Информационные технологии. 10 класс (Базовый уровень)

.png)
С помощью запросов в базах данных выполняют такие операции, как отбор данных, их сортировка и фильтрация. Запрос можно использовать для выполнения расчетов, объединения данных из разных таблиц, а также для добавления, изменения или удаления данных в таблице. Это очень гибкий инструмент, и существует много типов запросов, а выбор типа определяется назначением запроса.
Запрос — объект БД, который используется для реализации эффективного поиска и обработки данных.
Источником данных для запросов могут быть не только одна или несколько таблиц, но другие запросы. Запросы не хранят данные, а только отображают данные источников. На основе запросов могут быть построены формы и отчеты.
Самый распространенный вид запросов — запрос на выборку. Он предназначен для отбора данных из источника в соответствии с некоторым условием. Условие запроса — это выражение, которое СУБД сравнивает со значениями в полях запроса, чтобы определить, следует ли включать в результат записи, содержащие то или иное значение.
Запрос на выборку позволяет:
1. Просматривать значения только из полей, которые вас интересуют.
2. Просматривать записи, которые отвечают указанным вами условиям.
3. Использовать выражения в качестве полей.
По особенностям действия среди запросов на выборку можно выделить простые запросы, групповые запросы и запросы с вычисляемым полем.
Основные режимы работы с запросами в Access:
1. Режим таблицы. Отображает информацию запроса на выборку в режиме таблицы.
2. Конструктор. В этом режиме определяется структура запроса и условия выбора данных (см. Приложение к главе 1).
Создать запрос можно с помощью Мастера запросов либо в Конструкторе (пример 5.2).
Мастер запросов позволяет автоматически создавать запросы на выборку. Однако при использовании мастера не всегда можно контролировать процесс создания запроса, но таким способом запрос создается быстрее. Необходимо просто выполнить последовательность действий, предлагаемых мастером на каждом этапе (пример 5.3).
Основные этапы создания запроса на выборку:
1. Выбор инструмента создания запроса.
2. Определение вида запроса.
3. Выбор источника(ов) данных.
4. Добавление из источника(ов) данных полей, которые должен содержать запрос.
5. Определение условий, которые формируют набор записей в запросе.
6. Добавление группировки, сортировки и вычислений (может отсутствовать).
Действие простых запросов на выборку ограничивается отбором данных по некоторым условиям без их обработки.
Примеры записи условий в запросах:
Действие в запросе
Поля с числовым типом данных
Выбираются записи, у которых значение в этом поле больше 0 и меньше 8.
Выбираются записи, у которых значение в этом поле не равно 0.
Поля с текстовым типом данных
Если значение в поле записи равно Орша, то запись включается в результат запроса.
В результат запроса включаются записи, у которых значение соответствующего поля заканчивается на букву к. После выполнения запроса условие будет дополнено оператором Like, который позволяет использовать символы шаблона.
Правила записи условий для поля с типом данных Дата и время такие же, как для поля с числовым типом данных. После выполнения запроса в этом случае в условие будут добавлены знаки #.
Если необходимо найти несколько значений полей, можно использовать оператор In . Этот оператор позволяет выполнить проверку на равенство любому значению из списка, который задается в круглых скобках.
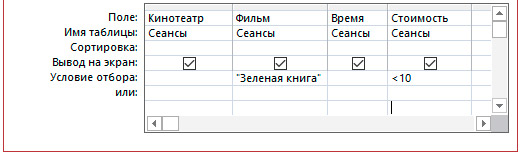
Если требуется использование нескольких условий для разных полей, необходимо учитывать, что между условиями, записанными в одной строке, выполняется логическая операция And , а между условиями, записанными в разных строках, выполняется логическая операция Or .
В режиме конструктора процесс создания запроса находится под вашим контролем, однако здесь есть вероятность допустить ошибку и необходимо больше времени, чем в мастере (пример 5.4).
После создания запроса на выборку его необходимо запустить, чтобы посмотреть результаты, т. е. открыть в режиме таблицы. Сохранив запрос, его можно использовать в качестве источника данных для формы, отчета или другого запроса.
Все запросы, которые рассмотрены в примерах 5.3 и 5.4 , содержат конкретные значения названий, имен, времени и т. д. Если требуется повторить такой запрос с другими значениями в условиях отбора, его нужно будет открыть в конструкторе, изменить условие и выполнить. Чтобы не делать многократно этих операций, можно создать запрос с параметрами. При выполнении такого запроса выдается диалоговое окно Введите значение параметра, в котором пользователь может ввести конкретное значение, а затем получить нужный результат. Параметр запроса определяется в строке Условие отбора конструктора для столбца, содержащего запрашиваемые значения. Параметром является слово или фраза, заключенные в квадратные скобки. Параметр будет выдаваться в виде приглашения в диалоговом окне при выполнении запроса (пример 5.5).
В запросах так же, как и в отчетах, можно создавать вычисляемые поля. Для решения ряда вопросов работы с данными используется запрос итоговых значений. Такой запрос представляет собой запрос на выборку, позволяющий группировать данные и производить вычисления.
В запросе итоговых значений в вычисляемом поле используют статистические функции. Задать статистическую функцию для вычисления итоговых значений по каждому из полей запроса можно путем выбора ее из раскрывающегося списка, который появляется после установки курсора в строке Групповая операция (пример 5.6).
Наряду с запросами на выборку часто применяются запросы на действие. С помощью таких запросов можно обновлять значения полей записей, добавлять новые или удалять уже существующие записи. В СУБД Access такие запросы можно создать в режиме конструктора, воспользовавшись инструментами группы Тип запроса:

Пример 5.1. Режимы работы с запросами.

Режим SQL позволяет создавать и просматривать запросы с помощью инструкций языка SQL.
SQL (англ. structured query language — язык структурированных запросов). Применяется для создания, редактирования и управления данными в реляционной базе данных.
Пример 5.2. Группа инструментов Запросы вкладки Создание.

Пример 5.3. Создание запроса на выборку с помощью Мастера запросов.

1. Выбрать инструмент .
2. Выбрать вид запроса.
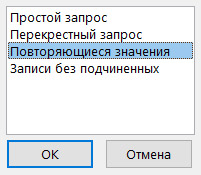
3. Выбрать источник данных.

4. Задать поле, содержащее повторяющееся значение.
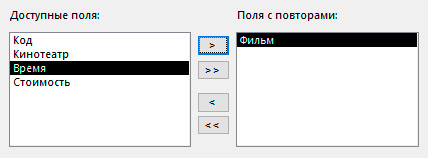
5. Выбрать поля для отображения вместе с повторяющимися значениями.
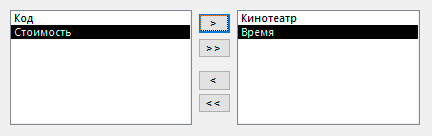
6. Просмотреть и/или сохранить запрос.
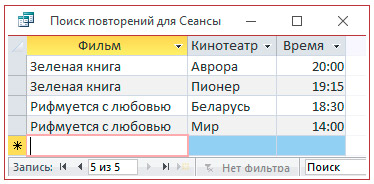
Пример 5.4. Создание простых запросов на выборку с помощью Конструктора запросов.
1. Выбрать инструмент

2. Выбрать источник данных.
3. Добавить поля таблицы, которые будет содержать запрос. Для этого выполнить двойной щелчок по каждому из названий полей в макете таблицы.
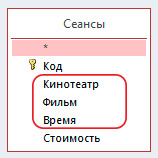
4. Записать условие формирования набора записей в запросе.
4.1. Выбор по полю с текстовым типом данных.
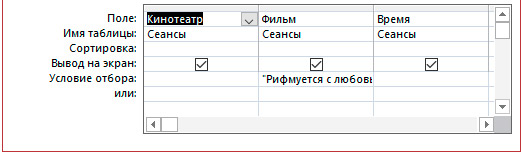
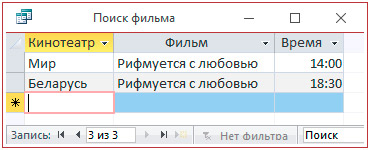
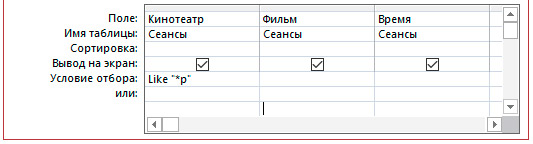
4.2. Выбор по полю с числовым типом данных.

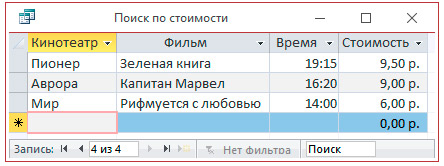
4.3. Использование составного условия.
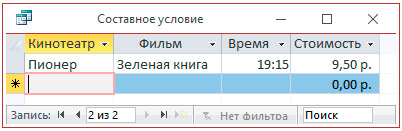
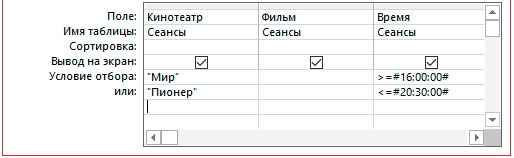
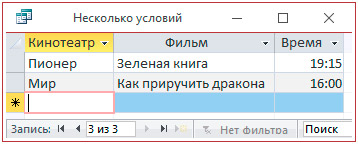
5. Сохранить запросы.
Пример 5.5. Создание запроса с параметрами.
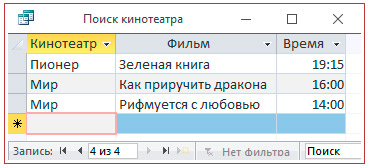
1. Открыть один из запросов, созданных в примере 5.4 в конструкторе.
2. Изменить условия отбора на:
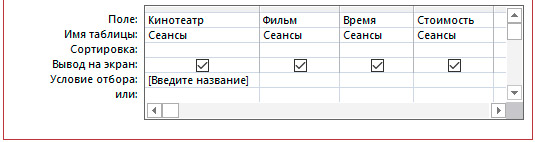
3. Сохранить с новым именем и открыть в режиме таблицы.
4. В диалоговом окне набрать одно из названий кинотеатра.
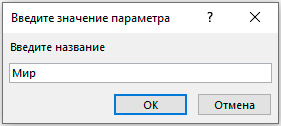
5. Просмотреть запрос.
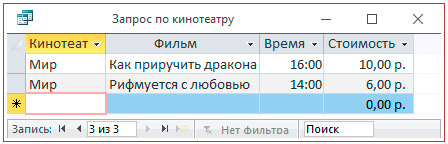
Пример 5.6. Создание итогового запроса.
Создать итоговый запрос, определяющий, сколько мальчиков и сколько девочек посещают факультатив по математике.
1. Источник данных — таблица «Учащиеся».
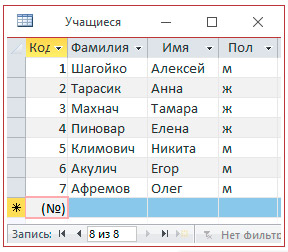
2. Создать запрос с помощью конструктора (добавить в запрос только поле «Пол»).
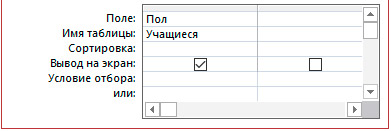

3. Сгруппировать данные по полю «Пол» (нажать кнопку в группе Показать или скрыть).
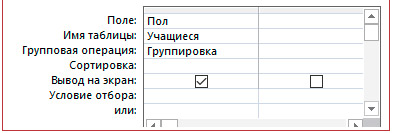
4. Добавить вычисляемое поле (в строке нового поля Групповая операция в списке выбрать функцию Count).

5. Сохранить и просмотреть запрос.
Основы правил проектирования базы данных
Как это часто бывает, архитектору БД нужно разработать базу данных под конкретное решение.
Однажды в пятницу вечером, возвращаясь на электричке домой с работы, я подумал о том, как бы я создал сервис по найму сотрудников в разные компании. Ведь ни один из существующих сервисов не позволяет быстро понять насколько подходит тебе кандидат. Нет возможности создать сложные фильтры, включающие или исключающие совокупность определенных навыков, проектов или позиций. Максимум, что обычно предлагают сервисы — фильтры по компаниям и частично по навыкам.
В данной статье я позволю себе немного разбавить строгое изложение материала, смешав техническую информацию с не техническими примерами из жизни.
Для начала, разберем создание базы данных в MS SQL Server для сервиса поиска соискателей на работу.
Этот материал можно перенести и на другую СУБД такую как MySQL или PostgreSQL.
Основы правил проектирования
Для проектирования схемы базы данных, нужно вспомнить 7 формальных правил и саму концепцию нормализации и денормализации. Они и лежат в основе всех правил проектирования.
Опишем более детально 7 формальных правил:
-
отношение один к одному:
1.1) с обязательной связью:
примером может выступать гражданин и его паспорт: у любого гражданина должен быть паспорт; паспорт один для каждого гражданина
Реализовать данную связь можно двумя способами:
1.1.1) в одной сущности (таблице):

Рис.1. Сущность Citizen
Здесь таблица Citizen представляет собой сущность гражданина, а атрибут (поле) PassportData содержит все паспортные данные гражданина и не может быть пустым (NOT NULL).
1.1.2) в двух разных сущностях (таблицах):

Рис.2. Отношение сущностей Citizen и PassportData
Здесь таблица Citizen представляет собой сущность гражданина, а таблица PassportData — сущность паспортных данных гражданина (самого паспорта). Сущность гражданина содержит атрибут (поле) PassportID, который ссылается на первичный ключ таблицы PassportData. В свою очередь сущность паспортных данных содержит атрибут (поле) CitizenID, которое ссылается на первичный ключ CitizenID таблицы Citizen. Поле PassportID таблицы Citizen не может быть пустым (NOT NULL). Также здесь важно поддерживать целостность поля CitizenID таблицы PassportData, чтобы обеспечить связь один к одному. Иными словами, поле PassportID таблицы Citizen и поле CitizenID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), представленная в пункте 1.1.1.
1.2) с необязательной связью:
примером может выступать человек, имеющий или не имеющий паспорт конкретной страны. В первом случае он будет являться гражданином рассматриваемой страны, а во втором — нет.
Реализовать данную связь можно двумя способами:
1.2.1) в одной сущности (таблице):

Рис.3. Сущность Person
Таблица Person представляет собой сущность человека, а атрибут (поле) PassportData содержит все его паспортные данные и может быть пустым (NULL).
1.2.2) в двух сущностях (таблицах):
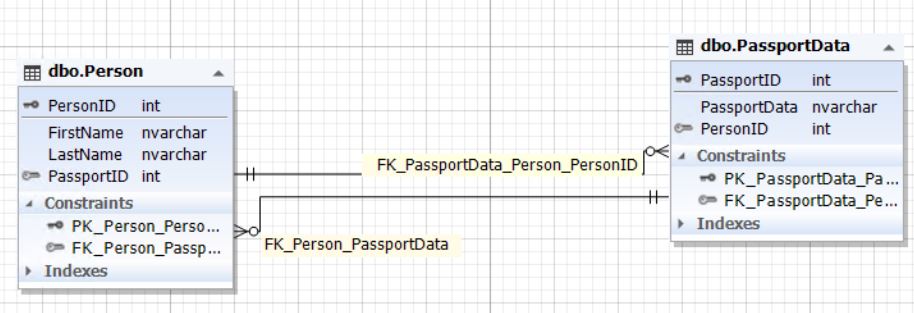
Рис.4. Отношение сущностей Person и PassportData
Таблица Person представляет собой сущность человека, а таблица PassportData — сущность паспортных данных человека (самого паспорта). Сущность человека содержит атрибут (поле) PassportID, который ссылается на первичный ключ таблицы PassportData. В свою очередь сущность паспортных данных содержит атрибут (поле) PersonID, которое ссылается на первичный ключ PersonID таблицы Person. Поле PassportID таблицы Person может быть пустым (NULL). Здесь также важно поддерживать целостность поля PersonID таблицы PassportData. Это нужно, чтобы обеспечить связь один к одному. Поле PassportID таблицы Person и поле PersonID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), показанная в пункте 1.2.1. Или же данные поля должны быть неопределенными, то есть, содержать NULL.
отношение один ко многим:
2.1) с обязательной связью:
примером могут выступать родитель и его дети. У каждого родителя есть как минимум один ребенок.
Реализовать данную связь можно двумя способами:
2.1.1) в одной сущности (таблице):
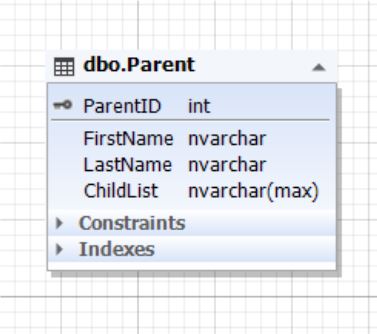
Рис.5. Сущность Parent
Таблица Parent представляет сущность родителя, а атрибут (поле) ChildList содержит информацию о детях. Данное поле не может быть пустым (NOT NULL). Обычно типом поля ChildList выступают неполно структурированные данные (NoSQL) такие как XML, JSON и т д.
2.1.2) в двух сущностях (таблицах):
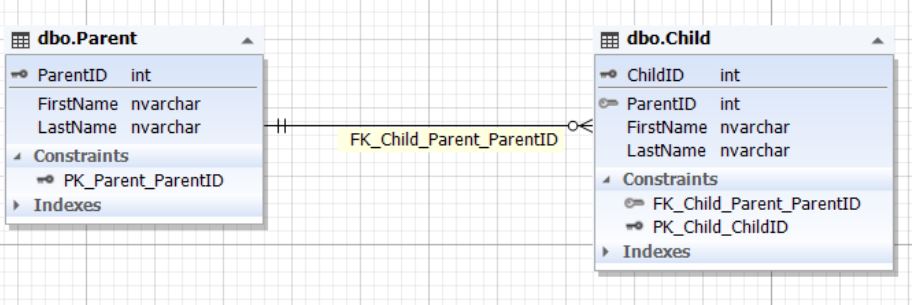
Рис.6. Отношение сущностей Parent и Child
Таблица Parent представляет сущность родителя, а таблица Child — сущность ребенка. У таблицы Child есть поле ParentID, ссылающееся на первичный ключ ParentID таблицы Parent. Поле ParentID таблицы Child не может быть пустым (NOT NULL).
2.2) с необязательной связью:
примером может выступать человек, у которого могут быть дети или их может не быть.
Реализовать данную связь можно двумя способами:
2.2.1) в одной сущности (таблице):
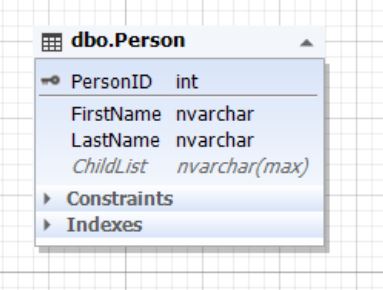
Рис.7. Сущность Person
Таблица Parent представляет сущность родителя, а атрибут (поле) ChildList содержит информацию о детях. Данное поле может быть пустым (NULL). Обычно типом поля ChildList выступают неполно структурированные данные (NoSQL) такие как XML, JSON и т д.
2.2.2) в двух сущностях (таблицах):
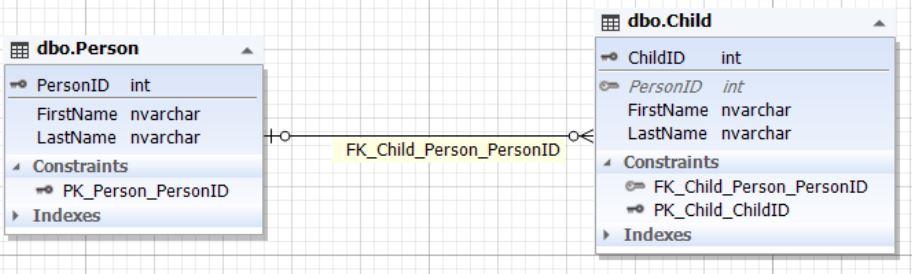
Рис.8. Отношение сущностей Person и Child
Таблица Parent представляет сущность родителя, а таблица Child — сущность ребенка. У таблицы Child есть поле ParentID, ссылающееся на первичный ключ ParentID таблицы Parent. Поле ParentID таблицы Child может быть пустым (NULL).
2.2.3) в одной сущности со ссылкой на саму себя при условии, что у сущностей (таблиц) родителя и ребенка будут одинаковые наборы атрибутов (полей) без учета ссылки на родителя:

Рис.9. Сущность Person со связью на саму себя
Сущность (таблица) Person содержит атрибут (поле) ParentID, который ссылается на первичный ключ PersonID этой же таблицы Person и может содержать пустое значение (NULL).
Примером может выступить недвижимость: она может быть в собственности как одного человека, так и нескольких. С другой стороны, один человек может владеть несколькими домами или долями нескольких домов.
Реализовать данное отношение, с привлечением NoSQL, можно так же, как в описанных выше отношениях. Однако, в рамках реляционной модели обычно такое отношение реализуют через 3 сущности (таблицы):
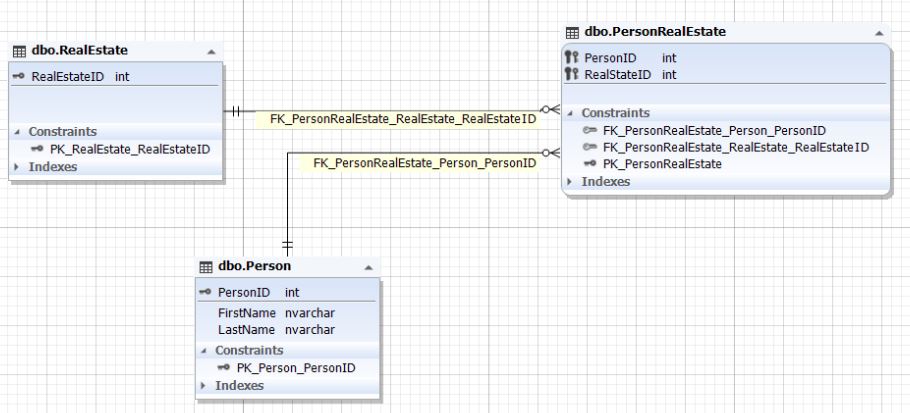
Рис.10. Отношение сущностей Person и RealEstate
Таблицы Person и RealEstate представляют соответственно сущности человека и недвижимости. Связываются данные сущности (таблицы) через сущность (таблицы) PersonRealEstate. Атрибуты (поля) PersonID и RealEstateID ссылаются на первичные ключи PersonID таблицы Person и RealEstateID таблицы RealEstate соответственно. Обратите внимание, что для таблицы PersonRealEstate пара (PersonID; RealEstateID) всегда является уникальной и потому может выступать первичный ключем для самой связующей сущности PersonRealEstate.
А где же семь формальных правил?
- п.1 (п.1.1 и п.1.2) — первое и второе формальные правила
- п.2 (п.2.1 и п.2.2) — третье и четвертое формальные правила
- п.3 (аналогично п.2) — пятое и шестое формальные правила
- п.4 — седьмое формальное правило
Говоря о нормализации, нужно понимать ее суть. Нормализация ведет к уменьшению повторяемости хранения информации, а следовательно и к уменьшению возможности появления аномалий в данных. Однако, нормализация при дроблении сущностей приводит к более сложным построениям запросов для манипуляций с данными (вставки, модификации, выборки и удаления).
Обратным процессом нормализации называется денормализация. Это упрощение построения запросов доступа к данным за счет укрупнения и вложенности сущностей (например, как было показано выше в пунктах 2.1.1 и 2.2.1 с помощью неполно-структурированных данных (NoSQL)).
Вот и вся суть правил проектирования баз данных.
А вы уверены, что поняли отношения в семи формальных правилах? Именно поняли, а не узнали? Ведь знать и понимать — две совершенно разных концепции.
Объясню более детально. Спросите себя, можете ли вы за пару часов набросать пусть и укрупненную по сущностям, но модель базы данных для любой предметной области и для любой информационной системы? (тонкости и детали можно достроить, поспрашивав аналитиков и представителей заказчиков). Если вопрос вас удивил, и вы думаете, что это невозможно, значит вы знаете семь формальных правил, но не понимаете их.
Почему-то многие источники игнорируют тот факт, что эти отношения были не придуманы, а выявлены. Они изначально существуют в реальном мире как между субъектами, так и между субъектами и объектами.
Также, эти отношения могут меняться, переходя из один к одному к одному ко многим, многие к одному или многие ко многим. Обязательность связи может меняться или остаться неизменной.
Позволю себе рассказать об одном случае, когда от знания семи формальных правил я пришел именно к пониманию этих отношений.
В свое время меня смущало то, что в ВУЗе я знал эти семь формальных правил, но на производственной практике (ВУЗ отправляет студентов в различные компании для приобретения профессионального опыта) очень долго строил модели баз для разных предметных областей. Я задумался и понял, что не понимаю этих отношений.
Мне помогло наблюдение за людьми, а суть отношений раскрылась в сновидении. Этот сон я перескажу в упрощенной форме: только то, что позволяет лучше понять именно эти семь формальных правил — без детализации всего остального.
Сон был про семью, в которой есть отец, мать и дети. Отец погибает в автомобильной катастрофе, а мать начинает пить, и детей в итоге забирают в детский дом. Эти дети надолго остаются без родителей. Затем у некоторых детей появляются попечители, их тоже несколько.
Вы проследили, какие отношения были между субъектами, и как менялись эти отношения?
Давайте присмотримся внимательнее.
- Когда семья была полной, с несколькими детьми, отношение между родителями и детьми имело вид многие ко многим.
- Когда остались мать и дети, отношение между родителем и детьми стало один ко многим с обязательной связью. Однако, в любой семье, где может и не быть детей, это отношение будет таким же, но уже с необязательной связью.
- А вот со стороны детей отношение к родителю было как многие к одному с обязательной связью пока родителя не лишили родительских прав.
- Когда дети оказались в детском доме — отношение изменилось на многие к одному с необязательной связью.
- Когда у детей появились попечители, связь между ними стала многие ко многим: у каждого попечителя могут быть другие подопечные дети, а у каждого ребенка могут быть другие попечители (родители).
Надеюсь, теперь вы значительно приблизились к пониманию этих семи формальных правил.
Стоит постоянно практиковаться: наблюдать за людьми и выявлять существующие отношения как между субъектами, так и между субъектами и объектами. Выше описывался гражданин и его паспорт как отношение один к одному с обязательной связью. В тоже время, пример человека и его паспорта — это отношение один к одному с необязательной связью.
Поняв семь формальных правил, вы сможете без труда спроектировать модель базы данных любой сложности для любой информационной системы.
Также вы увидите, что реализовать отношение можно разными способами, а сами отношения могут меняться. Модель (схема) базы данных — это «снимок» отношений между сущностями в определенный момент времени. Именно поэтому важно определить как сами сущности — образы объектов из реального мира или предметной области, так и их отношения между собой с учетом изменений в будущем.
Хорошо спроектированную модель базы данных с учетом изменения отношений в реальности или в предметной области не понадобится менять годами или даже десятилетия. Это особенно важно для хранилищ данных, где изменения влекут пересохранение больших объемов данных (от нескольких гигабайт до многих терабайт).
Важно запомнить, что таблицы в реляционной модели — это отношения сущностей, а строки (кортежи) — это экземпляры этих отношений. Но чтобы было проще, под таблицами часто понимаются сущности, а под строками таблицы — экземпляры сущностей. Их отношения выражаются через связи в форме внешних ключей.
Проектирование схемы базы данных для поиска соискателей на работу
После того, как мы описали основы правил проектирования БД в первой части, давайте создадим схему базы данных для поиска соискателей на работу.
Для начала, определим, что важно для сотрудников из компании, которые ищут кандидатов:
- Сотрудник (Employee)
- Компания (Company)
- Позиция (должность) (Position)
- Проект (Project)
- Навык (Skill)
- Компании и сотрудники относятся как многие ко многим, так как сотрудник мог работать в нескольких компаниях, а в компании работают многие люди.
- Аналогично относятся позиции и сотрудники: несколько сотрудников могут занимать одну позицию как в рамках как одной, так и нескольких компаний.
- С другой стороны, сотрудник мог работать на разных позициях как в рамках одной, так разных компаний. Таким образом, отношение между позициями и компаниями — многие ко многим.
- Аналогично и по проектам: проекты относятся ко всем выше рассмотренным сущностям как многие ко многим.
- Для простоты будем считать, что в проекте сотрудник использует один набор навыков.
- Тогда проекты и навык относятся как многие ко многим.
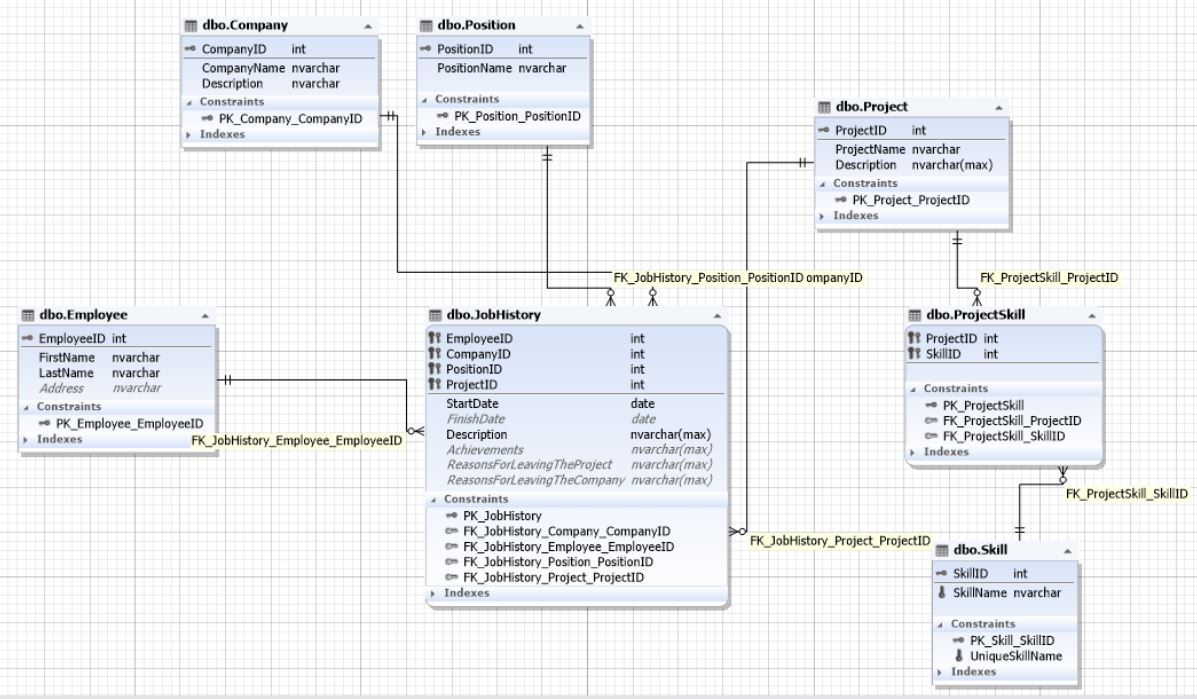
Рис.11. Схема базы данных для поиска соискателей на работу
Здесь таблица JobHistory выступает как сущность истории работы каждого соискателя. То есть, это резюме, которое педставляет отношения многие ко многим между сущностями сотрудник, компания, позиция и проект.
Проекты и навыки относятся друг другу как многие ко многим и потому связываются между собой через сущность (таблицу) ProjectSkill.
Когда вы понимаете отношения между субъектами и между субъектами и объектами — уже упомянутые семь формальных правил — эту или схожую схему можно реализовать «на коленке»: на листке бумаги, мене чем за час. И это еще с учетом усталости после плодотворного рабочего дня.
Здесь можно было упростить схему добавления данных, если «навыки» вложить в сущность «проекты» через неполно структурированные данные (NoSQL) в виде XML, JSON или просто перечислять названия навыков через точку с запятой. Но это бы усложнило выборку с группировкой по навыкам и фильтрацию по отдельным навыкам.
Подобная модель лежит в основе базы данных проекта Geecko.
Как видите, ничего сложного в проектировании информационных систем в части проектирования базы данных нет. Это всего лишь отражение объектов и субъектов из реальности, перенесенное в «сущности» схемы базы данных. Отношения между этими сущностями фиксируются на определенный момент времени, с учетом будущих изменений.
Что именно мы возьмем из реальности и вложим в сущность схемы, и какие отношения построим в модели, будет зависеть от того, что мы хотим от информационной системы в общем, здесь и в будущем. Иными словами — какие данные мы хотим получить в текущий момент времени и через определенное время в будущем.
Немного лирики
После того, как вы внедрите модель в работу, остановитесь на миг и подумайте: только что был создан новый маленький мир. В нем есть свои сущности из реального мира и свои отношения. Да, это цифровой мир, но он теперь будет развиваться своей дорогой. Он будет общаться (интегрироваться) с другими системами (мирами), тоже созданными по своим правилам. Данные будут течь в этих системах, как кровь в живом организме.
А перед сном подумайте о том, что семь формальных правил были всегда, и что они окружают нас всюду. Не больше и не меньше, всегда семь. Все отношения реальной жизни можно разложить на эти семь формальных правил. А когда вы думаете или видите сны, как там сущности относятся друг к другу — не по тем же семи формальным правилам?
Вообще, я уверен, что эти отношения (семь формальных правил) выявил очень хороший психотерапевт, возможно — женщина. Это было очень давно, задолго до появления самого понятия информационных технологий. И самое интересное, что эти отношения живут вне базы данных и ИТ — последние лишь используют их для моделирования информационных систем.
Но мы немного отошли от темы. Я лишь призываю в момент создания новой системы подойти к этому процессу с душой. И тогда поверьте, случится момент творения. Спроектированная таким образом система будет живее всех живых в цифровом мире.
Послесловие
Диаграммы для примеров были реализованы с помощью инструмента Database Diagram Tool for SQL Server. Однако, подобный функционал есть и в DBeaver.
Источники
- SQL Database Design Basics with Example
- Geecko
- Microsoft SQL documentation
- SSMS
- Database Diagram Tool for SQL Server
Что такое база данных – особенности, принцип работы и выбора системы управления
Что такое база данных? Это инструмент, используемый для управления информацией и ее хранения. Она является основой для многих цифровых приложений, таких как онлайн-банкинг, социальные сети, поисковые системы и сайты электронной коммерции.
В чем преимущества? Прежде всего, базы данных позволяют предприятиям хранить сведения в больших объемах в упорядоченном виде. Кроме того, они безопасны и надежны, а также полезны при анализе эффективности бизнеса, что может помочь скорректировать дальнейшую работу.
В статье рассказывается:
- Преимущества работы с базами данных
- Задачи, которые ставят перед БД
- Свойства базы данных
- Система хранения информации в базах данных
- Проектирование баз данных
- Требования к проектированию БД
- Виды баз данных
- Примеры использования баз данных
- Системы управления базами данных
- Виды СУБД по способу доступа
- Популярные системы управления базами данных
- Сравнение SQL и NoSQL
- На что ориентироваться при выборе базы данных
Пройди тест и узнай, какая сфера тебе подходит:
айти, дизайн или маркетинг.
Бесплатно от Geekbrains
Преимущества работы с базами данных
Таблицы упрощают нам жизнь. В табличном виде удобно представлять меню ресторана, создавать квитанции для квартплаты и т. д. Для чтения таблиц не нужны никакие дополнительные инструменты — все данные легко и быстро читаются. Другое дело, когда число строк и столбцов начинает исчисляться сотнями тысяч. В таких случаях с обработкой табличных данных возникают сложности даже при использовании редакторов типа MS Excel.
На помощь приходят разбивка одной крупной таблицы на несколько и организация связей между значениями. Таким образом возникают базы данных. В итоге они представляют собой упорядоченную информацию, которая хранится в цифровом (электронном) виде.
Чтобы разобраться, что такое база данных, рассмотрим в качестве примера двух друзей, решивших открыть кофейню. Стоит задача определить ассортимент напитков. Прежде всего нужно проанализировать меню конкурентов. Результаты заносятся в специально созданную базу данных. Это поможет определить спрос на отдельные напитки, одни из которых обеспечат выручку кофейне, другие — привлекут посетителей уникальным составом.
Далее изучаются поставщики. Здесь также происходит деление. Кто-то поставляет свежие кофейные зерна, кто-то торгует специальным оборудованием, а у кого-то можно закупать посуду. Вся эта информация также заносится в базу. В сравнении с обычными таблицами это более удобный формат по нескольким причинам:
- Имеется возможность хранения, обработки и структурирования гораздо большего объема данных.
- Благодаря встроенному языку запросов и удаленному доступу множество людей могут одновременно выполнять операции с БД. Современные электронные таблицы также подразумевают групповую работу через интернет, но в системах управления базами данных этот процесс более организован, безопасен и оперативен.
- БД могут содержать огромные массивы данных, что никак не влияет на скорость обработки. А, к примеру, таблица Google, состоящая из нескольких сотен строк или столбцов, уже будет загружаться заметно медленнее.
Задачи, которые ставят перед БД
Крупнейшие мировые компании работают с огромными объемами информации, оперативный доступ к которой должен обеспечиваться даже в ответ на сложные запросы. Администраторам баз данных необходимо повышать производительность используемого программного обеспечения с целью:
- эффективного управления непрерывно растущими массивами информации, получаемой от различных источников;
- обеспечения безопасности данных, включая минимизацию риска утечки этой информации и защиту ее от хакерских атак;
- обеспечения быстрого доступа к информации для своевременного принятия важных решений пользователями БД;
- управления базами данных, включая регулярный мониторинг на наличие ошибок, проведение профилактики, обновление ПО и исправление возникающих проблем;
- поиска новых возможностей управления для развития бизнеса.
Узнай, какие ИТ — профессии
входят в ТОП-30 с доходом
от 210 000 ₽/мес
Павел Симонов
Исполнительный директор Geekbrains
Команда GeekBrains совместно с международными специалистами по развитию карьеры подготовили материалы, которые помогут вам начать путь к профессии мечты.
Подборка содержит только самые востребованные и высокооплачиваемые специальности и направления в IT-сфере. 86% наших учеников с помощью данных материалов определились с карьерной целью на ближайшее будущее!
Скачивайте и используйте уже сегодня:

Павел Симонов
Исполнительный директор Geekbrains
Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда
Подборка 50+ бесплатных нейросетей для упрощения работы и увеличения заработка
Только проверенные нейросети с доступом из России и свободным использованием
ТОП-100 площадок для поиска работы от GeekBrains
Список проверенных ресурсов реальных вакансий с доходом от 210 000 ₽
Получить подборку бесплатно
Уже скачали 23671
Современные СУБД усложняются, а объемы обрабатываемых данных возрастают. Это требует привлечения и обучения новых специалистов для решения перечисленных выше задач.
Свойства базы данных
Системы управления базами данных очень удобны в использовании. Это достигается благодаря наличию следующих свойств:
- Быстродействие системы. Система поиска позволяет легко находить нужную информацию даже в больших массивах данных. В обычных электронных таблицах это делать сложнее.
- Простота получения и изменения данных. Для добавления и обновления информации оператору требуется совершить минимальное количество действий.
- Безопасность. Большая часть баз данных настраивается под разные уровни доступа. Возможно разрешение либо запрет просмотра или редактирования записей определенным пользователям.
- Многопользовательский доступ. Современные СУБД поддерживают одновременную работу нескольких пользователей с одной базой.
- Поддержка очень больших объемов данных. В БД можно хранить действительно огромные массивы информации. Далее будет подробно разъяснено, что такое запись. База данных позволяет обрабатывать информацию, содержащуюся в миллионах таких записей.
Система хранения информации в базах данных
БД можно представить в виде трехуровневой структуры. Перечислим данные уровни по порядку от большего к меньшему.
БД
Вся база данных занимает самый верхний уровень, где объединяются абсолютно все данные, хранение которых продиктовано конкретной целью.
Каждый веб-сайт независимо от разновидности и предназначения, как правило, имеет отдельную БД, внутри которой содержится вся необходимая информация.
Таблица
База данных состоит из таблиц, коих в одной БД может насчитываться несколько тысяч.
Разберемся на простом примере, что такое таблица. База данных, допустим, представляет собой большой шкаф. Тогда все содержимое (например, коробки из-под обуви) можно сравнить с таблицами.
Иными словами, этот компонент БД служит для хранения данных какого-то одного типа. Например, создается таблица списка городов или пользователей интернет-ресурса. Фактически она может храниться в виде файла Excel или даже обычного набора строк и столбцов.
Любому пользователю компьютера такой формат знаком. Табличный файл позволяет легко подсчитать количество строк и столбцов, прочитать заголовки, внести нужные данные в таблицу.
Аналогичным образом организован процесс и в базе данных. В системе создается таблица, для которой пользователь определяет вид и структуру.
Запись
Это низший уровень иерархии БД. Запись является частью таблицы, фактически формируя ее наполнение. Данный компонент неделим. К примеру, при заполнении формы на сайте введенная информация вносится в таблицу базы как одна запись, распределяясь по столбцам и строкам этой таблицы. Объем вносимых данных должен быть заранее определен.
В качестве примера разберем процесс создания онлайн-дневника. С точки зрения системы БД выполняются следующие действия:
- Создание новой базы данных сайта с именем «private diary»
- Создание таблицы с именем «diary log»
- Задание столбца «День недели» с типом данных «текст»
- Задание столбца «День» с типом данных «дата»
- Задание столбца «Номер записи» с типом данных «число»
- Задание столбца «Настроение» с типом данных «число» и ограничением от 0 до 5 (от плохого до отличного соответственно)
- Задание столбца «Комментарий» с типом данных «текст»
- Добавление новой записи с заполнением соответствующих полей в таблице каждый раз при сохранении формы
Сформированная таким образом база данных позволит хранить всю вводимую пользователями информацию и предоставит быстрый доступ к ней.
Проектирование баз данных
Проектирование БД включает в себя не только создание таблиц, определение имен столбцов и указание типов данных. Этот процесс в целом намного сложнее. Он требует наличия специальных навыков и знаний. Под типами данных здесь понимается в числе прочего способ записи этих данных (символы, строки, числа, даты, пустые данные NULL и т. д.).
Для вас подарок! В свободном доступе до 29.10 —>
Скачайте ТОП-10
бесплатных нейросетей
для программирования
Помогут писать код быстрее на 25%
Чтобы получить подарок, заполните информацию в открывшемся окне
Основная проблема проектирования БД заключается в ограниченной вычислительной мощности оборудования. Малый объем данных обрабатывается относительно быстро. Но со временем количество информации растет, а это ведет к снижению быстродействия компьютера. Соответственно, запросы обрабатываются медленнее. Здесь стоит вкратце упомянуть, что такое реляционная база данных.
Новые записи в эти СУБД добавляются весьма быстро, а вот выборка определенной информации тратит достаточно много ресурсов. Впрочем, скорость обработки запросов зависит и от конкретных настроек системы.
Требования к проектированию БД
Ранее мы разобрались, в чем заключаются главные особенности реляционных баз данных. Теперь стоит поговорить о проблемах, возникающих при проектировании этих БД. Весь процесс начинается с постановки задач в зависимости от требований, сферы использования проектируемой базы, а также плюсов и минусов выбранной СУБД. В качестве примера рассмотрим популярную систему MySQL.
Формируем структуру базы, исходя из следующих требований:
- Необходимо обеспечить простую обработку данных.
- БД должна быть максимально компактной и лаконичной, но с сохранением всей функциональности.
Помимо этого, могут формулироваться и другие требования, иногда даже противоречащие друг другу. Основная задача проектировщика — найти оптимальный баланс в архитектуре БД с учетом изначально запланированного назначения продукта.
В роли специалиста, занимающегося проектированием, обычно выступает профессиональный серверный администратор или опытный архитектор БД. В этой работе важно понимать, какого результата необходимо достичь. Требуется также знать, что такое структура базы данных, и насколько сложной она может быть. Иные БД состоят из сотен таблиц, которые могут быть весьма замысловато связаны друг с другом. В грамотном создании структуры и состоит основная трудность проектирования.
Дарим скидку от 60%
на курсы от GeekBrains до 29 октября
Уже через 9 месяцев сможете устроиться на работу с доходом от 150 000 рублей
В результате должна получиться подробная диаграмма или схема, где определены все типы хранимых данных, указаны количество и типы столбцов в таблицах, показаны взаимосвязи этих таблиц и т. д. Грамотно выполненное проектирование обеспечит стабильную работу базы. В противном случае возникнут весьма серьезные проблемы. Нужно помнить, что самые грубые ошибки рождаются как раз на этапе построения архитектуры конечного продукта.
Виды баз данных
Мы разобрались, что такое база данных. Виды БД, количество которых сегодня исчисляется десятками, можно структурировать по степени популярности. Ниже перечислим наиболее популярные разновидности:
- Реляционные БД. Стали активно распространяться, начиная с 1980-х годов. Главной особенностью этого вида баз данных является организация структуры. Элементы реляционной БД представлены в виде таблиц, содержащих строки и столбцы. Благодаря этому максимально упрощается доступ к структурированным данным.
- Объектно-ориентированные БД. Здесь данные по аналогии с современными языками программирования рассматриваются как объекты.
- Хранилища данных. Служат для оперативного анализа и выполнения запросов.
- Распределенные БД. Состоят из нескольких файлов, находящихся на разных компьютерах. Одна такая база физически может как располагаться на одном узле, так и распределяться по нескольким сетям.
- Графовые БД. Данные здесь представлены как определенным образом взаимосвязанные друг с другом сущности.
- Иерархические БД. В качестве формы представления используется древовидная структура.
- Нереляционные БД. Также называются NoSQL. Предназначаются для хранения и обработки неструктурированной информации и данных со слабо выраженной структурой.
- Аналитические БД. Другое название — OLTP. Используются разными пользователями для выполнения множества операций.
Стремительное развитие сектора ИТ привело к появлению принципиально новых разновидностей баз данных:
- автономные БД;
- облачные БД;
- БД с открытым исходным кодом;
- документные БД (или JSON);
- многомодельные БД.
Примеры использования баз данных
Любая компания использует информацию, которую необходимо структурировать, где-то хранить и каким-то образом обновлять.
Показания счетчиков
Если организация располагается в отдельном помещении, она потребляет электричество и воду. Расходы этих ресурсов учитываются счетчиками. Автоматические приборы сами передают показания в управляющие компании, на основании чего потребителю выставляется счет.
Успешная оплата отображается в базе данных, где также указывается, что задолженность отсутствует. Каждая управляющая компания обслуживает огромное количество абонентов. Для хранения такого массива показаний и нужны базы данных, позволяющие сортировать счетчики по различным критериям (номера квартир, задолженности и пр.). Средствами обычных электронных таблиц эту задачу решить не получится.
Сведения о персонале
Если штат сотрудников небольшой, информацию о них можно фиксировать в обычной таблице. Но для обеспечения безопасности нужно ограничить доступ к этим данным, что легко реализуется с помощью СУБД. Персональные сведения о каждом сотруднике включают в себя конфиденциальную информацию, например, касающуюся заработной платы.
База данных в таком случае будет храниться на стороне банка. Непосредственному начальнику потребуется лишь контролировать своевременное начисление зарплаты.
База потенциальных клиентов
В различных кафе часто практикуется предложение клиентам поучаствовать в программах лояльности. Для этого собираются контактные данные покупателей. Хранение этой информации и ее обработка также невозможны без организации БД.
Налоги
Налоговые службы обрабатывают огромный массив информации о налогоплательщиках. Здесь в любом случае требуется использование СУБД. Возможностей Excel было бы недостаточно для ежемесячного оповещения всех резидентов о начисленных налогах.
Заказы в кофейне
Безусловно владельцу заведения можно лишь приблизительно оценивать посещаемость по дням недели. Однако это дает незначительный результат. Гораздо больший позитивный эффект обеспечивает работающая база данных, содержащая всю информацию о заказах и посетителях.
Только до 2.11
Скачай подборку материалов, чтобы гарантированно найти работу в IT за 14 дней
Список документов:

ТОП-100 площадок для поиска работы от GeekBrains
20 профессий 2023 года, с доходом от 150 000 рублей
Чек-лист «Как успешно пройти собеседование»
Чтобы зарегистрироваться на бесплатный интенсив и получить в подарок подборку файлов от GeekBrains, заполните информацию в открывшемся окне
Сайт
Любой полноценный веб-сайт строится на основе БД. В базе хранятся абсолютно все данные, которые необходимы для нормальной работы ресурса, включая изображения, сведения о зарегистрированных пользователях, статистику посещений и т. д.
Системы управления базами данных
Физически БД являются обычными файлами на компьютере и служат местом хранения структурированной информации. Добавлять в себя данные, изменять их эти файлы сами не могут. Для этого требуется система управления (СУБД). Именно с ее помощью пользователи управляют таблицами и записями.
Итак, что такое система управления базой данных и как она организована? Фактически это набор программных средств, позволяющих добавлять, удалять, сортировать, фильтровать и искать определенные элементы БД. Также данные инструменты необходимы для изменения структуры базы и создания резервных копий.
СУБД является непосредственным исполнителем пользовательских запросов к конкретной БД.
Ядро этой системы отвечает за хранение базы, обслуживает ее и фиксирует изменения. Обработкой запросов пользователя занимается процессор или компилятор специального языка программирования . Как правило, в качестве последнего в реляционных и объектно-ориентированных БД используется SQL. В отдельных СУБД могут иметься внутренние языки запросов.
Также частью данных систем являются сервисные утилиты, поставляемые зачастую в большом количестве для выполнения конкретных задач обслуживания базы. В большинстве случаев имеется поддержка дополнительно подключаемых пользовательских модулей.
Виды СУБД по способу доступа
Для хранения БД используется сервер, который может либо располагаться на одном компьютере, либо находиться на разных устройствах, соединенных в единую сеть. В первом случае говорят о локальной СУБД, во втором — о распределенной СУБД. Базой данных, размещенной локально на компьютере, можно пользоваться лишь с этого компьютера.
Хранение информации и обеспечение к ней доступа могут организовываться тремя способами.
- Клиент-серверная архитектура подразумевает размещение базы и СУБД на одном удаленном сервере.
К этой БД могут подключаться пользователи, являющиеся в данном случае клиентами. В частности, таким образом делается запрос сведений об определенном сайте.
Обработка клиентских обращений осуществляется исключительно сервером. Клиенты же не должны напрямую взаимодействовать с базой. Иными словами, конечному пользователю не нужно устанавливаться специализированное ПО, чтобы, к примеру, получить доступ к сайту. Эта работа выполняется серверной частью, строго отделенной от клиентской.
Такая архитектура применяется наиболее часто. Она обеспечивает базам данных высокую надежность и доступность.
- Файл-серверная архитектура организует хранение базы на специальном файл-сервере, системы управления при этом располагаются на клиентских компьютерах.
Таким образом, доступ к БД имеют лишь те клиенты, на устройствах которых установлена СУБД.
В настоящее время данная архитектура используется в очень редких случаях, связанных главным образом с обеспечением работы приложений в локальных сетях. Для реализации крупных проектов файл-серверные СУБД практически не применяют.
- Встраиваемая архитектура реализуется в виде небольшой локальной системы управления, настроенной под потребности конкретного программного обеспечения.
Фактически СУБД встраивается в программу в качестве модуля. Необходимость в такой архитектуре возникает при разработке локального ПО. Система обладает малым размером и полностью устанавливается на одно устройство вместе с приложением.
Популярные системы управления базами данных
MySQL
Эта популярнейшая СУБД используется многими мировыми корпорациями (Twitter, Amazon, LinkedIn и т. д.). Она относится к реляционным системам и распространяется по принципам свободного ПО.
Перечислим характерные особенности.
- Пользователям предоставляется для работы большой выбор типов таблиц, включая такие редко используемые, как MERGE и HEAP.
- Система регулярно обновляется. Разработчики продолжают добавлять в нее поддержку новых типов таблиц.
- MySQL поддерживает многопользовательский режим, оставаясь при этом одной из самых быстрых систем. На скорость также не влияет и огромное количество строк в таблицах, достигающее 50 млн.
- Благодаря сравнительно малому количеству функций работа с данной системой не вызовет особых затруднений у новичков.
MySQL может работать как в графическом, так и в текстовом режимах. А c использованием программы phpMyAdmin администрирование БД возможно и через обычный браузер. Знать команды запросов SQL при этом необязательно.
Итак, система MySQL удобна и проста в использовании. Она обладает гибкостью и вполне пригодна в работе с крупными и средними проектами.
Oracle
Данная СУБД относится к объектно-реляционному типу. Название системе дала одноименная компания-разработчик. Взаимодействие с базой данных осуществляется посредством языка Java и расширения PL/SQL.
Приведем главные особенности системы.
- База легко восстанавливается после произошедшего сбоя. Реализована надежная система резервного копирования. Также присутствуют множество других полезных функций.
- Хранящиеся пользовательские данные надежно защищены.
- Перед использованием систему следует активировать. Это весьма дорогостоящая операция, поэтому данная СУБД может быть недоступна для начинающих администраторов и небольших компаний.
PostgreSQL
Эта СУБД также является объектно-реляционной, но в отличие от предыдущей распространяется свободно. От системы MySQL отличается более широким функционалом с внедрением инноваций. Работа с PostgreSQL осуществляется посредством языка SQL.
Какая информация добавляется к базе данных на каждом этапе
Библиотека: А. Горев, С. Макашарипов, Р. Ахаян. Эффективная работа с СУБД
Если вам удалось осмыслить задачу, поставленную перед вами заказчиком, примерно так, как было описано в предыдущей главе, вы на правильном пути. Но это не означает, что наконец-то настала пора воплощать задуманное в «материализованном» виде. Необходимо потратить еще немного усилий для приведения полученной от заказчика информации к наиболее подходящему виду.
2.1. Информационная модель данных
При проектировании системы обработки данных именно данные и интересуют нас в первую очередь. Причем больше всего нас интересует организация данных. Помочь понять организацию данных призвана информационная модель.
В этом параграфе мы познакомимся:
- с общими принципами разработки информационной модели;
- с отличиями между концептуальной, логической и физической моделями данных;
- с различными видами взаимосвязей между элементами модели.
Система автоматизированной обработки данных основывается на использовании определенной модели данных или информационной модели. Модель данных отражает взаимосвязи между объектами.
Последовательность создания информационной модели
Процесс создания информационной модели начинается с определения концептуальных требований ряда пользователей (рис. 2.1). Концептуальные требования могут определяться и для некоторых задач (приложений), которые в ближайшее время реализовывать не планируется. Это может несколько повысить трудоемкость работы, однако поможет наиболее полно учесть все нюансы функциональности, требуемой для разрабатываемой системы, и снизит вероятность ее переделки в дальнейшем. Требования отдельных пользователей интегрируются в едином «обобщенном представлении». Последнее называют концептуальной моделью.
Рис. 2.1. Процесс проектирования информационной модели —> Концептуальная модель представляет объекты и их взаимосвязи без указания способов их физического хранения.
Таким образом, концептуальная модель является, по существу, моделью предметной области. При проектировании концептуальной модели все усилия разработчика должны быть направлены в основном на структуризацию данных и выявление взаимосвязей между ними без рассмотрения особенностей реализации и вопросов эффективности обработки. Проектирование концептуальной модели основано на анализе решаемых на этом предприятии задач по обработке данных. Концептуальная модель включает описания объектов и их взаимосвязей, представляющих интерес в рассматриваемой предметной области и выявляемых в результате анализа данных. Здесь имеются в виду данные, используемые как в уже разработанных прикладных программах, так и в тех, которые только будут реализованы.
Концептуальная модель транслируется затем в модель данных, совместимую с выбранной СУБД. Возможно, что отраженные в концептуальной модели взаимосвязи между объектами окажутся впоследствии нереализуемыми средствами выбранной СУБД. Это потребует изменения концептуальной модели. Версия концептуальной модели, которая может быть обеспечена конкретной СУБД, называется логической моделью.
Логическая модель отражает логические связи между элементами данных вне зависимости от их содержания и среде хранения.
Логическая модель данных может быть реляционной, иерархической или сетевой. Пользователям выделяются подмножества этой логической модели, называемые внешними моделями (в некоторых источниках их также называют подсхемами), отражающие их представления о предметной области. Внешняя модель соответствует представлениям, которые пользователи получают на основе логической модели, в то время как концептуальные требования отражают представления, которые пользователи первоначально желали иметь и которые легли в основу разработки концептуальной модели. Логическая модель отображается в физическую память, такую, как диск, лента или какой-либо другой носитель информации.
Физическая модель, определяющая размещение данных, методы доступа и технику индексирования, называется внутренней моделью системы.
Внешние модели никак не связаны с типом физической памяти, в которой будут храниться данные, и с методами доступа к этим данным. Это положение отражает первый уровень независимости данных. С другой стороны, если концептуальная модель способна учитывать расширение требований к системе в будущем, то вносимые в нее изменения не должны оказывать влияния на существующие внешние модели. Это — второй уровень независимости данных. Уровни независимости данных показаны на рис. 2.1. Важно помнить, что построение логической модели обусловлено требованиями используемой СУБД. Поэтому при замене СУБД она также может измениться.
С точки зрения прикладного программирования независимость данных определяется не техникой программирования, а его дисциплиной. Например, для того чтобы при любом изменении системы избежать перекомпиляции приложения, рекомендуется не определять константы (постоянные значения данных) в программе. Лучшее решение состоит в передаче программе значений в качестве параметров.
Все актуальные требования предметной области и адекватные им «скрытые» требования на стадии проектирования должны найти свое отражение в концептуальной модели. Конечно, нельзя предусмотреть все возможные варианты использования и изменения базы данных. Но в большинстве предметных областей такие основные данные, как объекты и их взаимосвязи, относительно стабильны. Меняются только информационные требования, то есть способы использования данных для получения информации.
Степень независимости данных определяется тщательностью проектирования базы данных. Всесторонний анализ объектов предметной области и их взаимосвязей минимизирует влияние изменения требований к данным в одной программе на другие программы. В этом и состоит всеобъемлющая независимость данных.
Основное различие между указанными выше тремя типами моделей данных (концептуальной, логической и физической) состоит в способах представления взаимосвязей между объектами. При проектировании БД нам потребуется различать взаимосвязи между объектами, между атрибутами одного объекта и между атрибутами различных объектов.
Взаимосвязи в модели
Взаимосвязь выражает отображение или связь между двумя множествами данных. Различают взаимосвязи типа «один к одному», «один ко многим» и «многие ко многим».
В рассматриваемой задаче по автоматизации управления работой дилера по продаже легковых автомобилей, если клиент производит заказ на покупку автомобиля впервые, осуществляется первичная регистрация его данных и сведений о сделанном заказе. Если же клиент производит заказ повторно, осуществляется регистрация только данного заказа. Вне зависимости от того, сколько раз данный клиент производил заказы, он имеет уникальный идентификационный номер (уникальный ключ клиента). Информация о каждом клиенте включает наименование клиента, адрес, телефон, факс, фамилию, имя, отчество, признак юридического лица и примечание. Таким образом, атрибутами объекта КЛИЕНТ являются «УНИКАЛЬНЫЙ КЛЮЧ КЛИЕНТА», «НАИМЕНОВАНИЕ КЛИЕНТА», «АДРЕС КЛИЕНТА» и т. д.
Следующий представляющий для нас интерес объект — МОДЕЛЬ АВТОМОБИЛЯ. Этот объект имеет атрибуты «УНИКАЛЬНЫЙ КЛЮЧ МОДЕЛИ», «НАИМЕНОВАНИЕ МОДЕЛИ» и т. д.
Третий рассматриваемый объект — ЗАКАЗ. Его атрибутами являются «НОМЕР ЗАКАЗА», «КЛЮЧ КЛИЕНТА» и «КЛЮЧ МОДЕЛИ».
И четвертый рассматриваемый объект — ПРОДАВЕЦ. Его атрибутами являются «УНИКАЛЬНЫЙ КЛЮЧ ПРОДАВЦА», «ИМЯ ПРОДАВЦА», «ФАМИЛИЯ» и «ОТЧЕСТВО».
Взаимосвязь «один к одному» (между двумя типами объектов)
Мысленно вернемся к временам планово-распределительной экономики. Допустим, в определенный момент времени один клиент может сделать только один заказ. В этом случае между объектами КЛИЕНТ и ЗАКАЗ устанавливается взаимосвязь «один к одному», обозначаемая одинарными стрелками, как это показано на рис. 2.2,а.
Рис. 2.2. Взаимосвязи между двумя объектами: а) «один к одному»; б) «один ко многим»; в) «многие ко многим» —>
Между данными, хранящимися в объектах КЛИЕНТ и ЗАКАЗ, будет существовать взаимосвязь, в которой каждая запись в одном объекте будет однозначно указывать на запись в другом объекте. На рис. 2.3 приведен пример такой взаимосвязи между данными. Ни в одном, ни в другом объекте не может существовать записи, не связанной с какой-либо записью в другом объекте.
Рис. 2.3. Взаимосвязь между данными при отношении «один к одному»
Взаимосвязь «один ко многим» (между двумя типами объектов)
В определенный момент времени один клиент может стать обладателем нескольких моделей автомобилей, при этом несколько клиентов не могут являться обладателями одного автомобиля. Взаимосвязь «один ко многим» можно обозначить с помощью одинарной стрелки в направлении к «одному» и двойной стрелки в направлении ко «многим», как это показано на рис. 2.2,б.
В этом случае одной записи данных первого объекта (его часто называют родительским или основным) будет соответствовать несколько записей второго объекта (дочернего или подчиненного). Взаимосвязь «один ко многим» очень распространена при разработке реляционных баз данных. В качестве родительского объекта часто выступает справочник, а в дочернем хранятся уникальные ключи для доступа к записям справочника. В нашем примере в качестве такого справочника можно представить объект КЛИЕНТ, в котором хранятся сведения о всех клиентах. При обращении к записи для определенного клиента нам доступен список всех покупок, которые он сделал и сведения о которых хранятся в объекте МОДЕЛЬ АВТОМОБИЛЯ, как это показано на рис. 2.4. В случае, если в дочернем объекте будут какие-то записи, для которых нет соответствующих записей в объекте КЛИЕНТ, то мы их не увидим. В этом случае говорят, что объект содержит потерянные (одинокие) записи. Это не допустимо, и в дальнейшем вы узнаете, как избегать подобных ситуаций.
Рис. 2.4. Взаимосвязь между данными при отношении «один ко многим»
Если мы будем просматривать записи объекта МОДЕЛЬ АВТОМОБИЛЯ, то в объекте КЛИЕНТ мы сможем получить данные о клиенте, купившем данный автомобиль (см. рис. 2.4). Обратите внимание, что для потерянных записей сведений о клиенте мы не получим.
Взаимосвязь «многие ко многим» (между двумя типами объектов)
В рассматриваемом примере каждый продавец может обслуживать нескольких клиентов. С другой стороны, приобретая автомобили в различное время, каждый клиент вполне может быть обслужен различными продавцами. Между объектами КЛИЕНТ и ПРОДАВЕЦ существует взаимосвязь «многие ко многим». Такая взаимосвязь обозначается двойными стрелками, как это показано на рис. 2.2,в. На рис. 2.5 приведена схема, по которой в этом случае будут взаимосвязаны данные. При просмотре данных в объекте КЛИЕНТ мы сможем узнать, какие продавцы обслуживали определенного клиента. Однако в объекте ПРОДАВЕЦ в этом случае нам придется завести несколько записей для каждого продавца. Каждая строчка будет соответствовать каждому обслуживанию продавцом клиента. При таком подходе мы столкнемся с серьезными проблемами. Например, не сможем ввести в объект ПРОДАВЕЦ уникальный ключ для каждого продавца, так как неизбежно один продавец будет обслуживать нескольких клиентов, и в этом случае у нас появится несколько записей для одного и того же продавца.
Рис. 2.5. Взаимосвязь между данными при отношении «многие ко многим»
Согласно теории реляционных баз данных для хранения взаимосвязи «многие ко многим» требуются три объекта: по одному для каждой сущности и один для хранения связей между ними (промежуточный объект). Промежуточный объект будет содержать идентификаторы связанных объектов, как это показано на рис. 2.6.
Рис. 2.6.
Взаимосвязи между объектами являются частью концептуальной модели и должны отображаться в базе данных.
Наряду с взаимосвязями между объектами существуют взаимосвязи между атрибутами объекта. Здесь также различают взаимосвязи типа «один к одному», «один ко многим» и «многие ко многим».
Взаимосвязь «один к одному» (между двумя атрибутами)
Мы предполагаем, что ключ (номер) клиента является его уникальным идентификатором, то есть он не изменяется и при последующих поступлениях заказов от данного клиента. Если наряду с номером клиента в базе данных хранится и другой его уникальный идентификатор (например, номер паспорта), то между такими двумя уникальными идентификаторами существует взаимосвязь «один к одному». На рис. 2.7,а эта взаимосвязь обозначается одинарными стрелками.
Взаимосвязь «один ко многим» (между двумя атрибутами)
Имя клиента и его номер существуют совместно. Клиентов с одинаковыми именами может быть много, но все они имеют различные номера. Каждому клиенту присваивается уникальный номер. Это означает, что данному номеру клиента соответствует только одно имя. Взаимосвязь «один ко многим» обозначается одинарной стрелкой в направлении к «одному» и двойной стрелкой в направлении ко «многим» (рис. 2.7,б).
Взаимосвязь «многие ко многим» (между двумя атрибутами)
Несколько клиентов с одинаковыми именами могли быть обслужены несколькими продавцами. Несколько продавцов с одинаковыми именами могли полу-чить заказы от нескольких клиентов. Между атрибутами «имя клиента» и «имя продавца» существует взаимосвязь «многие ко многим». Мы обозначаем эту взаимосвязь двойными стрелками (рис. 2.7,в).
Типы моделей данных
Иерархическая и сетевая модели данных стали применяться в системах управления базами данных в начале 60-х годов. В начале 70-х годов была предложена реляционная модель данных. Эти три модели различаются в основном способами представления взаимосвязей между объектами.
Иерархическая модель данных строится по принципу иерархии типов объектов, то есть один тип объекта является главным, а остальные, находящиеся на низших уровнях иерархии, — подчиненными (рис. 2.8). Между главным и подчиненными объектами устанавливается взаимосвязь «один ко многим». Иными словами, для данного главного типа объекта существует несколько подчиненных типов объекта. В то же время для каждого экземпляра главного объекта может быть несколько экземпляров подчиненных типов объектов. Таким образом, взаимосвязи между объектами напоминают взаимосвязи в генеалогическом дереве за единственным исключением: для каждого порожденного (подчиненного) типа объекта может быть только один исходный (главный) тип объекта.
На рис. 2.8 узлы и ветви образуют иерархическую древовидную структуру. Узел является совокупностью атрибутов, описывающих объект. Наивысший в иерархии узел называется корневым (это главный тип объекта). Корневой узел находится на первом уровне. Зависимые узлы (подчиненные типы объектов) находятся на втором, третьем и т. д. уровнях
Рис. 2.8.
В сетевой модели данных понятия главного и подчиненных объектов несколько расширены. Любой объект может быть и главным и подчиненным (в сетевой модели главный объект обозначается термином «владелец набора», а подчиненный — термином «член набора»). Один и тот же объект может одновременно выступать и в роли владельца, и в роли члена набора. Это означает, что каждый объект может участвовать в любом числе взаимосвязей. Схема сетевой модели приведена на рис. 2.9. В реляционной модели данных объекты и взаимосвязи между ними представляются с помощью таблиц, как это показано на рис. 2.10. Взаимосвязи также рассматриваются в качестве объектов. Каждая таблица представляет один объект и состоит из строк и столбцов. В реляционной базе данных каждая таблица должна иметь первичный ключ (ключевой элемент) — поле или комбинацию полей, которые единственным образом идентифицируют каждую строку в таблице. Благодаря своей простоте и естественности представления реляционная модель получила наибольшее распространение в СУБД для персональных компьютеров. Все рассматриваемые в книге средства разработки пользовательских приложений поддерживают именно реляционную модель данных.
2.2. Проектирование базы данных
Все тонкости построения информационной модели преследуют одну-единственную цель — получить хорошую базу данных. А что это такое?
Существует очень простое понятие базы данных как большого по объему хранилища, в которое организация помещает все используемые ею данные и из которого различные пользователи могут их получать, используя различные приложения. Такая единая база данных представляется идеальным вариантом, хотя на практике это решение по различным причинам труднодостижимо. Поэтому чаще всего под базой данных понимают любой набор хранящихся в компьютере взаимосвязанных данных.
В этом параграфе мы изучим:
- методику проектирования базы данных на основе последовательного построения информационной модели;
- принципы нормализации данных;
- основные требования к реализации физической модели.
В основу проектирования БД должны быть положены представления конечных пользователей конкретной организации — концептуальные требования к системе. Именно конечный пользователь в своей работе принимает решения с учетом получаемой в результате доступа к базе данных информации. От оперативности и качества этой информации будет зависеть эффективность работы организации. Данные, помещаемые в базу данных, также предоставляет конечный пользователь.
При рассмотрении требований конечных пользователей необходимо принимать во внимание следующее:
- База данных должна удовлетворять актуальным информационным потребностям организации. Получаемая информация должна по структуре и содержанию соответствовать решаемым задачам.
- База данных должна обеспечивать получение требуемых данных за приемлемое время, то есть отвечать заданным требованиям производительности.
- База данных должна удовлетворять выявленным и вновь возникающим требованиям конечных пользователей.
- База данных должна легко расширяться при реорганизации и расширении предметной области.
- База данных должна легко изменяться при изменении программной и аппаратной среды.
- Загруженные в базу данных корректные данные должны оставаться корректными.
- Данные до включения в базу данных должны проверяться на достоверность.
- Доступ к данным, размещаемым в базе данных, должны иметь только лица с соответствующими полномочиями.
Этапы проектирования базы данных с учетом рассмотренных выше аспектов представлены на рис. 2.11.
В результате анализа поставленной заказчиком задачи и обработки требований конечных пользователей составляется концептуальная модель.
При разработке логической модели базы данных прежде всего необходимо решить, какая модель данных наиболее подходит для отображения конкретной концептуальной модели предметной области. Коммерческие системы управления базами данных поддерживают одну из известных моделей данных или некоторую их комбинацию. Почти что все популярные системы для персональных компьютеров поддерживают реляционную модель данных.
Отображение концептуальной модели данных на реляционную модель производится относительно просто. Каждый прямоугольник концептуальной модели отображается в одно отношение, которое отражает представление пользователя в удобном для него табличном формате. Простота отображения связана с тем, что при разработке концептуальной модели использовался реляционный подход.
Рассмотрим этапы проектирования базы данных, которые должны обеспечить необходимую независимость данных и выполнение эксплуатационных требований (пожеланий пользователей).
Этап 1. Определение сущностей
Исходя из задачи, описанной в первой главе, выделим следующие сущности:
- МОДЕЛЬ;
- АВТОМОБИЛЬ;
- КЛИЕНТ;
- ПРОДАВЕЦ;
- ЗАКАЗ;
- ПРОДАЖА;
- СЧЕТ.
Этап 2. Определение взаимосвязей между сущностями
Определим для включенных в модель сущностей взаимосвязи в соответствии с рекомендациями, данными в предыдущем параграфе. Полученная после этого информационная модель представлена на рис. 2.12.
Необходимо отметить что на рис. 2.2,а взаимосвязь между объектами КЛИЕНТ и ЗАКАЗ рассматривается в определенный момент времени, для примера связи «один к одному». Однако анализируя данную взаимосвязь более широко, получим, что один клиент в разное время может производить несколько заказов. С другой стороны, один заказ принадлежит только одному клиенту и поэтому на рис. 2.12 между сущностями КЛИЕНТ и ЗАКАЗ установлена взаимосвязь «один ко многим».
Этап 3. Задание первичных и альтернативных ключей, определение атрибутов сущностей
Для каждой сущности определим атрибуты, которые мы будем хранить в БД. При этом необходимо учитывать тот факт, что при переходе от логической к физической модели данных может произойти усечение числа объектов. На самом деле, как правило, значительное число данных, необходимых пользователю, может быть достаточно легко подсчитано в момент вывода информации. В то же время, в связи с изменением алгоритмов расчета или исходных величин, некоторые расчетные показатели приходится записывать в БД, чтобы гарантированно обеспечить фиксацию их значений. Выбор показателей, которые обязательно следует хранить в БД, достаточно сложен. Нечасто можно найти однозначное решение этой проблемы, и в любом случае оно потребует тщательного изучения работы предприятия и анализа концептуальной модели.
Атрибуты, включаемые в состав БД для рассматриваемой модели, приведены в табл. 2.1. Информационная модель после третьего этапа проектирования приведена на рис. 2.13.
Рис. 2.13. Таблица 2.1. Атрибуты и первичные ключи сущностей информационной модели
| Сущность | Первичный ключ | Атрибуты |
|---|---|---|
| МОДЕЛЬ | Уникальный ключ модели | Уникальный ключ модели |
| Наименование модели | ||
| Наименование фирмы | ||
| Наименование страны | ||
| Рабочий объем двигателя | ||
| Количество цилиндров | ||
| Мощность | ||
| Крутящий момент | ||
| Наименование топлива | ||
| Максимальная скорость | ||
| Время разгона до 100 км/ч | ||
| Наименование шин | ||
| Наименование кузова | ||
| Количество дверей | ||
| Количество мест | ||
| Длина | ||
| Ширина | ||
| Высота | ||
| Расход топлива при 90 км/ч | ||
| Расход топлива при 120 км/ч | ||
| Расход топлива при городском цикле | ||
| АВТОМОБИЛЬ | Уникальный ключ автомобиля | Уникальный ключ автомобиля |
| Уникальный ключ модели | ||
| Дата выпуска | ||
| Стоимость | ||
| КЛИЕНТ | Уникальный ключ клиента | Уникальный ключ клиента |
| Наименование клиента | ||
| Адрес | ||
| Телефон | ||
| Факс | ||
| Фамилия | ||
| Имя | ||
| Отчество | ||
| Признак юридического лица | ||
| Примечание | ||
| ПРОДАЖА | Счет | Счет |
| Дата продажи | ||
| Сумма | ||
| СЧЕТ | Номер записи | Номер записи |
| Счет | ||
| Уникальный ключ клиента | ||
| Уникальный ключ автомобиля | ||
| Дата выписки | ||
| Пометка об оплате | ||
| Сумма | ||
| ЗАКАЗ | Уникальный ключ заказа | Уникальный ключ заказа |
| Уникальный ключ клиента | ||
| Уникальный ключ модели | ||
| Уникальный ключ продавца | ||
| ПРОДАВЕЦ | Уникальный ключ продавца | Уникальный ключ продавца |
| Фамилия | ||
| Имя | ||
| Отчество |
Этап 4. Приведение модели к требуемому уровню нормальной формы
Приведение модели к требуемому уровню нормальной формы является основой построения реляционной БД.
В процессе нормализации элементы данных группируются в таблицы, представляющие объекты и их взаимосвязи. Теоpия ноpмализации основана на том, что опpеделенный набоp таблиц обладает лучшими свойствами при включении, модификации и удалении данных, чем все остальные наборы таблиц, с помощью которых могут быть представлены те же данные. Введение нормализации отношений при разработке информационной модели обеспечивает минимальный объем физической, то есть записанной на каком-либо носителе, БД, и ее максимальное быстродействие, что впрямую отражается на качестве функционирования информационной системы. Нормализация информационной модели выполняется в несколько этапов.
Данные, представленные в виде двумерной таблицы, являются первой нормальной формой реляционной модели данных.
Первый этап нормализации заключается в образовании двумерной таблицы, содержащей все необходимые атрибуты информационной модели, и в выделении ключевых атрибутов. Очевидно, что полученная весьма внушительная таблица будет содержать очень разнородную информацию. В этом случае будут наблюдаться аномалии включения, обновления и удаления данных, так как при выполнении этих действий нам придется уделить внимание данным (вводить или заботиться о том, чтобы они не были стерты), которые не имеют к текущим действиям никакого отношения. Например, может наблюдаться такая парадоксальная ситуация. При включении в каталог продаж новой модели автомобиля нам сразу придется указать купившего ее клиента.
Отношение задано во второй нормальной форме, если оно является отношением в первой нормальной форме и каждый атрибут, не являющийся первичным атрибутом в этом отношении, полностью зависит от любого возможного ключа этого отношения.
Если все возможные ключи отношения содержат по одному атрибуту, то это отношение задано во второй нормальной форме, так как в этом случае все атрибуты, не являющиеся первичными, полностью зависят от возможных ключей. Если ключи состоят более чем из одного атрибута, отношение, заданное в первой нормальной форме, может не быть отношением во второй нормальной форме. Приведение отношений ко второй нормальной форме заключается в обеспечении полной функциональной зависимости всех атрибутов от ключа за счет разбиения таблицы на несколько, в которых все имеющиеся атрибуты будут иметь полную функциональную зависимость от ключа этой таблицы. В процессе приведения модели ко второй нормальной форме в основном исключаются аномалии дублирования данных.
Отношение задано в третьей нормальной форме, если оно задано во второй нормальной форме и каждый атрибут этого отношения, не являющийся первичным, не транзитивно зависит от каждого возможного ключа этого отношения.
Транзитивная зависимость выявляет дублирование данных в одном отношении. Если A, B и C — три атрибута одного отношения и C зависит от B, а B от A, то говорят, что C транзитивно зависит от A, как это схематично показано на рис. 2.14,а. Преобразование в третью нормальную форму происходит за счет разделения исходного отношения на два, как это показано на рис. 2.14,б.
Рис. 2.14. Пример транзитивной зависимости: а) отношения между объектами с транзитивной зависимостью; б) отношения между объектами без транзитивной зависимости —>
Например, если все данные о моделях автомобилей и самих поступающих автомобилях хранятся в одном отношении, то для нескольких автомобилей одной модели пришлось бы многократно указывать тип кузова, количество дверей и другие технические характеристики. В этом случае технические характеристики зависят от модели автомобиля и при наличии нескольких автомобилей одной модели будут дублироваться. Дублирование исчезает, если из одного отношения выделить отношение, в котором будут храниться данные о моделях, и отношение, в котором будут храниться данные об автомобилях.
Существуют и более высокие формы нормализации, но авторы не встречались с необходимостью их применения за достаточно длительную историю создания систем обработки данных и поэтому сочли возможным уберечь читателя от потока теории.
Давайте сформулируем основные правила, которым нужно следовать при проектировании базы данных:
Исключайте повторяющиеся группы — для каждого набора связанных атрибутов создайте отдельную таблицу и снабдите ее первичным ключом. Выполнение этого правила автоматически приведет ко второй нормальной форме. Помимо теоретических указаний в этом правиле есть и чисто практический смысл. Представьте, что в вашем списке заказов вы указываете имена ваших клиентов. Клиент «Хитрая лиса» достаточно активен и часто делает у вас заказы. Бьемся об заклад, что найдутся считанные люди, которые в десяти упоминаниях напишут это имя абсолютно одинаково. Ну кто-то где-нибудь да напишет «Хитрый лис», а для СУБД это уже другой клиент. Поэтому гораздо лучше вести список своих клиентов в отдельной таблице, а в списке заказов использовать только присвоенные им уникальные идентификаторы.
Исключайте избыточные данные — если атрибут зависит только от части составного ключа, переместите атрибут в отдельную таблицу. Это правило помогает избежать потери одних данных при удалении каких-то других. Везде, где возможно использование идентификаторов вместо описания, выносите в отдельную таблицу список идентификаторов с пояснениями к ним.
Исключайте столбцы, которые не зависят от ключа — если атрибуты не вносят свою лепту в описание ключа, переместите их в отдельную таблицу.
С учетом выше изложенного в нашей модели необходимо видоизменить список атрибутов сущности МОДЕЛЬ и добавить такие новые сущности, как ТОПЛИВО, ШИНЫ, КУЗОВ, ФИРМА, СТРАНА (рис. 2.15).
В основном изменения в модели связаны с введением искусственных атрибутов, которые в виде кодов участвуют в отношениях вместо естественных атрибутов (вид топлива, марка шин и т. п.). К необходимости введения в модель искусственных атрибутов мы пришли в процессе нормализации. В общем случае мы рекомендуем использовать вместо естественных атрибутов коды в следующих случаях:
В предметной области может наблюдаться синомия, то есть естественный атрибут отношения не обладает свойством уникальности. Например, среди сотрудников фирмы могут быть однофамильцы или даже полные тезки. В этом случае решить проблему помогает уникальный табельный номер.
Если отношение участвует во многих связях, то для их отображения создается несколько таблиц, в каждой из которых повторяется идентификатор отношения. Для того чтобы не использовать во всех таблицах длинный естественный атрибут объекта, можно применять более короткий код. Это также будет способствовать повышению быстродействия вашей системы.
Если естественный атрибут может изменяться во времени (например, фамилия), то это может вызвать очень большие сложности при эксплуатации системы. Представьте, что ваш лучший продавец, очаровательная девушка Карина, вышла замуж. Что будет с данными, которые привязаны к ее девичьей фамилии? Использование неизменяемого кода (табельного номера) позволит избежать этих сложностей.
Атрибуты, включаемые в измененные или добавленные в модель сущности, приведены в табл. 2.2.
Таблица 2.2. Атрибуты и первичные ключи измененных или добавленных сущностей информационной модели
| Сущность | Первичный ключ | Атрибуты |
|---|---|---|
| МОДЕЛЬ | Уникальный ключ модели | Уникальный ключ модели |
| Наименование модели | ||
| Уникальный ключ фирмы | ||
| Наименование страны | ||
| Рабочий объем двигателя | ||
| Количество цилиндров | ||
| Мощность | ||
| Крутящий момент | ||
| Уникальный ключ топлива | ||
| Максимальная скорость | ||
| Время разгона до 100 км/ч | ||
| Уникальный ключ шин | ||
| Уникальный ключ кузова | ||
| Количество дверей | ||
| Количество мест | ||
| Длина | ||
| Ширина | ||
| Высота | ||
| Расход топлива при 90 км/ч | ||
| Расход топлива при 120 км/ч | ||
| Расход топлива при городском цикле | ||
| ТОПЛИВО | Уникальный ключ топлива | Уникальный ключ топлива |
| Наименование топлива | ||
| ШИНЫ | Уникальный ключ шин | Уникальный ключ шин |
| Наименование шин | ||
| КУЗОВ | Уникальный ключ кузова | Уникальный ключ кузова |
| Наименование кузова | ||
| ФИРМА | Уникальный ключ фирмы | Уникальный ключ фирмы |
| Наименование фирмы | ||
| Уникальный ключ страны | ||
| СТРАНА | Уникальный ключ страны | Уникальный ключ страны |
| Наименование страны |
Этап 5. Физическое описание модели
На этом этапе мы должны составить проекты таблиц, которые будут в дальнейшем реализовываться в конкретной СУБД. Назначения имен таблиц и их атрибутов отражены в табл. 2.3.
Таблица 2.3. Проект таблиц для физической модели
| Model (Модель) | + | 1 |
|---|---|---|
| № п/п | Наименование поля | Примечание |
| 1 | Key_model | Уникальный ключ модели |
| 2 | Name_model | Наименование модели |
| 3 | Key_firm | Уникальный ключ фирмы |
| 4 | Swept_volume | Рабочий объем, cм 3 |
| 5 | Quantity_drum | Количество цилиндров |
| 6 | Capacity | Мощность, л. с. |
| 7 | Torgue | Крутящий момент |
| 8 | Key_fuel_oil | Уникальный ключ топлива |
| 9 | Top_speed | Максимальная скорость,, км/ч |
| 10 | Starting | Время разгона до 100 км/ч,, с |
| 11 | Key_tyre | Уникальный ключ шин |
| 12 | Key_body | Уникальный ключ кузова |
| 13 | Quantity_door | Количество дверей |
| 14 | Quantity_sead | Количество мест |
| 15 | Length | Длина, мм |
| 16 | Width | Ширина, мм |
| 17 | Height | Высота, мм |
| 18 | Expense_90 | Расход топлива при 90 км/ч, л/100 км |
| 19 | Expense_120 | Расход топлива при 120 км/ч, л/100 км |
| 20 | Expense_town | Расход топлива при городском цикле, л/100 км |
| Firm (Фирма) | + | 2 |
| № п/п | Наименование поля | Примечание |
| 1 | Key_firm | Уникальный ключ фирмы |
| 2 | Name_firm | Наименование фирмы |
| 3 | Key_country | Уникальный ключ страны |
| Country (Страна) | + | 3 |
| № п/п | Наименование поля | Примечание |
| 1 | Key_country | Уникальный ключ страны |
| 2 | Name_country | Наименование страны |
| Fuel_oil (Топливо) | + | 4 |
| № п/п | Наименование поля | Примечание |
| 1 | Key_fuel_oil | Уникальный ключ топлива |
| 2 | Name_fuel_oil | Наименование топлива |
| Tyre (Шины) | + | 5 |
| № п/п | Наименование поля | Примечание |
| 1 | Key_tyre | Уникальный ключ шин |
| 2 | Name_tyre | Наименование шин |
| Body (Кузов) | + | 6 |
| № п/п | Наименование поля | Примечание |
| 1 | Key_body | Уникальный ключ кузова |
| 2 | Name_body | Наименование кузова |
| Automobile passenger car (Автомобиль) | + | 7 |
| № п/п | Наименование поля | Примечание |
| 1 | Key_auto | Уникальный ключ автомобиля |
| 2 | Key_model | Уникальный ключ модели |
| 3 | Date_issue | Дата выпуска в формате ДД.ММ.ГГ |
| 4 | Cost | Стоимость,, $ |
| Customer (Клиент) | + | 8 |
| № п/п | Наименование поля | Примечание |
| 1 | Key_custome | Уникальный ключ клиента |
| 2 | Name_customer | Наименование клиента |
| 3 | Address | Адрес |
| 4 | Tel | Телефон |
| 5 | Fax | Факс |
| 6 | Last_name | Фамилия |
| 7 | First_name | Имя |
| 8 | Patronymic | Отчество |
| 9 | Juridical | Признак юридического лица |
| 10 | Comment | Примечание |
| Sale (Продажа) | + | 9 |
| № п/п | Наименование поля | Примечание |
| 1 | Account | Счет |
| 2 | Date_sale | Дата продажи в формате ДД.ММ.ГГ |
| 3 | Sum_ | Сумма, $ |
| Account (Счет) | + | 10 |
| № п/п | Наименование поля | Примечание |
| 1 | Number_record | Номер записи |
| 2 | Account_ | Счет |
| 3 | Key_customer | Уникальный ключ клиента |
| 4 | Key_auto | Уникальный ключ автомобиля |
| 5 | Date_write | Дата выписки в формате ДД.ММ.ГГ |
| 6 | Selled | Пометка об оплате |
| 7 | Sum_ | Сумма, $ |
| Order_ (Заказ) | + | 11 |
| № п/п | Наименование поля | Примечание |
| 1 | Key_order | Уникальный ключ заказа |
| 2 | Key_customer | Уникальный ключ клиента |
| 3 | Key_model | Уникальный ключ модели |
| 4 | Key_salman | Уникальный ключ продавца |
| Salesman (Продавец) | + | 12 |
| № п/п | Наименование поля | Примечание |
| 1 | Key_salman | Уникальный ключ продавца |
| 2 | Last_name | Фамилия |
| 3 | First_name | Имя |
| 4 | Patronymic | Отчество |
На этапе физического проектирования мы должны задуматься о такой серьезной проблеме, как обеспечение безошибочности и точности информации, хранящейся в БД. Это называется обеспечением целостности базы данных.
Обеспечением целостности базы данных называется система мер, направленных на поддержание правильности данных в базе в любой момент времени.
Мы привыкли доверять достоверности данных, помещаемых в печатных изданиях. При подготовке книги помещаемые в нее данные проверяют несколько редакторов. Они же стараются сделать так, чтобы книга была написана литературным языком и соответствовала неким нормам, с которыми читатели подходят к книгам различного жанра. Удивительно было бы при чтении детектива встретить ссылки на научные источники в конце страницы.
При общении человека с компьютером наблюдается некий стойкий феномен. Мы приравниваем компьютер к книге из издательства с самой известной маркой. Мы априори верим всем данным, которые выдает нам это славное устройство. Мы не хотим ничего слышать о программных ошибках, сбоях и неправильном вводе данных. Вы встречали человека, размахивающего листком с распечаткой и неустанно повторяющего как молитву фразу: «Это я рассчитал на компьютере!» Мы встречали, и не раз.
Если же трезво взглянуть на проблему, ситуация начинает выглядеть совершенно иначе. При подготовке книги затраты на ее редактирование составляют незначительную часть от общих затрат на ее выпуск в свет. В системах обработки данных наоборот. Затраты на проверку и поддержание достоверности данных могут составлять значительную часть от общих эксплуатационных затрат. Например, в транспортных предприятиях для контроля правильности ввода данных с путевой документации практикуется параллельный ввод одних и тех же данных несколькими операторами. Считается, что вероятность совершения одной и той же ошибки в этом случае будет крайне мала и простое сравнение результатов ввода различных операторов поможет получить безошибочные данные.
Естественно появляется соблазн избежать дорогостоящей верификации данных. Как сказал один рабочий судоверфи другому, объясняя, почему он не заделал дыру в корпусе корабля: «Ее никто не увидит, она же под водой».
Ошибки в данных неприятны тем, что они остаются незамеченными до тех пор, пока не приведут к тяжелым последствиям, если только вы не позаботитесь обнаружить эти ошибки раньше. Достаточно убедительный довод, чтобы заранее воспользоваться предоставляемыми СУБД мерами для блокирования появления возможных ошибок в разрабатываемой базе данных.
В СУБД целостность данных обеспечивается набором специальных предложений, называемых ограничениями целостности.
Ограничения целостности — это набор определенных правил, которые устанавливают допустимость данных и связей между ними.
Ограничения целостности в большинстве случаев определяются особенностями предметной области. Например, мощность двигателя серийного легкового автомобиля вряд ли может быть ниже 30 л. с.
Ограничения целостности могут относиться к разным объектам БД: атрибутам (полям), записям, отношениям, связям между ними и т. п. Для полей могут использоваться следующие виды ограничений:
- Тип и формат поля автоматически допускают ввод только данных определенного типа. Выбор типа поля Date в формате ДД.ММ.ГГ позволит пользователю ввести только шесть чисел. При этом первая пара цифр не сможет превысить в лучшем случае значения 31, а вторая — 12.
- Задание диапазона значений, как правило, используется для числовых полей. Диапазон допустимых значений может быть ограничен с двух сторон (закрытый диапазон), а может с какой-то одной: верхней или нижней (открытый диапазон).
- Недопустимость пустого поля позволяет избежать появления в БД «ничейных» записей, в которых пропущены какие-либо обязательные атрибуты.
- Задание списка значений позволяет избежать излишнего разнообразия данных, если его можно ограничить. Например, для указания типа кузова мы можем ограничить фантазию пользователя только общепринятыми названиями: Седан, кабриолет и т. д.
- Проверка на уникальность значения какого-то поля позволяет избежать записей-дубликатов. Вряд ли будет удобно в справочнике клиентов иметь несколько записей для одного и того же лица.
Для реализации ограничений целостности, имеющих отношение к записи, таблицам или связям между ними, в СУБД используются триггеры.
Как конкретно реализуется в каждой из рассматриваемых СУБД ограничение целостности мы увидим на примере создания БД в шестой главе.
2.3. Словарь данных
Управленческим инструментарием разработки при проектировании базы данных является словарь данных (СД).
В этом параграфе мы познакомимся с тем, как правильно использовать возможности словаря данных при проектировании и эксплуатации БД.
Внедрение базы данных на любом предприятии занимает довольно продолжительное время. Ее расширение происходит по мере разработки и интеграции используемых прикладных программ. В процессе эксплуатации вводятся новые элементы данных, а те, которые использовались при проектировании базы данных, могут быть изменены.
Преимущества использования СД заключаются в эффективном накоплении, определении и управлении суммарным ресурсом данных предметной области. Словарь данных призван помогать пользователю в выполнении следующих функций:
- совместное использование данных с другими пользователями;
- осуществление простого и эффективного управления элементами данных при вводе в систему новых элементов или изменении описания существующих;
- уменьшение избыточности и противоречивости данных;
- определение степени влияния изменений в элементах данных на всю базу данных;
- централизация управления элементами данных с целью упрощения проектирования базы данных и ее расширения.
Идеальный СД содержит также сведения и о других категориях данных, таких, как группы элементов данных, корреспондирующиеся базы данных и перекрестные ссылки между группами элементов данных и базами данных. Кроме того, в нем фиксируются сведения о тех прикладных программах, которые используют базу данных, и имеются сведения о кодах защиты информации и разграничении доступа.
Прежде всего остановимся на вопросах использования СД при проектировании системы обработки данных.
На первом этапе проектирования базы данных необходимо собрать сведения о предметной области, в том числе о назначении, способах использования и о структуре данных, а по мере развития проекта осуществлять централизованное накопление информации о концептуальной, логической, внутренней и внешних моделях данных. Словарь данных является как раз тем средством, которое позволяет при проектировании, эксплуатации и развитии базы данных поддерживать и контролировать информацию о данных.
При сборе информации о данных следует установить правила присвоения имен элементам, добиться однозначного толкования различными подразделениями назначения источников и соглашений по присвоению имен, сформулировать приемлемые для всех пользователей описания элементов данных и выявить синонимы. Этот процесс включает несколько итераций и связан с необходимостью разрешения конфликтных ситуаций. Отдельные подразделения подчас переоценивают свою роль на предприятии, что приводит при разработке информационной системы к конфликтам. Разработчику в таких случаях придется выступать в роли арбитра. Если вам не по душе слушать крики: «Судью на мыло!», то для обеспечения эффективного сбора и накопления информации о данных желательно, чтобы все, кто имеет отношение к базе данных, пользовались автоматизированным словарем данных.
Словарь данных содержит информацию об источниках, форматах и взаимосвязях между данными, их описания, сведения о характере использования и распределении ответственности. Словарь данных можно рассматривать как «метабазу данных», в которой хранится информация о базе данных.
Одно из главных назначений словаря данных состоит в документировании данных. Так как база данных обслуживает множество пользователей, крайне необходимо, чтобы они правильно понимали, что представляют собой данные.
Проектировщик базы данных рассматривает различные характеристики данных. На ранней стадии проектирования прежде всего готовятся описания элементов данных на естественном языке. Эти описания или определения должны быть точными, недвусмысленными и согласованными.
Например, если три подразделения используют одни и те же данные по-разному, совсем не просто сформулировать приемлемое для всех одно описание разделяемого элемента. Поиск решений проблем такого рода является прерогативой администратора БД. Это часто создает конфликтные ситуации, разрешить которые гораздо сложнее, чем технические вопросы применения базы данных.
На этой стадии разработки текстовых описаний данных проектировщик абстрагируется от способа их физического представления в базе данных. В частности, ему не следует определять, как хранить данные — в упакованном, символьном или каком-либо другом виде.
Накопление информации в словаре данных целесообразно начинать уже на самой ранней стадии проектирования. В процессе работы разработчики выясняют у пользователей, какой должна быть система, какие данные будут входными, какого рода информацию они хотят получить из системы, вводя имена элементов данных, например «номер счета», «остаток» или «процент» в банковской системе. При этом обе стороны должны трактовать используемые термины однозначно, иначе может случиться так, что разработанная система не будет удовлетворять требованиям пользователей. Поэтому второе важное назначение словаря данных — обеспечить эффективное взаимодействие между различными категориями разработчиков и пользователей.
Рассмотрим следующий пример. В банковской системе одним из центральных элементов данных является «остаток». Каков остаток на данном счете? Для большинства неспециалистов ответ очевиден. Однако в главной таблице счетов соответствующей системы в записи по одному счету может храниться до двадцати пяти полей, в именах которых присутствует термин «остаток». Поэтому важно, чтобы и пользователь и разработчик представляли себе, какой именно остаток имеется в виду: «остаток на счете на начало дня», «остаток на счете на конец вчерашнего дня», «фактический остаток» или «остаток на сберегательной книжке». «Остаток на сберегательной книжке» увеличивается сразу после того, как клиент делает вклад, но если вклад сделан с помощью чека (вдруг вы разрабатываете систему обработки данных для использования на ужасном Западе), то «фактический остаток» увеличится только после оплаты чека. На самом деле существует гораздо больше различных полей «остаток». Словарь данных может использоваться для централизованного накопления информации обо всех элементах данных и для обеспечения эффективного взаимодействия между всеми участниками проекта.
Таким образом, два важнейших назначения словаря данных состоят в централизованном ведении и управлении данными как ресурсом на всех этапах проектирования, реализации и эксплуатации системы, а также в обеспечении эффективного взаимодействия между всеми участниками проекта.
В случае распределенной базы данных вся она или ее отдельные части могут размещаться на удаленных друг от друга вычислительных машинах, соединенных линиями связи. Одни рабочие станции в сети могут обращаться только к локальной базе данных, а другие — как к локальной, так и к внешним.
В этом случае в словарь данных может быть введена информация обо всех местах физического хранения данных, а также ограничения секретности, безопасности и доступа. С помощью этой информации словарь данных может «решить», каким образом удовлетворить запрос пользователя: обратиться к локальной базе данных или, если пользователь обладает соответствующими полномочиями, передать запрос на внешнюю ПЭВМ.
В настоящей книге словари данных рассматриваются в контексте совместного использования с СУБД. Существует мнение, что словарь данных можно вести «вручную на бумаге». Однако неавтоматизированный словарь данных не может обеспечить получение по-разному отсортированных списков элементов данных, которыми пользуются разработчики. Один и тот же элемент может неодинаково использоваться в различных приложениях. На ранней стадии проектирования выявляются далеко не все связи между данными. Впоследствии обнаруживается, что данные применяются в разнообразных приложениях. Они могут встречаться, например, во входных и выходных форматах, связанных между собой, и всякий раз рассматриваются в различных контекстах. Чтобы учесть все возможные ограничения, необходимо приложить значительные усилия. Процесс проектирования же становится в таком случае трудно управляемым. Гораздо проще организовать и управлять разработкой с помощью автоматизированного словаря данных.
Для успешного применения словаря данных при разработке системы следует централизовать накопление информации в этом — едином — источнике, из которого программисты смогут копировать описания структур данных и включать их в свои программы на всех этапах проектирования. В случае применения «ручного» или не интегрированного словаря в нем время от времени может происходить нарушение непротиворечивости информации по отношению к фактическому состоянию системы.
В идеальном случае интерфейс между СУБД и словарем данных должен обеспечивать доступ системы словаря к справочникам СУБД, в которых хранится информация о ее текущем состоянии. Модификация типов данных может производиться только после того, как это будет зарегистрировано в словаре данных. Обновление самих данных допускается лишь после проверки их корректности средствами СУБД. Таким образом, словарь данных, СУБД и база данных образуют замкнутый контур.
В идеале словарь данных должен быть неотъемлемой составной частью всей системы обработки данных. За ввод данных в словарь ответственность несет администратор БД. Поскольку словарь данных является центральным звеном системы, необходимо постоянно поддерживать его копию, которая может использоваться для восстановления словаря после возникновения отказа всей системы или в случае непреднамеренного разрушения его рабочей версии. За сохранность словаря данных как жизненно важной части системы с базой данных полностью отвечает администрация базы данных.
Если словарь данных применяется для разграничения доступа к базе данных, то доступ к нему надо также разграничить. Следует строго ограничить круг лиц, которым разрешено модифицировать словарь данных. В отношении хранимой в словаре информации должен быть реализован режим секретности.
Внедрение словаря данных должно быть хорошо продумано по времени и объему, так как неверный шаг здесь может привести к неудаче всего проекта системы обработки данных. В то же время не следует думать, что существуют готовые решения, которые подходят для всех без исключения предприятий. Как и другие планируемые действия в системе обработки данных, план реализации словаря зависит от особенностей предметной области.
Подчас не только реализация всеобъемлющего словаря данных, но и создание интегрированной базы данных всей предметной области может оказаться преждевременным. Ведение словаря данных предполагает обучение пользователей, и до тех пор, пока в этом направлении не будут достигнуты определенные успехи, его установку производить не следует.
В качестве первого приложения словаря данных можно избрать один из следующих вариантов.
Традиционная прикладная система. Словарь данных может применяться в прикладной системе средних размеров, не слишком тесно взаимодействующей с другими системами. Кроме того, система должна решать важные для предприятия задачи. И наконец, она должна быть развивающейся. Только при этих условиях могут быть использованы все преимущества использования словаря данных.
Несколько приложений для обработки данных. Скорее всего эксплуатируемые с использованием СУБД прикладные программы имеют большое значение для предприятия и, кроме того, со временем претерпевают определенные изменения. Если предполагается расширить круг прикладных программ, то внедрение системы словаря данных позволит использовать его возможности по обеспечению взаимодействия между пользователями, в области централизованного накопления информации, а также при подготовке и распространении документации.
Новые прикладные программы. Если предприятие планирует расширить круг используемых прикладных программ, то это самый подходящий случай для внедрения словаря данных. Программисты не всегда хорошо относятся к необходимости документирования уже существующих прикладных программ. Однако при разработке новых прикладных систем эта работа выполняется впервые, и документирование новых приложений неизбежно.
На прилагаемой к книге дискете вы найдете пример словаря данных для рассматриваемой в качестве примера системы обработки данных AUTO STORE.
С помощью этой программы вы сможете создать базу данных и словарь данных, где будет отражаться структура БД Auto_Store. В этой же программе после построения СД вы сможете проектировать словарь данных, а именно: редактировать имена полей таблиц, изменять их тип, разрядность, правила проверки, текст сообщения, значение по умолчанию, заголовок поля, комментарий для поля, устанавливать значение NULL, редактировать имена индексов, изменять их тип, трансформировать имена таблиц и наглядно анализировать связи между таблицами.
Данная программа позволяет создавать ту же БД Auto_Store на MS SQL Server, а также регистрировать пользователей на MS SQL Server и предоставлять определенные права доступа к БД Auto_Store или, точнее, права доступа к полям таблиц базы данных. Права доступа каждого из пользователей можно просмотреть, выбрав пункт «Права» из главного пункта меню «Разработка и проектирование».
Вход в программу. После запуска программы на экране появится форма, показанная на рис. 2.16. Для дальнейшей работы с программой необходимо ввести пароль. Пароль соответствует имени пользователя, что можно узнать из подсказки. При успешном наборе пароля откроется доступ к кнопке «Вход». Выбор пользователей производится из списка, находящегося на панели инструментов (рис. 2.17). Обратите внимание на уровень доступа, их всего пять.
Рис. 2.16. Вход в программу
Рис. 2.17. Панель инструментов для выбора пользователя
Создание базы данных. Здесь все очень просто. Выбираем пункт «Создание Базы Данных» из главного пункта меню «Создание и построение» и в открывшейся форме щелкаем по кнопке «Старт». На рис. 2.18 изображена форма в момент создания базы данных. Не забудьте щелкнуть по кнопке «Финиш» по завершении создания базы. После выполнения описанной процедуры предоставится возможность построения словаря данных.
Построение словаря данных. Аналогично строится словарь данных. Выбираем пункт «Построение Словаря Данных» из главного пункта меню «Создание и построение» и в открывшейся форме щелкаем по кнопке «Старт». На рис. 2.19 изображена форма в момент построения словаря данных. После щелчка по кнопке «Финиш» можно начинать проектирование словаря данных.
Рис. 2.18.
Рис. 2.19
Словарь данных. На рис. 2.20 показана форма словаря данных, предусматривающая следующие действия:
- Щелчком левой кнопки мыши по заголовку таблицы активизируется список полей данной таблицы.
- Щелчок правой кнопки мыши по заголовку таблицы приводит к замене наименования заголовка на физическое наименование таблицы, если перед этим заголовок имел вид русского эквивалента наименования таблицы, и, наоборот, изменяет наименование заголовка русским эквивалентом наименования таблицы, если заголовок имел вид наименования таблицы.
- Двойной щелчок левой кнопки мыши по заголовку таблицы позволяет переименовать заголовок таблицы (рис. 2.21).
- Щелчок левой кнопки мыши по списку полей таблицы активизирует список полей данной таблицы.
- Двойной щелчок левой кнопки мыши по списку полей таблицы вызывает Конструктор таблицы на вкладке поля (рис. 2.22).
- Щелчок левой кнопки мыши по имени индекса под списком полей таблицы активизирует индекс данной таблицы.
- Двойной щелчок левой кнопки мыши по имени индекса под списком полей таблицы вызывает Конструктор таблицы на вкладке индексов (рис. 2.23).
Рис. 2.23. —> - Щелчок левой кнопки мыши по связи между таблицами позволяет выделить данную связь.
Мы думаем, что после просмотра данного примера у вас появится желание создать собственный словарь данных и включить туда целый ряд дополнительных возможностей, например, для каждого поля таблицы включить определение класса, обеспечивающего работу с данными.
2.4. Администрирование базы данных
С базой данных, как правило, взаимодействуют несколько пользователей. Эти пользователи в организации могут выполнять совершенно различные функции, иметь различные представления об используемых данных, но пользоваться ими одновременно. Поэтому при эксплуатации БД крайне необходим учет различных требований и наличие алгоритма разрешения конфликтов. Иными словами, нужно ввести долгосрочную функцию администрирования, направленную на координацию и выполнение всех этапов проектирования, реализации и ведения интегрированной базы данных. В соответствии с этой функцией на определенных лиц возлагается ответственность за сохранность такого важного ресурса, как данные.
В этом параграфе мы познакомимся с задачами и функциями администрирования БД, которое необходимо обеспечить на самых ранних стадиях разработки.
Характерное для многопользовательской среды использование хранящихся в компьютере данных заключается в «захватывании» файла данных. Каждый пользователь блокирует свои данные, не допуская остальных к их использованию. Это вынуждает других пользователей накапливать те же самые данные. С появлением баз данных необходимость в индивидуальном хранении и использовании информации отпала. Но появилась потребность в управлении коллективным использованием данных.
Администратором базы данных (АБД) называется лицо, ответственное за выполнение функции администрирования базы данных.
АБД — не «обладатель» базы данных, а ее «хранитель». С усложнением предметной области неизбежно усложняется процесс формирования информации и принятия решений. В результате расширяется спектр функций администрирования. Так как в случае использования базы данных прикладной программист «устраняется» от непосредственного управления данными, он утрачивает с ними контакт, а следовательно, и чувство ответственности за них. Это требует разработки процедур обеспечения непротиворечивости данных, которые должны быть скоординированы с функцией администрирования базы данных.
Администрирование базы данных предполагает обслуживание пользователей базы данных. Можно провести аналогию между АБД и ревизором предприятия. Ревизор защищает ресурсы предприятия, которые называются деньгами, а АБД — ресурсы, которые называются данными. Во многих организациях по странной традиции АБД рассматривают только как квалифицированного технического специалиста, часто совмещающего функции программиста. Это не соответствует целям администрирования. Уровень АБД в иерархии организации должен быть достаточно высоким, чтобы он мог определять структуру данных и право доступа к ним и нести за это ответственность. АБД обязан хорошо представлять себе, как работает предприятие и как оно использует данные. Хотя от АБД и требуется техническая компетентность, не менее важным является понимание им предметной области, а также умение общаться с людьми и подчинять альтернативы стандартным процедурам. В противном случае АБД не сможет эффективно выполнять свои функции.
Весьма заманчиво наделить АБД широкими полномочиями, однако его положение на предприятии может быть различным. Оно зависит прежде всего от степени значимости базы данных для жизнедеятельности данного предприятия. Вторым фактором является уровень сложности обработки данных и организации коммерческой деятельности. Как мы уже отмечали, АБД чаще всего назначается из числа прикладных программистов отдела обработки данных, что не всегда оправдано.
АБД должен координировать действия по сбору сведений, проектированию и эксплуатации базы данных, а также по обеспечению защиты данных. АБД обязан учитывать как перспективные, так и текущие информационные требования предметной области. Это одна из его главных задач. Следовательно, при проектировании базы данных необходимо добиваться ее максимальной гибкости или максимальной независимости данных.
Переход при обработке информации на технологию баз данных и расширение существующей базы данных связаны со значительными финансовыми затратами, что предопределяет необходимость тщательного планирования и управления этим процессом. Кроме того, количество данных, помещаемых в базу, растет день ото дня, и параллельно с этим усложняются обрабатывающие эти данные прикладные программы. Все это требует наличия централизованного управления на каждом этапе жизненного цикла системы с базой данных.
Правильная реализация функций администрирования БД существенно улучшает контроль и управление ресурсами данных предметной области. С этой точки зрения функции АБД являются скорее управляющими, чем техническими. Принципы работы АБД и его функции определяются подходом к данным как к ресурсам организации. Поэтому решение проблем, связанных с администрированием БД, часто начинается с установления общих принципов эксплуатации СУБД, хотя между СУБД и администрированием БД имеется различие. В большинстве случаев СУБД покупается в виде программного пакета, а администрирование БД является прерогативой предприятия. АБД обеспечивает обобщенное представление о предметной области в виде концептуальной модели, которая представляет модель данных предприятия. Одной из целей создания базы данных является обеспечение информацией пользователей, работающих в различных функциональных областях предприятия. Однако это часто означает, что ни один из этих пользователей не испытывает чувства ответственности и об общих интересах заботится в последнюю очередь. Неизбежным результатом такого отношения является превращение АБД в координатора. Во многих случаях, организуя базу данных, АБД идет по пути решения технических проблем, то есть прежде всего вопросов, связанных с использованием СУБД.
Первая важная задача АБД состоит в устранении противоречий между различными направлениями деятельности организации при создании концептуальной, а затем и логической модели базы данных предметной области. Выступая в роли посредника между отделами, он должен добиваться не только того, чтобы различные специалисты пришли к соглашению относительно объектов предметной области, но и того, чтобы это соглашение было «правильным». Кроме определения данных и прав доступа к ним от АБД может потребоваться разработка процедур и руководств по ведению данных. Для выполнения функций АБД необходимо хорошо представлять себе состояние дел предприятия и перспективы его развития, а также знать позицию руководства. На начальной стадии разработки базы данных АБД следует сконцентрировать внимание на следующих проблемах:
- определение элементов данных и объектов предметной области;
- присвоение различных имен, которые будут использоваться для обращения к элементам одного и того же типа;
- установление взаимосвязей между элементами данных; выпуск текстового описания элементов данных;
- выделение отделов или пользователей, ответственных за обеспечение точности данных (например, контролирующих обновление данных, их непротиворечивость);
- определение путей применения элементов данных в целях управления и планирования, то есть распределении функций между персоналом.
Сбор всей этой информации из различных источников и необходимость ликвидации возникающих между отделами трений требуют, чтобы АБД обладал еще и дипломатическими способностями.
Как уже отмечалось, понятие «единоличного владения» данными неприменимо к базе данных. Однако оно существует, и это иногда существенно усложняет работу АБД. АБД приходится убеждать некоторые отделы, чтобы они «передали» свою собственность в общее пользование, либо контролировать доступ к легко искажаемой информации.
Идея «разделения» может не только вызвать противодействие со стороны некоторых отделов, но и настроить их враждебно против всего проекта разработки базы данных в целом. АБД должен одних убедить, других уговорить, третьих ободрить, а кого-то, если необходимо, и принудить. Это означает, что АБД должен уметь пользоваться своей властью и влиянием, обладать определенным стажем работы и хорошо разбираться в обстановке на данном предприятии. Очевидно, функции АБД не может исполнять человек, восстановивший за время работы против себя многих сотрудников.
Таким образом, к вопросу выбора АБД администрация предприятия должна подходить чрезвычайно серьезно. При выдвижении кандидатуры на пост АБД следует руководствоваться теми же критериями, что и при назначении на посты других управляющих, поскольку рассмотрению долговременных потребностей предприятия АБД обязан уделять не меньшее (если не большее) внимание, чем текущим проблемам. Выполнение этой обязанности осложняется еще и тем, что база данных предусматривает объединение данных без учета функциональных границ.
Реализация руководящих материалов может быть успешной только в том случае, когда все сотрудники, имеющие отношение к базе данных, ознакомлены с ними и несут ответственность за выполнение стандартов, устанавливаемых АБД. Прикладные программисты, сотрудники служб эксплуатации и сопровождения системы должны понимать процедуры, требуемые для решения стоящих перед ними задач. Это означает, что АБД необходимо установить эффективную взаимосвязь со всеми группами сотрудников, которым приходится обращаться к базе данных.
Возвращаясь к рассмотренной в конце предыдущего параграфа программе Auto_Store, заметим, что она позволяет: добавлять, удалять пользователей, назначать существующим пользователям имена, пароли, уровни доступа, назначать привилегии доступа относительно каждого уровня доступа. На рис. 2.24 и 2.25 изображены формы, соответствующие описанным функциям.
Рис. 2.24.
Рис. 2.25.
Кроме того, с помощью этой программы можно регистрировать пользователей для обращения к серверу, как это показано на рис. 2.26.