окно, относящееся к видеоподсистеме. Туда же можно попасть, выбрав пункт “System Information” из меню “View”.
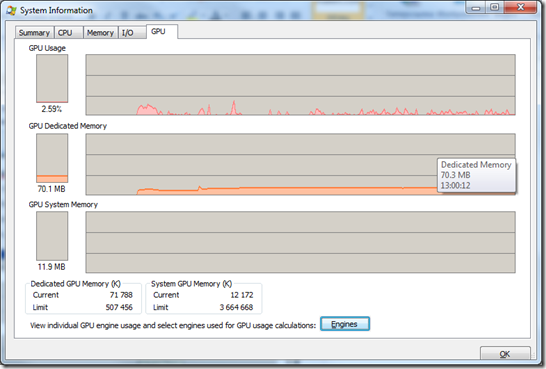
Здесь GPU Usage— это загрузка видеочипа, GPU Dedicated memory –использование собственной памяти видеокарты, и GPU System Memory— количество используемой оперативной. На скриншоте выше- ситуация, когда запущено несколько программ и включен Aero, на скриншоте ниже- тот же набор программ, но Aero выключен.

Происходит такое потому, что при включении Aero прорисовку интерфейса Windows берёт на себя видеокарта, а при отключении –как и в ХР, процессор. Соответственно изменяется и нагрузка на процессор. Кстати, с оперативной памятью системы – такая же ситуация, со включенным Aero система использует примерно на 50мб больше оперативки, чем без него.
Как посмотреть, насколько были задействованы ресурсы видеокарты во время игры? Запускаем Process Explorer, сворачиваем, запускаем игру. На графике отображается ~5 минут событий, обновление графика –каждую секунду.
Можно изменить время обновления графика, от полусекунды до 10-и секунд (меню “View”-“Update interval”, относится к данным во всей программе). Есть смысл ставить 10 секунд, получив усреднённые данные за больший период времени.
Для примера – в Fallout3 на максимальных настройках качества ресурсы видеочипа у меня (это видеокарта geforce 9600m gt ddr3 512mb в ноутбуке с 4gb опертивки и процессором core3duo P8600) использовались примерно наполовину, а загрузка видеопамяти составляла не более 400 мегабайт.
CUDA: Работа с памятью. Часть I.
В процессе работы с CUDA я практически не касался вопросов об использовании памяти видеокарты. Настало время убрать этот пробел.
Так как тема весьма объемная, то я решил разделить её на несколько частей. В этой части я расскажу об основных видах памяти, доступных на видеокарте и приведу пример, как влияет выбор типа памяти на производительность вычислений на GPU.
Видеокарта и типы памяти
При использовании GPU разработчику доступно несколько видов памяти: регистры, локальная, глобальная, разделяемая, константная и текстурная память. Каждая из этих типов памяти имеет определенное назначение, которое обуславливается её техническими параметрами (скорость работы, уровень доступа на чтение и запись). Иерархия типов памяти представлена на рис. 1.

Рис. 1. Типы памяти видеокарты
- Регистровая память (register) является самой быстрой из всех видов. Определить количество регистров доступных GPU можно с помощью уже хорошо известной функции cudaGetDeviceProperties. Рассчитать количество регистров, доступных одной нити GPU, так же не составляет труда, для этого необходимо разделить общее число регистров на произведение количества нитей в блоке и количества блоков в гриде. Все регистры GPU 32 разрядные. В CUDA нет явных способов использования регистровой памяти, всю работу по размещению данных в регистрах берет на себя компилятор.
- Локальная память (local memory) может быть использована компилятором при большом количестве локальных переменных в какой-либо функции. По скоростным характеристикам локальная память значительно медленнее, чем регистровая. В документации от nVidia рекомендуется использовать локальную память только в самых необходимых случаях. Явных средств, позволяющих блокировать использование локальной памяти, не предусмотрено, поэтому при падении производительности стоит тщательно проанализировать код и исключить лишние локальные переменные.
- Глобальная память (global memory) – самый медленный тип памяти, из доступных GPU. Глобальные переменные можно выделить с помощью спецификатора __global__, а так же динамически, с помощью функций из семейства cudMallocXXX. Глобальная память в основном служит для хранения больших объемов данных, поступивших на device с host’а, данное перемещение осуществляется с использованием функций cudaMemcpyXXX. В алгоритмах, требующих высокой производительности, количество операций с глобальной памятью необходимо свести к минимуму.
- Разделяемая память (shared memory) относиться к быстрому типу памяти. Разделяемую память рекомендуется использовать для минимизации обращение к глобальной памяти, а так же для хранения локальных переменных функций. Адресация разделяемой памяти между нитями потока одинакова в пределах одного блока, что может быть использовано для обмена данными между потоками в пределах одного блока. Для размещения данных в разделяемой памяти используется спецификатор __shared__.
- Константная память (constant memory) является достаточно быстрой из доступных GPU. Отличительной особенностью константной памяти является возможность записи данных с хоста, но при этом в пределах GPU возможно лишь чтение из этой памяти, что и обуславливает её название. Для размещения данных в константной памяти предусмотрен спецификатор __constant__. Если необходимо использовать массив в константной памяти, то его размер необходимо указать заранее, так как динамическое выделение в отличие от глобальной памяти в константной не поддерживается. Для записи с хоста в константную память используется функция cudaMemcpyToSymbol, и для копирования с device’а на хост cudaMemcpyFromSymbol, как видно этот подход несколько отличается от подхода при работе с глобальной памятью.
- Текстурная память (texture memory), как и следует из названия, предназначена главным образом для работы с текстурами. Текстурная память имеет специфические особенности в адресации, чтении и записи данных. Более подробно о текстурной памяти я расскажу при рассмотрении вопросов обработки изображений на GPU.
Пример использования разделяемой памяти
Чуть выше я вкратце рассказал о различных типах памяти, которые доступны при программировании GPU. Теперь я хочу привести пример использования разделяемой памяти при операции транспонирования матрицы.
Перед тем, как приступить к написанию основного кода, приведу небольшой способ отладки. Как известно, функции из CUDA runtime API могут возвращать различные коды ошибок, но в предыдущий раз я ни как это не учитывал. Чтобы упростить себе жизнь можно использовать следующий макрос для отлова ошибок:
#define CUDA_CHECK_ERROR(err) \
if (err != cudaSuccess) < \
printf( «Cuda error: %s\n» , cudaGetErrorString(err)); \
printf( «Error in file: %s, line: %i\n» , __FILE__, __LINE__); \
> \
#endif
* This source code was highlighted with Source Code Highlighter .
Как видно, в случае, если определена переменная среды CUDA_DEBUG, происходит проверка кода ошибки и выводиться информация о файле и строке, где она произошла. Эту переменную можно включить при компиляции под отладку и отключить при компиляции под релиз.
Приступаем к основной задаче.
Для того чтобы увидеть, как влияет использование разделяемой памяти на скорость вычислений, так же следует написать функцию, которая будет использовать только глобальную память.
Пишем эту функцию:
// Функция транспонирования матрицы без использования разделяемой памяти
//
// inputMatrix — указатель на исходную матрицу
// outputMatrix — указатель на матрицу результат
// width — ширина исходной матрицы (она же высота матрицы-результата)
// height — высота исходной матрицы (она же ширина матрицы-результата)
//
__global__ void transposeMatrixSlow( float * inputMatrix, float * outputMatrix, int width, int height)
int xIndex = blockDim.x * blockIdx.x + threadIdx.x;
int yIndex = blockDim.y * blockIdx.y + threadIdx.y;
if ((xIndex < width) && (yIndex < height))
//Линейный индекс элемента строки исходной матрицы
int inputIdx = xIndex + width * yIndex;
//Линейный индекс элемента столбца матрицы-результата
int outputIdx = yIndex + height * xIndex;
outputMatrix[outputIdx] = inputMatrix[inputIdx];
>
>
* This source code was highlighted with Source Code Highlighter .
Данная функция просто копирует строки исходной матрицы в столбцы матрицы-результата. Единственный сложный момент – это определение индексов элементов матриц, здесь необходимо помнить, что при вызове ядра может быть использованы различные размерности блоков и грида, для этого и используются встроенные переменные blockDim, blockIdx.
Пишем функцию транспонирования, которая использует разделяемую память:
// Функция транспонирования матрицы c использования разделяемой памяти
//
// inputMatrix — указатель на исходную матрицу
// outputMatrix — указатель на матрицу результат
// width — ширина исходной матрицы (она же высота матрицы-результата)
// height — высота исходной матрицы (она же ширина матрицы-результата)
//
__global__ void transposeMatrixFast( float * inputMatrix, float * outputMatrix, int width, int height)
__shared__ float temp[BLOCK_DIM][BLOCK_DIM];
int xIndex = blockIdx.x * blockDim.x + threadIdx.x;
int yIndex = blockIdx.y * blockDim.y + threadIdx.y;
if ((xIndex < width) && (yIndex < height))
// Линейный индекс элемента строки исходной матрицы
int idx = yIndex * width + xIndex;
//Копируем элементы исходной матрицы
temp[threadIdx.y][threadIdx.x] = inputMatrix[idx];
>
//Синхронизируем все нити в блоке
__syncthreads();
xIndex = blockIdx.y * blockDim.y + threadIdx.x;
yIndex = blockIdx.x * blockDim.x + threadIdx.y;
if ((xIndex < height) && (yIndex < width))
// Линейный индекс элемента строки исходной матрицы
int idx = yIndex * height + xIndex;
//Копируем элементы исходной матрицы
outputMatrix[idx] = temp[threadIdx.x][threadIdx.y];
>
>
* This source code was highlighted with Source Code Highlighter .
В этой функции я использую разделяемую память в виде двумерного массива.
Как уже было сказано, адресация разделяемой памяти в пределах одного блока одинакова для всех потоков, поэтому, чтобы избежать коллизий при доступе и записи, каждому элементу в массиве соответствует одна нить в блоке.
После копирования элементов исходной матрицы в буфер temp, вызывается функция __syncthreads. Эта функция синхронизирует потоки в пределах блока. Её отличие от других способов синхронизации заключаеться в том, что она выполняеться только на GPU.
В конце происходит копирование сохраненных элементов исходной матрицы в матрицу-результат, в соответствии с правилом транспонирования.
Может показаться, что эта функция должна выполняться медленне, чем её версия без разделяемой памяти, где нет никаких посредников. Но на самом деле копирование из глобальной памяти в глобальную работает значительно медленее, чем связка глобальная память – разделяемая память – глобальная память.
Хочу заметить, что проверять границы массивов матриц стоит вручную, в GPU нет аппаратных средств для слежения за границами массивов.
Ну и напоследок напишем функцию транспонирования, которая исполняется только на CPU:
// Функция транспонирования матрицы, выполняемая на CPU
__host__ void transposeMatrixCPU( float * inputMatrix, float * outputMatrix, int width, int height)
for ( int y = 0; y < height; y++)
for ( int x = 0; x < width; x++)
outputMatrix[x * height + y] = inputMatrix[y * width + x];
>
>
>* This source code was highlighted with Source Code Highlighter .
Теперь необходимо сгенерировать данные для расчетов, скопировать их с хоста на девайс, в случае использования GPU, произвести замеры производительности и очистить ресурсы.
Так как эти этапы примерно такие же, что я описывал в предыдущий раз, то привожу этого фрагмента сразу:
#define GPU_SLOW 1
#define GPU_FAST 2
#define CPU 3
#define ITERATIONS 20 //Количество нагрузочных циклов
__host__ int main()
<
int width = 2048; //Ширина матрицы
int height = 1536; //Высота матрицы
int matrixSize = width * height;
int byteSize = matrixSize * sizeof ( float );
//Выделяем память под матрицы на хосте
float * inputMatrix = new float [matrixSize];
float * outputMatrix = new float [matrixSize];
//Заполняем исходную матрицу данными
for ( int i = 0; i < matrixSize; i++)
inputMatrix[i] = i;
>
//Выбираем способ расчета транспонированной матрицы
printf( «Select compute mode: 1 — Slow GPU, 2 — Fast GPU, 3 — CPU\n» );
int mode;
scanf( «%i» , &mode);
//Записываем исходную матрицу в файл
printMatrixToFile( «before.txt» , inputMatrix, width, height);
if (mode == CPU) //Если используеться только CPU
<
int start = GetTickCount();
for ( int i = 0; i < ITERATIONS; i++)
transposeMatrixCPU(inputMatrix, outputMatrix, width, height);
>
//Выводим время выполнения функции на CPU (в миллиекундах)
printf ( «CPU compute time: %i\n» , GetTickCount() — start);
>
else //В случае расчета на GPU
float * devInputMatrix;
float * devOutputMatrix;
//Выделяем глобальную память для храния данных на девайсе
CUDA_CHECK_ERROR(cudaMalloc(( void **)&devInputMatrix, byteSize));
CUDA_CHECK_ERROR(cudaMalloc(( void **)&devOutputMatrix, byteSize));
//Копируем исходную матрицу с хоста на девайс
CUDA_CHECK_ERROR(cudaMemcpy(devInputMatrix, inputMatrix, byteSize, cudaMemcpyHostToDevice));
//Конфигурация запуска ядра
dim3 gridSize = dim3(width / BLOCK_DIM, height / BLOCK_DIM, 1);
dim3 blockSize = dim3(BLOCK_DIM, BLOCK_DIM, 1);
cudaEvent_t start;
cudaEvent_t stop;
//Создаем event’ы для синхронизации и замера времени работы GPU
CUDA_CHECK_ERROR(cudaEventCreate(&start));
CUDA_CHECK_ERROR(cudaEventCreate(&stop));
//Отмечаем старт расчетов на GPU
cudaEventRecord(start, 0);
if (mode == GPU_SLOW) //Используеться функция без разделяемой памяти
for ( int i = 0; i < ITERATIONS; i++)
transposeMatrixSlow>>(devInputMatrix, devOutputMatrix, width, height);
>
>
else if (mode == GPU_FAST) //Используеться функция с разделяемой памятью
for ( int i = 0; i < ITERATIONS; i++)
transposeMatrixFast>>(devInputMatrix, devOutputMatrix, width, height);
>
>
//Отмечаем окончание расчета
cudaEventRecord(stop, 0);
float time = 0;
//Синхронизируемя с моментом окончания расчетов
cudaEventSynchronize(stop);
//Рассчитываем время работы GPU
cudaEventElapsedTime(&time, start, stop);
//Выводим время расчета в консоль
printf( «GPU compute time: %.0f\n» , time);
//Копируем результат с девайса на хост
CUDA_CHECK_ERROR(cudaMemcpy(outputMatrix, devOutputMatrix, byteSize, cudaMemcpyDeviceToHost));
//
//Чистим ресурсы на видеокарте
//
//Записываем матрицу-результат в файл
printMatrixToFile( «after.txt» , outputMatrix, height, width);
//Чистим память на хосте
delete[] inputMatrix;
delete[] outputMatrix;
* This source code was highlighted with Source Code Highlighter .
В случае если расчеты выполняются только на CPU, то для замера времени расчетов используется функция GetTickCount(), которая подключается из windows.h. Для замера времени расчетов на GPU используеться функция cudaEventElapsedTime, прототип которой имеет следующий вид:
- time – указатель на float, для записи времени между event’ами start и end (в миллисекундах),
- start – хендл первого event’а,
- end – хендл второго event’а.
- cudaSuccess – в случае успеха
- cudaErrorInvalidValue – неверное значение
- cudaErrorInitializationError – ошибка инициализации
- cudaErrorPriorLaunchFailure – ошибка при предыдущем асинхронном запуске функции
- cudaErrorInvalidResourceHandle – неверный хендл event’а
Так же я записываю исходную матрицу и результат в файлы через функцию printMatrixToFile. Чтобы удостовериться, что результаты верны. Код этой функции следующий:
__host__ void printMatrixToFile( char * fileName, float * matrix, int width, int height)
FILE* file = fopen(fileName, «wt» );
for ( int y = 0; y < height; y++)
for ( int x = 0; x < width; x++)
fprintf(file, «%.0f\t» , matrix[y * width + x]);
>
fprintf(file, «\n» );
>
fclose(file);
>
* This source code was highlighted with Source Code Highlighter .
Если матрицы очень большие, то вывод данных в файлы может сильно замедлить выполнение программы.
Заключение
В процессе тестирования я использовал матрицы размерностью 2048 * 1536= 3145728 элементов и 20 итераций в нагрузочных циклах. После результатов замеров у меня получились следующие результаты (рис. 2).

Рис. 2. Время расчетов. (меньше –лучше).
Как видно, GPU версия с разделяемой памятью выполняется почти в 20 раз быстрее, чем версия на CPU. Так же стоит отметить, что при использовании разделяемой памяти расчет выполняется примерно в 4 раза быстрее, чем без неё.
В своем примере я не учитываю время копирования данных с хоста на девайс и обратно, но в реальных приложениях их так же необходимо брать в расчет. Количество перемещений данных между CPU и GPU по-возможности необходимо свести к минимуму.
P.S. Надеюсь, вам понравился прирост производительности, который можно получить с помощью GPU.
Memory clock – что это такое в видеокарте и стоит ли им пользоваться

Всем привет! Сегодня я расскажу, что такое Memory Clock в видеокарте, как влияет этот параметр на производительность, для чего его увеличивать и как сделать это правильно.
Memory clock — характеристика, которая отображает частоту видеопамяти в графической карте. Она не отображается в БИОСе, но ее можно посмотреть с помощью диагностических утилит — например, GPU-Z или Everest.
Второй важный параметр, который следует учитывать, это GPU Speed или GPU Clock, частота графического ядра. Обе частоты традиционно измеряются в Mhz.
Частота ядра — характеристика, которая определяет, насколько быстро графический процессор будет обрабатывать данные. Частота памяти — насколько быстро работает видеопамять, которая хранит всю промежуточную информацию, а также большинство объектов — например, в играх или программах для 3D моделирования.
Зачем их увеличивать? Естественно, для того чтобы поднять характеристики графической платы, сделав ее более производительной. Такая опция не всегда доступна: есть модели, у которых возможность разгона залочена производителем еще на заводе.
Те же видеоадаптеры, которые поддерживают такую возможность, разгоняются с помощью специальных утилит.
Интерфейс у них почти не отличается: в MSI Afterburner, ASUS GPU Tweak, Gigabute OC Guru или Riva Tuner для Memory Clock или GPU Clock есть отдельные ползунки и индикаторы с цифровым отображением текущего значения этих параметров.
Разгон видеокарты — процедура гораздо проще, чем может показаться неподготовленному юзеру. Благодаря грамотной реализации «защиты от дурака» очень сложно сломать видеокарту, так как при возникновении критических ошибок компьютер попросту отключится, страхуя дорогую аппаратуру.
Делается это так: перетаскиваете оба ползунка вправо, поднимая каждое из значений на 10-20 пунктов. Обязательно должна быть установлена галочка «Автоматически определять скорость вентилятора», иначе от недостатка охлаждения видеокарта может перегреться.
Так нужно повторить несколько раз, пока на экране не начнут появляться артефакты — абстрактные фигуры или вертикальные полосы отличного от основного изображения цвета. Как только вы их увидите, снизьте частоту ядра и памяти на 10-15 пунктов, чтобы артефакты пропали. Готовый пресет можно применить и сохранить.
В таком режиме видеокарта будет работать «на износ» и потреблять больше энергии, чем обычно.
Неприятно, но часто это единственный способ запустить новую игру, если ваш графический ускоритель ее не тянет. После чего можете проверить как увеличилась производительность, но это уже в отдельной статье.
Понравилась статья? Поделитесь ею в социальных сетях — так вы поможете другим пользователям получить качественную информацию. До скорой встречи!
С уважением, автор блога Андрей Андреев.
Выделение памяти на GPU.
Вот что я заметил — моя аппликация на старте хапает 2 гига памяти (это нормально, столько текстуры и занимают), обший обьем памяти (Dedicated Memory) получается 3.5 гига и программа успешно стартует на картах с 4 гигами. Но при этом в Shared GPU Memory (т.е. в зеркало на стороне CPU) уходит 1.5 гига. Которых там изначально не было (т.е. был 0). Вроде логично, туда уходит среда из которой я свою программу запустил. Но когда я попробовал то же самое с программами сделанными на стандартных движках (Unity и Unreal), то там в shared memory ничего не попадает, программа хапает 3.7 гига на 4х гигабайтной карте и в разделяемом сегменте ничего нет. Запускал из той же среды. Значит я что-то делаю неправильно, но что?
Нашел хорошую статью, хотя не совсем на эту тему — http://3dgep.blogspot.com/2016/02/a-journey-through-directx-12-dynamic.html — она внесла некоторую ясность как мне можно распределять память, но не как быть с разделяемой . Т.е. я не пойму почему у них в Shared Memory ничего не попадает и следовательно не требуется ничего качать по медленной шине. У меня это вызызывает дерганье картинки.
#1
6:48, 22 мар 2020
san
> Но когда я попробовал то же самое с программами сделанными на стандартных
> движках (Unity и Unreal)
с каким рендером ?
#2
6:54, 22 мар 2020
innuendo
> с каким рендером ?
. Сам понял что спросил?
#3
6:57, 22 мар 2020
san
> . Сам понял что спросил?
там есть dx11 dx12
#4
7:02, 22 мар 2020
Откуда я знаю на чем написана аппликация? Но какая разница — если это можно сделать на DX11 то можно сделать и на DX12. Обратное не всегда верно. Я работаю на DX12.
#5
7:33, 22 мар 2020
san
> Откуда я знаю на чем написана аппликация? Но какая разница — если это можно
> сделать на DX11 то можно сделать и на DX12.
там по дефолту скорее всего было DX11
> Но при этом в Shared GPU Memory (т.е. в зеркало на стороне CPU) уходит 1.5
> гига.
ты это как меряешь?
#6
8:01, 22 мар 2020
Во первых есть программа Task Manager который показывает Dedicated Memory и Shared Memory, во вторых есть функция QueryVideoMemoryInfo который показывает сколько я занял. Ну и для гурманов есть D3DKMTQueryStatistics, ежели первым двум нет доверия.
Меня не методика рассчета интересует, а как движки резервируют видеопамять.
#7
8:12, 22 мар 2020
san
> а как движки резервируют видеопамять.
посредством вызовов апи
#8
2:29, 23 мар 2020
san
> а как движки резервируют видеопамять.
ну можно на GPU себе текстур насоздавать призапас.
#9
4:14, 23 мар 2020
gamedevfor
>ну можно на GPU себе текстур насоздавать призапас.
Так проблема как раз в том, что видео памяти для всех текстур не хватает. Точнее есть два режима, каждый со своими текстурами и по отдельности у каждого они в память влазят. Но не оба в месте. При переключении режимов драйвер секунд 20 разбирается какие текстуры выгрузить, какие загрузить. Все это время картинка подергивается.
По идее надо сделать две кучи, каждая в суммарный размер текстур для каждого режима. Засадить текстуры в эти кучи. И менять их одним чохом. Для этого текстуры нужно будет создавать не Committed (как у меня сейчас), а Reserved. Но дело осложняется тем, что некоторая часть текстур присутствует в обоих режимах. Но это еще решаемо. Хуже что нет нормальных (простых) примеров показывающих как такой режим реализовать.
Ну и меня смущает что аппликации на фирмовых движках не залазят в разделяемую память, а у меня там оказывается до 3.5 гиг. Очень бы не хотелось переделать кучу кода, а потом окажется что все зря.
#10
6:12, 23 мар 2020
san
когда выделяешь память для текстур, ты указываешь, где она лежит: либо device only, тогда она будет находиться только в видюхе, либо со staging buffer’ом, тогда она будет находиться на видюхе и копия будет сидеть в оперативе. раньше это контролировалось через memory pool’ы (default, managed, etc). теперь в вулкане это контролируется через memory property flags, в dx12 должно быть что-то такое же.
innuendo
> > а как движки резервируют видеопамять.
> посредством вызовов апи
чувак, это приз за самый бесполезный ответ месяца.
#11
6:26, 23 мар 2020
Suslik
> > > а как движки резервируют видеопамять.
> > посредством вызовов апи
> чувак, это приз за самый бесполезный ответ месяца.
какой вопрос такой ответ