Встречаем Veracity — новую распределенную систему контроля версий

Здравствуй, мой любознательный %username%!
Несколько месяцев назад я случайно наткнулся на еще одну перспективную систему управления версий — Veracity, о которой и хотел бы сегодня рассказать, чтобы тебе было что поковырять на выходных. Несмотря на то, что разработка Veracity идет уже больше года, на Хабре ее имя было лишь пару раз вскользь упомянуто в комментариях. Под катом тебя ждет краткое описание Veracity и ссылки, где можно получить более подробную информацию о ней.
Итак, Veracity (англ. «правдивость», «достоверность», «точность») — это распределенная система контроля версий, схожая с Git, разрабатываемая по лицензии Apache 2.0 в фирме SourceGear.
Основные отличия от Git
- Наличие локальных номеров ревизий. Veracity, как и Git, использует криптографические хэш-функции для версионного контроля отдельных файлов. Однако в локальном репозитории каждый коммит получает уникальный номер ревизии, как это происходит в Subversion. Номер ревизии и хэш могут использоваться наравне друг с другом и часто указываются через двоеточие.
- Поддержка нескольких хэш-функций. Всем известно, что Git в своей работе использует функцию SHA-1. Veracity позволяет выбрать между SHA-1, SHA-2 или Skein.
- Формальное переименование файлов. Git при переименовании файлов реально удаляет файл, а затем создает файл с таким же содержимым и новым именем. Veracity делает именно переименование существующего файла.
- Поддержка блокировок файлов. Централизованные системы контроля версий наподобие Subversion поддерживают 2 схемы работы: блокировка файлов (svn lock \ svn unlock) и слияние изменений (svn merge). Хотя Git и другие распределенные системы контроля версий часто используют в работе центральный репозиторий, в них отсутствует механизм блокировки файлов. Veracity исправляет этот недостаток. Понятно, что для блокировки файлов, необходим доступ к удаленным репозиториям через сеть.
- Поддержка штампов. Veracity включает в себя абсолютно новую функциональность, называемую штампами. Штамп (stamp) — это отметка из произвольного текста, которую разработчик может прикрепить к любому коммиту. В отличие от тегов (tag), сопоставляющих каждому коммиту уникальное имя, один и тот же штамп может помечать произвольное число коммитов. Например, при использовании системы непрерывной интеграции можно ставить штамп «Tests passed» на коммиты, прошедшие серию тестов без ошибок, ровно также как производители техники ставят штампик «qc pass» (quality controll passed) на каждый произведенный образец.
- Децентрализованная база данных репозитория. Многие системы контроля версий хранят данные о репозитории внутри рабочего каталога. Например, Git имеет папку .git, в которой хранятся бинарные объекты, деревья, объекты коммитов, индекс, конфигурация, хуки и т.д. Veracity хранит большинство служебной информации о репозитории вне рабочего каталога в специальной базе данных. Это, например, позволяет иметь сразу несколько рабочих каталогов для одного репозитория.
- Встроенный интерпретатор Javascript. Veracity использует Javascript в качестве основного скриптового языка. Например, можно писать хуки в виде функций Javascript. Также имеется встроенный API для Javascript, который можно использовать для написания серверной части веб-приложений, использующих Veracity. Вполне логично, что для хранения сериализованных данных используется JSON.
- Встроенное веб-приложение для обзора репозитория. Одной командой можно запустить встроенный веб-сервер с приложением, позволяющим просматривать содержимое репозитория, историю изменений, статус сборки проекта или баг-трекер.
Установка
- Собрать из исходных кодов. Система написана на языке C, как и некоторые другие системы контроля версий (например, Git, Subversion или Fossil), поэтому нам придется иметь дело с установкой исходных кодов зависимостей и утилитами наподобие cmake и make. Для тех, кто любит подобные вещи вот инструкции по сборке для Linux и для Windows.
- Установить из бинарного пакета. Чтобы быстрее начать ковырять Veracity, гораздо проще будет воспользоваться бинарными пакетами, которые можно скачать на странице загрузок. Имеются бинарные пакеты для Debian-совместимых систем (*.deb: x86, x64) и для Windows (*.msi: x86, x64).
Основные команды
$vv add filename1 filename2 ~/thisdir$vv addremove dirname1$vv branch $vv branch add devel$vv cat filename$vv checkout$vv clone http://example.com/repos/reponame reponame$vv comment --rev=123 --message='A new comment'$vv commit --message='Commit message'$vv config set whoami/username vania-pooh$vv diff --rev=3 filename$vv diffmerge --rev=3 filename$vv export reponame ~/copyhere$vv fast-export reponame ~/backupname.fi$vv fast-import --hash=SHA2/512 ~/backupname.fi$vv heads$vv help branch new $vv history $vv incoming $vv init reponame dirname$vv leaves$vv lock filename$vv locks$vv merge -r 37939b07309af8232c44048ca0a1633c982b7506$vv move filename ~/newdir$vv outgoing$vv parents$vv pull #Для того, чтобы применить изменения к рабочему каталогу следует использовать команду vv update$vv push #Для того, чтобы не указывать удаленный репозиторий нужно прописать его в конфигурации$vv remove ~/repo/filename$vv rename ~/repo/oldfile ~/repo/newfile$vv repo info$vv resolve ~/filename #Спрашивает как разрешить конфликт для каждой конфликтующей строчки файла$vv revert ~/filename1 ~/filename2$vv serve --port=8080 --public$vv stamp add approved --rev=3$vv status$vv tag add tagname --rev=3$vv unlock filename$vv update$vv user create vania-pooh$vv version$vv whoami anotherUser$vv zip ~/backup/archive.zipРасположение файлов
Как уже было сказано раньше, Veracity хранит метаданные репозиториев отдельно от файлов рабочего каталога. Это позволяет иметь несколько рабочих каталогов. В документации по Veracity сказано, что он поддерживает несколько различных движков хранения, однако, по-умолчанию используется движок FS3. Этот движок использует базу данных SQLite3 и текстовые файлы, хранящие запросы к базе данных. Для того, чтобы иметь возможность просматривать содержимое базы вы можете установить расширение SQLite Manager для Firefox. По-умолчанию, все данные репозиториев хранятся в каталоге ~/.sgcloset/. Кроме того каждая рабочая копия имеет скрытый каталог .sgdrawer, содержащий ссылку на имя репозитория и некоторые другие метаданные. Если вы хотите игнорировать файлы репозитория, то поместите их в файл .sgignores или .vvignores, как показано здесь. Veracity на данный момент имеет всего 2 исполняемых файла — vv и vscript. Первый отвечает за исполнение команд версионного контроля, а второй позволяет запускать скрипты, написанные на Javascript.
Встроенное приложение Veracity
Как уже было сказано выше Veracity содержит встроенный веб-сервер и веб-приложение для управления проектом, использующим Veracity. Для того, чтобы запустить веб-приложение, просто введите команду:
$vv serve --port=8080 --public #Ключ --public разрешает подключение с удаленных хостов.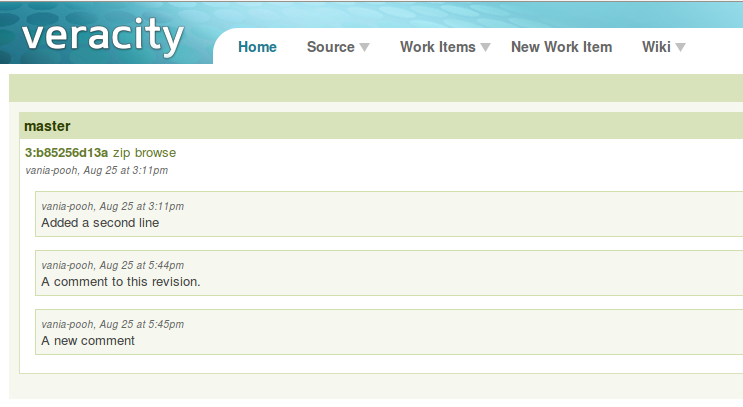
Приложение стартует на указанном порту и становится доступно из браузера. Вот как это выглядит:
На картинке видно, что указанный коммит имеет 3 комментария. Один добавлен при создании коммита, остальные с помощью команды vv comment.
Хостинг проектов Veracity
Разработчики Veracity понимают, что конкурировать с Git без наличия хостинга проектов наподобие Github будет очень трудно. Именно поэтому совсем недавно был запущен сайт onveracity.com. В целом сайт повторяет функциональность Github, а скриншоты можно посмотреть на его главной странице.
Ссылки
- Официальный сайт
- Хостинг репозиториев Veracity
- Книга по Veracity, на данный момент единственное более-менее подробное описание основных команд и цикла работы.
Заключение
Информации по Veracity пока что не так много. Сами разработчики отвечают на вопросы пользователей на странице вопросов. Некоторые сведения можно почерпнуть из книги, указанной выше. Будем надеяться, что этот проект также найдет свое место под солнцем.
- veracity
- scm
- dvcs
- почитать на выходных
- поковырять в свободное время
- Программирование
- Git
- Системы управления версиями
Введение
В рамках первой лекции мы познакомимся с тем, что такое системы управления версиями (мне хотелось рефлекторно в конце добавить кода , но это не так. Об этом чуть позже). Сначала мы расскажем о происхождении инструментов для контроля версий, узнаем, какие системы управления версиями сейчас популярны и в чем у них основные различия. Безусловно, рассмотрим, почему именно GIT и познакомимся с ним. Разберемся, как начать работу с Git’ом — как установить и запустить Git на вашей машине и наконец, как настроить его так, чтоб можно было приступить к работе. К концу этой лекции вы будете понимать, зачем Git вообще сделан, почему вам стоит им пользоваться, и будете готовы начать с ним работать.
О контроле версий
Что такое контроль версий, и зачем он вам нужен?
Система контроля версий (СКВ) — это система, регистрирующая изменения в одном или нескольких файлах с тем, чтобы в дальнейшем была возможность вернуться к определённым старым версиям этих файлов.
В последнее время файлы являются конечным результатом для многих профессий, здесь можно назвать, для примера, писательскую деятельность, научные работы и конечно разработку программного обеспечения. Тратится много времени и сил на разработку и поддержку этих файлов и никто не хочет, чтобы пришлось тратить еще больше времени и сил на восстановление данных потерянных в результате каких-либо изменений.
Представим, что программист разрабатывает проект состоящий из одного небольшого файла (кстати, пример вполне реальный, не синтетический). После выпуска первой версии проекта перед ним встает непростой выбор: необходимо исправлять проблемы о которых сообщают пользователи первой версии и, в тоже время, разрабатывать что-то новое для второй. Даже если надо просто исправлять возникающие проблемы, то велика вероятность, что после какого-либо изменения проект перестает работать, и надо определить, что было изменено, чтобы было проще локализовать проблему. Также желательно вести какой-то журнал внесенных изменений и исправлений, чтобы не делать несколько раз одну и ту же работу.
В простейшем случае вышеприведенную проблему можно решить хранением нескольких копий файлов, например, один для исправления ошибок в первой версии проекта и второй для новых изменений. Так как изменения обычно не очень большие по сравнению с размером файла, то можно хранить только измененные строки используя утилиту diff и позже объединять их с помощью утилиты patch. Но что если проект состоит из нескольких тысяч файлов и над ним работает сотня человек? Если в этом случае использовать метод с хранением отдельных копий файлов (или даже только изменений) то проект застопорится очень быстро.
Для примеров мы будем использовать исходные коды программ, но на самом деле под версионный контроль можно поместить файлы практически любого типа.
Если вы графический или веб-дизайнер и хотели бы хранить каждую версию изображения или макета — а этого вам наверняка хочется — то пользоваться системой контроля версий будет очень мудрым решением. СКВ даёт возможность возвращать отдельные файлы к прежнему виду, возвращать к прежнему состоянию весь проект, просматривать происходящие со временем изменения, определять, кто последним вносил изменения во внезапно переставший работать модуль, кто и когда внёс в код какую-то ошибку, и многое другое. Вообще, если, пользуясь СКВ, вы всё испортите или потеряете файлы, всё можно будет легко восстановить. Вдобавок, накладные расходы за всё, что вы получаете, будут очень маленькими.
Локальные системы контроля версий
Как уже говорилось ранее — один из примеров локальной СУВ предельно прост: многие предпочитают контролировать версии, просто копируя файлы в другой каталог (как правило добавляя текущую дату к названию каталога). Такой подход очень распространён, потому что прост, но он и чаще даёт сбои. Очень легко забыть, что ты не в том каталоге, и случайно изменить не тот файл, либо скопировать файлы не туда, куда хотел, и затереть нужные файлы.
Чтобы решить эту проблему, программисты уже давно разработали локальные СКВ с простой базой данных, в которой хранятся все изменения нужных файлов
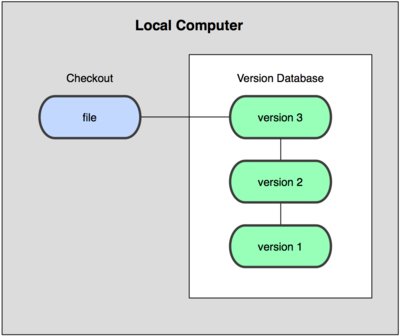
Одной из наиболее популярных СКВ такого типа является RCS (Revision Control System, Система контроля ревизий), которая до сих пор устанавливается на многие компьютеры. Даже в современной операционной системе Mac OS X утилита rcs устанавливается вместе с Developer Tools.
RCS была разработана в начале 1980-х годов Вальтером Тичи (Walter F. Tichy). Система позволяет хранить версии только одного файла, таким образом управлять несколькими файлами приходится вручную. Для каждого файла находящегося под контролем системы информация о версиях хранится в специальном файле с именем оригинального файла к которому в конце добавлены символы ‘,v’ . Например для файла file.txt версии будут храниться в файле file.txt,v . Эта утилита основана на работе с наборами патчей между парами версий (патч — файл, описывающий различие между файлами). Это позволяет пересоздать любой файл на любой момент времени, последовательно накладывая патчи. Для хранения версий система использует утилиту diff .
Рассмотрим пример сессии с RCS. Когда мы хотим положить файл под контроль RCS мы используем команду ci (от check-in, регистрировать):
$ ci file.txt Данная команда создает файл file.txt,v и удаляет исходный файл file.txt (если не сказано этого не делать). Также эта команда запрашивает описание для всех хранимых версий. Так как исходный файл был удален системой мы должны запросить его обратно, что бы вносить изменения. Для этого мы используем команду co (от check-out, контролировать):
$ co file.txt Эта команда вынимает последнюю версию нашего файла из file.txt,v . Теперь мы можем отредактировать файл file.txt и после того как закончим изменения опять выполнить команду ci для того что бы сохранить новую измененную версию файла:
$ ci file.txt При выполнении этой команды система запросит у нас описание изменений и затем сохранит новую версию файла.
Хотя RCS соответствует минимальным требованиям к системе контроля версий она имеет следующие основные недостатки, которые также послужили стимулом для создания следующей рассматриваемой системы:
- Работа только с одним файлом, каждый файл должен контролироваться отдельно;
- Неудобный механизм одновременной работы нескольких пользователей с системой, хранилище просто блокируется пока заблокировавший его пользователь не разблокирует его;
- От бекапов вас никто не освобождает, вы рискуете потерять всё.
Централизованные системы контроля версий
Следующей основной проблемой оказалась необходимость сотрудничать с разработчиками за другими компьютерами. Чтобы решить её, были созданы централизованные системы контроля версий (ЦСКВ). В таких системах, например CVS , Subversion и Perforce , есть центральный сервер, на котором хранятся все файлы под версионным контролем, и ряд клиентов, которые получают копии файлов из него. Много лет это было стандартом для систем контроля версий.
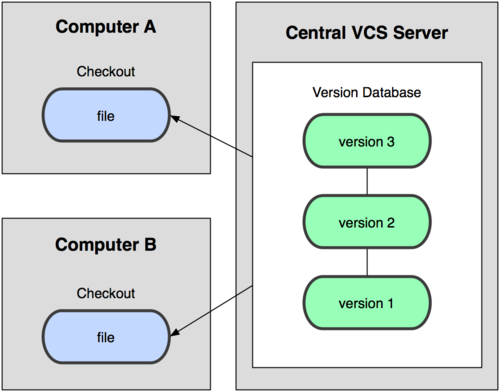
Рисунок 1-2. Схема централизованного контроля версий.
Такой подход имеет множество преимуществ, особенно над локальными СКВ. К примеру, все знают, кто и чем занимается в проекте. У администраторов есть чёткий контроль над тем, кто и что может делать, и, конечно, администрировать ЦСКВ намного легче, чем локальные базы на каждом клиенте.
Однако при таком подходе есть и несколько серьёзных недостатков. Наиболее очевидный — централизованный сервер является уязвимым местом всей системы. Если сервер выключается на час, то в течение часа разработчики не могут взаимодействовать, и никто не может сохранить новой версии своей работы. Если же повреждается диск с центральной базой данных и нет резервной копии, вы теряете абсолютно всё — всю историю проекта, разве что за исключением нескольких рабочих версий, сохранившихся на рабочих машинах пользователей.
CVS
CVS (Concurrent Versions System, Система совместных версий) пока остается самой широко используемой системой, но быстро теряет свою популярность из-за недостатков которые я рассмотрю ниже. Дик Грун (Dick Grune) разработал CVS в середине 1980-х. Для хранения индивидуальных файлов CVS (также как и RCS) использует файлы в RCS формате, но позволяет управлять группами файлов расположенных в директориях. Также CVS использует клиент-сервер архитектуру в которой вся информация о версиях хранится на сервере. Использование клиент-сервер архитектуры позволяет использовать CVS даже географически распределенным командами пользователей где каждый пользователь имеет свой рабочий директорий с копией проекта.
Как следует из названия пользователи могут использовать систему совместно. Возможные конфликты при изменении одного и того же файла разрешаются тем, что система позволяет вносить изменения только в самую последнюю версию файла. Таким образом всегда рекомендуется перед заливкой своих изменений обновлять свою рабочую копию файлов на случай возможных конфликтующих изменений. При обновлении система вносит изменения в рабочую копию автоматически и только в случае конфликтующих изменений в одном из мест файла требуется ручное исправление места конфликта.
CVS также позволяет вести несколько линий разработки проекта с помощью ветвей ( branches ) разработки. Таким образом, как уже упоминалось выше, можно исправлять ошибки в первой версии проекта и параллельно разрабатывать новую функциональность.
Рассмотрим небольшой пример сессии с CVS. Прежде всего надо импортировать проект в CVS, это делается с помощью команды import (импортировать):
$ cd some-project $ cvs import -m "New project" path-in-repository none start Здесь опция -m позволяет задать описание изменений прямо в командной строке и если ее опустить, то будет вызван текстовый редактор. Далее указывается путь по которому проект будет храниться в репозитории ( path-in-repository в нашем случае) и после него две метки: метка разработчика (может пригодится в случае использования CVS для работы над проектами разработанными кем-то другим) и метка проекта.
После того как мы залили наш проект в репозиторий необходимо создать новый директорий в котором будет находится рабочая копия проекта под контролем CVS и загрузить проект с помощью команды checkout (контроль), или сокращенно co:
$ cd some-working-dir $ cvs checkout path-in-repository Для команды checkout мы указываем путь к нашему проекту в репозитории который мы указывали выше в команде import.
Теперь мы можем внести в проект изменения и залить их в репозиторий с помощью команды commit (совершить изменения), или сокращенно ci :
$ cvs commit -m "Some changes" Также как и для команды import мы указываем комментарий к нашим изменениям с помощью опции -m .
Если мы хотим обновить наш рабочий директорий новой версией проекта из репозитория мы используем команду update (обновить), или сокращенно up :
$ cvs update CVS использовалась большим количеством проектов, но конечно не была лишена недостатков которые позднее привели к появлению следующей рассматриваемой системы. Рассмотрим основные недостатки:
- Так как версии хранятся в файлах RCS нет возможности сохранять версии директорий. Стандартный способ обойти это препятствие — это сохранить какой-либо файл (например, README.txt) в директории;
- Перемещение, или переименование файлов не подвержено контролю версий. Стандартный способ сделать это: сначала скопировать файл, удалить старый с помощью команды cvs remove и затем добавить с его новым именем с помощью команды cvs add ;
Subversion
Subversion (SVN) был разработан в 2000 году по инициативе фирмы CollabNet. SVN изначально разрабатывался как “лучший CVS” и основной задачей разработчиков было исправление ошибок допущенных в дизайне CVS при сохранении похожего интерфейса. SVN также как и CVS использует клиент-сервер архитектуру. Из наиболее значительных изменений по сравнению с CVS можно отметить:
- Атомарное внесение изменений ( commit ). В случае если обработка коммита была прервана не будет внесено никаких изменений.
- Переименование, копирование и перемещение файлов сохраняет всю историю изменений.
- Директории, символические ссылки и мета-данные подвержены контролю версий.
- Эффективное хранение изменений для бинарных файлов.
Рассмотрим примеры команд, хотя надо заметить, что большинство из них практически повторяют команды CVS. Что бы использовать проект с SVN его надо сначала импортировать в репозиторий с помощью команды import (импортировать):
$ cd some-project $ svn import -m "New project" path-in-repository В отличие от CVS не нужно указывать метки разработчика и проекта, которые не часто использовались на практике.
Теперь нам нужно создать рабочую копию проекта с помощью команды checkout (контроль), или co :
$ cd some-working-dir $ svn checkout path-in-repository После внесения изменений мы используем команду commit (совершить изменения) , или ci для сохранения изменений в репозитории:
$ svn commit -m "Some changes" И для обновления рабочей копии проекта используется команда update (обновить), или up :
$ svn up Распределённые системы контроля версий
И в этой ситуации в игру вступают распределённые системы контроля версий (РСКВ). В таких системах как Git , Mercurial , Bazaar или Darcs клиенты не просто выгружают последние версии файлов, а полностью копируют весь репозиторий. Поэтому в случае, когда “умирает” сервер, через который шла работа, любой клиентский репозиторий может быть скопирован обратно на сервер, чтобы восстановить базу данных. Каждый раз, когда клиент забирает свежую версию файлов, он создаёт себе полную копию всех данных.
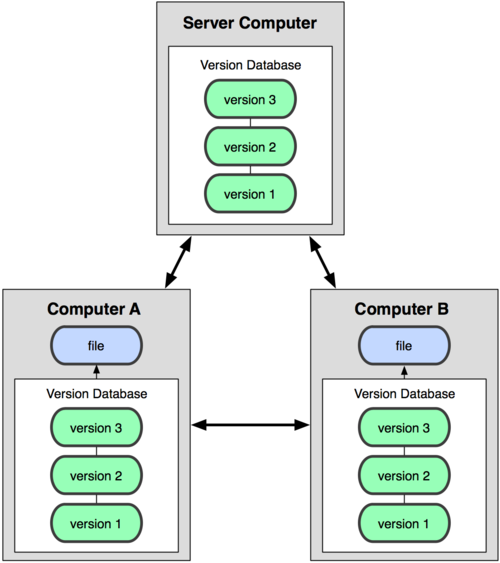
Рисунок 1-3. Схема распределённой системы контроля версий.
Кроме того, в большей части этих систем можно работать с несколькими удалёнными репозиториями, таким образом, можно одновременно работать по-разному с разными группами людей в рамках одного проекта. Так, в одном проекте можно одновременно вести несколько типов рабочих процессов, что не возможно в централизованных системах.
Зачем нужны распределенные системы?
Как следует из названия одна из основных идей распределенных систем — это отсутствие четко выделенного центрального хранилища версий — репозитория. В случае распределенных систем набор версий может быть полностью, или частично распределен между различными хранилищами, в том числе и удаленными. Такая модель отлично вписывается в работу распределенных команд, например, распределенной по всему миру команды разработчиков работающих над одним проектом с открытым исходным кодом. Разработчик такой команды может скачать себе всю информацию по версиям и после этого работать только на локальной машине. Как только будет достигнут результат одного из этапов работы, изменения могут быть залиты в один из центральных репозиториев или, опубликованы для просмотра на сайте разработчика, или в почтовой рассылке. Другие участники проекта, в свою очередь, смогут обновить свою копию хранилища версий новыми изменениями, или попробовать опубликованные изменения на отдельной, тестовой ветке разработки. К сожалению, без хорошей организации проекта отсутствие одного центрального хранилища может быть минусом распределенных систем. Если в случае централизованных систем всегда есть один общий репозиторий откуда можно получить последнюю версию проекта, то в случае распределенных систем нужно организационно решить какая из веток проекта будет основной.
Почему распределенная система контроля версий может быть интересна кому-то, кто уже использует централизованную систему — такую как Subversion? Любая работа подразумевает принятие решений, и в большинстве случаев необходимо пробовать различные варианты: при работе с системами контроля версий для рассмотрения различных вариантов и работы над большими изменениями служат ветки разработки. И хотя это достаточно естественная концепция, пользоваться ей в Subversion достаточно не просто. Тем более, все усложняется в случае множественных последовательных объединений с одной ветки на другую — в этом случае нужно безошибочно указывать начальные и конечные версии каждого изменения, что бы избежать конфликтов и ошибок. Для распределенных систем контроля версий ветки разработки являются одной из основополагающих концепций — в большинстве случаев каждая копия хранилища версий является веткой разработки. Таким образом, механизм объединения изменений с одной ветки на другую в случае распределенных систем является одним из основных, что позволяет пользователям прикладывать меньше усилий при пользовании системой.
Краткое описание популярных распределенных СУВ
- Git (http://git-scm.com/) — распределенная система контроля версий, разработанная Линусом Торвальдсом. Изначально Git предназначалась для использования в процессе разработки ядра Linux, но позже стала использоваться и во многих других проектах — таких, как, например, X.org и Ruby on Rails, Drupal. На данный момент Git является самой быстрой распределенной системой, использующей самое компактное хранилище ревизий. Но в тоже время для пользователей, переходящих, например, с Subversion интерфейс Git может показаться сложным;
- Mercurial (http://www.selenic.com/mercurial/) — распределенная система, написанная на языке Python с несколькими расширениями на C. Из использующих Mercurial проектов можно назвать, такие, как, Mozilla и MoinMoin.
- Bazaar (http://bazaar-vcs.org/) — система разработка которой поддерживается компанией Canonical — известной своими дистрибутивом Ubuntu и сайтом https://launchpad.net/. Система в основном написана на языке Python и используется такими проектами, как, например, MySQL.
- Codeville (http://codeville.org/) — написанная на Python распределенная система использующая инновационный алгоритм объединения изменений (merge). Система используется, например, при разработке оригинального клиента BitTorrent.
- Darcs (http://darcs.net/) — распределенная система контроля версий написанная на Haskell используемая, например, проектом Buildbot.
- Monotone (http://monotone.ca/) — система написанная на C++ и использующая SQLite как хранилище ревизий.
Краткая история Git
Как и многие замечательные вещи, Git начинался с, в некотором роде, разрушения во имя созидания и жарких споров. Ядро Linux — действительно очень большой открытый проект. Бо́льшую часть существования ядра Linux (1991-2002) изменения к нему распространялись в виде патчей и заархивированных файлов. В 2002 году проект перешёл на проприетарную РСКВ BitKeeper.
В 2005 году отношения между сообществом разработчиков ядра Linux и компанией, разрабатывавшей BitKeeper, испортились, и право бесплатного пользования продуктом было отменено. Это подтолкнуло разработчиков Linux (и в частности Линуса Торвальдса, создателя Linux) разработать собственную систему, основываясь на опыте, полученном за время использования BitKeeper. Основные требования к новой системе были следующими:
- Скорость
- Простота дизайна
- Поддержка нелинейной разработки (тысячи параллельных веток)
- Полная распределённость
- Возможность эффективной работы с такими большими проектами, как ядро Linux (как по скорости, так и по размеру данных)
С момента рождения в 2005 году Git развивался и эволюционировал, становясь проще и удобнее в использовании, сохраняя при этом свои первоначальные качества. Он невероятно быстр, очень эффективен для больших проектов, а также обладает превосходной системой ветвления для нелинейной разработки.
Основы Git
Так что же такое Git в двух словах? Эту часть важно усвоить, поскольку если вы поймёте, что такое Git, и каковы принципы его работы, вам будет гораздо проще пользоваться им эффективно. Изучая Git, постарайтесь освободиться от всего, что вы знали о других СКВ, таких как Subversion или Perforce. В Git’е совсем не такие понятия об информации и работе с ней как в других системах, хотя пользовательский интерфейс очень похож. Знание этих различий защитит вас от путаницы при использовании Git’а.
Слепки вместо патчей
Главное отличие Git’а от любых других СКВ (например, Subversion и ей подобных) — это то, как Git смотрит на свои данные. В принципе, большинство других систем хранит информацию как список изменений (патчей) для файлов. Эти системы (CVS, Subversion, Perforce, Bazaar и другие) относятся к хранимым данным как к набору файлов и изменений, сделанных для каждого из этих файлов во времени.
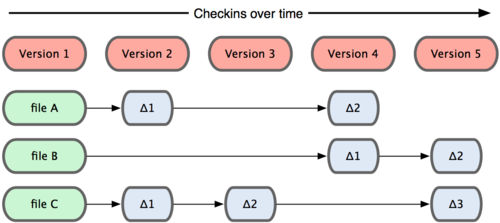
Рисунок 1-4. Другие системы хранят данные как изменения к базовой версии для каждого файла.
Git не хранит свои данные в таком виде. Вместо этого Git считает хранимые данные набором слепков небольшой файловой системы. Каждый раз, когда вы фиксируете текущую версию проекта, Git, по сути, сохраняет слепок того, как выглядят все файлы проекта на текущий момент. Ради эффективности, если файл не менялся, Git не сохраняет файл снова, а делает ссылку на ранее сохранённый файл. То, как Git подходит к хранению данных.
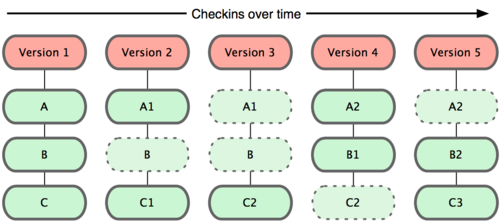
Рисунок 1-5. Git хранит данные как слепки состояний проекта во времени.
Это важное отличие Git’а от практически всех других систем контроля версий. Из-за него Git вынужден пересмотреть практически все аспекты контроля версий, которые другие системы переняли от своих предшественниц. Git больше похож на небольшую файловую систему с невероятно мощными инструментами, работающими поверх неё, чем на просто СКВ. Позже, коснувшись работы с ветвями в Git’е, мы узнаем, какие преимущества даёт такое понимание данных.
Почти все операции — локальные
Для совершения большинства операций в Git’е необходимы только локальные файлы и ресурсы, т.е. обычно информация с других компьютеров в сети не нужна. Если вы пользовались централизованными системами, где практически на каждую операцию накладывается сетевая задержка, вы, возможно, подумаете, что боги наделили Git неземной силой. Поскольку вся история проекта хранится локально у вас на диске, большинство операций кажутся практически мгновенными.
К примеру, чтобы показать историю проекта, Git’у не нужно скачивать её с сервера, он просто читает её прямо из вашего локального репозитория. Поэтому историю вы увидите практически мгновенно. Если вам нужно просмотреть изменения между текущей версией файла и версией, сделанной месяц назад, Git может взять файл месячной давности и вычислить разницу на месте, вместо того чтобы запрашивать разницу у СКВ-сервера или качать с него старую версию файла и делать локальное сравнение.
Кроме того, работа локально означает, что мало чего нельзя сделать без доступа к Сети или VPN. Если вы в самолёте или в поезде и хотите немного поработать, можно спокойно делать коммиты, а затем отправить их, как только станет доступна сеть. Если вы пришли домой, а VPN-клиент не работает, всё равно можно продолжать работать. Во многих других системах это не возможно или же крайне неудобно. Например, используя Perforce, вы мало что можете сделать без соединения с сервером. Работая с Subversion и CVS, вы можете редактировать файлы, но сохранить изменения в вашу базу данных нельзя (потому что она отключена от репозитория). Вроде ничего серьёзного, но потом вы удивитесь, насколько это меняет дело.
Git следит за целостностью данных
Перед сохранением любого файла Git вычисляет контрольную сумму, и она становится индексом этого файла. Поэтому невозможно изменить содержимое файла или каталога так, чтобы Git не узнал об этом. Эта функциональность встроена в сам фундамент Git’а и является важной составляющей его философии. Если информация потеряется при передаче или повредится на диске, Git всегда это выявит.
Механизм, используемый Git’ом для вычисления контрольных сумм, называется SHA-1 хешем. Это строка из 40 шестнадцатеричных символов (0-9 и a-f), вычисляемая в Git’е на основе содержимого файла или структуры каталога. SHA-1 хеш выглядит примерно так:
24b9da6552252987aa493b52f8696cd6d3b00373 Работая с Git’ом, вы будете встречать эти хеши повсюду, поскольку он их очень широко использует. Фактически, в своей базе данных Git сохраняет всё не по именам файлов, а по хешам их содержимого.
Чаще всего данные в Git только добавляются
Практически все действия, которые вы совершаете в Git’е, только добавляют данные в базу. Очень сложно заставить систему удалить данные или сделать что-то неотменяемое. Можно, как и в любой другой СКВ, потерять данные, которые вы ещё не сохранили, но как только они зафиксированы, их очень сложно потерять, особенно если вы регулярно отправляете изменения в другой репозиторий.
Поэтому пользоваться Git’ом — удовольствие, потому что можно экспериментировать, не боясь что-то серьёзно поломать. Подробнее о том, как Git хранит свои данные и как восстановить то, что кажется уже потерянным, мы рассмотрим позже в курсе лекций.
Три состояния
Теперь внимание. Это самое важное, что нужно помнить про Git, если вы хотите, чтобы дальше изучение шло гладко. В Git’е файлы могут находиться в одном из трёх состояний: зафиксированном, изменённом и подготовленном. “Зафиксированный” значит, что файл уже сохранён в вашей локальной базе. К изменённым относятся файлы, которые поменялись, но ещё не были зафиксированы. Подготовленные файлы — это изменённые файлы, отмеченные для включения в следующий коммит.
Таким образом, в проектах, использующих Git, есть три части:
- каталог Git’а (Git directory),
- рабочий каталог (working directory),
- область подготовленных файлов (staging area).
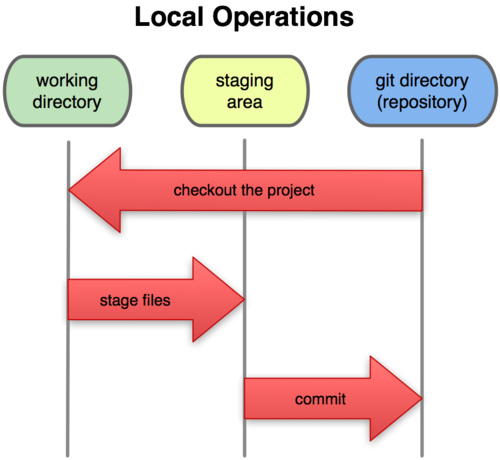
Рисунок 1-6. Рабочий каталог, область подготовленных файлов, каталог Git’а.
Каталог Git’а — это место, где Git хранит метаданные и базу данных объектов вашего проекта. Это наиболее важная часть Git’а, и именно она копируется, когда вы клонируете репозиторий с другого компьютера.
Рабочий каталог — это извлечённая из базы копия определённой версии проекта. Эти файлы достаются из сжатой базы данных в каталоге Git’а и помещаются на диск для того, чтобы вы их просматривали и редактировали.
Область подготовленных файлов — это обычный файл, обычно хранящийся в каталоге Git’а, который содержит информацию о том, что должно войти в следующий коммит. Иногда его называют индексом (index), но в последнее время становится стандартом называть его областью подготовленных файлов (staging area).
Стандартный рабочий процесс с использованием Git’а выглядит примерно так:
- Вы вносите изменения в файлы в своём рабочем каталоге.
- Подготавливаете файлы, добавляя их слепки в область подготовленных файлов.
- Делаете коммит, который берёт подготовленные файлы из индекса и помещает их в каталог Git’а на постоянное хранение.
Если рабочая версия файла совпадает с версией в каталоге Git’а, файл считается зафиксированным. Если файл изменён, но добавлен в область подготовленных данных, он подготовлен. Если же файл изменился после выгрузки из БД, но не был подготовлен, то он считается изменённым. Поподробнее об этих трёх состояниях и как можно либо воспользоваться этим, либо пропустить стадию подготовки мы рассмотрим на следующей лекции.
Установка Git
Настало время немного ознакомиться с использованием Git’а. Первое, что вам необходимо сделать, — установить его. Есть несколько способов сделать это; два основных — установка из исходников и установка собранного пакета для вашей платформы.
Установка из исходников
Если есть возможность, то, как правило, лучше установить Git из исходных кодов, поскольку так вы получите самую свежую версию. Каждая новая версия Git’а обычно включает полезные улучшения пользовательского интерфейса, поэтому получение последней версии — часто лучший путь, если, конечно, вас не затрудняет установка программ из исходников. К тому же, многие дистрибутивы Linux содержат очень старые пакеты. Поэтому, если только вы не на очень свежем дистрибутиве или используете пакеты из экспериментальной ветки, установка из исходников может быть самым выигрышным решением.
Для установки Git’а вам понадобятся библиотеки, от которых он зависит:
Например, если в вашей системе менеджер пакетов — yum (Fedora), или apt-get (Debian, Ubuntu), можно воспользоваться следующими командами, чтобы разрешить все зависимости:
$ yum install curl-devel expat-devel gettext-devel openssl-devel zlib-devel $ apt-get install libcurl4-gnutls-dev libexpat1-dev gettext libz-dev libssl-dev Установив все необходимые библиотеки, можно идти дальше и скачать последнюю версию с сайта Git’а:
http://git-scm.com/download Теперь скомпилируйте и установите:
$ tar -zxf git-1.7.2.2.tar.gz $ cd git-1.7.2.2 $ make prefix=/usr/local all $ sudo make prefix=/usr/local install После этого вы можете скачать Git с помощью самого Git’а, чтобы получить обновления:
$ git clone git://git.kernel.org/pub/scm/git/git.git Установка в Linux
Если вы хотите установить Git под Linux как бинарный пакет, это можно сделать, используя обычный менеджер пакетов вашего дистрибутива. Если у вас Fedora, можно воспользоваться yum’ом:
$ yum install git-core Если же у вас дистрибутив, основанный на Debian, например, Ubuntu, попробуйте apt-get:
$ apt-get install git Установка на Mac
Есть два простых способа установить Git на Mac. Самый простой — использовать графический инсталлятор Git’а, который вы можете скачать со страницы на Google Code:
http://code.google.com/p/git-osx-installer 
Рисунок 1-7. Инсталлятор Git’а под OS X.
Другой распространённый способ установки Git’а — через MacPorts ( http://www.macports.org ). Если у вас установлен MacPorts, установите Git так:
$ sudo port install git-core +svn +doc +bash_completion +gitweb Вам не обязательно устанавливать все дополнения, но, вероятно, вам понадобится +svn, если вы когда-нибудь захотите использовать Git вместе с репозиториями Subversion.
Установка в Windows
Установить Git в Windows очень просто. У проекта msysGit процедура установки — одна из самых простых. Просто скачайте exe-файл инсталлятора со страницы проекта на GitHub’е и запустите его:
http://msysgit.github.com/ После установки у вас будет как консольная версия (включающая SSH-клиент, который пригодится позднее), так и стандартная графическая.
Пожалуйста, используйте Git только из командой оболочки, входящей в состав msysGit, потому что так вы сможете запускать сложные команды, приведённые в примерах в настоящей книге. Командная оболочка Windows использует иной синтаксис, из-за чего примеры в ней могут работать некорректно.
Первоначальная настройка Git
Теперь, когда Git установлен в вашей системе, хотелось бы сделать кое-какие вещи, чтобы настроить среду для работы с Git’ом под себя. Это нужно сделать только один раз — при обновлении версии Git’а настройки сохранятся. Но вы можете поменять их в любой момент, выполнив те же команды снова.
В состав Git’а входит утилита git config , которая позволяет просматривать и устанавливать параметры, контролирующие все аспекты работы Git’а и его внешний вид. Эти параметры могут быть сохранены в трёх местах:
- Файл /etc/gitconfig содержит значения, общие для всех пользователей системы и для всех их репозиториев. Если при запуске git config указать параметр —system , то параметры будут читаться и сохраняться именно в этот файл.
- Файл ~/.gitconfig хранит настройки конкретного пользователя. Этот файл используется при указании параметра —global .
- Конфигурационный файл в каталоге Git’а ( .git/config ) в том репозитории, где вы находитесь в данный момент. Эти параметры действуют только для данного конкретного репозитория. Настройки на каждом следующем уровне подменяют настройки из предыдущих уровней, то есть значения в .git/config перекрывают соответствующие значения в /etc/gitconfig .
В системах семейства Windows Git ищет файл .gitconfig в каталоге $HOME ( C:\Documents and Settings\$USER или C:\Users\$USER для большинства пользователей). Кроме того Git ищет файл /etc/gitconfig, но уже относительно корневого каталога MSys, который находится там, куда вы решили установить Git, когда запускали инсталлятор.
Имя пользователя
Первое, что вам следует сделать после установки Git’а, — указать ваше имя и адрес электронной почты. Это важно, потому что каждый коммит в Git’е содержит эту информацию, и она включена в коммиты, передаваемые вами, и не может быть далее изменена:
$ git config --global user.name "John Doe" $ git config --global user.email johndoe@example.com Повторюсь, что, если указана опция —global , то эти настройки достаточно сделать только один раз, поскольку в этом случае Git будет использовать эти данные для всего, что вы делаете в этой системе. Если для каких-то отдельных проектов вы хотите указать другое имя или электронную почту, можно выполнить эту же команду без параметра —global в каталоге с нужным проектом.
Выбор редактора
Вы указали своё имя, и теперь можно выбрать текстовый редактор, который будет использоваться, если будет нужно набрать сообщение в Git’е. По умолчанию Git использует стандартный редактор вашей системы, обычно это Vi или Vim. Если вы хотите использовать другой текстовый редактор, например, Emacs, можно сделать следующее:
$ git config --global core.editor emacs Утилита сравнения
Другая полезная настройка, которая может понадобиться — встроенная diff-утилита, которая будет использоваться для разрешения конфликтов слияния. Например, если вы хотите использовать vimdiff:
$ git config --global merge.tool vimdiff Git умеет делать слияния при помощи kdiff3, tkdiff, meld, xxdiff, emerge, vimdiff, gvimdiff, ecmerge и opendiff, но вы можете настроить и другую утилиту.
Проверка настроек
Если вы хотите проверить используемые настройки, можете использовать команду git config —list , чтобы показать все, которые Git найдёт:
$ git config --list user.name=Scott Chacon user.email=schacon@gmail.com color.status=auto color.branch=auto color.interactive=auto color.diff=auto . Некоторые ключи (названия) настроек могут появиться несколько раз, потому что Git читает один и тот же ключ из разных файлов (например из /etc/gitconfig и ~/.gitconfig ). В этом случае Git использует последнее значение для каждого ключа.
Также вы можете проверить значение конкретного ключа, выполнив git config :
$ git config user.name Scott Chacon Как получить помощь?
Если вам нужна помощь при использовании Git’а, есть три способа открыть страницу руководства по любой команде Git’а:
$ git help $ git --help $ man git-
Например, так можно открыть руководство по команде config:
$ git help config Эти команды хороши тем, что ими можно пользоваться всегда, даже без подключения к сети. Если руководства и этой книги недостаточно и вам нужна персональная помощь, вы можете попытаться поискать её на каналах #git и #github IRC-сервера Freenode (irc.freenode.net). Обычно там сотни людей, отлично знающих Git, которые могут помочь.
Итоги
Теперь у вас должно быть общее понимание, что такое Git, и в чём его отличие от тех ЦСКВ, которыми вы, вероятно, пользовались раньше. Также у вас должна быть установлена рабочая версия Git’а с вашими личными настройками. Настало время перейти к изучению основ Git’а.
системы контроля версий
Системы контроля версий. Что такое контроль версий и для чего он необходим. Системы контроля версий CVS, SVN, GIT, Mercurial.
Что такое VCS? Система управления версиями ( Version
Control System, VCS) — программное обеспечение для облегчения работы с изменяющейся информацией. Система управления версиями позволяет хранить несколько версий одного и того же документа, при необходимости возвращаться к более ранним версиям, определять, кто и когда сделал то или иное изменение, и многое другое.
Какие задачи решает VCS?Архивации и восстановления — ведётся
история изменения файлов с возможностью обновления до указанного состояния;
Ведение истории – при каждом изменении пользователи вносят комментарии, где описывают, для чего были внесены изменения;
Создание веток (альтернативные реализации) – VCS позволяет создавать разные варианты одного документа, так называемые ветки, с общей историей изменений до точки ветвления и с разными — после неё.
Что нам дает использование VCS?
Полную уверенность в том, что файлы, которые мы получаем из системы, являются актуальными всегда, в любой момент времени.
Возможность получить требуемую версию с любого компьютера, который позволит подключиться к серверу.
Сохраняя файл в VCS, не нужно думать о том, что кто-то, работающий с этим же файлом, пересохранит и удалит изменения.
Для разработчиков программных продуктов использование системы также позволяет производить принятие/отклонение изменений, сделанных одним из разработчиков.
Классификация VCS Централизованные / распределенные- в
централизованных системах контроля версий вся работа производится с центральным репозиторием, в распределённых- у каждого разработчика есть локальная копия репозитория.
Блокирующие/не блокирующие – блокирующие системы контроля версий позволяют наложить запрет на изменение файла, пока один из разработчиков работает над ним, в не блокирующих один файл может одновременно изменятся несколькими разработчиками.
Для текстовых данных/для бинарных данных – для VCS для текстовых данных очень важна поддержка слияния изменений, для VCS с бинарными данными важна возможность блокировки.
Централизованные системы управления версиями
Распределённые системы управления версиями
Ежедневный цикл работы.
Обновление рабочей копии. Разработчик выполняет операцию обновления
рабочей копии (update) насколько возможно. Модификация проекта. Разработчик локально модифицирует проект,
изменяя входящие в него файлы в рабочей копии.
Фиксация изменений. Завершив очередной этап работы над
заданием, разработчик фиксирует (commit) свои изменения, передавая их на сервер. VSC может требовать от разработчика перед фиксацией выполнить обновление.
ВетвлениеВетвь(branch ) — направление разработки,
независимое от других.Ветвь представляет собой копию части (как
правило, одного каталога) хранилища, в которую можно вносить свои изменения, не влияющие на другие ветви.
Документы в разных ветвях имеют одинаковую историю до точки ветвления и разные — после неё.
Изменения из одной ветви можно переносить в другую.
Ствол(trunk, mainline, master) — основная ветвь разработки проекта.
Терминология working copy — рабочая (локальная) копия документов. repository, depot — хранилище документов — место, где система
управления версиями хранит все документы вместе с историей их изменения и другой служебной информацией.
revision — версия документа. Новые изменения(changeset) создают новую ревизию репозитория.
check-in, commit, submit — фиксация изменений. check-out, clone — извлечение документа из хранилища и
создание рабочей копии. update, sync — синхронизация рабочей копии до некоторого
заданного состояния хранилища ( в т.ч. и к более старому состоянию ,чем текущее).
merge, integration — cлияние — объединение независимых изменений в единую версию документа.
conflict — конфликтная ситуация, когда несколько пользователей сделали изменения одного и того же участка документа.
head — самая свежая версия (revision ) в хранилище.
Разнообразие систем контроля версий.
Краткое описание популярных VCS
Git (http://git-scm.com/) — распределенная система контроля версий, разработанная Линусом Торвальдсом. Изначально Git предназначалась для использования в процессе разработки ядра Linux, но позже стала использоваться и во многих других проектах — таких, как, например, X.org и Ruby on Rails, Drupal. На данный момент Git является самой быстрой распределенной системой, использующей самое компактное хранилище ревизий.
Mercurial (http://www.selenic.com/mercurial/) — распределенная система, написанная на языке Python с несколькими расширениями на C. Из использующих Mercurial проектов можно назвать, такие, как, Mozilla и MoinMoin.
Bazaar (http://bazaar-vcs.org/) — система разработка которой поддерживается компанией Canonical — известной своими дистрибутивом Ubuntu и сайтом https://launchpad.net/. Система в основном написана на языке Python и используется такими проектами, как, например, MySQL.
Monotone (http://monotone.ca/) — система написанная на C++ и использующая SQLite как хранилище ревизий.
Бесплатные VCS серверы
Есть много серверов, которые представляют открытые репозитории для совместной работы:
Распределенная система контроля версий Bazaar
Когда активно работаешь с файлами, будь то исходные тексты программ, файлы конфигурации, или статья, то в большинстве случаев нужно использовать какую-либо систему контроля версий. Например, в данный момент я переписываю это введение и так как я использую систему контроля версий, то смогу в любой момент вернуться к одному из предыдущих вариантов, если мне не понравится этот. Так как основная работа с файлами — это их изменение, то наличие возможности вернуться к предыдущей версии дает огромную уверенность, что в свою очередь положительно влияет на производительность. Если работа идет в команде, то система контроля версий просто необходима, в противном случае, в какой-то момент времени работа команды может просто застопориться.
От централизованных систем к распределенным
Рассмотрим что сейчас происходит в области систем контроля версий с открытым исходным кодом. Пока это может быть не так очевидно, но просматривается постепенный рост количества распределенных систем и идет явное движение в эту строну. Например, из централизованных систем большинство могут назвать следующие:
- CVS (http://www.nongnu.org/cvs/) — постепенно исчезающая, но все еще популярная система, разработанная поверх формата RCS файлов;
- Subversion (http://subversion.tigris.org/) — на данный момент наиболее популярная централизованная система контроля версий, изначально разработанная как «лучший CVS» и, в итоге, исправившая многие ошибки в дизайне CVS;
А что же распределенные системы? Вот наиболее популярные и активно развивающиеся системы:
- Git (http://git-scm.com/) — распределенная система контроля версий, разработанная Линусом Торвальдсом. Изначально Git предназначалась для использования в процессе разработки ядра Linux, но позже стала использоваться и во многих других проектах — таких, как, например, X.org и Ruby on Rails. На данный момент Git является самой быстрой распределенной системой, использующей самое компактное хранилище ревизий. Но в тоже время для пользователей, переходящих, например, с Subversion интерфейс Git может показаться сложным;
- Mercurial (http://www.selenic.com/mercurial/) — распределенная система, написанная на языке Python с несколькими расширениями на C. Из использующих Mercurial проектов можно назвать, такие, как, Mozilla и MoinMoin.
- Bazaar (http://bazaar-vcs.org/) — система разработка которой поддерживается компанией Canonical — известной своими дистрибутивом Ubuntu и сайтом https://launchpad.net/. Система в основном написана на языке Python и используется такими проектами, как, например, MySQL и Drupal.
- Codeville (http://codeville.org/) — написанная на Python распределенная система использующая инновационный алгоритм объединения изменений (merge). Система используется, например, при разработке оригинального клиента BitTorrent.
- Darcs (http://darcs.net/) — распределенная система контроля версий написанная на Haskell используемая, например, проектом Buildbot.
- Monotone (http://monotone.ca/) — система написанная на C++ и использующая SQLite как хранилище ревизий.
Ниже я рассмотрю одну из наиболее гибких, на мой взгляд, распределенных систем контроля версий — Bazaar. Одним из примеров гибкости Bazaar может служить возможность использования как централизованной модели, так и распределенной и даже смешивание этих моделей контроля версий. Даже, если вы не согласны со мной по вопросу выбора конкретной системы, эта статья поможет вам понять общие принципы работы распределенных систем и затем остановить свой выбор на одной из перечисленных выше.
Зачем нужны распределенные системы?
Как следует из названия одна из основных идей распределенных систем — это отсутствие четко выделенного центрального хранилища версий — репозитория. В случае распределенных систем набор версий может быть полностью, или частично распределен между различными хранилищами, в том числе и удаленными. Такая модель отлично вписывается в работу распределенных команд, например, распределенной по всему миру команды разработчиков работающих над одним проектом с открытым исходным кодом. Разработчик такой команды может скачать себе всю информацию по версиям и после этого работать только на локальной машине. Как только будет достигнут результат одного из этапов работы, изменения могут быть залиты в один из центральных репозиториев или, опубликованы для просмотра на сайте разработчика, или в почтовой рассылке. Другие участники проекта, в свою очередь, смогут обновить свою копию хранилища версий новыми изменениями, или попробовать опубликованные изменения на отдельной, тестовой ветке разработки. К сожалению, без хорошей организации проекта отсутствие одного центрального хранилища может быть минусом распределенных систем. Если в случае централизованных систем всегда есть один общий репозиторий откуда можно получить последнюю версию проекта, то в случае распределенных систем нужно организационно решить какая из веток проекта будет основной.
Почему распределенная система контроля версий может быть интересна кому-то, кто уже использует централизованную систему — такую как Subversion? Любая работа подразумевает принятие решений, и в большинстве случаев необходимо пробовать различные варианты: при работе с системами контроля версий для рассмотрения различных вариантов и работы над большими изменениями служат ветки разработки. И хотя это достаточно естественная концепция, пользоваться ей в Subversion достаточно не просто. Тем более, все усложняется в случае множественных последовательных объединений с одной ветки на другую — в этом случае нужно безошибочно указывать начальные и конечные версии каждого изменения, что бы избежать конфликтов и ошибок. Для распределенных систем контроля версий ветки разработки являются одной из основополагающих концепций — в большинстве случаев каждая копия хранилища версий является веткой разработки. Таким образом, механизм объединения изменений с одной ветки на другую в случае распределенных систем является одним из основных, что позволяет пользователям прикладывать меньше усилий при пользовании системой.
Основные концепции Bazaar
Итак, начнем ближе рассматривать Bazaar (http://bazaar-vcs.org/). На момент написания этой статьи последняя версия Bazaar 1.6. Но прежде чем рассматривать работу с этой системой контроля версий, сначала обратим внимание на основные концепции, лежащие в ее основе. Если эти термины уже знакомы вам по централизованным системам, они могут иметь немного другое значение в приложении к распределенной системе Bazaar, и их понимание важно для дальнейшего рассмотрения.
-
Ревизия — это сохраненное состояние файлов и директорий, включая их содержимое и иерархию в заданный момент времени. С ревизией также связана мета-информация, например: — Автор изменения; — Дата изменения; — Комментарий связанный с изменением; — Родительские ревизии от которых произведена данная ревизия; После создания, ревизии не меняются и могут быть идентифицированы глобально уникальным номером ревизии (revision-id), например таким:
pqm@pqm.ubuntu.com-20071129184101-u9506rihe4zbzyyz
- Номер ревизии для данной ветки, от которой были произведены объединенные изменения;
- Порядковый номер (счетчик) объединенной ветки. Так как объединение может затрагивать сразу несколько веток, этот номер служит их счетчиком;
- Порядковый номер ревизии с момента создания объединяемой ветки;
Такое разделение концепций позволяет более гибко использовать Bazaar, в том числе и как централизованную систему. Рассмотрим набор сценариев в основе которых лежат описанные выше концепции:
- Разделяемые репозитории (Shared repositories) — в этом случае рабочее дерево и ветка находятся в одной директории, но репозиторий находится на одну директорию выше, что позволяет хранить информацию о ревизиях только в одном месте. Такой сценарий позволяет не тратить место на полные копии ревизий, если ветки, находящиеся под репозиторием отличаются незначительно, например, относятся к одному проекту.
- Легковесные рабочие копии (Lightweight checkouts) — ветка и рабочее дерево находятся в разных местах. Этот сценарий похож на использование централизованной системы контроля версий, когда удаленный репозиторий хранит всю информацию о ревизиях, а рабочая копия представляет из себя только рабочие файлы и директории.
Мы рассмотрели все основные концепции лежащие в основе Bazaar, и теперь можно приступать к изучению интерфейса командной строки.
Начинаем работать с Bazaar
Во многих UNIX-совместимых операционных системах Bazaar может быть установлен штатными средствами системы. Для Windows и других ОС, в которых Bazaar не доступен для установки штатными средствами, его можно скачать с официального сайта: http://bazaar-vcs.org/Download. Хотя для Bazaar есть графические интерфейсы которые также могут быть установлены и вместе с основной программой мы будем рассматривать только интерфейс командной строки, являющийся основным интерфейсом работы с Bazaar. Интерфейс командной строки представлен командой bzr, и первое, что можно сделать, это проверить установку следующей командой:
bzr version
В ответ будет выведена текущая версия Bazaar, пути используемых системой файлов и директорий, а также лицензионная информация (Bazaar использует GPL2). Для получения списка основных команд можно использовать команду help:
bzr help
После команды help можно указывать любую другую команду по которой нужно получить подробную информацию, например:
bzr help version
Или можно вывести все команды Bazaar, в том числе и определенные подключаемыми модулями, командой:
bzr help commands
Первое, что нужно сделать перед началом работы с Bazaar, это указать свое имя и e-mail которыми будут подписываться все ревизии. Это делается командной whoami, например:
bzr whoami "John Doe "
Эта же команда без параметров выводит текущее установленное имя:
$ bzr whoami John Doe
Если вы хотите использовать разные имена для разных веток, то можно воспользоваться опцией —branch для установки имени только для текущей ветки:
bzr whoami --branch "John Doe "
Конфигурационные файлы Bazaar хранятся в директории $HOME/.bazaar для UNIX-подобных операционных систем и в директории C:Documents and SettingsApplication DataBazaar2.0 для Windows. В этом директории хранятся три основных файла конфигурации:
- bazaar.conf — описывает конфигурационные параметры по умолчанию;
- locations.conf — описывает конфигурационные параметры для отдельных веток;
- authentication.conf — описывает идентификационную информацию для доступа к удаленным серверам;
Каждая ветка также может содержать файл конфигурации, в этом случае, он находится в каталоге .bzr/branch/branch.conf внутри ветки.
После того, как мы настроили свое имя и email командой whoami , эта информация записывается в файл bazaar.conf и, в простейшем случае, он будет выглядеть так:
[DEFAULT] emai = John Doe
Работаем в одиночестве
Даже если вы работаете в команде, в какой-то момент времени все равно приходится работать одному и с точки зрения многих команд Bazaar в этом случае мало что меняется. Если у вас уже есть готовый проект и его надо поставить под контроль версий нужно начать со следующей цепочки команд:
$ cd project-directory $ bzr init $ bzr add $ bzr commit -m "Импортирование проекта"
Здесь первая команда init создает в рабочей директории project-directory служебную директорию .bzr , в котором хранится репозиторий и ветка проекта.
Следующая команда, add рекурсивно добавляет все файлы и директории в рабочем каталоге под контроль версий. Если нет необходимости в рекурсивном добавлении, то можно использовать опцию —no-recurse , или перечислить необходимые для добавления объекты сразу вслед за командной. Bazaar может контролировать и, соответственно добавлять командой add , файлы , директории и символические ссылки (для ссылок хранится значение ссылки, а не объект на, который она ссылается). Если в процессе работы над проектом создаются новые файлы и директории, которые нужно хранить под контролем версий, они также должны быть добавлены командой add , или внесены в список игнорируемых файлов, описанной ниже, командой ignore. Если этого не сделать файлы будут показываться Bazaar как неизвестные.
И последняя команда, commit фиксирует изменения на ветке и в репозитории, создавая новую ревизию. Опция -m позволяет указать комментарий к ревизии прямо из командной строки. Без этой опции для создания комментария будет вызван текстовый редактор. На данный момент в Bazaar нет жесткого ограничения на размер комментария (единственное ограничение — это, достаточно большой, максимальный размер строки в Python), но рекомендуется делать их разумной длины, достаточной для описания сделанных изменений. По умолчанию команда commit фиксирует все изменения на ветке, даже если запущена из поддиректории ветки. Если требуется зафиксировать только отдельную директорию, или набор файлов, их можно указать вслед за командой, как здесь:
bzr commit -m "Изменения" README.txt src
Если при создании нового проекта планируется создавать несколько локальных веток, то можно воспользоваться описанным выше разделяемым репозиторием для экономии места:
$ bzr init-repo repo $ cd repo $ bzr init trunk $ cd trunk Создание файлов. $ bzr add $ bzr commit -m "Испортирование проекта"
Первая команда init-repo создает в директории repo разделяемый репозиторий и под директорией repo могут хранится различные ветки проекта. Основную ветку мы создаем следующей командой init , которая уже была описана выше. В случае создания разделяемого репозитория в директории, repo/.bzr хранится репозиторий и в директории repo/trunk/.bzr ветка.
Если при добавлении мы хотим игнорировать какие-либо объекты можно воспользоваться командой ignore:
bzr ignore имена объектов
Эта команда создаст в корневой директории ветки файл .bzrignore , в котором будут записаны имена, или шаблоны для игнорирования. Если удобно, то данный файл также можно редактировать в текстовом редакторе. Глобальные правила игнорирования можно задать в конфигурационном файле ignore в каталоге с конфигурацией, ~/.bazaar/ignore для UNIX-подобных систем. Кроме задания полных имен и шаблонов используемых командной оболочкой, таких как *.py[co], *.o , можно использовать регулярные выражения:
bzr ignore "RE:lib/.*\.o"
Просмотр изменений
Когда закончен очередной этап изменений хорошей практикой, прежде чем фиксировать эти изменения в системе контроля версий, может быть их просмотр. Команда status показывает изменения в рабочем дереве с момента последней ревизии:
$ bzr status modified: README.txt unknown: db.tmp
Команда diff показывает изменения в текстовых файлах в стандартной унифицированной форме:
$ bzr diff === added file 'README.txt' --- README.txt 1970-01-01 00:00:00 +0000 +++ README.txt 2008-01-20 14:23:29 +0000 @@ -0,0 +1,1 @@ +Файл README
Просматривать изменения между заданными ревизиями можно с использованием опции -r :
bzr diff -r 100.. bzr diff -r 100..120
Первая команда показывает все изменения, начиная с ревизии 100, а вторая между ревизией 100 и 120.
Для просмотра истории ревизий используется команда log . Bazaar использует иерархическую историю, где объединенные с данной веткой ревизии показываются с отступами в виде дерева. В этом случае визуально проще отделить объединенные изменения от изменений на основной ветке:
$ bzr log ------------------------------------------------------------ revno: 100 committer: John Doe branch nick: trunk timestamp: Tue 2008-08-19 16:25:36 +0100 message: Объединены изменения с работы ------------------------------------------------------------ revno: 100.1.1 committer: John Doe branch nick: work timestamp: Tue 2008-08-19 09:54:08 -0500 message: Добавлен файл README.txt
С командой log также, как и с командой diff можно использовать опцию -r для указания необходимых ревизий для просмотра. Для просмотра краткой истории изменений, не включающей описание ревизий с объединенных веток, можно воспользоваться опцией —short :
$ bzr log --short 100 John Doe 2008-08-19 [merge] Объединены изменения с работы
Кроме того, историю ревизий можно просматривать для отдельного файла или директории добавив его имя после команды:
bzr log README.txt
Команда cat выводит содержимое файла для ревизии заданной опцией -r :
$ bzr cat -r 100 README.txt Файл README
После просмотра изменений их можно зафиксировать командой commit, которая была описана выше.
Выпуск проекта
После некоторого количества ревизий наступает долгожданный момент выпустить очередную версию проекта. Для упаковки новой версии можно воспользоваться командой export , которая упаковывает проект, в зависимости от заданного расширения файла. Например, следующая команда создаст ZIP архив проекта:
bzr export ../releases/project-1.0.zip
При выпуске каждой версии имеет смысл помечать ее, что бы в будущем можно было использовать более простые символические имена для работы с этой ревизией. Это можно сделать командой tag :
bzr tag version-1.0
После этого созданную метку можно использовать в других командах следующим образом:
bzr diff -r tag:version-1.0
Исправление ошибок
К сожалению, ошибок невозможно избежать, они случаются и это надо просто принимать и быть к этому готовым. Bazaar разработан таким образом, что большинство ошибок можно исправлять, в том числе и с использованием отдельных команд. Рассмотрим различные ситуации и их разрешение.
Если вы случайно поставили под контроль версий не то рабочее дерево, то можно просто удалить служебный каталог .bzr, хотя стоит быть внимательным, что бы не удалить что-то нужное.
Если случайно под контроль версий был поставлен файл, который нет необходимости хранить под контролем версий, то его можно удалить командной remove, но без использования опций команда не будет удалять измененный файл:
bzr add file.txt bzr remove file.txt bzr: ERROR: Can't safely remove modified or unknown files: added: file.txt Use --keep to not delete them, or --force to delete them regardless.
Соответственно, можно использовать опцию —keep , что бы оставить файл на диске, но удалить его регистрацию, или опцию —force , что бы удалить и регистрацию и файл. Надо заметить, что если вы удалите файл, не используя Bazaar, то Bazaar будет считать, что необходимо удалить и регистрацию файла.
Команда revert возвращает все файлы и директории в состояние на момент последней фиксации, но при этом сохраняет измененные файлы под другими именами. Она действует рекурсивно, и, если нужно вернуть только несколько файлов, то надо быть внимательным и указывать в командной строке только их:
bzr revert
Если вы случайно сделали фиксацию, то можно использовать команду uncommit , что бы убрать последнюю ревизию и вернуть рабочее дерево в состояние до момента фиксации. Эта команда позволяет также исправлять и комментарии к ревизии:
bzr commit -m "Исправлен файл README" bzr uncommit bzr commit -m "Исправлен файл README.txt"
Кроме того, команда uncommit позволяет отменить несколько последних ревизий, например, 3 последние:
bzr uncommit -r -3
Если нет необходимости удалять ревизии, а нужно только вернуть рабочее дерево в прежнее состояние, то можно использовать команду revert с опцией -r :
bzr revert -r -3
Исправить неправильно поставленные метки можно с помощью команды tag , например, перенести метку на другую ревизию можно с помощью опции —force , а удалить с помощью опции —delete :
bzr tag --delete version-1.0 bzr tag --force version-2.0
Работаем в команде
После того как мы рассмотрели работу с Bazaar в одиночестве, рассмотрим распределенные возможности при работе в команде (или по такому же сценарию вы просто можете работать из нескольких мест, например c работы и из дома). В простейшем случае, если вы работаете в команде кто-то из разработчиков уже мог создать центральную ветку Bazaar, или при работе в паре это может быть просто одна из локальных веток другого разработчика, которую вам необходимо скопировать к себе. Кроме работы с файловой системой Bazaar может работать со следующими протоколами: FTP, HTTP, HTTPS, SFTP и собственным оптимизированным протоколом bzr. Одним из простейших способов открыть к ветке доступ для чтения может быть использование HTTP/HTTPS. В этом случае достаточно в конфигурации Web-сервера открыть, с учетом необходимых ограничений, директорию с веткой на доступ как и любую другую директорию. Для доступа на запись рекомендуется использовать соединение через SSH, которое можно установить используя схему bzr+ssh://. В этом случае автоматически будет использоваться собственный протокол Bazaar через SSH туннель. К сожалению, на данный момент собственный протокол сам по себе не имеет никаких ограничений на доступ.
Для копирования ветки используется команда branch которая, по умолчанию, копирует все ревизии из указанного места в локальный каталог, создавая новую ветку. В примере ниже мы создаем разделяемый репозиторий для экономии места и затем копируем удаленную ветку, создавая ветку в каталоге remote и в итоге создаем еще одну копию копируя локальную ветку в каталог local:
$ cd projects $ bzr init-repo project $ cd project $ bzr branch bzr+ssh://some.host/some/project remote Branched 10 revision(s). $ bzr branch remote local Branched 10 revision(s).
Если теперь в каталоге remote мы посмотрим информацию о ветке командной info , то увидим ассоциированную родительскую ветку:
$ cd remote $ bzr info Standalone tree (format: pack-0.92) Location: branch root: . Related branches: parent branch: bzr+ssh://some.host/some/project
Хотя возможно большое количество сценариев работы, в нашем примере все локальные изменения будут делаться на ветке в каталоге local, а ветка в каталоге remote будет отслеживать все изменения сделанные на удаленной ветке. Но в простейшем случае можно использовать и только одну локальную ветку.
Итак, представим, что мы проделали некоторую работу и создали несколько ревизий на ветке local. Теперь мы обновим копию удаленной ветки изменениями, сделанными другими разработчиками, и потом объединим наши изменения. Для обновления ветки нужно выполнить команду pull в каталоге remote, при этом будут скачаны и добавлены все ревизии, которые были сделаны на родительской ветке после момента последнего обновления:
bzr pull
Так как изменения на ветке local происходили параллельно с изменениями на удаленной ветке, то мы не можем просто сделать pull , а должны объединить изменения с помощью команду merge в каталоге remote:
bzr merge ../local
Если путь не указан, то merge как и pull будет использовать путь к родительской ветке. При объединении изменяется только рабочее дерево, что бы сохранить объединенные изменения, нужно сделать фиксацию командой commit. Bazaar использует качественный алгоритм объединения, учитывающий возможные прошлые объединения, и во многих случаях не надо заботиться о таких тонкостях, как начальная и конечная ревизии для объединения.
В случае, если в параллельных ветках было изменено одно и тоже место в файле автоматическое объединение может не сработать и требуется устранить конфликты вручную. При объединении бинарных файлов, по умолчанию, любые параллельные изменения всегда будут конфликтовать, но есть возможность подключения модулей поддерживающих объединение конкретных бинарных форматов. Файлы, в которых не удалось сделать автоматическое объединение, можно посмотреть по команде status , или conflicts . При обнаружении конфликта Bazaar создаст дополнительно 3 файла для каждого файла с конфилктами:
- имя.BASE — файл с содержимым из предыдущей, или последней ревизии текущей ветки
- имя.THIS — файл с содержимым из последней ревизии, или рабочая копия из текущей ветки
- имя.OTHER — файл с содержимым из другой ветки
После того, как конфликт был исправлен вручную нужно использовать команду resolve , что бы сказать Bazaar об этом, при этом ей можно указать только имена исправленных файлов:
bzr resolve
Также часто бывает полезно определить кто поменял конкретные строчки в файле, для этого в Bazaar можно использовать команду annotate :
bzr annotate
После того как все изменения сделаны на ветке remote нужно их перенести на удаленную ветку, для этого используется команда push, которая переносит все недостающие ревизии на родительскую ветку. Если родительская ветка также была изменена, то Bazaar скажет о расхождении веток и нужно будет сначала сделать их объединение и только затем push :
bzr push
Иногда нужно просто передать изменения для просмотра, не обновляя родительскую ветку. В каком-то случае можно опубликовать свою ветку с изменениями через один из протоколов, поддерживаемых Bazaar, или можно послать изменения по e-mail. Для этого в Bazaar есть команды send и bundle . Команда bundle может быть использована для создания пакета с изменениями, который можно приложить к e-mail сообщению. Команда send позволяет послать сообщение с изменениями прямо из командной строки.
Работа в централизованном стиле
Кроме всего прочего Bazaar позволяет работать в централизованном стиле, когда все изменения в момент фиксации сразу идут и на одну центральную ветку. Рекомендуется все центральные ветки располагать в разделяемом репозитории, что может соответствовать корню репозитория в Subversion. Так как в центральном репозитории есть смысл хранить только историю изменений его можно создать без рабочего дерева. Рассмотрим процесс создания основной центральной ветки, копирование ее на локально и добавление файлов:
$ bzr init-repo --no-trees sftp://central.host/bzr/repo $ bzr init sftp://central.host/bzr/repo/trunk $ bzr checkout sftp://central.host/bzr/repo/trunk $ cd trunk $ cp -ar ../some-files/ . $ bzr add $ bzr commit -m "Импорт проекта"
Здесь мы использовали команду checkout , что бы скопировать и связать удаленную ветку с локальной. Кроме использования этой команды можно связать любые ветки с помощью команды bind . В этом случае в момент фиксации все изменения сразу пойдут и на связанную ветку. Если до момента фиксации на связанной ветке произошли изменения, то команда commit скажет о них и нужно будет прежде выполнить, описанную ниже, команду update :
bzr bind sftp://central.host/bzr/repo/trunk
Также в любой момент можно отвязать локальную ветку командой unbind , что бы вернуться к режиму «локальные фиксации и публикация»:
bzr unbind
Надо заметить, что команда checkout копирует всю историю локально. Если в этом нет необходимости, то можно использовать ее с ключом —lightweight :
bzr checkout --lightweight sftp://central.host/bzr/repo/trunk
После того как мы сделали checkout обновления из центральной ветки можно получать командой update как и в централизованных системах:
bzr update
Если при использовании центральной ветки вам в какой-то момент необходимо сделать фиксацию локально можно использовать опцию —local команды commit :
bzr commit --local
Что дальше?
К сожалению, не удалось включить в эту статью другие возможности, или принципы работы Bazaar, о которых хотелось бы рассказать. За кадром остались, например, такие темы:
- Подключаемые модули, позволяющие расширять возможности Bazaar;
- Как создавать псевдонимы для команд;
- Примеры использования Bazaar в различных ситуациях;
- Импорт и экспорт ревизий из других систем контроля версий;
- Организация веток в виде стека;
Таким образом эти темы остаются для самостоятельного изучения, или могут быть темой одной из будущих статей. В любом случае я практически уверен, что изучение одной из распределенных систем контроля версий поможет вам увеличить продуктивность вашей работы.
Copyright © 2001-2013 Dmitry Vasiliev