Byte array to string и обратно
Вывод в консоль этой строки дает следующий результат
str1 text: [B@16daa9
str.equals(str1) = false
Пробовал менять на разные кодировки при преобразовании и пользоваться конструктором new String при приведении к строке. Не помогло.
Если кто нибудь знает как корректно выполнить эту операцию отпишитесь пожалуйста
Лучшие ответы ( 1 )
94731 / 64177 / 26122
Регистрация: 12.04.2006
Сообщений: 116,782
Ответы с готовыми решениями:
Что-то не так с Encoding данных туда и обратно: byte в string и обратно в byte
Добрый день, коллеги! Столкнулся с такой проблемой, причём заметил её не сразу ("вроде бы всё.
convert string of byte 2 byte array
Есть длиииный стринг ’00 05 0F 7B’ и тд и тп, нада все это дело запихать в байтный массив (чтобы.

из array of String в array of Byte
имеется массив стринг "a:array" из 3 строк вот пример: 00111101 01101110 00011000 нужно.
Byte array to string
Добрый день! Имеется девайс: U-Prox-Keypad Задача: считать с клавиатуры символы 0-9 и *, и # и.
2883 / 2295 / 769
Регистрация: 12.05.2014
Сообщений: 7,978
1 2 3
byte[] array = new byte[] {97, 98, 99}; String str = new String(array); System.out.println(str); // -> "abc";
![]()
4090 / 3824 / 745
Регистрация: 18.05.2010
Сообщений: 9,331
Записей в блоге: 11
Akolmistly, Вы вызываете совршенно разные, не связанные между собой, преобразования.
Зачем вы хотите из массива байт получить строку? Для отладки (Arrays.toString)? Или все таки эти байты содержат реальные символы (new String(byte[], Charset))?
Преобразование массива байт в hex-строку
В процессе разработки часто бывает необходимо отобразить «сырой» массив данных, состоящий из массива байт, в виде читаемой строки. При этом далеко не все возможные значения байта (которых всего 256) отображаются в виде читаемых символов. Общепринятным подходом является отображение значения байта в шестандцатеричном формате (hexadecimal или hex).
В данном формате значения от 0 до 9 отображаются как есть, затем 10 заменяется на первую букву английского алфавита A, 11 преобразуется в B и т.д. И так до значения 15, т.е. до F. Затем значение 16 в шестнадцатеричном формате отображается в виде 10 (переполнился первый разряд, который стал нулём и мы заняли второй разряд). И далее 17 становится 11, 18 преобразуется в 12 и т.д. Максимальное значение байта 255 отображается как FF.
В Java (а, значит, и в Kotlin) наиболее простой способ отображения числа в шестнадцатеричном виде – это использование специального шаблона в методе String.format(). Рассмотрим код на kotlin:
fun ByteArray.toHexString() = this .joinToString(separator = «» ) < "%02X" .format(it) >
Здесь мы объявляем функцию расширения для ByteArray. В ней мы форматируем каждый байт по шаблону %02X. % в данном случае означает начало шаблона, 2 говорит о длине формируемой строки, 0 – о том, что если число занимает меньше символов, чем требуется, то недостающие разряды будут заполнены нулями. Ну а X отвечает за шестнадцатеричный формат. При использовании прописной X строка будет также содержать прописные буквы, а при использовании строчной x – строчные. Далее мы склеиваем каждую такую строку с помощью метода joinToString() и в качестве разделителя указываем пустую строку.
Теперь мы можем вызывать нашу функцию расширения на любом байтовом массиве:
val bytes = byteArrayOf( 1 , 2 , 10 , 15 )
val hexString = bytes.toHexString() // строка «01020A0F»
Для создания массива байт используем byteArrayOf(), но в реальных приложениях чаще всего это содержимое строки или файла. Далее метод toHexString() возвращает строку в hex-формате. Каждое число представлено двумя символами. Обратите внимание на ведущие нули для каждого из значений.
2 примера для преобразования массива Byte [] в строку в Java
Преобразование байтового массива в String кажется простым, но трудно сделать это правильно. Многие программисты делают ошибку, игнорируя кодировку символов всякий раз, когда байты преобразуются в String или char или наоборот. Как программист, мы все знаем, что компьютер понимает только двоичные данные, то есть 0 и 1. Все, что мы видим и используем, например изображения, текстовые файлы, фильмы или любые другие мультимедийные файлы, хранится в виде байтов, но что более важно это процесс кодирования или декодирования байтов в символ. Преобразование данных является важной темой на любом собеседовании по программированию, и из-за хитрости кодирования символов эти вопросы являются одним из самых популярных вопросов о интервью в формате String в интервью Java. При чтении строки из входного источника, например, файлов XML, HTTP-запроса, сетевого порта или базы данных, вы должны обратить внимание на то, какую кодировку символов (например, UTF-8, UTF-16 и ISO 8859-1) они кодируют. Если вы не будете использовать ту же кодировку символов при преобразовании байтов в строку , вы получите поврежденную строку, которая может содержать совершенно неправильные значения. Вы могли видеть ?, квадратные скобки после преобразования byte [] в String, это из-за значений, которые ваша текущая кодировка символов не поддерживает, и просто показывает некоторые значения мусора.
Я пытался понять, почему программы делают ошибки кодирования символов чаще, чем нет, и мои небольшие исследования и собственный опыт позволяют предположить, что это может быть вызвано двумя причинами: во-первых, недостаточно для интернационализации и кодировки символов, а во-вторых, потому что символы ASCII поддерживаются почти все популярные схемы кодирования и имеют одинаковые значения. Поскольку мы в основном имеем дело с кодировкой, такой как UTF-8, Cp1252 и Windows-1252, которая отображает символы ASCII (в основном алфавиты и цифры) без сбоев, даже если вы используете другую схему кодирования. Настоящая проблема возникает, когда ваш текст содержит специальные символы, например «é» , который часто используется во французских именах. Если кодировка символов вашей платформы не распознает этот символ, то либо вы увидите другой символ, либо что-то в этом роде, и, к сожалению, пока вы не обожгете руки, вы вряд ли будете осторожны с кодировкой символов. В Java все немного сложнее, потому что многие классы ввода-вывода, например InputStreamReader, по умолчанию используют кодировку символов платформы. Это означает, что если вы запустите свою программу на другом компьютере, вы, скорее всего, получите другой вывод из-за разного кодирования символов, используемого на этом компьютере. В этой статье мы узнаем, как преобразовать byte [] в String в Java как с помощью JDK API, так и с помощью общих утилит Guava и Apache.
Как преобразовать byte [] в строку в Java
Есть несколько способов изменить байтовый массив на String в Java, вы можете использовать методы из JDK или использовать бесплатные API с открытым исходным кодом, такие как Apache commons и Google Guava. Этот API предоставляет как минимум два набора методов для создания байтового массива формы String; один, который использует кодировку платформы по умолчанию, а другой – кодировку символов. Вы всегда должны использовать позже, не полагайтесь на кодировку платформы. Я знаю, что это может быть то же самое, или вы, возможно, не сталкивались с какими-либо проблемами, но лучше быть в безопасности, чем потом сожалеть. Как я указывал в своем последнем посте о печати байтового массива в виде шестнадцатеричной строки , это также один из лучших способов указания кодировки символов при преобразовании байтов в символы на любом языке программирования. Возможно, ваш байтовый массив содержит непечатаемые символы ASCII. Давайте сначала посмотрим, как JDK преобразует byte [] в String:
-
Вы можете использовать конструктор String, который принимает байтовый массив и кодировку символов:
[Перевод] Java Best Practices. Преобразование Char в Byte и обратно
Сайт Java Code Geeks изредка публикует посты в серии Java Best Practices — проверенные на production решения. Получив разрешение от автора, перевёл один из постов. Дальше — больше.
Продолжая серию статей о некоторых аспектах программирования на Java, мы коснёмся сегодня производительности String, особенно момент преобразования character в байт-последовательность и обратно в том случае, когда используется кодировка по умолчанию. В заключение мы приложим сравнение производительности между неклассическими и классическими подходами для преобразования символов в байт-последовательность и обратно.
Все изыскания базируются на проблемах в разработке крайне эффективных систем для задач в области телекоммуникации (ultra high performance production systems for the telecommunication industry).
Перед каждой из частей статьи очень рекомендуем ознакомиться с Java API для дополнительной информации и примеров кода.
Эксперименты проводились на Sony Vaio со следующими характеристиками:
ОС: openSUSE 11.1 (x86_64)
Процессор (CPU): Intel® Core(TM)2 Duo CPU T6670 @ 2.20GHz
Частота: 1,200.00 MHz
ОЗУ (RAM): 2.8 GB
Java: OpenJDK 1.6.0_0 64-Bit
Со следующими параметрами:
Одновременно тредов: 1
Количество итераций эксперимента: 1000000
Всего тестов: 100
Преобразование Char в Byte и обратно:
Задача преобразования Char в Byte и обратно широко распространена в области коммуникаций, где программист обязан обрабатывать байтовые последовательности, сериализовать String-и, реализовывать протоколы и т.д.
Для этого в Java существует набор инструментов.
Метод «getBytes(charsetName)» класса String, наверное, один из популярнейших инструментов для преобразования String в его байтовый эквивалент. Параметр charsetName указывает на кодировку String, в случае отсутствия оного метод кодирует String в последовательность байт используя стоящую в ОС по умолчанию кодировку.
Ещё одним классическим подходом к преобразованию массива символов в его байтовый эквивалент является использование класса ByteBuffer из пакета NIO (New Input Output).
Оба подхода популярны и, безусловно, достаточно просты в использовании, однако испытывают серьёзные проблемы с производительностью по сравнению с более специфическими методами. Помните: мы не конвертируем из одной кодировки в другую, для этого вы должны придерживаться «классических» подходов с использованием либо «String.getBytes (charsetName)» либо возможностей пакета NIO.
В случае ASCII мы имеем следующий код:
public static byte[] stringToBytesASCII(String str) < char[] buffer = str.toCharArray(); byte[] b = new byte[buffer.length]; for (int i = 0; i < b.length; i++) < b[i] = (byte) buffer[i]; >return b; > Массив b создаётся путём кастинга (casting) значения каждого символа в его байтовый эквивалент, при этом учитывая ASCII-диапазон (0-127) символов, каждый из которых занимает один байт.
Массив b можно преобразовать обратно в строку с помощью конструктора «new String(byte[])»:
System.out.println(new String(stringToBytesASCII("test"))); Для кодировки по умолчанию мы можем использовать следующий код:
public static byte[] stringToBytesUTFCustom(String str) < char[] buffer = str.toCharArray(); byte[] b = new byte[buffer.length >8); b[bpos + 1] = (byte) (buffer[i]&0x00FF); > return b; > Каждый символ в Java занимает 2 байта, для преобразования строки в байтовый эквивалент нужно перевести каждый символ строки в его двухбайтовый эквивалент.
И обратно в строку:
public static String bytesToStringUTFCustom(byte[] bytes) < char[] buffer = new char[bytes.length >> 1]; for(int i = 0; i < buffer.length; i++) < int bpos = i return new String(buffer); > Мы восстанавливаем каждый символ строки из его двухбайтового эквивалента и затем, опять же с помощью конструктора String(char[]), создаём новый объект.
Примеры использования возможностей пакета NIO для наших задач:
public static byte[] stringToBytesUTFNIO(String str) < char[] buffer = str.toCharArray(); byte[] b = new byte[buffer.length public static String bytesToStringUTFNIO(byte[] bytes)
А теперь, как и обещали, графики.
String в byte array:
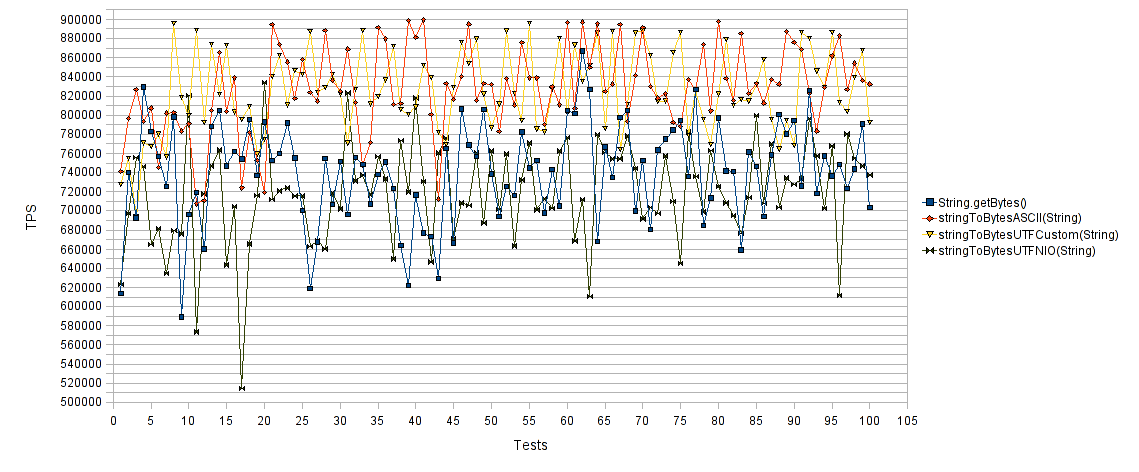
Ось абсцисс — количество тестов, ординат — количество операций в секунду для каждого теста. Что выше — то быстрее. Как и ожидалось, «String.getBytes()» и «stringToBytesUTFNIO(String)» отработали куда хуже «stringToBytesASCII(String)» и «stringToBytesUTFCustom(String)». Наши реализации, как можно увидеть, добились почти 30% увеличения количества операций в секунду.
Byte array в String:
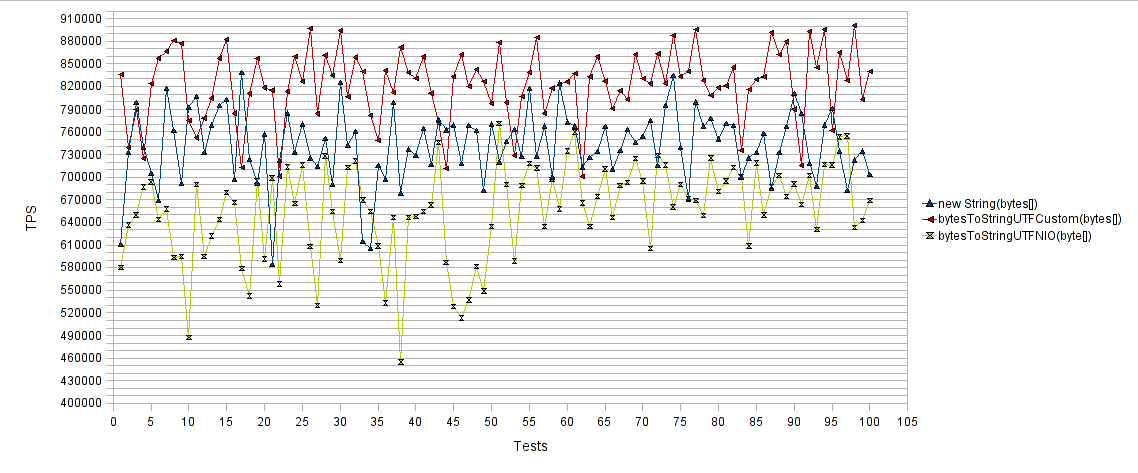
Результаты опять же радуют. Наши собственные методы добились 15% увеличения количества операций в секунду по сравнению с «new String(byte[])» и 30% увеличения количества операций в секунду по сравнению с «bytesToStringUTFNIO(byte[])».
В качестве вывода: в том случае, если вам необходимо преобразовать байтовую последовательность в строку или обратно, при этом не требуется менять кодировки, вы можете получить замечательный выигрыш в производительности с помощью самописных методов. В итоге, наши методы добились в общем 45% ускорения по сравнению с классическими подходами.