Как создать свой язык программирования: теория, инструменты и советы от практика
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
На протяжении последних шести месяцев я работал над созданием языка программирования (ЯП) под названием Pinecone. Я не рискну назвать его законченным, но использовать его уже можно — он содержит для этого достаточно элементов, таких как переменные, функции и пользовательские структуры данных. Если хотите ознакомиться с ним перед прочтением, предлагаю посетить официальную страницу и репозиторий на GitHub.
Введение
Я не эксперт. Когда я начал работу над этим проектом, я понятия не имел, что делаю, и всё еще не имею. Я никогда целенаправленно не изучал принципы создания языка — только прочитал некоторые материалы в Сети и даже в них не нашёл для себя почти ничего полезного.
Тем не менее, я написал абсолютно новый язык. И он работает. Наверное, я что-то делаю правильно.
В этой статье я постараюсь показать, каким образом Pinecone (и другие языки программирования) превращают исходный код в то, что многие считают магией. Также я уделю внимание ситуациям, в которых мне приходилось искать компромиссы, и поясню, почему я принял те решения, которые принял.
Текст точно не претендует на звание полноценного руководства по созданию языка программирования, но для любознательных будет хорошей отправной точкой.
Первые шаги
«А с чего вообще начинать?» — вопрос, который другие разработчики часто задают, узнав, что я пишу свой язык. В этой части постараюсь подробно на него ответить.
Компилируемый или интерпретируемый?
Компилятор анализирует программу целиком, превращает её в машинный код и сохраняет для последующего выполнения. Интерпретатор же разбирает и выполняет программу построчно в режиме реального времени.
Технически любой язык можно как компилировать, так и интерпретировать. Но для каждого языка один из методов подходит больше, чем другой, и выбор парадигмы на ранних этапах определяет дальнейшее проектирование. В общем смысле интерпретация отличается гибкостью, а компиляция обеспечивает высокую производительность, но это лишь верхушка крайне сложной темы.
Я хотел создать простой и при этом производительный язык, каких немного, поэтому с самого начала решил сделать Pinecone компилируемым. Тем не менее, интерпретатор у Pinecone тоже есть — первое время запуск был возможен только с его помощью, позже объясню, почему.
Выбор языка
Своеобразный мета-шаг: язык программирования сам является программой, которую надо написать на каком-то языке. Я выбрал C++ из-за производительности, большого набора функциональных возможностей, и просто потому что он мне нравится.
Но в целом совет можно дать такой:
- интерпретируемый ЯП крайне рекомендуется писать на компилируемом ЯП (C, C++, Swift). Иначе потери производительности будут расти как снежный ком, пока мета-интерпретатор интерпретирует ваш интерпретатор;
- компилируемый ЯП можно писать на интерпретируемом ЯП (Python, JS). Возрастёт время компиляции, но не время выполнения программы.
Проектирование архитектуры
У структуры языка программирования есть несколько ступеней от исходного кода до исполняемого файла, на каждой из которых определенным образом происходит форматирование данных, а также функции для перехода между этими ступенями. Поговорим об этом подробнее.
Лексический анализатор / лексер
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Первый шаг в большинстве ЯП — это лексический анализ. Говоря по-простому, он представляет собой разбиение текста на токены, то есть единицы языка: переменные, названия функций (идентификаторы), операторы, числа. Таким образом, подав лексеру на вход строку с исходным кодом, мы получим на выходе список всех токенов, которые в ней содержатся.
Обращения к исходному коду уже не будет происходить на следующих этапах, поэтому лексер должен выдать всю необходимую для них информацию.
Flex
При создании языка первым делом я написал лексер. Позже я изучил инструменты, которые могли бы сделать лексический анализ проще и уменьшить количество возникающих багов.
Одним из основных таких инструментов является Flex — генератор лексических анализаторов. Он принимает на вход файл с описанием грамматики языка, а потом создаёт программу на C, которая в свою очередь анализирует строку и выдаёт нужный результат.
Моё решение
Я решил оставить написанный мной анализатор. Особых преимуществ у Flex я в итоге не увидел, а его использование только создало бы дополнительные зависимости, усложняющие процесс сборки. К тому же, мой выбор обеспечивает больше гибкости — например, можно добавить к языку оператор без необходимости редактировать несколько файлов.
Синтаксический анализатор / парсер
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Следующая стадия — парсер. Он преобразует исходный текст, то есть список токенов (с учётом скобок и порядка операций), в абстрактное синтаксическое дерево, которое позволяет структурно представить правила создаваемого языка. Сам по себе процесс можно назвать простым, но с увеличением количества языковых конструкций он сильно усложняется.
Bison
На этом шаге я также думал использовать стороннюю библиотеку, рассматривая Bison для генерации синтаксического анализатора. Он во многом похож на Flex — пользовательский файл с синтаксическими правилами структурируется с помощью программы на языке C. Но я снова отказался от средств автоматизации.
Преимущества кастомных программ
С лексером моё решение писать и использовать свой код (длиной около 200 строк) было довольно очевидным: я люблю задачки, а эта к тому же относительно тривиальная. С парсером другая история: сейчас длина кода для него — 750 строк, и это уже третья попытка (первые две были просто ужасны).
Тем не менее, я решил делать парсер сам. Вот основные причины:
- минимизация переключения контекста;
- упрощение сборки;
- желание справиться с задачей самостоятельно.
В целесообразности решения меня убедило высказывание Уолтера Брайта (создателя языка D) в одной из его статей:
Абстрактный семантический граф
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
В этой части я реализовал структуру, по своей сути наиболее близкую к «промежуточному представлению» (intermediate representation) в LLVM. Существует небольшая, но важная разница между абстрактным синтаксическим деревом (АСД) и абстрактным семантическим графом (АСГ).
АСГ vs АСД
Грубо говоря, семантический граф — это синтаксическое дерево с контекстом. То есть, он содержит информацию наподобие какой тип возвращает функция или в каких местах используется одна и та же переменная. Из-за того, что графу нужно распознать и запомнить весь этот контекст, коду, который его генерирует, необходима поддержка в виде множества различных поясняющих таблиц.
Запуск
После того, как граф составлен, запуск программы становится довольно простой задачей. Каждый узел содержит реализацию функции, которая получает некоторые данные на вход, делает то, что запрограммировано (включая возможный вызов вспомогательных функций), и возвращает результат. Это — интерпретатор в действии.
Варианты компиляции
Вы, наверное, спросите, откуда взялся интерпретатор, если я изначально определил Pinecone как компилируемый язык. Дело в том, что компиляция гораздо сложнее, чем интерпретация — я уже упоминал ранее, что столкнулся с некоторыми проблемами на этом шаге.
Написать свой компилятор
Сначала мне понравилась эта мысль — я люблю делать вещи сам, к тому же давно хотел изучить язык ассемблера. Вот только создать с нуля кроссплатформенный компилятор — сложнее, чем написать машинный код для каждого элемента языка. Я счёл эту идею абсолютно не практичной и не стоящей затраченных ресурсов.
LLVM
LLVM — это коллекция инструментов для компиляции, которой пользуются, например, разработчики Swift, Rust и Clang. Я решил остановиться на этом варианте, но опять не рассчитал сложности задачи, которую перед собой поставил. Для меня проблемой оказалось не освоение ассемблера, а работа с огромной многосоставной библиотекой.
Транспайлинг
Мне всё же нужно было какое-то решение, поэтому я написал то, что точно будет работать: транспайлер (transpiler) из Pinecone в C++ — он производит компиляцию по типу «исходный код в исходный код», а также добавил возможность автоматической компиляции вывода с GCC. Такой способ не является ни масштабируемым, ни кроссплатформенным, но на данный момент хотя бы работает почти для всех программ на Pinecone, это уже хорошо.
Дальнейшие планы
Сейчас мне не достаёт необходимой практики, но в будущем я собираюсь от начала и до конца реализовать компилятор Pinecone с помощью LLVM — инструмент мне нравится и руководства к нему хорошие. Пока что интерпретатора хватает для примитивных программ, а транспайлер справляется с более сложными.
Заключение
Надеюсь, эта статья окажется кому-нибудь полезной. Я крайне рекомендую хотя бы попробовать написать свой язык, несмотря на то, что придётся разбираться во множестве деталей реализации — это обучающий, развивающий и просто интересный эксперимент.
Вот общие советы от меня (разумеется, довольно субъективные):
- если у вас нет предпочтений и вы сомневаетесь, компилируемый или интерпретируемый писать язык, выбирайте второе. Интерпретируемые языки обычно проще проектировать, собирать и учить;
- с лексерами и парсерами делайте, что хотите. Использование средств автоматизации зависит от вашего желания, опыта и конкретной ситуации;
- если вы не готовы / не хотите тратить время и силы (много времени и сил) на придумывание собственной стратегии разработки ЯП, следуйте цепочке действий, описанной в этой статье. Я вложил в неё много усилий и она работает;
- опять же, если не хватает времени / мотивации / опыта / желания или ещё чего-нибудь для написания классического ЯП, попробуйте написать эзотерический, типа Brainfuck. (Советуем помнить, что если язык написан развлечения ради, это не значит, что писать его — тоже сплошное развлечение. — прим. перев.)
Я делал довольно много ошибок по ходу разработки, но большую часть кода, на которую они могли повлиять, я уже переписал. Язык сейчас неплохо функционирует и будет развиваться (на момент написания статьи его можно было собрать на Linux и с переменным успехом на macOS, но не на Windows).
О том, что ввязался в историю с созданием Pinecone, ни в коем случае не жалею — это отличный эксперимент, и он только начался.

Следите за новыми постами по любимым темам
Подпишитесь на интересующие вас теги, чтобы следить за новыми постами и быть в курсе событий.
ЯП с нуля до прототипа (Лексер) #1
Привет, первая статья на Хабре. Поправляйте если что-то не так.
Предисловие
Идея написать свой ЯП появилась достаточно давно, но не хватало мотивации приступить к изучению. Отталкивало то, что крупные компании годами разрабатывают свои языки, чтобы они были работоспособны, а тут я хочу обойти их всех разом и создать удобный для себя ЯП. Но с чего—то всё таки нужно начинать. Хотя бы калькулятор уже бы был победой. Далее я буду называть свой язык программирования — Lize(читай «Лайз»).
Внимание: Я ничего не знаю про то как делать ЯП, я буду изучать всё и одновременно писать статью
Что делаем?
Это будет транспилятор из Lize в Typescript, написанный на . Typescript. Что касается будущего синтаксиса, то пока это опустим, вернёмся к этому когда будет достаточно знаний. В дополнение я буду публиковать весь код на github.
Первое же гугление дало мне знание о таких вещах как Лексер, Парсер, AST (Абстрактное синтаксическое дерево). Ничего не знаю про два последних, забудем пока про них и начнём с первого.
Что такое лексер?
Лексер — он же сканер, он же токенизатор. Первый этап преобразования простого текста который мы считаем за программу на нашем языке (Lize) в программу которую поймёт компьютер (но в нашем случае мы обойдёмся транспиляцией/переводом из нашего ЯП в TypeScript)
В моей голове это просто такая вещь которая превращает последовательность символов в последовательность подстрок имеющих некоторый id и значение.

Мы будем представлять его так: [имя: значение] или так: (строка:столбец;ширина) [имя: значение] .
Стоит уточнить, что символ звёздочки или слэш ни в коем случае не должен считаться знаком умножения или деления. Этап токенизации должен просто разбить исходник на токены, а потом на этапе парсинга определять, это умножение или разыменование.
// ❌ Не правильно tokenize(`4 * 3 / 2`) // [number: 4], [multiply], [number: 3], [divide], [number: 2] // ✅ правильно tokenize(`4 * 3 / 2`) // [number: 4], [asterisk], [number: 3], [slash], [number: 2]Я люблю писать утилиты и абстракции, чтобы всё усложнить упростить и сделать код элегантнее. Так что осторожно, некоторый код может показаться бессмысленным или страшным, но мне от него на душе легче.
Обработка ошибок
Мы же любим когда наш любимый ЯП тыкает нам носом туда где мы облажались. Давайте забудем про проблему ошибок раз и навсегда. Функция error это магия JS и TS, позволяет создавать ошибки в одну строчку. Я опустил реализацию, дабы не нагружать статью, весь код вы сможете посмотреть на github.
// Примеры ошибок export namespace LexerErrors < export const SampleError = error('SampleError', 'Sample error message') export const ErrorWithArgument = error('ErrorWithArgument', 'Argument: <>') export const UnexpectedCharacter = error<[line: number, column: number]>('UnexpectedCharacter', 'Unexpected character at <>:<>') > // Пример throw new SampleError throw new ErrorWithArgument('hey') throw new UnexpectedCharacter(1, 2)Реализация лексера
Для начала разберёмся со структурой токена как объекта. У него будет имя/идентификатор по которому мы сможем его опознать, значение токена, если это например число или строка и его положение в исходном коде.
Создадим класс Span , У него будет три свойства, это исходная программа, начало токена и его конец, метод width , чтобы быстро узнать длину токена. Не будем тянуть и реализуем возможность получить номер строки и столбца
export class Span < constructor( private readonly src: string, readonly start: number, readonly end: number, ) <>get width() < return this.end - this.start >get line() < return (this.src.slice(0, this.start).match(/\n/g) || '').length >get column() < const lines = this.src.slice(0, this.start).split('\n') if(lines.length === 1) return this.start return this.start - lines.slice(0, lines.length - 1).join('\n').length - 1 >>Ну а теперь сам Token . В качестве идентификатора токена будет выступать сам класс, а точнее его имя. Например, чтобы проверить что некоторый токен это символ звёздочки, просто используйте token instanceof Asterisk
export class Token < constructor(readonly value: string, readonly span: Span) <>> // Тип конструктора пригодится позже export type TokenKind = typeof TokenДобавим статический метод tokenize , который мы будем переопределять для каждого токена. Он будет искать токены, принимая строку исходного кода и возвращая длину токена. Если возвращённое число -1, будем считать, что токен найти не удалось. Пока не думайте про that , это просто ссылка на лексер. Мы не предполагаем, что Token будет инстансирован напрямую без наследования, поэтому кинем ошибку
static tokenize(that: any, src: string): number < throw new AbstractToken // Abstract token can't be used >Искать токены мы будем при помощи регулярных выражений, это невероятно просто и красиво. А чтобы проще и быстрей создавать виды токенов я решил написать билдер. Это может немного сбить с толку, но по сути это функция которая за нас реализует каждый класс токена.
// Пачка типов. T - это тип ссылки на лексер. type GroupString = string | RegExp type GroupValue = GroupString | ((that: T) => GroupString) type ConditionFn = (that: T) => boolean type Subscriber = (that: T, result: number) => void interface Condition < not?: boolean fn: ConditionFn> interface Group < value: GroupValuemain?: boolean escape?: boolean > // "Макрос" для реализации видов токенов export const kind = (name: string) => < const extends Token < // Группы токенизации, по простому просто части одного // регулярного выражения private static readonly _groups: Group[] = [] // Условия при соблюдении которых токен будет засчитываться private static readonly _conditions: Condition[] = [] // Подписчики. Они будут вызваны если токен будет найден private static readonly _subscribers: Subscriber[] = [] // Regex группа может быть вычислена // resolveGroup вернёт вычисленную группу, // если её можно вычислить private static resolveGroup(that: T, group: GroupValue) < return typeof group === 'function' ? group(that) : group >// Добавляем группу(ы) static group(. parts: GroupValue[]): typeof Class < Class._groups.push(. parts.map(value =>(< value >))) return Class > // Устанавливаем главную группу, // ту, длину которой засчитает лексер static main(part: GroupValue): typeof Class < Class._groups.push(< value: part, main: true >) return Class > // Добавляем разрешающее условие(я) static allow(. conditions: ConditionFn[]): typeof Class < Class._conditions.push(. conditions.map(fn =>(< fn >))) return Class > // Добавляем запрещающее условие(я) static disallow(. conditions: ConditionFn[]): typeof Class < Class._conditions.push(. conditions.map(fn =>(< fn, not: true >))) return Class > // Устанавливаем группу для последовательности символов static plain(text: GroupValue): typeof Class < Class._groups.push(< value: text, escape: true, main: true >) return Class > // Добавляем подписчика static on(. subscriber: Subscriber[]): typeof Class < Class._subscribers.push(. subscriber) return Class >// Оповещаем подписчиков об успешной токенизации private static emit(that: T, value: number) < Class._subscribers.forEach(s =>s(that, value)) > // Компилируем все условия и получаем полное регулярное выражение // при соблюдении всех условий private static compile(that: T, doMatch = true): RegExp | undefined < // Собираем результаты условий for (const condition of this._conditions) < // Вычисляем результат let result = condition.fn(that) // Меняем на противоположный, если добавляли через // disallow if (condition.not) result = !result if (!result) < doMatch = false return >> // Формируем регулярное выражение return RegExp(`^$ < // Вычисляем группу const group = Class.resolveGroup(that, g.value) // Проверяем разные кейсы и в зависимости от этого // устанавливаем конечное значение группы const value = typeof group === 'object' ? group.source : g.escape ? escapeRegex(group) : group // оборачиваем группу return `($)` >).join('')>`) > // Прибавляем 1, поскольку метод match возвращает // всё совпадение, а потом группы. // И смотрите как удобно, если главной группы нет, // то берём всё, тк -1 + 1 = 0, а 0 это всё совпадение private static getMainIndex() < return Class._groups.findIndex(g =>g.main === true) + 1 > // Реализуем главный метод токенизации static tokenize(that: T, src: string) < // Компилируем выражение, если его нет, то пропускаем токен const regex = Class.compile(that) if (!regex) return -1 // матчим строку const matches = src.match(regex) if (!matches) return -1 // Берём главную группу const result: number = matches[Class.getMainIndex()].length // Оповещаем подписчиков об успешной находке if (result >= 0) Class.emit(that, result) // Возвращаем длину токена return result > >, name) return Class > Если вы всё таки любитель читать код, что не скажешь по комментариям, то могу рассказать, что такое that . С помощью that я ссылкаюсь на текущий лексер, таким образом все условия и подписки будут работать независимо от лексера, если вы читали статью раньше, то that не было и из-за этого каждый новый экземпляр лексера ломал токены добавляя повторяющиеся правила.
Теперь можем приступить к созданию видов токенов. Начнём с чего-то простого. Токенизируем простое числовое выражение.
Вот какие виды токенов мы может тут найти: Число, Открывающая Круглая Скобка, Закрывающая Круглая Скобка, Звёздочка, Слэш и Пробел(да, мы его тоже считаем)
// scripts/1.ts const src = `(2 * 3) / 6` const Number = kind('Number').main(/\d+/) const Asterisk = kind('Asterisk').plain('*') const Slash = kind('Slash').plain('/') const OpenParen = kind('OpenParen').plain('(') const CloseParen = kind('CloseParen').plain(')') const Whitespace = kind('Whitespace').main(/[^\S\r\n]+/)Приступим к классу лексера. Я также буду использовать подход с использованием итератора, чтобы мы могли контролировать процесс.
export class Lexer < // Длина проанализированного текста private index = 0 constructor( // Берём на вход исходник private src: string, // Виды(kinds) токенов private readonly kinds: TokenKind[], ) <>next() < /* . */>// Реализуем итератор [Symbol.iterator]() < return < next: () => < return < done: this.done, value: this.next() >>, > > // Вернуть true если всё токенизировали get done() < return this.index === this.src.length >>Реализуем метод next . Он будет перебирать виды токенов и подставлять в них строку исходника, если метод tokenize каждого вида токена не вернёт число больше -1, то кидаем ошибку: «Неожиданный токен» иначе возвращаем экземпляр токена.
next() < // Выполняем проход по всем видам токенов for (const kind of this.kinds) < // Токенизируем исходную строку начиная с this.index // . Отдаёт тот самый that const result = kind.tokenize?.(this, this.src.slice(this.index)) ?? -1\ // Если не нашли, то идём дальше if (result === -1) continue // возвращаем экземпляр токена и обновляем this.index return new kind(this.src.slice(this.index, this.index + result), new Span(this.src, this.index, this.index += result)) >// Если ни один из токенов не дал о себе знать, // то мы наткнулись на неизвестную или неверную часть программы throw new UnexpectedToken >Добавим функцию для сбора всех токенов.
export const tokenize = (lexer: Lexer) =>
Теперь можем упаковать токены в нужном порядке и посмотреть на результат
const kinds = [Number, Asterisk, Slash, OpenParen, CloseParen, Whitespace] const result = tokenize(new Lexer(src, kinds)) // (0:0;1) [OpenParen: (] // (0:1;1) [Number: 2] // (0:2;1) [Whitespace: •] // (0:3;1) [Asterisk: *] // (0:4;1) [Whitespace: •] // (0:5;1) [Number: 3] // (0:6;1) [CloseParen: )] // (0:7;1) [Whitespace: •] // (0:8;1) [Slash: /] // (0:9;1) [Whitespace: •] // (0:10;1) [Number: 6]Производительность
console.time в среднем демонстрирует результат 0.3ms для выражения выше, однако первый старт занимает около 2.75ms. Не знаю хорошо это или не очень; в будущем попробуем тоже самое на rust и сравним производительность.
Заключение
Теперь мы научились преобразовывать символы в токены. В следующей части как только я разберусь мы приступим к созданию парсера.
Напоминаю также, что вы можете поиграться и самостоятельно изучить код клонировав репозиторий из github со всем кодом который был тут предоставлен. Я понимаю, что лексер можно было бы сделать в пару строк, но это вы и так найдёте в гугле, я же стремлюсь сделать проект максимально расширяемым, я понимаю, что не весь код может быть понятен тут, поэтому оставляю ссылку на репозиторий, вы также можете задать вопрос в комментариях.
Бонус
Токенизируем шаблонную строку
const src = "`I'm $!`"// Ещё не забыли про that. Так вот зачем он нужен // Обычный текст, ищем только если в состоянии шаблонной строки const Plain = kind('Plain').main(/.+?/).group(/\$<|>|`/).allow(that => that.template) const Asterisk = kind('Asterisk').plain('*') const Number = kind('Number').main(/\d+/) const Whitespace = kind('Whitespace').main(/[^\S\r\n]+/) // Символ шаблонной строки (`) если находим, то переключаем состояние const Backtick = kind('Backtick').plain('`').on(that => that.template = !that.template) // Начало шаблонного выражения, ищем если в состоянии шаблонной строки, // если находим, ВЫключаем режим шаблонной строки const OpenDollarBrace = kind('OpenDollarBrace').main(/\$ that.template).on(that => that.template = false) // Конец шаблонного выражения, ищем если НЕ в состоянии шаблонной строки // если находим, Включаем режим шаблонной строки const CloseBrace = kind('CloseBrace').main(/>/).disallow(that => that.template).on(that => that.template = true)// Расшиярем лексер, чтобы хранить собственное состояние class CustomLexer extends Lexer < template = false constructor(src: string) < // Тот случай когда порядок важен // Plain берёт любые символы и если он будет в начале, // то просто "съест" начало шаблонного выражения super(src, [Backtick, OpenDollarBrace, CloseBrace, Asterisk, Number, Whitespace, Plain]) >>const result = tokenize(new CustomLexer(src)) // (0:0;1) [Backtick: `] // (0:1;4) [Plain: I'm•] // (0:5;2) [OpenDollarBrace: $] // (0:13;1) [Plain: !] // (0:14;1) [Backtick: `]А чё там с рекурсией?
const recursive = "`Hey $`>`"Я прям потел когда смотрел на такую строку, но лексер сделал своё дело
(0:0;1) [Backtick: `] (0:1;4) [Plain: Hey•] (0:5;2) [OpenDollarBrace: $] (0:30;1) [Backtick: `] (0:31;1) [CloseBrace: >] (0:32;1) [Backtick: `]Спасибо что прочитали ВСЁ, ПРЯМ ВСЁ. Огромное спасибо. Буду очень рад оценке и комментарию.
- javascript
- typescript
- язык программирования с нуля
- lexer
- лексер
Объясняем бабушке, как написать свой язык программирования
Это игровая площадка, где я попытаюсь объяснить, как создать малюсенький язык программирования (Mu). Можно посмотреть вживую на открытые исходники здесь или скачать тут. Туториал можете прочитать прямо сейчас.

Пишем свой язык программирования (на Swift)
Для того, чтобы написать свой язык программирования, необязательно иметь степень в Computer Science, достаточно понимать 3 базовых шага.
Язык: Mu(μ)
Mu — это минимальный язык, который содержит постфиксный оператор, бинарную операцию и «одноциферные» числа.
Пример: (s 2 4) or (s (s 4 5) 4) or (s (s 4 5) (s 3 2))…

Подходы к двух- и трехступечатому проектированию, которые мы используем на проектах в EDISON Software Development Centre.
Шаги:
Lexer
В компьютерных науках лексический анализ — это процесс аналитического разбора входной последовательности символов (например, такой как исходный код на одном из языков программирования) с целью получения на выходе последовательности символов, называемых «токенами» (подобно группировке букв в словах).
Группа символов входной последовательности, идентифицируемая на выходе процесса как токен, называется лексемой. В процессе лексического анализа производится распознавание и выделение лексем из входной последовательности символов.
— Википедия
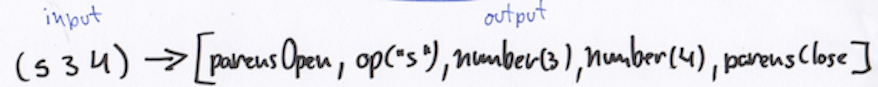
Из-за того, что Mu так мал — только один оператор и числа — вы можете просто совершать итерации ввода и проверять каждый символ.
enum Token < case parensOpen case op(String) case number(Int) case parensClose >struct Lexer < static func tokenize(_ input: String) ->[Token] < return input.characters.flatMap < switch $0 < case "(": return Token.parensOpen case ")": return Token.parensClose case "s": return Token.op($0.description) default: if "0". "9" ~= $0 < return Token.number(Int($0.description)!) >> return nil > > > let input = "(s (s 4 5) 4)" let tokens = Lexer.tokenize(input) Parser
Парсер или синтаксический анализатор — это часть программы, преобразующей входные данные (как правило, текст) в структурированный формат. Парсер выполняет синтаксический анализ текста.
Grammar:
expression: parensOpen operator primaryExpression primaryExpression parensClose primaryExpression: expression | number parensOpen: "(" parensClose: ")" operator: "s" number: [0-9]Грамматика Mu — это бесконтекстная грамматика, что означает, что она описывает все возможные варианты строк в языке. Парсер начинает с верха (корня сгенерированного дерева) и двигается до самого нижнего узла.
Совет: код должен быть прямым представлением граммматики
func parseExpression() -> ExpressionNode < . firstPrimaryExpression = parsePrimaryExpression() secondPrimaryExpression = parsePrimaryExpression() . >func parseExpression() -> PrimaryExpressionNode
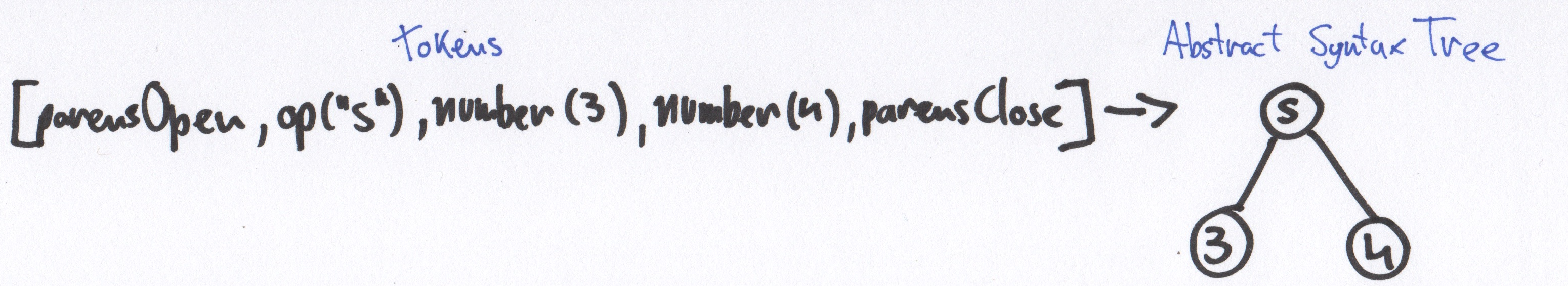
indirect enum PrimaryExpressionNode < case number(Int) case expression(ExpressionNode) >struct ExpressionNode < var op: String var firstExpression: PrimaryExpressionNode var secondExpression: PrimaryExpressionNode >struct Parser < var index = 0 let tokens: [Token] init(tokens: [Token]) < self.tokens = tokens >mutating func popToken() -> Token < let token = tokens[index] index += 1 return token >mutating func peekToken() -> Token < return tokens[index] >mutating func parse() throws -> ExpressionNode < return try parseExpression() >mutating func parseExpression() throws -> ExpressionNode < guard case .parensOpen = popToken() else < throw ParsingError.unexpectedToken >guard case let Token.op(_operator) = popToken() else < throw ParsingError.unexpectedToken >let firstExpression = try parsePrimaryExpression() let secondExpression = try parsePrimaryExpression() guard case .parensClose = popToken() else < throw ParsingError.unexpectedToken >return ExpressionNode(op: _operator, firstExpression: firstExpression, secondExpression: secondExpression) > mutating func parsePrimaryExpression() throws -> PrimaryExpressionNode < switch peekToken() < case .number: return try parseNumber() case .parensOpen: let expressionNode = try parseExpression() return PrimaryExpressionNode.expression(expressionNode) default: throw ParsingError.unexpectedToken >> mutating func parseNumber() throws -> PrimaryExpressionNode < guard case let Token.number(n) = popToken() else < throw ParsingError.unexpectedToken >return PrimaryExpressionNode.number(n) > > //MARK: Utils extension ExpressionNode: CustomStringConvertible < public var description: String < return "\(op) ->[\(firstExpression), \(secondExpression)]" > > extension PrimaryExpressionNode: CustomStringConvertible < public var description: String < switch self < case .number(let n): return n.description case .expression(let exp): return exp.description >> > let input = "(s 2 (s 3 5))" let tokens = Lexer.tokenize(input) var parser = Parser(tokens: tokens) var ast = try! parser.parse()Interpreter
В computer science, интерпретатор — это программа, которая последовательно выполняет инструкции, написанные на языке программирования или скриптовом языке, без предварительной компиляции в машинный код. (Википедия)
Интерпретатор Mu будет проходить через свои A.S.T и вычислять значения, применяя оператор к дочерним узлам.
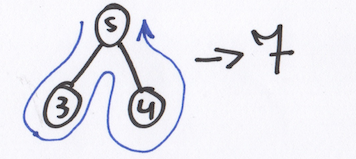
enum InterpreterError: Error < case unknownOperator >struct Interpreter < static func eval(_ expression: ExpressionNode) throws ->Int < let firstEval = try eval(expression.first) let secEval = try eval(expression.second) if expression.op == "s" < return firstEval + secEval >throw InterpreterError.unknownOperator > static func eval(_ prim: PrimaryExpressionNode) throws -> Int < switch prim < case .expression(let exp): return try eval(exp) case .number(let n): return Int(n) >> > let input = "(s (s 5 2) 4)" let tokens = Lexer.tokenize(input) var parser = Parser(tokens: tokens) let ast = try! parser.parse() try! Interpreter.eval(ast)Заключение
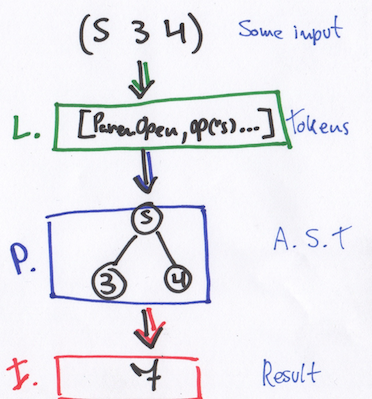
-
Ввод let input plaintext»>var parser = Parser(tokens: tokens) let ast = try! parser.parse()
- Проходим по дереву, вычисляя значения, находящиеся внутри узлов (Interpreting). let result = try! Interpreter.eval(ast)
Resources
- ruslanspivak.com/lsbasi-part1
- www.amazon.com/Compilers-Principles-Techniques-Tools-2nd/dp/0321486811
- llvm.org/docs/tutorial
Как написать лексер

МЕРОПРИЯТИЯ
Всероссийский хакатон по биометрии
Комментарии
Популярные По порядку
Не удалось загрузить комментарии.
ВАКАНСИИ

Методист-педагогический дизайнер в Proglib.Academy
по итогам собеседования
Преподаватель на курс БД SQL в Proglib.Academy
по итогам собеседования
ЛУЧШИЕ СТАТЬИ ПО ТЕМЕ
ООП на Python: концепции, принципы и примеры реализации
Программирование на Python допускает различные методологии, но в его основе лежит объектный подход, поэтому работать в стиле ООП на Python очень просто.
3 самых важных сферы применения Python: возможности языка
Существует множество областей применения Python, но в некоторых он особенно хорош. Разбираемся, что же можно делать на этом ЯП.
Программирование на Python: от новичка до профессионала
Пошаговая инструкция для всех, кто хочет изучить программирование на Python (или программирование вообще), но не знает, куда сделать первый шаг.