Rtsp

python 2.7 opencv 3.2 rtsp
opencv python rtsp
c++ ffmpeg opencv
C++ получение изображения из rtsp камеры
c++ rtsp библиотека
Защищенный стриминг с веб-камеры
rtsp streaming vlc
Борьба с IP камерой.
Не выходит получить видеопоток по протоколу rtsp
camera gentoo opencv
nginx-rtmp-module как поднять поток после недоступности RTSP-источника более 5 минут
flv module nginx
Запись RTSP потоков с IP-камер в *.mp4 файлы с датой-временем в имени файла
mp4 program recording
Захват видео из своей программы
capture ip-cam rtsp
Детектор движения на С/С++ с IP камеры, помогите начать
Стриминг, порт-форвардинг и т.п.
gstreamer onvif rtsp
Не получается вещание в vlc по rtsp
rtsp streaming video vlc
gstreamer rtsp #2
Gstreamer проигрывание видео и запись из rtsp
gstreamer rtsp virtualbox
ffmpeg, rtsp поток: Наложение изображения на поток
Базовые принципы IP — телефония
![]()
Большинство организаций заинтересованы в улучшении своей бизнес инфраструктуры. Телефония на базе IP – это комплексное масштабируемое решение, которое позволяет компании снизить расходы, повысить лояльность клиентов и улучшить KPI (Key Performance Indicators).
Что же такое «IP — телефония»?
IP — телефония — это набор протоколов, алгоритмов и соглашений об обслуживании (QoS).
Среди протоколов можно выделить протокол сигнализации и протоколы, которые переносят сами медиа данные (голос). Сигнализации в терминологии телефонии, это набор событий и логика их обработки. К таким событиям можно отнести установление телефонного соединения, удержание, трансфер, завершение вызова и т.д. Хочется отметить, что сигнализацией между двумя телефонами всегда управляет телефонная станция. Перенос самих медиа данных осуществляется напрямую между двумя телефонами.
Обратим внимание на рисунок ниже:

В данном примере телефонная станция обозначена как сервер, программное обеспечение которого занимается обработкой телефонной сигнализации. Давайте разберемся с участками сигнализации, обозначенными пунктиром.
На сегодняшний день, широко используется протокол SIP (Session Initiation Protocol), описанный в рекомендации RFC 3261. Это открытый стандарт, поддерживаемый всеми известными АТС. SIP удобен в использовании и обнаружении проблем, т.к имеет структуру, коды и синтаксис во многом схожий с протоколом HTTP. Так же в корпоративном сегменте часто встречается проприетарный SCCP (Skinny Client Control Protocol), разработанный компанией Cisco Systems, и стандарт H.323. Именно эти протоколы полностью контролируют процесс телефонного разговора.
Теперь, когда мы понимаем, что такое телефонная сигнализация, давайте посмотрим на процесс передачи медиа – потока. Эти функции выполняет протокол RTP (Real-time Transport Protocol), описанный в RFC 3550. Специально разработанный для аудио и видео данных, RTP назначает каждому пакету номер и временной тэг. Когда поток данных приходит в узел получатель, пакеты обрабатываются и декодируются в правильной последовательности. Представьте, если бы IP-пакеты приходили к получателю в не правильном порядке? Разговор вряд ли бы состоялся, т.к разобрать речь не представлялось бы возможным.
Картина начинает складываться. Под управлением протоколов сигнализации RTP поток передается от отправителя к получателю. Теперь имеет смысл подумать над тем, как обеспечить интеграцию интернет и телефонного трафика, без взаимного влияния друг на друга. В телефонии, зачастую под цели голосового трафика выделяют отдельные VLAN. Это позволяет разграничить телефонный и интернет трафик на логическом уровне. Но самым важным и надежным механизмом является QoS (Quality of Service). Это алгоритм приоритизации трафика, обработки очередей, выделений необходимой полосы пропускания, задержки, джиттера и др. В треке CCNP Voice (Cisco Certified Network Professional Voice), под QoS выделен целый экзамен. В следующих статьях мы постараемся описать данный механизм более подробно.
Хочется подвести небольшой итог: IP — телефония – это неотъемлемая часть успешного бизнеса. Мы, как команда опытных профессионалов готовы оказать вам помощь в установке, настройке офисной телефонии. Провести консультации, помочь с выбором провайдера и спроектировать оптимальное решение для уже существующего сетевого ландшафта.
Как вынуть h264 из rtp потока c IP камеры или в чём мои ошибки?
Приветствую.
Есть камера, устанавливаю соединение по RTSP, открываю UDP порт, камера шлёт пакеты.
С этим проблем почти не возникло,
возникли проблемы как из UDP потока выцепить h264 и просто записать в файл.
Алгоритм такой:
1. Из RTSP получаю для h264 параметры SPS и PPS из DSP, что пришёл в DSP ответе на DESCRIBE,
2. Записываю в файл: 000001 SPS 000001 PPS
3. Начинаю читать RTP пакеты с камеры
4. Получаю N`нный пакет целиком
5.1 Беру из него буфер заголовка фрейма (первые 12 байт, с проверкой что нету контрольных сумм и отступов, иначе пришлось бы увеличивать )
5.2. Беру из него буфер данных фрейма (с отступом от начала соразмерно заголовку и до конца)
5.3 Из заголовков выясняю Sequence что бы быть уверенным, что пакеты идут по порядку
6. Беру первый байт из буфера данных — NAL юнит
7. Смотрю его тип: (NAL & 0x1f)
7.1.1 Если тип 28, значит фрейм не влезает в один пакет
7.1.2 Беру второй байт из буфера данных — fuHeader заголовок фрагмента
7.1.3. Выясняю, какой это фрагмент:
начала ( f = fuHeader & 0x80 f!=0 )
середины ( m = fuHeader & 0xE0 m==0)
или конечный ( e = fuHeader & 0x40 e!=0)
7.1.4. Если фрагмент начала, то пишу в итоговый буфер
000001 — разделитель
восстанавливаю NAL (NAL & 0xE0) ^ (fuHeader & & 0x1f) и записываю в файл
записываю буфер данных фрейма со сдвигом от начала на 2 байта (без NAL и fuHeader)
7.1.5 Если фрагмент середины, то пишу в итоговый буфер
пишу буфер данных фрейма со сдвигом от начала на 2 байта (без NAL и fuHeader)
7.1.6 Если фрагмент конца, то пишу в итоговый буфер
пишу буфер данных фрейма со сдвигом от начала на 2 байта (без NAL и fuHeader)
записываю итоговый буфер в файл и очищаю итоговый буфер
8. И снова на шаг №4
В итоге файл воспроизводиться но в файле сплошные артефакты, если камеру подвигать,
что-то можно разобрать но опять же сплошные артефакты и прыжки.
По логу смотрел
— пакеты принимаются по порядку (показания Sequence)
— потерь ( разница Sequence от прошлого пакета) практически нет (один на 20-30)
— тип NAL всегда 28 (изредка проскакивает 6, но его игнорирую)
Если через ffmpeg записывать, то всё идеально.
Ставил у ffmpeg loglevel trace — моё RTSP подключение совпадает по параметрам.
Что я делаю не так? Правилен ли алгоритм?
P.S. Статья прочитана: https://habrahabr.ru/post/233237/ сверялся с ней — вроде всё правильно.
Посмотрел исходники примера — в примере делается так же (часть получегия и обработки),
разве что где-то ещё какая-то обработка стоит, но в Java разбираюсь крайне слабо.
- Вопрос задан более трёх лет назад
- 3285 просмотров
Python, Go или… готовим сырой видеопоток с полсотни камер

В проектах, связанных с машинным зрением и обучением приходится работать с сырым видеопотоком с камер. Чтобы принимать, предобрабатывать и передавать эти данные нейросетям необходим отдельный программный компонент, который мы условно называем «видеоридер». Это микросервис, который выполняет функцию декодирования RTSP-потоков с камер, отбирает определенные кадры и отправляет в базу данных для дальнейшего анализа. И все это в режиме реального времени.
В этой статье мы расскажем о том, почему на создание видеоридера понадобилось 6 месяцев, почему пришлось его переписывать и какие еще сложности были на этом пути. Поскольку велосипед изобретали трижды, наши выводы могут пригодиться всем разработчикам, которые реализуют крупные проекты с долей исследовательской работы.
От стабильности видеоридера зависит эффективность всей системы машинного зрения: если он некорректно декодирует видеопотоки или передает искаженные кадры — это снижает стабильность и качество распознавания объектов.
Также важно, чтобы видеоридер работал без перебоев и непредсказуемых задержек, которые приводят к скачкам FPS. В свою очередь, для надежного трекинга объектов необходима стабильная подача кадров с правильными метаданными — временными метками (time-stamp), которые проставляются по каждому событию захвата или создания кадра. С помощью меток определяется время, когда произошло какое-то событие или началась запись, а еще они отвечают за согласованность между разными камерами. Непредсказуемое изменение частоты кадров сильно затрудняет работу с движущимися объектами.
Что такое хороший видеоридер:
- это точно не монолит, далее объясним почему;
- он должен гарантированно справляться с высокими нагрузками — тоже остановимся на этом подробнее ниже;
- и соответственно, его нужно писать на «эффективном языке».
В общем, создавать нужно хороший видеоридер, а плохой не создавать. Теперь, к подробностям.
Как работает видеоридер
С технической точки зрения, видеоридер получает статус, обрабатывает запросы на включение, отключение, распределение видеопотоков с группы камер, а также подготавливает кадры для подачи другим алгоритмам.
Возьмем, например, распознавание направления движения грузовика с камеры, установленной на строительной площадке, — как минимум, одновременно работают процессы, отвечающие за декодирование видеопотока, детекцию объекта и трекинг. Если добавить к этому еще какие-то нейронки, уже получится значительная нагрузка на сервер, а ведь речь не об одной камере.
Микросервисная архитектура в данной ситуации — удачное решение, ведь нужно заранее предусмотреть возможность масштабирования. Монолит скорее всего, не позволит оперативно подключить к такому конвейеру еще сотню-другую дополнительных камер. В то же время микросервисы достаточно легко размножить и распределить по разным серверам — их можно оптимизировать, совершенствовать и даже переписывать с нуля по отдельности.
Процесс работы с RTSP-потоком
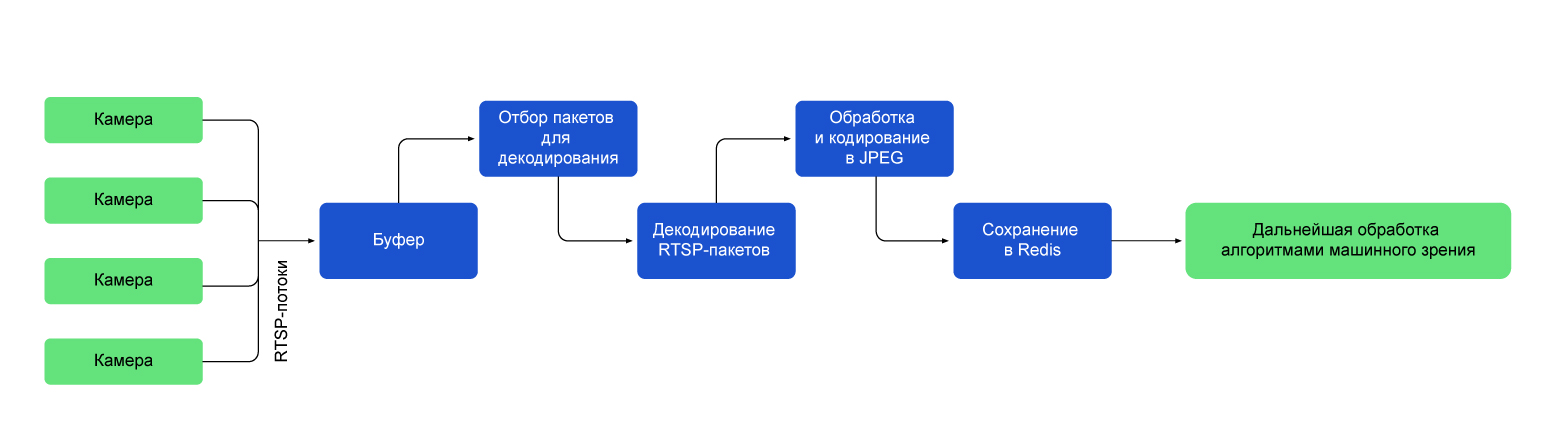
1. Видеоридер инициирует соединение с сервером, предоставляющим RTSP-поток по TCP. Есть и более быстрая альтернатива — UDP (User Datagram Protocol), но он плохо показал себя в тестах. Попробовав использовать UDP, мы столкнулись с проблемой: в некоторых случаях кадры приходили с артефактами, которые делали их непригодными для обработки или анализа. Пришлось использовать протокол TCP, который хоть и менее производителен по сравнению с UDP, но обеспечивает надежную передачу данных и допускает повторную передачу потерянных пакетов данных.
2. После установки соединения отправляется запрос на установку сессии для конкретного RTSP-потока. В этом запросе можно указать параметры потока (например, разрешение видео или битрейт).
3. Успешная установка сессии позволяет видеоридеру начать получать мультимедийные данные с камер, как раз они и составляют RTSP-поток.
4. Пакеты считываются и помещаются в буфер FFmpeg.
5. Далее идет подготовка к декодированию в сырое изображение: происходит «прокрутка буфера», то есть перерасчет пакетов из буфера относительно предыдущих пакетов и отбор пакетов. Этот этап необходим, чтобы отрегулировать частоту кадров. Например, если брать каждый 6 кадр из 60, то на выходе получим 10 FPS.
6. Декодирование избранных RTSP-пакетов в сырое изображение.
5. Затем кадры кодируются в JPEG и передаются в сжатом виде в базу данных для дальнейшей обработки.
6. По завершении работы с RTSP-потоком видеоридер отправляет запрос на завершение сессии (или переподключение, в случае возникновения проблем).

Для нормальной работы в составе высоконагруженной системы машинного зрения, видеоридер должен выполнять все эти операции одновременно с несколькими камерами. Мы ориентировались на то, что каждый экземпляр микросервиса будет параллельно обрабатывать более 40 видеопотоков. Это довольно высокая планка, и она вызвала множество проблем при разработке.
Как мы писали свой видеоридер
Идея создания своего микросервиса-видеоридера, который мы могли бы использовать в разных проектах достаточно давно витала в воздухе, и одна такая попытка в компании уже была. Первую, экспериментальную версию видеоридера, коллеги по-быстрому написали на Python. Она работала не так уж плохо, но лишь с небольшим количеством камер.
Почему не стоило выбирать Python
Как интерпретируемый язык, Python обычно менее эффективен по сравнению с компилируемыми альтернативами. К тому же в нем присутствует GIL. Глобальная блокировка ограничивает возможности многопоточной работы, что является существенным недостатком для задач, где требуется интенсивная параллельная обработка. Чтобы избавиться от этих недостатков, мы решили переписать видеоридер на Go.
Почему выбрали Golang
У этого языка есть свои плюсы: Go является компилируемым и обеспечивает высокую производительность там, где нужны быстрые вычисления. Goroutines и channels делают управление многозадачностью в Go более эффективным и удобным, чем в Python. К тому же язык достаточно прост и имеет чистую синтаксическую структуру, а это ускоряет разработку.
Но в этой бочке меда присутствует и деготь, ведь мы не учли ряд ограничений языка. Хотя мы использовали библиотеки, оптимизированные для многопоточности, они не позволяли задействовать GPU. Первоначально мы берегли видеокарты для нейронок и рассчитывали, что видеоридер будет работать исключительно на центральном процессоре, но никакие распространенные CPU не вывозили одновременно полсотни камер и другие микросервисы, задействованные в трекинге объектов. Видеоридеру оставалось не так уж много ресурсов: Intel Xeon Gold 5218R в тестовом стенде загружался под 100% уже после подключения восьми камер.
Никакие оптимизации не смогли бы ускорить видеоридер в пять раз. Нужно было разгружать центральный процессор и перекладывать декодирование RTSP на GPU. Тут-то и выяснилось, что мы не можем просто взять и перенести вычисления на видеокарту. У Go нет стандартной библиотеки для работы с GPU, нет нативной интеграции с GPU-драйверами, а попытка использовать с этой версией видеоридера OpenCV вызвала переполнение буфера и отставание от реалтайма.
Оценив масштаб задач, мы поняли, что проще будет собрать волю в кулак и снова переписать видеоридер — не то чтобы это решило сразу все проблемы, но существенно помогло.
Зачем переписали все на C++
Да, этот язык программирования не позволял переиспользовать уже готовые наработки, и все пришлось переписывать с нуля, но «выстрелило» преимущество выбранной архитектуры. Изменения ограничились внутренностями единственного микросервиса. Переход на C++ помог частично справиться с проблемой падения FPS при большом количестве подключенных камер.
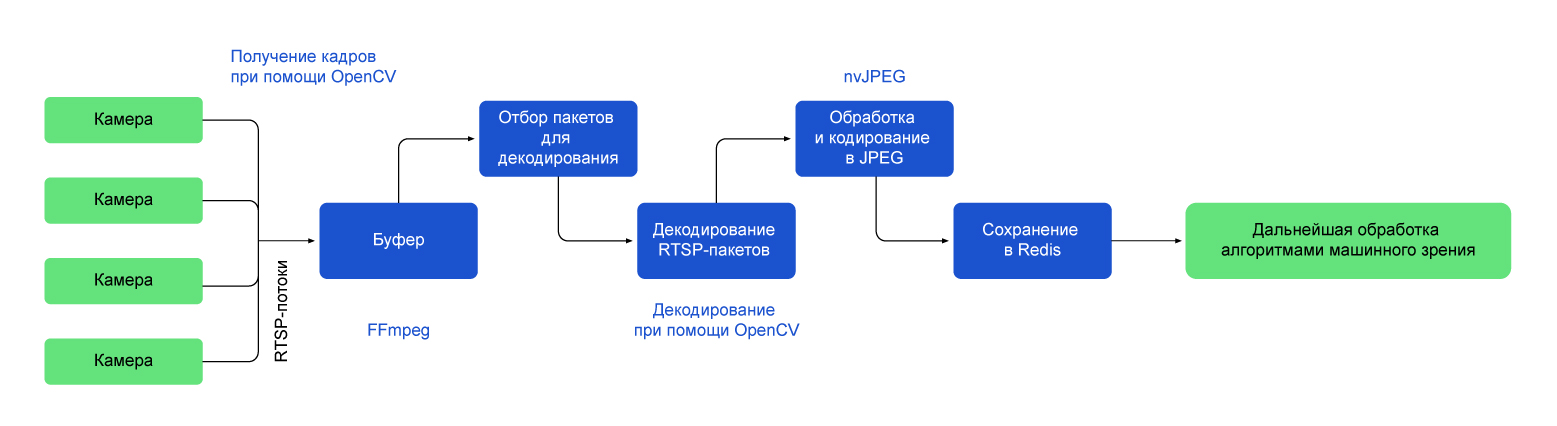
Как выглядит текущее решение:
- Для выполнения различных операций, связанных с видеопотоками, включая захват, обработку и анализ видеоданных мы используем OpenCV. Библиотеку удалось оптимизировать для работы с GPU. Она работает совместно с FFmpeg.
- FFmpeg-бэкенд выполняет роль буфера, куда складываются RTSP-пакеты, которые мы должны отобрать и декодировать.
- Прокрутка буфера пакетов выполняется функцией OpenCV cv::VideoCapture::grab(), а декодирование функцией cv::VideoCapture::retrieve(cv::Mat)
- Процесс повторного кодирования отдельных кадров в JPEG происходит с помощью модуля pynvjpeg, который задействует nvJPEG.
- Обработка кадров осуществляется с использованием CUDA. Параллельные вычисления на графическом процессоре особенно полезны, когда считаешь нечто тяжелое в реальном времени — это как раз наш случай.
- Кадры из видеоридера, кодированные в JPEG, складываем в Redis: отсюда мы забираем их для анализа нейронными сетями или для других задач (трекинг, определение смещения камеры) и здесь же храним до тех пор, пока не закончим работу с ними.
Этот набор технологий позволил снять большую часть нагрузки на CPU и, наконец, увеличить количество обрабатываемых потоков до целевого уровня в 40-50 камер. Единственный значимый минус такого решения в том, что у нас остаются сложности с управляемостью буфера FFmpeg-а. В случае если в буфер набилось слишком много пакетов, мы информируем систему, очищаем буфер и переподключаемся к камерам.
Это происходит редко, но это узкое место, которое мешает подключать еще больше камер, и мы экспериментируем с ним прямо сейчас. Верхнеуровнево регулировать размер и «прокрутку буфера» не получается из-за ограничений архитектуры и используемых библиотек. Если рассуждать о возможных вариантах решения, можно рассмотреть еще два подхода:
- Обеспечить управляемость буфера, проанализировав и частично переписав код библиотеки, отвечающей за кодирование и декодирование видео. В таком случае можно будет выполнять обработку пакетов recv и декодирование кадров в одном потоке и подавать их в собственный поточно-безопасный круговой буфер. Это должно решить проблему переполнения и улучшить управляемость процесса, но у нас не реализован UDP, мы подключаемся по TCP-протоколу.
- Альтернативой может стать использование многопоточности, когда каждый кадр обрабатывается в отдельном потоке. Например, можно взять ThreadPool, который обычно применяют в приложениях с параллельной обработкой большого количества задач. Такой подход позволяет ускорить обработку кадров и эффективно управлять большим объемом данных. Однако, в случае неупорядоченных потоков, такого рода параллельная обработка может привести к трудностям с поддержанием правильного порядка кадров, не говоря о том, что этот вариант требует дополнительных усилий для управления синхронизацией.
На этот раз мы примем окончательный выбор только после дополнительных исследований.
Что мы вынесли из проекта
Какой вывод можно сделать теперь, когда наш видеоридер работает в ряде пилотных проектов? Хотелось бы сказать, что у нас был план, и мы его придерживались, но это не совсем так. Если бы команда разработки изначально провела глубокий анализ существующих решений, мы бы избежали многих граблей.
- Детальное планирование и анализ — ключ к успеху, не стоит на них экономить, если проект нужно было сделать еще вчера. Отсутствие четкого плана может привести к неожиданным проблемам и задержкам в разработке.
- Выбор языка программирования и библиотек играет критическую роль в производительности и успехе любого проекта.
- Работа с видео и обработка данных в реальном времени требует высокой производительности. Не стоит размениваться по мелочам, сразу выбирайте наиболее оптимизированные библиотеки и закладывайте возможность переноса вычислений на GPU, даже если кажется, что без этого можно обойтись.
Из неочевидных моментов, связанных с переводом видеоридера на C++, приходится учитывать потенциальные риски, связанные с управлением памятью и низкоуровневым кодом. Их можно снизить, применяя специфические практики и инструменты, например, такие как RAII (Resource Acquisition Is Initialization). Этот подход заключается в том, что ресурсы, например, динамическую память, выделяют и освобождают в конструкторе и деструкторе объектов.
В случае видеоридера, мы не выделяли динамическую память, а полагались на интеллектуальные указатели типа std::shared_ptr. Они позволяют управлять временем жизни объектов и ресурсов, что помогает предотвратить утечки памяти и повышает стабильность микросервиса. Плюс, в деструкторе рабочего класса отдельно прописали отключение от камеры, отключение сессии Redis и освобождение GPU.
Для создания рабочих потоков использовали стандартный std::thread, а для их синхронизации с основным потоком std::mutex. Более сложные инструменты не потребовались. При этом при разработке классов приходилось держать в голове корректное использование семантики перемещения, value category и правило 5-ми/7-ми/0-ля.
- Блог компании Magnus Tech
- Работа с видео
- Программирование
- Анализ и проектирование систем
- Машинное обучение