Pandas: вернуть строку с максимальным значением в определенном столбце
Вы можете использовать следующие методы, чтобы вернуть строку кадра данных pandas, содержащую максимальное значение в определенном столбце:
Метод 1: вернуть строку с максимальным значением
df[df['my_column'] == df['my_column']. max ()] Метод 2: вернуть индекс строки с максимальным значением
df['my_column']. idxmax () В следующих примерах показано, как использовать каждый метод на практике со следующими пандами DataFrame:
import pandas as pd #create DataFrame df = pd.DataFrame() #view DataFrame print(df) team points assists rebounds 0 A 18 5 11 1 B 22 7 8 2 C 19 7 10 3 D 14 9 6 4 E 14 12 6 5 F 11 9 5 6 G 28 9 9 7 H 20 4 12 Пример 1: возвращаемая строка с максимальным значением
В следующем коде показано, как вернуть строку в DataFrame с максимальным значением в столбце точек :
#return row with max value in points column df[df['points'] == df['points']. max ()] team points assists rebounds 6 G 28 9 9 Максимальное значение в столбце точек равно 28 , поэтому была возвращена строка, содержащая это значение.
Пример 2: возвращаемый индекс строки с максимальным значением
В следующем коде показано, как вернуть только индекс строки с максимальным значением в столбце точек :
#return row that contains max value in points column df['points']. idxmax () 6 Строка в позиции индекса 6 содержала максимальное значение в столбце точек , поэтому было возвращено значение 6 .
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные задачи в pandas:
Python, pandas и решение трёх задач из мира Excel
Excel — это чрезвычайно распространённый инструмент для анализа данных. С ним легко научиться работать, есть он практически на каждом компьютере, а тот, кто его освоил, может с его помощью решать довольно сложные задачи. Python часто считают инструментом, возможности которого практически безграничны, но который освоить сложнее, чем Excel. Автор материала, перевод которого мы сегодня публикуем, хочет рассказать о решении с помощью Python трёх задач, которые обычно решают в Excel. Эта статья представляет собой нечто вроде введения в Python для тех, кто хорошо знает Excel.

Загрузка данных
Начнём с импорта Python-библиотеки pandas и с загрузки в датафреймы данных, которые хранятся на листах sales и states книги Excel. Такие же имена мы дадим и соответствующим датафреймам.
import pandas as pd sales = pd.read_excel('https://github.com/datagy/mediumdata/raw/master/pythonexcel.xlsx', sheet_name = 'sales') states = pd.read_excel('https://github.com/datagy/mediumdata/raw/master/pythonexcel.xlsx', sheet_name = 'states') Теперь воспользуемся методом .head() датафрейма sales для того чтобы вывести элементы, находящиеся в начале датафрейма:
print(sales.head()) Сравним то, что будет выведено, с тем, что можно видеть в Excel.

Сравнение внешнего вида данных, выводимых в Excel, с внешним видом данных, выводимых из датафрейма pandas
Тут можно видеть, что результаты визуализации данных из датафрейма очень похожи на то, что можно видеть в Excel. Но тут имеются и некоторые очень важные различия:
- Нумерация строк в Excel начинается с 1, а в pandas номер (индекс) первой строки равняется 0.
- В Excel столбцы имеют буквенные обозначения, начинающиеся с буквы A , а в pandas названия столбцов соответствуют именам соответствующих переменных.
Реализация возможностей Excel-функции IF в Python
В Excel существует очень удобная функция IF , которая позволяет, например, записать что-либо в ячейку, основываясь на проверке того, что находится в другой ячейке. Предположим, нужно создать в Excel новый столбец, ячейки которого будут сообщать нам о том, превышают ли 500 значения, записанные в соответствующие ячейки столбца B . В Excel такому столбцу (в нашем случае это столбец E ) можно назначить заголовок MoreThan500 , записав соответствующий текст в ячейку E1 . После этого, в ячейке E2 , можно ввести следующее:
=IF([@Sales]>500, "Yes", "No") Использование функции IF в Excel
Для того чтобы сделать то же самое с использованием pandas, можно воспользоваться списковым включением (list comprehension):
sales['MoreThan500'] = ['Yes' if x > 500 else 'No' for x in sales['Sales']] 
Списковые включения в Python: если текущее значение больше 500 — в список попадает Yes, в противном случае — No
Списковые включения — это отличное средство для решения подобных задач, позволяющее упростить код за счёт уменьшения потребности в сложных конструкциях вида if/else. Ту же задачу можно решить и с помощью if/else, но предложенный подход экономит время и делает код немного чище. Подробности о списковых включениях можно найти здесь.
Реализация возможностей Excel-функции VLOOKUP в Python
В нашем наборе данных, на одном из листов Excel, есть названия городов, а на другом — названия штатов и провинций. Как узнать о том, где именно находится каждый город? Для этого подходит Excel-функция VLOOKUP , с помощью которой можно связать данные двух таблиц. Эта функция работает по принципу левого соединения, когда сохраняется каждая запись из набора данных, находящегося в левой части выражения. Применяя функцию VLOOKUP , мы предлагаем системе выполнить поиск определённого значения в заданном столбце указанного листа, а затем — вернуть значение, которое находится на заданное число столбцов правее найденного значения. Вот как это выглядит:
=VLOOKUP([@City],states,2,false) Зададим на листе sales заголовок столбца F как State и воспользуемся функцией VLOOKUP для того чтобы заполнить ячейки этого столбца названиями штатов и провинций, в которых расположены города.
Использование функции VLOOKUP в Excel
В Python сделать то же самое можно, воспользовавшись методом merge из pandas. Он принимает два датафрейма и объединяет их. Для решения этой задачи нам понадобится следующий код:
sales = pd.merge(sales, states, how='left', on='City') - Первый аргумент метода merge — это исходный датафрейм.
- Второй аргумент — это датафрейм, в котором мы ищем значения.
- Аргумент how указывает на то, как именно мы хотим соединить данные.
- Аргумент on указывает на переменную, по которой нужно выполнить соединение (тут ещё можно использовать аргументы left_on и right_on , нужные в том случае, если интересующие нас данные в разных датафреймах названы по-разному).
Сводные таблицы
Сводные таблицы (Pivot Tables) — это одна из самых мощных возможностей Excel. Такие таблицы позволяют очень быстро извлекать ценные сведения из больших наборов данных. Создадим в Excel сводную таблицу, выводящую сведения о суммарных продажах по каждому городу.
Создание сводной таблицы в Excel
Как видите, для создания подобной таблицы достаточно перетащить поле City в раздел Rows , а поле Sales — в раздел Values . После этого Excel автоматически выведет суммарные продажи для каждого города.
Для того чтобы создать такую же сводную таблицу в pandas, нужно будет написать следующий код:
sales.pivot_table(index = 'City', values = 'Sales', aggfunc = 'sum') - Здесь мы используем метод sales.pivot_table , сообщая pandas о том, что мы хотим создать сводную таблицу, основанную на датафрейме sales .
- Аргумент index указывает на столбец, по которому мы хотим агрегировать данные.
- Аргумент values указывает на то, какие значения мы собираемся агрегировать.
- Аргумент aggfunc задаёт функцию, которую мы хотим использовать при обработке значений (тут ещё можно воспользоваться функциями mean , max , min и так далее).
Итоги
Из этого материала вы узнали о том, как импортировать Excel-данные в pandas, о том, как реализовать средствами Python и pandas возможности Excel-функций IF и VLOOKUP , а также о том, как воспроизвести средствами pandas функционал сводных таблиц Excel. Возможно, сейчас вы задаётесь вопросом о том, зачем вам пользоваться pandas, если то же самое можно сделать и в Excel. На этот вопрос нет однозначного ответа. Python позволяет создавать код, который поддаётся тонкой настройке и глубокому исследованию. Такой код можно использовать многократно. Средствами Python можно описывать очень сложные схемы анализа данных. А возможностей Excel, вероятно, достаточно лишь для менее масштабных исследований данных. Если вы до этого момента пользовались только Excel — рекомендую испытать Python и pandas, и узнать о том, что у вас из этого получится.
А какие инструменты вы используете для анализа данных?
Напоминаем, что у нас продолжается конкурс прогнозов, в котором можно выиграть новенький iPhone. Еще есть время ворваться в него, и сделать максимально точный прогноз по злободневным величинам.
Основы Pandas №2 // Агрегация и группировка
Во втором уроке руководства по работе с pandas речь пойдет об агрегации (min, max, sum, count и дргуих) и группировке. Это популярные методы в аналитике и проектах data science, поэтому убедитесь, что понимаете все в деталях!
Примечание: это руководство, поэтому рекомендуется самостоятельно писать код, повторяя инструкции!
Агрегация данных — теория
Агрегация — это процесс превращения значений набора данных в одно значение. Например, у вас есть следующий набор данных…
| animal | water_need |
|---|---|
| zebra | 100 |
| lion | 350 |
| elephant | 670 |
| kangaroo | 200 |
…простейший метод агрегации для него — суммирование water_needs , то есть 100 + 350 + 670 + 200 = 1320. Как вариант, можно посчитать количество животных — 4. Теория не так сложна. Но пора переходить к практике.
Агрегация данных — практика
Где мы остановились в последний раз? Открыли Jupyter Notebook, импортировали pandas и numpy и загрузили два набора данных: zoo.csv и article_reads . Продолжим с этого же места. Если вы не прошли первую часть, вернитесь и начните с нее.
Начнем с набора zoo . Он был загружен следующим образом:
pd.read_csv('zoo.csv', delimiter = ',') 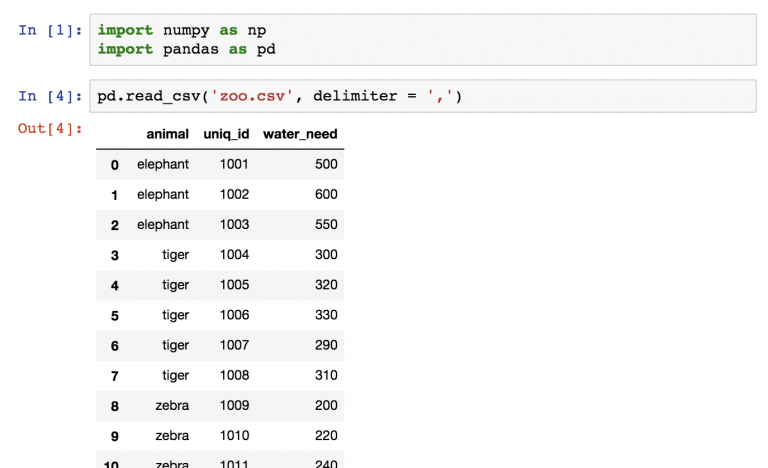
Дальше сохраним набор данных в переменную zoo .
zoo = pd.read_csv('zoo.csv', delimiter = ',') Теперь нужно проделать пять шагов:
- Посчитать количество строк (количество животных) в zoo .
- Посчитать общее значение water_need животных.
- Найти наименьшее значение water_need .
- И самое большое значение water_need .
- Наконец, среднее water_need .
Агрегация данных pandas №1: .count()
Посчитать количество животных — то же самое, что применить функцию count к набору данных zoo :
zoo.count() 
А что это за строки? На самом деле, функция count() считает количество значений в каждой колонке. В случае с zoo было 3 колонки, в каждой из которых по 22 значения.
Чтобы сделать вывод понятнее, можно выбрать колонку animal с помощью оператора выбора из предыдущей статьи:
zoo[['animal']].count() В этом случае результат будет даже лучше, если написать следующим образом:
zoo.animal.count() Также будет выбрана одна колонка, но набор данных pandas превратится в объект series (а это значит, что формат вывода будет отличаться).

Агрегация данных pandas №2: .sum()
Следуя той же логике, можно с легкостью найти сумму значений в колонке water_need с помощью:
zoo.water_need.sum() 
Просто из любопытства можно попробовать найти сумму во всех колонках:
zoo.sum() 
Примечание: интересно, как .sum() превращает слова из колонки animal в строку названий животных. (Кстати, это соответствует всей логике языка Python).
Агрегация данных pandas №3 и №4: .min() и .max()
Какое наименьшее значение в колонке water_need ? Определить это несложно:
zoo.water_need.min() 
То же и с максимальным значением:
zoo.water_need.max() 
Агрегация данных pandas №5 и №6: .mean() и .median()
Наконец, стоит посчитать среднестатистические показатели, например среднее и медиану:
zoo.water_need.mean() 
zoo.water_need.median() 
Это было просто. Намного проще, чем агрегация в SQL.
Но можно усложнить все немного с помощью группировки.
Группировка в pandas
Работая аналитиком или специалистом Data Science, вы наверняка постоянно будете заниматься сегментациями. Например, хорошо знать количество необходимой воды ( water_need ) для всех животных (это 347,72 ). Но удобнее разбить это число по типу животных.
Вот упрощенная репрезентация того, как pandas осуществляет «сегментацию» (группировку и агрегацию) на основе значений колонок!
Функция .groupby в действии
Проделаем эту же группировку с DataFrame zoo .
Между переменной zoo и функцией . mean() нужно вставить ключевое слово groupby :
zoo.groupby('animal').mean() 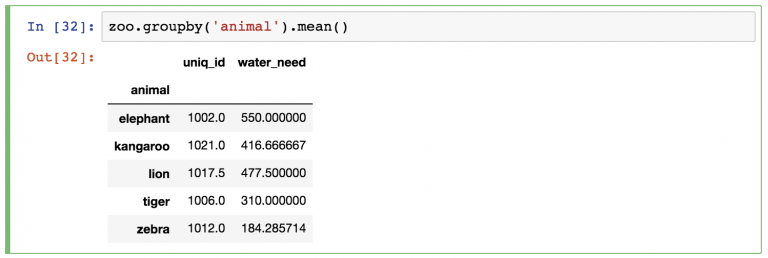
Как и раньше, pandas автоматически проведет расчеты . mean() для оставшихся колонок (колонка animal пропала, потому что по ней проводилась группировка). Можно или игнорировать колонку uniq_id или удалить ее одним из следующих способов:
zoo.groupby(‘animal’).mean()[[‘water_need’]] — возвращает объект DataFrame.
zoo.groupby(‘animal’).mean().water_need — возвращает объект Series.
Можно поменять метод агрегации с . mean() на любой изученный до этого.
Проверить себя №1
Вернемся к набору данных article_read .
Примечание: стоит напомнить, что в этом наборе хранятся данные из блога о путешествиях. Скачать его можно отсюда. Пошаговый процесс загрузки, открытия и сохранения есть в прошлом материале руководства.
Если все готово, вот первое задание:
Какой источник используется в article_read чаще остальных?
Правильный ответ:
Reddit!
Получить его можно было с помощью кода:
article_read.groupby('source').count() Взять набор данных article_read , создать сегменты по значениям колонки source ( groupby(‘source’) ) и в конце концов посчитать значения по источникам ( .count() ).

Также можно удалить ненужные колонки и сохранить только user_id :
article_read.groupby('source').count()[['user_id']] Проверить себя №2
Вот еще одна, более сложная задача:
Какие самые популярные источник и страна для пользователей country_2 ? Другими словами, какая тема из какого источника принесла больше всего просмотров из country_2 ?
Правильный ответ: Reddit (источник) и Азия (тема) с 139 прочтениями.
Вот Python-код для получения результата:
article_read[article_read.country == 'country_2'].groupby(['source', 'topic']).count() 
Вот краткое объяснение:
В первую очередь отфильтровали пользователей из country_2 ( article_read[article_read.country == ‘country_2’] ). Затем для этого подмножества был использован метод groupby . (Да, группировку можно осуществлять для нескольких колонок. Для этого их названия нужно собрать в список. Поэтому квадратные скобки используются между круглыми. Это что касается части groupby([‘source’, ‘topic’]) ).
А функция count() — заключительный элемент пазла.
Итого
Это была вторая часть руководства по работе с pandas. Теперь вы знаете, что агрегация и группировка в pandas— это простые операции, а использовать их придется часто.
Примечание: если вы ранее пользовались SQL, сделайте перерыв и сравните методы агрегации в SQL и pandas. Так лучше станет понятна разница между языками.
В следующем материале вы узнаете о четырех распространенных методах форматирования данных: merge , sort , reset_index и fillna .
Обзор типов данных Pandas¶
В процессе анализа данных важно убедиться, что вы используете правильные типы данных; в противном случае можете получить неожиданные результаты или ошибки. В этой статье будут обсуждаться основные типы данных pandas (также известные как dtypes ), их сопоставление с типами данных Python и NumPy, а также варианты преобразования.
Типы данных Pandas¶
Тип данных — это, по сути, внутреннее представление, которое язык программирования использует для понимания того, как данные хранить и как ими оперировать. Например, программа должна понимать, что вы хотите сложить два числа, например 5 + 10 , чтобы получить 15 . Или, если у вас есть две строки, такие как «кошка» и «шляпа» вы можете объединить (сложить) их вместе, чтобы получить «кошкашляпа» .
Проблема с типами данных pandas заключается в том, что между pandas, Python и NumPy существует некоторое совпадение.
В следующей таблице приведены основные ключевые моменты:
| Pandas | Python | NumPy | Использование |
|---|---|---|---|
| object | str или смесь | string, unicode, смешанные типы | Текстовые или смешанные числовые и нечисловые значения |
| int64 | int | int_, int8, int16, int32, int64, uint8, uint16, uint32, uint64 | Целые числа |
| float64 | float | float_, float16, float32, float64 | Числа с плавающей точкой |
| bool | bool | bool_ | Значения True/False |
| datetime64 | datetime | datetime64[ns] | Значения даты и времени |
| timedelta[ns] | NA | NA | Разность между двумя datetimes |
| category | NA | NA | Ограниченный список текстовых значений |
В этом Блокноте я сосредоточусь на следующих типах данных pandas:
Про тип category смотрите в отдельной статье.
Тип данных object может фактически содержать несколько разных типов. Например, столбец a может включать целые числа, числа с плавающей точкой и строки, которые вместе помечаются как object . Следовательно, вам могут потребоваться некоторые дополнительные методы для обработки смешанных типов данных.
В этой статье (а тут перевод статьи на русский язык) вы найдете инструкцию по очистке данных, представленных ниже.
Почему нас это волнует?¶
Типы данных — одна из тех вещей, о которых вы, как правило, не заботитесь, пока не получите ошибку или неожиданные результаты. Это также одна из первых вещей, которую вы должны проверить после загрузки новых данных в pandas для дальнейшего анализа.
Я буду использовать очень простой CSV файл, чтобы проиллюстрировать пару распространенных ошибок, которые вы можете встретить.
import pandas as pd import numpy as np
df = pd.read_csv("https://github.com/dm-fedorov/pandas_basic/blob/master/%D0%B1%D1%8B%D1%81%D1%82%D1%80%D0%BE%D0%B5%20%D0%B2%D0%B2%D0%B5%D0%B4%D0%B5%D0%BD%D0%B8%D0%B5%20%D0%B2%20pandas/data/sales_data_types.csv?raw=True")
| Customer Number | Customer Name | 2016 | 2017 | Percent Growth | Jan Units | Month | Day | Year | Active | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 10002.0 | Quest Industries | $125,000.00 | $162500.00 | 30.00% | 500 | 1 | 10 | 2015 | Y |
| 1 | 552278.0 | Smith Plumbing | $920,000.00 | $101,2000.00 | 10.00% | 700 | 6 | 15 | 2014 | Y |
| 2 | 23477.0 | ACME Industrial | $50,000.00 | $62500.00 | 25.00% | 125 | 3 | 29 | 2016 | Y |
| 3 | 24900.0 | Brekke LTD | $350,000.00 | $490000.00 | 4.00% | 75 | 10 | 27 | 2015 | Y |
| 4 | 651029.0 | Harbor Co | $15,000.00 | $12750.00 | -15.00% | Closed | 2 | 2 | 2014 | N |
На первый взгляд данные выглядят нормально, поэтому попробуем выполнить некоторые операции.
Сложим продажи за 2016 и 2017 годы:
df['2016'] + df['2017']
0 $125,000.00$162500.00 1 $920,000.00$101,2000.00 2 $50,000.00$62500.00 3 $350,000.00$490000.00 4 $15,000.00$12750.00 dtype: object
Выглядит странно. Мы хотели суммировать значения столбцов, но pandas их объединил, чтобы создать одну длинную строку.
Ключ к разгадке проблемы — это строка, в которой написано dtype: object .
object — это строка в pandas, поэтому он выполняет строковую конкатенацию вместо математического сложения.
Если мы хотим увидеть все типы данных, которые находятся в кадре данных ( DataFrame ), то воспользуемся атрибутом dtypes :
df.dtypes
Customer Number float64 Customer Name object 2016 object 2017 object Percent Growth object Jan Units object Month int64 Day int64 Year int64 Active object dtype: object
Кроме того, функция df.info() показывает много полезной информации:
df.info()
RangeIndex: 5 entries, 0 to 4 Data columns (total 10 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Customer Number 5 non-null float64 1 Customer Name 5 non-null object 2 2016 5 non-null object 3 2017 5 non-null object 4 Percent Growth 5 non-null object 5 Jan Units 5 non-null object 6 Month 5 non-null int64 7 Day 5 non-null int64 8 Year 5 non-null int64 9 Active 5 non-null object dtypes: float64(1), int64(3), object(6) memory usage: 528.0+ bytes
После просмотра автоматически назначаемых типов данных возникает несколько проблем:
- Customer Number (Номер клиента) — float64 , но должен быть int64 .
- Столбцы 2016 и 2017 хранятся как objects , а не числовые значения, такие как float64 или int64 .
- Percent Growth (Единицы процентного роста) и Jan Units также хранятся как objects , а не числовые значения.
- У нас есть столбцы Month , Day и Year , которые нужно преобразовать в datetime64 .
- Столбец Active должен быть логическим ( boolean ).
Без проведения очистки данных будет сложно провести дополнительный анализ.
- Используйте метод astype() , чтобы принудительно задать тип данных.
- Создайте настраиваемую (custom) функцию для преобразования данных.
- Используйте функции to_numeric() или to_datetime() .
Использование функции astype()¶
Самый простой способ преобразовать столбец данных в другой тип — использовать astype() . Например, чтобы преобразовать Customer Number (Номер клиента) в целое число, можем сделать так:
df['Customer Number'].astype('int') # pandas понимает, что в итоге нужен int64
0 10002 1 552278 2 23477 3 24900 4 651029 Name: Customer Number, dtype: int64
Чтобы изменить Customer Number в исходном кадре данных, обязательно присвойте его обратно столбцу, так как функция astype() возвращает копию:
df["Customer Number"] = df['Customer Number'].astype('int') df.dtypes
Customer Number int64 Customer Name object 2016 object 2017 object Percent Growth object Jan Units object Month int64 Day int64 Year int64 Active object dtype: object
А вот новый кадр данных с Customer Number в качестве целого числа:
| Customer Number | Customer Name | 2016 | 2017 | Percent Growth | Jan Units | Month | Day | Year | Active | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 10002 | Quest Industries | $125,000.00 | $162500.00 | 30.00% | 500 | 1 | 10 | 2015 | Y |
| 1 | 552278 | Smith Plumbing | $920,000.00 | $101,2000.00 | 10.00% | 700 | 6 | 15 | 2014 | Y |
| 2 | 23477 | ACME Industrial | $50,000.00 | $62500.00 | 25.00% | 125 | 3 | 29 | 2016 | Y |
| 3 | 24900 | Brekke LTD | $350,000.00 | $490000.00 | 4.00% | 75 | 10 | 27 | 2015 | Y |
| 4 | 651029 | Harbor Co | $15,000.00 | $12750.00 | -15.00% | Closed | 2 | 2 | 2014 | N |
Все это выглядит хорошо и кажется довольно простым.
Давайте попробуем проделать то же самое со столбцом 2016 и преобразовать его в число с плавающей точкой:
# здесь появится исключение: # df['2016'].astype('float')
Аналогичным образом мы можем попытаться преобразовать столбец Jan Units в целое число:
# здесь тоже появится исключение: # df['Jan Units'].astype('int')
Оба примера возвращают исключения ValueError , т.е. преобразования не сработали.
В каждом из случаев данные включали значения, которые нельзя было интерпретировать как числа. В столбцах продаж данные включают символ валюты $ , а также запятую. В столбце Jan Units последним значением является Closed (Закрыто), которое не является числом; так что мы получаем исключение.
Пока что astype() как инструмент для преобразования выглядит не очень хорошо.
Мы должны попробовать еще раз в столбце Active .
df['Active'].astype('bool')
0 True 1 True 2 True 3 True 4 True Name: Active, dtype: bool
На первый взгляд все выглядит нормально, но при ближайшем рассмотрении обнаруживается проблема. Все значения были интерпретированы как True , но последний клиент в столбце Active имеет флаг N вместо Y .
Вывод из этого раздела такой — astype() будет работать, если:
- данные чистые и могут быть просто интерпретированы как число;
- вы хотите преобразовать числовое значение в строковый объект, т.е. вызвать astype(‘str’) .
Если данные содержат нечисловые символы или неоднородны, то astype() будет плохим выбором для преобразования типов. Вам потребуется выполнить дополнительные преобразования, чтобы изменение типа работало правильно.
Дополнительно¶
Отметим, что astype() может принимать словарь имен столбцов и типов данных:
df.astype('Customer Number': 'int', 'Customer Name': 'str'>).dtypes
Customer Number int64 Customer Name object 2016 object 2017 object Percent Growth object Jan Units object Month int64 Day int64 Year int64 Active object dtype: object
Пользовательские функции преобразования¶
Поскольку эти данные немного сложнее преобразовать, можно создать настраиваемую (custom) функцию, которую применим к каждому значению и преобразовать в соответствующий тип данных.
Для конвертации валюты (этого конкретного набора данных) мы можем использовать простую функцию:
def convert_currency(val): """ Преобразует числовое значение строки в число с плавающей точкой: - удаляет $ - удаляет запятые - преобразует в число с плавающей точкой """ new_val = val.replace(',', '').replace('$', '') return float(new_val)
В коде используются строковые функции Python, чтобы очистить символы $ и , , а затем преобразовать значение в число с плавающей точкой. В этом конкретном случае мы могли бы преобразовать значения в целые числа, но я предпочитаю использовать плавающую точку.
Я также подозреваю, что кто-нибудь рекомендует использовать тип данных Decimal для валюты. Это не встроенный тип в pandas, поэтому я намеренно придерживаюсь подхода с плавающей точкой.
Также следует отметить, что функция преобразует число в питоновский float , но pandas внутренне преобразует его в float64 . Как упоминалось ранее, я рекомендую разрешить pandas выполнять такие преобразования. Вам не нужно пытаться понижать до меньшего или повышать до большего размера байта, если вы действительно не знаете, зачем это нужно.
Теперь мы можем использовать функцию apply , чтобы применить ее ко всем значениям в столбце 2016 .