Как сделать датасет
Создание датасетов, чартов, дашбордов в YandexDataLens.
В этой статье познакомимся с датасетами, чартами и дашбордами в YandexDataLens. А также, рассмотрим алгоритмы создания их в сервисе YandexDataLens Яндекс.Облака.
Датасет в YandexDataLens.
Датасет описывает набор данных и его структуру. Набор данных датасета представлен в виде полей.
Поле может быть одним из следующих типов:
Измерение. Содержит значения, которые определяют характеристику данных. Например, город, дата покупки, категория продукта. К полю с измерением не применяется функция агрегации, в противном случае поле становится показателем. В интерфейсе измерения отображаются зеленым цветом.
Показатель. Содержит числовые значения, к которым применяются функции агрегации (сведения). Например, сумма кликов, количество переходов. Если снять с такого поля функцию агрегации, оно станет измерением. В интерфейсе показатели отображаются синим цветом.
При создании датасета вы можете дублировать существующие поля и создавать новые.
DataLens позволяет создавать вычисляемые поля с помощью функций агрегации и функций, которые доступны для источника данных.
Режимы работы датасета с источником данных.
Датасет работает с источником данных в следующих режимах:
Прямой доступ. — Все запросы к данным исполняются на стороне источника. Если в качестве источника данных вы используете Metrika API, то DataLens будет использовать прямой доступ к данным.
Единовременная материализация. — Данные загружаются во внутреннее хранилище Yandex Datalens единовременно. Все последующие запросы обрабатываются на загруженных данных. Чтобы синхронизировать хранилище Yandex Datalens с источником, данные можно загрузить повторно. Если в качестве источника данных вы используете CSV-файл, то DataLens автоматически материализует датасет. Данные загружаются в хранилище Yandex Datalens периодически по правилу. Правило задается в настройках датасета.
Алгоритм создание датасета.
1. На главной странице сервиса Yandex Datalens выбираем «Создать датасет».
2. Выбираем подключение. Если в списке нет доступных подключений, нужно его создать.
3. Вводим название датасета. Если создаем датасет из подключения к базе данных, необходимо выбрать базу данных и таблицу для датасета.
4. Нажимаем «Создать». После откроется окно с настройкой датасета.
Алгоритм создание поля в датасете.
1. Открываем созданный датасет.
2. Нажимаем значок «+» «Добавить поле».
- Имя.
- Не отображать в визарде. Позволяет скрыть поле.
- Добавить описание. Позволяет дополнительно описать поле.
- Источник данных. Задает источник данных для поля. Если выбрано значение Формула, то в нижней части будет доступны поля создания формулы.
- Тип. Задает тип данных поля.
- Агрегация. Задает тип агрегации.
Настройка прав доступа к датасету.
1. Выбираем датасет, к которому нужно изменить права доступа.
2. Нажимаем на значок «…» и выбираем пункт «Настроить доступ».
3. Вводим имя пользователя в поле «Добавить участников» и нажимаем «Выбрать».
4. В появившемся окне выбираем тип прав доступа и нажимаем «Добавить».
Чарт в YandexDataLens.
Чарт — это визуализация данных из датасета в виде таблицы или диаграммы.
Чарты создаются в визарде на основе данных из датасета. На базе одного датасета может быть создано неограниченное количество чартов.
Рабочая область в интерфейсе визарда разделена на три основные панели:
1. Панель выбора, где отображаются поля датасета.
2. Панель настройки визуализации, где можно выбрать представление.
3. Панель превью, где отображается визуализация.
Чарт позволяет провести быстрый анализ и проверить гипотезу. Также чарты можно сохранять и выносить на дашборды в виде виджетов.
Типы чартов в Yandex Datalens.
Таблица — Отображает данные в табличном виде, где в первой строке определяются наименования полей, в остальных — их значения.
Сводная таблица — Отображает данные в табличном виде, где в строках и столбцах могут быть значения измерений, а в ячейках на их пересечении — показатели.
Линейная диаграмма — Отображает изменение показателей по измерениям в виде горизонтальной линии.
Диаграмма с областями — Отображает изменение показателей по измерениям в виде областей, показывая вклад каждой линии в значение общей суммы.
Круговая диаграмма — Отображает размер элементов одного ряда данных относительно суммы элементов в виде круга.
Столбчатая диаграмма — Отображает данные в виде плоских вертикальных столбцов.
Древовидная диаграмма — Отображается в виде набор прямоугольников. Диаграмма позволяет сравнить пропорции в иерархии.
Диаграмма позволяет сравнить пропорции в иерархии.
Точечная диаграмма — Отображает точки данных для сравнения пар значений.
Все типы чартов имеют ссылку на официальный сайт, где прописываются алгоритмы создания каждого из чартов в Yandex Datalens.
Как создать свой датасет с Киркоровым и Фейсом на Яндекс.Толоке

Нейронными сетями уже никого не удивишь. Практически каждый человек знает, что такое машинное обучение, линейная регрессия, random forest. Каждый год тысячи людей проходят курсы по машинному обучению на ODS и Coursera. Любой школьник за пару недель теперь может освоить keras и клепать нейроночки. Но в нейронных сетях, как и во всем машинном обучении, помимо создания хорошего алгоритма, необходимы данные, на которых алгоритм будет обучаться.
Разрешите представиться, меня зовут Куцев Роман. Я работаю в RnD команде в Prisma AI и занимаюсь созданием датасетов под наши задачи.
Итак, вдруг поступает продуктовый запрос: нам срочно нужна нейронка, которая будет отличать Киркорова от Фейсa (конечно, пример вымышленный, мы такой ерундой не занимаемся).
Спрашиваю у Антона (главный по нейронкам), в каком виде нужны данные, в ответ слышу: “Две папки, в одной изображения Фейсa, в другой Киркорова, желательно где-то по 500 изображений на класс, и чтобы 299х299 были”.
Где найти данные?
- Смотрим публичные датасеты, такие как ImageNet, COCO, openimages.
- Если нужных размеченных данных в популярных публичных датасетах нет, то гуглим, открываем на arxiv.org статьи по этим темам в надежде, что где-нибудь там будет ссылка на нужный нам датасет.
- Если первые два пункта провалились, значит нужного датасета нет, и его надо создать!
Очевидно, что никто раньше не занимался задачей классификации Киркорова и Фейса. Поэтому придется самим создать такой датасет.
- Скачиваем из гугла по 1к изображений Киркорова и Фейса.
- Ресайзим к нужному размеру.
- Проверяем их фрилансерами на Яндекс Толоке.
Для скачивания воспользуемся Google Images Download.
В терминале пишем:
googleimagesdownload -k ‘Киркоров’ -l 1000 -t photo -s '>400*300' -o 'Kirkorov' googleimagesdownload -k ‘репер Face’ -l 1000 -t photo -s '>400*300' -o 'Face'(на самом деле все не так просто, за один запрос можно скачать только 100 изображений, поэтому приходится выкачивать с разными настройками)
Сразу ресайзнем изображения до размера 299х299, для этого я набросал такую функцию:
from PIL import Image import multiprocessing, time, os def resize_img(img_path): img = Image.open(os.path.join('Kirkorov',img_path)) img = img.resize((299,299), Image.ANTIALIAS) img.save(os.path.join('Kirkorov_resize',img_path)) num_processes = multiprocessing.cpu_count() pool = multiprocessing.Pool(processes=num_processes) st = time.time() pool.map(resize_img, os.listdir('Kirkorov')) print("Execution time: ", time.time()-st)Посмотрев на изображения, видим, что в основном скачались нужные изображения, но местами присутствует мусор.



Отлично, первые два пункта готовы, остался третий.
Если вы до сих пор не знаете, что такое Яндекс Толока, то советую прочитать эту и эту статью.
В двух словах: Толока — фриланс биржа на стероидах, где заказчик создает задание, загружает данные и фрилансеры его выполняют. Конечно, есть и другие инструменты для разметки, но для данной задачи удобнее всего воспользоваться Толокой.
Как начать пользоваться Яндекс Толокой:
1. Регистрируемся на sandbox.toloka.yandex.ru и toloka.yandex.ru в качестве заказчика (sandbox — песочница, в которой вы создаете задания, проверяете на корректность со стороны фрилансеров, и, если все хорошо, переносите его в toloka.yandex.ru).
2. В личном кабинете toloka.yandex.ru пополняем свой баланс.
3. В sandbox.toloka.yandex.ru во вкладке «Проекты» выбираем «Создать проект».

4. Вам будут предложены готовые шаблоны. Из всех шаблонов нам лучше всего подходит шаблон «Категоризация изображений». Выбираем его.

5. Создаем инструкцию для фрилансеров и название проекта.
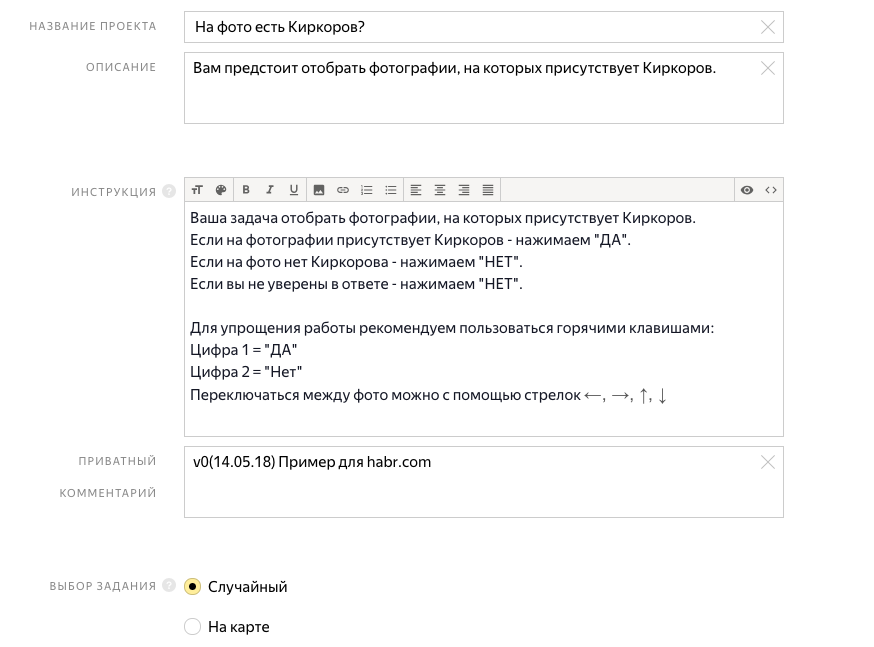
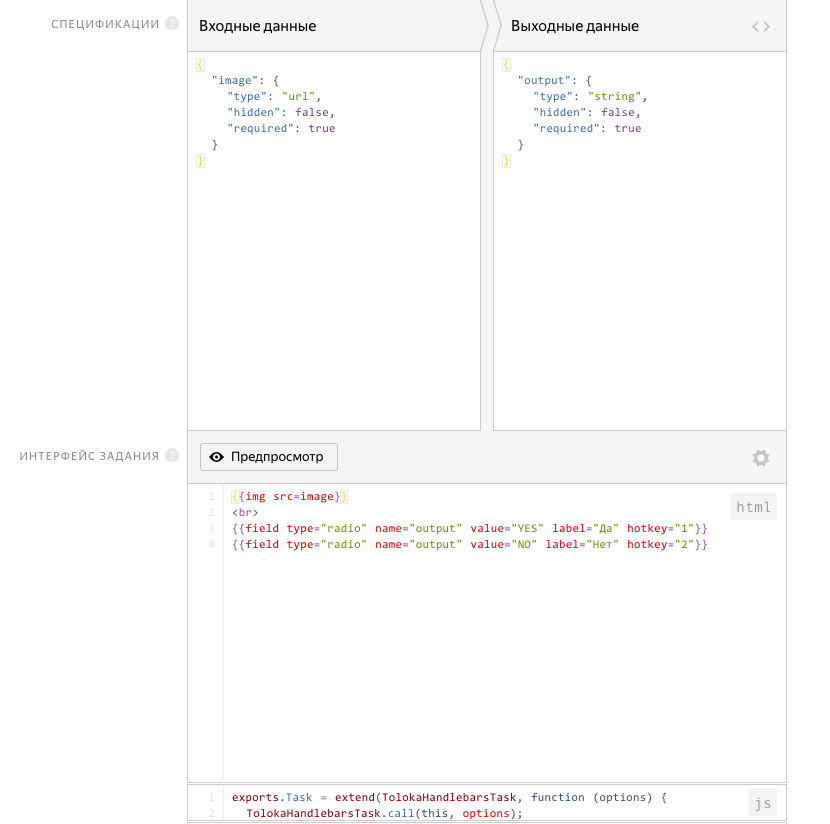
6. Во входных параметрах к заданию у нас будет URL на изображение. В выходных: строка output. Интерфейс задания пишется на html и javascript (это очень удобно, так как практически под любую задачу мы можем сверстать страничку, которая будет показываться исполнителям). Чуть-чуть изменяем шаблон html, и все готово. Сохраняем проект.
7. Проект готов. Теперь можно добавить пул заданий. В данной статье я не буду создавать пул обучения (надеясь на то, что фрилансеры способны сразу выполнить наше наисложнейшее задание). Но вы всегда создавайте в своем задании пул обучения. Это позволит:
- Отсеять людей, которые не поняли задание.
- Не допустить к заданию ботов, которые всегда выбирают один и тот же ответ.
- Научить исполнителей правильно и качественно выполнять задание.
Придумываем название пула (оно видно только нам). Задаем цену 0.01$ за страницу заданий. Жадный Яндекс берет комиссию 0.005$. Время на задание: 10 минут. Перекрытие: 3 (каждая наша фотография будет показываться трем разным людям). Включим «КОНТЕНТ ДЛЯ ВЗРОСЛЫХ», а то мало-ли что плохого мы из интернета могли скачать. И активируем «ОТЛОЖЕННАЯ ПРИЕМКА», чтобы не дать денег тем фрилансерам, которые будут плохо выполнять задание.
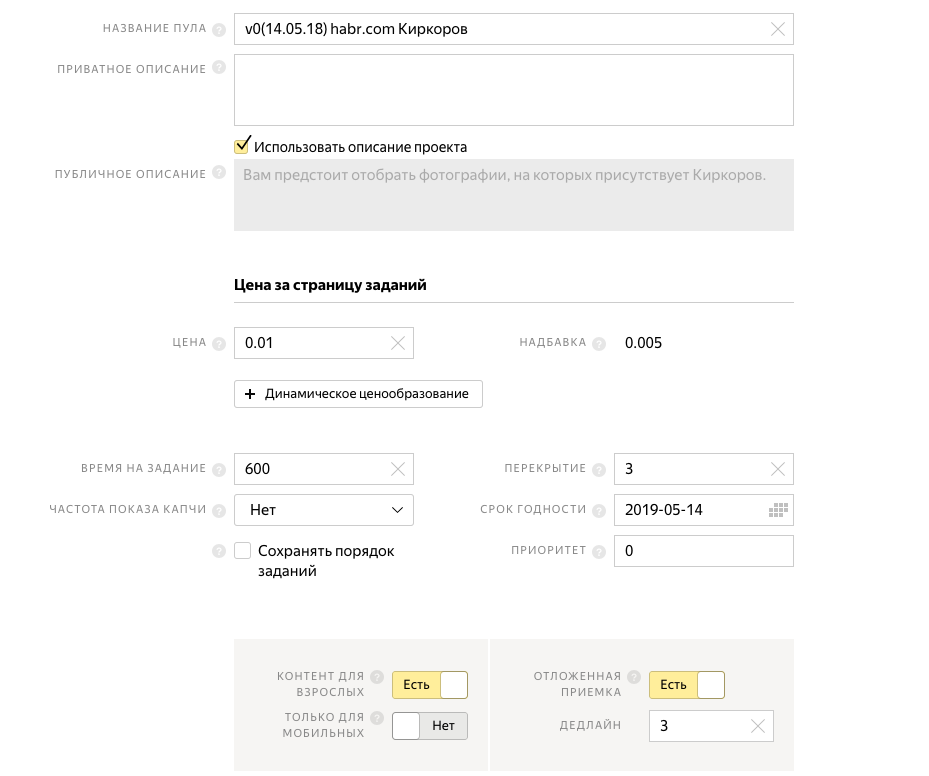
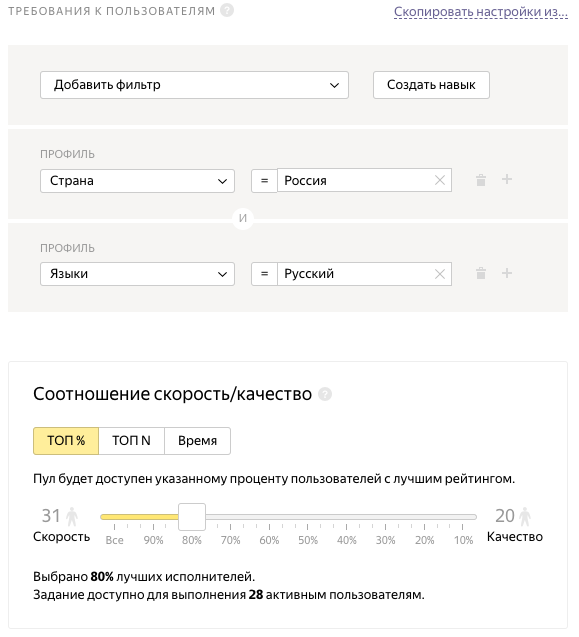
Далее идет пункт: «ТРЕБОВАНИЯ К ПОЛЬЗОВАТЕЛЯМ», в котором мы можем предъявить требования к исполнителям. В нашем случае исполнитель должен быть из России и владеть русским языком. Каждый исполнитель имеет свой рейтинг и мы можем выбрать исполнителей только с хорошим рейтингом. Выберем 80% лучших исполнителей.
Самым важным и самым сложным в плане освоения является блок контроля качества. Отдельное его описание потянет на целую статью, так что рекомендую ознакомиться с ним самостоятельно. В нашем проекте я выбрал ограничение на быстрые ответы. Если исполнитель 3 раза из 5 отвечает быстрее, чем за 40 секунд, то система его заблокирует.
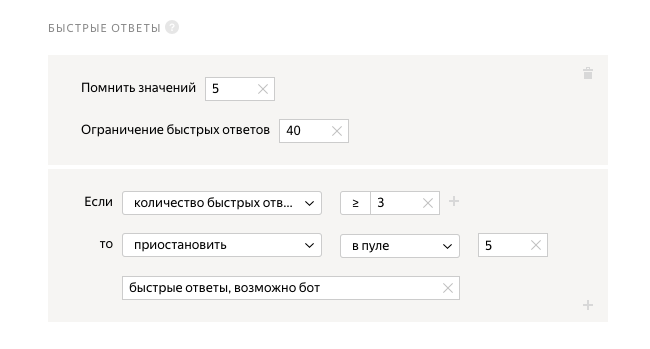
Отлично, мы на финишной прямой, осталось чуть-чуть. Сохраняем пул.
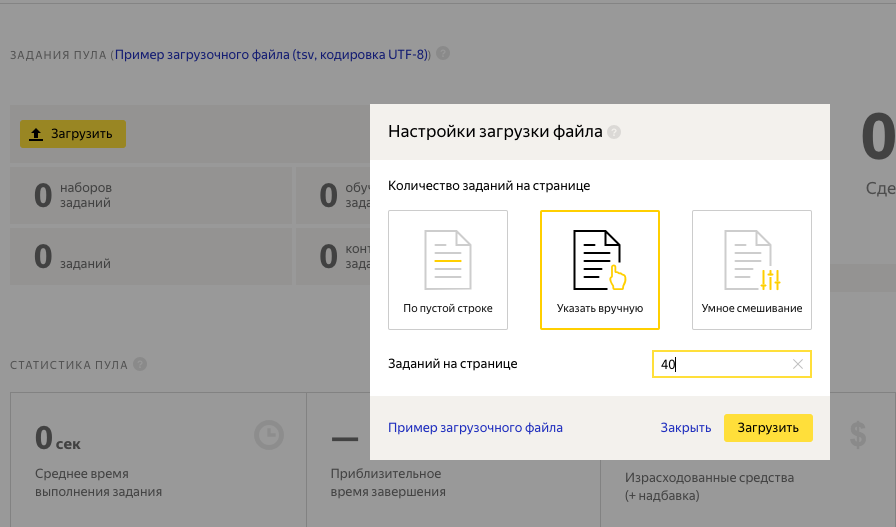
8. В созданном пуле скачиваем пример загрузочного файла. Загружаем наши изображения на Яндекс Диск или к себе на сервер, чтобы они были доступны по ссылке. В поле «INPUT:image» вставляем URL на наши изображения. Пример:
INPUT:image http://kucev.ru/Kirkorov/Kirkorov-pink_17_ 21787_l_jpg.jpg http://kucev.ru/Kirkorov/Kirkorov-green_82_ hqdefault_jpg.jpg http://kucev.ru/Kirkorov/Kirkorov-pink_25_ hqdefault_jpg.jpgЗагружаем полученный tsv файл на Яндекс Толоку. Указываем сколько изображений будет показываться исполнителю за один раз.
Отлично, никаких ошибок не вылезло, значит мы все сделали правильно и можем запустить наш пул.
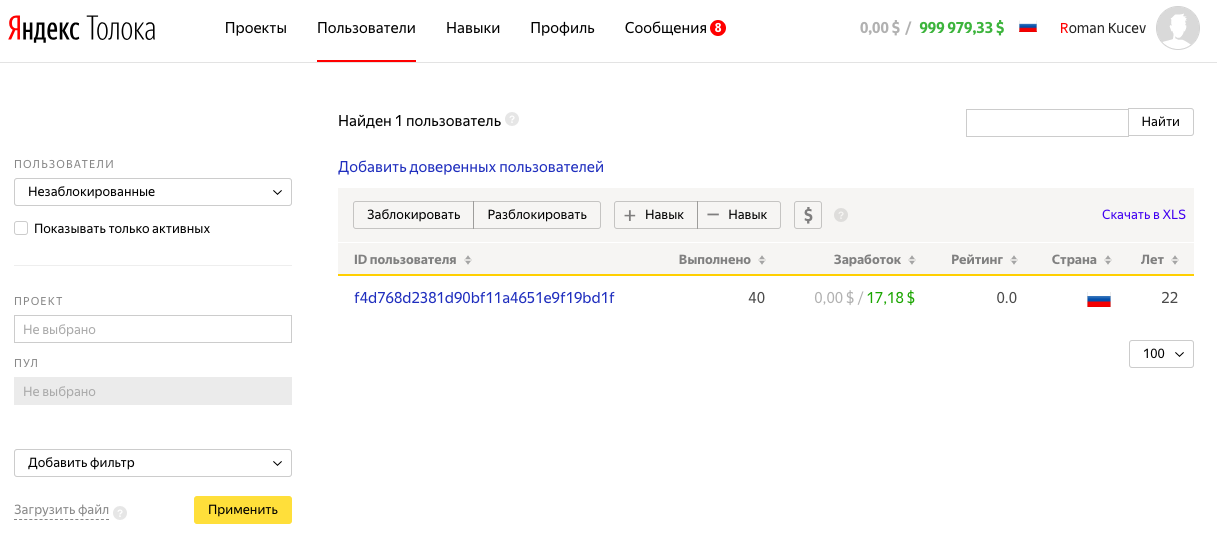
9. Теперь нам надо проверить, что со стороны исполнителя все отображается правильно. Для этого создаем новый аккаунт на sandbox.toloka.yandex.ru, только теперь в качестве исполнителя. В аккаунте заказчика выбираем вкладку «Пользователи» и добавляем наш новый аккаунт исполнителя в список доверенных пользователей.
Отлично, если наш пул запущен, то теперь из тестового аккаунта исполнителя доступно наше задание.
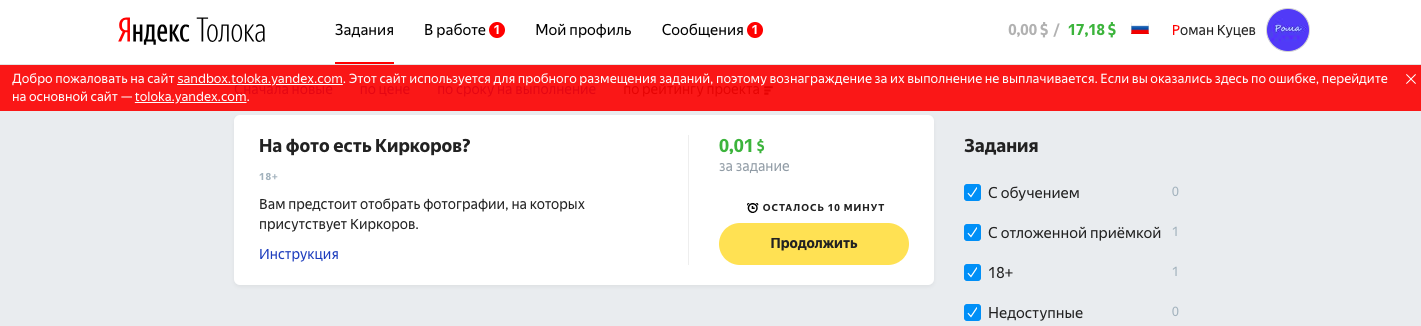
Нажимаем «Продолжить». Вот так будет выглядеть наша страничка для исполнителей:
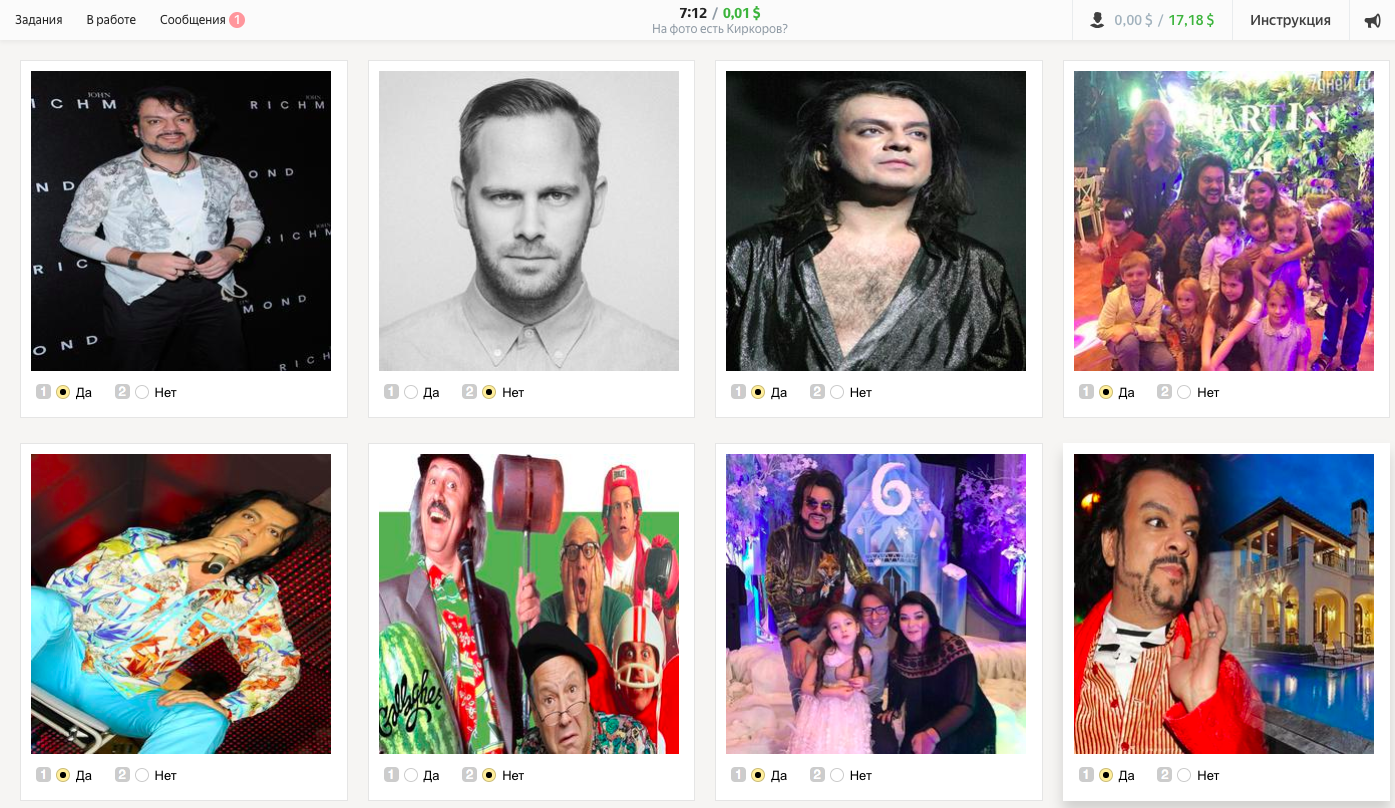
Проверяем, что все работает правильно и никаких багов не возникает.
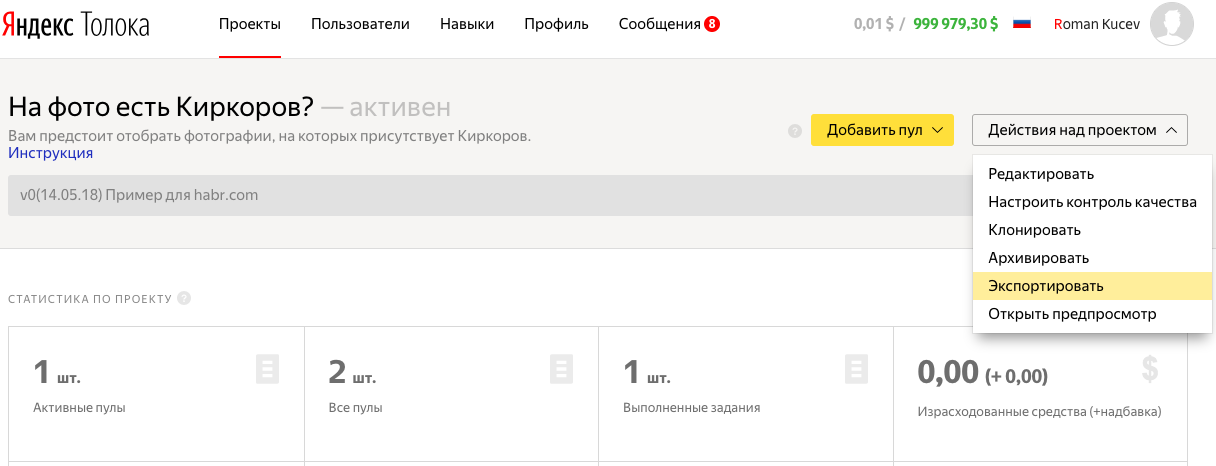
10. Если вы довольны результатом, то пора отпустить младенца в большой мир, т.е перенести наш проект из sandbox на основную Толоку. Для этого в аккаунте исполнителя во вкладке «Действия над проектом» выбираем «Экспортировать».
Заходим на toloka.yandex.ru и видим, что наш проект удачно экспортировался.
Открываем его, еще раз проверяем, что все верно. Как-то раз я допустил ошибку, неправильно сформировав задание и 2000 исполнителей, выполнив его, не смогли отправить результат (до сих пор неизвестно, сколько людей я убил).
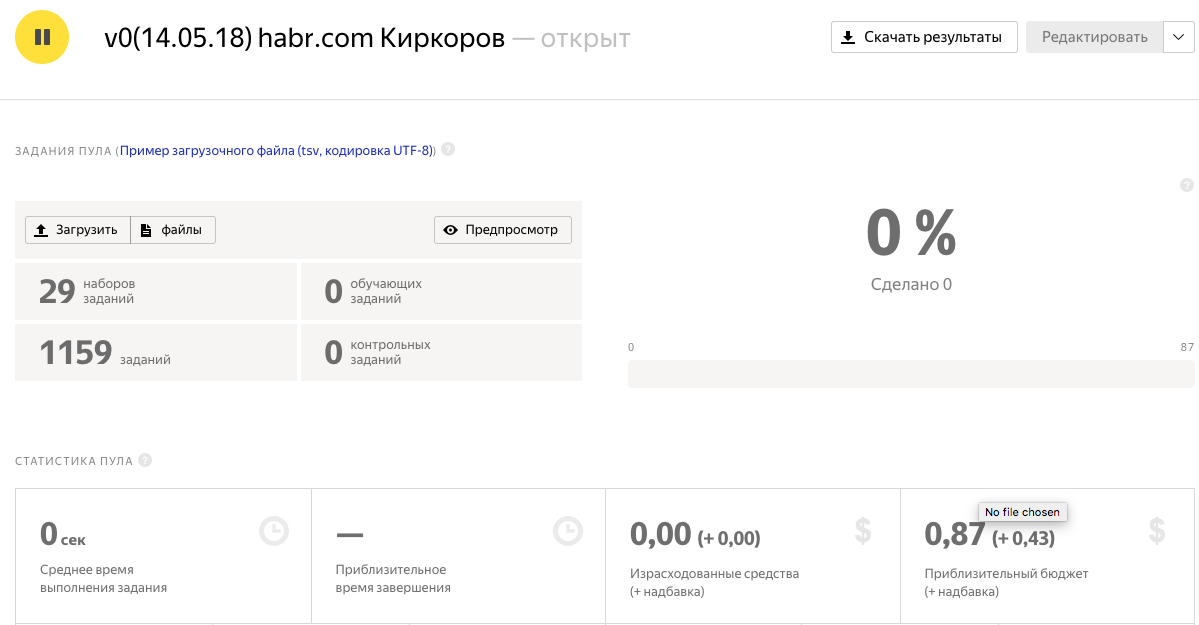
11. Запускаем пул, ждем 20 мин и получаем результат:

Итого: у нас было 1159 фото. На одной страничке для фрилансера размещалось по 40 фото. Т.е. было 1159 / 40 = 29 наборов заданий. Но мы делали с перекрытием 3, значит всего было показано 29 x 3 = 87 страничек. За одну страничку мы платим 0.01$ + 0.005$. Следовательно, чтобы проверить 1159 фото, у нас ушло 1.3$ или 80 руб. При этом фрилансеры получили всего 0.87$ или 50 руб, приблизительно потратив 97 сек x 87 заданий = 2 часа 20 минут. А готовы ли вы работать за 25 руб в час?
12. Проверяем задания и скачиваем результат.
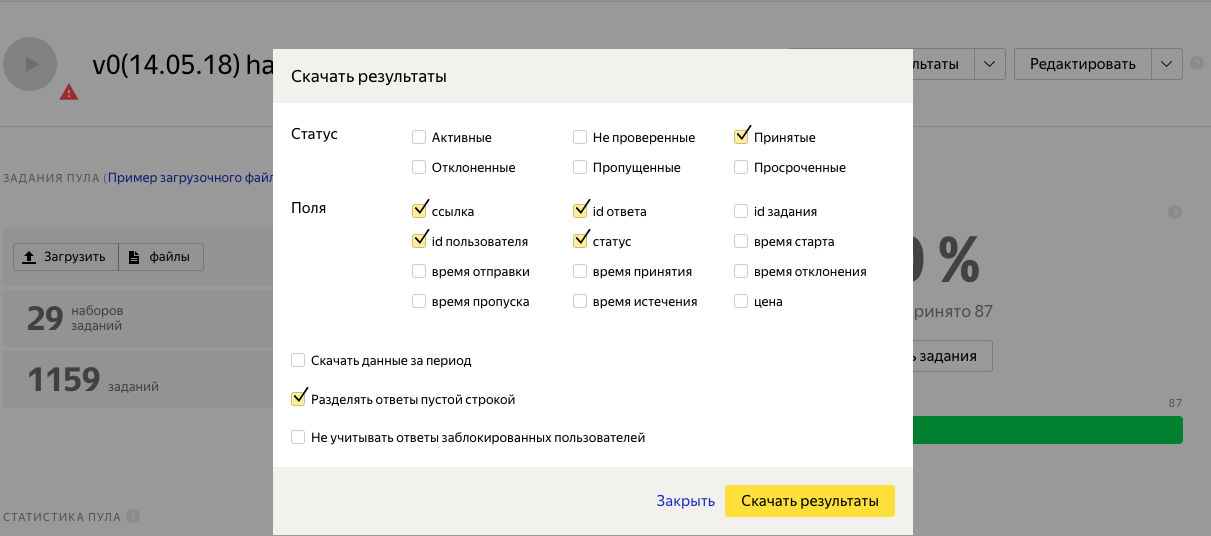
Открываем полученный файл в pandas, групируем по «INPUT:image»
import pandas as pd data = pd.read_csv('assignments_v0(14.05.18).tsv',sep = '\t') data['OUTPUT:output'] = data['OUTPUT:output'].map() data_groupby = data.groupby('INPUT:image').sum()
data_groupby['OUTPUT:output'].value_counts() 3.0 634 0.0 445 2.0 57 1.0 23Используя метод голосования, и считая, что на фото Киркоров, если хотя бы два исполнителя проголосовали за него, получили 634 + 57 = 691 фото.
Подводя итог, хочется сказать, что:
- Толока — гибкий инструмент, который можно подстроить под любую задачу.
- На Толоке очень дешевая рабочая сила.
- На Толоке порядка 10000 исполнителей, что позволяет размечать огромные объемы данных за очень короткий промежуток времени.
- Толока обладает очень удобными инструментами для контроля исполнителей, что позволяет создавать качественную разметку датасета.
Из огромных минусов: нельзя на Толоке размечать персональные данные, так как с исполнителями не подписываются никакие NDA и это будет являеться нарушением 152-ФЗ и GDPR.
Если вам интересна тема по созданию датасетов, то ставьте плюсы и в следующей статье я расскажу, как создавать датасеты для приложения sticky-ai.
- толока
- краудсорсинг
- машинное обучение
- искусственный интеллект
- Блог компании Open Data Science
- Data Mining
- Обработка изображений
- Big Data
- Машинное обучение
О важности датасета и о том, как сделать его лучше. Опыт нашей компании

Мы подготовили 7 основных шагов, которые превратят набор картинок из гугла не просто в мощный базовый блок системы компьютерного зрения, но и основной инструмент по выявлению и устранению ошибок распознавания.
Краеугольный камень любого проекта, связанного с компьютерным зрением — датасет. Это не просто набор изображений, который передается нейросети. Датасет — это базовый блок, который определит качество и точность определения объектов в рамках вашего проекта.
Нельзя просто собрать набор изображений из гугла и успокоиться — полученная куча изображений не будет нести гордое название «датасет» и испортит проект, вынуждая разработчика и компьютерное железо тренировать модель снова и снова.
Часто работа над датасетом занимает самое большое количество времени, чем над каким-либо еще этапом разработки системы компьютерного зрения, и это неспроста. Чем лучше будет подготовлен датасет, тем меньше времени потребуется на отладку модели, ее тренировки, поиск и устранение неточностей распознавания, а также в целом сделает модель «умнее».

Шаг 1: Размерность
Размер самих изображений, находящихся в датасете, не так важен: перед подачей модели на обучение данные нормализуются, чтобы соответствовать размеру сетки, например, 300 на 300 пикселей.
Размер входного слоя нейросети — размер изображений, с которыми будет работать сетка.
При формировании датасета важно иметь ввиду размерность сетки, с которой предстоит работать, и максимально близко подгонять размер изображений к размеру модели. Если этого не делать, то можно наткнуться на большое количество сюрпризов.
Например, один наш клиент обратился нам за помощью: его нейросеть должна была определять марку автомобиля и его номер, и если с первым обученная модель справлялась на «ура», то со вторым не справлялась вовсе. Ответы вроде «неподходящая модель», «маленькое количество данных», «невыполнимая для компьютерного зрения на данном этапе задача» оказались неверны, а реальный ответ был куда проще — клиент не принял во внимание размер модели нейросети, с которой работал.

Нейросети, использованной в данном проекте, на вход давали изображения с шириной 1024 пикселя, а входной размер самой модели — 300х300 пикселей. Изображения сильно сжимались в размере, и если автомобиль мог пережить данную трансформацию и оставался узнаваемым, то номер превращался в неузнаваемую кашу из пикселей. Если бы наш клиент прочитал это руководство по составлению идеального датасета, он бы смог сам довольно просто решить свою проблему, всего лишь обрезав изображения, приблизив их тем самым к размеру его модели нейросети.

Если для решения поставленной задачи критично важно использовать изображения большого размера, то уже существуют object detection модели, которые могут работать с большими изображениями. Например, модель YOLOv5x6 может работать с изображениями шириной до 1280 пикс. Данные модели очень полезны в условиях распознавания маленьких объектов на больших фотографиях, например, на спутниковых снимках.
Шаг 2: Реальные условия
Главное правило любого датасета — изображения должны быть максимально приближены к реальным условиям, в которых будет работать модель нейросети. До начала сбора изображений важно знать какие именно изображения будет получать на вход модель, где будет стоять камера, разрешение камеры.
Важно понимать, что если камера имеет маленькое разрешение и будет захватывать маленькие по размеру изображения, то и фото в датасете должны быть небольшими. Новички в разработке систем машинного обучения часто игнорируют это правило, предполагая, что чем больше и детализированнее изображение будет подано сетке в момент обучения, тем лучше она выучит предмет и тем выше будут показатели точности на реальных данных.
Пренебрежение данным шагом может «подкосить» даже проект с современной нейросетью и большим датасетом. Один из наших клиентов поставил перед собой задачу определять птиц, попавших в объектив веб-камеры. Во время составления датасета клиент собирал фото птиц разных видов из гугла: четкие, насыщенные изображения, на которых птица видна как правило в фас или в бок и занимает большую часть самого изображения. На валидационном датасете нейросеть показывала отличные разультаты. Однако в реальных условиях нейросеть работала крайне плохо.
Реальность оказалось далека от гугла. Птицы, запечатленные на заднем дворе с помощью простой веб-камеры, выглядели куда более тускло, часто были расположены к камере спиной или были видны лишь частично. Сами изображения были куда меньше, хуже по качеству, часто содержали разные помехи — капли дождя или насекомое на объективе, засвет солнцем, туман. Нейросеть просто не могла определить что находилось на таком изображении, ведь птицы на фото из датасета выглядели совсем по-другому.
Нам пришлось провести большую работу по сбору фотографий птиц в реальных условиях, после чего система заработала с высокими показателями точности.
Данный шаг часто представляет довольно большую сложность, т.к. у клиентов часто нет возможности собрать реальные фото объектов до того, как проект будет запущен. Однако его нельзя игнорировать, ведь от того, насколько данные в датасете близки к реальным данным, зависит качество распознавания.
Шаг 3: Проверка формата и аннотаций
Этот шаг особенно важен для проектов, которые используют уже готовый датасет, найденный на просторах интернета. Важно проверить, что изображения в датасете находятся в том формате, с которым сможет работать выбранный фреймворк. Современные фреймворки работают с большим количеством разных форматов, однако до сих пор встречаются проблематичные форматы, например, jfif.
Если изображения не будут находиться в нужном формате, процесс тренировки просто не сможет быть закончен, поэтому важно оказать этой, как может показаться, мелочи достаточно внимания.
Необходимо также проверить аннотации и их формат. Изображения в датасете могут отвечать всем вышеперечисленным требованиям, но если аннотации не будут в том формате, с которым работает фреймворк и архитектура модели нейросети, то ничего работать не будет.
В одних форматах аннотации, т.е. расположение bounding бокса на изображении, указывается в абсолютных значениях, в других — в относительных. Некоторые фреймворки, например YOLO, просят для каждого изображения cat.jpg приложить файл cat.txt с аннотацией, а другие, например TensorFlow, просит аннотации в формате .csv, некоторые просят приложить для тренировочного датасета один файл train.txt, который содержит все аннотации разом.
На этапе работы с датасетом важно знать с какой моделью будет вестись работа, ведь от этого зависит формат аннотаций и формат самих изображений.
Шаг 4: Разбивка датасета на TRAIN и VALIDATE
Разбивка датасета на Train и Validate — важный этап работы с датасетом, делающий тренировку нейросети возможной. Как правило, при разбивке датасета пользуются следующими правилами:
70-80% изображений идут в Train, 20-30% — в Validate

Train — то, на чем учится нейросеть, из чего извлекает свойства объекта под вопросом. После окончания эпохи тренировки нейросеть должна проверить правильно ли она выучила как выглядит объект, для чего она обращается к сету Validate.
Используя обретенные с помощью Train знания, нейросеть пытается угадать какой объект находится на изображении из Validate. Если предположение нейросети оказалось неправильным, то делается анализ ошибки для предотвращения такой ошибки в следующих итерациях.
Без сета Validate невозможно обучить модель. Данный способ часто применяется в системах машинного обучения, работает достаточно хорошо и является неким негласным стандартом работы с датасетом.
Однако наши разработчики используют несколько иной подход:
70% изображений идут в Train, 20% идут в Validate, 10% — в Test

По нашему опыту, изначально датасет нужно разбивать так, чтобы оставались изображения, которые нейросеть еще не видела. Процесс обучения остается прежним — сетка изучает изображения в Train и проверяет свои знания на изображениях из Validate, однако после завершения тренировки мы добавляем дополнительный этап — тестирование. Нейросеть анализирует изображения из Test, которые она ни разу не видела, а мы можем проверить, работает ли нейросеть на самом деле. Данный этап позволяет выяснить, где ошибается нейросеть, какие классы вызывают у нее сложности.
Шаг 5: Утечка данных
Для начала кратко поясним, что такое утечка данных, и почему это плохо.
Допустим, мы хотим научить нейросеть отличать кроликов от зайцев. Возьмем два изображения зайца, которые отличаются друг от друга небольшим изменением положения его тела:

Для человека данные изображения разные, поэтому они оба могут попасть в датасет. Далее мы, как обычно, разбиваем наш датасет на Train и Validate. Однако случилось так, что первое изображение зайца попало в Train, а второе — в Validate. Начинаем тренировку нашей нейросети, она извлекает свойства зайца с первого изображения, после завершения эпохи нейросети показывают второе изображение зайца. Наша модель безошибочно угадает, что это заяц, а не кролик, ведь почти точно такое же изображение она видела в Train. Получилась ситуация, когда нейросеть не выучила информацию, а запомнила.

Как только наша нейросеть получит на вход изображение, где заяц сильно повернул голову, развернулся или лег на спину — она тут же растеряется и не сможет понять, что ей показывают.
Данные, которые перетекают из Train в Validate не дают нейросети учиться. В процессе обучения значение accuracy будет приближено к 100%, однако в реальных условиях ситуация будет куда более плачевной.
К вопросу утечки данных нужно подходить серьезно. Многие при разбивке датасета сначала используют Shuffle, затем берут первые 70% и помещают в Train, а оставшееся — в Validate, но данных подход приводит к утечке данных. Важно сделать так, чтобы в сете Validate не было картинок, которые есть в Train.

Чтобы избежать утечки данных, можно использовать скрипты и библиотеки, которые удаляют дубликаты. Можно настроить порог удаления — например, удалять идентичные картинки или схожие на 90% картинки. Чем больше дубликатов и похожих изображений будет удалено, тем лучше для нейросети.
На нашей практике мы сталкивались с ситуациями, когда утечка данных значительно влияла на качество определения. В одном из наших проектов нейросеть стабильно ошибалась при определении объектов из определенного класса. Ручным тестированием мы обнаружили утечку данных. После удаления дубликатов ошибка пропала.
Часто можно встретить мнение, что датасет нужно делать как можно более объемным, чем больше датасет — тем лучше качество распознавания. Однако в случае с утечкой данных, лучше уменьшить количество данных, повысив тем самым качество датасета.
Вообще стоит отметить, что датасет по идее неприкосновенен, но его иногда нужно «перетряхивать» в поисках неточностей, дубликатов, неравномерно наполненных классов.
Шаг 6: База данных
Работая с большим датасетом, где речь идет о десятках и сотнях тысяч изображений и десятках классов и подклассов, сложной структуре и изображениях из множества разных источников, мы практикуем создание простой, но очень полезной базы данных, содержащей основную информацию об изображениях.
Зачем это нужно? При работе с большим датасетом гораздо удобнее и быстрее анализировать информацию посредством базы данных, а некоторые виды анализа возможны только с БД.
Сама база данных имеет очень простую структуру и содержит в себе информацию об изображениях:
- название;
- абсолютный путь;
- данные об аннотации;
- класс, к которому принадлежит изображение;
- Свойства изображения, например, вид птицы, марка автомобиля, источник изображения (веб-камера, гугл) и пр.
База данных позволяет быстро работать с датасетом, например, собирать статистику по датасету, чтобы понять его структуру, увидеть дисбаланс по классам, проверить количество изображений из разных источников для каждого класса.
С помощью БД можно составлять графики по количеству изображений, который позволяет визуально легко определить недостаток качественных (с точки зрения тренировки модели) изображений и дисбаланс изображений по классам.
Например, анализируя качество определения видов птиц мы заметили, что нейросеть плохо определяет воробьев. Проанализировав датасет с помощью БД мы увидели, что треть изображений из класса «воробей» были взяты из гугла. Пройдя по всем классам, мы определили пороговое значение гугловских изображений, в нашем случае — 20%. Если в классе «плохих» изображений было больше, то модель начинала ошибаться.
Данный анализ был бы невозможен или очень затруднен, если бы мы вручную просматривали каждый класс и не имели перед собой общую статистику. Стоит отметить, что создание базы данных имеет смысл только при работе с большими датасетами.
Все эти работы проделываются до начала обучения, ведь как вы могли понять из всего вышеизложенного обучение — не главный вопрос, а вот подготовка является основным и самым важным этапом разработки. Разработчику и клиенту важно знать свой датасет, знать из чего он состоит, какую структуру имеет. Это позволит быстро устранять ошибки определения.
Шаг 7: Аугментация
Аугментация — быстрый, простой и эффективный способ увеличить объем датасета в условиях недостаточного количества изображений. С помощью специальных инструментов, например, открытой библиотеки на Python, можно трансформировать одно изображение и в результате получить несколько разных:

Существует два типа аугментаций:
Pre training augmentation — модификация изображений до начала тренировки. Данный тип аугментаций важно проводить только после разбивки датасета на Train и Validate Intraining augmentation — аугментации, встроенные в фреймворк по умолчанию.
Почему же важно проводить до тренировочную аугментацию только после разделения датасета? Дело в том, что может произойти частичная утечка данных: аугментированные изображения могут попасть в Validate, с точки зрения обучения модели нейросети аугментированные фото являются дубликатами, что плохо сказывается на тренировочном процессе.
Аугментировать датасет можно и нужно, но главная мысль этого шага — не увлекаться аугментациями. При увеличении объема датасета в 7 раз сетка не станет в 7 раз эффективнее, но она может начать работать хуже. Стоит использовать только те аугментации, которые реально помогут, т.е. те, что отвечают реальным условиям. Если камера будет стоять внутри помещения, то аугментация “снег” или “туман” только навредит, ведь данных искажений в реальной жизни не будет.
Итак, мы перечислили основные шаги, которые позволят разработчикам создавать датасеты лучше, чем они это делали вчера, а клиентам понять как можно улучшить свой датасет до того, как он будет передан разработчикам. Безусловно, этот список не исчерпывающий, но наш опыт подсказывает, что эти шаги являются самыми важными.
Спасибо за внимание! Оставайтесь на связи, впереди еще много интересных текстов по ML.
- разметка данных
- data labeling
- computer vision
- компьютерное зрение
- машинное обучение
- data annotation
- dataset
- training data
- ml
- ai
- Data Mining
- Обработка изображений
- Машинное обучение
- Искусственный интеллект
- Data Engineering
Создание виртуальных датасетов
Superset позволяет создавать виртуальные датасеты на основе SQL-запросов.
Для создания виртуального датасета необходимо перейти в Редактор SQL.
- Заполнить имя базы данных и наименование схемы (1).
- В пустое поле по центру сверху ввести соответствующий SQL-запрос.
- Есть возможность ВЫПОЛНИТЬ (2) его для предварительного просмотра датасета.
- Для сохранения запроса как датасет необходимо нажать ОБЗОР ГРАФИКА (3).
В открывшемся окне ввести наименование нового датасета и нажать СОХРАНИТЬ И ИССЛЕДОВАТЬ.
Новый датасет откроется в режиме создания графика, и сохраниться в списке датасетов с типом Virtual.
ПАО Сбербанк использует cookie для персонализации сервисов и удобства пользователей.
Вы можете запретить сохранение cookie в настройках своего браузера.