Сверточные нейронные сети с нуля
Используем NumPy для разработки сверточной нейронной сети.
13 min read
Feb 26, 2019
Внимание! Данная статья является переводом. Оригинал можно найти по этой ссылке.
Когда Ян ЛеКун опубликовал свою работу, посвященную новой нейросетевой архитектуре [1], получившей название CNN (Convolutional Neural Network), она не произвела достаточного впечатления на мир науки и техники и долгое время оставалась незамеченной. Потребовалось 14 лет и огромные усилия команды исследователей из Торонтского университета, чтобы донести до общества всю ценность открытий Яна ЛеКуна.
Все изменилось в 2012 году, когда состоялись соревнования по компьютерному зрению на основе базы данных ImageNet. Алекс Крижевский и его команда разработали сверточную нейронную сеть, которая способна классифицировать миллионы изображений из тысяч различных категорий с ошибкой всего в 15.8% [2].
В наше время сверточные сети развились до такого уровня, что они превосходят человеческие способности! [3] Взгляните на статистику на рис. 1.
Результаты многообещающие. Меня это настолько вдохновило, что я решил в деталях изучить, как функционируют сверточные нейронные сети.
Ричард Фейнман как-то отметил: “Я не могу понять то, что не могу построить”. Вот я и “построил” с нуля сверточную нейронную сеть на Python, чтобы самостоятельно “прощупать” все интересующие меня моменты. Как только я закончил с программированием, стало ясно, что нейронные сети не настолько и сложные, как это кажется на первый взгляд. Вы сами в этом убедитесь, когда пройдете со мной этот путь от начала и до конца.
Весь код, который я буду приводить в этой статье, можно найти здесь.
Задача
Сверточные сети отличаются очень высокой способностью к распознаванию паттернов на изображениях. Поэтому и задача, рассматриваемая в этой статье, будет касаться классификации изображений.
Один из самых распространенных бенчмарков для оценки скорости работы алгоритма компьютерного зрения является его обучение на базе данных MNIST. Она представляет из себя коллекцию из 70 тыс. написанных от руки цифр (от 0 до 9). Задача заключается в разработке настолько точного алгоритма распознавания цифр, насколько это возможно.
После примерно пяти часов обучения, за которые удалось охватить две эпохи, нейронная сеть, представленная далее, способна определить рукописную цифру с точностью до 98%. Это означает, что почти каждая цифра будет определена верно, что есть хорошим показателем.
Давайте по отдельности рассмотрим компоненты, формирующие сверточную нейронную сеть, и объединим эти знания, чтобы в конечном итоге понять, каким образом формируются предсказания. После рассмотрения каждого компонента мы запрограммируем нейронную сеть на Python с использованием библиотеки NumPy и обучим ее. (Готовый код можно найти тут.)
Важно сообщить, что для успешного прохождения всех этапов вам нужно иметь хотя бы общее представление о линейной алгебре, вычислениях и языке программирования Python. Если вы в какой-то из областей чувствуете себя не очень уверенно, можно отступить немного в сторону и укрепить свои знания, а после вернуться к этой статье.
По линейной алгебре я рекомендую вот эту публикацию. В ней простым языком описано все, что нужно знать об алгебре для решения задач машинного обучения. А тут вы сможете быстро научиться программировать на Python.
Если вы готовы, давайте двигаться дальше.
Как обучаются сверточные нейронные сети
Свертки
Сверточные нейронные сети работают на основе фильтров, которые занимаются распознаванием определенных характеристик изображения (например, прямых линий). Фильтр — это коллекция кернелов; иногда в фильтре используется один кернел. Кернел — это обычная матрица чисел, называемых весами, которые “обучаются” (подстраиваются, если вам так удобнее) с целью поиска на изображениях определенных характеристик. Фильтр перемещается вдоль изображения и определяет, присутствует ли некоторая искомая характеристика в конкретной его части. Для получения ответа такого рода совершается операция свертки, которая является суммой произведений элементов фильтра и матрицы входных сигналов.
Для лучшего понимания самых базовых концепций рекомендую взглянуть на эту статью. В ней вы найдете более подробное описание всех этих штуковин.
Если некоторая искомая характеристика присутствует во фрагменте изображения, операция свертки на выходе будет выдавать число с относительно большим значением. Если же характеристика отсутствует, выходное число будет маленьким.
На рисунках 4 и 5 приведен пример, наглядно представляющий операцию свертки. Фильтр, ответственный за поиск левосторонних кривых, перемещается вдоль исходного изображения. Когда рассматриваемый в данный момент фрагмент содержит искомую кривую, результатом свертки будет большое число (6600 в нашем случае). Но когда фильтр перемещается на позицию, где нет левосторонней кривой, результатом свертки выступает маленькое число (в нашем случае — нуль).
Надеюсь, что на данном этапе вам все понятно. Ведь это центральная идея, вокруг которой все крутится в мире сверточных нейронных сетей. Ее понимание открывает для вас большие возможности по разработке сколько угодно сложных систем анализа данных.
Результатом перемещения данного фильтра вдоль всего изображения есть матрица, состоящая из результатов единичных сверток.
Следует обратить внимание на то, что количество каналов фильтра должно соответствовать количеству каналов исходного изображения; только тогда операция свертки будет производить должный эффект. Например, если исходная картинка состоит из трех каналов (RGB: Red, Green, Blue), фильтр также должен иметь три канала.
Фильтр может перемещаться вдоль матрицы входных сигналов с шагом, отличным от единицы. Шаг перемещения фильтра называется страйдом (stride). Страйд определяет, на какое количество пикселов должен сместиться фильтр за один присест.
Количество выходных значений после операции свертки может быть рассчитано по формуле 1. Где n_in — кол-во входных пикселов, f — кол-во пикселов в фильтре, s — страйд. Для примера на рис. 6 даную формулу следует применить таким образом: (25-9)/2+1=3 .
Для того, чтобы обучение весов, заключенных в кернелах, было эффективным, в результаты сверток следует ввести некоторое смещение (bias) и нелинейность.
Смещение — это статическая величина, на которую следует “сместить” выходные значения. По своей сути это обычная операция сложения каждого элемента выходной матрицы с величиной смещения. Если объяснять очень поверхностно, это нужно для того, чтобы вывести нейронную сеть из тупиковых ситуаций, имеющих сугубо математические причины.
Нелинейность представляет из себя функцию активации. Благодаря ней картина, формируемая с помощью операции свертки, получает некоторое искажение, позволяющее нейронной сети более ясно оценивать ситуацию. Эту необходимость очень грубо можно сравнить с необходимостью людям со слабым зрением носить контактные линзы. А вообще-то такая необходимость связана с тем, что входные данные по своей природе нелинейны, поэтому нужно умышленно искажать промежуточные результаты, чтобы ответ нейронной сети был соответствующим.
Часто в качестве функции активации используют ReLU (Rectified Linear Unit). Ее график изображен на рис. 7.
Как вы можете видеть, эта функция довольно-таки проста. Входные значения, меньшие или равные нулю, превращаются в нуль; значения, превышающие нуль, не изменяются.
Обычно в сверточных слоях используется более одного фильтра. Когда это имеет место, результаты работы каждого из фильтров собираются вдоль некоторой оси, что в результате дает трехмерную матрицу выходных данных.
Программирование сверток
Благодаря библиотеке NumPy программирование сверток не составит большого труда.
На самом верхнем уровне будет находиться цикл for, который будет применять фильтры к исходному изображению. В рамках каждой итерации будет использовано два цикла while, которые будут перемещать фильтр вдоль изображения (горизонтально и вертикально).
На каждом этапе будет получено поэлементное произведение пикселов фильтра и фрагмента изображения (оператор * ). Результирующая матрица будет посредством суммирования схлопнута в число, к которому будет прибавлено смещение (bias).
Благодаря максимальному объединению уменьшается количество пикселов, что в свою очередь приводит к уменьшению количества выполняемых программой операций, и, соответственно, к экономии вычислительных ресурсов.
Количество выходных пикселов после применения максимального объединения можно рассчитать по формуле 2. В этой формуле n_in — количество входных пикселов, f — количество пикселов просеивающего окна, s — величина страйда.
Операция максимального объединения имеет и некоторые другие побочные эффекты позитивного характера. Благодаря ней нейронная сеть способна концентрироваться на действительно весомых характеристиках изображения, отбрасывая несущественные детали. Также нейронная сеть становится менее подверженной переобучению, что часто становится весьма трудоемкой проблемой.
Программирование “максимального объединения”
Реализация операции максимального объединения сводится к применению цикла for на самом верхнем уровне, в рамках которого будут присутствовать два цикла while. Цикл for нужен для того, чтобы перебрать все каналы изображения. Задача же циклов while заключается в перемещении “просеивающего окна” вдоль изображения. На каждом этапе отбора пиксела захваченного фрагмента матрицы будет применена функция max, входящая в состав библиотеки NumPy с целью поиска максимального значения.
Из рисунка видно, что операция развертывания заключается в “склеивании” строк в единый — огромной длины — числовой ряд. Это будет поистине большой вектор, который нужно будет еще и преобразовать с помощью многослойной сети с полными связями!
Если вы не знаете, как работает полносвязный слой, вот простое описание механизма: каждый элемент вектора умножается на вес связи, эти произведения далее суммируются между собой и с некоторым смещением, после чего результат подвергается преобразованию с помощью функции активации. На рис. 10 описанное представлено в наглядной форме.
Стоит отметить, что Ян ЛеКун в этом посте на Фейсбуке сказал, что “в сверточных нейронных сетях нет такого понятия, как полносвязный слой”. И он совершенно прав! Если внимательно присмотреться, то станет совершенно очевидно, что принцип работы полносвязного слоя аналогичен тому, что имеет место в сверточном слое с кернелом размерностью 1×1. То есть, если в нашем распоряжении 128 фильтров размерностью n×n, которые будут взаимодействовать с изображением размерностью n×n, на выходе мы получим вектор, в котором будет 128 элементов.
Программирование полносвязного слоя
P.S. В оригинальной статье существуют попытки разделения понятий “fully connected layer” и “dense layer”. В действительности же данные понятия являются синонимами. Хорошее объяснения этих (и некоторых других) “скользких” понятий приведено на этом форуме. (Простите, но там все на английском.)
Благодаря NumPy программирование полносвязного слоя — задача чересчур простая. Как видно из нижеприведенного сниппета, будет достаточно всего нескольких строк кода. (Обратите внимание на метод reshape; он всегда облегчает жизнь программистам нейронных сетей.)
Программирование функции активации
Как и всегда, благодаря NumPy задача будет решена в несколько строчек кода.
В формуле 4 ŷ — фактический ответ нейронной сети, y — желаемый ответ нейронной сети. Ответом в нашем случае является некоторое число; в более широком смысле ответ представляет категорию. Для получения общего показателя потерь, характерного для всех категорий в целом, берут среднее от значений по каждой категории.
Программирование функции потерь
Код реализации CCELF невероятно прост.
Программирование нейронной сети
Давайте следовать представленной выше архитектуре и воплощать ее в жизнь слой за слоем.
Вы также можете воспользоваться готовым кодом из моего репозитория.
Шаг 1. Извлечение данных
Коллекцию тренировочных и контрольных рукописных цифр вы сможете найти тут. Файлы из этой коллекции хранят изображения и соответствующие им маркеры в виде тензоров. Благодаря этому работа с данными, по сравнению с реальными изображениями, значительно упрощается.
Для извлечения данных из файлов мы воспользуемся такими функциями:
Во время выполнения команды терминал будет показывать прогресс и нагрузку (в пределах данного пакета обучения).
На моем MacBook Pro обучение нейронной сети заняло примерно 5 часов. Обученные параметры уже есть на GitHub под именем params.pkl .
Для оценки эффективности нейронной сети запустите в терминале такую команду:
python3 measure_performance.py '.pkl'
Вместо укажите имя файла с параметрами обученной нейронной сети. Если хотите использовать полученные мною параметры, укажите имя params .
Как только вы запустите эту команду, все 10 тыс. примеров из контрольного множества будут использованы для испытания нейронной сети. Значение, характеризующее эффективность сети, будет отображено в терминале, как это показано на рис. 14.
Забыл выше упомянуть, что для установки всех зависимостей в моей кодовой базе нужно воспользоваться командой, приведенной ниже. Надеюсь, что это не слишком поздно. 🙂
pip install -r requirements.txt
Результаты
После двух эпох обучения эффективность нейронной сети приблизилась к 98%, что является вполне достойным результатом. После того, как я увеличил число эпох до 3, я обнаружил, что эффективность сети начала падать. Думаю, что такое происходит по той причине, что сеть перенасыщается тренировочными данными и теряет способность к обобщению информации. Лучшее решение этой проблемы — увеличение тренировочного множества.
Обратите внимание на то, как скачет график производительности компьютера. Так происходит потому, что обработка данных в процессе обучения сети производится пакетно.
Для оценки обученных параметров нейронной сети следует оценить ее память. Это даст понимание того, насколько хорошо сеть способна решать поставленную задачу классификации. Это, по сути, и является оценкой эффективности нейронной сети. Память — это характеристика точности определения класса.
Вот вам наглядный пример:
В контрольном множестве определенное количество семерок (можете воображать любую цифру). Как много правильных ответов дала нейронная сеть, пытаясь определить, что каждое из предоставленных образов является семеркой?
График на рис. 16 показывает характеристику памяти нейронной сети для каждой цифры.
Приведенный выше график показывает, что разработанная нами нейронная сеть обучилась определять каждый класс почти со стопроцентной достоверностью.
Заключение
Надеюсь, что эта статья позволила вам получить наглядное представление о том, как работают сверточные нейронные сети. Если что-то осталось для вас непонятным или трудным для понимания, пишите об этом в комментариях. 🙂
Ссылки
[1]: Lecun, Y., et al. “Gradient-Based Learning Applied to Document Recognition.” Proceedings of the IEEE, vol. 86, no. 11, 1998, pp. 2278–2324., doi:10.1109/5.726791.
[2]: Krizhevsky, Alex, et al. “ImageNet Classification with Deep Convolutional Neural Networks.” Communications of the ACM, vol. 60, no. 6, 2017, pp. 84–90., doi:10.1145/3065386.
[3]: He, Kaiming, et al. “Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification.” 2015 IEEE International Conference on Computer Vision (ICCV), 2015, doi:10.1109/iccv.2015.123.
Спасибо всем, кто поддерживает мою деятельность переводчика. Надеюсь, этот материал позволит вам глубже понять эти удивительные нейронные сети.
Что такое нейронная сеть?

Нейронная сеть — это метод в искусственном интеллекте, который учит компьютеры обрабатывать данные таким же способом, как и человеческий мозг. Это тип процесса машинного обучения, называемый глубоким обучением, который использует взаимосвязанные узлы или нейроны в слоистой структуре, напоминающей человеческий мозг. Он создает адаптивную систему, с помощью которой компьютеры учатся на своих ошибках и постоянно совершенствуются. Таким образом, искусственные нейронные сети пытаются решать сложные задачи, такие как резюмирование документов или распознавание лиц, с более высокой точностью.
В чем заключается важность нейронных сетей?
Нейронные сети помогают компьютерам принимать разумные решения с ограниченным участием человека. Они могут изучать и моделировать отношения между нелинейными и сложными входными и выходными данными. Например, нейронные сети могут выполнять следующие задачи.
Обобщать и делать выводы
Нейронные сети могут понимать неструктурированные данные и делать общие наблюдения без специального обучения. Например, они могут распознать, что два разных входных предложения имеют одинаковое значение:
- Не подскажете как произвести оплату?
- Как мне перевести деньги?
Нейронная сеть поймет, что оба предложения означают одно и то же. Также она может определить, что Бакстер-роуд — это место, а Бакстер Смит — это имя человека.
Для чего используются нейронные сети?
Нейронные сети распространены во множестве отраслей. В их числе:
- Диагностика с помощью классификации медицинских изображений
- Целевой маркетинг с помощью фильтрации социальных сетей и анализа поведенческих данных
- Финансовые прогнозы с помощью обработки исторических данных финансовых инструментов
- Прогнозирование электрической нагрузки и потребности в энергии
- Контроль соответствия требованиям и качества
- Определение химических соединений
Ниже представлены четыре важнейших задачи, которые помогают решить нейронные сети.
Машинное зрение
Машинное зрение — это способность компьютеров извлекать информацию и смысл из изображений и видео. С помощью нейронных сетей компьютеры могут различать и распознавать изображения так, как это делают люди. Машинное зрение применяется в нескольких областях, например:
- Визуальное распознавание в беспилотных автомобилях, чтобы они могли реагировать на дорожные знаки и других участников движения
- Модерация контента для автоматического удаления небезопасного или неприемлемого контента из архивов изображений и видео
- Распознавание лиц для идентификации людей и распознавания таких атрибутов, как открытые глаза, очки и растительность на лице
- Маркировка изображения для идентификации логотипов бренда, одежды, защитного снаряжения и других деталей изображения
Распознавание речи
Нейронные сети могут анализировать человеческую речь независимо от ее речевых моделей, высоты, тона, языка и акцента. Виртуальные помощники, такие как Amazon Alexa и программное обеспечение для автоматической транскрипции, используют распознавание речи для выполнения следующих задач:
- Помощь операторам колл-центра и автоматическая классификация звонков
- Преобразование клинических рекомендаций в документацию в режиме реального времени
- Точные субтитры к видео и записям совещаний для более широкого охвата контента
Обработка естественного языка
Обработка естественного языка (NLP) — это способность обрабатывать естественный, созданный человеком текст. Нейронные сети помогают компьютерам извлекать информацию и смысл из текстовых данных и документов. NLP имеет несколько сфер применения, в том числе:
- Автоматизированные виртуальные агенты и чат-боты
- Автоматическая организация и классификация записанных данных
- Бизнес-аналитика длинных документов: например, электронных писем и форм
- Индексация ключевых фраз, указывающих на настроение: например, положительных и отрицательных комментариев в социальных сетях
- Обобщение документов и генерация статей по заданной теме
Сервисы рекомендаций
Нейронные сети могут отслеживать действия пользователей для разработки персонализированных рекомендаций. Они также могут анализировать все действия пользователей и обнаруживать новые продукты или услуги, которые интересуют конкретного потребителя. Например, стартап из Филадельфии Curalate помогает брендам конвертировать сообщения в социальных сетях в продажи. Бренды используют службу интеллектуальной маркировки продуктов (IPT) Curalate для автоматизации сбора и обработки контента пользователей социальных сетей. IPT использует нейронные сети для автоматического поиска и рекомендации продуктов, соответствующих активности пользователя в социальных сетях. Потребителям не нужно рыться в онлайн-каталогах, чтобы найти конкретный продукт по изображению в социальных сетях. Вместо этого они могут использовать автоматическую маркировку Curalate, чтобы с легкостью приобрести продукт.
Как работают нейронные сети?
Архитектура нейронных сетей повторяет структуру человеческого мозга. Клетки человеческого мозга, называемые нейронами, образуют сложную сеть с высокой степенью взаимосвязи и посылают друг другу электрические сигналы, помогая людям обрабатывать информацию. Точно так же искусственная нейронная сеть состоит из искусственных нейронов, которые взаимодействуют для решения проблем. Искусственные нейроны — это программные модули, называемые узлами, а искусственные нейронные сети — это программы или алгоритмы, которые используют вычислительные системы для выполнения математических вычислений.
Архитектура базовой нейронной сети
Базовая нейронная сеть содержит три слоя взаимосвязанных искусственных нейронов:
Входной слой
Информация из внешнего мира поступает в искусственную нейронную сеть из входного слоя. Входные узлы обрабатывают данные, анализируют или классифицируют их и передают на следующий слой.
Скрытый слой
Скрытые слои получают входные данные от входного слоя или других скрытых слоев. Искусственные нейронные сети могут иметь большое количество скрытых слоев. Каждый скрытый слой анализирует выходные данные предыдущего слоя, обрабатывает их и передает на следующий слой.
Выходной слой
Выходной слой дает окончательный результат обработки всех данных искусственной нейронной сетью. Он может иметь один или несколько узлов. Например, при решении задачи двоичной классификации (да/нет) выходной слой будет иметь один выходной узел, который даст результат «1» или «0». Однако в случае множественной классификации выходной слой может состоять из более чем одного выходного узла.
Архитектура глубокой нейронной сети
Глубокие нейронные сети или сети глубокого обучения имеют несколько скрытых слоев с миллионами связанных друг с другом искусственных нейронов. Число, называемое весом, указывает на связи одного узла с другими. Вес является положительным числом, если один узел возбуждает другой, или отрицательным, если один узел подавляет другой. Узлы с более высокими значениями веса имеют большее влияние на другие узлы.
Теоретически глубокие нейронные сети могут сопоставлять любой тип ввода с любым типом вывода. Однако стоит учитывать, что им требуется гораздо более сложное обучение, чем другим методам машинного обучения. Таким узлам нужны миллионы примеров обучающих данных, а не сотни или тысячи, как в случае с простыми сетями.
.ac2f31378926b5f99a4ba9d741c4aebe3b7a29e2.png)
Какие типы нейронных сетей существуют?
Искусственные нейронные сети можно классифицировать по тому, как данные передаются от входного узла к выходному узлу. Ниже приведены несколько примеров.
Нейронные сети прямого распространения
Нейронные сети прямого распространения обрабатывают данные в одном направлении, от входного узла к выходному узлу. Каждый узел одного слоя связан с каждым узлом следующего слоя. Нейронные сети прямого распространения используют процесс обратной связи для улучшения прогнозов с течением времени.
Алгоритм обратного распространения
Искусственные нейронные сети постоянно обучаются, используя корректирующие циклы обратной связи для улучшения своей прогностической аналитики. Проще говоря, речь идет о данных, протекающих от входного узла к выходному узлу по множеству различных путей в нейронной сети. Правильным является только один путь, который сопоставляет входной узел с правильным выходным узлом. Чтобы найти этот путь, нейронная сеть использует петлю обратной связи, которая работает следующим образом:
- Каждый узел делает предположение о следующем узле на пути.
- Он проверяет, является ли предположение правильным. Узлы присваивают более высокие значения веса путям, которые приводят к более правильным предположениям, и более низкие значения веса путям узлов, которые приводят к неправильным предположениям.
- Для следующей точки данных узлы делают новый прогноз, используя пути с более высоким весом, а затем повторяют шаг 1.
Сверточные нейронные сети
Скрытые слои в сверточных нейронных сетях выполняют определенные математические функции (например, суммирование или фильтрацию), называемые свертками. Они очень полезны для классификации изображений, поскольку могут извлекать из них соответствующие признаки, полезные для распознавания и классификации. Новую форму легче обрабатывать без потери функций, которые имеют решающее значение для правильного предположения. Каждый скрытый слой извлекает и обрабатывает различные характеристики изображения: границы, цвет и глубину.
Как обучать нейронные сети?
Обучение нейронной сети — это процесс обучения нейронной сети выполнению задачи. Нейронные сети обучаются путем первичной обработки нескольких больших наборов размеченных или неразмеченных данных. На основе этих примеров сети могут более точно обрабатывать неизвестные входные данные.
Контролируемое обучение
При контролируемом обучении специалисты по работе с данными предлагают искусственным нейронным сетям помеченные наборы данных, которые заранее дают правильный ответ. Например, сеть глубокого обучения, обучающаяся распознаванию лиц, обрабатывает сотни тысяч изображений человеческих лиц с различными терминами, связанными с этническим происхождением, страной или эмоциями, описывающими каждое изображение.
Нейронная сеть медленно накапливает знания из этих наборов данных, которые заранее дают правильный ответ. После обучения сеть начинает делать предположения об этническом происхождении или эмоциях нового изображения человеческого лица, которое она никогда раньше не обрабатывала.
Что такое глубокое обучение в контексте нейронных сетей?
Искусственный интеллект — это область компьютерных наук, которая исследует методы предоставления машинам возможности выполнять задачи, требующие человеческого интеллекта. Машинное обучение — это метод искусственного интеллекта, который дает компьютерам доступ к очень большим наборам данных для дальнейшего обучения. Программное обеспечение для машинного обучения находит шаблоны в существующих данных и применяет эти шаблоны к новым данным для принятия разумных решений. Глубокое обучение — это разновидность машинного обучения, в котором для обработки данных используются сети глубокого обучения.
Машинное обучение и глубокое обучение
Традиционные методы машинного обучения требуют участия человека, чтобы программное обеспечение работало должным образом. Специалист по работе с данными вручную определяет набор соответствующих функций, которые должно анализировать программное обеспечение. Это ограничение делает создание и управление программным обеспечением утомительным и трудозатратным процессом.
С другой стороны, при глубоком обучении специалист по работе с данными предоставляет программному обеспечению только необработанные данные. Сеть глубокого обучения извлекает функции самостоятельно и обучается более независимо. Она может анализировать неструктурированные наборы данных (например, текстовые документы), определять приоритеты атрибутов данных и решать более сложные задачи.
Например, при обучении программного обеспечения с алгоритмами машинного обучения правильно идентифицировать изображение домашнего животного вам потребуется выполнить следующие шаги:
- Найти и вручную отметить тысячи изображений домашних животных: кошек, собак, лошадей, хомяков, попугаев и т. д.
- Сообщить программному обеспечению с алгоритмами машинного обучения, какие функции необходимо найти, чтобы оно могло идентифицировать изображение методом исключения. Например, оно может подсчитать количество ног, а затем проверить форму глаз, ушей, хвоста, цвет меха и так далее.
- Вручную оценить и изменить помеченные наборы данных, чтобы повысить точность программного обеспечения. Например, если в вашем тренировочном наборе слишком много изображений черных кошек, программное обеспечение правильно определит черную кошку, но не белую.
- При глубоком обучении нейронные сети будут обрабатывать все изображения и автоматически определять, что сначала им требуется проанализировать количество ног и форму морды, а уже после посмотреть на хвосты, чтобы правильно идентифицировать животное на изображении.
Что такое сервисы глубокого обучения в AWS?
Сервисы глубокого обучения AWS используют возможности облачных вычислений, чтобы вы могли масштабировать свои нейронные сети глубокого обучения с меньшими затратами и оптимизировать их для повышения скорости. Вы также можете использовать подобные сервисы AWS для полного управления конкретными приложениями глубокого обучения:
- Amazon Rekognition для добавления предварительно обученных или настраиваемых функций машинного зрения в ваше приложение.
- Amazon Transcribe для автоматического распознавания и точной расшифровки речи.
- Amazon Lex для создания интеллектуальных чат-ботов, которые понимают намерения, поддерживают диалоговый контекст и автоматизируют простые задачи на разных языках.
Начните работу с нейронными сетями глубокого обучения в AWS с помощью Amazon SageMaker, чтобы быстро и легко создавать, обучать и развертывать модели в любом масштабе. Также можно использовать решение AMI глубокого обучения AWS для разработки пользовательских сред и рабочих процессов для глубокого обучения.
Создайте бесплатный аккаунт AWS, чтобы начать работу уже сегодня.
Понимание нейронной сети
Нейронная сеть – это вычислительный алгоритм, который используется при создании моделей глубокого обучения для прогнозов и классификаций. Он основан на самообучении и обучении, а не на прямом программировании.
Нейронные сети сделаны по образу и подобию центральной нервной системы человека; нейронные сети имеют соединенные узлы, которые очень похожи на нейроны в человеческом теле.

В этой статье я построю нейронную сеть с использованием глубокого обучения, чтобы вы поняли, как работают нейронные сети.
Архитектура нейронной сети
Чтобы спроектировать архитектуру нейронной сети, вам нужно определить, сколько скрытых слоев будет в вашей нейронной сети. Я построю нейронную сеть с двумя скрытыми слоями. Определение количества скрытых слоев в ваших нейронных сетях является частью архитектурного проектирования нейронной сети. Роль каждого скрытого слоя нейронных сетей состоит в том, чтобы преобразовать входные данные во что-то, с чем может работать выходной слой.
Скрытый слой 1

Входной слой и скрытый слой 1
В процессе вам также необходимо определить, сколько узлов будет присутствовать в скрытом слое. Эти узлы также называются нейронами. На рисунке выше каждый нейрон представлен кружком. В скрытом слое каждый нейрон соответствует слову в наборе данных. Каждый нейрон имеет значение веса, и на этапе подготовки нейрон изменяет эти значения, чтобы получить наиболее точный результат.
Скрытый слой два
Скрытый слой номер два делает то же самое, что и скрытый слой номер один, но теперь вход скрытого слоя два является выходом скрытого слоя номер один.
Выходной слой
И вот, наконец, мы подошли к выходному слою. В выходном слое вы будете использовать горячую кодировку, чтобы увидеть результаты слоев. В этом процессе кодировки только один бит будет иметь значение «1», а все остальные будут иметь значение «0». Например, если мы кодируем три случайные категории:
Классификация текста с помощью нейронных сетей
Теперь я построю нейронную сеть, чтобы показать вам, как она работает. Набор данных, который я буду использовать здесь, содержит много текстов на английском языке. Теперь я буду манипулировать этими данными, чтобы передать их в нейронную сеть.
import numpy as np #numpy is a package for scientific computing from collections import Counter vocab = Counter() text = "Hi from Brazil" #Get all words for word in text.split(' '): vocab[word]+=1 #Convert words to indexes def get_word_2_index(vocab): word2index = <> for i,word in enumerate(vocab): word2index[word] = i return word2index #Now we have an index word2index = get_word_2_index(vocab) total_words = len(vocab) #This is how we create a numpy array (our matrix) matrix = np.zeros((total_words),dtype=float) #Now we fill the values for word in text.split(): matrix[word2index[word]] += 1 print(matrix)
Результат:
[ 1. 1. 1.]
В приведенном выше коде текст был «Привет из Бразилии», а матрица выдала [1. 1. 1.]. Что, если бы текст был только «Hi»?
matrix = np.zeros((total_words),dtype=float) text = "Hi" for word in text.split(): matrix[word2index[word.lower()]] += 1 print(matrix)
Результат:
[ 1. 0. 0.]
Теперь я проделаю то же самое с метками, здесь вы увидите, что означает горячая кодировка:
y = np.zeros((3),dtype=float) if category == 0: y[0] = 1. # [ 1. 0. 0.] elif category == 1: y[1] = 1. # [ 0. 1. 0.] else: y[2] = 1. # [ 0. 0. 1.]
Теперь давайте поработаем с набором данных для построения нейронных сетей. Начнем с загрузки набора данных:
from sklearn.datasets import fetch_20newsgroups categories = ["comp.graphics","sci.space","rec.sport.baseball"] newsgroups_train = fetch_20newsgroups(subset='train', categories=categories) newsgroups_test = fetch_20newsgroups(subset='test', categories=categories)
Модель обучения для построения нейронной сети
На языке нейронных сетей одна эпоха означает один прямой проход, что означает получение выходных значений и одно обратное прохождение всех обучающих выборок.
n_input = total_words # Words in vocab n_classes = 3 # Categories: graphics, sci.space and baseball input_tensor = tf.placeholder(tf.float32,[None, n_input],name="input") output_tensor = tf.placeholder(tf.float32,[None, n_classes],name="output")
Теперь разделю обучающие данные на партии:
training_epochs = 10 # Launch the graph with tf.Session() as sess: sess.run(init) #inits the variables (normal distribution, remember?) # Training cycle for epoch in range(training_epochs): avg_cost = 0. total_batch = int(len(newsgroups_train.data)/batch_size) # Loop over all batches for i in range(total_batch): batch_x,batch_y = get_batch(newsgroups_train,i,batch_size) # Run optimization op (backprop) and cost op (to get loss value) c,_ = sess.run([loss,optimizer], feed_dict=)
Итак, мы обучили нашу модель для нейронных сетей, теперь давайте протестируем нашу модель, посмотрев на ее точность.
# Test model index_prediction = tf.argmax(prediction, 1) index_correct = tf.argmax(output_tensor, 1) correct_prediction = tf.equal(index_prediction, index_correct) # Calculate accuracy accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) total_test_data = len(newsgroups_test.target) batch_x_test,batch_y_test = get_batch(newsgroups_test,0,total_test_data) print("Accuracy:", accuracy.eval())
Результат:
Epoch: 0001 loss= 1133.908114347
Epoch: 0002 loss= 329.093700409
Epoch: 0003 loss= 111.876660109
Epoch: 0004 loss= 72.552971845
Epoch: 0005 loss= 16.673050320
Epoch: 0006 loss= 16.481995190
Epoch: 0007 loss= 4.848220565
Epoch: 0008 loss= 0.759822878
Epoch: 0009 loss= 0.000000000
Epoch: 0010 loss= 0.079848485
Optimization Finished! Accuracy: 0.75
И, наконец, мы создали модель глубокого обучения с использованием нейронных сетей для классификации текстов по категориям.
Нейронные сети для начинающих. Часть 2

Добро пожаловать во вторую часть руководства по нейронным сетям. Сразу хочу принести извинения всем кто ждал вторую часть намного раньше. По определенным причинам мне пришлось отложить ее написание. На самом деле я не ожидал, что у первой статьи будет такой спрос и что так много людей заинтересует данная тема. Взяв во внимание ваши комментарии, я постараюсь предоставить вам как можно больше информации и в то же время сохранить максимально понятный способ ее изложения. В данной статье, я буду рассказывать о способах обучения/тренировки нейросетей (в частности метод обратного распространения) и если вы, по каким-либо причинам, еще не прочитали первую часть, настоятельно рекомендую начать с нее. В процессе написания этой статьи, я хотел также рассказать о других видах нейросетей и методах тренировки, однако, начав писать про них, я понял что это пойдет вразрез с моим методом изложения. Я понимаю, что вам не терпится получить как можно больше информации, однако эти темы очень обширны и требуют детального анализа, а моей основной задачей является не написать очередную статью с поверхностным объяснением, а донести до вас каждый аспект затронутой темы и сделать статью максимально легкой в освоении. Спешу расстроить любителей “покодить”, так как я все еще не буду прибегать к использованию языка программирования и буду объяснять все “на пальцах”. Достаточно вступления, давайте теперь продолжим изучение нейросетей.
Что такое нейрон смещения?
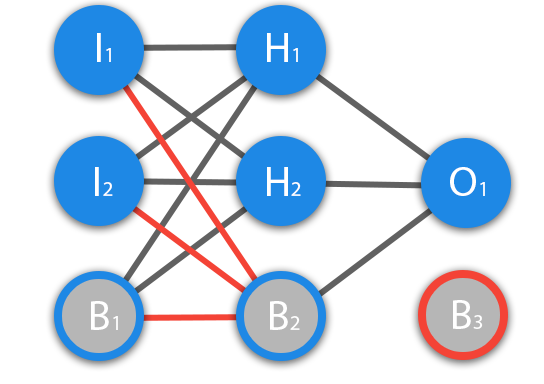
Перед тем как начать нашу основную тему, мы должны ввести понятие еще одного вида нейронов — нейрон смещения. Нейрон смещения или bias нейрон — это третий вид нейронов, используемый в большинстве нейросетей. Особенность этого типа нейронов заключается в том, что его вход и выход всегда равняются 1 и они никогда не имеют входных синапсов. Нейроны смещения могут, либо присутствовать в нейронной сети по одному на слое, либо полностью отсутствовать, 50/50 быть не может (красным на схеме обозначены веса и нейроны которые размещать нельзя). Соединения у нейронов смещения такие же, как у обычных нейронов — со всеми нейронами следующего уровня, за исключением того, что синапсов между двумя bias нейронами быть не может. Следовательно, их можно размещать на входном слое и всех скрытых слоях, но никак не на выходном слое, так как им попросту не с чем будет формировать связь.
Для чего нужен нейрон смещения?

Нейрон смещения нужен для того, чтобы иметь возможность получать выходной результат, путем сдвига графика функции активации вправо или влево. Если это звучит запутанно, давайте рассмотрим простой пример, где есть один входной нейрон и один выходной нейрон. Тогда можно установить, что выход O2 будет равен входу H1, умноженному на его вес, и пропущенному через функцию активации (формула на фото слева). В нашем конкретном случае, будем использовать сигмоид.
Из школьного курса математики, мы знаем, что если взять функцию y = ax+b и менять у нее значения “а”, то будет изменяться наклон функции (цвета линий на графике слева), а если менять “b”, то мы будем смещать функцию вправо или влево (цвета линий на графике справа). Так вот “а” — это вес H1, а “b” — это вес нейрона смещения B1. Это грубый пример, но примерно так все и работает (если вы посмотрите на функцию активации справа на изображении, то заметите очень сильное сходство между формулами). То есть, когда в ходе обучения, мы регулируем веса скрытых и выходных нейронов, мы меняем наклон функции активации. Однако, регулирование веса нейронов смещения может дать нам возможность сдвинуть функцию активации по оси X и захватить новые участки. Иными словами, если точка, отвечающая за ваше решение, будет находиться, как показано на графике слева, то ваша НС никогда не сможет решить задачу без использования нейронов смещения. Поэтому, вы редко встретите нейронные сети без нейронов смещения.
Также нейроны смещения помогают в том случае, когда все входные нейроны получают на вход 0 и независимо от того какие у них веса, они все передадут на следующий слой 0, но не в случае присутствия нейрона смещения. Наличие или отсутствие нейронов смещения — это гиперпараметр (об этом чуть позже). Одним словом, вы сами должны решить, нужно ли вам использовать нейроны смещения или нет, прогнав НС с нейронами смешения и без них и сравнив результаты.
ВАЖНО знать, что иногда на схемах не обозначают нейроны смещения, а просто учитывают их веса при вычислении входного значения например:
input = H1*w1+H2*w2+b3
b3 = bias*w3
Так как его выход всегда равен 1, то можно просто представить что у нас есть дополнительный синапс с весом и прибавить к сумме этот вес без упоминания самого нейрона.
Как сделать чтобы НС давала правильные ответы?
Ответ прост — нужно ее обучать. Однако, насколько бы прост не был ответ, его реализация в плане простоты, оставляет желать лучшего. Существует несколько методов обучения НС и я выделю 3, на мой взгляд, самых интересных:
- Метод обратного распространения (Backpropagation)
- Метод упругого распространения (Resilient propagation или Rprop)
- Генетический Алгоритм (Genetic Algorithm)
Что такое градиентный спуск?
Это способ нахождения локального минимума или максимума функции с помощью движения вдоль градиента. Если вы поймете суть градиентного спуска, то у вас не должно возникнуть никаких вопросов во время использования метода обратного распространения. Для начала, давайте разберемся, что такое градиент и где он присутствует в нашей НС. Давайте построим график, где по оси х будут значения веса нейрона(w) а по оси у — ошибка соответствующая этому весу(e).
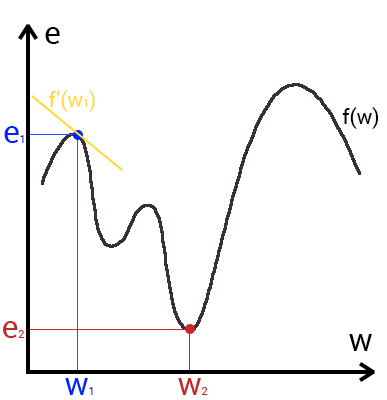
Посмотрев на этот график, мы поймем, что график функция f(w) является зависимостью ошибки от выбранного веса. На этом графике нас интересует глобальный минимум — точка (w2,e2) или, иными словами, то место где график подходит ближе всего к оси х. Эта точка будет означать, что выбрав вес w2 мы получим самую маленькую ошибку — e2 и как следствие, самый лучший результат из всех возможных. Найти же эту точку нам поможет метод градиентного спуска (желтым на графике обозначен градиент). Соответственно у каждого веса в нейросети будет свой график и градиент и у каждого надо найти глобальный минимум.
Так что же такое, этот градиент? Градиент — это вектор который определяет крутизну склона и указывает его направление относительно какой либо из точек на поверхности или графике. Чтобы найти градиент нужно взять производную от графика по данной точке (как это и показано на графике). Двигаясь по направлению этого градиента мы будем плавно скатываться в низину. Теперь представим что ошибка — это лыжник, а график функции — гора. Соответственно, если ошибка равна 100%, то лыжник находиться на самой вершине горы и если ошибка 0% то в низине. Как все лыжники, ошибка стремится как можно быстрее спуститься вниз и уменьшить свое значение. В конечном случае у нас должен получиться следующий результат:
Представьте что лыжника забрасывают, с помощью вертолета, на гору. На сколько высоко или низко зависит от случая (аналогично тому, как в нейронной сети при инициализации веса расставляются в случайном порядке). Допустим ошибка равна 90% и это наша точка отсчета. Теперь лыжнику нужно спуститься вниз, с помощью градиента. На пути вниз, в каждой точке мы будем вычислять градиент, что будет показывать нам направление спуска и при изменении наклона, корректировать его. Если склон будет прямым, то после n-ого количества таких действий мы доберемся до низины. Но в большинстве случаев склон (график функции) будет волнистый и наш лыжник столкнется с очень серьезной проблемой — локальный минимум. Я думаю все знают, что такое локальный и глобальный минимум функции, для освежения памяти вот пример. Попадание в локальный минимум чревато тем, что наш лыжник навсегда останется в этой низине и никогда не скатиться с горы, следовательно мы никогда не сможем получить правильный ответ. Но мы можем избежать этого, снарядив нашего лыжника реактивным ранцем под названием момент (momentum). Вот краткая иллюстрация момента:
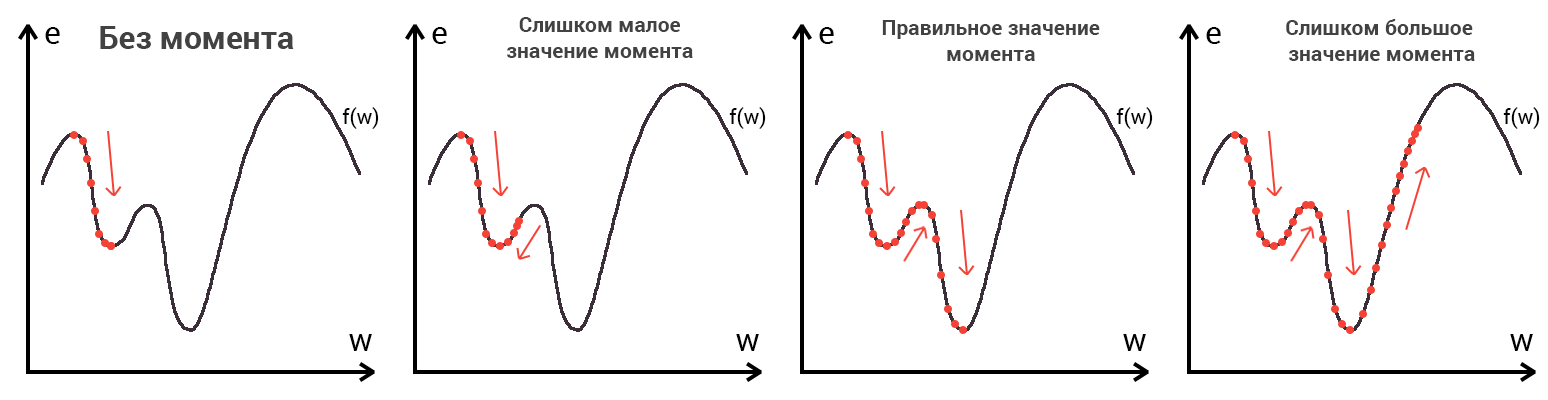
Как вы уже наверное догадались, этот ранец придаст лыжнику необходимое ускорение чтобы преодолеть холм, удерживающий нас в локальном минимуме, однако здесь есть одно НО. Представим что мы установили определенное значение параметру момент и без труда смогли преодолеть все локальные минимумы, и добраться до глобального минимума. Так как мы не можем просто отключить реактивный ранец, то мы можем проскочить глобальный минимум, если рядом с ним есть еще низины. В конечном случае это не так важно, так как рано или поздно мы все равно вернемся обратно в глобальный минимум, но стоит помнить, что чем больше момент, тем больше будет размах с которым лыжник будет кататься по низинам. Вместе с моментом в методе обратного распространения также используется такой параметр как скорость обучения (learning rate). Как наверняка многие подумают, чем больше скорость обучения, тем быстрее мы обучим нейросеть. Нет. Скорость обучения, также как и момент, является гиперпараметром — величина которая подбирается путем проб и ошибок. Скорость обучения можно напрямую связать со скоростью лыжника и можно с уверенностью сказать — тише едешь дальше будешь. Однако здесь тоже есть определенные аспекты, так как если мы совсем не дадим лыжнику скорости то он вообще никуда не поедет, а если дадим маленькую скорость то время пути может растянуться на очень и очень большой период времени. Что же тогда произойдет если мы дадим слишком большую скорость?
Как видите, ничего хорошего. Лыжник начнет скатываться по неправильному пути и возможно даже в другом направлении, что как вы понимаете только отдалит нас от нахождения правильного ответа. Поэтому во всех этих параметрах нужно находить золотую середину чтобы избежать не сходимости НС (об этом чуть позже).
Что такое Метод Обратного Распространения (МОР)?
Вот мы и дошли до того момента, когда мы можем обсудить, как же все таки сделать так, чтобы ваша НС могла правильно обучаться и давать верные решения. Очень хорошо МОР визуализирован на этой гифке:
А теперь давайте подробно разберем каждый этап. Если вы помните то в предыдущей статье мы считали выход НС. По другому это называется передача вперед (Forward pass), то есть мы последовательно передаем информацию от входных нейронов к выходным. После чего мы вычисляем ошибку и основываясь на ней делаем обратную передачу, которая заключается в том, чтобы последовательно менять веса нейронной сети, начиная с весов выходного нейрона. Значение весов будут меняться в ту сторону, которая даст нам наилучший результат. В моих вычисления я буду пользоваться методом нахождения дельты, так как это наиболее простой и понятный способ. Также я буду использовать стохастический метод обновления весов (об этом чуть позже).
Теперь давайте продолжим с того места, где мы закончили вычисления в предыдущей статье.
Данные задачи из предыдущей статьи

Данные: I1=1, I2=0, w1=0.45, w2=0.78 ,w3=-0.12 ,w4=0.13 ,w5=1.5 ,w6=-2.3.
H1input = 1*0.45+0*-0.12=0.45
H1output = sigmoid(0.45)=0.61
H2input = 1*0.78+0*0.13=0.78
H2output = sigmoid(0.78)=0.69
O1input = 0.61*1.5+0.69*-2.3=-0.672
O1output = sigmoid(-0.672)=0.33
O1ideal = 1 (0xor1=1)
Результат — 0.33, ошибка — 45%.
Так как мы уже подсчитали результат НС и ее ошибку, то мы можем сразу приступить к МОРу. Как я уже упоминал ранее, алгоритм всегда начинается с выходного нейрона. В таком случае давайте посчитаем для него значение δ (дельта) по формуле 1.
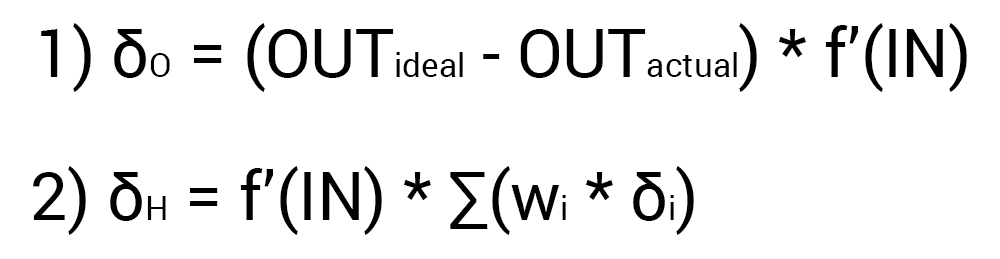 Так как у выходного нейрона нет исходящих синапсов, то мы будем пользоваться первой формулой (δ output), следственно для скрытых нейронов мы уже будем брать вторую формулу (δ hidden). Тут все достаточно просто: считаем разницу между желаемым и полученным результатом и умножаем на производную функции активации от входного значения данного нейрона. Прежде чем приступить к вычислениям я хочу обратить ваше внимание на производную. Во первых как это уже наверное стало понятно, с МОР нужно использовать только те функции активации, которые могут быть дифференцированы. Во вторых чтобы не делать лишних вычислений, формулу производной можно заменить на более дружелюбную и простую формула вида:
Так как у выходного нейрона нет исходящих синапсов, то мы будем пользоваться первой формулой (δ output), следственно для скрытых нейронов мы уже будем брать вторую формулу (δ hidden). Тут все достаточно просто: считаем разницу между желаемым и полученным результатом и умножаем на производную функции активации от входного значения данного нейрона. Прежде чем приступить к вычислениям я хочу обратить ваше внимание на производную. Во первых как это уже наверное стало понятно, с МОР нужно использовать только те функции активации, которые могут быть дифференцированы. Во вторых чтобы не делать лишних вычислений, формулу производной можно заменить на более дружелюбную и простую формула вида: 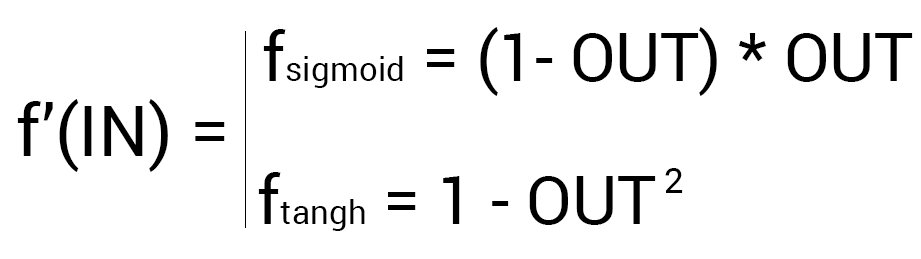
Таким образом наши вычисления для точки O1 будут выглядеть следующим образом.
Решение
O1output = 0.33
O1ideal = 1
Error = 0.45
δO1 = (1 — 0.33) * ( (1 — 0.33) * 0.33 ) = 0.148
На этом вычисления для нейрона O1 закончены. Запомните, что после подсчета дельты нейрона мы обязаны сразу обновить веса всех исходящих синапсов этого нейрона. Так как в случае с O1 их нет, мы переходим к нейронам скрытого уровня и делаем тоже самое за исключение того, что формула подсчета дельты у нас теперь вторая и ее суть заключается в том, чтобы умножить производную функции активации от входного значения на сумму произведений всех исходящих весов и дельты нейрона с которой этот синапс связан. Но почему формулы разные? Дело в том что вся суть МОР заключается в том чтобы распространить ошибку выходных нейронов на все веса НС. Ошибку можно вычислить только на выходном уровне, как мы это уже сделали, также мы вычислили дельту в которой уже есть эта ошибка. Следственно теперь мы будем вместо ошибки использовать дельту которая будет передаваться от нейрона к нейрону. В таком случае давайте найдем дельту для H1:
Решение
H1output = 0.61
w5 = 1.5
δO1 = 0.148
δH1 = ( (1 — 0.61) * 0.61 ) * ( 1.5 * 0.148 ) = 0.053
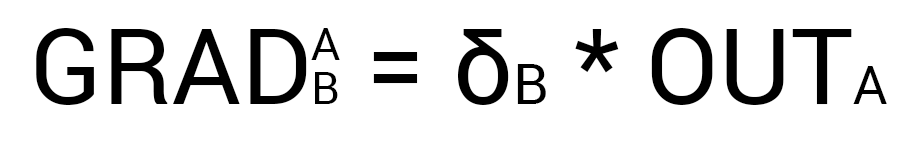
Теперь нам нужно найти градиент для каждого исходящего синапса. Здесь обычно вставляют 3 этажную дробь с кучей производных и прочим математическим адом, но в этом и вся прелесть использования метода подсчета дельт, потому что в конечном счете ваша формула нахождения градиента будет выглядеть вот так:
Здесь точка A это точка в начале синапса, а точка B на конце синапса. Таким образом мы можем подсчитать градиент w5 следующим образом:
Решение
H1output = 0.61
δO1 = 0.148
GRADw5 = 0.61 * 0.148 = 0.09

Сейчас у нас есть все необходимые данные чтобы обновить вес w5 и мы сделаем это благодаря функции МОР которая рассчитывает величину на которую нужно изменить тот или иной вес и выглядит она следующим образом:
Настоятельно рекомендую вам не игнорировать вторую часть выражения и использовать момент так как это вам позволит избежать проблем с локальным минимумом.
Здесь мы видим 2 константы о которых мы уже говорили, когда рассматривали алгоритм градиентного спуска: E (эпсилон) — скорость обучения, α (альфа) — момент. Переводя формулу в слова получим: изменение веса синапса равно коэффициенту скорости обучения, умноженному на градиент этого веса, прибавить момент умноженный на предыдущее изменение этого веса (на 1-ой итерации равно 0). В таком случае давайте посчитаем изменение веса w5 и обновим его значение прибавив к нему Δw5.
Решение
E = 0.7
Α = 0.3
w5 = 1.5
GRADw5 = 0.09
Δw5(i-1) = 0
Δw5 = 0.7 * 0.09 + 0 * 0.3 = 0.063
w5 = w5 + Δw5 = 1.563
Таким образом после применения алгоритма наш вес увеличился на 0.063. Теперь предлагаю сделать вам тоже самое для H2.
Решение
H2output = 0.69
w6 = -2.3
δO1 = 0.148
E = 0.7
Α = 0.3
Δw6(i-1) = 0
δH2 = ( (1 — 0.69) * 0.69 ) * ( -2.3 * 0.148 ) = -0.07
GRADw6 = 0.69 * 0.148 = 0.1
Δw6 = 0.7 * 0.1 + 0 * 0.3 = 0.07
w6 = w6 + Δw6 = -2.2
И конечно не забываем про I1 и I2, ведь у них тоже есть синапсы веса которых нам тоже нужно обновить. Однако помним, что нам не нужно находить дельты для входных нейронов так как у них нет входных синапсов.
Решение
w1 = 0.45, Δw1(i-1) = 0
w2 = 0.78, Δw2(i-1) = 0
w3 = -0.12, Δw3(i-1) = 0
w4 = 0.13, Δw4(i-1) = 0
δH1 = 0.053
δH2 = -0.07
E = 0.7
Α = 0.3
GRADw1 = 1 * 0.053 = 0.053
GRADw2 = 1 * -0.07 = -0.07
GRADw3 = 0 * 0.053 = 0
GRADw4 = 0 * -0.07 = 0
Δw1 = 0.7 * 0.053 + 0 * 0.3 = 0.04
Δw2 = 0.7 * -0.07 + 0 * 0.3 = -0.05
Δw3 = 0.7 * 0 + 0 * 0.3 = 0
Δw4 = 0.7 * 0 + 0 * 0.3 = 0
w1 = w1 + Δw1 = 0.5
w2 = w2 + Δw2 = 0.73
w3 = w3 + Δw3 = -0.12
w4 = w4 + Δw4 = 0.13
Теперь давайте убедимся в том, что мы все сделали правильно и снова посчитаем выход НС только уже с обновленными весами.
Решение
I1 = 1
I2 = 0
w1 = 0.5
w2 = 0.73
w3 = -0.12
w4 = 0.13
w5 = 1.563
w6 = -2.2
H1input = 1 * 0.5 + 0 * -0.12 = 0.5
H1output = sigmoid(0.5) = 0.62
H2input = 1 * 0.73 + 0 * 0.124 = 0.73
H2output = sigmoid(0.73) = 0.675
O1input = 0.62* 1.563 + 0.675 * -2.2 = -0.51
O1output = sigmoid(-0.51) = 0.37
O1ideal = 1 (0xor1=1)
Результат — 0.37, ошибка — 39%.
Как мы видим после одной итерации МОР, нам удалось уменьшить ошибку на 0.04 (6%). Теперь нужно повторять это снова и снова, пока ваша ошибка не станет достаточно мала.
Что еще нужно знать о процессе обучения?
Нейросеть можно обучать с учителем и без (supervised, unsupervised learning).
Обучение с учителем — это тип тренировок присущий таким проблемам как регрессия и классификация (им мы и воспользовались в примере приведенном выше). Иными словами здесь вы выступаете в роли учителя а НС в роли ученика. Вы предоставляете входные данные и желаемый результат, то есть ученик посмотрев на входные данные поймет, что нужно стремиться к тому результату который вы ему предоставили.
Обучение без учителя — этот тип обучения встречается не так часто. Здесь нет учителя, поэтому сеть не получает желаемый результат или же их количество очень мало. В основном такой вид тренировок присущ НС у которых задача состоит в группировке данных по определенным параметрам. Допустим вы подаете на вход 10000 статей на хабре и после анализа всех этих статей НС сможет распределить их по категориям основываясь, например, на часто встречающихся словах. Статьи в которых упоминаются языки программирования, к программированию, а где такие слова как Photoshop, к дизайну.
Существует еще такой интересный метод, как обучение с подкреплением (reinforcement learning). Этот метод заслуживает отдельной статьи, но я попытаюсь вкратце описать его суть. Такой способ применим тогда, когда мы можем основываясь на результатах полученных от НС, дать ей оценку. Например мы хотим научить НС играть в PAC-MAN, тогда каждый раз когда НС будет набирать много очков мы будем ее поощрять. Иными словами мы предоставляем НС право найти любой способ достижения цели, до тех пор пока он будет давать хороший результат. Таким способом, сеть начнет понимать чего от нее хотят добиться и пытается найти наилучший способ достижения этой цели без постоянного предоставления данных “учителем”.
Также обучение можно производить тремя методами: стохастический метод (stochastic), пакетный метод (batch) и мини-пакетный метод (mini-batch). Существует очень много статей и исследований на тему того, какой из методов лучше и никто не может прийти к общему ответу. Я же сторонник стохастического метода, однако я не отрицаю тот факт, что каждый метод имеет свои плюсы и минусы.
Вкратце о каждом методе:
Стохастический (его еще иногда называют онлайн) метод работает по следующему принципу — нашел Δw, сразу обнови соответствующий вес.
Пакетный метод же работает по другому. Мы суммируем Δw всех весов на текущей итерации и только потом обновляем все веса используя эту сумму. Один из самых важных плюсов такого подхода — это значительная экономия времени на вычисление, точность же в таком случае может сильно пострадать.
Мини-пакетный метод является золотой серединой и пытается совместить в себе плюсы обоих методов. Здесь принцип таков: мы в свободном порядке распределяем веса по группам и меняем их веса на сумму Δw всех весов в той или иной группе.
Что такое гиперпараметры?
Гиперпараметры — это значения, которые нужно подбирать вручную и зачастую методом проб и ошибок. Среди таких значений можно выделить:
- Момент и скорость обучения
- Количество скрытых слоев
- Количество нейронов в каждом слое
- Наличие или отсутствие нейронов смещения
Что такое сходимость?
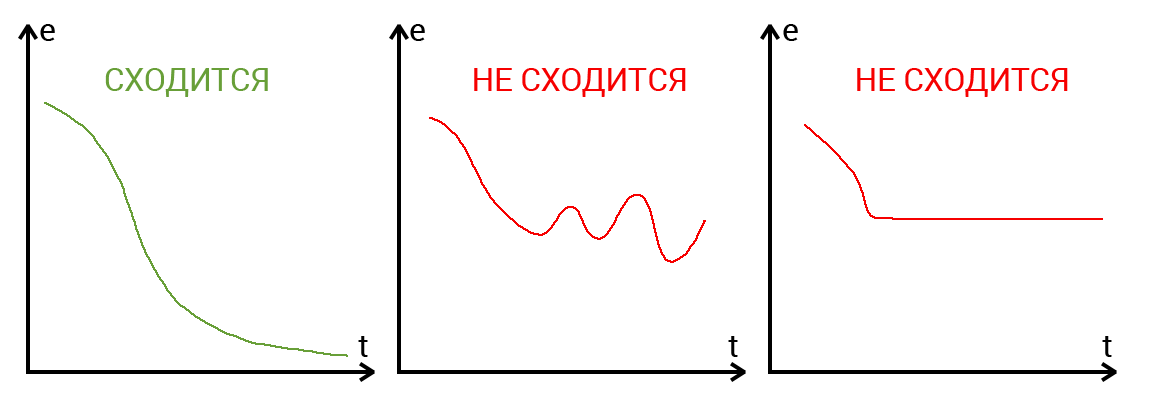
Сходимость говорит о том, правильная ли архитектура НС и правильно ли были подобраны гиперпараметры в соответствии с поставленной задачей. Допустим наша программа выводит ошибку НС на каждой итерации в лог. Если с каждой итерацией ошибка будет уменьшаться, то мы на верном пути и наша НС сходится. Если же ошибка будет прыгать вверх — вниз или застынет на определенном уровне, то НС не сходится. В 99% случаев это решается изменением гиперпараметров. Оставшийся 1% будет означать, что у вас ошибка в архитектуре НС. Также бывает, что на сходимость влияет переобучение НС.
Что такое переобучение?
Переобучение, как следует из названия, это состояние нейросети, когда она перенасыщена данными. Это проблема возникает, если слишком долго обучать сеть на одних и тех же данных. Иными словами, сеть начнет не учиться на данных, а запоминать и “зубрить” их. Соответственно, когда вы уже будете подавать на вход этой НС новые данные, то в полученных данных может появиться шум, который будет влиять на точность результата. Например, если мы будем показывать НС разные фотографии яблок (только красные) и говорить что это яблоко. Тогда, когда НС увидит желтое или зеленое яблоко, оно не сможет определить, что это яблоко, так как она запомнила, что все яблоки должны быть красными. И наоборот, когда НС увидит что-то красное и по форме совпадающее с яблоком, например персик, она скажет, что это яблоко. Это и есть шум. На графике шум будет выглядеть следующим образом.
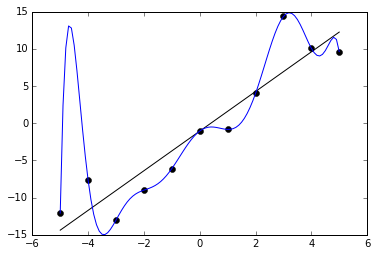
Видно, что график функции сильно колеблется от точки к точке, которые являются выходными данными (результатом) нашей НС. В идеале, этот график должен быть менее волнистый и прямой. Чтобы избежать переобучения, не стоит долго тренировать НС на одних и тех же или очень похожих данных. Также, переобучение может быть вызвано большим количеством параметров, которые вы подаете на вход НС или слишком сложной архитектурой. Таким образом, когда вы замечаете ошибки (шум) в выходных данных после этапа обучения, то вам стоит использовать один из методов регуляризации, но в большинстве случаев это не понадобиться.
Заключение
Надеюсь эта статья смогла прояснить ключевые моменты такого нелегко предмета, как Нейронные сети. Однако я считаю, что сколько бы ты статей не прочел, без практики такую сложную тему освоить невозможно. Поэтому, если вы только в начале пути и хотите изучить эту перспективную и развивающуюся отрасль, то советую начать практиковаться с написания своей НС, а уже после прибегать к помощи различных фреймворков и библиотек. Также, если вам интересен мой метод изложения информации и вы хотите, чтобы я написал статьи на другие темы связанные с Машинным обучением, то проголосуйте в опросе ниже за ту тему которую вам интересна. До встречи в будущих статьях 🙂