Применение сверточных нейронных сетей для задач NLP
Когда мы слышим о сверточных нейронных сетях (CNN), мы обычно думаем о компьютерном зрении. CNN лежали в основе прорывов в классификации изображений — знаменитый AlexNet, победитель соревнования ImageNet в 2012 году, с которого начался бум интереса к этой теме. С тех пор сверточные сети достигли большого успеха в распознавании изображений, в силу того факта, что они устроены наподобие зрительной коры головного мозга — то есть умеют концентрироваться на небольшой области и выделять в ней важные особенности. Но, как оказалось, CNN хороши не только для этого, но и для задач обработки естественного языка (Natural Language Processing, NLP). Более того, в недавно вышедшей статье [1] от коллектива авторов из Intel и Carnegie-Mellon University, утверждается, что они подходят для этого даже лучше RNN, которые безраздельно властвовали областью на протяжении последних лет.
Сверточные нейронные сети
Для начала немного теории. Что такое свертка? Мы не будем на этом останавливаться подробно, так как про это написана уже тонна материалов, но все-таки кратко пробежаться стоит. Есть красивая визуализация от Стэнфорда, которая позволяет ухватить суть:
Источник
Надо ввести базовые понятия, чтобы потом мы понимали друг друга. Окошко, которое ходит по большой матрице называется фильтром (в англоязычном варианте kernel, filter или feature detector, так что можно встретить переводы и кальки этих терминов не пугайтесь, это все одно и то же). Фильтр накладывается на участок большой матрицы и каждое значение перемножается с соответствующим ему значением фильтра (красные цифры ниже и правее черных цифр основной матрицы). Потом все получившееся складывается и получается выходное (“отфильтрованное”) значение.
Окно ходит по большой матрице с каким-то шагом, который по-английски называется stride. Этот шаг бывает горизонтальный и вертикальный (хотя последний нам не пригодится).
Еще осталось ввести важный концепт канала. Каналами в изображениях называются известные многим базовые цвета, например, если мы говорим о простой и распространенной схеме цветового кодирования RGB (Red — красный, Green — зеленый, Blue — голубой), то там предполагается, что из трех этих базовых цветов, путем их смешения мы можем получить любой цвет. Ключевое слово здесь — “смешение”, все три базовых цвета существуют одновременно, и могут быть получены из, например, белого света солнца с помощью фильтра нужного цвета (чувствуете, терминология начинает обретать смысл?).
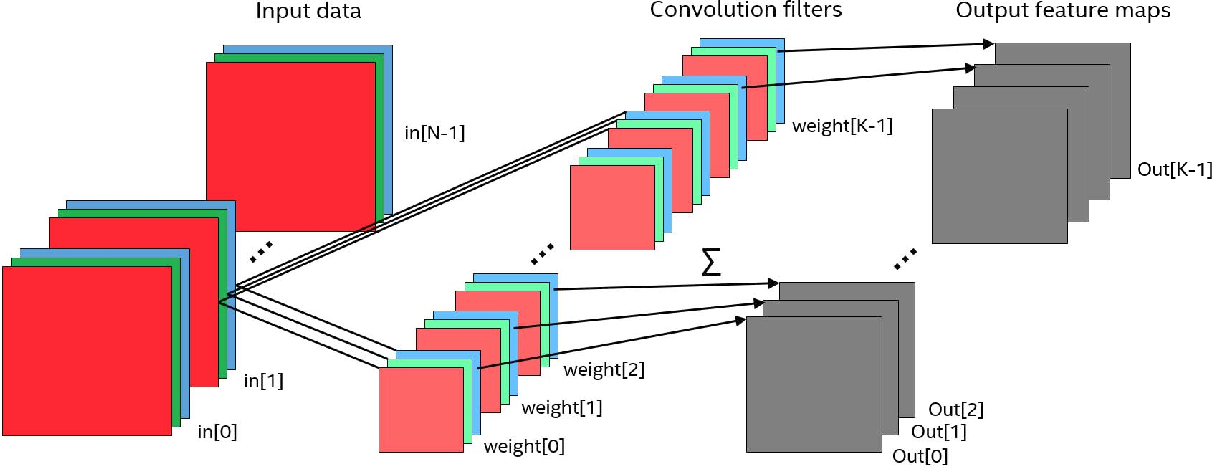
И вот получается, что у нас есть изображение, в нем есть каналы и по нему с нужным шагом ходит наш фильтр. Осталось понять — что собственно делать с этими каналами? С этими каналами мы делаем с следующее — каждый фильтр (то есть матрица небольшого размера) накладывается на исходную матрицу одновременно на все три канала. Результаты же просто суммируются (что логично, если разобраться, в конце концов каналы — это наш способ работать с непрерывным физическим спектром света).
Нужно упомянуть еще одну деталь, без которой понимание дальнейшего будет затруднено: открою вам страшную тайну, фильтров в сверточных сетях гораздо больше. Что значит гораздо больше? Это значит, что у нас существует n фильтров выполняющих одну и ту же работу. Они ходят с окном по матрице и что-то рассматривают. Казалось бы, зачем делать одну работу два раза? Одну да не одну — из-за различной инициализации фильтрующих матриц, в процессе обучения они начинают обращать внимание на разные детали. К примеру один фильтр смотрит на линии, а другой на определенный цвет.

Источник: cs231n
Это визуализация разных фильтров одного слоя одной сети. Видите, что они смотрят на совершенно разные особенности изображения?
Все, мы вооружены терминологией для того, чтобы двигаться дальше. Параллельно с терминологией мы разобрались, как работает сверточный слой. Он является базовым для сверточных нейронных сетей. Есть еще один базовый слой для CNN — это так называемый pooling-слой.
Проще всего его объяснить на примере max-pooling. Итак, представьте, что в уже известном вам сверточном слое матрица фильтра зафиксирована и является единичной (то есть умножение на нее никак не влияет на входные данные). А еще вместо суммирования всех результатов умножения (входных данных по нашему условию), мы выбираем просто максимальный элемент. То есть мы выберем из всего окна пиксель с наибольшей интенсивностью. Это и есть max-pooling. Конечно, вместо функций максимум может быть другая арифметическая (или даже более сложная) функция.
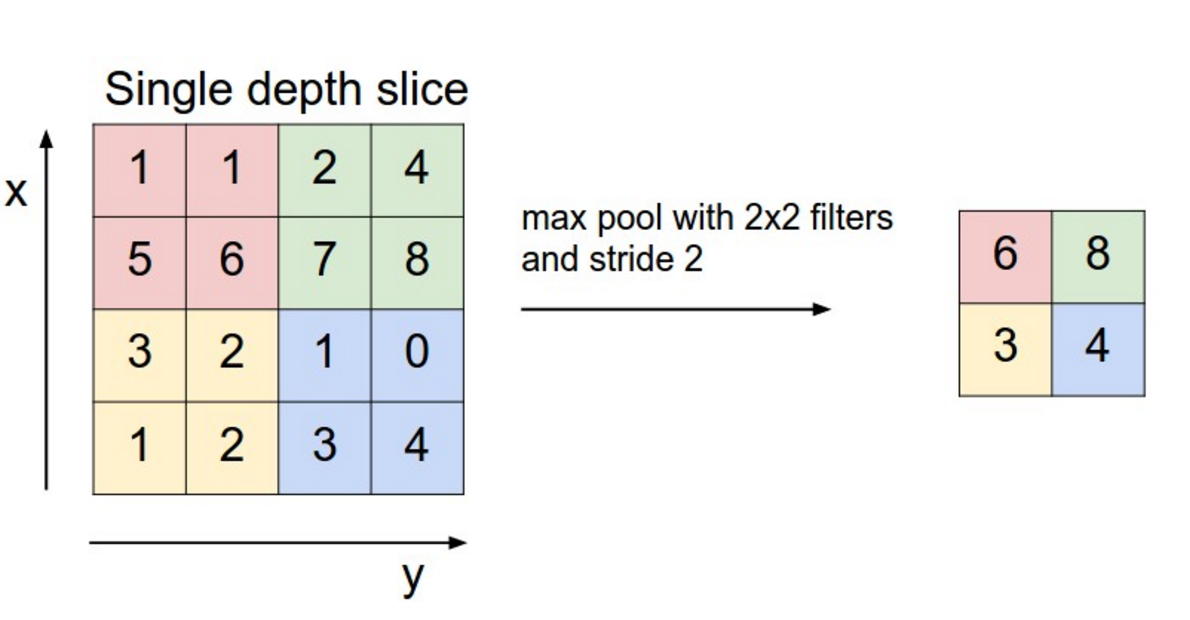
Источник: cs231n
В качестве дальнейшего чтения по этому поводу я рекомендую пост Криса Ола (Chris Olah).
Все вышеназванное — это хорошо, но без нелинейности у нейронных сетей не будет так необходимого нам свойства универсального аппроксиматора. Соответственно, надо сказать пару слов про них. В рекуррентных и полносвязных сетях бал правят такие нелинейности, как сигмоида и гиперболический тангенс.
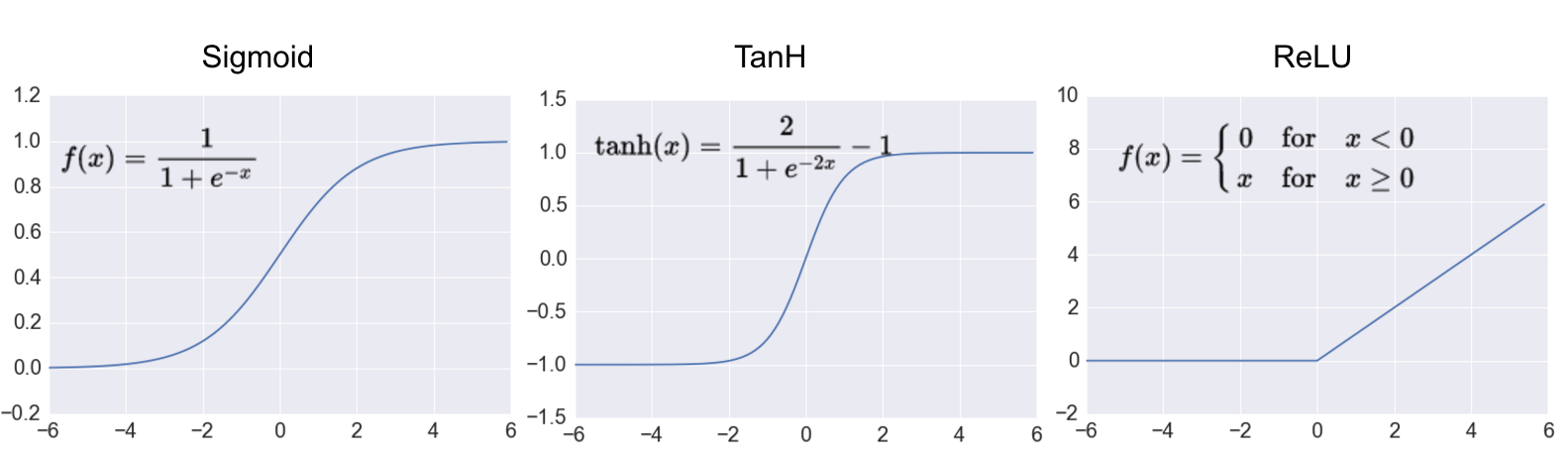
Источник
Это хорошие нелинейные гладкие функции, но они все-таки требуют существенных вычислений по сравнению с той, которая правил бал в CNN: ReLU — Rectified Linear Unit. По-русски ReLU принято называть линейным фильтром (вы еще не устали от использования слова фильтр?). Это простейшая нелинейная функция, к тому же не гладкая. Но зато она вычисляется за одну элементарную операцию, за что ее очень любят разработчики вычислительных фреймворков.
Ладно, мы с вами уже обсудили сверточные нейронные сети, как устроено зрение и всякое такое. Но где же про тексты, или я вас бессовестно обманывал? Нет, я вас не обманывал.
Применение сверток к текстам

Вот эта картинка практически полностью объясняет, как мы работает с текстом с помощью CNN. Непонятно? Давайте разбираться. Прежде всего вопрос — откуда у нас возьмется матрица для работы? CNN же работают с матрицами, не так ли? Здесь нам нужно вернуться немного назад и вспомнить, что такое embedding (по этому поводу есть отдельная статья).
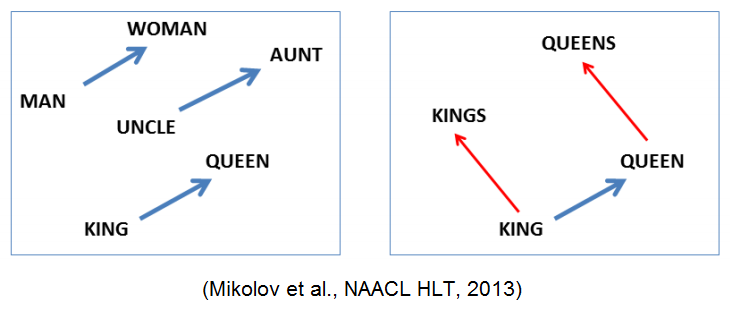
Если вкратце, embedding — это сопоставление точки в каком-то многомерном пространстве объекту, в нашем случае — слову. Примером, возможно, самым известным такого embedding является Word2Vec. У него кстати есть семантические свойства, вроде word2vec(“king”) — word2vec(“man”) + word2vec(“woman”) ~= word2vec(“queen”) . Так вот, мы берем embedding для каждого слова в нашем тексте и просто ставим все вектора в ряд, получая искомую матрицу.
Теперь следующий шаг, матрица — это хорошо, и она вроде бы даже похожа на картинку — те же два измерения. Или нет? Подождите, у нас в картинке есть еще каналы. Получается, что в матрице картинки у нас три измерения — ширина, высота и каналы. А здесь? А здесь у нас есть только ширина (на заглавной картинке раздела матрица для удобства отображения транспонирована) — это последовательность токенов в предложении. И — нет, не высота, а каналы. Почему каналы? Потому что embedding слова имеет смысл только полностью, каждое отдельное его измерение нам ни о чем не скажет.
Хорошо, разобрались с матрицей, теперь дальше про свертки. Получается, что свертка у нас может ходить только по одной оси — по ширине. Поэтому для того, чтобы отличить от стандартной свертки, ее называют одномерной (1D convolution).
И сейчас уже практически все понятно, кроме загадочного Max Over Time Pooling. Что это за зверь? Это уже обсуждавшийся выше max-pooling, только примененный ко всей последовательности сразу (то есть ширина его окна равна всей ширине матрицы).
Примеры использования сверточных нейронных сетей для текстов

Картинка для привлечения внимания. На самом деле иллюстрация из работы [4].
Сверточные нейронные сети хороши там, где нужно увидеть кусочек или всю последовательность целиком и сделать какой-то вывод из этого. То есть это задачи, например, детекции спама, анализа тональности или извлечения именованных сущностей. Разбор статей может быть сложен для вас, если вы только что познакомились с нейронными сетями, этот раздел можно пропустить.
В работе [2] Юн Ким (Yoon Kim) показывает, что CNN хороши для классификации предложений на разных датасетах. Картинка, использованная для иллюстрации раздела выше — как раз из его работы. Он работает с Word2Vec, но можно и работать непосредственно с символами.
В работе [3] авторы классифицируют тексты исходя прямо из букв, выучивая embedding для них в процессе обучения. На больших датасетах они показали даже лучшие результаты, чем сети, работавшие со словами.
У сверточных нейронных сетей есть существенный недостаток, по сравнению с RNN — они могут работать только со входом фиксированного размера (т.к. размеры матриц в сети не могут меняться в процессе работы). Но авторы вышеупомянутой работы [1] смогли решить эту проблему. Так что теперь и это ограничение снято.
В работе [4] авторы классифицируют тексты исходя прямо из символов. Они использовали набор из 70 символов для того чтобы представить каждый символ как one-hot вектор и установили фиксированную длину текста в 1014 символа. Таким образом, текст представлен бинарной матрицей размером 70×1014. Сеть не имеет представления о словах и видит их как комбинации символов, и информация о семантической близости слов не предоставлена сети, как в случаях заранее натренированных Word2Vec векторов. Сеть состоит из 1d conv, max-pooling слоев и двух fully-connected слоев с дропаутом. На больших датасетах они показали даже лучшие результаты, чем сети, работавшие со словами. К тому же этот подход заметно упрощает preprocessing шаг что может поспособствовать его использованию на мобильных устройствах.
В другой работе [5] авторы пытаются улучшить применение CNN в NLP использованием наработок из компьютерного зрения. Главные тренды в компьютерно зрении в последнее время это увеличивание глубины сети и добавление так называемых skip-связей (e.g., ResNet) которые связывают слои которые не соседствуют друг с другом. Авторы показали что те же принципы применимы и в NLP, они построили CNN на основе символов с 16-размерными embedding, которое учились вместе с сетью. Они натренировали сети разной глубины (9, 17, 29 и 49 conv слоёв) и поэкспериментировали со skip-связями, чтобы выяснить, как они влияют на результат. Они пришли к выводу, что увеличение глубины сети улучшает результаты на выбранных датасетах, но производительность слишком глубоких сетей (49 слоев) ниже чем умеренно глубоких (29 слоев). Применение skip-связей привел к улучшению результатов сети из 49 слоев, но все равно не превзошел показатель сети с 29 слоями.
Другая важная особенность CNN в компьютерном зрении это возможность использования весов сети натренированной на одном большом датасете (типичный пример — ImageNet) в других задачах компьютерного зрения. В работе [6] авторы исследуют применимость этих принципов в задаче классификации текстов с помощью CNN с word embedding. Они изучают, как перенос тех или иных частей сети (Embedding, conv слои и fully-connected слои) влияет на результаты классификации на выбранных датасетах. Они приходят к выводу что в NLP задачах семантическая близость источника на котором заранее тренировалась сеть играет важную роль, то есть сеть, натренированная на рецензиях к фильмам, будет хорошо работать на другом датасете с кинорецензиями. К тому же они отмечают, что использование тех же embedding для слов увеличивает успех трансфера и рекомендуют не замораживать слои, а дотренировывать их на целевом датасете.
Практический пример
Давайте на практике посмотрим, как сделать sentiment analysis на CNN. Мы разбирали похожий пример в статье про Keras, поэтому за всеми деталями я отсылаю вас к ней, а здесь будут рассмотрены только ключевые для понимания особенности.
Прежде всего на понадобится концепция Sequence из Keras. Собственно, это и есть последовательность в удобном для Keras виде:
x_train = tokenizer.texts_to_sequences(df_train["text"]) x_test = tokenizer.texts_to_sequences(df_test["text"]) x_val = tokenizer.texts_to_sequences(df_val["text"])Здесь text_to_sequences — функция, которая переводит текст в последовательность целых чисел путем а) токенизации, то есть разбиения строки на токены и б) замены каждого токена на его номер в словаре. (Словарь в этом примере составлен заранее. Код для его составления в полном ноутбуке.)
Далее получившиеся последовательности нужно выровнять — как мы помним CNN пока не умеют работать с переменной длиной текста, это пока не дошло до промышленного применения.
x_train = pad_sequences(x_train, maxlen=max_len) x_test = pad_sequences(x_test, maxlen=max_len) x_val = pad_sequences(x_val, maxlen=max_len)После этого все последовательности будут либо обрезаны, либо дополнены нулями до длины max_len .
А теперь, собственно самое важное, код нашей модели:
model = Sequential() model.add(Embedding(input_dim=max_words, output_dim=128, input_length=max_len)) model.add(Conv1D(128, 3)) model.add(Activation("relu")) model.add(GlobalMaxPool1D()) model.add(Dense(num_classes)) model.add(Activation('softmax'))Первым слоем у нас идет Embedding , который переводит целые числа (на самом деле one-hot вектора, в которых место единицы соответствует номеру слова в словаре) в плотные вектора. В нашем примере размер embedding-пространства (длина вектора) составляет 128, количество слов в словаре max_words , и количество слов в последовательности — max_len , как мы уже знаем из кода выше.
После embedding идет одномерный сверточный слой Conv1D . Количество фильтров в нем — 128, а ширина окна для фильтров равна 3. Активация должна быть понятна — это всеми любимый ReLU.
После ReLU идет слой GlobalMaxPool1D . «Global» в данном случае означает, что он берется по всей длине входящей последовательности, то есть это ни что иное, как вышеупомянавшийся Max Over Time Pooling. Кстати, почему он называется Over Time? Потому что последовательность слов у нас имеет естественный порядок, некоторые слова приходят к нам раньше в потоке речи/текста, то есть раньше по времени.
Вот какая модель у нас получилась в итоге:

На картинке можно заметить интересную особенность: после сверточного слоя длина последовательности стала 38 вместо 40. Почему так? Потому что мы с вами не разговаривали и не применяли padding, технику, позволяющую виртуально «добавить» данных в исходную матрицу, чтобы светка могла выйти за ее пределы. А без этого свертка длины 3 с шагом равным 1 сможет сделать по матрице шириной 40 только 38 шагов.
Ладно, что же у нас получилось в итоге? На моих тестах этот классификатор дал качество 0.57, что, конечно, немного. Но вы легко сможете улучшить мой результат, если приложите немного усилий. Дерзайте.
P.S.: Спасибо за помощь в написании этой статьи Евгению Васильеву somesnm и Булату Сулейманову khansuleyman.
Литература
[1] Bai, S., Kolter, J. Z., & Koltun, V. (2018). An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arxiv.org/abs/1803.01271
[2] Kim, Y. (2014). Convolutional Neural Networks for Sentence Classification. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP 2014), 1746–1751.
[3] Heigold, G., Neumann, G., & van Genabith, J. (2016). Neural morphological tagging from characters for morphologically rich languages. arxiv.org/abs/1606.06640
[4] Character-level Convolutional Networks for Text Classification. Xiang Zhang, Junbo Zhao, Yann LeCun arxiv.org/abs/1509.01626
[5] Very Deep Convolutional Networks for Text Classification. A Conneau, H Schwenk, L Barrault, Y Lecun arxiv.org/abs/1606.01781
[6] A Practitioners’ Guide to Transfer Learning for Text Classification using Convolutional Neural Networks. T Semwal, G Mathur, P Yenigalla, SB Nair arxiv.org/abs/1801.06480
- neural networks
- text mining
- convolutional neural network
- classification
- Блог компании Open Data Science
- Python
- Data Mining
- Машинное обучение
- Natural Language Processing
Свёрточные нейронные сети — надежда и опора генеративного ИИ
![]()
Искусственный интеллект корректнее было бы называть искусственной интуицией: машина ведь не мыслит в человеческом понимании этого термина — она буквально по наитию ставит в соответствие набору входных параметров определённый результат. Другое дело, что наитие это вполне поддаётся математическому описанию
⇣ Содержание
- Отбрасывая несущественное
- Только не в трубочку!
- Что здесь?
Согласно определению из «Философского словаря», интеллект есть способность мыслить, т. е. совокупность тех умственных функций — включая сравнение, порождение абстракций, формирование понятий, суждений, умозаключений и проч., — что превращают восприятие (иными словами, неизбирательную фиксацию потока входящей информации) в знание (обладающее потенциалом практического действия структурированное понимание подноготной объекта, процесса, явления). В этом смысле генеративный ИИ — да и в целом модели машинного обучения — никаким интеллектом, ясное дело, не обладает. Наученная распознавать изображения кошечек с точностью 99,999% машина не способна сформулировать, что есть «кошечка» в её представлении, т. е. свести выработанные ею критерии этого самого распознавания к виду, заведомо постижимому биологическим оператором. А значит, прямого знания она ему не передаст, — лишь продемонстрирует результат работы своей интуиции.
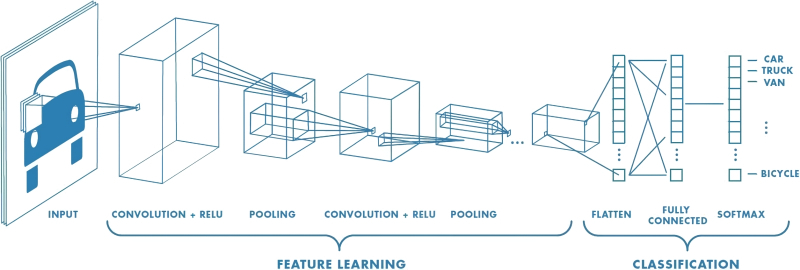
Общая схема работы нейросети, распознающей (классифицирующей) объекты на изображениях: feature learning — участок со свёрточными подсетями (источник: Saturn Cloud)
Зато интуиция, согласно тому же словарю, — это переживание или вдохновенное постижение, приобретённое непосредственно. То бишь реализованное не путём интроспективного размышления (рефлексии), без которого непредставима работа интеллекта, а через подспудное, неосознаваемое в явном виде, неинтерпретируемое ухватывание (кто сказал: «Извлечение из латентного пространства»?) некой сути. Вот же она, корректная расшифровка второй литеры в акрониме «ИИ», — «интуиция»! Хорошо натренированная система просто берёт и ставит в соответствие одной оцифрованной сущности другую. Запросу «напиши за меня курсовую» — адекватно отвечающий определению «курсовой» убедительно складный текст; подсказке «заброшенный замок на мрачной скале» — проникнутую ожидаемым настроением картинку и т. д. Притом ни чуточки не рефлексируя в процессе выдачи над тем, в какой мере соответствуют действительности сделанные в тексте выводы или к какой исторической эпохе либо фэнтезийной вселенной могла бы относиться (если это не указано явно в подсказке) воспроизводимая в изображении структура. Интуиция в чистом виде.
Роднит с человеческой интуицией (да и с животной, кстати, тоже — в отличие от развитого интеллекта это вовсе не видовая особенность Homo sapiens) работу генеративного ИИ и сам принцип действия цифровой нейросети. По многослойной плотной связке искусственных нейронов (перцептронов) проходят сигналы, формируя не поддающиеся адекватной интерпретации человеком промежуточные результаты, — но в итоге получается текст, или картинка, или иная выдача, вполне доступная для постижения тем же самым человеком. Более того, в ряде случаев ИИ справляется с задачами распознавания определённых объектов (на снимках из космоса, например) лучше занимавшихся этим годами живых операторов — просто потому, что не подвержен усталости, минутной рассеянности и иным влияющим на человека факторам. Ключевую же роль в процессе формирования искусственной интуиции — выявления в наборе входных данных закономерностей, не поддающихся чёткой фиксации, зато прекрасно работающих, — играют свёрточные нейронные сети.
⇡#Отбрасывая несущественное
В первом приближении устройство и принцип действия компьютерных нейросетей мы уже описывали: будем надеяться, представление о перцептроне и о многослойной плотной нейронной сети унитарной размерности (с одним и тем же числом перцептронов в каждом слое) у внимательного и памятливого читателя уже имеется. И оно придётся, именно как основа, весьма кстати для понимания того, о чём мы собираемся говорить далее, — поскольку свёрточная нейронная сеть (convolutional neural network, CNN) отличается переменной размерностью: не все её слои равновелики. Именно за счёт этого она способна, как станет вскоре понятно, более эффективно — в сравнении с унитарной — решать поставленные перед нею практические задачи. Чаще всего — распознавание образов на статичных изображениях и видео, а также обработку определённых данных внутри более крупных генеративных моделей машинного обучения.
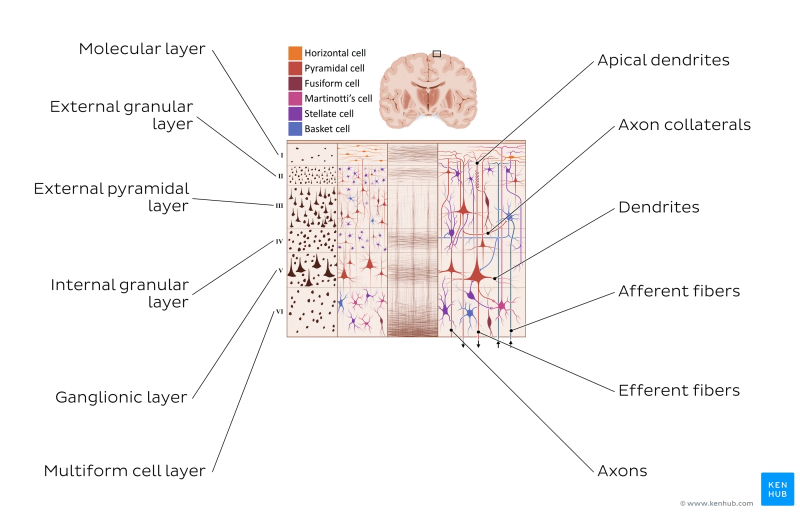
Различные слои и клетки коры головного мозга (источник: Kenhub)
Откуда вообще взялась идея усложнить конструкцию нейросети, дифференцировав различные её слои? Начнём с того, что такая эталонная природная нейросетевая структура, как кора головного мозга человека, существенным образом неоднородна. Даже не говоря уже о том, что в ней выделяются зоны, выполняющие различные задачи (распознавание речи, восприятие тактильных ощущений и т. п.), сама кора в целом многослойна, причём различные участки её слоёв устроены по-разному и содержат разные же — и по габаритам, и по числу образуемых связей — нервные клетки. Более того: даже в пределах одного уровня одного и того же слоя активность разных нейронов может значительным образом различаться.
В частности, зрительная кора, благодаря которой в сознании формируется визуальная картина окружающего мира, составлена из весьма неоднородных клеток. У каждого из зрительных нейронов имеется своё рецептивное поле — участок с рецепторами, реагирующими на те или иные стимулы. Например, для ганглиозной клетки сетчатки глаза рецепторами служат знакомые по школьному курсу физиологии человека палочки и колбочки — клетки, реагирующие на силу воспринимаемого света и/или его спектральный состав. В свою очередь, определённая совокупность ганглиозных клеток работает в качестве рецептивного поля для нейрона, расположенного уже в зрительной коре головного мозга — в затылочной его части, довольно далеко от сетчатки. И критерии срабатывания этих нейронов довольно избирательны: к примеру, часть нейронов в зрительной зоне V1 возбуждается исключительно в ответ на появление в поле зрения вертикальных структур (сплошных линий — либо выстроенных по вертикали точек, штрихов и т. п.), а другая часть — только горизонтальных.
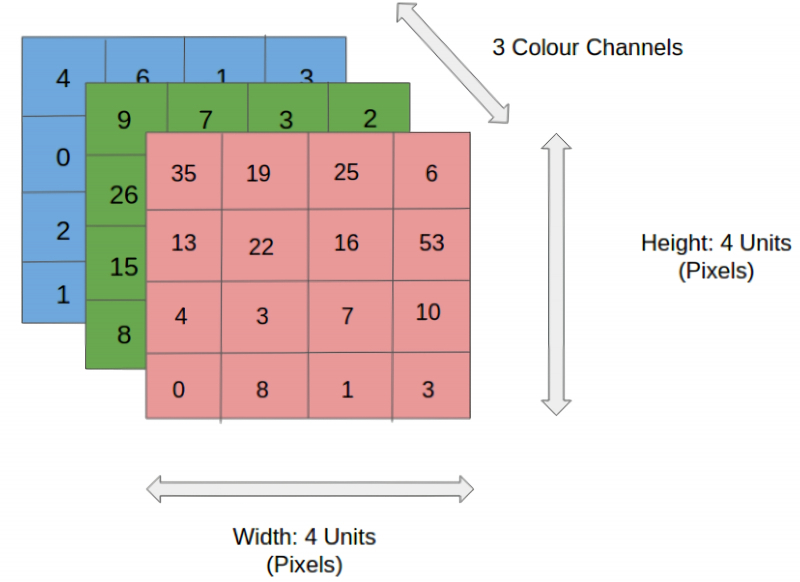
Кодирование цветного изображения 4 × 4 × 3 — с разбиением на квадрат 4х4 пискела и заданием трёх каналов цветности (источник: Saturn Cloud)
Помимо очевидного соображения «раз эволюция выбирает для обработки визуальных данных нейросети с понижением размерности в последующих слоях, это может оказаться наиболее эффективно», для предпочтения CNN машинным сетям унитарной размерности есть и другое обоснование, не менее убедительное: технико-экономическое. Допустим, некая квадратная цветная картинка в первом грубом приближении может быть закодирована всего 16 пикселами, — в сетке 4 × 4 (схожую задачу, только в обратную сторону, решают системы преобразования текстовых подсказок в изображения, вроде рассматривавшейся нами ранее Stable Diffusion: они мозаику из разноцветных крупных пятен преобразуют, постепенно добавляя в нужных местах нужного «шума», в идентифицируемое человеком изображение). Кстати, не стоит забывать, что для сохранения информации о цвете потребуется сформировать уже три матрицы 4 × 4 — для красного, зелёного и синего каналов. Таким образом, запись данных даже о столь грубо закодированной картинке будет представлена не 16, а 48 числами (кодировка 4 × 4 × 3, где первые два значения соответствуют размерности изображения, а последнее указывает на число цветовых каналов: если выбрать кодировку CMYK, последних станет уже 4).
Да, технически совсем не сложно преобразовать эти 48 чисел из матричного формата в векторный (из нескольких таблиц — в единый столбец) и подать получившуюся последовательность данных на вход унитарной полносвязной нейросети с обратным распространением ошибок — пусть выискивает там закономерности. Но с ростом габаритов исходной картинки задача становится всё менее подъёмной. Для кодирования обоев «Рабочего стола» в Full HD понадобится 1920 × 1080 × 3 ≈ 6,22 млн чисел — вот почему, кстати, формат BMP (картинки в котором примерно схожим неэкономным образом и сохранялись) к настоящему времени практически вышел из употребления: слишком уж непрактично тяжёлыми становятся представленные в таком виде файлы. Понятно теперь, что и нейросеть для обработки изображений в высоком разрешении — будь то классификация объектов на них или же, напротив, создание картинок по текстовым подсказкам — нуждается в понижении размерности; из соображений хотя бы разумной достаточности затрачиваемых на её функционирование вычислительных мощностей. Но каким именно образом производить это понижение?
⇡#Только не в трубочку!
Собственно, «свёрточная» в названии CNN как раз и указывает на способ, применяемый для понижения размерности слоёв нейросети и именуемый попросту свёрткой. Интуитивно ясно, что «свернуть» в приложении к данным значит не просто «сократить» (тогда логичнее было бы сказать «обрезать» или «округлить»), а «компактифицировать с сохранением наиболее важной информации». И вот каким образом это делают CNN.
Последовательное применение операции свёртки к одному из слоёв исходного оцифрованного изображения (источник: Saturn Cloud)
Пусть имеется исходная матрица значений — допустим, пикселы какого-то изображения — высокой размерности. В нашем примере — 5 × 5 (точнее, 5 × 5 × 1, — не будем забывать, что каждой позиции может соответствовать не просто число, но вектор, кодирующий некую дополнительную информацию). Для операции свёртки применяется так называемое ядро или фильтр (kernel/filter) — небольшая матрица весов, представленных обычно целыми числами. Точно так же, как веса на входах перцептронов, составляющие ядро весовые компоненты могут (и должны, в общем случае!) корректироваться в процессе работы нейросети методом обратного распространения ошибки, но пока для определённости примем, что ядро — фиксированная матрица 3 × 3 следующего вида:
Собственно свёртка заключается в:
- наложении ядра последовательно на исходную матрицу, начиная с верхнего левого угла,
- перемножении чисел в соответствующих ячейках, суммировании полученных результатов —
- и записи суммы в ячейку выходной матрицы, которая будет уже обладать заведомо меньшей размерностью, чем изначальная.
Квадрат 3 × 3 допускает перемещение по матрице 5 × 5 со сдвигом на одну позицию (без выхода за её пределы) ровно три раза и по горизонтали, и по вертикали — потому в рассматриваемом примере выходная матрица будет иметь размерность 3 × 3. Если бы при том же ядре (3 × 3) исходная матрица была 7 × 7, выходная получила бы уже размерность 5 × 5.
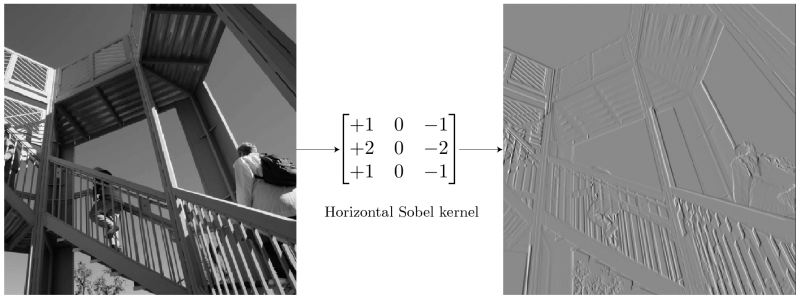
Классический фильтр Собеля производит свёртку исходного изображения по одному из измерений, явственно выделяя края вытянутых в этом же измерении структур (источник: TowardsDataScience)
Сегодня практически у каждого под рукой, а именно в предустановленном почти на любой смартфон простеньком фоторедакторе, имеется аналоговый свёрточный фильтр Собеля — средство для усиления границ объектов на изображении. В частности, горизонтальный фильтр Собеля представляет собой матрицу
при умножении исходного изображения (в оцифрованном виде, конечно) на которую пропадают малоконтрастные детали, а резкие границы ещё более усиливаются. Причина в том, что в ходе такой операции соседние пикселы — ячейки исходной матрицы — с примерно равными величинами (в данном случае яркости) после свёртки с матрицей-фильтром дают на выходе близкие к нулю значения, а если соседние значения в ячейках сильно разнились, то в результате эта разница окажется существенно усиленной.
Собственно, в этом и состоит цель свёртки: не просто понизить размерность изначальной матрицы в целях снижения вычислительной нагрузки на аппаратную часть системы, — но выявить в исходном массиве данных некие закономерности, причём в различных каналах (т. е. на каждом этапе свёртка производится не с одним, а с несколькими фильтрами, и далее эти потоки данных — каналы — обрабатываются раздельно). Очередная операция свёртки преобразует входной массив данных в очищенный линейный блок (rectified linear unit, ReLU), что представляет собой карту усиленных (за счёт отбрасывания всего малозначимого; отсюда термин «очищенный») отличительных особенностей этого массива, в которой с каждой итерацией всё более и более явно проступают нелинейные связи между её компонентами.
Если исходное изображение оцифровано трёхканальной матрицей M × N × 3, для корректной свёртки могут потребоваться разные фильтры для каждого из цветокодирующих каналов (источник: Saturn Cloud)
Однако не следует забывать, что интерпретировать сколько-нибудь явным (постижимым для человеческого сознания) образом результаты свёртки имеет смысл лишь в том случае, когда эта операция применяется к самой первой матрице данных — в рассматриваемом примере к оцифрованному и разбитому на пикселы изображению. Современные же нейросети существенно многослойны, и, когда операция свёртки выполняется для одного из глубинных (скрытых) слоёв модели, да ещё и с применением фильтра со скорректированными в процессе обратного распространения ошибки весами, уже по сути невозможно зафиксировать смысловое наполнение получаемых в итоге этой операции величин. На этом, собственно, и основано предложение сопоставлять работу ИИ с интуицией и наитием, а не со строго логичными операциями естественного интеллекта.
Помимо свёртки с понижением размерности и единичным сдвигом фильтра по исходной матрице применяются и другие операции, такие как сдвиг с перескоком ядра на 2 ячейки (в этом случае может потребоваться дополнение исходной матрицы строками и/или столбцами с нулевыми значениями, чтобы соблюсти размерность) и даже «раздувание» — своего рода обратная свёртка, на выходе которой получается матрица большей размерности. Свёрточная арифметика — существенно важная для области глубокого машинного обучения дисциплина, но углубляться в неё в рамках обзорной статьи было бы излишним.
Если исходное изображение оцифровано трёхканальной матрицей M × N × 3, для корректной свёртки могут потребоваться разные фильтры для каждого из цветокодирующих каналов (источник: Saturn Cloud)
Поскольку сами свёрточные слои располагаются один за другим последовательно (переложенные слоями группировки, речь о которых пойдёт чуть ниже), это позволяет выявлять в исходном массиве данных скрытые закономерности всё более высокого уровня — от обнаружения пары горизонтальных и пары вертикальных отрезков переходить к отождествлению изображённого на картинке квадрата, например. Грубо говоря, схожий принцип лежит в основе процесса устойчивого размывания (stable diffusion), благодаря которому нейросеть сперва обучают ставить в соответствие термину «квадрат» (точнее, кодирующему его набору токенов) вполне определённые веса на свёрточных матрицах, а затем инвертируют процесс — так что из исходной мешанины разноцветных пятен по соответствующей подсказке за несколько итераций проступает вполне геометрически правильная фигура.
После свёртки отдельные слои в ИИ-модели подвергаются несколько иной, хотя во многом и схожей операции — объединению, или группировке (pooling). Вместо того чтобы — как в случае свёртки — поэлементно перемножать фрагмент исходной матрицы на весовые коэффициенты фильтра и затем суммировать полученное, при группировке производится вычисление некой статистической функции для фрагмента исходной матрицы, покрытого фильтром-ядром. Эта функция чаще всего оказывается простым «максимальным значением»: если выборка 3 × 3 выделила такой вот фрагмент матрицы —
— то «максимальным значением» для взятых таким образом элементов в данном случае окажется «3» (а если бы хотя бы в одной ячейке оказалась четвёрка — тогда было бы «4»). Можно применять и более ресурсоёмкую функцию — вычисление среднего. Суть процедуры группировки заключается, во-первых, в понижении размерности матрицы (что опять-таки облегчает нагрузку на аппаратную часть ИИ-системы), а во-вторых — в более эффективном, чем у свёртки, выявлении инвариантных признаков представленного исходной матрицей объекта. Грубо говоря, если прямоугольное окно показано на оцифрованной картинке в перспективе, да ещё и снято под углом (dutch angle shot), для отождествления такого объекта нейросетью именно как окна одних свёрточных слоёв потребуется в общем случае больше, чем если комбинировать их с группировочными. Объединение в целом оптимизировано для обнаружения обобщённых и высокоуровневых признаков, не сводимых к простым геометрическим закономерностям, — с последним как раз лучше справляется свёртка.
Операция группировки с выборкой максимального значения в каждом из фрагментов исходной матрицы, покрываемом на очередном шаге фильтром (источник: Saturn Cloud)
Обыкновенно в системах машинного обучения, ориентированных на распознавание образов, свёрточные и группировочные слои в каждом канале располагаются парами, причём число таких пар может быть весьма велико. В результате на каждом уровне обработки исходной матрицы (разбитого на пикселы изображения) исходная картинка порождает абстракции всё более высокого уровня, отбрасывая несущественные детали — включая шум, незначительные цветовые градиенты и даже частичное затенение/перекрытие. Скажем, античная колонна, видимая сквозь ветви деревьев, будет в итоге классифицирована благодаря свёрткам — и в особенности группировкам — именно как единый цельный объект заднего плана. Однако чтобы разглядеть «образ античной колонны» в ячейках соответствующей матрицы в глубине свёрточной нейросети, представленный в виде целого ряда заполненных числами таблиц, любопытствующему энтузиасту понадобятся сверхспособности — вроде тех, которыми обладали «натуральные» (рождённые вне Матрицы) операторы из культовой киносаги братьев Вачовски.
⇡#Что здесь?
В приведённом примере с нейросетью, ориентированной на распознавание визуальных образов, структура самой этой сети разделена на два крупных блока: «выявление особенностей» (feature learning) и собственно «категоризация» (classification). Причём если над выявлением особенностей трудится многослойная подсеть из пар свёрточных и группировочных слоёв, то классификацией занимается тоже многослойная, но уже унитарная полносвязная подсеть, в которой каждый слой образован одним и тем же числом перцептронов. «Полносвязная» в данном случае означает, что выходы каждого из перцептронов предыдущего слоя передают сигналы на входы каждого из искусственных нейронов последующего.
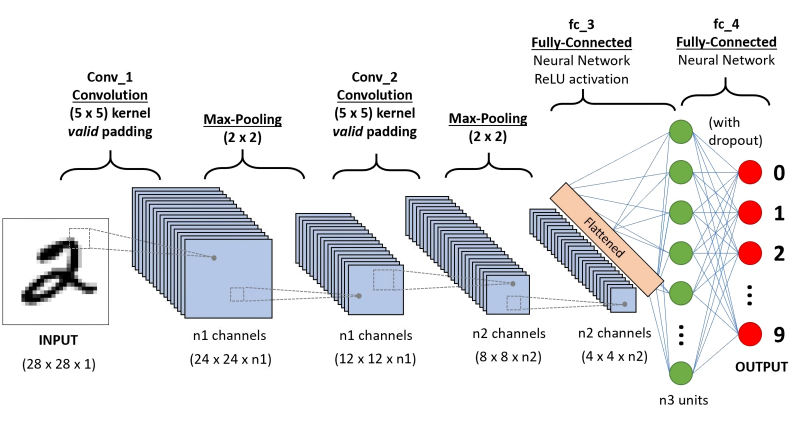
Принципиальная схема CNN, применяемой для распознавания рукописных цифр: после двукратного повторения операций свёртки и выборки во множестве каналов выдача «уплощается» из матрицы в вектор и передаётся на вход полносвязной плотной нейросети (источник: Saturn Cloud)
Строго говоря, такая полносвязная сеть и сама в состоянии заниматься уверенным распознаванием образов, — в предыдущем материале на эту тему мы для примера рассматривали устройство именно такой сети с обратным распространением ошибок, занятой идентификацией рукописной тройки. Другое дело, что для крупных, высокодетализированных изображений распознавание через полносвязную унитарную сеть обойдётся слишком дорого — и по времени, и по затраченным аппаратным ресурсам, и по расходу электроэнергии. Блок выявления особенностей, производящий раз за разом операции свёртки и группировки, нужен именно для того, чтобы самым существенным образом понизить размерность исходного массива данных, сохранив притом всю содержавшуюся в нём ключевую информацию (в закодированном, многократно преобразованном виде, конечно).
И вот уже этот высокорафинированный (многократно ректифицированный, если вспомнить о ReLU) набор данных подаётся на вход полносвязной нейросети, отлично справляющейся с задачей классификации по существенно разнородным признакам, — как и было продемонстрировано нами ранее. Причём здесь не имеет значения, каких размеров был исходный массив: полносвязная нейросеть в любом случае будет работать с одномерным и сравнительно недлинным вектором данных. Получается он крайне незамысловато: допустим, исходное изображение обрабатывалось в блоке выявления особенностей по 50 каналам, каждый из которых на выходе серии операций свёртки и группировки выдал по одной матрице 3 × 3. Эти матрицы преобразуются в векторы (первая ячейка в первой строке становится первым элементов вектора, последняя — третьим, первая во второй строке — четвёртым и т. д.), а затем векторы точно так же прямолинейно выстраиваются в один общий — размерностью в данном случае 450 × 1. Дальнейший процесс классификации на полносвязной нейросети с обратным распространением ошибок должен уже быть в общих чертах знаком нашим читателям.
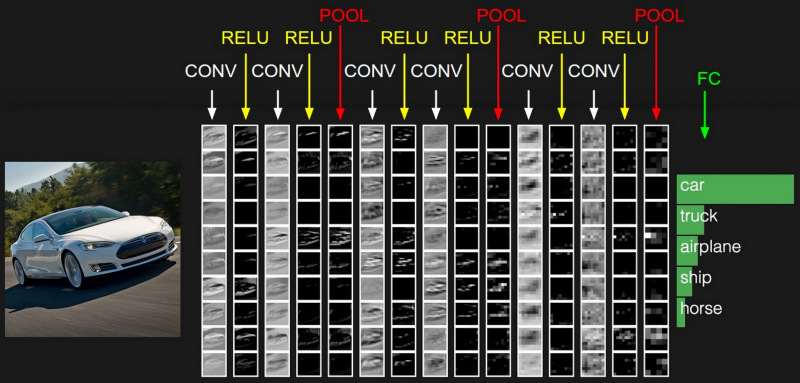
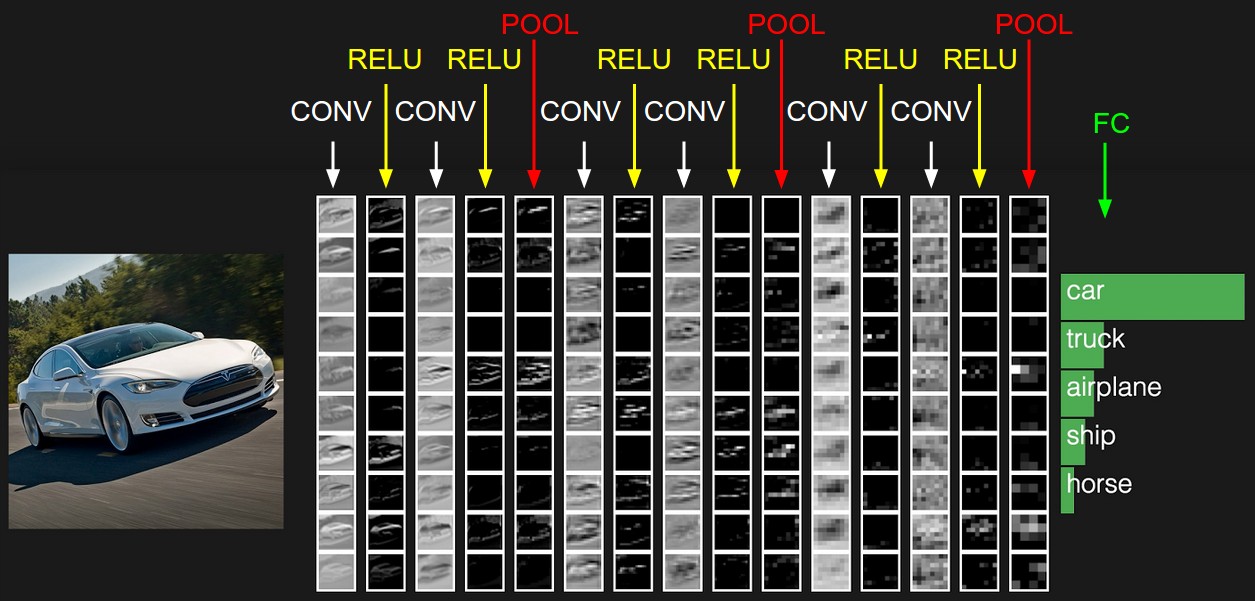
Попытка постичь, какие именно закономерности выявляет нейросеть в исходной картинке, за счёт визуализации (превращения матриц в изображения по пикселам) на каждом шаге работы CNN: свёртка (CONV), очистка (RELU), группировка (POOL) — и на выходе классификация полносвязной (fully connected, FC) подсетью (источник: Stanford University)
Свёрточные сети в течение многих лет исправно служили делу машинного зрения, поскольку ранее для выявления важнейших особенностей изображений применялись статичные инструменты, вроде упомянутого ранее фильтра Собеля. CNN же с обратным распространением ошибок для тонкой настройки фильтров в процессе обучения дали возможность, в частности, автоматизировать выявление определённых объектов на фото/видео, — причём делать это на сравнительно скромной аппаратной базе, включая интегрированные чипы не самых дорогостоящих веб-камер. Однако в последнее время у них появилось ещё более впечатляющее (по крайней мере, для заметной части интернет-аудитории) приложение: работа в составе генеративно-состязательных сетей (generative adversarial networks, GAN). Тех самых, что после обучения на обширном массиве аннотированных визуальных данных становятся способны сами создавать изображения объектов реального либо фантастического мира — с человеческой точки зрения вполне достоверные. Ну или абстрактные/сюрреалистичные, но ровно в той степени, в какой этого ожидает составивший соответствующую текстовую подсказку оператор.
Наиболее общим образом генеративное моделирование — кстати, не так уж и важно, чего именно: изображений, видеоряда, звуков или текстов — определяется как результат автоматизированного (т. е. реализуемого в ходе машинного обучения в отсутствие учителя, unsupervised learning) выявления неких закономерностей в большом массиве входных данных с последующим применением полученной модели для порождения настолько правдоподобных с точки зрения человека-оператора объектов аналогичной природы, что они могли бы быть включены им в исходный массив тренировочной информации. Звучит несколько уроборосно, но по сути так оно и есть: цель генеративного моделирования — машинное порождение таких сущностей (для определённости — картинок), которые, на взгляд человека, оказались бы неотличимы от созданных другими людьми.
Действительно, генеративный ИИ, однажды натренированный с получением фиксированной модели (определённого набора весов на входах всех своих перцептронов, — того, что в ИИ-рисовании принято называть чекпойнтом), прекрасно справляется с самостоятельным — в отсутствие дополнительного стороннего надзора — рисованием картинок по текстовым подсказкам: в этом читатели соответствующих «Мастерских» могли убедиться на собственном опыте. Но вот чтобы такой чекпойнт натренировать, необходимо уже обучение с учителем (supervised learning) в рамках упомянутой чуть выше генеративно-состязательной сети. Оно подразумевает деятельную совместную — да вдобавок ещё и состязательную! — работу двух ИИ-моделей, выступающих соответственно в ролях творца (generator) и критика (discriminator).
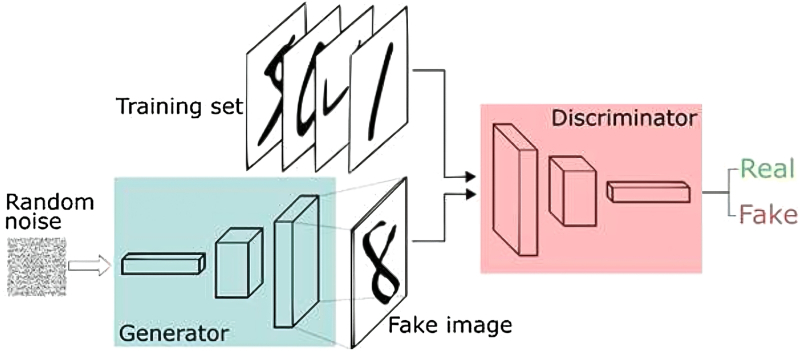
Структура типичной GAN: на вход предварительно натренированного генератора подаётся белый шум, на основе которого создаётся «поддельный» (не входивший в тренировочный набор данных) образ, — а дискриминатор, анализируя тот же исходный набор (но не прямым перебором, а тоже как нейросеть), решает, фейковую ему предложили картинку или нет (источник: Journal of Real-Time Image Processing)
Генератор натренировывается на создание новых образов на основе переработки исходного массива данных; дискриминатор же пытается распознать, принадлежит очередное полученное генератором изображение к обучающему пулу — или разительно отличается от него. Окончанием обучения обычно считается момент, когда критик начинает принимать за априори входящие в исходный массив картинки более половины из тех, что создаёт творец. То бишь в данном случае «обучение с учителем» подразумевает участие не живого оператора, а ещё одной ИИ-модели, задача которой — проверять, успешен ли генератор в создании обманчиво правдоподобных изображений. Или синтезированных под человеческий голос фраз, или притворяющихся авторскими текстов, — словом, всего, что поддаётся оцифровке для формирования первичного (тренировочного) пула данных. Важно, что обе модели в составе GAN обучаются одновременно: как генератор со временем становится успешнее в создании походящих на исходные сущностей, так и дискриминатор — в выявлении недостоверных.
Так вот, одним из наиболее распространённых подходов при построении GAN стала архитектура глубоких свёрточных генеративно-состязательных сетей (deep convolutional generative adversarial networks, DCGAN). Достоинство её в том, что DCGAN ощутимо снижает вероятность обрушения режима (коллапса режима, mode collapse) в ситуации, когда разброс вариативности выдач генератора оказывается значительно ýже, чем широта исходного набора данных по некоторому параметру. Это своего рода аналог перетренировки перцептронной модели, о которой шла речь в одном из прежних наших материалов: если в ответ на текстовую подсказку «собака» чекпойнт, которому добросовестно скармливали в процессе обучения множество изображений самых разных пород, с вероятностью 0,6 рисует шарпеев, а с вероятностью 0,4 — колли, это прямое свидетельство обрушения режима. Загвоздка здесь в том, что, поскольку тренировка генератора производится в отсутствие человеческого присмотра, а машина на данном этапе технологической эволюции всё-таки не мыслит, mode collapse автоматически крайне сложно отловить: дискриминатор ведь исправно подтверждает, что получаемые им для проверки изображения шарпеев и колли вполне адекватны имеющимся в тренировочной базе.
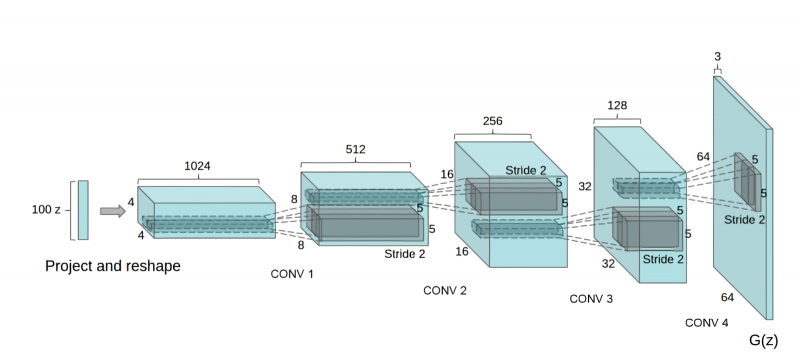
Архитектура генератора DCGAN напоминает запущенную в обратную сторону CNN для распознавания образов (источник: GeeksForGeeks)
Суть архитектуры DCGAN заключается в том, что на вход дискриминатора образцы для контроля подаются не поодиночке, а небольшими группами, а структура этой нейронной сети организована таким образом, что на каждом шаге свёртки размерность обрабатываемых матриц увеличивается, а число каналов параллельной обработки сокращается. В целом дизайн дискриминатора напоминает устройство самой обычной свёрточной нейросети — с рядом специфических особенностей вроде того, что шаг сдвига фильтра (convolutional stride) вместо типичной для сетей распознавания образов единицы обычно принимается равным двум, что позволяет эффективнее отбрасывать незначительные детали и выявлять более общие закономерности в исследуемом изображении.
Работа нейронной сети, порождающей некие воспринимаемые человеком сущности, в первом приближении сводится к двум операциям — кодированию и декодированию; сжатию информации и развёртыванию полученной компактной формы до итогового изображения, текста, набора звуков и пр. Но, в отличие от алгоритмической архивации (когда исходный массив данных без потерь информации уменьшается в объёме, а затем восстанавливается), в процессе отсечения нейросетью всего лишнего порождается латентное (скрытое) пространство сущностей, в котором сохраняется лишь наиболее существенная информация — и полностью игнорируется любой шум.

Затравочное изображение, проходя через генеративную ИИзобразительную нейросеть, постепенно словно бы освобождается от излишнего шума — в соответствии с текстовым описанием (источник: ИИ-генерация на основе модели SDXL 1.0)
Сохраняется, например, понятие о «собаке в общем» — точнее, интуитивное понимание сути этого термина, сформированное у модели в процессе обучения, — а в конкретное изображение пса той или иной породы в том или ином ракурсе и антураже оно преобразуется уже псевдослучайным образом в процессе декодирования — восстановления с применением, в частности, свёрточной нейросети.
Так что если бы не эти сети — кто знает, могли бы мы сегодня с такой же лёгкостью извлекать из латентного пространства всё то, чему имеем возможность удивляться, радоваться и даже чем можем возмущаться сейчас?
Сверточные нейронные сети с нуля
Используем NumPy для разработки сверточной нейронной сети.
13 min read
Feb 26, 2019
Внимание! Данная статья является переводом. Оригинал можно найти по этой ссылке.
Когда Ян ЛеКун опубликовал свою работу, посвященную новой нейросетевой архитектуре [1], получившей название CNN (Convolutional Neural Network), она не произвела достаточного впечатления на мир науки и техники и долгое время оставалась незамеченной. Потребовалось 14 лет и огромные усилия команды исследователей из Торонтского университета, чтобы донести до общества всю ценность открытий Яна ЛеКуна.
Все изменилось в 2012 году, когда состоялись соревнования по компьютерному зрению на основе базы данных ImageNet. Алекс Крижевский и его команда разработали сверточную нейронную сеть, которая способна классифицировать миллионы изображений из тысяч различных категорий с ошибкой всего в 15.8% [2].
В наше время сверточные сети развились до такого уровня, что они превосходят человеческие способности! [3] Взгляните на статистику на рис. 1.
Результаты многообещающие. Меня это настолько вдохновило, что я решил в деталях изучить, как функционируют сверточные нейронные сети.
Ричард Фейнман как-то отметил: “Я не могу понять то, что не могу построить”. Вот я и “построил” с нуля сверточную нейронную сеть на Python, чтобы самостоятельно “прощупать” все интересующие меня моменты. Как только я закончил с программированием, стало ясно, что нейронные сети не настолько и сложные, как это кажется на первый взгляд. Вы сами в этом убедитесь, когда пройдете со мной этот путь от начала и до конца.
Весь код, который я буду приводить в этой статье, можно найти здесь.
Задача
Сверточные сети отличаются очень высокой способностью к распознаванию паттернов на изображениях. Поэтому и задача, рассматриваемая в этой статье, будет касаться классификации изображений.
Один из самых распространенных бенчмарков для оценки скорости работы алгоритма компьютерного зрения является его обучение на базе данных MNIST. Она представляет из себя коллекцию из 70 тыс. написанных от руки цифр (от 0 до 9). Задача заключается в разработке настолько точного алгоритма распознавания цифр, насколько это возможно.
После примерно пяти часов обучения, за которые удалось охватить две эпохи, нейронная сеть, представленная далее, способна определить рукописную цифру с точностью до 98%. Это означает, что почти каждая цифра будет определена верно, что есть хорошим показателем.
Давайте по отдельности рассмотрим компоненты, формирующие сверточную нейронную сеть, и объединим эти знания, чтобы в конечном итоге понять, каким образом формируются предсказания. После рассмотрения каждого компонента мы запрограммируем нейронную сеть на Python с использованием библиотеки NumPy и обучим ее. (Готовый код можно найти тут.)
Важно сообщить, что для успешного прохождения всех этапов вам нужно иметь хотя бы общее представление о линейной алгебре, вычислениях и языке программирования Python. Если вы в какой-то из областей чувствуете себя не очень уверенно, можно отступить немного в сторону и укрепить свои знания, а после вернуться к этой статье.
По линейной алгебре я рекомендую вот эту публикацию. В ней простым языком описано все, что нужно знать об алгебре для решения задач машинного обучения. А тут вы сможете быстро научиться программировать на Python.
Если вы готовы, давайте двигаться дальше.
Как обучаются сверточные нейронные сети
Свертки
Сверточные нейронные сети работают на основе фильтров, которые занимаются распознаванием определенных характеристик изображения (например, прямых линий). Фильтр — это коллекция кернелов; иногда в фильтре используется один кернел. Кернел — это обычная матрица чисел, называемых весами, которые “обучаются” (подстраиваются, если вам так удобнее) с целью поиска на изображениях определенных характеристик. Фильтр перемещается вдоль изображения и определяет, присутствует ли некоторая искомая характеристика в конкретной его части. Для получения ответа такого рода совершается операция свертки, которая является суммой произведений элементов фильтра и матрицы входных сигналов.
Для лучшего понимания самых базовых концепций рекомендую взглянуть на эту статью. В ней вы найдете более подробное описание всех этих штуковин.
Если некоторая искомая характеристика присутствует во фрагменте изображения, операция свертки на выходе будет выдавать число с относительно большим значением. Если же характеристика отсутствует, выходное число будет маленьким.
На рисунках 4 и 5 приведен пример, наглядно представляющий операцию свертки. Фильтр, ответственный за поиск левосторонних кривых, перемещается вдоль исходного изображения. Когда рассматриваемый в данный момент фрагмент содержит искомую кривую, результатом свертки будет большое число (6600 в нашем случае). Но когда фильтр перемещается на позицию, где нет левосторонней кривой, результатом свертки выступает маленькое число (в нашем случае — нуль).
Надеюсь, что на данном этапе вам все понятно. Ведь это центральная идея, вокруг которой все крутится в мире сверточных нейронных сетей. Ее понимание открывает для вас большие возможности по разработке сколько угодно сложных систем анализа данных.
Результатом перемещения данного фильтра вдоль всего изображения есть матрица, состоящая из результатов единичных сверток.
Следует обратить внимание на то, что количество каналов фильтра должно соответствовать количеству каналов исходного изображения; только тогда операция свертки будет производить должный эффект. Например, если исходная картинка состоит из трех каналов (RGB: Red, Green, Blue), фильтр также должен иметь три канала.
Фильтр может перемещаться вдоль матрицы входных сигналов с шагом, отличным от единицы. Шаг перемещения фильтра называется страйдом (stride). Страйд определяет, на какое количество пикселов должен сместиться фильтр за один присест.
Количество выходных значений после операции свертки может быть рассчитано по формуле 1. Где n_in — кол-во входных пикселов, f — кол-во пикселов в фильтре, s — страйд. Для примера на рис. 6 даную формулу следует применить таким образом: (25-9)/2+1=3 .
Для того, чтобы обучение весов, заключенных в кернелах, было эффективным, в результаты сверток следует ввести некоторое смещение (bias) и нелинейность.
Смещение — это статическая величина, на которую следует “сместить” выходные значения. По своей сути это обычная операция сложения каждого элемента выходной матрицы с величиной смещения. Если объяснять очень поверхностно, это нужно для того, чтобы вывести нейронную сеть из тупиковых ситуаций, имеющих сугубо математические причины.
Нелинейность представляет из себя функцию активации. Благодаря ней картина, формируемая с помощью операции свертки, получает некоторое искажение, позволяющее нейронной сети более ясно оценивать ситуацию. Эту необходимость очень грубо можно сравнить с необходимостью людям со слабым зрением носить контактные линзы. А вообще-то такая необходимость связана с тем, что входные данные по своей природе нелинейны, поэтому нужно умышленно искажать промежуточные результаты, чтобы ответ нейронной сети был соответствующим.
Часто в качестве функции активации используют ReLU (Rectified Linear Unit). Ее график изображен на рис. 7.
Как вы можете видеть, эта функция довольно-таки проста. Входные значения, меньшие или равные нулю, превращаются в нуль; значения, превышающие нуль, не изменяются.
Обычно в сверточных слоях используется более одного фильтра. Когда это имеет место, результаты работы каждого из фильтров собираются вдоль некоторой оси, что в результате дает трехмерную матрицу выходных данных.
Программирование сверток
Благодаря библиотеке NumPy программирование сверток не составит большого труда.
На самом верхнем уровне будет находиться цикл for, который будет применять фильтры к исходному изображению. В рамках каждой итерации будет использовано два цикла while, которые будут перемещать фильтр вдоль изображения (горизонтально и вертикально).
На каждом этапе будет получено поэлементное произведение пикселов фильтра и фрагмента изображения (оператор * ). Результирующая матрица будет посредством суммирования схлопнута в число, к которому будет прибавлено смещение (bias).
Благодаря максимальному объединению уменьшается количество пикселов, что в свою очередь приводит к уменьшению количества выполняемых программой операций, и, соответственно, к экономии вычислительных ресурсов.
Количество выходных пикселов после применения максимального объединения можно рассчитать по формуле 2. В этой формуле n_in — количество входных пикселов, f — количество пикселов просеивающего окна, s — величина страйда.
Операция максимального объединения имеет и некоторые другие побочные эффекты позитивного характера. Благодаря ней нейронная сеть способна концентрироваться на действительно весомых характеристиках изображения, отбрасывая несущественные детали. Также нейронная сеть становится менее подверженной переобучению, что часто становится весьма трудоемкой проблемой.
Программирование “максимального объединения”
Реализация операции максимального объединения сводится к применению цикла for на самом верхнем уровне, в рамках которого будут присутствовать два цикла while. Цикл for нужен для того, чтобы перебрать все каналы изображения. Задача же циклов while заключается в перемещении “просеивающего окна” вдоль изображения. На каждом этапе отбора пиксела захваченного фрагмента матрицы будет применена функция max, входящая в состав библиотеки NumPy с целью поиска максимального значения.
Из рисунка видно, что операция развертывания заключается в “склеивании” строк в единый — огромной длины — числовой ряд. Это будет поистине большой вектор, который нужно будет еще и преобразовать с помощью многослойной сети с полными связями!
Если вы не знаете, как работает полносвязный слой, вот простое описание механизма: каждый элемент вектора умножается на вес связи, эти произведения далее суммируются между собой и с некоторым смещением, после чего результат подвергается преобразованию с помощью функции активации. На рис. 10 описанное представлено в наглядной форме.
Стоит отметить, что Ян ЛеКун в этом посте на Фейсбуке сказал, что “в сверточных нейронных сетях нет такого понятия, как полносвязный слой”. И он совершенно прав! Если внимательно присмотреться, то станет совершенно очевидно, что принцип работы полносвязного слоя аналогичен тому, что имеет место в сверточном слое с кернелом размерностью 1×1. То есть, если в нашем распоряжении 128 фильтров размерностью n×n, которые будут взаимодействовать с изображением размерностью n×n, на выходе мы получим вектор, в котором будет 128 элементов.
Программирование полносвязного слоя
P.S. В оригинальной статье существуют попытки разделения понятий “fully connected layer” и “dense layer”. В действительности же данные понятия являются синонимами. Хорошее объяснения этих (и некоторых других) “скользких” понятий приведено на этом форуме. (Простите, но там все на английском.)
Благодаря NumPy программирование полносвязного слоя — задача чересчур простая. Как видно из нижеприведенного сниппета, будет достаточно всего нескольких строк кода. (Обратите внимание на метод reshape; он всегда облегчает жизнь программистам нейронных сетей.)
Программирование функции активации
Как и всегда, благодаря NumPy задача будет решена в несколько строчек кода.
В формуле 4 ŷ — фактический ответ нейронной сети, y — желаемый ответ нейронной сети. Ответом в нашем случае является некоторое число; в более широком смысле ответ представляет категорию. Для получения общего показателя потерь, характерного для всех категорий в целом, берут среднее от значений по каждой категории.
Программирование функции потерь
Код реализации CCELF невероятно прост.
Программирование нейронной сети
Давайте следовать представленной выше архитектуре и воплощать ее в жизнь слой за слоем.
Вы также можете воспользоваться готовым кодом из моего репозитория.
Шаг 1. Извлечение данных
Коллекцию тренировочных и контрольных рукописных цифр вы сможете найти тут. Файлы из этой коллекции хранят изображения и соответствующие им маркеры в виде тензоров. Благодаря этому работа с данными, по сравнению с реальными изображениями, значительно упрощается.
Для извлечения данных из файлов мы воспользуемся такими функциями:
Во время выполнения команды терминал будет показывать прогресс и нагрузку (в пределах данного пакета обучения).
На моем MacBook Pro обучение нейронной сети заняло примерно 5 часов. Обученные параметры уже есть на GitHub под именем params.pkl .
Для оценки эффективности нейронной сети запустите в терминале такую команду:
python3 measure_performance.py '.pkl'
Вместо укажите имя файла с параметрами обученной нейронной сети. Если хотите использовать полученные мною параметры, укажите имя params .
Как только вы запустите эту команду, все 10 тыс. примеров из контрольного множества будут использованы для испытания нейронной сети. Значение, характеризующее эффективность сети, будет отображено в терминале, как это показано на рис. 14.
Забыл выше упомянуть, что для установки всех зависимостей в моей кодовой базе нужно воспользоваться командой, приведенной ниже. Надеюсь, что это не слишком поздно. 🙂
pip install -r requirements.txt
Результаты
После двух эпох обучения эффективность нейронной сети приблизилась к 98%, что является вполне достойным результатом. После того, как я увеличил число эпох до 3, я обнаружил, что эффективность сети начала падать. Думаю, что такое происходит по той причине, что сеть перенасыщается тренировочными данными и теряет способность к обобщению информации. Лучшее решение этой проблемы — увеличение тренировочного множества.
Обратите внимание на то, как скачет график производительности компьютера. Так происходит потому, что обработка данных в процессе обучения сети производится пакетно.
Для оценки обученных параметров нейронной сети следует оценить ее память. Это даст понимание того, насколько хорошо сеть способна решать поставленную задачу классификации. Это, по сути, и является оценкой эффективности нейронной сети. Память — это характеристика точности определения класса.
Вот вам наглядный пример:
В контрольном множестве определенное количество семерок (можете воображать любую цифру). Как много правильных ответов дала нейронная сеть, пытаясь определить, что каждое из предоставленных образов является семеркой?
График на рис. 16 показывает характеристику памяти нейронной сети для каждой цифры.
Приведенный выше график показывает, что разработанная нами нейронная сеть обучилась определять каждый класс почти со стопроцентной достоверностью.
Заключение
Надеюсь, что эта статья позволила вам получить наглядное представление о том, как работают сверточные нейронные сети. Если что-то осталось для вас непонятным или трудным для понимания, пишите об этом в комментариях. 🙂
Ссылки
[1]: Lecun, Y., et al. “Gradient-Based Learning Applied to Document Recognition.” Proceedings of the IEEE, vol. 86, no. 11, 1998, pp. 2278–2324., doi:10.1109/5.726791.
[2]: Krizhevsky, Alex, et al. “ImageNet Classification with Deep Convolutional Neural Networks.” Communications of the ACM, vol. 60, no. 6, 2017, pp. 84–90., doi:10.1145/3065386.
[3]: He, Kaiming, et al. “Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification.” 2015 IEEE International Conference on Computer Vision (ICCV), 2015, doi:10.1109/iccv.2015.123.
Спасибо всем, кто поддерживает мою деятельность переводчика. Надеюсь, этот материал позволит вам глубже понять эти удивительные нейронные сети.
Свёрточные нейронные сети (CNN / ConvNets)

Свёрточные нейронные сети очень похожи на обычные нейронные сети, которые мы изучали в прошлой главе (отсылка к прошлой главе курса CS231n): они состоят из нейронов, которые, в свою очередь, содержат изменяемые веса и смещения. Каждый нейрон получает какие-то входные данные, вычисляет скалярное произведение и, опционально, использует нелинейную функцию активации. Вся сеть по-прежнему представляет собой единственную дифференциируемую функцию оценки: из исходного набора пикселей (изображения) на одном конце до распределения вероятностей принадлежности к определённому классу на другом конце. У этих сетей по-прежнему есть функция потерь (например, SVM/Softmax) на последнем (полносвязном) слое и все те советы и рекомендации, которые были даны в предыдущей главе относящейся к обычным нейронным сетям, актуальны и для свёрточных нейронных сетей.
Так что же изменилось? Архитектура свёрточных нейронных сетей явно предполагает получение на входе изображений, что позволяет нам учесть определённые свойства входных данных в самой архитектуре сети. Эти свойства позволяют реализовать функцию прямого распространения эффективнее и сильно уменьшают общее количество параметров в сети.
Обзор архитектуры
Вспоминаем обычные нейронные сети. Как мы уже видели в предыдущей главе, нейронные сети получают входные данные (единственный вектор) и преобразовывают его «проталкивая» через серию скрытых слоёв. Каждый скрытый слой состоит из определённого количества нейронов, каждый из которых связан со всеми нейронами предыдущего слоя и где нейроны на каждом слое полностью независимы от других нейронов на этом же уровне. Последний полносвязный слой называется «выходным слоем» и в задачах классификации представляет собой распределение оценок по классам.
Обычные нейронные сети плохо масштабируются для бОльших изображений. В наборе данных CIFAR-10, изображения размером 32х32х3 (32 пикселя высота, 32 пикселя ширина, 3 цветовых канала). Для обработки такого изображения полносвязный нейрон в первом скрытом слое обычной нейронной сети будет иметь 32х32х3 = 3072 весов. Такое количество всё ещё является допустимым, но становится очевидным тот факт, что подобная структура не будет работать с изображениями бОльшего размера. Например, изображение большего размера — 200х200х3, приведёт к тому, что количество весов станет равным 200х200х3 = 120 000. Более того, нам понадобится не один подобный нейрон, поэтому общее количество весов быстро начнёт расти. Становится очевидным тот факт, что полносвязность чрезмерна и большое количество параметров быстро приведут сеть к переобученности.
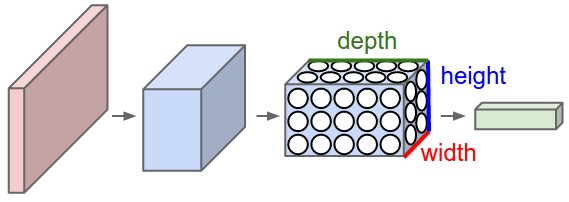
3D-представления нейронов. Свёрточные нейронные сети используют тот факт, что входные данные — изображения, поэтому они образуют более чувствительную архитектуру к подобному типу данных. В частности, в отличие от обычных нейронных сетей, слои в свёрточной нейронной сети располагают нейроны в 3 измерениях — ширине, высоте, глубине (Заметка: слово «глубина» относится к 3-му измерению активационных нейронов, а не глубине самой нейронной сети измеряемой в количестве слоёв). Например, входные изображения из набора данных CIFAR-10 являются входными данными в 3D-представлении, размерность которых равна 32х32х3 (ширина, высота, глубина). Как мы увидим позднее, нейроны в одном слое будут связаны с небольшим количеством нейронов в предыдущем слое, вместо того чтобы быть связанными со всеми предыдущими нейронами слоя. Более того, выходной слой для изображения из набора данных CIFAR-10 будет иметь размерность 1х1х10, потому что подбираясь к концу нейронной сети мы уменьшим размер изображения до вектора оценок по классам, расположенного вдоль глубины (3-го измерения).
| Стандартная нейронная сеть | Свёрточная нейронная сеть |
|---|---|
 |
 |
С левой стороны: стандартная 3-х слойная нейронная сеть.
С правой стороны: свёрточная нейронная сеть располагает свои нейроны в 3-х измерениях (ширине, высоте, глубине), как это показано на одном из слоёв. Каждый слой свёрточной нейронной сети преобразует 3D-представление входных данных в 3D-представление выходных данных в виде нейронов активации. В этом примере красный входной слой содержит изображение, поэтому его размеры будут равны размерам изображения, а глубина будет равна 3 (три канала — red, green, blue).
Свёрточная нейронная сеть состоит из слоёв. Каждый слой представляет собой простой API: преобразует входное 3D-представление в выходное 3D-представление некой дифференциируемой функцией, которая может содержать, а может и не содержать параметров.
Слои, используемые для построения свёрточных нейронных сетей
Как мы уже описали выше, простая свёрточная нейронная сеть это набор слоёв, где каждый слой преобразует одно представление в другое с использованием некой дифференциируемой функцией. Мы используем три главных типа слоёв для построения свёрточных нейронных сетей: свёрточный слой, слой подвыборки и полносвязный слой (такой же, какой мы используем в обычной нейронной сети). Располагаем эти слои последовательно для получения архитектуры СНС.
Пример архитектуры: обзор. Чуть ниже мы погрузимся в детали, а пока для набора данных CIFAR-10 архитектура нашей свёрточной нейронной сети может быть такой [INPUT -> CONV -> RELU -> POOL -> FC] . Теперь подробнее:
- INPUT [32x32x3] будет содержать исходные значения пикселей изображения, в нашем случае изображение размерами 32px в ширину, 32px в высоту и 3 цветовыми каналами R, G, B.
- CONV -слой произведёт набор выходных нейронов, которые будут связаны с локальной областью входного исходного изображения; каждый такой нейрон будет вычислять скалярное произведение между своими весами и той небольшой частью исходного изображения с которым он связан. Выходным значением может быть 3D-представление размером 32х32х12 , если, например, мы решим использовать 12 фильтров.
- RELU -слой будет применять по-элементно функцию активации max(0, x) . Это преобразование не изменит размерности данных — [32x32x12] .
- POOL -слой произведёт операцию сэмплирования изображения по двум измерениям — высоте и ширине, что в результате даст нам новое 3D-представление [16х16х12] .
- FC -слой (полносвязный слой) подсчитает оценки по классам, результатирующая размерность будет равна [1x1x10] , где каждое из 10 значений будет соответствовать оценке определенного класса среди 10 категорий изображений из CIFAR-10. Как и в обычных нейронных сетях, каждый нейрон этого слоя будет связан со всеми нейронами предыдущего слоя (3D-представления).
Именно таким образом свёрточная нейронная сеть преобразует исходное изображение, слой за слоем, от начального значения пикселя до итоговой оценки класса. Обратите внимание, что некоторые слои содержат параметры, а некоторые — нет. В частности, CONV/FC -слои осуществляют трансформацию, которая является не только функцией зависящей от входных данных, но и зависящей от внутренних значений весов и смещений в самих нейронах. С другой стороны, RELU/POOL -слои применяют непараметризованные функции. Параметры в CONV/FC -слоях будут натренированы градиентным спуском таким образом, чтобы входные данные получали соответствующие корректные выходные метки.
- Архитектура свёрточной нейронной сети, в своём простейшем представлении, представляет собой упорядоченный набор слоёв преобразующий представление изображения в другое представление, например, оценки принадлежности к классам.
- Существует несколько различных типов слоёв (CONV — свёрточный слой, FC — полносвязный, RELU — функция активации, POOL — слой подвыборки — наиболее популярные).
- Каждый слой на вход получает 3D-представление, преобразует его в выходное 3D-представление используя дифференциируемую функцию.
- Каждый слой может иметь и не иметь параметров (CONV/FC — имеют параметры, RELU/POOL — нет).
- Каждый слой может иметь и не иметь гипер-параметров (CONV/FC/POOL — имеют, RELU — нет)
Исходное представление содержит значения пикселей изображения (слева) и оценки по классам к которым относится объект на изображении (справа). Каждая трансформация представления отмечена в виде столбца.
Свёрточный слой
Свёрточный слой является основным слоем при построении свёрточных нейронных сетей.
Обзор без погружения в особенности работы головного мозга. Давайте сперва попробуем разобраться в том, что же всё-таки вычисляет CONV-слой без погружения и затрагивания темы мозга и нейронов. Параметры свёрточного слоя состоят из набора обучаемых фильтров. Каждый фильтр представляет собой небольшую сетку вдоль ширины и высоты, но простирающуюся по всей глубине входного представления.
Например, стандартный фильтр на первом слое свёрточной нейронной сети может иметь размеры 5х5х3 (5px — ширина и высота, 3 — количество цветовых каналов). Во время прямого прохода мы перемещаем (если быть точными — свёртываем) фильтр вдоль ширины и высоты входного представления и вычисляем скалярное произведение между значениями фильтра и подлежащими значениями входного представления в любой точке. В процессе перемещения фильтра вдоль ширины и высоты входного представления мы формируем 2х мерную карту активации, которая содержит значения применения данного фильтра к каждой из областей входного представления. Интуитивно становится ясно, что сеть обучит фильтры активироваться при виде определённого визуального признака, например, прямой под определённым углом или колесообразных представлений на более высоких уровнях. Теперь, когда мы применили все наши фильтры к исходному изображению, например, их было 12. В результате применения 12 фильтров мы получили 12 активационных карт размерностью 2. Чтобы произвести выходное представление — объединим эти карты (последовательно по 3-му измерению) и получим представление размерностью [WxHx12].
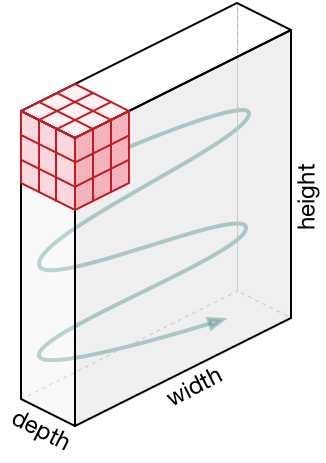
Обзор к которому мы подключим мозг и нейроны. Если вы фанат мозга и нейронов, то можете себе представить, что каждый нейрон «смотрит» на большой участок входного представления и передаёт информации об этом участке соседствующими с ним нейронам. Чуть ниже мы обсудим детали связности нейронов, их расположения в пространстве и механизм совместного использования параметров.
Локальная связность. Когда мы имеем дело с входными данными с большим количеством измерений, например, как в случае с изображениями, то, как мы уже видели, нет абсолютно никакой необходимости связывать нейроны со всеми нейронами на предыдущем слое. Вместо этого мы будем соединять нейроны только с локальными областями входного представления. Пространственная степень связности является одним из гипер-параметров и называется receptive field (рецептивное поле нейрона — размер того самого фильтра / ядра свёртки). Степень связности вдоль 3-го измерения (глубины) всегда равна глубине исходного представления. Очень важно вновь акцентировать на этом внимание, внимание на том, как мы определяем пространственные измерения (ширину и высоту) и глубину: связи нейрона локальны по ширине и высоте, но всегда простираются по всей глубине входного представления.
Пример 1. Представим, что входное представление имеет размер 32х32х3 (RGB, CIFAR-10). Если размер фильтра (рецептивное поле нейрона) будет размером 5х5, тогда каждый нейрон в свёрточном слое будет иметь веса к области размером 5х5х3 исходного представления, что в итоге приведёт к установлению 5х5х3 = 75 связей (весов) + 1 параметр смещения. Обратите внимание, что степень связности по глубине должна быть равна 3, так как это размерность исходного представления.
Пример 2. Представим, что входное представление имеет размер 16х16х20. Используя в качестве примера рецептивное поле нейрона размером 3х3, каждый нейрон свёрточного слоя будет иметь 3х3х20 = 180 связей (весов) + 1 параметр смещения. Обратите внимание, что связность локальна по ширине и высоте, но полная в глубину (20).
| #1 | #2 |
|---|---|
 |
 |
C левой стороны: входное представление отображено красным цветом (например, изображение размером 32х32х3 CIFAR-10) и пример представления нейронов в первом свёрточном слое. Каждый нейрон в свёрточном слое связан только с локальной областью входного представления, но полностью по глубине (в примере — по всем цветовым каналам). Обратите внимание, что на изображении множество нейронов (в примере — 5) и расположены они по 3-му измерению (глубине) — чуть ниже будут даны пояснения относительно такого расположения.
С правой стороны: нейроны из нейронной сети по-прежнему остаются неизменными: они по-прежнему вычисляют скалярное произведение между своими весами и входными данными, применяют функцию активации, но их связность теперь ограничена пространственной локальной областью.
Пространственное расположение. Мы уже разобрались со связностью каждого нейрона в свёрточном слое с входным представлением, но ещё не обсудили сколько этих нейронов или как они располагаются. Три гипер-параметра влияют на размер выходного представления: глубина, шаг и выравнивание.
- Глубина выходного представления является гипер-параметром: соответствует количество фильтров, которые мы хотим применить, каждый из которых обучается чему-то другому в исходном представлении. Например, если первый свёрточный слой принимает на вход изображение, тогда разные нейроны вдоль 3-го измерения (глубины) могут активироваться при присутствии различных ориентаций прямых в определённой области или скоплений определенного цвета. Набор нейронов, которые «смотрят» на одну и ту же область входного представления, мы будем называть глубинным столбцом (или «фиброй» — волокном).
- Мы должны определить шаг (размер смещения в пикселях) с которым будет перемещаться фильтр. Если шаг равен 1, то мы смещаем фильтр на 1 пиксель за одну итерацию. Если шаг равен 2 (или, что ещё реже используется — 3 и более), то смещение происходит на каждые два пикселя за одну итерацию. Больший шаг приводит к меньшему размеру выходного представления.
- Как мы вскоре увидим, иногда необходимо будет дополнять входное представление по краям нулями. Размер выравнивания (количество нулевых дополняемых столбцов / строк) так же является гипер-параметром. Приятной особенностью использования выравнивания является тот факт, что выравнивание позволит нам контролировать размерность выходного представления (чаще всего мы будем сохранять исходные размеры представления — сохранение ширины и высоты входного представления с шириной и высотой выходного представления).
Мы можем вычислить итоговую размерность выходного представления представив её функцией от размеров входного представления (W), размером рецептивного поля нейронов свёрточного слоя (F), шагом (S) и размером выравнивания (P) на границах. Вы можете убедиться сами, что корректная формула для подсчёта количества нейронов в выходном представлении выглядит следующим образом (W — F + 2P) / S + 1. Например, для входного представления размером 7х7 и размером фильтра 3х3, шагом 1 и выравниванием 0, мы получим выходное представление размером 5х5. С шагом 2 мы бы получили выходное представление размером 3х3. Давайте рассмотрим ещё один пример, на этот раз проиллюстрированный графически:

Иллюстрация пространственного расположения. В этом примере только одно пространственное измерение (x-ось), один нейрон с рецептивным полем F=3, размер входного представления W=5 и выравниванием P = 1. С левой стороны: рецептивное поле нейрона перемещается с шагом S = 1, что в результате даёт размер выходного представления (5 — 3 + 2) / 1 + 1 = 5. С правой стороны: нейрон использует рецептивное поле размером S = 2, что в результате даёт размер выходного представления (5 — 3 + 2) / 2 + 1 = 3. Обратите внимание, что размер шага S = 3 не может быть использован, так как при таком размере шага рецептивное поле не захватит часть изображения. Если использовать нашу формулу, то (5 — 3 + 2) = 4 не кратно 3. Веса нейронов в этом примере равны [1, 0, -1] (как показано на самой правой картинке), а смещение равно нулю. Эти веса совместно используются всеми жёлтыми нейронами.
Использование выравнивания. Обратите внимание на пример с левой стороны, который содержит 5 элементов на выходе и 5 элементов на выходе. Это сработало потому, что размер рецептивного поля (фильтра) был равен 3 и мы воспользовались выравниванием P = 1. Если бы не было выравнивания, то размер выходного представления был бы равен 3, потому что именно столько нейронов туда «поместилось» бы. В общем, установление размера выравнивания P = (F — 1) / 2 при шаге равном S = 1 позволяет получить размер выходного представления аналогичный входному представлению. Подобный подход с использованием выравнивания часто применяется на практике, а причины мы обсудить чуть ниже, когда будем говорить об архитектуре свёрточных нейронных сетей.
Ограничения на размер шага. Обратите внимание, что гипер-параметры отвечающие за пространственное расположение, так же связаны между собой ограничениями. Например, если входное представление имеет размер W = 10, P = 0 и размер рецептивного поля F = 3, тогда использовать размер шага равный S = 2 становится невозможно, так как (W — F + 2P)/S + 1 = (10 — 3 + 0)/2 + 1 = 4.5, что даёт нецелочисленное значение количества нейронов. Таким образом подобная конфигурация гипер-параметров считается недействительной и библиотеки по работе со свёрточными нейронными сетями выбросят исключение, принудительно произведут выравнивание, либо вообще обрежут входное представление. Как мы увидим в следующих секциях данной главы, определение гипер-параметров свёрточного слоя доставляет ещё ту головную боль, которую можно уменьшить используя определённые рекомендации и «правила хорошего тона» при проектировании архитектуры свёрточных нейронных сетей.
Пример из реальной жизни. Архитектура свёрточной нейронной сети Krizhevsky et al., которая выиграла соревнование ImageNet в 2012 году принимала изображения размером 227х227х3. На первом свёрточном слое она использовала рецептивное поле размером F = 11, шаг S = 4 и размер выравнивания P = 0. Поскольку (227 — 11)/4 + 1 = 55, а свёрточный слой был глубиной K = 96, то выходная размерность представления была 55х55х96. Каждый из 55х55х96 нейронов в этом представлении был связан с областью размером 11х11х3 во входном представлении. Более того, все 96 нейронов в глубинном столбце связаны с такой же областью 11х11х3, но с другими весами. А теперь немного юмора — если вы решите ознакомиться с оригиналом документа (исследования), то обратите внимание, что в документе утверждается, что на вход поступают изображения размером 224х224, что не может быть правдой, потому что (224 — 11) / 4 + 1 никаким образом не дадут целочисленное значение. Подобного рода ситуации часто вводят в замешательство людей в историях со свёрточными нейронными сетями. По моим догадкам Алекс использовал размер выравнивания P = 3, но забыл упомянуть об этом в документе.
Совместное использование параметров. Механизм совместного использования параметров в свёрточных слоях используется для контроля количества параметров. Обратите внимание на приведённый выше пример, как можно увидеть там есть 55х55х96 = 290 400 нейронов на первом свёрточном слое и каждый из нейронов имеет 11х11х3 = 363 веса + 1 значение смещения. Суммарно, если перемножить эти два значения, получится 290400х364 = 105 705 600 параметров только на первом слое свёрточной нейронной сети. Очевидно, что это огромное значение!
Оказывается есть возможность значительно снизить количество параметров делая одно допущение: если некоторое свойство, вычисленное в позиции (x, y), имеет значение для нас, то это же свойство вычисленно в позиции (x2, y2) так же будет иметь для нас значение. Другими словами, обозначая двумерный «слой» в глубину как «глубинный слой» (например, представление [55x55x96] содежит 96 глубинных слоёв, каждый из которых размером 55х55), мы будем выстраивать нейроны в глубину с одними и теми же весами и смещением. При такой схеме совместного использования параметров первый свёрточный слой в нашем примере теперь будет содержать 96 уникальных наборов весов (каждый набора на каждый глубинный слой), всего будет 96х11х11х3 = 34 848 уникальных весов или 34 944 параметров (+96 смещений). Кроме того, все 55х55 нейронов на каждом глубинном слое будут теперь использовать те же параметры. На практике, во время обратного распространения, каждый нейрон в этом представлении будет вычислять градиент для собственных весов, но эти градиенты будут суммироваться по каждому глубинному слою и обновлять только единственный набор весов на каждом уровне.
Обратите внимание, если бы все нейроны на одном глубинном слое использовали одинаковые веса, то при прямом распространении через свёрточный слой вычислялась бы свёртка между значениями весов нейрона и входными данными. Именно поэтому принято называть единый набор весов — фильтром (ядром).

Примеры фильтров, которые были получены при обучении модели Krizhevsky et al. Каждый из 96 фильтров показанных тут размером 11х11х3 и каждый из них совместно используется всеми 55х55 нейронами одного глубинного слоя. Обратите внимание, что предположение о совместном использовании одних и те же весов имеет смысл: если детектирование горизонтальной линии важно в одной части изображения, то интуитивно понятно, что подобное детектирование важно и в другой части этого изображения. Поэтому нет никакого смысла каждый раз переобучаться находить горизонтальные линии в каждом из 55х55 различных мест изображения в свёрточном слое.
Стоит иметь ввиду, что допущение о совместном использовании параметров не всегда может иметь смысл. Например, в случае, если на вход свёрточной нейронно сети подаётся изображение с некоторой центрированной структурой, где бы мы хотели иметь возможность в одной части изображении обучиться одному свойству, а на другой части изображения — другому свойству. Практический пример — изображения с центрированными лицами. Можно предположить, что разные глазные признаки или признаки волос могут быть определены в различных областях изображения, поэтому в таком случае используется релаксация весов и слой называется локально связным.
Примеры с Numpy. Предыдущие обсуждения стоит перенести в плоскость конкретики и на примерах с кодом. Представьте, что входное представление это numpy -массив X . Тогда:
- Глубинный столбец (нить) на позиции (x,y) будет представлен следующий образом X[x,y,:] .
- Глубинный слой, или как мы ранее называли такой слой — карта активации на глубине d будет представлена следующим образом X[. d] .
Пример свёрточного слоя. Представим, что входное представление X имеет размеры X.shape: (11,11,4) . Представим так же, что размер выравнивания P=1, размер рецептивного поля (фильтра) F=5 и шаг S=1. Выходное представление будет размером 4х4, исходя из значения формулы — (11-5)/2+1=4. Карта активации выходного представления (назовём её V ), будет выглядеть таким образом (в этом примере представлены только несколько элементов):
- V[0,0,0] = np.sum(X[:5,:5,:] * W0) + b0
- V[1,0,0] = np.sum(X[2:7,:5,:] * W0) + b0
- V[2,0,0] = np.sum(X[4:9,:5,:] * W0) + b0
- V[3,0,0] = np.sum(X[6:11,:5,:] * W0) + b0
Напоминаем, что в numpy , операция * относится к операции поэлементного умножения массивов. Обратите так же внимание, что вектор весов W0 является вектором весов нейрона и b0 его смещением. В нашем примере W0 имеет размеры W0.shape: (5,5,4) , так как размер фильтра равен 5, а глубина равна 4. Как и при работе с обычными нейронными сетями мы вычисляем скалярное произведение между фильтром и соответствующей областью входного представления. Так же обратите внимание на тот факт, что мы используем одни и те же значения весов и смещений, а каждый раз смещаем рецептивное поле на 2 пикселя (размер шага). При построении второй карты активаций в выходном представлении у нас уже будет следующее:
- V[0,0,1] = np.sum(X[:5,:5,:] * W1) + b1
- V[1,0,1] = np.sum(X[2:7,:5,:] * W1) + b1
- V[2,0,1] = np.sum(X[4:9,:5,:] * W1) + b1
- V[3,0,1] = np.sum(X[6:11,:5,:] * W1) + b1
- V[0,1,1] = np.sum(X[:5,2:7,:] * W1) + b1 (пример, где мы смещаемся уже на оси y )
- V[2,3,1] = np.sum(X[4:9,6:11,:] * W1) + b1 (пример, где мы смещаемся по обеим осям)
Таким образом мы формируем карту активации второго слоя — другие значения весов W1 и смещений b1 . Мы намеренно упростили операции в примере, чтобы показать какие действия выполнить свёрточный слой для заполнения всех карт активаций выходного массива V . В дополнение имейте ввиду, что карты активации затем передаются на вход функции активации, например, ReLU , в которой осуществляется поэлементная обработка значений из карты. В примере этого мы не показали.
Резюме. Подводим итоги по свёрточному слою:
- Принимает на вход представление размером W1 x H1 x D1
- Требует 4 гипер-параметра:
- Количество фильтров K,
- их пространственные размер F,
- размер шага S,
- размер выравнивания P.
- W2 = (W1 — F + 2P)/S + 1
- H2 = (H1 — F + 2P)/S + 1
- D2 = K
Стандартными значениями для гипер-параметров являются F = 3, S = 1, P = 1. Такие значения обоснованы рядом практических наблюдений и рекомендаций. Подробнее будет рассказано в разделе «Архитектура свёрточных нейронных сетей».
Демо. Чуть ниже мы показали пример работы свёрточного слоя. Так как 3D-представления сложно визуализировать (синий — входное представление, красное — веса, зеленое — выходное представление), мы представили каждый слой в виде стопок — один под другим. Размер входного представления W1 = 5, H1 = 5, D1 = 3, а параметры свёрточного слоя K = 2, F = 3, S = 2, P = 1. Итак, у нас есть два фильтра размером 3х3, которые применяются с шагом 2. Таким образом выходное представление будет иметь размер (5 — 3 + 2)/2 + 1 = 3. Более того, обратите внимание, что смещение P = 1 применяется ко входному представлению и дополняет его нулями. В визуализации ниже с правой стороны перемещается зеленый квадрат, который является результатом скалярного произведения части исходного представления (изображения) и фильтра, плюс значение смещения.
(здесь должна быть анимация, но она реализована на html+css в исходной странице, поэтому идём на исходную страницу и смотрим)
Реализация в виде матричного умножения. Операция свёртки основывается на скалярном произведении между значениями фильтра и локальной частью входного представления (изображения). Стандартным подходом к реализации свёрточного слоя является использование этого факта и реализация матричного умножения при прямом распространении следующим образом:
- Локальная область изображения выпрямляется в колонки операцией im2col. Например, если входные данные представляют собой изображение размером 227x227x3 к которому будет применена операция свёртки фильтром размером 11х11х3 и шагом 4, то и фильтр мы так же выпрямим в вектор размером 11х11х3 = 363 элемента. Повторяя данный процесс, каждый раз смещаясь на 4 пикселя по исходному представлению, мы получим (227 — 11) / 4 + 1 = 55 участков вдоль ширины и высоты, которые будут преобразованы и в результате получится выходная матрица X_col размером 363х3025, в которой каждая строка будет представлять собой выпрямленный фильтр и всего таких строк будет 3025. Обратите внимание, что значения пикселей, через которые проходит фильтр, дублируются (пересекаются), поэтому в результатирующей матрице будет много повторяющихся значений в различных строках.
- Веса свёрточного слоя выпрямляются в одномерный вектор таким же образом. Например, если у нас 96 фильтров размером 11х11х3, то в результате мы получим матрицу W_row размером 96х363.
- Результат операции свёртки теперь эквивалентен выполнению скалярного произведения полученных на предыдущих двух шагах матрицах — np.dot(W_row, X_col), которое вычисляет скалярное произведение каждого фильтра с каждым участком входного представления. В нашем примере размеры выходного представления будут равны 96х3025.
- Результат выполнения скалярного произведения теперь должен быть преобразован обратно в нужное представления размером 55х55х96.
У такого подхода, безусловно, можно заметить серьёзный недостаток — большой объём используемой памяти в связи с многократным дублированием значений при смещениях рецептивного поля, значения под которым пересекаются. Однако, несмотря на этот недостаток, у метода есть и преимущество — существует множество эффективных методов реализации матричного умножения (например, часто используемые в BLAS API). Более того, используемый нами метод im2col может быть использован повторно для выполнения операции подвыборки, которую мы обсудить чуть позже в этой главе.
Обратное распространение. Обратный проход (обратное распространение изменений) операции свёртки (как для входных данных, так и для весов) это тоже операция свёртки (только с пространственно-перевёрнутыми фильтрами). К такому умозаключение просто прийти, если рассмотреть одномерный вымышленный пример.
1х1 свёртка. Отойдём немного от нашей темы и рассмотрим свёртку размером 1х1, примеры использования которой впервые приводятся в Network in Network. Некоторые удивляются, когда впервые видят размер свёртки 1х1, особенно удивляются те, кто пришел с опытом в обработке сигналов. Обычно, сигналы представлены в 2-х мерном пространстве, поэтому свёртка 1х1 не имеет смысла (это всего лишь точечное изменение масштабов). Однако в свёрточных нейронных сетях всё обстоит совершенно иначе, потому что стоит всегда помнить о том, что в свёрточных нейронных сетях мы оперируем с 3-х мерным представлением, где фильтры применяются всегда по всей глубине входного представления. Например, если входное представление размером 32х32х3, а над ним выполняется операция свёртки с размером фильтра 1х1, то, по факту, мы выполняем скалярное произведение единичных значений по 3м измерениям (R, G, B — три канала, глубина).
Операция свёртки с расширением. Недавние исследования вводят ещё один гипер-параметр в свёрточные нейронные сети называемый расширением. До этого момента мы рассматривали свёрточные нейронные сети с непрерывными фильтрами. Однако можно использовать и фильтры у которых есть пробелы между ячейками, так называемые расширения. В качестве примера рассмотрим одномерный фильтр w размера 3 применённый к входному представлению x: w[0] x[0] + w[1] x[1] + w[2] x[2]. Это пример с расширением равным 0. При расширении равном 1 и применении фильтра мы получим следующий результат: w[0] x[0] + w[1] x[2] + w[2] x[4]. Другими словами в фильтре есть «дыра» в 1 значение между каждым элементом. Такой подход может быть крайне полезным в случаях, когда необходимо более агрессивно выделять пространственные признаки входного представления используя меньшее количество слоёв. Например, если расположить последовательно 2 свёрточных слоя размером 3х3, то можно убедиться в том, что второй слой нейронов будет являться функцией получающей на вход представление размером 5х5 (можем называть размер 5х5 эффективным рецептивным полем нейронов). При использовании расширений в операциях свёртки размер эффективных рецептивных полей будет очень быстро увеличиваться.
Слой подвыборки
Обычное дело — чередовать свёрточные слои в архитектуре свёрточной нейронной сети со слоями подвыборки. Задачей слоя подвыборки является снижение пространственных размеров входного представления, что приводит к снижению количества используемых параметров и сложности вычислений в самой сети, кроме этого слой подвыборки позволяет контролировать переобучение модели. Слой подвыборки применяется к каждому глубинному слою входного представления независимо, снижая его пространственные размеры используя операцию MAX. Наиболее распространен размер подвыборки 2х2 с шагом 2, который позволяет уменьшить каждый глубинный слой в 2 раза, исключая тем самым 75% активаций. Применение операции MAX в данном случае будет выбирать максимальное значение пикселя из поля размером 2х2. Количество глубинных слоёв остаётся неизменным. В обобщённом виде, слой подвыборки:
- Принимает представление размером W1 x H1 x D1
- Требует 2 гипер-параметра:
- размер рецептивного поля F,
- шаг S,
- W2 = (W1 — F)/S + 1
- H2 = (H1 — F)/S + 1
- D2 = D1
Стоит упомянуть о том, что на практике встречаются два наиболее распространенных варианта конфигурации слоёв подвыборки: слой подвыборки с F=3, S=2 (так же называемый пересекающейся подвыборкой), и более распространенный — F=2, S=2. Слои подвыборки с большими значениями гипер-параметров являются более деструктивными.
Операция подвыборки общего вида. Кроме операции подвыборки по максимальному значению, слой подвыборки может выполнять и другие операции, например, подвыборку по среднему значению или даже L2-подвыборку. Подвыборка по среднему значению использовалась на протяжении длительного времени, однако в последнее время начала вытесняться операцией подвыборки по максимальному значению, которая показала большую эффективность на практике.
#1 #2 
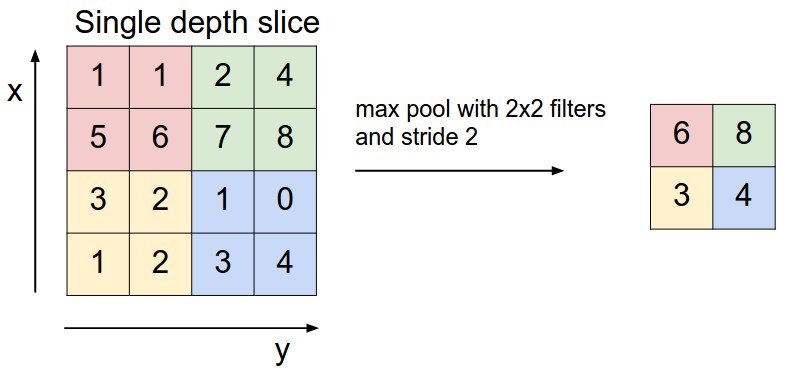
Слой подвыборки уменьшает пространственные размеры входного представления независимо друг от друга по каждому глубинному слою. Слева: в этом примере входное представление размером 224х224х64 подвергается применению операции подвыборки с размером фильтра 2х2 и шагом 2, формируя выходное представление размером 112х112х64. Обратите внимание, что количество глубинных слоёв осталось неизменным. Справа: наиболее частая операция подвыборки — по максимальному значению (max-pooling), здесь показана с размером шага 2. Максимальное значение выбирается из каждых 4 значений (небольшой области размером 2х2)
Обратное распространение. Вспомните из главы об обратном распространении, что обратное распространение операции max(a,b) имеет простую интерпретацию — перенос градиента входных данных у которого было максимальное значение при прямом распространении. Таким образом, во время прямого распространения через слой подвыборки имеет смысл хранить индекс максимального значения (иногда называется переключателем), чтобы при последующем обратном распространении вычислять градиент эффективно.
Избавляемся от подвыборки. Многим не нравится операция подвыборки и они считают, что от неё можно избавиться и отказаться в свёрточных нейронных сетях. Например, в статье Борьба за простоту: Свёрточные нейронные сети, предлагается избавиться от слоёв подвыборки и заменить их последовательностью свёрточный слоёв. Для уменьшения размера представления предлагают использовать большие размеры шагов в некоторых свёрточных слоях. Исключение слоёв подвыборки показало себя так же с хорошей стороны при тренировке генеративных моделей, таких как вариационные автокодировщики (VAEs) или генеративно состязательные сети (GANs). Кажется, что будущие архитектуры будут всё-таки без слоёв подвыборки, либо с малых количеством.
Слой нормализации
Много типов слоёв нормализации было предложено для использования в свёрточных нейронных сетях, иногда намеренно применяя такие архитектурные решения, которые наблюдаются в природе и биологическом мозге. Однако, эти слои со временем перестали использоваться, так как на практике выяснилась их минимальная эффективность и влияние на результат. Для углублённого рассмотрения типов нормализаций можно ознакомиться с этой статьёй.
Полносвязный слой
Нейроны в полносвязном слое связаны со всеми активационными нейронами предыдущего слоя, как это происходит в обычной нейронной сети. Их активационные значения могут быть вычислены через матричным произведением и добавлением значения смещения.
Преобразуем полносвяный слой в свёрточный слой
Стоит отметить, что единственной разницей между полносвязным слоем и свёрточным слоем является то, что нейроны в свёрточном слое связаны только с локальной областью входного представления и совместно используют параметры (веса и смещения). Однако нейроны в обоих слоях по-прежнему вычисляют скалярное произведение, а это значит что их функциональная структура идентична. Таким образом становится очевидно, что возможно преобразование между полносвязным слоем и свёрточным слоем:
- Для любого свёрточного слоя существует полносвязный слой, который реализует ту же функцию прямого распространения. Матрица весов, по больше части, будет заполнена нулями, кроме той области, которая является отображением локальных значений входного представления и значения в которой будут одинаковы в связи с тем фактом, что слои совместно используют веса.
- Напротив, любой полносвязный слой может быть преобразован в свёрточный слой. Например, полносвязный слой с K=4096 (количество фильтров), находящийся над областью размером 7х7х12 может быть эквивалентно представлен в виде свёрточного слоя с гипер-параметрами F=7, P=0, S=1, K=4096. Другими словами мы устанавливаем размеры фильтра таким образом, чтобы он соответствовал размерам входного представления и в таком случае выходное представление будет размерами 1х1х4096, давай идентичный результат начального полносвязного слоя.
Полносвяный слой в свёрточный слой. Из перечисленных двух преобразований, возможность преобразования полносвязного слоя в свёрточный слой является наиболее полезной на практике. Давайте рассмотрим на примере архитектуру свёрточной нейронной сети, которая на входе принимает изображение размером 224х224х3 и затем использует серию свёрточных слоёв и слоёв подвыборки для уменьшения размера изображения до размера активационных карт 7х7х512 (в архитектуре свёрточной нейронной сети AlexNet, как мы увидим позднее, это реализовано с использованием 5 слоёв подвыборки, которые снижают размерность изображения каждый раз в два раза до 7 — 224/2/2/2/2/2 = 7). После этого AlexNet использует два полносвязных слоя размером 4096 и, наконец, последний полносвязный слой с 1000 нейронов, которые вычисляют оценку по классу. Мы можем преобразовать каждый из этих трёх полносвязных слоёв в свёрточный слой как описано ниже:
- Заменить первый полносвязный слой, который «смотрит» на область размером 7х7х512, на свёрточный слой с размером фильтра F=7, что на выходе даст представление размером 1х1х4096.
- Заменить второй полносвязный слой на свёрточный слой с размером фильтра F=1, на выходе будет представление размером 1х1х4096.
- Заменить последний полносвязный слой таким же образом с размером фильтра F=1, на выходе будет представление размером 1х1х1000.
Каждое из этих преобразований, на практике, может включать и преобразование (изменение размеров и форм) матрицы весов W в каждом полносвязной слое в фильтр в свёрточном слое. Оказывается, что подобного рода преобразование позволяет нам «двигать» (перемещать) исходную свёрточную сеть очень эффективно по всем областям большого изображения за один проход.
Например, если при размерах изображения 224х224 на входе, получаем 7х7х512 на выходе — снижая размер в 32 раза, то подавая на вход изображение уже размером 384х384 можно получить на выходе представление размером 12х12х512, так как 384/32 = 12. Если проделать такую операцию с теми свёрточными слоями к которым при пришли в ходе преобразования полносвязных слоёв, то итоговый размер представления, после прохождения всех слоёв, будет равен 6х6х1000, так как (12 — 7)/1 + 1 = 6. Обратите внимание, что вместо единственного вектора с оценками размера 1х1х1000 мы получаем весь массив 6х6 оценок по всем 384х384 изображениям.
Подавая на вход исходной свёрточной нейронной сети (с полносвязными слоями) независимо все изображения размером 384х384, обрезанные до 224х244 с шагом 32 пикселя, даст те же результаты, что и единственный проход новой свёрточной нейронной сети.
Логично предположить, что подавая на вход сразу несколько изображений даёт прирост производительности и скорости вычислений, нежели последовательное вычисление во всех 36 точках, так как все 36 вычислений используют общие параметры. Этот трюк используется на практике для повышения производительности, например в тех случаях, где возникает необходимость изменять размеры изображения делая его больше. Использование новой архитектуры свёрточной нейронной сети позволяет вычислить оценки по классам во множестве пространственных позициях и затем усреднить их.
Что, если бы мы захотели более эффективно использовать исходную свёрточную нейронную сеть, но с шагом меньше 32 пикселей? Мы могли бы этого добиться через множественные прямые распространения (несколько итераций прямого распространения). Например, если бы мы захотели использовать шаг равный 16 пикселям, то могли бы это сделать через объединение представлений полученных при прямом распространении 2 раза: первый раз проведя преобразования над исходным изображением и второй раз над изображением смещённым на 16 пикселей вдоль ширины и высоты.
Архитектура свёрточных нейронных сетей
Как мы уже успели понять свёрточные нейронные сети, в основном, состоят из 3 различных типов слоёв: свёрточный слой, слой подвыборки (подразумеваем подвыборка по максимальному значению, если не отмечено другое) и полносвязный слой. Мы так же явно вынесем активационную функцию ReLU в отдельный слой, которая применяется по-элементно добавляя нелинейности. В этой части мы обсудим каким образом эти слои чередуются для формирования всей свёрточной нейронной сети.
Наиболее часто используемая архитектура свёрточной нейронной сети представляет собой последовательность нескольких CONV-RELU-слоёв, после них следует POOL-слой и подобная комбинация повторяется такое количество раз, пока исходное представление изображения не будет небольшого размера. В какой-то момент происходит переход к полносвязному слою. Последний полносвязный слой содержит выходные данные, например, оценки по классам. Другими словами, наиболее частая архитектура свёрточной нейронной сети выглядит так:
INPUT -> [[CONV -> RELU]*N -> POOL?] * M -> [FC -> RELU]*K -> FCгде операция * обозначает повторение, а POOL? обозначает опциональность слоя подвыборки. Более того, N >= 0 (обычно N = 0 , K >= 0 (обычно K < 3 ). Например, вот наиболее частые архитектуры свёрточных нейронных сетей, которые удовлетворяют приведённому выше паттерну:
- INPUT -> FC , реализует линейный классификатор. N = M = K = 0 .
- INPUT -> CONV -> RELU -> FC
- INPUT -> [CONV -> RELU -> POOL] * 2 -> FC -> RELU -> FC , тут мы видим наличие единственного свёрточного слоя между каждым слоем подвыборки.
- INPUT -> [CONV -> RELU -> CONV -> RELU -> POOL] * 3 -> [FC -> RELU] * 2 -> FC . Тут мы уже видим 2 свёрточных слоя перед каждым слоем подвыборки. В целом, это хорошее решение для больших и глубоких сетей, потому что несколько подряд идущих свёрточных слоёв способны выделить более сложные признаки во входных данных перед деструктивной операцией подвыборки.
Выбирайте группировку нескольких свёрточных слоёв с небольшим размером фильтра нежели свёрточный слой с большим размером фильтра. Предположим что мы разместили подряд 3 свёрточных слоя размером 3х3 (с RELU слоем между ними, конечно же). В таком расположении каждый нейрон первого свёрточного слоя имеет «обзор» области размером 3х3 входного представления. Нейрон на втором слое имеет «обзор» области размером 3х3 уже выходного представления первого слоя, а с учетом выравнивания — размеры входного представления равны 5х5. Аналогичным образом нейрон на третем слое имеет «обзор» области 3х3 выходного представления уже второго слоя, с учетом выравнивания — размер области 7х7. Теперь представим, что вместо трёх свёрточных слоёв 3х3 мы хотели бы использовать один свёрточный слой с размером фильтра 7х7. У нейронов этого слоя был бы такой же «обзор» области 7х7 (с учетом выравниваний) как и у нашей предыдущей структуры, но с рядом недостатков. Во-первых, нейроны будут вычислять линейную функцию по входным данным, в то время как наши 3 подряд идущих свёрточных слоя содержат нелинейность, которая позволит сделать значимые признаки более заметными. Во-вторых, если мы предположим что все представления содержат C каналов, тогда можно заметить, что наш единственный 7х7 свёрточный слой будет содержать (Cх(7х7хС)) = 49xСxC параметров, в то время как три свёрточных слоя 3х3 будут содержать только 3х(Сх(3х3хС)) = 27хСхС параметра. Интуитивно становится понятно, что последовательное размещение свёрточных слоёв с небольшими фильтрами вместо размещения одного свёрточного слоя с большим размером фильтра, позволяет выделить больше значимых признаков из входных данных с меньшим количеством параметров. С практической точки зрения у такого подхода есть свой недостаток — необходимо больше памяти для хранения промежуточных результатов вычислений свёрточных слоёв, если мы планируем реализовывать обратное распространение.
Отступления. Стоит отметить тот факт, что последовательное расположение свёрточных слоёв подвергает испытаниям, в архитектурах свёрточных сетей от компании Google, а так же в архитектурах сетей от компании Microsoft. Обе из этих архитектур представляют собой более интересные структуры с разной организацией соединений между слоями.
На практике: используйте то, что наилучшим образом работает на наборах данных ImageNet. Если ты уже чувствуешь себя немного потерянным при мыслях о выборе подходящей архитектуры свёрточной нейронной сети, то будешь приятно удивлён, что в 90% случаев тебе не стоит об этом беспокоиться. Мне нравится выражение для данной ситуации — «не будь героем»: вместо того, чтобы изобретать собственные архитектуры для решения задачи, стоит взглянуть на существующие решения и выбрать оптимальные, те которые работают наилучшим образом на наборах данных ImageNet — загрузить обученные модели, докрутить их на своих данных и использовать. Редко когда тебе понадобится обучать свёрточную нейронную сеть с нуля или проектировать архитектуру с нуля.
Паттерны при выборе размеров слоёв
До сих пор мы опускали вопрос выбора значений гипер-параметров, используемых в наших слоях в свёрточной нейронной сети. Сперва мы озвучим рекомендации, а затем перейдём к их обсуждению:
Входной слой (содержащий изображение) должен делиться на 2 множество раз. Стандартные значения включают 32 (например, CIFAR-10), 64, 96 (например, STL-10), или 224 (например, ImageNet), 384 и 512.
В свёрточном слое рекомендуется использовать фильтры небольшого размера (например, 3х3 или, максимум 5х5), с использованием шага S=1 и, что не менее важно, размером выравнивания таким образом, чтобы свёрточный слой не изменял пространственные размеры входного представления. Таким образом, F=3 и при P=1 будет возможность сохранить исходные пространственные размеры входного представления. При F=5, P=2. Для обобщённого размера F может быть определено, что при P=(F-1)/2 размеры исходного представления будут сохранены. Если по каким-то причинам необходимо использовать фильтры большего размера (такие как 7х7), то есть смысл использовать их только на первом слое свёрточной нейронной сети при работе с исходным изображением.
Слой подвыборки отвечает за снижение размерности входного представления. Наиболее частой конфигурацией является использование слоя подвыборки по максимальному значению размером 2х2 (F=2) и шагом 2 (S=2). Учтите, что подобная конфигурация исключает 75% активаций входного представления (из-за сэмплирования, в два раза по ширине и высоте). Другой, менее распространенной конфигурацией, является конфигурация с параметрами 3х3 (размер фильтр) и 2 (размер шага). Изредка вы увидите размеры фильтра больше 3х3 для слоя подвыборки, потому что подвыборка представляет собой очень агрессивную функцию при применении которой теряется информация по признакам. Такой подход обычно приводит к плохой производительности.
Уменьшаем головные боли при выборе значений размеров. Представленные выше рекомендации выглядят приятными, потому что все свёрточные слои сохраняют пространственные размеры входных представлений, а за уменьшение размеров представления отвечает слой подвыборки. При альтернативных значениях, где мы используем шаг больше 1 или не выполняем операцию выравнивания входных представлений, мы должны очень внимательно будем следить за размером входных представлений по мере прохождения через слои и убедиться в том, что всё работает как надо и архитектура свёрточной нейронной сети выровнена и симметрична.
Почему используют размер шага равный 1 в свёрточном слое? На практике меньшего размера шаги работают лучше. Как мы уже ранее отмечали, размер шага равный 1 позволяет делегировать сэмплирование входного представления слою подвыборки (изменение размеров входного представления по ширине и высоте), сохраняя за свёрточным слоем только преобразование в глубину.
Зачем использовать выравнивание? В дополнение к приведённым выше аргументу по сохранению размерности выходного представления после прохождения через свёрточный слой, выравнивание позволяет повысить производительность. Если бы свёрточные слои не использовали выравнивание входных представлений, а лишь выполняли операцию свёртки, тогда размер выходных представлений уменьшался бы каждый раз на небольшое количество пикселей, а информация на краях входного представления исчезала бы слишком быстро.
Компромиссы основанные на ограничениях памяти. В некоторых ситуациях (особенно на ранних стадиях развития архитектур свёрточных нейронных сетей), количество требуемой памяти может очень быстро увеличиваться, если следовать всем рекомендациям выше. Например, применяя три свёрточных слоя по 64 фильтра каждый с размером 3х3 и шагом 1 к изображению 224х224х3, создаст на выходе активационное представление размером 224х224х64. Это, примерно, равно 10 млн активаций, или 72 Мб памяти (на изображение, как для активаций так и для градиентов). Так как бутылочным горлышком в процессе вычислений является размер доступной памяти GPU, то приходится идти на компромиссы. На практике, одним из компромиссов может быть использование первого свёрточного слоя с размером фильтра 7х7 и шагом 2. Другой компромисс, как это сделано в AlexNet, использовать фильтр размером 11х11 и шагом 4.
Исследования существующих решений
Существует несколько архитектур свёрточных нейронных сетей у которых есть собственные имена. Вот некоторые из них:
- LeNet. Первая успешная реализация свёрточной нейронной сети была разработана Yann LeCun в 1990. Из них самой известной стала архитектура LeNet, которая использовалась для чтения ZIP-кодов, цифры и др.
- AlexNet. Первая работа, которая популяризовала свёрточные нейронные сети в компьютерном зрении, разработана Alex Krizhevsky, Ilya Sutskever и Geoff Hinton. AlexNet была протестирована на соревновании ImageNet ILSVRC в 2012 году и значительно опередила конкурента на втором месте (процент ошибок: 16% против 26%). Архитектура сети была очень похожа на архитектуру LeNet, но была глубже, больше и использовала последовательности свёрточных слоёв (до этого было стандартной практикой использоватье только комбинацию свёрточного слоя сразу за которым следовал слой подвыборки).
- ZFNet. Победителем ILSVRC 2013 года стала свёрточная нейронная сеть от Matthew Zeiler и Rob Fergus. Стала она известна под названием ZFNet. Это была усовершенствованная версия AlexNet, которая использовала другие значения гипер-параметров, в частности увеличивавшая размер среднего свёрточного слоя и уменьшавшая шаг и размер фильтра на первом свёрточном слое.
- GoogLeNet. Победителем ILSVRC 2014 года стала свёрточная нейронная сеть от Szegedy et al. из Google. Основным изменением в архитектура стал Inception-модуль, который позволял значительно снизить количество параметров в сети (4 Мб против 60 Мб в AlexNet). В добавок к этому сеть использует подвыборку по среднему значению вместо полносвязных слоёв к концу сети, исключая тем самым большое количество параметров, которые не имеют большого значения. У данной версии сети есть несколько модификаций, одна из последних — Inveption-v4.
- VGGNet. Вслед за победителем 2014 ILSVRC была сеть от Karen Simonyan и Andrew Zisserman, которая стала так же известна как VGGNet. Основным вкладом этой нейронной сети в развития представлений о свёрточных нейронных сетях был тот факт, что глубина сети является ключевым компонентом хорошей производительности. Финальная версия их сети содержала 16 пар свёрточныйх + полносвязных слоёв и использовала единые размеры фильтров (3х3 для свёртки и 2х2 для операции подвыборки). Их предобученная модель находится в публичном доступе и с ней можно поэкспериментировать. Обратная сторона медали VGGNet — стоимость вычислений и использование большого количества памяти (140Мб). Большинство из этих параметров находятся на первом полносвязном слое и, как было в дальнейшем изучено и протестировано, эти полносвязные слои могут быть исключены без влияния на производительность, но с колоссальным уменьшением количества требуемых параметров.
- ResNet. Residual-сеть была разработана Kaiming He et al. и стала победителем в ILSVRC 2015. Она активно использует пропуск связей и блоковую нормализацию. В архитектуре так же отсутствуют полносвязные слои в конце сети. На данный момент это лучшее решение с использованием свёрточных нейронных сетей (на май 2016).
VGGNet в деталях. Давайте рассмотрим VGGNet подробнее в качестве эксперимента. Вся сеть VGGNet состоит из свёрточных слоёв, которые выполняют операцию свёртки с применением фильтра размером 3х3, шагом 1 и выравниванием 1, слой подвыборки с конфигурацией размера фильтра 2х2 и шагом 2. Мы можем зафиксировать размер представлений на каждом шаге выполнения (прохождения через слои свёрточной нейронной сети) и общее количество весов:
INPUT: [224x224x3] memory: 224*224*3=150K weights: 0 CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*3)*64 = 1,728 CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*64)*64 = 36,864 POOL2: [112x112x64] memory: 112*112*64=800K weights: 0 CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*64)*128 = 73,728 CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*128)*128 = 147,456 POOL2: [56x56x128] memory: 56*56*128=400K weights: 0 CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*128)*256 = 294,912 CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824 CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824 POOL2: [28x28x256] memory: 28*28*256=200K weights: 0 CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*256)*512 = 1,179,648 CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296 CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296 POOL2: [14x14x512] memory: 14*14*512=100K weights: 0 CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296 CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296 CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296 POOL2: [7x7x512] memory: 7*7*512=25K weights: 0 FC: [1x1x4096] memory: 4096 weights: 7*7*512*4096 = 102,760,448 FC: [1x1x4096] memory: 4096 weights: 4096*4096 = 16,777,216 FC: [1x1x1000] memory: 1000 weights: 4096*1000 = 4,096,000 TOTAL memory: 24M * 4 bytes ~= 93MB / image (only forward! ~*2 for bwd) TOTAL params: 138M parametersКак это обычно наблюдается при работе со свёрточными нейронными сетями, обратите внимание на то, что большая часть памяти (и время вычислений) приходятся на ранние свёрточные слои, а большинство параметров находятся на последних полносвязных слоях. В данном конкретном случае полносвязный слой содержит 100 млн весов из всех 140 млн.
Вычислительные примечания
Самым узким местом при конструировании архитектур свёрточных нейронных сетей является память. Многие современные GPU ограничены 3/4/6 Гб памяти, а лучшие GPU — 12 Гб памяти. Три основных источника затрат по памяти, которые стоит иметь ввиду:
- Промежуточные представления: общее количество активаций на каждом свёрточном слое в свёрточной нейронной сети, а так же их градиенты (такого же размера). Обычно, большинство активаций приходится на ранние слоя. Они остаются в архитектуре потому что используются при обратном распространении, но более продвинутые реализации значительно уменьшают количество активаций благодаря хранению только текущих активаций на любом слое и не храня активации на всех предыдущих слоях ниже.
- Размеры параметров: параметры, которые хранят значения сети, их градиенты во время обратного распространения и размеры шагов. Таким образом количество памяти, требуемое для хранения только вектора параметров, обычно стоит умножать на х3 или более.
- Реализация каждой свёрточной нейронной сети должна ещё поддерживать возможность хранения других данных, вроде данных самого изображения и его анализируемых копий блоков, возможно перевёрнутые версии изображений и т.д.
Как только у вас появляется грубая оценка общего количества значений (активаций, градиентов и прочих), то это значение должно быть приведено к размеру в Гб. Возьмите количество полученных значений, умножайте его на 4 для получения количества байт (каждое значение с плавающей точкой занимает 4 байта, при использовании значений с двойной точностью — на 8), а затем разделите полученное значение на 1024 несколько раз, чтобы получить сперва Кб, затем Мб и в конце Гб. Если сеть «не помещается», то стандартной практикой сжатия является уменьшение размеров блоков, так как большая часть памяти приходится на активации.
… и стандартные call-to-action — подписывайся, ставь плюс и делай share 🙂
YouTube
Telegram
ВКонтакте