Как скачать все файлы разом или цепочкой
у меня на странице есть кнопка «скачать тендерную документацию» это обычная ссылка в которой я передаю id тендера. Далее в контроллере я нахожу все прикрепленные файлы к этому тендеру и отправляю на скачивание. Все работает, но только для одного файла а если допустим к тендерной заявке в базе прикреплено несколько файлов как мне сделать что бы при нажатии на кнопку скачивались файлы друг за другом? На стороне vue просто ссылка в которой передаю id тендера
$files = FileStore::where('el_type_obj_code', 'tenders') ->where('type_object_id', $id)->get(); foreach ($files as $file) < $client = new Client([ 'base_uri' =>'http://localhost:8000', 'timeout' => 60.0 ]); $response = $client->get('/docs/receive/' . $file->file_id, [ 'headers' => [ 'Authorization' => "Bearer " . env('FILE_STORE_API_TOKEN'), 'Accept' => 'multipart/byteranges' ] ]); foreach ($response->getHeader('content-disposition') as $header) < $file_name = Str::after($header, 'filename='); >return response()->streamDownload(function () use ($response) < echo $response->getBody()->getContents(); >, $file_name); > >
Отслеживать
d3mocratia
задан 3 окт 2022 в 9:48
d3mocratia d3mocratia
1 2 2 бронзовых знака
3 окт 2022 в 9:49
Зравствуйте, исправил
3 окт 2022 в 9:54
Вам нужно либо архивировать все файлы на сервере и отдавать этот архив, либо возвращать список ссылок, и запросы на скачивание будут инициированы на клиенте, хотя скорее первое так как у вас есть авторизация с файловым хранилищем на сервере.
3 окт 2022 в 14:41
0
Сортировка: Сброс на вариант по умолчанию
Знаете кого-то, кто может ответить? Поделитесь ссылкой на этот вопрос по почте, через Твиттер или Facebook.
- laravel
- vue.js
11 фишек для извлечения и сохранения данных с сайтов

В закладки

БЕЗ скриптов, макросов, регулярных выражений и командной строки.
Эта статья пригодится студентам, которые хотят скачать все картинки с сайта разом, чтобы потом одним движением вставить их в Power Point и сразу получить готовую презентацию. Владельцам электронных библиотек, которые собирают новые книги по ресурсам конкурентов. Просто людям, которые хотят сохранить интересный сайт/страницу в соцсети, опасаясь, что те могут скоро исчезнуть, а также менеджерам, собирающим базы контактов для рассылок.
Есть три основные цели извлечения/сохранения данных с сайта на свой компьютер:
- Чтобы не пропали;
- Чтобы использовать чужие картинки, видео, музыку, книги в своих проектах (от школьной презентации до полноценного веб-сайта);
- Чтобы искать на сайте информацию средствами Spotlight, когда Google не справляется (к примеру поиск изображений по exif-данным или музыки по исполнителю).
Ситуации, когда неожиданно понадобится автоматизированно сохранить какую-ту информацию с сайта, могут случиться с каждым и надо быть к ним готовым. Если вы умеете писать скрипты для работы с утилитами wget/curl, то можете смело закрывать эту статью. А если нет, то сейчас вы узнаете о самых простых приемах сохранения/извлечения данных с сайтов.
1. Скачиваем сайт целиком для просмотра оффлайн
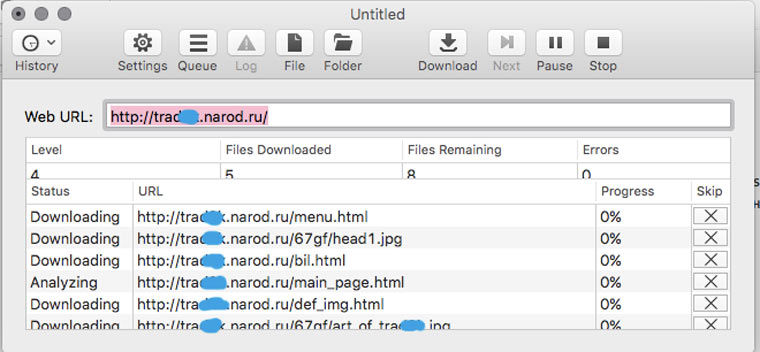
В OS X это можно сделать с помощью приложения HTTrack Website Copier, которая настраивается схожим образом.
Пользоваться Site Sucker очень просто. Открываем программу, выбираем пункт меню File -> New, указываем URL сайта, нажимаем кнопку Download и дожидаемся окончания скачивания.
Чтобы посмотреть сайт надо нажать на кнопку Folder, найти в ней файл index.html (главную страницу) и открыть его в браузере. SiteSucker скачивает только те данные, которые доступны по протоколу HTTP. Если вас интересуют исходники сайта (к примеру, PHP-скрипты), то для этого вам нужно в открытую попросить у его разработчика FTP-доступ.
2. Прикидываем сколько на сайте страниц
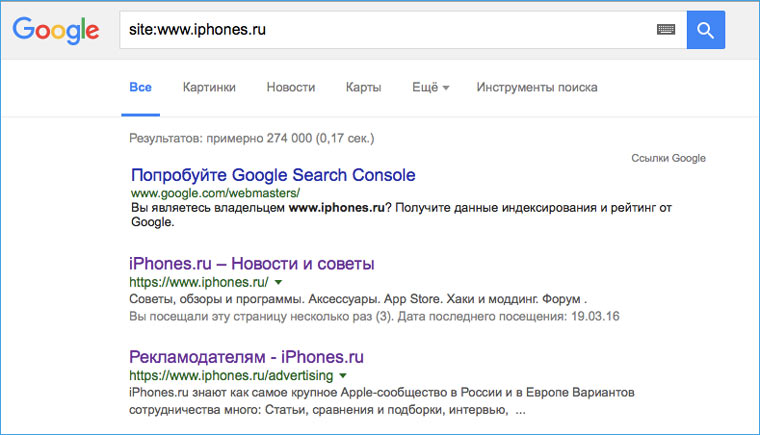
Перед тем как браться за скачивание сайта, необходимо приблизительно оценить его размер (не затянется ли процесс на долгие часы). Это можно сделать с помощью Google. Открываем поисковик и набираем команду site: адрес искомого сайта. После этого нам будет известно количество проиндексированных страниц. Эта цифра не соответствуют точному количеству страниц сайта, но она указывает на его порядок (сотни? тысячи? сотни тысяч?).
3. Устанавливаем ограничения на скачивание страниц сайта
![]()
Если вы обнаружили, что на сайте тысячи страниц, то можно ограничить число уровней глубины скачивания. К примеру, скачивать только те страницы, на которые есть ссылка с главной (уровень 2). Также можно ограничить размер загружаемых файлов, на случай, если владелец хранит на своем ресурсе tiff-файлы по 200 Мб и дистрибутивы Linux (и такое случается).
Сделать это можно в Settings -> Limits.
4. Скачиваем с сайта файлы определенного типа
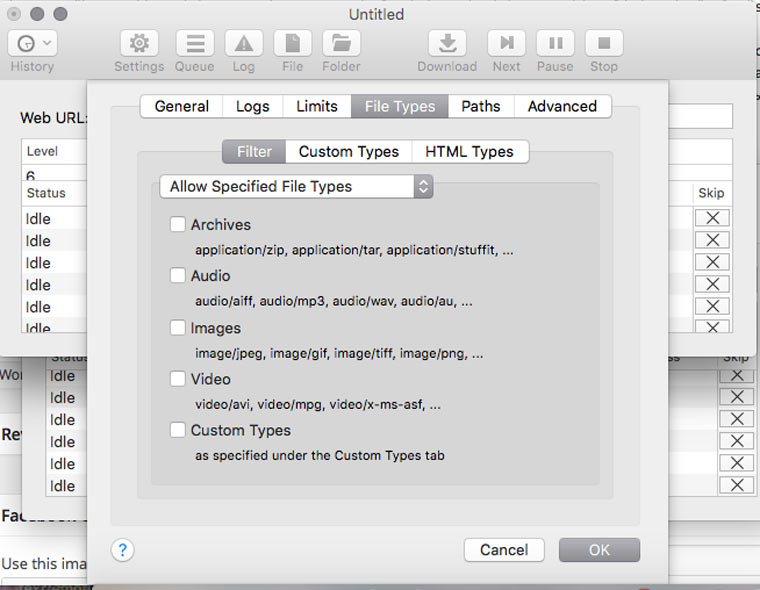
В Settings -> File Types -> Filters можно указать какие типы файлов разрешено скачивать, либо какие типы файлов запрещено скачивать (Allow Specified Filetypes/Disallow Specifies Filetypes). Таким образом можно извлечь все картинки с сайта (либо наоборот игнорировать их, чтобы места на диске не занимали), а также видео, аудио, архивы и десятки других типов файлов (они доступны в блоке Custom Types) от документов MS Word до скриптов на Perl.
5. Скачиваем только определенные папки
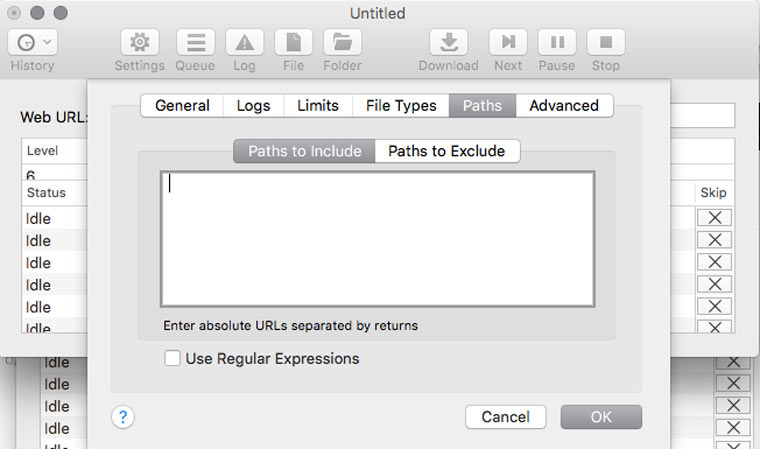
Если на сайте есть книги, чертежи, карты и прочие уникальные и полезные материалы, то они, как правило, лежат в отдельном каталоге (его можно отследить через адресную строку браузера) и можно настроить SiteSucker так, чтобы скачивать только его. Это делается в Settings -> Paths -> Paths to Include. А если вы хотите наоборот, запретить скачивание каких-то папок, то их адреса надо указать в блоке Paths to Exclude
6. Решаем вопрос с кодировкой
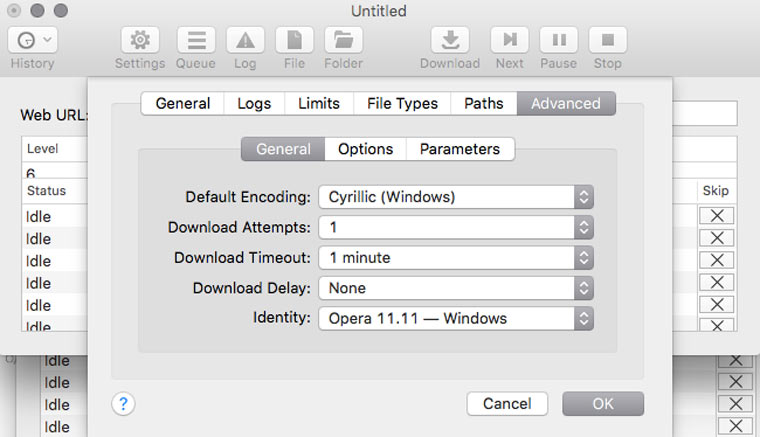
Если вы обнаружили, что скачанные страницы вместо текста содержат кракозябры, там можно попробовать решить эту проблему, поменяв кодировку в Settings -> Advanced -> General. Если неполадки возникли с русским сайтом, то скорее всего нужно указать кодировку Cyrillic Windows. Если это не сработает, то попробуйте найти искомую кодировку с помощью декодера Лебедева (в него надо вставлять текст с отображающихся криво веб-страниц).
7. Делаем снимок веб-страницы

Сделать снимок экрана умеет каждый. А знаете ли как сделать снимок веб-страницы целиком? Один из способов — зайти на web-capture.net и ввести там ссылку на нужный сайт. Не торопитесь, для сложных страниц время создания снимка может занимать несколько десятков секунд. Еще это можно провернуть в Google Chrome, а также в других браузерах с помощью дополнения iMacros.
Это может пригодиться для сравнения разных версий дизайна сайта, запечатления на память длинных эпичных перепалок в комментариях или в качестве альтернативы способу сохранения сайтов, описанного в предыдущих шести пунктах.
8. Сохраняем картинки только с определенной страницы
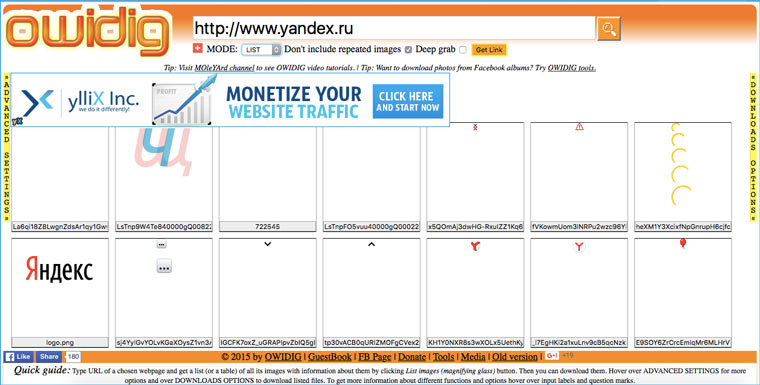
Идем на owdig.com, указываем нужную ссылку, ждем когда отобразятся все картинки и кликаем на оранжевую полоску справа, чтобы скачать их в архиве.
9. Извлекаем HEX-коды цветов с веб-сайта
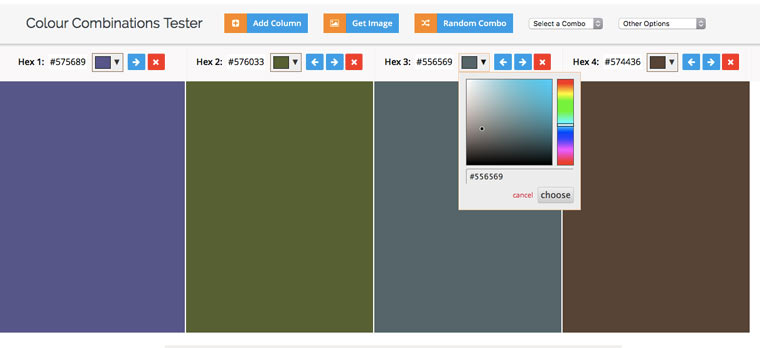
Идем на colorcombos.com и набираем адрес искомой страницы и получаем полный список цветов, которые использованы на ней.
10. Извлекаем из текста адреса электронной почты

Предположим, что вам надо сделать рассылку по сотрудникам компании, а их email-адреса есть только на странице корпоративного сайта и копировать их оттуда в ручную займет лишние 20-30 минут. В такой ситуации на помощь приходит сервис emailx.discoveryvip.com. Просто вставьте туда текст и через секунду вы получите список всех адресов электронной почты, которые в нем найдены.
11. Извлекаем из текста номера телефонов
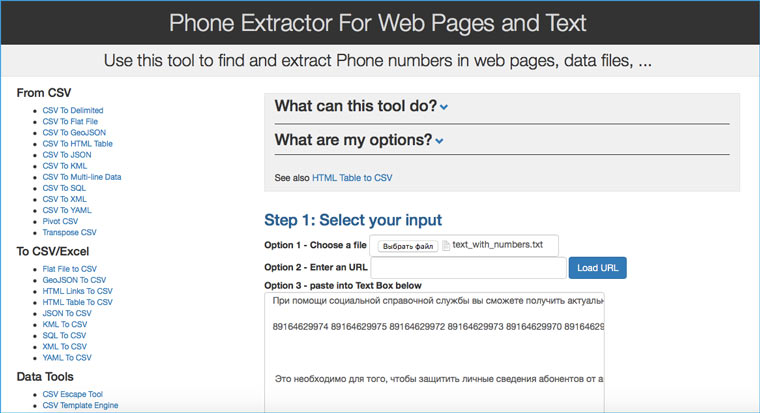
Идем на convertcsv.com/phone-extractor.htm, копируем в форму текст/html-код, содержащий номера телефонов и нажимаем на кнопку Extract.
А если надо отфильтровать в тексте заголовки, даты и прочую информацию, то к вам на помощь придут регулярные выражения и Sublime Text.
Есть и другие способы извлечения данных с сайтов. Можно попросить какую-ту информацию непосредственно у владельца ресурса, cохранять части веб-страниц с помощью iMacros и парсить сайты с помощью Google Apps Script. Еще можно пойти традиционным путем и написать для парсинга bash-скрипт, но статей об этом на iPhones.ru пока нет.
(4 голосов, общий рейтинг: 4.50 из 5)
�� Хочешь больше? Подпишись на наш Telegram.
В закладки
БЕЗ скриптов, макросов, регулярных выражений и командной строки. Эта статья пригодится студентам, которые хотят скачать все картинки с сайта разом, чтобы потом одним движением вставить их в Power Point и сразу получить готовую презентацию. Владельцам электронных библиотек, которые собирают новые книги по ресурсам конкурентов. Просто людям, которые хотят сохранить интересный сайт/страницу в соцсети, опасаясь, что.
Массовое скачивание файлов по ссылкам — 3 способа


Необходимость скачать несколько файлов возникает по разным причинам: кто-то хочет загрузить на гаджет несколько мультиков для детей, кому-то нужно обработать большой массив данных по работе. В любом случае, нажимать на каждую ссылку по отдельности и ждать загрузки файла – не рационально. Тем более, что есть несколько способов упростить и оптимизировать эту задачу.
Выбирать тот или иной метод нужно, исходя из ваших навыков работы с кодом и умения создавать алгоритмы. В статье мы рассмотрим 3 самых популярных способа скачивания нескольких файлов по ссылкам: они подходят для тех, кто может написать скрипт самостоятельно, а также для тех, кому требуется максимально простая методика.
1 способ: пакетная загрузка через ZENNOPOSTER
ZennoPoster – это универсальное программное решение, которое часто используют в работе digital-специалисты. За считанные минуты с помощью созданных шаблонов и алгоритмов вы можете автоматизировать любое действие в браузере, в том числе и парсинг ссылок для скачивания. Главный плюс ресурса в том, что вам не нужны специальные навыки для работы – вы можете использовать готовые скрипты и шаблоны от других пользователей либо создать их самостоятельно.
Общая схема работы программы выглядит так:
- Утилита находит ссылку на файл.
- Активирует ее.
- Сохраняет на компьютер.
- Возвращается к первому пункту.
Чаще всего, если речь идет о скачивании ссылок с одного ресурса, то они имеют статический параметр (например, все начинаются с http://savok.name/uploads/music/), а имя имеет уникальное численное значение. Ниже проиллюстрирована схема проекта.

Сперва мы устанавливаем первое значение переменной, которая возрастает в последующих наименованиях ссылок. В результате скачивание идет с первого файла. Общая схема работы выглядит следующим образом:
- Ставим первое значение переменной.
- Получаем ссылки в виде переменных.
- Выбираем место, куда нужно сохранять файлы.
- Прописываем GET-запрос в виде: .mp3, где — переменная, имеющая значение в статической части, — значение счетчика, mp3 — расширение файла, которое не меняется.
- Приходит уведомление о скачивании файла.
- Значение счетчика увеличиваем на 1.
- Возвращаемся к первому пункту.
Каждый раз программа обращается к статической части ссылки файла, сохраняет ее, увеличивает значение имени на 1 и переходит к следующему скачиванию. Схема гибкая и подходит для большинства случаев.
2 способ: загрузка через Browser Automation Studio
BAS (Browser Automation Studio) – это один из самых популярных аналогов ZennoPoster, который практически дублирует функционал программы. Разработка создавалась частными лицами, а не большой командой, но от этого функционал не уменьшился. В рамках утилиты пользователь может создавать разные шаблоны для повторяющихся действий, даже если нужно работать на нескольких потоках (доступно до 2000).
Функционал программы включает несколько полезных вещей:
- массовая загрузка файлов;
- смена разрешения;
- создание скриншотов;
- ввод текста;
- запуск скриптов;
- решение капч и другое.
Как и его аналог, программа работает с кодом, создает сложные скрипты для выполнения цепочки действий. Вы можете как написать собственный шаблон, так и приобрести готовые варианты от других пользователей, которые размещены в магазине приложений. Стоимость скрипта для BAS на данный момент от 1000 рублей.

3 способ: скачивание по подготовленному списку с утилитой WGET
Этот способ подходит для тех, кто собрал предварительно перечень всех ссылок с помощью парсера или вручную, но сразу скачать не получилось их по какой-либо причине. Загрузку нескольких файлов производят с помощью утилиты WGET, которая когда-то принадлежала полностью Linux, а сейчас распространяется как свободная программа в интернете.
- Для начала подготовьте список в следующем формате:
https://site.com/files/file_image_3.jpg и так далее.
- Сохраните перечень ссылок в текстовом файле.
- Скачиваем утилиту WGET, распаковываем архив. Она не имеет графического интерфейса, поэтому предварительно нужно прописать в свойствах системы путь к папке, чтобы запустить ее из командной строки.

- Правой кнопкой мыши нажимаем «Мой компьютер» — «Свойства ПК» — «Свойства системы» — «Дополнительные параметры системы» — «Переменные среды» — «Дополнительные параметры системы».
- В окне выбираем переменную Path и нажимаем команду «Изменить».
- Создаем новое значение с путем к папке c:wget. Сохраняем.

Когда мы сделали основные пункты, то открываем консоль командой Win + R, вводим cmd и нажимаем enter.
wget -i c:url-list.txt —secure-protocol=auto -nc -c -P c:files
Остановимся на разборе команды:
- -i — это путь для файла со списком URL для скачивания;
- -secure-protocol=auto — применяем, если на сайте защищенный протокол HTTPS, если же он простой, то эту часть не пишите;
- -nc – проверка на наличие такого файла: если он уже есть в системе, то загрузка его пропустит;
- -c – в случае неполной закачки, она продолжится;
- -P — путь, куда сохраняют данные.
Можно дополнительно добавить команду -x , если важно сохранить структуру как в источнике. Когда команда готова, то остается нажать enter и загрузка пойдет в указанную папку. На экране отображается только ЛОГ операции.
Вывод
На просторах Интернета вы дополнительно можете найти готовые парсеры и приложения, которые предлагают аналогичные услуги для скачивания файлов потоком. Однако большинство из них требуют знания кода и умения составлять скрипты. Хорошая новость в том, что шаблонами могут поделиться опытные пользователи на форумах.
Рациональнее использовать такие конструкторы как ZennoPoster или BAS, а также поработать с парсером и утилитой WGET. Они более понятны для пользователя и в большинстве случаев не требуют навыков кодирования.
А вы пользуетесь сервисами за массовой закачки файлов?
0 голосов
Simple Mass Downloader — скачиваем картинки и прочий контент с сайтов в Chrome в пакетном режиме

Когда вам предлагают скачать контент с некой веб-страницы, то чаще всего имеют ввиду какой-то конкретный файл — дистрибутив программы, документ, изображение и тому подобное. Но давайте представим, что у вас возникла необходимость скачать с этой страницы не один, не два и не три файла, а все файлы по имеющимся на ней ссылкам причем сразу. Возможно ли такое? Конечно. Сталкиваться с подобной задачей приходится не так уже и редко, примером чему может послужить скачивание изображений из галереи.
Simple Mass Downloader — скачиваем картинки и прочий контент с сайтов в Chrome в пакетном режиме
Упростить эту задачу вам поможет Simple Mass Downloader — бесплатное расширение для браузера Chrome, способное самостоятельно находить на странице или даже нескольких страницах ссылки и скачивать расположенные по ним файлы, причем под ссылками мы имеем ввиду не только гипертекст, но также и графику, одним словом всё то, что связано между собой и внешними ресурсами по URL. Итак, заходим на страницу расширения в Магазине и устанавливаем его.
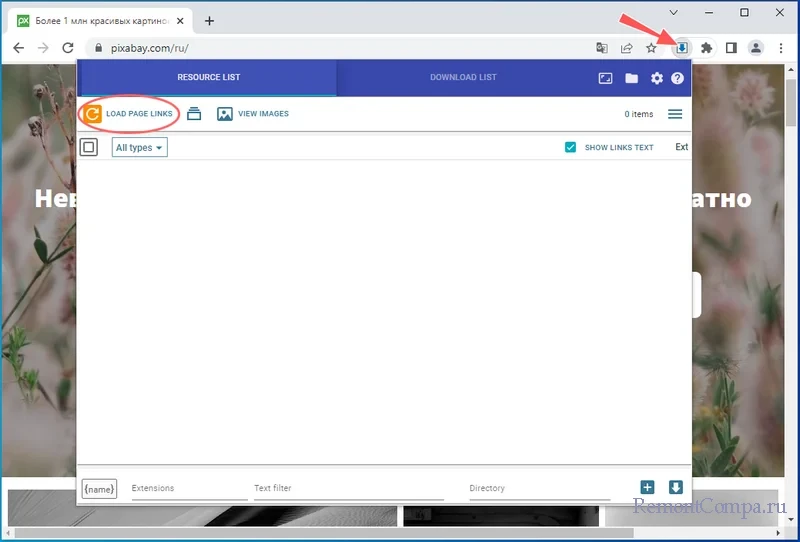
Мы это уже сделали, поэтому сразу приступим к демонстрации работы инструмента. Заходим на сайт с изображениями и кликаем по иконке расширения на панели инструментов Chrome. На экране тут же появляется панель с обнаруженными ссылками и доступным по ним контентом. Панель может быть и пустой, в этом случае жмем «LOAD PAGE LINKS», дабы проанализировать страницу.
Обнаружены и захвачены будут все ссылки: и те, которые ведут на другие страницы, и те, на которых «висят» файлы. Чтобы не скачивать ненужное, фильтруем контент, вбивая расширение файла в расположенную в нижней области панели неприметную на первый взгляд форму «Extension». А вообще отсеивать контент можно не только по расширению, но и по названию, хотя эта опция вряд ли вам пригодится. 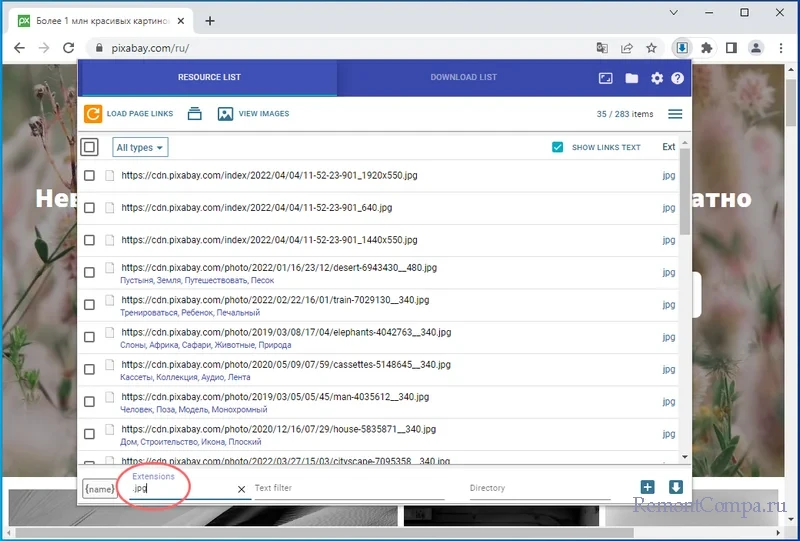 Если вашей целью являются только картинки, можно пойти и другим путем, а именно нажать кнопку «All Types» и выбрать в выпадающем меню пункт «Images», тем самым очистив список от прочих элементов.
Если вашей целью являются только картинки, можно пойти и другим путем, а именно нажать кнопку «All Types» и выбрать в выпадающем меню пункт «Images», тем самым очистив список от прочих элементов.  Кстати, в Simple Mass Downloader имеется возможность предпросмотра изображений, для этого нужно нажать кнопку «VIEW IMAGES». Данный режим сортировки хорош еще и тем, что позволяет отбирать картинки по размеру (ширине и высоте). Далее всё просто — жмем кнопку загрузки и запускаем процедуру загрузки, которые будут сохранены в пользовательский каталог скачиваемых файлов по умолчанию.
Кстати, в Simple Mass Downloader имеется возможность предпросмотра изображений, для этого нужно нажать кнопку «VIEW IMAGES». Данный режим сортировки хорош еще и тем, что позволяет отбирать картинки по размеру (ширине и высоте). Далее всё просто — жмем кнопку загрузки и запускаем процедуру загрузки, которые будут сохранены в пользовательский каталог скачиваемых файлов по умолчанию. 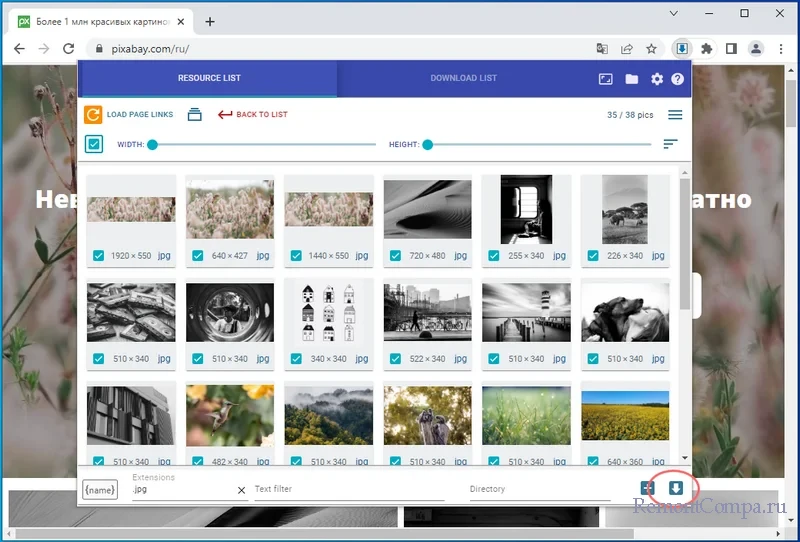
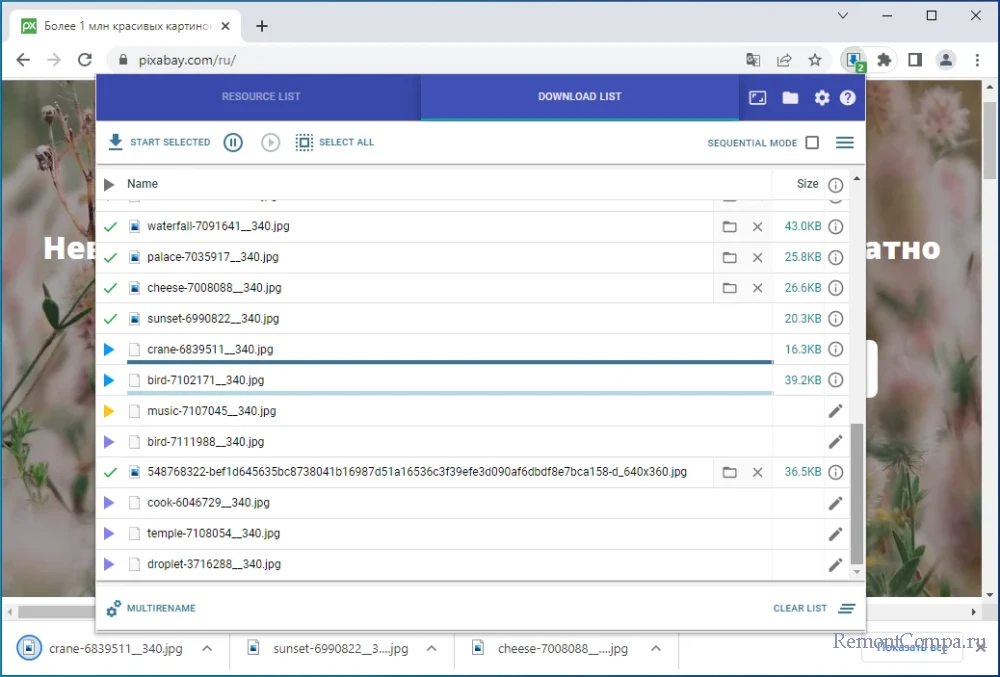 Что касается настроек, в особой конфигурации Simple Mass Downloader не нуждается. В параметрах расширения можно включить захват неактивных источников, указать собственные загрузочные каталоги, количество одновременных загрузок и тому подобное. В настройках вы также найдете опцию создания резервной копии настроек расширения.
Что касается настроек, в особой конфигурации Simple Mass Downloader не нуждается. В параметрах расширения можно включить захват неактивных источников, указать собственные загрузочные каталоги, количество одновременных загрузок и тому подобное. В настройках вы также найдете опцию создания резервной копии настроек расширения.
Резюме Simple Mass Downloader — мощный и эффективный инструмент скачивания контента с веб-сайтов. Бесплатное и удобное, расширение позволяет скачивать даже те файлы, которые не имеют прямых ссылок, правда, касается это в первую очередь изображений, представленных на сайтах вроде Imgur или Reddit уменьшенными копиями-превью. Стопроцентной гарантии, что расширение с одинаковой эффективностью станет работать на всех сайтах без исключения дать нельзя, поскольку многое также зависит от работы генерирующих содержимое веб-страницы скриптов. Расширение в Магазине: chrome.google.com/webstore/detail/simple-mass-downloader/abdkkegmcbiomijcbdaodaflgehfffed/related