Как искать логи в кибане
Kibana provides a front-end to Elasticsearch. Quoting the introduction from Kibana’s User Guide,
Kibana allows to search, view and interact with the logs, as well as perform data analysis and visualize the logs in a variety of charts, tables and maps.
Viewing logs in Kibana is a straightforward two-step process.
Step 1: create an index pattern
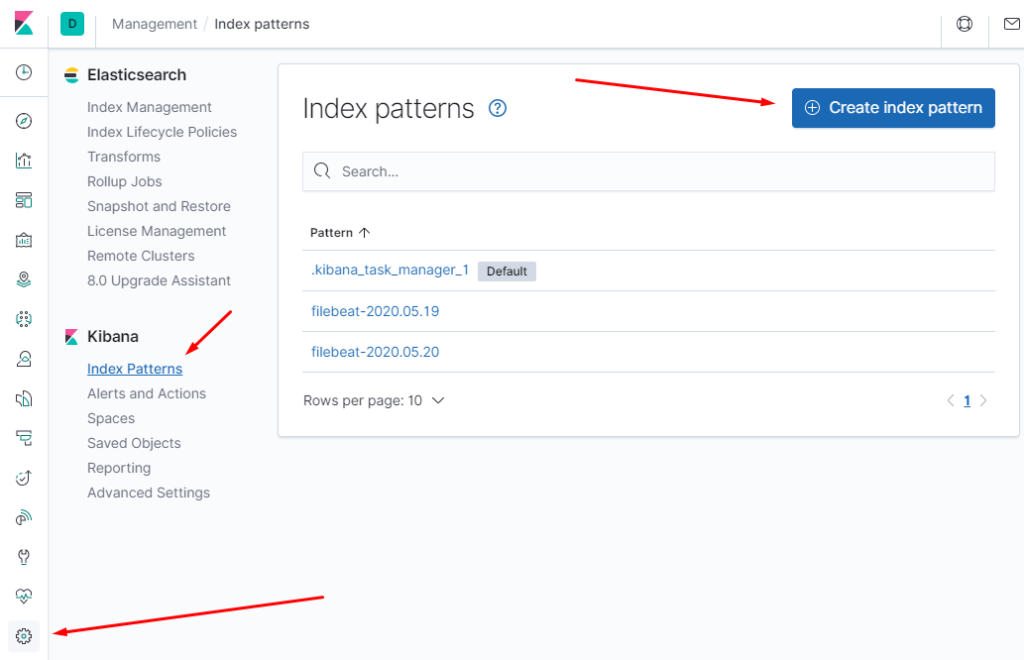
Open Kibana at kibana.example.com . Select the Management section in the left pane menu, then Index Patterns . Then, depending on Kibana’s version, either click Add or + .
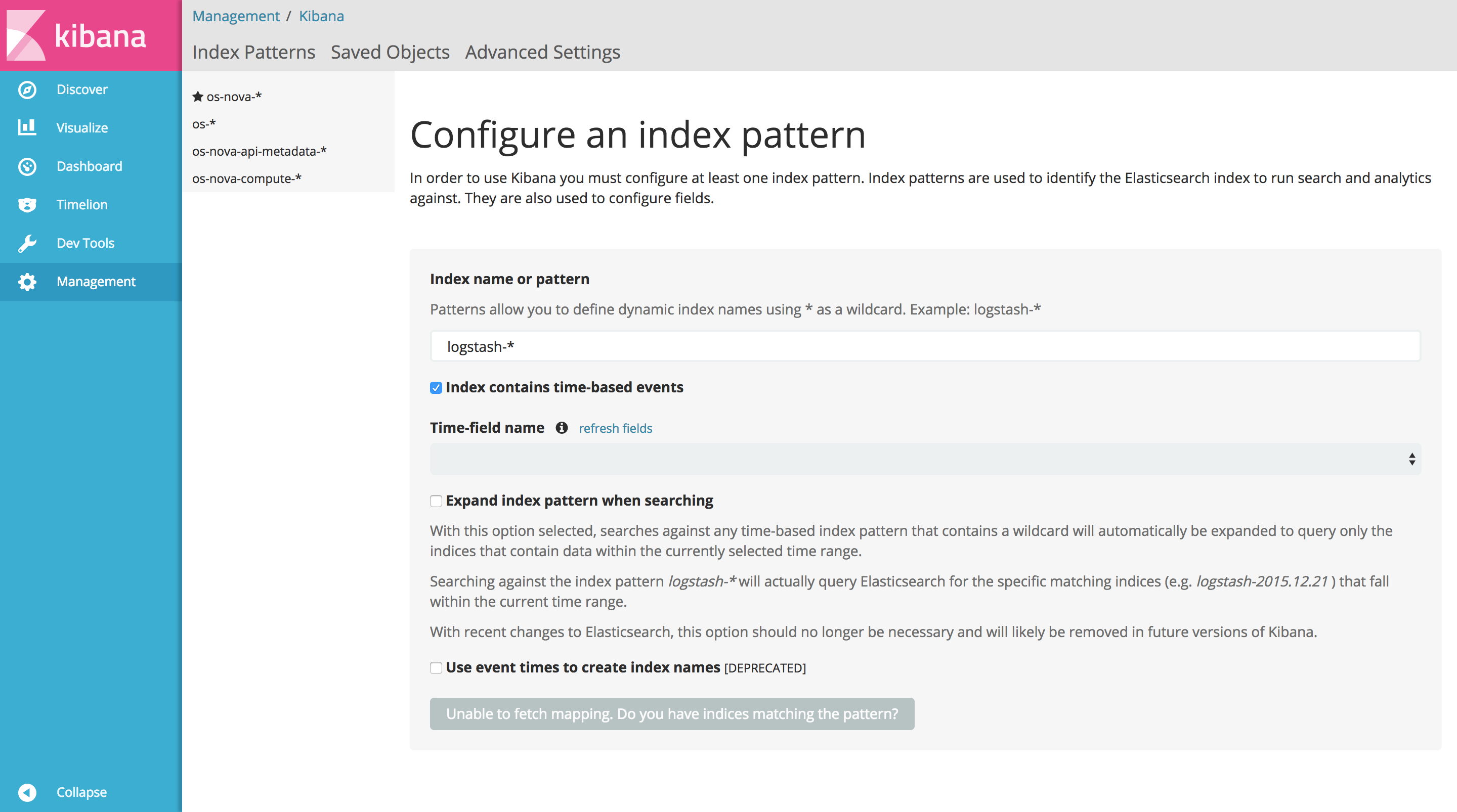
Enter the index pattern, and uncheck Index contains time-based events . As soon as Kibana checks the index pattern against Elasticsearch and the result is positive, the button at the bottom will activate and display Create .

Click Create to configure the index pattern.
Step 2: view the logs
Navigate to the Discover section in the left pane menu. On the left of the page, just under the search bar, select the index pattern just created and all the logs matching the index will be displayed.

Every log entry can be inspected by clicking the small triangular bullet just besides it on the left. Each entry can be viewed as either table or JSON.

Search results can be filtered, using the following buttons

to respectively filter for value, filter out value, toggle column view in the table, and filter for field present.
However, the search bar is the best place for querying and filtering the logs, using the Lucene query syntax or the full JSON-based Elasticsearch Query DSL. More details on searching data, managing searches, etc. are here.
Kibana. Использование языка запросов KQL при поиске логов
Kibana (wiki) используется для мониторинга и анализа ИТ-инфраструктуры в составе Elastic Stack, в который помимо нее входят Elasticsearch и Logstash. Logstash отвечает за логирование и поставляет входящий поток данных в Elasticsearch для хранения, классификации и поиска. Kibana, в свою очередь, получает доступ к данным Elasticsearch для их визуализации в различных визуальных форматах.
У Kibana имеется свой язык запросов KQL (Kibana Query Language) — официальный источник.
С помощью этого языка можно составлять запросы, которые помогают отфильтровывать и найти необходимую информацию.
Подключение к Kibana для просмотра логов
Перейти по URL Kibana — http://37.46.129.245:5601/app/home#/ (данной информацией поделился Евгений Сычёв — PM и QA Lead финтех проектов, для практики поиска логов) .
Ввести данные для авторизации:
- Логин: practice_user
- Пароль: promirit
Выбрать Kibana → Discover:
Режим для KQL включен по умолчанию.

Выбрать значение в Change index pattern, где необходимо проверить логи. Сперва для разбора я выберу ‘logstash‘, а затем для разбора рассмотрим ‘forum‘, так как логи идут от форума клана по игре Властелин колец онлайн — http://forum.free-peoples.ru/, за который отвечает также Евгений Сычёв (предупреждение: требование наличия сертификата -> довериться).
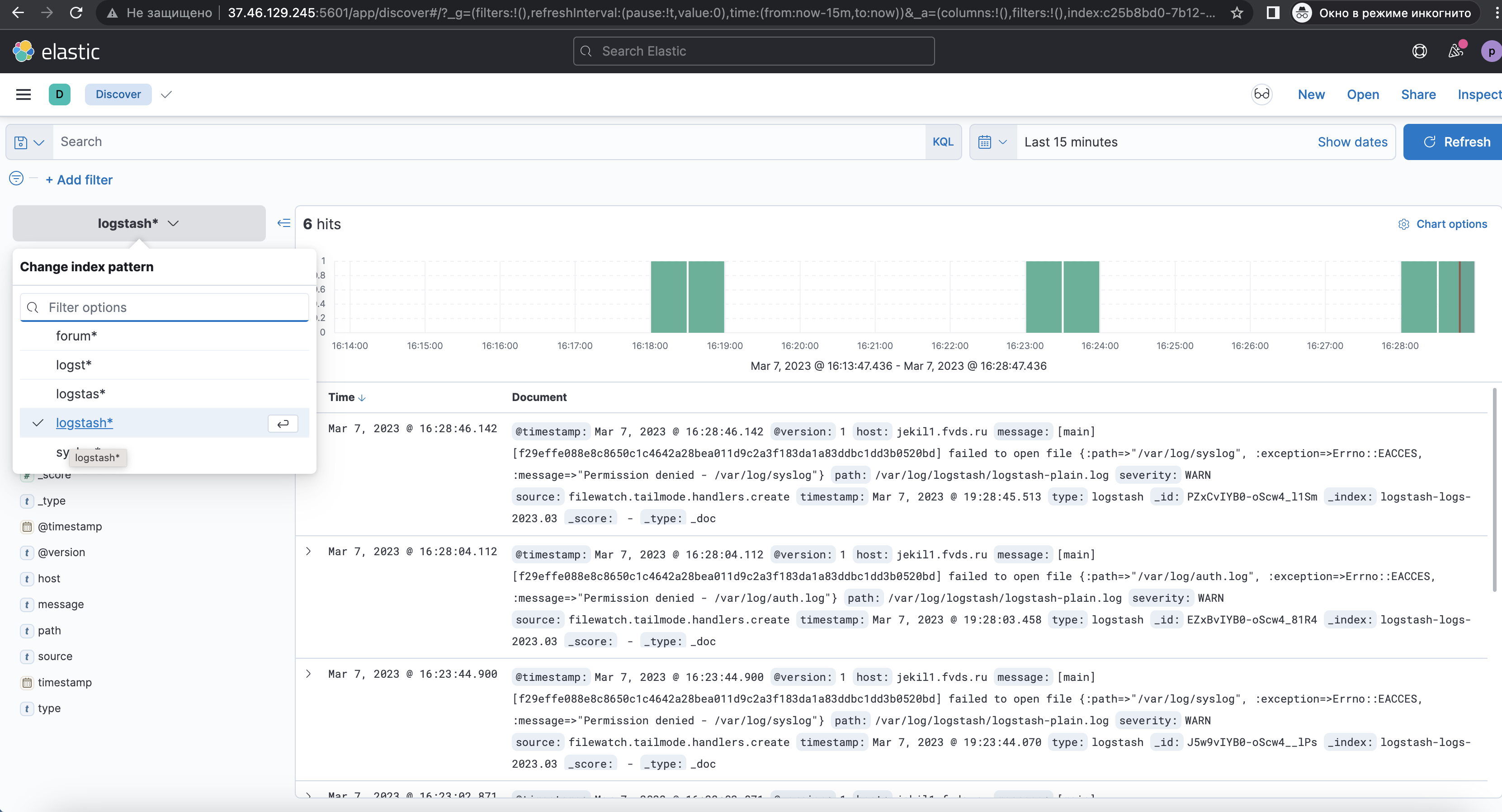
Основные блоки для работы с логами
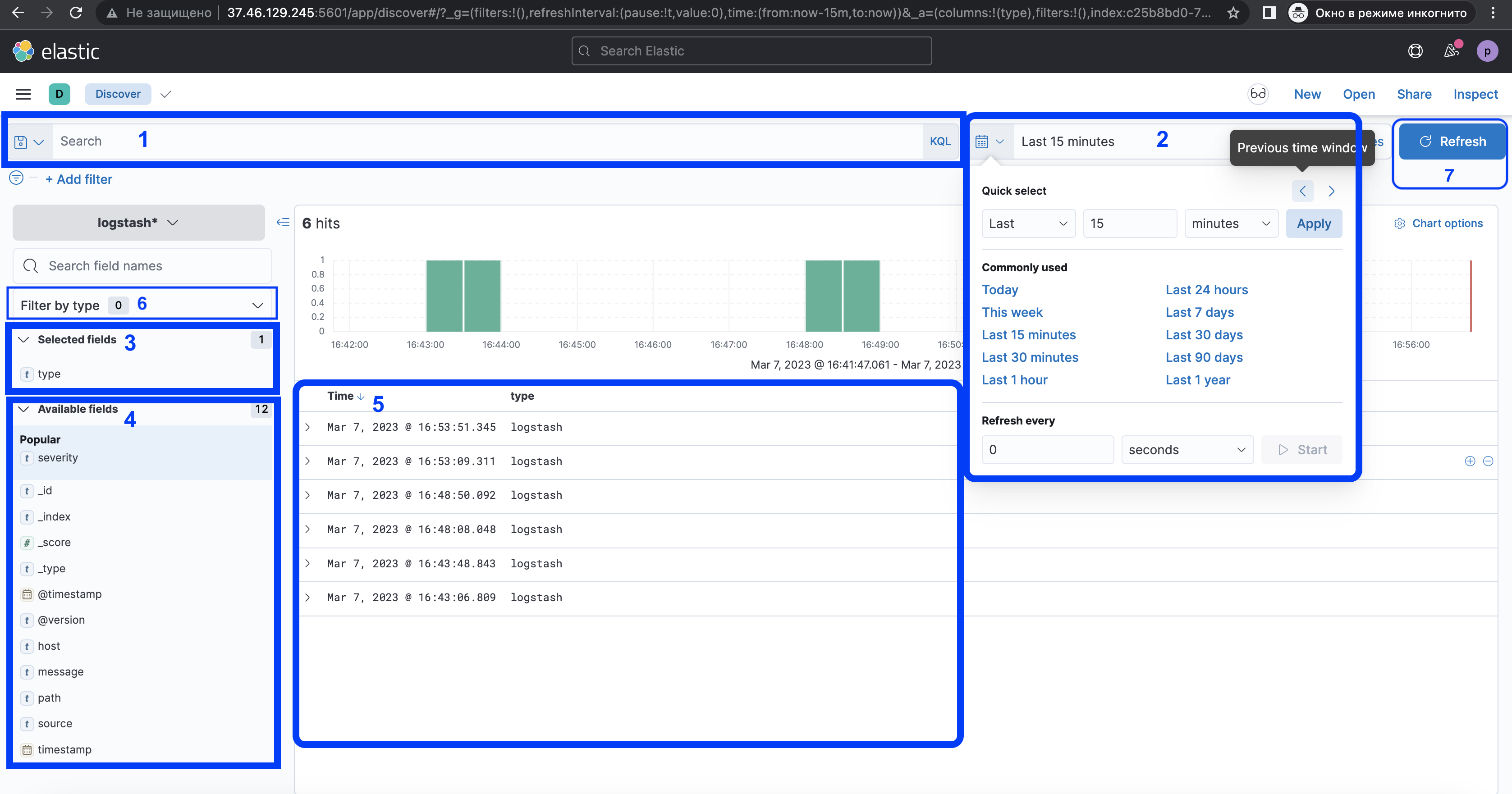
- Блок для ввода поиска логов с использованием KQL-запроса и без;
- Блок с выбором временного промежутка (Today, This week, Last 15 minutes (по умолчанию), Last 30 minutes, Last 1 hour, Last 24 hours, Last 7 days, Last 30 days, Last 90 days, Last 1 year);
- Блок с выбранными фильтрами для вывода логов («Selected fields»);
- Блок с доступными фильтрами («Available fields«);
- Блок результатов поиска логов под выбранные фильтры или без них;
- Блок фильтров по типу данных «Filter by type«;
- Кнопки «Refresh / Update«.
Использование KQL
Указать курсор в строку для составления KQL запросов.
Отображаются возможные ключевые атрибуты для поиска логов.
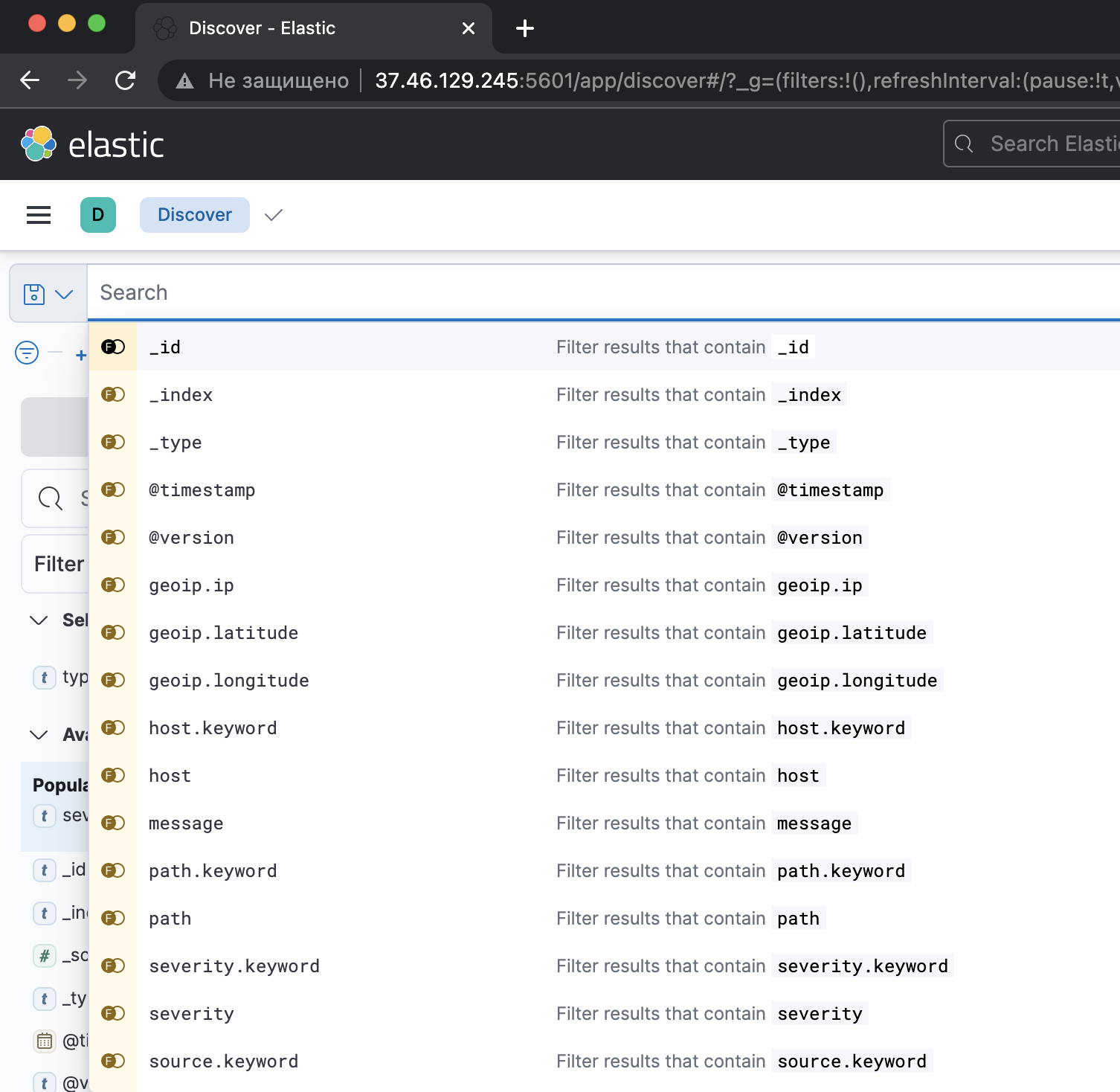
Указать, например, атрибут «message» (Filter results that contain message).
Скриншоты из документации про описание основных параметров.
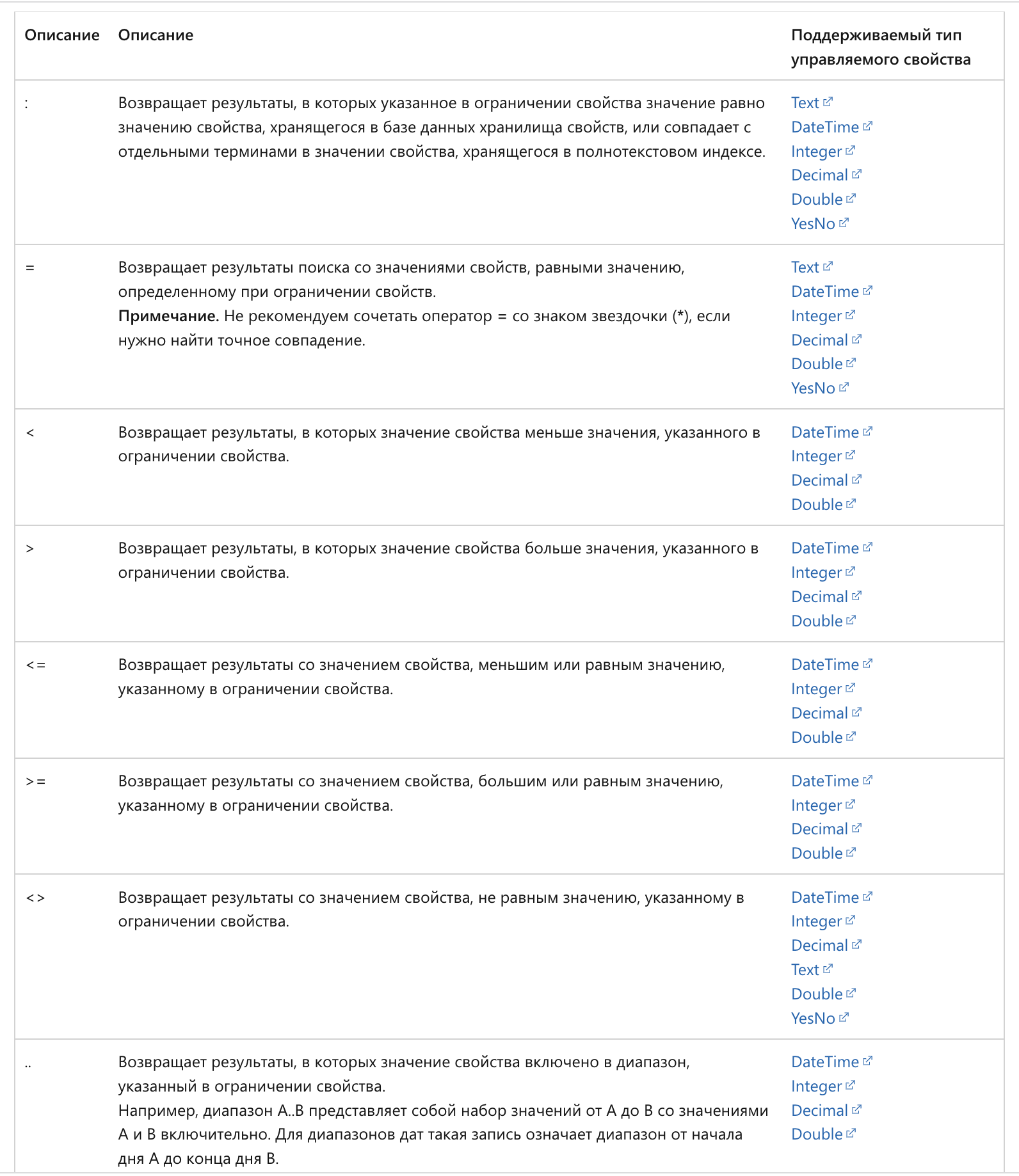

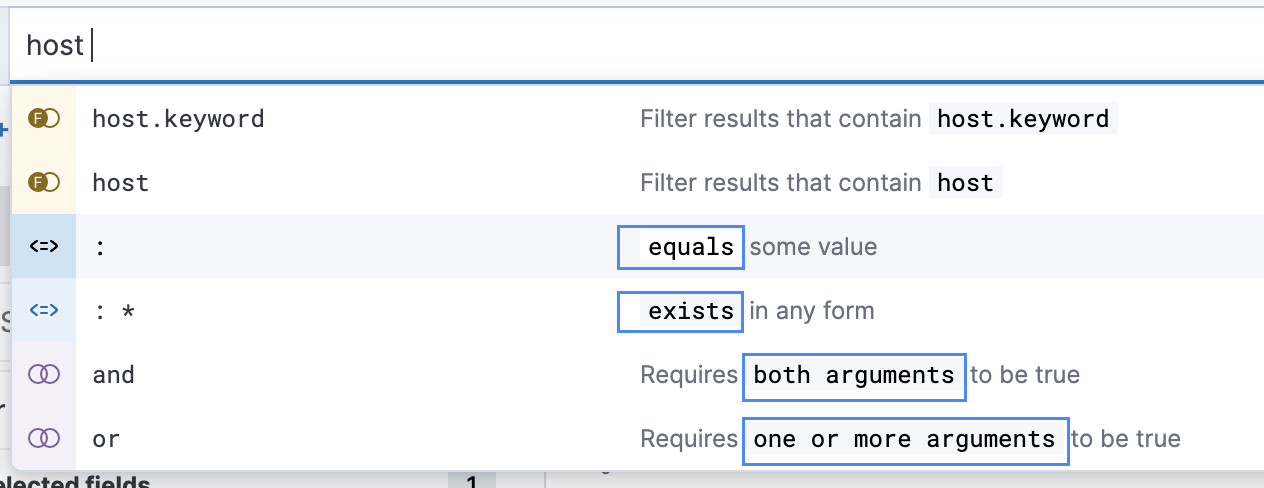
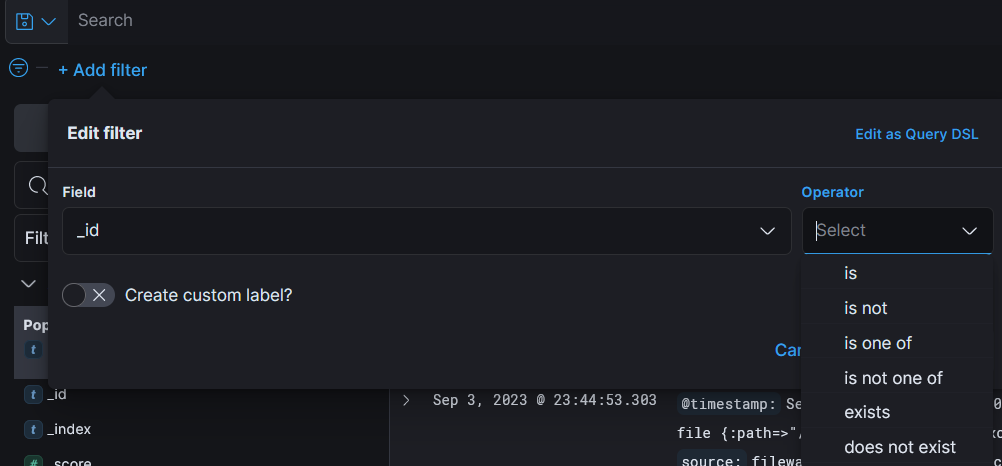
Разберем примеры, поле «host» имеет тип данных «string«, при которых отображаются следующие параметры для поля строки :
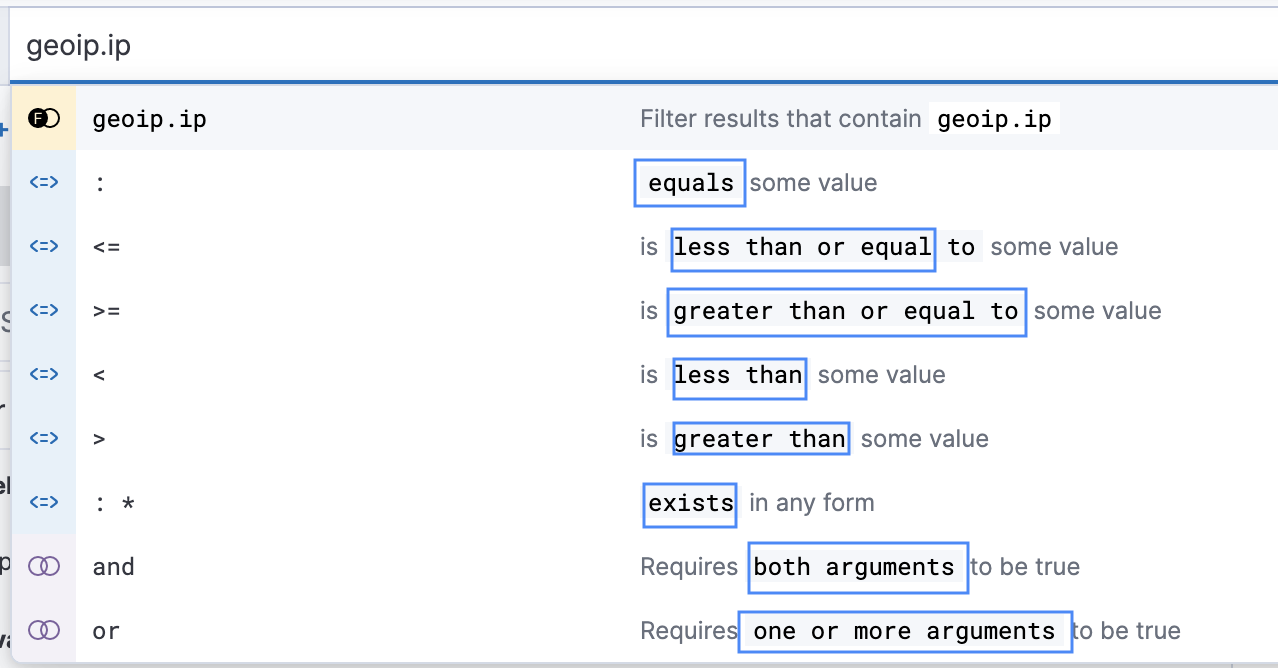
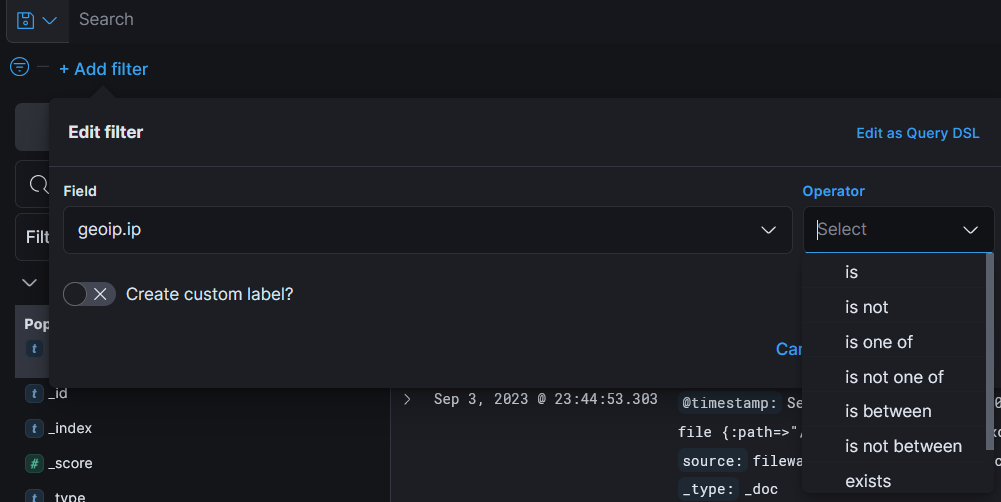
Поле «geoip.ip» имеет тип данных «number«, в котором отображаются следующие параметры для числового поля :
Составление простого KQL-запроса
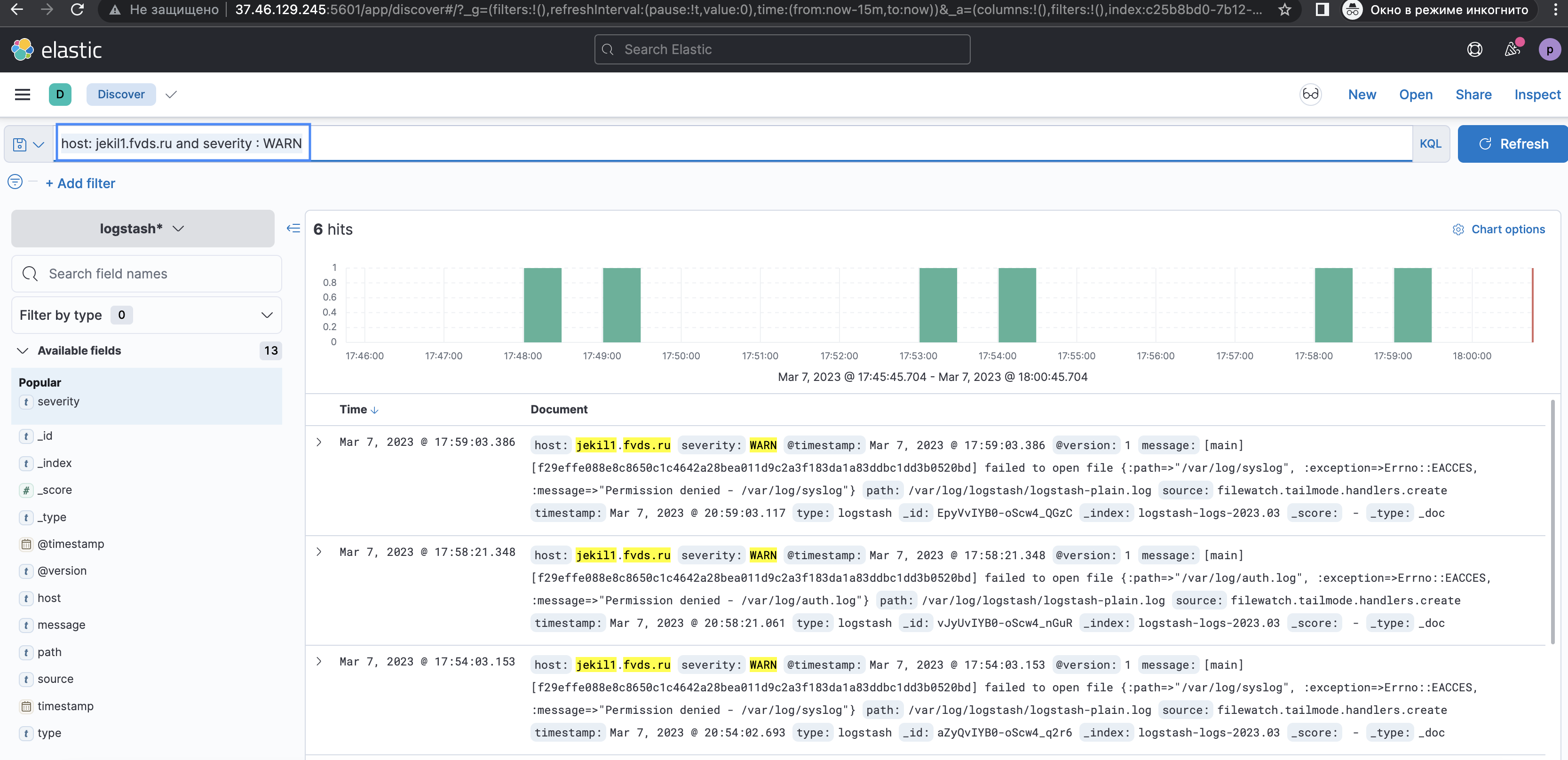
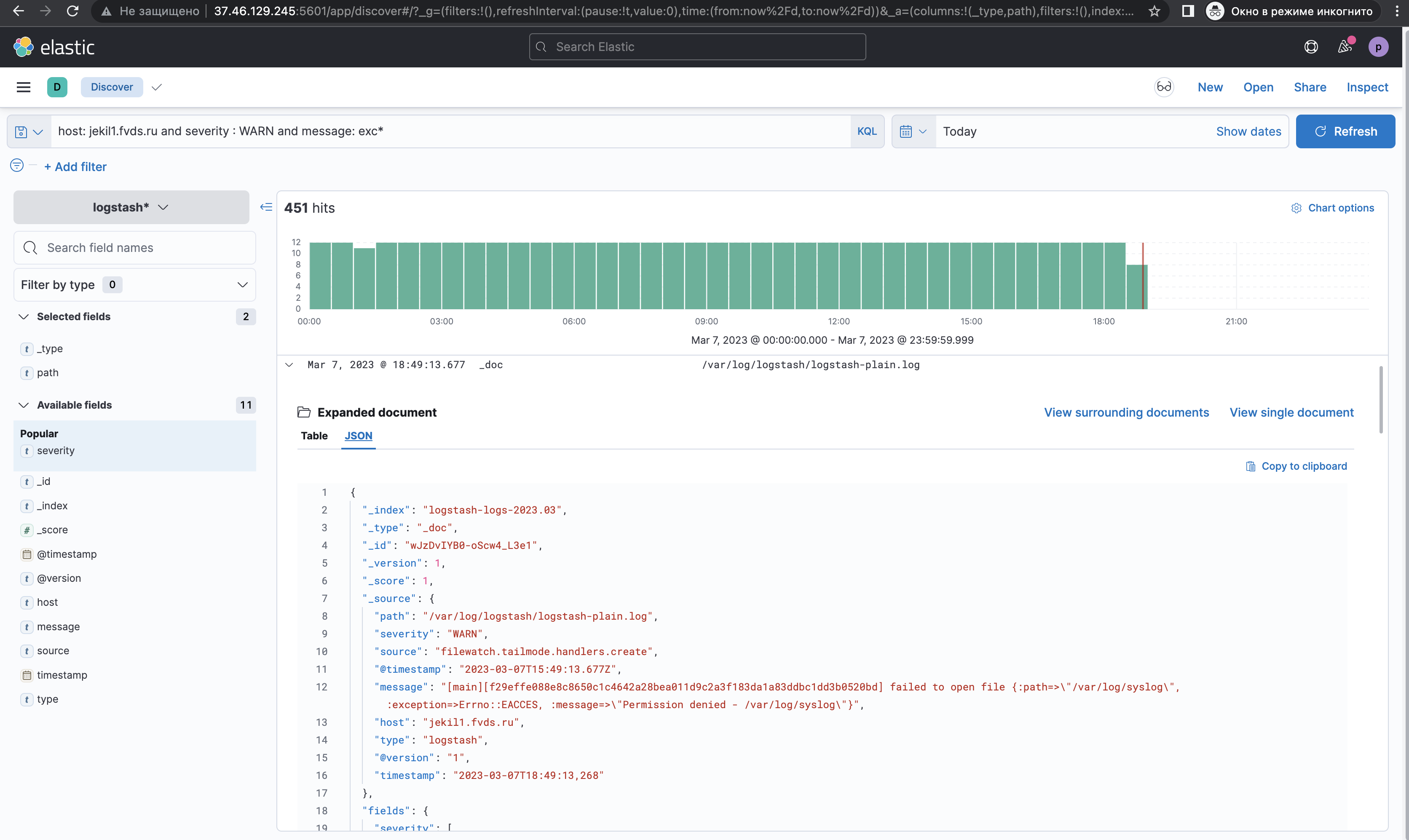
host: jekil1.fvds.ru and severity : WARN( : ) — оператор, который отвечает за поиск совпадений.
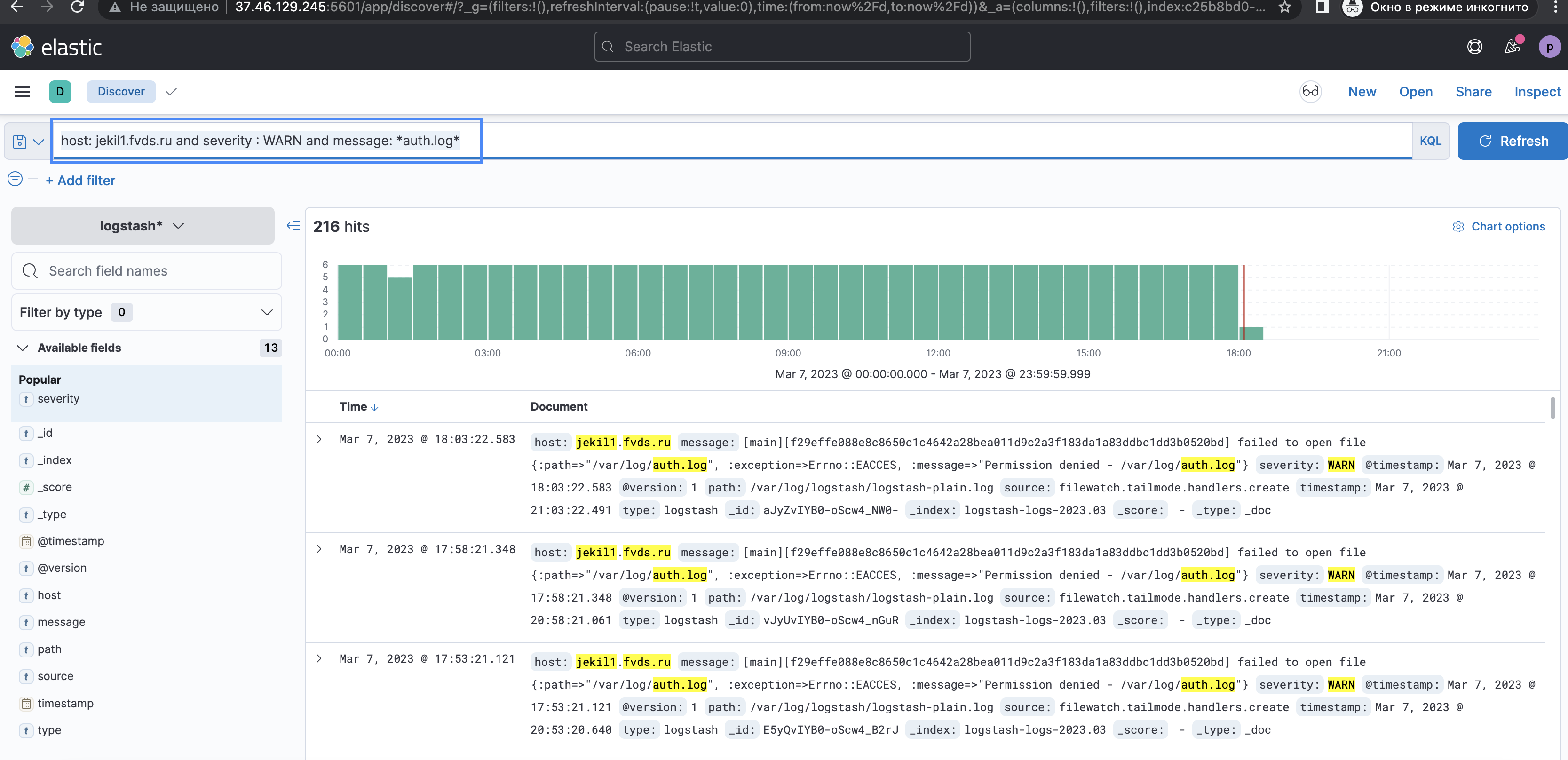
Следующий запрос: host: jekil1.fvds.ru and severity : WARN and message: *auth.log**auth.log*, где (*) обозначает подстановочный знак.
*auth.log* — находит любые значения, которые имеют «oauth.log» в любой позиции
exc* — находит любые значения, которые начинаются с «exc».
Можно использовать оператор подстановочного знака после фразы.
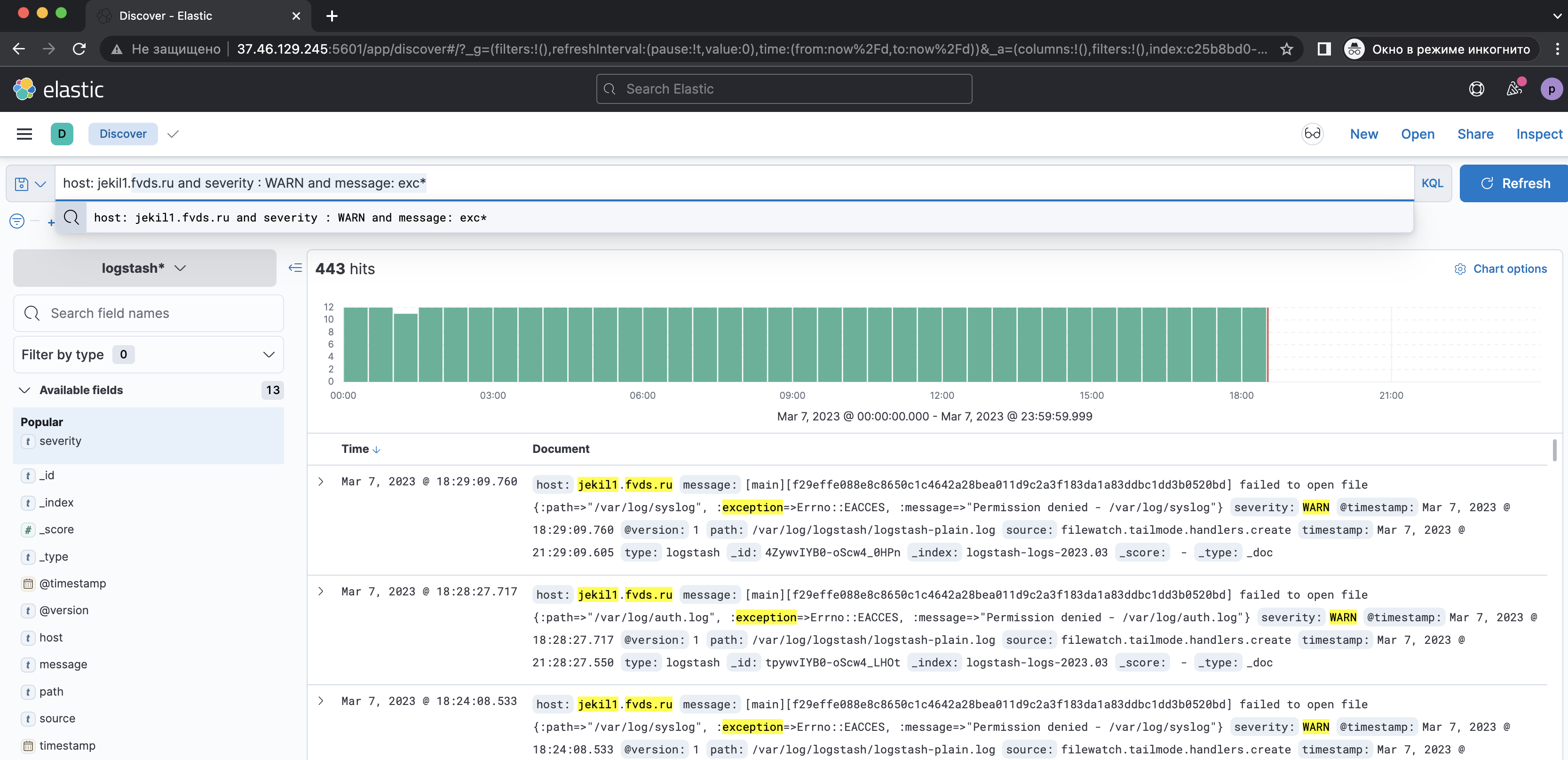
*exc — находит любые значения, которые заканчиваются на «exc».
KQL-запросы не поддерживают сопоставление суффиксов, поэтому в запросах с произвольным текстом нельзя использовать оператор подстановочного знака перед фразой.
Двойные кавычки в KQL-запросе
Чтобы задать предложение в KQL-запросе, необходимо использовать оператор — двойные кавычки » «.
Например, при указании следующего KQL-запроса:
message: exception=>Errno::EACCESSearch Error Expected AND, OR, end of input, whitespace but ">" found. message: exception=>Errno::EACCES -------------------^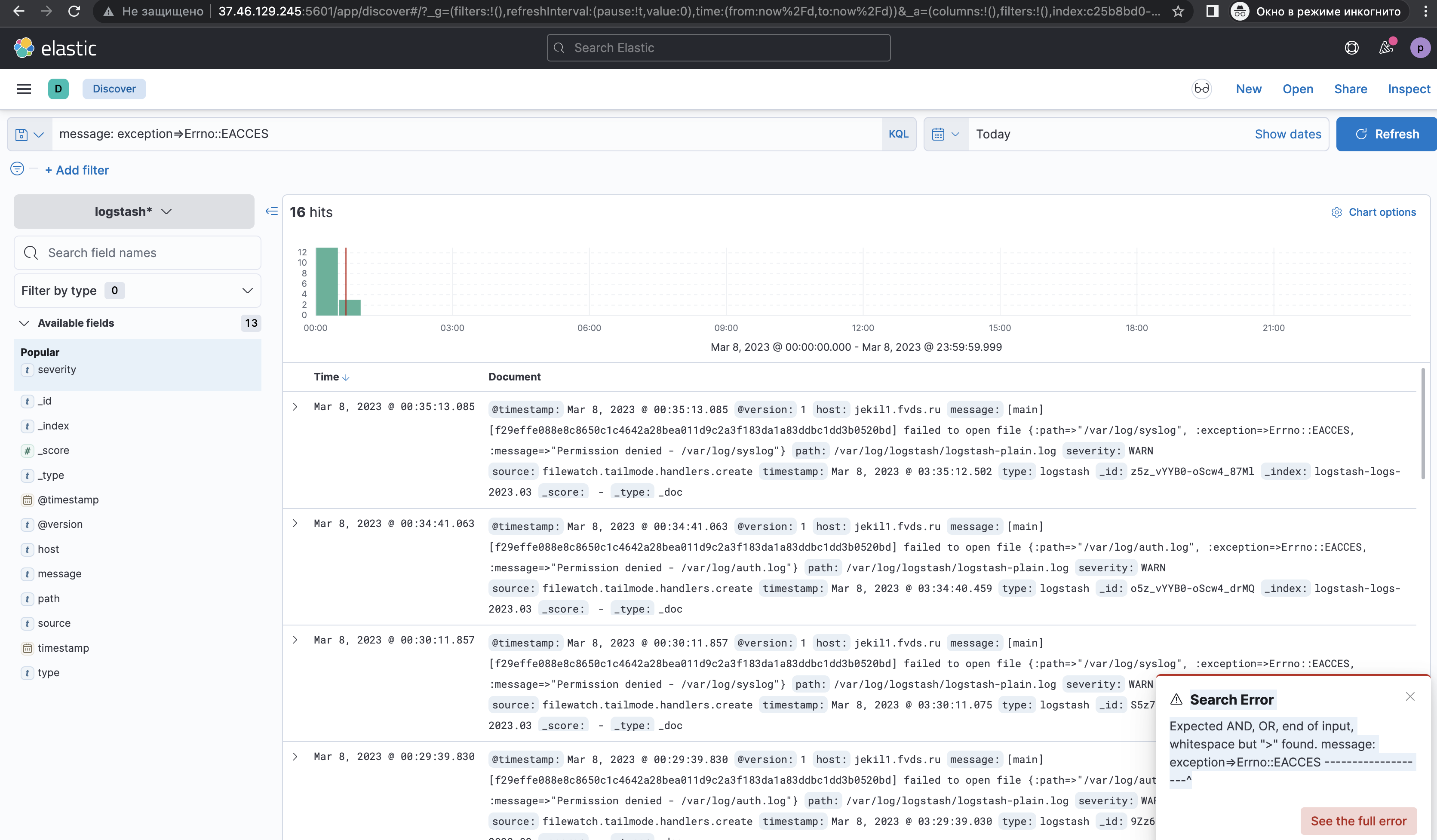
А при указании KQL-запроса с кавычками:
message: "exception=>Errno::EACCES"будет следующий результат совпадений:
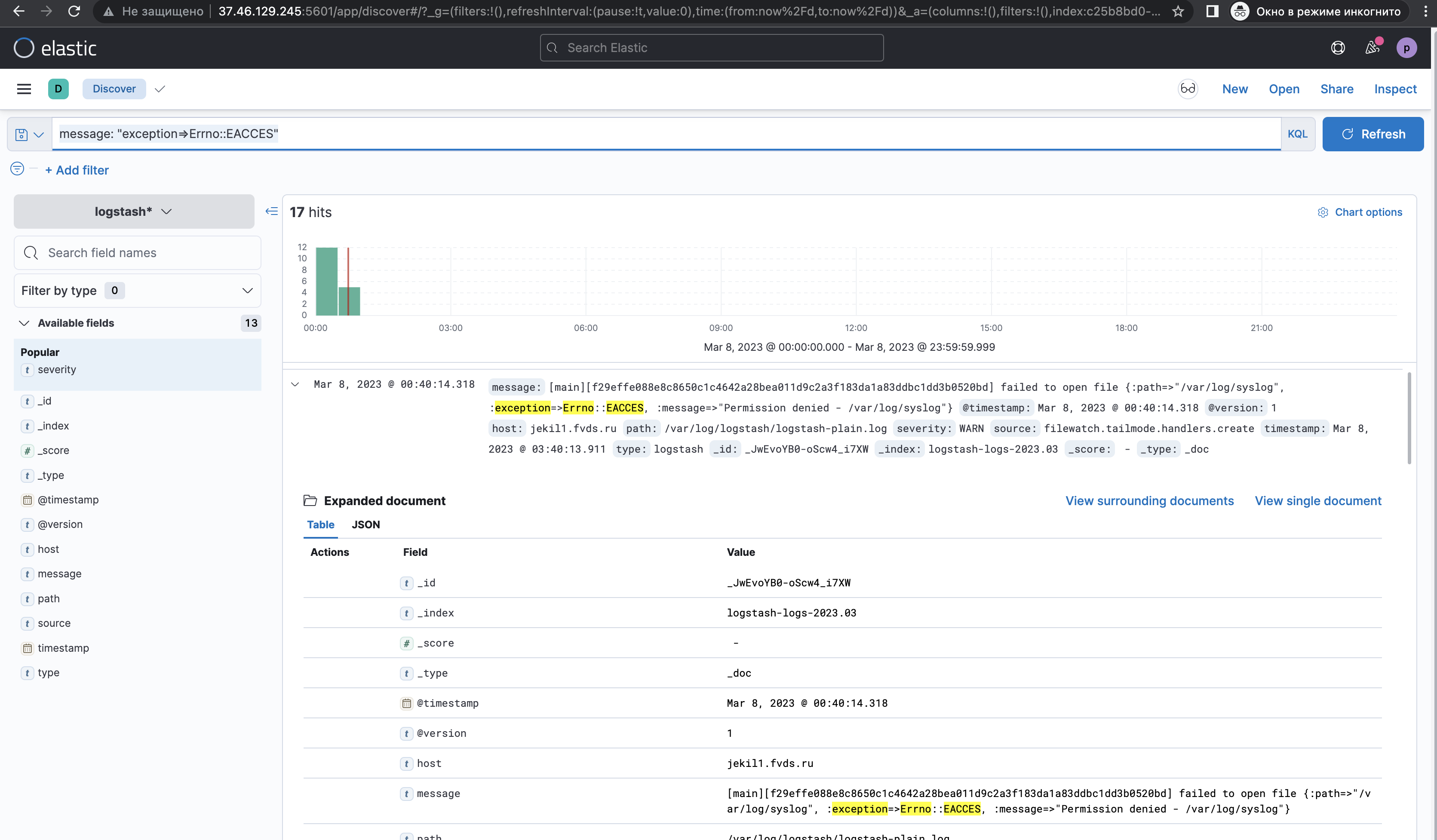
Хочу отметить, что двойные кавычки очень нужны при поиске логов.
KQL c фильтром «Filter by type»
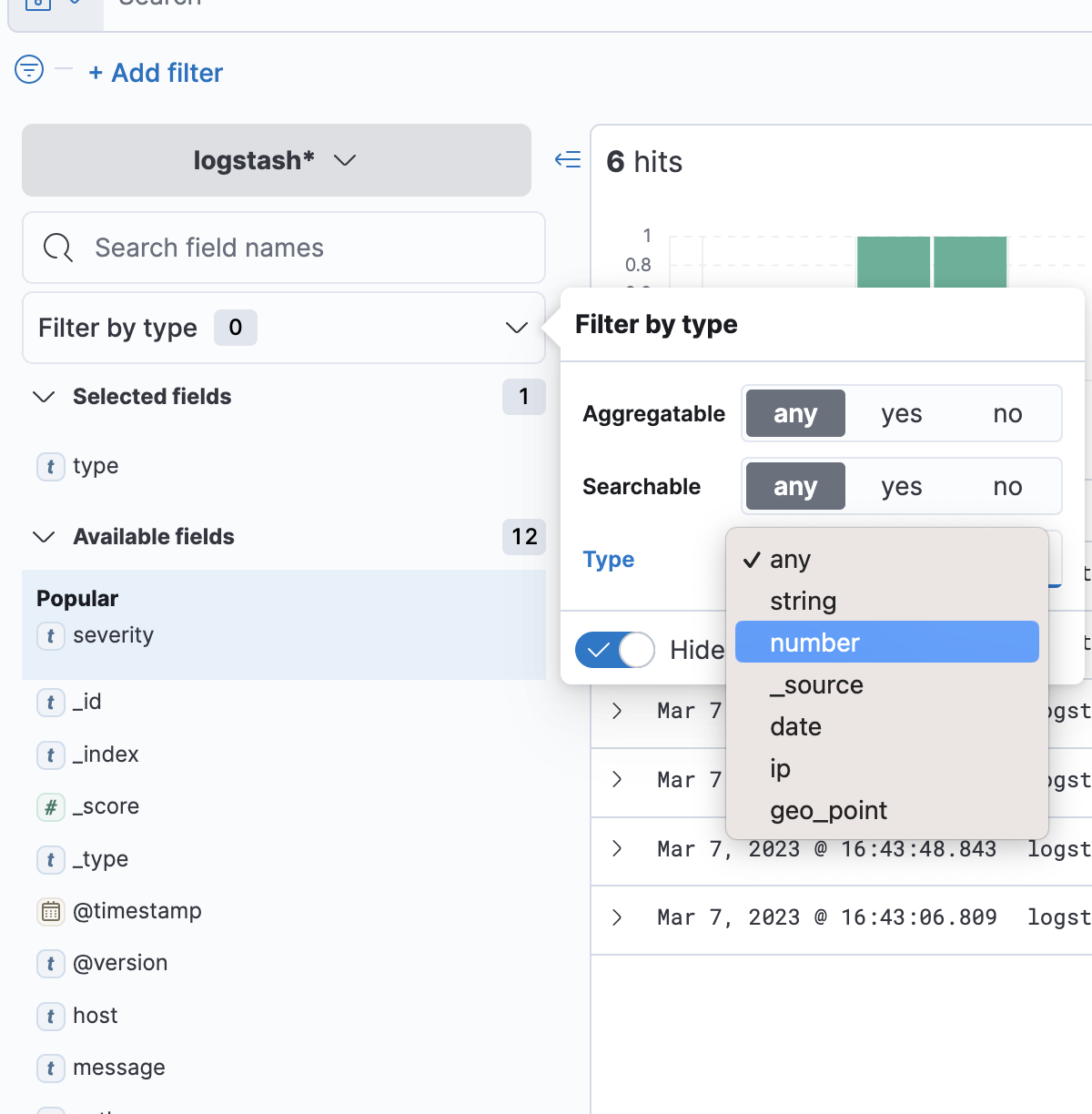
Добавить поле «_type» в фильтр через «Filter by type»:

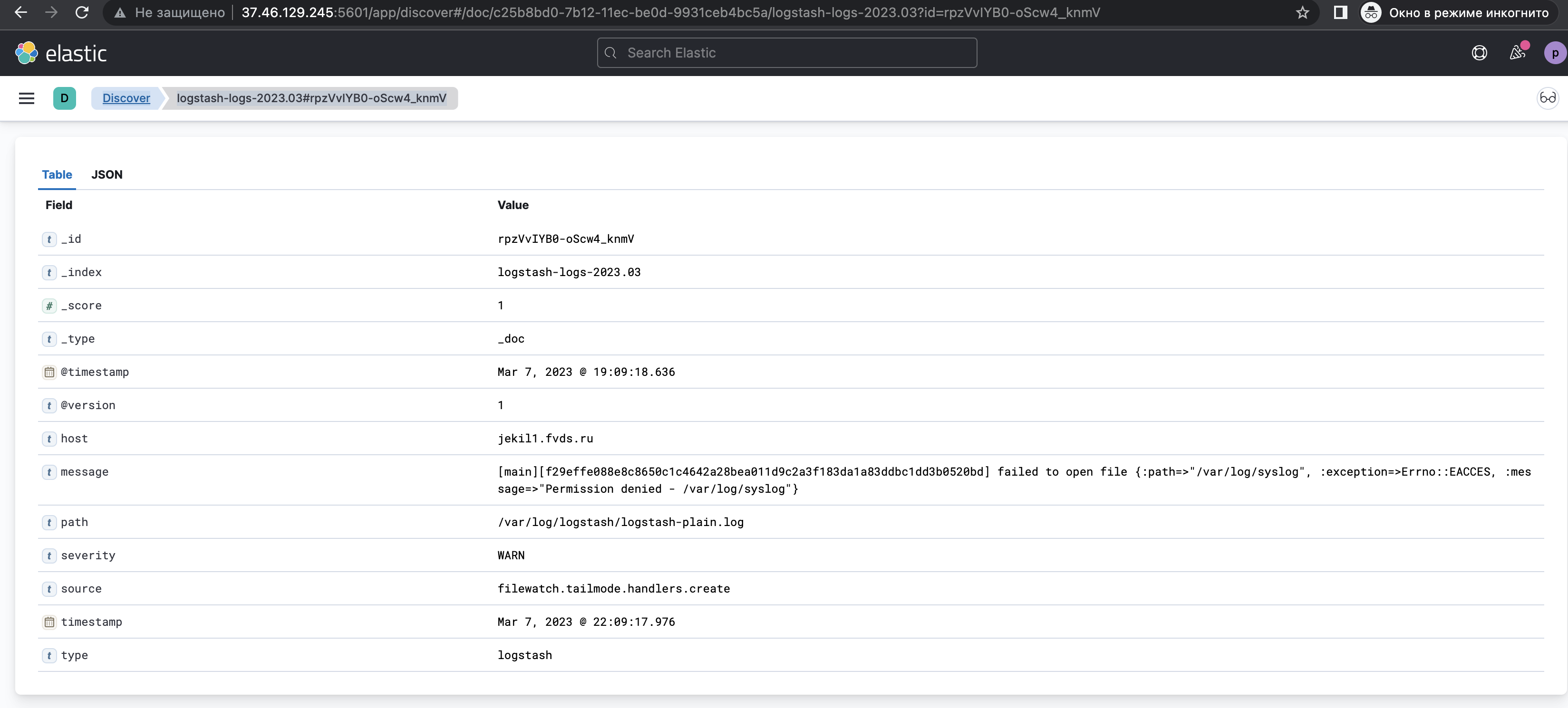
Результаты совпадений отображаются в виде Table или JSON:
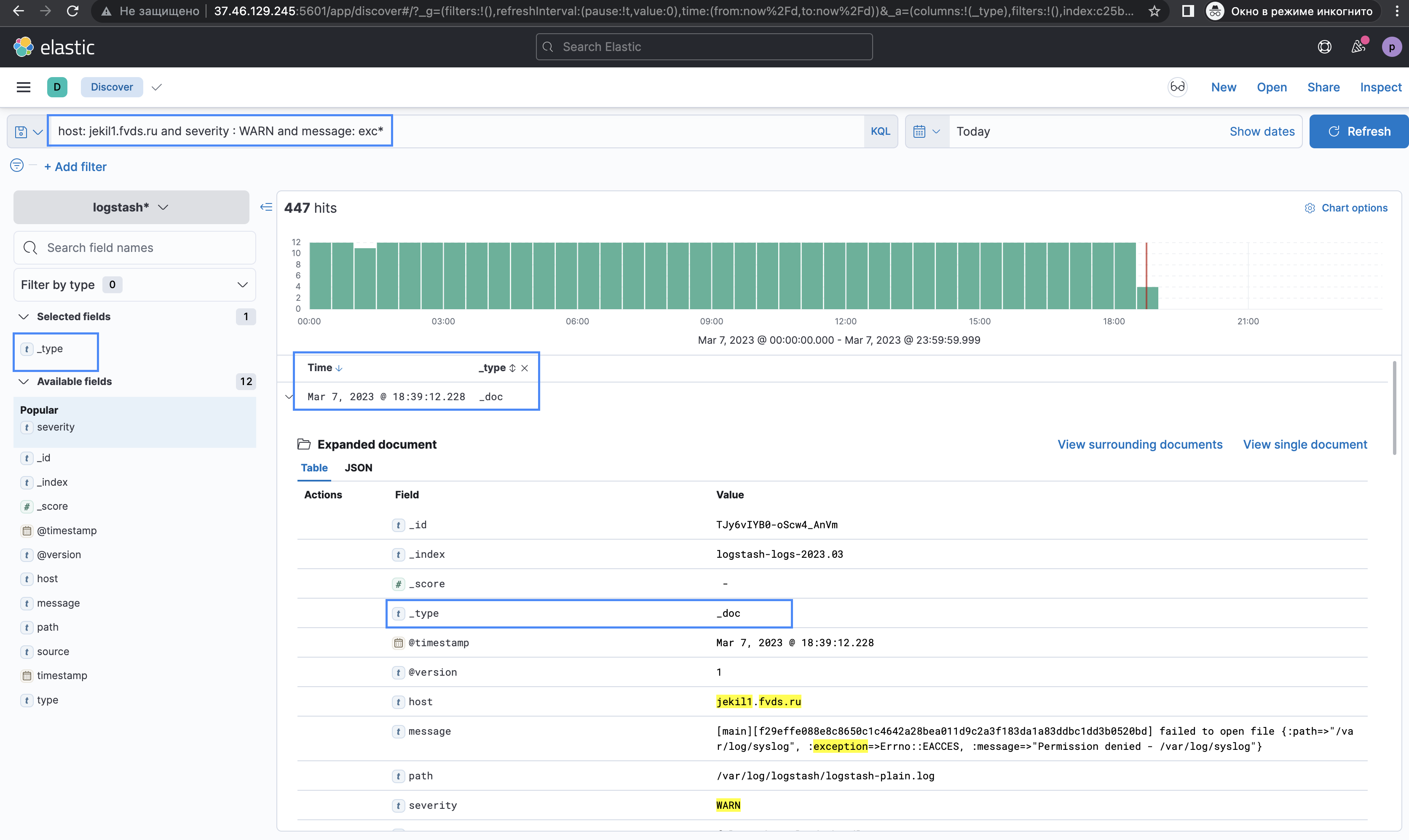
1. Ввести "host: jekil1.fvds.ru and severity : WARN and message: exc*" в блоке для запросов; 2. Выбрать "Today" в блоке временного интервала; 3. Выбрать только "_type" в блоке используемых фильтров; 4. Нажать на кнопку "Refresh/Update"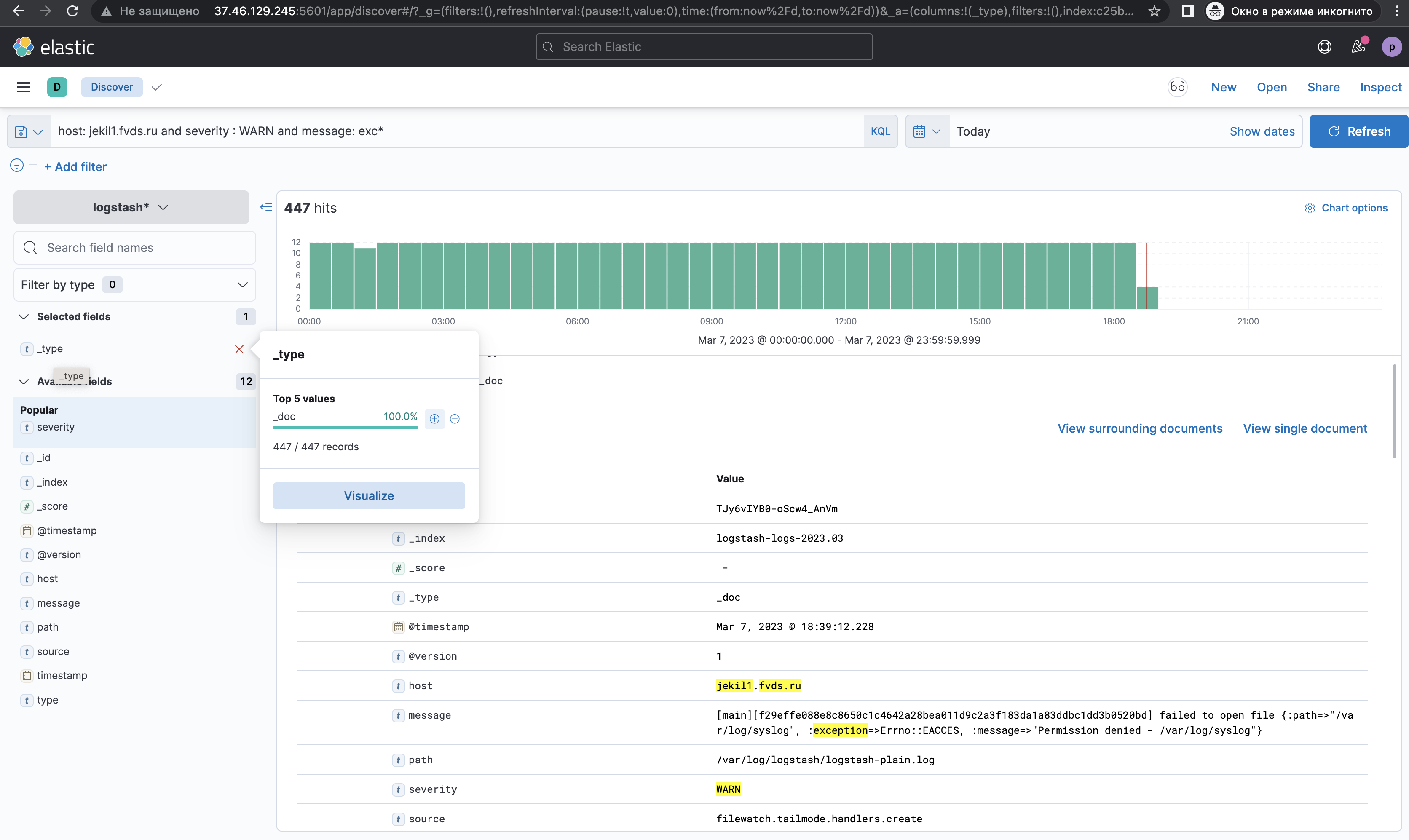
Результаты поиска по фильтру selected fields, выбрав «_type» и «path»:
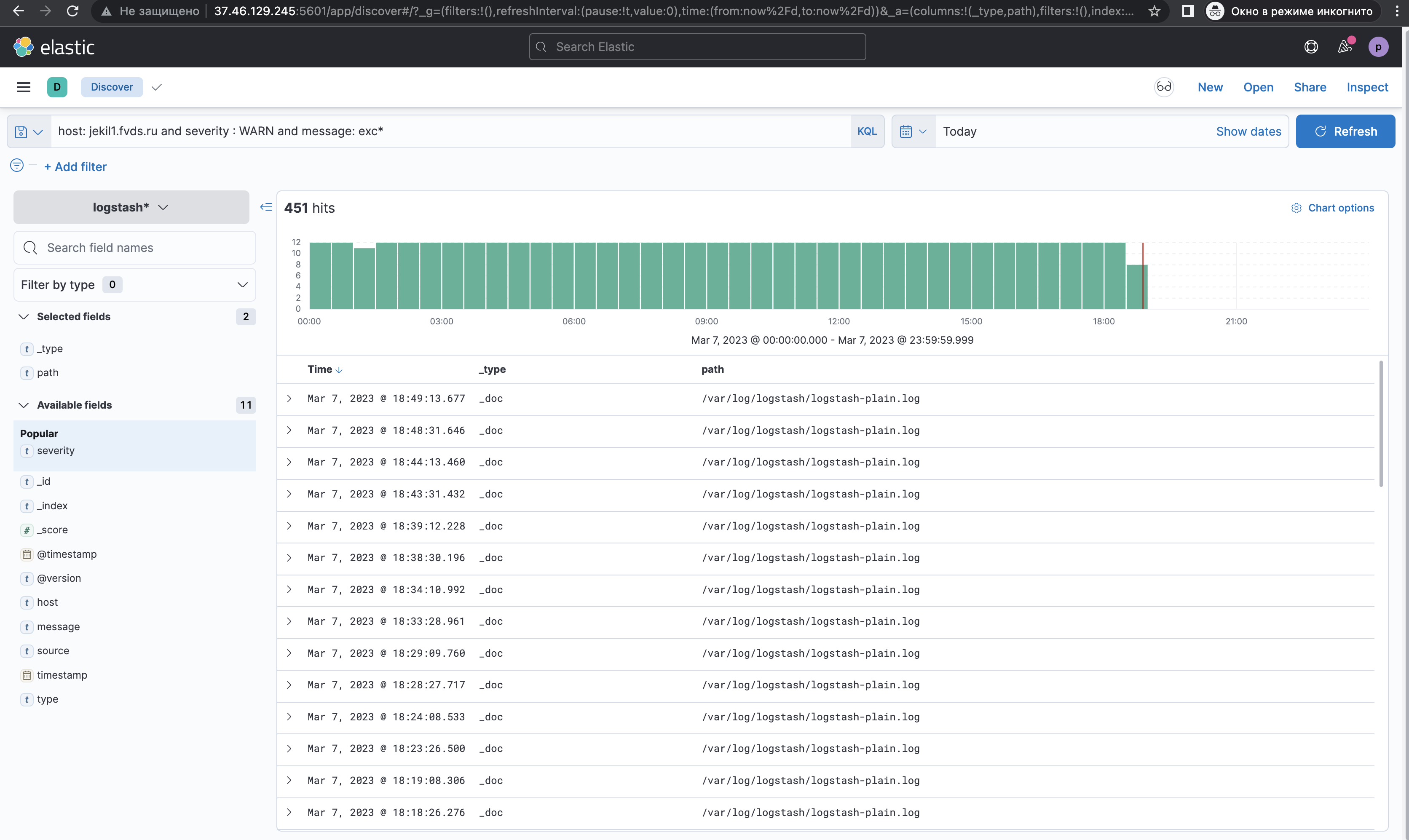
KQL c фильтром «Filter for value»
Дополнительно, поле «host» можно добавить в «Filter for value»:


Благодарю @Kinskiза полезный комментарий.
Обратите внимание на скриншоте примера 3 имеется ссылка «Edit as Query DSL» (где DSL — Domain Specific Language), при нажатии на нее открывется окно ввода, которое позволяет вставить JSON запрос в формате Elastic и даёт возможность, например, осуществлять фильтрацию по regexp.
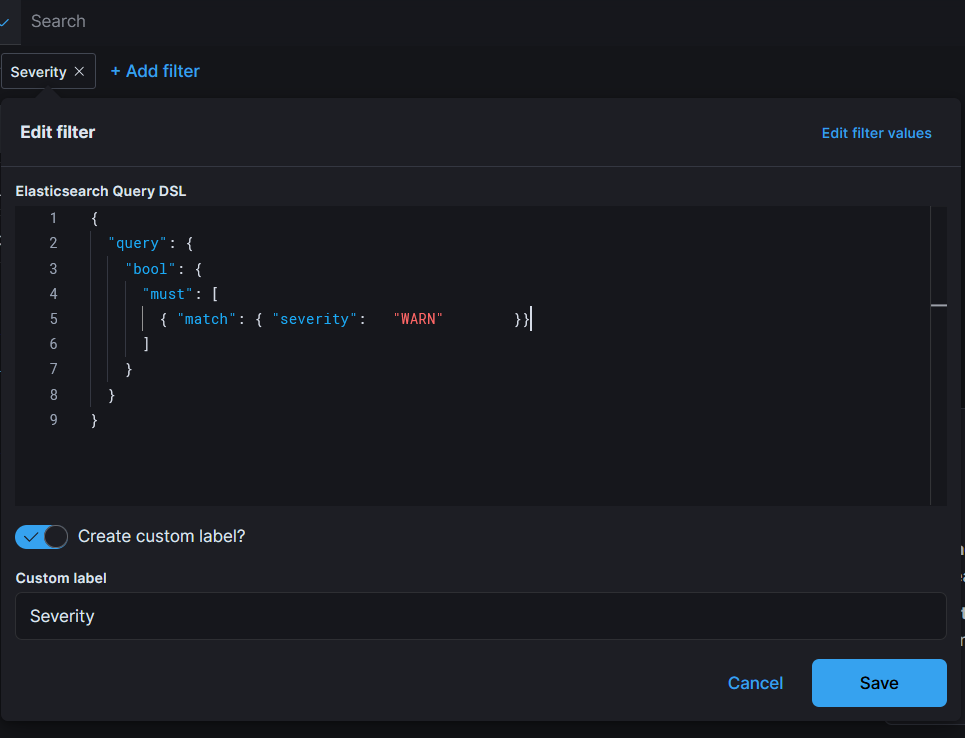
Дать название фильтру как «Severity» и нажать на кнопку «Save». Результат совпадений будет следующим:
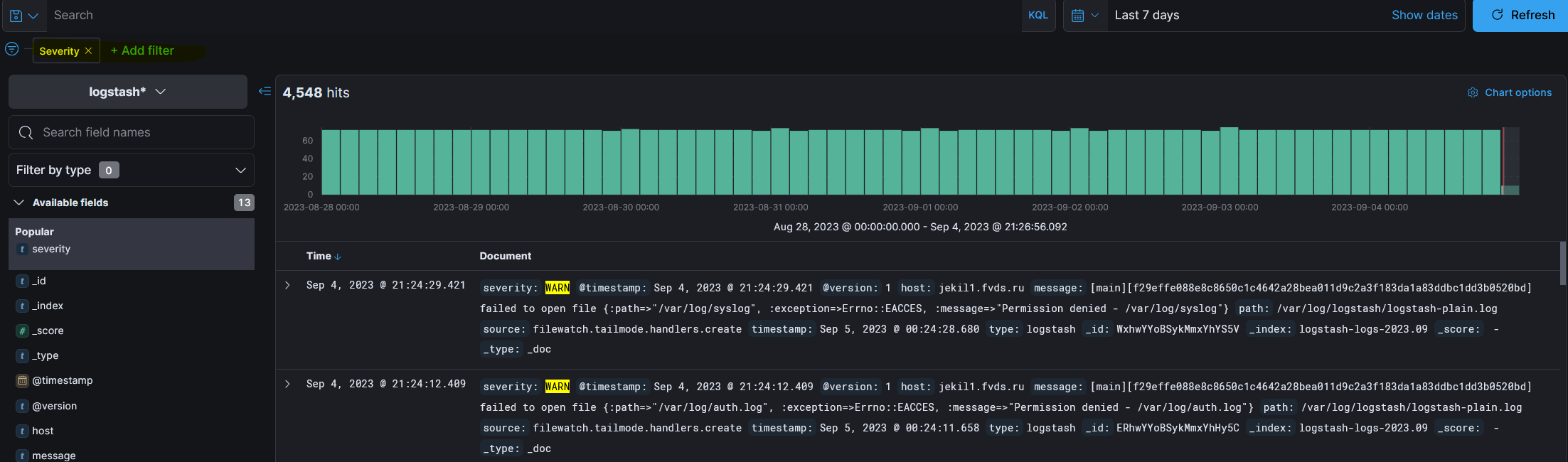
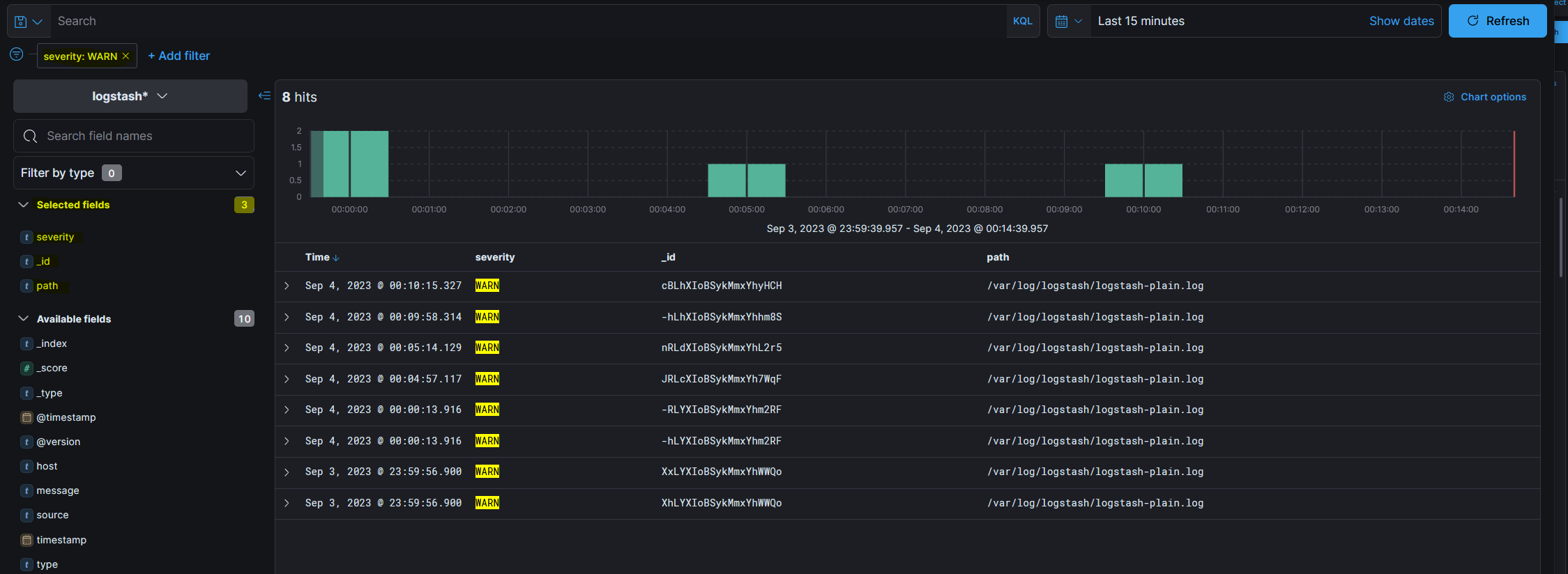
Значение «WARN» подсвечивается желтым цветом, так как указано в фильтре по значениям в правом верхнем углу.
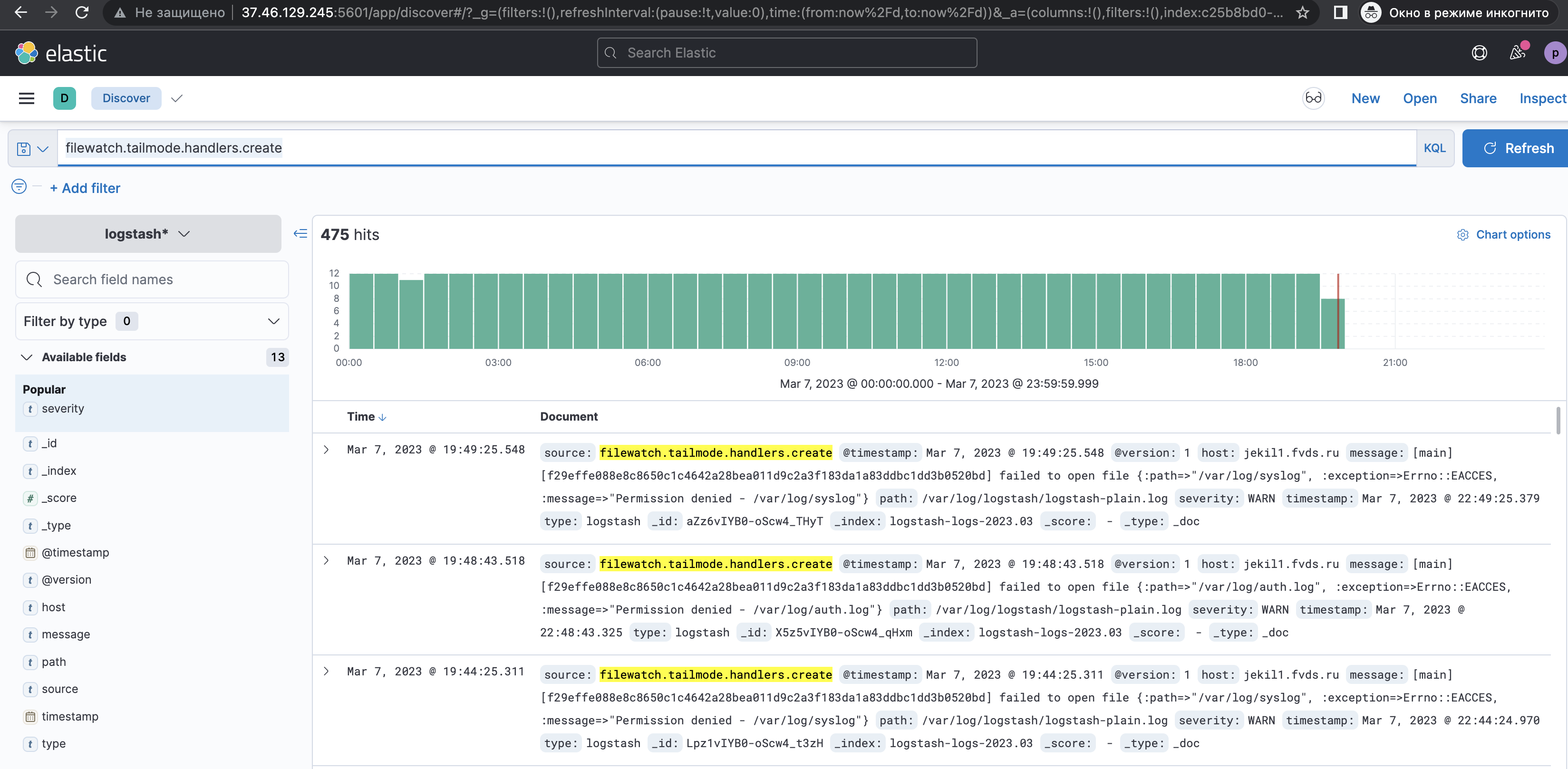
Поиск логов без использования KQL
1. Ввести, например, значение поля "source" = "filewatch.tailmode.handlers.create" в блок для запросов; 2. Выбрать "Today" в блоке с временным интервалом ; 3. Нажать на кнопку "Refresh"; 4. Удалить выбранные фильтры из "Filter for value" и "Filter by type".Результаты поиска совпадений:
Практика
- Перейти по ссылке форума клана по игре Властелин колец онлайн — https://forum.free-peoples.ru/. (зайти на свой страх и риск -> ‘Advanced’);
- Ввести невалидные «Имя пользователя:» = «test» и «Пароль:» = «test» на странице форума;
- Нажать на кнопку «Вход»;
- Зафиксировать время;
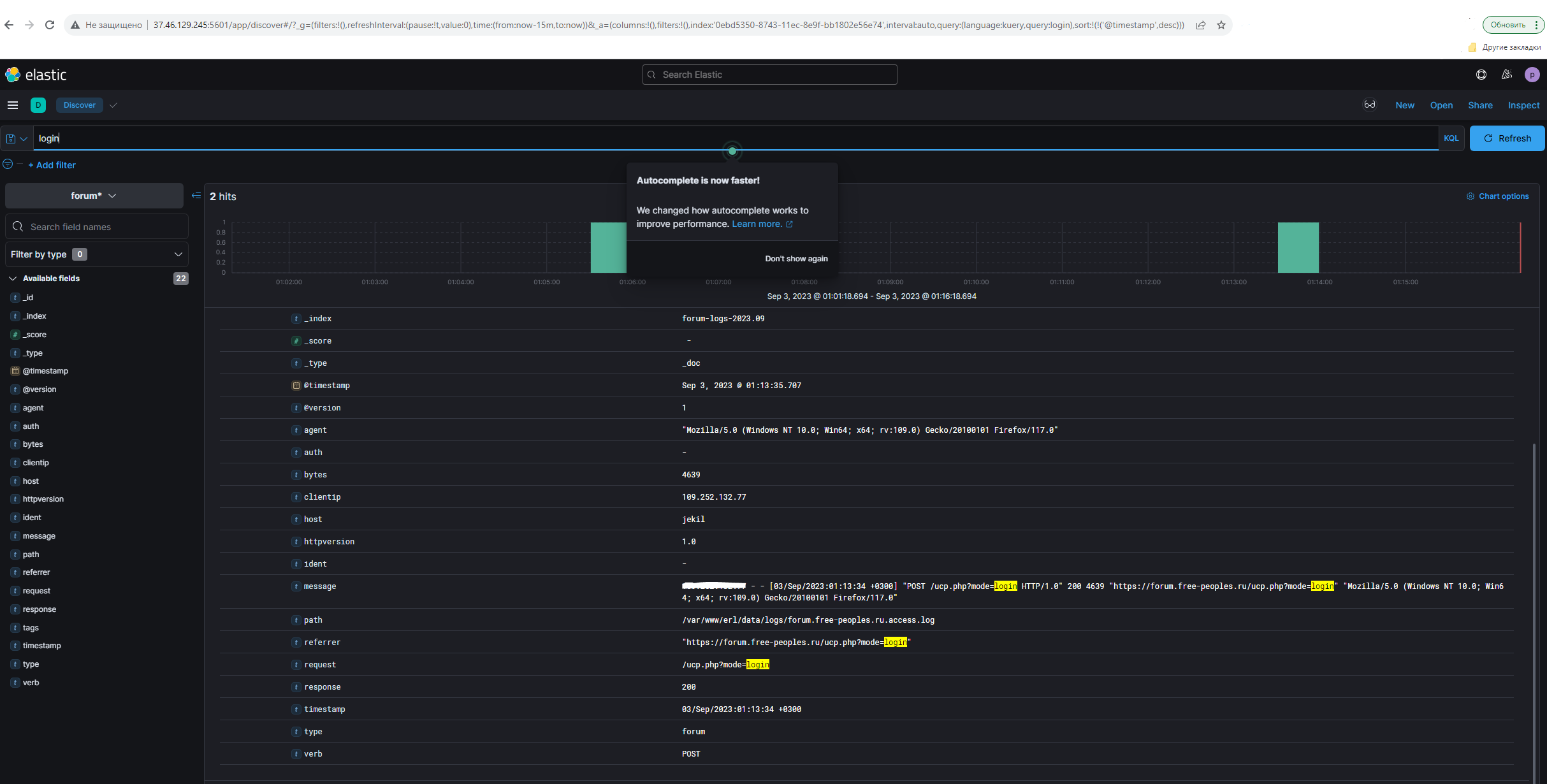
- Перейти по ссылке http://37.46.129.245:5601/app/home#/ -> пройти авторизацию -> выбрать «Discover» -> выбрать «forum» в Change index pattern;
- Ввести значение «login» в строке запроса;
- Нажать на «Refresh»;
- Убедиться, что найдены результаты и просмотреть поле «message»;
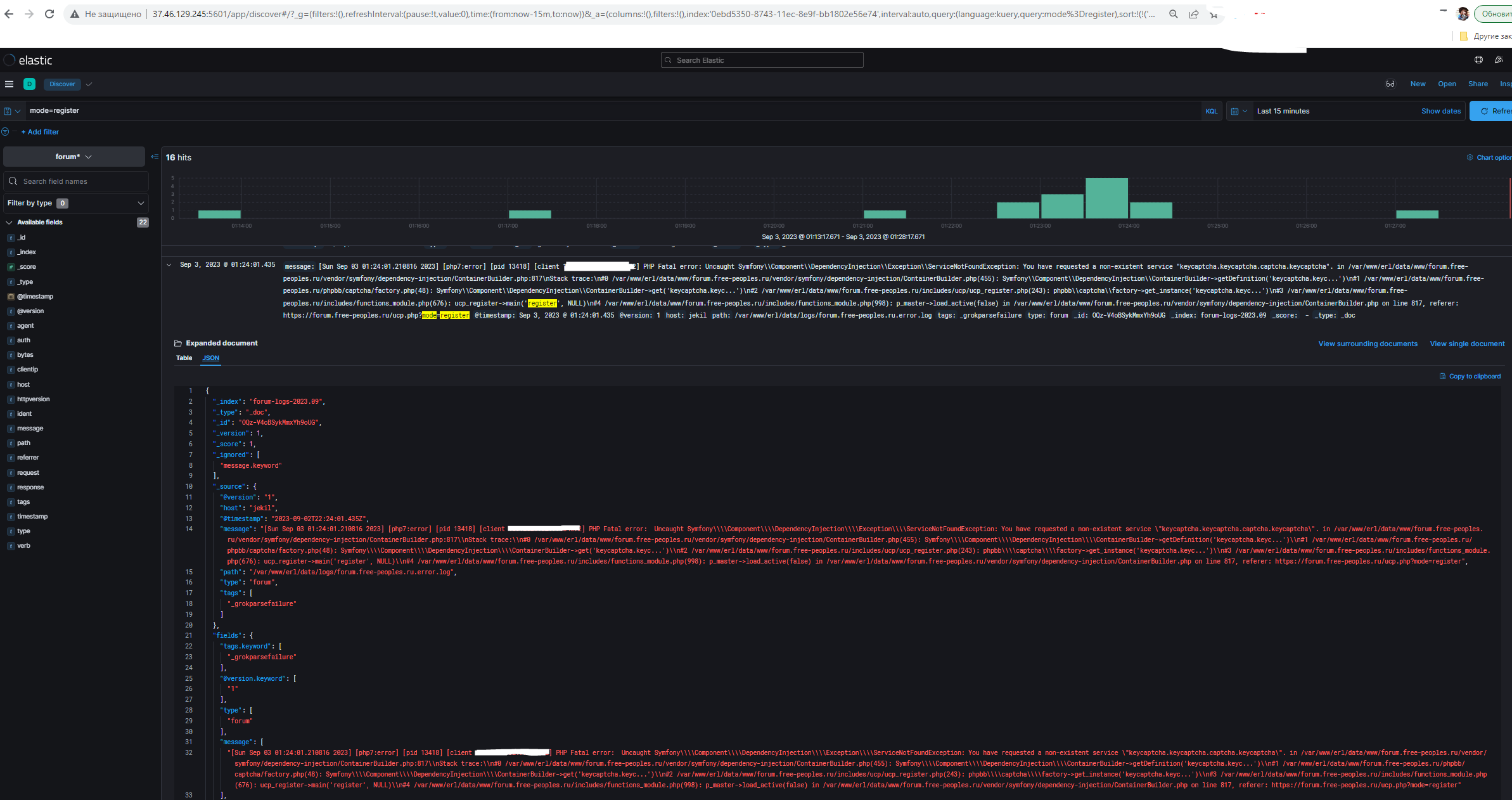
- Нажать на ссылку «Регистрация» на сайте https://forum.free-peoples.ru/ucp.php?mode=register . Отображается ошибка на новой странице;
- Зафиксировать время;
- Найти лог с текстом «mode=register» в Kibana;
- Выбрать показ лога в формате JSON;
- Убедиться, что найдены логи с ошибкой.
Дополнительная информация
Просмотр лога в формате JSON.
- операторы поиска с учетом расположения NEAR и ONEAR;
- операторы поиска синонимов WORDS;
- операторы включения и исключения «+» и «-» ;
- операторы динамического ранжирования XRANK
Из документации: «Можно объединять разные части запросов по ключевым словам с помощью открывающей скобки » ( » и закрывающей скобки » ) «. Каждой открывающей скобке » ( » должна соответствовать закрывающая скобка » ) «. Пробел до или после скобки не влияет на запрос.»
Также можно добавить фильтры из блока со всеми фильтрами в область с используемыми (выбранными) фильтрами.
Заключение
Обычно я ищу логи в Kibana по уровню логирования ERROR, а также указывая необходимые данные по системе. Дополнительно можно искать логи по sessionId, Id, UUID, сообщениям от ответа сервера, данным запроса.
Данной инструкцией, опираясь на полезные источники, хотела донести знакомство как составлять KQL-запросы, научить читать логи и применить эти знания в своей работе.
Благодарю за прочтение.
С уважением, Надежда Дудник (protestinginfo), главный инженер по тестированию в финтехе и ментор по тестированию ПО.
И желаю достичь своей цели!
Использование Elasticsearch и Kibana для сбора логов в Asterisk
В данной статье мы продолжим рассмотрение стека ELK. Детальней разберем настройку ElasticSearch, а также рассмотрим Kibana как инструмент для визуализации логов. Изучить первоначальную настройку и узнать немного теории про стек ELK вы можете, заглянув в статью «Использование ElasticSearch для Asterisk». Настройка Для начала создадим конфигурационнай файл для logstash, открываем файл o /etc/logstash/conf.d/logstash.conf и вносим туда […]
В данной статье мы продолжим рассмотрение стека ELK. Детальней разберем настройку ElasticSearch, а также рассмотрим Kibana как инструмент для визуализации логов.
Изучить первоначальную настройку и узнать немного теории про стек ELK вы можете, заглянув в статью «Использование ElasticSearch для Asterisk» .
Информер! Тестирование проводим на том же сервере, что и наш Asterisk + freePBX. В рабочем решению делать так не рекомендуется, т.к. стек ELK потребляет слишком много ресурсов.
Настройка
Для начала создадим конфигурационнай файл для logstash, открываем файл o /etc/logstash/conf.d/logstash.conf и вносим туда следующее:
input < beats < port =>5044 > > # Парсим сообщения по заданным паттернам Grok filter < if [type] == "asterisk-log" < grok < patterns_dir =>[ "/usr/share/logstash/patterns" ] match => < "message" =>"\[(%|%)\]\s*%\s*\[%\](\[%\])?\s*%:\s*%" > > > if [type] == "asterisk-cdr" < csv < separator =>"," # На тот случай если захотите парсить CDR-CSV columns => ["accountcode","src","dst","dcontext","clid","channel","dstchannel","lastapp","lastdata","start","answer","end","duration","billsec","disposition", "amaflags","userfield","uniqueid"] convert => < # "accountcode" =>"string" # "src" => "string" # "dst" => "string" # "dcontext" => "string" # "clid" => "string" # "channel" => "string" # "dstchannel" => "string" # "lastapp" => "string" # "lastdata" => "string" "start" => "date_time" "answer" => "date_time" "end" => "date_time" "duration" => "integer" "billsec" => "integer" # "disposition" => "string" # "amaflags" => "string" # "userfield" => "string" # "uniqueid" => "string" > > > > # Отбравка данных в ElasticSearch output < elasticsearch < hosts =>"localhost:9200" user => elastic password => changeme manage_template => false index => "%-%" document_type => "%" > # for debug purpose of pipeline with command: ./logstash -f /etc/logstash/conf.d/logstash.conf # stdout < codec =>rubydebug > >Т.к. мы используем Grok для парсинга данных из логов, то необходимо его установить, а также дополнительные зависимости. Выполняем
· wget --no-check-certificate https://github.com/jordansissel/grok/tarball/master -O grok.tar.gz · tar zxf grok.tar.gz · yum install -y gcc gperf make libevent-devel pcre-devel tokyocabinet-devel · make grok · make install · ldconfigСоздаем каталог patterns в директории /usr/share/logstash/ а в нём файл asterisk-grok-patterns, в который вносим следующее:
ASTLEVEL (?:VERBOSE|ERROR|NOTICE|INFO|DEBUG|DTMF|WARNING) ASTPID [0-9]+ ASTCHANNEL_ID C\-[A-Za-z0-9]+ ASTSRC [-a-z._0-9\/]+Далее Вносим настройки в файл /etc/filebeat/filebeat.yml
#----------------------------- Logstash prospectors --------------------------- filebeat.inputs: - input_type: log enabled: true paths: - /var/log/asterisk/full* document_type: asterisk-log encoding: "utf-8" scan_frequency: 5s env: production #----------------------------- Logstash output -------------------------------- output.logstash: # The Logstash hosts hosts: ["127.0.0.1:5044"] xpack.monitoring: enabled: true elasticsearch: hosts: ["http://127.0.0.1:9200"] #================================ Logging ===================================== logging.level: debug logging.selectors: ["*"]В данном файле, мы говорим, что парсить будем логи Full.
Информер! Не забудьте указать параметр enabled: true, иначе парсинг производиться не будет.
Теперь, после того как все настройки внесены, мы можем перейти на веб-интерфейс Kibana для создания паттернов. Напоминаю, что Kibana использует порт 5601
Далее перейдем в настройки patterns как показано на рисунке и создадим новый паттерн.
Далее выбираем доступный нам pattern, который начинается со слов filebeat и вносим его имя целиком в index name
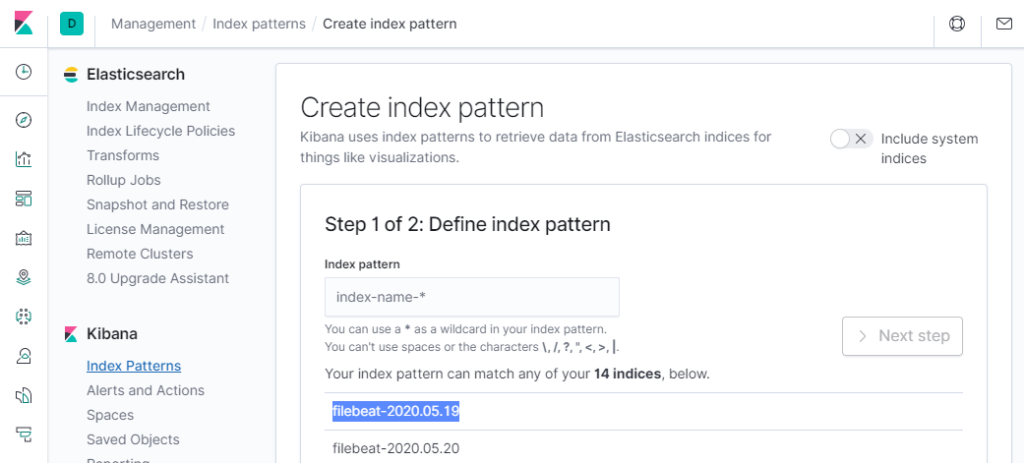
После нажатия кнопки next выбираем Time Filter, нам доступен только timestamp
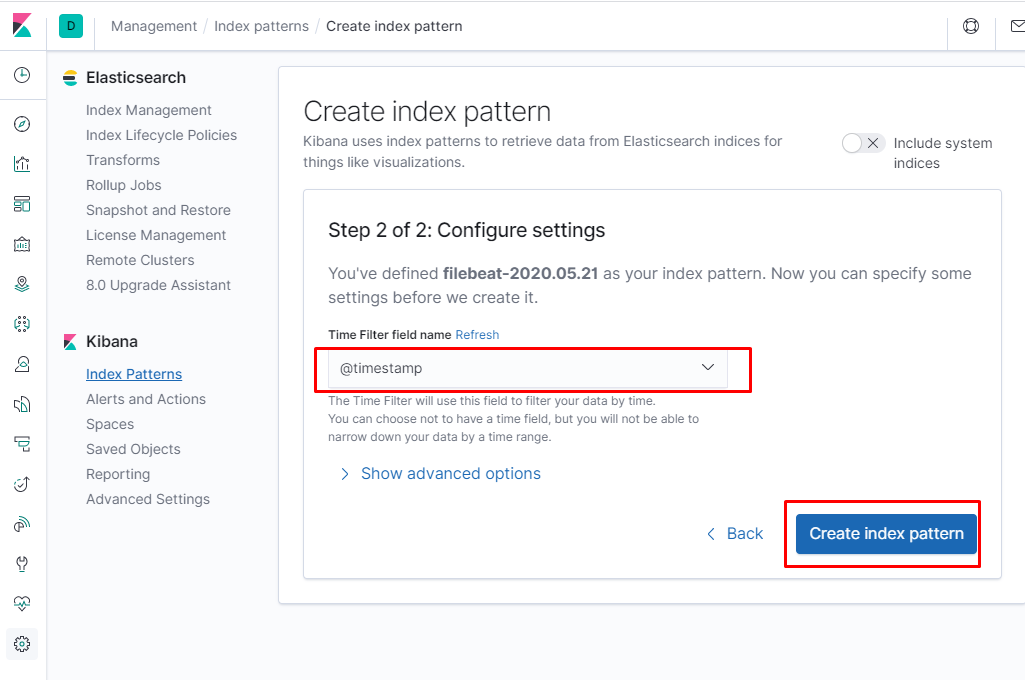
После настройки паттернов переходим в раздел Discover и там выбираем наш паттерн по которому будем смотреть логи.
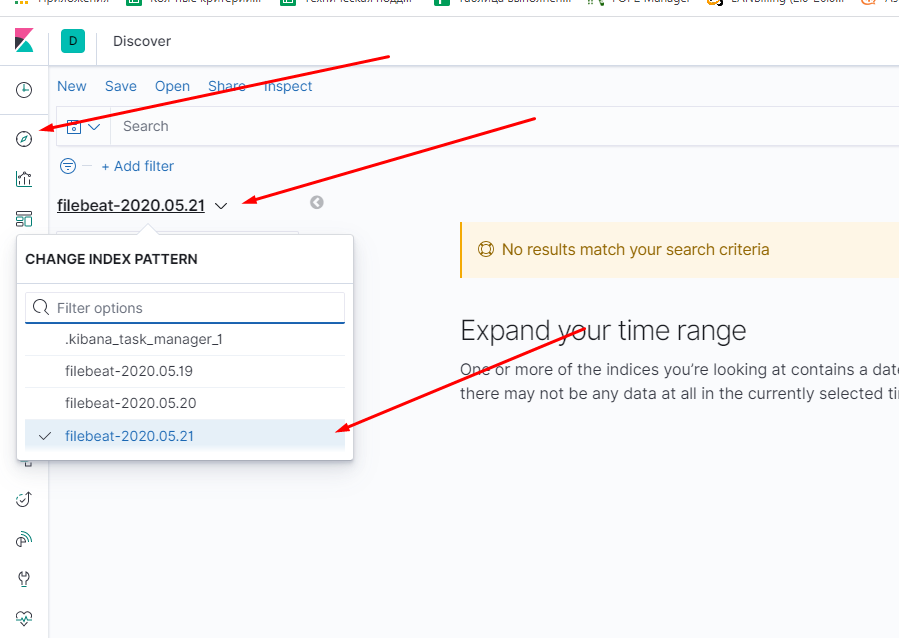
После этого, в строке поиска и можем написать ключевое слово, по которому будем делать визуализацию, для примера возьмём слово warning.
Как видим на скриншоте, у нас встречался всего 1 warning, который как раз и отражен на графике.
На этом настройка ElasticSearch + Kibana, для Asterisk завершена.

Книга 101 функция Asterisk
Познакомьтесь с возможностями Asterisk. Найдите инструменты, которые помогут вашей компании развиваться.
Введение в ELK: собираем, фильтруем и анализируем большие данные
Что, если я скажу вам, что логи могут быть не только полезными и содержать тонну важной информации, но и что работа с ними может быть классной, интересной и увлекательной? Настолько же увлекательной, интересной и классной, как кликанье через удобный интерфейс в браузере, позволяющий в считанные секунды вывести любой график и сравнить его с другим графиком? Да чего там: что, если я скажу вам, что после прочтения этой статьи вы сможете развернуть полноценный аналог Google Analytics для ваших логов? А я это и скажу. Точнее, я это уже сказал. Погнали!
Подготовим vagrant-коробку
Прежде чем перейдём к самой сути, нам необходимо провести небольшую подготовительную работу. Возможно, вы уже использовали Vagrant. Если нет – обязательно узнайте что это такое и начните использовать. Знание Vagrant не нужно для этой статьи, но будет классно (и позволит избежать возможных несоответствий в результате), если вы будете запускать примеры кода ниже используя такой же как у меня конфиг vagrant-бокса.
Итак, создаём новую папку, выполняем в ней vagrant init , открываем Vagrantfile и помещаем туда этот конфиг:
# Vagrantfile API/syntax version. Don't touch unless you know what you're doing! VAGRANTFILE_API_VERSION = "2" Vagrant.configure(VAGRANTFILE_API_VERSION) do |config| config.vm.box = "hashicorp/precise64" config.ssh.forward_agent = true config.vm.network "forwarded_port", guest: 9200, host: 9200 config.vm.network "forwarded_port", guest: 9292, host: 9292 config.vm.network "forwarded_port", guest: 5601, host: 5601 end Затем выполняем vagrant up и, пока наша виртуальная машинка создаётся, настраивается и запускается, читаем дальше.
ELK stack
ELK расшифровывается как elasticsearch, logstash и kibana. Раньше это были три самостоятельных продукта, но в какой-то момент они стали принадлежать одной компании и развиваться в одном направлении. Каждый из этих инструментов (с небольшими оговорками ниже) является полноценным независимым open source продуктом, а все вместе они составляют мощное решение для широкого спектра задач сбора, хранения и анализа данных. Теперь по порядку о каждом из них.
logstash
logstash – это утилита для сборки, фильтрации и последующего перенаправления в конечное хранилище данных. Вы могли слышать о fluentd – logstash решает ту же самую задачу, но написан на jruby и чуть более лучше дружит с elasticsearch (потому что теперь это продукт одной и той же компании, помните?).
Типичная конфигурация logstash представляет из себя несколько входящих потоков информации (input), несколько фильтров для этой информации (filter) и несколько исходящих потоков (output). Выглядит это как один конфигурационный файл, который в простейшем варианте (который не делает вообще ничего) выглядит вот так:
input < >filter < >output
Не волнуйтесь, мы скоро перейдём к настоящим примерам.
– Так, так, стоп, Кирилл. Чё ещё за входящие потоки, какие ещё фильтры? Может пример какой приведёшь для этих терминов?
Привожу: допустим, у вас есть лог веб-сервера (nginx). Это входящий поток информации, input. Допустим, вы хотите каждую запись лога не только превратить в json-объект, но ещё и добавить гео-информацию о ней, основываясь на ip. Это фильтр, filter. А после того, как запись лога обработана и обогащена гео-данными, вы хотите отправить её в elasticsearch (скоро поймём почему). Это исходящий поток информации, output.
При этом у вас может быть сколько захочется input’ов, сколько приспичит фильтров (но не забудьте, что чем больше фильтров, тем больше ресурсов понадобится на обработку каждой записи) и сколько душе угодно output’ов. Logstash предоставляет из коробки внушительный набор готовых решений, поэтому вам не придётся писать свой фильтр для гео-данных, например. Он уже есть из коробки. Это, кстати, выгодно отличает logstash от fluentd.
elasticsearch
Изначально, elasticsearch – это решение для полнотекстового поиска, построенное поверх Apache Lucene, но с дополнительными удобствами, типа лёгкого масштабирования, репликации и прочих радостей, которые сделали elasticsearch очень удобным и хорошим решением для высоконагруженных проектов с большими объёмами данных.
Особенно доставляет в elasticsearch его простота и работоспособность из коробки. Конфигурация по-умолчанию скорее всего будет работать как надо для проектов средней и относительно высокой нагруженности. При этом вокруг ES сложилось отличное сообщество, которое всегда подскажет, как правильно настроить ваш ES-кластер для вашей конкретной задачи.
В какой-то момент elasticsearch стал настолько хорош, что использовать его только для поиска по товарам в интернет-магазинах (ну или там поиску по Basecamp) стало глупо и множество компаний начали основывать на ES свои решения по централизованному хранению логов и различной аналитики.
kibana
И вот у нас есть logstash, который собирает и обрабатывает данные со всех ваших тысяч серверов и elasticsearch, который изо всех сил эти данные хранит и позволяет искать по ним. Чего не хватает? Верно, не хватает Angular.js.
Поэтому в какой-то момент товарищ Rashid Khan написал для elasticsearch красивое Angular.js приложение kibana, позволяющее брать\искать данные по elasticsearch и строить множество красивых графиков. Ребята из elasticsearch не дураки, поэтому, увидев всё удобство этого решения, они забрали разработчика kibana к себе на борт.
Помните, я сказал, что все элементы ELK – независимые продукты? На самом деле, kibana бесполезна без elasticsearch. Это очень (очень) удобный интерфейс, позволяющий любому в вашей компании построить себе красивую панельку, на которую выводить аналитику всего, что logstash отправил в elasticsearch.
Пора практиковаться!
У меня возникла проблема: в какой-то момент в mkdev.me произошла какая-то беда, и чтобы разобраться в ней мне нужно было внимательно изучить что-то вроде сотни с лишним мегабайт логов. Удовольствие от использования grep для этой задачи сомнительное, поэтому я решил взять лог с сервера, залить его в elasticsearch при помощи logstash и спокойно проанализировать проблему через браузер при помощи kibana.
Внимание! Возможно, у вас нет пары сотен с лишним мегабайт логов production приложения и вы скажете «э! а мне то чего пихать в elasticsearch»? Честно – не знаю. Но я почти уверен, что у вас локально лежит какое нибудь Ruby on Rails приложение, над которым вы работаете. А значит в папке log этого приложения есть необходимый вам файлик. Вот его и возьмите. А если нет такого файла, то можете попробовать найти в интернете чужие логи.
Не отдам же я вам логи mkdev, в самом-то деле.
Заходим в виртуалку: vagrant ssh .
Установка logstash
Я использовал logstash 2.2.0, документация по его установке валяется на оф. сайте. Прежде чем перейти к установке необходимо дополнительно установить на машине java. Выполняем одно за другим:
sudo apt-get update sudo apt-get install openjdk-7-jdk curl curl -O https://download.elasticsearch.org/logstash/logstash/logstash-2.2.0.tar.gz tar zxvf logstash-2.2.0.tar.gz cd logstash-2.2.0 Всё, готово. Установили.
Установка elasticsearch
Версия elasticsearch тоже 2.2.0
sudo apt-get install unzip curl -L -O https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-2.2.0.zip unzip elasticsearch-2.2.0.zip cd elasticsearch-2.2.0 Установка kibana
Используемая версия Kibana: 4.4.2. В реальных условиях, конечно, kibana должна быть отделена от logstash и elasticsearch и крутиться на отдельном сервере.
curl -O https://download.elastic.co/kibana/kibana/kibana-4.4.2-linux-x64.tar.gz tar zxvf kibana-4.4.2-linux-x64.tar.gz Конфигурируем logstash
У нас будет всего один input – stdin, стандартный ввод. Он позволит нам загрузить все данные из нашего лог-файла стандартной программой cat . Обратите внимание на type – к каждой итоговой записи, попадающей в output будет добавлено это поле.
input < stdin < type =>"rails" > > Самая сложная часть – фильтры. Я использую multiline, потому что каждая запись в логах rails занимает несколько строчек. Опция pattern указывает на начало каждой записи.
filter < multiline < pattern =>"(?m)Started" negate => true what => "previous" > # . grok – это регулярные выражения на стероидах. Позволяет определять конкретные шаблоны регулярных выражений, которые могут содержать в себе другие шаблоны. В logstash куча встроенных шаблонов grok. К сожалению, для rails там встроенного шаблона нет. После недолгих поисков в интернете я нашёл почти готовый шаблон, немного отредактировал его и он отлично сработал для логов mkdev.me (см. чуть ниже).
# . grok < match =>[ "message", "%" ] > if "_grokparsefailure" in [tags] < drop < >> # .
Найдите в папке logstash-2.2.0 папку patterns , закиньте туда файл rails со следующим содержанием:
RCONTROLLER (?[^#]+)#(?\w+) RAILS (?m)Started % \"%\" for % at (?%-%-% %:%:% %).*Processing by % as (?\S+)(?:\W*Parameters: >\W*)? Объяснение структуры этого файла не входит в мои планы, но обратите внимание на такие вещи, как, например, IPORHOST:clientip – встроенный шаблон для распознавания ip-адресов. Выглядят grok-шаблоны уродливо, но с ними приходит великая сила. Есть отдельный сервис, на котором можно тестировать свои шаблоны: http://grokdebug.herokuapp.com/.
Если какая-то запись не соответствует шаблону grok, то logstash добавит к ней тег _grokparsefailure . Если у записи есть такой тег, то мы её просто выкидываем. Заметьте, что фильтры выполняются сверху вниз.
Последний фильтр – date. Парсит дату, записывает её в поле @timestamp (формат, понятный kibana), а затем выкидывает оригинальное поле timestamp (чтобы избежать дубликации). Без этого фильтра все записи будут иметь сегодняшнюю дату, а не дату события из лога.
# . date < match =>[ "timestamp", "YYYY-MM-dd HH:mm:ss Z"] target => "@timestamp" remove_field => "timestamp" > >
Целиком секция с фильтрами выглядит следующим образом:
filter < multiline < pattern =>"(?m)Started" negate => true what => "previous" > grok < match =>[ "message", "%" ] > if "_grokparsefailure" in [tags] < drop < >> date < match =>[ "timestamp", "YYYY-MM-dd HH:mm:ss Z"] target => "@timestamp" remove_field => "timestamp" > > output < elasticsearch_http < host =>"localhost" > > Итоговый logstash.conf я загрузил в gist.
Конфигурируем elastisearch
Прежде чем мы перейдём к настоящим чудесам, нам необходимо добавить кое-что в конфиг elasticsearch. Открываем elastichsearch-2.2.0/config/elasticsearch.yml и добавляем в самый конец строчку http.cors.enabled: true . Это позволит проводить CORS-запросы из kibana в ES.
Заливаем данные в elasticsearch
Переходим непосредственно к насыщенному экшену. Сначала запустим (из папки elasticsearch-2.2.0, созданной ранее при разархивировании) elasticsearch командой bin/elasticsearch —config=./config/elasticsearch.yml . Затем заходим в папку с logstash и выполняем:
cat production.log | nice bin/logstash -f logstash.conf Вместо production.log подставьте путь к своему лог-файлу. На обработку и сохранение данных уйдёт какое-то время, особенно с учётом того, что мы всё это дело запускаем в виртуалке и того, что и logstash и elasticsearch любят брать много памяти (java же всё таки).
Смотрим данные
После того как обработка данных закончена мы можем их смотреть и анализировать. Это самая приятная часть.
Сначала покажем Kibana где у нас Elasticsearch:
config/kibana.yml elasticsearch.url: "http://localhost:9200” Затем запускаем kibana командой bin/kibana . И открываем в браузере localhost:5601 . Не выключайте elasticsearch, так как kibana берёт все данные оттуда.
Интерфейс kibana должен быть относительно простым и интуитивным. Можно добавлять много разных панелей и проводить любые поддерживаемые elasticsearch поисковые запросы. Немного поигравшись, я построил вот такую панель, выводящую распределение запросов содержащих dashboard и admin по времени, а так же табличку с наиболее популярными контроллерами. Стоит ещё сказать, что это kibana 3. На момент написания статьи kibana 4 ещё не вышла из беты.

Замечания
Естественно, приведённая выше конфигурация не является идеальной и не рекомендуется для production окружения. grok-шаблон, например, распознает далеко не все записи из рельсовых логов. Тем не менее, принцип работы остаётся тем же: logstash берёт данные, обрабатывает их и посылает в elasticsearch, к которому затем цепляется kibana.
Если вас интересует как развернуть и автоматизировать production-ready elasticsearch кластер со всеми сопутствующими сервисами вокруг него и при помощи chef – обращайтесь ко мне на почту.
Круто?!
Теперь, дорогие читатели, вы можете стать настоящими властелинами данных. Области применения ELK стэка ограничены лишь вашей фантазией. Централизованное хранилище логов – лишь простейший пример. Другая популярная задача – сбор различных бизнес-событий из приложений и их аналитика. В конце концов, лог – это любая строчка текста, к которой прикреплены дата и время.
Не стоит забывать, что использовать ELK для небольших проектов не имеет особого смысла и затратно. Разворачивать на единственном маленьком сервере помимо самого приложение ещё и elasticsearch с logstash точно не стоит – как минимум память закончится очень быстро.
Настоятельно рекомендую попробовать разные типы input’ов, фильтров и output’ов logstash. Буду рад ответить на любые вопросы в комментариях.
© Copyright 2014 — 2023 mkdev | Privacy Policy