Что такое нормализация баз данных?
Порядок в работе с данными важен в любой сфере деятельности. В данной статье мы рассмотрим нормализацию базы данных и ее виды. Также приведем примеры для полноты понимания отношений между разными таблицами в нормализованной базе данных.
Нормализация БД представляет собой процесс организации информации определенным образом и по установленным рекомендациям проектирования. Все таблицы и отношения (связи) между ними должны создаваться согласно правилам. Таким образом, будет обеспечиваться необходимый уровень сохранности и безопасности данных, а сама база может своевременно дополняться и корректироваться. Оператор сможет быстро устранять из нее все несогласованные избыточности или зависимости.
Плюсы нормализации баз данных
Нормализацию нельзя назвать обязательным мероприятием, но у нее есть целый ряд положительных черт.
- Нормализация упрощает процессы выборки. В данном случае речь идет об упрощении составления запросов. Пользователь легко может получить информацию по простейшему запросу.
- Обеспечение целостности данных. В процессе нормализации сокращается вероятность искажения и потери важной информации.
- Улучшенная масштабируемость. При соблюдении всех правил нормализации постепенно создаются благоприятные условия для расширения такой базы.
- Отсутствие избыточности. Большой объем информации задействует огромную часть свободного места на жестком диске и усложняет процесс обслуживания информации. В некоторых случаях возникают множественные повторяющиеся записи и одинаковая информация сразу в нескольких местах. Из-за этого пользователи вынуждены вносить изменения сразу во все источники информации. Это очень трудоемкое занятие нередко приводит к ошибкам. Намного проще сделать таким образом, чтобы данные по одному подразделению или участку хранились в соответствующей таблице и больше нигде. Избыточность предполагает постоянное дублирование данных, усложняет работу с базой данных и раздувает ее размер.
- Отсутствие несогласованных зависимостей. Всевозможные нестыковки и несогласованные зависимости также усложняют доступ к информации, поскольку путь к данным может быть нелогичным и неверным. Например, в таблице «Sities» более логично искать адреса и количество жителей, а не адреса и имена жителей. Для этой информации надо создавать другую таблицу, к примеру «Sitizens».
1С:MDM Управление нормативно-справочной информацией
Консолидация и управление данными из разных информационных систем компании.
- Быстрый поиск информации;
- Интеграция данных между различными системами;
- Повышение точности и качества информации;
- Удобство управления всеми данными одной системе.
Как выполнить нормализацию базы данных?
Для того, чтобы привести конкретную базу данных к нормальному виду, необходимо сделать следующее:
- Объединить все данные в тематических группах.
- Установить логические связи между группами для обеспечения правильности связей, чтобы связанные поля имели один тип.
Если таблица не нормализована, то в ней может храниться информация сразу о нескольких сущностях, а также множество повторяющихся столбцов и одинаковых значений. Если таблица нормализована, то в ней будет сохранена информация только об одной сущности.
При нормализации необходимо использовать неформальный подход к структуре собранных данных. Но важно учитывать несколько строгих правил нормализации. Каждое такое правило носит название «нормальная форма» (НФ). Все формы кроме первой предполагают, что к имеющимся данным муже была применена предыдущая нормальная форма — 1НФ. А при выполнении трех правил – она должна выражаться в третьей нормальной форме – 3НФ.
Всего существует семь форм (уровней) нормализации. На практике будет достаточно нормализовать базу данных до третьей нормальной формы. То есть, база данных будет считаться нормализованной, когда к ней будет применена 3НФ и выше.
Полное обеспечение соответствия для всех спецификаций – это не всегда выполнимая задача, поскольку для нормализации нужно будет создавать другие таблицы. Иногда это вовсе неприемлемо. Но если правила придется нарушать, то нужно быть готовым к таким проблемам, как несогласованные избыточности и зависимости. Они будут учитываться в работе системы и никак не нарушат ее работоспособность.
Примеры правил нормализации базы данных
Первая нормальная форма – 1НФ
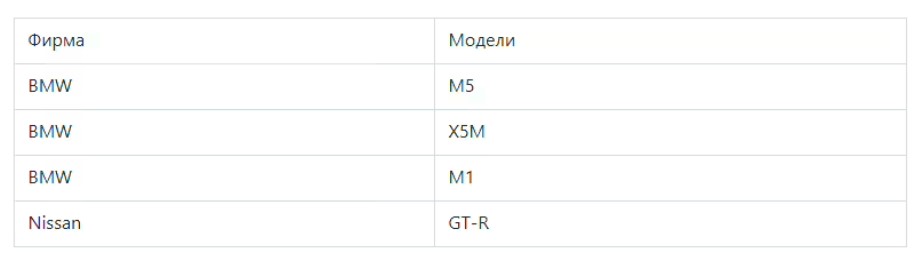
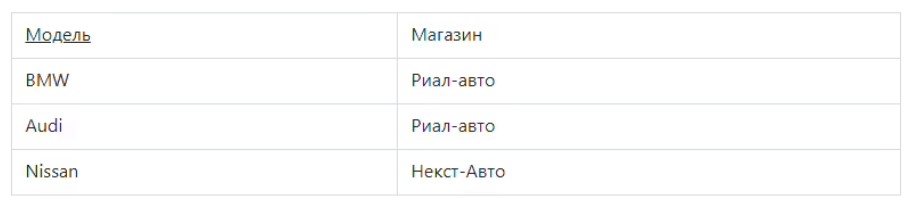
Согласно установленным правилам, атрибуты в таблице должны иметь простой и понятный вид, а все сохраненные данные в строках и столбцах должны содержать скалярные значения. Здесь не допускается наличие повторяющихся строк. В качестве примера можно рассмотреть таблицу с автомобилями

Следует обратить внимание на нарушение нормализации в моделях BMW. В таблице в одной ячейке находится перечень сразу из трех элементов – М5, Х5М и М1. Это свидетельствует об отсутствии атомарности. После проведенного преобразования 1НФ таблица будет иметь другой вид.
Вторая нормальная форма 2НФ
Отношения в таблице будут соответствовать 2НФ при условии, что база данных находится в 1 НФ и каждый ее столбец зависит от первичного ключа. Рассмотрим еще одну таблицу.
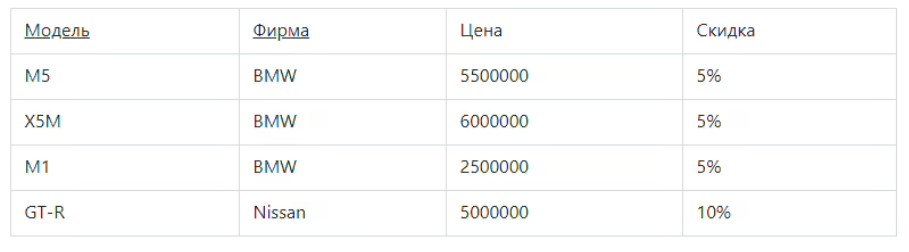
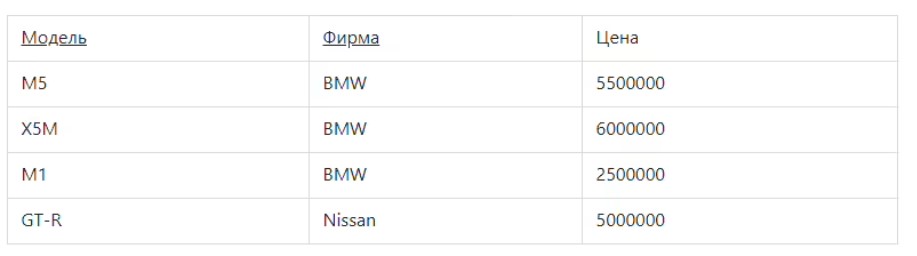
Представленная выше таблица приведена в форму 1НФ, но не в форму 2НФ. Здесь стоимость автомобилей зависит от производителя и модели. Также размер скидки зависит от производителя, поэтому прямая функциональная зависимость от самого первого ключа будет неполной. Это можно исправить, если выполнить декомпозицию сразу на 2 отношения, где не ключевые атрибуты будут зависеть только от первого ключа.

Третья нормальная форма 3НФ
В данном случае таблица должна находиться в форме 2НФ, а каждый лишний столбец, не являющийся ключом, должен зависеть от первичного ключа.
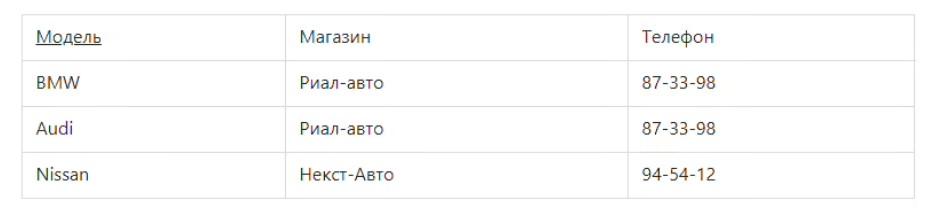
В представленной таблице в отношении атрибут первым ключом является «Модель». Поскольку свои телефоны у автомобилей отсутствуют, то необходимо указывать номера продаваемых их магазинов. В результате создается связь функционального типа или зависимость следующего вида:

Такая модель транзитивна, поэтому ее отношение не отражается в 3НФ. Если разделить исходное отношение, то можно получить два отношения, которые будут отражены в форме 3НФ.

Хотите получать подобные статьи по четвергам?
Быть в курсе изменений в законодательстве?
Подпишитесь на рассылку
Что такое нормализация баз данных?
Статья расскажет о том, что такое нормализация баз данных, для чего она нужна, и какие виды нормализации существуют. Для наилучшего понимания отношений между таблицами в нормализованной базе данных будут приведены практические примеры.
При создании базы нужно учитывать некоторые правила. Исходя из вышесказанного, можно привести следующую формулировку: нормализация БД — это процесс организации данных определенным образом и рекомендации по проектированию. То есть таблицы и связи между ними (отношения) создаются в соответствии с правилами. В результате обеспечивается нужный уровень безопасности данных, а сама база становится более гибкой. Также устраняются несогласованные зависимости и избыточность.
Плюсы
Нормализация не является обязательной, но приносит следующие преимущества: — упрощается процесс выборки. Речь идет об упрощении работы по составлению запросов, то есть пользователь сможет получать нужную информацию относительно простыми запросами; — обеспечивается целостность данных. Можно говорить о минимизации искажения информации и снижении вероятности потери данных; — улучшается масштабируемость. При соблюдении правил нормализации формируются благоприятные предпосылки к росту БД; — отсутствует избыточность (data redundancy). Избыточность — известная проблема непродуктивного использования свободного места на жестком диске, затрудняющая обслуживание БД. В отдельных случаях эту проблему усугубляет и то, что в случае необходимости изменения записей однотипных данных, хранимых в нескольких местах (таблицах), пользователю придется вносить требуемые изменения везде, что весьма трудоемкое занятие. Гораздо проще сделать так, чтобы, к примеру, данные о городах хранились только в таблице Cities и нигде больше. Если подытожить вышесказанное, избыточность предполагает дублирование данных, а это не только усложняет работу с БД, но и увеличивает ее размер; — отсутствие несогласованных зависимостей. Несогласованные зависимости затрудняют доступ к данным, ведь путь к такой информации может быть неправилен и нелогичен. В той же таблице Cities логично искать города, количество жителей и т. п., но не адреса и имена жителей — для этой информации уже нужна другая таблица — Citizens.
Как выполнить нормализацию?
Чтобы привести БД к нормальной форме, необходимо: 1. Объединить имеющиеся данные в группы. 2. Выяснить логические связи между группами. Чтобы обеспечить правильность связей, связываемые поля должны иметь один тип.
Если таблица не нормализована, она может хранить информацию о нескольких сущностях и включать в себя повторяющиеся столбцы, а они, в свою очередь, могут хранить дублируемые значения. Если же нормализована, то каждая таблица хранит информацию лишь об одной сущности.
При нормализации предполагается использование нормальных форм по отношению к структуре имеющихся данных. Есть несколько правил нормализации. Каждое из них носит название «нормальная форма» (НФ). Каждая такая форма, кроме первой, предполагает, что к данным уже применили предыдущую нормальную форму. При выполнении первого правила БД представлено в первой нормальной форме (1НФ), при выполнении трех правил — в третьей нормальной форме (3НФ).
Таких форм (уровней) — семь, однако на практике для большей части приложений вполне достаточно нормализовать БД до третьей нормальной формы (строго говоря, БД и будет считаться нормализованной, когда к ней применяется 3НФ и выше).
Да, обеспечить полное соответствие правилам и спецификациям — задача не всегда выполнимая, ведь для нормализации придется создавать дополнительные таблицы, а это не всегда приемлемо или не находит отклика у клиентов. Но если правила приходится нарушать, надо понимать, что все, связанные с этим проблемы, включая несогласованные зависимости и избыточность, будут учтены, и что это допустимо для приложения, не нарушит его работоспособность.
Правила нормализации на примерах
Первая нормальная форма (1НФ)
Согласно правилам, все атрибуты в такой таблице должны быть простыми, все сохраняемые данные на пересечении столбцов и строк — содержать лишь скалярные значения. Также не должно быть повторяющихся строк.
Для примера возьмем таблицу с автомобилями:

Обратите внимание на нарушение нормализации в моделях BMW — в одной ячейке находится перечень из трех элементов: M5, X5M, M1, то есть можно говорить об отсутствии атомарности. После преобразования в 1НФ таблица меняет вид:
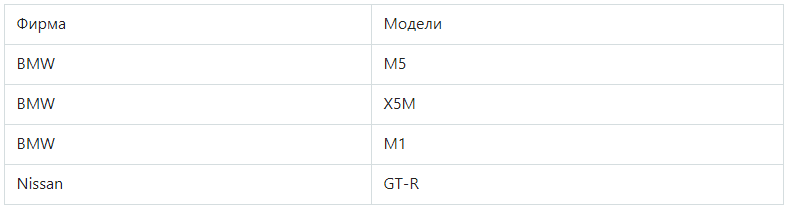
Вторая нормальная форма (2НФ)
Отношения будут соответствовать 2НФ, если сама БД находится в 1НФ, а каждый столбец, который не является ключом, зависит от первичного ключа.
Рассмотрим очередную таблицу:
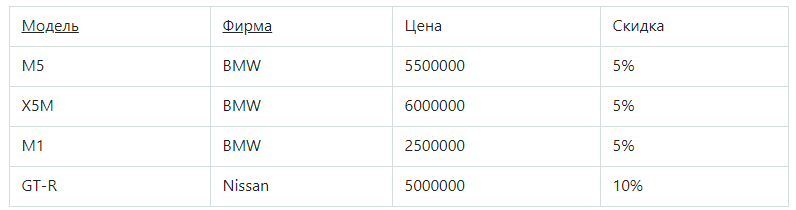
Она в 1НФ, но не во 2НФ. Стоимость авто зависит от модели и производителя. Размер скидки зависит от производителя, поэтому функциональная зависимость от первичного ключа является неполной. Исправить это можно, выполнив декомпозицию на 2 отношения, где неключевые атрибуты будут зависеть от первичного ключа.
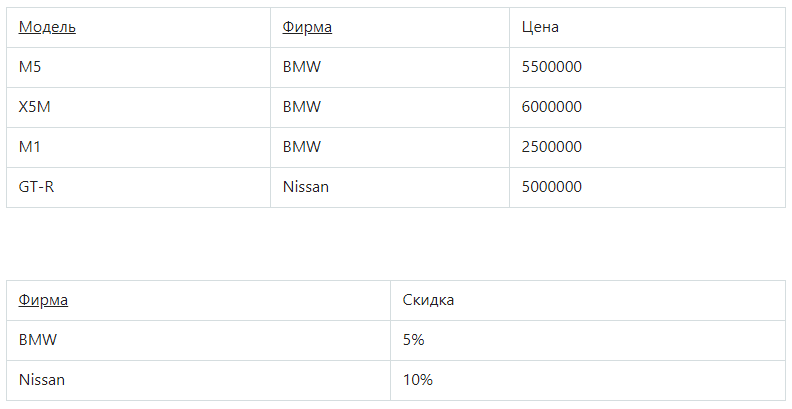
Третья нормальная форма (3НФ)
Таблица должна находиться во 2НФ, плюс любой столбец, который не является ключом, должен зависеть лишь от первичного ключа.
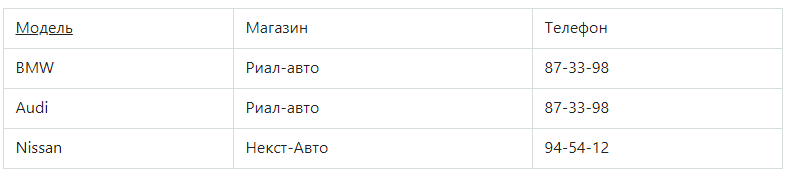
В таблице в отношении атрибут первичным ключом является «Модель». Так как собственные телефоны у автомашин отсутствуют, телефон зависит только от магазина.
В результате можно говорить о наличии в связях следующих функциональных зависимостей:
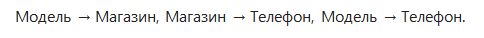
Зависимость «Модель → Телефон» — транзитивна, поэтому отношение не находится в 3НФ.
Разделив исходное отношение, можно получить 2 отношения, и они уже будут находиться в 3НФ:
Остальные виды соотношений и правил, можно посмотреть по ссылкам ниже: — https://ru.wikipedia.org/wiki/Нормальная_форма; — https://habr.com/ru/post/254773/.
P. S. Очень надеемся, что теперь у вас сложилось представление о том, что такое нормализация базы данных. Если же вы хотите освоить работу с БД на профессиональном уровне, добро пожаловать на курсы OTUS!
Что такое нормализация данных?
В эпоху, которую мы переживаем, данные — это новое золото. Настоящим сокровищем, которым обладают компании, теперь являются данные. Количество данных, которыми располагает компания или организация, и то, как она может их использовать, имеет огромное значение для ее успеха. Это связано с тем, что сегодня решения, маркетинг, развитие, рост, управление клиентами и продажи основываются на данных. Большой проблемой для компаний сегодня является работа с огромным количеством данных, поэтому мы все чаще сталкиваемся с нормализацией данных. Но что такое нормализация данных? Зачем она нам нужна? И каковы ее преимущества? В этой статье мы ответим на все эти и другие вопросы.
Что такое нормализация данных?
Нормализация данных, или нормализация базы данных, — это процесс организации и структурирования базы данных с целью сокращения избыточности данных. Проще говоря, процесс нормализации базы данных — это способ убедиться в том, что каждое поле и запись организованы логически таким образом, чтобы не только избежать избыточности, но и сделать использование любой реляционной базы данных более эффективным: избежать ошибок ввода данных, случайного удаления, а также облегчить процесс обновления данных. Понять нормализацию данных очень просто, но этот процесс сложнее, чем кажется. Нормализация данных подчиняется определенным правилам, которые диктуют, как должна быть организована база данных.
Преимущества нормализации данных
Используете ли вы реляционные базы данных, CRM платформы, анализ данных или каким-либо образом связаны с разработкой приложений, вам понадобится нормализация данных. Вы можете думать, что нормализация базы данных может стать дополнительной работой для вас и вашей команды, но как только вы узнаете о ее преимуществах, вы измените свое мнение. Итак, каковы преимущества нормализации данных?
Уменьшение размера базы данных
Когда у вас есть данные, которые повторяются в вашей базе данных, вам нужно много места для хранения этих данных, но это совершенно напрасная трата. Нормализация данных приводит к уменьшению пространства для хранения базы данных, а это, как вы знаете, означает экономию ресурсов и денег.
Упрощение запросов
Искать информацию в хорошо организованной базе данных всегда проще, чем в беспорядочной, независимо от того, делаете ли вы это вручную или с помощью автоматизированного цифрового инструмента.
Облегчение обслуживания
Нормализация базы данных предотвращает проблемы и облегчает обслуживание базы данных. Опять же, это позволяет избежать напрасной траты ресурсов и денег.
Улучшение производительности
Как вы, возможно, уже знаете, базы данных лежат в основе функционирования каждого приложения или программного обеспечения в целом. Нормализация базы данных ускоряет процесс извлечения данных, что, соответственно, повышает производительность вашего приложения.
Кому нужна нормализация данных?
Нормализация данных нужна всем, кто имеет дело с данными и базами данных в любых целях. Нет смысла иметь избыточную, плохо организованную базу данных. Однако есть некоторые области, где нормализация данных особенно важна:
- анализ данных: если вам нужно извлечь полезную информацию из нескольких баз данных, необходимо, чтобы они были нормализованы.
- разработка программного обеспечения: нормализация данных имеет огромное значение при оптимизации производительности любого приложения. Она становится чрезвычайно важной, когда разработчикам необходимо интегрировать данные из приложения «программное обеспечение как услуга » в процесс разработки.
- бизнес: каждой компании необходимо собирать данные, а затем использовать их для принятия решений, развития бизнеса, разработки маркетинговой стратегии и т.д.
- профессионалы: каждый, кто имеет независимую работу, нуждается в организации своих клиентов, их информации, каталога услуг/продуктов и т.д. Другими словами, им нужны базы данных и нормализация данных.
Как работает нормализация данных
До сих пор мы говорили о нормализации данных как о теоретической концепции. Однако, когда мы углубились в ее практические аспекты, мы обнаружили, что это процесс, состоящий из стандартов и определенных правил, которые необходимо знать, если вы хотите оптимизировать свои базы данных и использовать все преимущества, о которых мы говорили выше.
По своей сути, нормализация данных — это определение стандартов для всех данных, вводимых в базы данных. Например, если у нас есть база данных клиентов с их номерами телефонов и адресами, наши стандарты могут быть следующими:
- Все имена записаны в такой форме: Дурсли, Вернон.
- Все номера телефонов записываются в такой форме: 530-000-0000.
- Все адреса пишутся в такой форме: 4, Private Drive, San Francisco.
Попробуйте no-code платформу AppMaster
AppMaster поможет создать любое веб, мобильное или серверное приложение в 10 раз быстрее и 3 раза дешевле
Однако некоторые стандарты являются общими для всех, кто имеет дело с базами данных, где бы они ни находились и чем бы ни занимались. Существуют некоторые правила, сгруппированные в уровни, называемые нормальными формами. Они организованы таким образом, что каждая нормальная форма основывается на предыдущей; другими словами, вы можете применить вторую нормальную форму только в том случае, если вы уже применили первую.
Стандартизировано несколько нормальных форм, но самыми распространенными и наиболее важными для знания являются первые три — именно поэтому в этой статье мы рассматриваем их более подробно. Однако, помимо нормальных форм, существуют и другие общие правила, которых необходимо придерживаться. Например, таблицы в базе данных должны содержать первичный ключ. Значения первичного ключа отличают каждую строку и связывают каждую запись с уникальным идентификатором. Поэтому, прежде чем переходить к первой нормальной форме, убедитесь, что ваша база данных или таблица содержит поле первичного ключа.
Первая нормальная форма (1НФ)
Первая нормальная форма диктует, что каждое поле вашей базы данных должно хранить только одно значение и что в одной базе данных не должно быть двух полей, одинаково хранящих информацию. Давайте поясним это на примере. Это база данных, в которой хранится информация о курсах и профессорах, которые их преподают.
Эта база данных нарушает первую нормальную форму двумя способами:
- В одном поле два значения, так как профессор Митчелл преподает два курса;
- Имеются два поля, хранящие схожую информацию: Professor ID и Professor Name оба предоставляют информацию о личности профессора.
Чтобы нормализовать нашу базу данных, нам нужно разделить ее на две части:
- Первая будет содержать информацию, связанную с личностью профессоров, и будет включать два поля: ID профессора и Имя профессора.
- Вторая будет содержать два поля: одно для курсов и одно для ID профессора, соответствующего профессору, который преподает этот курс.
Итак, у нас есть две базы данных, где первая имеет связь «один ко многим» со второй. Две таблицы соединены внешним ключом, то есть полем ID профессора.
Вторая нормальная форма (2НФ)
Вторая нормальная форма направлена на уменьшение избыточности, гарантируя, что каждое поле хранит информацию, которая говорит нам что-то о первичном ключе. Другими словами:
- Каждая база данных должна иметь только один первичный ключ
- Все непервичные ключи должны полностью зависеть от первичного ключа.
Эти два принципа гарантируют, что каждая база данных хранит последовательную информацию об одном и том же аргументе, который содержится в первичном ключе. Опять же, давайте поможем нашему пониманию на примере.
У нас есть база данных Professor Birthday and Department, которая выглядит следующим образом:
| Профессор Имя | День рождения | Кафедра |
| Гарри Грей | Июль, 1 | Литература |
| Виктория Уайт | Сентябрь, 19 | Литература |
| Павел Саул | Март, 1 | Литература |
| Джеймс Смит | Июнь, 5 | Наука |
Приведенная выше база данных следует первой нормальной форме, потому что каждое поле содержит только один фрагмент информации, и все поля предоставляют разную информацию. Однако она не соответствует второй нормальной форме, потому что, в то время как поле «День рождения» полностью зависит от их имени, поле «Факультет», к которому они принадлежат, не зависит от их дня рождения.
Попробуйте no-code платформу AppMaster
AppMaster поможет создать любое веб, мобильное или серверное приложение в 10 раз быстрее и 3 раза дешевле
Чтобы нормализовать эту базу данных, нам снова нужно разделить ее на две части:
- База данных «День рождения профессора», которая включает два поля: имя профессора и день рождения
- База данных «Кафедра профессора», которая включает два поля: имя профессора и кафедра
Третья нормальная форма (3НФ)
База данных соответствует третьей нормальной форме, если в ней нет ни одной переходной зависимости. Что такое переходная зависимость? Переходная зависимость возникает, когда столбец B в вашей базе данных зависит от столбца A, который зависит от первичного ключа. Чтобы нормализовать базу данных в соответствии с третьей нормальной формой, необходимо удалить столбец B, который не зависит напрямую от первичного ключа, и хранить эту информацию во второй базе данных с собственным первичным ключом.
Приведем еще один пример. У нас есть база данных заказов:
| ID заказа | Дата заказа | Идентификатор клиента | Почтовый индекс клиента |
| D001 | 01/3/2022 | C001 | 97438 |
| D002 | 06/15/2022 | C002 | 08638 |
В этой базе данных не соблюдается третья нормальная форма, потому что у нас есть первичный ключ, ID заказа. Дата заказа и ID клиента полностью зависят от него, но Zip Code клиента зависит от ID клиента, который не является первичным ключом. Как мы уже говорили, для нормализации этой базы данных в соответствии с третьей нормальной формой нам нужно создать вторую базу данных Customer Zip Code Database, которая свяжет каждый ID клиента с его Zip Code.
Что такое SQL-ключи?
Нормализация данных становится, конечно же, очень важной, когда мы имеем дело с базой данных SQL. SQL — это стандартный язык для реляционных систем баз данных, используемый любым компьютером для хранения, манипулирования и извлечения данных из реляционной базы данных. SQL ключи — это атрибуты (это может быть один или несколько атрибутов), используемые для получения данных из базы данных или таблицы. Они также используются для создания связей между различными базами данных.
Существуют наиболее важные типы SQL-ключей:
- Суперключ: суперключ — это комбинация одного или нескольких столбцов в таблице, которая однозначно идентифицирует одну строку в таблице.
- Внешний ключ: он важен, когда у вас есть две связанные базы данных. В примере, который мы привели для второй нормальной формы, у нас было две нормализованные базы данных, которые «делили» поле Professor ID. Идентификатор профессора — это внешний ключ, который служит для того, чтобы сообщить базам данных, что они связаны.
- Первичный ключ: это разновидность ключа SQL . Как мы уже говорили, согласно первой нормальной форме, в каждой таблице не может быть более одного первичного ключа, и все поля должны напрямую и полностью зависеть от него.
Заключение
В этой статье мы обсудили важность нормализации данных. Как мы уже упоминали, она может показаться процессом, замедляющим рабочий процесс и усложняющим его, но преимущества ее таковы, что она стоит дополнительной работы.
Нормализация данных — это также пример того, как управление базами данных может стать чрезвычайно сложным. По этой причине важно полагаться на инструменты, которые могут максимально упростить работу. В этой связи стоит порекомендовать no-code инструмент AppMaster s, который позволяет создавать приложения и управлять их базами данных без написания кода. Возможно, вам все же придется выучить правила нормализации данных, но применять их станет намного проще!
Цели и средства нормализации
Нормализация помогает привести базу данных к виду обеспечивающему минимальную логическую избыточность. Эта цель достигается благодаря тому, что в полностью нормализованном проекте предикаты переменных отношения имеют более простой вид.
Цели
- Исключение некоторых типов избыточности
- Устранение аномалий
- Разработка проекта базы данных, который является достаточно «качественным» представлением реального мира, интуитивно понятен и может служить хорошей основой для последующего расширения
- Упрощение процедуры применения необходимых ограничений целостности
Следствия
Полная нормализация приводит к увеличению количества логически независимых переменных отношения, что может привести к снижению скорости выборки ⇒ к замедлению работы базы данных.
Средства нормализации
Для приведения базы данных в нормальную форму будет применяться декомпозиция без потерь. При построении такой декомпозиции используются операции соединения и проекции.
Проекция
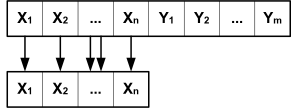
Соединение
Операция соединения имеет несколько разных вариантов, но чаще всего рассматривается естественное соединение.
- Можно понимать как соединение по совпадающим атрибутам
- Коммутативно: [math]R_1 ⋈ R_2 = R_2 ⋈ R_1[/math]
- Ассоциативно: [math](R_1 ⋈ R_2) ⋈ R_3 = R_1 ⋈ (R_2 ⋈ R_3)[/math]
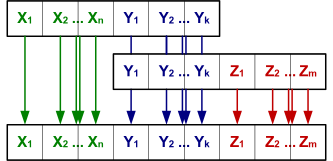
Декомпозиция
Процедура нормализации предусматривает разбиение, или декомпозицию, данной переменной отношения на другие переменные отношения, причем декомпозиция должна быть обратимой, т.е. выполняться без потерь информации, то есть, соединение отношений, полученных при декомпозиции множества, должно давать исходное отношение Декомпозиция отношения [math]R[/math] на множества атрибутов [math]A[/math] и [math]B[/math] : [math]R(A, B) = \pi_A(R) ⋈ \pi_B(R)[/math]
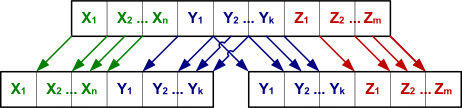
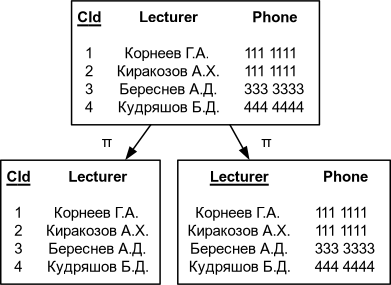
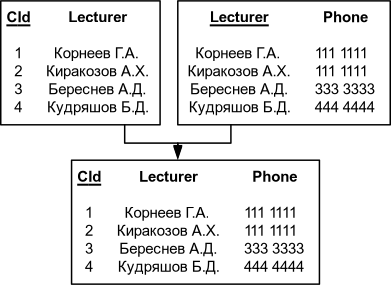
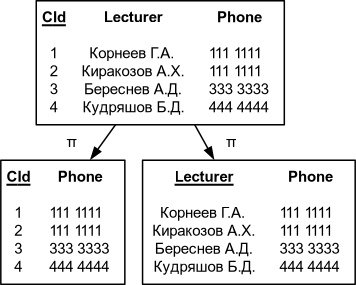
Пример корректной декомпозиции
| Проекции на CId Phone и Lecturer Phone | Соединение CId Lecturer и Lecturer Phone |
 |
 |
Пример некорректной декомпозиции
При обратном соединении полученных отношений исходное отношений не было восстановлено — появились записи, которых не было ⇒ декомпозиция некорректна.
| Проекции на CId Phone и Lecturer Phone | Соединение CId Phone и Lecturer Phone |
 |
 |
Теорема Хита
Теорема Хита утверждает, что если некоторая декомпозиция выполняется в соответствии с определенной функциональной зависимостью, то она будет выполнена без потерь.
Пусть [math]R(XYZ)[/math] является отношением, где [math]X[/math] , [math]Y[/math] и [math]Z[/math] — неперескающиеся множества атрибутов. Если [math]R[/math] удовлетворяет функциональной зависимости [math]X → Y[/math] , то [math]R[/math] равно соединению его проекций по атрибутам [math]X[/math] , [math]Y[/math] и [math]X[/math] , [math]Z[/math] : [math]R=\pi_
Докажем равенство в обе стороны:
1. Докажем, что исходное отношение [math]R[/math] — подмножество соединения проекций.
Рассмотрим произвольный кортеж [math]r[/math] из отношения [math]R[/math] .
Для проекций кортежа [math]r[/math] на [math]XY[/math] и [math]XZ[/math] выполняетя: [math]π_(r) ∈ π_(R), π_(r) ∈ π_(R)[/math] .
Из этого следует, что [math]r[/math] — подмножество соединения проекций [math]⇒ ∀ r∈R: r ∈ \pi_(R)[/math] ⋈ [math]\pi_(R)[/math] .
2. Докажем, что любой кортеж полученного соединения является кортежем отношения [math]R[/math] .
Рассмотрим кортеж [math](x, y, z)[/math] , принадлежащий соединению [math]π_(R) ⋈ π_(R)[/math]
Для того, чтобы [math](x, y, z)[/math] был в соеденении, необходимо, чтобы существовали кортежи [math](x, y) ∈ π_(R)[/math] и [math](x, z) ∈ π_(R)[/math]
Из [math](x, z) ∈ π_(R)[/math] следует, что существует кортеж [math](x, y’, z) ∈ R[/math] для некоторого [math]y'[/math] . Это означает, что должен существовать кортеж [math](x, y’) ∈ π_(R)[/math]
Доказательсто первого пункта не опирается на наличие функциональной зависимости ⇒ справедливо следствие:
Следствие Исходное отношение [math]R[/math] всегда является подмножеством соединения отношений, полученных при декомпозиции.
См. также
- Функциональные зависимости: замыкание, эквивалентность и правила вывода
- Нормальные формы: первая и вторая
- Нормальные формы: третья и Бойса-Кодда
- Многозначные зависимости и четвертая нормальная форма
- Зависимости соединения и пятая нормальная форма
Источники информации
- kgeorgiy.info Тема 4. Нормализация баз данных
- Дейт К.: Введение в системы баз данных (Глава 12)