Apache Cassandra заменит СУБД Oracle в системах ДБО


Компания R-Style Softlab объявляет о переходе к использованию открытой платформы Apache Cassandra в качестве замены реляционной СУБД Oracle для высоконагруженных компонент систем дистанционного банковского обслуживания.
Предпосылкой к такому решению стала успешная реализация для одного из крупнейших банков страны сложной задачи: с учетом растущих объемов данных и нагрузки надо было разработать архитектурное решение, позволяющее масштабировать платформу, обеспечивающую функционирование мобильного и интернет-банка. В рамках подготовки к данному проекту были проведены всесторонние исследования различных СУБД и определен лидер по производительности и потенциалу к масштабированию — система Apache Cassandra.
Поскольку принципы работы реляционных баз данных и noSQL-систем существенно отличаются, в ходе выполнения проекта и подготовки решения к промышленной эксплуатации потребовалась значительная переработка его функциональной и архитектурной составляющих. Были выработаны механизмы разделения и управления крупными пулами клиентов, реализован функционал, обеспечивающий бесперебойную работу всего комплекса, а также средства организации взаимодействия такой распределенной системы с основными бэк-офисными системами банка.
С точки зрения бизнеса банка новая архитектура имеет ряд преимуществ:
• Централизованная база данных позволяла масштабировать решение только вертикально, т.е. путем добавления нового «железа». Новая архитектура открыла возможность горизонтального масштабирования за счет добавления новых узлов без необходимости использовать дополнительное дорогостоящее зарубежное оборудование.
• Банк получил практически не ограниченные возможности по масштабированию.
• Решение позволяет отказаться от дорогостоящей СУБД Oracle в пользу системы с открытым исходным кодом, что в современных реалиях имеет решающее значение.
Последние темы на форумах:
Cassandra. Как не умереть, если знаешь только Oracle
Меня зовут Миша Бутримов, я хотел бы хотел немного рассказать про Cassandra. Мой рассказ будет полезен тем, кто никогда не сталкивался с NoSQL-базами, — у нее есть очень много особенностей реализации и подводных камней, про которые нужно знать. И если кроме Oracle или любой другой реляционной базы вы ничего не видели, эти вещи спасут вам жизнь.
Чем хороша Cassandra? Это NoSQL-база данных, cпроектированная без единой точки отказа, которая хорошо масштабируется. Если вам нужно добавить пару терабайт для какой-нибудь базы, вы просто добавляете ноды в кольцо. Расширить ее на еще один дата-центр? Добавляете ноды в кластер. Увеличить обрабатываемый RPS? Добавляете ноды в кластер. В обратную сторону тоже работает.

В чем еще она хороша? В том, чтобы обрабатывать много запросов. Но много — это сколько? 10, 20, 30, 40 тысяч запросов в секунду — это немного. 100 тысяч запросов в секунду на запись — тоже. Есть компании, которые говорили, что они держат 2 млн. запросов в секунду. Вот им, наверное, придется поверить.
И в принципе у Cassandra есть одно большое отличие от реляционных данных — она вообще на них не похожа. И об этом очень важно помнить.
Не все, что выглядит одинаково, работает одинаково
Как-то ко мне пришел коллега и спросил: «Вот СQL Cassandra query language, и в нем есть select statement, в нем есть where, в нем есть and. Я пишу буквы, и не работает. Почему?». Если относиться к Cassandra как к реляционной базе данных, то это идеальный способ закончить жизнь жестоким самоубийством. И я не пропагандирую, это запрещено в России. Вы просто спроектируете что-нибудь неправильно.
Например, к нам приходит заказчик и говорит: «Давайте построим базу данных для сериалов, или базу данных для справочника рецептов. У нас там будут блюда с продуктами или список сериалов и актеров в нем». Мы говорим радостно: «Давайте!». Это два байта переслать, пара табличек и все готово, все будет работать очень быстро, надежно. И все прекрасно, пока заказчики не приходят и не говорят, что домохозяйки решают еще и обратную задачу: у них есть список продуктов, и они хотят узнать, какое блюдо они хотят приготовить. Вы мертвы.
Все потому, что Cassandra — гибридная база данных: она одновременно и key value, и хранит данные в широких столбцах. Если говорить на языке Java или Kotlin, это можно было бы описать вот так:
То есть мапа, внутри которой лежит еще и отсортированная мапа. Первым ключом к этой мапе является Row key или Partition key — ключ партиционирования. Второй ключ, который является ключом к уже отсортированной мапе, это Clustering key.
Для иллюстрации распределенности базы данных нарисуем три ноды. Теперь нужно понять, как разложить данные на ноды. Потому что если мы будем пихать все в одну (их, кстати, может быть тысяча, две тысячи, пять — сколько угодно), это не очень-то про распределенность. Поэтому нам нужна математическая функция, которая будет возвращать число. Просто число, длинный int, который будет попадать в какой-то диапазон. И у нас одна нода будет отвечать за один диапазон, вторая — за второй, n-ная — за n-ый.

Это число берется с помощью хеш-функции, которая применяется как раз к тому, что мы называем Partition key. Это тот столбец, который указывается в директиве Primary key, и это тот столбец, который будет первым и самым основным ключом мапы. Он определяет, на какую ноду какие данные попадут. Таблица создается в Cassandra почти с таким же синтаксисом, как в SQL:
CREATE TABLE users ( user_id uu id, name text, year int, salary float, PRIMARY KEY(user_id) ) Primary key в данном случае состоит из одной колонки, и она же является ключом партиционирования.
Как у нас лягут пользователи? Часть попадет на одну ноду, часть — на другую, и часть — на третью. Получается обыкновенная хэш-таблица, она же map, она же в Python — словарь, она же — простая Key value-структура, из которой мы можем читать все значения, читать и писать по ключу.

Select: когда allow filtering превращается в full scan, или как не надо делать
Давайте напишем какой-нибудь select statement: select * from users where, userid = . Получается вроде бы как в Oracle: пишем select, указываем условия и все работает, пользователи достаются. Но если выбрать, например, пользователя с определенным годом рождения, Cassandra ругается, что она не может выполнить запрос. Потому что она вообще ничего не знает про то, как у нас распределяются данные о годе рождения — у нее в качестве ключа указана только одна колонка. Тогда она говорит: «Хорошо, я могу по-прежнему выполнить этот запрос. Добавьте allow filtering». Мы добавляем директиву, все работает. И в этот момент происходит страшное.
Когда мы гоняем на тестовых данных, то все прекрасно. А когда вы выполняем запрос в продакшене, где у нас, к примеру, 4 миллиона записей, то у нас все не очень хорошо. Потому что allow filtering — это директива, которая позволяет Cassandra собрать все данные из этой таблицы со всех нод, всех дата-центров (если их много в этом кластере), и только потом уже отфильтровать. Это аналог Full Scan, и вряд ли от него кто-то в восторге.
Если бы нам нужны были пользователи только по идентификаторам, нас бы это устроило. Но иногда нам нужно писать другие запросы и накладывать другие ограничения на выборку. Поэтому вспоминаем: это все у нас мапа, у которой есть ключ партиционирования, но внутри нее — отсортированная мапа.
И у нее тоже есть ключ, который мы называем Сlustering Key. Этот ключ, который, в свою очередь, состоит из колонок, которые мы выберем, с помощью которого Cassandra понимает, как у нее данные физически отсортируются и будут лежать на каждой ноде. То есть, для какого-то Partition key Clustering key расскажет, как именно данные запихнуть в это дерево, какое место они там займут.
Это реально дерево, там просто вызывается компаратор, в который мы передаем некий набор колонок в виде объекта, и задается он тоже в виде перечисления колонок.
CREATE TABLE users_by_year_salary_id ( user_id uuid, name text, year int, salary float, PRIMARY KEY((year), salary, user_id) Обратите внимание на директиву Primary key, у нее первый аргумент (в нашем случае год) всегда идет Partition key. Он может состоять из одной или нескольких колонок, это не важно. Если колонок несколько, его нужно еще раз в скобки убрать, чтобы препроцессор языка понял, что это именно Primary key, а за ним все остальные колонки — Clustering key. При этом они будут в компараторе передаваться в том порядке, в котором они идут. То есть, первая колонка более значимая, вторая — менее значимая и так далее. Как мы для data classes пишем, например, поля equals: перечисляем поля, и для них пишем, какие больше, а какие меньше. В Cassandra это, условно говоря, поля data class, к которому будет применяться написанный для него equals.
Задаем сортировку, накладываем ограничения
Нужно помнить, что порядок сортировки (убывающая, возрастающая, не важно) задается в тот же момент, когда создается ключ, и поменять его потом будет нельзя. Он физически определяет, как будут рассортированы данные и как они будут лежать. Если нужно будет изменить Clustering key или порядок сортировки, придется создавать новую таблицу и переливать в нее данные. С уже существующей так не получится.
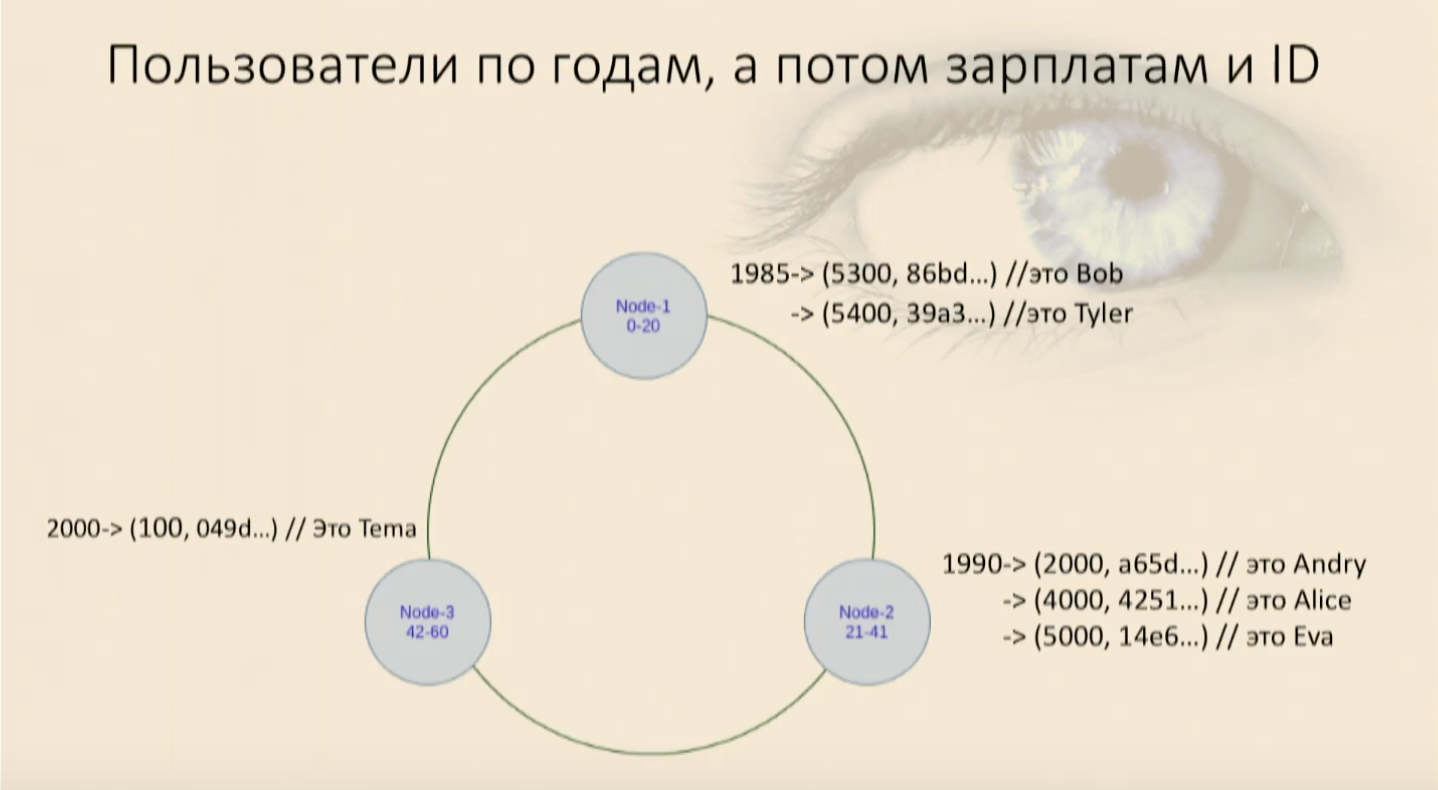
Мы заполнили нашу таблицу пользователями и увидели, что они легли в кольцо сначала по году рождения, а потом внутри на каждой ноде по зарплате и по user ID. Теперь мы можем селектить, накладывая ограничения.
Появляется снова наш работающий where, and , и пользователи нам достаются, и все снова хорошо. Но если мы попробуем использовать только часть Clustering key, причем менее значимую, то Cassandra тут же ругнется, что не может в нашей мапе найти место, где этот объект, у которого вот эти поля для компаратора null, а вот этот, который только что задали, — где он лежит. Мне придется снова поднять все данные с этой ноды и отфильтровать их. И это аналог Full Scan в рамках ноды, это плохо.
В любой непонятной ситуации создавай новую таблицу
Если мы хотим иметь возможность доставать пользователей по ID или по возрасту, или по зарплате, что делать? Ничего. Просто использовать две таблицы. Если надо будет доставать пользователей тремя разными способами — таблиц будет три. Прошли те времена, когда мы экономили место на винте. Это самый дешевый ресурс. Он стоит гораздо дешевле, чем время ответа, которое может быть губительным для пользователя. Пользователю гораздо приятнее получить что-то за секунду, чем за 10 минут.
Мы обмениваем излишнее занимаемое место, денормализованные данные на возможность хорошо масштабироваться, надежно работать. Ведь на самом деле кластер, который состоит из трех дата-центров, в каждом из которых по пять нод, при приемлемом уровне сохранения данных (когда точно ничего не потеряется), способен пережить гибель одного дата-центра полностью. И еще по две ноды в каждом из двух оставшихся. И вот только после этого начнутся проблемы. Это довольно хорошее резервирование, оно стоит пары-тройки лишних ssd-накопителей и процессоров. Поэтому для того, чтобы использовать Cassandra, которая ни разу не SQL, в которой нет отношений, внешних ключей, нужно знать простые правила.
Проектируем все от запроса. Главными становятся не данные, а то, как приложение собирается с ними работать. Если ему нужно получать разные данные разными способами или одни и те же данные разными способами, мы должны положить их так, как будет удобно приложению. Иначе мы будем проваливаться в Full Scan и никакого преимущества Cassandra нам не даст.
Денормализовать данные — это норма. Забываем про нормальные формы, у нас больше не реляционные базы. Положим что-нибудь 100 раз, будет лежать 100 раз. Это все равно дешевле, чем стормозить.
Выбираем ключи для партиционирования так, чтобы они нормально распределялись. Нам не нужно, чтобы хэш от наших ключей попадал в один узкий диапазон. То есть, год рождения в примере выше — плохой пример. Вернее, он хороший, если у нас пользователи по году рождения нормально распределены, и плохой, если речь идет об учениках 5-го класса — там не очень хорошо будет партиционироваться.
Сортировка выбирается один раз на этапе создания Clustering Key. Если ее нужно будет изменить, то придется переливать нашу таблицу с другим ключом.
И самое важное: если нам нужно 100 разными способами забрать одни и те же данные, значит у нас будет 100 разных таблиц.
- cassandra
- nosql
- oracle
- базы данных
- администрирование баз данных
- хранение данных
- денормализация
- масштабирование
- Блог компании QIWI
- NoSQL
- Администрирование баз данных
- Хранение данных
R-Style Softlab заменит СУБД Oracle на Apache Cassandra в системах ДБО
R-Style Softlab объявила о переходе к использованию открытой платформы Apache Cassandra в качестве замены реляционной СУБД Oracle для высоконагруженных компонент систем дистанционного банковского обслуживания.
Предпосылкой к такому решению стала успешная реализация для одного из крупнейших банков страны сложной задачи: с учетом растущих объемов данных и нагрузки надо было разработать архитектурное решение, позволяющее масштабировать платформу, обеспечивающую функционирование мобильного и интернет-банка. В рамках подготовки к данному проекту были проведены всесторонние исследования различных СУБД и определен лидер по производительности и потенциалу к масштабированию — система Apache Cassandra.
Поскольку принципы работы реляционных баз данных и noSQL-систем существенно отличаются, в ходе выполнения проекта и подготовки решения к промышленной эксплуатации потребовалась значительная переработка его функциональной и архитектурной составляющих. Были выработаны механизмы разделения и управления крупными пулами клиентов, реализована функциональность, обеспечивающая бесперебойную работу всего комплекса, а также средства организации взаимодействия такой распределенной системы с основными бэк-офисными системами банка.
Иван Чернов, UserGate — об ответственности ИБ-вендоров перед рынком
Безопасность

Как отмечают в R-Style Softlab, с точки зрения бизнеса банка новая архитектура имеет ряд преимуществ: централизованная база данных позволяла масштабировать решение только вертикально, то есть путем добавления нового «железа». Новая архитектура открыла возможность горизонтального масштабирования за счет добавления новых узлов без необходимости использовать дополнительное дорогостоящее зарубежное оборудование; банк получил практически не ограниченные возможности по масштабированию; решение позволяет отказаться от дорогостоящей СУБД Oracle в пользу системы с открытым исходным кодом, что в современных реалиях имеет решающее значение.
«На наш взгляд, успешная реализация подобного проекта в крупном банке говорит о высоком потенциале программного обеспечения с открытым исходным кодом и его использовании в секторе корпоративных клиентов при обработке больших объемов данных и высокой транзакционной нагрузке, — сказал Артем Оганесян, заместитель директора департамента цифровых решений R-Style Softlab. — Мы планируем продолжить развитие данного направления и предлагаем российским заказчикам недорогой способ обработки данных и горизонтального масштабирования баз данных на основе платформы InterBank RS».
Разбираемся в типах NoSQL СУБД
В этой статье мы познакомимся с 4 основными типами NoSQL баз данных: ключ-значение, документоориентированной, колоночной и графовой.
В этой статье мы познакомимся с разными типами NoSQL СУБД.
Всего есть 4 основных типа:
- Хранилище «ключ-значение» — в нём есть большая хеш-таблица, содержащая ключи и значения. Примеры: Riak, Amazon DynamoDB;
- Документоориентированное хранилище — хранит документы, состоящие из тегированных элементов. Пример: CouchDB;
- Колоночное хранилище — в каждом блоке хранятся данные только из одной колонки. Примеры: HBase, Cassandra;
- Хранилище на основе графов — сетевая база данных, которая использует узлы и рёбра для отображения и хранения данных. Пример: Neo4J.
База данных типа «ключ-значение»
Отсутствие схемы в базах данных «ключ-значение», например, Riak, — это как раз то, что вам нужно для хранения данных. Ключ может быть синтетическим или автосгенерированным, а значение может быть представлено строкой, JSON, блобом (BLOB, Binary Large Object, большой двоичный объект) и т.д.
Такие базы данных как правило используют хеш-таблицу, в которой находится уникальный ключ и указатель на конкретный объект данных. Существует понятие блока (bucket) — логической группы ключей, которые не группируют данные физически. В разных блоках могут быть идентичные ключи.
Производительность сильно вырастает за счёт кеширующих механизмов, которые работают на основе маппингов. Чтобы прочитать значение, вам нужно знать как ключ, так и блок, поскольку на самом деле ключ является хешем (блок + ключ).
В модели «ключ-значение» нет ничего сложного, так как реализовать её проще простого. Не лучший способ, если вам нужно только обновить часть значения или сделать запрос к базе данных.
Если поразмыслить о теореме CAP, то становится довольно очевидно, что такие хранилища хороши в плане доступности (Availability) и устойчивости к разделению (Partition tolerance), но явно проигрывают в согласованности данных (Consistency).
Пример: посмотрим на набор данных, представленных таблицей ниже. Здесь ключ — это название страны, а значение — список адресов в этой стране:
База данных такого типа позволяет читать и записывать значения с помощью ключа следующим образом:
- Get(key) возвращает значение, связанное с переданным ключом;
- Put(key, value) связывает значение с ключом;
- Multi-get(key1, key2, . keyN) возвращает список значений, связанных с переданным ключами;
- Delete(key) удаляет запись для ключа из хранилища.
И хотя базы данных типа «ключ-значение» могут пригодиться в определённых ситуациях, они не лишены недостатков. Первый заключается в том, что модель не предоставляет стандартные возможности баз данных вроде атомарности транзакций или согласованности данных при одновременном выполнении нескольких транзакций. Такие возможности должны предоставляться самим приложением.
Второй недостаток в том, что при увеличении объёмов данных, поддержание уникальных ключей может стать проблемой. Для её решения необходимо как-то усложнять процесс генерации строк, чтобы они оставались уникальными среди очень большого набора ключей.
Riak и Dynamo от Amazon — самые популярные СУБД данных такого типа.
Документоориентированная база данных
Данные, представленные парами ключ-значение, сжимаются как хранилище документов схожим с хранилищем «ключ-значение» образом, с той лишь разницей, что хранимые значения (документы) имеют определённую структуру и кодировку данных. XML, JSON и BSON — некоторые из стандартных распространённых кодировок.
В следующем примере можно увидеть данные в виде «документа» который отображает названия определённых магазинов. Обратите внимание, что, хотя все три примера содержат местоположение, они отображают его по-разному:
Одним из ключевых различий между хранилищем «ключ-значение» и документоориентированным является то, что последний включает метаданные, связанные с хранимым содержимым, что даёт возможность делать запросы на основе содержимого. Например, в указанном примере можно попробовать найти все документы, в которых «City» равно «Noida», что вернёт все документы, связанные с магазинами в этом городе.
Apache CouchDB — пример документоориентированной СУБД. CouchDB использует JSON для хранения данных, JavaScript в качестве языка запросов с использованием MapReduce и HTTP для API. Данные и отношения не хранятся в таблицах так, как в традиционных реляционных базах данных, а по сути являются набором независимых документов.
Тот факт, что такие базы данных работают без схемы, делает простой задачей добавление полей в JSON-документы без необходимости сначала заявлять об изменениях.
Couchbase и MongoDB — самые популярные документоориентированные СУБД.
Колоночная база данных
В колоночных NoSQL базах данных данные хранятся в ячейках, сгруппированных в колонки, а не в строки данных. Колонки логически группируются в колоночные семейства. Колоночные семейства могут состоять из практически неограниченного количества колонок, которые могут создаваться во время работы программы или во время определения схемы. Чтение и запись происходит с использованием колонок, а не строк.
В сравнении с хранением данных в строках, как в большинстве реляционных баз данных, преимущества хранения в колонках заключаются в быстром поиске/доступе и агрегации данных. Реляционные базы данных хранят каждую строку как непрерывную запись на диске. Разные строки хранятся в разных местах на диске, в то время как колоночные базы данных хранят все ячейки, относящиеся к колонке, как непрерывную запись, что делает операции поиска/доступа быстрее.
Пример: получение списка заголовков нескольких миллионов статей будет трудоёмкой задачей при использовании реляционных баз данных, так как для извлечения заголовков придётся проходить по каждой записи. А можно получить все заголовки с помощью только одной операции доступа к диску.
- Колоночное семейство — структура, которая может легко группировать колонки и суперколонки;
- Ключ — постоянное имя записи. У ключей может быть разное количество колонок, поэтому база данных может расширяться неравномерно;
- Пространство ключей — определяет самый внешний уровень организации, как правило, имя приложения/базы данных.
- Колонка — имеет упорядоченный список элементов — кортежей с именами и значениями.
Самыми известными примерами являются Google BigTable и HBase с Cassandra, вдохновлённые BigTable.
BigTable представляет собой высокопроизводительное, сжатое и проприетарное хранилище данных от Google. У него есть следующие атрибуты:
- Разреженность — некоторые ячейки могут быть пустыми;
- Распределённость — данные разделены между многими узлами;
- Постоянство — хранится на диске;
- Многомерность — более 1 измерения;
- Сопоставление — ключ и значение;
- Отсортированность — сопоставления обычно не сортируются, но этот случай — исключение.
Двумерная таблица, состоящая из строк и колонок, является частью реляционной системы баз данных.
Эту таблицу можно представить в виде BigTable-сопоставления следующим образом:
< 3PillarNoida: < city: Noida pincode: 201301 >, details: < strength: 250 projects: 20 >> < 3PillarCluj: < address: < city: Cluj pincode: 400606 >, details: < strength: 200 projects: 15 >>, < 3PillarTimisoara: < address: < city: Timisoara pincode: 300011 >, details: < strength: 150 projects: 10 >> < 3PillarFairfax : < address: < city: Fairfax pincode: VA 22033 >, details: < strength: 100 projects: 5 >> - Внешние ключи «3PillarNoida», «3PillarCluj», «3PillarTimisoara» и «3PillarFairfax» являются аналогами строк.
- «address» и «details» — колоночные семейства.
- В колоночном семействе «address» есть колонки «city» и «pincode».
- В колоночном семействе «details» есть колонки «strength» и «projects».
На колонки можно ссылаться с помощью колоночного семейства.
Графовая база данных
В графовой базе данных вы не найдёте строгого формата SQL или представления таблиц и колонок, вместо этого используется гибкое графическое представление, которое идеально подходит для решения проблем масштабируемости. Графовые структуры используются вместе с рёбрами, узлами и свойствами, что обеспечивает безиндексную смежность. При использовании графового хранилища данные могут быть легко преобразованы из одной модели в другую.
- Такие базы данных используют рёбра и узлы для представления данных.
- Узлы связаны между собой определённым отношениями, представленными рёбрами между ними.
- У узлов и отношений есть некоторые свойства.
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Далее описаны некоторые особенности графовой базы данных на основе примера ниже:
Помеченный, направленный, атрибутированный мультиграф: граф содержит узлы, которые помечены определёнными свойствами и которые имеют связи друг с другом, что представлено направленными рёбрами. Например, связь «Элис знает Боба» выражена ребром с некоторыми свойствами.
Хотя реляционные базы данных могут скопировать поведение графовых, рёбрам потребуется соединение (JOIN), что дорого обойдётся.
Любой рейтинг «Рекомендовано вам», который можно увидеть на разных сайтах, зачастую составляется исходя из того, как другие пользователи оценили продукт. Графовые базы данных отлично подходят для такого случая.
InfoGrid и Infinite Graph — самые популярные графовые базы данных. InfoGrid позволяет соединять множество рёбер (Relationships) и узлов (MeshObjects), что упрощает представление набора информации со сложными взаимными ссылками.
InfoGrid предлагает два типа баз данных:
- MeshBase — подходящий вариант для автономного развёртывания;
- NetMeshBase — подойдёт для больших распределённых графов и имеет дополнительные возможности для взаимодействия с другими похожими NetMeshBase.
Смотрите также: SQL против NoSQL на примере MySQL и MongoDB

Следите за новыми постами по любимым темам
Подпишитесь на интересующие вас теги, чтобы следить за новыми постами и быть в курсе событий.