GetHashCode — вычисление хэш
a1 и a2, по логике вещей, совершенно идентичны. Но для C# нет. Их хэши различны. Конечно же, понятно, что это различие может быть оправдано, например, различием адресами в памяти, ну или временем создания, в конце концов :). Так вот хочется точно узнать, как же формируются хэши объектов и чем обосновывается их различие для идентичных пользовательских объектов.
Отслеживать
23.8k 3 3 золотых знака 46 46 серебряных знаков 61 61 бронзовый знак
задан 2 мар 2013 в 22:07
13.6k 13 13 золотых знаков 61 61 серебряный знак 122 122 бронзовых знака
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
Для начала, поскольку ваш класс A не переопределяет GetHashCode() , эта функция наследуется от object .
Точный алгоритм вычисления GetHashCode() для object не специфицирован:
Реализация GetHashCode по умолчанию не гарантирует уникальные значения для различных объектов. Кроме того, .NET Framework не гарантирует, что реализация GetHashCode по умолчанию, в том числе значения, возвращаемые ей, не поменяются при смене версии фреймворка. Соответственно, значение функции GetHashCode по умолчанию не должно быть использована как уникальный идентификатор объекта с целью хеширования.
То, что вам два объекта кажутся идентичными, не гарантирует, что у них при реализации по умолчанию совпадут хеш-коды. С другой стороны, посудите сами: если у двух людей совпадает имя и фамилия, это ведь ещё не значит, что это один и тот же человек? Так и .NET framework, если у двух экземпляров класса A совпадают все поля, ещё не считает эти экземпляры одним и тем же объектом. Соответственно, по умолчанию используется что угодно — например, адрес при создании или время создания, документация не говорит о точном методе. Если вас не устраивает поведение по умолчанию, вы должны его перекрыть.
Если ваш класс не использует операцию Equals и не является ключом в хеш-таблицах, в принципе можно ничего и не делать, вас должно устраивать и поведение по умолчанию. Но если ваш класс служит ключом, вам необходимо переопределить как Equals , так и GetHashCode() , причём согласованным образом: если x.Equals(y) возвращает true , то и хеш-коды у x и y обязаны совпадать.
Отсюда следует, что вы должны переопределять функцию GetHashCode() вместе с функцией Equals . Например, так:
public class A < public int b = 0; public int c; public override bool Equals(object obj) < return Equals(obj as A); >public bool Equals(A that) < if (that == null) return false; return this.b == that.b && this.c == that.c; >public override int GetHashCode() < return b.GetHashCode() * 13 + c.GetHashCode(); >> В C#, в отличие от многих других языков, есть объекты двух типов: объекты, полностью определяющиеся своими атрибутами (то есть, полями), и объекты, представляющие собой самостоятельную сущность, не сводящуюся лишь к значениям атрибутов.
Примером объекта первого типа являются, например, числа: если вы пишете
x = 5; y = 5; — нет никакой разницы между первой и второй пятёркой, это одна и та же сущность. Подобные штуки называются в .NET типами-значениями и вводятся ключевым словом struct . Для них метод Equals по умолчанию сравнивает значения всех полей, и если они равны, заключает, что и структуры равны, одинаковы. Поэтому структуры можно копировать по значению, структуру можно безболезненно заменить на её копию. (Метод GetHashCode по умолчанию определён соответствующим образом: для равных структур он гарантированно возвращает одинаковый хеш.)
Примером другой сущности может служить, например, автомобиль, атрибутами которого являются марка, год выпуска, мощность двигателя и т. п. Два автомобиля с одинаковыми техническими параметрами — это всё же разные автомобили. Такие объекты в C# называются ссылочными типами и вводятся ключевым словом class . Для классов, соответственно, реализация Equals по умолчанию не имеет права предполагать, что одинаковые значения полей автоматически означают равенство, каждый экземпляр класса считается уникальным.
Подумайте, не нужна ли вам на самом деле вместо класса A структура?
Вопрос о том, определяемся ли мы все, люди, лишь нашим набором параметров, или в нас есть что-то вне этого, не так уж прост.
Для чего существует GetHashCode()
Я понял что он разных для каждые объектов и его советуют переопределят если нужно использовать для сравнение.
Это должен быть лишь кодовый идентификатор для объекта,если так можно сказать?
Я могу писать и так
1 2 3 4 5 6 7 8 9 10
class ob { int i = 0; } public override string GetHashCode() //и тут обязательно наверное тип int,если переопределяем { i++; return i.ToString() + "a"; }//то-есть алгоритм сравнение я буду писать сам
и это тоже будет своего рода идентификатор я правильно понимаю?
или нужно копать глубже и нырять до уровня битов?
Лучшие ответы ( 3 )
94731 / 64177 / 26122
Регистрация: 12.04.2006
Сообщений: 116,782
Ответы с готовыми решениями:

Какой алгоритм getHashCode использовать как для больших значений, так и для маленьких
Есть некий класс с какими-то числовыми полями. Причем значения полей могут варьироваться во всей.
Как лучше переопределить GetHashCode() для моего класса
Здравствуйте, уважаемые форумчане, возник вопрос к знающим людям. Имеется простой класс, с парой.
Как перегрузить методы Equals() и GetHashCode(), для сравнения свойств объектов?
Есть два объекта класса Квадрат.Необходимо сравнить их по площади заданной свойством. Для этого.
Для чего существует метод html.hidden?
Можете обьяснить для чего метод html.hidden(желательно на примерах).Смотрел msdn не сильно понял.
430 / 431 / 93
Регистрация: 16.07.2012
Сообщений: 886
Сообщение было отмечено как решение
Решение
GetHashCode используется для ускорения сравнения двух объектов. То есть если требуется узнать, одинаковы ли какие-то два объекта, то сначала сравниваются их хэш-коды. Если они различаются, то значит и объекты различны. Если же совпадают, то тогда начинается дорогостоящее «настоящее» сравнение через Equals.
Таким образом, GetHashCode, во-первых, должен совпадать для одинаковых объектов, во-вторых, по-возможности отличаться для разных объектов и в-третьих, достаточно быстро вычисляться (чтобы в его использовании вообще был смысл).
В вашем случае вряд ли преобразование целых в строку и затем их сравнение будет выполняться быстрее чем сравнение чисел напрямую.
Темная сторона .Net
592 / 489 / 39
Регистрация: 21.07.2012
Сообщений: 1,668
Но он не всегда будет разным для разных объектов,каким образом их можно переопределить что б
это правило соблюдалось.
Но,я могу придумать какой-то свой алгоритм сравнения,если он будет быстрым? и так и должно быть
если я правильно понял документацию мсдн.
![]() Сообщение от canopen
Сообщение от canopen 
GetHashCode используется для ускорения сравнения двух объектов. То есть если требуется узнать, одинаковы ли какие-то два объекта, то сначала сравниваются их хэш-коды. Если они различаются, то значит и объекты различны. Если же совпадают, то тогда начинается дорогостоящее «настоящее» сравнение через Equals.
GetHashCode неявно вызывает Equals если совпадают? 0о
Добавлено через 48 секунд
И когда имеет смысл переопределять GetHashCode();
только для своих объектов,правильно?
430 / 431 / 93
Регистрация: 16.07.2012
Сообщений: 886
Сообщение было отмечено как решение
Решение
GetHashCode, конечно, не вызывает Equals. Это делает соответствующий алгоритм при поиске, например, ключа в словаре — сначала сравнивает хэши, потом, если необходимо Equals.
Добавлено через 6 минут
Простейшие примеры реализации:
-если у вас в классе одно целое поле int i, то в GetHashCode вы его и возвращаете: return i
-если у вас в классе два целых поля int i и int j, то вы возвращаете XOR: return i^j
и так далее.
Очевидно что если у двух объектов поля i равны и поля j равны, то и i^j, то есть хэши, будут равны. С другой стороны, если хотя бы одно из полей не совпадает, то с высокой долей вероятности и i^j не будет совпадать. Плюс сравнить хэш коды быстрее, чем сравнить две пары целых. Что и требуется для хорошей хэш-функции.
Добавлено через 3 минуты
А про переопределение GetHashCode четко сказано в документации — если переопределяете Equals (то есть задаете свое правило сравнения объектов), то и GetHashCode надо переопределить (чтобы он новому вашему правилу соответствовал). А если не переопределяете, то и не надо GetHashCode трогать. Все объекты будут по ссылке сравниваться.
Темная сторона .Net
592 / 489 / 39
Регистрация: 21.07.2012
Сообщений: 1,668
![]() Сообщение от canopen
Сообщение от canopen
если переопределяете Equals (то есть задаете свое правило сравнения объектов), то и GetHashCode надо переопределить
Там же написано,что стандартным GetHashCode лучше не пользоваться при сравнении ссылочных типов и при возможности переопределить
430 / 431 / 93
Регистрация: 16.07.2012
Сообщений: 886
Это где вы такое прочитали? По-умолчанию Equals сравнивает адреса объектов, а GetHashCode видимо просто возвращает адрес объекта. Куда уж проще и эффективнее? А если вы захотите чтобы при сравнение учитывались не только адреса, но и содержимое полей, то вам в любом случае переопределять Equals придется.
Регистрация: 14.01.2012
Сообщений: 127
If two objects compare as equal, the GetHashCode method for each object must return the same value
Если объекты равны, то равны их хеш-коды
However, if two objects do not compare as equal, the GetHashCode methods for the two object do not have to return different values.
Если объекты не равны, то их хеш-коды не обязаны быть различны.
Непонятно. Каким образом его вообще тогда использовать?
Темная сторона .Net
592 / 489 / 39
Регистрация: 21.07.2012
Сообщений: 1,668
the default implementation of this method must not be used as a unique object identifier for hashing purposes
и еще Шилдт писал что лучше по возможности переопределить GetHashCode
немного ошибся в постановке предыдущего вопроса,хотя еще вопрос —
GetHashCode видимо просто возвращает адрес объекта
как тогда для разных объектов он может вернуть одинаковый адрес
Я у Лип-забыл как его там,читал почему,но интересно ваше мнение.
430 / 431 / 93
Регистрация: 16.07.2012
Сообщений: 886
Предположим у вас есть много больших файлов, каждый с контрольной суммой (хэшем). Если вы будете их напрямую сравнивать, это будет очень долго — файлы ведь большие. Но вы можете сначала сравнивать их хэши, если хэши не совпадут, значит и файлы уже отличаются, можно дальше не сравнивать. Если же хэши совпадут, то вам конечно все-таки придется файлы напрямую побайтно сравнить. Но за счет тех случаев, когда хэши не совпали и дорогостоящего сравнения не потребовалось, вы и получите выигрыш.
Темная сторона .Net
592 / 489 / 39
Регистрация: 21.07.2012
Сообщений: 1,668
![]() Сообщение от nrv
Сообщение от nrv
Каким образом его вообще тогда использовать?
Нужно гарантировать что для разных объектов он не вернет одинаковый код.Это правило.
Как,я пока пытаюсь выяснить
430 / 431 / 93
Регистрация: 16.07.2012
Сообщений: 886
![]() Сообщение от Noob.net
Сообщение от Noob.net
как тогда для разных объектов он может вернуть одинаковый адрес
Для разных и не может.
Темная сторона .Net
592 / 489 / 39
Регистрация: 21.07.2012
Сообщений: 1,668
canopen, вот за это спасибо,напомнили что после идет сравнение)
Добавлено через 36 секунд
![]() Сообщение от canopen
Сообщение от canopen
Для разных и не может.
Ну вот мне сказали выше — может)
430 / 431 / 93
Регистрация: 16.07.2012
Сообщений: 886
![]() Сообщение от Noob.net
Сообщение от Noob.net
Нужно гарантировать что для разных объектов он не вернет одинаковый код.Это правило.
Вот в этом вы ошибаетесь. Нужно чтобы вероятность совпадения хэшей была как можно ниже, но не обязательно же нулевой.
Добавлено через 2 минуты
Еще один пример. Вам нужно две строки символов сравнить. Как вы будете действовать? Логично будет сначала проверить что длины строк совпадают. Потому что если даже длины различаются, то уж сами строки тем более отличаются. Можно считать длину строки в этом случае простейшим хэшем. Конечно существует много разных строк одинаковой длины, для которых такой «хэш» бесполезным окажется, но в других случаях выигрыш мы получим.
Темная сторона .Net
592 / 489 / 39
Регистрация: 21.07.2012
Сообщений: 1,668
Ну вот когда строки одинаковой длины,где выигрыш тогда?
Может лучше другой пример)
А за каким алгоритмом его лучше переписывать если уж придется?
Master of Orion
![]()
6096 / 4952 / 905
Регистрация: 10.07.2011
Сообщений: 14,522
Записей в блоге: 5
Хэш-функция используется для быстрого создания числа (хэш-кода), соответствующего значению объекта. Обычно каждому объекту Type соответствует своя хэш-функция, у которой для обеспечения уникальности в качестве входного аргумента должно использоваться хотя бы одно из полей экземпляра.
Хэш-функции должны обладать следующими свойствами:
Если два объекта при сравнении оказались равны, методы GetHashCode обоих этих объектов должны возвращать одинаковые значения. Однако если при сравнении оказалось, что эти объекты не равны, методы GetHashCode этих объектов не обязательно должны возвращать разные значения.
Метод GetHashCode должен последовательно возвращать для объекта один и тот же хэш-код, пока в состоянии объекта не произойдут изменения, определяющие значения, возвращаемые для объекта методом Equals. Обратите внимание, что это справедливо только для текущего выполнения приложения, и при повторном запуске приложения может возвращаться другой хэш-код.
Для оптимальной производительности значения хэш-функции должны подчиняться случайному распределению для всех входных аргументов.
Иными словами, для переопределния хеш функции требуется, чтобы наблюдалось пуассоновское распредление на возможном интервале (то есть, чтобы вероятность коллизии стремилась к нулю).
![]()
2347 / 1720 / 148
Регистрация: 06.03.2009
Сообщений: 3,675
Сообщение было отмечено как решение
Решение
![]() Сообщение от Noob.net
Сообщение от Noob.net
Нужно гарантировать что для разных объектов он не вернет одинаковый код.Это правило.
Вы видимо не совсем понимаете, что подразумевается под разностью. Давайте рассмотрим на примере. Предположим, нам требуется создать класс для представления комплексных чисел, вот такой:
1 2 3 4 5 6 7 8 9 10 11 12
public class Complex { private double _real; private double _imaginary; public Complex(double real, double imaginary) { _real = real; _imaginary = imaginary; } public double Real { get { return _real; } } public double Imaginary { get { return _imaginary; } } };
Мы создаем два экземпляра класса Complex с одинаковыми значениями полей:
Complex first = new Complex(1.0, 2.0); Complex second = new Complex(1.0, 2.0);
С точки зрения расположения в памяти объекты first и second являются разными и поэтому дефолтная реализация Equals будет возвращать false, а GetHashCode разные значения для этих объектов.
Но с математической точки зрения эти объекты эквивалентны, т.к. действительная и мнимая части равны. Т.к. мы пытаемся смоделировать комплексные числа именно с математической точки зрения, очевидно, что дефолтные реализации Equals и GetHashCode нас не устраивают, поэтому мы их переопределим:
1 2 3 4 5 6 7 8 9 10 11 12
public override int GetHashCode() { return _real.GetHashCode() ^ _imaginary.GetHashCode(); } public override bool Equals(Object obj) { Complex other = obj as Complex; if (other == null) return false; return other._real == _real && other._imaginary == _imaginary; }
Тем самым мы реализовали проверку на эквивалетность именно с точки зрения математики, Equals вернет true тогда и только тогда, когда действительная и мнимая части двух объектов совпадают, GetHashCode с высокой вероятностью вернет одинаковые значения только тогда, когда действительная и мнимая части двух объектов опять же совпадают.
Т.е. нужно разделять понятия «идентичность» и «эквивалетность». Идентичность характеризуется считай адресом объекта в памяти, и любой объект идентичен себе и только себе. Дефолтная реализация для ссылочных типов как раз таки проверяет идентичность. Эквивалетность же диктуется обычно предметной областью, в данном случае математикой, которая устанавливает правила сравнения комплесных чисел на равенство.
И еще важный момент. Не бросайтесь переопределять методы GetHashCode и Equals где не попадя. Это имеет смысл только там, где это действительно требуется.
Gethashcode c что это
Все классы в .NET, даже те, которые мы сами создаем, а также базовые типы, такие как System.Int32 , являются неявно производными от класса Object. Даже если мы не указываем класс Object в качестве базового, по умолчанию неявно класс Object все равно стоит на вершине иерархии наследования. Поэтому все типы и классы могут реализовать те методы, которые определены в классе System.Object. Рассмотрим эти методы.
ToString
Метод ToString служит для получения строкового представления данного объекта. Для базовых типов просто будет выводиться их строковое значение:
int i = 5; Console.WriteLine(i.ToString()); // выведет число 5 double d = 3.5; Console.WriteLine(d.ToString()); // выведет число 3,5
Для классов же этот метод выводит полное название класса с указанием пространства имен, в котором определен этот класс. И мы можем переопределить данный метод. Посмотрим на примере:
Person person = new Person < Name = "Tom" >; Console.WriteLine(person.ToString()); // выведет название класса Person Clock clock = new Clock < Hours = 15, Minutes = 34, Seconds = 53 >; Console.WriteLine(clock.ToString()); // выведет 15:34:53 class Clock < public int Hours < get; set; >public int Minutes < get; set; >public int Seconds < get; set; >public override string ToString() < return $"::"; > > class Person < public string Name < get; set; >= ""; >
Для переопределения метода ToString() в классе Clock, который представляет часы, используется ключевое слово override (как и при обычном переопределении виртуальных или абстрактных методов). В данном случае метод ToString() выводит в строке значения свойств Hours, Minutes, Seconds.
Класс Person не переопределяет метод ToString, поэтому для этого класса срабатывает стандартная реализация этого метода, которая выводит просто название класса.
Кстати в данном случае мы могли задействовать обе реализации:
Person tom = new Person < Name = "Tom" >; Console.WriteLine(tom.ToString()); // Tom Person undefined = new Person(); Console.WriteLine(undefined.ToString()); // Person class Person < public string Name < get; set; >= ""; public override string? ToString() < if (string.IsNullOrEmpty(Name)) return base.ToString(); return Name; >>
То есть если имя — свойство Name не имеет значения, оно представляет пустую строку, то возвращается базовая реализация — название класса. Стоит отметить, что базовая реализация возвращает не просто строку, а объект string? — то есть это может быть строка string, либо значение null , которое указывает на отсутствие значения. И в реальности в качестве возвращаемого типа для метода мы можем использовать как string , так и string?
Если же имя у объекта Person установлено, то возвращается значение свойства Name. Для проверки строки на наличие значения применяется метод String.IsNullOrEmpty() .
Стоит отметить, что различные технологии на платформе .NET активно используют метод ToString для разных целей. В частности, тот же метод Console.WriteLine() по умолчанию выводит именно строковое представление объекта. Поэтому, если нам надо вывести строковое представление объекта на консоль, то при передаче объекта в метод Console.WriteLine необязательно использовать метод ToString() — он вызывается неявно:
Person person = new Person < Name = "Tom" >; Console.WriteLine(person); // Tom Clock clock = new Clock < Hours = 15, Minutes = 34, Seconds = 53 >; Console.WriteLine(clock); // выведет 15:34:53
Метод GetHashCode
Метод GetHashCode позволяет возвратить некоторое числовое значение, которое будет соответствовать данному объекту или его хэш-код. По данному числу, например, можно сравнивать объекты. Можно определять самые разные алгоритмы генерации подобного числа или взять реализацию базового типа:
class Person < public string Name < get; set; >= ""; public override int GetHashCode() < return Name.GetHashCode(); >>
В данном случае метод GetHashCode возвращает хеш-код для значения свойства Name. То есть два объекта Person, которые имеют одно и то же имя, будут возвращать один и тот же хеш-код. Однако в реальности алгоритм может быть самым различным.
Получение типа объекта и метод GetType
Метод GetType позволяет получить тип данного объекта:
Person person = new Person < Name = "Tom" >; Console.WriteLine(person.GetType()); // Person
Этот метод возвращает объект Type , то есть тип объекта.
С помощью ключевого слова typeof мы получаем тип класса и сравниваем его с типом объекта. И если этот объект представляет тип Person, то выполняем определенные действия.
object person = new Person < Name = "Tom" >; if (person.GetType() == typeof(Person)) Console.WriteLine("Это реально класс Person");
Причем поскольку класс Object является базовым типом для всех классов, то мы можем переменной типа object присвоить объект любого типа. Однако для этой переменной метод GetType все равно вернет тот тип, на объект которого ссылается переменная. То есть в данном случае объект типа Person.
Стоит отметить, что проверку типа в примере выше можно сократить с помощью оператора is :
object person = new Person < Name = "Tom" >; if (person is Person) Console.WriteLine("Это реально класс Person");
В отличие от методов ToString, Equals, GetHashCode метод GetType() не переопределяется.
Метод Equals
Метод Equals позволяет сравнить два объекта на равенство. В качестве параметра он принимает объект для сравнения в виде типа object и возврашает true , если оба объекта равны:
public override bool Equals(object? obj)
Например, реализуем данный метод в классе Person:
class Person < public string Name < get; set; >= ""; public override bool Equals(object? obj) < // если параметр метода представляет тип Person // то возвращаем true, если имена совпадают if (obj is Person person) return Name == person.Name; return false; >// вместе с методом Equals следует реализовать метод GetHashCode public override int GetHashCode() => Name.GetHashCode(); >
Метод Equals принимает в качестве параметра объект любого типа, который мы затем приводим к текущему классу — классу Person.
Если переданный объект представляет тип Person, то возвращаем результат сравнения имен двух объектов Person. Если же объект представляет другой тип, то возвращается false.
В данном случае для примера применяется довольно простой алгоритм сравнения, однако при необходимости реализацию метода можно сделать более сложной, например, сравнивать по нескольким свойствам при их наличии.
Стоит отметить, что вместе с методом Equals следует реализовать метод GetHashCode.
var person1 = new Person < Name = "Tom" >; var person2 = new Person < Name = "Bob" >; var person3 = new Person < Name = "Tom" >; bool person1EqualsPerson2 = person1.Equals(person2); // false bool person1EqualsPerson3 = person1.Equals(person3); // true Console.WriteLine(person1EqualsPerson2); // false Console.WriteLine(person1EqualsPerson3); // true
И если следует сравнивать два сложных объекта, как в данном случае, то лучше использовать метод Equals, а не стандартную операцию ==.
Откуда растут руки у GetHashCode в .NET
Данная статья посвящена теме генерации хеш-кодов на платформе .NET. Тема является достаточно интересной, и думаю любой уважающий себя .NET разработчик должен ее знать. Поэтому поехали!
Что хранится в объектах помимо их полей?
Начнем нашу статью с того, что узнаем что хранится у объектов ссылочного типа помимо их полей.
У каждого объекта ссылочного типа есть так называемый заголовок (Header), который состоит из двух полей: указатель на тип которым является данный объект (MethodTablePointer), а так же индекс синхронизации (SyncBlockIndex).
Для чего они нужны?
Первое поле необходимо для того, чтобы каждый управляемый объект мог предоставить информацию о своем типе во время выполнения, то есть нельзя выдать один тип за другой, это сделано для безопасности типов. Так же этот указатель используется для реализации динамической диспетчеризации методов, фактически через него вызываются методы данного объекта. Метод Object.GetType фактически возвращает именно указатель MethodTablePointer.
Второе поле необходимо для многопоточного окружения, а именно для того чтобы каждый объект можно было использовать потокобезопасно.
Когда загружается CLR, она создает так называемый пул блоков синхронизации, можно сказать обычный массив этих блоков синхронизации. Когда объекту необходимо работать в многопоточном окружении (это делается с помощью метода Monitor.Enter или конструкции языка C# lock), CLR отыскивает свободный блок синхронизации в своем списке и записывает его индекс в то самое поле в заголовке объекта. Как только объект перестает нуждаться в многопоточном окружение, CLR просто присваивает значение -1 этому полю и тем самым освобождает блок синхронизации.
Блоки синхронизации — это фактически новое воплощение критических секций из С++. Создатели CLR посчитали, что ассоциировать с каждым управляемым объектом структуру критической секции будет слишком накладно, учитывая, что большинство объектов вообще не используют многопоточное окружение.
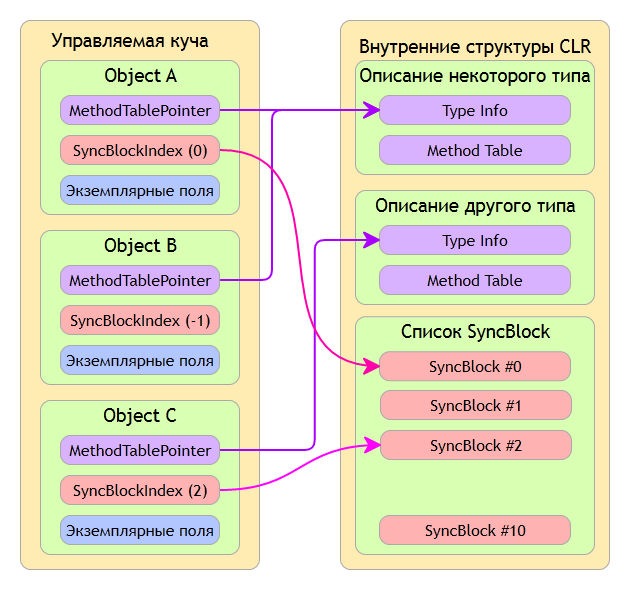
Для большего понимания ситуации рассмотрим следующую картинку:
По картинке видно, что ObjectA и ObjectB имеют один тип, поскольку их MethodTablePointer-ы указывают на один и тот же тип. ObjectC же имеет другой тип. Так же видно, что ObjectA и ObjectC задействуют пул блоков синхронизации, то есть фактически используют многопоточное окружение. ObjectB не использует пул поскольку его SyncBlockIndex = -1.
Теперь после того как мы рассмотрели как хранятся объекты, мы можем перейти к генерации хеш-кодов.
Как работает GetHashCode у ссылочных типов
То, что метод GetHashCode возвращает адрес объекта в управляемой куче — это миф. Этого быть не может, в виду его не постоянства, сборщик мусора, уплотняя кучу, смещает объекты и соответственно меняет им всем адреса.
Я не зря начал статью с объяснения того, что такое SyncBlock, поскольку в первых версиях фреймворка в качестве хеш-кода ссылочного типа использовался именно свободный индекс некоторого SyncBlock-а. Таким образом, в .NET 1.0 и .NET 1.1 вызов метода GetHashCode приводил к созданию SyncBlock и занесением его индекса в заголовок объекта в поле SyncBlockIndex. Как вы понимаете это не очень хорошая реализация для хеш-функции, поскольку во-первых создаются не нужные внутренние структуры, которые занимают память + тратиться время на их создание, во-вторых хеш-коды будут идти подряд, то есть будут предсказуемыми. Вот ссылка на блог, в котором один из разработчиков CLR говорит, что такая реализация плохая, и что они ее поменяют в следующей версии.
Начиная с .NET 2.0 алгоритм хеширования изменился. Теперь он использует manage идентификатор потока, в котором выполняется метод. Если верить реализации в SSCLI20, то метод выглядит так:
inline DWORD GetNewHashCode() < // Every thread has its own generator for hash codes so that we won't get into a situation // where two threads consistently give out the same hash codes. // Choice of multiplier guarantees period of 2**32 - see Knuth Vol 2 p16 (3.2.1.2 Theorem A) DWORD multiplier = m_ThreadId*4 + 5; m_dwHashCodeSeed = m_dwHashCodeSeed*multiplier + 1; return m_dwHashCodeSeed; >Таким образом, каждый поток имеет свой собственный генератор для хэш-кодов, так что мы не можем попасть в ситуацию, где два потока последовательно генерируют одинаковые хэш-коды.
Как и раньше хеш-код вычисляется один раз и сохраняется в заголовке объекта в поле SyncBlockIndex (это оптимизация CLR). Теперь возникает вопрос, что если после вызова метода GetHashCode нам понадобиться использовать индекс синхронизации? Куда его записывать? И что делать с хеш-кодом?
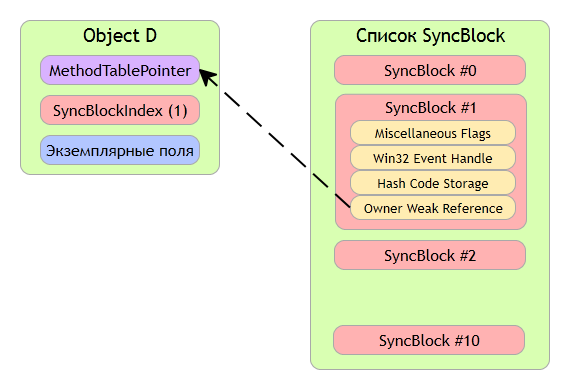
Для ответа на эти вопросы рассмотрим структуру SyncBlock.
При первом вызове метода GetHashCode CLR вычисляет хеш-код и заносит его в поле SyncBlockIndex. Если при этом с объектом ассоциирован SyncBlock, то есть поле SyncBlockIndex используется, то CLR записывает хеш-код в сам SyncBlock, на рисунке показано место в SyncBlock, отвечающее за хранение хеш-кода. Как только SyncBlock освобождается, CLR копирует хеш-код из его тела в заголовок объекта SyncBlockIndex. Вот и все.
Как работает GetHashCode у значимых типов
Теперь поговорим о том, как работает метод GetHashCode у значимых типов. Скажу заранее, он работает достаточно интересно.
Первое, что надо сказать так это то, что создатели CLR рекомендуют всегда переопределять данный метод у пользовательских типов, поскольку он может работать не очень быстро, да и поведение его по умолчанию, возможно, не всегда Вас удовлетворит.
На самом деле у CLR есть две версии реализации метода GetHashCode для значимых типов, и то какая версия будет использована, исключительно зависит от самого типа.
Первая версия:
Если структура не имеет ссылочных полей, а так же между ее полями нет свободного места, то используется быстрая версия метода GetHashCode. CLR просто xor — ит каждый 4 байта структуры и получает ответ. Это хороший хеш, так как задействовано всё содержимое структуры. Например, структура, у которой есть поле типа bool и int будет иметь свободное пространство в 3 байта, поскольку JIT когда размещает поля выравнивает их по 4 байта, а, следовательно, будет использована вторая версия для получения хеш-кода.
Кстати, в реализации данной версии был баг, который исправлен только в .NET 4. Он заключается в том, что хеш-код для типа decimal вычислялся не правильно.
decimal d1 = 10.0m; decimal d2 = 10.00000000000000000m; С точки зрения чисел d1 и d2 равны, но их битовые представления отличаются (из-за особенностей представления decimal). А поскольку CLR xor — ит каждый 4 байта (которых всего 4 так как decimal занимает 16 байт), то получаются разные хеш-коды. Кстати, данный баг проявлялся не только у decimal, но и у любой структуры, которая содержит данный тип, а так же использует быструю версию для вычисления хеш-кода.
Вторая версия:
Если структура содержит ссылочные поля или между ее полями имеется свободное пространство, то используется медленная версия метода. CLR выбирает первое поле структуры, на основание которого и создает хеш-код. Это поле по возможности должно быть неизменяемым, например, иметь тип string, иначе при его изменении хеш-код будет так же меняться, и мы не сможем уже найти нашу структуру в хеш-таблице, если она использовалась в качестве ключа. Получается, если первое поле структуры будет изменяемым, то это ломает стандартную логику метода GetHashCode. Это еще одна причина по которой структуры должны быть не изменяемыми. CLR xor-ит хеш-код данного поля с указателем на тип данного поля (MethodTablePointer). CLR не рассматривает статические поля, так как статичным полем может быть поле с данным же типов, в результате чего мы впадем в бесконечную рекурсию.
Комментарий разработчиков CLR к методу GetHashCode у ValueType:
/*=================================GetHashCode================================== ** Action: Our algorithm for returning the hashcode is a little bit complex. We look ** for the first non-static field and get it's hashcode. If the type has no ** non-static fields, we return the hashcode of the type. We can't take the ** hashcode of a static member because if that member is of the same type as ** the original type, we'll end up in an infinite loop. **Returns: The hashcode for the type. **Arguments: None. **Exceptions: None. ==============================================================================*/ [MethodImplAttribute(MethodImplOptions.InternalCall)] public extern override int GetHashCode(); // Note that for correctness, we can't use any field of the value type // since that field may be mutable in some way. If we use that field // and the value changes, we may not be able to look up that type in a // hash table. For correctness, we need to use something unique to // the type of this object. // HOWEVER, we decided that the perf of returning a constant value (such as // the hash code for the type) would be too big of a perf hit. We're willing // to deal with less than perfect results, and people should still be // encouraged to override GetHashCode. На заметку
Структуры не могут содержать экземплярные поля своего же типа. То есть следующий код не будет компилироваться:
public struct Node
Связано это с тем, что структура не может принимать значения null. Следующий код подтверждение тому, что это невозможно:
var myNode = new Node(); myNode.node.node.node.node.node.node.node.node.node. Однако вполне допускаются статические поля своего же типа, поскольку они хранятся в единственном экземпляре у типа данной структуры. То есть следующий код вполне допустим.
public struct Node
На заметку
Чтобы понять ситуацию лучше рассмотрим следующий код:
var k1 = new KeyValuePair(10, 29); var k2 = new KeyValuePair(10, 31); Console.WriteLine("k1 - , k2 - ", k1.GetHashCode(), k2.GetHashCode()); var v1 = new KeyValuePair(10, "abc"); var v2 = new KeyValuePair(10, "def"); Console.WriteLine("v1 - , v2 - ", v1.GetHashCode(), v2.GetHashCode()); В первом случае у структуры нет ссылочных полей и нет свободного расстояние между полями, поскольку поле int занимает 4 байта, поэтому используется быстрая версия для вычисления хеш-кода, таким образом, будет выведено на консоль:
k1 — 411217769, k2 — 411217771
Во втором же случае, у структуры есть ссылочное поле (string), поэтому используется медленная версия. CLR в качестве поля для генерации хеш- кода выбирает поле с типом int, а строковое поле просто игнорируется в результате чего на консоль будет выведено следующее:
v1 — 411217780, v2 — 411217780
Теперь думаю понятно, почему разработчики CLR говорят, чтобы все пользовательские значимые типы данных (да и не только значимые, а все вообще) переопределяли метод GetHashCode. Во-первых, он может работать не очень быстро, во-вторых, чтобы избежать непонимания того, почему хеш-коды разных объектов равны, как во втором случае примера.
Если не переопределить метод GetHashCode можно получить большой удар по производительности при использование значимого типа в качестве ключа в хеш-таблице.
Как работает GetHashCode у строкового типа
Класс String переопределяет метод GetHashCode. Его реализация в.NET 4.5 выглядит так:
GetHashCode X64
public override unsafe int GetHashCode() < if (HashHelpers.s_UseRandomizedStringHashing) return string.InternalMarvin32HashString(this, this.Length, 0L); fixed (char* chPtr1 = this) < int num1 = 5381; int num2 = num1; char* chPtr2 = chPtr1; int num3; while ((num3 = (int) *chPtr2) != 0) < num1 = (num1 else break; > return num1 + num2 * 1566083941; > > Это код для 64 разрядной машины, но если взглянем на общий код с директивами
GetHashCode
public int GetHashCode() < #if FEATURE_RANDOMIZED_STRING_HASHING if(HashHelpers.s_UseRandomizedStringHashing) < return InternalMarvin32HashString(this, this.Length, 0); >#endif // FEATURE_RANDOMIZED_STRING_HASHING unsafe < fixed (char* src = this) < #if WIN32 int hash1 = (5381<<16) + 5381; #else int hash1 = 5381; #endif int hash2 = hash1; #if WIN32 // 32 bit machines. int* pint = (int *)src; int len = this.Length; while (len >2) < hash1 = ((hash1 > 27)) ^ pint[0]; hash2 = ((hash2 > 27)) ^ pint[1]; pint += 2; len -= 4; > if (len > 0) < hash1 = ((hash1 > 27)) ^ pint[0]; > #else int c; char* s = src; while ((c = s[0]) != 0) < hash1 = ((hash1 #endif return hash1 + (hash2 * 1566083941); > > > то заметим, что имеются отличия в зависимости от того какая машина 32 или 64 разрядная.
Следует сказать, что реализация данного метода меняется с каждым выходом .NET. Об этом писал Эрик Липперт. Он предупреждал, чтобы наш код ни в коем случае не сохранял хеши, которые сгенерированы стандартным путем в базе данных или на диске, поскольку они, скорее всего, поменяют реализацию в следующем выпуски .NET. Так оно и происходило на протяжения последних 4 выпусков .NET.
Реализация хеширования у строкового типа не подразумевает кэширования результата. То есть каждый раз при вызове метода GetHashCode мы будем заново вычислять хеш-код для строки. По словам Эрика Липперта, это сделано чтобы сэкономить память, лишние 4 байта для каждого объекта строкового типа того не стоят. Учитывая, что реализация очень быстрая, думаю это правильное решение.
Если вы заметили, в реализации метода GetHashCode появился код, которого раньше не было:
if (HashHelpers.s_UseRandomizedStringHashing) return string.InternalMarvin32HashString(this, this.Length, 0L); Оказывается в .NET 4.5 появилась возможность вычислять хеш-код для строк для каждого домена. Таким образом, установив значение атрибута в 1 можно добиться, чтобы хеш-код вычислялся на основе домена, в котором вызывается метод. Таким образом, одинаковые строки в разных доменах будут иметь разные хеш-коды. Метод, который генерирует этот хеш-код, является секретным и его реализация не раскрывается.
Как работает GetHashCode у делегатов
Прежде чем переходить к рассмотрению реализации метода GetHashCode у делегатов поговорим о том, как они реализованы.
Каждый делегат наследуется от класса MulticastDelegate, который в свою очередь наследуется от класса Delegate. Эта иерархия сложилась исторически, поскольку можно было бы обойтись одним классом MulticastDelegate.
Реализация метода GetHashCode в классе Delegate выглядит так
public override int GetHashCode()
то есть фактически возвращается хеш-код типа делегата. Получается, делегаты одного типа содержащие разные методы для вызова всегда возвращают один и тот же хеш-код.
Как известно, делегаты могут содержать цепочки методов, то есть вызов одного делегата приведет к вызову несколько методов, в таком случае такая реализация не годится так как у делегатов одного типа не зависимо от количества методов был бы один хеш-код, что не совсем хорошо, поэтому в MulticastDelegate метод GetHashCode переопредели таким образом, что он задействует каждый метод лежащий в основе делегата. Однако если количество методов и тип делегатов все же совпадают, то хеш-коды будут так же одинаковы.
Реализация метода в классе MulticastDelegate выглядит так
public override sealed int GetHashCode()
Как известно, делегат хранит свои методы в списке _invocationList только в том случае если их более одного.
Если делегат содержит только один метод, то в коде выше objArray = null и соответственно хеш-код делегата будет равен хеш-коду типа делегата.
object[] objArray = this._invocationList as object[]; if (objArray == null) return base.GetHashCode(); Для прояснения ситуации рассмотрим следующий код
Func f1 = () => 1; Func f2 = () => 2; хеш-коды данных делегатов равны хеш-коду типа Func, то есть равны между собой.
Func f1 = () => 1; Func f2 = () => 2; f1 += () => 3; f2 += () => 4; В данном случае хеш-коды делегатов так же совпадают хоть и методы разные. В этом случае для вычисления хеш-кода используется следующий код
int num = 0; for (int index = 0; index < (int) this._invocationCount; ++index) num = num * 33 + objArray[index].GetHashCode(); return num; И последний случай
Func f1 = () => 1; Func f2 = () => 2; f1 += () => 3; f1 += () => 5; f2 += () => 4; Хеш-коды будут отличаться, из-за того, что количество методов у данных делегатов не равно (каждый метод оказывает влияние на результирующий хеш-код).
Как работает GetHashCode у анонимных типов
Как известно, анонимные типы — это новая фича в языке C# 3.0. Причем, это именно фича языка, так называемый синтаксический сахар поскольку CLR о них ничего не знает.
Метод GetHashCode у них переопределен таким образом, что использует каждое поле. Используя такую реализацию, два анонимных типа возвращают одинаковый хеш-код в том и только в том случае если их все поля равны. Такая реализация делает анонимные типы хорошо подходящими для ключей в хеш-таблицах.
var newType = new < Name = "Timur", Age = 20, IsMale = true >; Для такого анонимного типа будет сгенерирован следующий код:
public override int GetHashCode() < return -1521134295 * (-1521134295 * (-1521134295 * -974875401 + EqualityComparer.Default.GetHashCode(this.Name)) + EqualityComparer.Default.GetHashCode(this.Age)) + EqualityComparer.Default.GetHashCode(this.IsMale); > На заметку
Учитывая, что метод GetHashCode переопределен метод Equals, так же должен быть переопределен соответствующим образом.
var newType = new < Name = "Timur", Age = 20, IsMale = true >; var newType1 = new < Name = "Timur", Age = 20, IsMale = true >; if (newType.Equals(newType1)) Console.WriteLine("method Equals return true"); else Console.WriteLine("method Equals return false"); if (newType == newType1) Console.WriteLine("operator == return true"); else Console.WriteLine("operator == return false"); На консоль будет выведено следующее:
method Equals return true
operator == return false
Все дело в том, что анонимные типы переопределяют метод Equals таким образом, что он проверяет все поля как это сделано у ValueType (только без рефлексии), но не переопределяет оператор равенства. Таким образом, метод Equals сравнивает по значению, в то время как оператор равенства сравнивает по ссылкам.
Для чего надо было переопределять методы Equals и GetHashCode?
Учитывая, что анонимные типы были созданы для упрощения работы с LINQ, ответ становится понятным. Анонимные типы удобно использовать в качестве хеш-ключей в операциях группировки (group) и соединения (join) в LINQ.
На заметку
Заключение
Как видите генерация хеш-кодов — дело весьма не простое. Для того чтобы сгенерировать хорошие хеши, нужно приложить не мало усилий, и разработчикам CLR пришлось пойти на многие уступки, чтобы облегчить нам жизнь. Сгенерировать хеш-код хорошо, для всех случаев невозможно, поэтому лучше переопределять метод GetHashCode для ваших пользовательских типов, тем самым подстраивая их к конкретной вашей ситуации.
Спасибо за прочтение! Надеюсь, статья оказалось полезной.
Благодарность пользователю DreamWalker за любезное предоставление обновленных картинок к статье.