Сборка проекта на С++ в GNU/Linux
Язык С++ является компилируемым, то есть трансляция кода с языка высокого уровня на инструкции машинного кода происходит не в момент выполнения, а заранее — в процессе изготовления так называемого исполняемого файла (в ОС Windows такие файлы имеют расширение .exe , а в ОС GNU/Linux чаще всего не имеют расширения).
hello.cpp
Пример простой программы на С++, которая печатает «Привет, Мир!»:
#include int main() std::cout <"Hello, World!" <std::endl; return 0; >
Для вывода здесь используется стандартная библиотека iostream , поток вывода std::cout .
Исполняемые операторы в программах на С++ не могут быть сами по себе — они должны быть обязательно заключены в функции.
Функция main() — это главная функция, выполнение программы начинается с её вызова и заканчивается выходом из неё. Возвращаемое значение main() в случае успешных вычислений должно быть равно 0, что значит «ошибка номер ноль», то есть «нет ошибки». В противном процесс, вызвавший программу, может посчитать её выполнившейся с ошибкой.
Чтобы выполнить программу, нужно её сохранить в текстовом файле hello.cpp и скомпилировать следующей командой:
$ g++ -o hello hello.cpp
Опция -o сообщает компилятору, что итоговый исполняемый файл должен называться hello . g++ — это компилятор языка C++, входящий в состав проекта GCC (GNU Compiler Collection). g++ не является единственным компиляторм языка C++. Помимо него в ходе курса мы будет использовать компилятор clang , поскольку он обладает рядом преимуществ, из которых нас больше всего интересует одно — этот компилятор выдаёт более понятные сообщения об ошибках по сравнению с g++ .
Упражнение №1
Скомпилируйте и выполните данную программу.
Ввод и вывод на языке С++
В Python и в С ввод и вывод синтаксически оформлены как вызов функции, а в С++ — это операция над объектом специального типа — потоком.
Потоки определяются в библиотеке iostream, где определены операции ввода и вывода для каждого встроенного типа.
Вывод
Все идентификаторы стандартной библиотеки определены в пространстве имен std , что означает необходимость обращения к ним через квалификатор std:: .
std::cout "mipt"; std::cout 2018; std::cout '.'; std::cout true; std::cout std::endl;
Заметим, что в С++ мы не прописываем типы выводимых значений, компилятор неким (пока непонятным) способом разбирается в типе выводимого значения и выводит его соответствующим образом.
Вывод в один и тот же поток можно писать в одну строчку:
std::cout "mipt" 2018 '.' true std::endl;
Для вывода в поток ошибок определён поток std::cerr .
Ввод
Поток ввода с клавиатуры называется std::cin , а считывание из потока производится другой операцией — >> :
std::cin >> x;
Тип считываемого значения определяется автоматически по типу переменной x .
Для всех типов, кроме char , считывание будет производиться с пропуском символов-разделителей и до следующего символа-разделителя. При этом пробел и табуляция так же, как и символ перевода каретки, являются корректными разделителями. Считывание в char происходит посимвольно независимо от типа символа.
Например для введенной строки «Иван Иванович Иванов»,
std::string name; std::cin >> name;
считает в name только первое слово «Иван».
Считать всю строку целиком можно с помощью функции getline() :
std::string name; std::getline(std::cin, name);
Считывать несколько значений можно и в одну строку:
std::cin >> x >> y >> z;
Упражнение №2
Напишите программу, которая считает гипотенузу прямоугольного треугольника по двум катетам. Ввод и вывод стандартные.
| Ввод | Вывод |
| 3 4 | 5 |
Сумма первых n натуральных чисел
Пример программы, которая подсчитывает сумму первых n натуральных чисел:
#include int main() int n = 0; std::cin >> n; int sum = 0; for (int i = 1; i n; i++) sum += i; > std::cout <sum <std::endl; return 0; >
Как известно, если сложную задачу разбить на несколько простых подзадач, то её решение сильно упрощается. Поэтому не стоит писать весь код в одной функции main() . Лучше разбивать код на отдельные функции, каждая из которых решает свою несложную подзадачу, но делает это хорошо. Например, в предыдущем примере можно вынести функциональность подсчёта суммы первых n натуральных чисел в отдельную функцию:
#include int GetNaturalsSum(const int n) int sum = 0; for (int i = 1; i n; i++) sum += i; > return sum; > int main() int n = 0; std::cin >> n; std::cout <GetNaturalsSum(n) <std::endl; return 0; >
Эмперическое правило: каждая функция не должна превышать по размеру 1 экран вашего монитора.
Этапы сборки: препроцессинг, компиляция, компоновка
Компиляция исходных текстов на Си в исполняемый файл происходит в три этапа.
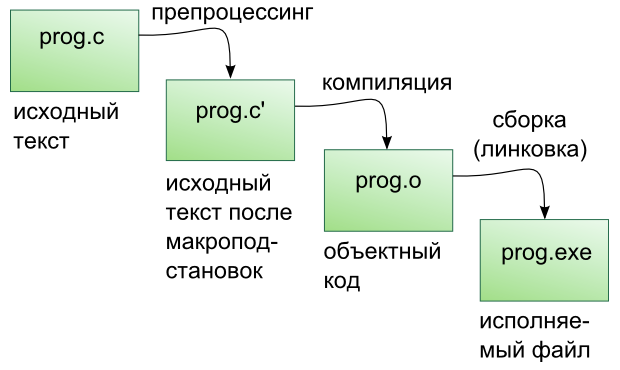
Препроцессинг
Эту операцию осуществляет текстовый препроцессор.
Исходный текст частично обрабатывается — производятся:
- Замена комментариев пустыми строками
- Текстовое включение файлов — #include
- Макроподстановки — #define
- Обработка директив условной компиляции — #if , #ifdef , #elif , #else , #endif
Компиляция
Процесс компиляции состоит из следующих этапов:
- Лексический анализ. Последовательность символов исходного файла преобразуется в последовательность лексем.
- Синтаксический анализ. Последовательность лексем преобразуется в дерево разбора.
- Семантический анализ. Дерево разбора обрабатывается с целью установления его семантики (смысла) — например, привязка идентификаторов к их декларациям, типам, проверка совместимости, определение типов выражений и т. д.
- Оптимизация. Выполняется удаление излишних конструкций и упрощение кода с сохранением его смысла.
- Генерация кода. Из промежуточного представления порождается объектный код.
Результатом компиляции является объектный код.
Объектный код — это программа на языке машинных кодов с частичным сохранением символьной информации, необходимой в процессе сборки.
При отладочной сборке возможно сохранение большого количества символьной информации (идентификаторов переменных, функций, а также типов).
Компоновка
Компоновка также называется связывание или линковка. На этом этапе отдельные объектные файлы проекта соединяются в единый исполняемый файл.
На этом этапе возможны так называемые ошибки связывания: если функция была объявлена, но не определена, ошибка обнаружится только на этом этапе.
Упражнение №3
Выполните в консоли для ранее созданного файла hello.cpp последовательно операции препроцессинга, компиляции и компоновки:
$ g++ -E -o hello1.cpp hello.cpp
- Компиляция:
$ g++ -c -o hello.o hello1.cpp
- Компоновка:
$ g++ -o hello hello.o
Принцип раздельной компиляции
Компиляция — алгоритмически сложный процесс, для больших программных проектов требующий существенного времени и вычислительных возможностей ЭВМ. Благодаря наличию в процессе сборки программы этапа компоновки (связывания) возникает возможность раздельной компиляции.
В модульном подходе программный код разбивается на несколько файлов .cpp , каждый из которых компилируется отдельно от остальных.
Это позволяет значительно уменьшить время перекомпиляции при изменениях, вносимых лишь в небольшое количество исходных файлов. Также это даёт возможность замены отдельных компонентов конечного программного продукта, без необходимости пересборки всего проекта.
Пример модульной программы с раздельной компиляцией на С++
Рассмотрим пример: есть желание вынести часть кода в отдельный файл — пользовательскую библиотеку.
program.cpp
#include "mylib.hpp" const int MAX_DIVISORS_NUMBER = 10000; int main() int number = read_number(); int Divisor[MAX_DIVISORS_NUMBER]; int Divisor_top = 0; factorize(number, Divisor, &Divisor_top); print_array(Divisor, Divisor_top); return 0; >
Подключение пользовательской библиотеки в С++ на самом деле не так просто, как кажется.
Сама библиотека должна состоять из двух файлов: mylib.hpp и mylib.cpp :
mylib.hpp
#ifndef MY_LIBRARY_H_INCLUDED #define MY_LIBRARY_H_INCLUDED #include //считываем число int read_number(); //получаем простые делители числа // сохраняем их в массив, чей адрес нам передан void factorize(int number, int *Divisor, int *Divisor_top); //выводим число void print_number(int number); //распечатывает массив размера A_size в одной строке через TAB void print_array(int A[], size_t A_size); #endif // MY_LIBRARY_H_INCLUDED
mylib.cpp
#include #include "mylib.hpp" //считываем число int read_number() int number; std::cin >> number; return number; > //получаем простые делители числа // сохраняем их в массив, чей адрес нам передан void factorize(int x, int *Divisor, int *Divisor_top) for (int d = 2; d x; d++) while (x%d == 0) Divisor[(*Divisor_top)++] = d; x /= d; > > > //выводим число void print_number(int number) std::cout <number <std::endl; > //распечатывает массив размера A_size в одной строке через TAB void print_array(int A[], size_t A_size) for(int i = A_size-1; i >= 0; i--) std::cout <A[i] <'\t'; > std::cout <std::endl; >
Препроцессор С++, встречая #include «mylib.hpp» , полностью копирует содержимое указанного файла (как текст) вместо вызова директивы. Благодаря этому на этапе компиляции не возникает ошибок типа Unknown identifier при использовании функций из библиотеки.
Файл mylib.cpp компилируется отдельно.
А на этапе компоновки полученный файл mylib.o должен быть включен в исполняемый файл program .
Cреда разработки обычно скрывает весь этот процесс от программиста, но для корректного анализа ошибок сборки важно представлять себе, как это делается.
Упражнение №4
Давайте сделаем это руками:
$ g++ -c mylib.cpp # 1 $ g++ -c program.cpp # 2 $ g++ -o program mylib.o program.o # 3
Теперь, если изменения коснутся только mylib.cpp , то достаточно выполнить только команды 1 и 3. Если только program.cpp, то только команды 2 и 3. И только в случае, когда изменения коснутся интерфейса библиотеки, т.е. заголовочного файла mylib.hpp , придётся перекомпилировать оба объектных файла.
Утилита make и Makefile
Утилита make предназначена для автоматизации преобразования файлов из одной формы в другую. По отметкам времени каждого из имеющихся объектных файлов (при их наличии) она может определить, требуется ли их пересборка.
Правила преобразования задаются в скрипте с именем Makefile , который должен находиться в корне рабочей директории проекта. Сам скрипт состоит из набора правил, которые в свою очередь описываются:
- целями (то, что данное правило делает);
- реквизитами (то, что необходимо для выполнения правила и получения целей);
- командами (выполняющими данные преобразования).
В общем виде синтаксис Makefile можно представить так:
# Отступ (indent) делают только при помощи символов табуляции, # каждой команде должен предшествовать отступ : .
То есть, правило make это ответы на три вопроса:
—> [Как делаем? (команды)] —>
Несложно заметить что процессы трансляции и компиляции очень красиво ложатся на эту схему:
Простейший Makefile
Для компиляции hello.cpp достаточно очень простого мэйкфайла:
hello: hello.cpp gcc -o hello hello.cpp
Данный Makefile состоит из одного правила, которое в свою очередь состоит из цели — hello , реквизита — hello.cpp , и команды — gcc -o hello hello.cpp .
Теперь, для компиляции достаточно дать команду make в рабочем каталоге. По умолчанию make станет выполнять самое первое правило, если цель выполнения не была явно указана при вызове:
Makefile для модульной программы
program: program.o mylib.o g++ -o program program.o mylib.o program.o: program.cpp mylib.hpp g++ -c program.cpp mylib.o: mylib.cpp mylib.hpp g++ -c hylib.cpp
Попробуйте собрать этот проект командой make или make hello . Теперь измените любой из файлов .cpp и соберите проект снова. Обратите внимание на то, что во время повторной компиляции будет транслироваться только измененный файл.
После запуска make попытается сразу получить цель program , но для ее создания необходимы файлы program.o и mylib.o , которых пока еще нет. Поэтому выполнение правила будет отложено и make станет искать правила, описывающие получение недостающих реквизитов. Как только все реквизиты будут получены, make`вернется к выполнению отложенной цели. Отсюда следует, что `make выполняет правила рекурсивно.
Фиктивные цели
На самом деле в качестве make целей могут выступать не только реальные файлы. Все, кому приходилось собирать программы из исходных кодов, должны быть знакомы с двумя стандартными в мире UNIX командами:
$ make $ make install
Командой make производят компиляцию программы, командой make install — установку. Такой подход весьма удобен, поскольку все необходимое для сборки и развертывания приложения в целевой системе включено в один файл (забудем о скрипте configure ). Обратите внимание на то, что в первом случае мы не указываем цель, а во втором целью является вовсе не создание файла install , а процесс установки приложения в систему. Проделывать такие фокусы нам позволяют так называемые фиктивные (phony) цели. Вот краткий список стандартных целей:
all — является стандартной целью по умолчанию. При вызове make ее можно явно не указывать; clean — очистить каталог от всех файлов полученных в результате компиляции; install — произвести инсталляцию; uninstall — и деинсталляцию соответственно.
Для того чтобы make не искал файлы с такими именами, их следует определить в Makefile , при помощи директивы .PHONY . Далее показан пример Makefile с целями all , clean , install и uninstall :
.PHONY: all clean install uninstall all: program clean: rm -rf mylib *.o program.o: program.cpp mylib.hpp gcc -c -o program.o program.cpp mylib.o: mylib.cpp mylib.hpp gcc -c -o mylib.o mylib.cpp program: program.o mylib.o gcc -o mylib program.o mylib.o install: install ./program /usr/local/bin uninstall: rm -rf /usr/local/bin/program
Теперь мы можем собрать нашу программу, произвести ее инсталлцию/деинсталляцию, а так же очистить рабочий каталог, используя для этого стандартные make цели.
Обратите внимание на то, что в цели all не указаны команды; все что ей нужно — получить реквизит program . Зная о рекурсивной природе make, не сложно предположить, как будет работать этот скрипт. Также следует обратить особое внимание на то, что если файл program уже имеется (остался после предыдущей компиляции) и его реквизиты не были изменены, то команда make ничего не станет пересобирать. Это классические грабли make. Так, например, изменив заголовочный файл, случайно не включенный в список реквизитов (а надо включать!), можно получить долгие часы головной боли. Поэтому, чтобы гарантированно полностью пересобрать проект, нужно предварительно очистить рабочий каталог:
$ make clean $ make
P.S. Неплохая статья с описанием мейкфайлов.
Сайт построен с использованием Pelican. За основу оформления взята тема от Smashing Magazine. Исходные тексты программ, приведённые на этом сайте, распространяются под лицензией GPLv3, все остальные материалы сайта распространяются под лицензией CC-BY-SA.
В чем набрать и чем собрать C++ проект
Задавшись этим вопросом я, в первую очередь, сформулировал требования: жесткие и опциональные (но желательные) для системы сборки и графической среды разработки.
Сразу хочу отметить что речь идет о написании C++ кода не под какую-то специфичную платформу типа Android или фреймворка, например Qt, — где все уже готово, как с построением так и с редактированием кода, а об generic коде не привязанному к конкретной платформе или фреймворку.
Общие:
- Свободный.
- Кросплатформенный (по крайней мере Windows и Linux).
Система сборки:
- Единая команда для сборки на разных платформах.
- Инкрементальная сборка с корректным учетом всех зависимостей: заголовочных файлов и сторонних компонентов, использующихся для сборки.
- Сборочный скрипт должен содержать только необходимый минимум конфигурации специфичный для конкретного проекта. Общая логика билда не должна кочевать из скрипта в скрипт, а находится в билд системе или ее плагинах.
- Встроенная параллельная сборка.
- Поддержка различных тулчейнов (хотя бы gcc, Visual C++, CLang).
- Возможность смены тулчейна с минимальными затратами, без переписывания всего билд скрипта.
- Легко переключаемые варианты построения: Debug и Release.
- Совершенно нежелательны зависимости на какие-то дополнительные низкоуровневые тулзы типа make. Одним словом система сборки должна быть самодостаточной.
- Очень желательна интеграция системы сборки с репозиториями сторонних компонентов типа pkg-config или как Maven Central для JVM.
- Система сборки должна быть расширяемой плагинами, т.к. процедура сборки для каждого конкретного проекта может оказаться сложнее типовой концепции построения (генерация кода, например, или сборка некоего нестандартного образа).
- Удобно, когда сценарий сборки представляет собой какой-то высокоуровневый язык программирования или еще лучше DSL. Это позволит не особо затратно и выразительно менять поведение построения прямо в скрипте.
- При настройке компилятора и линковщика из сценария сборки весьма удобно когда билд системой предоставляются хотя бы базовые абстракции: например, хочется добавить макрос — зачем думать какой параметр командной строки компилятора отвечает за это? /D на MSVC или -D на gcc — пусть система сборки разрулит эти несущественные детали сама.
- Хорошая интеграция с графическими средами разработки (IDE).
IDE:
- Способность IDE корректно «понимать» C++ код. IDE должна уметь индексировать все файлы проекта, а также все сторонние и системные заголовочные файлы и определения (defines, macro).
- IDE должна предоставлять возможность кастомизации команд для построения проекта, а так же где искать заголовочные файлы и определения.
- Должна эффективно помогать в наборе кода, т.е. предлагать наиболее подходящие варианты завершения, предупреждать об ошибках синтаксиса и т.д.
- Навигация по большому проекту должна быть удобной, а нахождение использования быстрым и простым.
- Предоставлять широкие возможности для рефакторинга: переименование и т.д.
- Также необходима способность к генерации шаблонного кода — создание каркаса нового класса, заголовочного файла и файла с реализацией. Генерация геттеров/сеттеров, определения методов, перегрузка виртуальных методов, шаблоны реализации чисто виртуальных классов (интерфейсов) и т.д.
- Подсветка и поддержка тегов документирования кода, таких, как Doxygen.
Make — [античность] мастодонт и заслуженный ветеран систем сборки, которого все никак не хотят отпустить на пенсию, а заставляют везти на себе все новые и новые проекты. Это очень низкоуровневая тулза со своим специфичном языком, где за пробел вместо таба вам сразу же грозит расстрел на месте. С помощью make можно сделать все, что угодно — билд любой сложности, но за это придется заплатить усилиями для написания скрипта, а также его поддержки в актуальном состоянии. Переносить логику билда из проекта в проект также будет накладно. Существуют некие современные «заменители» make-а: типа ninja и jam, но сути они не меняют — это очень низкоуровневые инструменты. Так же, как и на ассемблере можно написать все что угодно, только стоит ли?
CMake — [средневековье] первая попытка уйти от низкоуровневых деталей make-а. Но, к сожалению, далеко уйти не удалось — движком здесь служит все тот же make для которого CMake генерирует огромные make-файлы на основе другого текстового файла с более выскоуровневым описанием билда. По схожему принципу работает и qmake. Такой подход напоминает мне красивый фасад старого деревянного дома, который заботливо обшили свежим пластиком. CMake стабильная и хорошо зарекомендовавшая себя система, есть даже встроенная интеграция с Eclipse, но, к сожалению, мне не подошла потому что противоречит части требований изложенных в начале статьи. Под Linux все вроде бы хорошо, но если нужно построить тот же проект под Windows с помощью MSVC — а я предпочитаю нативный компилятор MinGW-шному, будут сгенерированы файлы для NMake. Т.е. зависимости на еще одну тулзу и разные команды на сборку для другой платформы. И все это следствия чуток кривоватой архитектуры, когда основная часть работы выполняется другими «помощниками».
Ant — [эпоха возрождения] своеобразный клон make для Java. Скажу честно, я потратил совсем немного времени для проверки Ant (а так же Maven) в качестве билд системы для C++. И у меня сразу же появилось ощущение что поддержка С++ здесь чисто «для галочки» и недостаточно развита. К тому же даже в Java проектах Ant уже используется достаточно редко. В качестве языка сценария (так же как и для Maven) здесь выбран XML — этот гнусный птичий язык :). Этот факт оптимизма мне совсем не прибавил для дальнейшего погружения в тему.
SCons — [новые времена] самодостаточная, кросплатформенная билд система, написанная на Python. SCons одинаково хорошо справляется как с Java так и с C++ билдами. Зависимости хидеров для инкрементальной сборки отрабатываются корректно (насколько я понял создается некая база данных с метаданными билда), а на Windows «без бубна» работает MSVC. Язык сценария сборки — Python. Весьма достойная система, и я даже хотел закончить свои изыскания на ней, но как известно, нет пределу совершенства, и при более детальном осмотре выявились некоторые минусы в свете вышеизложенных требований.
Нет никаких абстрактных настроек для компилятора, поэтому если, например, возникнет необходимость сменить тулчейн, возможно, понадобиться искать места в билд скрипте для внесения изменений. Те же макросы придется прописывать с вложенными условиями — если это Виндовс то сделай так, если это GCC сделай так и т.д.
Нет поддержки удаленных артефакториев и высокоуровневой зависимости одного билда на другой.
Общая архитектура построена так, что так называемые user defined builders существуют практически изолированно и нет возможности заиспользовать уже существующую логику билда, чтобы дополнить ее своей через несложный плагин. Но в целом это достойный выбор для небольших проектов.
Gradle [современность] — у меня уже был позитивный опыт использования Gradle для Java и Kotlin проектов и я возлагал на него большие надежды.
Для JVM языков в Gradle очень удобная концепция работы с библиотеками, необходимыми для построения проекта (билд зависимостями):
- В скрипте прописываются адреса репозиториев с артефактами: maven или ivy — например. Так же это может быть репозиторий любого другого типа/формата — лишь бы был плагин для него. Это может быть удаленный репозиторий, какой-нибудь Maven Central или ваш личный хостинг где-нибудь в сети или просто локальная репа на файловой системе.
- Так же в специальном разделе скрипта указываются непосредственно зависимости для построения — список необходимых бинарных артефактов с указанием версий.
- Перед началом построения Gradle пытается зарезолвить все зависимости и ищет артефакты с заданными версиями по всем репозиториям. Бинарники загружаются в кэш и автоматически добавляются в билд. Это очень удобно и я надеялся, что для C++, возможно, сделали нечто подобное.
Но, оказалось, что есть и «новые» плагины для поддержки C++: `cpp-application` — для приложений, `cpp-library` для библиотек: статических и динамических и наконец `cpp-unit-test` для юнит тестирования. И это было то что я искал! 🙂
Структура папок проекта по умолчанию похожа на проект для Java:
- src/main/cpp — корневая папка для основных файлов *.cpp проекта.
- src/main/headers — папка для внутренних заголовочных файлов.
- src/main/public — папка для экспортируемых заголовков — для библиотек.
- src/test/cpp — папка для файлов *.cpp юнит теста.
Кстати, билд скрипт — обычно build.gradle, это DSL языка Groovy или Kotlin (build.gradle.kts) на выбор. Внутри скрипта всегда доступен Gradle API и API добавленных в скрипт плагинов.
Для библиотек можно выбрать тип: статическая или динамическая (или собрать оба варианта).
По умолчанию сконфигурированы два варианта построения: Debug (gradle assemble) и Release (gradle assembleRelease).
Принцип запуска юнит тестирования такой же как в Java: gradle test выполнит постройку основного компонента, потом тестов, если они есть в папке src/test/cpp, а затем выполнит тестовое приложение.
Пресловутые дефайны можно задавать абстрактно — Gradle сам сгенерирует необходимые параметры компилятора. Есть еще несколько абстрактных настроек типа оптимизации, отладочной информации и т.д.
Из коробки поддерживаются GCC, Microsoft Visual C++, CLang.
Система плагинов очень развита, а архитектура расширений устроена удобно — можно взять готовую логику и задекорировать/расширить ее. Плагины бывают двух видов: динамические, которые пишутся прямо на Groovy и встраиваются в скрипт или написанные на Java (или на другом языке с JVM) и скомпилированные в бинарные артефакты. Для плагинов существует бесплатный Gradle-артифакторий, в котором любой желающий может разместить свой плагин, который будет доступен всем. Что успешно и проделал автор этой статьи 🙂 но об этом чуть позже.
Хотелось бы подробнее остановиться теперь на системе работы с бинарными компонентами в Gradle для C++: она почти такая же как в Java! Билд зависимости работают практически так же как я описал выше.
Возьмем для примера композитный билд:
- utils — папка с библиотекой
- app — папка с приложением, которое использует utils.
- settings.gradle — Gradle файл для объединения этих двух компонент в композитный билд.
dependencies
А все остальное проделает Gradle! Добавит в компилятор путь для поиска заголовочных файлов utils и прилинкует бинарь библиотеки.
И все это одинаково хорошо сработает как под Linux GCC, так и под Windows MSVC.
Инкрементальная сборка, естественно, тоже замечательно работает и при изменении хидеров в utils будет перестроен app.
Как оказалось, в Gradle пошли дальше и реализовали возможность выкладывать C++ артефакты в Maven Repository! Для этого используется стандартный `maven-publish` плагин.
В скрипте необходимо указать репозиторий куда вы хотите выложить свой артефакт и сделать gradle publish (или gradle publishToMavenLocal для локальной публикации). Gradle сбилдит проект и
выложит в специальном формате — с учетом версии, платформы, архитектуры и варианта билда.
Выкладываются сами бинарные файлы библиотек и публичные заголовочные файлы — из папки src/main/public.
Понятно что выложить С++ артефакт на Maven Cental нельзя — он не пройдет обязательные проверки системы. Но поднять Maven репозиторий в сети совсем нетрудно, а для локального репозитория вообще ничего делать не нужно — это просто папка на диске.
Теперь если вы хотите использовать в своем проекте чью-то библиотеку вы можете написать в билд скрипте что-то вроде:
repositories < maven < url = 'https://akornilov.bitbucket.io/maven' >> unitTest < dependencies < implementation 'org.bitbucket.akornilov.tools:gtest:1.8.1' >>
Здесь говориться что для юнит тестирования нужно использовать артефакт gtest версии 1.8.1 из Maven репозитория.
Это, кстати, вполне реальный репозиторий в котором выложен мой билд Google Test v1.8.1, простроенный с помощью Gradle для Windows и Linux x86_64.
Естественно, что всю низкоуровневую работу по конфигурированию компилятора и линковщика для работы с внешним компонентом Gradle берет на себя. Вам достаточно заявить о своих намерениях использовать такую-то библиотеку с такой-то версией из такого-то репозитория.
Для интеграции с IDE в Gradle есть два встроенных плагина для Visual Studio и XCode. Они хорошо работают, за исключением того что Visual Studio плагин игнорирует код юнит тестов из папки src/test/cpp и генерирует проект только для основного кода.
Теперь пришло время поговорить об IDE и о том как подружить их с Gradle
Eclipse CDT (2018-12R) — зрелый и качественный продукт. Если ему удалось успешно пропарсить Ваш проект, значит Вам повезло — редактировать будет комфортно. Скорее всего он даже «поймет» самые замороченные типы auto. Но если нет… Тогда он будет яростно подчеркивать красным пунктиром все подряд и ругаться нехорошими словами. Например, он не переваривает стандартные заголовочные файлы MSVC и Windows SDK. Даже вполне безобидный printf подчеркивается красным пунктиром и не воспринимается как нечто осмысленное. Там же оказался и std::string. Под Linux с родным ему gcc все замечательно. Но даже при попытке заставить его индексировать проект из родственного Android Native начались проблемы. В заголовках bionic он в упор отказывался видеть определение size_t, а заодно и всех функций которые его использовали. Наверное, под Windows можно исправить ситуацию если вместо заголовочных файлов Microsoft подсунуть ему, например, Cygwin или MinGW SDK, но мне такие фокусы не очень интересны, мне бы все же хотелось чтобы софт такого уровня «кушал то что дают», а не только то что он «любит».
Возможности по навигации, рефакторингу и генерации шаблонного кода замечательные, но вот к помощнику при наборе букв есть вопросы: допустим набираем несколько символов из какого-то длиннющего имени, почему бы не предложить варианты завершения? Нет, помощник терпеливо дожидается пока пользователь доберется до. или -> или . Приходится постоянно нажимать Ctrl + Space — раздражает. В Java эту досадную недоделку можно было исправить выбрав в качестве триггера весь алфавит в CDT же я не нашел простого решения.


NetBeans 8.1/10.0 — доводилось пользоваться этим IDE для Java, запомнился как неплохой и легковесный софт со всем необходимым функционалом. Для C++ у него есть плагин разработанный не сообществом, а непосредственно NetBeans. Для C++ проектов существует довольная жесткая зависимость на make и gcc. Редактор кода неторопливый. В генераторе шаблонного кода не нашел очень простую вещь: добавляем новый метод в заголовочном файле класса — нужно сгенерировать тело метода в cpp файле — не умеет. Степень «понимания» кода средняя, вроде бы что-то парсит, а что-то нет. Например, итерирование по мапе с автоитератором для него уже сложновато. На макросы из Google Test ругается. Закастомизировать билд команды проблематично — на Linux при доступном gcc и make (это при том что используется уже другая билд система) сработает, на Windows потребует MinGW, но даже при его наличии откажется построить. В целом работа в NetBeans с C++ возможна, но комфортной я бы ее не назвал, наверное, надо очень любить эту среду, чтобы не замечать разные ее болячки.

KDevelop 5.3.1 — когда-то задумывался как инструмент разработчика для KDE (Linux), но сейчас есть версия и под Windows. Имеет быстрый и приятный редактор кода с красивой подсветкой синтаксиса (основан на Kate). Закостомизировать левую билд систему не получится — для него основная система сборки CMake. Толерантно относится к MSVC и Windows SDK заголовкам, во всяком случае printf и std::string точно не приводят его в ступор как Eclipse CDT. Очень шустрый помощник по написанию кода — хорошие варианты завершения предлагает почти сразу во время набора текста. Имеет интересную возможность по генерации шаблонного кода: можно написать свой шаблон и выложить его онлайн. При создании по шаблону можно подключиться к базе данных готовых шаблонов и загрузить понравившийся. Единственное что расстроило: встроенный шаблон по созданию нового класса криво работает как под Windows так и под Linux. Wizard-а по созданию класса имеет несколько окон, в которым можно много чего настроить: какие конструкторы нужны, какие члены класса и т.д. Но на финальной стадии под Windows выскакивает какая-то ошибка успеть разглядеть текст которой невозможно и создаются два файла h и cpp размером 1 байт. В Linux почему-то нельзя выбрать конструкторы — вкладка пустая, а на выходе корректно генерится только заголовочный файл. В общем-то, детские болезни для такого зрелого продукта смотрятся как-то несерьезно.


QtCreator 4.8.1 (open source edition) — наверное, услышав это название, Вы недоумеваете, как сюда затесался этот монстр заточенный под Qt с дистрибутивом в гигабайт с гаком. Но речь идет о «легкой» версии среды для generic проектов. Его дистрибутив весит всего около 150 Мб и не тащит с собой вещи специфичные для Qt: download.qt.io/official_releases/qtcreator/4.8.
Собственно, он умеет делать почти все, о чем я написал в своих требованиях, быстро и корректно. Он парсит стандартные заголовки как Windows так и Linux, кастомизируется под любую билд систему, подсказывает варианты завершения, удобно генерит новый классы, тела методов, позволяет выполнять рефакторинг и навигацию по коду. Если хочется просто комфортно работать, не думая постоянно о том, как побороть ту или иную проблему есть смысл присмотреться к QtCreator-у.


Собственно, осталось рассказать о том, чего мне не хватило в Gradle для полноценной работы: интеграция с IDE. Чтобы билд система сама сгенерировала бы проектные файлы для IDE, в которых уже были бы прописаны команды для построения проекта, перечислены все исходные файлы, необходимы пути для поиска заголовочных файлов и определения.
Для этой цели мной был написан плагин для Gradle `cpp-ide-generator` и опубликован на Gradle Plugin Portal.
Плагин может использоваться только совместно с `cpp-application`, `cpp-library` и `cpp-unit-test`.
Вот пример его использования в build.gradle:
plugins < id ‘cpp-library’ id ‘maven-publish’ id ‘cpp-unit-test’ id ‘org.bitbucket.akornilov.cpp-ide-generator’ version ‘0.3’ >library < // Library specific parameters >// Configuration block of plugin: ide
Плагин поддерживает интеграцию со всеми вышеперечисленными графическими средами разработки, но в конфигурационном блоке плагина — ide можно отключить поддержку ненужных IDE:
kdevelop = false
Если параметр autoGenerate выставлен в true, проектные файлы для всех разрешенных IDE будут автоматически генерироваться прямо во время билда. Также в режиме автоматической генерации проектные файлы будут удаляться при очистке билда: gradle clean.
Поддерживается инкрементальная генерация, т.е. обновляться будут только те файлы, которые требуют реального обновления.
Вот список целей, которые добавляет плагин:
- generateIde — сгенерировать проектные файлы для всех разрешенных IDE.
- cleanIde — удалить проектные файлы для всех разрешенных IDE.
- generateIde[имя] — сгенерировать проектные файлы для IDE с заданным именем (IDE должно быть разрешено), например generateIdeQtCreator.
- Доступные имена: Eclipse, NetBeans, QtCreator, KDevelop.
- cleanIde[имя] — удалить проектные файлы для IDE с заданным именем, например cleanIdeQtCreator.
Второй плагин, который мне пришлось сделать, называется `cpp-build-tuner` и он также работает в паре с cpp-application`, `cpp-library` и `cpp-unit-test`.
У плагина нет никаких настроек, его достаточно просто зааплаить:
plugins
Плагин выполняет небольшие манипуляции с настройками тулчейнов (компилятора и линковщика) для разных вариантов билда — Debug и Release. Поддерживаются MSVC, gcc, CLang.
Особенно это актуально для MSVC, потому что по умолчанию в результате релизного билда Вы получите «жирный», не эстетичный бинарь с дебажной информацией и статически прилинкованной стандартной библиотекой. Часть настроек для MSVC я «подсмотрел» в самой Visual Studio, которые по дефолту он добавляет в свои C++ проекты. Как для gcc/CLang так и для MSVC в профиле Release включаются link time optmizations.
Заметка: Плагины проверялись с последней версией Gradle v5.2.1 и не тестировались на совместимость с предыдущими версиями.
Исходные коды плагинов, а так же простенькие примеры использования Gradle для библиотек: статических и динамических, а так же приложения, которое их использует можно посмотреть: bitbucket.org/akornilov/tools дальше gradle/cpp.
Так же в примерах показано, как пользоваться Google Test для юнит тестирования библиотек.
Версии QtCreator под Windows старше 4.6.2 (и по крайней мере, на момент написания этих строк, до 4.10 включительно) «разучились» понимать SDK MSVC. Все из пространства std:: подчеркивают красным и отказываются индексировать. Поэтому, на данный момент, версия 4.6.2 наиболее подходящая для работы под Windows.
Была выпущена новая версия плагина cpp-build-tuner v1.0 (и cpp-ide-generator v0.5 – небольшие улучшения).
1) В cpp-build-tuner добавлен блок конфигурации.
buildTuner < lto = false gtest = '1.8.1' libraries < common = ['cutils.lib'] windows = ['ole32', 'user32'] linux = ['pthread', 'z'] >libDirs.common = ['../build/debug', '../release'] > lto (булевое значение) –разрешает или запрещает LTO для релизного билда. По умолчанию включено.
gtest (строка) – добавлет поддержку Google Test для юнит тестов. На данный момент поддерживается только версия 1.8.1 для GCC, MinGW-W64, и MSVC.
libraries (контейнер) – список библиотек для линковки. Внутри контейнера есть три поля (список строк): common – библиотеки для любой платформы, windows – только для Windows и linux – только для Linux.
libDirs (контейнер) – список папок для поиска библиотек линковщиком. Структура контейнера такая же как и у списка библиотек.
2) Добавлена возможность запуска приложения для cpp-application . Плагин добавляет в проект дополнительные задачи для этого: run , runDebug (тоже самое, что и run ) и runRelease . Задачи зависят от assemble , assembleDebug и assembleRelease соответственно.
Аналогично стандартному плагину “Java Application plugin” можно передавать параметры командной строки при запуске: gradle run —args=»arg1 arg2 . » .
В связи со сменой хостинга плагинов, была изменена группа:
Как собрать проект со всеми необходимыми библиотеками? [дубликат]
Всем привет,в общем,я написал свой софт и продаю его.Но у большинства возникают проблемы,программа требует vcruntime140.dll.Можно ли как нибудь прикомпилировать ее к проекту или сделать чтоб программа не требовала никакие внешние библиотеки?Почему вообще программа на с++ требует какие то внешние библиотеки?Как это исправить?Устал каждому просто говорить скачивать все версии visual c++.Почему тогда другие программы у них не требуют эту библиотеку?
Отслеживать
задан 12 мар 2020 в 22:30
Barracudach Barracudach
892 6 6 серебряных знаков 23 23 бронзовых знака
ниже вам дали развернутый верный ответ, но вы его заминусовали.
13 мар 2020 в 4:33
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
Я конечно удивлён что вы что то продаёте но при этом не знаете о рантайм либах но да ладно. Все эти либы идут вместе с инсталятором, самый простой вариант это тупо класть их рядом со своим софтом в инсталяторе. Более сложный это определять установлен ли необходимый vc runtime. Возможно вы встречали сообщение «Установить распространяемый компонент Microsoft Visual C++?» это вот оно.
Конкретных рекомендаций «Как собрать проект со всеми необходимыми библиотеками», дать сложно, всё зависит от конкретно вашего цикла CI/CD.
Отслеживать
ответ дан 12 мар 2020 в 22:59
655 5 5 серебряных знаков 12 12 бронзовых знаков
-
Важное на Мете
Связанные
Похожие
Дизайн сайта / логотип © 2023 Stack Exchange Inc; пользовательские материалы лицензированы в соответствии с CC BY-SA . rev 2023.10.27.43697
Нажимая «Принять все файлы cookie» вы соглашаетесь, что Stack Exchange может хранить файлы cookie на вашем устройстве и раскрывать информацию в соответствии с нашей Политикой в отношении файлов cookie.
Как собрать проект c
БлогNot. Как собрать проект C++ с github из исходников и подключить его к Visual Studio
Как собрать проект C++ с github из исходников и подключить его к Visual Studio
P.S. В новых сборках Visual Studio проекты из репозиториев открываются просто из меню Файл — Клонировать репозиторий. В статье речь идёт о ситуации, когда так сделать невозможно.
Благодаря менеджеру пакетов winget, уже входящему в актуальные сборки масдайки, теперь в Windows 10 можно инсталлировать приложения одной простой консольной командой (см. также доку от Микрософта).
Но мы рассмотрим сейчас ситуацию, когда у нас есть только ссылка на исходники проекта, скажем, на Гитхабе (возьмём для примера библиотеку для простых чисел primesieve) и нужно каким-то образом «вручную» скомпилировать внешний проект в своей Studio, чтобы воспользоваться его возможностями в своём приложении.
В противном случае, конечно же, нестандартный include вроде этого, который вы нашли в коде-образце
#include
работать не будет ни за что.
Первым делом скачаем все исходники внешнего проекта «как есть» в архиве .zip, для этого у нас на гитхабе есть кнопка «Download ZIP»:

Как загрузить проект с github в архиве .zip
Развернём проект, не создавая новой папки, если у вашего архиватора нет такого же пункта меню, просто сотрите предлагаемое архиватором имя новой папки, потому что папка уже есть в архиве:

Извлечь внешний проект из архива, не создавая новой папки
Если покопаться в файле readme.md проекта, как правило, можно найти инструкцию по установке (Build instructions) и даже «Detailed build instructions», где говорится, в числе прочего, и о компиляции проекта под Microsoft Visual C++:

Команды cmake для компиляции проекта со страницы документации
Откроем свой «некомпилируемый» без нужной библиотеки проект в Studio (я использую актуальную сборку версии 2019) и обратимся к команде меню Вид — Терминал. Выберем инструмент «Командная строка разработчика» (по умолчанию в новых сборках теперь выбран PowerShell, впрочем, если в документации приведены команды PowerShell, то применяйте их).
У Микрософта инструмент описан вот здесь.

Командная строка разработчика в Studio
В командной строке пишем команды из документации, но сначала, конечно, нужно перейти в ту папку, где у вас развёрнут скачанный проект. Мне понадобилось ввести в консоли следующее, завершая каждую команду нажатием Enter:
d: cd \temp\primesieve-master
— теперь я в нужной папке, так как развернул свой архив в папку d:\temp
Далее как написано:
cmake -G "Visual Studio 16 2019" . cmake --build . --config Release
Можно просто копировать команды со страницы документации, в окне консоли вверху есть стандартная кнопочка «Вставить». А вот точка в записи команд имеет значение, это ссылка на текущую папку!
Ну и, конечно, для другой версии Studio будет другое указание компилятора, узнать своё можно командой
cmake -G
Нужный генератор будет помечен в списке «звёздочкой».
Если что-то пошло не так, ошибаетесь в консольных командах и получаете сообщения об ошибках кэша — сотрите файл CMakeCache.txt из папки скопированного проекта и попробуйте снова.
Теперь проект можно открывать в Studio и работать с ним, все нужные файлы есть в папке d:\temp\primesieve-master
Но мы хотим подключить всё, что нужно, к своему имеющемуся проекту, а не пытаться модифицировать чужую библиотеку.
- Меню Проект — Свойства, слева выбираем Свойства конфигурации, C/C++, Общие, раскрываем поле «Дополнительные каталоги включаемых файлов», говорим «Изменить» и показываем на папку D:\Temp\primesieve-master\include . В вашем проекте, как правило, тоже будет вложенная папка include .
- В том же окне выбираем Компоновщик — Общие — Дополнительные каталоги библиотек, «Изменить» и добавляем путь D:\Temp\primesieve-master\Release . Этого может оказаться мало, у вашего проекта и внешнего должны быть выбраны одинаковые конфигурации решения. Так как я выбрал Release для внешнего проекта, то и в своём проекте в списке «Конфигурации решения» (на стандартной панели инструментов) указал Release и платформу x64. Можно было работать и с Debug, но тогда и внешний проект компилируем как Debug и потом выбираем путь D:\Temp\primesieve-master\Debug .
- В списке C/C++ — Создание кода — Библиотека времени выполнения выбрал Многопоточный DLL (/MD), иначе будет «LNK2038: обнаружено несоответствие для ‘RuntimeLibrary’: значение ‘MT_StaticRelease’ не соответствует значению ‘MD_DynamicRelease’ в file.obj».
- Сам файл библиотеки, как правило имеющий тип .lib , тоже нужно прописать. Всё в том же окне свойства проекта выбираем список Компоновщик — Ввод, раскрываем список «Дополнительные зависимости», жмём «Изменить» и указываем в поле ввода имя файла библиотеки primesieve.lib
- На всякий случай, проверяем, что у нас в списке Компоновщик — Система — Подсистема, у меня там просто Консоль (/SUBSYSTEM:CONSOLE) , для других типов проектов может понадобиться изменение и этой настройки.
После этого у меня всё заработало.
Ну а конкретная задача, на которой я проверял библиотеку — печать самых длинных цепочек последовательных простых чисел, в которых разница между соседними значениями строго возрастает или строго убывает, предел счёта равен 1000000, вот сама программа:
#include #include #include #include void print_diffs(const std::vector& vec) < for (size_t i = 0, n = vec.size(); i != n; ++i) < if (i != 0) std::cout std::cout int main() < std::vector asc, desc; std::vector
Ответы вышли такие:
Longest run(s) of ascending prime gaps up to 1000000: 128981 (2) 128983 (4) 128987 (6) 128993 (8) 129001 (10) 129011 (12) 129023 (14) 129037 402581 (2) 402583 (4) 402587 (6) 402593 (8) 402601 (12) 402613 (18) 402631 (60) 402691 665111 (2) 665113 (4) 665117 (6) 665123 (8) 665131 (10) 665141 (12) 665153 (24) 665177 Longest run(s) of descending prime gaps up to 1000000: 322171 (22) 322193 (20) 322213 (16) 322229 (8) 322237 (6) 322243 (4) 322247 (2) 322249 752207 (44) 752251 (12) 752263 (10) 752273 (8) 752281 (6) 752287 (4) 752291 (2) 752293
За счёт хорошо оптимизированного кода библиотеки считается всё мгновенно.
Это задача из списка задач на простые числа
21.10.2021, 13:15 [9547 просмотров]