Что такое набор данных? Полное руководство
В этой статье мы рассмотрим, что такое набор данных, какие существуют типы наборов данных и как извлечь из данных максимальную пользу.
1 min read
Ella Siman
Product Marketing Manager
В статье мы рассмотрим следующее:
- Определение набора данных
- Типы наборов данных
- Как создать набор данных
- Преимущества использования набора данных
- Варианты использования набора данных
- Пример набора данных
Определение набора данных
Набор данных или датасет — это коллекция данных, которая касается определенной темы или отрасли. Наборы данных включают различные типы информации: текст, изображения, видео и аудио, и могут храниться в различных форматах, таких, как CSV, JSON или SQL. Таким образом, набор данных обычно включает структурированные данные для определенной цели и относится к одной теме.
Вы можете использовать наборы данных для проведения маркетинговых исследований, анализа конкурентов, сравнения цен, определения и изучения тенденций или обучения моделей машинного обучения. Это лишь несколько примеров. Наборы данных полезны в различных областях и ситуациях.
Типы наборов данных
Наборы данных можно классифицировать несколькими способами. Вот некоторые из наиболее важных типов наборов данных.
В зависимости от типа данных
- Числовые наборы данных: Содержат числа и используются для количественного анализа.
- Наборы текстовых данных: Содержат посты, текстовые сообщения и документы.
- Наборы мультимедийных данных: Содержат изображения, видео и аудиофайлы.
- Наборы данных временных рядов: Содержат данные, собранные за определенный период времени для анализа тенденций и закономерностей.
- Наборы пространственных данных: Содержат информацию с географической привязкой, например данные GPS.
На основании структуры данных
- Структурированные наборы данных: Организованы в определенные структуры, чтобы упростить запрос и анализ данных.
- Неструктурированные наборы данных: Не имеют четко определенной схемы. Они могут включать в себя различные типы данных.
- Гибридные наборы данных: Включают как структурированные, так и неструктурированные данные.
По статистике
Числовые наборы данных: Включают только числа. Двумерные наборы данных: Включают две переменные данных. Многомерные наборы данных: Включают три или более переменных данных. Категориальные наборы данных: Состоят из категориальных переменных, которые могут принимать только ограниченный набор значений. Наборы корреляционных данных: Содержат переменные данных, которые связаны друг с другом.
Машинное обучение
- Наборы данных для обучения ML: используются для обучения модели.
- Наборы данных для валидации: используются для уменьшения переобучения и повышения точности модели.
- Набор данных для тестирования: используется для тестирования конечного результата модели, чтобы подтвердить ее точность.
Как создать набор данных
Чтобы понять преимущества наборов данных, вы должны сначала узнать, как они создаются. Есть два способа сделать это.
Первый – создать собственный анализатор данных для извлечения данных из нескольких источников. Эта задача упрощается с помощью продвинутого инструмента. В частности, инструмент веб-скрапинга Bright Data имеет встроенные функции парсинга и возможности прокси-сервера для анонимного извлечения данных из Интернета.
Второй вариант — купить уже существующие наборы данных, что сэкономит ваше время и силы. Опять же, Bright Data предлагает широкий спектр наборов данных, доступных для загрузки.
Преимущества использования набора данных
Ниже приведены три наиболее важных преимущества использования наборов данных.
Улучшают процесс принятия решений
Информация, содержащаяся в наборах данных, может использоваться для поддержки стратегических решений. В частности, наборы данных позволяют выявлять рыночные тенденции, анализировать поведение клиентов, определять закономерности и взаимосвязи в данных и измерять производительность. Затем вы можете использовать наборы данных для принятия обоснованных решений, основанных на данных, которые помогут вашей компании понять, куда распределять ресурсы, как разрабатывать новые продукты и сколько брать за новые услуги. В результате улучшится ваше конкурентное преимущество и способность реагировать на потребности рынка.
Улучшают пользовательский опыт
Наборы данных, содержащие отзывы пользователей, могут помочь вам понять, как улучшить общее качество обслуживания клиентов. Например, вы можете использовать эту информацию для создания персонализированного опыта, улучшения дизайна продукта, адаптации или добавления новых функций, а также оптимизации пути пользователя. Предоставляя лучший пользовательский опыт, вы повышаете удовлетворенность клиентов.
Экономят время и затраты
Вы можете использовать набор данных, чтобы раскрыть возможности экономии времени и затрат. Например, наборы данных могут помочь выявить неэффективность процесса разработки, что позволит упростить операции, сократить количество отходов и сэкономить время. Точно так же можно исследовать наборы данных, чтобы выявить избыточные процессы, бизнес-направления, тратящие больше, чем необходимо, и неэффективность в цепочке поставок, что поможет снизить ваши расходы.
Варианты использования набора данных
Давайте рассмотрим некоторые из наиболее популярных вариантов использования наборов данных.
Сравнение цен
Наборы данных, содержащие цены на товары с разных сайтов электронной коммерции, помогают находить лучшие предложения, отслеживать конкурентов и изменения цен. К сожалению, извлечь данные с сайтов электронной коммерции непросто. Например, Amazon состоит из страниц с различной структурой и реализовал несколько методов защиты от парсинга, таких, как CAPTCHA. Bright Data предлагает набор данных Amazon, который дает вам доступ к десяткам миллионов продуктов, продавцов и обзоров. Кроме того, решение Bright Data для анализа данных электронной коммерции предоставляет полезную информацию для инвесторов, розничных продавцов, мировых брендов и аналитиков.
Мониторинг социальных сетей
Наборы данных социальных сетей включают общедоступные данные из Facebook, Reddit и других платформ. Эти наборы данных полезны для сбора информации о ЦА или изучения поведения, предпочтений и вовлеченности пользователей. Кроме того, наборы данных соцсетей важны для поиска инфлюенсеров для партнерства, анализа настроений и мониторинга брендов. Купите наборы данных соцсетей Bright Data, чтобы получить доступ к множеству данных, собранных с нескольких платформ.
Найм людей
Процесс набора новых сотрудников долгий и сложный. Поиск подходящего кандидата может занять месяцы. Проблема в том, что такие платформы, как LinkedIn, не позволяют людям свободно фильтровать и исследовать свои данные. Наборы данных, содержащие интересующие данные, можно анализировать по вашему усмотрению, что упрощает задачу. Bright Data предлагает набор данных LinkedIn, содержащий полные данные из многих открытых профилей.
Пример набора данных
Давайте рассмотрим простой пример, чтобы понять, как выглядит набор данных. Вот первые несколько строк файла avocado_prices.xlsx:
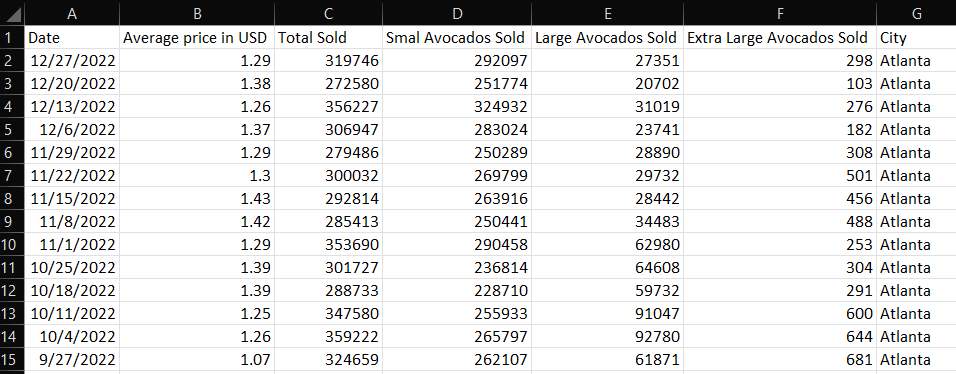
Как видите, набор данных содержит данные о цене и количестве авокадо, которые ежедневно продаются в крупных городах США. Эти записи могут помочь вам отслеживать цены на авокадо, которые обычно сильно коррелируют с уровнем инфляции в стране.
Набор данных содержит данные CSV, организованные в записи со следующими столбцами:
- Дата : День, в который были собраны данные.
- Средняя цена в USD : Средняя стоимость одного авокадо в городе в USD.
- Всего продано : Общее количество авокадо, проданных в городе за один день.
- Продано маленьких авокадо : Количество 4046 авокадо, проданных в городе за один день.
- Продано больших авокадо : Количество 4225 авокадо, проданных в городе за один день.
- Продано очень больших авокадо : Количество 4770 авокадо, проданных в городе за один день.
- Город : Город, в котором были собраны данные.
Заключение
В этой статье вы познакомились с определением набора данных, примером набора CSV и различными типами датасетов. Мы подробно рассказали, какие преимущества могут обеспечить наборы данных в различных случаях использования. Кроме того, у вас была возможность изучить наиболее распространенные подходы к созданию датасетов. К ним относятся сбор данных из Интернета или покупка набора данных, адаптированного к вашим потребностям. Обе эти услуги предлагает Bright Data – лучший поставщик наборов данных на рынке!
Датасет: почему аналитику данных не обойтись без этого инструмента
![]()
Задача аналитика — искать закономерности, но есть данные неопределенные и неструктурированные, которые нельзя обработать инструментами анализа и с их помощью невозможно обучать нейронные сети. По этой причине специалисту требуются подготовленные данные — датасет.
Что означает датасет и как он помогает в анализе
Датасет — это структурированная информация в табличном виде, где у каждого объекта прописаны определенные свойства: характеристики, связи или конкретные места. Этот механизм применяют для построения гипотез, анализа результатов или обучения нейросети на основе данных.
Приведем пример: представьте набор карточек с рисунками разных собак. Эти карточки по отдельности — просто необработанные данные, их нельзя использовать для анализа или машинного обучения. Для того чтобы из этого набора сделать датасет, нужно прописать, какие именно собаки нарисованы на карточках и какое между ними отличие.
Из каких компонентов состоит датасет:
- объект: изображение, фотография, аудиозапись, болезнь, номер дома;
- характеристики: определенные признаки, связи между другими объектами или их место в таблице.
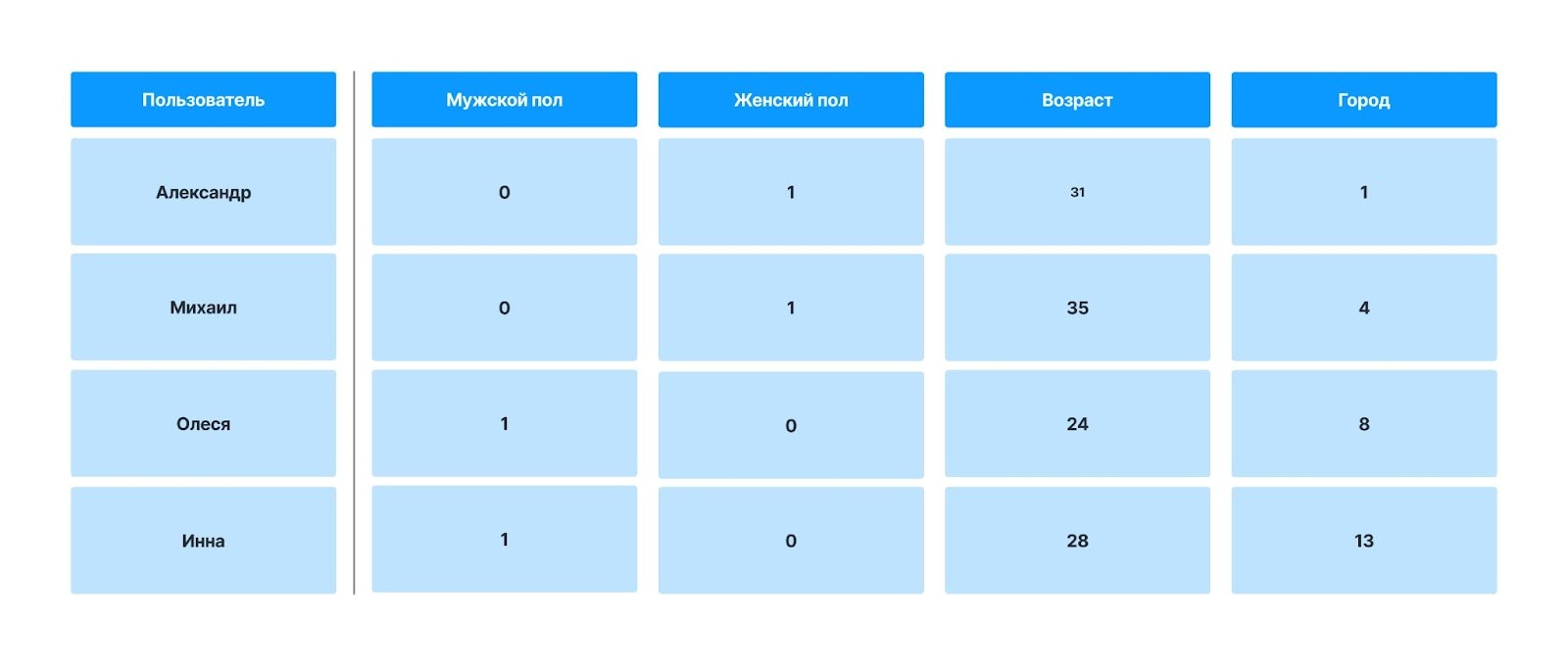
Как правило, свойства объекта описываются не фразами, а числами. Например, необходимо указать пол пользователя. Отмечать будут не привычными буквами «М» и «Ж», а обозначать каждый признак цифрами «Мужской» — 0, «Женский» — 1.
Пройдите онлайн-курсы бесплатно и откройте для себя новые возможности Начать изучение
Какие виды датасетов бывают
- Простая запись
Это таблица, в строках которой размещены объекты, а в колонках — свойства. Конкретных связей между данными нет, признаки просто совпадают с определенными объектами. Обычно многие датасеты строятся именно таким образом.
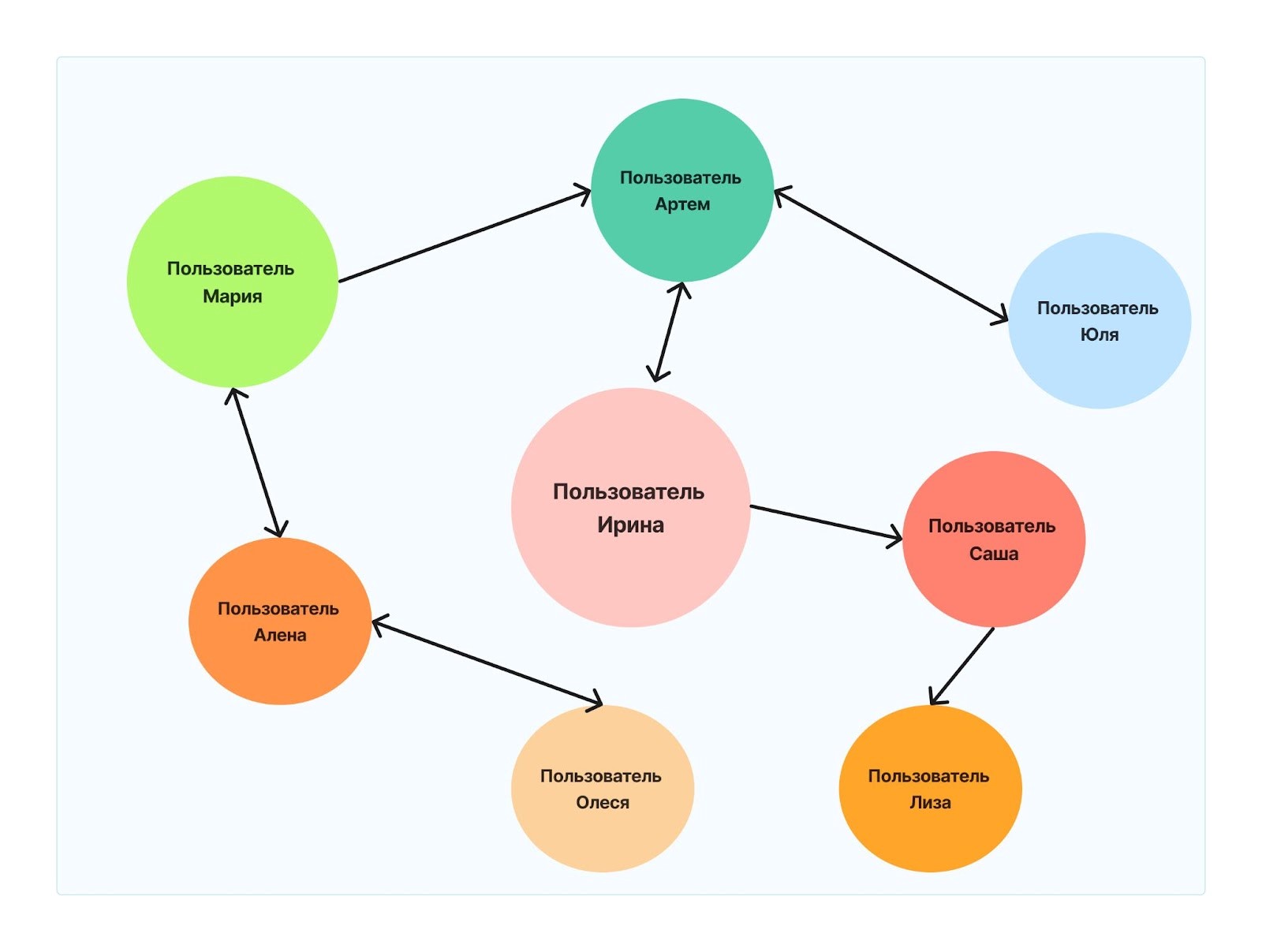
Данные и их связи сгруппированы в виде схемы, объекты которой соединены стрелками. Граф бывает разных видов: структурированный и неструктурированный. У структурированных объекты соотносятся между собой. У неструктурированных эти связи направленные — например, один объект соотносится со вторым, а у второго с первым уже нет связи. Кроме того, у таких соотношений может быть еще и разный вес.
- Упорядоченные записи
Здесь соотношение объектов не так важно, главное — какое конкретное место объект занимает в таблице с данными.
Если вы интересуетесь AI, ML, Big Data или Data Science и хотите пройти обучение, а также поучаствовать в создании продуктов с искусственным интеллектом вместе с другими разработчиками, то вам точно нужно подать заявку в наш проекте «Цифровой прорыв. Сезон: искусственный интеллект».
Читайте нас в Telegram — stranavozmojnostey Поделиться в социальных сетях
Что такое датасет
Собранные данные часто представлены в виде датасета – таблицы, в строках которой представлены объекты наблюдений, а в столбцах – переменные, характеризующие объекты.
Например, в датасете ниже объект наблюдения – это дети. А переменные – их имя, пол и возраст.
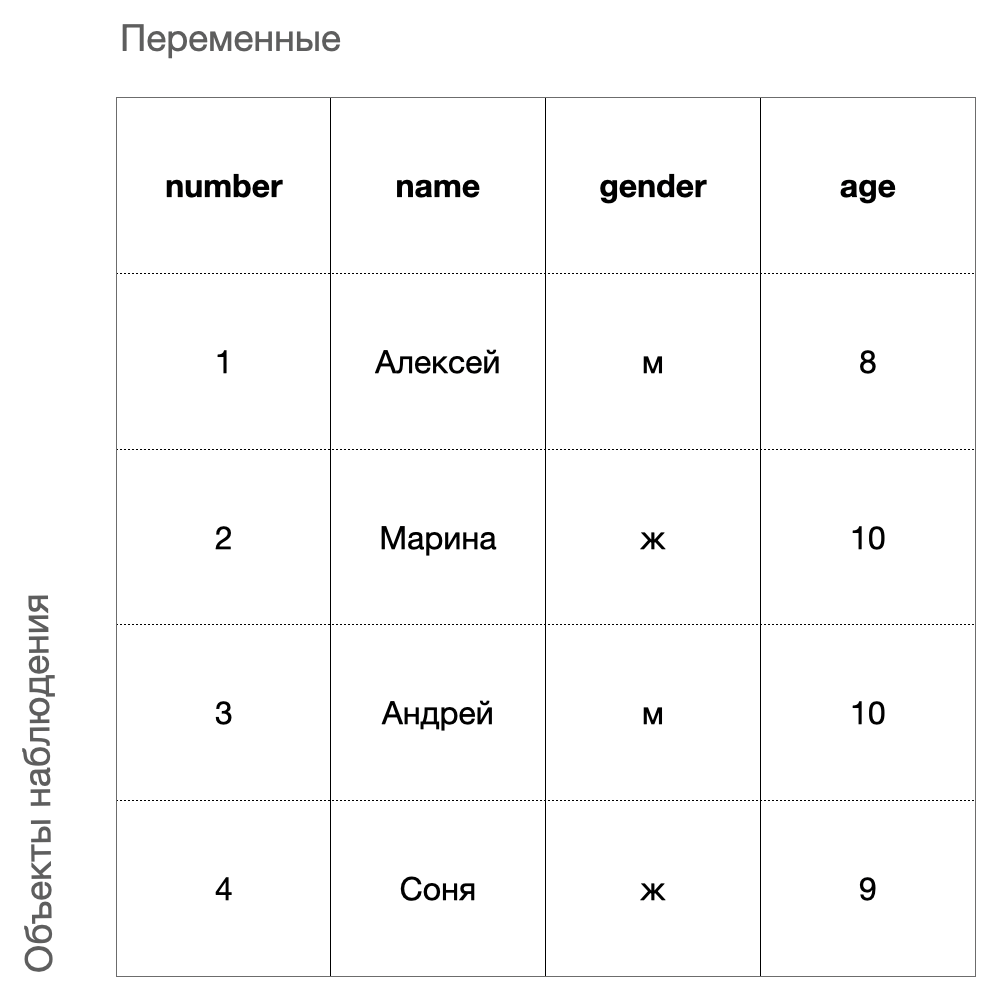
Датасет – является основной единицей, с которой мы будем работать при исследовании данных.
О важности датасета и о том, как сделать его лучше. Опыт нашей компании

Мы подготовили 7 основных шагов, которые превратят набор картинок из гугла не просто в мощный базовый блок системы компьютерного зрения, но и основной инструмент по выявлению и устранению ошибок распознавания.
Краеугольный камень любого проекта, связанного с компьютерным зрением — датасет. Это не просто набор изображений, который передается нейросети. Датасет — это базовый блок, который определит качество и точность определения объектов в рамках вашего проекта.
Нельзя просто собрать набор изображений из гугла и успокоиться — полученная куча изображений не будет нести гордое название «датасет» и испортит проект, вынуждая разработчика и компьютерное железо тренировать модель снова и снова.
Часто работа над датасетом занимает самое большое количество времени, чем над каким-либо еще этапом разработки системы компьютерного зрения, и это неспроста. Чем лучше будет подготовлен датасет, тем меньше времени потребуется на отладку модели, ее тренировки, поиск и устранение неточностей распознавания, а также в целом сделает модель «умнее».

Шаг 1: Размерность
Размер самих изображений, находящихся в датасете, не так важен: перед подачей модели на обучение данные нормализуются, чтобы соответствовать размеру сетки, например, 300 на 300 пикселей.
Размер входного слоя нейросети — размер изображений, с которыми будет работать сетка.
При формировании датасета важно иметь ввиду размерность сетки, с которой предстоит работать, и максимально близко подгонять размер изображений к размеру модели. Если этого не делать, то можно наткнуться на большое количество сюрпризов.
Например, один наш клиент обратился нам за помощью: его нейросеть должна была определять марку автомобиля и его номер, и если с первым обученная модель справлялась на «ура», то со вторым не справлялась вовсе. Ответы вроде «неподходящая модель», «маленькое количество данных», «невыполнимая для компьютерного зрения на данном этапе задача» оказались неверны, а реальный ответ был куда проще — клиент не принял во внимание размер модели нейросети, с которой работал.

Нейросети, использованной в данном проекте, на вход давали изображения с шириной 1024 пикселя, а входной размер самой модели — 300х300 пикселей. Изображения сильно сжимались в размере, и если автомобиль мог пережить данную трансформацию и оставался узнаваемым, то номер превращался в неузнаваемую кашу из пикселей. Если бы наш клиент прочитал это руководство по составлению идеального датасета, он бы смог сам довольно просто решить свою проблему, всего лишь обрезав изображения, приблизив их тем самым к размеру его модели нейросети.

Если для решения поставленной задачи критично важно использовать изображения большого размера, то уже существуют object detection модели, которые могут работать с большими изображениями. Например, модель YOLOv5x6 может работать с изображениями шириной до 1280 пикс. Данные модели очень полезны в условиях распознавания маленьких объектов на больших фотографиях, например, на спутниковых снимках.
Шаг 2: Реальные условия
Главное правило любого датасета — изображения должны быть максимально приближены к реальным условиям, в которых будет работать модель нейросети. До начала сбора изображений важно знать какие именно изображения будет получать на вход модель, где будет стоять камера, разрешение камеры.
Важно понимать, что если камера имеет маленькое разрешение и будет захватывать маленькие по размеру изображения, то и фото в датасете должны быть небольшими. Новички в разработке систем машинного обучения часто игнорируют это правило, предполагая, что чем больше и детализированнее изображение будет подано сетке в момент обучения, тем лучше она выучит предмет и тем выше будут показатели точности на реальных данных.
Пренебрежение данным шагом может «подкосить» даже проект с современной нейросетью и большим датасетом. Один из наших клиентов поставил перед собой задачу определять птиц, попавших в объектив веб-камеры. Во время составления датасета клиент собирал фото птиц разных видов из гугла: четкие, насыщенные изображения, на которых птица видна как правило в фас или в бок и занимает большую часть самого изображения. На валидационном датасете нейросеть показывала отличные разультаты. Однако в реальных условиях нейросеть работала крайне плохо.
Реальность оказалось далека от гугла. Птицы, запечатленные на заднем дворе с помощью простой веб-камеры, выглядели куда более тускло, часто были расположены к камере спиной или были видны лишь частично. Сами изображения были куда меньше, хуже по качеству, часто содержали разные помехи — капли дождя или насекомое на объективе, засвет солнцем, туман. Нейросеть просто не могла определить что находилось на таком изображении, ведь птицы на фото из датасета выглядели совсем по-другому.
Нам пришлось провести большую работу по сбору фотографий птиц в реальных условиях, после чего система заработала с высокими показателями точности.
Данный шаг часто представляет довольно большую сложность, т.к. у клиентов часто нет возможности собрать реальные фото объектов до того, как проект будет запущен. Однако его нельзя игнорировать, ведь от того, насколько данные в датасете близки к реальным данным, зависит качество распознавания.
Шаг 3: Проверка формата и аннотаций
Этот шаг особенно важен для проектов, которые используют уже готовый датасет, найденный на просторах интернета. Важно проверить, что изображения в датасете находятся в том формате, с которым сможет работать выбранный фреймворк. Современные фреймворки работают с большим количеством разных форматов, однако до сих пор встречаются проблематичные форматы, например, jfif.
Если изображения не будут находиться в нужном формате, процесс тренировки просто не сможет быть закончен, поэтому важно оказать этой, как может показаться, мелочи достаточно внимания.
Необходимо также проверить аннотации и их формат. Изображения в датасете могут отвечать всем вышеперечисленным требованиям, но если аннотации не будут в том формате, с которым работает фреймворк и архитектура модели нейросети, то ничего работать не будет.
В одних форматах аннотации, т.е. расположение bounding бокса на изображении, указывается в абсолютных значениях, в других — в относительных. Некоторые фреймворки, например YOLO, просят для каждого изображения cat.jpg приложить файл cat.txt с аннотацией, а другие, например TensorFlow, просит аннотации в формате .csv, некоторые просят приложить для тренировочного датасета один файл train.txt, который содержит все аннотации разом.
На этапе работы с датасетом важно знать с какой моделью будет вестись работа, ведь от этого зависит формат аннотаций и формат самих изображений.
Шаг 4: Разбивка датасета на TRAIN и VALIDATE
Разбивка датасета на Train и Validate — важный этап работы с датасетом, делающий тренировку нейросети возможной. Как правило, при разбивке датасета пользуются следующими правилами:
70-80% изображений идут в Train, 20-30% — в Validate

Train — то, на чем учится нейросеть, из чего извлекает свойства объекта под вопросом. После окончания эпохи тренировки нейросеть должна проверить правильно ли она выучила как выглядит объект, для чего она обращается к сету Validate.
Используя обретенные с помощью Train знания, нейросеть пытается угадать какой объект находится на изображении из Validate. Если предположение нейросети оказалось неправильным, то делается анализ ошибки для предотвращения такой ошибки в следующих итерациях.
Без сета Validate невозможно обучить модель. Данный способ часто применяется в системах машинного обучения, работает достаточно хорошо и является неким негласным стандартом работы с датасетом.
Однако наши разработчики используют несколько иной подход:
70% изображений идут в Train, 20% идут в Validate, 10% — в Test

По нашему опыту, изначально датасет нужно разбивать так, чтобы оставались изображения, которые нейросеть еще не видела. Процесс обучения остается прежним — сетка изучает изображения в Train и проверяет свои знания на изображениях из Validate, однако после завершения тренировки мы добавляем дополнительный этап — тестирование. Нейросеть анализирует изображения из Test, которые она ни разу не видела, а мы можем проверить, работает ли нейросеть на самом деле. Данный этап позволяет выяснить, где ошибается нейросеть, какие классы вызывают у нее сложности.
Шаг 5: Утечка данных
Для начала кратко поясним, что такое утечка данных, и почему это плохо.
Допустим, мы хотим научить нейросеть отличать кроликов от зайцев. Возьмем два изображения зайца, которые отличаются друг от друга небольшим изменением положения его тела:

Для человека данные изображения разные, поэтому они оба могут попасть в датасет. Далее мы, как обычно, разбиваем наш датасет на Train и Validate. Однако случилось так, что первое изображение зайца попало в Train, а второе — в Validate. Начинаем тренировку нашей нейросети, она извлекает свойства зайца с первого изображения, после завершения эпохи нейросети показывают второе изображение зайца. Наша модель безошибочно угадает, что это заяц, а не кролик, ведь почти точно такое же изображение она видела в Train. Получилась ситуация, когда нейросеть не выучила информацию, а запомнила.

Как только наша нейросеть получит на вход изображение, где заяц сильно повернул голову, развернулся или лег на спину — она тут же растеряется и не сможет понять, что ей показывают.
Данные, которые перетекают из Train в Validate не дают нейросети учиться. В процессе обучения значение accuracy будет приближено к 100%, однако в реальных условиях ситуация будет куда более плачевной.
К вопросу утечки данных нужно подходить серьезно. Многие при разбивке датасета сначала используют Shuffle, затем берут первые 70% и помещают в Train, а оставшееся — в Validate, но данных подход приводит к утечке данных. Важно сделать так, чтобы в сете Validate не было картинок, которые есть в Train.

Чтобы избежать утечки данных, можно использовать скрипты и библиотеки, которые удаляют дубликаты. Можно настроить порог удаления — например, удалять идентичные картинки или схожие на 90% картинки. Чем больше дубликатов и похожих изображений будет удалено, тем лучше для нейросети.
На нашей практике мы сталкивались с ситуациями, когда утечка данных значительно влияла на качество определения. В одном из наших проектов нейросеть стабильно ошибалась при определении объектов из определенного класса. Ручным тестированием мы обнаружили утечку данных. После удаления дубликатов ошибка пропала.
Часто можно встретить мнение, что датасет нужно делать как можно более объемным, чем больше датасет — тем лучше качество распознавания. Однако в случае с утечкой данных, лучше уменьшить количество данных, повысив тем самым качество датасета.
Вообще стоит отметить, что датасет по идее неприкосновенен, но его иногда нужно «перетряхивать» в поисках неточностей, дубликатов, неравномерно наполненных классов.
Шаг 6: База данных
Работая с большим датасетом, где речь идет о десятках и сотнях тысяч изображений и десятках классов и подклассов, сложной структуре и изображениях из множества разных источников, мы практикуем создание простой, но очень полезной базы данных, содержащей основную информацию об изображениях.
Зачем это нужно? При работе с большим датасетом гораздо удобнее и быстрее анализировать информацию посредством базы данных, а некоторые виды анализа возможны только с БД.
Сама база данных имеет очень простую структуру и содержит в себе информацию об изображениях:
- название;
- абсолютный путь;
- данные об аннотации;
- класс, к которому принадлежит изображение;
- Свойства изображения, например, вид птицы, марка автомобиля, источник изображения (веб-камера, гугл) и пр.
База данных позволяет быстро работать с датасетом, например, собирать статистику по датасету, чтобы понять его структуру, увидеть дисбаланс по классам, проверить количество изображений из разных источников для каждого класса.
С помощью БД можно составлять графики по количеству изображений, который позволяет визуально легко определить недостаток качественных (с точки зрения тренировки модели) изображений и дисбаланс изображений по классам.
Например, анализируя качество определения видов птиц мы заметили, что нейросеть плохо определяет воробьев. Проанализировав датасет с помощью БД мы увидели, что треть изображений из класса «воробей» были взяты из гугла. Пройдя по всем классам, мы определили пороговое значение гугловских изображений, в нашем случае — 20%. Если в классе «плохих» изображений было больше, то модель начинала ошибаться.
Данный анализ был бы невозможен или очень затруднен, если бы мы вручную просматривали каждый класс и не имели перед собой общую статистику. Стоит отметить, что создание базы данных имеет смысл только при работе с большими датасетами.
Все эти работы проделываются до начала обучения, ведь как вы могли понять из всего вышеизложенного обучение — не главный вопрос, а вот подготовка является основным и самым важным этапом разработки. Разработчику и клиенту важно знать свой датасет, знать из чего он состоит, какую структуру имеет. Это позволит быстро устранять ошибки определения.
Шаг 7: Аугментация
Аугментация — быстрый, простой и эффективный способ увеличить объем датасета в условиях недостаточного количества изображений. С помощью специальных инструментов, например, открытой библиотеки на Python, можно трансформировать одно изображение и в результате получить несколько разных:

Существует два типа аугментаций:
Pre training augmentation — модификация изображений до начала тренировки. Данный тип аугментаций важно проводить только после разбивки датасета на Train и Validate Intraining augmentation — аугментации, встроенные в фреймворк по умолчанию.
Почему же важно проводить до тренировочную аугментацию только после разделения датасета? Дело в том, что может произойти частичная утечка данных: аугментированные изображения могут попасть в Validate, с точки зрения обучения модели нейросети аугментированные фото являются дубликатами, что плохо сказывается на тренировочном процессе.
Аугментировать датасет можно и нужно, но главная мысль этого шага — не увлекаться аугментациями. При увеличении объема датасета в 7 раз сетка не станет в 7 раз эффективнее, но она может начать работать хуже. Стоит использовать только те аугментации, которые реально помогут, т.е. те, что отвечают реальным условиям. Если камера будет стоять внутри помещения, то аугментация “снег” или “туман” только навредит, ведь данных искажений в реальной жизни не будет.
Итак, мы перечислили основные шаги, которые позволят разработчикам создавать датасеты лучше, чем они это делали вчера, а клиентам понять как можно улучшить свой датасет до того, как он будет передан разработчикам. Безусловно, этот список не исчерпывающий, но наш опыт подсказывает, что эти шаги являются самыми важными.
Спасибо за внимание! Оставайтесь на связи, впереди еще много интересных текстов по ML.
- разметка данных
- data labeling
- computer vision
- компьютерное зрение
- машинное обучение
- data annotation
- dataset
- training data
- ml
- ai
- Data Mining
- Обработка изображений
- Машинное обучение
- Искусственный интеллект
- Data Engineering